RagFlow优化代码解析(一)
引子
前文写到RagFlow的环境搭建&推理测试,感兴趣的童鞋可以移步(RagFlow环境搭建&推理测试-CSDN博客)。前文也写过RagFLow参数配置&测试的文档,详见()。很少写关于具体代码的blog,这个不涉密,OK,那我们开始吧。
一、RagFlow检索优化--ES替换为Infitity
在上一篇文章中,我尝试新建了两个知识库,一个知识库中有两个文档,其中一个比较大,另外一个知识库上传的时QA对的excel表格。我在聊天设置中选择了两个知识库,我提出文档,到得到答案差不多要3mins,这个。。。呃,需要排查下。那我们就采用控制变量法来找到问题原因吧,既然时两个知识库,那我们先删除一个QA对知识库。。。好家伙,提出一个问题,依然需要3mins才出答案。那我们继续,剩下的一个知识库中两个文档,那我们先禁用一个长的文档,来看看效果。呃。。时间略快一点,还是要2mins。
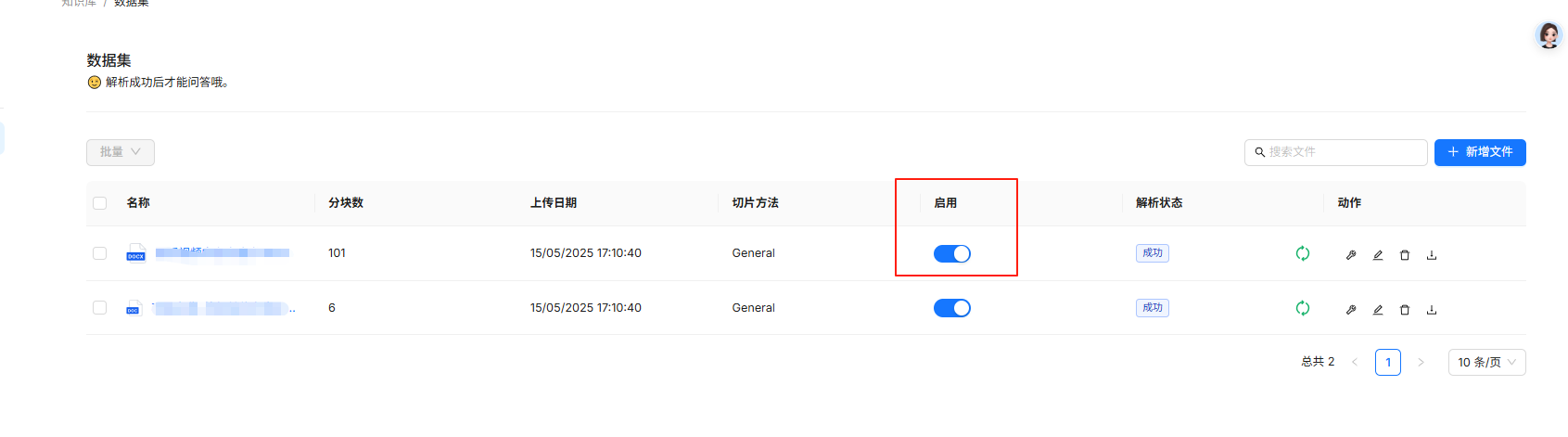
根据上一篇博客里所讲,我这里选择了reranker模型,那么在混合查询中的向量相似度部分将被rerank打分代替。那就去掉rerank,我们再测试下,emm 。。。时间略有缩短,可以看到显示搜索中这个过程十分耗时。当然有可能是我的机器配置比较差的缘故,但进一步分析,目前设置是使用关键词相似度与向量余弦相似度相结合的混合查询方式。采用的是ES数据库的查询结果计算的。
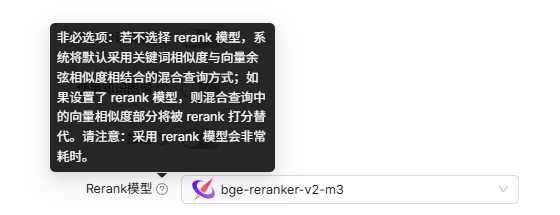
刚好看到RagFlow中配置文档中有替换Infinity的部分,那就先来了解下Infinity到底是什么。
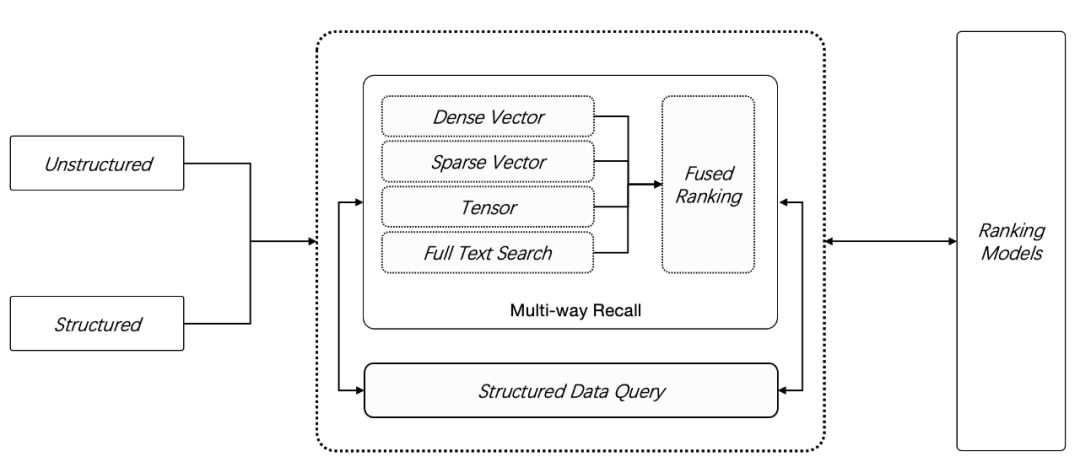
开源 AI 原生数据库 Infinity,23年12月 正式开源发布,提供了 2 种新数据类型:稀疏向量 Sparse Vector 和 张量 Tensor,在此前的全文搜索和向量搜索之外, Infinity 提供了更多的召回手段,如下图所示,用户可以采用任意 N 路召回(N ≥ 2)进行混合搜索,这是目前功能最强大的 RAG 专用数据库。
我们知道,仅仅依靠向量搜索(默认情况下,它用来特指稠密向量)并不总能提供令人满意的结果。当用户问题中的特定关键词与存储的数据不准确匹配时,这种问题尤为明显。这是因为向量本身不具备精确语义表征能力:一个词,一句话,乃至一篇文章,都可以只用一个向量来表示,这时向量本质上表达的是这段文字的“语义”,也就是这段文字跟其他文字在一个上下文窗口内共同出现概率的压缩表示 ,因此向量天然无法表示精确的查询。例如如果用户询问“2024 年 3 月我们公司财务计划包含哪些组合”,那么很可能得到的结果是其他时间段的数据,或者得到运营计划,营销管理等其他类型的数据。
因此,在一种好的解决方案是,利用基于关键词的全文搜索提供精确查询,它跟向量搜索共同工作,这就是全文搜索 + 向量搜索 的 2 路召回,又被称为混合搜索(hybrid search)。
多了 那么多我们来看下ES和Infinity执行效率上的对比吧。如下图:

我们可以看到infinity的执行效率是Especially的40倍左右,那我们就替换下试试。
关闭docker容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml down -v
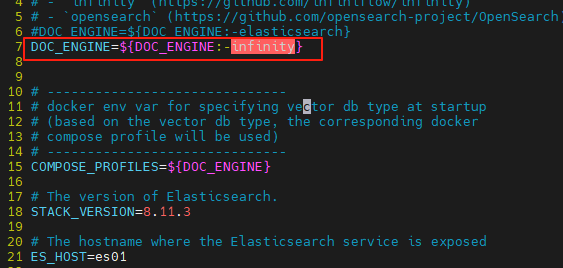
修改参数
vi .env
重启容器
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml up -d

会去拉取infinity的docker镜像,更新之后,速度果然大幅度提升,几秒内响应。
二、代码解析
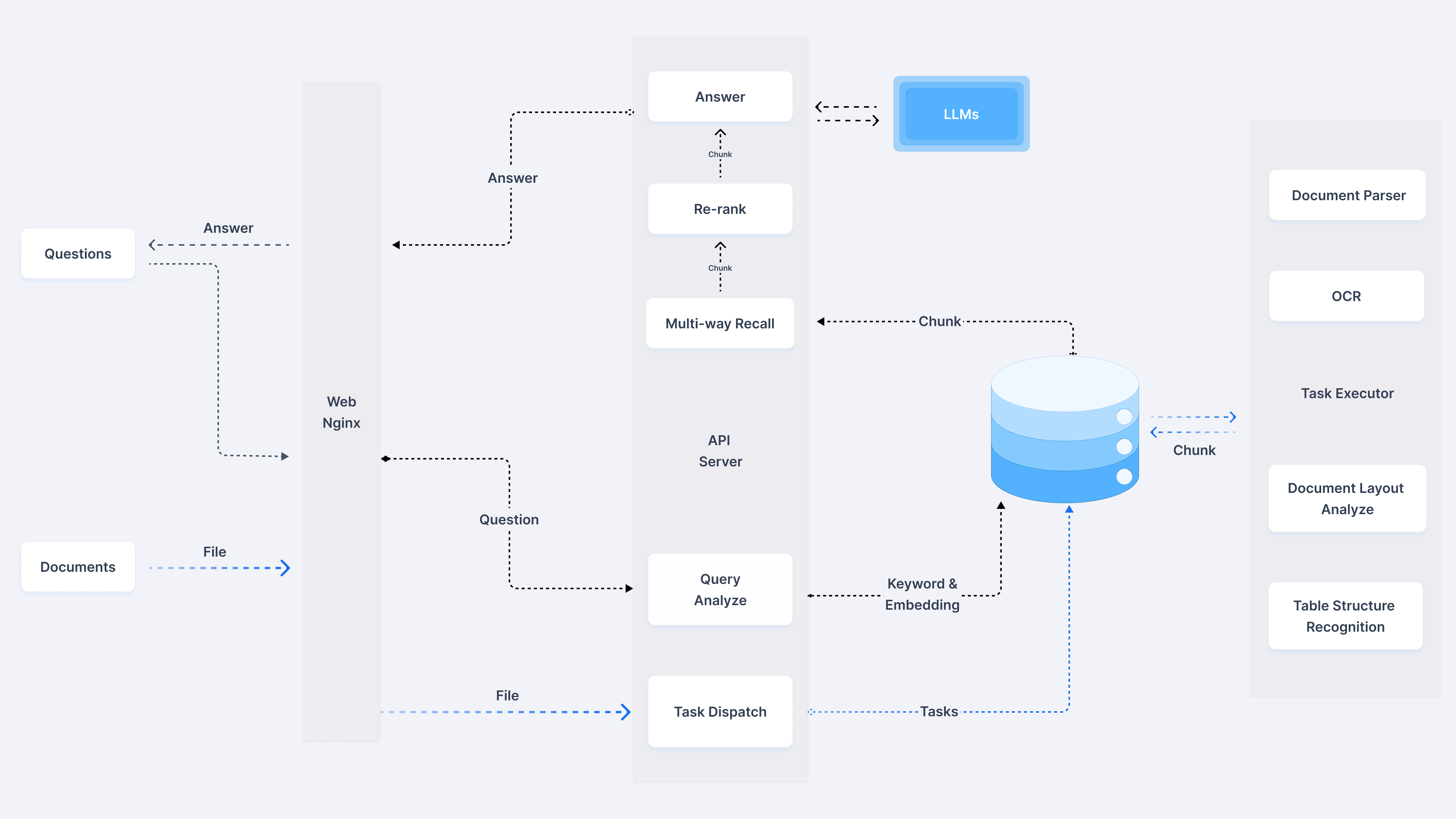
1、整体架构
我们从官方的架构图入手,我们可以看到从左往右,是我们在实际在线应用的时候的流程架构,从右到左,是知识库离线生成的流程架构。很明显,这张图中把知识库部分画的很大,彰显它在整个RagFlow项目中的核心地位。于此同时,最右侧详细介绍了文件解析的各种手段,比如 OCR, Document Layout Analyze 等,这些在常规的 RAG 中可能会作为一个不起眼的 Unstructured Loader 包含进去,可以猜到 RagFlow 的一个核心能力在于文件的解析环节。在官方文档中也反复强调 Quality in, quality out, 反映出 RAGFlow 的独到之处在于细粒度文档解析。另外文档中提到其没有使用任何 RAG 中间件,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系,也可以理解文档的解析是其 RagFlow 的核心亮点。
2、代码结构
我们来看看代码结构(版本:v0.18.0)
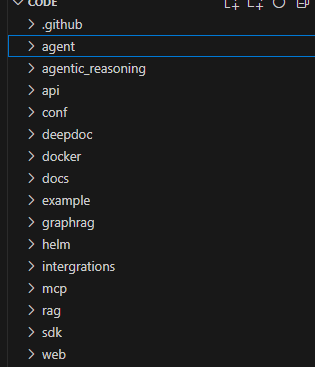
agent:RagFlow新增的一个模块,即工作流(注:实际上工作流和agent不是一个概念,agent可以作为workflow的一部分),通过“Graph"是一个由节点和边组成的数学概念。它被用来构建复杂的工作流或代理。
agentic_reasoning:代理推理
api:后端的 API
conf :配置信息
deepdoc: 文件解析模块
docker:docker配置安装启动部署文件
docs:文档
example:案例
graphrag:图rag
helm:打包管理工具
intergreations:集成插件工具
mcp:模型上下文协议
web:对应的是前端页面,TypeScript 开发
其他的一些技术中间件
Web 服务:Flask
业务数据库:Mysql
向量数据库: ElasticSearch (常规关键词搜索用的也是它),前文已经替换 infinity
文件存储: MinIO,支持分布式存储
缓存中间件:valkey/valkey:8 是从 Redis 7.2.4 fork 而来,旨在作为 Redis 的开源替代品,特别是在 Redis Labs 更改了 Redis 的源码使用协议之后。它保持了与 Redis 的兼容性,同时引入了许多性能和功能上的改进。在网络应用中,Valkey 可以用作缓存、消息队列、会话存储等多种用途,适用于需要快速数据访问和低延迟的场景。
3、源码解析
(1)加载文件
常规的 RAG 服务都是在上传时进行文件的加载和解析,但是 RAGFlow 的上传仅仅包含上传至 MinIO,需要手工点击触发文件的解析。根据实际体验,RAGFlow 的解析相当慢,资源开销也比较大,所以这就是采取二次手工确认的产品方案的原因吧。

实际的文件解析通过接口 /v1/document/run 进行触发的,实际的处理是在 api/db/services/task_service.py 中的 queue_tasks() 中完成的,此方法会根据文件创建一个或多个异步任务,方便异步执行。实现如下所示:
def queue_tasks(doc: dict, bucket: str, name: str, priority: int):def new_task():return {"id": get_uuid(), "doc_id": doc["id"], "progress": 0.0, "from_page": 0, "to_page": 100000000}parse_task_array = []# pdf 文件的解析,根据不同的类型设置单个任务最多处理的页数# 默认单个任务处理 12 页 pdf,paper 类型的 pdf 一个任务处理 22 页,其他 pdf 不分页if doc["type"] == FileType.PDF.value:file_bin = STORAGE_IMPL.get(bucket, name)do_layout = doc["parser_config"].get("layout_recognize", "DeepDOC")pages = PdfParser.total_page_number(doc["name"], file_bin)page_size = doc["parser_config"].get("task_page_size", 12)if doc["parser_id"] == "paper":page_size = doc["parser_config"].get("task_page_size", 22)if doc["parser_id"] in ["one", "knowledge_graph"] or do_layout != "DeepDOC":page_size = 10 ** 9page_ranges = doc["parser_config"].get("pages") or [(1, 10 ** 5)]for s, e in page_ranges:s -= 1s = max(0, s)e = min(e - 1, pages)for p in range(s, e, page_size):task = new_task()task["from_page"] = ptask["to_page"] = min(p + page_size, e)parse_task_array.append(task)# 表格数据单个任务处理 3000 行elif doc["parser_id"] == "table":file_bin = STORAGE_IMPL.get(bucket, name)rn = RAGFlowExcelParser.row_number(doc["name"], file_bin)for i in range(0, rn, 3000):task = new_task()task["from_page"] = itask["to_page"] = min(i + 3000, rn)parse_task_array.append(task)else:parse_task_array.append(new_task())chunking_config = DocumentService.get_chunking_config(doc["id"])# 任务插入 Redis 消息队列,方便异步处理for task in parse_task_array:hasher = xxhash.xxh64()for field in sorted(chunking_config.keys()):if field == "parser_config":for k in ["raptor", "graphrag"]:if k in chunking_config[field]:del chunking_config[field][k]hasher.update(str(chunking_config[field]).encode("utf-8"))for field in ["doc_id", "from_page", "to_page"]:hasher.update(str(task.get(field, "")).encode("utf-8"))task_digest = hasher.hexdigest()task["digest"] = task_digesttask["progress"] = 0.0task["priority"] = priorityprev_tasks = TaskService.get_tasks(doc["id"])ck_num = 0if prev_tasks:for task in parse_task_array:ck_num += reuse_prev_task_chunks(task, prev_tasks, chunking_config)TaskService.filter_delete([Task.doc_id == doc["id"]])chunk_ids = []for task in prev_tasks:if task["chunk_ids"]:chunk_ids.extend(task["chunk_ids"].split())if chunk_ids:settings.docStoreConn.delete({"id": chunk_ids}, search.index_name(chunking_config["tenant_id"]),chunking_config["kb_id"])DocumentService.update_by_id(doc["id"], {"chunk_num": ck_num})bulk_insert_into_db(Task, parse_task_array, True)DocumentService.begin2parse(doc["id"])unfinished_task_array = [task for task in parse_task_array if task["progress"] < 1.0]for unfinished_task in unfinished_task_array:assert REDIS_CONN.queue_product(get_svr_queue_name(priority), message=unfinished_task), "Can't access Redis. Please check the Redis' status."从上面的实现来看,文件的解析是根据内容拆分为多个任务,通过 Redis 消息队列进行暂存(生产者),之后就可以离线异步处理。直接查看对应的消息队列的消费模块(消费者),对应在 rag/svr/task_executor.py 中的 main() 方法中。实现如下所示:
async def main():logging.info(r"""______ __ ______ __/_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____/ / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___// / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
/_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/""")logging.info(f'TaskExecutor: RAGFlow version: {get_ragflow_version()}')settings.init_settings()print_rag_settings()if sys.platform != "win32":signal.signal(signal.SIGUSR1, start_tracemalloc_and_snapshot)signal.signal(signal.SIGUSR2, stop_tracemalloc)TRACE_MALLOC_ENABLED = int(os.environ.get('TRACE_MALLOC_ENABLED', "0"))if TRACE_MALLOC_ENABLED:start_tracemalloc_and_snapshot(None, None)signal.signal(signal.SIGINT, signal_handler)signal.signal(signal.SIGTERM, signal_handler)threading.Thread(name="RecoverPendingTask", target=recover_pending_tasks).start()async with trio.open_nursery() as nursery:nursery.start_soon(report_status)while not stop_event.is_set():async with task_limiter:nursery.start_soon(handle_task)logging.error("BUG!!! You should not reach here!!!")相关文章:
RagFlow优化代码解析(一)
引子 前文写到RagFlow的环境搭建&推理测试,感兴趣的童鞋可以移步(RagFlow环境搭建&推理测试-CSDN博客)。前文也写过RagFLow参数配置&测试的文档,详见()。很少写关于具体代码的blog,…...

【python与生活】用 Python 从视频中提取音轨:一个实用脚本的开发与应用
在当今数字化的时代,视频内容无处不在。无论是学习教程、会议记录、在线讲座还是娱乐视频,我们每天都会接触到大量的视频资源。有时候,我们可能只对视频中的音频部分感兴趣,比如提取讲座的音频用于后续收听,或者从电影…...

深度强化学习赋能城市消防优化,中科院团队提出DRL新方法破解设施配置难题
在城市建设与发展中,地理空间优化至关重要。从工业园区选址,到公共服务设施布局,它都发挥着关键作用。但传统求解方法存在诸多局限,如今,深度学习技术为其带来了新的转机。 近日,在中国地理学会地理模型与…...

云原生周刊:探索 Gateway API v1.3.0
开源项目推荐 WatchAlert WatchAlert 是一个轻量级、云原生的多数据源监控告警引擎,支持 AI 驱动的智能告警分析,旨在帮助升级您的监控系统架构。该项目基于 Go 和 React 开发,提供了现代化的前后端架构。后端使用 Go 语言,结合…...

008房屋租赁系统技术揭秘:构建智能租赁服务生态
房屋租赁系统技术揭秘:构建智能租赁服务生态 在房地产租赁市场日益活跃的当下,房屋租赁系统成为连接房东与租客的重要数字化桥梁。该系统集成用户管理、房屋信息等多个核心模块,面向管理员、房东和用户三类角色,通过前台展示与后…...

Python训练打卡Day41
简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 → Batch…...
spring-boot-admin实现对微服务监控
spring-boot-admin可以对微服务的状态进行监控,步骤如下: 1、添加spring-boot-admin和nacos依赖 <!-- nacos注册中心 --> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-n…...

Linux 权限管理入门:从基础到实践
文章目录 引言一、Linux 权限管理概述二、文件权限值的表示方法三、文件访问权限的设置(chmod)四、file指令:快速识别文件类型五、目录的权限六、普通文件的权限七、权限总结八、粘滞位 引言 在 Linux 系统中,权限管理是确保多用…...
Mycat的监控
参考资料: 参考视频 参考博客 Mysql分库分表(基于Mycat)的基本部署 MySQL垂直分库(基于MyCat) Mysql水平分表(基于Mycat)及常用分片规则 视频参考资料及安装包: https://pan.b…...
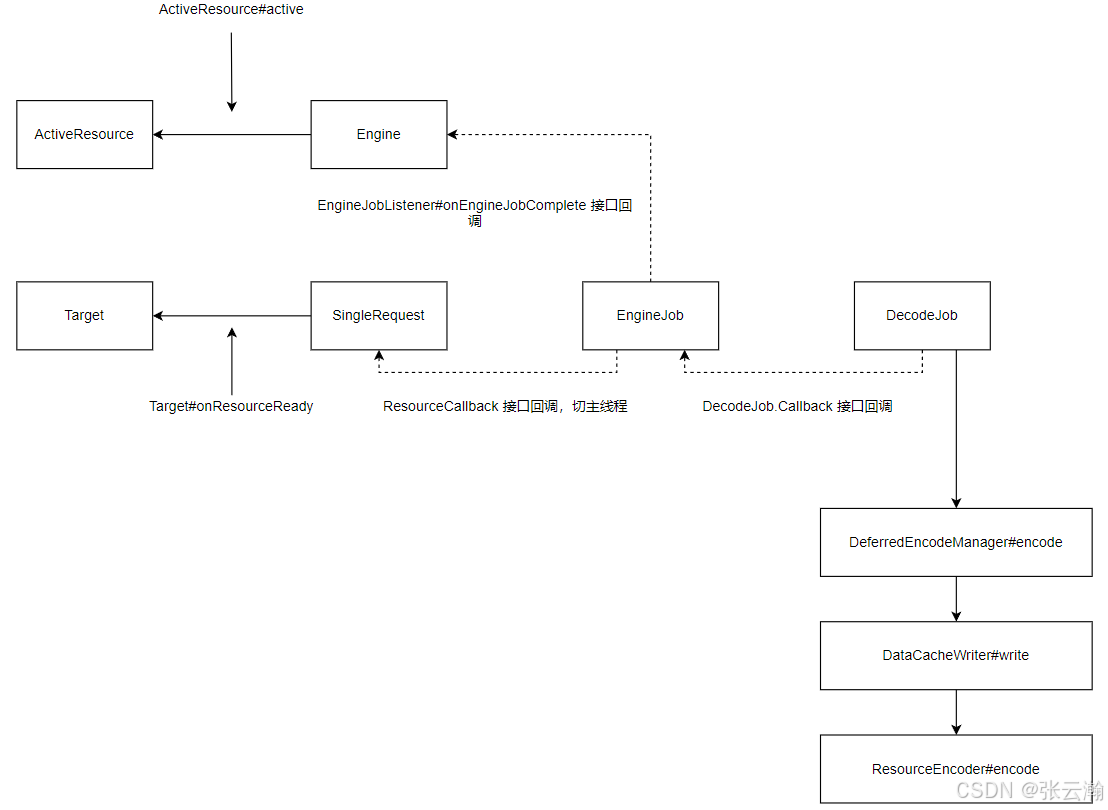
Glide源码解析
前言 Glide是一款专为Android设计的开源图片加载库。有以下特点:1.支持高效加载网络、本地及资源图片;2.具备良好的缓存策略及生命周期管理策略;3.提供了简易的API和强大的功能。本文将对其源码进行剖析。 基本使用 dependencies {compile …...
7.RV1126-OPENCV cvtColor 和 putText
一.cvtColor 1.作用 cvtColor 是 OPENCV 里面颜色转换的转换函数。能够实现 RGB 图像转换成灰度图、灰度图转换成 RGB 图像、RGB 转换成 HSV 等等 2.API CV_EXPORTS_W void cvtColor( InputArray src, OutputArray dst, int code, int dstCn 0 ); 第一个参数:…...
)
Android 之 kotlin 语言学习笔记二(编码样式)
参考官方文档:https://developer.android.google.cn/kotlin/style-guide?hlzh-cn#whitespace 1、源文件命名 所有源文件都必须编码为 UTF-8。如果源文件只包含一个顶级类,则文件名应为该类的名称(区分大小写)加上 .kt 扩展名。…...
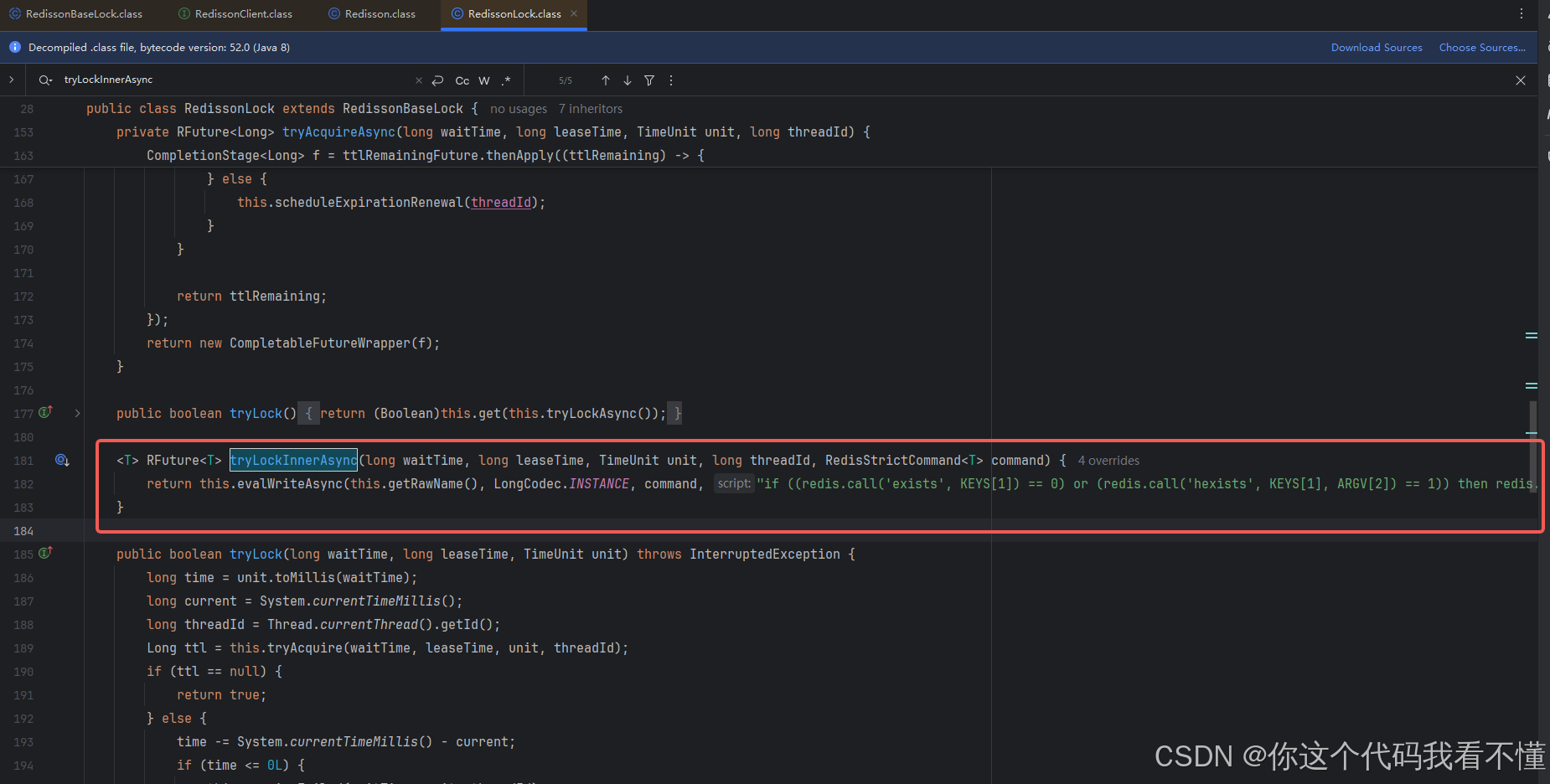
Redisson单机模式
redisson调用unlock的过程 Redisson 是一个基于 Redis 的 Java 驻内存数据网格(In-Memory Data Grid)框架,提供了分布式和可扩展的数据结构和服务。Redisson 的 unlock 方法用于释放锁。下面是 unlock 方法的调用过程: 获取锁的状…...

数据结构第6章 图(竟成)
第 6 章 图 【考纲内容】 1.图的基本概念 2.图的存储及基本操作:(1) 邻接矩阵法;(2) 邻接表法;(3) 邻接多重表、十字链表 3.图的遍历:(1) 深度优先搜索;(2) 广度优先搜索 4.图的基本应用:(1) 最小 (代价) 生…...

机器人现可完全破解验证码:未来安全技术何去何从?
引言 随着计算机视觉技术的飞速发展,机器学习模型现已能够100%可靠地解决Google的视觉reCAPTCHAv2验证码。这标志着一个时代的结束——自2000年代初以来,CAPTCHA("全自动区分计算机与人类的图灵测试"的缩写)一直是区分…...

CppCon 2014 学习:(Costless)Software Abstractions for Parallel Architectures
硬件和科学计算的演变关系: 几十年来的硬件进步:计算机硬件不断快速发展,从提升单核速度,到多核并行。科学计算的驱动力:科学计算需求推动硬件创新,比如需要更多计算能力、更高性能。当前的解决方案是并行…...
网络爬虫 - App爬虫及代理的使用(十一)
App爬虫及代理的使用 一、App抓包1. App爬虫原理2. reqable的安装与配置1. reqable安装教程2. reqable的配置3. 模拟器的安装与配置1. 夜神模拟器的安装2. 夜神模拟器的配置4. 内联调试及注意事项1. 软件启动顺序2. 开启抓包功能3. reqable面板功能4. 夜神模拟器设置项5. 注意事…...
SASL认证(zookeeper))
Kafka集群部署(docker容器方式)SASL认证(zookeeper)
一、服务器环境 序号 部署版本 版本 1 操作系统 CentOS Linux release 7.9.2009 (Core) 2 docker Docker version 20.10.6 3 docker-compose docker-compose version 1.28.2 二、服务规划 序号 服务 名称 端口 1 zookeeper zookeeper 2181,2888,3888 2 ka…...

【python爬虫】利用代理IP爬取filckr网站数据
亮数据官网链接:亮数据官网...
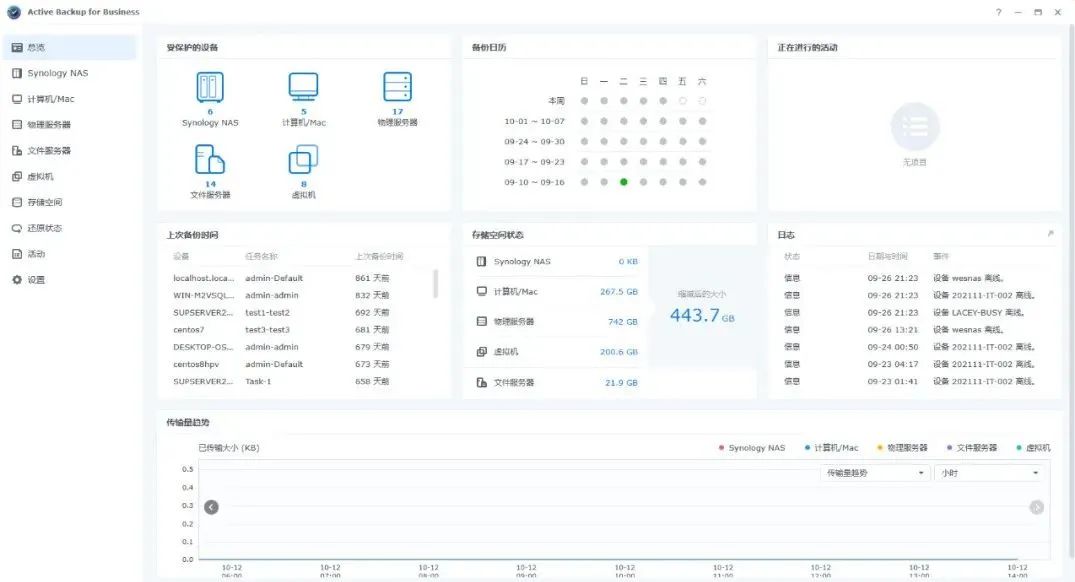
群晖 NAS 如何帮助培训学校解决文件管理难题
在现代教育环境中,数据管理和协同办公的效率直接影响到教学质量和工作流畅性。某培训学校通过引入群晖 NAS,显著提升了部门的协同办公效率。借助群晖的在线协作、自动备份和快照功能,该校不仅解决了数据散乱和丢失的问题,还大幅节…...
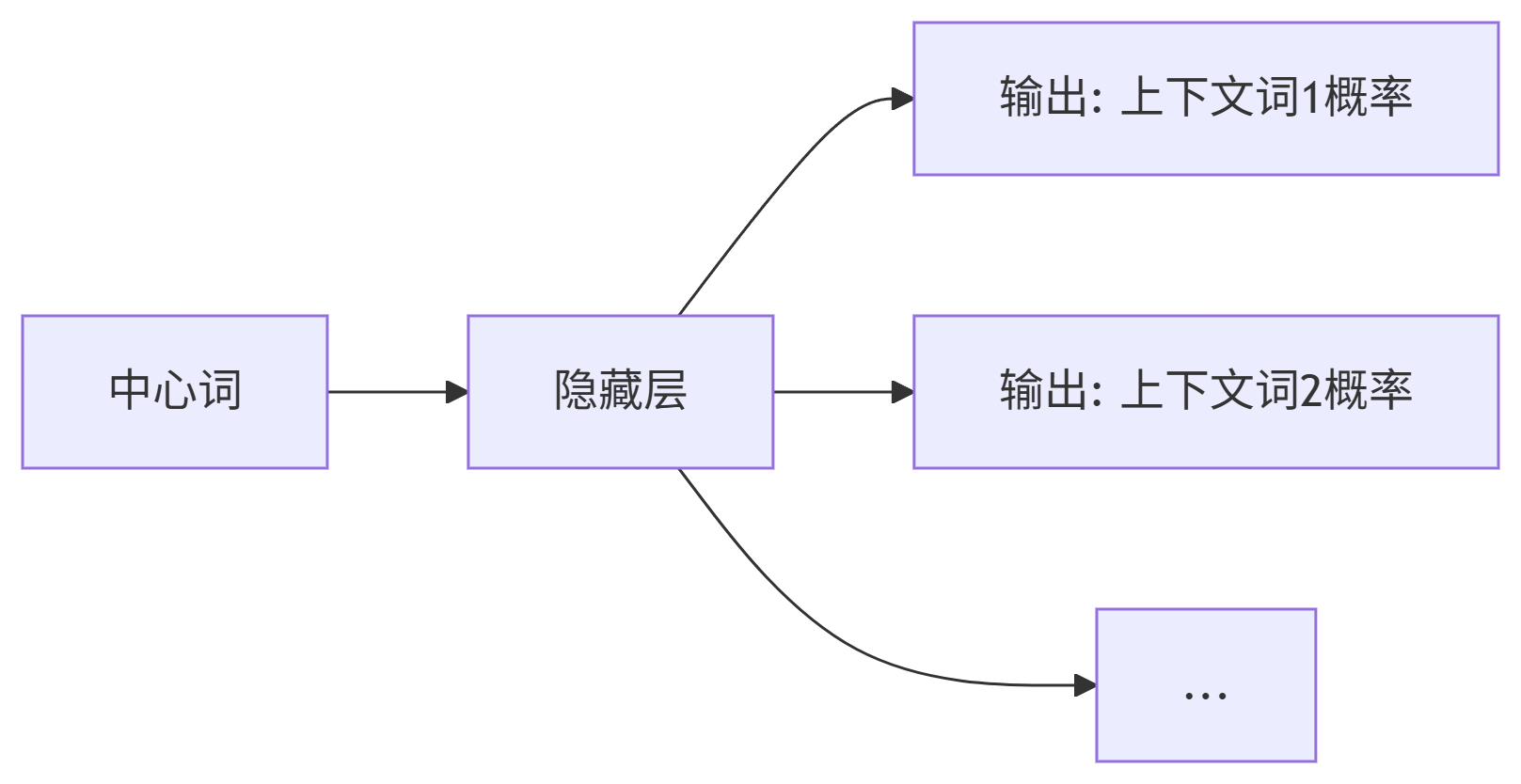
NLP学习路线图(十八):Word2Vec (CBOW Skip-gram)
自然语言处理(NLP)的核心挑战在于让机器“理解”人类语言。传统方法依赖独热编码(One-hot Encoding) 表示单词,但它存在严重缺陷:每个单词被视为孤立的符号,无法捕捉词义关联(如“国…...

P1438 无聊的数列/P1253 扶苏的问题
因为这两天在写线性代数的作业,没怎么写题…… P1438 无聊的数列 题目背景 无聊的 YYB 总喜欢搞出一些正常人无法搞出的东西。有一天,无聊的 YYB 想出了一道无聊的题:无聊的数列。。。 题目描述 维护一个数列 ai,支持两种操…...
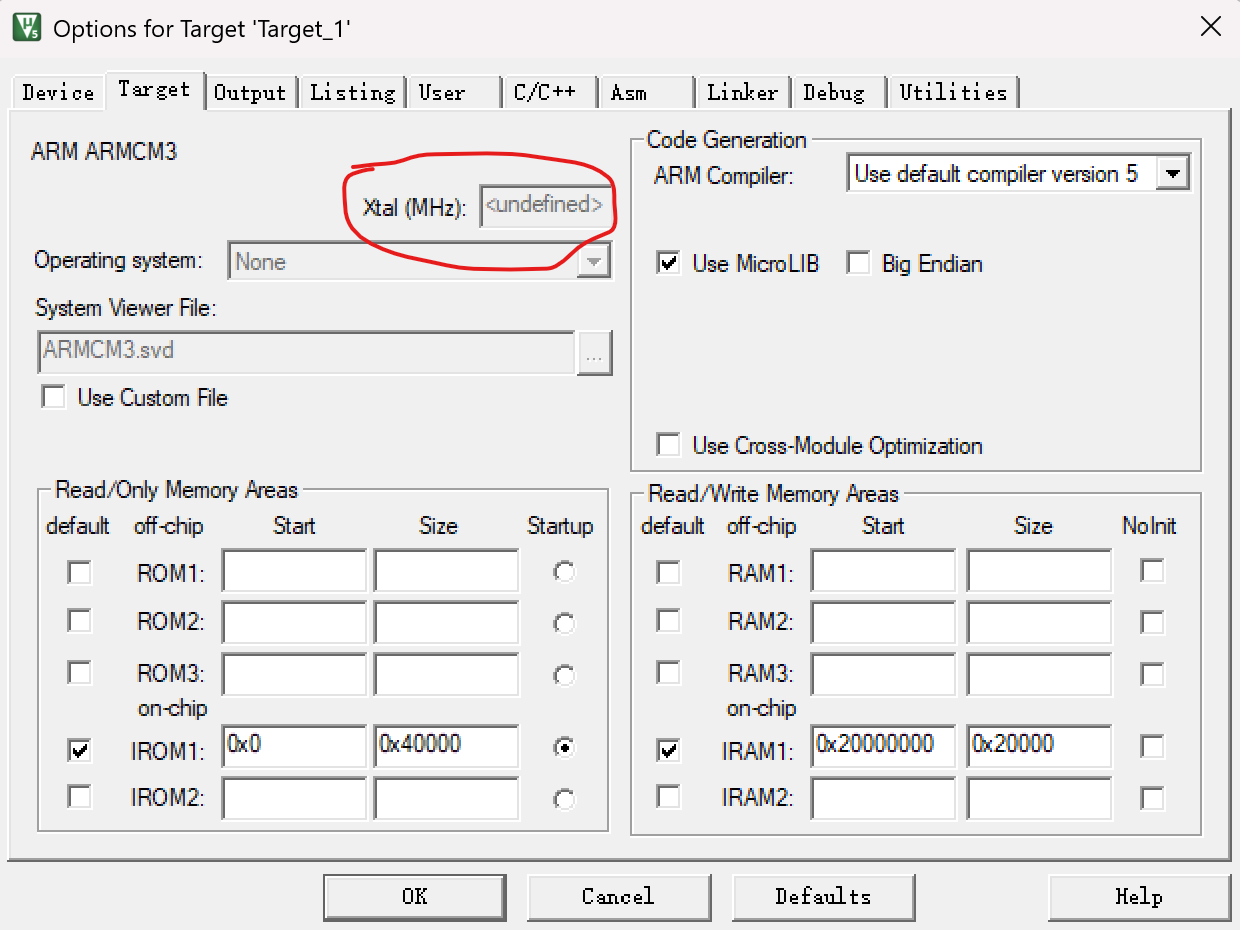
嵌入式学习笔记 - 新版Keil软件模拟时钟Xtal灰色不可更改的问题
在新版Keil软件中,模拟时钟无法修改XTAL频率,默认只能使用12MHz时钟。这是因为Keil MDK从5.36版本开始,参数配置界面不再支持修改系统XTAL频率,XTAL选项变为灰色,无法修改。这会导致在软件仿真时出现时间错误的问题&…...

k8s的出现解决了java并发编程胡问题了
Kubernetes(K8s)作为一种开源的容器编排平台,极大地简化了应用程序的部署、管理和扩展。这不仅解决了很多基础设施方面的问题,也间接解决了Java并发编程中的一些复杂问题。本文将详细探讨Kubernetes是如何帮助解决Java并发编程中的…...

如何利用大语言模型生成特定格式文风的报告类文章
在这个算法渗透万物的时代,我们不再仅仅满足于大语言模型(LLM)能“写”,更追求它能“写出精髓,写出风格”。尤其在专业且高度格式化的报告类文章领域,仅仅是内容正确已远远不够,文风的精准复刻才是决定报告是否“对味儿”、能否被目标受众有效接受的关键。这不再是简单的…...

黑马Java面试笔记之 集合篇(算法复杂度+ArrayList+)
一. 算法复杂度分析 1.1 时间复杂度 时间复杂度分析:来评估代码的执行耗时的 常见的复杂度表示形式 常见复杂度 1.2 空间复杂度 空间复杂度全称是渐进空间复杂度,表示算法占用的额外存储空间与数据规模之间的增长关系 二. 数组 数组(Array&a…...

【从0-1的HTML】第2篇:HTML标签
文章目录 1.标题标签2.段落标签3.文本标签brbstrongsubsup 4.超链接标签5.图片标签6.表格标签7.列表标签有序列表ol无序列表ul定义列表dl 8.表单标签9.音频标签10.视频标签11.HTML元素分类块级元素内联元素 12.HTML布局13.内联框架13.内联框架 1.标题标签 标题标签:…...

从“Bucharest”谈起:词语翻译的音译与意译之路
在翻译中,面对地名、人名或新兴术语时,我们常常会遇到一个抉择:到底是“音译”,保留其原发音风貌,还是“意译”,让它意义通达? 今天我们以“Bucharest”为例,展开一次语言与文化的微…...

Nginx+Tomcat负载均衡
目录 Tomcat简介 Tomcat 的核心功能 Tomcat架构 Tomcat 的特点 Tomact配置 关闭防火墙及系统内核 Tomcar 主要文件信息 配置文件说明 案例一:Java的Web站点 案例二:NginxTomcat负载均衡、动静分离 Tomcat简介 Tomcat 是由 Apache 软件基金会&am…...

JVM——JVM中的字节码:解码Java跨平台的核心引擎
引入 在Java的技术版图中,字节码(Bytecode)是连接源代码与机器世界的黄金桥梁。当开发者写下第一行public class HelloWorld时,编译器便开始了一场精密的翻译工程——将人类可读的Java代码转化为JVM能够理解的字节码指令。这些由…...