Spring AI Advisor机制
Spring AI Advisors 是 Spring AI 框架中用于拦截和增强 AI 交互的核心组件,其设计灵感类似于 WebFilter,通过链式调用实现对请求和响应的处理5。以下是关键特性与实现细节:
核心功能
1. 请求/响应拦截
- 通过 AroundAdvisor 接口动态修改聊天请求(AdvisedRequest)和响应(AdvisedResponse),支持日志记录、内容转换等场景。
- 处理流程遵循责任链模式,请求按顺序通过所有 Advisor,响应则逆序返回。
2. 上下文共享
- 通过 AdvisorContext(一个 Map<String, Object>)在 Advisor 链中传递数据,实现跨拦截器的状态共享。
3. 多模型兼容性
- 封装通用 AI 模式(如记忆管理、日志记录),确保代码可复用且兼容不同大模型(如 GPT、Claude、通义千问等)16。
典型应用
- 记忆管理:通过 MessageChatMemoryAdvisor 保存对话历史,实现多轮上下文关联7。
- 日志记录:内置 SimpleLoggerAdvisor 可记录交互详情,便于调试7。
- 动态提示词修改:在请求链中实时调整发送给大模型的提示内容58。
配置示例
// 添加记忆和日志 Advisor
chatClient.prompt().user(message).advisors(new MessageChatMemoryAdvisor(chatMemory),new SimpleLoggerAdvisor()).call();
var chatClient = ChatClient.builder(chatModel).defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build(), // chat-memory advisorQuestionAnswerAdvisor.builder((vectorStore).builder() // RAG advisor).build();var conversationId = "678";String response = this.chatClient.prompt()// Set advisor parameters at runtime.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, conversationId)).user(userText).call().content();
核心组件
由非流式处理方案和 for 流式处理方案组成。 它还包括表示 Chat Completion 响应的未密封 Prompt 请求。两者都在 advisor 链中持有 to share 状态。
CallAroundAdvisor CallAroundAdvisorChain StreamAroundAdvisor StreamAroundAdvisorChain AdvisedRequest AdvisedResponse advise-context
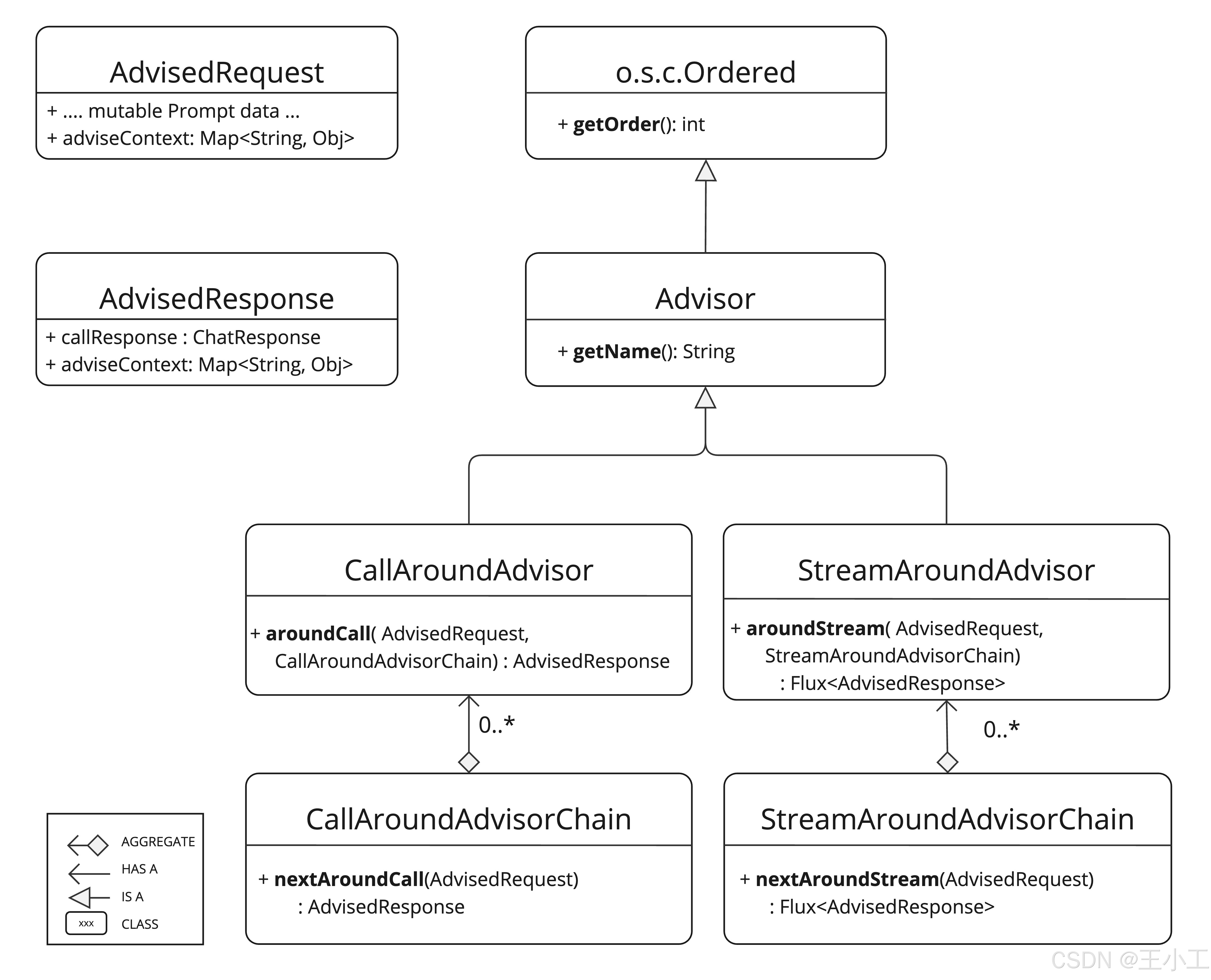
关键 advisor 方法,通常执行各种作,例如检查未密封的 Prompt 数据、自定义和扩充 Prompt 数据、调用 advisor 链中的下一个实体、选择性地阻止请求、检查聊天完成响应以及引发异常以指示处理错误。nextAroundCall() nextAroundStream()
此外,该方法确定链中的 advisor 顺序,同时提供唯一的 advisor 名称。getOrder() getName()
由 Spring AI 框架创建的 Advisor 链允许按顺序调用多个按其值排序的 advisor。 首先执行较低的值。 自动添加的最后一个 advisor 将请求发送到 LLM。getOrder()
以程图说明了Advisor链和聊天模型之间的交互:
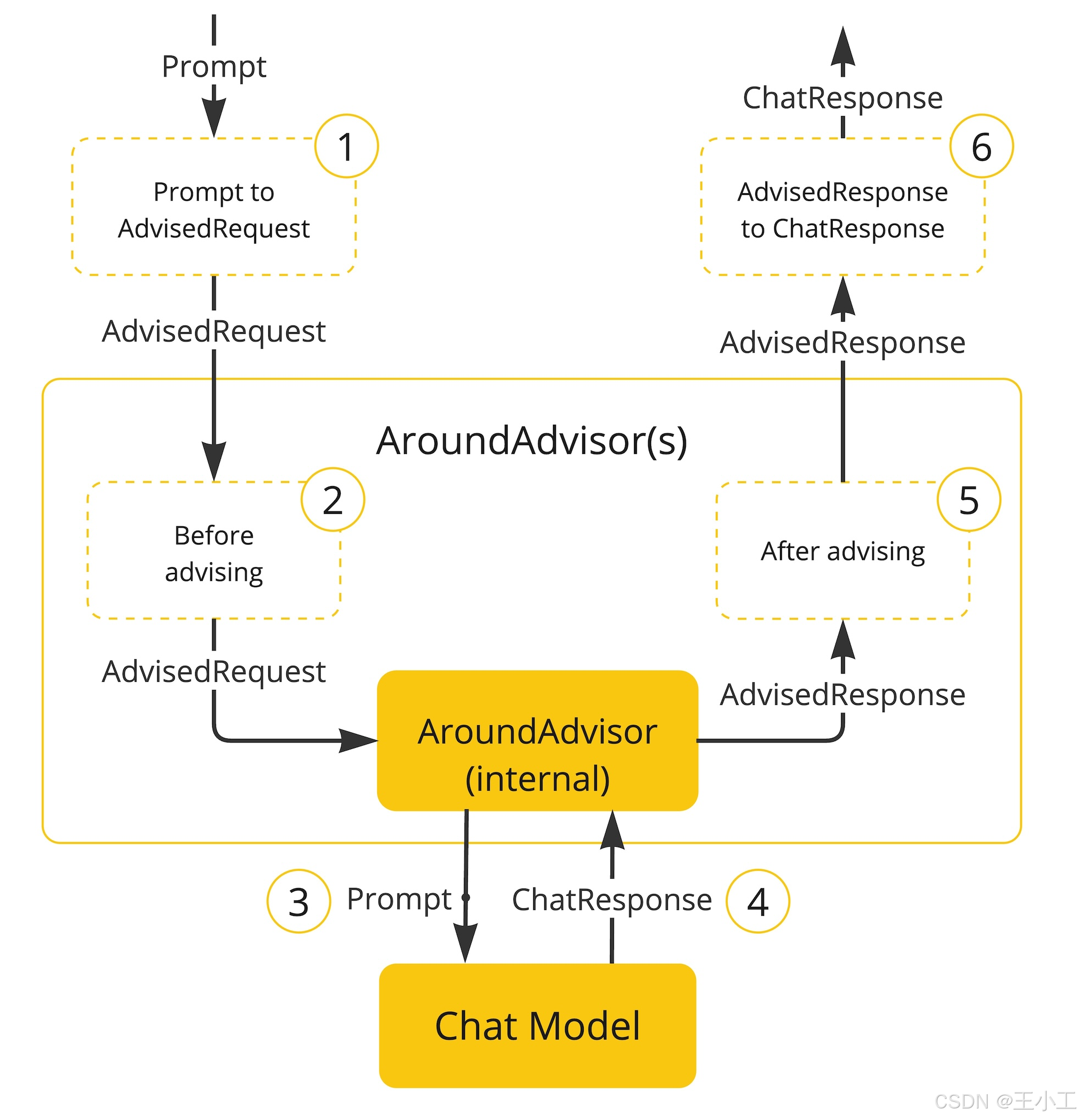
- Spring AI 框架创建一个 from user’s 以及一个空对象。AdvisedRequestPromptAdvisorContext
- 链中的每个 advisor 都会处理请求,并可能对其进行修改。或者,它也可以选择通过不调用下一个实体来阻止请求。在后一种情况下,Advisor负责填写回复。
- 框架提供的最后一个 advisor 将请求发送到 .Chat Model
- 然后,聊天模型的响应将通过Advisor链传回并转换为 .later 包括共享实例。AdvisedResponseAdvisorContext
- 每个Advisor都可以处理或修改响应。
- final 通过提取 .AdvisedResponseChatCompletion
API 概述
主要的 Advisor 。以下是在创建自己的 advisor 时会遇到的关键界面:org.springframework.ai.chat.client.advisor.api
public interface Advisor extends Ordered {String getName();
}
同步和反应式 Advisor 的两个子接口是
public interface CallAroundAdvisor extends Advisor {/*** Around advice that wraps the ChatModel#call(Prompt) method.* @param advisedRequest the advised request* @param chain the advisor chain* @return the response*/AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain);}
和
public interface StreamAroundAdvisor extends Advisor {/*** Around advice that wraps the invocation of the advised request.* @param advisedRequest the advised request* @param chain the chain of advisors to execute* @return the result of the advised request*/Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain);}
要继续 Advice 链,请在 Advice 实现中使用 :CallAroundAdvisorChain StreamAroundAdvisorChain
这些接口包括
public interface CallAroundAdvisorChain {AdvisedResponse nextAroundCall(AdvisedRequest advisedRequest);
}
和
public interface StreamAroundAdvisorChain {Flux<AdvisedResponse> nextAroundStream(AdvisedRequest advisedRequest);
}
Advisor
要创建 advisor,请实现一下。要实现的关键方法是针对非流式处理或流式处理Advisor。CallAroundAdvisor StreamAroundAdvisor nextAroundCall() nextAroundStream()
日志记录样例:
可以实现一个简单的日志 advisor,记录对链中下一个 advisor 的调用之前和之后。 请注意,advisor 仅观察请求和响应,不会修改它们。 此实现支持非流式处理和流式处理方案。AdvisedRequest AdvisedResponse
public class SimpleLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);@Overridepublic String getName() {return this.getClass().getSimpleName();}@Overridepublic int getOrder() {return 0;}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {logger.debug("BEFORE: {}", advisedRequest);AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);logger.debug("AFTER: {}", advisedResponse);return advisedResponse;}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {logger.debug("BEFORE: {}", advisedRequest);Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);return new MessageAggregator().aggregateAdvisedResponse(advisedResponses,advisedResponse -> logger.debug("AFTER: {}", advisedResponse));}
}
- 为 advisor 提供唯一名称。
- 可以通过设置 order 值来控制执行顺序。较低的值首先执行。
- 它是一个实用程序类,用于将 Flux 响应聚合到单个 AdvisedResponse 中。 这对于记录或其他观察整个响应而不是流中单个项目的处理非常有用。 请注意,不能更改 中的响应,因为它是只读作。MessageAggregator MessageAggregator
重读 (Re2) Advisor
“Re-Reading Improves Reasoning in Large Language Models” 一文介绍了一种称为 Re-Reading (Re2) 的技术,该技术可以提高大型语言模型的推理能力。 Re2 技术需要像这样扩充输入提示:
{Input_Query}
Read the question again: {Input_Query}
实现将 Re2 技术应用于用户输入查询的 advisor 可以像这样完成:
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {private AdvisedRequest before(AdvisedRequest advisedRequest) {Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());advisedUserParams.put("re2_input_query", advisedRequest.userText());return AdvisedRequest.from(advisedRequest).userText("""{re2_input_query}Read the question again: {re2_input_query}""").userParams(advisedUserParams).build();}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {return chain.nextAroundCall(this.before(advisedRequest));}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {return chain.nextAroundStream(this.before(advisedRequest));}@Overridepublic int getOrder() {return 0;}@Overridepublic String getName() {return this.getClass().getSimpleName();}
}
- 该方法应用 Re-Reading 技术来增强用户的输入查询。before
- 该方法拦截非流式处理请求并应用 Re-Reading 技术。aroundCall
- 该方法拦截流请求并应用 Re-Reading 技术。aroundStream
- 可以通过设置 order 值来控制执行顺序。较低的值首先执行。
- 为 advisor 提供唯一名称。
内置Advisor程序
Spring AI 框架提供了几个内置的Advisor程序来增强您的 AI 交互。以下是可用Advisor的概述:
聊天记忆Advisor
这些Advisor在聊天内存存储中管理对话历史记录:
- MessageChatMemoryAdvisor
检索内存并将其作为消息集合添加到提示符中。此方法维护会话历史记录的结构。请注意,并非所有 AI 模型都支持此方法。 - PromptChatMemoryAdvisor
检索内存并将其合并到提示的系统文本中。 - VectorStoreChatMemoryAdvisor
从 VectorStore 中检索内存,并将其添加到提示符的系统文本中。此 advisor 可用于从大型数据集中高效搜索和检索相关信息。
问题解答Advisor
- QuestionAnswerAdvisor
此 advisor 使用向量存储来提供问答功能,实现 RAG(检索增强生成)模式。
内容安全Advisor
- SafeGuardAdvisor
一个简单的 advisor,旨在防止模型生成有害或不适当的内容。
MessageChatMemoryAdvisor
Spring AI中的MessageChatMemoryAdvisor是一个关键组件,主要用于管理AI应用中的聊天记忆和上下文增强。以下是其核心特性和工作原理:
1. 基本功能
- 负责将用户提问和AI回复存入历史记录,形成上下文记忆链
- 通过维护对话状态提升聊天机器人的连贯性和相关性
- 工作流程
- 采用链式处理结构,作为请求/响应流程的中间件
- 处理流程:接收请求 → 存储用户消息 → 传递修改后的请求 → 接收响应 → 存储AI回复
- 技术实现
- 继承自AroundAdvisor基类,支持请求/响应的动态修改
- 与ChatMemory组件协同工作,支持多种存储后端(内存/JDBC/Neo4j等)
- 典型应用场景
- 多轮对话系统中保持上下文一致性
- 实现角色预设(通过SystemMessage)
- 控制对话窗口大小(如GPT模型的token限制)
PromptChatMemoryAdvisor
PromptChatMemoryAdvisor是Spring AI框架中用于管理对话上下文的核心组件,主要功能是将历史对话信息动态注入到当前提示词中23。以下是其关键特性:
1. 核心功能
- 自动检索与当前会话ID关联的历史消息
- 将历史消息注入系统提示文本(SystemMessage),增强AI模型的上下文理解能力
- 支持通过ChatMemory接口实现多种存储策略(内存/JDBC/向量库等)
- 技术实现
- 基于Spring AOP的AroundAdvisor机制拦截请求/响应流程
- 默认使用InMemoryChatMemory存储对话记录
- 通过CONVERSATION_ID标识会话(原CHAT_MEMORY_CONVERSATION_ID_KEY)
- 配置参数
- TOP_K参数控制历史消息检索数量(原CHAT_MEMORY_RETRIEVE_SIZE_KEY)
- DEFAULT_TOP_K默认值从100调整为20
- 支持通过SystemMessage设定对话角色和规则
VectorStoreChatMemoryAdvisor
核心功能
1. 长期记忆管理
通过向量数据库存储历史对话记录,实现跨会话的上下文记忆功能
支持语义检索相似历史消息,增强模型对用户意图的理解能力
2. 工作流程
- 检索阶段:从向量库中检索与当前会话相关的历史消息
- 提示增强:将检索结果注入系统提示文本,构建上下文感知的输入
- 存储阶段:自动保存新生成的对话记录到向量数据库
- 技术特性
- 向量存储集成
支持多种向量数据库(如Azure Cosmos DB、Weaviate等),通过语义相似度检索历史消息
默认检索结果数量从100条优化为20条(DEFAULT_TOP_K参数) - 提示模板定制
使用独立占位符模板long_term_memory管理长期记忆的注入逻辑
应用场景
- 多轮复杂对话
解决LLM无状态限制,保持跨会话的连贯性35 - RAG增强
与RetrievalAugmentationAdvisor协同实现检索增强生成5
配置要点
// 示例配置代码
@Bean
VectorStoreChatMemoryAdvisor advisor(VectorStore vectorStore, ChatMemory chatMemory // 需配合MessageWindowChatMemory等实现
) {return new VectorStoreChatMemoryAdvisor(vectorStore, chatMemory);
}
QuestionAnswerAdvisor
核心功能
1. RAG流程封装
实现检索增强生成(Retrieval-Augmented Generation)全流程,包括知识库检索、上下文拼接和回答生成38
当用户提问时,自动从向量数据库检索相似文档,并作为上下文注入提示词310
2. 智能拒答机制
若知识库检索结果相似度低于阈值(默认0.5),可能直接拒绝回答而非生成错误信息28
技术实现
-
检索优化
- 支持配置similarityThreshold(相似度阈值)和topK(返回结果数量)参数,平衡精度与召回率
- 通过EmbeddingModel将用户问题向量化后执行语义搜索
-
提示工程
内置默认系统提示模板,动态组合以下要素:- 用户原始问题
- 检索到的相关文档
- 生成格式约束
典型配置示例
@Bean
QuestionAnswerAdvisor advisor(VectorStore vectorStore, EmbeddingModel embeddingModel
) {return QuestionAnswerAdvisor.builder(vectorStore).searchRequest(SearchRequest.builder().similarityThreshold(0.6) // 调高精度要求.topK(5) // 限制返回条目数.build()).build();
}
该组件与VectorStoreChatMemoryAdvisor协同工作时,可同时实现短期对话记忆和长期知识检索。
SafeGuardAdvisor
以下是关于Spring AI中SafeGuardAdvisor的详细解析:
核心功能
1. 敏感内容拦截
自动检测用户输入中的敏感词(如政治、暴力等违规内容),触发拦截时直接终止请求处理流程
支持自定义敏感词库,可通过动态更新适配不同业务场景的合规要求
2. 资源保护机制
在请求被标记为敏感时,立即阻断后续模型调用,避免不必要的计算资源消耗
与日志审计模块联动,记录完整的拦截事件信息供合规审查
技术实现
-
多级过滤管道
采用正则表达式匹配结合语义分析(需集成NLP模型)实现高精度检测
支持配置白名单机制,允许特定角色绕过敏感词检查 -
轻量级拦截器
基于Spring AOP实现,对原有业务逻辑侵入性低,平均延迟增加<5ms
默认集成到ChatClient的请求处理链中,优先级通常设为最高
典型配置示例
@Bean
SafeGuardAdvisor safeGuardAdvisor() {return SafeGuardAdvisor.builder().blockThreshold(0.8) // 敏感词置信度阈值.customBlockWords(List.of("内部资料")) // 追加自定义敏感词.build();
}
该组件常与QuestionAnswerAdvisor组合使用,形成"先过滤后增强"的安全处理链路。在金融、医疗等强监管领域应用尤为广泛。
流式处理与非流式处理
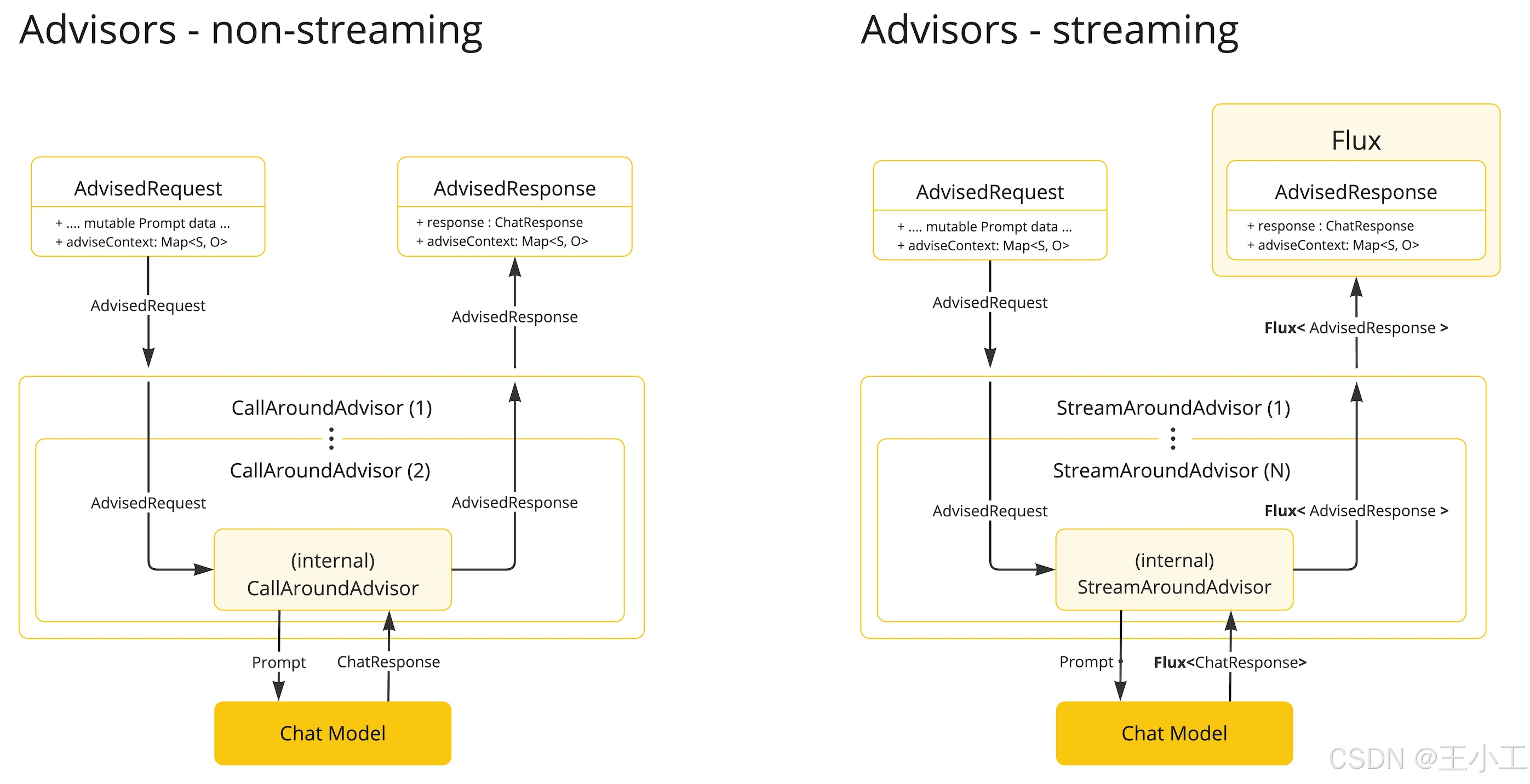
- 非流式处理Advisor处理完整的请求和响应。
- Streaming advisor 使用反应式编程概念(例如,用于响应的 Flux)将请求和响应作为连续流处理。
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {return Mono.just(advisedRequest).publishOn(Schedulers.boundedElastic()).map(request -> {// This can be executed by blocking and non-blocking Threads.// Advisor before next section}).flatMapMany(request -> chain.nextAroundStream(request)).map(response -> {// Advisor after next section});
}
最佳实践
- 让Advisor专注于特定任务,以实现更好的模块化。
- 必要时使用 to share state between advisors。adviseContext
- 实施 advisor 的流式处理和非流式处理版本,以实现最大的灵活性。
- 仔细考虑 Advisor 在供应链中的顺序,以确保数据正常流动。
相关文章:
Spring AI Advisor机制
Spring AI Advisors 是 Spring AI 框架中用于拦截和增强 AI 交互的核心组件,其设计灵感类似于 WebFilter,通过链式调用实现对请求和响应的处理5。以下是关键特性与实现细节: 核心功能 1. 请求/响应拦截 通过 AroundAdvisor 接口动态修…...
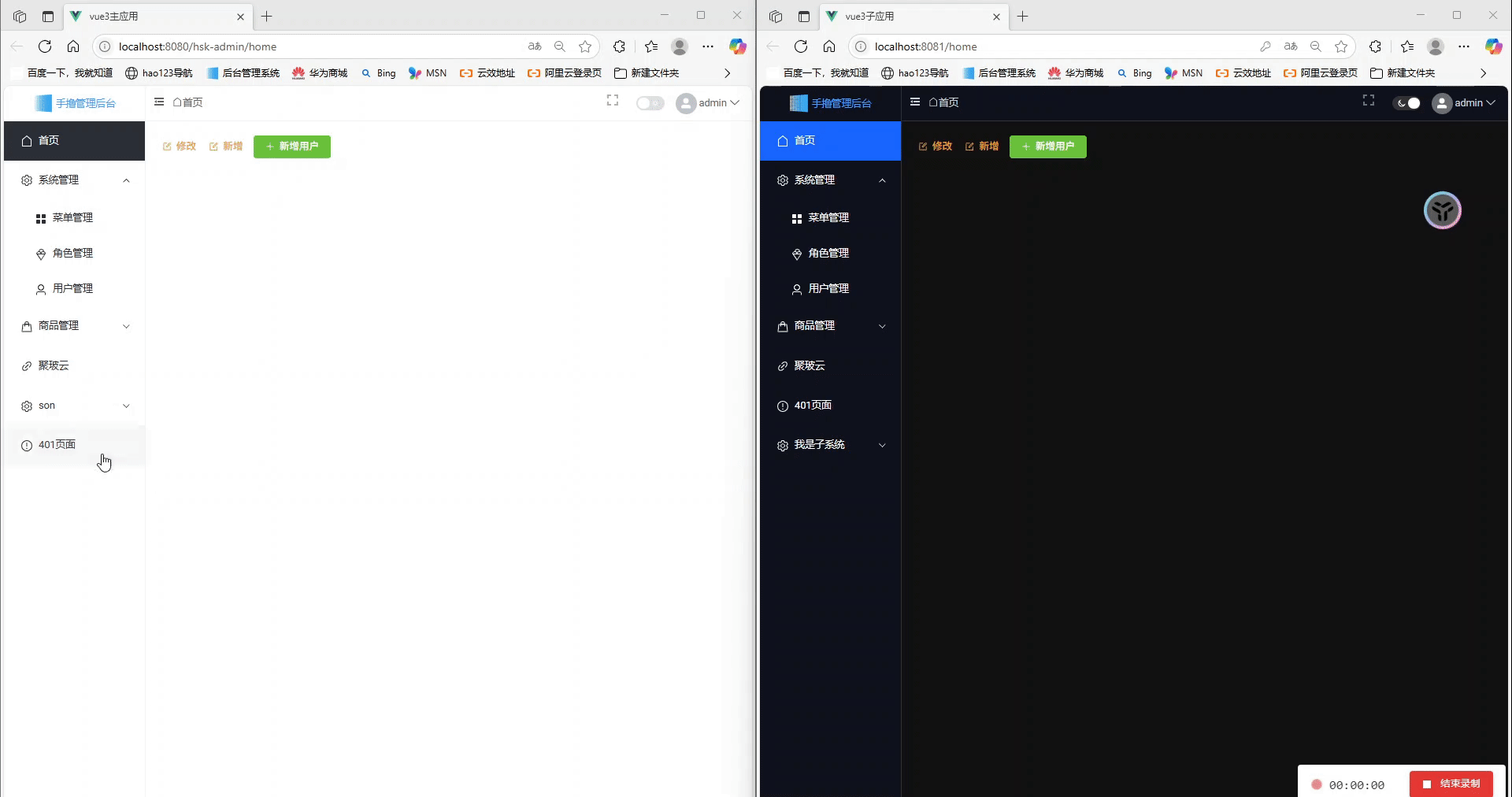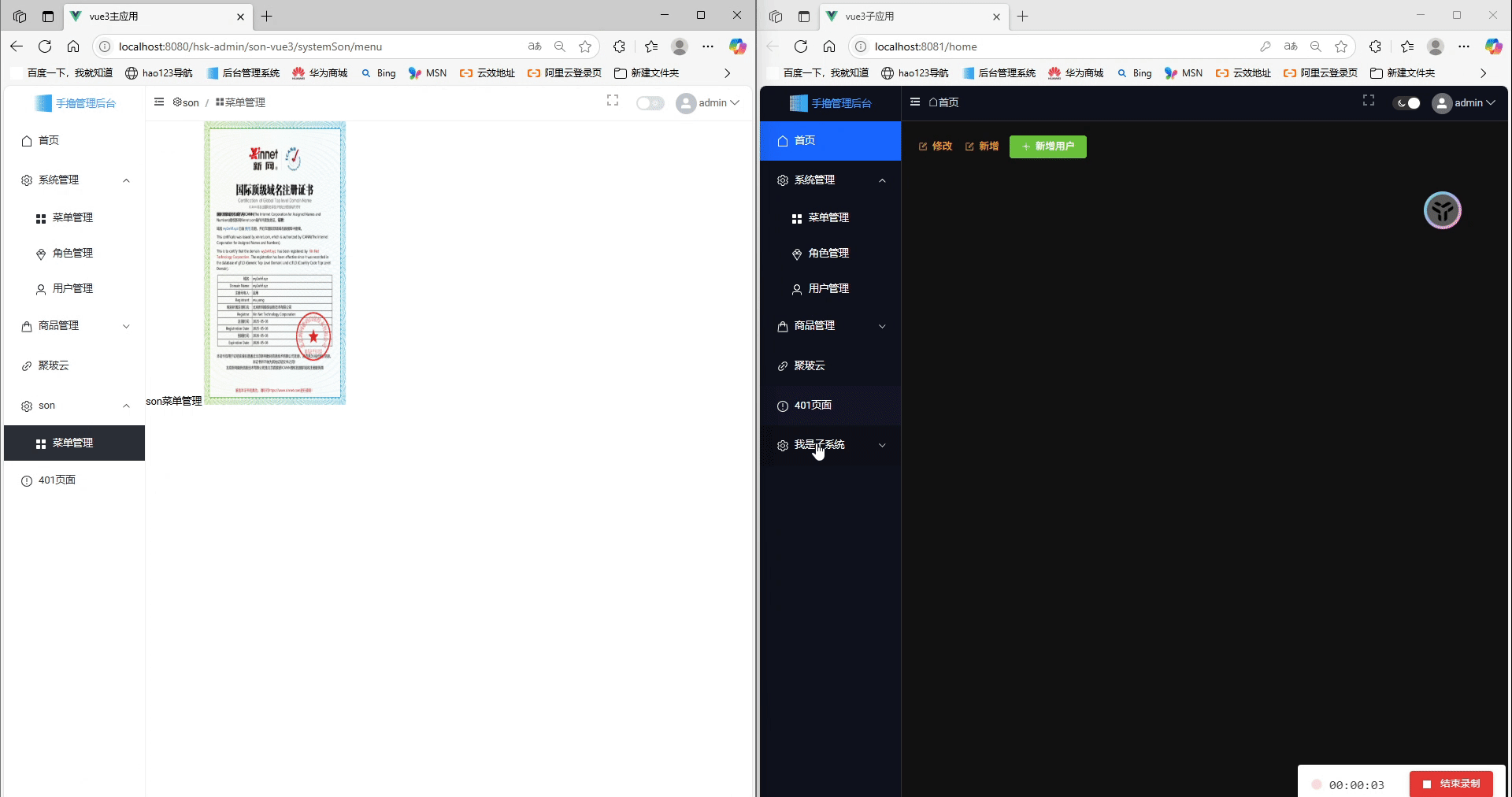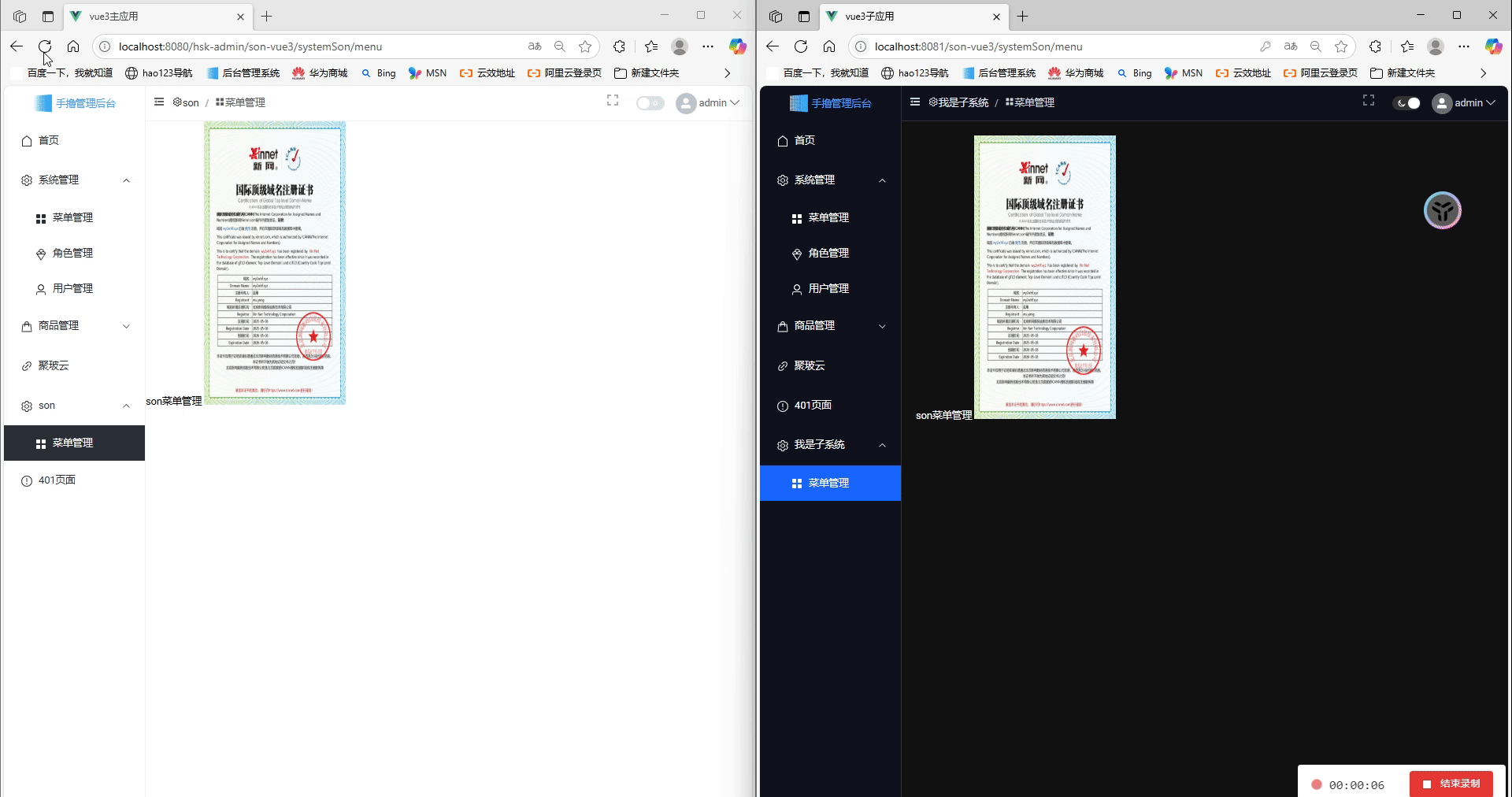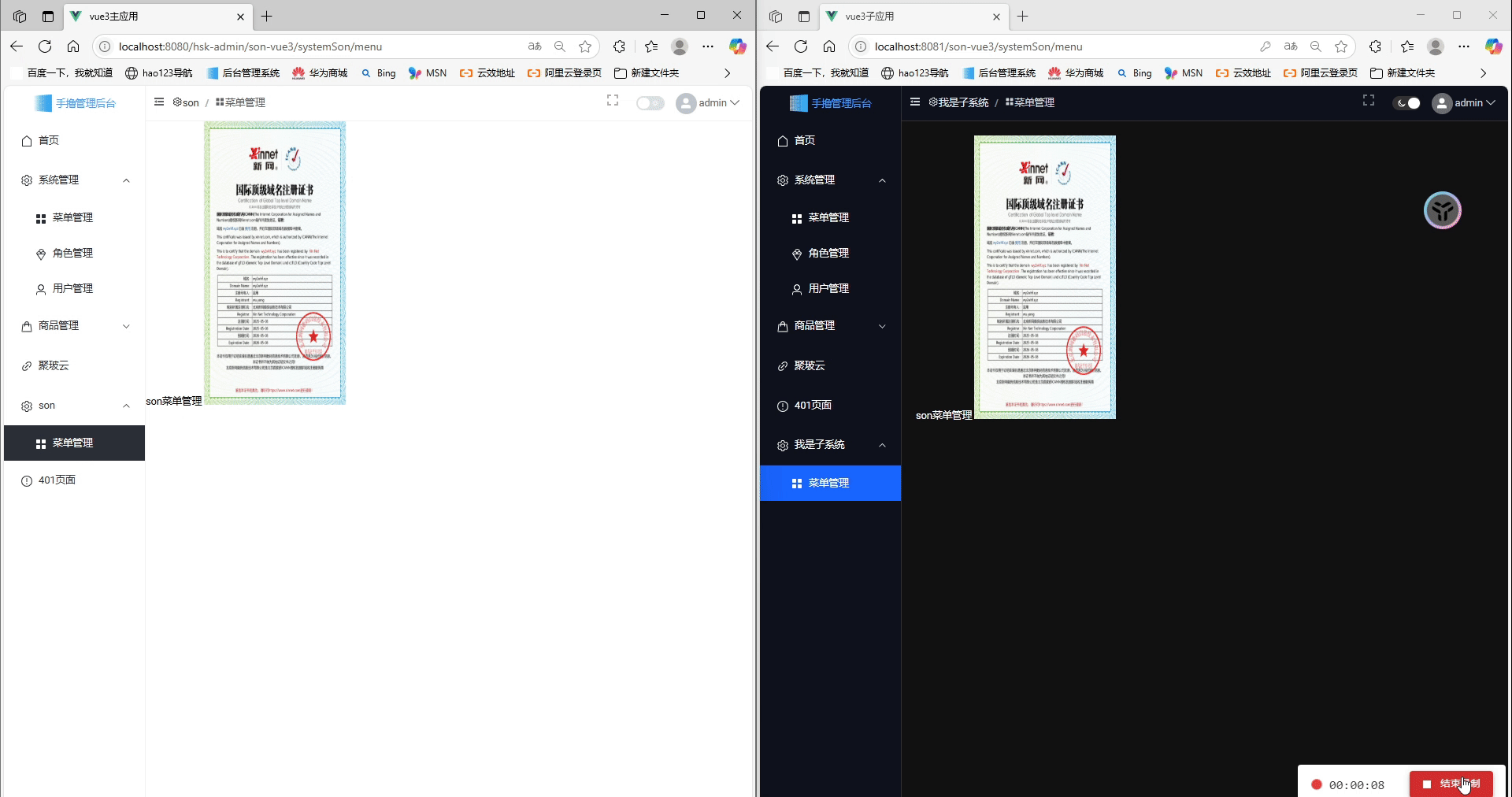
Vue3 + Vite:我的 Qiankun 微前端主子应用实践指南
前言 实践文章指南 vue微前端qiankun框架学习到项目实战,基座登录动态菜单及权限控制>>>>实战指南:Vue 2基座 Vue 3 Vite TypeScript微前端架构实现动态菜单与登录共享>>>>构建安全的Vue前后端分离架构:利用长Token与短Tok…...

使用ArcPy生成地图系列
设置地图布局 在生成地图系列之前,需要先设置地图布局。这包括定义地图的页面大小、地图框的位置和大小、标题、图例等元素。ArcPy提供了arcpy.mp.ArcGISProject方法来加载ArcGIS Pro项目文件(.aprx),并操作其中的地图布局。 Py…...
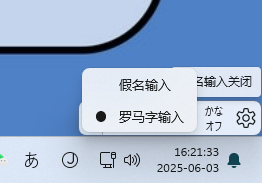
日语输入法怎么使用罗马字布局怎么安装日语输入法
今天帮客户安装日语输入法的时候遇到了一个纠结半天的问题,客户一直反馈说这个输入法不对,并不是他要的功能。他只需要罗马字的布局,而不是打出来字的假名。 片假名、平假名,就好像英文26个字母,用于组成日文单词。两…...

U盘挂载Linux
在 只能使用 Telnet 的情况下,如果希望通过 U盘 传输文件到 Linux 系统,可以按照以下步骤操作: 📌 前提条件 U盘已插入 Linux 主机的 USB 接口。Linux 主机支持自动挂载 U盘(大多数现代发行版默认支持)。T…...

数据结构:栈(Stack)和堆(Heap)
目录 内存(Memory)基础 程序是如何利用主存的? 🎯 静态内存分配 vs 动态内存分配 栈(stack) 程序执行过程与栈帧变化 堆(Heap) 程序运行时的主存布局 内存(Memo…...

用 Vue 做一个轻量离线的“待办清单 + 情绪打卡”小工具
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

3D Gaussian splatting 05: 代码阅读-训练整体流程
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...

Linux——计算机网络基础
一、网络 1.概念 由若干结点和连接结点的链路组成。结点可以是计算机,交换机,路由器等。 2.互联网 多个网络连接起来就是互联网。 因特网:最大的互联网。 二、IP地址和MAC地址 1.IP地址 (1)概念 IP地址是给因…...

第2章_Excel_知识点笔记
来自: 第2章_Excel_知识点笔记 原笔记 Excel 知识点总结(第2章) Excel_2.1 知识点 基础操作 状态栏:快速查看计数/求和等数据(右键可配置)。筛选(CtrlShiftL):按条件显…...

缩量和放量指的是什么?
在股票市场中,“缩量”和“放量”是描述成交量变化的两个核心概念,它们反映了市场参与者的情绪和资金动向,对判断股价趋势有重要参考价值。以下是具体解析: 📉 一、缩量(成交量明显减少) 1. 定…...
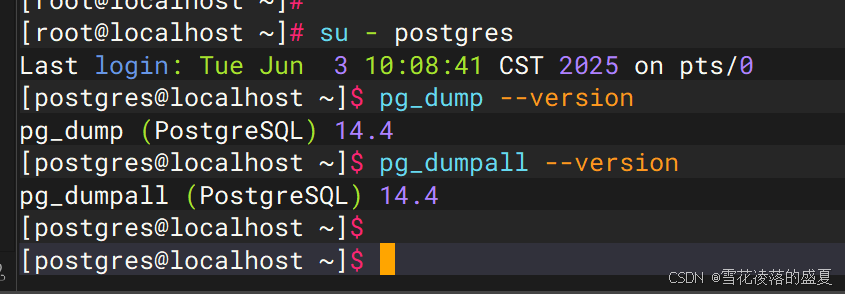
PostgreSQL数据库备份
文章目录 pg_dump 和 pg_dumpall使用 pg_dump 备份单个数据库示例 使用 pg_dumpall 备份整个数据库集群基本用法 恢复备份恢复 pg_dump 备份恢复 pg_dumpall 备份 Tips pg_dump 和 pg_dumpall 在 PostgreSQL 中,pg_dump 和 pg_dumpall 是两个常用的备份工具&#x…...

企业级Spring MVC高级主题与实用技术讲解
企业级Spring MVC高级主题与实用技术讲解 本手册旨在为具备Spring MVC基础的初学者,系统地讲解企业级应用开发中常用的高级主题和实用技术,涵盖RESTful API、统一异常处理、拦截器、文件处理、国际化、前端集成及Spring Security基础。内容结合JavaConf…...
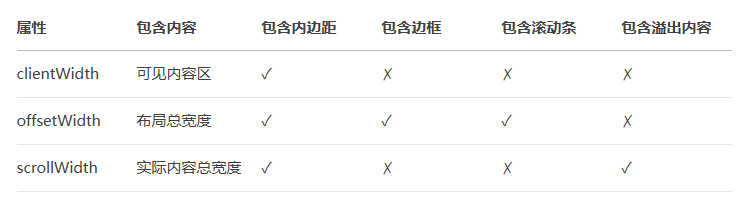
js-day7
JS学习之旅-day7 1.事件流1.1 事件流与两个阶段说明1.2 事件捕获1.3 事件冒泡1.4 阻止1.5 解绑事件 2. 事件委托3. 其他事件3.1 页面加载事件3.2 页面滚动事件3.3 页面尺寸事件 4. 元素尺寸与位置 1.事件流 1.1 事件流与两个阶段说明 事件流指的是事件完整执行过程中的流动路…...

【算法训练营Day04】链表part2
文章目录 两两交换链表中的节点删除链表的倒数第 N 个结点链表相交环形链表 II链表总结 两两交换链表中的节点 题目链接:24. 两两交换链表中的节点 算法逻辑: 添加一个虚拟头节点初始化一个交换指针,代表每次交换指针的后两个节点࿰…...

【ROS2】各种相关概念汇总解释
包含概念 ROS2自带的标准接口ament_cmake是什么? 标准接口 似乎没有一个确定的名称,就是通俗的叫做“ROS2自带的消息接口” 这些接口存放在 /opt/ros/humble/share 路径下 ament_cmake 是 ROS 2 中基于 CMake 的构建系统 系统越复杂,构…...

解决Vditor加载Markdown网页很慢的问题(Vite+JS+Vditor)
1. 引言 在上一篇文章《使用Vditor将Markdown文档渲染成网页(ViteJSVditor)》中,详细介绍了通过Vditor将Markdown格式文档渲染成Web网页的过程,并且实现了图片格式居中以及图片源更换的功能。不过,笔者发现在加载这个渲染Markdown网页的时候…...

Flowise 本地部署文档及 MCP 使用说明
一、Flowise 简介 Flowise 是一个开源的拖放式 UI 工具,用于构建自定义的 LLM 工作流程。它允许用户通过可视化界面连接不同的 AI 组件,无需编写代码即可创建复杂的 AI 应用。 二、Docker 环境安装 1. 构建 Docker 镜像 docker build -t node22-ubuntu-dev .其中Dockerfi…...

YOLO学习笔记 | 一种用于海面目标检测的多尺度YOLO算法
多尺度YOLO算法用于海面目标检测 核心挑战分析 恶劣天气:雨雾、低光照干扰图像质量波浪干扰:动态背景产生大量噪声多尺度目标:船只(大)、浮标(小)等尺度差异大目标遮挡:波浪导致目标部分遮挡算法原理 多尺度YOLO架构(基于YOLOv5改进): graph TD A[输入图像] --&g…...

鸿蒙5.0项目开发——横竖屏切换开发
横竖屏切换开发 【高心星出品】 文章目录 横竖屏切换开发运行效果窗口旋转配置module.json5的orientation字段调用窗口的setPreferredOrientation方法案例代码解析Index1页面代码:EntryAbility在module.json5的配置信息:Index页面的代码信息࿱…...
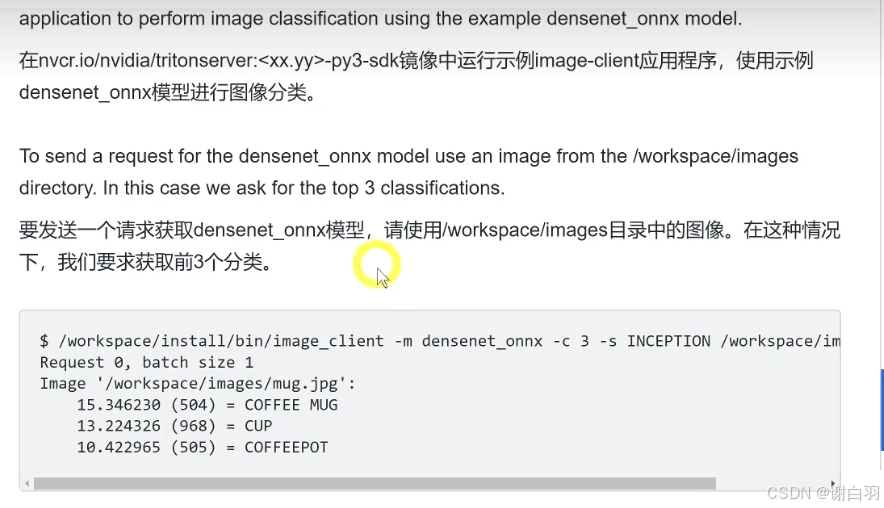
Triton推理服务器部署YOLOv8(onnxruntime后端和TensorRT后端)
文章目录 一、Trition推理服务器基础知识1)推理服务器设计概述2)Trition推理服务器quickstart(1)创建模型仓库(Create a model Repository)(2)启动Triton (launching triton)并验证是否正常运行(3)发送推理请求(send a inference request)3)Trition推理服务器架…...

TDengine 的 AI 应用实战——电力需求预测
作者: derekchen Demo数据集准备 我们使用公开的UTSD数据集里面的电力需求数据,作为预测算法的数据来源,基于历史数据预测未来若干小时的电力需求。数据集的采集频次为30分钟,单位与时间戳未提供。为了方便演示,按…...
NLP学习路线图(二十一): 词向量可视化与分析
在自然语言处理(NLP)的世界里,词向量(Word Embeddings)犹如一场静默的革命。它将原本离散、难以捉摸的词语,转化为稠密、富含语义的连续向量,为机器理解语言铺平了道路。然而,这些向…...

【分布式技术】KeepAlived高可用架构科普
KeepAlived高可用架构 Keepalived 架构详解一、核心架构组件二、VRRP 协议详解1. **VRRP 核心概念**2. **VRRP 工作流程**3. **VRRP 通信机制** 三、高可用架构模型四、健康检查机制五、配置文件详解配置文件关键参数说明: 六、高可用实现流程七、脑裂问题与解决方案…...

如何配置mvn镜像源为华为云
如何配置mvn镜像源为华为云 # 查找mvn 配置文件 mvn -X help:effective-settings | grep settings.xml# 配置mvn镜像源为华为云,/home/apache-maven-3.9.5/conf/settings.xml文件路径需要根据上一步中查询结果调整 cat > /home/apache-maven-3.9.5/conf/setting…...

Linux平台排查CPU占用高的进程和线程指南
基础排查工具 1. top命令 - 实时进程监控 top操作指令: 按 P:按CPU使用率排序按 1:显示每个CPU核心的使用情况按 H:切换显示线程视图按 M:按内存使用排序按 q:退出 2. htop命令 - 增强版top(…...

多模态大语言模型arxiv论文略读(105)
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文标题:UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model ➡️ 论文作者:Zhaowei…...

简述MySQL 超大分页怎么处理 ?
针对MySQL超大分页(深度分页)的性能问题,核心优化方案如下: 1. 子查询 覆盖索引(延迟关联) 原理: 子查询仅扫描覆盖索引(如主键),避免回表操作…...

Pyhton中的命名空间包(Namespace Package)您了解吗?
在 Python 中,命名空间包(Namespace Package) 是一种特殊的包结构,它允许将模块分散在多个独立的目录中,但这些目录在逻辑上属于同一个包命名空间。命名空间包的核心特点是:没有 __init__.py 文件ÿ…...

Java设计模式之备忘录模式详解
Java设计模式之备忘录模式详解 一、备忘录模式核心思想 核心目标:捕获对象内部状态并在需要时恢复,同时不破坏对象的封装性。如同游戏存档系统,允许玩家保存当前进度并在需要时回退到之前的状态。 二、备忘录模式类图(Mermaid&am…...