一文清晰理解目标检测指标计算
一、核心概念
1.交并比IoU
预测边界框与真实边界框区域的重叠比,取值范围为[0,1]
设预测边界框为,真实边界框为
公式: IoU计算为两个边界框交集面积与并集面积之比,图示如下
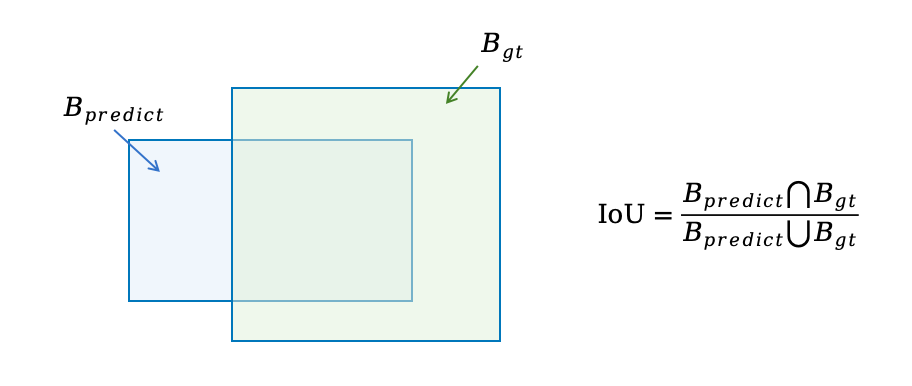
IoU值越高,表示预测边界框与真实边界框的对齐越好,意味着定位性能越优异。
2.置信度
分类器预测一个锚框中包含某个对象的概率。衡量了模型对一个预测框中包含特定类别对象的确定程度。
置信度的计算方式有多种,与检测方法是相关的,具体可以参考下面的内容:
目标检测预测框置信度(Confidence Score)计算方式-CSDN博客
3.TP、FP、FN

一些讲解视频列出的评判标准,但是这个不是很容易理解,具体实现的时候直接用下面的各种情况判定即可。
(1)TP:True Positive
预测框判定为真阳性,需同时满足两个条件:
① 其与一个真实边界框的IoU大于或等于预设阈值(通常为0.5);
② 其预测类别标签与真实类别标签正确匹配 。
值得注意的是,每个真实目标只能被一个预测边界框匹配为TP。
(2)FP:False Positive
预测边界框被归类为假阳性,如果它在以下任一情况下发生:
① 其与所有真实边界框的IoU都低于指定阈值;
② 它是对已匹配真实目标的重复检测 ;
③ 它虽然正确定位了目标(IoU达到阈值),但分配了错误的类别标签 。
(3)FN:False Negtive
模型未能检测到图像中实际存在的真实目标时,就会发生假阴性。这包括两种主要情况:
① 没有预测边界框与某个真实目标对应 ;
② 存在与真实目标有足够IoU的预测边界框,但其类别标签不正确 。在目标检测AP计算中,通常不明确评估真阴性(正确识别的背景)。
(4) TN:True Negtive
此指标无意义,忽略。
二、核心指标
注:在目标检测中谨慎使用混淆矩阵概念【这块容易误导理解】
1.Precision精确度
衡量模型正向预测的准确性。其定义为真阳性(TP)与模型所有正向预测(TP + FP)之比 。高精度意味着模型误报率低。
也叫查准率,是在识别出的物体中,正确的正向预测 (True Positive,TP) 所占的比率,越接近1越好。
2.Recall召回率
也叫查全率,正确识别出来的目标(TP)占所有需要检测的目标(也就是GT内的标记数量)比例。
越接近1越好。
3.AP和mAP
Average Precision,AP是非常流行的目标检测度量指标,通常来说一个越好的分类器,AP值越高。P(纵轴)-R(横轴)曲线与横轴的面积,一般采用插值法计算得到。
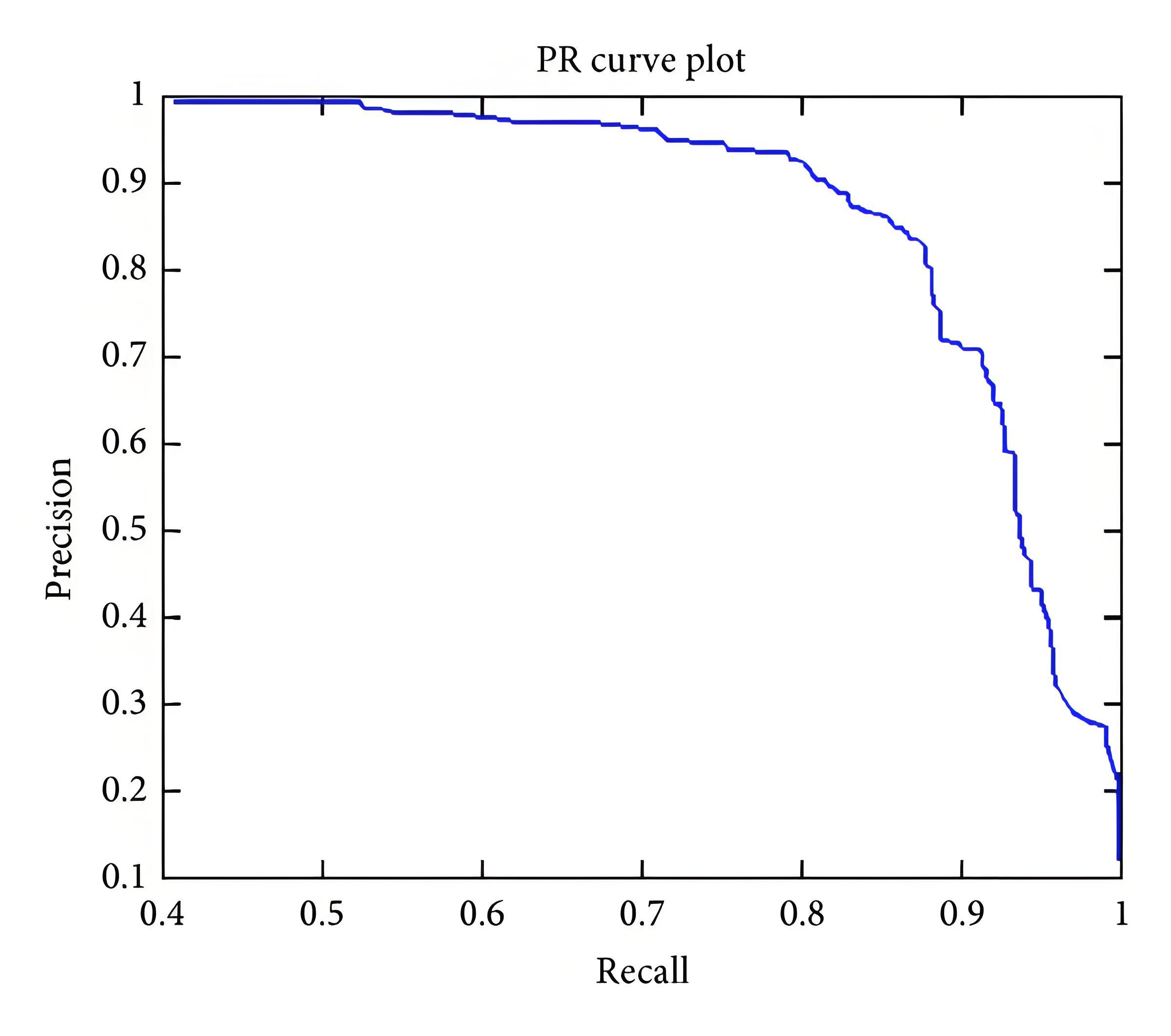
下面介绍一下COCO AP的计算过程(101点插值法):
(1) 按置信度排序预测: 对于数据集中每个目标类别,所有预测边界框都按其置信度分数降序排列 。
(2) 分类结果(TP/FP): 遍历排序后的预测。对于每个预测,根据其与真实边界框的IoU以及类别匹配情况,判断其是真阳性(TP)还是假阳性(FP),并使用特定的IoU阈值 。
(3) 计算累积指标: 随着预测的逐个处理,累积的TP和FP计数被维护,并计算累积精度和召回率值 。
例:每处理一个预测框,计算当前的召回率和精度
处理到第 k 个预测框 累计 TP 累计 FP 召回率 精度 k=1 1 0 1/5 = 0.2 1/1 = 1.0 k=2 2 0 2/5 = 0.4 2/2 = 1.0 k=3 2 1 2/5 = 0.4 2/3 ≈ 0.667 k=4 3 1 3/5 = 0.6 3/4 = 0.75 k=5 4 1 4/5 = 0.8 4/5 = 0.8 k=6 4 2 4/5 = 0.8 4/6 ≈ 0.667 k=7 4 3 4/5 = 0.8 4/7 ≈ 0.571 k=8 5 3 5/5 = 1.0 5/8 = 0.625 k=9 5 4 5/5 = 1.0 5/9 ≈ 0.556 k=10 5 5 5/5 = 1.0 5/10 = 0.5 得到原始点对(10个):( r , p )
(0.2,1.0), (0.4,1.0), (0.4,0.667), (0.6,0.75), (0.8,0.8), (0.8,0.667), (0.8,0.571), (1.0,0.625), (1.0,0.556), (1.0,0.5)
(4) 精度插值: 为了平滑PR曲线并使其单调递减,对精度进行插值。对于每个召回率水平 r ,插值精度取为在召回率 r' 大于或等于 r 时观察到的最大精度 。COCO评估专门使用101个等间距的召回率水平(从0到1,步长为0.01)进行此插值 。
例:与上面例子对应,如果此时选择 r 为0.8,那么召回率大于等于0.8时的最高准确率为0.8,那么此时的PR曲线的 r = 0.8 处的 p 即为 0.8。
(5) 计算单个IoU阈值下类别的AP: 特定类别在给定IoU阈值下的AP,通过平均这101个插值召回率水平上的精度值来计算 。也就是用101个点构建出PR曲线,计算对应面积即为特定IoU阈值下单类别的AP。如果IoU阈值为0.5,那么一般表示为AP50或者AP@0.5,当多类别时需要计算平均值,即为mAP50或mAP@0.5。
(6) 计算类别AP(跨IoU阈值平均): COCO AP的一个关键特点是,它将步骤(5)中计算的AP值在多个交并比(IoU)阈值上进行平均。具体而言,COCO使用10个IoU阈值,范围从0.50到0.95,步长为0.05(即0.50、0.55、0.60、...、0.95)。此指标通常表示为AP@[0.5:0.95]或简称为AP50:95。这种多阈值平均方式(AP50:95 = (AP50 + AP55 +... + AP95) / 10) 特别奖励那些具有更优异定位准确性的检测器 。
(7) 计算最终AP(mAP): 最终报告的AP(COCO通常将其称为mAP,因为它在类别上进行平均,没有明确区分)是步骤(6)中计算的AP值在数据集中所有目标类别上的平均值 。这种多层次的平均是其有时被俗称为“平均、平均、平均精度”的原因 。
这里对上面方法有些需要注意的地方总结一下
① 确定IoU阈值,然后在这样的阈值下计算TP、FP、FN等指标
② 随着一个一个预测框的处理,我们需要不断地记录用动态的TP、FP、FN等指标计算得到动态的P和R(这个地方很重要,对应于上面的(3)计算累积指标和(4)精度差值),进而使用插值法得到PR曲线图的面积值,即当前IoU阈值下的AP。
③ 不同的算法指标说法(YOLO或DETR等)可能不一样,要详细看看计算方式是什么做出正确的判断。
4.COCO AP的深层含义
COCO AP指标通过其多IoU阈值(0.50至0.95)的平均计算方式 ,对定位准确性给予了显著的权重,这与传统的PASCAL VOC仅使用0.5 IoU阈值形成鲜明对比 。这种设计选择意味着COCO不仅奖励模型检测目标的能力,更重要的是奖励其精确地定位目标的能力。一个预测框与真实框的IoU达到0.9的模型,其价值远高于仅勉强达到0.5阈值的模型,即使两者在0.5阈值下都被计为TP。
这推动了模型预测更紧密、更准确的边界框。因此,COCO AP已成为行业标准,因为它反映了自动驾驶、机器人操作和医学影像等实际应用中对精确目标边界日益增长的需求。
COCO AP的“平均、平均、平均精度”这一概念 ,精辟地概括了该指标的多维度特性。它意味着在召回率点(101个水平)、IoU阈值(10个水平)以及所有目标类别上进行多层次平均。
三、区分不同检测模型输出处理方式
1.基于RPN/NMS的模型(例如Faster R-CNN)
(1) 架构概述:RPN与Fast R-CNN
Faster R-CNN是两阶段目标检测器的典型代表,以其高准确性而闻名 。其架构逻辑上分为两个主要阶段
第一阶段:区域提议网络(RPN)
这是一个全卷积神经网络,旨在高效生成大量可能包含目标的候选区域(边界框)。
RPN通过在共享CNN骨干网络提取的特征图上应用一个小的滑动窗口来操作 。
在每个滑动窗口位置,RPN利用一组预定义的锚框。这些锚框是具有不同尺度和长宽比的参考框(例如,每位置3种尺度x3种长宽比=9个锚框),旨在捕获不同大小和形状的目标 。
对于每个锚框,RPN预测两个关键参数:“目标性分数”(一个二元概率,指示锚框是否包含目标)和相对于锚框的边界框调整量(偏移和尺度)。
第二阶段:Fast R-CNN检测器
该组件接收RPN生成的区域提议,并执行最终的目标分类和精确的边界框回归 。
它使用ROI池化(或ROI Align)层从RPN提议的每个感兴趣区域(ROI)中提取固定长度的特征向量,无论原始提议的尺寸如何 。
这些提取的特征向量随后被送入全连接层,输出最终的类别概率(N+1个类别,包括背景类别)和进一步精细化的边界框坐标 。
(2) 非极大值抑制(NMS)在过滤检测结果中的作用
RPN通常会生成大量高度重叠的区域提议,一张图像中可能多达数百甚至数千个 。
非极大值抑制(NMS)是一种关键后处理算法,应用于这些原始预测结果。其主要目的是消除冗余和高度重叠的边界框预测,确保每个检测到的目标只保留一个最自信和最准确的边界框 。
NMS过程:
① 所有预测边界框(针对特定类别)根据其置信度分数降序排列 。
② 选择置信度分数最高的边界框,并将其添加到最终检测结果列表中。
③ 抑制所有与已选边界框显著重叠的其他边界框(即,它们与已选边界框的IoU超过预定义的NMS阈值,通常为0.5或0.7)。
④ 重复步骤②和③,直到没有剩余的(未被抑制的)边界框。
NMS是一个启发式过程,独立于神经网络的端到端训练。它对于生成用于评估和实际使用的干净、非冗余的最终检测结果集至关重要 。
(3) 详细示例:从原始预测到NMS过滤后的检测结果及随后的AP/混淆矩阵计算
场景: 假设一张图像中有一个真实目标:“狗”,其坐标为``。
① 原始RPN/检测器输出(NMS之前): 模型可能为这只“狗”生成多个高度重叠的预测,同时还有一些虚假检测:
P1:类别:狗,边界框分数:0.98(与真实框IoU = 0.9)
P2:类别:狗,边界框分数:0.95(与真实框IoU = 0.88)
P3:类别:狗,边界框分数:0.92(与真实框IoU = 0.85)
P4:类别:猫,边界框分数:0.70(无真实猫)
P5:类别:人,边界框分数:0.60(无真实人)
② NMS应用(NMS IoU阈值 = 0.5):
按分数排序预测:P1 (0.98), P2 (0.95), P3 (0.92), P4 (0.70), P5 (0.60)。
选择P1。将P1添加到最终检测结果。
抑制重叠边界框:P2和P3与P1有高IoU(例如,> 0.5)。抑制P2和P3。
下一个最高分数是P4。选择P4。将P4添加到最终检测结果(P4不与P1重叠)。
下一个最高分数是P5。选择P5。将P5添加到最终检测结果(P5不与P1或P4重叠)。
③最终NMS过滤后的检测结果:
D1:类别:狗,边界框分数:0.98
D2:类别:猫,边界框分数:0.70
D3:类别:人,边界框分数:0.60
(4) 对AP计算的影响
用于计算AP的TP/FP/FN仅基于这些NMS过滤后的检测结果。
对于AP:
D1(狗)与真实狗:IoU > 0.5,类别正确 -> TP。
D2(猫)与真实目标:无真实猫 -> FP。
D3(人)与真实目标:无真实人 -> FP。
如果存在其他未被检测到的真实目标,它们将是FN。
精度-召回率曲线随后根据这些TP/FP计数构建。
2.端到端方式的直接预测(以DETR为代表)
(1) 架构概述:Transformer编码器-解码器与直接集合预测
DETR(DEtection TRansformer)代表了目标检测领域的一次范式转变,它将目标检测任务重新定义为一个直接的集合预测问题 。这种创新方法从根本上消除了对传统手工设计组件(如锚框生成和非极大值抑制(NMS))的需求 。
(2) 核心组件
① CNN骨干网络: 类似于基于RPN的模型,CNN(例如ResNet-50)从输入图像中提取层次化的特征图 。
② Transformer编码器: 该组件处理扁平化的图像特征。利用其自注意力机制,编码器捕获图像中全局上下文信息和长距离依赖关系,从而实现对目标关系的更整体理解 。
③ Transformer解码器: 解码器是DETR直接预测的核心。它接收固定数量的“目标查询”(学习到的位置嵌入)作为输入。每个查询通过对编码器输出的交叉注意力,直接预测一个边界框及其对应的类别标签 。
④ 预测头: 连接到每个解码器输出的简单前馈网络(FFN)。这些预测头直接输出归一化后的边界框中心坐标、高度、宽度,以及所有可能类别标签的softmax概率分布 。
DETR旨在输出一个固定大小的N个预测结果集(例如,原始论文中N=100),其中N通常远大于图像中实际目标的预期数量。为了处理目标数量少于N的情况,一个特殊的“无目标”类别(∅)用于表示未使用的预测槽位 。
(3) 二分匹配(匈牙利算法)在消除NMS中的作用
由于DETR直接输出一个预测集合,并且这些预测的顺序是任意的(由于Transformer的置换不变性),因此在训练期间需要一个复杂的匹配机制来唯一地将每个预测目标分配给一个真实目标 。
二分匹配(匈牙利算法): 这种强大的图论算法用于在固定大小的N个预测集与真实目标集(用∅“无目标”条目填充以匹配大小N)之间找到最优的一对一分配(特定排列)。目标是最小化配对预测和真实目标之间的总匹配成本 。
匹配成本: 匹配预测框ŷ_i与真实框y_j的成本函数通常同时考虑类别预测(负对数概率)和边界框相似度(例如L1损失和广义IoU损失)。
消除NMS: 由于匈牙利算法建立了一对一的唯一映射,它从根本上解决了重复检测问题,并为每个真实目标分配最多一个预测,从而消除了单独的NMS后处理步骤的需求 。
(4) 详细示例:从原始预测到二分匹配检测结果及随后的AP计算
场景: 相同的图像,包含一个真实目标(“狗”)。DETR输出N=100个预测。
原始DETR输出: 解码器输出100个预测(类别、边界框、分数)元组。其中许多将属于∅(无目标)类别。一些可能指向“狗”(例如,P1:狗,bbox1,0.9;P2:狗,bbox2,0.85;P3:∅,bbox3,0.1;...)。即使P1和P2都预测为“狗”,它们最初也是独立的预测。
二分匹配应用(训练期间): 匈牙利算法将为单个真实“狗”与N个预测中的一个找到最佳匹配。它很可能将真实狗与“P1”匹配,因为它具有最高的“狗”类别置信度以及良好的IoU。所有其他N-1个未匹配的预测将被隐式分配给∅(无目标)类别。
推理与评估:在推理后,通常会丢弃具有∅标签或置信度分数非常低的预测(例如,< 0.05)。由于训练目标,剩余的预测本质上是非冗余的。在我们的示例中,过滤后可能只剩下“P1”(狗,置信度0.98,边界框)。这个单一的、过滤后的边界框(P1)随后用于计算TP/FP/FN,并与真实目标进行比较。如果它与真实狗匹配(IoU > IoU_阈值且类别正确),则为TP。如果它不匹配,则为FP。如果真实狗完全被漏检(即没有预测为“狗”的边界框通过置信度阈值),则为FN。
关键点: DETR的训练目标(二分匹配)从根本上处理了冗余,消除了推理后NMS的需求。这简化了评估的后处理流程,因为模型直接输出一个稀疏的、高质量的、非重叠的检测结果集。
相关文章:
一文清晰理解目标检测指标计算
一、核心概念 1.交并比IoU 预测边界框与真实边界框区域的重叠比,取值范围为[0,1] 设预测边界框为,真实边界框为 公式: IoU计算为两个边界框交集面积与并集面积之比,图示如下 IoU值越高,表示预测边界框与真实边界框的对…...

【MySQL】索引下推减少回表次数
一、简述索引下推 “索引下推”是数据库领域的一个术语,主要出现在MySQL(尤其是InnoDB存储引擎)中,英文名叫 Index Condition Pushdown,简称 ICP。就是过滤的动作由下层的存储引擎层通过使用索引来完成,而…...
Artificial Analysis2025年Q1人工智能发展六大趋势总结
2025年第一季度人工智能发展六大趋势总结 ——基于《Artificial Analysis 2025年Q1人工智能报告》 趋势一:AI持续进步,竞争格局白热化 前沿模型竞争加剧:OpenAI凭借“o4-mini(高智能版)”保持领先,但谷歌&…...

DeepSeek模型高级应用:提示工程与Few-shot学习实战指南
引言 在DeepSeek模型的实际应用中,提示工程(Prompt Engineering)和Few-shot学习正成为提升模型性能的关键技术。相比全参数微调,这些技术能以更低成本实现领域适配。本文将深入解析DeepSeek模型的高级提示技巧、动态Few-shot实现方案,以及混合微调策略,帮助开发者在资源受…...

Android高级开发第三篇 - JNI异常处理与线程安全编程
Android高级开发第三篇 - JNI异常处理与线程安全编程 Android高级开发第三篇 - JNI异常处理与线程安全编程引言为什么要关注异常处理和线程安全?第一部分:JNI异常处理基础什么是JNI异常?检查和处理Java异常从C代码抛出Java异常异常处理的最佳…...

企业级应用狂潮:从Spotify到LinkedIn的Llama实战手册
当Spotify用Llama生成的个性化推荐文案让用户播放时长激增30%, 当LinkedIn靠开源框架将社交推荐延迟降低40%—— 企业级AI战场正经历从“技术炫技”到“利润引擎”的残酷蜕变。 核心数据:企业采用率爆发式增长(2025 Gartner调研) 指标2023年2025年增幅开源模型采用率42%87%…...

高效管理 Python 项目的 UV 工具指南
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...

QT中子线程触发主线程弹窗并阻塞等待用户响应
目录 QT中子线程触发主线程弹窗并阻塞等待用户响应一、使用QMetaObject::invokeMethod实现子线程安全触发主线程弹窗并阻塞等待:🔧 Qt多线程弹窗:安全阻塞等待方案(QMetaObject::invokeMethod详解)🧠 一、核…...

初识vue3(vue简介,环境配置,setup语法糖)
一,前言 今天学习vue3 二,vue简介及如何创建vue工程 Vue 3 简介 Vue.js(读音 /vjuː/,类似 “view”)是一款流行的渐进式 JavaScript 框架,用于构建用户界面。Vue 3 是其第三代主要版本,于 …...

HarmonyOS NEXT~鸿蒙开发工具CodeGenie:AI驱动的开发效率革命
HarmonyOS NEXT~鸿蒙开发工具CodeGenie:AI驱动的开发效率革命 一、CodeGenie概述 DevEco CodeGenie是华为鸿蒙开发生态中的一款AI辅助编程工具,集成于DevEco Studio IDE中,为开发者提供全方位的智能编程支持。这款工具通过AI技术…...
LeetCode-链表操作题目
虚拟头指针,在当前head的前面建立一个虚拟头指针,然后哪怕当前的head的val等于提供的val也能进行统一操作 203移除链表元素简单题 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(…...

【ARM】MDK浏览信息的生成对于构建时间的影响
1、 文档目标 用于了解MDK的代码浏览信息的生成对于工程的构建是否会产生影响。 2、 问题场景 客户在MDK中使用Compiler 5对于工程进行构建过程中发现,对于是否产生浏览信息会对于构建时间产生一定的影响。在Options中Output栏中勾选了Browse Information后&#…...

Python模块中__all__变量失效问题深度解析
文章目录 Python模块中__all__变量失效问题深度解析一、__all__ 的正确作用场景二、__all__ 不起作用的常见原因1. 未使用 from ... import \* 导入2. __all__ 定义不完整或错误3. 子模块未正确导出4. Python 解释器缓存问题5. 相对导入路径错误 三、解决方案1. 确保使用 from …...

py爬虫的话,selenium是不是能完全取代requests?
selenium适合动态网页抓取,因为它可以控制浏览器去点击、加载网页,requests则比较适合静态网页采集,它非常轻量化速度快,没有浏览器开销,占用资源少。当然如果不考虑资源占用和速度,selenium是可以替代requ…...
docker B站学习
镜像是一个只读的模板,用来创建容器 容器是docker的运行实例,提供了独立可移植的环境 https://www.bilibili.com/video/BV11L411g7U1?spm_id_from333.788.videopod.episodes&vd_sourcee60c804914459274157197c4388a4d2f&p3 目录挂载 尚硅谷doc…...
SpringBoot高校宿舍信息管理系统小程序
概述 基于SpringBoot的高校宿舍信息管理系统小程序项目,这是一款非常适合高校使用的信息化管理工具。该系统包含了完整的宿舍管理功能模块,采用主流技术栈开发,代码结构清晰,非常适合学习和二次开发。 主要内容 这个宿舍管理系…...

深度解析 Dockerfile 配置:构建高效轻量的FastAPI 应用镜像
目录 引言 Dockerfile构建FastAPI镜像的示例 一、基础镜像选择:轻量与安全优先 二、元数据声明:镜像维护者信息 三、依赖管理:分层构建与缓存优化 1. 复制依赖文件 2. 安装依赖 四、应用代码复制:最小化镜像内容 五、启动…...

ICASSP2025丨融合语音停顿信息与语言模型的阿尔兹海默病检测
阿尔兹海默病(Alzheimers Disease, AD)是一种以认知能力下降和记忆丧失为特征的渐进性神经退行性疾病,及早发现对于其干预和治疗至关重要。近期,清华大学语音与音频技术实验室(SATLab)提出了一种将停顿信息…...

[蓝桥杯]春晚魔术【算法赛】
目录 输入格式 输出格式 样例输入 样例输出 运行限制 解决思路 代码说明 复杂度分析 问题描述 在蓝桥卫视春晚的直播现场,魔术师小蓝表演了一个红包魔术。只见他拿出了三个红包,里边分别装有 A、B 和 C 个金币。而后,他挥动魔术棒&a…...

LeetCode - 965. 单值二叉树
目录 题目 深度优先搜索方法 正确的写法 题目 965. 单值二叉树 - 力扣(LeetCode) 深度优先搜索方法 什么是深度优先搜索:深度优先搜索(DFS)是一种图或树的遍历算法,它从起始节点开始,尽可能深地沿着一条路径探索&…...
LabVIEW杂草识别与精准喷洒
基于LabVIEW构建了一套集成机器视觉、智能决策与精准控制的农业杂草识别系统。通过高分辨率视觉传感器采集作物图像,利用 LabVIEW 的 NI Vision 模块实现图像颜色匹配与特征分析,结合 Arduino 兼容的工业级控制硬件,实现杂草定位与除草剂精准…...

分布式不同数据的一致性模型
1. 强一致性(Strong Consistency) 定义:所有节点在任何时间点看到的数据完全一致,读操作总是返回最近的写操作结果。特点: 写操作完成后,所有后续读操作都能立即看到更新。通常需要同步机制(如…...

“application/json“,“text/plain“ 分别表示什么
这两个字符串:“application/json” 和 “text/plain” 是 MIME 类型(媒体类型),用于告诉接收方消息内容的格式,它们出现在 ContentType 字段中。 它告诉系统或程序:“这段数据是什么格式?” 格…...
)
SQL: 窗口滑动(Sliding Window)
目录 什么是“窗口”? 什么是“滑动”? 🔍 滑动窗口的核心: 🕒 什么是时间窗口?(Time Window) 时间窗口的基本结构 时间窗口的三种常见形式 📊 什么是行窗口&…...
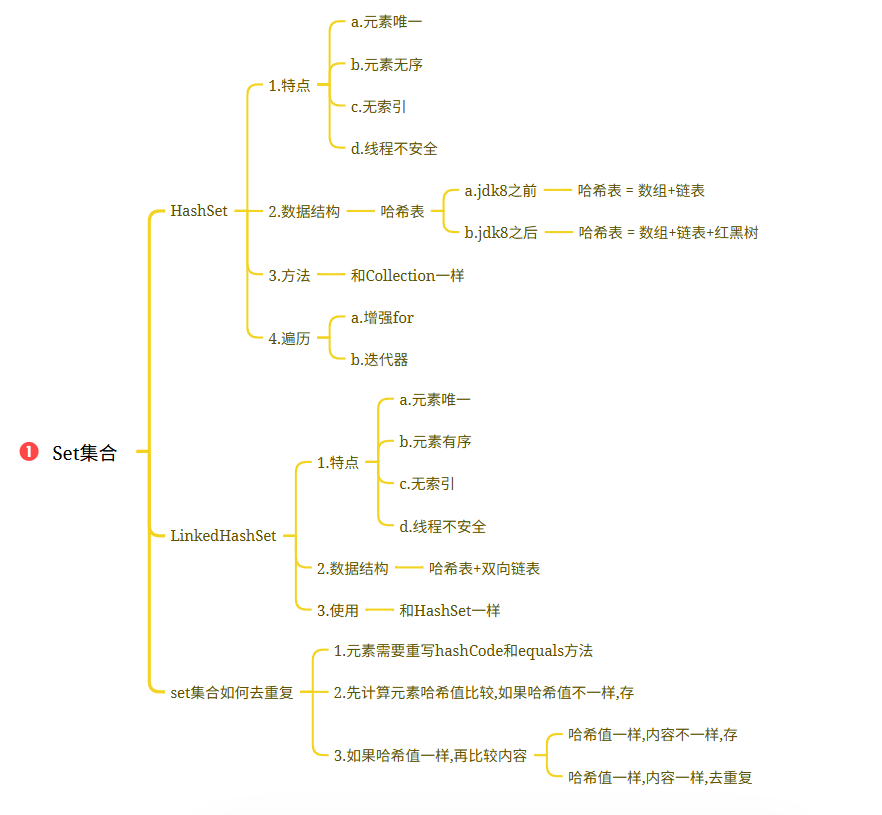
学习日记-day20-6.1
完成目标: 知识点: 1.集合_Collections集合工具类 方法:static <T> boolean addAll(Collection<? super T> c, T... elements)->批量添加元素 static void shuffle(List<?> list) ->将集合中的元素顺序打乱static <T>…...

【音视频】 FFmpeg 解码H265
一、概述 实现了使用FFmpeg读取对应H265文件,并且保存为对应的yuv文件 二、实现流程 读取文件 将H265/H264文件放在build路径下,然后指定输出为yuv格式 在main函数中读取外部参数 if (argc < 2){fprintf(stderr, "Usage: %s <input file&…...

Linux 系统 Docker Compose 安装
个人博客地址:Linux 系统 Docker Compose 安装 | 一张假钞的真实世界 本文方法是直接下载 GitHub 项目的 release 版本。项目地址:GitHub - docker/compose: Define and run multi-container applications with Docker。 执行以下命令将发布程序加载至…...

软件测试|FIT故障注入测试工具——ISO 26262合规下的智能汽车安全验证引擎
FIT(Fault Injection Tester)是SURESOFT专为汽车电子与工业控制设计的自动化故障注入测试工具,基于ISO 26262等国际安全标准开发,旨在解决传统测试中效率低、成本高、安全隐患难以复现的问题,其核心功能包括…...
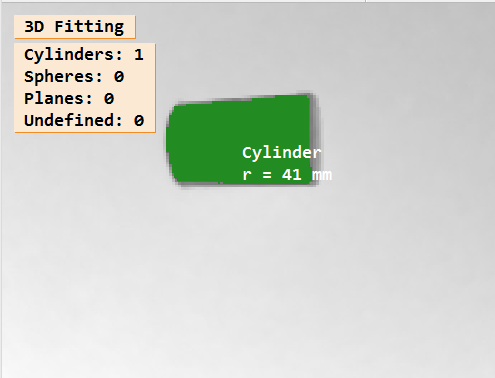
3D拟合测量水杯半径
1,目的。 测量水杯的半径 如图所示: 2,原理。 对 3D 点云对象 进行圆柱体拟合,获取拟合后的半径。 3,注意事项。 在Halcon中使用fit_primitives_object_model_3d进行圆柱体拟合时,输出的primitive_para…...
量子计算对密码学的影响)
(21)量子计算对密码学的影响
文章目录 2️⃣1️⃣ 量子计算对密码学的影响 🌌🔍 TL;DR🚀 量子计算:密码学的终结者?⚡ 量子计算的破坏力 🔐 Java密码学体系面临的量子威胁🔥 受影响最严重的Java安全组件 🛡️ 后…...