3D Gaussian splatting 05: 代码阅读-训练整体流程
目录
- 3D Gaussian splatting 01: 环境搭建
- 3D Gaussian splatting 02: 快速评估
- 3D Gaussian splatting 03: 用户数据训练和结果查看
- 3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云
- 3D Gaussian splatting 05: 代码阅读-训练整体流程
- 3D Gaussian splatting 06: 代码阅读-训练参数
- 3D Gaussian splatting 07: 代码阅读-训练载入数据和保存结果
- 3D Gaussian splatting 08: 代码阅读-渲染
训练整体流程
程序入参
训练程序入参除了训练过程参数, 另外设置了ModelParams, OptimizationParams, PipelineParams三个参数组, 分别控制数据加载、渲染计算和优化训练环节, 详细的说明查看下一节 06: 代码阅读-训练参数
# 命令行参数解析器parser = ArgumentParser(description="Training script parameters")# 模型相关参数lp = ModelParams(parser)op = OptimizationParams(parser)pp = PipelineParams(parser)parser.add_argument('--ip', type=str, default="127.0.0.1")parser.add_argument('--port', type=int, default=6009)parser.add_argument('--debug_from', type=int, default=-1)parser.add_argument('--detect_anomaly', action='store_true', default=False)parser.add_argument("--test_iterations", nargs="+", type=int, default=[7_000, 30_000])parser.add_argument("--save_iterations", nargs="+", type=int, default=[7_000, 30_000])parser.add_argument("--quiet", action="store_true")parser.add_argument('--disable_viewer', action='store_true', default=False)parser.add_argument("--checkpoint_iterations", nargs="+", type=int, default=[])parser.add_argument("--start_checkpoint", type=str, default = None)args = parser.parse_args(sys.argv[1:])
开始训练
程序调用 training() 这个方法开始训练
torch.autograd.set_detect_anomaly(args.detect_anomaly)
training(lp.extract(args), op.extract(args), pp.extract(args), args.test_iterations, args.save_iterations, args.checkpoint_iterations, args.start_checkpoint, args.debug_from)
初始化
以下是 training() 这个方法中初始化训练的代码和对应的注释说明
# 如果指定了 sparse_adam 加速器, 检查是否已经安装
if not SPARSE_ADAM_AVAILABLE and opt.optimizer_type == "sparse_adam":sys.exit(f"Trying to use sparse adam but it is not installed, please install the correct rasterizer using pip install [3dgs_accel].")
# first_iter用于记录当前是第几次迭代
first_iter = 0
# 创建本次训练的输出目录和日志记录器, 每次执行训练, 都会在 output 目录下创建一个随机目录名
tb_writer = prepare_output_and_logger(dataset)
# 初始化 Gaussian 模型
gaussians = GaussianModel(dataset.sh_degree, opt.optimizer_type)
# 初始化训练场景, 这里会载入相机参数和稀疏点云等数据
scene = Scene(dataset, gaussians)
# 初始化训练参数
gaussians.training_setup(opt)
# 如果存在检查点, 则载入
if checkpoint:(model_params, first_iter) = torch.load(checkpoint)gaussians.restore(model_params, opt)# 设置背景颜色
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")# 初始化CUDA事件
iter_start = torch.cuda.Event(enable_timing = True)
iter_end = torch.cuda.Event(enable_timing = True)# 是否使用 sparse adam 加速器
use_sparse_adam = opt.optimizer_type == "sparse_adam" and SPARSE_ADAM_AVAILABLE
# Get depth L1 weight scheduling function
depth_l1_weight = get_expon_lr_func(opt.depth_l1_weight_init, opt.depth_l1_weight_final, max_steps=opt.iterations)# Initialize viewpoint stack and indices
viewpoint_stack = scene.getTrainCameras().copy()
viewpoint_indices = list(range(len(viewpoint_stack)))
# Initialize exponential moving averages for logging
ema_loss_for_log = 0.0
ema_Ll1depth_for_log = 0.0# 初始化进度条
progress_bar = tqdm(range(first_iter, opt.iterations), desc="Training progress")
迭代训练
从大约73行开始, 进行迭代训练
first_iter += 1
for iteration in range(first_iter, opt.iterations + 1):
对外连工具展示渲染结果
# 这部分处理网络连接, 对外展示当前训练的渲染结果if network_gui.conn == None:network_gui.try_connect()while network_gui.conn != None:try:net_image_bytes = None# Receive data from GUIcustom_cam, do_training, pipe.convert_SHs_python, pipe.compute_cov3D_python, keep_alive, scaling_modifer = network_gui.receive()if custom_cam != None:# Render image for GUInet_image = render(custom_cam, gaussians, pipe, background, scaling_modifier=scaling_modifer, use_trained_exp=dataset.train_test_exp, separate_sh=SPARSE_ADAM_AVAILABLE)["render"]net_image_bytes = memoryview((torch.clamp(net_image, min=0, max=1.0) * 255).byte().permute(1, 2, 0).contiguous().cpu().numpy())# Send image to GUInetwork_gui.send(net_image_bytes, dataset.source_path)if do_training and ((iteration < int(opt.iterations)) or not keep_alive):breakexcept Exception as e:network_gui.conn = None
更新学习率, 选中相机进行渲染
# 记录迭代的开始时间iter_start.record()# 更新学习率, 底下都是调用的 get_expon_lr_func(), 一个学习率调度函数, 根据训练步数计算当前的学习率, 学习率从初始值指数衰减到最终值.gaussians.update_learning_rate(iteration)# 每1000次迭代, 球谐函数(SH, Spherical Harmonics)的阶数加1, 直到设置的最大的阶数, 默认最大为3, # 每个3D高斯点需要存储(阶数 + 1)^2 个球谐系数, 3阶时为16个系数, 每个系数有RGB 3个值所以一共48个值if iteration % 1000 == 0:gaussians.oneupSHdegree()# 当栈为空时, 复制一份训练帧的相机位姿列表并创建对应的索引列表if not viewpoint_stack:viewpoint_stack = scene.getTrainCameras().copy()viewpoint_indices = list(range(len(viewpoint_stack)))# 从中随机选取一个相机位姿rand_idx = randint(0, len(viewpoint_indices) - 1)# 从当前栈中弹出, 避免重复选取, 这样最终会按随机的顺序遍历完所有的相机位姿viewpoint_cam = viewpoint_stack.pop(rand_idx)vind = viewpoint_indices.pop(rand_idx)# 如果到了开启debug的迭代次数, 开启debugif (iteration - 1) == debug_from:pipe.debug = True# 如果设置了随机背景, 创建随机背景颜色张量bg = torch.rand((3), device="cuda") if opt.random_background else background# 用当前选中的相机视角, 渲染当前的场景render_pkg = render(viewpoint_cam, gaussians, pipe, bg, use_trained_exp=dataset.train_test_exp, separate_sh=SPARSE_ADAM_AVAILABLE)# 读出渲染结果image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"]# 处理摄像机视角的alpha遮罩(透明度), 将alpha遮罩数据从CPU内存转移到GPU显存, 将当前图像与alpha遮罩进行逐像素相乘, # alpha值为1时保留原像素, alpha值为0时使像素完全透明if viewpoint_cam.alpha_mask is not None:alpha_mask = viewpoint_cam.alpha_mask.cuda()image *= alpha_mask
计算损失
# 从viewpoint_cam对象中获取原始图像数据, 使用.cuda()方法将数据从CPU内存转移到GPU显存, # 调用L1损失函数, 计算渲染结果与原图gt_image之间的像素级绝对差平均值gt_image = viewpoint_cam.original_image.cuda()Ll1 = l1_loss(image, gt_image)# 计算两个图像之间的结构相似性指数(SSIM), 如果 fused_ssim 可用则使用 fused_ssim, 否则使用普通的ssim# Calculate SSIM using fused implementation if availableif FUSED_SSIM_AVAILABLE:# 用unsqueeze(0)来增加一个维度,fused_ssim需要批量输入ssim_value = fused_ssim(image.unsqueeze(0), gt_image.unsqueeze(0))else:ssim_value = ssim(image, gt_image)# 结合L1损失和SSIM损失计算混合损失, (1.0 - ssim_value) 将SSIM相似度转换为损失值, 因为SSIM值越大损失越小loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim_value)# Depth regularization 深度正则化, 引入单目深度估计作为弱监督信号改善几何一致性, 缓解漂浮物伪影, 增强遮挡区域的重建效果Ll1depth_pure = 0.0if depth_l1_weight(iteration) > 0 and viewpoint_cam.depth_reliable:# 从渲染结果中获取逆向深度图(1/depth)invDepth = render_pkg["depth"]# 获取单目深度估计的逆向深度图并转移到GPUmono_invdepth = viewpoint_cam.invdepthmap.cuda()# 深度有效区域的掩码(标记可靠区域)depth_mask = viewpoint_cam.depth_mask.cuda()# 计算带掩码的L1损失 = 绝对差(渲染深度 - 单目深度) * 掩码 → 取均值Ll1depth_pure = torch.abs((invDepth - mono_invdepth) * depth_mask).mean()# 应用动态权重系数(可能随迭代次数衰减)Ll1depth = depth_l1_weight(iteration) * Ll1depth_pure # 将加权后的深度损失加入总损失loss += Ll1depth# 将Tensor转换为Python数值用于记录Ll1depth = Ll1depth.item()else:Ll1depth = 0
反向计算梯度并优化
# 执行反向传播算法, 自动计算所有可训练参数关于loss的梯度loss.backward()# 记录迭代结束时间iter_end.record()# End iteration timing# torch.no_grad() 临时关闭梯度计算的上下文管理器with torch.no_grad():# Progress barema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_logema_Ll1depth_for_log = 0.4 * Ll1depth + 0.6 * ema_Ll1depth_for_logif iteration % 10 == 0:progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}", "Depth Loss": f"{ema_Ll1depth_for_log:.{7}f}"})progress_bar.update(10)if iteration == opt.iterations:progress_bar.close()# 输出日志, 当迭代次数为 testing_iterations 时(默认为7000和30000), 会做一次整体评估, 间隔5取5个样本, 取一部分相机视角计算L1和SSIM损失, iter_start.elapsed_time(iter_end) 计算耗时training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end), testing_iterations, scene, render, (pipe, background, 1., SPARSE_ADAM_AVAILABLE, None, dataset.train_test_exp), dataset.train_test_exp)# 当迭代次数为 saving_iterations(默认为7000和30000)时,保存if (iteration in saving_iterations):print("\n[ITER {}] Saving Gaussians".format(iteration))# 里面会调用 gaussians.save_ply() 保存ply文件scene.save(iteration)# 当迭代次数小于致密化结束的右边界时if iteration < opt.densify_until_iter:# 可见性半径更新, 记录每个高斯点在所有视角下的最大可见半径, 用于后续剪枝判断. visibility_filter过滤出当前视角可见的高斯点# Keep track of max radii in image-space for pruninggaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])# 累积视空间位置梯度统计量, 用于后续判断哪些高斯点需要分裂(高梯度区域)或克隆(高位置变化区域)gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)# 当迭代次数大于致密化开始的左边界, 并且满足致密化间隔时, 进行致密化与修剪处理if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:# 如果迭代次数小于不透明度重置间隔(3000)则返回20作为2D尺寸限制, 否则不限制size_threshold = 20 if iteration > opt.opacity_reset_interval else None# 致密化与修剪gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold, radii)# 定期(默认3000一次)重置不透明度, 恢复被错误剪枝的高斯点, 调整新生成高斯的可见性, 适配白背景场景的特殊初始化if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):gaussians.reset_opacity()# Optimizer阶段, 反向优化模型参数if iteration < opt.iterations:gaussians.exposure_optimizer.step()gaussians.exposure_optimizer.zero_grad(set_to_none = True)if use_sparse_adam:visible = radii > 0gaussians.optimizer.step(visible, radii.shape[0])gaussians.optimizer.zero_grad(set_to_none = True)else:gaussians.optimizer.step()gaussians.optimizer.zero_grad(set_to_none = True)# 到达预设的checkpoint, 默认为7000和30000, 保存当前的训练进度if (iteration in checkpoint_iterations):print("\n[ITER {}] Saving Checkpoint".format(iteration))torch.save((gaussians.capture(), iteration), scene.model_path + "/chkpnt" + str(iteration) + ".pth")
如果有错误请留言指出
相关文章:

3D Gaussian splatting 05: 代码阅读-训练整体流程
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...

Linux——计算机网络基础
一、网络 1.概念 由若干结点和连接结点的链路组成。结点可以是计算机,交换机,路由器等。 2.互联网 多个网络连接起来就是互联网。 因特网:最大的互联网。 二、IP地址和MAC地址 1.IP地址 (1)概念 IP地址是给因…...

第2章_Excel_知识点笔记
来自: 第2章_Excel_知识点笔记 原笔记 Excel 知识点总结(第2章) Excel_2.1 知识点 基础操作 状态栏:快速查看计数/求和等数据(右键可配置)。筛选(CtrlShiftL):按条件显…...

缩量和放量指的是什么?
在股票市场中,“缩量”和“放量”是描述成交量变化的两个核心概念,它们反映了市场参与者的情绪和资金动向,对判断股价趋势有重要参考价值。以下是具体解析: 📉 一、缩量(成交量明显减少) 1. 定…...
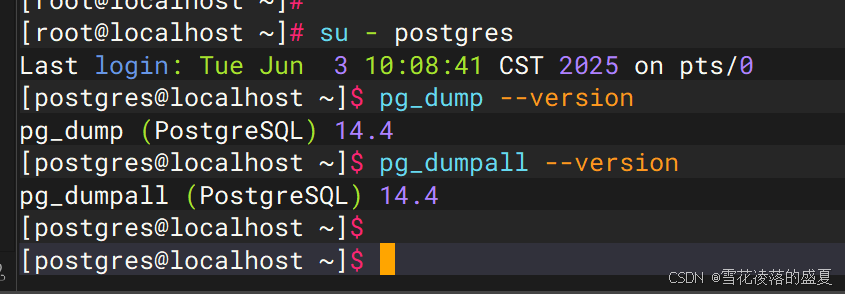
PostgreSQL数据库备份
文章目录 pg_dump 和 pg_dumpall使用 pg_dump 备份单个数据库示例 使用 pg_dumpall 备份整个数据库集群基本用法 恢复备份恢复 pg_dump 备份恢复 pg_dumpall 备份 Tips pg_dump 和 pg_dumpall 在 PostgreSQL 中,pg_dump 和 pg_dumpall 是两个常用的备份工具&#x…...

企业级Spring MVC高级主题与实用技术讲解
企业级Spring MVC高级主题与实用技术讲解 本手册旨在为具备Spring MVC基础的初学者,系统地讲解企业级应用开发中常用的高级主题和实用技术,涵盖RESTful API、统一异常处理、拦截器、文件处理、国际化、前端集成及Spring Security基础。内容结合JavaConf…...
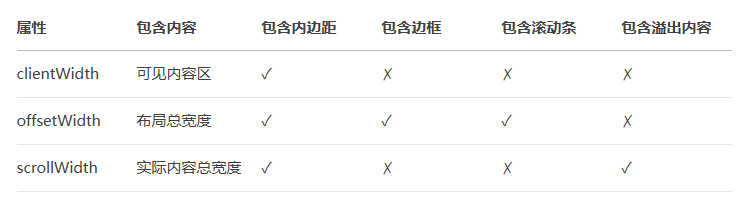
js-day7
JS学习之旅-day7 1.事件流1.1 事件流与两个阶段说明1.2 事件捕获1.3 事件冒泡1.4 阻止1.5 解绑事件 2. 事件委托3. 其他事件3.1 页面加载事件3.2 页面滚动事件3.3 页面尺寸事件 4. 元素尺寸与位置 1.事件流 1.1 事件流与两个阶段说明 事件流指的是事件完整执行过程中的流动路…...

【算法训练营Day04】链表part2
文章目录 两两交换链表中的节点删除链表的倒数第 N 个结点链表相交环形链表 II链表总结 两两交换链表中的节点 题目链接:24. 两两交换链表中的节点 算法逻辑: 添加一个虚拟头节点初始化一个交换指针,代表每次交换指针的后两个节点࿰…...

【ROS2】各种相关概念汇总解释
包含概念 ROS2自带的标准接口ament_cmake是什么? 标准接口 似乎没有一个确定的名称,就是通俗的叫做“ROS2自带的消息接口” 这些接口存放在 /opt/ros/humble/share 路径下 ament_cmake 是 ROS 2 中基于 CMake 的构建系统 系统越复杂,构…...

解决Vditor加载Markdown网页很慢的问题(Vite+JS+Vditor)
1. 引言 在上一篇文章《使用Vditor将Markdown文档渲染成网页(ViteJSVditor)》中,详细介绍了通过Vditor将Markdown格式文档渲染成Web网页的过程,并且实现了图片格式居中以及图片源更换的功能。不过,笔者发现在加载这个渲染Markdown网页的时候…...

Flowise 本地部署文档及 MCP 使用说明
一、Flowise 简介 Flowise 是一个开源的拖放式 UI 工具,用于构建自定义的 LLM 工作流程。它允许用户通过可视化界面连接不同的 AI 组件,无需编写代码即可创建复杂的 AI 应用。 二、Docker 环境安装 1. 构建 Docker 镜像 docker build -t node22-ubuntu-dev .其中Dockerfi…...

YOLO学习笔记 | 一种用于海面目标检测的多尺度YOLO算法
多尺度YOLO算法用于海面目标检测 核心挑战分析 恶劣天气:雨雾、低光照干扰图像质量波浪干扰:动态背景产生大量噪声多尺度目标:船只(大)、浮标(小)等尺度差异大目标遮挡:波浪导致目标部分遮挡算法原理 多尺度YOLO架构(基于YOLOv5改进): graph TD A[输入图像] --&g…...

鸿蒙5.0项目开发——横竖屏切换开发
横竖屏切换开发 【高心星出品】 文章目录 横竖屏切换开发运行效果窗口旋转配置module.json5的orientation字段调用窗口的setPreferredOrientation方法案例代码解析Index1页面代码:EntryAbility在module.json5的配置信息:Index页面的代码信息࿱…...
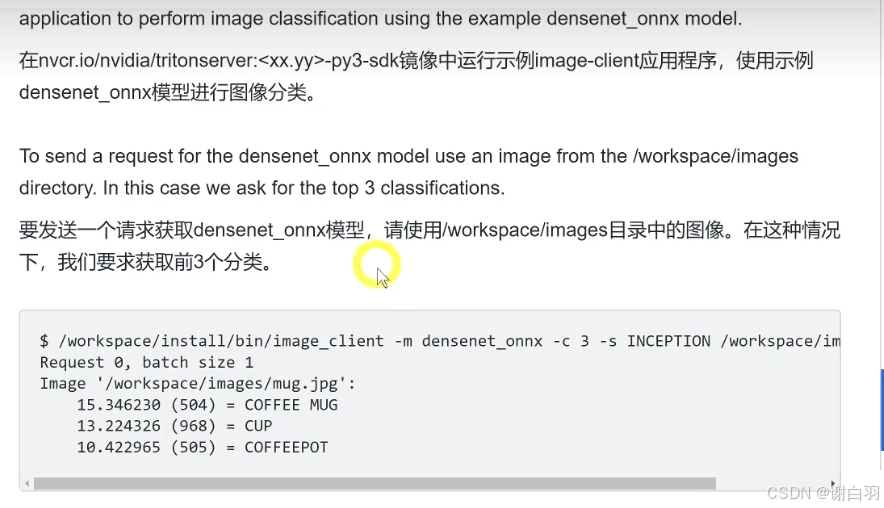
Triton推理服务器部署YOLOv8(onnxruntime后端和TensorRT后端)
文章目录 一、Trition推理服务器基础知识1)推理服务器设计概述2)Trition推理服务器quickstart(1)创建模型仓库(Create a model Repository)(2)启动Triton (launching triton)并验证是否正常运行(3)发送推理请求(send a inference request)3)Trition推理服务器架…...

TDengine 的 AI 应用实战——电力需求预测
作者: derekchen Demo数据集准备 我们使用公开的UTSD数据集里面的电力需求数据,作为预测算法的数据来源,基于历史数据预测未来若干小时的电力需求。数据集的采集频次为30分钟,单位与时间戳未提供。为了方便演示,按…...
NLP学习路线图(二十一): 词向量可视化与分析
在自然语言处理(NLP)的世界里,词向量(Word Embeddings)犹如一场静默的革命。它将原本离散、难以捉摸的词语,转化为稠密、富含语义的连续向量,为机器理解语言铺平了道路。然而,这些向…...

【分布式技术】KeepAlived高可用架构科普
KeepAlived高可用架构 Keepalived 架构详解一、核心架构组件二、VRRP 协议详解1. **VRRP 核心概念**2. **VRRP 工作流程**3. **VRRP 通信机制** 三、高可用架构模型四、健康检查机制五、配置文件详解配置文件关键参数说明: 六、高可用实现流程七、脑裂问题与解决方案…...

如何配置mvn镜像源为华为云
如何配置mvn镜像源为华为云 # 查找mvn 配置文件 mvn -X help:effective-settings | grep settings.xml# 配置mvn镜像源为华为云,/home/apache-maven-3.9.5/conf/settings.xml文件路径需要根据上一步中查询结果调整 cat > /home/apache-maven-3.9.5/conf/setting…...

Linux平台排查CPU占用高的进程和线程指南
基础排查工具 1. top命令 - 实时进程监控 top操作指令: 按 P:按CPU使用率排序按 1:显示每个CPU核心的使用情况按 H:切换显示线程视图按 M:按内存使用排序按 q:退出 2. htop命令 - 增强版top(…...

多模态大语言模型arxiv论文略读(105)
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文标题:UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文作者:Zhaowei…...

简述MySQL 超大分页怎么处理 ?
针对MySQL超大分页(深度分页)的性能问题,核心优化方案如下: 1. 子查询 覆盖索引(延迟关联) 原理: 子查询仅扫描覆盖索引(如主键),避免回表操作…...

Pyhton中的命名空间包(Namespace Package)您了解吗?
在 Python 中,命名空间包(Namespace Package) 是一种特殊的包结构,它允许将模块分散在多个独立的目录中,但这些目录在逻辑上属于同一个包命名空间。命名空间包的核心特点是:没有 __init__.py 文件ÿ…...

Java设计模式之备忘录模式详解
Java设计模式之备忘录模式详解 一、备忘录模式核心思想 核心目标:捕获对象内部状态并在需要时恢复,同时不破坏对象的封装性。如同游戏存档系统,允许玩家保存当前进度并在需要时回退到之前的状态。 二、备忘录模式类图(Mermaid&am…...

Azure DevOps Server 2022.2 补丁(Patch 5)
微软Azure DevOps Server的产品组在4月8日发布了2022.2 的第5个补丁。下载路径为:https://aka.ms/devops2022.2patch5 这个补丁的主要功能是修改了代理(Agent)二进制安装文件的下载路径;之前,微软使用这个CND(域名为vstsagentpackage.azuree…...

手摸手还原vue3中reactive的get陷阱以及receiver的作用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、实例是什么?二、new Prxoy三、实现代码1.引入代码2.读入数据 总结 前言 receiver不是为解决get陷阱而生,而是为解决Proxy中的this绑…...

小明的Java面试奇遇之互联网保险系统架构与性能优化
一、文章标题 小明的Java面试奇遇之互联网保险系统架构与性能优化🚀 二、文章标签 Java,Spring Boot,MyBatis,Redis,Kafka,JVM,多线程,互联网保险,系统架构,性能优化 三、文章概述 本文模拟了程序员小明在应聘互联网保险系统开发岗位时,参与的一场深…...
C++学习-入门到精通【13】标准库的容器和迭代器
C学习-入门到精通【13】标准库的容器和迭代器 目录 C学习-入门到精通【13】标准库的容器和迭代器一、标准模板库简介1.容器简介2.STL容器总览3.近容器4.STL容器的通用函数5.首类容器的通用typedef6.对容器元素的要求 二、迭代器简介1.使用istream_iterator输入,使用…...
C# 面向对象特性
面向对象编程的三大基本特性是:封装、继承和多态。下面将详细介绍这三大特性在C#中的体现方式。 封装 定义:把对象的数据和操作代码组合在同一个结构中,这就是对象的封装性。 体现方式: 使用访问修饰符控制成员的可见性 通过属…...
ElasticStack技术之logstash介绍
一、什么是Logstash Logstash 是 Elastic Stack(ELK Stack)中的一个开源数据处理管道工具,主要用于收集、解析、过滤和传输数据。它支持多种输入源,如文件、网络、数据库等,能够灵活地对数据进行处理,比如…...

前端与后端
实例一 处理登录页面请求 # 处理登录页面请求 app.route(/c, methods[GET, POST]) # /c是网页地址 def login(): usernameaa passwordbb print(username,password) if request.method POST: username request.form.get(yhm) password requ…...