探索大语言模型(LLM):RSE流程详解——从文档中精准识别高相关片段
前言
在信息爆炸的时代,如何从海量的文本数据中快速准确地提取出有价值的信息,成为了众多领域面临的共同挑战。RSE(检索增强摘要生成)流程应运而生,它通过一系列精细化的步骤,能够有效地从原始文档中识别出高相关片段,为后续的信息处理和分析提供有力支持。本文将深入解析RSE流程的各个步骤,并结合具体案例和示例代码展示其应用过程。
RSE流程详解
1. 数据切分
数据切分是RSE流程的第一步,也是后续处理的基础。在这一步中,原始文档被切分为固定大小的片段。例如,一个长文档可能被切分为多个连续的文本块,如“Chunk1”、“Chunk2”、“Chunk3”等。这些切分后的片段随后会被转换为向量形式,并存储到向量库中。向量化的过程使得文本数据能够以数学方式进行处理,便于后续的相似度计算和比较。
2. 相似度筛选
在数据切分之后,RSE流程会计算每个片段与查询或目标的相似度。这一步骤旨在过滤出与查询或目标高度相关的片段。相似度计算的方法可以多种多样,如余弦相似度、欧氏距离等。在筛选过程中,通常会设定一个相似度阈值,只有相似度超过该阈值的片段才会被保留下来,作为高相关片段。
3. 上下文窗口查找
相似度筛选之后,RSE流程会进行上下文窗口查找。这一步骤的目的是捕捉可能跨越原始切分边界的相关信息。假设窗口大小为2,RSE流程会从每个高相似度片段开始,向下连续查找指定数量的片段。例如,对于相似度数组[0.8, 0.7, 0.2, 0.1, 0.6, 0.5, 0.1, 0.2],RSE流程可能会将其划分为片段1至片段5,每个片段包含两个相似度值,如片段1为[0.8, 0.7],片段2为[0.2, 0.1]等。通过这种方式,RSE流程能够考虑到片段之间的上下文关系,从而更全面地捕捉相关信息。
4. 片段总值计算
在上下文窗口查找之后,RSE流程会对每个窗口内的片段相似度值进行求和,得到片段的总值。这一步骤是对片段相关性的综合评估。例如,片段1的总值可能为0.8 + 0.7 = 1.5,片段2的总值可能为0.2 + 0.1 = 0.3等。通过计算片段总值,RSE流程能够量化每个窗口内片段的整体相关性。
5. 阈值筛选
最后,RSE流程会应用一个阈值来筛选片段。只有片段总值超过该阈值的片段才会被保留下来,作为最终的高相关片段。例如,如果设定阈值为1.0,那么片段1和片段2(假设其总值分别为1.5和1.1)可能会被保留下来,而其他总值较低的片段则会被过滤掉。通过阈值筛选,RSE流程能够确保最终返回的片段具有较高的相关性。
案例分析
为了更具体地展示RSE流程的应用过程,我们来看一个案例。假设原始文档为“Chunk1Chunk3Chunk5Chunk7”,经过相似度过滤后得到的相似度数组为[0.8, 0.7, 0.2, 0.1, 0.6, 0.5, 0.1, 0.2]。根据RSE流程,我们首先进行数据切分和向量化存储。然后,通过相似度筛选保留高相关片段。接着,进行上下文窗口查找,假设窗口大小为2,得到片段1至片段5。计算每个片段的总值后,应用阈值筛选(假设阈值为1.0),保留片段1和片段2。最终,RSE流程返回“Chunk1 Chunk2”和“Chunk5 Chunk6”作为高相关片段。
示例代码
以下是一个Python代码示例,用于模拟RSE流程中的关键步骤:
import numpy as npdef rse_process(document, similarities, window_size=2, threshold=1.0):# 数据切分(这里简化处理,假设document已经切分好,similarities对应切分后的片段)# 相似度筛选(这里简化处理,直接使用提供的similarities数组)# 上下文窗口查找segments = []for i in range(len(similarities) - window_size + 1):segment = similarities[i:i+window_size]segments.append(segment)# 片段总值计算segment_values = {f'segment{i+1}': np.sum(segment) for i, segment in enumerate(segments)}# 阈值筛选retained_segments = {k: v for k, v in segment_values.items() if v > threshold}# 构造返回结果(这里简化处理,直接返回片段编号,实际应根据Chunk编号构造)retained_chunks = []for segment, value in retained_segments.items():if segment == 'segment1':retained_chunks.append("Chunk1 Chunk2")elif segment == 'segment2':retained_chunks.append("Chunk5 Chunk6")# 可以根据需要添加更多条件来处理其他片段return retained_chunks
示例使用
document = "Chunk1Chunk3Chunk5Chunk7"
similarities = [0.8, 0.7, 0.2, 0.1, 0.6, 0.5, 0.1, 0.2]
retained_chunks = rse_process(document, similarities)
print(retained_chunks)
这段代码定义了一个rse_process函数,它接收原始文档、相似度数组、窗口大小和阈值作为输入,并返回最终保留的高相关片段。在示例使用部分,我们使用了与案例中相同的原始文档和相似度数组,并打印了输出结果。
RSE的优势与应用场景
相比传统的文本处理方法,RSE流程具有显著的优势。它能够更精准地捕捉上下文信息,提高摘要生成的准确性。同时,RSE流程还具有较好的灵活性和可扩展性,可以适应不同领域和场景的需求。因此,RSE流程在信息检索、摘要生成、问答系统等领域具有广泛的应用前景。
未来展望
随着技术的不断发展,RSE流程也有望得到进一步的改进和优化。例如,可以通过优化切分策略来提高片段的粒度和相关性;通过改进相似度计算方法来提高筛选的准确性;通过引入更先进的机器学习算法来提高整个流程的自动化和智能化水平。未来,RSE流程有望在处理长文本数据方面发挥更大的作用,为信息处理和分析提供更加高效和精准的工具。
结论
RSE流程通过一系列精细化的步骤,能够有效地从原始文档中识别出高相关片段。本文详细解析了RSE流程的各个步骤,并结合具体案例和示例代码展示了其应用过程。通过RSE流程,我们可以更精准地捕捉上下文信息,提高文本处理的准确性和效率。未来,随着技术的不断发展,RSE流程有望在更多领域发挥重要作用。
相关文章:
:RSE流程详解——从文档中精准识别高相关片段)
探索大语言模型(LLM):RSE流程详解——从文档中精准识别高相关片段
前言 在信息爆炸的时代,如何从海量的文本数据中快速准确地提取出有价值的信息,成为了众多领域面临的共同挑战。RSE(检索增强摘要生成)流程应运而生,它通过一系列精细化的步骤,能够有效地从原始文档中识别出…...

【C++】类的构造函数
类的构造函数 1. 作用:2.语法规则:示例代码:构造函数语法 2.1 特点:示例代码:自定义了构造函数,系统不会再生成默认构造函数示例代码:构造函数重载 3.构造函数常见的写法3.1 无参构造函数3.2 带…...
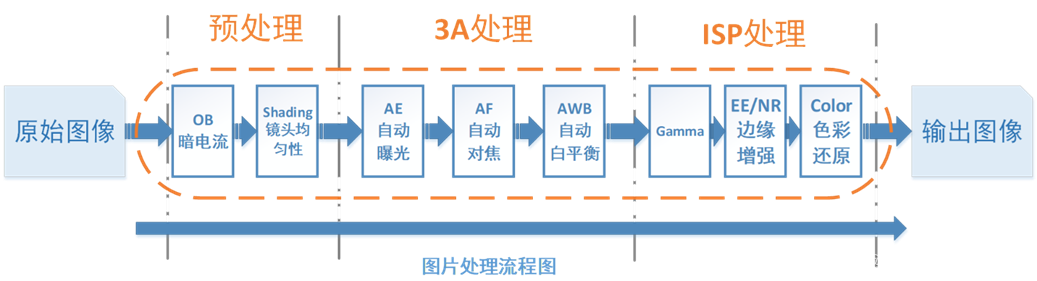
【ISP算法精粹】动手实战:用 Python 实现 Bayer 图像的黑电平校正
在数字成像领域,图像信号处理器(ISP)如同幕后英雄,默默将传感器捕获的原始数据转化为精美的图像。而黑电平校正,作为ISP预处理流程中的关键一环,直接影响着最终图像的质量。今天,我们就通过Pyth…...

分布式存储技术全景解析:从架构演进到场景实践
目录 技术演进与市场新格局核心架构设计深度剖析前沿技术创新与性能突破行业应用场景实践挑战与未来发展趋势1. 技术演进与市场新格局 1.1 从集中式到分布式的范式转移 传统集中式存储(如NAS/SAN)在扩展性和容错性方面面临根本性瓶颈,而分布式存储通过水平扩展架构和多节点…...

JVM——从JIT到AOT:JVM编译器的云原生演进之路
引入 在Java的世界里,一段代码从开发者手中的文本到计算机执行的机器指令,需要跨越"字节码"这座桥梁。而JVM编译器正是架起这座桥梁的工程师,它的每一次技术演进都推动着Java性能的跃迁。从早期逐行翻译的解释器,到智能…...
Linux中的mysql逻辑备份与恢复
一、安装mysql社区服务 二、数据库的介绍 三、备份类型和备份工具 一、安装mysql社区服务 这是小编自己写的,没有安装的去看看 Linux换源以及yum安装nginx和mysql-CSDN博客 二、数据库的介绍 2.1 数据库的组成 数据库是一堆物理文件的集合,主要包括…...

[HTML5]快速掌握canvas
背景 canvas 是 html5 标准中提供的一个标签, 顾名思义是定义在浏览器上的画布 通过其强大的绘图接口,我们可以实现各种各样的图形,炫酷的动画,甚至可以利用他开发小游戏,包括市面上很流行的数据可视化框架底层都用到了Canvas。…...
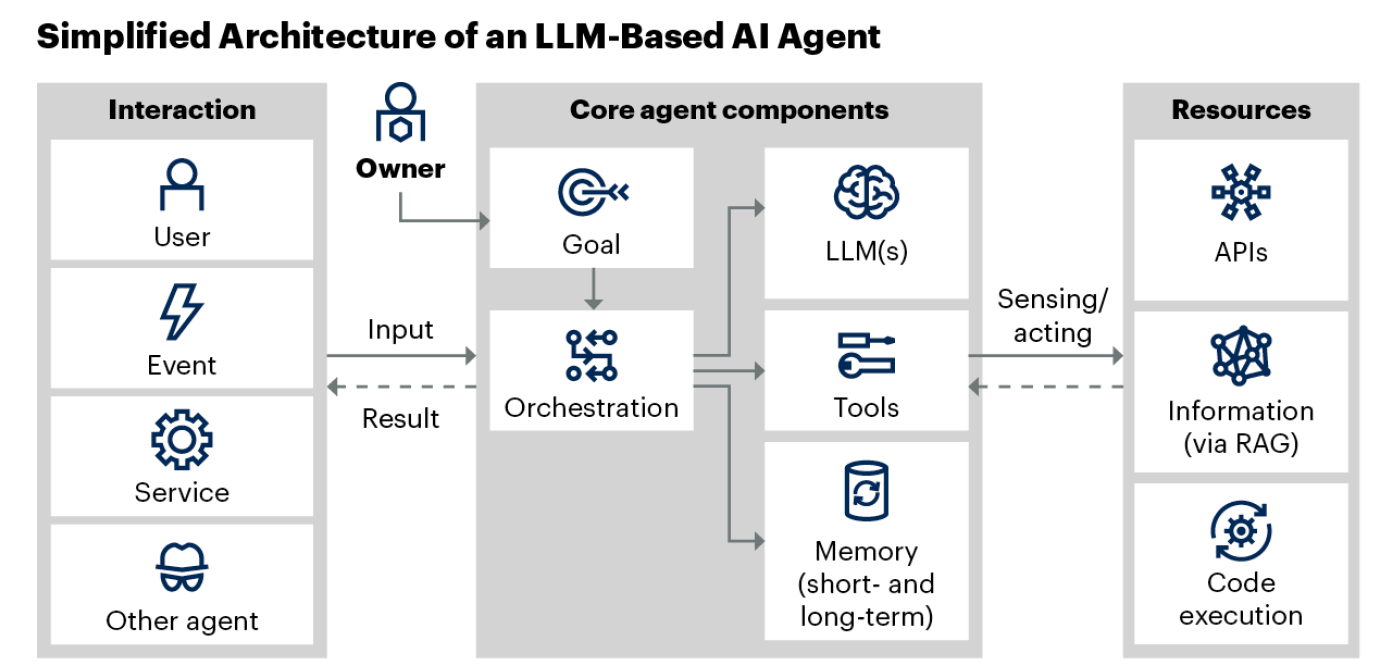
Gartner《Emerging Patterns for Building LLM-Based AIAgents》学习心得
一、AI代理概述 2024年,AI代理成为市场热点,它们能自主规划和行动以实现用户目标,与仅能感知、决策、行动和达成目标的AI助手及聊天机器人有本质区别。Gartner定义的AI代理是使用AI技术在数字或物理环境中自主或半自主运行的软件实体。 二、LLM基础AI代理的特性和挑战 优势…...

Hive SQL优化实践:提升大数据处理效率的关键策略
在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛应用于海量数据的离线分析场景。然而,随着数据量的指数级增长和业务复杂度的提升,低效的Hive SQL可能导致资源浪费和查询性能瓶颈。本文将从存储优化、计算优化、资源配置三…...

vue中父子参数传递双向的方式不同
在面试中被问到。平时也有用到,但是缺少总结 父传子。父页面会给子页面中定义的props属性传参,子页面接收子传父。父页面需要监听事件来接收子页面通过$emit发送的消息其实说的以上两种都是组件之间传递。还可以通过路由传参, 状态管理器的方式传递 下面…...

LLM 使用 MCP 协议及其原理详解
LLM 使用 MCP 协议及其原理详解 🧠 一、MCP 协议概述 1. MCP 是什么? MCP(Modular Communication Protocol)是一种面向语言模型设计的通用通信协议,其设计目标是: 模块化(Modular࿰…...

DAY 36神经网络加速器easy
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 ●作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。 ●探索性作业(随意完成):尝试进入…...
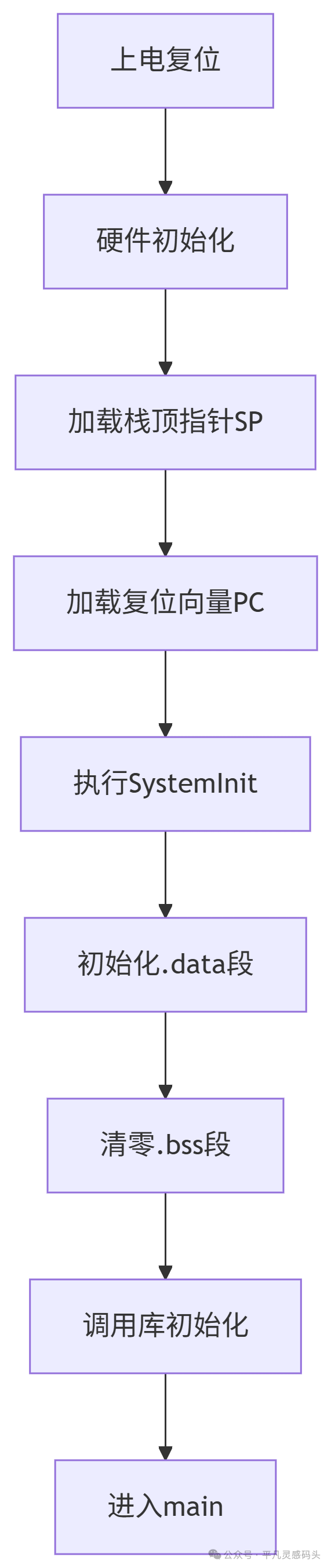
STM32 单片机启动过程全解析:从上电到主函数的旅程
一、为什么要理解启动过程? STM32 的启动过程就像一台精密仪器的开机自检,它确保所有系统部件按既定方式初始化,才能顺利运行我们的应用代码。对初学者而言,理解启动过程能帮助解决常见“程序跑飞”“不进 main”“下载后无反应”…...
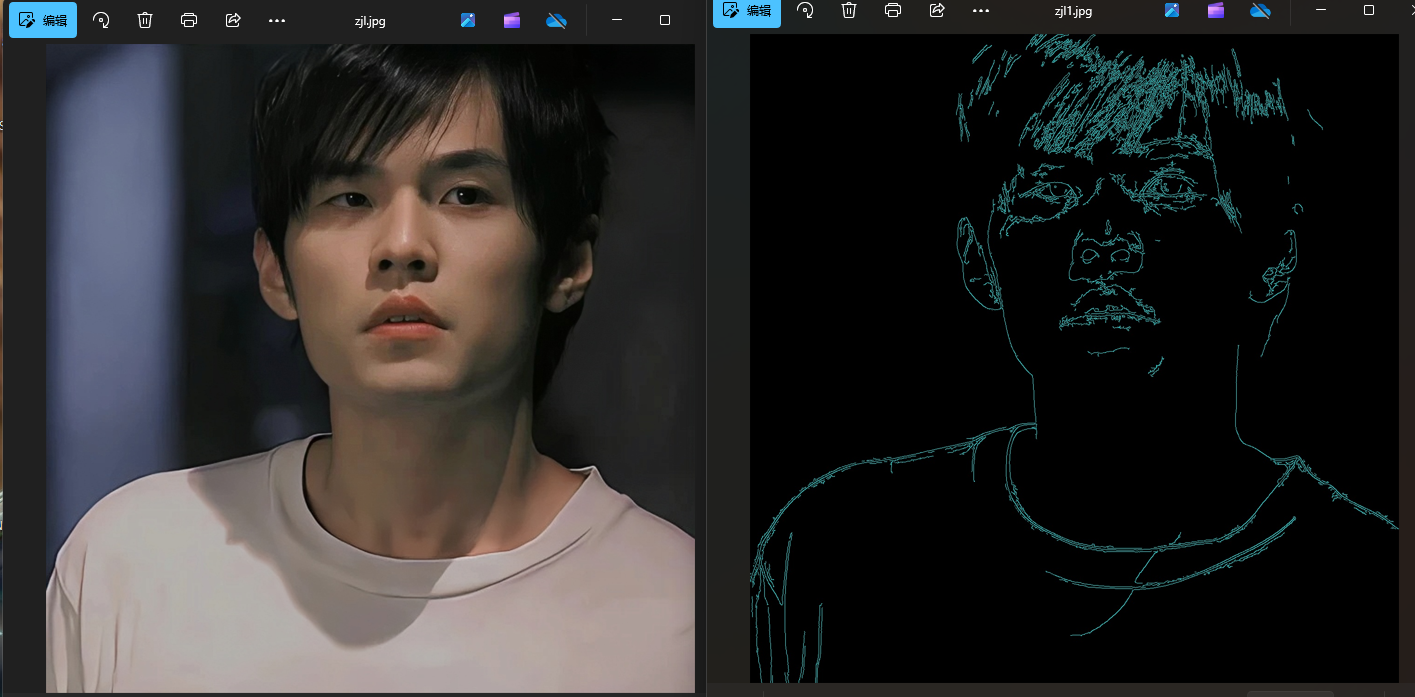
4.RV1126-OPENCV 图像轮廓识别
一.图像识别API 1.图像识别作用 它常用于视觉任务、目标检测、图像分割等等。在 OPENCV 中通常使用 Canny 函数、findContours 函数、drawContours 函数结合在一起去做轮廓的形检测。 2.常用的API findContours 函数:用于寻找图片的轮廓,并把所有的数…...
WEB3——开发者怎么查看自己的合约日志记录
在区块链中查看合约的日志信息(也叫事件 logs),主要有以下几种方式,具体方法依赖于你使用的区块链平台(如 Ethereum、BSC、Polygon 等)和工具(如 Etherscan、web3.js、ethers.js、Hardhat 等&am…...

TDengine 集群容错与灾备
简介 为了防止数据丢失、误删操作,TDengine 提供全面的数据备份、恢复、容错、异地数据实时同步等功能,以保证数据存储的安全。本节简要说明 TDengine 中的容错与灾备。 容错 TDengine 支持 WAL 机制,实现数据的容错能力,保证数…...
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件 MG影视App电视版是一款资源丰富、免费便捷、且专为大屏优化的影视聚合应用,聚合海量资源,畅享电视直播,是您电视盒子和…...
)
如何成为一名优秀的产品经理(自动驾驶)
一、 夯实核心基础 深入理解智能驾驶技术栈: 感知: 摄像头、雷达(毫米波、激光雷达)、超声波传感器的工作原理、优缺点、融合策略。了解目标检测、跟踪、SLAM等基础算法概念。 定位: GNSS、IMU、高精地图、轮速计等定…...

BAT脚本编写详细教程
目录 第一部分:BAT脚本简介第二部分:创建和运行BAT脚本第三部分:基本命令和语法第四部分:变量使用第五部分:流程控制第六部分:函数和子程序第七部分:高级技巧第八部分:实用示例第一部分:BAT脚本简介 BAT脚本(批处理脚本)是Windows操作系统中的一种脚本文件,扩展名…...

快速了解 GO之接口解耦
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

【多线程初阶】内存可见性问题 volatile
文章目录 再谈线程安全问题内存可见性问题可见性问题案例编译器优化 volatileJava内存模型(JMM) 再谈线程安全问题 如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该有的结果,则说这个程序是线程安全的,反之,多线程环境中,并发执行后,产生bug就是线程不安全…...

C++ 类模板三参数深度解析:从链表迭代器看类型推导与实例化(为什么迭代器类模版使用三参数?实例化又会是怎样?)
本篇主要续上一篇的list模拟实现遇到的问题详细讲解:<传送门> 一、引言:模板参数的 "三角锁钥" 在 C 双向链表实现中,__list_iterator类模板的三个参数(T、Ref、Ptr)如同精密仪器的调节旋钮&#x…...

MySQL强化关键_018_MySQL 优化手段及性能分析工具
目 录 一、优化手段 二、SQL 性能分析工具 1.查看数据库整体情况 (1)语法格式 (2)说明 2.慢查询日志 (1)说明 (2)开启慢查询日志功能 (3)实例 3.s…...

ASP.NET MVC添加模型示例
ASP.NET MVC高效构建Web应用ASP.NET MVC 我们总在谈“模型”,那到底什么是模型?简单说来,模型就是当我们使用软件去解决真实世界中各种实际问题的时候,对那些我们关心的实际事物的抽象和简化。比如,我们在软件系统中设…...
【Part 3 Unity VR眼镜端播放器开发与优化】第二节|VR眼镜端的开发适配与交互设计
文章目录 《VR 360全景视频开发》专栏Part 3|Unity VR眼镜端播放器开发与优化第一节|基于Unity的360全景视频播放实现方案第二节|VR眼镜端的开发适配与交互设计一、Unity XR开发环境与设备适配1.1 启用XR Plugin Management1.2 配置OpenXR与平…...

第1天:认识RNN及RNN初步实验(预测下一个数字)
RNN(循环神经网络) 是一种专门设计用来处理序列数据的人工神经网络。它的核心思想是能够“记住”之前处理过的信息,并将其用于当前的计算,这使得它非常适合处理具有时间顺序或上下文依赖关系的数据。 核心概念:循环连…...

全文索引详解及适用场景分析
全文索引详解及适用场景分析 1. 全文索引基本概念 1.1 定义与核心原理 全文索引(Full-Text Index)是一种特殊的数据库索引类型,专门设计用于高效处理文本数据的搜索需求。与传统的B树索引不同,全文索引不是基于精确匹配,而是通过建立倒排索引(Inverted Index)结构来实现对…...

利用DeepSeek编写能在DuckDB中读PostgreSQL表的表函数
前文实现了UDF和UDAF,还有一类函数是表函数,它放在From 子句中,返回一个集合。DuckDB中已有PostgreSQL插件,但我们可以用pqxx库实现一个简易的只读read_pg()表函数。 提示词如下: 请将libpqxx库集成到我们的程序&#…...
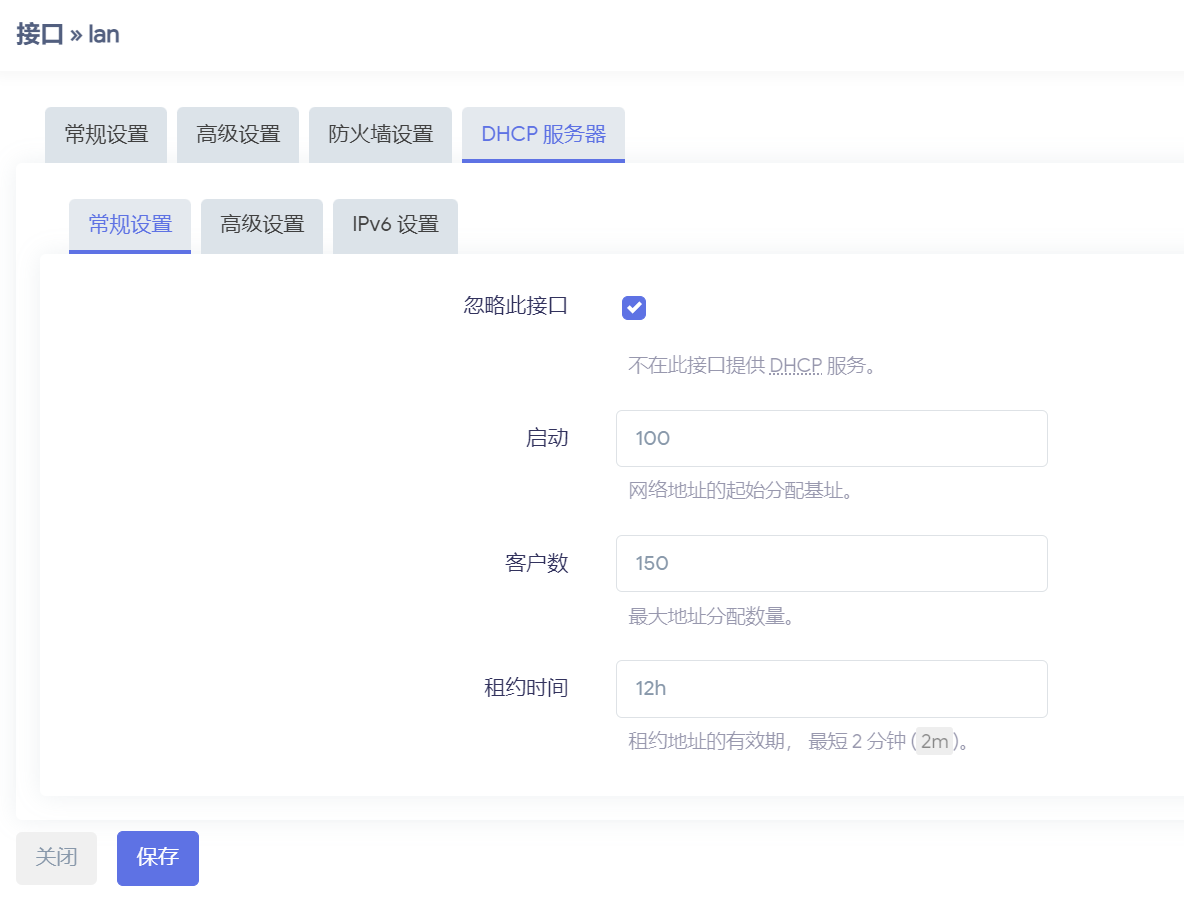
树莓派安装openwrt搭建软路由(ImmortalWrt固件方案)
🤣👉我这里准备了两个版本的openwrt安装方案给大家参考使用,分别是原版的OpenWrt固件以及在原版基础上进行改进的ImmortalWrt固件。推荐使用ImmortalWrt固件,当然如果想直接在原版上进行开发也可以,看个人选择。 &…...

排序算法——详解
排序算法 (冒泡、选择、插入、快排、归并、堆排、计数、桶、基数) 稳定性 (Stability): 如果排序算法能保证,当待排序序列中存在值相等的元素时,排序后这些元素的相对次序保持不变,那么该算法就是稳定的。 例如&#…...