CppCon 2014 学习:Defensive Programming Done Right.
这段摘要讲的是:
- 在组件化开发中,每个开发者负责让自己写的软件易懂且好用,且不易被误用。
- 常见误用之一是调用库函数时未满足前置条件,导致未定义行为。
- 未定义行为的契约(contract)不一定不好,很多工程上也许是最佳选择。
- 大多数人认为库检测到前置条件违反时不应默默继续,但具体怎么处理可能有不同意见。
- 验证前置条件需要额外的运行时代码,增加代码量会影响速度,有人认为不应强制库用户为冗余检查买单。
- 是否及如何验证前置条件、检测违规后如何处理,最好由应用程序自身决定(即“main”的拥有者决定)。
- 该演讲提出“Defensive Programming Done Right”,介绍设计契约(Design-By-Contract,DbC)和防御式编程(Defensive Programming,DP)的基础概念。
- 讲解如何将防御式编程机制内置于库,使应用程序能灵活选择防御检查的运行时预算(无、部分、大量)及违规时的动作(终止、抛异常、自旋等)。
- 还涉及现代编译器、链接器、二进制兼容性以及违反单一定义规则(one-definition rule)在混合构建中的影响。
- 最后介绍“负向测试”策略和测试工具,确保防御检查在组件测试中能正确捕捉和报告违约使用。
大规模 C++ 软件开发中面临的核心问题:
主要挑战:
- 逻辑与物理复杂性交织
大规模 C++ 软件包含许多微妙的逻辑和物理方面的问题(如语义、状态、构建依赖、ABI等),处理起来很复杂。 - 需要模块化设计能力
必须具备将逻辑功能清晰隔离并模块化为细粒度的物理组件的能力(例如,一个个小的.cpp文件和头文件、库)。 - 精确定义逻辑行为 + 管理物理依赖
设计者不仅要精确描述组件的行为契约(接口/语义),还要管理其与其他底层组件之间的物理依赖(比如头文件依赖、链接依赖)。 - 即便组件本身完美,也容易被误用
就算一个组件设计良好、文档齐全、测试充分,如果调用者(client)用错了它,整个系统依然会出错。
总结一句话:
大型 C++ 软件要求不仅要正确实现组件,还要通过良好的设计和防御性机制防止客户端误用,否则系统仍会“broken”。
主要聚焦在如何构建逻辑上和物理上健壮的组件、接口及其契约。
主要目标如下:
- 介绍如何设计/说明健壮组件
- 包括:
- 逻辑行为的定义(函数应该做什么)
- 物理结构的设计(代码、模块、依赖)
- 合同(contract):即组件的前置条件、后置条件、不变式等
- 包括:
- 强调清晰文档化行为的重要性
- 特别是:明确哪些行为是定义的,哪些是未定义的
- 这样做有助于使用者正确理解和使用组件
- 解释未定义行为的工程价值
- 虽然“未定义行为”通常被视为危险,但在适当使用下可以带来好处:
- 降低初始开发成本
- 简化测试与维护
- 提高运行效率(无需添加额外检查)
- 减小代码体积
- 虽然“未定义行为”通常被视为危险,但在适当使用下可以带来好处:
- 展示如何利用未定义行为进行错误检测
- 利用
bsls_assert设施(Bloomberg 的断言机制) - 当客户端代码违背前置条件时,可以通过断言立刻发现错误
- 利用
总结一句话:
本讲座通过DbC(契约式设计)+ 防御式编程 + 明确的接口契约,教你如何构建既高效又健壮的 C++ 库组件,并说明为何适度利用“未定义行为”是一种工程上的权衡与优化。
大纲(Outline),主要介绍了五个内容模块,涵盖从物理设计到负向测试的全过程,具体如下:
1. Brief Review of Physical Design(物理设计简述)
- 介绍组件在大型 C++ 系统中的组织方式(模块、文件、依赖等)。
- 如何将逻辑功能映射到物理结构(如
.h和.cpp分离、命名空间、层次结构等)。 - 目的:实现良好的封装、解耦与重用性。
2. Interfaces and Contracts(接口与契约)
- 接口(Interface):函数或类对外暴露的调用方式。
- 契约(Contract):调用接口前提下应满足的条件(如“参数不能为 null”)。
- 关键点:区分语法和语义(Syntax vs. Semantics):
- 语法正确 ≠ 合同满足(程序可以编译,但未必安全运行)
- 定义行为 vs. 未定义行为(Defined vs. Undefined Behavior)
3. ‘Good’ Contracts(什么是“好”的契约)
- 什么是好用、可维护、安全的接口契约?
- 介绍**Defensive Programming(防御式编程)**思想:
- Narrow Contracts(窄契约):假定调用方完全负责满足前置条件(高效,但危险)
- Wide Contracts(宽契约):组件尽量容忍错误输入(更安全,但更复杂)
4. Implementing Defensive Checks(实现防御式检查)
- 如何在实现中添加契约检查,而不会影响生产效率?
- 介绍 Bloomberg 提供的
bsls_assert:- 一种可配置的运行时断言机制
- 支持应用自定义:是否启用断言、如何响应(抛异常、终止、忽略)
5. Negative Testing(负向测试)
- 使用
bsls_asserttest组件验证断言是否能在错误用法下触发 - 目的:
- 确保防御性代码工作正常
- 避免“沉默失败”
- 这是一种面向契约的测试方法,验证组件对“坏用法”的反应
总结
这个大纲展示了如何从系统设计、接口约定,到实现防御、测试验证,全流程构建健壮、可控、可测的 C++ 组件库。
C++ 组件化开发中“逻辑设计(Logical Design)”与“物理设计(Physical Design)”的区别:
Logical Design(逻辑设计)
- 关注:程序的行为与职责分配
- 包括:
- 类(Classes):封装数据和行为
- 函数(Functions):完成具体操作
- 接口、契约(Interface / Contract)
- 表示“我们希望系统如何工作”
示例:
class Account {
public:void deposit(double amount);void withdraw(double amount);
};
Physical Design(物理设计)
- 关注:程序的组织结构和部署方式
- 包括:
- 头文件(
.h/.hpp) - 实现文件(
.cpp) - 静态库、动态库(
.a,.so,.dll)
- 头文件(
- 表示“我们如何组织代码和构建产物”
示例:
account.h // 声明类 Account
account.cpp // 实现类 Account 的方法
libbanking.a // 编译出的静态库,供其他程序链接使用
总结对比
| 特性 | Logical Design | Physical Design |
|---|---|---|
| 本质 | 行为的设计 | 结构和文件的组织方式 |
| 关注点 | 类、函数、契约 | 文件、模块、编译边界 |
| 作用范围 | 面向设计者和维护者 | 面向构建、发布与部署 |
| 示例 | 类 Account 的职责划分 | .h/.cpp 的划分与依赖 |
逻辑内容被组织进物理层次结构中
拆解说明:
- 逻辑内容(Logical content):
- 指的是类(classes)、函数(functions)、接口(interfaces)、契约(contracts)等软件设计中抽象的逻辑结构。
- 例如:一个
Account类负责账户操作逻辑,Transaction类负责交易逻辑。
- 物理层次结构(Physical hierarchy):
- 指的是文件系统结构:头文件(
.h)、源文件(.cpp)、模块目录、库文件等。 - 比如:
/banking/├── account.h├── account.cpp├── transaction.h└── transaction.cpp
- 指的是文件系统结构:头文件(
核心观点:
- 在实际开发中,我们必须把逻辑上的类和函数映射成物理结构中的文件和模块。
- 这些映射形成了一个层次结构(例如组件 > 包 > 模块 > 系统)。
示例(可视化映射):
| 逻辑设计(类、接口) | 物理实现(文件、路径) |
|---|---|
Account 类 | banking/account.h, account.cpp |
TransactionProcessor 类 | banking/transaction_processor.cpp |
BankInterface 抽象接口 | interfaces/bank_interface.h |
| 总结:逻辑设计是“我们想怎么组织功能”,物理设计是“我们怎么组织代码文件来支持这些功能”。好的物理设计能清晰反映出背后的逻辑结构,从而提升可维护性、可测试性与可扩展性。 |
C++ 组件的标准物理结构(Uniform Physical Structure of a Component),即一个组件(component)在实际文件系统中的组织方式。
一个组件(component)通常包含三个文件:
| 文件名 | 说明 |
|---|---|
component.h | 公共头文件,声明 API,供其他组件使用。 |
component.cpp | 实现文件,实现 .h 中声明的函数。 |
component.t.cpp | 测试驱动程序(test driver),测试该组件。 |
示例结构:
component/
├── component.h // 声明接口
├── component.cpp // 实现接口
└── component.t.cpp // 单元测试(test driver)
为什么这样设计?
- 一致性:每个组件都有相同的结构,便于理解、维护、自动化构建。
- 分离关注点:
.h文件用于声明 —— 提供接口,不暴露实现。.cpp文件用于定义 —— 封装实现细节。.t.cpp文件用于验证 —— 提供组件级测试。
- 可测试性强:每个组件带有专属的测试文件,易于进行独立验证。
小结:
这一结构体现了 “组件级开发” 的核心理念,即将逻辑功能模块化,并映射为清晰、可复用、可测试的物理单元。
这部分讲的是 组件之间的逻辑关系(Logical Relationships) 和 由逻辑关系产生的依赖层级(Implied Dependency & Level Numbers)。它通过一个示例图(围绕 Shape、Polygon、PointList 等)逐步引出模块之间的各种依赖关系类型。
核心思想总结:
① 四种主要的逻辑关系类型:
| 关系类型 | 含义说明 |
|---|---|
| Is-A | 继承关系(如:Polygon 是一个 Shape) |
| Uses-in-the-Interface | 在接口中使用(如:函数参数或返回值中引用某类型) |
| Uses-in-the-Implementation | 在内部实现中使用(如:函数内部临时变量引用某类型) |
| Uses-in-name-only | 仅仅出现在注释或文档中,编译器无法察觉,但读者可以感知(例如注释中提到某类) |
② Implied Dependency(隐式依赖):
这些逻辑关系会导致不同组件在 物理构建和链接 上产生依赖。例如:
Polygon在接口中用到PointList,意味着其.h头文件需要包含PointList;- 如果
Polygon在实现中用到PointList_Link,那就是实现层面的依赖。
所有这些关系,不管编译器是否强制要求,都影响系统的可维护性、耦合度和构建顺序。
③ Level Numbers(层级编号):
通过分析依赖图,我们可以为每个组件打上“层号”,表示它在整个系统中依赖链的深度:
| 组件 | 层级号(Level) | 说明 |
|---|---|---|
Point, PointList_Link | 1 | 基础组件,无依赖 |
PointList | 2 | 依赖 Point 与 PointList_Link |
Polygon | 3 | 依赖 PointList |
Shape | 1 | 无依赖(或者视作抽象基类) |
| 这种 “层级编号” 有助于: |
- 理解组件初始化顺序
- 管理构建依赖
- 拆分库文件(.so 或 .a)
- 控制耦合度
小结:
逻辑关系 → 物理依赖 → 构建顺序 → 设计质量。
模块间的关系不仅影响代码结构,也深刻影响构建流程和团队协作。越早在设计阶段建立清晰的依赖关系,后期的维护成本就越低。
这部分是对刚才“Physical Design 简要回顾”的总结性提问,目的是确保读者能掌握以下三个核心问题:
1️ What distinguishes Logical from Physical Design?
- Logical Design(逻辑设计):
- 关注抽象结构,如类(Class)、函数(Function)、接口(API)设计。
- 体现为“谁用谁”、“继承关系”、“组合关系”等。
- 是从软件功能角度进行的设计。
- Physical Design(物理设计):
- 关注实现结构,如
.cpp、.h文件划分,库的组织,编译单元的依赖。 - 是从代码实现与部署角度进行的设计。
- 决定了源文件之间的依赖顺序、编译顺序、链接方式等。
- 关注实现结构,如
2️ How do we infer physical relationships (Depends-On) from logical relationships (e.g., Is-A and Uses)?
- 每种逻辑关系(如 Is-A、Uses-in-interface、Uses-in-implementation)都可能带来物理依赖(Depends-On)。
- 举例:
- 若
PolygonIs-AShape→ 必然在.h中包含Shape.h→Polygon物理上依赖Shape。 - 若
Polygon的方法参数或返回值包含PointList→ 产生接口依赖 → 物理上依赖PointList。 - 即使只是实现细节(e.g., 局部变量用到
PointList_Link),也会导致.cpp的依赖。
- 若
- 这些依赖会反映在编译依赖图中,影响构建、测试、重构的难易度。
3️ What are level numbers?
- Level Number 是一种用于衡量组件在依赖树中深度的指标:
- Level 1:无任何依赖的底层组件。
- Level N:依赖于一个或多个 Level < N 的组件。
- 它们帮助我们:
- 组织构建顺序(越底层越先编译);
- 评估耦合度(越高级越依赖多);
- 优化设计(鼓励浅层依赖、避免环依赖)。
总结
| 问题 | 核心答案 |
|---|---|
| 逻辑 vs 物理设计 | 抽象结构 vs 实现结构 |
| 逻辑关系如何导出物理依赖 | Is-A、Uses 关系决定物理文件间的包含和链接 |
| Level Numbers 是什么 | 用于衡量依赖深度,指导构建与设计 |
提纲(Outline),概述了要讲解的 5 个核心部分。下面是对每一部分的简要解释,帮助你构建整体理解框架:
1. Brief Review of Physical Design
复习组件物理结构设计:
- 区分逻辑设计 vs 物理设计
- 组件如何组织成
.h、.cpp、.t.cpp文件 - 理解依赖关系与层级(Level Numbers)
2. Interfaces and Contracts
接口与契约:
- 明确区分语法(Syntax)与语义(Semantics)
- 强调接口不仅是函数声明,还包括调用者必须遵守的前提条件(Preconditions)
- 引出 “undefined behavior”(未定义行为) 概念,说明何时可以接受它,并如何文档化它
3. ‘Good’ Contracts
什么是好的契约?
- 引入 Defensive Programming(防御式编程):避免错误使用库导致程序崩溃或行为不可预期
- 区分:
- Narrow Contract:要求使用者必须满足严格前提,库假设调用者总是正确的
- Wide Contract:库自己会检测前提是否满足,具备更强健的容错能力
4. Implementing Defensive Checks
如何实现防御性检查:
- 使用
bsls_assert组件(Bloomberg 自研的断言库) - 根据应用需求,灵活设置:
- 检查开销(性能 vs 安全性)
- 违反前提的处理策略(abort, throw, log, spin 等)
5. Negative Testing
负向测试(验证契约检查机制):
- 使用
bsls_asserttest组件 - 测试用例故意违反前提条件,确保断言触发
- 确保防御性机制确实有效,能够及时发现错误使用
总结表格:
| 模块 | 内容简介 |
|---|---|
| 1. Physical Design | 理解组件的结构与依赖 |
| 2. Interfaces & Contracts | 明确前提条件与未定义行为 |
| 3. Good Contracts | 学会区分并选择 Narrow/Wide Contract |
| 4. Defensive Checks | 用断言检测并防止错误使用 |
| 5. Negative Testing | 验证断言机制的可靠性 |
这里是在讲解 接口(Interface) 和 契约(Contract) 的概念,并用一个具体的函数例子来说明。
2. Interfaces and Contracts
Interface vs Contract
- 接口(Interface):指的是函数、类或组件对外暴露的可见部分,比如函数的签名(参数、返回值类型)和可调用的成员函数。
- 契约(Contract):是对接口的补充说明,明确调用该接口时必须满足的前提条件(preconditions)、函数行为的语义(比如对输入参数的要求,输出结果的保证等),以及函数的副作用。
举例:函数接口与契约
函数声明:
std::ostream& print(std::ostream& stream,int level = 0,int spacesPerLevel = 4) const;
- 接口:函数名、参数类型、默认参数、返回类型。
- 契约(文档注释中说明):
- 功能:格式化该对象到输出流
stream。 - 参数说明:
level:指定缩进等级,负值表示第一行不缩进。spacesPerLevel:每个缩进等级的空格数,负值表示输出在一行,除了初始缩进外无其它缩进。
- 预期行为:
- 如果传入的
stream在调用时无效,函数无任何作用。
- 如果传入的
- 返回值:
- 返回传入的
stream的引用,方便链式调用。
- 返回传入的
- 功能:格式化该对象到输出流
重点
- 接口只是“形式”,契约明确“语义”
- 契约告诉使用者:
- 在什么条件下调用函数是合法的(preconditions)
- 函数会做什么(postconditions)
- 如果违反前提,结果会怎样(undefined behavior 或者异常)
这个部分用一个类的例子来说明接口和契约的区别和关系。
2. Interfaces and Contracts — 类的例子
类接口(Public Interface)
class Date {// 该类表示一个有效的日期,范围是 0001/01/01 到 9999/12/31。
public:Date(int year, int month, int day);// 构造一个有效的日期对象。// 预条件(contract):传入的 year, month, day 必须表示一个有效日期,// 即在范围 [0001/01/01 .. 9999/12/31] 内,否则行为未定义。Date(const Date& original);// 拷贝构造函数,创建一个值与 original 相同的 Date 对象。
};
重点
- 接口:
- 函数签名(构造函数),参数类型,成员可见性(
public)等。
- 函数签名(构造函数),参数类型,成员可见性(
- 契约:
- 具体行为说明:比如构造函数的参数必须满足什么条件(预条件),否则行为未定义。
- 说明了有效的日期范围,是调用者必须遵守的约束。
总结
- 接口定义了使用该类的“形状”和“形式”。
- 契约明确了使用该接口时的语义规则和假设。
- 契约不仅告诉你函数做什么,也告诉你“在什么条件下调用是合法的”。
- 未满足契约的调用可能导致未定义行为。
2. Interfaces and Contracts — 组件的“公共接口”
示例:Date 组件的公共接口包括:
- 类声明(
class Date),公开成员函数(构造函数等) - 非成员操作符重载:
bool operator==(const Date& lhs, const Date& rhs);
// 判断两个 Date 对象是否相等(年、月、日都相同返回 true)
bool operator!=(const Date& lhs, const Date& rhs);
// 判断两个 Date 对象是否不等(只要年、月、日有一项不同返回 true)
std::ostream& operator<<(std::ostream& stream, const Date& date);
// 按 "yyyy/mm/dd" 格式把日期写入输出流,并返回该流的引用
要点:
- 这些函数和操作符是 组件的公共接口 的一部分,调用者通过它们与
Date组件交互。 - 接口的定义清楚说明了:
- 函数做什么(语义)
- 参数和返回值的类型和含义
- 这是组件提供给使用者的约定(契约的一部分),保证了正确使用时的行为一致性。
总结
- 接口:函数签名 + 语义说明
- 契约:接口上的具体要求(参数范围、行为保证等)
- 操作符重载让组件能更自然地被使用,符合习惯(比如比较和打印)
函数的前置条件(Precondition)和后置条件(Postcondition),特别是用 sqrt 函数作为示例:
2. Interfaces and Contracts
Preconditions and Postconditions (前置条件与后置条件)
示例函数:
double sqrt(double value);
// 返回指定 value 的平方根。
// **前置条件**:必须保证 'value >= 0'。
// 否则,行为未定义。
关键点:
- 前置条件(Precondition):调用该函数前必须满足的条件。
- 例如这里
value >= 0。 - 这是对输入的限制,保证调用函数时输入是合法的。
- 例如这里
- 后置条件(Postcondition):函数调用结束后应保证的条件或函数返回的结果。
- 这里是函数返回
value的平方根。
- 这里是函数返回
- 行为未定义:如果不满足前置条件,函数的行为可能是崩溃、异常、或者错误结果,调用者不能依赖函数的结果。
为什么重要?
- 保证接口使用正确:调用者必须遵守前置条件,否则不保证程序正确。
- 接口契约的一部分:清晰表达函数责任和调用者责任。
总结
- 前置条件:函数要求调用者满足的条件(输入有效性约束)。
- 后置条件:函数保证的输出或状态。
这部分补充了前置条件和后置条件在**对象方法(Object Method)**中的含义,核心要点总结如下:
2. Interfaces and Contracts
Preconditions and Postconditions for Object Methods
前置条件(Preconditions):
- 必须对对象的状态和方法的输入参数同时成立。
- 如果不满足,方法的行为就是未定义的(Undefined Behavior)。
- 也就是说,调用者必须保证对象处于正确的状态,且输入有效。
后置条件(Postconditions):
- 当且仅当前置条件全部满足时,方法必须保证的一些行为或结果。
- 这些是对象状态和方法输入共同决定的结果。
额外补充:
- Essential Behavior(基本行为) 是后置条件的超集。
- 它包括行为保证,例如方法的运行时间复杂度等性能特征。
小结:
| 条件类型 | 作用对象 | 含义 |
|---|---|---|
| 前置条件 | 对象状态 + 方法输入 | 调用前必须满足,否则行为未定义 |
| 后置条件 | 对象状态 + 方法输入 | 满足前置条件时,方法必须保证的行为或结果 |
| 基本行为 (Essential Behavior) | 后置条件的超集 | 还包括性能保证等更广泛的行为规范 |
| 这部分强调了接口契约不仅仅是函数输入输出的约束,还包括对象状态的一致性和性能保证。 |
这部分内容核心在区分 Defined Behavior、Essential Behavior、Undefined Behavior 以及它们在接口契约中对前置条件和后置条件的影响。
核心概念解析
| 类型 | 含义 | 例子/说明 |
|---|---|---|
| Defined Behavior | 行为被明确规定(specified),实现中必须做到的行为 | 比如 print 方法定义了如何格式化输出,明确说明了参数含义和返回值。 |
| Essential Behavior | 核心的、必须保证的行为(是 Defined Behavior 的一部分) | 例如返回流引用、正确格式化输出、保持指定的缩进等。 |
| Undefined Behavior | 违反前置条件,行为不确定,可能导致程序崩溃或不可预测的结果 | Date 构造函数传入无效日期时行为未定义。 |
| Defined but not Essential Behavior | 明确定义但非核心或非必需保证的行为 | 实现细节依赖或结果的非关键特性,比如输出中额外空白的处理、某些性能细节等。 |
| Unspecified and Implementation Dependent | 行为明确但具体实现可以不同,非必需保证 | 输出格式中的某些细节可能因实现不同而不同,但不影响功能。 |
例子详解
print 方法(Defined & Essential Behavior 示例)
std::ostream& print(std::ostream& stream,int level = 0,int spacesPerLevel = 4) const;
// 作用:将对象格式化输出到指定的输出流 `stream`。
// 参数说明:
// - level: 缩进级别(负值时,首行不缩进)
// - spacesPerLevel: 每级缩进空格数(负值时,输出为一行,不缩进)
// 返回值:返回传入的流引用。
// 约定:如果输入的 `stream` 无效,操作无效,但不导致错误。
// 行为保证:格式化和缩进符合描述,返回流引用。
// 未定义行为:若调用前 `stream` 状态异常等。
- 这是Defined和Essential行为,因为它定义了方法核心的行为和效果,且是调用者依赖的保证。
Date 构造函数(Undefined Behavior 示例)
Date(int year, int month, int day);
// 创建有效日期,行为未定义除非year/month/day有效且在范围内[0001/01/01 .. 9999/12/31]。
- 若传入非法日期,行为未定义,调用者必须遵守前置条件。
总结
- 前置条件不满足时,行为未定义(Undefined Behavior),程序不保证任何事情。
- 行为必须被明确定义(Defined Behavior)且核心行为为Essential Behavior,保证接口使用时的可靠性。
- 某些行为可能定义但非核心,允许实现细节差异。
- 接口契约通过区分这些行为类型,明确了调用者和实现者的责任边界。
这里主要强调了 (Object) Invariants(对象不变式) 和它们与 前置条件(Preconditions) 以及 后置条件(Postconditions) 的关系。
核心要点整理:
1. 对象不变式(Object Invariants)是什么?
- 是对象状态必须始终满足的条件。
- 在对象的整个生命周期中,不论何时观察对象,它的状态必须保持这些不变式为真。
- 例如,
Date类的对象不变式就是日期必须有效,必须在0001/01/01到9999/12/31范围内。
2. 前置条件(Preconditions)与对象不变式的关系
- 前置条件确保传入数据和方法调用时的对象状态符合不变式要求。
- 例如,构造函数
Date(int year, int month, int day)的前置条件是传入的年月日必须构成有效日期。 - 违反前置条件时,行为是未定义的(undefined behavior),对象不保证正确状态。
3. 后置条件(Postconditions)与对象不变式的关系
- 后置条件保证方法执行结束后,对象仍满足不变式。
- 构造函数成功后,创建的
Date对象必须满足不变式,即表示有效日期。
举个例子
class Date {
public:Date(int year, int month, int day);Date(const Date& original);// ...
};
- 前置条件:传给构造函数的
year/month/day必须是有效日期。 - 后置条件:构造函数完成后,Date 对象必须表示一个有效日期(满足不变式)。
- 如果前置条件未满足,行为未定义,Date 对象可能处于非法状态。
这样设计的好处
- 明确对象有效状态范围,保证代码的健壮性。
- 利用前置和后置条件控制错误输入,减少隐藏的bug。
- 方便维护和扩展,后续方法只需确保不变式不被破坏。
Design by Contract(设计契约,简称 DbC),它是软件设计中的一种方法论,核心思想是:
Design by Contract (DbC) 核心
“If you give me valid input (including valid state), I will behave如约而至;否则,行为不保证。”
这句话的意思是:
- 只要调用者满足前置条件(输入数据和对象状态有效),被调用者就保证按照合同执行功能(后置条件和不变式保持正确)。
- 反之,若前置条件不满足,调用结果不可预测(可能崩溃、异常、错误结果等)。
设计契约的文档包含五个方面:
- What it does(功能说明)
说明方法做了什么。 - What it returns(返回值)
说明方法返回什么。 - Essential Behavior(核心行为)
保证前置条件满足时,方法必然完成的行为和状态。 - Undefined Behavior(未定义行为)
说明违反前置条件时,行为不保证。 - Note that…(注意事项)
可能包含特殊说明、性能保证、异常安全等额外信息。
这个方法的好处
- 清晰职责:调用者负责保证输入合法,方法负责实现功能。
- 降低耦合:双方明确责任边界。
- 易于测试和维护:可以有针对性地验证前置条件和后置条件。
- 增强代码文档:方法行为和限制明确可见。
你这部分讲的是 Design by Contract(设计契约) 中的 验证(Verification),主要内容包括:
设计契约的验证要点
- Preconditions(前置条件)
- 调用者负责满足前置条件。
- 验证方法:
- RTFM(Read the Manual),即“读文档”,确保使用正确。
- 在调试模式或安全模式下,使用断言(
assert)来检测输入和状态是否合法。
- Postconditions(后置条件)
- 由组件的单元测试(Component-level test drivers)来验证方法执行后是否满足预期的后置条件。
- Invariants(不变式)
- 对象的不变条件必须在对象生命周期内始终保持成立。
- 通常在析构函数(destructor)中断言检查不变式,确保对象销毁时状态有效。
额外说明
- 断言(assert)通常只在调试或安全模式开启,生产环境可关闭以提升性能。
- 断言帮助及时发现违反契约的错误,方便调试。
- 以后讲座的第四部分会详细介绍断言和安全模式。
这些问题是设计契约(Design-by-Contract, DbC)这部分想要回答的核心内容,帮助我们全面掌握设计契约的理念和实践:
设计契约中要回答的问题总结:
- 设计契约的核心理念是什么?
- 通过明确的契约(合同)定义调用者和被调用者之间的责任和保证,从而提高代码的可靠性和可维护性。
- 接口(Interface)和契约(Contract)有什么区别?
- 接口描述的是功能的可用性(比如函数签名),
- 契约则明确规定输入输出条件和行为保证(前置条件、后置条件、不变式)。
- 什么是前置条件、后置条件和不变式?
- 前置条件:调用者必须满足的条件。
- 后置条件:被调用者保证执行后成立的条件。
- 不变式:对象生命周期中始终保持为真的条件。
- 什么是“本质行为”(essential behavior)和“未定义行为”(undefined behavior)?
- 本质行为是契约中承诺的行为。
- 未定义行为是在契约前置条件不满足时,行为不保证,可能出现异常或崩溃。
- 即使违反了一个或多个前置条件,代码是否必须保持不变式?
- 不一定;违反前置条件时,行为未定义,但良好设计应尽量保证不变式不会被破坏。
- 如何记录函数的契约?
- 文档中明确说明“做什么”、“返回什么”、“前置条件”、“后置条件”、“不变式”以及注意事项。
- 如何确保后置条件被满足?
- 通过单元测试和断言验证。
- 如何测试不变式是否被保持?
- 在构造、修改、销毁对象时使用断言检查不变式,确保其持续成立。
这些问题一起构成了设计契约体系的理论基础和实践指南,帮助我们编写健壮、易维护的代码。
- 在构造、修改、销毁对象时使用断言检查不变式,确保其持续成立。
“防御式编程(Defensive Programming,DP)”的定义、利弊,以及它要防御的对象。帮你总结和扩展一下:
防御式编程(DP)简介
定义:
防御式编程是指在代码中加入冗余的运行时检查,用来检测和报告程序中的缺陷(bugs),但不负责“处理”或“隐藏”这些缺陷。它主要是为了在开发或测试阶段尽早发现问题。
防御式编程的优缺点
- 优点:
- 能及早发现bug,有助于定位和修复问题。
- 提高代码的健壮性。
- 缺点:
- 增加运行时开销(性能损失)。
- 可能导致代码臃肿,影响代码简洁性。
防御式编程和设计契约(DbC)的比较
- 防御式编程和设计契约不冲突,就像“你是坐公交车去学校,还是带午餐”一样,选择因场景而异。
- DbC强调:只要前置条件满足,函数行为一定可靠;违反前置条件时,行为未定义。
- DP强调:即使前置条件被破坏,也会尽力检测和报告错误。
防御式编程防御的对象
- 我们用到的外部软件的bug
- 比如第三方库或底层系统组件的缺陷。
- 我们自己实现中引入的bug
- 自己写代码时无意间的错误。
- 客户的误用
- 用户调用接口时传入无效参数或错误操作。
#这部分内容在讲“窄契约(Narrow Contracts)”和“宽契约(Wide Contracts)”的区别,以及它们对程序行为的影响和设计选择。
我帮你总结一下重点:
- 用户调用接口时传入无效参数或错误操作。
窄契约 (Narrow Contracts) vs 宽契约 (Wide Contracts)
窄契约的特点
- 严格的前置条件,调用者必须确保输入满足契约要求,否则行为未定义。
- 典型例子:
strlen(nullptr)是未定义行为,程序不保证什么结果。 - 通常在**调试模式(debug mode)**使用断言(assert)检测违反契约的情况。
- 优点:接口简洁,代码性能好,明确责任边界。
- 缺点:如果调用者传入错误数据,可能导致程序崩溃或不确定行为。
宽契约的特点
- 允许更多输入,包括不完全满足前置条件的情况,代码负责处理错误输入并返回状态码或做适当响应。
- 典型例子:
strlen(nullptr)返回0(示例中假设)。 - 优点:更健壮,减少因误用导致的程序崩溃。
- 缺点:
- 代码更复杂,运行时检查增加开销。
- 容易掩盖潜在错误(bug),因为错误输入被“悄悄处理”了。
- 宽契约等于接口变“宽”,增加维护难度。
例子说明
strlen(const char *s):
// 窄契约:
// 假设 s 不能为空,调用者负责保证
size_t strlen(const char *s) {assert(s); // 只在调试模式下检查// 计算长度...
}
- 宽契约示例:
// 宽契约:
// 允许 s 为 nullptr,返回0表示空字符串
size_t strlen(const char *s) {if (!s) return 0;// 计算长度...
}
这里宽契约容易掩盖错误,比如用户本来不应该传 nullptr,传了却没报错。
关于接口设计的讨论
- 是否返回状态码?
返回状态码属于宽契约,意味着函数本身负责检测和处理错误输入。
不返回状态码,函数假定调用者遵守契约,是窄契约。 - 行为未定义意味着什么?
行为未定义的情况下,程序可以崩溃、异常或者表现任意结果。窄契约强调这种“风险”,要求调用者自律。 - 是否应该包含行为未定义的行为到合同中?
如果行为是合同的一部分,就是定义行为,不是未定义行为了。
实际应用
- 标准库如
vector<T>::operator[]是窄契约,未检查越界,行为未定义。 vector<T>::at()是宽契约,检查越界,抛出异常。
1. 行为未定义时怎么办?
以 vector<TYPE>::operator[](int idx) 举例:
- 行为未定义:当
idx超出范围,行为是未定义的。 - 这个未定义行为的具体表现,往往依赖于编译模式(debug模式可能断言崩溃,release模式可能无检查直接越界访问)。
- 因此,窄契约强调“调用者保证参数正确”,否则后果自负。
相对的: vector<TYPE>::at(int idx)是宽契约,检查越界,越界时抛异常,定义行为更明确。
2. 函数参数越界时,行为是否应该定义?
以 void insert(int idx, const TYPE& value); 举例:
- 问题是: 当
idx < 0或idx > length()时,应该怎么办? - 一些设计可能选择“自动修正索引”:
甚至用模运算循环索引,但这属于宽契约。if (idx < 0) idx = 0; if (idx > length()) idx = length(); - 而讲究窄契约的设计,答案是“不应该定义这些情况的行为”,而是断言(assert)崩溃提示错误。
void insert(int idx, const TYPE& value) {assert(0 <= idx && idx <= length());// ... } - 这鼓励调用者保证正确传参,不掩盖错误。
3. 窄契约应适度,不能太窄
举 replace(int index, const TYPE& value, int numElements); 例子:
- 如果
index == length()并且numElements == 0,这其实是合理的调用,代表不做任何替换(插入或删除0个元素)。 - 所以对这个边界条件,契约应该允许,即使这看起来像越界,也不应该断言失败。
- 这种“适度宽容”是“适度窄契约(Appropriately Narrow Contracts)”,既保持了接口的严格性,也能处理合理边界情况。
总结
| 设计原则 | 含义 | 例子 |
|---|---|---|
| 窄契约 (Narrow) | 明确断言,行为未定义时直接崩溃,调用者负责保证参数合法 | operator[],insert参数越界断言失败 |
| 宽契约 (Wide) | 函数内部处理错误输入,返回状态或修正参数,代码更健壮但可能掩盖错误 | at()越界抛异常,strlen(nullptr)返回0 |
| 适度窄契约 (Appropriately Narrow) | 对合理的边界值允许行为,保持契约的实用性和健壮性 | replace(index == length(), numElements == 0)允许不报错 |
契约(Contracts)与异常处理(Exceptions)之间的关系,重点如下:
1. 前置条件(Preconditions)决定后置条件(Postconditions)
- 如果函数在前置条件成立时无法满足其后置条件,函数就不能正常返回。
- 换句话说,函数不能偷偷“打马虎眼”——要么正常完成,要么抛异常(或终止程序)。
2. 异常的来源应是硬件限制
- 函数失败时的原因,应该是硬件资源不足(比如内存不足),而不是程序状态导致的逻辑错误。
- 这种失败是不可避免且不可修复的,除非换一台更大(更强)的机器。
3. 内存分配失败是唯一合适的异常来源
std::bad_alloc是库中唯一应该抛出的异常(特别是分配器相关的组件)。- 这意味着库其他部分应尽量避免抛异常,而是用断言或返回错误码处理逻辑错误。
4. 如果禁用异常,abort() 是合理的替代
- 在一些不支持异常的环境下,调用
abort()终止程序是一个可接受的选择,确保不会以错误状态继续执行。
5. 好库组件应当是异常中立的(Exception-neutral)
- 通过 RAII(资源获取即初始化)技术,确保即使抛出异常也不会导致资源泄露。
- 库内部不要依赖异常逻辑做太多事情,保持异常透明和健壮。
总结
- 契约的前提条件保证了函数的正常行为,否则函数应“干脆”失败,不做隐晦处理。
- 异常只用来表示不可避免的硬件资源问题,逻辑错误由契约断言等方式捕获。
- 设计库时保证异常中立,能让用户放心使用。
这段话是在列出我们这部分内容要回答的关键问题,主要围绕以下几个主题:
1. 什么是防御式编程(Defensive Programming,DP)?
- 它是一种编写程序的方法,目的在于增强程序的健壮性,提前检查和处理错误条件,避免程序因无效输入或异常情况崩溃。
2. 什么是窄契约(narrow contract)和宽契约(wide contract)?
- 窄契约:函数的前置条件严格,一旦不满足就可能导致未定义行为。
- 宽契约:函数允许更多输入范围,处理更广泛的情况。
- 例如:
std::strlen(0):是否应该对传入空指针进行合理处理?Date::setDate(int, int, int):是否应该返回状态码告诉调用者设置是否成功?
3. 未定义行为应该如何处理?
- 应该如何在组件契约中定义或不定义未定义行为的处理?
- 是让程序崩溃,断言失败,还是做某种容错处理?
4. 针对具体接口的行为,应该如何定义?
operator[](int index)是否应该检查 index 是否越界(小于0或大于长度)?- 如果 index 超出范围,程序应该怎么做?
5. insert(int index, const TYPE& value) 函数在 index 超出合法范围时行为应如何?
- index 大于长度或小于零时,这种行为是否应该定义?还是让其未定义?
6. replace(int index, const TYPE& value, int numElements) 在 index 等于长度且 numElements 为零时,行为应否定义?
- 这类边界条件是否应该允许,或者应被视为非法?
总结:
这些问题的核心都在于接口契约的设计——应该严格还是宽松?未定义行为的处理方式?如何平衡易用性和安全性?
如何实现防御性检查(Defensive Checks)以应对客户端错误使用库代码的情况,以及应该由谁来决定这些检查的力度和处理策略。
1. 如果客户端错误使用库代码,应该怎么办?
- 开发者是否应该因为客户端错误被解雇?
- 应该更小心?更充分测试?
- 应该让库自己警告或检测错误,而不是依赖客户端?
2. 作为库开发者,我们应该:
- 更好地文档化代码?
- 尝试检测未定义行为?
- 是否能检测所有未定义行为?(答案是否定的)
- 在检测客户端错误上,应该花多少CPU时间?选项包括:
- 少于5%
- 5%到20%
- 超过20%,但不超过常数因子
- “天花板”不限,甚至是 O(log n)、O(n) 等复杂度
3. 如果检测到客户端错误,库该如何响应?
选项包括:
- 忽略并继续?
- 正常返回?
- 立即终止程序?
- 抛出异常?
- 等待调试器中断?
- 或其他自定义处理?
4. 如何作为一个企业决定应对策略?
需要考虑的因素:
- 软件成熟度(alpha、beta、生产环境)
- 是否是性能关键型应用
- 是否有合理的应对方案,比如:
- 保存客户数据后终止程序
- 记录错误,放弃当前事务并继续
- 发送消息通知运维人员并等待处理
5. 谁应该决定防御检查的细节?
- 库组件开发者
- 立即使用该库的客户端开发者
- 应用所有者(负责整个应用,拥有 main 函数)
6. 高层要求
- 让应用所有者可以方便地指定:
- 库检测客户端违规行为时应花多少时间
- 违规行为被检测到时应采取的行动
- 让库开发者可以方便地在代码中实现配置化(编译时和运行时)的检测机制
使用 bsls_assert 组件实现防御性检查(Defensive Checks)的详细计划和示例,重点在于如何通过宏和失败处理器来检测和处理客户端误用库代码的情况。以下是对内容的理解和总结:
1. 计划(Part I):提供三种 BSLS_ASSERT 宏*
- 目标:为库开发者提供三种不同级别的
BSLS_ASSERT*宏,用于在不同场景下进行防御性检查。 - 三种宏及默认行为:
- BSLS_ASSERT_OPT(EXPR):
- 特点:始终激活。
- 开销:小于 5%(性能影响最小)。
- 用途:用于检查那些要么不可观察(not observable),要么对系统至关重要(critical)的条件。
- BSLS_ASSERT(EXPR):
- 特点:默认激活,但可以通过编译标志控制:
- 如果定义了
-DBDE_BUILD_TARGET_OPT,则禁用(优化模式)。 - 如果定义了
-DBDE_BUILD_TARGET_SAFE,则启用(安全模式)。
- 如果定义了
- 开销:5% 到 20%(性能影响中等)。
- 用途:用于检查那些成本低但不可忽略的条件。
- 特点:默认激活,但可以通过编译标志控制:
- BSLS_ASSERT_SAFE(EXPR):
- 特点:仅在
-DBDE_BUILD_TARGET_SAFE模式下激活。 - 开销:大于 20%,可能更高(性能影响较大)。
- 用途:用于可能开销较高的检查。
- 特点:仅在
- BSLS_ASSERT_OPT(EXPR):
- 总结:这三种宏根据性能开销和检查的必要性分级,允许开发者根据应用需求选择合适的检查级别。
2. 计划(Part II):提供全局回调机制和三种失败处理器
- 目标:提供一个全局回调机制,允许自定义失败处理,同时提供三种现成的失败处理器。
- 回调函数定义:
typedef void (*Handler)(const char *text, const char *file, int line);- 回调函数接受三个参数:失败的断言表达式(
text)、文件名(file)和行号(line)。
- 回调函数接受三个参数:失败的断言表达式(
- 三种现成的失败处理器:
- failAbort:
- 行为:将错误信息打印到
stderr,然后终止程序(调用abort())。 - 适用场景:适用于需要立即停止程序的严重错误。
- 行为:将错误信息打印到
- failThrow:
- 行为:将错误信息封装在
std::logic_error中并抛出异常。 - 适用场景:适用于希望通过异常机制处理错误的场景。
- 行为:将错误信息封装在
- failSleep(或
failSpin):- 行为:将错误信息打印到
stderr,然后进入循环/休眠状态(等待调试器介入)。 - 适用场景:适用于调试场景,允许开发者在程序暂停时介入。
- 行为:将错误信息打印到
- failAbort:
- 改进:根据 C++ 标准委员会 LEWG 的反馈,计划将回调参数整合为一个结构体,简化接口。
3. 示例 1:使用 BSLS_ASSERT
- 场景:实现一个计算阶乘的函数
factorial。 - 代码(
our_mathutil.h和our_mathutil.cpp):// our_mathutil.h struct MathUtil {static double factorial(int n);// 返回从 1 到 n 的乘积,若 n 为 0 则返回 1。// 要求:0 <= n <= 100,否则行为未定义。 }; // our_mathutil.cpp #include <our_mathutil.h> #include <bsls_assert.h> double MathUtil::factorial(int n) {BSLS_ASSERT(0 <= n); // 检查 n 是否非负BSLS_ASSERT(n <= 100); // 检查 n 是否不超过 100// 阶乘实现代码 } - 客户端代码(
my_client.cpp):#include <my_client.h> #include <our_mathutil.h> void someFunction() {double z = our::MathUtil::factorial(-5); // 误用:n < 0 } - 运行结果:
- 编译时需链接
bsls_assert.o。 - 运行时触发断言失败:
Assertion failed: 0 <= n, file our_mathutil.cpp, line 365 Abort (core dumped)
- 编译时需链接
- 分析:使用了
BSLS_ASSERT,默认失败处理器为failAbort,因此程序在检测到n < 0时打印错误并终止。
4. 示例 2:使用 BSLS_ASSERT_SAFE
- 场景:实现一个正方形类
Square,设置宽度。 - 代码(
our_square.h):#include <bsls_assert.h> class Square {double d_width; public:void setWidth(double width);// 要求:width >= 0.0,否则行为未定义。 }; inline void Square::setWidth(double width) {BSLS_ASSERT_SAFE(0.0 <= width); // 检查宽度非负d_width = width; } - 客户端代码(
my_client.cpp):#include <my_client.h> #include <our_square.h> void someFunction() {our::Square s;s.setWidth(-3.14); // 误用:width < 0 } - 运行结果:
- 编译时需启用
-DBDE_BUILD_TARGET_SAFE(否则BSLS_ASSERT_SAFE不生效)。 - 运行时触发断言失败:
Assertion failed: 0 <= width, file our_square.h, line 142 Abort (core dumped)
- 编译时需启用
- 分析:使用了
BSLS_ASSERT_SAFE,适合内联函数(inline functions),因为这种检查可能开销较高,只有在安全模式下才会触发。
5. 示例 3:使用 BSLS_ASSERT_SAFE
- 场景:实现一个二维点类
Kpoint。 - 代码(
our_kpoint.h):class Kpoint {short int d_x, d_y; public:Kpoint(int x, int y);// 要求:-1000 <= x, y <= 1000,否则行为未定义。 }; inline Kpoint::Kpoint(int x, int y) : d_x(x), d_y(y) {BSLS_ASSERT_SAFE(-1000 <= x); BSLS_ASSERT_SAFE(x <= 1000);BSLS_ASSERT_SAFE(-1000 <= y); BSLS_ASSERT_SAFE(y <= 1000); } - 分析:再次使用
BSLS_ASSERT_SAFE,因为构造函数是内联的,检查条件可能较昂贵,符合指南建议。
6. 示例 4:使用 BSLS_ASSERT
- 场景:实现一个哈希表类
HashTable,调整大小。 - 代码(
our_hashtable.h和our_hashtable.cpp):// our_hashtable.h class HashTable { public:void resize(double loadFactor);// 调整哈希表大小,要求:loadFactor > 0,否则行为未定义。 }; // our_hashtable.cpp void HashTable::resize(double loadFactor) {BSLS_ASSERT(0 < loadFactor); // 检查 loadFactor 正数// 实现代码 } - 分析:使用了
BSLS_ASSERT,因为resize不是内联函数,且检查成本较低,符合指南建议。
7. 示例 5:使用 BSLS_ASSERT_OPT 和自定义失败处理器
- 场景:实现一个交易系统类
TradingSystem。 - 代码(
our_tradingsystem.h和our_tradingsystem.cpp):// our_tradingsystem.h class TradingSystem { public:void executeTrade(int scalingFactor);// 要求:scalingFactor >= 0 且能被 100 整除,否则行为未定义。 }; // our_tradingsystem.cpp void TradingSystem::executeTrade(int scalingFactor) {BSLS_ASSERT_OPT(0 <= scalingFactor); // 检查非负BSLS_ASSERT_OPT(0 == scalingFactor % 100); // 检查整除// 实现代码 } - 客户端代码(自定义
failSpin):int main(int argc, const char *argv[]) {bsls_Assert::setFailureHandler(&bsls_Assert::failSpin); // 设置失败处理器return 0; } void clientFunction(our::TradingSystem *objectPtr) {objectPtr->executeTrade(10022); // 误用:10022 不能被 100 整除 } - 运行结果:
- 编译时启用
-DBDE_BUILD_TARGET_OPT(但BSLS_ASSERT_OPT始终生效)。 - 运行时触发断言失败:
(printed message sent to console room, waiting…)
- 编译时启用
- 分析:使用了
BSLS_ASSERT_OPT,因为条件对系统至关重要(critical),且开销极低。自定义了失败处理器为failSpin,程序会暂停并等待调试。
8. 选择 BSLS_ASSERT 的指南*
- BSLS_ASSERT_SAFE:
- 用途:检查开销可能较高(>20%)。
- 建议:用于内联函数(inline functions)。
- BSLS_ASSERT:
- 用途:检查成本低但不可忽略(5%-20%)。
- 建议:用于非内联函数(non-inline functions)。
- BSLS_ASSERT_OPT:
- 用途:检查要么不可观察,要么至关重要(<5%)。
- 建议:用于性能敏感或关键场景。
- 总结:指南根据性能开销和函数类型(内联/非内联)提供选择建议,平衡安全性和性能。
总体理解
bsls_assert组件通过三种宏(BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)提供分级防御性检查,允许开发者根据性能需求选择合适的检查级别。- 失败处理器(
failAbort、failThrow、failSleep/failSpin)提供了灵活的错误处理机制,支持终止、抛异常或调试。 - 示例展示了如何在不同场景(阶乘、几何、正方形、哈希表、交易系统)中使用这些宏,并通过客户端误用演示了断言触发的效果。
- 设计目标:在保证安全性的同时,尽量减少性能开销,并通过编译标志和自定义处理器提供灵活性,满足不同开发阶段和应用需求。
这段内容是关于软件开发中防御性检查(Defensive Checks)的进一步扩展,重点介绍了“硬未定义行为”(Hard Undefined Behavior)和“软未定义行为”(Soft Undefined Behavior)的区别,以及如何使用bsls_assert组件来处理这些情况。以下是对内容的理解和总结:
1. 硬未定义行为 (Hard UB) 与 软未定义行为 (Soft UB) 的概念
- 两种未定义行为 (Undefined Behavior, UB):
- 语言未定义行为 (Hard UB):
- 由编程语言(如 C++)定义的未定义行为。
- 后果极端且不可预测,例如内存损坏或程序崩溃,甚至可能导致荒谬的结果(如引用中提到的“你的猫可能怀孕”——Marshall Clow 的幽默表达)。
- 库未定义行为 (Soft UB):
- 由库的契约(Contract Violation)引起的未定义行为。
- 目前尚未导致严重后果,但可能演变为 Hard UB。
- 语言未定义行为 (Hard UB):
- 关系:
- Soft UB 是相对的概念,取决于开发者的视角。
- 如果开发者不了解库的实现,Soft UB(契约违反)可能直接导致 Hard UB。
- 如果开发者是库的实现者或测试驱动程序的开发者,Soft UB 可以保持在可控范围内,不一定升级为 Hard UB。
2. 软未定义行为的相对性
- 条件:
- 外部视角(不了解实现):
- 契约违反(Soft UB)可能引发 Hard UB,因为缺乏足够信息来预测行为。
- 内部视角(实现或测试驱动):
- 开发者可以利用内部知识,将契约违反限制为 Soft UB,避免升级为 Hard UB。
- 外部视角(不了解实现):
- 例子:
- 如果开发者知道如何处理契约违反(例如通过调试或修复),可以避免更严重的后果。
3. 示例分析:传递 0 是否为未定义行为
- 示例 1:
bsl::strlen函数bsl::size_t bsl::strlen(const char *string) // 要求:string 必须以 null 终止,否则行为未定义。 {BSLS_ASSERT_SAFE(string); // 断言检查const char *p = string;while (*p) { ++p; }return p - string; }- 分析:如果传入
nullptr(0),BSLS_ASSERT_SAFE会触发,因为string未满足 null 终止条件。这被归类为 Hard UB,因为它可能导致内存访问错误或崩溃。
- 分析:如果传入
- 示例 2:
Account::setName函数class Account {std::string d_name; public:void setName(const char *name)// 要求:name 必须以 null 终止,否则行为未定义。{BSLS_ASSERT_SAFE(name); // 断言检查d_name = name;} };- 分析:同样,传入
nullptr触发BSLS_ASSERT_SAFE,被归类为 Hard UB,因为它可能导致无效内存操作。
- 分析:同样,传入
- 示例 3:
badLibraryFunctionvs.goodLibraryFunction- 坏的实现:
void badLibraryFunction(std::string& result, ...) {BSLS_ASSERT_SAFE(&result); // 太晚了!// ... } int someClientFunction(std::string *resultId, ...) {// 要求:resultId 必须非空badLibraryFunction(*resultId, ...); }- 问题:
BSLS_ASSERT_SAFE检查太晚(在解引用resultId之后),如果resultId为nullptr,会导致 Hard UB(解引用空指针)。
- 问题:
- 好的实现:
void goodLibraryFunction(std::string *result, ...) {BSLS_ASSERT_SAFE(result); // 及时检查// ... } int someClientFunction(std::string *resultId, ...) {// 要求:resultId 必须非空goodLibraryFunction(resultId, ...); }- 分析:在解引用前检查
result,如果resultId为nullptr,触发BSLS_ASSERT_SAFE,保持为 Soft UB(契约违反),避免 Hard UB。
- 分析:在解引用前检查
- 坏的实现:
- 总结:及时的防御性检查可以将潜在的 Hard UB 转换为可控的 Soft UB。
4. 示例 6:使用 failThrow 失败处理器
- 代码(客户端):
int main(int argc, const char *argv[]) {bsls_Assert::setFailureHandler(&bsls_Assert::failThrow); // 设置抛出异常// 设置保存内部状态的逻辑try {// 所有有用工作在这里} catch (const std::logic_error& exception) {// 保存内部状态并退出}return 0; } - 分析:
- 使用
failThrow处理器,当断言失败时抛出std::logic_error异常。 - 通过
try-catch块捕获异常,允许在异常发生时保存状态并优雅退出。 - 提到其他回调类型也可以实现类似目标,表明灵活性。
- 使用
5. 支持条件编译
- 对应每个断言级别:
BSLS_ASSERT_OPT→BSLS_ASSERT_OPT_IS_ACTIVEBSLS_ASSERT→BSLS_ASSERT_IS_ACTIVEBSLS_ASSERT_SAFE→BSLS_ASSERT_SAFE_IS_ACTIVE
- 用途:通过条件编译宏,开发者可以根据激活状态动态调整代码行为。
6. 示例 7:使用 BSLS_ASSERT*_IS_ACTIVE
- 代码(
MyDate类):class MyDate {int d_serialDate; // 有效范围 [1 .. 3652061] public:MyDate();// 创建值为 '0001Jan01' 的对象#if defined(BSLS_ASSERT_SAFE_IS_ACTIVE)~MyDate(); // 仅在安全模式下定义析构函数#endif }; inline MyDate::MyDate() : d_serialDate(1) { } // 0001Jan01 #if defined(BSLS_ASSERT_SAFE_IS_ACTIVE) inline MyDate::~MyDate() {BSLS_ASSERT_SAFE(1 <= d_serialDate); // 检查下限BSLS_ASSERT_SAFE(d_serialDate <= 3652061); // 检查上限 } #endif - 分析:
- 析构函数和断言检查仅在
BSLS_ASSERT_SAFE_IS_ACTIVE定义时启用。 - 这允许在安全模式下验证
d_serialDate的有效性,优化模式下省略检查以提升性能。 - 符合条件编译的灵活性需求。
- 析构函数和断言检查仅在
总体理解
- 硬 vs. 软未定义行为:
- Hard UB 是语言级别的不可预测错误,Soft UB 是库级别的契约违反,可通过早期检查转化为可控错误。
- 软未定义行为的严重性取决于开发者对实现的了解程度。
- 防御性检查的重要性:
- 通过
BSLS_ASSERT*宏和及时的检查,可以将 Hard UB 风险降至最低。 - 示例展示了如何在不同场景下正确使用断言,避免未定义行为升级。
- 通过
- 灵活性与性能平衡:
- 提供多种失败处理器(
failThrow等)和条件编译支持,允许开发者根据需求调整行为和性能开销。
- 提供多种失败处理器(
- 实践指导:
- 及时的防御性检查(如
goodLibraryFunction)是关键,晚检查(如badLibraryFunction)可能导致 Hard UB。 - 条件编译(如
BSLS_ASSERT*_IS_ACTIVE)支持在不同构建目标间切换检查。
这段内容讨论了在实现防御性检查时,混合模式(Mixed-Mode)构建(即不同断言级别构建)带来的影响,特别是与 ABI 兼容性和 C++ 的**单一定义规则(One-Definition Rule, ODR)**相关的问题。以下是对内容的理解和总结:
- 及时的防御性检查(如
1. 混合模式构建的含义
- 背景:混合模式构建指的是在同一程序中,客户端代码和库代码可能以不同的断言级别(Assertion Level)编译,例如:
- 客户端可能启用
BSLS_ASSERT_OPT和BSLS_ASSERT,而库可能只启用BSLS_ASSERT_OPT。 - 这种差异可能出现在内联函数、函数模板等定义中,因为它们可能在头文件中被多次编译。
- 客户端可能启用
- 讨论的问题:
- 是否会导致 ABI 不兼容?
- 是否会违反 ODR?
2. 影响分析
1. ABI 兼容性
- 结论:不会导致 ABI 不兼容。
- 原因:
- 所有断言级别模式(
BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)必须设计为 ABI 兼容。 - 断言的唯一副作用是调用失败处理器(Failure Handler),不会改变函数的二进制接口(例如函数签名、参数传递方式等)。
- 所有断言级别模式(
2. 违反单一定义规则 (ODR)
- 结论:会违反 ODR。
- 原因:
- 在头文件中使用
bsls_assert(如内联函数或函数模板中)可能导致 ODR 违反。 - 场景:
- 内联函数定义(Inline-Function Definitions):在头文件中定义的内联函数可能在不同编译单元中以不同断言级别编译,导致函数定义不一致。
- 函数模板定义(Function-Template Definitions):类似地,函数模板可能因断言级别不同而生成不一致的实例。
- 在头文件中使用
3. ODR 违反的详细分析
场景 1:所有函数定义在 .cpp 文件中
- 表格分析:
- 客户端构建模式:启用
BSLS_ASSERT_OPT和BSLS_ASSERT。 - 库构建模式:
- 第一种情况:只启用
BSLS_ASSERT_OPT。- 问题:
BSLS_ASSERT在库中未激活,而在客户端中激活,导致行为不一致。
- 问题:
- 第二种情况:启用
BSLS_ASSERT_OPT和BSLS_ASSERT。- 问题:
BSLS_ASSERT在库和客户端中都激活,行为一致。
- 问题:
- 第一种情况:只启用
- 客户端构建模式:启用
- 结论:如果函数定义在
.cpp文件中,ODR 问题不明显,因为每个编译单元有独立的定义。但断言行为的不一致可能导致运行时问题。
场景 2:内联函数定义在 .h 文件中
- 表格分析:
- 客户端构建模式:启用
BSLS_ASSERT_OPT和BSLS_ASSERT。 - 库构建模式:启用
BSLS_ASSERT_OPT、BSLS_ASSERT和BSLS_ASSERT_SAFE。- 问题:
BSLS_ASSERT_SAFE在客户端中可能未激活,而在库中激活,导致内联函数的定义不一致(违反 ODR)。
- 问题:
- 客户端构建模式:启用
- 结论:内联函数在头文件中定义时,不同编译单元可能看到不同的断言级别,导致 ODR 违反。例如:
- 客户端可能跳过
BSLS_ASSERT_SAFE的检查,而库期望执行该检查。
- 客户端可能跳过
场景 3:函数模板定义在 .h 文件中
- 表格分析:
- 客户端构建模式:启用
BSLS_ASSERT_OPT和BSLS_ASSERT。 - 库构建模式:只启用
BSLS_ASSERT_OPT。- 问题:
BSLS_ASSERT在客户端中激活,但在库中未激活,导致函数模板实例化的定义不一致(违反 ODR)。
- 问题:
- 客户端构建模式:启用
- 结论:函数模板在不同编译单元中实例化时,断言级别的差异会导致生成的代码不一致,进一步违反 ODR。
4. 为什么违反 ODR 在此场景下是“可接受的”?
- 问题:尽管违反了 ODR,为什么这种行为被认为是“OK”的?
- 回答:
- 语法上(ABI)兼容:
- 不同断言级别的构建不会改变函数的 ABI(例如函数签名、参数类型等),因此二进制级别上是一致的。
- 语义上可替代:
- 组件级契约(Component-Level Contract):
- 如果违反了契约,行为是未定义的(Undefined Behavior),因此不同断言级别的行为差异符合预期(未定义行为允许任何结果)。
- 库级理解(Library-Level Understanding):
- 遵循“看到问题就报告”(See something, Say Something)的原则。断言级别的差异仅影响是否触发失败处理器,而不会改变核心功能。
- 组件级契约(Component-Level Contract):
- 语法上(ABI)兼容:
- 总结:虽然技术上违反了 ODR,但由于定义在 ABI 级别兼容,且语义上未定义行为允许差异,这种违反在实践中不会导致严重问题。
总体理解
- 混合模式构建指的是在同一程序中,不同模块以不同断言级别(
BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)编译。 - 影响:
- ABI 兼容性:断言级别不会影响 ABI,因此混合模式构建在二进制级别是安全的。
- ODR 违反:在头文件中使用
bsls_assert(如内联函数或函数模板)可能导致 ODR 违反,因为不同编译单元可能看到不一致的定义。
- ODR 违反的具体场景:
.cpp文件中的定义:影响较小,仅表现为断言行为不一致。- 头文件中的内联函数和函数模板:可能因断言级别不同而导致定义不一致,违反 ODR。
- 为何可接受:
- 所有定义在 ABI 级别兼容。
- 语义上,契约违反导致未定义行为,允许行为差异;同时,断言仅触发失败处理器,不会改变核心功能。
- 实践建议:
- 尽量避免在头文件中使用高开销的断言(如
BSLS_ASSERT_SAFE),以减少 ODR 违反的风险。 - 在混合模式构建中,需明确文档说明断言级别的预期行为,确保客户端和库开发者理解潜在差异。
这段内容强调了在防御性检查中,混合模式构建的复杂性及其对 ODR 的影响,同时提供了为什么这种违反在特定场景下可接受的理由。
- 尽量避免在头文件中使用高开销的断言(如
1. 示例 8:创建和使用自定义失败处理器
代码:定义自定义失败处理器
- 文件:
main.cpp - 代码:
#include <bsls_assert.h> #include <cstdio> // 为了使用 std::printf static bool globalEnableOurPrintingFlag = true; static void ourFailureHandler(const char *text, const char *file, int line) // 打印指定的表达式 'text'、文件名 'file' 和行号 'line' 到 stdout,格式为逗号分隔列表, // 将空字符串参数替换为空字符串(除非 globalEnableOurPrintingFlag 为 false 禁用打印); // 然后无条件终止进程。 {if (!text) text = ""; // 防止空指针,替换为 ""if (!file) file = ""; // 防止空指针,替换为 ""if (globalEnableOurPrintingFlag) {std::printf("%s, %s, %d\n", text, file, line); // 打印信息}std::abort(); // 终止进程 } - 功能:
ourFailureHandler是一个自定义失败处理器,符合bsls_assert组件的回调签名:void (*Handler)(const char*, const char*, int)。- 检查
text和file是否为nullptr,如果是则替换为空字符串。 - 根据全局标志
globalEnableOurPrintingFlag决定是否打印断言失败信息(格式:text, file, line)。 - 最后调用
std::abort()终止程序。
代码:安装和调用自定义失败处理器
- 代码:
int main(int argc, const char *argv[]) {bsls_Assert::Handler f = &::ourFailureHandler; // 获取函数指针bsls_Assert::setFailureHandler(f); // 设置自定义失败处理器bsls_Assert::invokeHandler("str1", "str2", 3); // 手动调用处理器return 0; } - 编译和运行:
$ CC -o a.out main.cpp $ ./a.out str1, str2, 3 Abort (core dumped) - 分析:
bsls_Assert::Handler是一个函数指针类型,用于存储失败处理器的地址。bsls_Assert::setFailureHandler设置自定义处理器ourFailureHandler。bsls_Assert::invokeHandler手动调用处理器,传入测试参数"str1"、"str2"和3。- 输出结果符合预期:打印
str1, str2, 3,然后程序因std::abort()终止。
2. 回顾计划(Part I):三种 BSLS_ASSERT 宏*
- 目标:为库开发者提供三种断言宏,根据性能开销和激活条件分级。
- 三种宏及默认行为:
- BSLS_ASSERT_OPT(EXPR):
- 开销:小于 5%(性能影响最小)。
- 默认行为:始终激活(Always active)。
- BSLS_ASSERT(EXPR):
- 开销:5% 到 20%(性能影响中等)。
- 默认行为:
- 如果定义了
-DBDE_BUILD_TARGET_OPT,则禁用(优化模式)。 - 如果定义了
-DBDE_BUILD_TARGET_SAFE,则启用(安全模式)。 - 否则,保持激活。
- 如果定义了
- BSLS_ASSERT_SAFE(EXPR):
- 开销:大于 20%,可能更高(性能影响较大)。
- 默认行为:仅在
-DBDE_BUILD_TARGET_SAFE模式下激活。
- BSLS_ASSERT_OPT(EXPR):
- 总结:这些宏根据性能开销和构建目标(Build Target)提供灵活的防御性检查选项。
3. 断言级别覆盖(Assertion-Level Overrides)
- 目标:允许开发者通过构建选项覆盖默认的断言级别(由
BDE_BUILD_TARGET_*标志决定)。 - 覆盖选项(在构建命令行中指定,必须选择恰好一个):
-D BSLS_ASSERT_LEVEL_NONE:- 效果:所有断言宏(
BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)都不激活。
- 效果:所有断言宏(
-D BSLS_ASSERT_LEVEL_ASSERT_OPT:- 效果:仅
BSLS_ASSERT_OPT激活,其他宏(BSLS_ASSERT和BSLS_ASSERT_SAFE)不激活。
- 效果:仅
-D BSLS_ASSERT_LEVEL_ASSERT:- 效果:
BSLS_ASSERT_OPT和BSLS_ASSERT激活,但BSLS_ASSERT_SAFE不激活。
- 效果:
-D BSLS_ASSERT_LEVEL_ASSERT_SAFE:- 效果:所有断言宏(
BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)都激活。
- 效果:所有断言宏(
- 示例:
- 在优化构建中启用所有断言宏:
CC -DBDE_BUILD_TARGET_OPT -DBSLS_ASSERT_LEVEL_ASSERT_SAFE ...- 说明:
-DBDE_BUILD_TARGET_OPT通常会禁用BSLS_ASSERT,但被-DBSLS_ASSERT_LEVEL_ASSERT_SAFE覆盖。- 结果:所有断言宏(包括
BSLS_ASSERT_SAFE)都激活,即使在优化模式下。
- 说明:
- 在优化构建中启用所有断言宏:
总体理解
- 自定义失败处理器:
- 示例 8 展示了如何通过
bsls_assert组件创建和使用自定义失败处理器ourFailureHandler。 - 处理器实现了灵活的错误处理逻辑:根据全局标志决定是否打印错误信息,并始终终止程序。
- 使用
bsls_Assert::setFailureHandler安装处理器,bsls_Assert::invokeHandler测试其行为。
- 示例 8 展示了如何通过
- 断言级别回顾:
- 三种
BSLS_ASSERT*宏(BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)根据性能开销分级,开发者可根据构建目标选择激活哪些宏。
- 三种
- 断言级别覆盖:
- 提供四种覆盖选项(
BSLS_ASSERT_LEVEL_*),允许开发者通过构建命令行精确控制断言行为。 - 覆盖选项可以绕过默认的
BDE_BUILD_TARGET_*设置,例如在优化构建中强制启用所有断言。
- 提供四种覆盖选项(
- 实践意义:
- 自定义失败处理器增加了错误处理的灵活性,适合特定调试或日志需求。
- 断言级别覆盖机制允许开发者在不同构建场景(优化、安全、调试)中平衡性能和安全性。
这段内容继续探讨防御性检查(Defensive Checks)的实现,重点在于二进制不兼容的检查(Binary-Incompatible Defensive Checks)和高开销检查(Disproportionally Expensive Checks),以及如何通过BDE_BUILD_TARGET_SAFE_2模式和bsls_assert组件处理这些情况。以下是对内容的理解和总结:
1. 二进制不兼容的防御性检查
动机示例:检查迭代器(Checked Iterators)
- 问题:
- 解除引用(dereferencing)一个因容器修改而失效的迭代器是未定义行为(Undefined Behavior)。
- 解决方案:
- 需要额外的实例数据来实现检查:
- 容器:需要维护一个额外的链表(linked list),存储指向迭代器的反向指针(back pointers)。
- 迭代器:需要维护一个额外的指针,指向其在链表中的节点。
- 需要额外的实例数据来实现检查:
- 问题:
- 这种检查是二进制不兼容的(NOT binary compatible)。
- 原因:添加额外数据(例如
d_backPointers链表)会改变容器和迭代器的内存布局(memory layout),从而改变类的 ABI(Application Binary Interface)。这意味着以不同模式编译的代码(启用检查 vs. 不启用检查)无法在二进制级别兼容。
2. 示例 9:使用 BDE_BUILD_TARGET_SAFE_2 处理二进制不兼容检查
- 代码(
my_string.h):class String {char *d_array_p; // 字符数组std::size_t d_length; // 字符串长度std::size_t d_capacity; // 容量bslma_Allocator *d_allocator_p; // 内存分配器#if defined(BDE_BUILD_TARGET_SAFE_2)bsl::list<iterator *> d_backPointers; // 反向指针链表#endifvoid removeAll() {#if defined(BDE_BUILD_TARGET_SAFE_2)// 使用 d_backPointers 使所有迭代器失效#endifd_length = 0; // 清空字符串} }; - 分析:
- 条件编译:通过
#if defined(BDE_BUILD_TARGET_SAFE_2)控制是否启用二进制不兼容的检查。 - 反向指针链表:在
BDE_BUILD_TARGET_SAFE_2模式下,String类会添加d_backPointers成员,用于跟踪所有迭代器。 - 功能:
removeAll方法在启用SAFE_2模式时会使用d_backPointers使所有迭代器失效,避免未定义行为。 - 二进制不兼容:如果
BDE_BUILD_TARGET_SAFE_2未定义,d_backPointers不存在,String类的内存布局不同,导致二进制不兼容。
- 条件编译:通过
3. 高开销检查(Disproportionally Expensive Checks)
动机示例:验证排序顺序(Sorted Order)
- 问题:
- 在一个排序数组上执行二分查找(Binary Search)的时间复杂度为 O(log n)。
- 但验证数组是否已排序(isSorted)的时间复杂度为 O(n),远高于二分查找本身。
- 扩展问题:
- 二进制不兼容检查:如前所述,这种检查通常也很昂贵(例如需要遍历所有迭代器,复杂度可能是 O(n))。
- 其他高开销检查:即使不涉及二进制不兼容,一些检查在安全模式(Safe Build)下也可能成本过高。
- 策略:
- 选择:决定不在“普通”安全模式(
BDE_BUILD_TARGET_SAFE)中启用那些最坏情况时间复杂度更高的检查(例如从 O(log n) 增加到 O(n))。 - 解决方法:将这类高开销检查放到更高级别的安全模式(如
BDE_BUILD_TARGET_SAFE_2)中。
- 选择:决定不在“普通”安全模式(
4. 示例 10:使用 BDE_BUILD_TARGET_SAFE_2 处理高开销检查
代码(my_algorithmutil.h 和 my_algorithmutil.cpp):
- 头文件(
my_algorithmutil.h):#include <bsls_assert.h> struct AlgorithmUtil {static bool isSorted(const std::vector<int>& a);// 检查向量是否已排序static bool isMember(const std::vector<int>& a, int v);// 检查 v 是否在向量 a 中// 要求:a 必须已排序,否则行为未定义 }; - 实现文件(
my_algorithmutil.cpp):bool AlgorithmUtil::isMember(const std::vector<T>& a, int v) {#if defined(BDE_BUILD_TARGET_SAFE_2)BSLS_ASSERT_SAFE(isSorted(a)); // 检查向量是否已排序#endif// 实现二分查找逻辑(省略) } - 分析:
- 高开销检查:
isSorted(a)的时间复杂度为 O(n),远高于二分查找的 O(log n)。 - 条件编译:仅在
BDE_BUILD_TARGET_SAFE_2模式下启用此检查,避免在普通安全模式下影响性能。 - 契约:
isMember方法要求输入向量已排序,否则行为未定义。通过BSLS_ASSERT_SAFE强制检查此条件。
- 高开销检查:
客户端使用:
- 要求:整个程序必须统一使用(或不使用)
-DBDE_BUILD_TARGET_SAFE_2构建。- 原因:
SAFE_2模式可能引入二进制不兼容的更改(如String类的d_backPointers),需要一致性。
- 原因:
- 默认行为:
- 在
SAFE_2模式下,所有断言级别(BSLS_ASSERT_OPT、BSLS_ASSERT、BSLS_ASSERT_SAFE)默认启用。
- 在
- 覆盖断言级别:
- 可以使用
BSLS_ASSERT_LEVEL_*覆盖默认断言级别,例如:CC -DBDE_BUILD_TARGET_SAFE_2 -DBSLS_ASSERT_LEVEL_ASSERT myalgorithms.cpp ...- 效果:在
SAFE_2模式下,启用高开销检查,但通过-DBSLS_ASSERT_LEVEL_ASSERT限制断言级别,仅激活BSLS_ASSERT_OPT和BSLS_ASSERT,禁用BSLS_ASSERT_SAFE。
- 效果:在
- 可以使用
5. 构建模式总结(Build-Mode Summary)
- BDE 构建目标(BDE Build Targets):
DEFAULT:默认模式(未指定其他目标)。-DBDE_BUILD_TARGET_OPT:优化模式。-DBDE_BUILD_TARGET_SAFE:安全模式。-DBDE_BUILD_TARGET_SAFE_2:更高级安全模式(支持二进制不兼容和高开销检查)。
- BSLS 断言覆盖(BSLS Assertion Overrides):
-DBSLS_ASSERT_LEVEL_NONE:禁用所有断言。-DBSLS_ASSERT_LEVEL_ASSERT_OPT:仅启用BSLS_ASSERT_OPT。-DBSLS_ASSERT_LEVEL_ASSERT:启用BSLS_ASSERT_OPT和BSLS_ASSERT。-DBSLS_ASSERT_LEVEL_ASSERT_SAFE:启用所有断言(包括BSLS_ASSERT_SAFE)。
- 表格(未完全展开,但含义清晰):
- 表示不同构建目标和断言覆盖的组合,决定了哪些断言宏会被激活。
总体理解
- 二进制不兼容检查:
- 问题:某些防御性检查(如检查迭代器失效)需要额外数据(如反向指针链表),这会改变类的内存布局,导致二进制不兼容。
- 解决方法:通过
BDE_BUILD_TARGET_SAFE_2模式控制此类检查,确保启用时整个程序一致构建。 - 示例:
String类在SAFE_2模式下添加d_backPointers,用于使迭代器失效。
- 高开销检查:
- 问题:某些检查(如验证数组是否排序)时间复杂度过高(例如 O(n)),不适合普通安全模式。
- 解决方法:同样使用
BDE_BUILD_TARGET_SAFE_2模式,仅在需要时启用此类检查。 - 示例:
AlgorithmUtil::isMember方法在SAFE_2模式下检查输入向量是否已排序。
- 构建模式:
BDE_BUILD_TARGET_SAFE_2专门用于处理二进制不兼容和高开销的检查,默认启用所有断言级别。- 可以通过
BSLS_ASSERT_LEVEL_*覆盖调整断言级别,平衡安全性和性能。
- 实践意义:
- 开发者可以根据需求选择合适的构建模式:
- 普通安全模式(
BDE_BUILD_TARGET_SAFE)用于常规检查。 - 高级安全模式(
BDE_BUILD_TARGET_SAFE_2)用于更彻底但成本更高的检查。
- 普通安全模式(
- 确保构建一致性,避免二进制不兼容问题。
这段内容是在探讨**“防御性检查(Defensive Checks)”的设计决策**,特别是在 BDE(Bloomberg Development Environment)风格下的库开发中,涉及bsls_assert宏、配置策略、编译目标等核心问题。下面是对你列出的问题的逐一解释和理解总结:
- 开发者可以根据需求选择合适的构建模式:
问题解析与理解
1. 谁应该决定:检查前置条件花多少 CPU 时间?违反时该怎么办?
- 答案:应该由**应用程序的拥有者(application owner)**来决定。原因:
- 他们拥有
main函数; - 对性能、鲁棒性、安全性有最终责任;
- 可以权衡开发效率与运行成本;
- 防御性检查的粒度应支持配置。
- 他们拥有
2. 为什么库开发者不在函数级契约中指定防御性检查内容?
- 原因:
- 因为检查是否启用是构建配置(build target)依赖的;
bsls_assert宏是否启用,在不同模式(如SAFE,OPT,DEBUG)下行为不同;- 因此,这些检查并非固定契约的一部分,而是依赖于上下文;
- 换句话说,不能强制客户端依赖它的存在或行为。
3. 何时使用 BSLS_ASSERT_SAFE vs BSLS_ASSERT vs BSLS_ASSERT_OPT?
- 用途区分:
宏 使用时机 检查级别 是否影响性能敏感路径? BSLS_ASSERT_SAFE开发初期、调试期间,检查非关键路径 最严 可能较慢 BSLS_ASSERT一般开发时默认启用,适中强度 中等 可接受的成本 BSLS_ASSERT_OPT性能敏感代码、发布版本中保留少量关键检查 最轻 通常很快 - 建议:
- 尽量用
SAFE做复杂校验; - 用
ASSERT保证一般契约; - 用
OPT检查基本但致命的错误。
- 尽量用
4. 什么是硬(hard)与软(soft)未定义行为?
- 硬未定义行为(Hard UB):
- 行为未定义且系统后果不可预测,例如:
- 解引用空指针;
- 越界访问数组;
- 使用未初始化变量。
- 可能导致程序崩溃或内存损坏。
- 行为未定义且系统后果不可预测,例如:
- 软未定义行为(Soft UB):
- 技术上未定义,但可以受控处理,例如:
- 输入无效参数但不立即崩溃;
- 调用顺序错误;
- 通常可以通过断言、日志、异常来探测和恢复。
- 技术上未定义,但可以受控处理,例如:
5. bsls_assert 宏为什么会违反 ODR(One Definition Rule)?为什么这可以接受?
- 两个主要原因:
bsls_assert的定义在不同构建目标中有不同实现;- 宏展开后,行为在不同编译单元中可能不同(比如一个模块是
SAFE,另一个是OPT);
- 为什么可以接受?
bsls_assert是一个调试辅助工具;- 它的语义是在“调试构建”时才真正生效,而不是功能契约的一部分;
- 在最终发布的 production build 中,这些宏可以被关闭,因此对一致性要求较低;
- Bloomberg 的构建系统(如 BDE)通过编译目标管理此一致性。
6. 为什么需要 BDE_BUILD_TARGET_SAFE_2?它与 BDE_BUILD_TARGET_SAFE 有何关系与区别?
BDE_BUILD_TARGET_SAFE_2的作用:- 是为了解决多个库或组件在链接时包含多个构建目标定义的问题;
- 特别是不同模块使用
BSLS_ASSERT_SAFE时避免冲突; - 它使得可以安全混合使用 SAFE 与非-SAFE 构建,而不会破坏 ABI。
- 与
BDE_BUILD_TARGET_SAFE的关系:SAFE_2是SAFE的扩展或替代,解决其在大规模构建系统中的ODR冲突问题;- 使用
SAFE_2可以使某些宏逻辑在 header 中同时兼容多个目标。
总结:本节重点
| 核心概念 | 要点 |
|---|---|
| 谁决策防御性检查? | 应用拥有者(因为性能与行为取舍) |
| 为什么不在函数契约中承诺断言行为? | 行为取决于构建配置,非固定的一部分 |
| 不同断言宏的使用时机? | 根据调试深度与性能要求灵活使用 |
| 硬/软未定义行为区别? | 硬UB不可恢复,软UB可检测处理 |
| 为什么允许 ODR 违规? | 宏行为不影响接口语义,是调试用途 |
| SAFE vs SAFE_2 | SAFE_2 是为避免 ODR 问题而引入的新机制 |
“组件级测试驱动(Component-Level Test Driver)” 的介绍,重点说明了它的结构、用途、行为、用户体验,以及调试支持。它是 Bloomberg BDE 测试框架的核心之一。下面是逐页内容的总结与理解:
什么是测试驱动(Test Driver)?
定义
- 是一个包含
main()函数的 C++ 文件; - 文件名通常形如
component.t.cpp; - 用于测试某个组件(component)的行为。
测试驱动的用途
- 开发时工具:帮助开发者验证功能正确性;
- 回归测试工具:作为自动测试系统的一部分,贯穿组件整个生命周期。
测试驱动包含什么内容?
1. 连续编号的测试用例(Test Cases)
- 每个测试用例以
case n:的形式出现; - 编号从
1开始,一直到n; - 每个测试用例包含多个
ASSERT(...)断言。
2. 测试结构范式
int main(int argc, char *argv[]) {int test = argc > 1 ? atoi(argv[1]) : DEFAULT_TEST;switch (test) {case 1: {// Test case 1ASSERT(...);...} break;case 2: {// Test case 2...} break;...default: {printf("WARNING: TEST CASE %d NOT FOUND.\n", test);return -1;}}return 0;
}
命令行接口/契约(Contract)
格式
testDriver [ testCase# [ addlArgs ... ] ]
行为
- 默认执行最新(编号最大的)测试用例;
- 如果指定
testCase#,只执行那个用例; - 可额外传入参数影响调试或行为模式。
返回值(Exit Code)
| 返回值 | 含义 |
|---|---|
0 | 成功,所有断言通过 |
n > 0 | 有 n 个断言失败 |
< 0 | 测试用例编号无效(not found) |
用户体验设计(User Experience)
正常情况
- 测试应“安静地”成功退出(无输出、状态码为 0);
错误情况
- 明确打印断言失败信息,带文件名和行号:
component.t.cpp(42): 2 == sqrt(4) (failed)
Verbose 模式(调试追踪)
启用方式:
- 如果命令行提供第二个参数(任何值),则开启 verbose 模式:
./component.t.exe 3 verbose
作用:
- 打印测试驱动的执行流程,方便调试与理解测试逻辑:
示例输出:
Testing length 0without aliasingwith aliasing
Testing length 1...
额外参数:
- 传入更多参数,可以进一步增强日志粒度(如打印具体步骤、数据内容等)。
总结:Component-Level Test Driver 要点
| 方面 | 要点 |
|---|---|
| 核心文件 | component.t.cpp,定义 main() |
| 测试结构 | switch + 连续编号 case |
| 断言方式 | 使用 ASSERT(...) 检查行为 |
| 命令行接口 | testDriver [ testCase# [ args... ] ] |
| 返回值语义 | 0=成功,n=断言失败数,负值=错误 |
| 用户体验 | 安静成功、有错提示、支持 verbose 输出 |
| 用途 | 初始开发 + 回归测试兼顾 |
BDE 风格的组件级测试驱动中如何编写一个完整的 Test Case,特别是带有负向测试(Negative Testing)的部分。下面是你提供材料的详细结构解析与总结,帮你 全面理解测试驱动的布局和每个测试用例的编写规范。
测试驱动的布局(Test Driver Layout)
一个典型的测试驱动 (component.t.cpp) 包括以下结构:
1. #include 指令
- 引入被测试的组件(如
#include <component.h>) - 引入测试工具,如
#include <bsl_cstdlib.h>,#include <iostream>等
2. TEST PLAN
- 明确列出每个测试用例对应测试哪些函数(每个函数至少在一个 case 中测试)
// [ 2] Point(int x, int y)
// [ 1] void setX(int x)
// [ 1] int y() const
// [ 4] void moveBy(int dx, int dy)
// [ 3] void moveTo(int x, int y)
3. 测试工具支持(Test Apparatus)
ASSERT宏定义- 通用辅助函数
- 设置
verbose变量支持调试
4. main 函数结构
int main(int argc, char *argv[]) {int test = argc > 1 ? atoi(argv[1]) : DEFAULT_TEST;bool verbose = argc > 2;switch (test) {case 1: {// TEST CASE 1} break;case 2: {// TEST CASE 2} break;// ...default: {cout << "WARNING: TEST CASE " << test << " NOT FOUND.\n";return -1;}}return 0;
}
单个测试用例结构(Test Case Layout)
每个 case N 中,按照以下规范书写测试内容:
示例(简化版):
case 2: {//-------------------------------------------------------// UNIQUE BIRTHDAY// The value returned for an input of 365 is small.//// Concerns://: 1 That it can represent the result as a 'double'.//: 2 That it returns decreasing values for increasing input.//: 6 That the special-case input of 0 returns 1.//// Plan:// Test explicit values near 0, 365, and INT_MAX.//// Testing:// double uniqueBirthday(int value);//-------------------------------------------------------if (verbose) cout << "\nUNIQUE BIRTHDAY\n===============\n";ASSERT(1 == uniqueBirthday(0)); // Concern 6ASSERT(1 == uniqueBirthday(1)); // Value near zeroASSERT(1 > uniqueBirthday(2)); // Decreasing behaviorASSERT(0 < uniqueBirthday(365)); // Value of interestASSERT(0 == uniqueBirthday(366)); // Boundary test
} break;
说明每部分含义
| 部分 | 内容与作用 |
|---|---|
| TITLE | 简短的标签,比如 UNIQUE BIRTHDAY,用于 verbose 输出 |
| CONCERNS | 明确列出测试这个函数可能出错的点(负向测试关注点) |
| PLAN | 如何用实际代码检测上述 concern,强调方法论而非细节 |
| TESTING | 与 test plan 呼应,列出当前测试的是哪个函数 |
| 测试代码 | 使用 ASSERT(...) 检查结果,确保覆盖所有 concern |
特别强调:负向测试(Negative Testing)
- 负向测试不是指 “让程序崩溃”,而是 “测试错误情况是否正确处理”。
- 比如:
- 输入非法值是否抛异常或断言失败;
- 边界条件是否正确处理;
- 违反 contract 是否触发
BSLS_ASSERT。
总结:BDE 测试驱动的黄金结构
| 区域 | 内容 |
|---|---|
| Include | 所有依赖头文件 |
| Test Plan | 用 [N] 标记函数与测试用例关系 |
| Test Apparatus | 定义 ASSERT、通用变量如 verbose |
main() 函数 | 解析测试编号,进入 switch 调用对应测试用例 |
| 每个测试用例 | 有 Title、Concerns、Plan、Testing 注释块,配合断言验证逻辑 |
| 返回值 | 0 成功,正数=断言失败数,负数=未找到测试编号 |
关于 Negative Testing(负向测试) 的详细解释,特别是在 BDE 测试体系中的应用。以下是你的内容的总结与深入解析,帮助你完全理解这个概念:
什么是 Negative Testing?
定义:
Negative Testing 是一种验证“未在文档中公开声明的防御性检查”是否在预期的 assertion-level build modes 中正确起作用的测试方式。
🌐 更通俗地说:
负向测试的目标是验证你写在库内部用来“防止用户滥用”的那些 BSLS_ASSERT/BSLS_ASSERT_SAFE/BSLS_ASSERT_OPT 是否 真的能在你预期的构建模式下触发并起作用。
为什么我们需要负向测试?
这部分你提到了一些“看起来傻”的问题,但其实是很有深度的讨论:
问题 1:为什么要测试 Undefined Behavior?
因为:
- 错误检测代码往往是最晚被真正验证的代码(i.e. 很少被触发)。
- 但一旦真的需要它时,它是最关键的部分。
例如:生产环境中的断言失败,往往是阻止数据损坏或系统崩溃的最后一道防线。
问题 2:行为未定义,怎么测试?
你提供的三点回答非常重要:
a. “软”Undefined Behavior ≠ 真正“未定义”
- Soft Undefined Behavior:比如函数参数是
nullptr但函数内部没有处理。 - 在 BDE 中,这类情况我们通常通过
BSLS_ASSERT等宏 主动插入防御性检查,所以行为是“已知”的(断言失败)。
b. 测试驱动是白盒的
- 测试驱动拥有白盒知识,知道哪些地方插入了断言。
- 所以我们可以刻意调用那些会违反 precondition 的情况,以确认断言是否会触发。
c. 防御性检查能在问题变成真正“致命”之前拦截
- 例如:你传了非法的指针,但断言会在解引用前拦截,避免崩溃或数据损坏。
总结:Negative Testing 的意义与应用
| 项目 | 内容 |
|---|---|
| 目的 | 确保防御性断言(如 BSLS_ASSERT)能在 debug/safe 构建中被正确触发 |
| 测试什么 | 违反 precondition 的调用是否触发断言(例如传非法参数) |
| 为什么重要 | 错误检测机制往往在运行时才被用到,必须在开发阶段被验证 |
| 可以测试吗? | 可以!因为我们知道断言具体位置(白盒) |
| 重点 | Soft undefined behavior 是测试的重点对象 |
示例:什么样的情况需要负向测试?
void setSize(int size) {BSLS_ASSERT(size > 0); // Defensive checkd_size = size;
}
测试代码:
if (veryVerbose) cout << "Testing setSize precondition failure\n";
// Negative test - deliberately violate precondition
ASSERT_SAFE_FAIL(obj.setSize(0)); // This should trigger BSLS_ASSERT_SAFE
ASSERT_SAFE_PASS(obj.setSize(1)); // Valid case
总结语
Negative Testing 是对库质量的关键保障机制。它不是“非正常测试”,而是有策略、有目的地 验证程序在遭遇非法输入时是否以可预期的方式失败(fail-fast)。这在金融系统、航空、医疗等高可靠性系统中至关重要。
Negative Testing(负向测试) 成功所需的条件,以及如何借助 bsls_asserttest 组件来实现它。以下是对你提供内容的全面整理和理解,方便你更系统地掌握这个主题。
Negative Testing 成功的条件(Requirements)
1. 可观察的 contract 违规
必须能够调用一个超出函数契约(contract)的用法,并能观察到这个误用被捕获了。
- 重点:观察到断言被触发。
- 前提:测试中必须避免真正的“硬” undefined behavior(比如:解引用空指针、数组越界写入等可能导致 crash 或数据损坏的操作)。
2. 实现必须简单易用
Negative testing 必须非常容易在任何测试环境(尤其是我们自己的)中实现。
- 测试者不应该花很多时间在“本来就不应该被调用”的代码上。
- 所以需要有标准的机制、宏、工具来辅助。
3. 运行必须高效、集中
Negative tests 必须容易并高效地运行。
- 不能每个负向测试都要一个独立进程(太繁琐)。
- 所有负向测试可以在一个测试驱动中集中运行,并捕获预期的断言失败。
附加注意事项(Additional Concerns)
1. 错误应由当前组件本身捕获
Contract violation 必须被当前测试的组件所捕获。
- 不要因为底层调用了其他组件的断言而误以为是本组件捕获了错误。
- 要测试的是你写的 defensive check 是否起效。
2. 仅在 defensive check 被激活的构建模式下调用违规行为
不要在防御性断言不启用的构建模式下执行负向测试。
- 否则会真正触发 undefined behavior。
- 例如只在
BSLS_ASSERT_SAFE_IS_ACTIVE时运行某些断言测试。
如何实现 Negative Testing?(Using bsls_asserttest)
1. 自定义断言失败处理机制
创建一个专门用于测试的断言失败处理器(test handler),它抛出一个特制的异常,该异常记录断言触发的详细信息:
异常内容包含:
| 字段 | 描述 |
|---|---|
a. | 组件文件名 |
b. | 源码行号 |
c. | 断言失败的表达式 |
d. | 断言的级别(如 SAFE / ASSERT / OPT) |
| 这是为了让测试代码能准确判断是不是预期的断言在预期位置触发。 |
2. 使用辅助宏和工具函数
bsls_asserttest 提供了一套宏和工具函数(如 BSLS_ASSERTTEST_ASSERT_SAFE_FAIL)用来简化负向测试。
示例:
#include <bsls_asserttest.h>
#include <cassert>
void setSize(int size) {BSLS_ASSERT_SAFE(size > 0);// ...
}
int main() {using namespace bsls;// 设置测试断言处理器AssertTest::setFailureHandler(AssertTest::failTestDriver);// 开始负向测试if (BSLS_ASSERT_SAFE_IS_ACTIVE) {ASSERT(AssertTest::tryFailure(BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(setSize(0))));ASSERT(AssertTest::tryPass (BSLS_ASSERTTEST_ASSERT_SAFE_PASS(setSize(5))));}return 0;
}
总结:Negative Testing 要点总览
| 关键点 | 解释 |
|---|---|
| 测试目的 | 验证内部断言机制能如预期那样“在需要时阻止错误调用” |
| 测试方式 | 使用白盒方式,故意违反 precondition 并确认断言被触发 |
| 工具支持 | bsls_asserttest 提供了标准宏、辅助类、失败处理机制 |
| 注意事项 | 不要在断言未激活的构建模式中做违规测试,防止硬崩溃 |
| 要求 | 实现要简单、运行要集中高效、异常要精确捕获信息 |
这段内容讨论了负向测试(Negative Testing),即通过 bsls_asserttest 组件测试函数在违反其契约(narrow contract)时的行为,验证防御性检查是否按预期触发。以下是对内容的理解和总结: |
1. 负向测试计划(Plan for Each Test Driver)
- 目标:为每个测试驱动程序(Test Driver)设计负向测试,以验证函数在超出定义行为边界时的表现。
- 步骤:
- 前提:
- 假设测试驱动程序中已定义标准的
ASSERT测试宏,用于处理负向测试中的错误。
- 假设测试驱动程序中已定义标准的
- 针对具有窄契约(narrow contract)的函数,在每个测试用例(test case)末尾执行以下操作:
- 安装自定义失败处理器:
- 使用
bsls_Assert::setFailureHandler设置bsls_AssertTest::failTestDriver作为失败处理器。
- 使用
- 调用函数,测试边界条件:
- 在定义行为的边界两侧(即合法和非法输入)调用函数,例如超出契约范围的输入。
- 观察断言触发情况:
- 检查断言是否按当前构建模式(build mode)的预期触发(或不触发)。
- 无需关注预期结果:
- 预期结果已在之前的测试中覆盖,这里仅关注断言行为。
- 安装自定义失败处理器:
- 前提:
2. 示例:测试 factorial(n) 函数
- 函数契约:
factorial(n)要求0 <= n <= 100,否则行为未定义。
- 测试代码(添加到测试用例末尾):
bsls_Assert::setFailureHandler(&bsls_AssertTest::failTestDriver); BSLS_ASSERTTEST_ASSERT_FAIL(factorial(-1)); // 超出下界,期望失败 BSLS_ASSERTTEST_ASSERT_PASS(factorial(0)); // 边界值,期望通过 BSLS_ASSERTTEST_ASSERT_PASS(factorial(100)); // 边界值,期望通过 BSLS_ASSERTTEST_ASSERT_FAIL(factorial(101)); // 超出上界,期望失败 - 分析:
- 安装处理器:
bsls_AssertTest::failTestDriver是一个专门用于测试的失败处理器,会抛出bsls_AssertTestException异常,而不是终止程序。 - 测试用例:
factorial(-1):n < 0,违反契约,期望断言触发(BSLS_ASSERTTEST_ASSERT_FAIL)。factorial(0):n = 0,符合契约,期望断言不触发(BSLS_ASSERTTEST_ASSERT_PASS)。factorial(100):n = 100,符合契约,期望断言不触发(BSLS_ASSERTTEST_ASSERT_PASS)。factorial(101):n > 100,违反契约,期望断言触发(BSLS_ASSERTTEST_ASSERT_FAIL)。
- 安装处理器:
3. 宏展开:BSLS_ASSERTTEST_ASSERT_FAIL 和 BSLS_ASSERTTEST_ASSERT_PASS
单个宏展开(以 BSLS_ASSERTTEST_ASSERT_FAIL(factorial(-1)) 为例):
- 展开后代码:
#if BSLS_ASSERT_IS_ACTIVE try {factorial(-1);ASSERT(false); // 如果未触发断言,则测试失败 } catch(const bsls_AssertTestException& e) {ASSERT(0 == strcmp("our_mathutil.cpp", e.filename())); // 验证断言来源文件 } #endif - 逻辑:
- 条件编译:仅在
BSLS_ASSERT_IS_ACTIVE启用时执行(即BSLS_ASSERT宏处于激活状态)。 - 尝试调用:调用
factorial(-1),期望触发断言。 - 异常捕获:
- 如果断言触发,
bsls_AssertTest::failTestDriver抛出bsls_AssertTestException。 - 捕获异常并验证断言来源文件(
our_mathutil.cpp)。
- 如果断言触发,
- 失败情况:
- 如果未触发断言(即
factorial(-1)没有失败),执行到ASSERT(false),测试失败。
- 如果未触发断言(即
- 条件编译:仅在
完整测试代码展开:
- 展开后代码:
bsls_Assert::setFailureHandler(&bsls_AssertTest::failTestDriver); #if BSLS_ASSERT_IS_ACTIVE try {factorial(-1);ASSERT(false); // 应触发断言,不应到达这里 } catch(const bsls_AssertTestException& e) {ASSERT(0 == strcmp("our_mathutil.cpp", e.filename())); } #endif factorial(0); // 期望通过,无需额外检查 factorial(100); // 期望通过,无需额外检查 #if BSLS_ASSERT_IS_ACTIVE try {factorial(101);ASSERT(false); // 应触发断言,不应到达这里 } catch(const bsls_AssertTestException& e) {ASSERT(0 == strcmp("our_mathutil.cpp", e.filename())); } #endif - 逻辑:
- 失败测试(
BSLS_ASSERTTEST_ASSERT_FAIL):factorial(-1)和factorial(101)违反契约,期望触发断言。- 使用
try-catch捕获bsls_AssertTestException,验证断言是否按预期触发。
- 通过测试(
BSLS_ASSERTTEST_ASSERT_PASS):factorial(0)和factorial(100)符合契约,调用时不期望触发断言。- 直接调用,不包裹在
try-catch中(未明确展开,但逻辑上不需要检查异常)。
- 失败测试(
4. 实现经验观察(Implementation Experience Observation)
- 虽然内容未完整展开,但可以推测:
- 观察:负向测试通过
bsls_asserttest组件验证了断言的正确性,确保函数在违反契约时按预期触发断言。 - 意义:这种方法有助于发现防御性检查的遗漏或错误,确保代码的鲁棒性。
- 观察:负向测试通过
总体理解
- 负向测试:
- 针对具有窄契约的函数,测试其在违反契约时的行为,确保防御性检查(如
BSLS_ASSERT)按预期工作。 - 测试边界条件(例如
factorial的n < 0和n > 100),验证断言触发。
- 针对具有窄契约的函数,测试其在违反契约时的行为,确保防御性检查(如
- 测试流程:
- 使用
bsls_AssertTest::failTestDriver处理器,捕获断言失败的异常。 - 使用
BSLS_ASSERTTEST_ASSERT_FAIL和BSLS_ASSERTTEST_ASSERT_PASS宏,分别验证断言触发和不触发的情况。
- 使用
- 宏展开:
BSLS_ASSERTTEST_ASSERT_FAIL:期望断言触发,捕获异常并验证。BSLS_ASSERTTEST_ASSERT_PASS:期望断言不触发,直接调用函数。
- 实践意义:
- 负向测试是单元测试的重要部分,确保函数在非法输入下不会默默失败。
bsls_asserttest组件提供了专门的工具(宏和失败处理器),简化了负向测试的实现。- 通过条件编译(
BSLS_ASSERT_IS_ACTIVE),测试可以适应不同的构建模式。
这段内容继续探讨负向测试(Negative Testing),使用bsls_asserttest组件测试防御性检查的行为,重点在于实现经验、特殊场景(如构造函数测试)以及 C++ 标准中noexcept的引入对防御性编程和负向测试的影响。以下是对内容的理解和总结:
1. 实现经验观察(Implementation Experience Observation)
- 问题:
- 如果“正向测试”(positive test)改变了对象状态(例如分配内存),需要在所有构建模式(build modes)下运行,否则清理代码会变得过于复杂。
- 原因:
- 状态变化:正向测试可能会修改对象状态(如
vector的内存分配),而负向测试可能依赖这些状态。 - 构建模式差异:
BSLS_ASSERTTEST_ASSERT_SAFE_FAIL仅在“安全模式”(Safe Mode,例如BDE_BUILD_TARGET_SAFE)下启用。BSLS_ASSERTTEST_ASSERT_SAFE_PASS则始终运行(无论构建模式)。
- 如果正向测试(如
push_back)仅在某些模式下运行,负向测试可能面临不一致的状态,导致清理逻辑复杂。
- 状态变化:正向测试可能会修改对象状态(如
示例:测试 bsl::vector<int>
- 代码:
bsl::vector<int> v; bsls_Assert::setFailureHandler(&bsls_AssertTest::failTestDriver); BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(v[0]); // 空向量,访问 v[0] 应失败 v.push_back(9); // 添加元素,改变状态 BSLS_ASSERTTEST_ASSERT_SAFE_PASS(v[0]); // 现在 v[0] 合法,期望通过 BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(v[1]); // v[1] 越界,期望失败 v.push_back(42); // 再次改变状态 BSLS_ASSERTTEST_ASSERT_SAFE_PASS(v[0]); // v[0] 合法,期望通过 BSLS_ASSERTTEST_ASSERT_SAFE_PASS(v[1]); // v[1] 合法,期望通过 BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(v[2]); // v[2] 越界,期望失败 v.pop_back(); // 移除元素,改变状态 BSLS_ASSERTTEST_ASSERT_SAFE_PASS(v[0]); // v[0] 仍合法,期望通过 BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(v[1]); // v[1] 越界,期望失败 - 分析:
- 状态依赖:
v.push_back和v.pop_back修改了向量状态,影响后续测试。 - 正向测试始终运行:
BSLS_ASSERTTEST_ASSERT_SAFE_PASS总是执行,确保状态变更(如push_back)在所有模式下发生。 - 负向测试依赖模式:
BSLS_ASSERTTEST_ASSERT_SAFE_FAIL仅在SAFE模式下运行,避免在禁用BSLS_ASSERT_SAFE的模式下测试不一致。 - 清理问题:如果正向测试(如
push_back)不运行,可能会导致内存泄漏或状态不一致,清理代码需要额外处理不同模式。
- 状态依赖:
2. 构造函数的独特问题
- 问题:
- 初始化列表可能先触发断言:
- 构造函数的初始化列表(Initializer List)可能在主体代码之前执行断言。
- 问题 1:虽然能正确检测误用,但可能返回错误的源文件名。
- 问题 2:如果初始化列表中的代码(如
MyDateImpUtil::toSerial)抛出测试异常(bsls_AssertTestException),会导致测试失败。
- 示例:
MyDate::MyDate(int y, int m, int d): d_serialDate(MyDateImpUtil::toSerial(y, m, d)) // 初始化列表可能触发断言 {BSLS_ASSERT(MyDate::isValid(y, m, d)); // 太晚了! }- 问题:
MyDateImpUtil::toSerial可能在初始化列表中触发断言,导致BSLS_ASSERT尚未执行。- 如果
toSerial抛出测试异常,异常信息中的文件名可能不是预期的(例如不是MyDate所在的源文件)。 - 更严重的是,契约违反可能导致未定义行为(Undefined Behavior),甚至在断言触发之前。
- 问题:
- 初始化列表可能先触发断言:
- 解决方案:
- 引入
_RAW宏:- 提供特殊版本的宏(如
BSLS_ASSERTTEST_ASSERT_FAIL_RAW和BSLS_ASSERTTEST_ASSERT_PASS_RAW),仅放宽文件名检查。
- 提供特殊版本的宏(如
- 测试代码:
bsls_Assert::setFailureHandler(&bsls_AssertTest::failTest); BSLS_ASSERTTEST_ASSERT_PASS_RAW(MyDate(2000, 7, 15)); // 合法日期,期望通过 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(0, 7, 15)); // 年份无效,期望失败 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(10000, 7, 15)); // 年份无效,期望失败 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(2000, 0, 15)); // 月份无效,期望失败 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(2000, 13, 15)); // 月份无效,期望失败 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(2000, 7, 0)); // 日期无效,期望失败 BSLS_ASSERTTEST_ASSERT_FAIL_RAW(MyDate(2000, 7, 32)); // 日期无效,期望失败 - 分析:
_RAW宏:放宽文件名检查,允许初始化列表中的断言触发时不验证文件名。- 测试用例:
- 合法输入:
MyDate(2000, 7, 15)应通过。 - 非法输入:年份(
0或10000)、月份(0或13)、日期(0或32)超出范围,期望触发断言。
- 合法输入:
- 引入
3. 负向测试 SAFE_2 模式下的检查
- 问题:
- 某些防御性检查仅在
SAFE_2模式(BDE_BUILD_TARGET_SAFE_2)下启用,测试代码需要匹配这种条件。
- 某些防御性检查仅在
- 解决方案:
- 使用条件编译包裹负向测试:
#if defined(BSLS_BUILD_TARGET_SAFE_2) BSLS_ASSERTTEST_ASSERT_SAFE_FAIL(…); BSLS_ASSERTTEST_ASSERT_SAFE_PASS(…); #endif - 原因:
- 确保仅在
SAFE_2模式下测试对应的防御性检查,避免在其他模式下运行不一致的测试。
- 确保仅在
- 使用条件编译包裹负向测试:
4. 负向测试相关问题解答
- 什么是负向测试,为什么重要?
- 定义:负向测试验证函数在违反契约时的行为,确保防御性检查(如断言)按预期触发。
- 重要性:防止未定义行为被忽视,提升代码健壮性和可靠性。
- 为什么可以可靠测试库的未定义行为?
- 使用
bsls_asserttest组件,捕获断言触发的异常(bsls_AssertTestException),从而安全地测试未定义行为。
- 使用
- 为什么断言级别构建模式对负向测试重要?
- 不同构建模式(例如
SAFE、SAFE_2)启用不同级别的断言,负向测试需要匹配当前模式,确保测试一致性。
- 不同构建模式(例如
- 为什么总是执行正向测试,但不总是执行负向测试?
- 正向测试可能改变状态(如分配内存),需要在所有模式下运行以保持一致性;负向测试(如
BSLS_ASSERTTEST_ASSERT_SAFE_FAIL)依赖构建模式,仅在断言启用时运行。
- 正向测试可能改变状态(如分配内存),需要在所有模式下运行以保持一致性;负向测试(如
- 为什么负向测试阶段不关心预期结果?
- 负向测试关注防御性检查的触发,而非函数返回值(预期结果已在正向测试中验证)。
- 构造函数为何有独特问题,如何处理?
- 问题:初始化列表可能先触发断言,导致文件名错误或未定义行为。
- 解决:使用
_RAW宏放宽文件名检查,允许测试继续验证断言行为。
- 如何负向测试
SAFE_2模式下的检查?- 使用条件编译(
#if defined(BSLS_BUILD_TARGET_SAFE_2))包裹测试代码,确保仅在对应模式下运行。
- 使用条件编译(
5. C++ 标准中的 noexcept(2011 年引入)
背景:
- 引入时间:2011 年 3 月,C++ 标准委员会引入
noexcept异常规范。 - 用途:
- 支持移动语义:移动构造函数和移动赋值操作通常具有宽契约(wide contracts),使用
noexcept确保不抛出异常。 - 优化:为函数添加
noexcept可带来速度和空间优化(例如编译器可省略异常处理代码)。 - 行为:如果
noexcept函数尝试抛出异常,程序会直接终止(调用std::terminate)。
- 支持移动语义:移动构造函数和移动赋值操作通常具有宽契约(wide contracts),使用
对防御性编程和负向测试的影响:
- 问题:
- 标准委员会倾向于广泛应用
noexcept,包括窄契约函数(如vector::front()和vector::operator[])。 - 窄契约函数:如果违反契约(例如访问空
vector的front()),防御性检查可能抛出异常(如bsls_AssertTestException),但noexcept会导致程序终止,无法捕获异常。
- 标准委员会倾向于广泛应用
- 作者的建议(2011 年 3 月 21 日):
- 仅用于移动语义:
noexcept应仅用于移动构造函数和移动赋值(语义需求)。 - 宽契约且永不抛出:
noexcept可用于宽契约函数,且保证不抛出异常(75% 共识)。 - 任何永不抛出的操作:
noexcept可用于任何契约中永不抛出的操作(作者强烈反对:“Over my dead body!”)。
- 仅用于移动语义:
- 结果:
- 委员会在 2011 年 3 月 25 日(马德里会议)批准了新标准,提前一天完成。
- 按上述准则,将
noexcept应用于整个 C++ 标准库的每个函数。
相关性:
- 防御性编程:
noexcept与窄契约函数冲突:防御性检查可能抛出异常(如测试异常),但noexcept会终止程序,破坏测试流程。- 建议:避免在窄契约函数上使用
noexcept,以保留防御性检查的灵活性。
- 负向测试:
- 负向测试依赖抛出异常(如
bsls_AssertTestException)来验证断言行为。 - 如果函数标记为
noexcept,测试无法捕获异常,导致测试失败或程序终止。
- 负向测试依赖抛出异常(如
6. 总结(Conclusion)
1. 物理设计回顾:
- 组件:软件设计的基本单位,包括
.h、.cpp和测试驱动文件(.t.cpp)。 - 关系:类之间的逻辑关系对应组件间的物理依赖。
- 层级:无环物理设计通过层级编号(level numbers)描述。
2. 接口与契约:
- 接口:语法层面;契约:语义层面,定义前置/后置条件。
- 未定义行为:违反前置条件导致未定义行为,行为不可预测。
- 测试:测试驱动程序验证必要行为(Essential Behavior);析构函数中的断言验证不变式。
3. 好的契约:
- 防御性编程:强调不容错(fault intolerance)。
- 窄契约:带来未定义行为,但好处包括:
- 降低开发/测试成本。
- 提升性能,减小代码体积。
- 实现实用有效的防御性编程。
- 允许按需添加有用行为。
4. 实现防御性检查(bsls_assert 组件):
- 协作:
bsls_assert组件允许应用和库开发者协作,平衡检查时间和处理方式。 - 优势:享受防御性编程的好处,避免传统缺点。
5. 负向测试(bsls_asserttest 组件):
- 重要性:测试防御性检查是确保正确性的关键。
- 工具:
bsls_asserttest使负向测试实用、高效。 - 注意:仅在断言激活时测试防御性检查。
- 构造函数:测试构造函数具有独特问题(初始化列表问题),通过
_RAW宏解决。
总体理解
- 负向测试实践:
- 负向测试验证防御性检查,确保函数在违反契约时按预期触发断言。
- 正向测试需始终运行以保持状态一致性,负向测试则依赖构建模式。
- 构造函数测试需特殊处理,使用
_RAW宏放宽文件名检查。 SAFE_2模式检查通过条件编译测试,确保一致性。
- C++ 标准中的
noexcept:noexcept的引入优化了移动语义和性能,但与窄契约函数冲突,可能影响防御性检查和负向测试。- 作者建议限制
noexcept使用,避免在窄契约函数上应用。
- 总结:
- 防御性编程和负向测试是确保代码健壮性的关键。
bsls_assert和bsls_asserttest组件提供了强大工具,支持灵活的检查和测试。- C++ 标准的演进(如
noexcept)需要与防御性编程策略协调,以避免冲突。
相关文章:

CppCon 2014 学习:Defensive Programming Done Right.
这段摘要讲的是: 在组件化开发中,每个开发者负责让自己写的软件易懂且好用,且不易被误用。常见误用之一是调用库函数时未满足前置条件,导致未定义行为。未定义行为的契约(contract)不一定不好,…...

《机器学习数学基础》补充资料:韩信点兵与拉格朗日插值法
本文作者:卓永鸿 19世纪的伟大数学家高斯,他对自己做的数学有非常高的要求,未臻完美不轻易发表。于是经常有这样的情况:其他也很厉害的数学家提出自己的工作,高斯便拿出自己的文章说他一二十年前就做出来了࿰…...
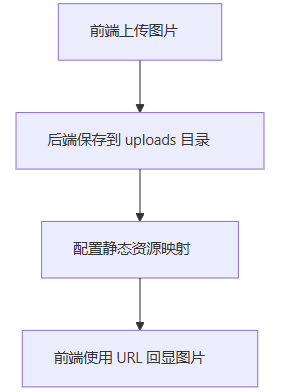
Spring Boot中保存前端上传的图片
在Spring Boot中保存前端上传的图片可以通过以下步骤实现: 1. 添加依赖 确保在pom.xml中已包含Spring Web依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifact…...

【HTML-15.2】HTML表单按钮全面指南:从基础到高级实践
表单按钮是网页交互的核心元素,作为用户提交数据、触发操作的主要途径,其重要性不言而喻。本文将系统性地介绍HTML表单按钮的各种类型、使用场景、最佳实践以及高级技巧,帮助开发者构建更高效、更易用的表单交互体验。 1. 基础按钮类型 1.1…...

2025最新 MacBook Pro苹果电脑M系列芯片安装zsh教程方法大全
2025最新 MacBook Pro苹果电脑M系列芯片安装zsh教程方法大全 本文面向对 macOS 环境和终端操作尚不熟悉的“小白”用户。我们将从最基础的概念讲起,结合实际操作步骤,帮助你在 2025 年最新 MacBook Pro(搭载苹果 M 系列芯片)的环境…...

43. 远程分布式测试实现
43. 远程分布式测试实现详解 一、远程测试环境配置 1.1 远程WebDriver服务定义 # Chrome浏览器远程服务地址 chrome_url rhttp://localhost:5143# Edge浏览器远程服务地址 edge_url rhttp://localhost:9438关键概念:每个URL对应一个独立的WebDriver服务典型配置…...
:RSE流程详解——从文档中精准识别高相关片段)
探索大语言模型(LLM):RSE流程详解——从文档中精准识别高相关片段
前言 在信息爆炸的时代,如何从海量的文本数据中快速准确地提取出有价值的信息,成为了众多领域面临的共同挑战。RSE(检索增强摘要生成)流程应运而生,它通过一系列精细化的步骤,能够有效地从原始文档中识别出…...

【C++】类的构造函数
类的构造函数 1. 作用:2.语法规则:示例代码:构造函数语法 2.1 特点:示例代码:自定义了构造函数,系统不会再生成默认构造函数示例代码:构造函数重载 3.构造函数常见的写法3.1 无参构造函数3.2 带…...
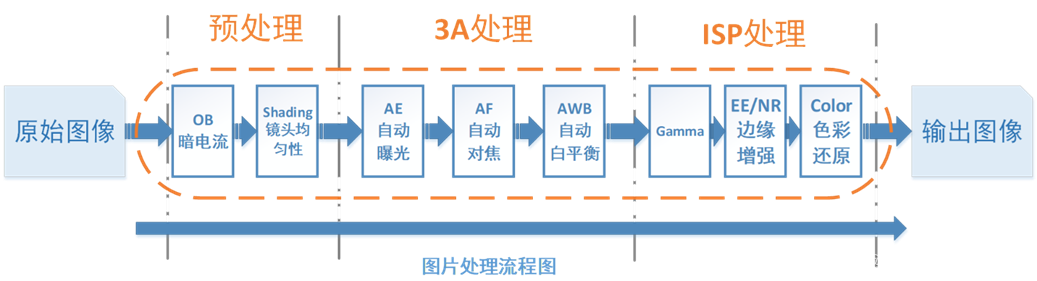
【ISP算法精粹】动手实战:用 Python 实现 Bayer 图像的黑电平校正
在数字成像领域,图像信号处理器(ISP)如同幕后英雄,默默将传感器捕获的原始数据转化为精美的图像。而黑电平校正,作为ISP预处理流程中的关键一环,直接影响着最终图像的质量。今天,我们就通过Pyth…...

分布式存储技术全景解析:从架构演进到场景实践
目录 技术演进与市场新格局核心架构设计深度剖析前沿技术创新与性能突破行业应用场景实践挑战与未来发展趋势1. 技术演进与市场新格局 1.1 从集中式到分布式的范式转移 传统集中式存储(如NAS/SAN)在扩展性和容错性方面面临根本性瓶颈,而分布式存储通过水平扩展架构和多节点…...

JVM——从JIT到AOT:JVM编译器的云原生演进之路
引入 在Java的世界里,一段代码从开发者手中的文本到计算机执行的机器指令,需要跨越"字节码"这座桥梁。而JVM编译器正是架起这座桥梁的工程师,它的每一次技术演进都推动着Java性能的跃迁。从早期逐行翻译的解释器,到智能…...
Linux中的mysql逻辑备份与恢复
一、安装mysql社区服务 二、数据库的介绍 三、备份类型和备份工具 一、安装mysql社区服务 这是小编自己写的,没有安装的去看看 Linux换源以及yum安装nginx和mysql-CSDN博客 二、数据库的介绍 2.1 数据库的组成 数据库是一堆物理文件的集合,主要包括…...

[HTML5]快速掌握canvas
背景 canvas 是 html5 标准中提供的一个标签, 顾名思义是定义在浏览器上的画布 通过其强大的绘图接口,我们可以实现各种各样的图形,炫酷的动画,甚至可以利用他开发小游戏,包括市面上很流行的数据可视化框架底层都用到了Canvas。…...
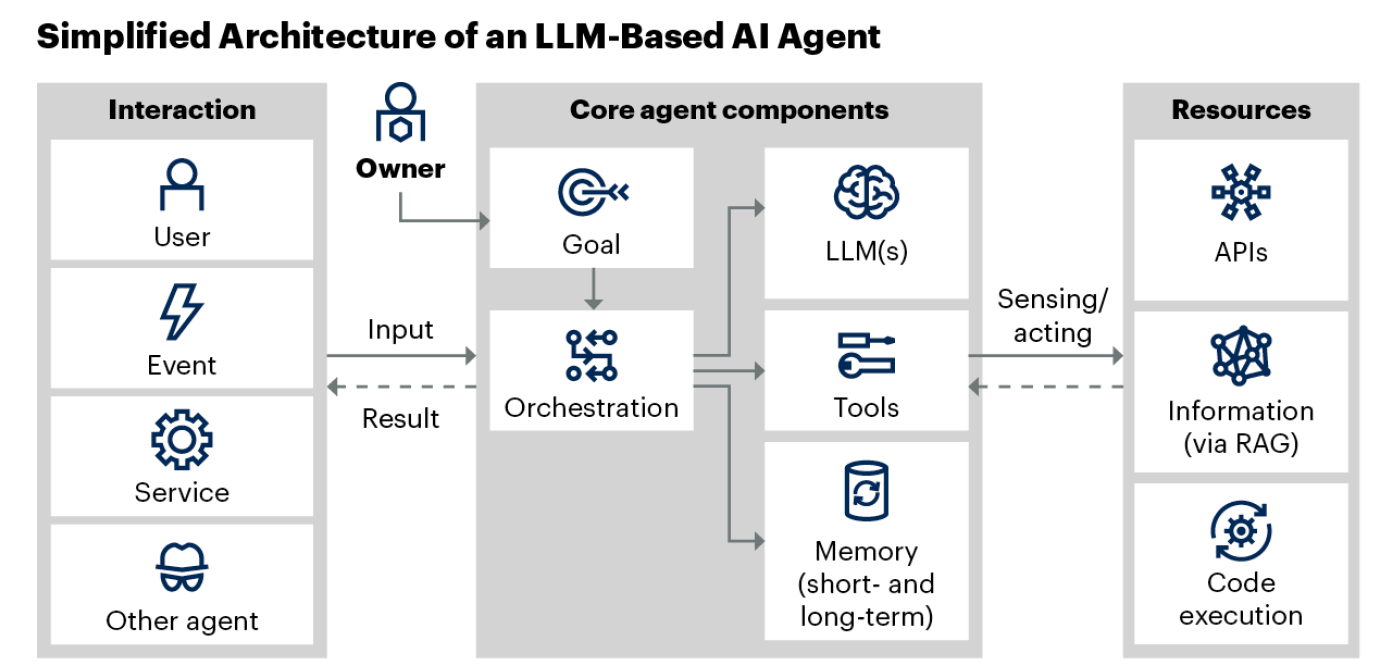
Gartner《Emerging Patterns for Building LLM-Based AIAgents》学习心得
一、AI代理概述 2024年,AI代理成为市场热点,它们能自主规划和行动以实现用户目标,与仅能感知、决策、行动和达成目标的AI助手及聊天机器人有本质区别。Gartner定义的AI代理是使用AI技术在数字或物理环境中自主或半自主运行的软件实体。 二、LLM基础AI代理的特性和挑战 优势…...

Hive SQL优化实践:提升大数据处理效率的关键策略
在大数据生态中,Hive作为基于Hadoop的数据仓库工具,广泛应用于海量数据的离线分析场景。然而,随着数据量的指数级增长和业务复杂度的提升,低效的Hive SQL可能导致资源浪费和查询性能瓶颈。本文将从存储优化、计算优化、资源配置三…...

vue中父子参数传递双向的方式不同
在面试中被问到。平时也有用到,但是缺少总结 父传子。父页面会给子页面中定义的props属性传参,子页面接收子传父。父页面需要监听事件来接收子页面通过$emit发送的消息其实说的以上两种都是组件之间传递。还可以通过路由传参, 状态管理器的方式传递 下面…...

LLM 使用 MCP 协议及其原理详解
LLM 使用 MCP 协议及其原理详解 🧠 一、MCP 协议概述 1. MCP 是什么? MCP(Modular Communication Protocol)是一种面向语言模型设计的通用通信协议,其设计目标是: 模块化(Modular࿰…...

DAY 36神经网络加速器easy
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 ●作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。 ●探索性作业(随意完成):尝试进入…...
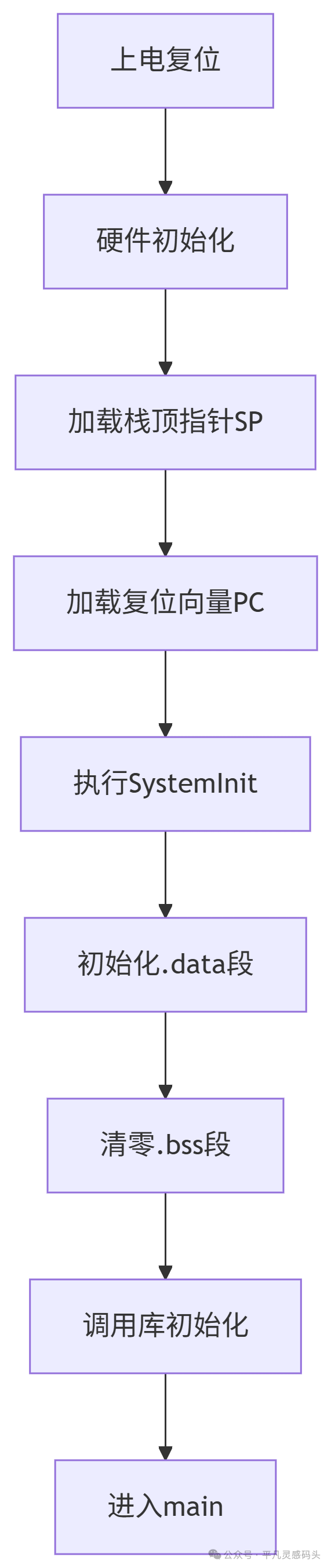
STM32 单片机启动过程全解析:从上电到主函数的旅程
一、为什么要理解启动过程? STM32 的启动过程就像一台精密仪器的开机自检,它确保所有系统部件按既定方式初始化,才能顺利运行我们的应用代码。对初学者而言,理解启动过程能帮助解决常见“程序跑飞”“不进 main”“下载后无反应”…...
4.RV1126-OPENCV 图像轮廓识别
一.图像识别API 1.图像识别作用 它常用于视觉任务、目标检测、图像分割等等。在 OPENCV 中通常使用 Canny 函数、findContours 函数、drawContours 函数结合在一起去做轮廓的形检测。 2.常用的API findContours 函数:用于寻找图片的轮廓,并把所有的数…...
WEB3——开发者怎么查看自己的合约日志记录
在区块链中查看合约的日志信息(也叫事件 logs),主要有以下几种方式,具体方法依赖于你使用的区块链平台(如 Ethereum、BSC、Polygon 等)和工具(如 Etherscan、web3.js、ethers.js、Hardhat 等&am…...

TDengine 集群容错与灾备
简介 为了防止数据丢失、误删操作,TDengine 提供全面的数据备份、恢复、容错、异地数据实时同步等功能,以保证数据存储的安全。本节简要说明 TDengine 中的容错与灾备。 容错 TDengine 支持 WAL 机制,实现数据的容错能力,保证数…...
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件
MG影视登录解锁永久VIP会员 v8.0 支持手机电视TV版影视直播软件 MG影视App电视版是一款资源丰富、免费便捷、且专为大屏优化的影视聚合应用,聚合海量资源,畅享电视直播,是您电视盒子和…...
)
如何成为一名优秀的产品经理(自动驾驶)
一、 夯实核心基础 深入理解智能驾驶技术栈: 感知: 摄像头、雷达(毫米波、激光雷达)、超声波传感器的工作原理、优缺点、融合策略。了解目标检测、跟踪、SLAM等基础算法概念。 定位: GNSS、IMU、高精地图、轮速计等定…...

BAT脚本编写详细教程
目录 第一部分:BAT脚本简介第二部分:创建和运行BAT脚本第三部分:基本命令和语法第四部分:变量使用第五部分:流程控制第六部分:函数和子程序第七部分:高级技巧第八部分:实用示例第一部分:BAT脚本简介 BAT脚本(批处理脚本)是Windows操作系统中的一种脚本文件,扩展名…...

快速了解 GO之接口解耦
更多个人笔记见: (注意点击“继续”,而不是“发现新项目”) github个人笔记仓库 https://github.com/ZHLOVEYY/IT_note gitee 个人笔记仓库 https://gitee.com/harryhack/it_note 个人学习,学习过程中还会不断补充&…...

【多线程初阶】内存可见性问题 volatile
文章目录 再谈线程安全问题内存可见性问题可见性问题案例编译器优化 volatileJava内存模型(JMM) 再谈线程安全问题 如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该有的结果,则说这个程序是线程安全的,反之,多线程环境中,并发执行后,产生bug就是线程不安全…...

C++ 类模板三参数深度解析:从链表迭代器看类型推导与实例化(为什么迭代器类模版使用三参数?实例化又会是怎样?)
本篇主要续上一篇的list模拟实现遇到的问题详细讲解:<传送门> 一、引言:模板参数的 "三角锁钥" 在 C 双向链表实现中,__list_iterator类模板的三个参数(T、Ref、Ptr)如同精密仪器的调节旋钮&#x…...

MySQL强化关键_018_MySQL 优化手段及性能分析工具
目 录 一、优化手段 二、SQL 性能分析工具 1.查看数据库整体情况 (1)语法格式 (2)说明 2.慢查询日志 (1)说明 (2)开启慢查询日志功能 (3)实例 3.s…...

ASP.NET MVC添加模型示例
ASP.NET MVC高效构建Web应用ASP.NET MVC 我们总在谈“模型”,那到底什么是模型?简单说来,模型就是当我们使用软件去解决真实世界中各种实际问题的时候,对那些我们关心的实际事物的抽象和简化。比如,我们在软件系统中设…...