【后端高阶面经:架构篇】51、搜索引擎架构与排序算法:面试关键知识点全解析

一、搜索引擎核心基石:倒排索引技术深度解析
(一)倒排索引的本质与构建流程
倒排索引(Inverted Index)是搜索引擎实现快速检索的核心数据结构,与传统数据库的正向索引(文档→关键词)不同,它通过关键词→文档集合的映射关系,将查询复杂度从O(N)降至O(1)。其构建流程如下:
1. 数据预处理:从原始文本到词元(Lexeme)
- 中文分词挑战:需解决分词歧义(如“乒乓球拍卖完了”可拆分为“乒乓球/拍卖/完了”或“乒乓球拍/卖/完了”)。
解决方案:使用IK分词器结合自定义词典(如电商领域词库),或基于深度学习的分词模型(如LSTM+CRF)。 - 词元处理:
- 小写转换(统一大小写)
- 停用词过滤(去除“的”“了”等无意义词汇)
- 词干提取(如将“running”转换为“run”)
2. 倒排表构建:从词元到文档列表
graph TDA[词元] --> B{倒排表}B --> C[文档ID列表]C --> D[词频(TF)]C --> E[位置信息]
- 示例:
文档1:“搜索引擎是用于检索海量数据的工具”
文档2:“Elasticsearch是分布式搜索引擎”
倒排索引如下:搜索引擎: [1,2] (TF: 1 in doc1, 1 in doc2) 检索: [1] (TF: 1) Elasticsearch: [2] (TF: 1)
3. 压缩与优化:提升存储与查询效率
- 差值编码(Delta Encoding):存储文档ID差值而非绝对值(如文档ID列表[100, 200, 300]→[100, 100, 100]),减少存储空间。
- 位图压缩(Bitmap Compression):用位运算快速实现布尔查询(如“搜索引擎 AND 分布式”等价于两词倒排表的位图交集)。
- 基于Lucene的实现:
// Lucene倒排索引构建伪代码 Directory directory = FSDirectory.open(Paths.get("index")); Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter writer = new IndexWriter(directory, config);Document doc = new Document(); doc.add(new TextField("content", "搜索引擎是用于检索海量数据的工具", Field.Store.YES)); writer.addDocument(doc); writer.close();
(二)倒排索引 vs 正向索引:核心差异对比
| 维度 | 正向索引 | 倒排索引 |
|---|---|---|
| 数据结构 | 文档→关键词列表 | 关键词→文档列表 |
| 查询复杂度 | O(N)(遍历所有文档) | O(1)(直接定位关键词) |
| 适用场景 | 数据库行级查询 | 全文检索、模糊查询 |
| 典型实现 | MySQL InnoDB B+树 | Elasticsearch Lucene |
二、分布式搜索引擎架构:应对PB级数据的关键
(一)分片(Shard)与副本(Replica)机制
1. 分片:将数据“分而治之”
- 水平拆分策略:
- 哈希分片:按文档ID哈希值分配至不同节点(如
doc_id % shard_num),适合均匀分布的数据。 - 范围分片:按时间范围(如按月存储日志)或数值范围(如用户年龄分段)划分,适合时序数据。
- 哈希分片:按文档ID哈希值分配至不同节点(如
- Elasticsearch示例:
# ES索引分片配置 settings:number_of_shards: 5 # 主分片数(建议≤节点数)number_of_replicas: 1 # 副本数(提升查询吞吐量)
2. 副本:高可用与负载均衡
- 主副本机制:每个主分片对应多个副本分片,主分片负责写入,副本分片分担读请求。
- 故障切换:当主分片所在节点故障时,副本分片自动升级为主分片(通过ES的Master节点协调)。
- 性能提升:1个主分片+2个副本可将读吞吐量提升3倍(假设各节点性能一致)。
(二)分布式查询流程:从请求到结果的全链路
graph LR用户-->ES集群: 查询请求(如“分布式搜索引擎”)ES协调节点-->分片1: 检索关键词“分布式”ES协调节点-->分片2: 检索关键词“搜索引擎”分片1-->协调节点: 返回文档列表1(含词频、评分)分片2-->协调节点: 返回文档列表2(含词频、评分)协调节点-->合并结果: 按相关性排序后返回用户
- 查询阶段(Query Phase):各分片返回匹配文档的ID和评分(TF-IDF或BM25算法)。
- 取回阶段(Fetch Phase):协调节点根据文档ID从各分片获取完整文档内容。
(三)与传统数据库的性能对比
| 场景 | MySQL(单节点) | Elasticsearch(5节点集群) |
|---|---|---|
| 百亿级数据模糊查询 | 超时(>30秒) | 200ms |
| 复杂布尔查询(AND/OR) | 全表扫描,效率低下 | 位运算快速合并结果 |
| 水平扩展能力 | 需分库分表,复杂度高 | 自动分片,线性扩展 |
三、近实时检索与数据同步:平衡实时性与性能
(一)准实时索引技术
1. Elasticsearch的段(Segment)机制
- 写入流程:
- 新数据先写入内存缓冲区(In-Memory Buffer)。
- 每隔1秒(默认Refresh间隔)生成新段(Segment)并写入磁盘,此时数据可被检索(准实时)。
- 定期合并小段为大段(Force Merge),减少I/O开销。
- 性能 trade-off:缩短Refresh间隔可提升实时性,但增加磁盘I/O和段数量(建议生产环境设为5-10秒)。
2. 增量数据同步方案
| 数据源 | 同步工具 | 典型场景 |
|---|---|---|
| MySQL | Canal + Kafka + Logstash | 电商商品信息同步 |
| 日志文件 | Fluentd + ES Client | 实时日志分析 |
| 分布式事务 | Apache RocketMQ + 事务消息 | 订单状态变更通知 |
(二)数据同步中间层设计
- Canal原理:模拟MySQL从库读取Binlog,解析数据变更(如INSERT/UPDATE/DELETE)。
- 幂等性保证:通过消息唯一ID(如UUID)避免重复写入(ES支持按ID幂等更新)。
四、混合检索架构:从关键词到语义向量的跨越
(一)向量数据库与语义检索
1. 非结构化数据向量化
- 技术栈:
- 图像:ResNet50提取特征→768维向量
- 文本:BERT编码→1024维向量
- 视频:3D卷积神经网络(如C3D)提取时空特征
- Milvus向量索引示例:
# Milvus创建HNSW索引 from pymilvus import Collection, IndexTypecollection = Collection("product_images") index_params = {"index_type": IndexType.HNSW, "metric_type": "L2", "params": {"M": 64, "efConstruction": 512}} collection.create_index("embedding", index_params)
2. 混合搜索(Hybrid Search)实现
graph TB用户查询-->解析器: 提取关键词(如“红色运动鞋”)解析器-->结构化查询: 品牌=耐克 AND 颜色=红色解析器-->向量查询: 运动鞋图片向量相似度检索结果合并器-->ES: 执行结构化过滤结果合并器-->Milvus: 执行向量匹配结果合并器-->排序: 综合得分(关键词匹配度+向量相似度)
- 应用案例:电商“以图搜物”场景中,用户上传图片→提取向量→Milvus检索相似商品→ES过滤品牌/价格等条件→按综合得分排序。
(二)GPU加速与性能优化
| 技术方案 | 加速场景 | 效率提升 |
|---|---|---|
| GPU向量检索 | Milvus HNSW索引查询 | 10亿向量检索从200ms→20ms |
| 向量化计算 | TF-IDF权重计算 | 单核CPU→GPU加速5-10倍 |
| 并行分词 | 中文分词(如Jieba多线程) | 处理速度提升4倍 |
五、搜索结果排序:从算法到工程的全链路优化
(一)经典排序算法解析
1. PageRank:链接分析的核心
- 原理:将网页视为图节点,超链接视为投票,网页权重由入链数量和质量决定。
公式:
P R ( A ) = ( 1 − d ) + d × ∑ i = 1 n P R ( T i ) C ( T i ) PR(A) = (1-d) + d \times \sum_{i=1}^n \frac{PR(T_i)}{C(T_i)} PR(A)=(1−d)+d×i=1∑nC(Ti)PR(Ti)
其中,d为阻尼系数(通常取0.85),T_i为指向A的网页,C(T_i)为T_i的出链数。 - 工程实现:
- 分布式计算:MapReduce批量处理网页链接关系。
- 增量更新:仅重新计算变更网页的权重,而非全量重新计算。
2. TF-IDF与BM25:文本相关性排序
- TF-IDF:词频(TF)越高、文档频率(DF)越低,关键词权重越高。
公式:
T F − I D F = T F × log ( N D F + 1 ) TF-IDF = TF \times \log(\frac{N}{DF+1}) TF−IDF=TF×log(DF+1N) - BM25:改进版TF-IDF,引入文档长度归一化。
公式:
B M 25 = ∑ ( k + 1 ) × T F T F + k × ( 1 − b + b × l e n ( d ) a v g l e n ) BM25 = \sum \frac{(k+1) \times TF}{TF + k \times (1 - b + b \times \frac{len(d)}{avg_len})} BM25=∑TF+k×(1−b+b×avglenlen(d))(k+1)×TF
(k、b为可调参数,通常k=1.2,b=0.75)
3. 业务场景定制排序
- UGC平台(如小红书):点赞数(社交权重)+ 词频(内容相关性)+ 发布时间(新鲜度)。
- 电商搜索(如淘宝):销量(商业权重)+ 价格(用户偏好)+ BM25(关键词匹配)。
(二)排序算法对比与选型
| 算法 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| PageRank | 全局权威性评估 | 实时性差,依赖链接结构 | 网页搜索(如Google) |
| TF-IDF/BM25 | 文本相关性精准计算 | 忽略语义,无法处理多模态 | 垂直领域文本搜索 |
| 向量排序 | 语义级匹配,支持多模态 | 计算复杂度高 | 图片/视频搜索 |
| 机器学习排序(如LambdaMART) | 综合多特征,动态调参 | 需要大量标注数据 | 个性化搜索(如电商) |
六、性能优化与容灾设计:保障高可用与低延迟
(一)索引与硬件优化
1. 索引策略选择
| 数据集大小 | 索引类型 | 检索延迟 | 存储成本 |
|---|---|---|---|
| <100万向量 | FLAT(精确索引) | 10ms | 100% |
| 100万-1亿向量 | IVF_PQ(乘积量化) | 50ms | 30%-50% |
| >1亿向量 | HNSW(层次化导航) | 20ms | 60%-70% |
2. 硬件加速方案
- 存储层:SSD替换HDD(随机读IOPS从100→5000+)。
- 网络层:RDMA网络(RoCEv2)降低节点间通信延迟(从100μs→20μs)。
- 计算层:Intel Optane持久内存(延迟10μs,容量达TB级)缓存热数据。
(二)容灾与监控体系
1. 高可用架构设计
- 多数据中心(Multi-DC):
- 主数据中心(如北京)与灾备中心(如上海)通过异步复制同步数据。
- 故障切换:通过Keepalived+DNS动态切换访问入口。
- Raft协议应用:ES的Master节点选举机制确保集群一致性(需至少3个节点形成多数派)。
2. 实时监控指标
| 指标 | 健康阈值 | 优化动作 |
|---|---|---|
| 分片延迟 | <50ms | 迁移分片至空闲节点 |
| 内存使用率 | <80% | 增加节点或淘汰冷数据 |
| 搜索超时率 | <1% | 优化查询语句或增加副本 |
| 段数量 | <1000/索引 | 执行Force Merge |
七、面试高频问题与解答
(一)基础概念题
问题1:倒排索引为什么比正向索引更适合全文检索?
回答:
- 正向索引按文档存储关键词,查询时需遍历所有文档,时间复杂度O(N)。
- 倒排索引按关键词存储文档列表,查询时直接定位关键词对应的文档集合,时间复杂度O(1),且通过压缩技术进一步提升效率。
问题2:Elasticsearch的分片和副本有什么区别?
回答:
- 分片(Shard):数据水平拆分的最小单元,解决单机存储和计算瓶颈。
- 副本(Replica):分片的复制版本,用于高可用(主分片故障时自动切换)和负载均衡(分担读请求)。
- 示例:5主分片+1副本=10个分片(5主+5副),可承受5个节点故障(每个主分片至少有1个副本)。
(二)架构设计题
问题:如何设计一个支持亿级商品的电商搜索系统?
解答:
- 数据分层:
- 热数据(近30天商品):Redis缓存高频查询结果。
- 温数据(30天-1年商品):Elasticsearch集群(10主分片+2副本,SSD存储)。
- 冷数据(>1年商品):HBase列式存储,按时间范围分片。
- 混合检索:
- 结构化查询:品牌、价格等通过ES的Term Query实现。
- 向量检索:商品图片通过Milvus存储向量,支持“以图搜物”。
- 排序策略:
- 实时排序:销量(Redis计数器)+ 库存(ES字段)+ BM25(关键词匹配)。
- 离线排序:每天用Spark计算商品权重(综合点击率、转化率等指标)。
- 容灾设计:
- 跨机房副本:主分片分布在3个机房(北京A、北京B、上海),通过Raft协议保证强一致性。
- 流量切换:当主集群故障时,通过DNS秒级切换至灾备集群。
(三)算法应用题
问题:如何优化PageRank算法在海量数据下的计算效率?
回答:
- 分布式计算:使用MapReduce将网页链接关系分片处理,每个Mapper计算部分网页的权重,Reducer合并结果。
- 增量更新:
- 维护活跃网页集合(如最近一周有变更的网页),仅重新计算这些网页的权重。
- 通过布隆过滤器快速判断网页是否需要更新。
- 近似算法:采用Power Iteration近似计算,减少迭代次数(如从100次→10次迭代,误差控制在5%以内)。
八、典型应用场景与实战案例
(一)电商搜索:从关键词到语义的升级
案例:某跨境电商搜索优化
- 挑战:百万级SKU,用户输入中英文混合查询(如“running shoes男”),传统关键词匹配效果差。
- 解决方案:
- 多语言分词:使用Jieba+ICU分词器处理中英文混合文本。
- 向量检索:商品标题通过BERT生成向量,Milvus实现语义模糊查询(如搜索“跑步鞋”匹配“running shoes”)。
- 实时推荐:结合用户浏览历史(Redis存储),在搜索结果中插入相关商品(如“用户曾浏览耐克跑鞋,优先展示耐克商品”)。
- 效果:搜索点击率提升35%,平均查询延迟从800ms降至200ms。
(二)日志分析:秒级定位系统异常
案例:某互联网公司实时日志监控
- 需求:每天处理TB级日志,支持秒级查询“ERROR级别日志+特定IP+近1小时”。
- 技术方案:
- 数据管道:Fluentd采集日志→Kafka缓冲→Logstash解析(提取IP、日志级别、时间戳)→ES存储。
- 索引设计:
- 主分片数:根据每天日志量动态计算(如1TB日志≈10个主分片)。
- 字段类型:IP设为IP类型(支持范围查询),时间戳设为Date类型(支持按小时聚合)。
- 可视化:Grafana实时展示ERROR日志趋势,设置阈值自动触发告警(如ERROR率>1%时通知运维)。
- 效果:故障定位时间从小时级降至分钟级,每日查询响应超时率从15%降至2%。
九、未来趋势:从搜索到智能问答
(一)多模态搜索的崛起
- 技术融合:文本+图像+语音的联合检索(如用户语音提问“推荐红色运动鞋”,系统同时解析语音文本和用户上传的图片)。
- 代表工具:Google Multisearch、微软Bing Visual Search。
(二)生成式AI与搜索引擎的结合
- 实时知识问答:基于大语言模型(LLM)生成回答,如用户搜索“如何配置ES分片”,直接返回步骤说明而非网页列表。
- 挑战:确保生成内容的准确性和时效性,避免“幻觉”问题。
(三)隐私增强技术(PETs)
- 联邦学习:在不泄露用户数据的前提下训练搜索排序模型(如各电商平台联合优化通用商品排序算法)。
- 同态加密:支持加密数据上的关键词检索(如医疗数据搜索场景)。
十、总结:搜索引擎架构的核心要素
搜索引擎实现海量数据瞬间检索的关键在于:
- 倒排索引:通过高效数据结构将查询复杂度降至常数级。
- 分布式架构:分片与副本机制实现水平扩展和高可用。
- 近实时技术:段机制与消息队列确保数据准实时可见。
- 混合检索:关键词匹配与向量语义检索结合,覆盖多模态数据。
- 工程优化:从索引算法到硬件加速的全链路性能调优。
相关文章:
【后端高阶面经:架构篇】51、搜索引擎架构与排序算法:面试关键知识点全解析
一、搜索引擎核心基石:倒排索引技术深度解析 (一)倒排索引的本质与构建流程 倒排索引(Inverted Index)是搜索引擎实现快速检索的核心数据结构,与传统数据库的正向索引(文档→关键词࿰…...

Windows应用-音视频捕获
下载“Windows应用-音视频捕获”项目 本应用可以同时捕获4个视频源和4个音频源,可以监视视频源图像,监听音频源;可以将视频源图像写入MP4文件,将音频源写入MP3或WAV文件;还可以录制系统播放的声音。本应用使用MFC对话框…...
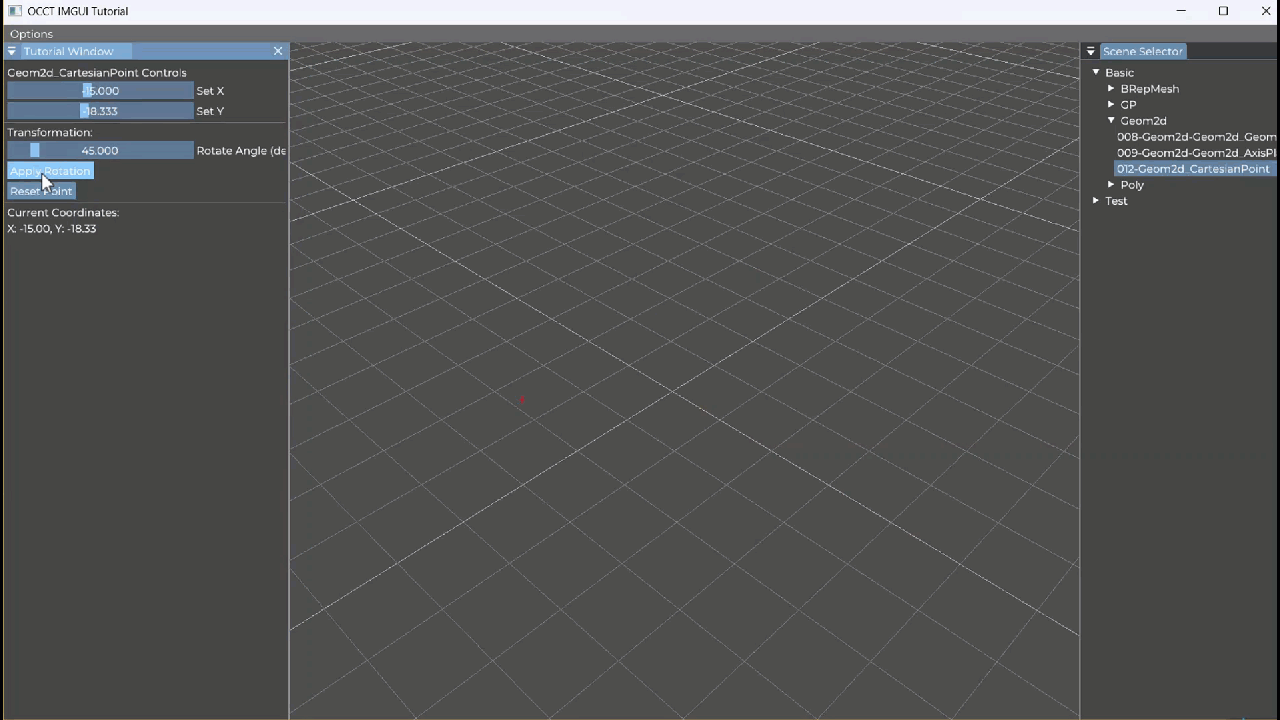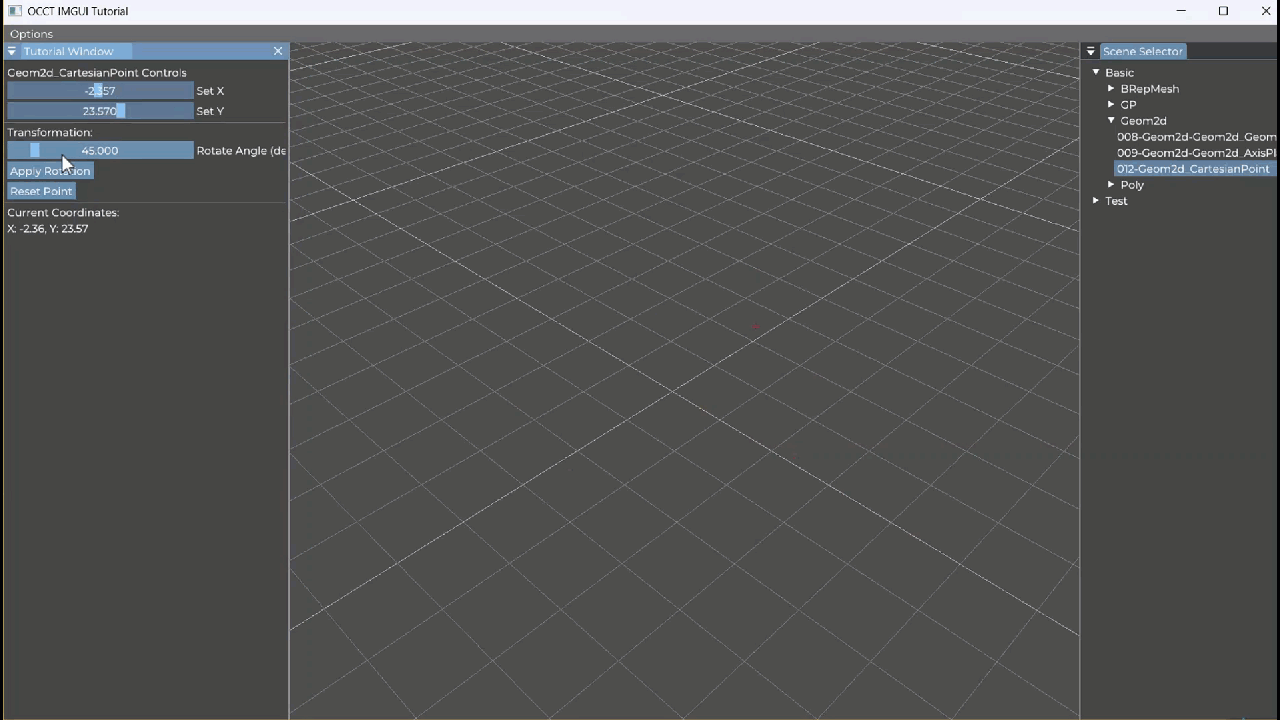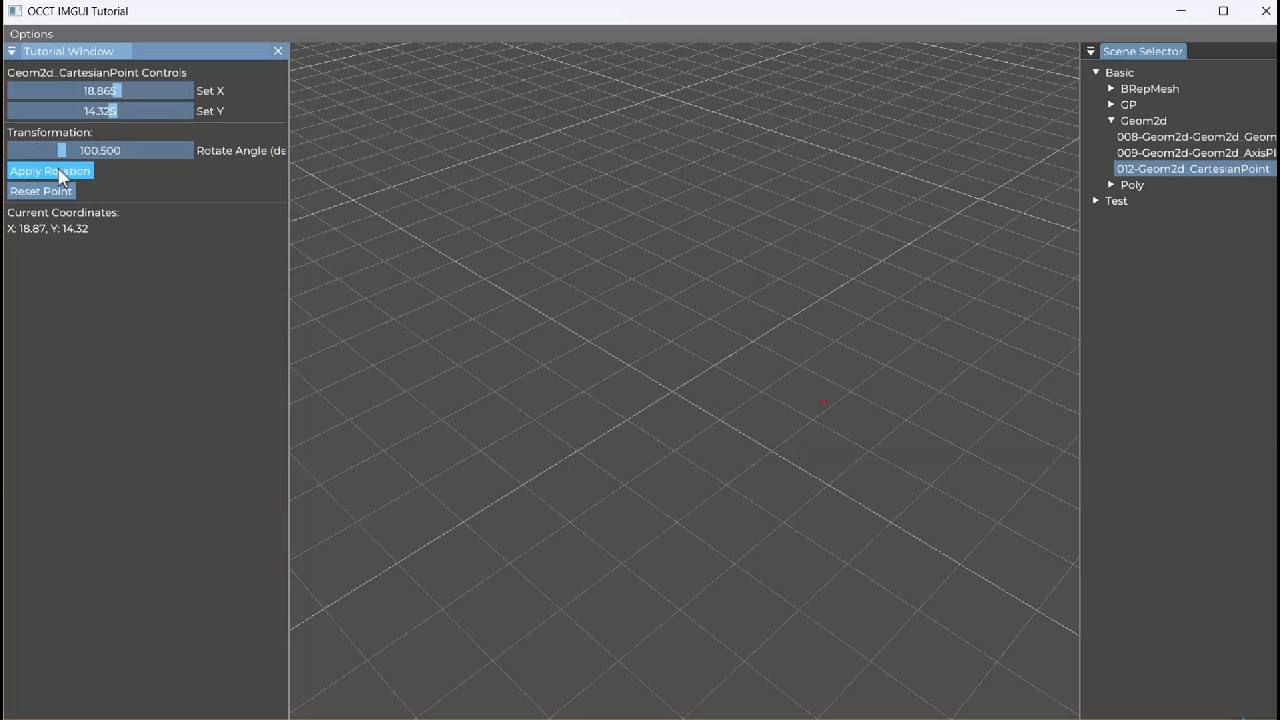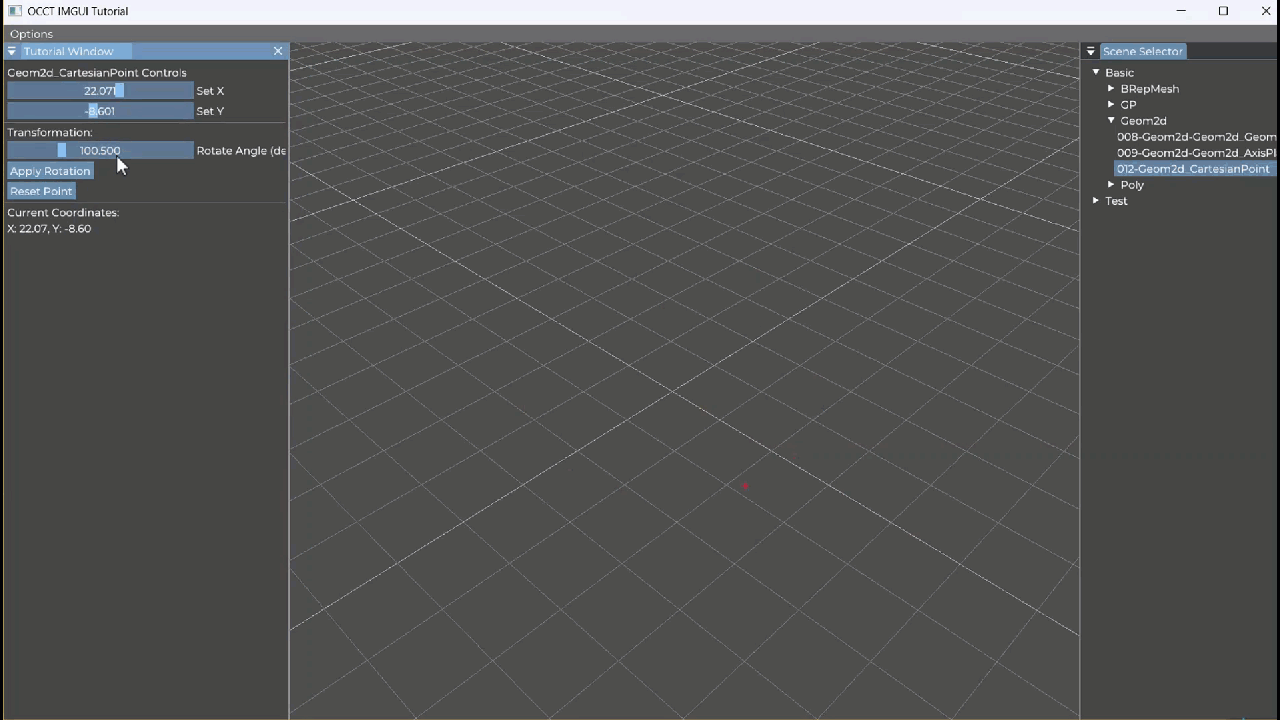
【OCCT+ImGUI系列】012-Geom2d_AxisPlacement
Geom2d_AxisPlacement 教学笔记 一、类概述 Geom2d_AxisPlacement 表示二维几何空间中的一个坐标轴(轴系),由两部分组成: gp_Pnt2d:原点(Location)gp_Dir2d:单位方向向量ÿ…...

优化WP外贸建站提升用户体验
WordPress作为一个强大的建站工具,通过合理的优化,可以提升用户体验,吸引更多潜在客户。本文将为您介绍一些优化WordPress外贸建站的实用建议。 1. 响应式设计 随着移动设备的普及,确保您的WordPress网站具有响应式设计变得至关…...
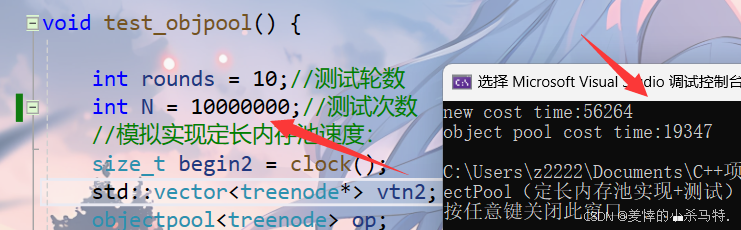
【C++高并发内存池篇】性能卷王养成记:C++ 定长内存池,让内存分配快到飞起!
📝本篇摘要 在本篇将介绍C定长内存池的概念及实现问题,引入内存池技术,通过实现一个简单的定长内存池部分,体会奥妙所在,进而为之后实现整体的内存池做铺垫! 🏠欢迎拜访🏠ÿ…...
mac下通过anaconda安装Python
本次分享mac下通过anaconda安装Python、Jupyter Notebook、R。 anaconda安装 点击👉https://www.anaconda.com/download, 点击Mac系统安装包, 选择Mac芯片:苹果芯片 or intel芯片, 选择苹果芯片图形界面安装&#x…...

第3篇:数据库路由模块设计与 SQL 路由策略解析
3.1 什么是数据库路由? 在分库分表或多数据库实例架构中,**数据库路由模块(SQL Router)**的作用是: 将客户端发来的 SQL 请求路由到正确的后端数据库实例或分片表中执行。 它是数据库中间件的核心组件之一。 3.2 数据…...

ARINC818编解码设计FPGA实现
一、设计内容 1.基于xilinx平台进行系列产品设计 2.基于GT高速进行进行设计 3.提供良好的技术支持和售后服务 4.比较详细的代码注释 二、模块设计内容 1.模块顶层设计 2.编码模块部分设计 内容包括: 帧信息产生/ojbect0帧格式产生和发送/object2_object3帧格式产生…...
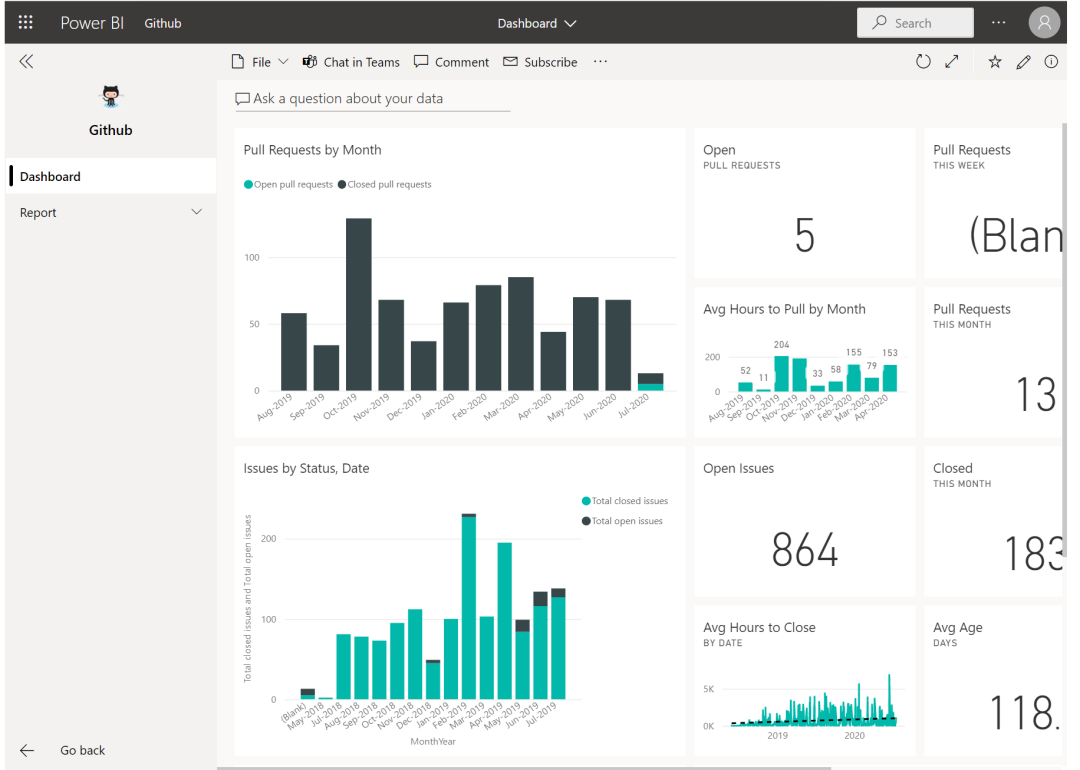
微软PowerBI考试 PL300-Power BI 入门
Power BI 入门 上篇更新了微软PowerBI考试 PL-300学习指南,今天分享PowerBI入门学习内容。 简介 Microsoft Power BI 是一个完整的报表解决方案,通过开发工具和联机平台提供数据准备、数据可视化、分发和管理。 Power BI 可以从使用单个数据源的简单…...
逻辑回归知识点
一、逻辑回归概念 逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。 注意: 尽管名称中有"回归"二字,但它实际上是一种分类算法。 解决二分类的问题。 API:sklearn.linear_model.Logis…...

YARN架构解析:大数据资源管理核心
一、YARN的设计目标 解耦资源管理与作业调度:将资源管理(Resource Management)和任务执行(Task Execution)分离,提升集群资源利用率。支持多种计算框架:不再局限于MapRedu…...

嵌入式学习笔记 - freeRTOS在程序开始在任务内创建任务的好处是什么
在FreeRTOS中,程序启动后优先在初始任务(而非main()函数)内创建其他任务是一种常见且推荐的设计模式,其主要优势包括以下几点: 以下来自deepseek的回答,很全面很正确: 🔧 1. 避免…...
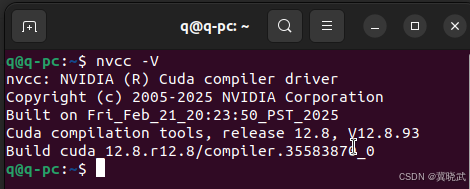
Ubuntu22.04 安装 CUDA12.8
1.下载CUDA 由于我装完 Ubuntu22.04 后就自动带了最新的显卡驱动,就没有再去配置驱动。 先查看驱动能支持的CUDA最高版本,这里显示可支持到12.8。 nvidia-smi在CUDA的 说明文档 可查看CUDA对应的驱动版本要求。 在 CUDA Toolkit Archive 查找需要的 …...
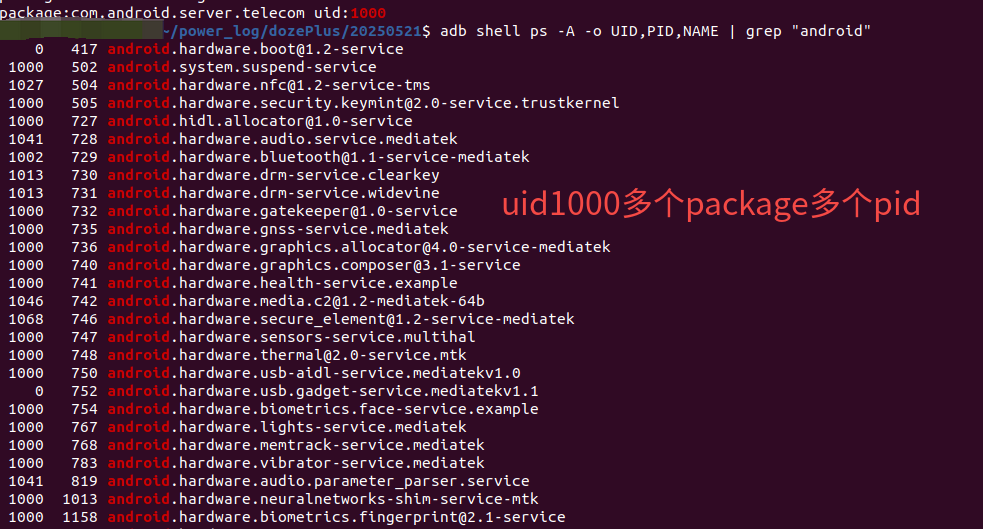
Android的uid~package~pid的关系
UID : Linux 系统级用户标识,Android 中每个应用安装时分配唯一 UID(如 1000)。 Package: Android 应用包名(例如android),一个 UID 可关联多个 Package(共享 UID 场景如android:sharedUserI…...

线段树刷题记录
一篇讲解很好的线段树博客:数据结构--线段树篇_数据结构线段树-CSDN博客 一、区间查询 无修改: (一)最值问题: 1.P1816 忠诚 - 洛谷 思路: 模板。 注意: 无。 代码: #include …...

20250530-C#知识:万物之父Object
C#知识:万物之父Object Object类(即object)是所有类的基类,这里面的方法还是需要好好了解一下。 1、Object类 是顶级父类,其他类默认都是Object类的子类(自定义类也会默认继承Object类)可以用O…...
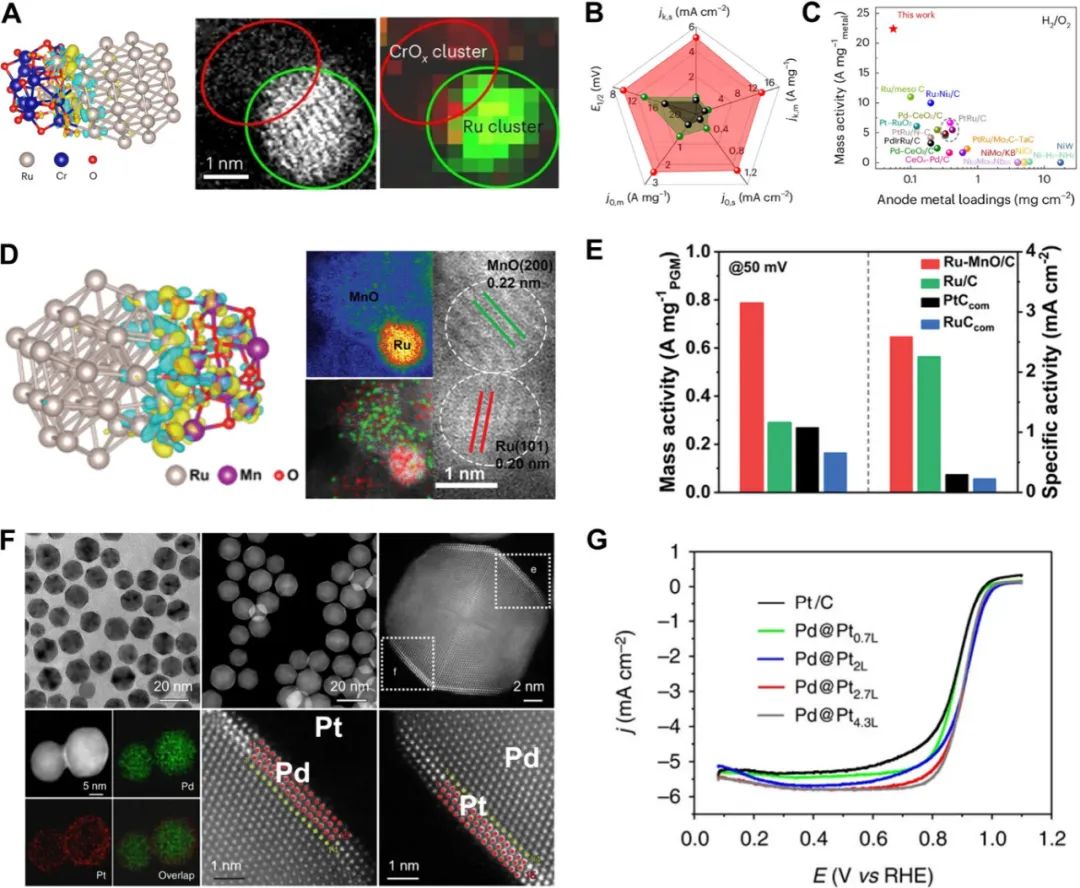
多元素纳米颗粒:开启能源催化新纪元
在能源转型的浪潮中,纳米催化剂正成为推动能源技术突破的关键力量。多元素纳米颗粒(Polyelemental Nanoparticles)凭借其独特的元素协同效应,展现出在能源催化领域的巨大潜力。然而,合成这些复杂体系的纳米颗粒面临着诸…...

分布式锁优化:使用Lua脚本保证释放锁的原子性问题
分布式锁优化(二):使用Lua脚本保证释放锁的原子性问题 💻黑马视频链接:Lua脚本解决多条命令原子性问题 在上一章节视频实现了一个可用的Redis分布式锁,采用SET NX EX命令实现互斥和过期自动释放机制&…...
电脑wifi显示已禁用怎么点都无法启用
一、重启路由器与电脑 有时候,简单的重启可以解决很多小故障。试着先断开电源让路由器休息一会儿再接通;对于电脑,则可选择重启系统看看情况是否有改善。 二、检查驱动程序 无线网卡驱动程序的问题也是导致WiFi无法启用的常见原因之一。我…...
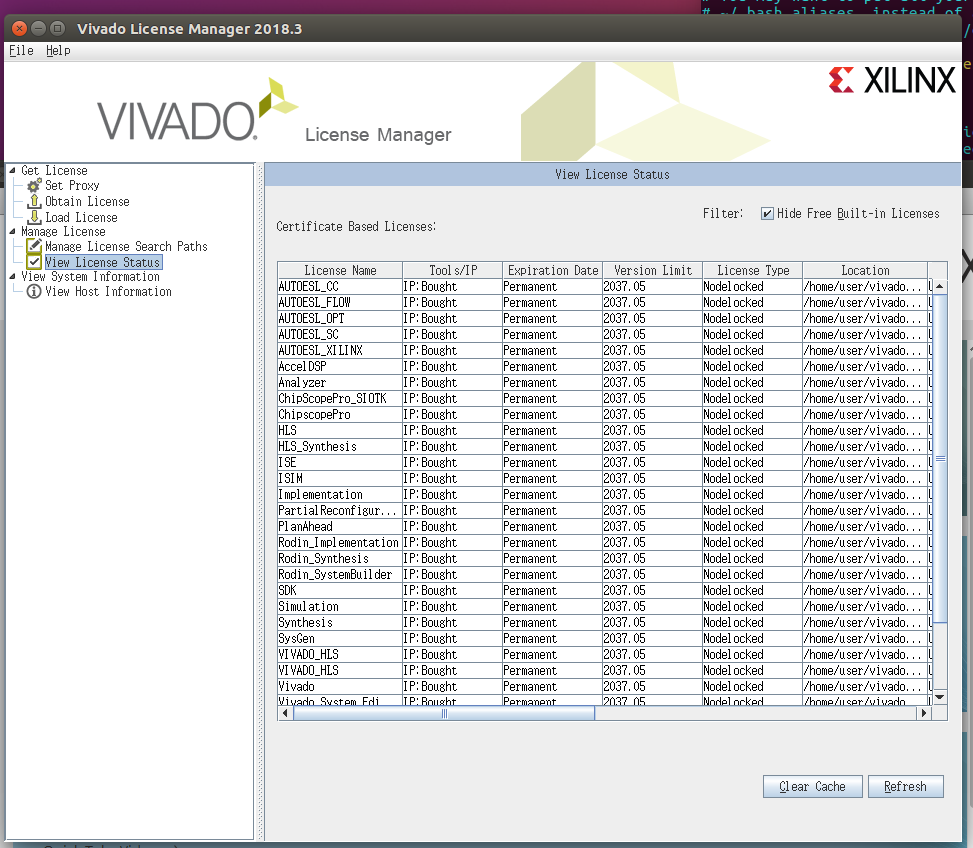
【FPGA开发】Ubuntu16.04环境下配置Vivado2018.3—附软件包
文章目录 环境介绍关键步骤记录安装虚拟机及镜像安装vivadolicense导入 环境介绍 vivado:2018.3 虚拟机:vmware 16 pro 镜像:Ubuntu16.04 64位 所有相关软件压缩包: 链接:https://pan.quark.cn/s/fd2730b46b20 提取码…...
vue-seamless-scroll 结束从头开始,加延时后滚动
今天遇到一个大屏需求: 1️⃣初始进入页面停留5秒,然后开始滚动 2️⃣最后一条数据出现在最后一行时候暂停5秒,然后返回1️⃣ 依次循环,发现vue-seamless-scroll的方法 ScrollEnd是监测最后一条数据消失在第一行才回调ÿ…...
和 MySQL/SQL)
不同的数据库操作方式:MongoDB(NoSQL)和 MySQL/SQL
这两种写法分别使用了不同的数据库操作方式:第一种是 MongoDB(NoSQL) 的写法,第二种是 MySQL/SQL 的写法。我们来对比它们的区别,并给出优化建议。 1. MongoDB(NoSQL)写法 const user await d…...

0-EATSA-GNN:基于图节点分类师生机制的边缘感知和两阶段注意力增强图神经网络(code)
code:https://github.com/afofanah/EATSA-GNN. 文章目录 Abstract1. Introduction1.1.动态图场景1.2.EATSA-GNN框架的背景化2. Background2.1.GNN边缘感知挑战2.2.GNN的可解释性问题2.3.EATSA-GNN可解释性3. Related worksAbstract 图神经网络(GNNs)从根本上改变了我们处理和…...
-spark数据倾斜)
大数据学习(124)-spark数据倾斜
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...
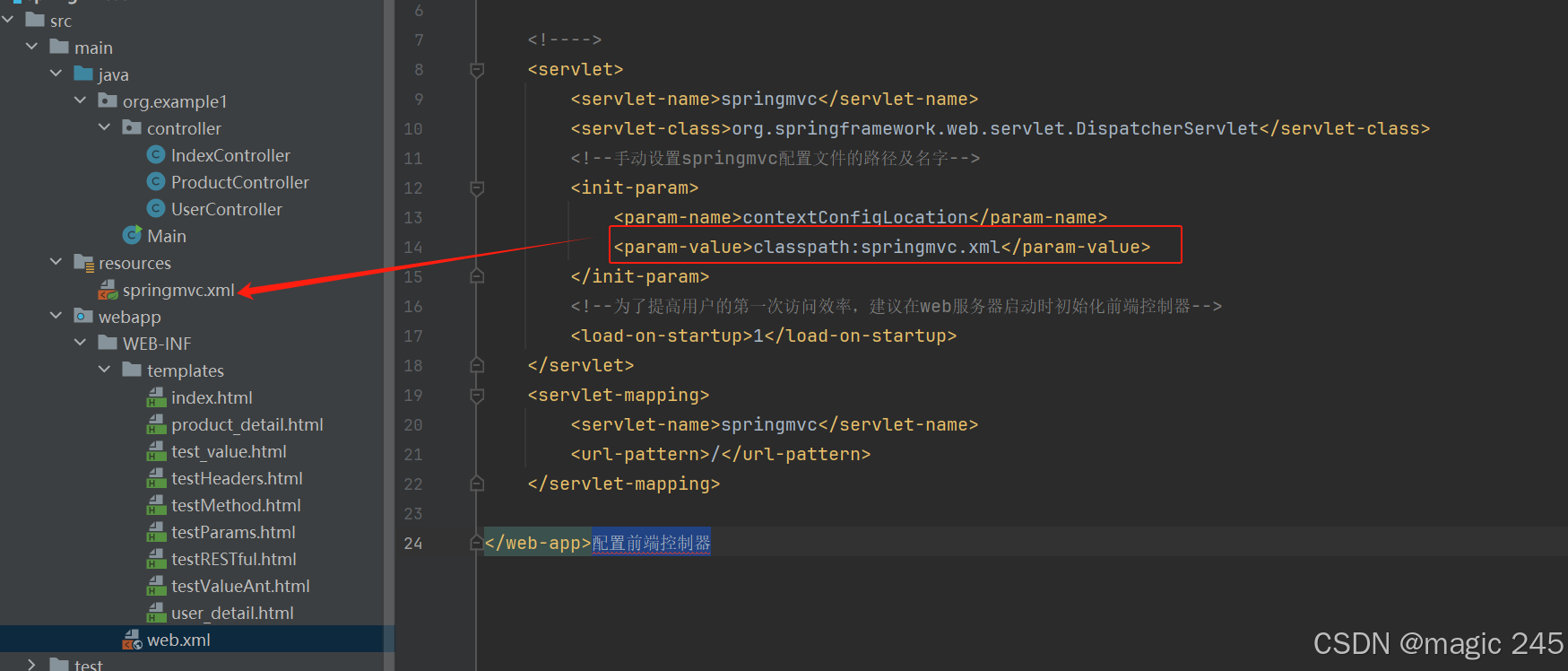
配置前端控制器
一、DispatcherServlet 详解 在使用 Spring MVC 框架构建 Web 应用时,DispatcherServlet是整个请求处理流程的核心。本文将深入解析DispatcherServlet的作用、工作原理及其在 Spring MVC 架构中的关键地位。 1.DispatcherServlet 是什么? DispatcherS…...

lua注意事项
感觉是lua的一大坑啊,它还不如函数内部就局部变量呢 注意函数等内部,全部给加上local得了...
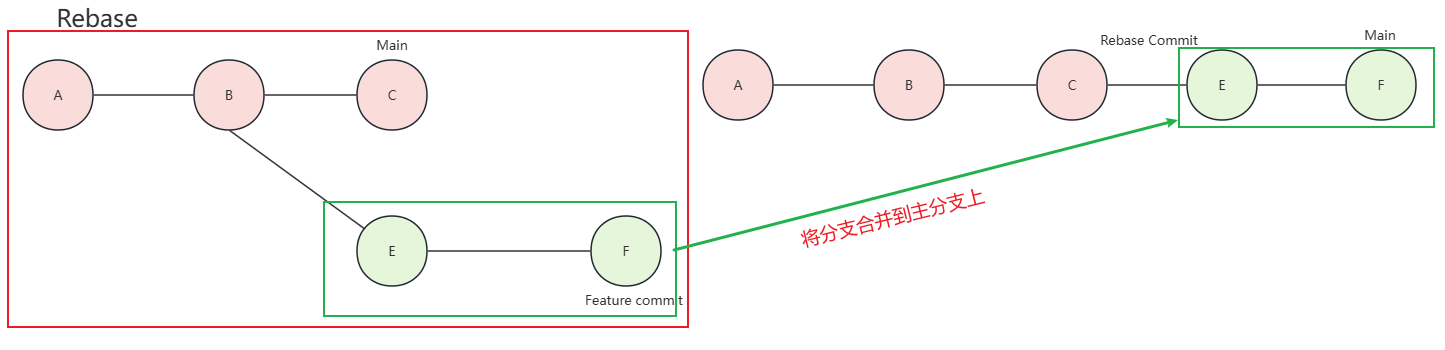
Git的三种合并方式
在 Gitee(码云)中合并分支主要有三种方式:普通合并(Merge Commit)、压缩合并(Squash Merge)和变基合并(Rebase Merge)。每种方式适用于不同的场景,各有…...

从零到一:我的技术博客导航(持续更新)
作者:冰茶 最后更新:2025年6月3日 本文收录了我的C#编程学习心得与技术探索,将持续更新 前言 作为一名.NET开发者,C#语言的学习与探索一直是我技术成长的核心路径。本文集整理了我在C#学习过程中的思考与实践,希望能够…...

SpringBoot整合Flowable【08】- 前后端如何交互
引子 在第02篇中,我通过 Flowable-UI 绘制了一个简单的绩效流程,并在后续章节中基于这个流程演示了 Flowable 的各种API调用。然而,在实际业务场景中,如果要求前端将用户绘制的流程文件发送给后端再进行解析处理,这种…...

DM达梦数据库开启SQL日志记录功能
DM达梦数据库开启SQL日志记录功能 配置SQL日志(非必须的配置步骤,与主备集群配置无关,如果没有需求可以跳过配置SQL日志) sqllog.ini 配置文件用于SQL日志的配置,当且仅当 INI(dm.ini) 参数 SV…...