基于本地模型+多级校验设计的高效缓存,有效节省token数量(有点鸡肋doge)。
前言
我是基于token有限而考虑的一个省钱方案,还能够快速返回结果,但是劣势也很明显,设计不好容易出问题,就如下面所介绍的语义飘逸和缓存污染,我认为在自己学习大模型的过程用来省钱非常可以,再加上学习过程中对于语义飘逸和缓存污染这些问题要求不是很高,只是基于大模型开发应用而已,还是得基于原生的大模型来解决。有点鸡肋了说实话(doge)。
一、方案可行性分析
优势
-
显著节省Token消耗:避免重复计算相似问题
-
提升响应速度:缓存命中时可立即返回结果
-
降低API成本:减少大模型调用次数
潜在问题
-
相似度计算本身消耗Token(需优化计算方式)
-
缓存污染风险:相似但不相同的问题返回错误答案,
-
语义漂移:过度依赖缓存导致结果偏离最新知识
以下是于缓存污染和语义漂移的方案,其中相似度计算可以使用本地模型来解决。
后续专门做一节ollama快速部署本地模型的文章。
一、缓存污染解决方案(
产生的原因:相似但不相同的问题返回错误答案。
举几个例子:
1. 多级相似度校验
def is_valid_cache(query, cached_query, cached_response):# 第一层:本地嵌入模型快速过滤(零Token消耗)local_sim = cosine_similarity(embed(query), embed(cached_query))if local_sim < 0.7: # 低置信度直接跳过return False# 第二层:关键词/实体对比(防止语义近似但关键信息不同)if not key_entities_match(query, cached_query):return False# 第三层:大模型精细验证(限制Token消耗)verification_prompt = f"""判断两个问题是否可共用同一答案(仅输出Y/N):Q1: {query}Q2: {cached_query}答案: {cached_response}需满足:1. 核心诉求一致2. 关键实体相同3. 答案完全适用输出:"""return llm.generate(verification_prompt, max_tokens=1).strip() == "Y"
2. 动态阈值调整
-
基于领域敏感度的阈值:
def get_dynamic_threshold(query):if is_high_risk_domain(query): # 如医疗、法律return 0.9elif is_creative_domain(query): # 如文案生成return 0.6else: # 通用场景return 0.8
3. 缓存条目加权
-
基于置信度的缓存权重:
class CacheEntry:def __init__(self, response, confidence):self.response = responseself.weight = confidence * recency_factor() # 综合置信度和时效性
-
检索时优先返回高权重结果,低权重条目自动淘汰
二、语义漂移解决方案(结果偏离最新知识)
1. 知识时效性管理
class TemporalCache:def __init__(self):self.time_aware_cache = {} # {hash: (response, timestamp)}def get_valid_response(self, query):entry = self.find_similar(query)if entry and is_fresh(entry.timestamp):return entry.responsereturn Nonedef is_fresh(self, timestamp):# 动态过期策略if is_fast_changing_domain(query):return time.now() - timestamp < timedelta(hours=1)else: # 静态知识return time.now() - timestamp < timedelta(days=30)
2. 版本化缓存
-
当检测到以下情况时自动失效缓存:
-
大模型版本更新
-
知识库更新时间戳变化
-
用户手动触发刷新
-
3. 增量验证机制
def validate_with_latest_knowledge(query, cached_response):# 从最新知识库抽取关键事实facts = knowledge_base.extract_facts(cached_response)# 快速验证事实有效性(无需调用大模型)for fact in facts:if not knowledge_verifier.verify(fact):return Falsereturn True
三、工程化实践方案
1. 缓存隔离策略
| 缓存分区 | 存储内容 | 刷新策略 | 典型TTL |
|---|---|---|---|
| 高频静态知识 | 数学公式、常识 | 手动更新 | 永久 |
| 中频半静态 | 产品功能说明 | 每周验证 | 7天 |
| 低频动态 | 新闻、股价 | 每次请求验证 | 1小时 |
2. 反馈闭环系统
def add_human_feedback(query, response, is_correct):if not is_correct:# 立即失效相关缓存cache.invalidate_similar(query)# 记录错误模式analytics.log_contamination(query, response)# 触发重新学习retrain_detector_model(error_case=(query, response))
3. 混合缓存架构
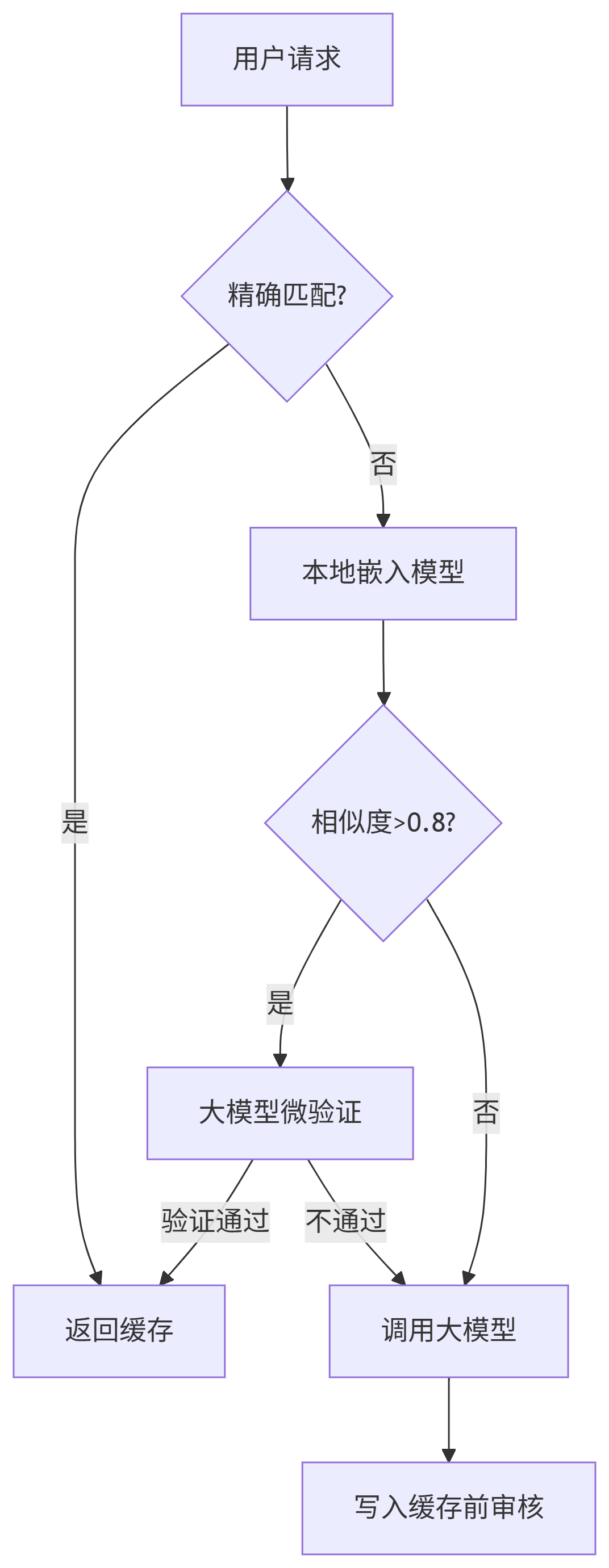
四、验证与监控指标
1. 实时监控看板
| 指标 | 预警阈值 | 监控手段 |
|---|---|---|
| 缓存污染率 | >2% | 人工抽样+自动规则检测 |
| 语义漂移率 | >5% | 知识库版本比对 |
| 平均置信度 | <0.7 | 相似度计算日志分析 |
2. 自动化测试框架
def run_contamination_test():# 注入已知污染案例test_cases = [("新冠疫苗副作用", "流感疫苗副作用"), # 相似但不同("2023年税率", "2022年税率") # 时效性失效]for q1, q2 in test_cases:assert cache.get(q1) != cache.get(q2), f"污染检测失败: {q1} vs {q2}"
五、进阶方案
1. 对抗训练增强
-
在缓存系统中注入对抗样本:
def generate_adversarial_examples():# 生成形似但语义不同的查询对return [("如何购买比特币", "如何出售比特币"),("Python的GIL问题", "Python的GIL优点")]# 定期用对抗样本测试系统
2. 基于RAG的缓存净化
def sanitize_cached_response(query, cached_response):# 用最新知识库修正缓存答案corrected = knowledge_base.correct_with_rag(query, cached_response)if corrected != cached_response:cache.update(query, corrected)return corrected
总结
通过多级校验、动态阈值、时效管理和反馈闭环的四层防御体系,可有效控制缓存污染和语义漂移。关键原则:
-
宁可漏存,不可错存:严格验证机制牺牲部分命中率换取准确性
-
持续进化:通过监控和对抗训练不断优化系统
-
领域适配:医疗/金融等高风险领域需更保守的策略
建议实施路线:
-
先建立基础缓存+本地嵌入模型
-
加入时效性管理
-
逐步引入大模型验证层
-
最终构建完整监控体系
相关文章:
基于本地模型+多级校验设计的高效缓存,有效节省token数量(有点鸡肋doge)。
前言 我是基于token有限而考虑的一个省钱方案,还能够快速返回结果,但是劣势也很明显,设计不好容易出问题,就如下面所介绍的语义飘逸和缓存污染,我认为在自己学习大模型的过程用来省钱非常可以,再加上学习过…...
逐步检索增强推理的跨知识库路由学习
摘要 多模态检索增强生成(MRAG)在多模态大语言模型(MLLM)中通过在生成过程中结合外部知识来减轻幻觉的发生,已经显示出了良好的前景。现有的MRAG方法通常采用静态检索流水线,该流水线从多个知识库ÿ…...

用Git管理你的服务器配置文件与自动化脚本:版本控制、变更追溯、团队协作与安全回滚的运维之道
更多服务器知识,尽在hostol.com 咱们在和服务器打交道的日子里,是不是经常要和各种各样的配置文件(Nginx的、Apache的、PHP的、防火墙的……)还有自己辛辛苦苦写下的自动化脚本打交道?那你有没有遇到过这样的“抓狂”…...
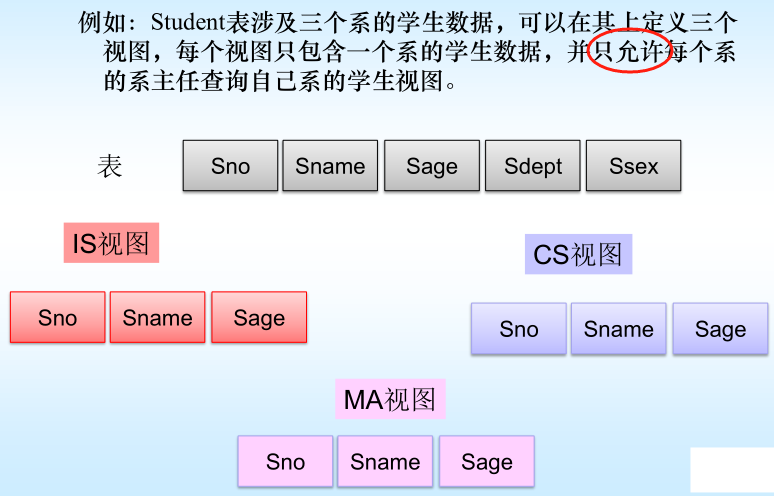
【数据库】关系数据库标准语言-SQL(金仓)下
4、数据查询 语法: SELECT [ALL | DISTINCT] <目标列表达式> [,<目标列表达式>] … FROM <表名或视图名>[, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <…...
Vue3+SpringBoot全栈开发:从零实现增删改查与分页功能
前言 在现代化Web应用开发中,前后端分离架构已成为主流。本文将详细介绍如何使用Vue3作为前端框架,SpringBoot作为后端框架,实现一套完整的增删改查(CRUD)功能,包含分页查询、条件筛选等企业级特性。 技术栈介绍 前端࿱…...

小黑大语言模型应用探索:langchain智能体构造源码demo搭建1(初步流程)
导入工具包 rom langchain_core.tools import BaseTool from typing import Sequence, Optional, List from langchain_core.prompts import BasePromptTemplate import re from langchain_core.tools import tool from langchain_core.prompts.chat import (ChatPromptTempla…...

极客时间:用 FAISS、LangChain 和 Google Colab 模拟 LLM 的短期与长期记忆
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

leetcode hot100刷题日记——35.子集
解答: 方法一:选or不选的dfs(输入视角) 思路:[1,2,3]的全部子集可以看成是对数组的每一位数字做选择。 eg.空集就是一个数字都不选,[1,2]就是1,2选,3不选。 class Solution { pub…...
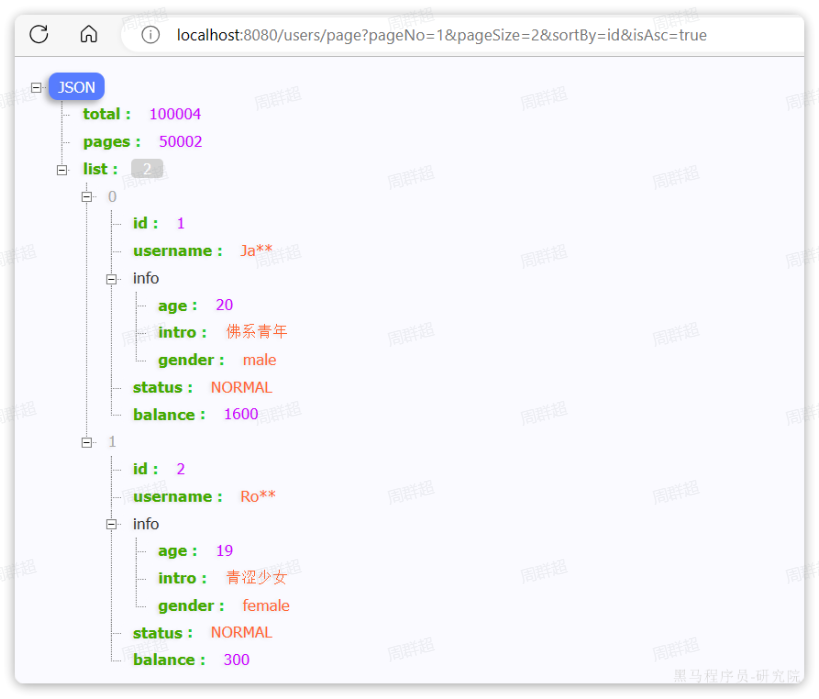
MybatisPlus(含自定义SQL、@RequiredArgsConstructor、静态工具类Db)
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是…...

React 组件异常捕获机制详解
1. 错误边界(Error Boundaries)基础 在React应用开发中,组件异常的有效捕获对于保证应用稳定性至关重要。React提供了一种称为"错误边界"的机制,专门用于捕获和处理组件树中的JavaScript错误。 错误边界是React的一种…...
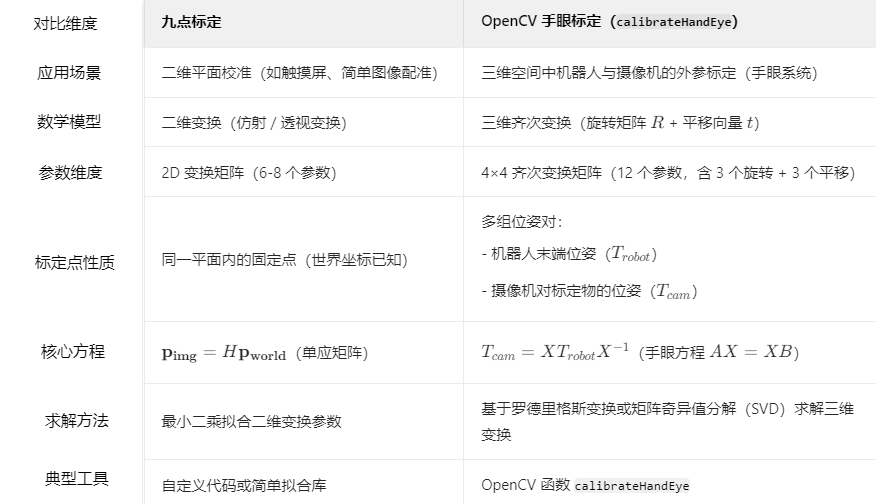
手眼标定:九点标定、十二点标定、OpenCV 手眼标定
因为一直使用6轴协作机器人,且主要应用是三维视觉,平常的手眼标定基本都是基于OpenCV来计算的,听说有九点标定和十二点标定,顺便了解下。 目录 1.九点标定1.1 基本原理1.2 关于最小二乘法1.3 具体示例 2.十二点标定3.OpenCV 手眼标…...

[总结]前端性能指标分析、性能监控与分析、Lighthouse性能评分分析
前端性能分析大全 前端性能优化 LightHouse性能评分 性能指标监控分析 浏览器加载资源的全过程性能指标分析 性能指标 在实现性能监控前,先了解Web Vitals涉及的常见的性能指标 Web Vitals 是由 Google 推出的网页用户体验衡量指标体系,旨在帮助开发者量…...

React-native的新架构
本文总结: 文章主要介绍了 React Native 的新架构,包括以下几个方面的内容:📱✨ 如何抹平 iOS 和 Android 样式差异,提升跨平台一致性; 分析了旧架构中存在的问题,如通信瓶颈、启动慢、维护复杂等&#x…...

【Android】MT6835 + MT6631 WiFi进入Meta模式出现WiFi_HQA_OpenAdapter failed
问题描述 WiFi进入Meta异常,出现WiFi_HQA_OpenAdapter failed [ 12.694501] mtk_wmtd_worker: [name:wlan_drv_gen4m_6835&][wlan][710]wlanProbeSuccessForLowLatency:(INIT INFO) LowLatency(ProbeOn) [ 12.699854] ccci_fsm: [name:ccci_md_all&][ccci1/fsm]M…...
Git 全平台安装指南:从 Linux 到 Windows 的详细教程
目录 一、Git 简介 二、Linux 系统安装指南 1、CentOS/RHEL 系统安装 2、Ubuntu/Debian 系统安装 3、Windows 系统安装 四、安装后配置(后面会详细讲解,现在了解即可) 五、视频教程参考 一、Git 简介 Git 是一个开源的分布式版本控制系…...
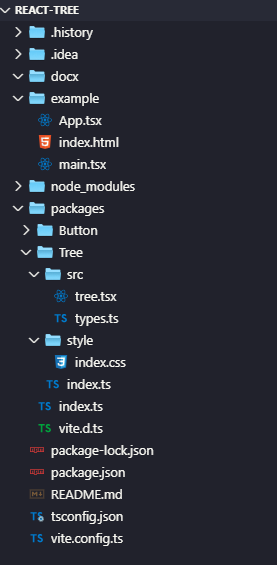
Tree 树形组件封装
整体思路 数据结构设计 使用递归的数据结构(TreeNode)表示树形数据每个节点包含id、name、可选的children数组和selected状态 状态管理 使用useState在组件内部维护树状态的副本通过deepCopyTreeData函数进行深拷贝,避免直接修改原始数据 核…...
AI书签管理工具开发全记录(五):后端服务搭建与API实现
文章目录 AI书签管理工具开发全记录(四):后端服务搭建与API实现前言 📝1. 后端框架选型 🛠️2. 项目结构优化 📁3. API路由设计 🧭分类管理书签管理 4. 数据模型定义 💾分类模型&…...

netTAP 100:在机器人技术中将 POWERLINK 转换为 EtherNet/IP
工业机器人服务专家 年轻的 More Robots 公司成立仅一年多,但其在许多应用领域的专业技术已受到广泛欢迎。这是因为More Robots提供 360 度全方位服务,包括从高品质工业机器人和协作机器人到咨询和培训。这包括推荐适合特定任务或应用的机器人࿰…...

多模态大语言模型arxiv论文略读(九十八)
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight ➡️ 论文标题:Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight ➡️ 论文作者:Ziyuan Huang, Kaixiang Ji, Biao Gong, Zhiwu Qing, Qinglong Zhang, Kecheng Zhe…...
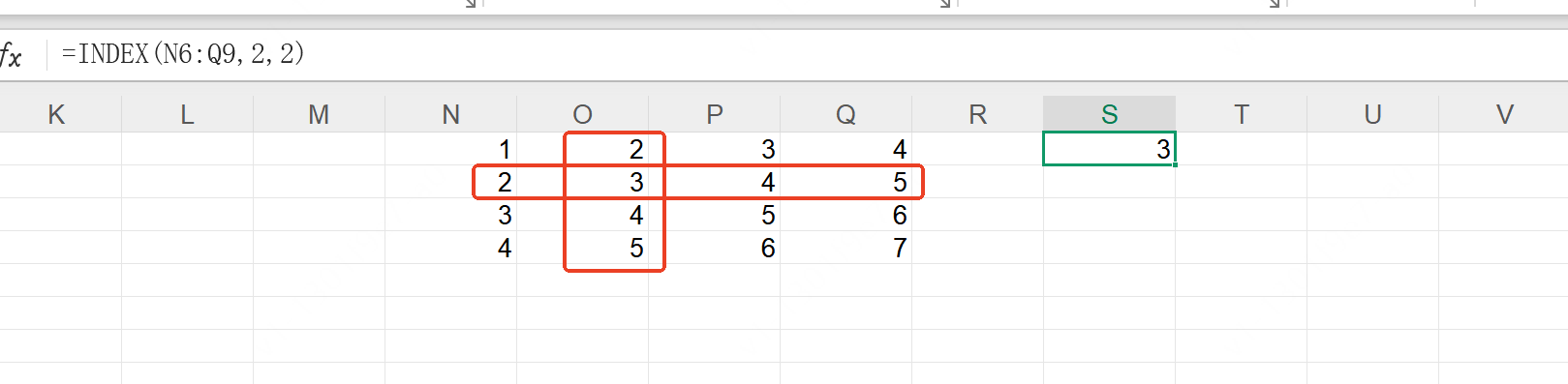
EXCEL--累加,获取大于某个值的第一个数
一、函数 LET(data,A1:A5,cumSum,SCAN(0,data,LAMBDA(a,b,ab)),idx,MATCH(TRUE,cumSum>C1,0),INDEX(data,idx)) 二、函数拆解 1、LET函数:LET(name1, value1, [name2, value2, ...], calculation) name1, name2...:自定义的变量名(需以字…...

【vscode】切换英文字母大小写快捷键如何配置
按 ⌘(Command) Shift P 打开命令面板搜索 "Transform to Uppercase" 或 "Transform to Lowercase" 点击Transform to Uppercase 命令后的齿轮图标 进入设置页面 然后就可以进行配置了 比如我是mac电脑, 切换大写可以配置为 shift alt…...

vue笔记-路由
文章目录 createWebHistory的使用router-linkrouter-link颜色是黑色,正常应该是蓝色router-link 跳转了但是不展示 其他 vue这个题目还是太大,路由单独拆出来。 createWebHistory的使用 推荐在vue-router4中使用。 1、导入。 import { createRouter, c…...
本地部署 DeepSeek R1(最新)【从下载、安装、使用和调用一条龙服务】
文章目录 一、安装 Ollama1.1 下载1.2 安装 二、下载 DeepSeek 模型三、使用 DeepSeek3.1 在命令行环境中使用3.2 在第三方软件中使用 一、安装 Ollama 1.1 下载 官方网址:Ollama 官网下载很慢,甚至出现了下载完显示 无法下载,需要授权 目…...

域名解析怎么查询?有哪些域名解析查询方式?
在互联网的世界里,域名就像是我们日常生活中的门牌号,帮助我们快速定位到想要访问的网站。而域名解析则是将这个易记的域名转换为计算机能够识别的IP地址的关键过程。当我们想要了解一个网站的域名解析情况,或者排查网络问题时,掌…...
win主机如何结束正在执行的任务进程并重启
最近遇到一个问题,一个java入库程序经常在运行了几个小时之后消息无法入库,由于已经没有研发人员来维护这个程序了,故此只能每隔一段时间来重启这个程序以保证一直有消息入库。 但是谁也不能保证一直有人去看这个程序,并且晚上也不…...

maven中的maven-resources-plugin插件详解
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 一、插件定位与核心功能 maven-resources-plugin是Maven构建工具的核心插件之一,主要用于处理项目中的资源文件(如…...

ROS云课基础篇-01-Linux-250529
ROS云课基础篇收到了很多反馈,正面评价比例高,还有很多朋友反馈需要写更具体一点。 ROS云课基础篇极简复习-C、工具、导航、巡逻一次走完-CSDN博客 于是,有了这篇以及之后的案例,案例均已经测试过8年,但没有在博客公…...

通俗易懂解析:@ComponentScan 与 @MapperScan 的异同与用法
在 Spring 和 MyBatis 集成开发中,ComponentScan 和 MapperScan 是两个核心注解,但它们的用途和工作机制截然不同。本文将通过通俗的语言和示例代码,带您轻松掌握它们的区别和使用方法。 一、基础概念 ComponentScan:Spring 的“通…...
深入了解 C# 异步编程库 AsyncEx
在现代应用程序开发中,异步编程已经成为提升性能和响应能力的关键,尤其在处理网络请求、I/O 操作和其他耗时任务时,异步编程可以有效避免阻塞主线程,提升程序的响应速度和并发处理能力。C# 提供了内建的异步编程支持(通…...

NodeJS全栈开发面试题讲解——P1Node.js 基础与核心机制
✅ 1.1 Node.js 的事件循环原理?如何处理异步操作? 面试官您好,我理解事件循环是 Node.js 的异步非阻塞编程核心。 Node.js 构建在 V8 引擎与 libuv 库之上。虽然 Node.js 是单线程模型,但它通过事件循环(event loop&a…...