RAG架构中用到的模型学习思考
前言
RAG(Retrieval-Augmented Generation,检索增强生成)架构结合了检索和生成能力,通过引入外部知识库来提升大语言模型(LLM)的回答准确性和可靠性。以下是RAG架构中常用的模型及其总结:
一、RAG架构核心模型分类
RAG架构主要由以下三类模型组成:
- Embedding模型:用于将文本转换为向量表示,支持相似度检索。
- LLM模型(生成模型):用于生成自然语言回答。
- 可选的Reranker模型:用于对检索结果进行排序和优化。
二、RAG架构核心模型学习
一、Embedding模型
Embedding模型是RAG架构中检索模块的核心,用于将问题和文档转换为向量表示,以便通过相似度计算找到相关文档。
1. 开源Embedding模型
| 模型名称 | 开发者/机构 | 特点 | 适用场景 |
|---|---|---|---|
| BGE Embedding | 智源研究院 | 中文优化,性能优越,支持多语言 | 中文文档检索、多语言场景 |
| text-embedding-ada-002 | OpenAI | OpenAI官方Embedding模型,支持多语言,性能稳定 | 通用文档检索、多语言场景 |
| Sentence-BERT | 德国图宾根大学 | 基于BERT的句子Embedding模型,适用于短文本相似度计算 | 短文本检索、句子相似度计算 |
2. 结构化数据Embedding模型
- SQLNet:用于将自然语言查询转换为SQL语句,适用于数据库检索场景。
- BGE-M3:智源研究院推出的多模态Embedding模型,支持文本、图像等多模态检索。
二、LLM模型(生成模型)
LLM模型是RAG架构中生成模块的核心,用于根据检索到的文档生成自然语言回答。
1. 开源LLM模型
| 模型名称 | 开发者/机构 | 特点 | 适用场景 |
|---|---|---|---|
| Qwen2 | 阿里云 | 支持多语言,性能优越,适合中文场景 | 中文问答、生成任务 |
| Llama 3.1 | Meta | 开源大模型,支持多语言,性能强大 | 通用问答、生成任务 |
| Mistral | Mistral AI | 开源大模型,性能高效,适合企业级应用 | 通用问答、生成任务 |
2. 商业LLM模型
- GPT-4o(OpenAI):性能强大,支持多语言,适合高精度问答和生成任务。
- 通义千问(阿里云):中文优化,适合企业级中文问答场景。
- 文心一言(百度):中文优化,支持多模态生成,适合中文场景。
三、Reranker模型
Reranker模型用于对检索结果进行排序和优化,提升检索的准确性和相关性。
1. 开源Reranker模型
- Cross-Encoder:基于BERT的交叉编码器,通过联合编码问题和文档对来计算相似度,性能优越但计算成本较高。
- MonoT5:基于T5的单编码器Reranker,通过将问题和文档拼接后输入模型来计算相似度,性能和计算成本之间取得平衡。
2. 商业Reranker服务
- OpenAI的Rerank API:提供高性能的Reranker服务,适合需要高精度排序的场景。
- 阿里云、百度等云服务商的Reranker服务:提供定制化的Reranker解决方案,适合企业级应用。
三、RAG架构中模型的选择总结
-
Embedding模型选择:
- 中文场景优先选择BGE Embedding或Qwen2的Embedding模块。
- 多语言场景可选择text-embedding-ada-002或Llama 3.1的Embedding模块。
- 结构化数据检索可选择SQLNet或BGE-M3。
-
LLM模型选择:
- 中文场景优先选择Qwen2或通义千问。
- 多语言场景可选择Llama 3.1或GPT-4o。
- 企业级应用可考虑Mistral等开源大模型或商业云服务。
-
Reranker模型选择:
- 对检索精度要求高的场景可选择Cross-Encoder或商业Reranker服务。
- 对计算成本敏感的场景可选择MonoT5或开源Reranker模型。
四、各种模型的获取方式小记
1. 开源Embedding模型
- BGE Embedding(智源研究院)
- 下载地址:
- GitHub仓库:GitHub - FlagOpen/FlagEmbedding: Retrieval and Retrieval-augmented LLMs
- HuggingFace:https://huggingface.co/BAAI/bge-large-zh(中文版)
- 下载步骤:
- 访问GitHub仓库或HuggingFace页面。
- 找到模型文件(通常为
.pt或.bin格式)。 - 使用
git clone命令克隆仓库,或直接从HuggingFace下载模型文件。 - 将模型文件加载到Python环境中(使用
transformers库)。
- 下载地址:
- text-embedding-3-large(Xenova团队)
- 下载地址:
- HuggingFace:https://huggingface.co/Xenova/text-embedding-3-large
- 下载步骤:
- 访问HuggingFace页面。
- 使用HuggingFace的
transformers库直接加载模型:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("Xenova/text-embedding-3-large") model = AutoModel.from_pretrained("Xenova/text-embedding-3-large")
- 下载地址:
2. 开源LLM模型
- Qwen2(阿里云)
- 下载地址:
- ModelScope平台:魔搭社区(搜索Qwen2)
- HuggingFace:https://huggingface.co/Qwen
- 下载步骤:
- 访问ModelScope或HuggingFace页面。
- 找到Qwen2模型并下载。
- 使用
transformers库加载模型:from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-7B-Instruct", trust_remote_code=True)
- 下载地址:
- Llama 3.1(Meta)
- 下载地址:
- Meta官方GitHub仓库:GitHub - meta-llama/llama: Inference code for Llama models(需申请许可)
- HuggingFace(部分版本):https://huggingface.co/meta-llama
- 下载步骤:
- 访问Meta官方GitHub仓库,按照指引申请模型许可。
- 获得许可后,下载模型文件。
- 使用
transformers库加载模型(需注意许可协议)。
- 下载地址:
3.Reranker模型下载总结
- BAAI/bge-reranker系列
- 模型介绍:由北京智源人工智能研究院(BAAI)推出,包括
bge-reranker-base、bge-reranker-large等版本,支持中文和英文,性能优越。 - 下载地址:
- Hugging Face:
bge-reranker-base:https://huggingface.co/BAAI/bge-reranker-basebge-reranker-large:https://huggingface.co/BAAI/bge-reranker-large
- 魔搭社区(ModelScope):可通过
modelscope库下载
- Hugging Face:
- 模型介绍:由北京智源人工智能研究院(BAAI)推出,包括
2.Cross-Encoder类模型
- 模型介绍:基于Transformer的交叉编码器模型,能够针对查询和文档对输出相似度分数,适用于精确重排序。
- 下载地址:
- Hugging Face:搜索
cross-encoder或相关模型名称,例如cross-encoder/ms-marco-MiniLM-L-6-v2。
- Hugging Face:搜索
3.其他开源Reranker模型
- 模型介绍:如
MonoT5、ColBERT等,可根据具体需求选择。 - 下载地址:
- Hugging Face:搜索相关模型名称。
- GitHub:搜索开源项目,例如通过
git clone命令下载。
4.其他注意事项
- 模型许可证:下载和使用模型时,请务必查看模型的许可证协议(如Apache 2.0、MIT等),确保合规使用。
- 模型选择:根据具体需求选择合适的Reranker模型,例如:
- 对于需要高精度的场景,可选择性能更强的模型(如
bge-reranker-large)。 - 对于中文场景,推荐使用
bge-reranker系列模型。
- 对于需要高精度的场景,可选择性能更强的模型(如
五、本地化部署与集成方法总结
- 开源模型本地化部署:
- 下载模型文件后,使用
transformers库加载到Python环境中。 - 结合向量数据库(如FAISS、Milvus)实现RAG架构的检索和生成功能。
- 下载模型文件后,使用
- 商业模型调用:
- 通过API接口调用商业模型,无需本地部署。
- 注意API调用的频率限制和费用计算。
- 模型优化与调优:
- 对开源模型进行微调,以适应特定业务场景。
- 使用企业自有数据对模型进行进一步训练,提高模型的准确性和性能。
六、具体获取模型实战举例
- 安装必要的库
- 推荐安装
transformers库,用于加载和使用Hugging Face上的模型:pip install transformers - 对于
bge-reranker模型,还可安装FlagEmbedding库:pip install -U FlagEmbedding
- 推荐安装
- 下载模型方法示例
- 通过Hugging Face下载:
from transformers import AutoModelForSequenceClassification, AutoTokenizer model_name = "BAAI/bge-reranker-large" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name) - 通过ModelScope下载(如
bge-reranker模型):from modelscope import snapshot_download model_dir = snapshot_download("BAAI/bge-reranker-large")
- 通过Hugging Face下载:
- 使用
FlagEmbedding库:from FlagEmbedding import FlagReranker reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) query = "what is panda?" passages = [ "hi", "The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China." ] scores = reranker.compute_score([[query, passage] for passage in passages]) print(scores) - 使用
transformers库:import torch from transformers import AutoModelForSequenceClassification, AutoTokenizer model_name = "BAAI/bge-reranker-large" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name) model.eval() pairs = [ ["what is panda?", "hi"], ["what is panda?", "The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China."] ] with torch.no_grad(): inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512) scores = model(**inputs, return_dict=True).logits.view(-1, ).float() print(scores)
七、总结
RAG架构中用到的模型主要包括Embedding模型、LLM模型和可选的Reranker模型。我们在选择模型时,应根据自身需求、场景特点和计算资源进行综合考虑。通过合理选择和集成模型,可以构建出高效、准确的RAG系统,提升知识检索和生成的效率和质量。
相关文章:

RAG架构中用到的模型学习思考
前言 RAG(Retrieval-Augmented Generation,检索增强生成)架构结合了检索和生成能力,通过引入外部知识库来提升大语言模型(LLM)的回答准确性和可靠性。以下是RAG架构中常用的模型及其总结: 一、…...
统信 UOS 服务器版离线部署 DeepSeek 攻略
日前,DeepSeek 系列模型因拥有“更低的成本、更强的性能、更好的体验”三大核心优势,在全球范围内备受瞩目。 本次,我们为大家提供了在统信 UOS 服务器版 V20(AMD64 或 ARM64 架构)上本地离线部署 DeepSeek-R1 模型的…...

美尔斯通携手北京康复辅具技术中心开展公益活动,科技赋能助力银龄健康管理
2025 年 5 月 30 日,北京美尔斯通科技发展股份有限公司携手北京市康复辅具技术中心,在朝阳区核桃园社区开展 “全国助残日公益服务” 系列活动。活动通过科普讲座、健康检测与科技体验,将听力保健与心脏健康服务送至居民家门口,助…...

《前端面试题:前端响应式介绍》
前端响应式设计完全指南:从理论到实战 掌握响应式设计是构建现代网站的核心能力,也是前端面试的必考内容 一、响应式设计:移动优先时代的必备技能 在当今多设备时代,用户通过手机、平板、笔记本、桌面显示器等多种设备访问网站。…...
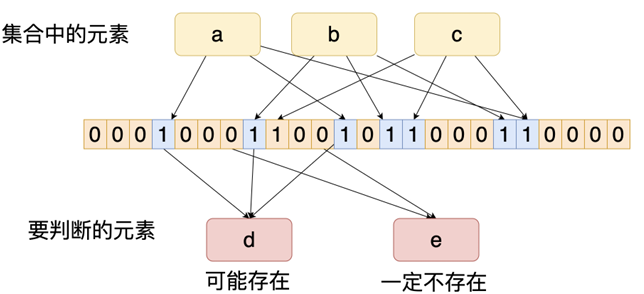
Redis Stack常见拓展
Redis JSON RedisJSON 是 Redis Stack 提供的模块之一,允许你以 原生 JSON 格式 存储、检索和修改数据。相比传统 Redis Hash,它更适合结构化文档型数据,并支持嵌套结构、高效查询和部分更新。 #设置⼀个JSON数据,其中$表示JSON数据的根节点…...

Linux 驱动之设备树
Linux 驱动之设备树 参考视频地址 【北京迅为】嵌入式学习之Linux驱动(第七期_设备树_全新升级)_基于RK3568_哔哩哔哩_bilibili 本章总领 1.设备树基本知识 什么是设备树? Linux之父Linus Torvalds在2011年3月17日的ARM Linux邮件列表…...
12、企业应收账款(AR)全流程解析:从发票开具到回款完成
在商业活动中,现金流如同企业的命脉,而应收管理则是维系这条命脉正常运转的重要保障。许多企业由于对应收账款缺乏有效管理,常常面临资金周转困难的问题。实践证明,建立科学的应收管理体系能够显著提升资金回笼效率,为…...

php 各版本下载
https://windows.php.net/downloads/releases/archives/ 参考资料:php5.6.40 在 win10下安装全过程 ( 图文教程、附官方下载链接 )...
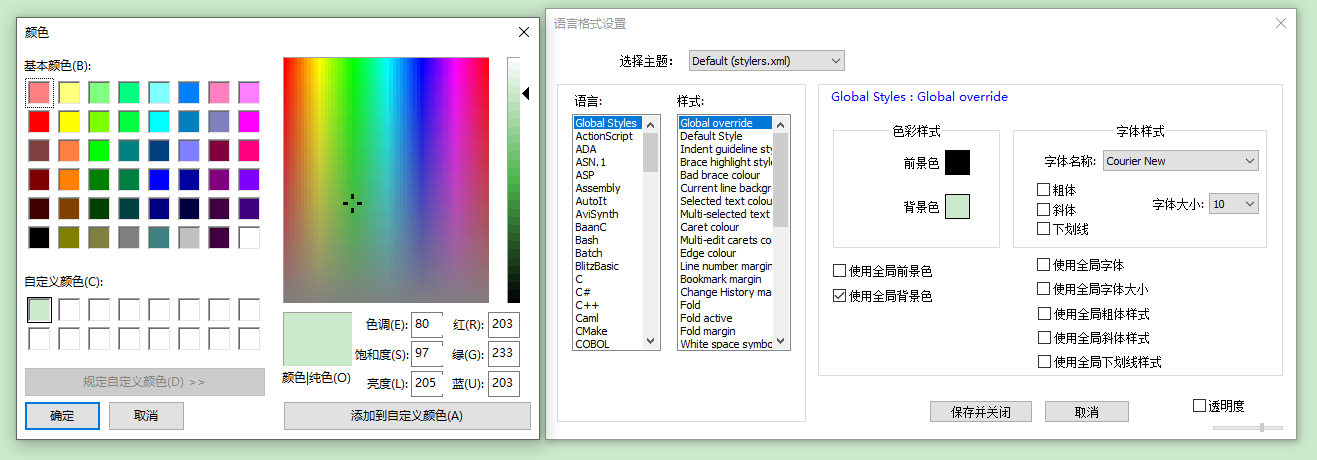
【notepad++】如何设置notepad++背景颜色?
如何设置notepad背景颜色? 设置--语言格式设置 勾选使用全局背景色 例如选择护眼色---80,97,205;...

使用 C++/OpenCV 制作跳动的爱心动画
使用 C/OpenCV 制作跳动的爱心动画 本文将引导你如何使用 C 和 OpenCV 库创建一个简单但有趣的跳动爱心动画。我们将通过绘制参数方程定义的爱心形状,并利用正弦函数来模拟心跳的缩放效果。 目录 简介先决条件核心概念 参数方程绘制爱心动画循环模拟心跳效果 代码…...

Go Modules 详解 -《Go语言实战指南》
Go Modules(简称 go mod)是 Go 官方推出的包依赖管理系统,自 Go 1.11 起引入,Go 1.16 起成为默认方式,取代了旧的 GOPATH 模式。 本章将全面讲解 Go Modules 的基本原理、使用方法以及常见问题处理。 一、Go Modules 简…...
在Oxygen编辑器中使用DeepSeek
罗马尼亚公司研制开发的Oxygen编辑器怎样与国产大模型结合,这是今年我在tcworld大会上给大家的分享,需要ppt的朋友请私信联系 - 1 - Oxygen编辑器中的人工智能助手 Oxygen编辑器是罗马尼亚的Syncro Soft公司开发的一款结构化文档编辑器。 它是用来编写…...
(Go语言版))
【LeetCode 热题100】BFS/DFS 实战:岛屿数量 腐烂的橘子(力扣200 / 994 )(Go语言版)
🌊 BFS/DFS 实战:岛屿数量 & 腐烂的橘子(LeetCode 200 & 994) 两道图论基础题,涉及 BFS 与 DFS 的应用,主要用于掌握二维网格中遍历与标记访问的技巧: 🏝️ 200. 岛屿数量…...

一、基础环境配置
一、虚拟机 主:192.168.200.200 从:192.168.200.201 从:192.168.200.202 二、docker docker基础搭建,有不会的自行百度。 1.目录结构 /opt/software:软件包/opt/module:解压包,自定义脚本…...

论文阅读笔记——FLOW MATCHING FOR GENERATIVE MODELING
Flow Matching 论文 扩散模型:根据中心极限定理,对原始图像不断加高斯噪声,最终将原始信号破坏为近似的标准正态分布。这其中每一步都构造为条件高斯分布,形成离散的马尔科夫链。再通过逐步去噪得到原始图像。 Flow matching 采取…...

SQL Views(视图)
目录 Views Declaring Views Example: View Definition Example: Accessing a View Advantages of Views Triggers on Views Interpreting a View Insertion(视图插入操作的解释) The Trigger Views A view is a relation defined in terms of…...
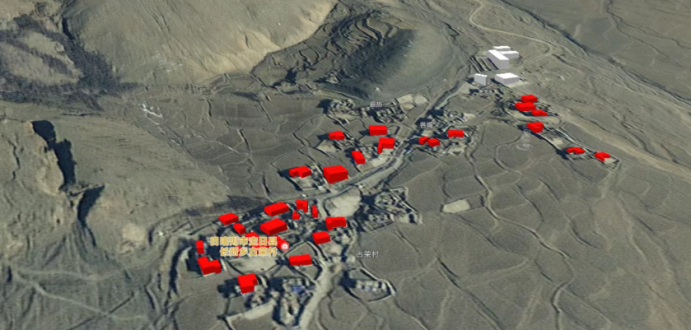
「卫星百科」“绿色守卫”高分六号
高分六号(GF-6)是中国高分辨率对地观测系统(高分专项)的重要组成卫星,于2018年6月2日成功发射。高分六号卫星凭借其高时空分辨率、红边波段、宽覆盖能力,在农业、生态、灾害等领域提供了重要的数据支撑。本…...

秋招Day12 - 计算机网络 - IP
IP协议的定义和作用? IP协议用于在计算机网络中传递数据包,定义了数据包的格式和处理规则,确保数据能够从一个设备传递到另一个设备,中间可能经过多个不同的设备(路由器)。 IP协议有哪些作用?…...

Servlet 快速入门
文章目录 概念SpringBoot 测试案例执行原理传统 Servlet在 SpringBoot (嵌入式 Tomcat Spring MVC) 中请求从浏览器到业务代码的完整步骤关键点流程图 参考 概念 运行在服务器端的小程序, Servlet 就是一个接口,定义 Java 类被浏…...

【前端】CSS面试八股
网上现有资料已经很丰富了,我挑了些自己押面试题时总结过的来写。 Q:回流和重绘 A: 回流reflow:计算元素的几何,引发layout重绘repaint:更新元素可见样式,引发paint 回流的成本比重绘高得多&…...

[蓝桥杯]找到给定字符串中的不同字符
题目描述 在不考虑字符排列的条件下,对于相差只有一个字符的两个字符串,实现一个算法来识别相差的那个字符。要求如下: 当传入的字符串为 aad 和 ad 时,结果为 a。 当传入的字符串为 aaabccdd 和 abdcacade 时,结果为…...
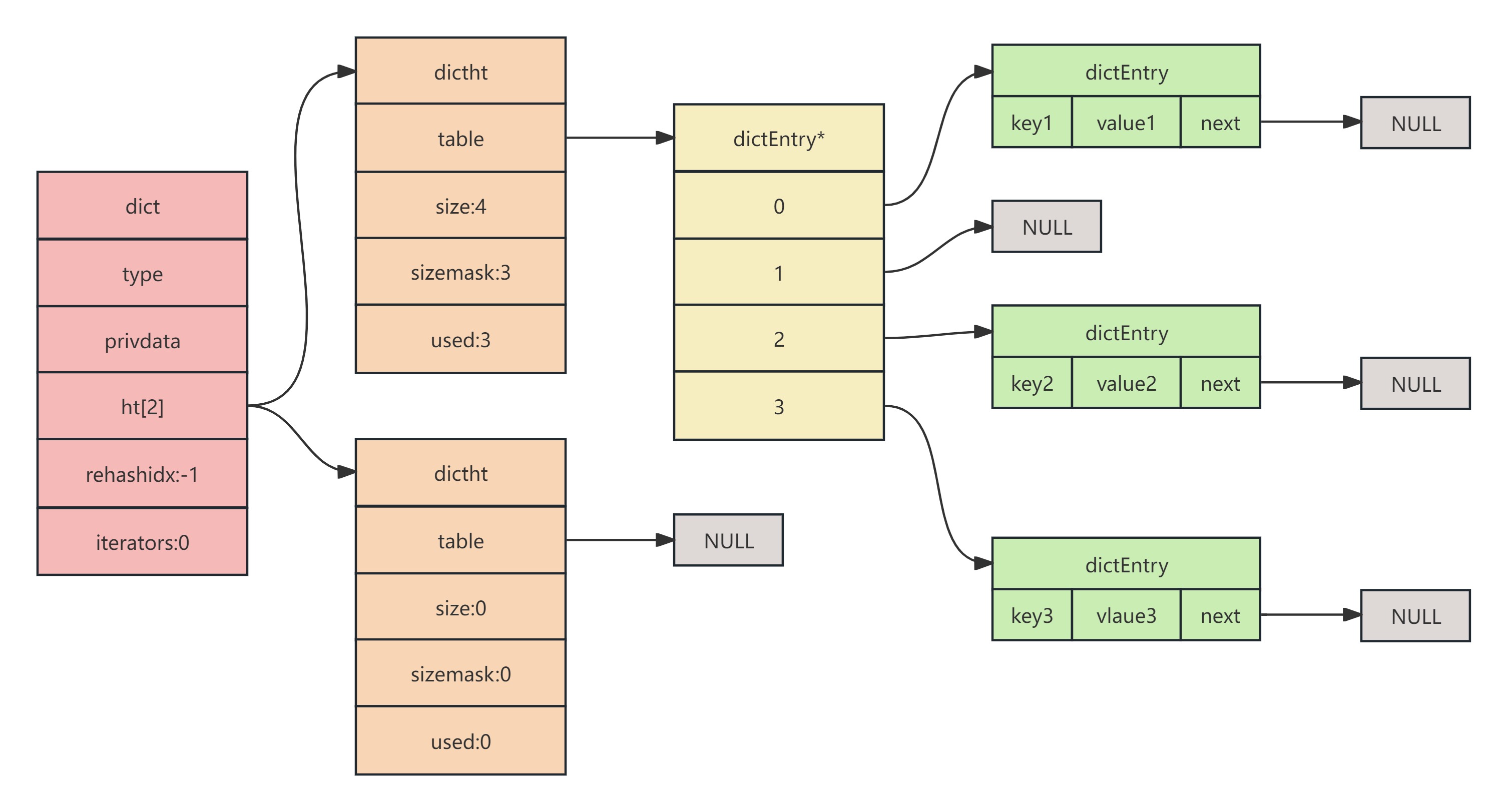
Redis底层数据结构之字典(Dict)
Dict基本结构 Dict我们可以想象成目录,要翻看什么内容,直接通过目录能找到页数,翻过去看。如果没有目录,我们需要一页一页往后翻,这样时间复杂度就与遍历的O(n)一样了,而用了Dict我们就可以在O(1)的时间复杂…...

佰力博科技与您探讨低温介电温谱测试仪的应用领域
低温介电温谱测试应用领域有如下: 一、电子材料: 低温介电温谱测试仪广泛应用于电子材料的性能测试,如陶瓷材料、半导体材料、压电材料等。通过该设备,可以评估材料在高温或低温环境下的介电性能,为材料的优化和应用提…...

ubuntu之开机自启frpc
在 Ubuntu 系统中为 frpc 设置开机自启(以 frpc -c frpc.toml 命令为例),可以通过 systemd 服务实现。以下是详细步骤: 创建 systemd 服务文件 sudo vim /etc/systemd/system/frpc.service 写入以下内容(根据你的路…...
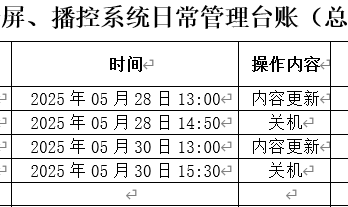
【办公类-48-04】202506每月电子屏台账汇总成docx-5(问卷星下载5月范围内容,自动获取excel文件名,并转移处理)
背景需求: 1-4月电子屏表格,都是用这个代码将EXCEL数据整理成分类成3个WORD表格。 【办公类-48-04】20250118每月电子屏台账汇总成docx-4(提取EXCLE里面1月份的内容,自制月份文件夹)-CSDN博客文章浏览阅读1.2k次&…...

对 `llamafactory-cli api -h` 输出的详细解读
llamafactory-cli 是 LlamaFactory 项目提供的命令行接口工具,它允许用户通过命令行参数来配置和运行大型语言模型的各种任务,如预训练(PT)、有监督微调(SFT)、奖励模型训练(RM)、基…...

基于 ZYNQ UltraScale+ OV5640的高速图像传输系统设计,支持国产替代
引 言 随着电子信息技术的不断进步,人工智能、医 疗器械、机器视觉等领域都在高速发展 [1] ,工业相机 是机器视觉系统中的一部分 [2] ,对工业相机而言,传 输图像的速率、传输过程的抗干扰能力是其关键, 工业相…...

demo_win10配置WSL、DockerDesktop环境,本地部署Dify,ngrok公网测试
win10配置WSL、DockerDesktop环境,本地部署Dify,ngrok分享测试 一、配置WSL 1.1 开启Hyper-V 安装WSL2首先要保证操作系统可以开启hyper-v功能,默认支持开启hyper-v的版本为:Windows11企业版、专业版或教育版,而家庭版是不支持…...

TablePlus:一个跨平台的数据库管理工具
TablePlus 是一款现代化的跨平台(Window、Linux、macOS、iOS)数据库管理工具,提供直观的界面和强大的功能,可以帮助用户轻松管理和操作数据库。 TablePlus 免费版可以永久使用,但是只能同时打开 2 个连接窗口ÿ…...
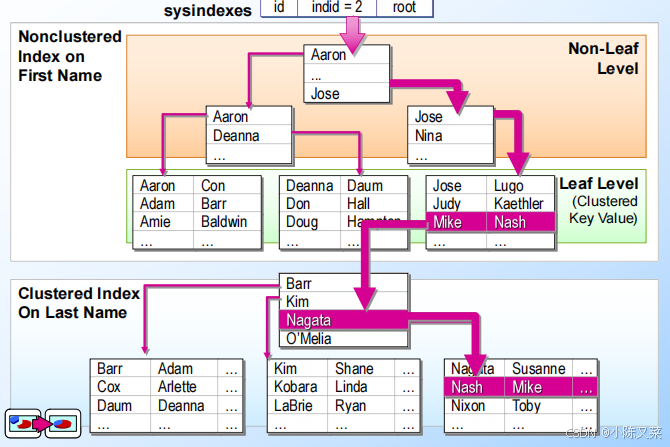
SQL Indexes(索引)
目录 Indexes Using Clustered Indexes Using Nonclustered Indexes Declaring Indexes Using Indexes Finding Rows Without Indexes Finding Rows in a Heap with a Nonclustered Index Finding Rows in a Clustered Index Finding Rows in a Clustered Index with …...