性能优化 - 案例篇:数据一致性
文章目录
- Pre
- 引言
- 1. 分布式缓存概念
- 2. Redis 与 Memcached 区别概览
- 3. Spring Boot 中使用 Redis
- 3.1 引入依赖与常用客户端
- 3.2 RedisTemplate 的基本用法
- 3.3 Spring Cache 注解式缓存
- 4. 秒杀业务简介及挑战
- 5. Lua 脚本实现原子库存扣减
- 5.1 准备阶段:数据预加载
- 5.2 Lua 脚本原理与关键命令
- 5.3 Java 端执行示例
- 5.4 多线程模拟与测试结果
- 6. 分布式缓存的三大常见问题
- 6.1 缓存穿透
- 6.2 缓存击穿
- 6.3 缓存雪崩
- 7. 缓存一致性
- 7.1 不一致场景举例
- 7.2 常见解决思路
- 7.3 典型不一致场景示例
- 8. 小结

Pre
性能优化 - 理论篇:常见指标及切入点
性能优化 - 理论篇:性能优化的七类技术手段
性能优化 - 理论篇:CPU、内存、I/O诊断手段
性能优化 - 工具篇:常用的性能测试工具
性能优化 - 工具篇:基准测试 JMH
性能优化 - 案例篇:缓冲区
性能优化 - 案例篇:缓存
- 引言:阐明分布式缓存的意义与场景;
- 分布式缓存概念:集中管理 vs 堆内缓存的对比;
- Redis 与 Memcached 区别概览;
- Spring Boot 中使用 Redis:
4.1 引入依赖与常用客户端(lettuce、jedis、redisson)对比;
4.2 RedisTemplate 和 SpringCache(注解式缓存)的基本用法; - 秒杀业务简介及挑战:
5.1 秒杀流量特性与数据库压力;
5.2 Redis 在秒杀中的加持:三大绝招(内存存储、异步处理、分布式扩展); - Lua 脚本实现原子库存扣减:
6.1 准备阶段:在 Redis Hash 中预载入商品信息;
6.2 Lua 脚本原理与关键命令(HMGET、HINCRBY);
6.3 Java 端执行示例及多线程测试结果; - 分布式缓存的三大常见问题:
7.1 缓存穿透:原因、示例与应对(空值缓存、布隆过滤器);
7.2 缓存击穿:原因与防范(热点数据不过期、错峰过期);
7.3 缓存雪崩:原因与防御(高可用 Redis Cluster、限流保护); - 缓存一致性:
8.1 四种操作带来的不一致风险(写入、更新、读取、删除);
8.2 常见解决思路:分布式锁与 Cache Aside Pattern;
8.3 典型场景示例与讨论; - 小结:回顾分布式缓存核心要点;
引言
在微服务或多节点架构中,每个服务实例各自维护一份堆内缓存(LoadingCache 等)会带来空间浪费和管理成本。若此时引入分布式缓存,则所有实例可共享同一份缓存数据,既减少整体内存消耗,又避免在各自缓存中出现“缓存击穿”或“缓存雪崩”时的多点宕机风险。本课时将全面讲解分布式缓存的概念、Spring Boot 中 Redis 的使用,以及在高并发秒杀场景下如何利用 Redis 实现库存扣减的原子操作,并深入讨论分布式缓存系统常见的穿透、击穿、雪崩与一致性问题及其解决方案。
1. 分布式缓存概念
“分布式缓存”是指在多个服务节点之间,集中管理同一份缓存数据。与进程内缓存相对:
- 堆内缓存(进程内):每个服务实例自身维护一份缓存,优点是访问延迟极低;缺点是数据会在多个实例间重复存储,此外如果某一节点缓存失效,会自行从后端数据库加载,难以统一协同。
- 分布式缓存:所有实例统一读写同一份缓存(通常部署在专门的缓存集群中,如 Redis Cluster)。优点是缓存容量可以动态扩展、缓存数据一致性容易维护;缺点是需跨网络访问,延迟略高于堆内缓存。
分布式缓存适用场景:
- 服务实例数量众多,担心堆内缓存“雪崩”或“击穿”时带来的多点负载过大;
- 缓存容量较大,单个实例无法承担全部缓存时;
- 需要在多个服务间共享同一缓存,避免数据冗余与缓存同步开销。
2. Redis 与 Memcached 区别概览
在分布式缓存领域,Redis 和 Memcached 是最常被提及的两款中间件。尽管 Memcached 现已逐渐被 Redis 取代,但面试中仍常会问它们的区别。
| 特性 | Redis | Memcached |
|---|---|---|
| 数据类型 | 支持丰富数据结构:String、Hash、List、Set、ZSet、Bitmap、HyperLogLog 等 | 仅支持简单的 String 键值对 |
| 持久化 | 支持 RDB 快照与 AOF 日志持久化 | 不支持持久化,仅纯内存缓存 |
| Lua 脚本 | 支持 | 不支持 |
| 内存管理 | 使用内置对象系统,支持 LRU、TTL、LFU 等多种回收策略 | 仅基于 LRU 或者随机回收 |
| 单线程模型 | 单线程主执行命令,保证原子性 | 多线程网络 I/O,但数据访问也主要集中在少数线程 |
| 发布/订阅 | 原生支持 | 不支持 |
| 高可用 | 提供主从复制、哨兵模式 & Cluster 支持 | 仅提供 memcached 本身的主从扩展方案 |
| 缓存容量 | 可配置极大(比如几十 GB),也可分布式扩容 | 通常用于内存较小场景 |
总结:Redis 功能更全面,除了做缓存,还常被用作消息队列、计数器、分布式锁等。而 Memcached 仅限于简单的键值缓存。
3. Spring Boot 中使用 Redis
在 Spring Boot 项目里,Redis 的接入非常简单。下面介绍两种常用方式:RedisTemplate 和 Spring Cache 注解式缓存。
3.1 引入依赖与常用客户端
<!-- Spring Boot Redis Starter,内部默认引入 lettuce 客户端 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency><!-- Spring Boot Cache Starter,用于注解式缓存 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
-
常见 Java 客户端
- lettuce:基于 Netty,异步非阻塞,性能较高;Spring Boot 2.x 默认推荐;
- jedis:早期最流行的客户端,使用线程池模式,简单易用;
- redisson:基于 Netty,支持分布式锁、流式操作等高级业务封装,使用体验类似 JUC。
3.2 RedisTemplate 的基本用法
Spring Boot 自动配置 RedisTemplate<String, Object>。常用操作示例:
@Autowired
private RedisTemplate<String, Object> redisTemplate;// 写入字符串
redisTemplate.opsForValue().set("key1", "value1", 60, TimeUnit.SECONDS);// 读取字符串
String val = (String) redisTemplate.opsForValue().get("key1");// 操作 Hash
redisTemplate.opsForHash().put("user:100", "name", "Alice");
Object name = redisTemplate.opsForHash().get("user:100", "name");// 操作 List
redisTemplate.opsForList().rightPush("queue", "task1");
Object task = redisTemplate.opsForList().leftPop("queue");// 执行 Lua 脚本
DefaultRedisScript<Long> script = new DefaultRedisScript<>();
script.setScriptText(luaScriptText);
script.setResultType(Long.class);
Long result = redisTemplate.execute(script, Collections.singletonList("seckill:goods:1"), "1");
- 如果只引入
spring-boot-starter-data-redis,无需额外配置即可使用RedisTemplate。
3.3 Spring Cache 注解式缓存
Spring 提供了统一的 spring-cache 缓存抽象,使用注解可透明替换不同底层缓存实现。使用步骤:
-
启动类启用缓存
@SpringBootApplication @EnableCaching public class Application { ... } -
配置 RedisCacheManager(若只有一个缓存框架,可省略,Spring Boot 会自动创建)
@Configuration public class CacheConfig {@Beanpublic RedisCacheManager cacheManager(RedisConnectionFactory factory) {RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofMinutes(10)) // 全局过期时间.disableCachingNullValues(); // 不缓存 nullreturn RedisCacheManager.builder(factory).cacheDefaults(config).build();} } -
在 Service 层使用缓存注解
@Service @CacheConfig(cacheNames = "users") public class UserService {// 方法返回值将自动缓存到 key "users::id:{id}"@Cacheable(key = "'id:' + #id")public User getById(Long id) { ... }// 每次调用都会更新缓存@CachePut(key = "'id:' + #user.id")public User update(User user) { ... }// 清除指定缓存项@CacheEvict(key = "'id:' + #id")public void delete(Long id) { ... } }
@Cacheable:方法执行前先检查缓存,若存在则直接返回;@CachePut:无论是否存在缓存,方法都会执行并将结果写入缓存;@CacheEvict:执行方法时清除缓存项,用于删除或更新场景。
4. 秒杀业务简介及挑战
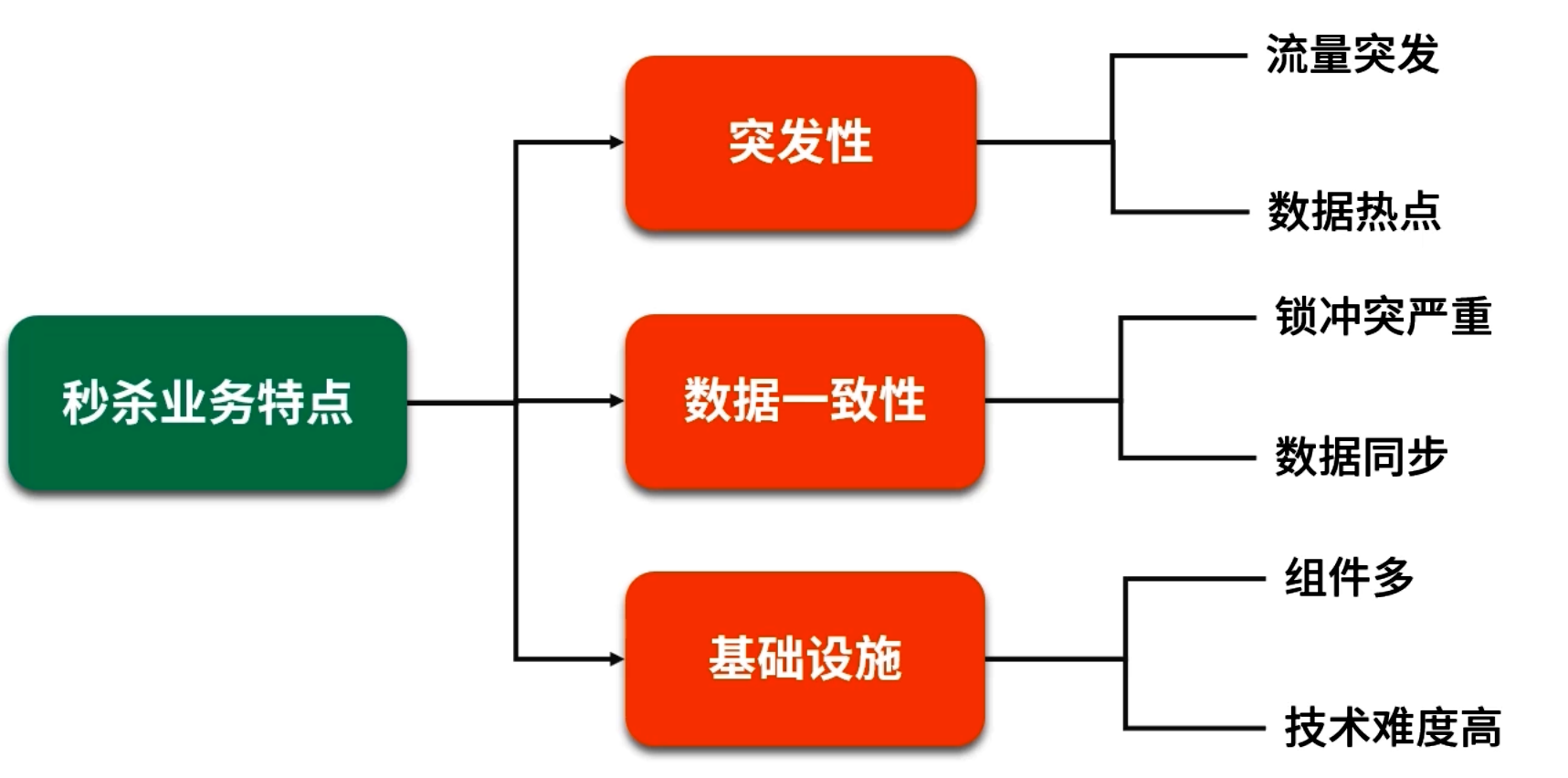
秒杀场景 本质上就是“短时高并发流量+有限库存” 的组合,对系统设计与性能提出极高要求。
-
秒杀流量特性
- 通常在极短时间内(几十毫秒或几秒内),会产生上万、几十万甚至几百万的并发请求;
- 下游数据库或者业务系统一旦同步处理,会出现大量锁等待、连接耗尽、CPU 飙升,导致整个系统不可用;
- 用户体验要求秒开页面、秒出结果,若排队或超时则会流失大量用户。
-
主要挑战
- 库存扣减的原子性与一致性:多个用户同时抢同一个商品,必须保证库存“先检查再扣减” 在同一时刻只能出现一次;
- 瞬时流量承载:同一个库存可能在毫秒级时间内被上万用户访问,直接击中数据库显然无法承受;
- 系统可用性:万一缓存系统(如 Redis)单点宕机,如何保障后端数据库不被瞬时洪流压垮(缓存雪崩)?
-
秒杀“三大绝招”
- 选择速度最快的内存存储:将库存信息、秒杀状态等载入 Redis,而不是依赖于数据库;
- 异步化:先将用户请求写入消息队列(例如 Kafka、RocketMQ 等),后端异步消费更新数据库与缓存;
- 分布式横向扩展:通过负载均衡将秒杀请求分发到多个应用节点和多个 Redis 实例,减少单点压力。
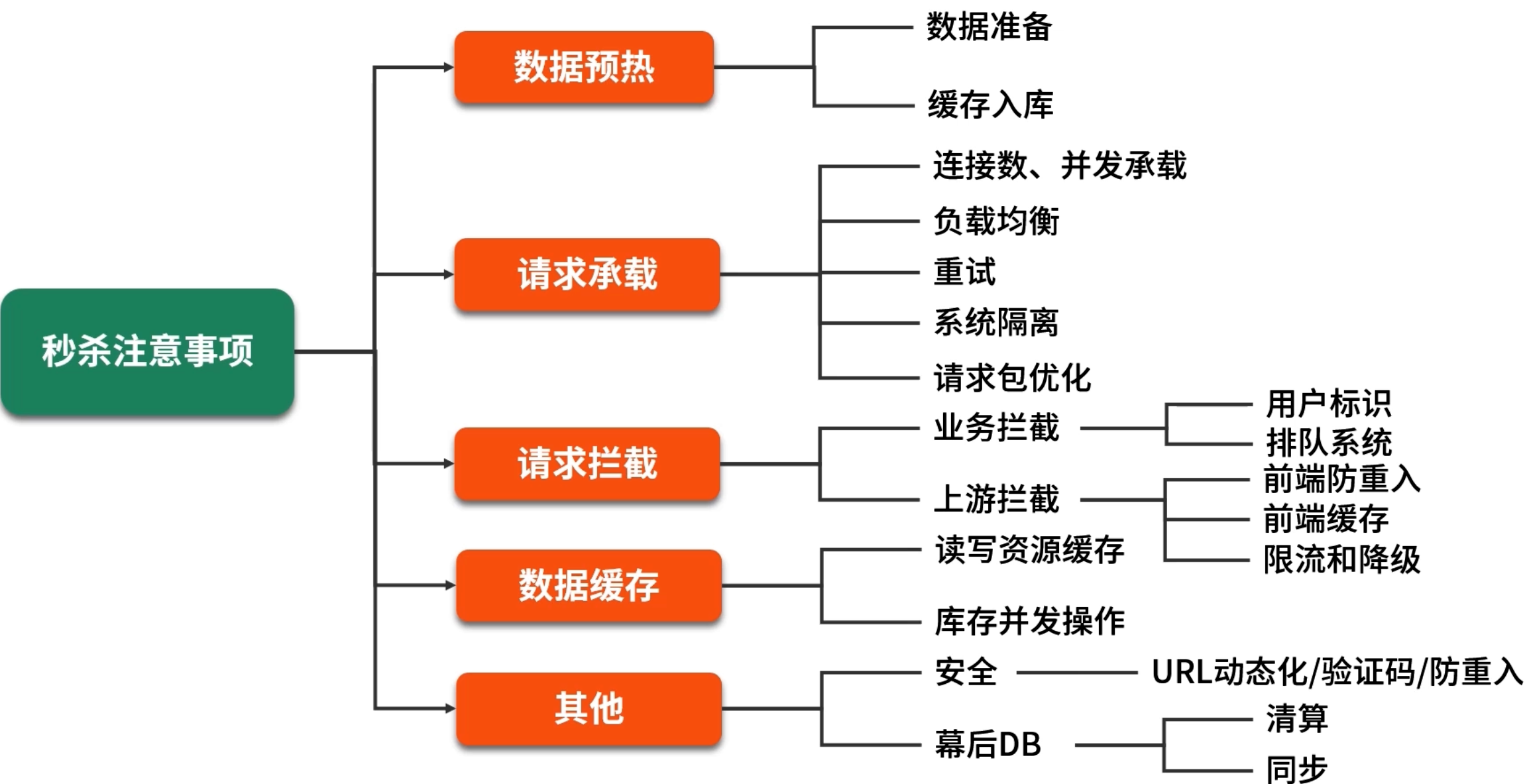
5. Lua 脚本实现原子库存扣减
在秒杀的核心环节——并发库存扣减 中,如果简单地在 Java 端分两次发命令:

HMGET seckill:goods:{id} total alloc—— 获取原库存与已分配数- 比较后再发
HINCRBY seckill:goods:{id} alloc {n}—— 扣减库存
此两次操作之间存在竞态:若两个线程同时 HMGET 返回相同结果,都认为库存足够,就会并发执行 HINCRBY,导致库存超卖。
为保证库存扣减的原子性,可将读取与更新合并到一个 Lua 脚本中,由 Redis 单线程保证执行期间无并发干扰。
5.1 准备阶段:数据预加载
在秒杀开始前,将商品库存信息存入 Redis Hash:
static final String GOODS_KEY = "seckill:goods:%s";public void prepare(String goodsId, int total) {String key = String.format(GOODS_KEY, goodsId);Map<String, Integer> map = new HashMap<>();map.put("total", total); // 可售库存map.put("start", 0); // 秒杀是否开始(0:未开始,1:已开始)map.put("alloc", 0); // 已分配数量redisTemplate.opsForHash().putAll(key, map);
}
total:秒杀商品的总库存;start:秒杀开关(0 表示未开始,秒杀开始后置为 1);alloc:已经分配给用户的库存记录。
5.2 Lua 脚本原理与关键命令
-- KEYS[1]:Hash 键名,例如 "seckill:goods:1001"
-- ARGV[1]:本次请求需扣减的数量 (n)local falseRet = "0"
local n = tonumber(ARGV[1])
local key = KEYS[1]-- 一次性获取 total 和 alloc
local goodsInfo = redis.call("HMGET", key, "total", "alloc")
local total = tonumber(goodsInfo[1])
local alloc = tonumber(goodsInfo[2])-- 若 total 为空,则商品不存在或未预加载,返回 0
if not total thenreturn falseRet
end-- 若还剩余库存(total >= alloc + n),则执行原子扣减
if total >= alloc + n thenlocal ret = redis.call("HINCRBY", key, "alloc", n)return tostring(ret)
end-- 库存不足,返回 0
return falseRet
HMGET key total alloc:同时读取库存和已分配数量;HINCRBY key alloc n:在满足条件时原子地增加alloc;- 最终返回最新的
alloc值(若库存不足或 key 不存在,则返回"0"表示秒杀失败)。
5.3 Java 端执行示例
// 在 Spring 应用中定义 Lua 脚本Bean
@Bean
public DefaultRedisScript<Long> seckillScript() {DefaultRedisScript<Long> script = new DefaultRedisScript<>();script.setScriptText("local falseRet = '0'\n" +"local n = tonumber(ARGV[1])\n" +"local key = KEYS[1]\n" +"local goodsInfo = redis.call('HMGET', key, 'total', 'alloc')\n" +"local total = tonumber(goodsInfo[1])\n" +"local alloc = tonumber(goodsInfo[2])\n" +"if not total then return falseRet end\n" +"if total >= alloc + n then\n" +" local ret = redis.call('HINCRBY', key, 'alloc', n)\n" +" return tostring(ret)\n" +"end\n" +"return falseRet");script.setResultType(Long.class);return script;
}// 秒杀接口调用
public int secKill(String goodsId, int quantity) {String key = String.format(GOODS_KEY, goodsId);// ARGV[1] 放入要扣减的数量Long result = redisTemplate.execute(seckillScript, Collections.singletonList(key), String.valueOf(quantity));return result.intValue(); // 0 表示失败,否则返回当前 alloc 数量
}
- 使用
redisTemplate.execute(script, keys, args)调用 Lua,Redis 会原子执行整个脚本; - 若返回值 > 0 且 ≤ total,则秒杀成功,否则库存不足。
5.4 多线程模拟与测试结果
在测试中,启动 1000 个并发线程对同一商品(库存 100)进行秒杀:
// testSeckill 方法示例
ExecutorService pool = Executors.newFixedThreadPool(200);
String goodsId = "1001";
prepare(goodsId, 100);CountDownLatch latch = new CountDownLatch(1000);
for (int i = 0; i < 1000; i++) {pool.execute(() -> {int alloc = secKill(goodsId, 1);// alloc > 0 表示本次秒杀成功if (alloc > 0 && alloc <= 100) {System.out.println("成功抢购,当前 alloc = " + alloc);}latch.countDown();});
}
latch.await();
pool.shutdown();
输出中可以看到仅有 100 条“成功抢购”记录,其他线程均返回 0,证明 Lua 脚本在高并发下保证了原子性与库存不超卖。
6. 分布式缓存的三大常见问题
引入分布式缓存后,系统性能大为改善,但也会产生新的挑战,主要集中在缓存穿透、缓存击穿、缓存雪崩 三个方面。
6.1 缓存穿透
定义:用户请求的 key 在缓存中不存在,同时后端数据库也返回 null,这类请求每次都会绕过缓存,直接落到数据库,从而造成数据库压力。
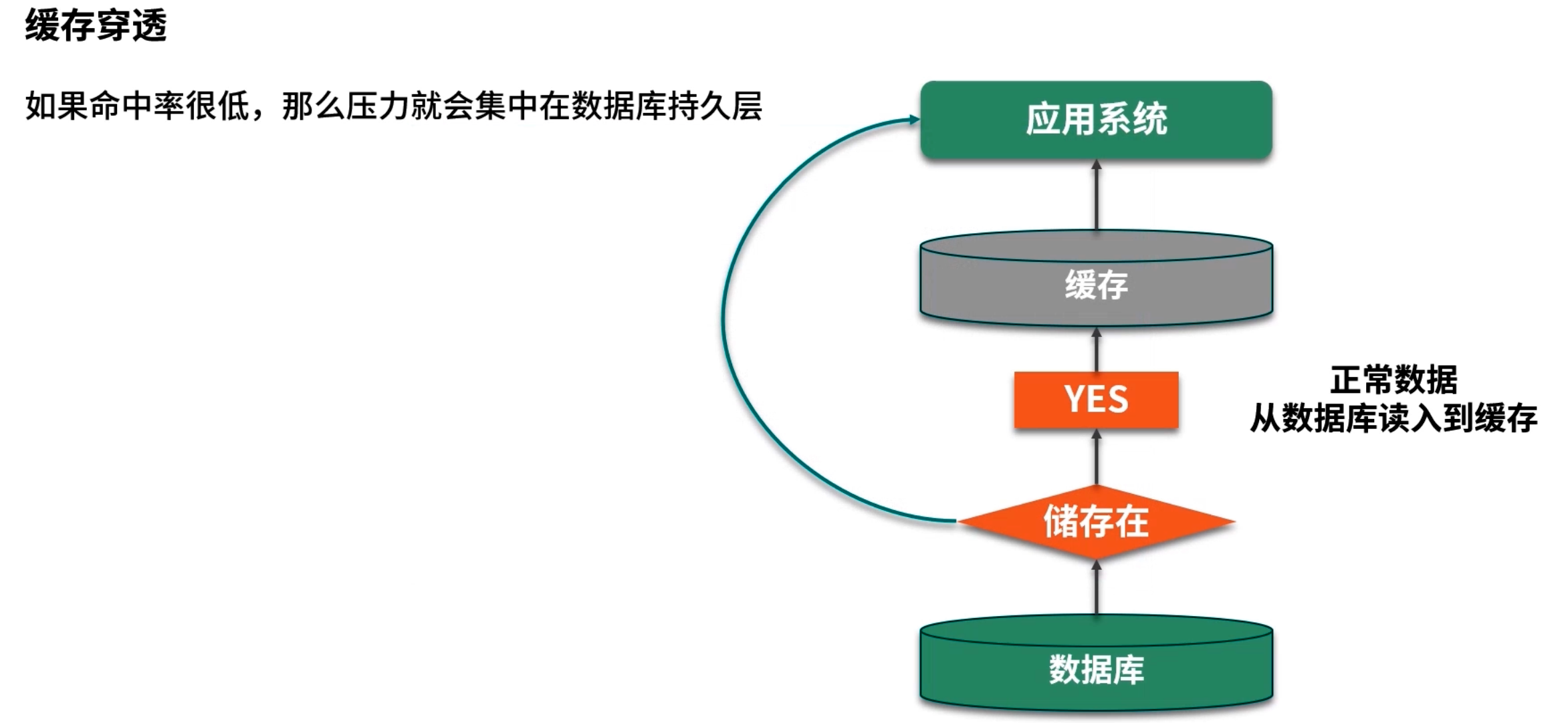
典型场景:某些接口允许外部传入任意 ID 或者用户自定义的数据,如果攻击者不断请求不存在的 key,就会触发缓存穿透。
解决方案:
-
缓存空值
- 当数据库未命中某个 key(即数据不存在)时,将 key 与空值(例如
null或"__NULL__")一起放入缓存,并设置一个较短的过期时间(如 1~5 分钟); - 下次访问相同 key 时,先命中缓存直接返回 null,避免落到数据库。
- 当数据库未命中某个 key(即数据不存在)时,将 key 与空值(例如
-
布隆过滤器(Bloom Filter)
- 在服务启动或后台维护时,将所有可能的合法 key(例如所有用户 ID、所有商品 ID)进行哈希后放入布隆过滤器;
- 请求到来时,先通过布隆过滤器判断该 key 是否“可能存在”;若返回“不存在”,直接返回 404;否则再访问缓存或数据库;
- 布隆过滤器可能产生误判(将不存在的 key 判定为存在),但绝不会漏判;适合大规模合法 key 场景。
6.2 缓存击穿
定义:某个热点 key 的缓存和数据库同时设置了过期时间,当它在某个时刻过期后,恰逢大量并发请求同时访问,发现缓存失效,都会并发去数据库拉取,造成数据库瞬间负载过大。
防范措施:
-
热点 key 永不过期
- 对于非常重要的热点数据(如用户会话、热门商品),可直接不设置过期时间或设置极长的过期时间;
- 在数据变更时手动调用
@CacheEvict或redisTemplate.delete(key)进行失效处理。
-
互斥锁 / 互斥加载
- 当缓存失效时,第一批请求可以获取到分布式锁(如 Redisson 的
RLock),去数据库加载并刷新缓存;其他并发请求看到缓存为空,则先尝试获取锁失败后等待或轮询,直到缓存被刷新; - 这样只有一个线程去数据库加载,避免过多并发直接访问数据库。
- 当缓存失效时,第一批请求可以获取到分布式锁(如 Redisson 的
-
提前重建缓存(错峰刷新)
- 在热点缓存接近过期时(例如剩余 TTL < 10s),可以异步或通过后端定时任务主动刷新缓存,而不让缓存真正过期后再由用户触发回源加载;
6.3 缓存雪崩
定义:当大规模缓存数据同时失效或缓存集群出现故障时,海量请求会全部落到后端数据库或业务系统,导致数据库或业务系统宕机,形成级联效应。
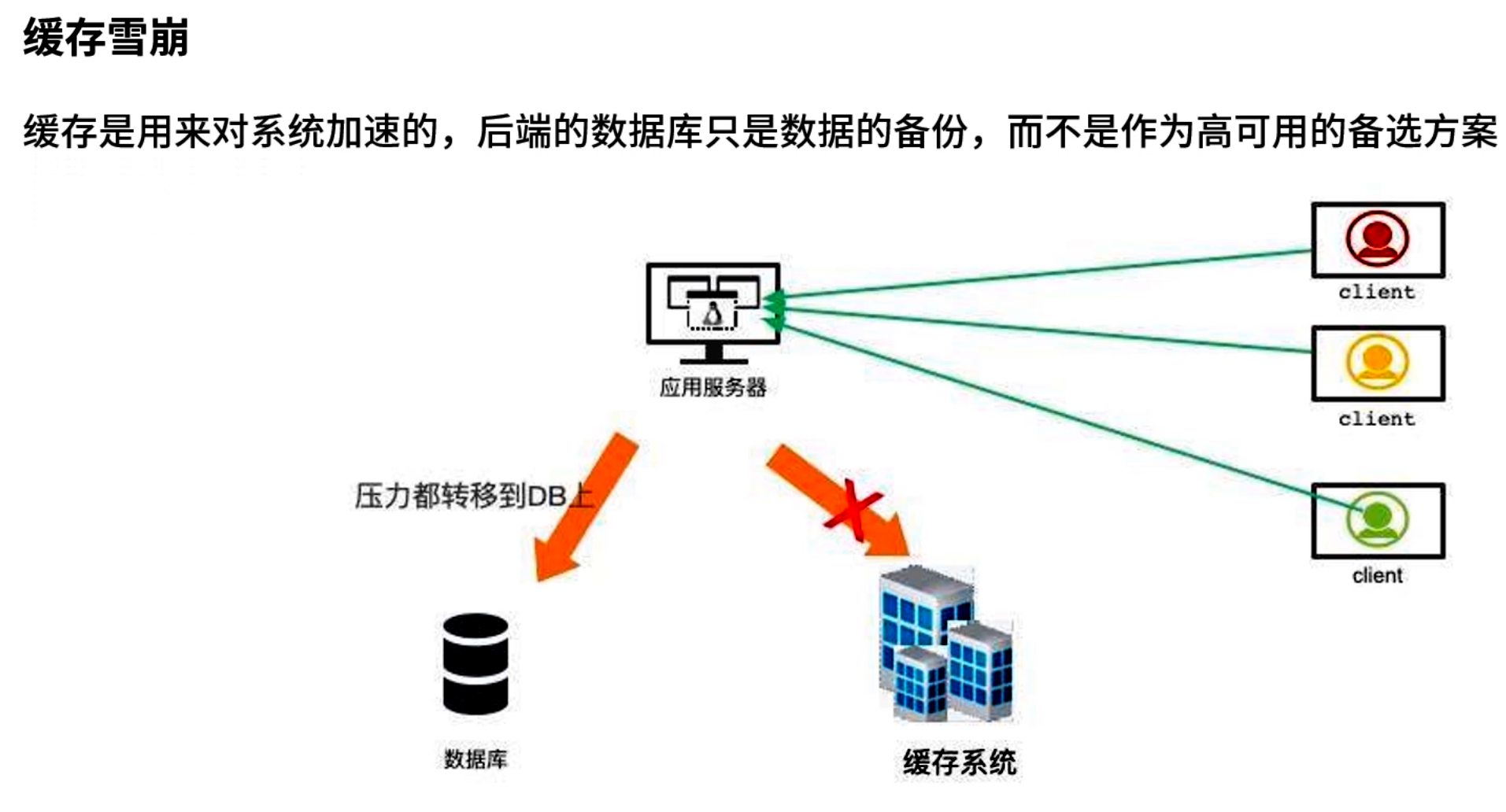
防御策略:
-
多级缓存 & 自动降级
- 引入多级缓存体系:客户端本地缓存(Caffeine 等)→ Redis 分布式缓存 → 数据库;
- 如果 Redis 宕机,可先通过本地缓存(TTL 非常短)继续服务,或直接限流降级;
-
缓存过期时间的随机化
- 不要让所有 key 同时过期,可在
expireTime = baseTime + random(0 ~ jitter)之上增加一个随机值,避免集中失效。
- 不要让所有 key 同时过期,可在
-
高可用 Redis 部署
- 使用 Redis Cluster 模式,每个分片做主从复制;或使用哨兵模式保证自动故障转移;
- 若某个节点仍然发生故障,可通过应用限流策略阻止请求全部涌向数据库;
-
请求限流与降级
- 在缓存层或应用层引入限流(如令牌桶、漏桶),控制最大 QPS;
- 缓存宕机时,先返回缓存降级响应(如固定的“系统繁忙”提示),从而保护下游数据库。
7. 缓存一致性
使用分布式缓存时,最常见的难题是 缓存与数据库之间的数据不一致。主要涉及对同一资源的四种操作:写入、更新、读取、删除。
7.1 不一致场景举例
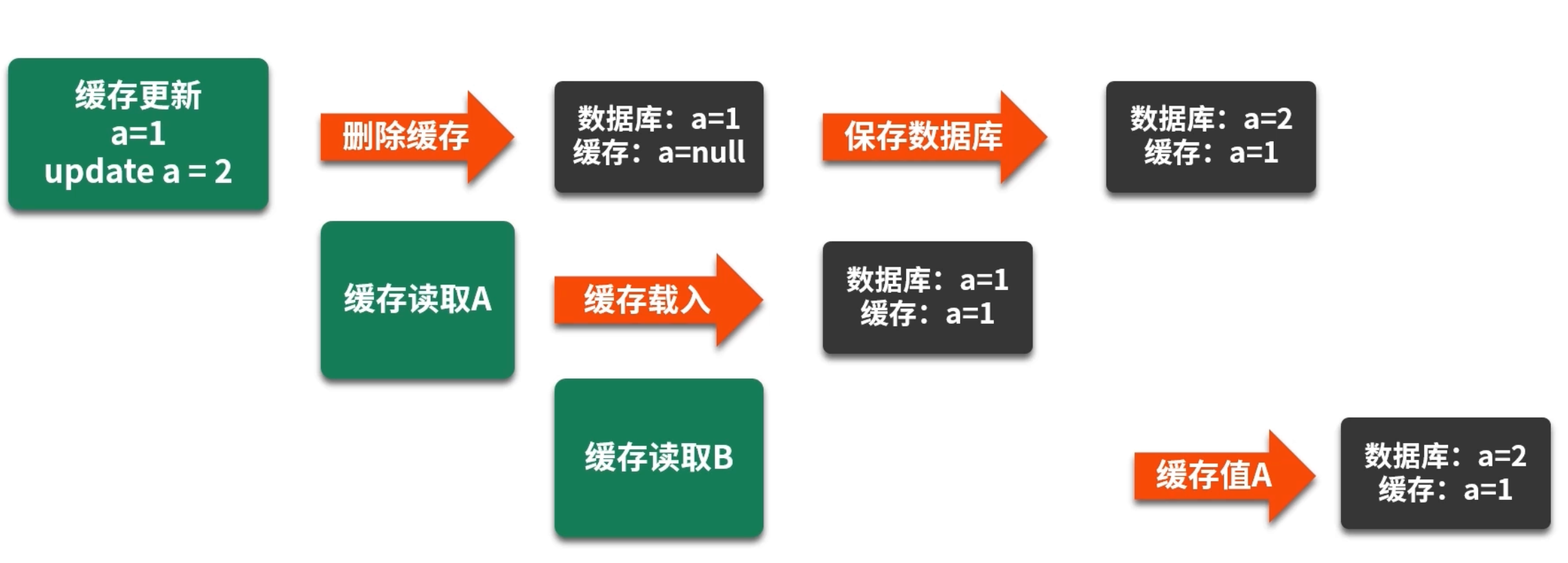
- 写入不一致:先将数据写入缓存,再写入数据库;若在写入数据库前应用崩溃,缓存中已有数据,而数据库没有,造成读到旧数据的风险。
- 更新不一致:更新数据库后再更新缓存,若更新缓存操作失败,会导致缓存与数据库不一致;反之,若先更新缓存再更新数据库,数据库未更新时,缓存已更新,读到缓存会读到新值,却数据未入库。
- 读取不一致:若读取先于更新完成,可能先读到老缓存,再执行更新,最终数据库已变更但缓存未更新。
- 删除不一致:删除数据库后再删除缓存,若删除缓存失败,后续读取会访问到已失效的缓存;若删除数据库前删除缓存,可能先失效缓存,然后数据库更新失败,导致缓存中再写入过期数据。
7.2 常见解决思路
-
分布式锁
- 在更新或删除某个 key 时,为该 key 加分布式锁(例如 Redisson 的
RLock或 Redlock); - 修改缓存与数据库操作都在锁内完成,释放锁后其他并发请求才可执行读/写;
- 缺点是:锁的性能开销、可能导致热点锁竞争,以及锁超时后引发的并发问题。
- 在更新或删除某个 key 时,为该 key 加分布式锁(例如 Redisson 的
-
Cache Aside Pattern(旁路缓存)
-
读取流程:先读取缓存,若命中则返回;若未命中,则从数据库加载并写回缓存后再返回;
-
写入流程:先更新数据库(事务提交成功后),再显式删除缓存,这样下一次读取会重新从数据库加载;
-
该模式最常用且易理解,不需要使用分布式锁。但在高并发更新场景下仍有短暂不一致窗口:
- 线程 A:更新数据库成功,将缓存删除;
- 线程 B:此时读取缓存,发现缓存为空,从数据库读取旧值并写入缓存;
- 线程 A:更新完成,数据库已更新为新值,但缓存已被线程 B 重新写回旧值;
- 导致数据库的新值被覆盖在缓存中,出现不一致。
-
常见改进:在更新完成后,延迟一段短暂时间(如几毫秒)再删除缓存,或者使用“先删除缓存,再更新数据库,再再删除缓存” 的“双删”策略。
-
-
消息通知同步
- 在数据库更新后,通过消息队列(如 RocketMQ、Kafka)发送“缓存失效”消息;
- 所有应用实例订阅该消息,收到后异步删除缓存;
- 优点在于异步解耦、高并发时可批量清理;缺点在于系统复杂度提升与消息中间件可靠性依赖。
-
读写分离+延迟双删
- 通过数据库读写分离,先将更新写到主库,再通过延迟任务或 binlog 通知刷新读库缓存;
- 采用“删除缓存 → 更新数据库 → 延迟删除缓存” 三步操作,常用于热点业务场景。
7.3 典型不一致场景示例
假设采用 Cache Aside Pattern,使用“先更新数据库→再删除缓存”方式:
时间线:
T1: User A 更新资源 X,执行数据库 UPDATE,UPDATE 成功。
T2: User B 读取资源 X,因缓存已过期(或从未缓存),从数据库读取到旧值(未更新前的数据),并写入缓存。
T3: User A 删除缓存中的 X 键。
此时缓存中已是旧值,但数据库中的 X 已经被更新。后续读取统统会读到错误的旧缓存而非新值,导致数据不一致。
解决方案示例:
-
双删策略:
// 更新流程 @Transactional public void updateResource(String id, ResourceDto dto) {// 1. 先删除缓存redisTemplate.delete("resource:" + id);// 2. 更新数据库resourceDao.update(id, dto);// 3. 延迟几 ms 后再删除缓存一次CompletableFuture.delayedExecutor(50, TimeUnit.MILLISECONDS).execute(() -> redisTemplate.delete("resource:" + id)); }延迟删除可保证在极短时间窗口内,即使有并发读写,也会在第二次删除缓存后将过期缓存清理干净。
8. 小结
主要围绕**分布式缓存(以 Redis 为代表)**展开:
-
分布式缓存 vs 堆内缓存
- 分布式缓存集中管理,适合多实例共享、大容量场景;
- 堆内缓存延迟更低,但不易扩展,管理成本较高,容易出现多份缓存一致性问题。
-
Redis 与 Memcached 对比
- Redis 功能更全面:多数据结构、持久化、Lua 脚本、发布/订阅、高可用集群;
- Memcached 仅支持简单 String 缓存,易用但功能受限,现已逐渐被 Redis 取代。
-
Spring Boot 中使用 Redis
RedisTemplate:灵活调用各种命令,包括 Lua;SpringCache注解:使用@Cacheable、@CachePut、@CacheEvict等快速实现缓存逻辑;- 推荐在性能敏感或业务逻辑较复杂场景下,直接使用
RedisTemplate进行底层细粒度控制。
-
秒杀业务与 Lua 原子脚本
- 秒杀场景下流量瞬间爆发,数据库难以承载;
- 利用 Redis 内存存储、Lua 脚本实现“读+判断+写”一步到位的原子扣减,避免并发超卖;
- Java 端通过
redisTemplate.execute()调用 Lua,可在高并发下稳定支持库存控制。
-
分布式缓存常见问题与防范
- 缓存穿透:用空值缓存或布隆过滤器;
- 缓存击穿:热点 key 过期 → 并发访问 → 多次回源 → 数据库压力 → 互斥锁/互斥加载/错峰加载;
- 缓存雪崩:大规模缓存同时失效或缓存集群故障 → 数据库洪峰 → 措施包括高可用 Redis Cluster、请求限流与本地降级、过期时间随机化;
-
缓存一致性
- 缓存与数据库双写或双删都有潜在不一致风险;
- 常见思路:分布式锁、Cache Aside Pattern、消息通知同步、双删+延迟删除等;
- 生产环境下需根据业务一致性要求、系统复杂度与现场流量特点综合选择。

相关文章:
性能优化 - 案例篇:数据一致性
文章目录 Pre引言1. 分布式缓存概念2. Redis 与 Memcached 区别概览3. Spring Boot 中使用 Redis3.1 引入依赖与常用客户端3.2 RedisTemplate 的基本用法3.3 Spring Cache 注解式缓存 4. 秒杀业务简介及挑战5. Lua 脚本实现原子库存扣减5.1 准备阶段:数据预加载5.2 …...

Spring框架学习day6--事务管理
Spring事务管理 Spring事务管理是在AOP的基础上,当我们的方法完全执行成功后,再提交事务,如果方法中有异常,就不提交事务 Spring中的事务管理有两种方式: 1.编程式事务 需要我们在业务代码中手动提交 2.声明式…...
免费酒店管理系统+餐饮系统+小程序点餐——仙盟创梦IDE
酒店系统主屏幕 房间管理 酒店管理系统的房间管理,可实现对酒店所有房间的实时掌控。它能清晰显示房间状态,如已预订、已入住、空闲等,便于高效安排入住与退房,合理分配资源,提升服务效率,保障酒店运营有条…...
Git企业级项目管理实战
目录 1. 准备工作 2. 添加成员 2.1 添加企业成员 2.2 添加项目成员 2.3 添加仓库开发人员 3. 开发场景 - 基于git flow模型的实践 3.1 新需求加入 3.2 修复测试环境 Bug 3.3 修改预发布环境Bug 3.4 修改正式环境 Bug 3.5 紧急修复正式环境 Bug 4. 拓展阅读 4.1 其…...
【实例】事业单位学习平台自动化操作
目录 一、创作背景: 二、实现逻辑: 三、代码分析【Deepseek分析】: 1) 主要功能 2)核心组件 2.1 GUI界面 (AutomationApp类) 2.2 浏览器自动化 2.3 平台特定处理 3) 关键技术 4)代码亮点 5)总结 四、运行截图: 五、程序代码: 特别声明:***本代码仅限编程学…...

4.8.3 利用SparkSQL统计每日新增用户
在本次实战中,我们的任务是利用Spark SQL统计每日新增用户数。首先,我们准备了用户访问历史数据,并将其上传至HDFS。然后,通过Spark的交互式编程环境,我们读取了用户文件并将其转换为结构化的DataFrame。接着ÿ…...

创建ipv6 only和ipv6+ip4的k8s集群的注意事项
关键字 : CNI calico vxlan flannel ipv6-only ipv6ipv4 在搭建ipv6-only或ipv6ipv4的k8s集群时,在worker节点加入集群后,发现worker节点上的CNI启动失败。 以下是calico的启动失败情况 : kubectl get pod -A输出如下 : NAMESPACE NAME …...

Qt概述:基础组件的使用
1. Qt框架简介 Qt是一个跨平台的C图形用户界面应用程序开发框架,它包含了丰富的GUI组件和强大的功能库。本次示例代码展示了Qt的几个核心概念: QMainWindow:主窗口类,提供标准的应用程序框架**信号与槽**机制:Qt的核…...

判断使用什么技术来爬取数据详细讲解
判断目标网站使用哪种数据加载形式是爬虫开发的第一步,也是最关键的一步。以下是系统化的诊断方法和步骤: 核心诊断流程 (使用浏览器开发者工具 - Chrome/Firefox为例) 初始观察 (肉眼判断) 页面加载后数据是否立刻可见? 是 → 可能是静态HTM…...
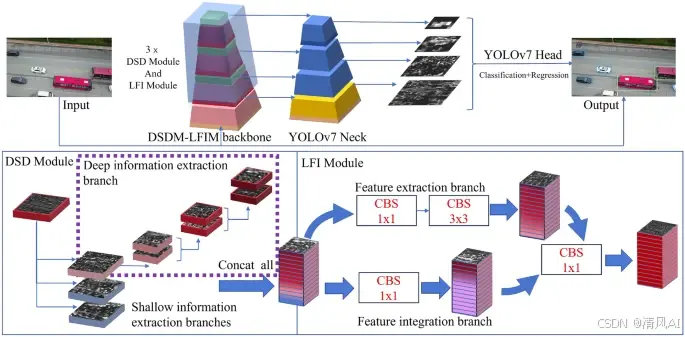
YOLOV7改进之融合深浅下采样模块(DSD Module)和轻量特征融合模块(LFI Module)
目录 一、研究背景 二. 核心创新点 2.1 避免高MAC操作 2.2 DSDM-LFIM主干网络 2.3 P2小目标检测分支 3. 代码复现指南 环境配置 关键修改点 4. 实验结果对比 4.1 VisDrone数据集性能 4.2 边缘设备部署 4.3 检测效果可视化 5. 应用场景 …...

【仿生机器人】仿生机器人认知-情感系统架构设计报告
来自 gemini 2.5 1. 执行摘要 本报告旨在为仿生机器人头部设计一个全面的认知-情感软件架构,以实现自然、情感智能的互动。拟议的架构将使机器人能够像人类一样,动态生成情绪、进行复杂的表情表达(包括情绪掩饰)、拥有强大的记忆…...

数学建模期末速成 多目标规划
内容整理自2-6-2 运筹优化类-多目标规划模型Python版讲解_哔哩哔哩_bilibili 求有效解的几种常用方法 线性加权法√ 根据目标的重要性确定一个权重,以目标函数的加权平均值为评价函数,使其达到最优。ɛ约束法 根据决策者的偏好,选择一个主要…...

常见ADB指令
目录 1. 设备连接与管理 2. 应用管理 3. 文件操作 4. 日志与调试 5. 屏幕与输入控制 6. 高级操作(需Root权限) 7. 无线调试(无需USB线) 常用组合示例 注意事项 以下是一些常用的 ADB(Android Debug Bridge&a…...

IoTGateway项目生成Api并通过swagger和Postman调用
IoTGateway项目生成Api并通过swagger和Postman调用-CSDN博客...

sl4j+log4j日志框架
sl4jlog4j日志框架 slf4j (Simple Loging Facade For Java) 即它仅仅是一个为 Java 程序提供日志输出的统一接口,并不是一个具体的日志实现方案,所以单独的 slf4j 是不能工作的,必须搭配其他具体的日志实现方案(例如:…...

小白的进阶之路系列之九----人工智能从初步到精通pytorch综合运用的讲解第二部分
张量是PyTorch中的核心数据抽象。这个交互式笔记本提供了一个深入的介绍torch. Tensor 类., 首先,让我们导入PyTorch模块。我们还将添加Python的数学模块来简化一些示例。 import torch import math创建张量 创建张量最简单的方法是调用torch.empty(): x = torch.empty(…...

深度学习与神经网络 前馈神经网络
1.神经网络特征 无需人去告知神经网络具体的特征是什么,神经网络可以自主学习 2.激活函数性质 (1)连续并可导(允许少数点不可导)的非线性函数 (2)单调递增 (3)函数本…...
NLP学习路线图(十四):词袋模型(Bag of Words)
在自然语言处理(NLP)的广阔天地中,词袋模型(Bag of Words, BoW) 宛如一块历经岁月沉淀的基石。它虽非当今最耀眼的明星,却为整个领域奠定了至关重要的基础,深刻影响了我们让计算机“理解”文本的…...

Oracle数据库事务学习
目录 一、什么是事务,事务的作用是什么 二、事务的四大特性(ACID) 1. 原子性(Atomicity) 2. 一致性(Consistency) 3. 隔离性(Isolation) 4. 持久性(Durability) 三、关于锁的概念——表锁、行锁、死锁、乐观/悲观锁、 1.行锁 2.表锁 3.死锁 4.乐观锁 5.…...

MySQL 全量 增量备份与恢复
目录 前言 一、MySQL 数据库备份概述 1. 数据备份的重要性 2. 数据库备份类型 2.1 从物理与逻辑的角度分类 2.2 从数据库的备份策略角度分类 3. 常见的备份方法 二、数据库完全备份操作 1. 物理冷备份与恢复 1.1 备份数据库 1.2 恢复数据库 2. mysqldump 备份与恢复…...

【仿生机器人系统设计】涉及到的伦理与安全问题
随着材料科学、人工智能与生物工程学的融合突破,仿生机器人正从科幻走向现实。它们被寄予厚望——在医疗康复、老年照护、极端环境作业甚至社交陪伴等领域释放巨大价值。然而,当机器无限趋近于“生命体”,其设计过程中潜伏的伦理与安全迷宫便…...

NodeJS全栈WEB3面试题——P5全栈集成与 DApp 构建
5.1 如何实现一个完整的 Web3 登录流程(前端 后端)? ✅ 核心机制:钱包签名 后端验签 Web3 登录是基于“消息签名”来验证用户链上身份,而非传统用户名/密码。 💻 前端(使用 MetaMask&#…...
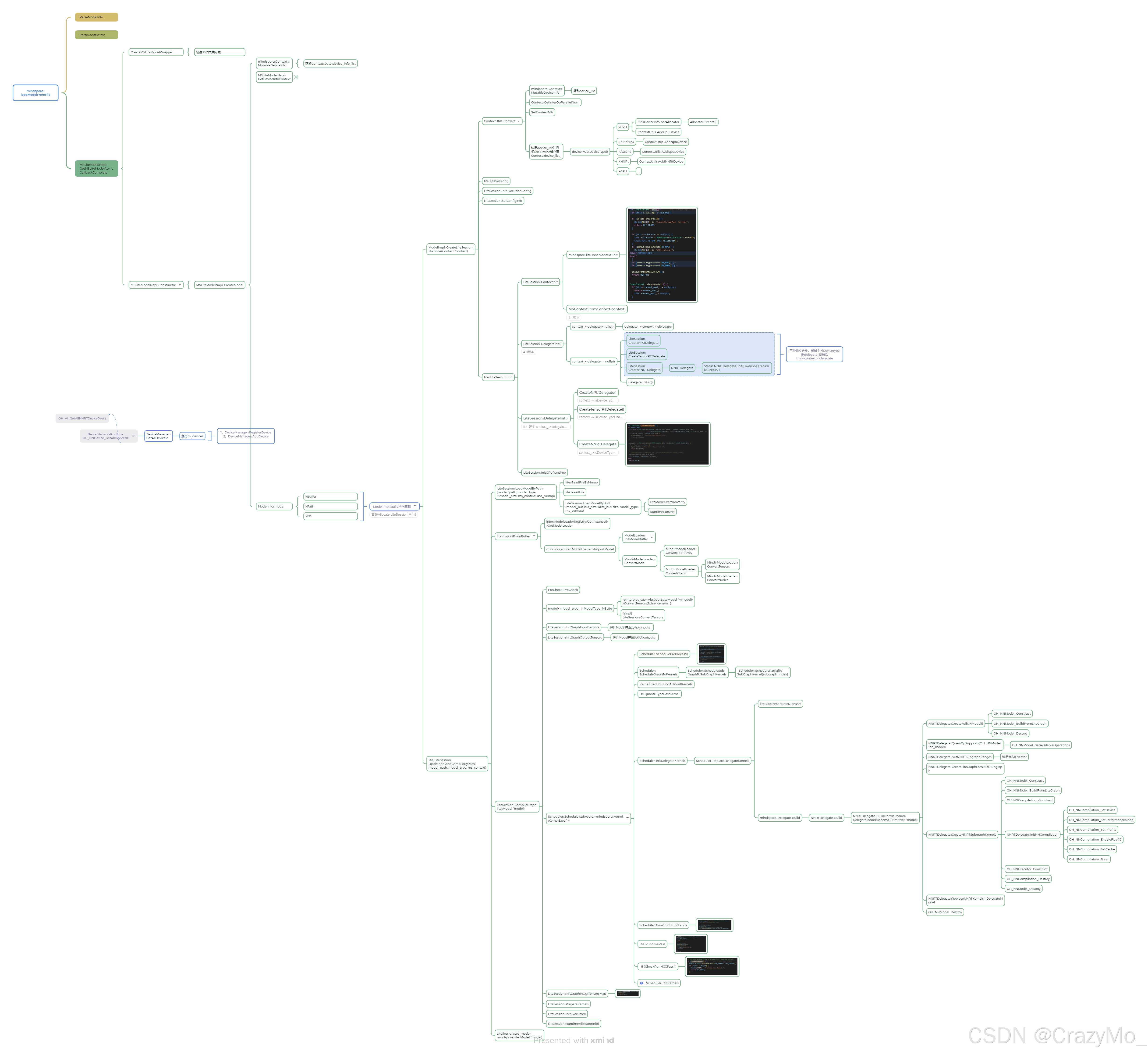
鸿蒙进阶——Mindspore Lite AI框架源码解读之模型加载详解(一)
文章大纲 引言一、模型加载概述二、核心数据结构三、模型加载核心流程 引言 Mindspore 是一款华为开发开源的AI推理框架,而Mindspore Lite则是华为为了适配在移动终端设备上运行专门定制的版本,使得我们可以在OpenHarmony快速实现模型加载和推理等功能&…...

【数据结构】图论核心算法解析:深度优先搜索(DFS)的纵深遍历与生成树实战指南
深度优先搜索 导读:从广度到深度,探索图的遍历奥秘一、深度优先搜索二、算法思路三、算法逻辑四、算法评价五、深度优先生成树六、有向图与无向图结语:深潜与回溯,揭开图论世界的另一面 导读:从广度到深度,…...

Mysql数据库 索引,事务
Mysql数据库 索引,事务 一.索引 简介 索引是数据库中用于提高查询效率的一种数据结构,它通过预先排序和存储特定列的值,帮助数据库快速定位符合条件的数据行,避免全表扫描。以下是关于索引的核心简介: 1. 核心作用…...
RESTful APInahamcon Fuzzies-write-up
RESTful API 路径详解 RESTful API(Representational State Transfer)是一种 基于 HTTP 协议的 API 设计风格,它通过 URL 路径 和 HTTP 方法(GET、POST、PUT、DELETE 等)来定义资源的访问方式。它的核心思想是 将数据…...

安装DockerDocker-Compose
Docker 1、换掉关键文件 vim /etc/yum.repos.d/CentOS-Base.repo ▽ [base] nameCentOS-$releasever - Base - Mirrors Aliyun baseurlhttp://mirrors.aliyun.com/centos/$releasever/os/$basearch/ gpgcheck1 enabled1 gpgkeyhttp://mirrors.aliyun.com/centos/RPM-GPG-KEY-C…...

2025年机械化设计制造与计算机工程国际会议(MDMCE 2025)
2025年机械化设计制造与计算机工程国际会议(MDMCE 2025) 2025 International Conference on Mechanized Design, Manufacturing, and Computer Engineering 一、大会信息 会议简称:MDMCE 2025 大会地点:中国贵阳 审稿通知&#…...

Java生态中的NLP框架
Java生态系统中提供了多个强大的自然语言处理(NLP)框架,以下是主要的NLP框架及其详细说明: 1、Apache OpenNLP 简介:Apache OpenNLP是Apache软件基金会的开源项目,提供了一系列常用的NLP工具。 主要功能: …...

NVM,Node.Js 管理工具
node_mirror: https://npmmirror.com/mirrors/node/ npm_mirror: https://npmmirror.com/mirrors/npm/ 一、什么是 NVM? NVM 是一个命令行工具,允许你在同一台机器上安装、切换和管理多个 Node.js 版本,解决项目间版本冲突问题。 二、安装 …...