Redis最佳实践——性能优化技巧之数据结构选择

Redis在电商应用中的数据结构选择与性能优化技巧
一、电商核心场景与数据结构选型矩阵
| 应用场景 | 推荐数据结构 | 内存占用 | 读写复杂度 | 典型操作 |
|---|---|---|---|---|
| 商品详情缓存 | Hash | 低 | O(1) | HGETALL, HMSET |
| 购物车管理 | Hash | 中 | O(1) | HINCRBY, HDEL |
| 用户会话管理 | Hash | 低 | O(1) | HSETEX, HGET |
| 商品分类目录 | Sorted Set | 高 | O(logN) | ZRANGE, ZREVRANK |
| 实时排行榜 | Sorted Set | 高 | O(logN) | ZADD, ZREVRANGE |
| 秒杀库存管理 | String + Lua | 极低 | O(1) | DECR, INCR |
| 用户行为记录 | Bitmap | 极低 | O(1) | SETBIT, BITCOUNT |
| 订单流水号生成 | String | 极低 | O(1) | INCR |
| 消息队列 | Stream | 中 | O(1) | XADD, XREAD |
| UV统计 | HyperLogLog | 极低 | O(1) | PFADD, PFCOUNT |
二、关键数据结构深度解析
1. String(字符串)
适用场景:
- 简单键值存储(库存计数器)
- 分布式锁
- 订单号生成器
优化技巧:
// 原子操作库存扣减
String stockKey = "stock:1001";
Long remain = jedis.decr(stockKey);// 分布式锁实现(带过期时间)
String lockKey = "lock:order:1001";
String result = jedis.set(lockKey, "locked", "NX", "EX", 30);
内存优化:
- 数值类型使用字符串存储(自动识别为整数编码)
- 启用压缩(
redis.conf中设置rdbcompression yes)
陷阱规避:
- 避免大Value(>10KB)导致网络阻塞
- 非数值类型INCR操作返回错误
2. Hash(哈希表)
适用场景:
- 商品详情缓存
- 购物车数据存储
- 用户属性集合
内存布局优化:
// 商品详情存储示例
Map<String, String> product = new HashMap<>();
product.put("name", "iPhone 15 Pro");
product.put("price", "9999");
product.put("stock", "1000");
jedis.hmset("product:1001", product);// 启用ziplist编码(节省30%+内存)
config set hash-max-ziplist-entries 512
config set hash-max-ziplist-value 64
性能对比:
| 操作类型 | 原生JDK HashMap | Redis Hash(ziplist) | Redis Hash(hashtable) |
|---|---|---|---|
| 插入10万字段 | 120ms | 450ms | 380ms |
| 遍历所有字段 | 65ms | 220ms | 180ms |
| 内存占用 | 48MB | 21MB | 32MB |
最佳实践:
- 字段数量控制在500个以内以保持ziplist编码
- 使用HSCAN代替HGETALL遍历大数据量Hash
3. Sorted Set(有序集合)
适用场景:
- 商品价格排序
- 销量排行榜
- 最近浏览记录
内存优化方案:
// 商品价格排序存储
jedis.zadd("price_sort:1001", 5999.0, "sku:2001");
jedis.zadd("price_sort:1001", 7999.0, "sku:2002");// 使用ziplist编码(元素<=128且score差值小)
config set zset-max-ziplist-entries 128
config set zset-max-ziplist-value 64
分页查询优化:
// 获取价格区间商品(6000-8000,分页显示)
Set<String> products = jedis.zrangeByScore("price_sort:1001", 6000, 8000, new ZRangeParams().limit(offset, pageSize));
性能数据:
| 元素数量 | ZADD(ops/sec) | ZRANGE(ops/sec) | 内存占用(万元素) |
|---|---|---|---|
| 1万 | 48,000 | 52,000 | 2.1MB |
| 10万 | 32,000 | 41,000 | 24MB |
| 100万 | 12,000 | 28,000 | 240MB |
4. HyperLogLog(基数统计)
适用场景:
- 每日UV统计
- 搜索词去重计数
- 点击去重统计
内存效率对比:
// 统计每日UV
jedis.pfadd("uv:20231111", "user1", "user2", "user3");
Long count = jedis.pfcount("uv:20231111");// 误差率0.81%时仅需12KB内存
// 传统Set存储百万用户需16MB
合并统计技巧:
// 合并多日UV统计
jedis.pfmerge("uv:weekly", "uv:20231111", "uv:20231112");
5. Bitmap(位图)
适用场景:
- 用户签到记录
- 特征标记存储
- 布隆过滤器实现
存储优化案例:
// 用户每月签到记录(每月仅需4MB存储千万用户)
String key = "sign:202311:user1001";
jedis.setbit(key, 15, true); // 第16天签到// 统计当月签到次数
Long count = jedis.bitcount(key);
内存对比:
| 用户量 | 传统存储 | Bitmap | 节省比例 |
|---|---|---|---|
| 100万用户 | 31.25MB | 0.125MB | 99.6% |
| 1亿用户 | 3.05GB | 12.5MB | 99.6% |
三、高级优化技巧
1. 内存编码优化
Redis内部编码策略:
# 查看Key编码类型
redis-cli object encoding product:1001# 常见编码类型对比
| 数据结构 | 编码类型 | 触发条件 |
|------------|----------------|----------------------------------|
| Hash | ziplist | field数量 ≤ hash-max-ziplist-entries |
| List | quicklist | 默认配置(链表节点含多个ziplist) |
| Set | intset | 元素都是整数且数量 ≤ set-max-intset-entries |
2. 分片存储策略
// 商品评论分片存储
public String getCommentKey(Long productId, int shard) {int hash = Math.abs(productId.hashCode()) % 1024;return "comments:" + productId + ":" + (hash % shard);
}// 分片查询聚合
public List<Comment> getComments(Long productId) {List<Comment> result = new ArrayList<>();for(int i=0; i<4; i++){String key = getCommentKey(productId, i);result.addAll(jedis.lrange(key, 0, -1));}return result;
}
3. Lua脚本原子操作
// 库存扣减+订单创建原子操作
String script = "local stock = tonumber(redis.call('get', KEYS[1]))\n" +"if stock <= 0 then\n" +" return 0\n" +"end\n" +"redis.call('decr', KEYS[1])\n" +"redis.call('lpush', KEYS[2], ARGV[1])\n" +"return 1";Long result = jedis.eval(script, Arrays.asList("stock:1001", "order_queue"),Arrays.asList("order:1001:user123"));
四、性能压测数据参考
1. 各数据结构基准性能
| 数据结构 | 写入QPS | 读取QPS | 内存占用(万条) |
|---|---|---|---|
| String | 125,000 | 145,000 | 4.8MB |
| Hash(ziplist) | 98,000 | 112,000 | 1.2MB |
| Sorted Set | 42,000 | 65,000 | 8.5MB |
| List | 78,000 | 85,000 | 3.2MB |
2. 不同编码类型对比
| 编码类型 | 写入速度 | 读取速度 | 内存消耗 |
|---|---|---|---|
| ziplist | 38,000 | 45,000 | 100% |
| hashtable | 52,000 | 61,000 | 165% |
| quicklist | 48,000 | 55,000 | 120% |
五、生产环境最佳实践
-
容量规划公式
预估内存 = (平均Key大小 + 平均Value大小) × Key数量 × 1.3(冗余系数) -
监控告警指标
# 关键监控项 redis-cli info memory | grep used_memory_human redis-cli info stats | grep instantaneous_ops_per_sec redis-cli latency history -
数据淘汰策略选择
# 推荐配置(根据场景选择) volatile-lru:适合会话数据 allkeys-lfu:适合缓存场景 -
大Key治理方案
// 大Key拆分示例 public void splitBigHash(String originKey, int shards) {Map<String, String> data = jedis.hgetAll(originKey);data.forEach((k,v) -> {int shard = k.hashCode() % shards;jedis.hset(originKey + ":" + shard, k, v);});jedis.del(originKey); }
六、典型场景实战案例
案例1:购物车优化
原始方案:String存储JSON
// 问题:每次修改都要全量更新
jedis.setex("cart:user1001", 3600, json);// 优化方案:Hash存储字段
jedis.hset("cart:user1001", "sku1001", "2");
jedis.hset("cart:user1001", "sku2002", "1");
性能提升:
| 指标 | String方案 | Hash方案 | 提升幅度 |
|---|---|---|---|
| 添加商品耗时 | 12ms | 2ms | 6倍 |
| 内存占用 | 8KB | 3KB | 62.5% |
案例2:秒杀库存管理
传统方案:数据库行锁
Redis方案:
// Lua脚本原子扣减
String script = "local stock = tonumber(redis.call('get', KEYS[1]))\n" +"if stock > 0 then\n" +" redis.call('decr', KEYS[1])\n" +" redis.call('publish', 'stock_update', ARGV[1])\n" +" return 1\n" +"else\n" +" return 0\n" +"end";
性能对比:
| 方案 | QPS | 成功率 |
|---|---|---|
| 数据库行锁 | 1,200 | 99.9% |
| Redis原子操作 | 85,000 | 99.99% |
七、总结与扩展
黄金准则:
- 优先选择时间复杂度为O(1)的数据结构
- 小数据量优先使用ziplist编码
- 读写分离处理热点Key
- 使用Pipeline批量处理减少网络开销
- 结合Lua脚本保证复杂操作原子性
扩展方向:
- 时序数据库:使用RedisTimeSeries存储监控数据
- 图数据库:RedisGraph实现社交关系分析
- AI集成:RedisAI加速推荐模型推理
通过合理的数据结构选择与优化,Redis在电商系统中可实现:
- 内存消耗降低60%+
- 读写性能提升5-10倍
- 服务可用性达到99.999%
- 开发效率提升3倍以上
相关文章:
Redis最佳实践——性能优化技巧之数据结构选择
Redis在电商应用中的数据结构选择与性能优化技巧 一、电商核心场景与数据结构选型矩阵 应用场景推荐数据结构内存占用读写复杂度典型操作商品详情缓存Hash低O(1)HGETALL, HMSET购物车管理Hash中O(1)HINCRBY, HDEL用户会话管理Hash低O(1)HSETEX, HGET商品分类目录Sorted Set高O…...

网络安全方向在校生有哪些证书适合考取?
工作7年得出结论:网络安全,考任何证书都没有用,实力才是根本。我是2021年考的 CISSP,报了培训班,花了1万一千块钱,签的保障班还是服务班不记得了,大概意思就是你放心去考,考不过可以…...
从0开始学习R语言--Day14--贝叶斯统计与结构方程模型
贝叶斯统计 在很多时候,我们经常会看到在统计分析中出现很多反直觉的结论,比如假如有一种病,人群中的患病率为1%,患者真患病时,检测结果为阳性的概率是99%,如果没有,则检测结果为阳性的概率是5…...

02-BTC-密码学原理 对hash算法如果出现漏洞的思考
如果比特币中某个哈希函数的抗碰撞性出现了漏洞怎么办,怎么补救? 答:(1)攻击场景: 伪造交易:攻击者可构造两个不同的交易(如正常交易和恶意双花交易)具有相同的TxID&…...

[Python] 如何使用 Python 调用 Dify 工作流服务实现自动化翻译
在实际项目中,自动化工作流服务可以大大简化复杂任务的处理流程。本文将介绍如何通过 Python 脚本调用 Dify 提供的工作流 API,实现文本翻译的自动化操作。该流程包括设置 API 接口、构造请求体并处理返回结果。 一、背景介绍:什么是 Dify 工作流服务? Dify 是一款支持多种…...

分布式微服务系统架构第142集:全栈开发
加群联系作者vx:xiaoda0423 仓库地址:https://webvueblog.github.io/JavaPlusDoc/ https://1024bat.cn/ https://github.com/webVueBlog/fastapi_plus https://webvueblog.github.io/JavaPlusDoc/ /*** 本地启动解决跨域问题* 打包发布请注释该类&#…...
PTA-根据已有类Worker,使用LinkedList编写一个WorkerList类,实现计算所有工人总工资的功能。
目录 1.问题描述 2.函数接口定义: 3.裁判测试程序样例: 4.输入和输出样例 输入样例: 输出样例: 5.实现代码 1.问题描述 Main类:在main方法中,调用constructWorkerList方法构建一个Worker对象链表…...

文档整合自动化
主要功能是按照JSON文件(Sort.json)中指定的顺序合并多个Word文档(.docx),并清除文档中的所有超链接。最终输出合并后的文档名为"sorted_按章节顺序.docx"。 主要分为几个部分: 初始化配置 定…...

微软markitdown PDF/WORD/HTML文档转Markdown格式软件整合包下载
本次和大家分享另一个微软发布的非常热门的文件文档转Markdown格式文档的软件markitdown,软件可以将PDF,word,ppt,Excel等十几种格式文档转换为markdown格式文档,我基于当前最新0.1.2版本制作了免安装一键启动整合包。…...

科普:Linux `su` 切换用户后出现 `$` 提示符,如何排查和解决?
科普:Linux su 切换用户后出现 $ 提示符,如何排查和解决? 在 Linux 系统管理中,su(Switch User)命令用于切换用户身份。正常情况下,从 root 切换到普通用户时,提示符会从 # 变成 $&…...

BayesFlow:基于神经网络的摊销贝叶斯推断框架
贝叶斯推断为不确定性条件下的推理、复杂系统建模以及基于观测数据的预测提供了严谨且功能强大的理论框架。尽管贝叶斯建模在理论上具有优雅性,但在实际应用中经常面临显著的计算挑战:后验分布通常缺乏解析解,模型验证和比较需要进行重复的推…...
)
NodeJS全栈开发面试题讲解——P9性能优化(Node.js 高级)
✅ 9.1 Node.js 的性能瓶颈一般出在哪?如何排查? Node.js 单线程 异步模型,瓶颈常出现在: 阻塞操作(如:同步 I/O、CPU 密集型计算) 数据库慢查询 / 索引失效 外部接口慢响应 大量并发请求导…...

NVMe IP现状扫盲
SSD优势 与机械硬盘(Hard Disk Driver, HDD)相比,基于Flash的SSD具有更快的数据随机访问速度、更快的传输速率和更低的功耗优势,已经被广泛应用于各种计算领域和存储系统。SSD最初遵循为HDD设计的现有主机接口协议,例…...

5G-A时代与p2p
5G-A时代正在走来,那么对P2P的影响有多大。 5G-A作为5G向6G过渡的关键技术,将数据下载速率从千兆提升至万兆,上行速率从百兆提升至千兆,时延降至毫秒级。这种网络性能的跨越式提升,为P2P提供了更强大的底层支撑&#x…...
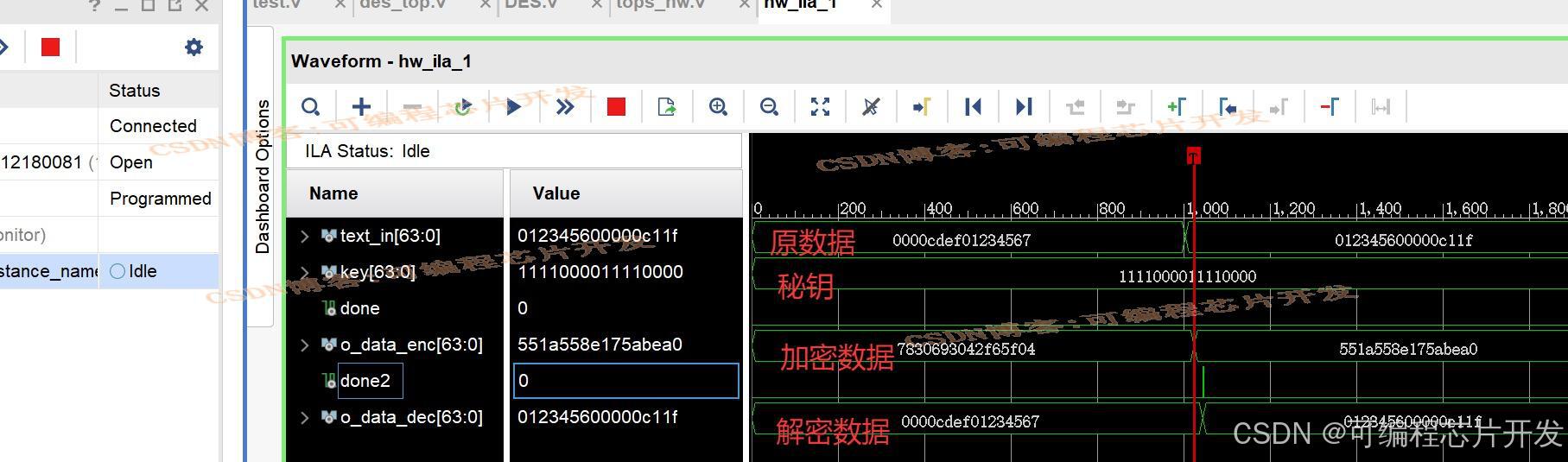
基于FPGA的DES加解密系统verilog实现,包含testbench和开发板硬件测试
目录 1.课题概述 2.系统测试效果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于FPGA的DES加解密系统verilog实现,包含testbench和开发板硬件测试。输入待加密数据,密钥,输出加密数据,然后通过解密模块输出解密后的原…...
)
基于生产-消费模式,使用Channel进行文件传输(Tcp方式)
Client端: #region 多文件传输 public class FileMetadata {public string FileName { get; set; }public long FileSize { get; set; } }class Program {const int PORT 8888;const int BUFFER_SIZE 60 * 1024 * 1024;//15s-50 25s-64 33s-32 27s-50 31s-40 25…...

tortoisegit 使用rebase修改历史提交
在 TortoiseGit 中使用 rebase 修改历史提交(如修改提交信息、合并提交或删除提交)的步骤如下: --- ### **一、修改最近一次提交** 1. **操作**: - 右键项目 → **TortoiseGit** → **提交(C)** - 勾选 **"Amend…...

Python----目标检测(《用于精确目标检测和语义分割的丰富特征层次结构》和R-CNN)
一、《用于精确目标检测和语义分割的丰富特征层次结构》 1.1、基本信息 原文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 中文译名:用于精确目标检测与语义分割的丰富特征层次结构 版本:第5版技…...

Ansible 进阶 - Roles 与 Inventory 的高效组织
Ansible 进阶 - Roles 与 Inventory 的高效组织 如果说 Playbook 是一份完整的“菜谱”,那么 Role (角色) 就可以被看作是制作这道菜(或一桌菜)所需的标准化“备料包”或“半成品组件”。例如,我们可以有一个“Nginx Web 服务器安装配置 Role”、“MySQL 数据库基础设置 Ro…...
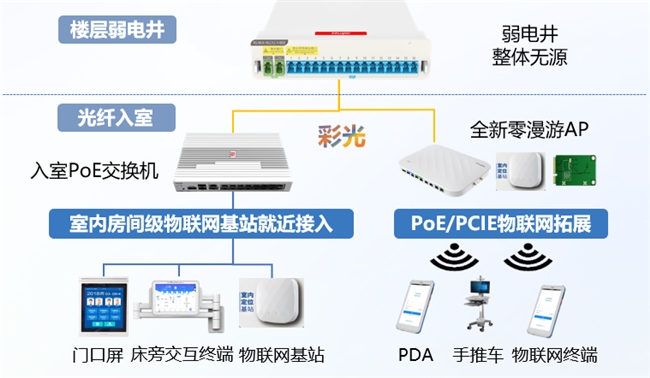
极简以太彩光网络解决方案4.0正式发布,“彩光”重构园区网络极简之道
5月28日下午,锐捷网络在京举办以“光,本该如此‘简单’”为主题的发布会,正式发布极简以太彩光网络解决方案4.0。作为“彩光”方案的全新进化版本,极简以太彩光4.0从用户需求出发,聚焦场景洞察,开启了一场从底层基因出发的极简革命,通过架构、部署、运维等多维度的创新升级,以强…...
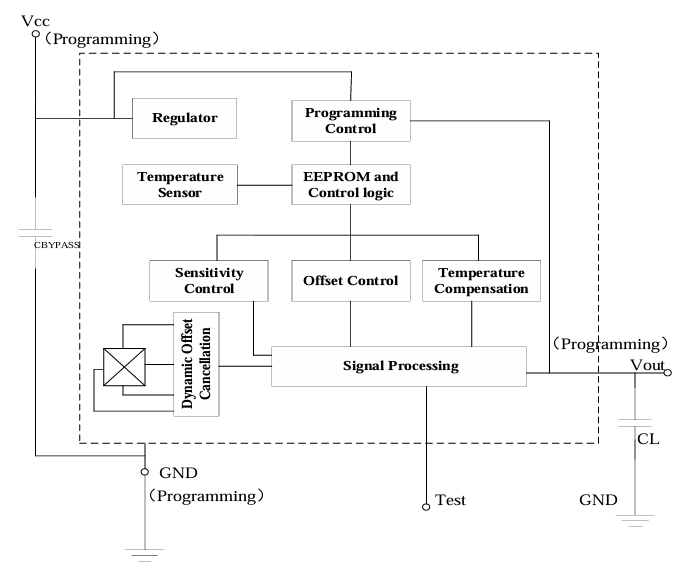
国芯思辰| 霍尔电流传感器AH811为蓄电池负载检测系统安全护航
在电动车、储能电站、不间断电源(UPS)等设备中,蓄电池作为关键的储能单元,其运行状态直接关系到设备的稳定性和使用寿命。而准确监测蓄电池的负载情况,是保障其安全、高效运行的关键。霍尔电流传感器 AH811凭借独特的技…...
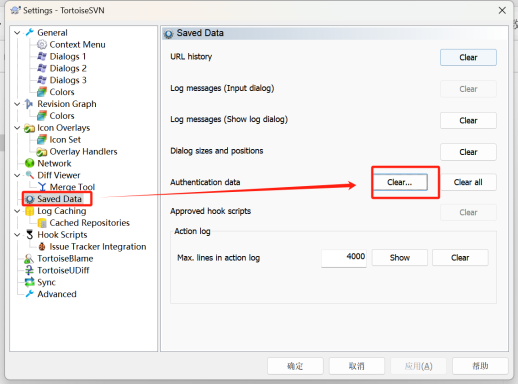
TortoiseSVN账号切换
SVN登录配置及账号切换 本文主要为了解答svn客户端如何进行账号登录及切换不同权限账号的方式。 一、环境准备与客户端安装 安装TortoiseSVN客户端 下载地址:TortoiseSVN官网 安装步骤: 双击安装包,按向导完成安装后&#x…...

2025年05月28日Github流行趋势
项目名称:agenticSeek 项目地址url:https://github.com/Fosowl/agenticSeek项目语言:Python历史star数:10352今日star数:2444项目维护者:Fosowl, steveh8758, klimentij, ganeshnikhil, apps/copilot-pull-…...
:商业模式与阶段匹配的指标体系构建)
精益数据分析(91/126):商业模式与阶段匹配的指标体系构建
精益数据分析(91/126):商业模式与阶段匹配的指标体系构建 在创业的不同阶段,企业面临的核心问题与目标差异显著,这就要求我们依据商业模式和所处阶段,动态调整关键指标体系。今天,我们将深入解…...
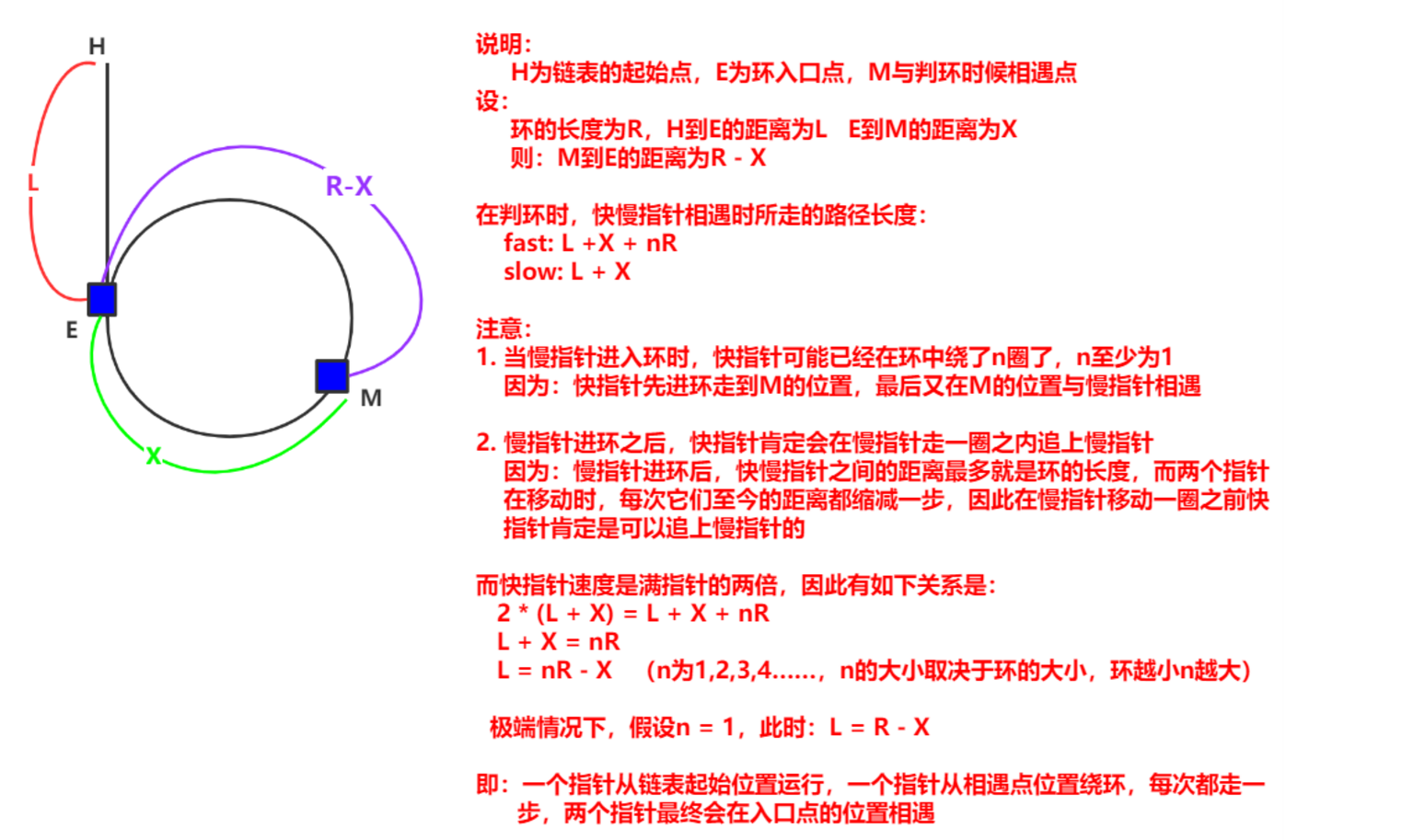
篇章五 数据结构——链表(一)
目录 1.ArrayList的缺陷 2. 链表 2.1 链表的概念及结构 2.2 链表结构 1. 单向或者双向 2.带头或者不带头 3.循环或者非循环 2.3 链表的实现 1.完整代码 2.图解 3.显示方法 4.链表大小 5. 链表是否存在 key 值 6.头插法 7.尾插法 8.中间插入 9.删除key值节点 10.…...
一文清晰理解目标检测指标计算
一、核心概念 1.交并比IoU 预测边界框与真实边界框区域的重叠比,取值范围为[0,1] 设预测边界框为,真实边界框为 公式: IoU计算为两个边界框交集面积与并集面积之比,图示如下 IoU值越高,表示预测边界框与真实边界框的对…...

【MySQL】索引下推减少回表次数
一、简述索引下推 “索引下推”是数据库领域的一个术语,主要出现在MySQL(尤其是InnoDB存储引擎)中,英文名叫 Index Condition Pushdown,简称 ICP。就是过滤的动作由下层的存储引擎层通过使用索引来完成,而…...
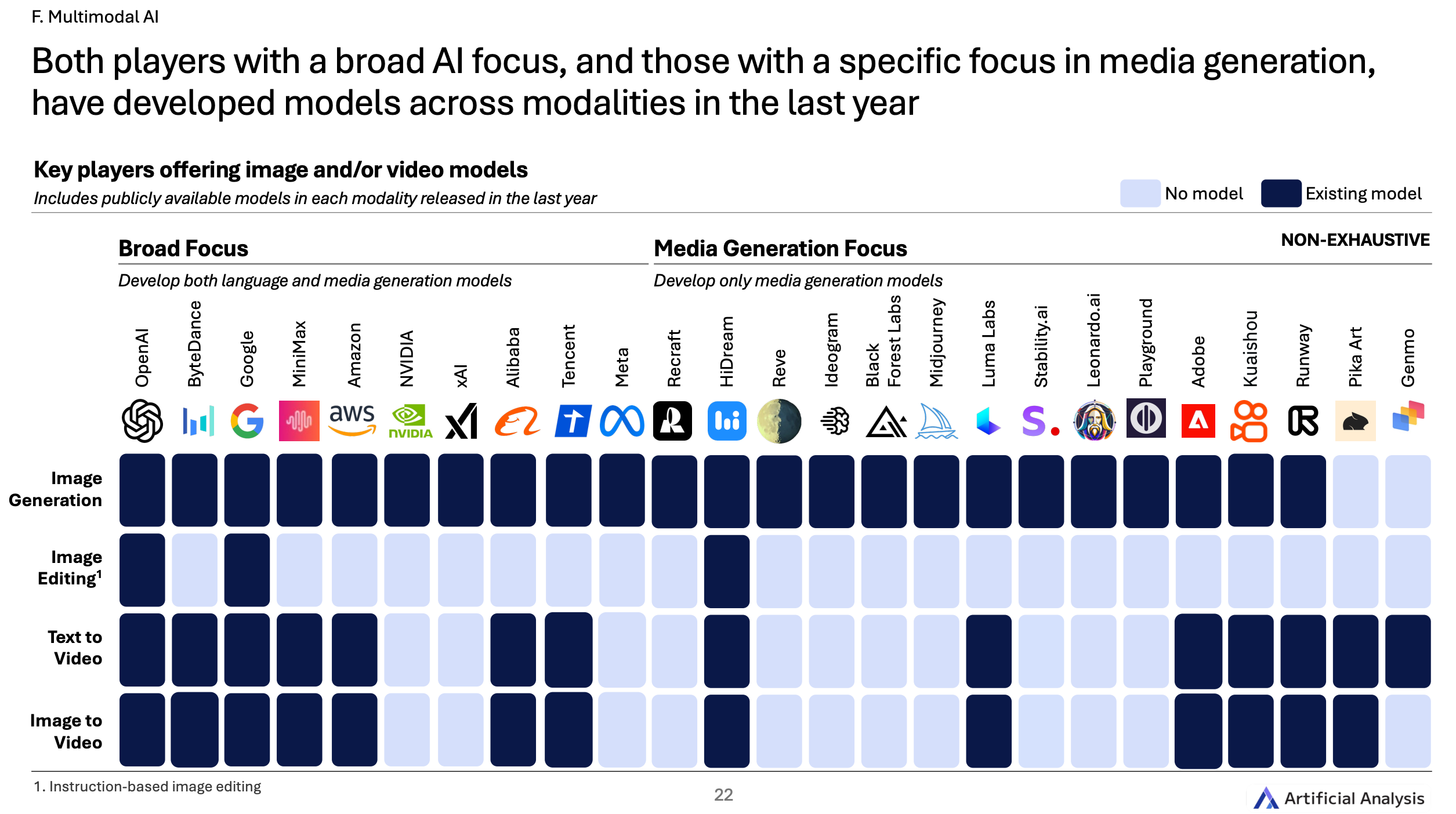
Artificial Analysis2025年Q1人工智能发展六大趋势总结
2025年第一季度人工智能发展六大趋势总结 ——基于《Artificial Analysis 2025年Q1人工智能报告》 趋势一:AI持续进步,竞争格局白热化 前沿模型竞争加剧:OpenAI凭借“o4-mini(高智能版)”保持领先,但谷歌&…...

DeepSeek模型高级应用:提示工程与Few-shot学习实战指南
引言 在DeepSeek模型的实际应用中,提示工程(Prompt Engineering)和Few-shot学习正成为提升模型性能的关键技术。相比全参数微调,这些技术能以更低成本实现领域适配。本文将深入解析DeepSeek模型的高级提示技巧、动态Few-shot实现方案,以及混合微调策略,帮助开发者在资源受…...

Android高级开发第三篇 - JNI异常处理与线程安全编程
Android高级开发第三篇 - JNI异常处理与线程安全编程 Android高级开发第三篇 - JNI异常处理与线程安全编程引言为什么要关注异常处理和线程安全?第一部分:JNI异常处理基础什么是JNI异常?检查和处理Java异常从C代码抛出Java异常异常处理的最佳…...