【深度学习】12. VIT与GPT 模型与语言生成:从 GPT-1 到 GPT4
VIT与GPT 模型与语言生成:从 GPT-1 到 GPT4
本教程将介绍 GPT 系列模型的发展历程、结构原理、训练方式以及人类反馈强化学习(RLHF)对生成对齐的改进。内容涵盖 GPT-1、GPT-2、GPT-3、GPT-3.5(InstructGPT)、ChatGPT 与 GPT-4,并简要提及 Vision Transformer 的演化。
1. GPT 模型的原理
Transformer 架构中包含 Encoder 与 Decoder 两部分。
- 如果我们只需要处理输入(如 BERT),可以去掉 Decoder;
- 如果我们只生成输出(如 GPT),可以只保留 Decoder。
GPT 是一种只使用 Transformer Decoder 堆叠结构的模型,其训练目标是根据前文预测下一个词,即语言建模任务:
给定前缀 { x 1 , x 2 , . . . , x t } \{x_1, x_2, ..., x_t\} {x1,x2,...,xt},模型预测 x t + 1 x_{t+1} xt+1。
2. GPT 与 ELMo/BERT 的比较
| 模型 | 参数量 | 架构 | 特点 |
|---|---|---|---|
| ELMo | 94M | 双向 RNN | 上下文嵌入 |
| BERT | 340M | Transformer Encoder | 掩码语言模型 + 下一句预测 |
| GPT | 可变(取决于版本) | Transformer Decoder | 自回归语言模型 |
GPT 使用自回归机制,一个词一个词地生成结果,适合生成任务。
3. GPT-1:生成式预训练语言模型
GPT-1 的两大创新:
- 利用海量无标注文本进行预训练(语言建模);
- 对具体任务进行监督微调(分类、情感分析、蕴含等)。
这种预训练 + 微调范式,开启了 NLP 模型训练的新方向。
预训练目标是最大化:
log P ( t 1 , t 2 , . . . , t n ) = ∑ i = 1 n log P ( t i ∣ t 1 , . . . , t i − 1 ) \log P(t_1, t_2, ..., t_n) = \sum_{i=1}^{n} \log P(t_i | t_1, ..., t_{i-1}) logP(t1,t2,...,tn)=i=1∑nlogP(ti∣t1,...,ti−1)
微调目标是最大化:
log P ( y ∣ x 1 , x 2 , . . . , x n ) \log P(y | x_1, x_2, ..., x_n) logP(y∣x1,x2,...,xn)
其中 y y y 是标签。
特定于任务的输入转换:为了在微调期间对模型的体系结构进行最小的更改,将特定下游任务的输入转换为有序序列
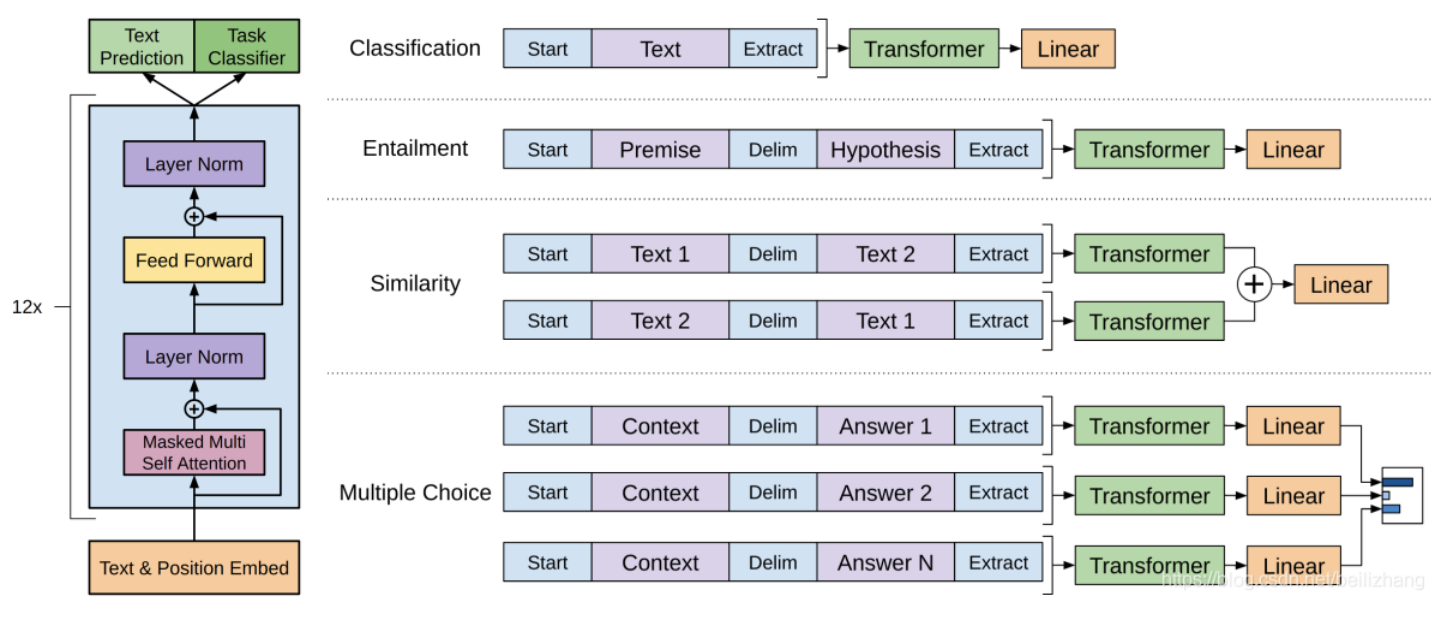
4. GPT-2:无监督多任务学习
GPT-2 扩展了 GPT-1:
- 更大的数据集(从 6GB 增长至 40GB);
- 更多的参数(117M → 1542M);
- 任务无需专门微调结构,只需修改输入格式,即可处理不同任务。
这一版本提出了“语言模型是无监督的多任务学习者”这一重要观点。
5. GPT-3:大规模语言模型与 Few-shot 能力
GPT-3 使用了 1750 亿参数,训练数据量达 45TB,计算资源非常庞大(28.5 万 CPU,1 万 GPU)。
其突破包括:
- 强大的 Few-shot / One-shot / Zero-shot 能力;
- 不再依赖下游微调,输入任务示例即可生成高质量输出。
其架构仍为标准 Transformer Decoder,无重大结构创新。
6. GPT-3.5 / InstructGPT:人类对齐
InstructGPT 引入了 人类反馈强化学习(RLHF),旨在让模型更符合用户意图:
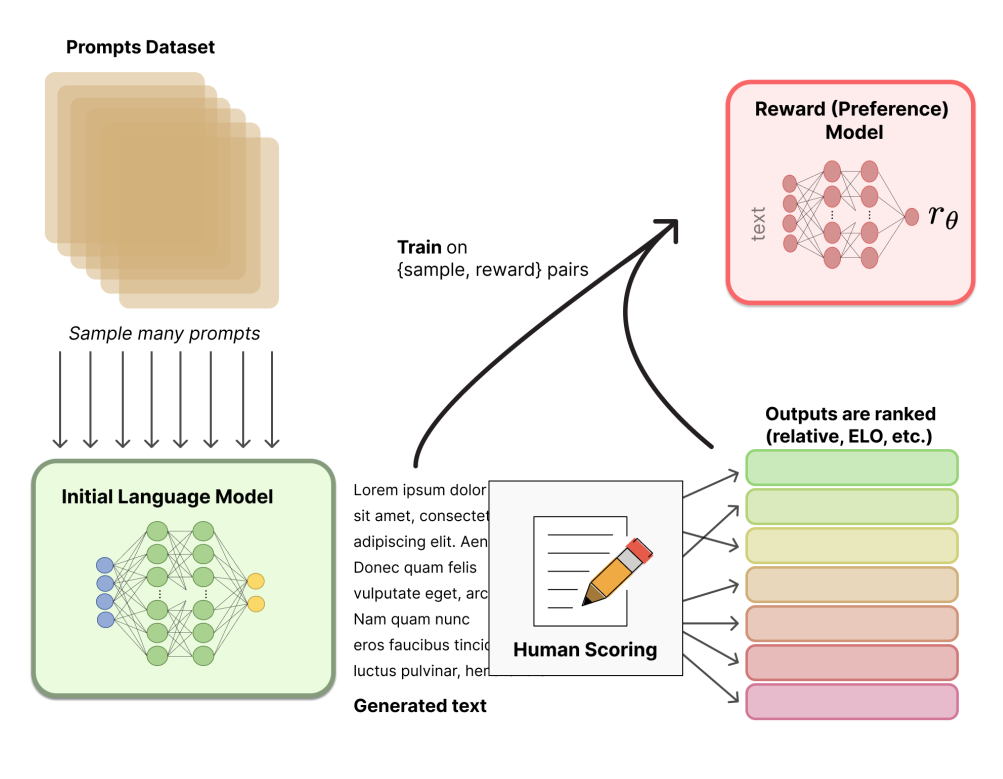
主要流程分为三阶段:
-
语言模型预训练(如 GPT-3);
RLHF一般使用预训练的LMs作为起点(例如,使用GPT-3)
这些预训练的模型可以根据额外的文本或条件进行微调,但这并不总是必要的。(人类增强文本可以用来调整人类的偏好)
-
奖励模型训练(由人工标注生成输出的排序);
Gathering data and training a Reward Model (RM)
- RLHF中的RM:接受文本序列并返回代表人类偏好的标量奖励
- RM的训练集:通过对提示进行采样并将其传递给初始LM以生成新文本,然后由人工注释器对其进行排序。
- 注意:标注对LM的输出进行排序,而不是直接给它们打分。
-
通过强化学习优化模型(使用 PPO 算法)。
-
示例提示
-
通过初始LM和RL策略(初始LM的副本)传递它
-
将策略的输出传递给RM来计算奖励,并使用初始LM和策略的输出来计算移位惩罚
-
采用奖惩结合的方式,通过PPO (Proximal policy)更新
-
结果是模型更加安全、有用且真实。
7. ChatGPT:对话能力与人类协作训练
ChatGPT 是 InstructGPT 的“对话版”,与用户进行多轮交流。
其训练包括:
- 初始监督微调:AI 教练扮演用户和助手角色生成对话;
- 奖励模型训练:对话中多个回复由 AI 教练排序评分;
- 最终强化学习:使用 PPO 方法优化回复。
它与 GPT-3.5 共享核心技术,但训练数据格式专为对话优化。
ChatGPT 的训练概述
ChatGPT 是 InstructGPT 的“兄弟模型”,主要目标是理解提示并生成详细回复。两者使用相同的 RLHF 方法,但 数据构造方式略有不同。
ChatGPT 的训练数据分两部分:
① 初始监督微调数据(Supervised Fine-tuning)
-
训练师(AI Trainers)模拟对话角色:
“The trainers acted as both users and AI assistants…”
即,训练师扮演用户与助手两个角色,人工构造对话数据集。
-
参考模型生成建议(model-written suggestions)**:
帮助训练师撰写回复,提高效率。 -
InstructGPT 数据集也被转换为对话格式并混入**新数据集中。
② 奖励模型数据(Reward Model,比较排序数据)
-
从 AI 训练师与模型的对话中提取**:
“Took conversations that AI trainers had with the chatbot”
-
随机抽取模型生成的回答**,训练师对多个候选答案进行排序打分,构成奖励数据。
总结:ChatGPT 相比 InstructGPT 的不同点
| 阶段 | InstructGPT | ChatGPT |
|---|---|---|
| 微调数据 | 任务式指令对 | 多轮对话,训练师模拟双方 |
| 奖励数据 | 人类写的参考回复 | 人类对多轮对话排序打分 |
8. GPT-4:多模态与推理能力提升
GPT-4 相较于 GPT-3.5 主要提升:
- 更强的创造力与推理能力;
- 多模态输入(文本+图像);
- 更长的上下文处理能力(约 25,000 字);
- 在专业考试中达到人类水平。
其方法未完全公开,但大体基于 ChatGPT 和 InstructGPT 技术演进。
9. Emergent Ability 与 CoT
Emergent Ability(涌现能力) 是指模型规模达到一定程度后,出现新的、未显式训练出的能力。
突发能力是指模型从原始训练数据中自动学习和发现新的高级特征和模式的能力。
Chain of Thought(CoT) 是一种通过 prompt 引导模型“逐步推理”的技巧,可大幅提升逻辑与数学任务表现。
生成思维链(一系列中间推理步骤)可以显著提高llm执行复杂推理的能力
10. Prompt Engineering 简介
Prompt 工程是通过设计输入提示来提升 LLM 输出质量的方法。
一个好的 Prompt 通常包含:
- 角色设定(如你是老师);
- 场景背景(如我们在深度学习课堂);
- 明确指令(解释 prompt engineering);
- 响应风格(应通俗易懂)。
常见方法包括:
- Chain of Thought;
- Self-consistency;
- Knowledge prompt 等。
11. GPT 系列演化总结
| 模型 | 技术路线 | 特点 |
|---|---|---|
| GPT-1 | 预训练 + 微调 | 引入生成式语言模型思想 |
| GPT-2 | 更大模型 | Few-shot、多任务泛化能力 |
| GPT-3 | 巨量参数 | 零样本/少样本迁移能力 |
| GPT-3.5 | RLHF | 对齐人类意图 |
| ChatGPT | 对话优化 | 多轮对话、任务跟踪 |
| GPT-4 | 多模态 + 长上下文 | 强逻辑推理、创造力 |
12. 未来方向:多模态与通用智能
未来的发展趋势将包括:
- 更强的多模态处理能力(语言 + 图像 + 音频);
- 更长文本记忆;
- 与人类交互更自然的代理;
- 融合强化学习、知识图谱等异构技术;
- 向通用人工智能(AGI)迈进。
GPT 是这一进化路线上的关键步骤。
13. Vision Transformer 的动机与背景
传统 CNN 利用局部感受野和共享权重处理图像,但难以建模全局依赖。
Transformer 本是为 NLP 设计,但其强大的全局建模能力被引入图像领域,催生了 Vision Transformer (ViT)。
核心观点:将图像切成 Patch,类比 NLP 中的 token,再用 Transformer 编码序列。
ViT 不再依赖卷积结构,是一种纯基于 Transformer 的视觉模型。
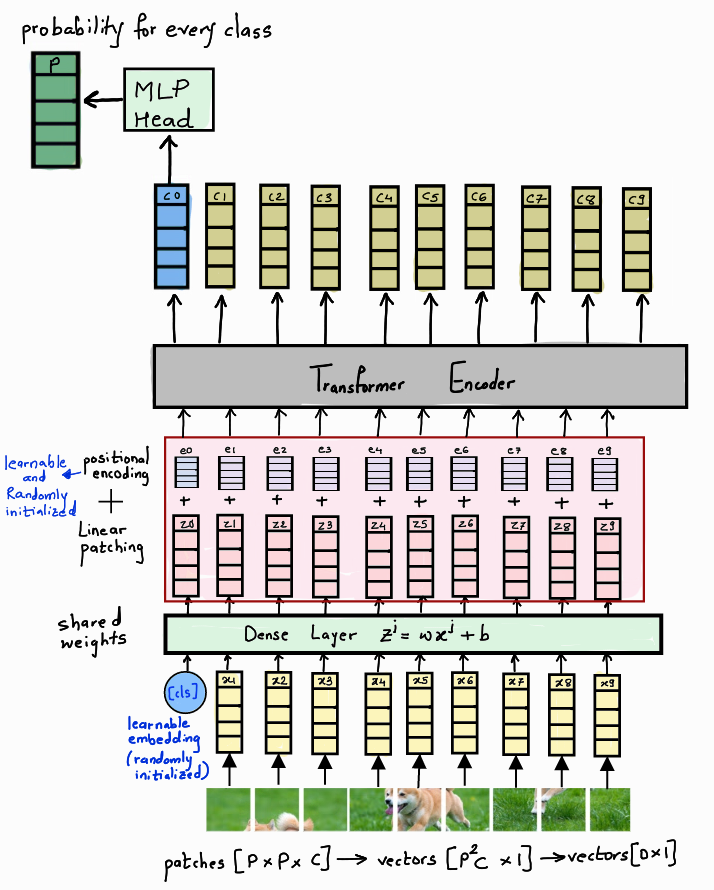
14. Vision Transformer 的核心构成(图像 → patch → 向量序列)
ViT 输入处理流程如下:
- 输入图像大小为 H × W × C H \times W \times C H×W×C;
- 将图像划分为 N N N 个 Patch,每个 Patch 为 P × P P \times P P×P;
- 展平每个 Patch 为长度为 P 2 ⋅ C P^2 \cdot C P2⋅C 的向量;
- 每个 Patch 映射为 D D D 维表示(通过全连接);
- 加入可学习的位置编码;
- 在序列前添加一个
[CLS]token,作为图像的全局表示; - 输入标准 Transformer Encoder。
最终分类结果由 [CLS] token 表示。
15. 多头注意力在 ViT 中的作用
与 NLP 中一样,ViT 中每个 token 都会计算 Query、Key、Value:
Q = X W Q , K = X W K , V = X W V Q = XW_Q,\quad K = XW_K,\quad V = XW_V Q=XWQ,K=XWK,V=XWV
然后进行多头注意力(Multi-Head Attention):
Attention ( Q , K , V ) = softmax ( Q K T d ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(dQKT)V
多个头并行计算后拼接,再映射到原始维度:
MultiHead ( X ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(X) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W_O MultiHead(X)=Concat(head1,...,headh)WO
注意力机制使模型可以捕捉图像各区域之间的长距离依赖。
16. 位置编码在 ViT 中的关键性
因为 Transformer 本身对输入顺序不敏感,ViT 必须引入 位置编码(Positional Encoding) 以告知 patch 的相对或绝对位置信息。
在 ViT 原始论文中,位置编码是 可学习的向量,维度与 patch 向量一致。
ViT 输入为:
z 0 = [ x class ; x p 1 ; x p 2 ; … ; x p N ] + E pos z_0 = [x_{\text{class}}; x_p^1; x_p^2; \dots; x_p^N] + E_{\text{pos}} z0=[xclass;xp1;xp2;…;xpN]+Epos
其中 x p i x_p^i xpi 表示第 i i i 个 patch 的向量表示, E pos E_{\text{pos}} Epos 是位置嵌入。
17. 类比 NLP 模型:ViT 与 BERT 输入结构对照
ViT 完全借鉴了 BERT 的编码形式:
- 使用
[CLS]token 获取图像全局信息; - patch 类比为 token;
- 添加位置编码。
| 模型 | 输入单位 | [CLS] | 位置编码 | Transformer 层 |
|---|---|---|---|---|
| BERT | token | 是 | 有 | Encoder Stack |
| ViT | patch | 是 | 有 | Encoder Stack |
因此,ViT 可视为一种图像版本的 BERT。
18. ViT 应用于图像分类任务(Encoder-only 模型)
ViT 的应用以图像分类为代表性任务。
其完整流程:
- 图像 → Patch → 向量序列;
- 加入位置编码;
- 输入多层 Transformer Encoder;
- 提取
[CLS]输出向量; - 使用全连接层进行分类预测。
ViT 是 Encoder-only 模型,不包含 Decoder,与 BERT 类似。
19. ViT 模型的训练策略与挑战
训练 ViT 时的挑战:
-
数据依赖性强,若使用小数据集(如 CIFAR-10),效果不如 CNN;
在JFT大数据集上才能略微强过ResNet
-
训练时间长,对正则化要求高;
-
无归纳偏置(不像 CNN 有平移不变性等先验),导致训练初期收敛慢。
解决方法包括:
- 使用 大规模预训练(如 ImageNet-21k);
- 引入 混合训练策略(如 Token Labeling、MixToken);
- 结合 CNN 结构(Hybrid ViT)。
20. 总结:ViT 与 GPT 的共同趋势
ViT 和 GPT 虽应用领域不同,但都体现了 Transformer 的优势:
- 使用统一的序列建模结构;
- 可用于多种下游任务(分类、生成、匹配);
- 都展现出随着模型规模扩大,性能提升的趋势;
- 需要大量数据与计算支持;
- 都引发了通用 AI 架构探索的热潮。
ViT 的出现标志着 Transformer 正式从 NLP 扩展至视觉领域,推动了多模态融合的发展。
相关文章:
【深度学习】12. VIT与GPT 模型与语言生成:从 GPT-1 到 GPT4
VIT与GPT 模型与语言生成:从 GPT-1 到 GPT4 本教程将介绍 GPT 系列模型的发展历程、结构原理、训练方式以及人类反馈强化学习(RLHF)对生成对齐的改进。内容涵盖 GPT-1、GPT-2、GPT-3、GPT-3.5(InstructGPT)、ChatGPT …...
常规算法学习
算法 1. 排序算法1. 归并排序1.1 普通归并排序1.2 优化后的归并排序(TimSort) 2. 插入排序2.1 直接插入排序2.2 二分插入排序2.3 成对插入排序 3. 快速排序3.1 单轴快速排序3.2 双轴快排 4. 计数排序 2. 树1. 红黑树(Red Black Treeÿ…...
Google 发布的全新导航库:Jetpack Navigation 3
前言 多年来,Jetpack Navigation 库一直是开发者的重要工具,但随着 Android 用户界面领域的发展,特别是大屏设备的出现和 Jetpack Compose 的兴起,Navigation 的功能也需要与时俱进。 今年的 Google I/O 上重点介绍了 Jetpack Na…...

Arbitrum Stylus 合约实战 :Rust 实现 ERC20
在《Arbitrum Stylus 深入解析与 Rust 合约部署实战》篇中,我们深入探讨了 Arbitrum Stylus 的核心技术架构,包括其 MultiVM 机制、Rust 合约开发环境搭建,以及通过 cargo stylus 实现简单计数器合约的部署与测试。Stylus 作为 Arbitrum Nitr…...

电脑故障基础知识
1.1 了解电脑故障 分类:分为软件故障(系统感染病毒、程序错误)和硬件故障(硬件物理损坏、接触不良)。 原因:人为操作失误、病毒破坏、工作环境恶劣(高温 / 灰尘)、硬件老化。 准备工…...

12.2Swing中JButton简单分析
JButton 的继承结构 public class JButton extends AbstractButton implements Accessible AbstractButton 是所有 Swing 按钮类(如 JToggleButton, JRadioButton, JCheckBox)的基类。它封装了按钮的核心逻辑:图标、文本、边框、动作事件等…...
内存管理--《Hello C++ Wrold!》(8)--(C/C++)--深入剖析new和delete的使用和底层实现
文章目录 前言C/C内存分布new和deletenew和delete的底层定位new表达式 内存泄漏作业部分 前言 在C/C编程中,内存管理是理解程序运行机制的核心基础,也是开发高效、稳定程序的关键。无论是局部变量的存储、动态内存的分配,还是对象生命周期的…...
)
JavaScript性能优化实战指南(详尽分解版)
JavaScript性能优化实战指南 一、加载优化 减少HTTP请求 // 合并CSS/JS文件 // 使用雪碧图CSS Sprites .icon {background-image: url(sprites.png);background-position: -20px 0; }代码分割与懒加载 // 动态导入模块 button.addEventListener(click, async () > {cons…...
)
从 AMQP 到 RabbitMQ:核心组件设计与工作原理(一)
一、引言 ** 在当今分布式系统盛行的时代,消息队列作为一种关键的中间件技术,承担着系统间异步通信、解耦和削峰填谷的重要职责。AMQP(Advanced Message Queuing Protocol)作为一种高级消息队列协议,为消息队列的实现…...
Java进阶---JVM
JVM概述 JVM作用: 负责将字节码翻译为机器码,管理运行时内存 JVM整体组成部分: 类加载系统(ClasLoader):负责将硬盘上的字节码文件加载到内存中 运行时数据区(RuntimeData Area):负责存储运行时各种数据 执行引擎(Ex…...

鸿蒙OSUniApp离线优先数据同步实战:打造无缝衔接的鸿蒙应用体验#三方框架 #Uniapp
UniApp离线优先数据同步实战:打造无缝衔接的鸿蒙应用体验 最近在开发一个面向鸿蒙生态的UniApp应用时,遇到了一个有趣的挑战:如何在网络不稳定的情况下保证数据的实时性和可用性。经过一番探索和实践,我们最终实现了一套行之有效…...

地震资料裂缝定量识别——学习计划
学习计划 地震资料裂缝定量识别——理解常规采集地震裂缝识别方法纵波各向异性方法蚁群算法相干体及倾角检测方法叠后地震融合属性方法裂缝边缘检测方法 非常规采集地震裂缝识别方法P-S 转换波方法垂直地震剖面方法 学习计划 地震资料裂缝定量识别——理解 地震资料裂缝识别&a…...
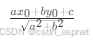
C++ 检查一条线是否与圆接触或相交(Check if a line touches or intersects a circle)
给定一个圆的圆心坐标、半径 > 1 的圆心坐标以及一条直线的方程。任务是检查给定的直线是否与圆相交。有三种可能性: 1、线与圆相交。 2、线与圆相切。 3、线在圆外。 注意:直线的一般方程是 a*x b*y c 0,因此输入中只给出常数 a、b、…...
23. Merge k Sorted Lists
目录 题目描述 方法一、k-1次两两合并 方法二、分治法合并 方法三、使用优先队列 题目描述 23. Merge k Sorted Lists 方法一、k-1次两两合并 选第一个链表作为结果链表,每次将后面未合并的链表合并到结果链表中,经过k-1次合并,即可得到…...

每日算法刷题计划Day20 6.2:leetcode二分答案3道题,用时1h20min
9.3048.标记所有下标的最早秒数(中等) 3048. 标记所有下标的最早秒数 I - 力扣(LeetCode) 思想 1.给你两个下标从 1 开始的整数数组 nums 和 changeIndices ,数组的长度分别为 n 和 m 。 一开始,nums 中所有下标都是未标记的&a…...

Spring Security安全实践指南
安全性的核心价值 用户视角的数据敏感性认知 从终端用户角度出发,每个应用程序都涉及不同级别的数据敏感度。以电子邮件服务与网上银行为例:前者内容泄露可能仅造成隐私困扰,而后者账户若被操控将直接导致财产损失。这种差异体现了安全防护需要分级实施的基本原则: // 伪…...

Unity + HybirdCLR热更新 入门篇
官方文档 HybridCLR | HybridCLRhttps://hybridclr.doc.code-philosophy.com/docs/intro 什么是HybirdCLR? HybridCLR(原名 huatuo)是一个专为 Unity 项目设计的C#热更新解决方案,它通过扩展 IL2CPP 运行时,使其支持动态加载和…...

QuickBASIC QB64 支持 64 位系统和跨平台Linux/MAC OS
QuickBASIC 的现代继任者 QB64 已发展成为一个功能强大的开源项目,支持 64 位系统和跨平台开发。以下是详细介绍: 项目首页 - QB64pe:The QB64 Phoenix Edition Repository - GitCode https://gitcode.com/gh_mirrors/qb/QB64pe 1. QB64 概述 官网&am…...
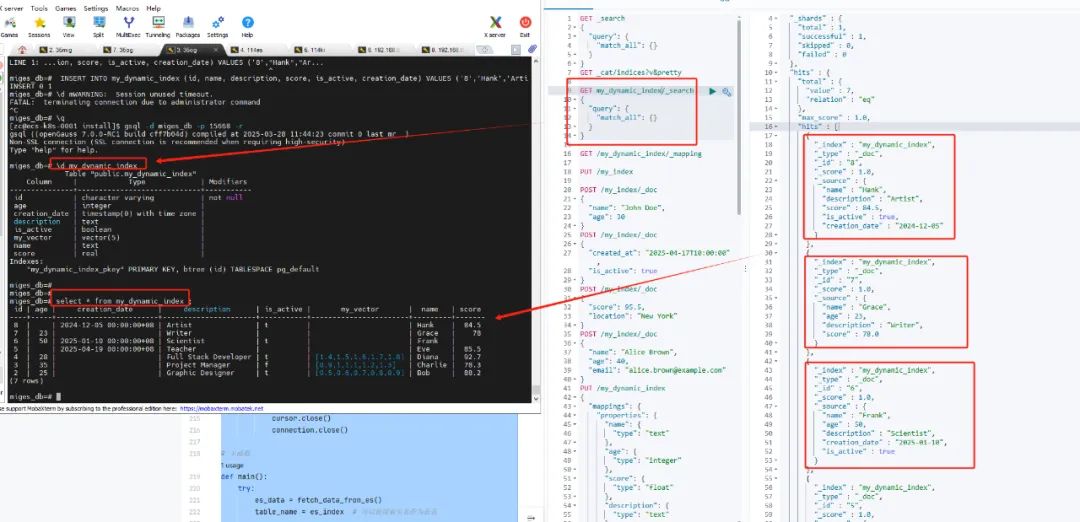
ElasticSearch迁移至openGauss
Elasticsearch 作为一种高效的全文搜索引擎,广泛应用于实时搜索、日志分析等场景。而 openGauss,作为一款企业级关系型数据库,强调事务处理与数据一致性。那么,当这两者的应用场景和技术架构发生交集时,如何实现它们之…...
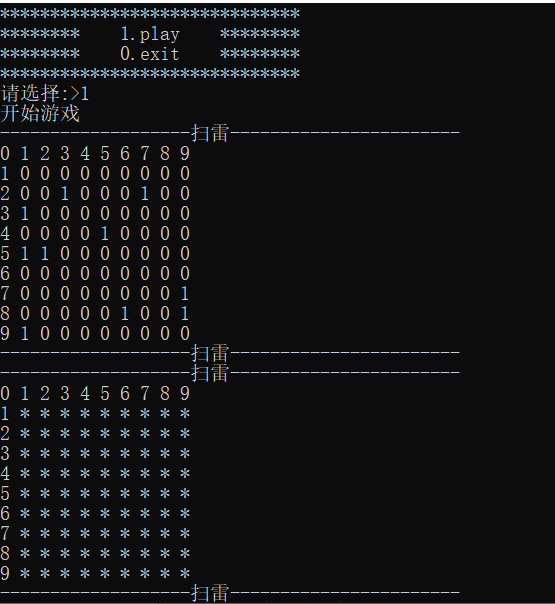
【C语言极简自学笔记】项目开发——扫雷游戏
一、项目概述 1.项目背景 扫雷是一款经典的益智游戏,由于它简单而富有挑战性的玩法深受人们喜爱。在 C 语言学习过程中,开发扫雷游戏是一个非常合适的实践项目,它能够综合运用 C 语言的多种基础知识,如数组、函数、循环、条件判…...

Global Security Markets 第5章知识点总结
一、章节核心内容概述 《Global Securities Markets》第五章聚焦全球主要证券交易所、关联存管机构及跨境交易实务,重点解析“乘客市场(Passenger Markets)”概念与合规风险,同时涵盖交易费用、监管规则等实操要点。考虑到市场的…...

电子电路:4017计数器工作原理解析
4017是CMOS十进制计数器/分频器,它属于CD4000系列,工作电压范围比较宽,可能3V到15V。我记得它有10个译码输出端,每个输出端依次在高电平和低电平之间循环,可能用于时序控制或者LED显示什么的。 4017内部应该由计数器和译码器两部分组成。计数器部分可能是一个约翰逊计数器…...

Vim 中设置插入模式下输入中文
在 Vim 中设置插入模式下输入中文需要配置输入法切换和 Vim 的相关设置。以下是详细步骤: 1. 确保系统已安装中文输入法 在 Linux 系统中,常用的中文输入法有: IBus(推荐):支持拼音、五笔等Fcitx…...
)
GitHub 趋势日报 (2025年05月31日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1153 prompt-eng-interactive-tutorial 509 BillionMail 435 ai-agents-for-begin…...
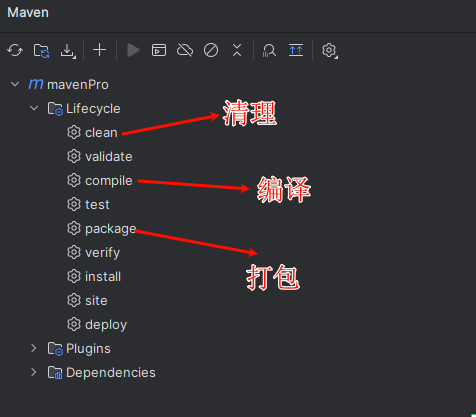
Maven概述,搭建,使用
一.Maven概述 Maven是Apache软件基金会的一个开源项目,是一个有优秀的项目构建(创建)工具,它用来帮助开发者管理项目中的jar,以及jar之间的依赖关系,完成项目的编译,测试,打包和发布等工作. 我在当前学习阶段遇到过的jar文件: MySQL官方提供的JDBC驱动文件,通常命名为mysql-…...

基于大模型的数据库MCP Server设计与实现
基于大模型的数据库MCP Server设计与实现 引言 随着大语言模型(LLM, Large Language Model)能力的不断提升,AI Agent(智能体)正在从简单的对话问答,向更复杂的自动化任务执行和业务流程管理演进。在企业和开发者的实际需求中,数据库操作是最常见、最核心的场景之一。如…...

【前端】macOS 的 Gatekeeper 安全机制阻止你加载 bcrypt_lib.node 文件 如何解决
这个弹窗是 macOS 的 Gatekeeper 安全机制阻止你加载 bcrypt_lib.node 文件,因为它不是 Apple 签名的文件。 你想 “忽视” 它,其实是让系统允许这个 .node 原生模块运行,解决方式如下: sudo xattr -d com.apple.quarantine nod…...
Unity 环境搭建
Unity是一款游戏引擎,可用于开发各种类型的游戏和交互式应用程序。它由Unity Technologies开发,并在多个平台上运行,包括Windows、macOS、Linux、iOS、Android和WebGL。Unity也支持虚拟现实(VR)和增强现实(AR)技术,允许用户构建逼…...
【入门】【练9.3】 加四密码
| 时间限制:C/C 1000MS,其他语言 2000MS 内存限制:C/C 64MB,其他语言 128MB 难度:中等 分数:100 OI排行榜得分:12(0.1*分数2*难度) 出题人:root | 描述 要将 China…...

使用 SASS 与 CSS Grid 实现鼠标悬停动态布局变换效果
最终效果概述 页面为 3x3 的彩色格子网格;当鼠标悬停任意格子,所在的行和列被放大;使用纯 CSS 实现,无需 JavaScript;利用 SASS 的模块能力大幅减少冗余代码。 HTML 结构 我们使用非常基础的结构,9 个 .i…...