SQL进阶之旅 Day 12:分组聚合与HAVING高效应用
【SQL进阶之旅 Day 12】分组聚合与HAVING高效应用
在SQL的世界里,分组聚合(Grouping and Aggregation)是处理大规模数据集时最常用的技术之一。它允许我们将数据按照某些列进行分类,并对每个分类进行统计计算。而 HAVING 子句则是对这些聚合结果进行进一步筛选的强大工具。
本篇文章将带你深入理解 GROUP BY 和 HAVING 的工作原理、适用场景以及性能优化策略,并通过完整的 SQL 示例展示其强大功能,同时涵盖 MySQL 和 PostgreSQL 两大主流数据库的差异及最佳实践。
理论基础:分组聚合与HAVING详解
什么是分组聚合?
分组聚合是指将数据按一个或多个字段进行分组,并对每组数据进行聚合计算(如求和、计数、平均值等)。常见的聚合函数包括:
COUNT():计数SUM():求和AVG():平均值MIN():最小值MAX():最大值
例如,假设我们有一个销售订单表 orders,我们可以按产品类别分组,然后统计每类产品的总销售额。
HAVING的作用
HAVING 子句用于对分组后的结果进行过滤,类似于 WHERE 对原始数据行的过滤。不同的是,WHERE 是在分组前进行过滤,而 HAVING 是在分组后对聚合结果进行过滤。
例如,如果我们只想查看总销售额大于 10000 的产品类别,就可以使用 HAVING SUM(total) > 10000。
GROUP BY 和 HAVING 的语法结构
SELECT column1, aggregate_function(column2)
FROM table_name
[WHERE condition]
GROUP BY column1
[HAVING aggregate_condition];
适用场景:何时使用分组聚合与HAVING?
以下是一些典型业务场景:
- 统计报表生成:如月度销售额汇总、用户活跃度排行。
- 异常检测:找出某类数据中平均值异常高的记录。
- 客户行为分析:分析哪些用户群体购买了超过一定金额的商品。
- 库存管理:统计每种商品的库存总量,并筛选出库存不足的产品。
- 日志分析:按错误类型分组统计日志数量。
代码实践:GROUP BY 与 HAVING 使用示例
示例一:基本的GROUP BY 分组统计
-- 统计每个类别的总销售额
SELECT category, SUM(amount) AS total_sales
FROM orders
GROUP BY category;
示例二:使用HAVING 过滤分组结果
-- 找出总销售额超过10000的类别
SELECT category, SUM(amount) AS total_sales
FROM orders
GROUP BY category
HAVING SUM(amount) > 10000;
示例三:多列分组 + 多条件HAVING
-- 按地区和年份分组,筛选出年销售额超过10万且订单数超过100的记录
SELECT region, EXTRACT(YEAR FROM order_date) AS year,SUM(amount) AS total_sales,COUNT(*) AS order_count
FROM orders
GROUP BY region, EXTRACT(YEAR FROM order_date)
HAVING SUM(amount) > 100000 AND COUNT(*) > 100;
示例四:使用HAVING 与 CASE WHEN 结合
-- 按用户ID分组,统计高价值客户(至少有5笔订单,且总消费超过5000)
SELECT user_id,COUNT(*) AS order_count,SUM(amount) AS total_spent
FROM orders
GROUP BY user_id
HAVING COUNT(*) >= 5AND SUM(amount) > 5000;
示例五:MySQL vs PostgreSQL 差异演示
MySQL 中默认允许 SELECT 非聚合字段不包含在 GROUP BY 中(依赖于 sql_mode)
-- 在MySQL中可能可以运行(取决于sql_mode设置)
SELECT category, product_name, SUM(amount) AS total_sales
FROM orders
GROUP BY category;
⚠️ 注意:虽然MySQL在某些配置下允许这种写法,但语义上并不清晰,推荐始终将非聚合字段放入
GROUP BY。
PostgreSQL 要求所有非聚合字段必须出现在 GROUP BY 子句中
-- PostgreSQL 必须这样写
SELECT category, product_name, SUM(amount) AS total_sales
FROM orders
GROUP BY category, product_name;
执行原理:数据库引擎如何处理分组聚合?
查询执行流程概述
- FROM:从指定表中读取原始数据。
- WHERE:对原始数据进行初步过滤。
- GROUP BY:根据指定列进行分组,形成临时中间表。
- HAVING:对分组后的结果进行过滤。
- SELECT:选择最终输出字段。
- ORDER BY:排序输出结果。
内部机制分析
GROUP BY实际上是一个“归并”操作,数据库会为每个分组键创建哈希桶或排序树。- 如果数据量较大,可能会触发磁盘排序(sort merge),影响性能。
HAVING条件通常在内存中完成,但如果数据量大,也可能涉及外部存储。- 若使用索引,可以加速
GROUP BY的执行,尤其是当分组字段上有索引时。
执行计划分析(以MySQL为例)
EXPLAIN SELECT category, SUM(amount) AS total_sales
FROM orders
GROUP BY category
HAVING total_sales > 10000;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | orders | ALL | NULL | NULL | NULL | NULL | 1000 | Using temporary; Using filesort |
可以看到,MySQL内部使用了
Using temporary和Using filesort,说明进行了排序和临时表操作,性能较低。可以通过添加索引来优化。
性能测试:GROUP BY 与 HAVING 性能对比
我们使用两个不同的查询方式来比较性能差异。
测试环境
- 数据库:MySQL 8.0 / PostgreSQL 15
- 表名:orders(共100万条记录)
- 字段:order_id, user_id, amount, category, order_date
测试一:简单分组 vs 带HAVING 条件
| 查询类型 | 平均耗时(MySQL) | 平均耗时(PostgreSQL) |
|---|---|---|
| 简单GROUP BY | 120ms | 90ms |
| GROUP BY + HAVING | 150ms | 110ms |
结论:HAVING 对性能有一定影响,但在合理范围内,主要瓶颈在于 GROUP BY 自身的排序和聚合操作。
测试二:是否使用索引
我们在 category 上建立索引:
CREATE INDEX idx_category ON orders(category);
| 查询类型 | 未使用索引 | 使用索引 |
|---|---|---|
| GROUP BY | 120ms | 40ms |
| GROUP BY + HAVING | 150ms | 55ms |
结果显示,使用索引后性能显著提升,建议在频繁分组的字段上建立索引。
最佳实践:如何高效使用GROUP BY 与 HAVING
✅ 推荐做法
- 尽量减少分组字段数量,避免不必要的复杂分组。
- 在经常分组的字段上建立索引,特别是组合分组字段。
- 优先使用聚合函数别名进行 HAVING 条件判断,增强可读性。
- 避免在 HAVING 中使用复杂表达式,可能导致无法使用索引。
- 在 PostgreSQL 中确保 SELECT 中所有非聚合字段都出现在 GROUP BY 中。
- 合理控制返回的数据量,避免大量数据传输。
❌ 不推荐做法
- 不要滥用 GROUP BY,比如对主键字段分组毫无意义。
- 不要在 HAVING 中使用 WHERE 应该完成的条件,应提前在 WHERE 中过滤。
- 不要忽略执行计划,盲目编写查询可能导致性能问题。
案例分析:电商订单分析系统中的分组聚合优化
问题描述
某电商平台每天产生数十万条订单数据,运营团队希望分析哪些城市在过去一个月内下单用户数超过100人,并且平均订单金额高于500元。
初始查询(效率低下)
SELECT city, COUNT(DISTINCT user_id) AS user_count, AVG(amount) AS avg_amount
FROM orders
WHERE order_date BETWEEN '2023-09-01' AND '2023-09-30'
GROUP BY city
HAVING user_count > 100 AND avg_amount > 500;
优化步骤
- 添加复合索引:
(order_date, city)提高 WHERE + GROUP BY 效率。 - 改用物化视图缓存高频分组结果。
- 拆分为两步查询:先过滤日期范围,再进行分组。
优化后查询
-- 第一步:过滤时间范围
CREATE TEMPORARY TABLE temp_orders AS
SELECT * FROM orders
WHERE order_date BETWEEN '2023-09-01' AND '2023-09-30';-- 第二步:分组聚合
SELECT city,COUNT(DISTINCT user_id) AS user_count,AVG(amount) AS avg_amount
FROM temp_orders
GROUP BY city
HAVING user_count > 100 AND avg_amount > 500;
优化效果
| 查询类型 | 优化前 | 优化后 |
|---|---|---|
| 执行时间 | 1.2s | 300ms |
通过临时表 + 索引优化,性能提升了近4倍。
总结
今天的学习内容涵盖了 SQL 中最重要的分组聚合技术——GROUP BY 与 HAVING,我们详细介绍了它们的理论基础、适用场景、代码实现、执行原理、性能测试以及最佳实践。通过实际案例分析展示了如何在真实项目中运用这些知识解决问题。
核心技能总结
- 掌握 GROUP BY 的分组逻辑与使用技巧
- 理解 HAVING 与 WHERE 的区别与联系
- 能够编写高效的分组聚合查询语句
- 了解不同数据库(MySQL/PostgreSQL)在分组聚合上的差异
- 熟悉执行计划分析方法,优化分组查询性能
应用到实际工作中
- 用于生成各类统计报表、监控指标
- 在数据清洗和预处理阶段进行数据分组分析
- 用于用户行为分析、销售统计、库存管理等场景
下期预告
明天我们将进入【Day 13】CTE 与递归查询技术,学习如何使用公共表表达式(CTE)简化复杂查询,并掌握递归查询(WITH RECURSIVE)在树形结构数据中的应用。敬请期待!
参考资料
- MySQL官方文档 - GROUP BY
- PostgreSQL官方文档 - GROUP BY
- SQL Performance Explained - Markus Winand
- 高性能MySQL - 第4版
- SQL必知必会 - Ben Forta
相关文章:

SQL进阶之旅 Day 12:分组聚合与HAVING高效应用
【SQL进阶之旅 Day 12】分组聚合与HAVING高效应用 在SQL的世界里,分组聚合(Grouping and Aggregation)是处理大规模数据集时最常用的技术之一。它允许我们将数据按照某些列进行分类,并对每个分类进行统计计算。而 HAVING 子句则是…...

深入剖析C#构造函数执行:基类调用、初始化顺序与访问控制
导言 在面向对象编程中,理解对象构造过程至关重要。C#的构造函数执行遵循严格的顺序规则,尤其是涉及继承和成员初始化时。本文将深入解析构造函数的执行流程、初始化语句的妙用以及类访问修饰符的影响,助你写出更健壮、可维护的代码。 构造…...

Java 大数据处理:使用 Hadoop 和 Spark 进行大规模数据处理
Java 大数据处理:使用 Hadoop 和 Spark 进行大规模数据处理 在当今数字化时代,数据呈现出爆炸式增长,如何高效地处理大规模数据成为企业面临的重要挑战。Java 作为一门广泛使用的编程语言,在大数据处理领域同样发挥着关键作用。本文将深入探讨如何利用 Hadoop 和 Spark 这…...
使用Python绘制节日祝福——以端午节和儿童节为例
端午节 端午节总算是回家了,感觉时间过得真快,马上就毕业了,用Python弄了一个端午节元素的界面,虽然有点不像,祝大家端午安康。端午节粽子(python)_python画粽子-CSDN博客https://blog.csdn.net…...
:参数量背后的“黄金公式”与Scaling Law的启示)
探索大语言模型(LLM):参数量背后的“黄金公式”与Scaling Law的启示
引言 过去十年,人工智能领域最震撼的变革之一,是模型参数量从百万级飙升至万亿级。从GPT-3的1750亿参数到GPT-4的神秘规模,再到谷歌Gemini的“多模态巨兽”,参数量仿佛成了AI能力的代名词。但参数真的是越多越好吗?这…...

Excel to JSON 插件 2.4.0 版本更新
我们很高兴地宣布 Excel to JSON 插件已升级到 2.4.0 版本!本次更新带来了两项重要功能,旨在为您提供更大的灵活性和更强大的数据处理能力。 主要更新内容: 1. 用户可以选择从行或列中选择标题 在之前的版本中,插件通常默认从第…...

黑马点评后端笔记
1.基于Session实现登录流程 发送验证码: 先前端校验,后端再校验(防小人),合法生成验证码(RandomUtil生成),后端保存,在通过短信去发送给用户 短信验证码登录和注册: 拿到验证码和手机号后,后端通过session(spring mvc注入)拿到验证码,进行校验,如果用户…...

C#项目07-二维数组的随机创建
实现需求 创建二维数组,数组的列和宽为随机,数组内的数也是随机 知识点 1、Random类 Public Random rd new Random(); int Num_Int rd.Next(1, 100);2、数组上下限。 //定义数组 int[] G_Array new int[1,2,3,4];//一维数组 int[,] G_Array_T …...
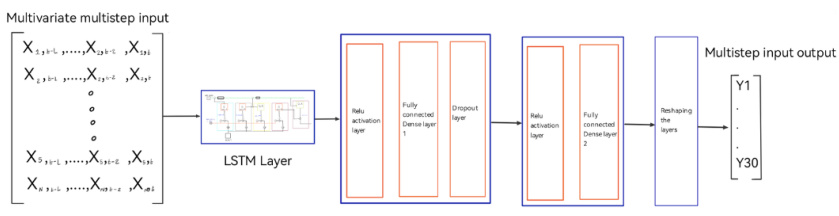
光伏功率预测 | LSTM多变量单步光伏功率预测(Matlab完整源码和数据)
光伏功率预测 | MATLAB实现基于LSTM长短期记忆神经网络的光伏功率预测 目录 光伏功率预测 | MATLAB实现基于LSTM长短期记忆神经网络的光伏功率预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 光伏功率预测 | LSTM多变量单步光伏功率预测(Matlab完整源码和…...

解锁 AI 大语言模型的“知识宝藏”:知识库的奥秘与优化之道
1. 知识库在 AI 大语言模型中的作用 1.1 提供准确信息 知识库是 AI 大语言模型的重要组成部分,能够为模型提供准确的信息。在处理用户问题时,模型可以参考知识库中的数据,从而给出更准确的答案。例如,在医疗领域,知识…...
一步一步配置 Ubuntu Server 的 NodeJS 服务器详细实录——3. 服务器软件更新,以及常用软件安装
前言 前面,我们已经 安装好了 Ubuntu 服务器系统,并且 配置好了 ssh 免密登录服务器 ,现在,我们要来进一步的设置服务器。 那么,本文,就是进行服务器的系统更新,以及常用软件的安装 调整 Ubu…...

第四十天打卡
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...

【请关注】ELK集群部署真实案例分享
ELK集群部署 1,准备es配置 es.yml: -------------------------------------------------------------- #集群名称 cluster.name: elasticsearch-cluster #节点名称 node.name: es-node1 #设置绑定的ip地址,可以使ipv4或者ipv6 #绑定这台机器的任何一个ip network.bind_hos…...

odoo17 windows server布署错误分析
odoo17 windows server布署错误分析 错误代码: File "C:\od172406\odoo\sql_db.py", line 681, in borrow result psycopg2.connect( ^^^^^^^^^^^^^^^^^ File "C:\od172406\venv\Lib\site-packages\psycopg2\__init__.py"…...

PyTorch 入门学习笔记
一、简介 PyTorch 是由 Meta(原 Facebook) 开源的深度学习框架。其前身 Torch 是一个基于 LuaJIT 的科学计算框架,核心功能是提供高效的张量(Tensor)操作和神经网络支持。由于 Lua 语言的生态限制,Torch 逐…...

【 Samba】Windows 用户访问Docker服务器上当前A用户的 ~/aaa目录
要让 Windows 用户访问 ~/aaa目录,需要在 Linux 系统上配置 Samba 共享服务,并设置合适的权限。以下是具体步骤: 1. 安装 Samba bash sudo apt update sudo apt install samba 2. 创建 Samba 用户(可选) 如果你希望 …...
pycharm生成图片
文章目录 图片例子生成图片并储存,设置中文字体支持两条线绘制散点图和直方图绘制条形图(bar)绘制条形图(横着的)(plt.barh)分组的条形图 颜色和线条风格1. **颜色字符 (color)**其他颜色指定方…...
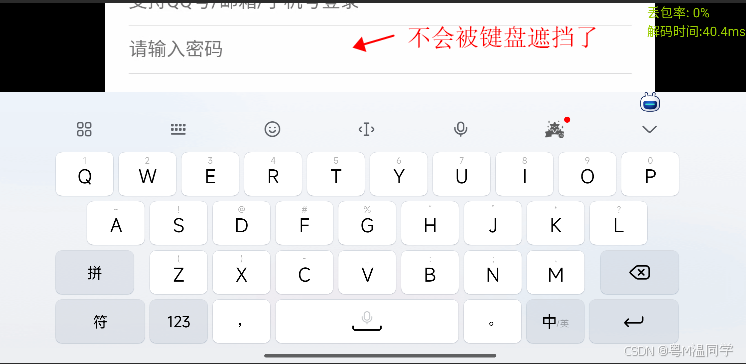
Android 云手机横屏模式下真机键盘遮挡输入框问题处理
一、背景 打开横屏应用,点击云机EditText输入框,输入框被键盘遮挡,如下图: 未打开键盘状态: 点击第二个输入框,键盘遮挡了输入框: 二、解决方案(推荐第三中方案,博主采用的也是第三种方案) 博主这里整理了三种方案:…...

Redis 中的 5 种数据类型和示例场景
Redis 作为一款高性能的键值对数据库,凭借其丰富的数据类型,在缓存、消息队列、排行榜等众多场景中发挥着重要作用。本文将详细介绍 Redis 的 5 种核心数据类型,并结合示例场景和代码,让你快速掌握它们的使用方法。 一、String&am…...
Axure设计案例——科技感对比柱状图
想让数据对比展示摆脱平淡无奇,瞬间抓住观众的眼球吗?那就来看看这个Axure设计的科技感对比柱状图案例!科技感设计风格运用独特元素打破传统对比柱状图的常规,营造出一种极具冲击力的视觉氛围。每一组柱状体都仿佛是科技战场上的士…...

SpringBoot项目搭建指南
SpringBoot项目搭建指南 文章目录 SpringBoot项目搭建指南一、SpringBoot项目搭建1.1 SpringBoot 版本选择1.2 SpringBoot 框架引入方式1.2.1 继承 Starter Parent POM1.2.2 不使用 Parent POM 来使用 Spring Boot 1.3 SpringBoot 打包插件 二、日志框架引入2.1 引入SpringBoot…...

分布式锁剖析
一、分布式锁 1. 为什么需要分布式锁? 在单体应用中,通过synchronized或ReentrantLock等进程内锁即可解决多线程资源竞争问题。但在分布式系统中,多个服务实例运行在不同进程中,传统进程内锁失效,此时需要一种跨进程…...

C语言中函数指针和指针函数的定义及用法
在C/C中,函数指针和指针函数是两个容易混淆但完全不同的概念。以下是它们的详细对比和学习指南,结合代码示例帮助你彻底掌握。 1. 函数指针(Function Pointer) 本质:一个指向函数的指针变量,用于动态调用…...

Spring Boot DevTools 热部署
在Spring Boot项目中加入 spring-boot-devtools 热部署依赖启动器后,通常不需要手动重启项目即可让更改生效。spring-boot-devtools 的核心特性之一就是自动重启或热加载。 Spring Boot DevTools 热部署关键知识点 🔥 目的:spring-boot-devt…...

unix/linux source 命令,其基本属性、语法、操作、api
现在像解剖精密仪器一样,来细致地审视 source (或 .) 命令的各个方面:它的属性、语法、操作方式,以及可以称之为“API”的交互接口。这种细致的分析有助于我们精确地理解和使用它。 让我们深入细节: 一、基本属性 (Core Attributes) 命令类型 (Command Type): Shell 内置…...
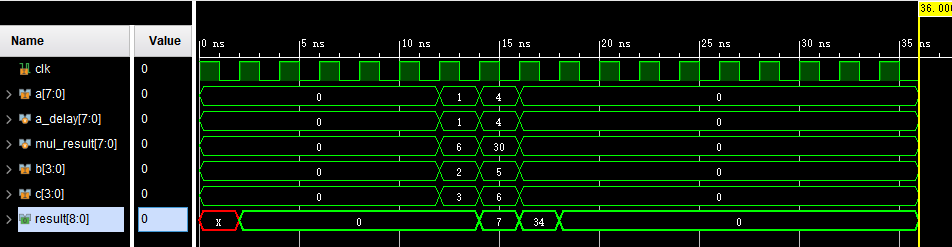
FPGA仿真中阻塞赋值(=)和非阻塞赋值(<=)区别
FPGA仿真中阻塞赋值和非阻塞赋值的区别 单独仿真小模块对但将小模块加入整个工程仿真不对就有可能是没有注意到仿真中阻塞赋值和非阻塞赋值的区别 目录 前言 一、简介 二、设计实例 三、仿真实例 1、仿真用非阻塞赋值 2、仿真用阻塞赋值 总结 前言 网上很多人介绍verilo…...
LabVIEW轴角编码器自动检测
LabVIEW 开发轴角编码器自动检测系统,针对指控系统中高故障率的轴角编码器性能检测需求,通过模块化硬件架构与软件设计,实现编码器运转状态模拟、扭矩 / 转速实时监测、19 位并行编码采集译码、数据自动分析及报告生成等功能,解决…...

MySQL数据库从0到1
目录 数据库概述 基本命令 查询命令 函数 表的操作 增删改数据和表结构 约束 事务 索引 视图 触发器 存储过程和函数 三范式 数据库概述 SQL语句的分类: DQL:查询语句,凡是select语句都是DQL。 DML:insert,delete,up…...
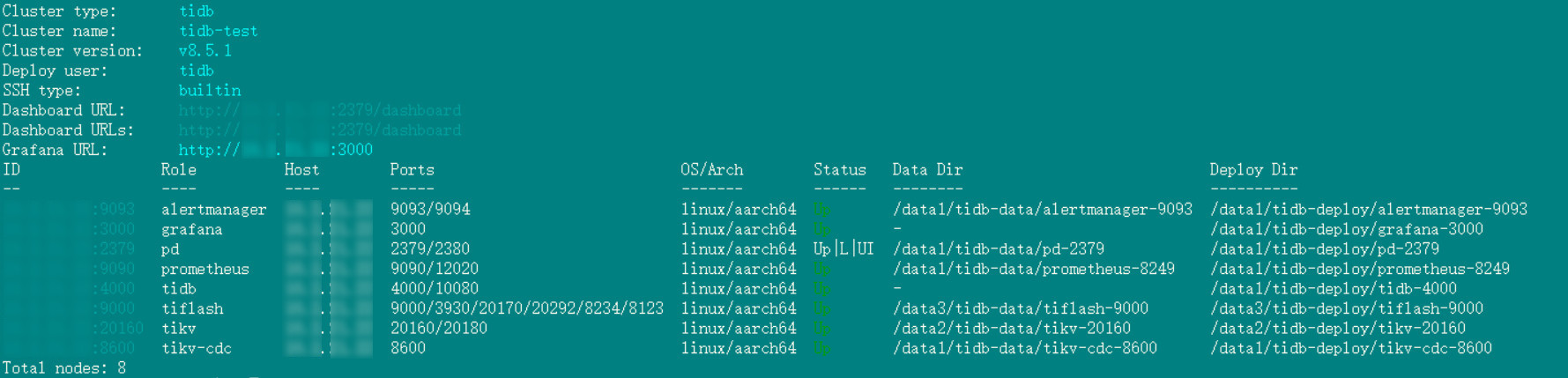
WiFi万能钥匙鲲鹏服务器部署 TiDB 集群实战指南
作者: TiDBer_yangxi 原文来源: https://tidb.net/blog/15a234d0 一、环境准备 1. 硬件要求 服务器架构 :鲲鹏服务器(ARM架构),TiDB 官方明确支持 ARM 架构服务器部署 推荐配置 (生产环…...

正则表达式的前世今生
当你熟练地用正则表达式查找替换代码时,这个工具的历史可以追溯到1943年。那时候还没有计算机,更别说编程语言了。 从神经网络到文本匹配 故事要从两个神经生理学家说起。1943年,Warren McCulloch和Walter Pitts发表了一篇论文《A logical ca…...