cacti导出的1分钟监控数据csv文件读取并按5分钟求平均值,然后计算95计费值,假设31天的月份
cacti导出的1分钟监控数据csv文件读取并按5分钟求平均值,然后计算95计费值,假设31天的月份
import pandas as pd
import openpyxl
from openpyxl.styles import Font
from openpyxl.utils.dataframe import dataframe_to_rows
import os
import chardet
import numpy as np# 文件路径
file_path = r'E:\data\feishu\BGP-CT-SN-同道新龙-9K-IN-AG.csv'
output_dir = r'E:\data\feishu'
output_file = os.path.join(output_dir, "处理结果.xlsx")# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)print(f"开始处理文件: {file_path}")# 第一步:检测文件编码
def detect_encoding(file_path):print("检测文件编码...")with open(file_path, 'rb') as f:rawdata = f.read(10000)result = chardet.detect(rawdata)encoding = result['encoding']confidence = result['confidence']print(f"检测到编码: {encoding} (置信度: {confidence:.2%})")return encoding# 第二步:读取文件并正确分割列
try:# 检测文件编码file_encoding = detect_encoding(file_path)# 如果置信度低,尝试常见中文编码if file_encoding is None or file_encoding.lower() == 'ascii':print("编码检测置信度低,尝试常见中文编码")for encoding in ['gb18030', 'gbk', 'big5', 'utf-8']:try:# 读取前5行检查实际分隔符with open(file_path, 'r', encoding=encoding) as f:sample_lines = [f.readline().strip() for _ in range(5)]# 分析最可能的分隔符possible_seps = [',', '\t', ';', '|']sep_counts = {sep: line.count(sep) for sep in possible_seps for line in sample_lines}most_common_sep = max(sep_counts, key=sep_counts.get)print(f"检测到最可能的分隔符: '{most_common_sep}'")# 使用检测到的分隔符读取文件df = pd.read_csv(file_path, sep=most_common_sep, encoding=encoding, header=None)print(f"成功使用 {encoding} 编码和分隔符 '{most_common_sep}' 读取文件")# 手动设置列名(根据列数)if df.shape[1] == 3:df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")else:raise Exception(f"列数异常: {df.shape[1]}列,应为3列")breakexcept Exception as e:print(f"尝试 {encoding} 编码失败: {e}")continueelse:raise Exception("无法使用常见中文编码读取文件")else:# 读取前5行检查实际分隔符with open(file_path, 'r', encoding=file_encoding) as f:sample_lines = [f.readline().strip() for _ in range(5)]# 分析最可能的分隔符possible_seps = [',', '\t', ';', '|']sep_counts = {sep: line.count(sep) for sep in possible_seps for line in sample_lines}most_common_sep = max(sep_counts, key=sep_counts.get)print(f"检测到最可能的分隔符: '{most_common_sep}'")# 使用检测到的分隔符读取文件df = pd.read_csv(file_path, sep=most_common_sep, encoding=file_encoding, header=None)print(f"使用检测到的编码 {file_encoding} 和分隔符 '{most_common_sep}' 成功读取文件")# 手动设置列名(根据列数)if df.shape[1] == 3:df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")else:raise Exception(f"列数异常: {df.shape[1]}列,应为3列")
except Exception as e:print(f"文件读取失败: {e}")print("尝试使用错误恢复模式读取...")try:# 尝试使用错误恢复模式df = pd.read_csv(file_path, sep=None, engine='python', encoding='gb18030',on_bad_lines='skip', header=None)print("使用错误恢复模式成功读取文件(可能丢失部分数据)")# 手动设置列名(根据列数)if df.shape[1] == 3:df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")else:raise Exception(f"列数异常: {df.shape[1]}列,应为3列")except:raise Exception("无法读取文件,请手动检查文件格式和编码")print(f"成功读取数据,行数: {len(df)}")
print("df.columns:", df.columns)# 检查必要列是否存在
required_columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']
print("检查必要列...")
for col in df.columns:print(f'列名: {col} (类型: {type(col)})')if not all(col in df.columns for col in required_columns):missing = [col for col in required_columns if col not in df.columns]raise Exception(f"文件缺少必要列: {missing}")
else:print("所有必要列都存在")# 转换数值列为浮点数
print("转换数值列为浮点数...")
for col in ['Total IN-MAX', 'Total OUT-MAX']:# 先尝试直接转换df[col] = pd.to_numeric(df[col], errors='coerce')# 检查转换失败的行failed_conversions = df[col].isna().sum()if failed_conversions > 0:print(f"警告: {col} 列有 {failed_conversions} 个值无法直接转换")# 尝试更复杂的转换(处理科学计数法)def try_convert(val):try:return float(val)except:# 尝试处理可能连接在一起的多个数值if isinstance(val, str) and 'e+' in val:parts = []current = ""for char in val:if char in '0123456789.e+-':current += charelif current:try:parts.append(float(current))current = ""except:current = ""if current:try:parts.append(float(current))except:passif parts:return np.mean(parts)return np.nan# 应用复杂转换df[col] = df[col].apply(try_convert)# 再次检查失败转换still_failed = df[col].isna().sum()if still_failed > 0:print(f"仍有 {still_failed} 个值无法转换,将被设为NaN")# 重命名列以便后续处理
df = df.rename(columns={'Date': '日期','Total IN-MAX': 'Total_in','Total OUT-MAX': 'Total_out'
})# 转换日期列
print("处理日期列...")
try:# 尝试多种日期格式df['日期'] = pd.to_datetime(df['日期'], format='%Y/%m/%d %H:%M', errors='coerce')if df['日期'].isna().any():print("尝试替代日期格式...")df['日期'] = pd.to_datetime(df['日期'], format='%Y-%m-%d %H:%M:%S', errors='coerce')# 检查是否有无效日期invalid_dates = df['日期'].isna().sum()if invalid_dates > 0:print(f"警告: 发现 {invalid_dates} 个无效日期")# 删除无效日期的行df = df.dropna(subset=['日期'])print(f"删除无效日期行后剩余: {len(df)} 行")
except Exception as e:print(f"日期转换错误: {e}")raise# 设置日期为索引并排序
df.set_index('日期', inplace=True)
df.sort_index(inplace=True) # 确保时间顺序正确
print(f"处理后数据点数: {len(df)}")# 每5分钟重采样求平均值 - 使用新的频率表示法
print("进行5分钟重采样...")
resampled = df.resample('5min').mean()
resampled.columns = ['Total_in_avg', 'Total_out_avg']# 计算每个5分钟区间的最大值
resampled['max_value'] = resampled[['Total_in_avg', 'Total_out_avg']].max(axis=1)# 对所有5分钟区间的最大值进行降序排序
sorted_max = resampled['max_value'].sort_values(ascending=False).reset_index()
sorted_max.columns = ['时间区间', '降序最大值']# 创建Excel工作簿
print("创建Excel工作簿...")
wb = openpyxl.Workbook()# 工作表1: 原始数据
ws1 = wb.active
ws1.title = "原始数据"
for r in dataframe_to_rows(df.reset_index(), index=False, header=True):ws1.append(r)# 工作表2: 5分钟平均值和最大值
ws2 = wb.create_sheet("5分钟平均值")
# 准备数据
avg_data = resampled.reset_index()
avg_data.columns = ['时间区间', 'Total_in_avg', 'Total_out_avg', 'max_value']
for r in dataframe_to_rows(avg_data, index=False, header=True):ws2.append(r)# 工作表3: 降序最大值序列
ws3 = wb.create_sheet("降序最大值")
for r in dataframe_to_rows(sorted_max, index=False, header=True):ws3.append(r)# 标记第447个值为红色(如果存在)
if len(sorted_max) >= 447:# 第447行(表头占第1行,数据从第2行开始)target_row = 447 + 1ws3.cell(row=target_row, column=2).font = Font(color="FF0000", bold=True)# 添加注释说明ws3.cell(row=1, column=3, value="说明")ws3.cell(row=2, column=3, value=f"第447个最大值已用红色标记 (值={sorted_max.iloc[446]['降序最大值']:.2e})")ws3.cell(row=target_row, column=3, value="← 第447个最大值")print(f"已标记第447个值: {sorted_max.iloc[446]['降序最大值']:.2e}")
else:print(f"警告: 数据不足447个点 (只有{len(sorted_max)}个点)")# 自动调整列宽
print("调整列宽...")
for sheet in wb.sheetnames:ws = wb[sheet]for col_idx, column in enumerate(ws.columns, 1):max_length = 0for cell in column:try:value = str(cell.value) if cell.value is not None else ""if len(value) > max_length:max_length = len(value)except:passadjusted_width = min(max_length + 2, 50) # 限制最大宽度为50ws.column_dimensions[openpyxl.utils.get_column_letter(col_idx)].width = adjusted_width# 保存Excel文件
print(f"保存Excel文件到: {output_file}")
wb.save(output_file)
print("处理完成!")
print("\n=== 处理结果统计 ===")
print(f"原始数据点数: {len(df)}")
print(f"5分钟区间数: {len(resampled)}")
print(f"最大值序列长度: {len(sorted_max)}")
if len(sorted_max) >= 447:print(f"第447个最大值: {sorted_max.iloc[446]['降序最大值']:.2e}")
相关文章:

cacti导出的1分钟监控数据csv文件读取并按5分钟求平均值,然后计算95计费值,假设31天的月份
cacti导出的1分钟监控数据csv文件读取并按5分钟求平均值,然后计算95计费值,假设31天的月份 import pandas as pd import openpyxl from openpyxl.styles import Font from openpyxl.utils.dataframe import dataframe_to_rows import os import chardet…...
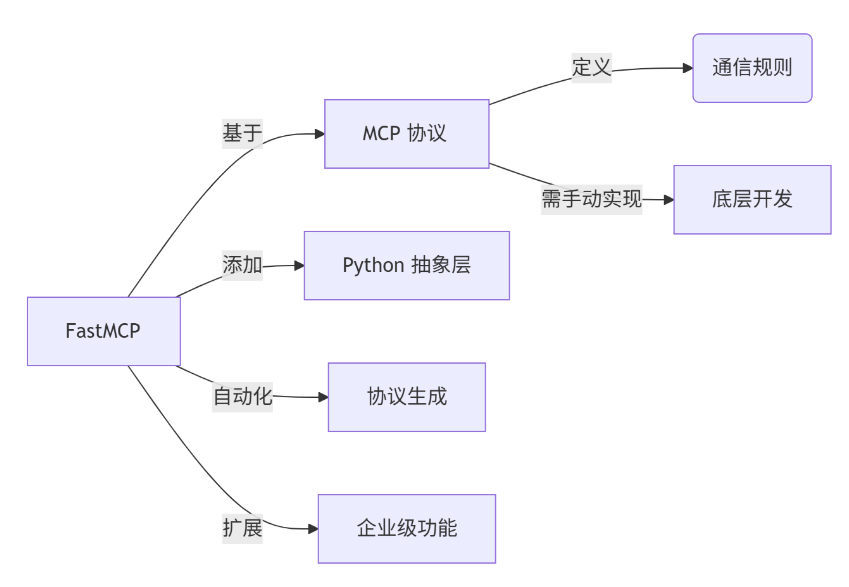
FastMCP vs MCP:协议标准与实现框架的协同
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...
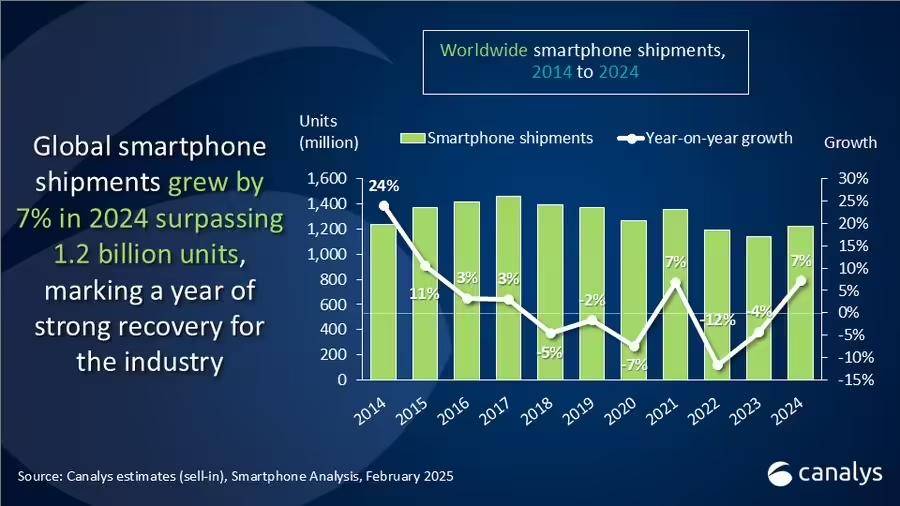
AI视频“入驻”手机,多模态成智能终端的新战场
文|乐乐 今天,无线蓝牙耳机(TWS)已经成为人人都用得起的产品。 但退回到9年前,苹果AirPods是全球第一款真正意义上的无线蓝牙耳机。靠着自研并申请专利的Snoop监听技术,苹果解决了蓝牙耳机左右延时和能耗…...

nginx+tomcat负载均衡群集
一 案例部署Tomcat 目录 一 案例部署Tomcat 1.案例概述 1.1案例前置知识点 (1)Tomcat简介 (2)应用场景 2.实施准备 (1)关闭Linux防火墙 (2)安装Java 2.1 安装配置TOMACT …...

DEEPSEEK帮写的STM32消息流函数,直接可用.已经测试
#include "main.h" #include "MessageBuffer.h"static RingBuffer msgQueue {0};// 初始化队列 void InitQueue(void) {msgQueue.head 0;msgQueue.tail 0;msgQueue.count 0; }// 检查队列状态 type_usart_queue_status GetQueueStatus(void) {if (msgQ…...

day45 python预训练模型
目录 知识点回顾 1. 预训练的概念 2. 常见的分类预训练模型 3. 图像预训练模型的发展史 4. 预训练的策略 5. 预训练代码实战:ResNet18 作业:在 CIFAR-10 上对比 AlexNet 预训练模型 实验结果对比 在深度学习领域,预训练模型已经成为了…...

二维 根据矩阵变换计算缩放比例
在二维空间中,根据矩阵变换计算缩放比例是一个常见的图形学问题。通常,我们通过分析变换矩阵的结构来提取出缩放(Scale)信息。以下是详细的分析和计算方法。 🧮 一、基础:二维变换矩阵结构 在二维仿射变换…...

Vue-Cropper:全面掌握图片裁剪组件
Vue-Cropper 完全学习指南:Vue图片裁剪组件 🎯 什么是 Vue-Cropper? Vue-Cropper 是一个简单易用的Vue图片裁剪组件,支持Vue2和Vue3。它提供了丰富的配置选项和回调方法,可以满足各种图片裁剪需求。 🌟 …...

建造者模式:优雅构建复杂对象
引言 在软件开发中,有时我们需要创建一个由多个部分组成的复杂对象,这些部分可能有不同的变体或配置。如果直接在一个构造函数中设置所有参数,代码会变得难以阅读和维护。当对象构建过程复杂,且需要多个步骤时,我们可…...

现场总线结构在楼宇自控系统中的技术要求与实施要点分析
在建筑智能化程度不断提升的当下,楼宇自控系统承担着协调建筑内各类设备高效运行的重任。传统的集中式控制系统在面对复杂建筑环境时,逐渐暴露出布线繁琐、扩展性差、可靠性低等问题。而现场总线结构凭借其分散控制、通信高效等特性,成为楼宇…...
)
Axure组件即拖即用:垂直折叠菜单(动态展开/收回交互)
亲爱的小伙伴,在您浏览之前,请关注一下,在此深表感谢!如有帮助请订阅专栏!免费哦! 你是不是也这样崩溃过? 明明设置了点击交互,菜单却像死机一样纹丝不动,F5按烂了都没反…...
学习路之PHP--easyswoole使用视图和模板
学习路之PHP--easyswoole使用视图和模板 一、安装依赖插件二、 实现渲染引擎三、注册渲染引擎四、测试调用写的模板五、优化六、最后补充 一、安装依赖插件 composer require easyswoole/template:1.1.* composer require topthink/think-template相关版本: "…...

《云原生安全攻防》-- K8s网络策略:通过NetworkPolicy实现微隔离
默认情况下,K8s集群的网络是没有任何限制的,所有的Pod之间都可以相互访问。这就意味着,一旦攻击者入侵了某个Pod,就能够访问到集群中任意Pod,存在比较大的安全风险。 在本节课程中,我们将详细介绍如何通过N…...
06 APP 自动化- H5 元素定位
文章目录 H5 元素定位1、APP 分类2、H5 元素3、H5 元素定位环境的搭建4、代码实现: H5 元素定位 1、APP 分类 1、Android 原生 APP2、混合 APP(Android 原生控件H5页面)3、纯 H5 App 2、H5 元素 H5 元素容器 WebViewWebView 控件实现展示网页 3、H5 元素定位环…...
)
Axure疑难杂症:中继器新增数据时如何上传并存储图片(玩转中继器)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 案例视频: 中继器新增数据时如何上传并存储图片 课程主题:中继器新增数据时如何上传并存储图片 主…...

定时线程池失效问题引发的思考
最近在做的一个新功能,在结果探测的时候使用了定时线程池和普通线程池结合,定时线程池周期性创建子任务并往普通线程池提交任务。 问题: 在昨天测试老师发现,业务实际上已经成功了,但是页面还是一直显示进行中。 收到…...

Vue-ref 与 props
一、前言 在 Vue 的组件化开发中,父子组件之间的数据传递 是一个非常核心的需求。常见的场景包括: 父组件向子组件传递数据;子组件向父组件发送事件或数据;父组件直接调用子组件的方法或访问其属性。 Vue 提供了多种机制来实现…...
AXURE安装+汉化-Windows
安装网站:https://www.axure.com/release-history/rp9 Axure中文汉化包下载地址 链接:https://pan.baidu.com/s/1U62Azk8lkRPBqWAcrJMFew?pwd5418 提取码:5418 下载完成之后,crtlc lang文件夹 到下载的Axure路径下 双击点进这个目录里面。ctrlv把lan…...
ArcGIS Pro字段计算器与计算几何不可用,显示灰色
“字段计算器”不可用 如果计算字段命令不可用,请考虑以下可能性: 由 ArcGIS 管理的字段无法手动编辑。因此,无法计算 ObjectID(OID 或 FID)字段或地理数据库要素类的 Shape_Length 和 Shape_Area 字段的字段值。表中…...

mac电脑安装 nvm 报错如何解决
前言 已知:安装nvm成功;终端输入nvm -v 有版本返回 1. 启动全局配置环境变量失败 source ~/.zshrc~ 返回: source: no such file or directory: /Users/你的用户名/.zshrc~2 安装node失败 nvm install 16.13返回: mkdir: /U…...
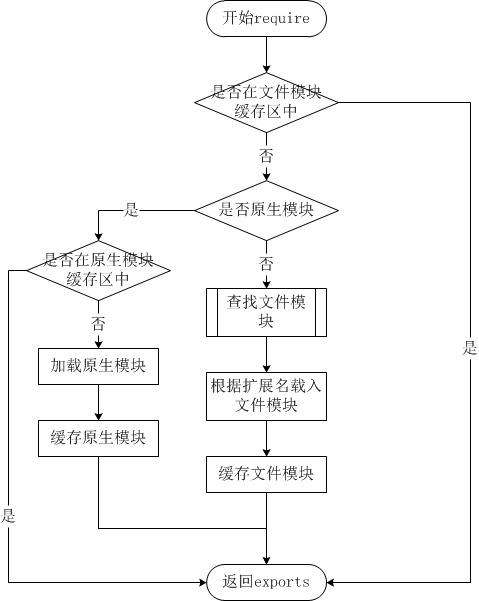
第11节 Node.js 模块系统
为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统。 模块是Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个 Node.js 文件就是一个模块,这个文件可能是JavaScript 代码、JSON 或者编译过的…...

上海工作机会:Technical Writer Senior Technical Writer - 中微半导体设备
大名鼎鼎的中微半导体招聘文档工程师了,就是那家由中国半导体产业的领军人物尹志尧领导的、全员持股的公司。如果你还不了解他,赶快Deepseek一下“尹志尧”了解。 招聘职位:Technical Writer & Senior Technical Writer 公司名称&#…...

String 学习总结
1. 存储机制 短字符串优化(SSO, Small String Optimization) 现代标准库中的字符串实现普遍采用 SSO 技术,将长度较短(例如 ≤15 字节)的字符串数据直接存储在字符串对象内部的固定缓冲区(栈上)…...

Python微积分可视化:从导数到积分的交互式教学工具
Python微积分可视化:从导数到积分的交互式教学工具 一、引言 微积分是理解自然科学的基础,但抽象的导数、积分概念常让初学者感到困惑。本文基于Matplotlib开发一套微积分可视化工具,通过动态图像直观展示导数的几何意义、积分的近似计算及跨学科应用,帮助读者建立"数…...
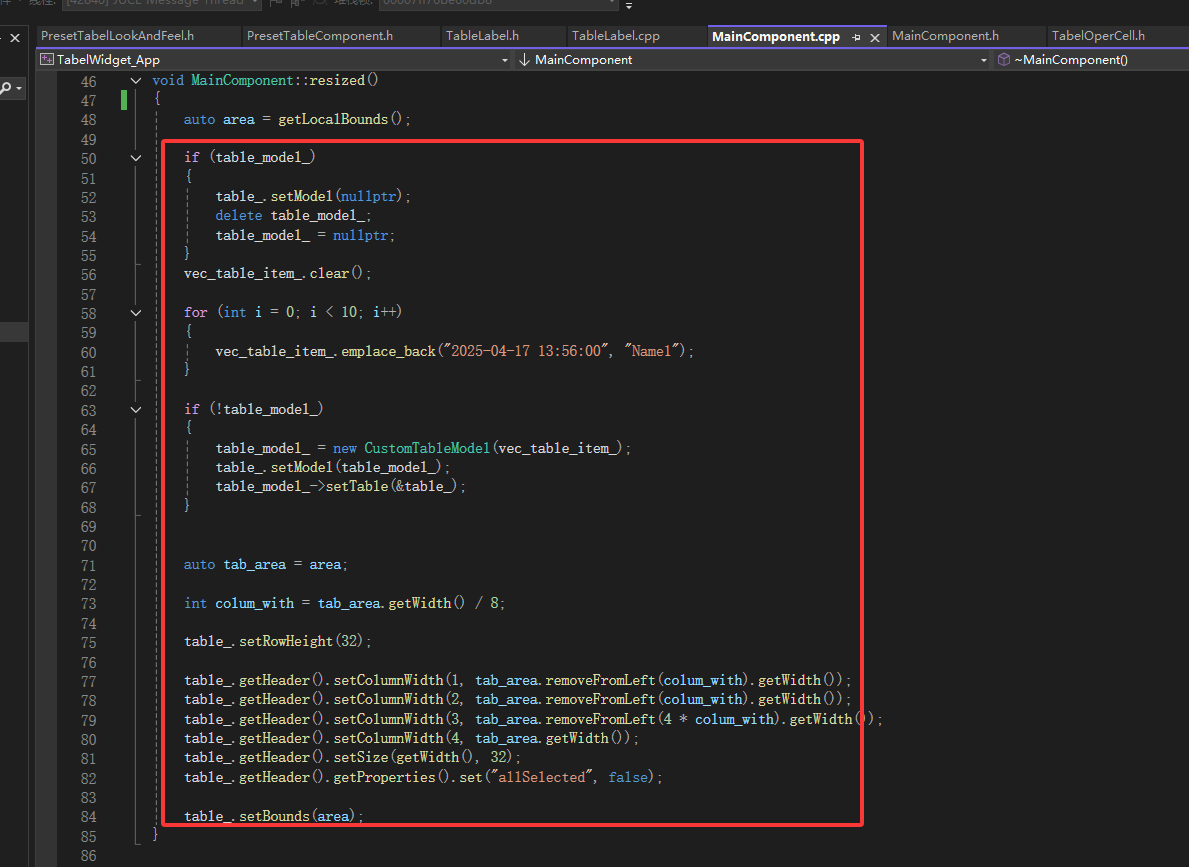
Juce实现Table自定义
Juce实现Table自定义 一.总体展示概及概述 在项目中Juce中TableList往往无法满足用户需求,头部和背景及背景颜色设置以及在Cell中添加自定义按钮,所以需要自己实现自定义TabelList,该示例是展示实现自定义TableList,实现自定义标…...

【25.06】fabric进行caliper测试加环境部署
前置条件 安装一个Ubuntu20+的镜像 基础环境安装 Git cURL vim jq sudo apt install -y git curl vim jq Docker和Docker-compose 这个命令会自动安装docker sudo apt install docker-compose sudo chmod +x /usr/bin/docker-compose docker versiondocker-compose vers…...

【后端高阶面经:架构篇】51、搜索引擎架构与排序算法:面试关键知识点全解析
一、搜索引擎核心基石:倒排索引技术深度解析 (一)倒排索引的本质与构建流程 倒排索引(Inverted Index)是搜索引擎实现快速检索的核心数据结构,与传统数据库的正向索引(文档→关键词࿰…...

Windows应用-音视频捕获
下载“Windows应用-音视频捕获”项目 本应用可以同时捕获4个视频源和4个音频源,可以监视视频源图像,监听音频源;可以将视频源图像写入MP4文件,将音频源写入MP3或WAV文件;还可以录制系统播放的声音。本应用使用MFC对话框…...
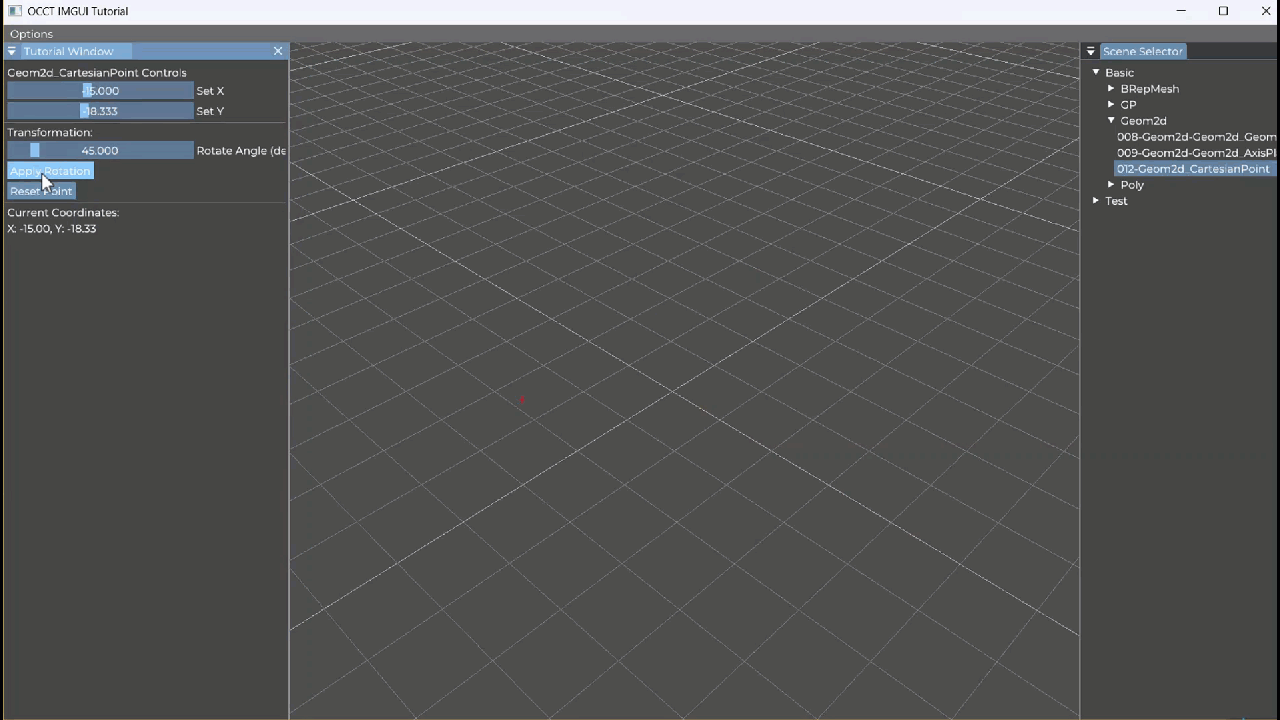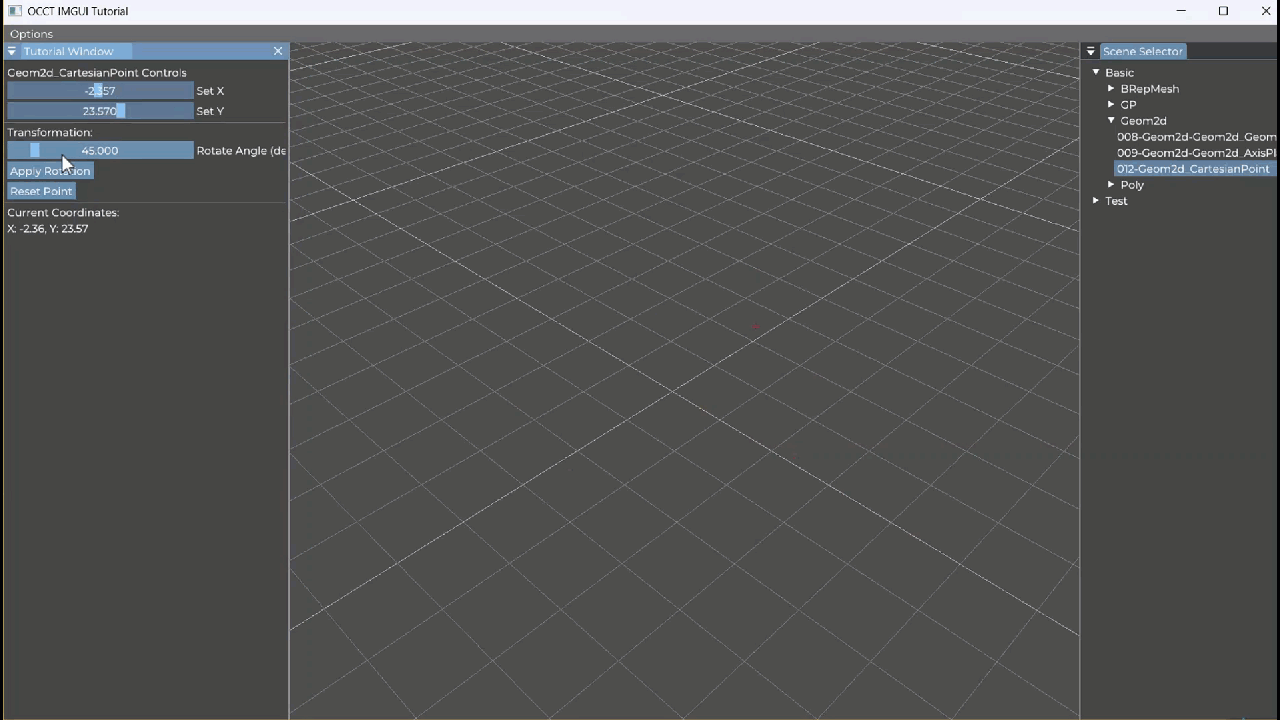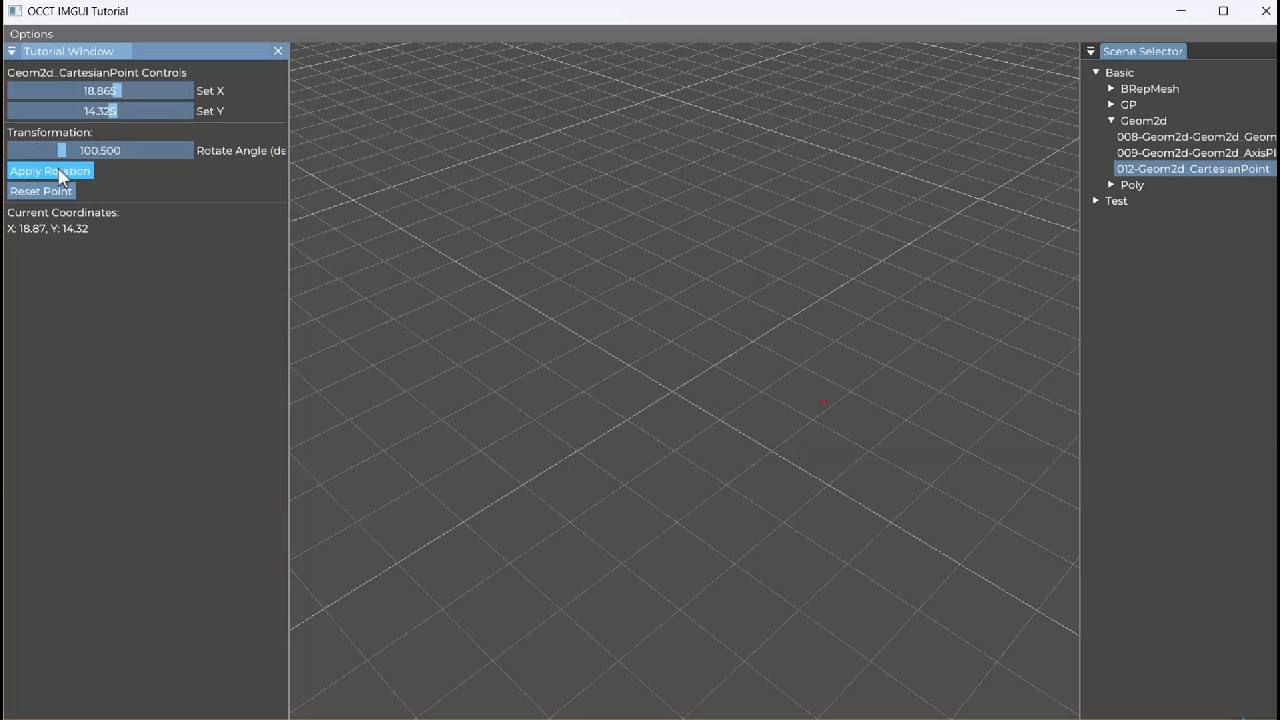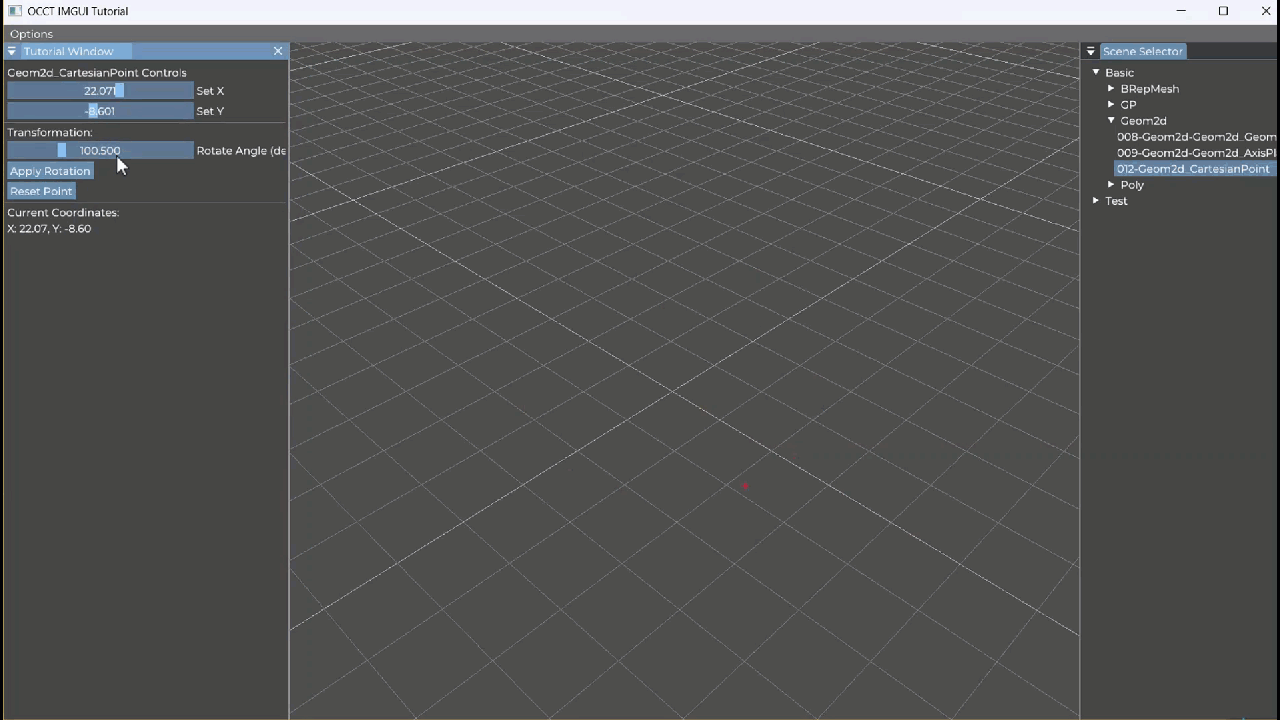
【OCCT+ImGUI系列】012-Geom2d_AxisPlacement
Geom2d_AxisPlacement 教学笔记 一、类概述 Geom2d_AxisPlacement 表示二维几何空间中的一个坐标轴(轴系),由两部分组成: gp_Pnt2d:原点(Location)gp_Dir2d:单位方向向量ÿ…...

优化WP外贸建站提升用户体验
WordPress作为一个强大的建站工具,通过合理的优化,可以提升用户体验,吸引更多潜在客户。本文将为您介绍一些优化WordPress外贸建站的实用建议。 1. 响应式设计 随着移动设备的普及,确保您的WordPress网站具有响应式设计变得至关…...