简单transformer运用
通俗易懂解读:hw04.py 文件内容与 Transformer 的应用
这个文件是一个 Python 脚本(hw04.py),用于完成 NTU 2021 Spring 机器学习课程的 HW4 作业任务:扬声器分类(Speaker Classification)。它主要通过 Transformer 模型(尤其是自注意力机制,Self-Attention)来实现分类,并提供了训练和推理代码。以下我会详细讲解文件的结构,重点教你如何使用 Transformer 和 Self-Attention,并让你明白如何训练模型、调整参数。
1. 文件概述
- 任务:从语音特征(梅尔频谱图,mel-spectrogram)中分类扬声器(600 个类别)。
- 数据集:Voxceleb2 数据集的子集,包含 600 个扬声器的音频特征。
- 目标:
- 学习使用 Transformer 模型(Simple 级别)。
- 调整 Transformer 参数(Medium 级别)。
- 构建 Conformer(Hard 级别,代码中未实现)。
- 进一步实现 Self-Attention Pooling 和 Additive Margin Softmax(Boss 级别,代码中未实现)。
- 代码结构:
- 数据准备:解压数据、加载数据集、定义 DataLoader。
- 模型定义:使用 TransformerEncoderLayer 实现分类器。
- 训练:实现训练循环、学习率调度和验证。
- 推理:加载模型,预测测试集扬声器并生成提交文件。
2. Transformer 和 Self-Attention 的原理与应用
先简单讲解 Transformer 和 Self-Attention 的原理,然后结合代码看它们如何被使用。
(1) Transformer 和 Self-Attention 原理
- Transformer:
- 由 Google 在 2017 年论文《Attention is All You Need》提出,是一种基于注意力机制的模型,取代了传统的 RNN。
- 核心组件:自注意力(Self-Attention) 和 前馈神经网络(Feedforward Network)。
- 优点:能并行处理序列(不像 RNN 逐个处理),捕捉长距离依赖。
- Self-Attention:
- 是一种注意力机制,让模型在处理序列中的每个元素时,关注整个序列的其他元素。
- 比如处理“[苹果, 香蕉, 橙子]”时,Self-Attention 会计算:
- “苹果”和其他元素(香蕉、橙子)的相关性。
- “香蕉”和其他元素的相关性,依此类推。
- 计算步骤:
- 将输入序列(每个元素是一个向量)映射为 Query(Q)、Key(K)、Value(V)三个向量。
- 计算注意力分数:Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V。
- 输出一个加权后的向量,表示当前元素对整个序列的关注结果。
(2) 代码中的 Transformer 和 Self-Attention
- 模型定义(Classifier 类):
python
收起自动换行运行
复制class Classifier(nn.Module): def __init__(self, d_model=80, n_spks=600, dropout=0.1): super().__init__() self.prenet = nn.Linear(40, d_model) self.encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, dim_feedforward=256, nhead=2 ) self.pred_layer = nn.Sequential( nn.Linear(d_model, d_model), nn.ReLU(), nn.Linear(d_model, n_spks), )- self.prenet:将输入特征(梅尔频谱图,维度为 40)投影到 d_model=80 的维度,为 Transformer 处理做准备。
- self.encoder_layer:使用 PyTorch 的 nn.TransformerEncoderLayer,这是一个标准的 Transformer 编码层,包含:
- Self-Attention:通过 nhead=2 设置多头注意力(Multi-Head Attention),将 d_model 均分为 2 头,每头处理 d_model/nhead=40 维度。
- Feedforward Network:通过 dim_feedforward=256 设置前馈网络的隐藏层维度。
- 默认使用 dropout(0.1)和 ReLU 激活函数。
- 代码中注释掉了一个 nn.TransformerEncoder,原本应该是堆叠多个 TransformerEncoderLayer(比如 num_layers=2),但当前只用了一层。
- 前向传播(forward 方法):
python
收起自动换行运行
复制def forward(self, mels): out = self.prenet(mels) # (batch size, length, 40) -> (batch size, length, d_model) out = out.permute(1, 0, 2) # (batch size, length, d_model) -> (length, batch size, d_model) out = self.encoder_layer(out) # Transformer 编码 out = out.transpose(0, 1) # (length, batch size, d_model) -> (batch size, length, d_model) stats = out.mean(dim=1) # 平均池化:(batch size, d_model) out = self.pred_layer(stats) # (batch size, n_spks) return out- Self-Attention 的作用:
- 输入 mels 是梅尔频谱图,形状为 (batch size, length, 40),表示一个 batch 的音频特征。
- 经过 self.prenet,维度变成 (batch size, length, d_model)。
- out = out.permute(1, 0, 2) 调整维度为 (length, batch size, d_model),因为 TransformerEncoderLayer 期望输入是 (sequence length, batch size, d_model)。
- self.encoder_layer(out) 执行 Self-Attention 和 Feedforward 操作:
- Self-Attention 计算每个时间步(帧)对其他所有帧的关注权重。
- Feedforward 对每个帧独立应用前馈网络。
- 最后通过平均池化(out.mean(dim=1))将序列维度压缩,得到每个样本的特征向量 (batch size, d_model),再通过 self.pred_layer 输出分类结果 (batch size, n_spks)。
- Self-Attention 的作用:
3. 如何使用 Transformer
通过这个代码,我教你如何在 PyTorch 中使用 Transformer 来完成一个分类任务。
(1) 定义 Transformer 模型
- 使用 nn.TransformerEncoderLayer 构建基本层:
python
收起自动换行运行
复制self.encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, # 输入和输出的特征维度 nhead=2, # 多头注意力的头数,d_model 必须能被 nhead 整除 dim_feedforward=256, # 前馈网络的隐藏层维度 dropout=0.1 # dropout 比例 ) - 如果需要堆叠多层,可以用 nn.TransformerEncoder:
python
收起自动换行运行
复制
(代码中注释掉了这部分,当前只用了一层。)self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
(2) 输入数据准备
- Transformer 需要输入形状为 (sequence length, batch size, d_model):
- 代码中通过 out.permute(1, 0, 2) 调整维度。
- 输入的 mels 是 (batch size, length, 40),先通过 self.prenet 投影到 d_model=80,再调整维度。
(3) 前向传播
- 直接调用 self.encoder_layer(out),PyTorch 会自动处理 Self-Attention 和 Feedforward。
- 输出需要根据任务调整:
- 这里是分类任务,所以用平均池化(out.mean(dim=1))压缩序列维度,然后通过全连接层输出分类结果。
(4) 应用场景
- Transformer 适合处理序列数据(如语音、文本)。
- Self-Attention 让模型能捕捉序列中任意两个位置之间的关系,比如语音中不同帧之间的关联。
4. 如何训练模型
训练一个模型需要准备数据、定义模型、设置优化器和学习率调度器,然后进入训练循环。以下是代码中的训练过程解析。
(1) 数据准备
- 数据集(myDataset 类):
- 加载梅尔频谱图(torch.load),随机截取 segment_len=128 帧。
- 标签是扬声器 ID(从 mapping.json 中获取)。
- DataLoader(get_dataloader 函数):
- 按 90%(训练)/10%(验证)划分数据集。
- 使用 collate_batch 函数填充批次数据,确保长度一致(填充值为 -20,表示极小的对数值)。
(2) 模型和优化器
- 模型:model = Classifier(n_spks=speaker_num).to(device),初始化 Classifier。
- 损失函数:criterion = nn.CrossEntropyLoss(),用于多分类任务。
- 优化器:optimizer = AdamW(model.parameters(), lr=1e-3),使用 AdamW 优化器,初始学习率 1e-3。
- 学习率调度器(get_cosine_schedule_with_warmup):
- 包含 Warmup 阶段(前 1000 步,学习率从 0 线性增加到 1e-3)。
- 之后按余弦衰减(Cosine Decay)降低学习率。
(3) 训练循环(main 函数)
- 训练步骤:
python
收起自动换行运行
复制for step in range(total_steps): batch = next(train_iterator) loss, accuracy = model_fn(batch, model, criterion, device) loss.backward() optimizer.step() scheduler.step() optimizer.zero_grad()- 每步从 train_loader 获取一个批次。
- 计算损失和准确率(model_fn)。
- 反向传播、优化器更新参数、调度器调整学习率、清空梯度。
- 验证:
- 每 2000 步(valid_steps)验证一次,计算验证集准确率。
- 保存最佳模型(best_accuracy)。
- 保存模型:每 10,000 步(save_steps)保存最佳模型到 model.ckpt。
(4) 推理(main 函数,推理部分)
- 加载训练好的模型,预测测试集扬声器,生成 output.csv(格式:Id, Category)。
5. 如何调整 Transformer 参数
调整 Transformer 参数是 HW4 的 Medium 级别任务。以下是代码中可以调整的部分,以及调整的意义。
(1) 调整参数的地方
- 在 Classifier 的 __init__ 中:
python
收起自动换行运行
复制self.encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, dim_feedforward=256, nhead=2 )- d_model=80:特征维度,增加会提升模型容量,但计算量更大。
- nhead=2:多头注意力头数,d_model 必须能被整除(当前 80/2=40)。
- dim_feedforward=256:前馈网络隐藏层维度,增加会增强模型表达能力。
- 堆叠多层(当前注释掉了):
python
收起自动换行运行
复制self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)- num_layers=2:增加层数会让模型更深,能捕捉更复杂的模式,但可能过拟合。
(2) 调整建议
- 增大 d_model:比如从 80 增加到 128,增强模型容量,但需要确保 nhead 能整除(比如 nhead=4)。
- 增加 nhead:比如从 2 增加到 4,允许多头注意力捕捉更多不同类型的依赖关系。
- 调整 dim_feedforward:比如从 256 增加到 512,增强前馈网络的能力。
- 增加层数:取消注释 self.encoder,设置 num_layers=3,让模型更深。
- 调整 dropout:默认 0.1,可以尝试 0.2 或 0.05,防止过拟合。
- 效果:文档中提到(HW04.pdf 第13页),调整参数后公共基准从 0.82523(Simple)提升到 0.90547(Medium)。
(3) 注意事项
- 增加参数会增加计算量,可能需要更大的 batch size 或更长的训练时间。
- 过大的模型可能过拟合,需要调整学习率或增加 dropout。
6. 总结:如何使用 Transformer 训练模型
- 步骤:
- 准备数据:加载梅尔频谱图,划分训练/验证集,用 DataLoader 批次加载。
- 定义模型:使用 nn.TransformerEncoderLayer,设置 d_model、nhead 等参数。
- 前向传播:通过 Self-Attention 处理序列,池化后输出分类结果。
- 训练:设置优化器、学习率调度器,循环计算损失、更新参数。
- 调整参数:修改 d_model、nhead、num_layers 等,优化性能。
- Self-Attention 的作用:捕捉序列中帧与帧之间的关系,比如语音中不同时间点的关联。
- 训练技巧:
- 使用 Warmup 学习率调度(代码中已实现)。
- 定期验证,保存最佳模型。
- 调整参数时,观察验证集准确率,避免过拟合。
7. 动手实践
如果你想自己训练一个类似模型,可以用以下步骤:
- 环境准备:
- 安装 PyTorch:pip install torch
- 下载数据集(代码中的链接已失效,可用其他语音数据集如 LibriSpeech 替代)。
- 修改代码:
- 调整 d_model=128、nhead=4、num_layers=3,观察效果。
- 实现 Conformer(参考 https://arxiv.org/abs/2005.08100)。
- 训练:
- 运行 main 函数,设置 total_steps=70000,观察验证准确率。
- 推理:
- 用训练好的模型预测测试集,生成提交文件
逐行讲解 Conformer 代码实现
由于你之前没有接触过 Conformer,我会从零开始详细讲解之前提供的 ConformerBlock 和 ConformerConvModule 的代码实现,逐行分析其功能、原理和实现细节。Conformer 是 Transformer 的变种,专为语音任务设计,结合了全局建模(Self-Attention)和局部建模(卷积)的优势。以下代码来自之前修改的 hw04.py,我们会重点聚焦 Conformer 的实现部分。
1. Conformer 代码实现
以下是 ConformerConvModule 和 ConformerBlock 的完整代码,我会逐行解释其作用。
import torch
import torch.nn as nn
import torch.nn.functional as F# 卷积模块,用于捕捉局部特征
class ConformerConvModule(nn.Module):def __init__(self, d_model=80, kernel_size=31, dropout=0.1):super().__init__()# Pointwise Convolution 1self.pointwise_conv1 = nn.Conv1d(d_model, d_model * 2, kernel_size=1, stride=1, padding=0, bias=True)self.glu = nn.GLU(dim=1) # Gated Linear Unit# Depthwise Convolutionself.depthwise_conv = nn.Conv1d(d_model,d_model,kernel_size=kernel_size,stride=1,padding=(kernel_size - 1) // 2,groups=d_model, # Depthwisebias=True)self.bn = nn.BatchNorm1d(d_model)self.swish = nn.Swish()# Pointwise Convolution 2self.pointwise_conv2 = nn.Conv1d(d_model, d_model, kernel_size=1, stride=1, padding=0, bias=True)self.dropout = nn.Dropout(dropout)def forward(self, x):# x: (batch, length, d_model) -> (batch, d_model, length) for convx = x.transpose(1, 2)# Pointwise Conv 1 + GLUx = self.pointwise_conv1(x)x = self.glu(x)# Depthwise Conv + BN + Swishx = self.depthwise_conv(x)x = self.bn(x)x = self.swish(x)# Pointwise Conv 2x = self.pointwise_conv2(x)x = self.dropout(x)# Back to (batch, length, d_model)x = x.transpose(1, 2)return x# Conformer 块,包含 FFN、Self-Attention 和卷积模块
class ConformerBlock(nn.Module):def __init__(self, d_model=80, nhead=2, dim_feedforward=256, dropout=0.1, kernel_size=31):super().__init__()# Feed-Forward Module (half-step)self.ffn1 = nn.Sequential(nn.LayerNorm(d_model),nn.Linear(d_model, dim_feedforward),nn.Swish(),nn.Dropout(dropout),nn.Linear(dim_feedforward, d_model))# Multi-Head Self-Attentionself.self_attention = nn.MultiheadAttention(d_model, nhead, dropout=dropout)self.norm1 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)# Convolution Moduleself.conv_module = ConformerConvModule(d_model, kernel_size, dropout)self.norm2 = nn.LayerNorm(d_model)self.dropout2 = nn.Dropout(dropout)# Feed-Forward Module (half-step)self.ffn2 = nn.Sequential(nn.LayerNorm(d_model),nn.Linear(d_model, dim_feedforward),nn.Swish(),nn.Dropout(dropout),nn.Linear(dim_feedforward, d_model))self.norm3 = nn.LayerNorm(d_model)self.dropout3 = nn.Dropout(dropout)def forward(self, x):# x: (length, batch, d_model)# FFN 1 (half-step)x = x + 0.5 * self.dropout1(self.ffn1(x))# Multi-Head Self-Attentionattn_output, _ = self.self_attention(x, x, x)x = self.norm1(x + self.dropout1(attn_output))# Convolution Modulex = self.norm2(x + self.dropout2(self.conv_module(x)))# FFN 2 (half-step)x = self.norm3(x + self.dropout3(self.ffn2(x)))return x2. 逐行讲解 ConformerConvModule
(1) 初始化方法 __init__
python
收起自动换行运行
复制
class ConformerConvModule(nn.Module): def __init__(self, d_model=80, kernel_size=31, dropout=0.1):
- class ConformerConvModule(nn.Module):定义一个卷积模块,继承 PyTorch 的 nn.Module 类,所有神经网络模块都需要继承这个类。
- d_model=80:输入和输出的特征维度(类似 Transformer 的隐藏维度)。
- kernel_size=31:卷积核大小,决定了捕捉局部特征的范围(越大,感受野越大)。
- dropout=0.1:Dropout 比例,防止过拟合。
python
收起自动换行运行
复制
super().__init__()
- 调用父类 nn.Module 的初始化方法,确保正确初始化模块。
python
收起自动换行运行
复制
self.pointwise_conv1 = nn.Conv1d(d_model, d_model * 2, kernel_size=1, stride=1, padding=0, bias=True)
- nn.Conv1d:一维卷积,适用于序列数据(如语音的梅尔频谱图)。
- d_model:输入通道数(特征维度)。
- d_model * 2:输出通道数,升维到两倍,用于后续 GLU(Gated Linear Unit)操作。
- kernel_size=1:点卷积(Pointwise Convolution),只对每个时间步独立操作,不涉及邻域。
- stride=1:步幅为 1,不改变序列长度。
- padding=0:无填充,因为 kernel_size=1 不需要填充。
- bias=True:包含偏置参数。
python
收起自动换行运行
复制
self.glu = nn.GLU(dim=1) # Gated Linear Unit
- nn.GLU:Gated Linear Unit,一种门控机制。
- dim=1:在通道维度上操作(因为输入是 (batch, channel, length))。
- GLU 的作用:将 d_model * 2 的通道分成两部分,一部分作为值,另一部分通过 sigmoid 激活作为门控,输出 d_model 个通道。公式为: GLU(x)=x1⋅σ(x2)\text{GLU}(x) = x_1 \cdot \sigma(x_2)GLU(x)=x1⋅σ(x2) 其中 x1 x_1 x1 和 x2 x_2 x2 是通道拆分的两部分。
python
收起自动换行运行
复制
self.depthwise_conv = nn.Conv1d( d_model, d_model, kernel_size=kernel_size, stride=1, padding=(kernel_size - 1) // 2, groups=d_model, # Depthwise bias=True )
- nn.Conv1d:定义深度可分离卷积(Depthwise Convolution)。
- d_model:输入和输出通道数保持一致。
- kernel_size=31:卷积核大小,捕捉局部特征。
- stride=1:步幅为 1。
- padding=(kernel_size - 1) // 2:自动计算填充,确保输出长度不变(例如 kernel_size=31 时,padding=15)。
- groups=d_model:深度卷积,每个输入通道独立卷积,减少参数量。
- bias=True:包含偏置。
python
收起自动换行运行
复制
self.bn = nn.BatchNorm1d(d_model)
- nn.BatchNorm1d:一维批归一化,作用于通道维度。
- 归一化每个通道的特征,加速训练,稳定梯度。
python
收起自动换行运行
复制
self.swish = nn.Swish()
- nn.Swish:激活函数,公式为 Swish(x)=x⋅σ(x) \text{Swish}(x) = x \cdot \sigma(x) Swish(x)=x⋅σ(x),比 ReLU 更平滑。
python
收起自动换行运行
复制
self.pointwise_conv2 = nn.Conv1d(d_model, d_model, kernel_size=1, stride=1, padding=0, bias=True)
- 第二个点卷积,将特征降维回 d_model。
python
收起自动换行运行
复制
self.dropout = nn.Dropout(dropout)
- Dropout 层,随机丢弃部分神经元,防止过拟合。
(2) 前向传播方法 forward
python
收起自动换行运行
复制
def forward(self, x):
- 定义前向传播,输入 x 是 (batch, length, d_model) 的张量。
python
收起自动换行运行
复制
x = x.transpose(1, 2)
- transpose(1, 2):将 (batch, length, d_model) 转换为 (batch, d_model, length),因为 nn.Conv1d 期望输入是 (batch, channel, length)。
python
收起自动换行运行
复制
x = self.pointwise_conv1(x)
- 应用第一个点卷积,将通道数从 d_model 升到 d_model * 2。
python
收起自动换行运行
复制
x = self.glu(x)
- 应用 GLU,将通道数降回 d_model,并通过门控机制选择性保留信息。
python
收起自动换行运行
复制
x = self.depthwise_conv(x)
- 应用深度卷积,捕捉局部特征(kernel_size=31 覆盖 31 个时间步)。
python
收起自动换行运行
复制
x = self.bn(x)
- 应用批归一化,稳定特征分布。
python
收起自动换行运行
复制
x = self.swish(x)
- 应用 Swish 激活,增加非线性。
python
收起自动换行运行
复制
x = self.pointwise_conv2(x)
- 应用第二个点卷积,进一步处理特征,保持维度为 (batch, d_model, length)。
python
收起自动换行运行
复制
x = self.dropout(x)
- 应用 Dropout,防止过拟合。
python
收起自动换行运行
复制
x = x.transpose(1, 2)
- 将维度转回 (batch, length, d_model),与输入一致。
python
收起自动换行运行
复制
return x
- 返回处理后的张量。
3. 逐行讲解 ConformerBlock
(1) 初始化方法 __init__
python
收起自动换行运行
复制
class ConformerBlock(nn.Module): def __init__(self, d_model=80, nhead=2, dim_feedforward=256, dropout=0.1, kernel_size=31):
- 定义 Conformer 块,参数与 ConformerConvModule 类似。
- nhead=2:多头注意力的头数。
- dim_feedforward=256:前馈网络的隐藏层维度。
python
收起自动换行运行
复制
super().__init__()
python
收起自动换行运行
复制
self.ffn1 = nn.Sequential( nn.LayerNorm(d_model), nn.Linear(d_model, dim_feedforward), nn.Swish(), nn.Dropout(dropout), nn.Linear(dim_feedforward, d_model) )
- 定义第一个前馈模块(FFN1)。
- nn.LayerNorm(d_model):层归一化,归一化每个时间步的特征。
- nn.Linear(d_model, dim_feedforward):将维度从 d_model 扩展到 dim_feedforward。
- nn.Swish():Swish 激活。
- nn.Dropout(dropout):Dropout。
- nn.Linear(dim_feedforward, d_model):降维回 d_model。
python
收起自动换行运行
复制
self.self_attention = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
- nn.MultiheadAttention:多头自注意力。
- d_model:输入维度。
- nhead=2:头数,每头处理 d_model/nhead=40 维度。
- dropout=dropout:注意力中的 Dropout。
python
收起自动换行运行
复制
self.norm1 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout)
- norm1 和 dropout1:用于自注意力后的归一化和 Dropout。
python
收起自动换行运行
复制
self.conv_module = ConformerConvModule(d_model, kernel_size, dropout)
- 调用 ConformerConvModule,处理局部特征。
python
收起自动换行运行
复制
self.norm2 = nn.LayerNorm(d_model) self.dropout2 = nn.Dropout(dropout)
- norm2 和 dropout2:卷积模块后的归一化和 Dropout。
python
收起自动换行运行
复制
self.ffn2 = nn.Sequential( nn.LayerNorm(d_model), nn.Linear(d_model, dim_feedforward), nn.Swish(), nn.Dropout(dropout), nn.Linear(dim_feedforward, d_model) )
- 定义第二个前馈模块(FFN2),结构与 FFN1 相同。
python
收起自动换行运行
复制
self.norm3 = nn.LayerNorm(d_model) self.dropout3 = nn.Dropout(dropout)
- norm3 和 dropout3:FFN2 后的归一化和 Dropout。
(2) 前向传播方法 forward
python
收起自动换行运行
复制
def forward(self, x):
- 输入 x 是 (length, batch, d_model),符合 Transformer 的输入格式。
python
收起自动换行运行
复制
x = x + 0.5 * self.dropout1(self.ffn1(x))
- 应用 FFN1,半步前馈(系数 0.5 是 Conformer 的设计)。
- self.ffn1(x):通过 FFN1 处理。
- self.dropout1(...):应用 Dropout。
- x + 0.5 * ...:残差连接,稳定训练。
python
收起自动换行运行
复制
attn_output, _ = self.self_attention(x, x, x)
- 应用多头自注意力。
- self.self_attention(x, x, x):输入 Query、Key、Value 均为 x,计算自注意力。
- attn_output:注意力输出,形状仍为 (length, batch, d_model)。
- _:忽略注意力权重。
python
收起自动换行运行
复制
x = self.norm1(x + self.dropout1(attn_output))
- x + self.dropout1(attn_output):残差连接。
- self.norm1(...):层归一化。
python
收起自动换行运行
复制
x = self.norm2(x + self.dropout2(self.conv_module(x)))
- 应用卷积模块。
- self.conv_module(x):通过 ConformerConvModule 处理。
- self.dropout2(...):Dropout。
- x + ...:残差连接。
- self.norm2(...):层归一化。
python
收起自动换行运行
复制
x = self.norm3(x + self.dropout3(self.ffn2(x)))
- 应用 FFN2,与 FFN1 类似。
python
收起自动换行运行
复制
return x
- 返回处理后的张量,形状不变。
4. 总结与使用
- ConformerConvModule:通过卷积捕捉局部特征,适合语音任务中的短时相关性。
- ConformerBlock:结合 FFN、Self-Attention 和卷积,平衡全局和局部建模。
- 如何使用:
- 在 Classifier 中替换 TransformerEncoderLayer 为 ConformerBlock。
- 堆叠多层:self.encoder = nn.Sequential(*[ConformerBlock(...) for _ in range(2)])。
- 调整参数(如 d_model、kernel_size)优化性能。
相关文章:
简单transformer运用
通俗易懂解读:hw04.py 文件内容与 Transformer 的应用 这个文件是一个 Python 脚本(hw04.py),用于完成 NTU 2021 Spring 机器学习课程的 HW4 作业任务:扬声器分类(Speaker Classification)。它…...

vscode不满足先决条件问题的解决——vscode的老版本安装与禁止更新(附安装包)
目录 起因 vscode更新设置的关闭 安装包 结语 起因 由于主包用的系统是centos的,且版本有点老了,再加上vscode现在不支持老版本的,这对主包来说更是雪上加霜啊 但是主包看了网上很多教程,眼花缭乱,好多配置要改&…...
RustDesk 搭建自建服务器并设置服务自启动
目录 0. 介绍 1. 事前准备 1.1 有公网 ip 的云服务器一台 1.2 服务端部署包 1.3 客户端安装包 2. 部署 2.1 服务器环境准备 2.2 上传服务端部署包 2.3 运行 pm2 3. 客户端使用 3.1 安装 3.2 配置 3.2.1 解锁网络设置 3.2.2 ID / 中级服务器 3.3 启动效果 > …...
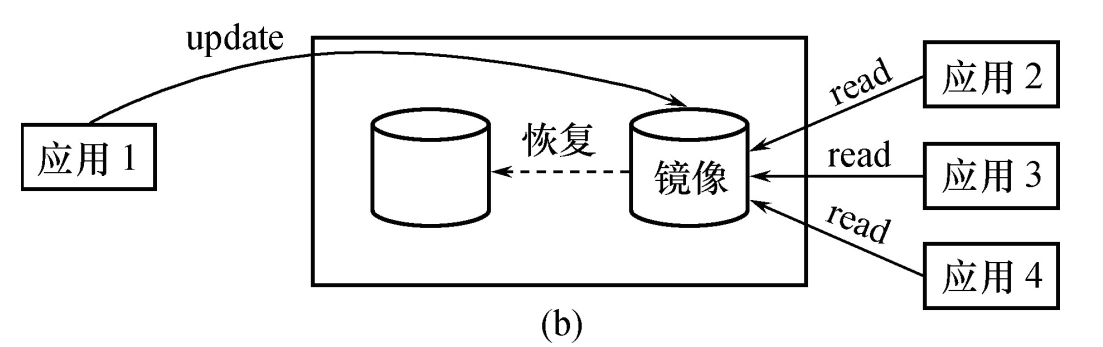
【数据库】数据库恢复技术
数据库恢复技术 实现恢复的核心是使用冗余,也就是根据冗余数据重建不正确数据。 事务 事务是一个数据库操作序列,是一个不可分割的工作单位,是恢复和并发的基本单位。 在关系数据库中,一个事务是一条或多条SQL语句,…...

Qt企业级串口通信实战:高效稳定的工业级应用开发指南
目录 一、前言 二、问题代码剖析 2.1 典型缺陷示例 2.2 企业级应用必备特性对比 三、关键优化策略与代码实现 3.1 增强型串口管理类 问题1:explicit关键字的作用 3.2 智能错误恢复机制 3.3 数据分帧处理算法 四、性能优化实测数据 五、工业级应用场景 六…...
力扣HOT100之动态规划:32. 最长有效括号
这道题放在动态规划里属实是有点难为人了,感觉用动态规划来做反而更难理解了,这道题用索引栈来做相当好理解,这里先讲下索引栈的思路。 索引栈做法 我们定义一个存放整数的栈,定义一个全局变量result来记录最长有效子串的长度&a…...

深入理解前端DOM:现代Web开发的基石
什么是DOM? DOM(Document Object Model,文档对象模型)是Web开发中最重要的概念之一。它是一个跨平台、语言独立的接口,将HTML或XML文档表示为树形结构,其中每个节点都是文档的一个部分(如元素、…...

Springboot中Controller接收参数的方式
在Spring Boot中,Controller或RestController可以通过多种方式接收客户端传递的参数,主要包括以下几种常见方式: 1. 接收路径参数(PathVariable) 从URL路径中提取参数,适用于RESTful风格的API。 示例 Re…...

从一堆数字里长出一棵树:中序 + 后序构建二叉树的递归密码
从一堆数字里长出一棵树:中序 + 后序构建二叉树的递归密码 一、写在前面:一棵树的“复活计划” 作为一个老程序员,看到「中序 + 后序重建二叉树」这种题,我内心是兴奋的。为啥?它不仅是数据结构基础的“期末大题”,更是递归分解思想的典范——简洁、优雅、极具思维训练价…...
Unity UI 性能优化终极指南 — Image篇
🎯 Unity UI 性能优化终极指南 — Image篇 🧩 Image 是什么? Image 是UGUI中最常用的基本绘制组件支持显示 Sprite,可以用于背景、按钮图标、装饰等是UI性能瓶颈的头号来源之一,直接影响Draw Call和Overdraw …...
Nginx + Tomcat 负载均衡、动静分离群集
一、 nginx 简介 Nginx 是一款轻量级的高性能 Web 服务器、反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在 BSD-like 协议下发行。其特点是占有内存少,并发能力强,在同类型的网页服务器中表现优异,常用…...
,安装使用完整教程】)
【maker-pdf 文档文字识别(包含ocr),安装使用完整教程】
测试效果还比较好,比markitdown要好 安装环境 conda create -n maker-pdf python3.12 conda activate marker-pdf pip install modelscope pip install marker-pdf -U下载模型 建议用modelscope上缓存的模型,不然下载会很慢 from modelscope import s…...
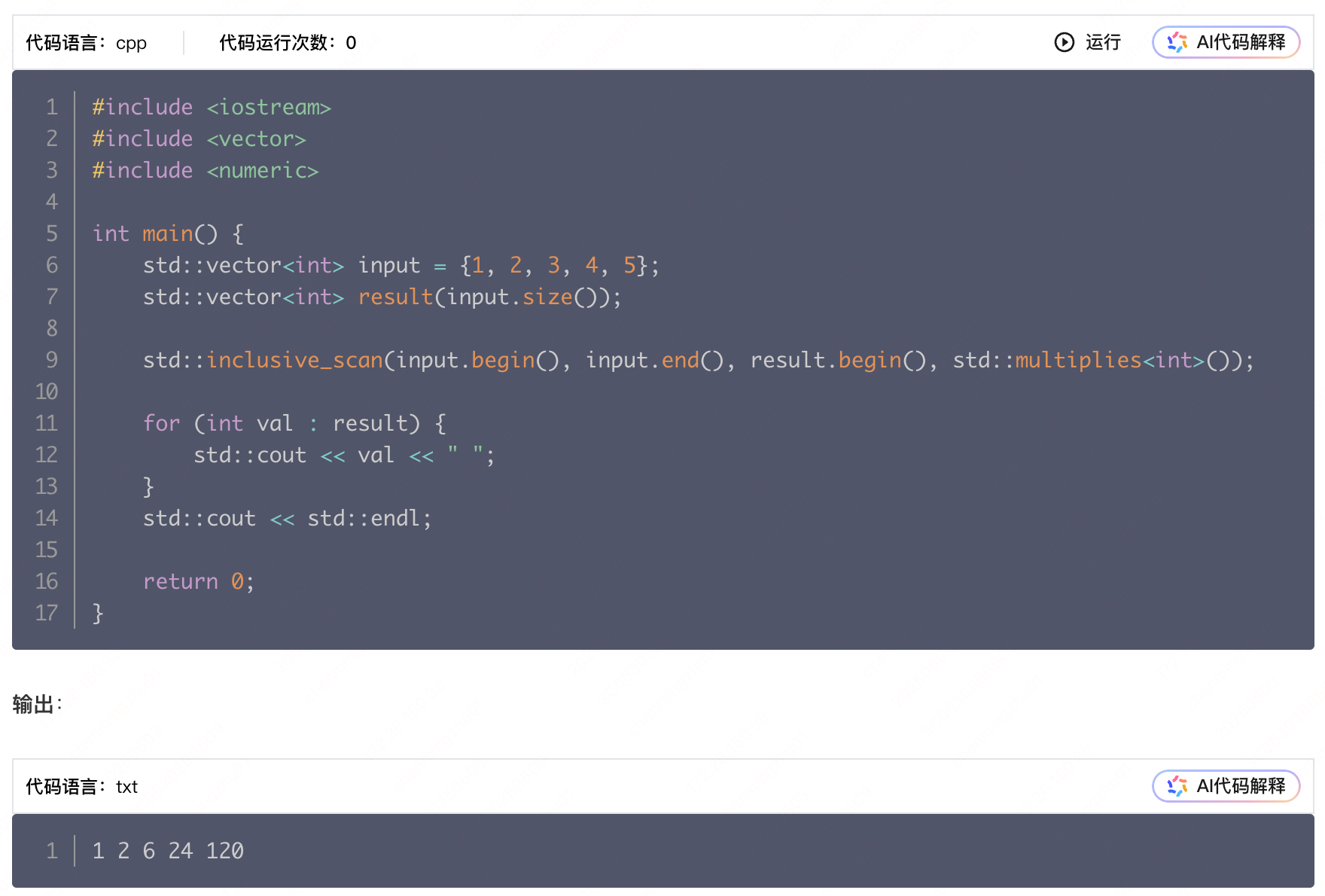
c++ algorithm
cheatsheet:https://hackingcpp.com transform 元素变换 https://blog.csdn.net/qq_44961737/article/details/146011174 #include <iostream> #include <vector> #include <algorithm>int main() {std::vector<int> a {1, 2, 3, 4, 5};…...
》)
《前端面试题:BFC(块级格式化上下文)》
前端BFC完全指南:布局魔法与面试必备 🎋 端午安康! 各位前端探险家,端午节快乐!🥮 愿你的代码如龙舟竞渡般乘风破浪,样式如香糯粽子般完美包裹!今天我们来解锁CSS中的布局魔法——B…...

HertzBeat的告警规则如何配置?
HertzBeat配置告警规则主要有以下步骤: 配置告警阈值 1. 登录HertzBeat管理界面,点击“阈值规则”菜单,选择“新增阈值”。 2. 选择要配置告警阈值的指标对象。例如,若监控Spring Boot应用,可选择如“状态线程数”等…...
安全-JAVA开发-第一天
目标: 安装环境 了解基础架构 了解代码执行顺序 与数据库进行连接 准备: 安装 下载IDEA并下载tomcat(后续出教程) 之后新建项目 注意点如下 1.应用程序服务器选择Web开发 2.新建Tomcat的服务器配置文件 并使用 Hello…...

6月2日上午思维训练题解
好好反思一下,自己在学什么,自己怎么在做训练赛的,真有这么难吗 ????? A - Need More Arrays 题解 想尽可能多的拆出新数组的个数,只需要从原本的数组中提取出最长的一…...

高考数学易错考点01 | 临阵磨枪
文章目录 前言集合与函数不等式数列三角函数前言 本篇内容下载于网络,网络上的都是以 WORD 版本呈现,缺字缺图很不完整,没法使用,我只是做了补充和完善。有空准备进行第二次完善,添加问题解释的链接。 集合与函数 1.进行集合的交、并、补运算时,不要忘了全集和空集的特…...
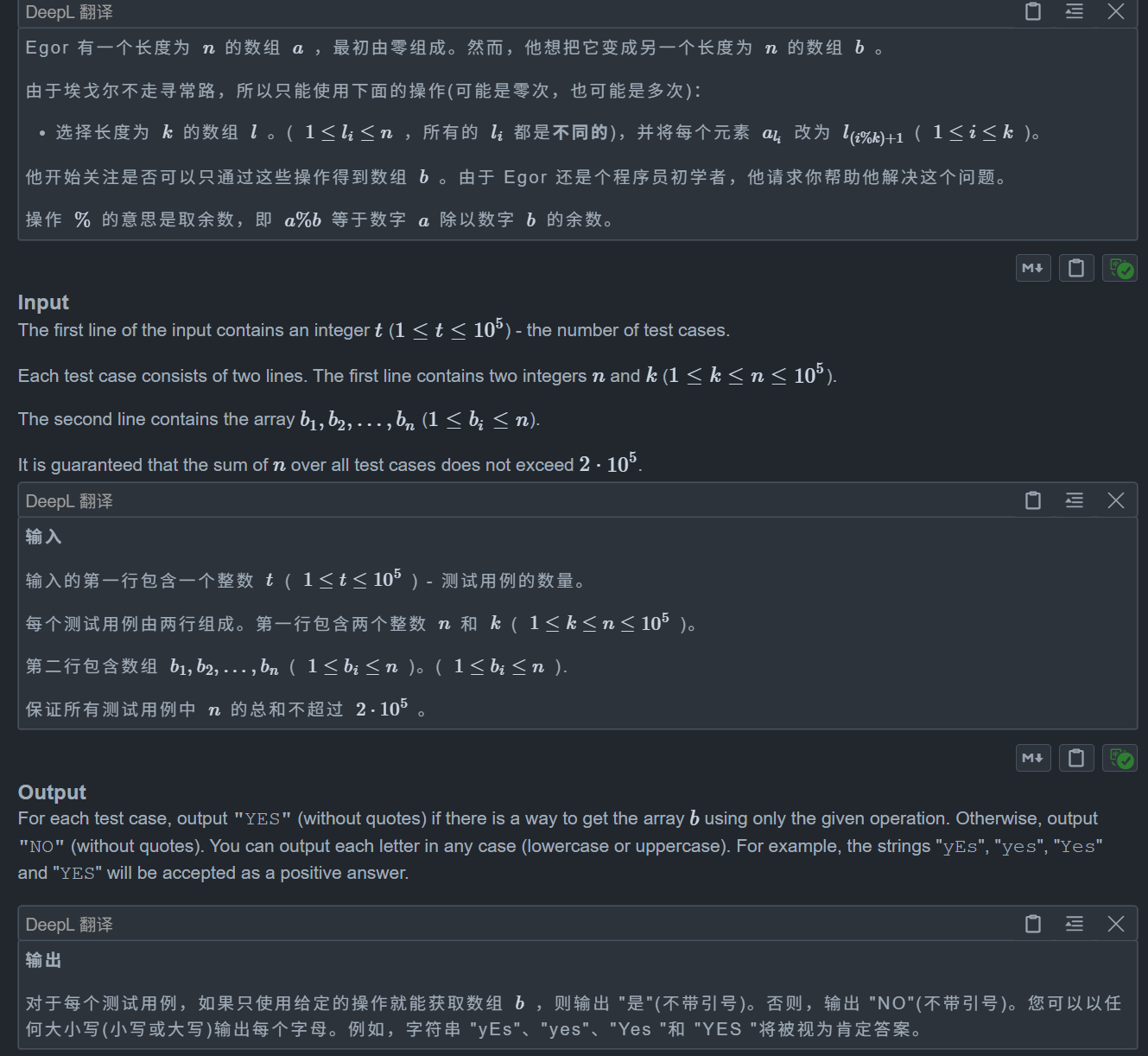
【CF】Day69——⭐Codeforces Round 897 (Div. 2) D (图论 | 思维 | DFS | 环)
D. Cyclic Operations 题目: 思路: 非常好的一题 对于这题我们要学会转换和提取条件,从特殊到一般 我们可以考虑特殊情况先,即 k n 和 k 1时,对于 k 1,我们可以显然发现必须满足 b[i] i,而…...

MySQL中的字符串分割函数
MySQL中的字符串分割函数 MySQL本身没有内置的SPLIT()函数,但可以通过其他方式实现字符串分割功能。以下是几种常见的方法: 1. SUBSTRING_INDEX函数 SUBSTRING_INDEX()是MySQL中最常用的字符串分割函数,它可以根据指定的分隔符从字符串中提…...
前端八股之Vue
目录 有使用过vue吗?说说你对vue的理解 你对SPA单页面的理解,它的优缺点分别是什么?如何实现SPA应用呢 一、SPA 是什么 二、SPA 和 MPA 的区别 三、SPA 的优缺点 四、实现 SPA 五、给 SPA 做 SEO 的方式(基于 Vueÿ…...

Matlab数值计算
MATLAB数值计算 数值计算函数句柄匿名函数线性与非线性方程组求解1. \(左除运算)2. fzero3. fsolve4. roots 函数极值的求解1. fminbnd2. fmincon3. fminsearch与fminunc 数值积分1. quad / quadl2. quadgk3. integral4. trapz5. dblquad, quad2d, integ…...
谷歌地图高清卫星地图2026中文版下载|谷歌地图3D卫星高清版 V7.3.6.9796 最新免费版下载 - 前端工具导航
谷歌地图高清卫星地图2024中文版是一款非常专业的世界地图查看工具。通过使用该软件,你就可以在这里看到外太空星系、大洋峡谷等场景,通过高清的卫星地图,可以清晰查看地图、地形、3D建筑、卫星图像等信息,让你可以更轻松的探索世…...

条形进度条
组件 <template><view class"pk-detail-con"><i class"lightning" :style"{ left: line % }"></i><i class"acimgs" :style"{ left: line % }"></i><view class"progress&quo…...

悟饭游戏厅iOS版疑似流出:未测试版
网传悟饭游戏厅iOS版安装包流出,提供百度网盘/夸克网盘双渠道下载。本文客观呈现资源信息,包含文件验证数据、安装风险预警及iOS正版替代方案。苹果用户请谨慎测试,建议优先考虑官方渠道。 一、资源基本信息 1.1 文件验证数据 属性夸克网盘…...

95. Java 数字和字符串 - 操作字符串的其他方法
文章目录 95. Java 数字和字符串 - 操作字符串的其他方法一、分割字符串二、子序列与修剪三、在字符串中搜索字符和子字符串四、将字符和子字符串替换为字符串五、String 类的实际应用 —— 文件名处理示例示例:Filename 类示例:FilenameDemo 类 总结 95…...
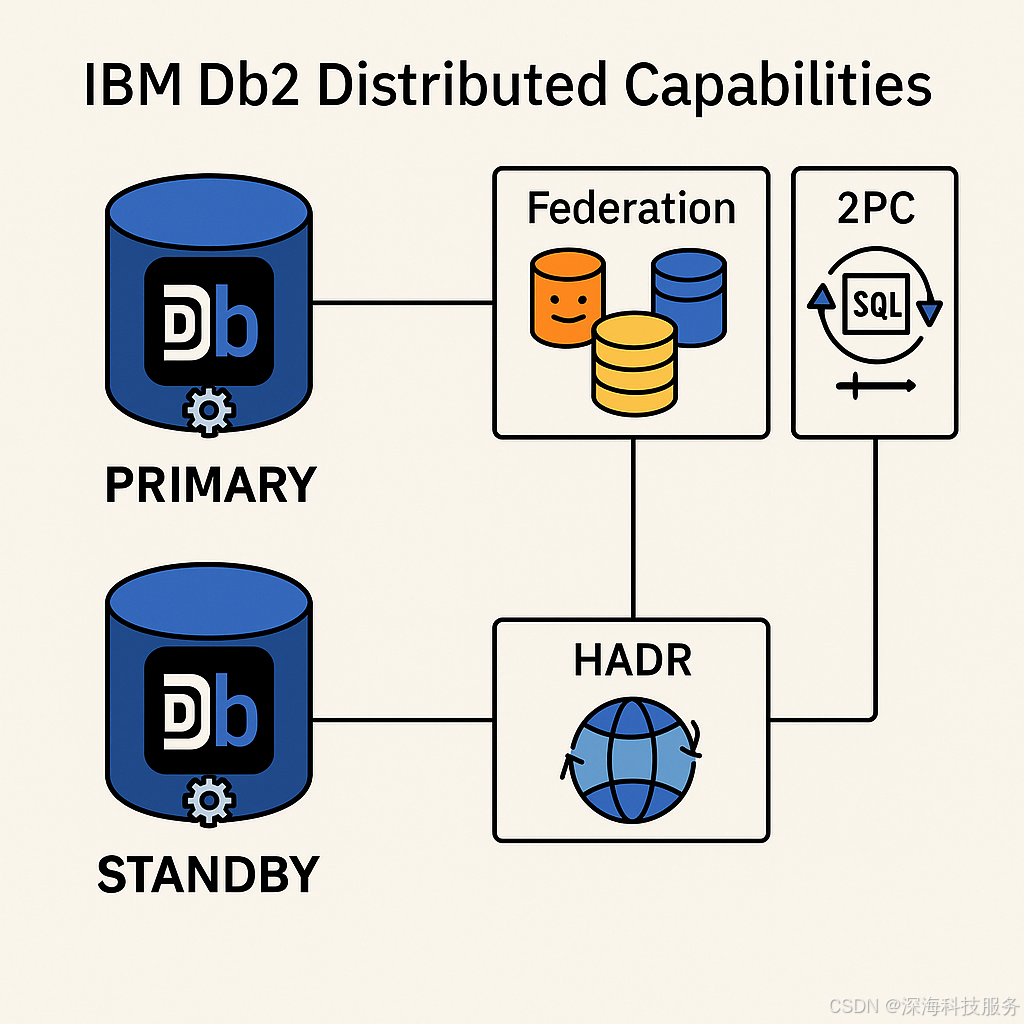
IBM DB2分布式数据库架构
一、什么是分布式数据库架构 分布式数据库架构是现代数据库系统的重要发展方向,特别适合处理大规模数据、高并发访问和高可用性需求的应用场景。下面我们从原理、架构模式、关键技术、实现方式和常见产品几个方面来系统讲 1、分布式数据库的基本概念与原理 1. 什…...
)
初始化已有项目仓库,推送远程(Git)
初始化Git仓库(如果还没初始化) git init 添加并提交文件 git add . ("."表示当前项目所有文件) git commit -m “first commit” 关联远程仓库(如果还没关联) git remote add origin http://xxxxxxxx 推送代码 …...
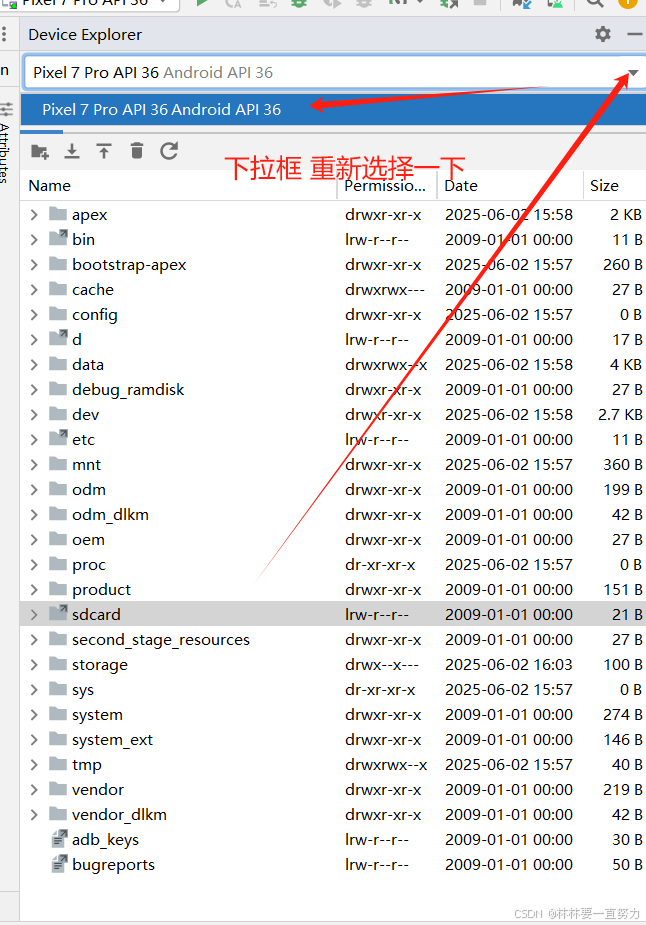
Android Studio 向模拟器手机添加照片、视频、音乐
Android Studio 向模拟器手机添加照片、视频、音乐(其实都是一样的,只是添加到不同的文件夹),例如我们在很多程序中功能例如:选择头像,跳转到手机相册选择头像,此时相册为空,即模拟器没有图片资…...
数据结构-算法学习C++(入门)
目录 03二进制和位运算04 选择、冒泡、插入排序05 对数器06 二分搜索07 时间复杂度和空间复杂度08 算法和数据结构09 单双链表09.1单双链表及反转09.2合并链表09.2两数相加09.2分隔链表 013队列、栈、环形队列013.1队列013.2栈013.3循环队列 014栈-队列的相互转换014.1用栈实现…...