第N1周:one-hot编码案例
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、one-hot编码概念
自然语言处理(NLP)中的文本数字化:文字对于计算机来说就仅仅只是一个个符号,计算机无法理解其中含义,更无法处理。因此,NLP第一步就是将文本数字化。
文本数字化方法:NLP中最早期的文本数字化方法,就是将文本转换为字典序列。如:“阿”是新华字典中第1个单词所以它的字典序列就是1。

one-hot编码(独热编码):将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。这样,每个类别之间就是相互独立的,不存在顺序或距离关系。例如,对于三个类别的情况,可以使用如下的one-hot编码:
- 类别1:[1,0,0]
- 类别2:[0,1,0]
- 类别3:[0,0,1]
举例:
- John likes to watch movies. Mary likes too.
- John also likes to watch football games.
以上两句构成一个词典:
{"John": 1, "likes": 2, "to": 3, "watch": 4,"movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9"too": 10}
one-hot可表示为:
John:[1,0,0,0,0,0,0,0,0,0]
likes:[0,1,0,0,0,0,0,0,0,0]
............等等,以此类推。
1.one-hot编码的优点:
解决了分类器不好处理离散数据的问题,能够处理非连续型数值特征。
2.one-hot编码的缺点:
- 在文本表征表示上有些缺点非常突出,首先one-hot 编码是一个词袋模型,是不考虑词和词之间的顺序问题,它是假设词和词之间是相互独立的,但是在大部分情况下词和词之间是相互影响的。
- one-hot编码得到的特征是离散稀疏的,每个单词的one-hot编码维度是整个词汇表的大小,维度非常巨大,编码稀疏,会使得计算代价变大。
二、英文案例
import torch
import torch.nn.functional as F#示例文本
texts = ['Hello, how are you?','I am doing well, thank you!','Goodbye.']# 构建词汇表
word_index={}
index_word={}
for i,word in enumerate(set(" ".join(texts).split())):word_index[word]=iindex_word[i]= word#将文本转化为整数序列
sequences = [[word_index[word] for word in text.split()] for text in texts]#获取词汇表大小
vocab_size =len(word_index)#将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts),vocab_size)
for i,seq in enumerate(sequences):one_hot_results[i, seq] = 1#打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n文本序列:")
print(sequences)
print("\none-Hot编码:")
print(one_hot_results)词汇表:
{'are': 0, 'thank': 1, 'am': 2, 'you!': 3, 'you?': 4, 'Hello,': 5, 'doing': 6, 'Goodbye.': 7, 'well,': 8, 'I': 9, 'how': 10}
文本:
['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']
文本序列:
[[5, 10, 0, 4], [9, 2, 6, 8, 1, 3], [7]]
one-Hot编码:
tensor([[1., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1.],
[0., 1., 1., 1., 0., 0., 1., 0., 1., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.]])
三、中文案例
1.以字为基本单位
import torch
import torch.nn.functional as F#示例中文文本
texts =['你好,最近怎么样?', '我过得很好,谢谢!', 'K同学啊']#构建词汇表
word_index={}
index_word ={}
for i,word in enumerate(set("".join(texts))):word_index[word]=iindex_word[i]= word#将文本转化为整数序列
sequences =[[word_index[word] for word in text] for text in texts]#获取词汇表大小
vocab_size = len(word_index)#将整数序列转化为one-hot编码
one_hot_results =torch.zeros(len(texts),vocab_size)
for i,seq in enumerate(sequences):one_hot_results[i,seq]=1#打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n文本序列:")
print(sequences)
print("\none-Hot编码:")
print(one_hot_results)词汇表:
{'?': 0, '同': 1, '样': 2, '得': 3, '你': 4, '啊': 5, ',': 6, '好': 7, '很': 8, 'K': 9, '我': 10, '近': 11, '学': 12, '谢': 13, '怎': 14, '最': 15, '么': 16, '过': 17, '!': 18}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', 'K同学啊']
文本序列:
[[4, 7, 6, 15, 11, 14, 16, 2, 0], [10, 17, 3, 8, 7, 6, 13, 13, 18], [9, 1, 12, 5]]
one-Hot编码:
tensor([[1., 0., 1., 0., 1., 0., 1., 1., 0., 0., 0., 1., 0., 0., 1., 1., 1., 0.,
0.],
[0., 0., 0., 1., 0., 0., 1., 1., 1., 0., 1., 0., 0., 1., 0., 0., 0., 1.,
1.],
[0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0.,
0.]])
2.使用结巴分词工具
import torch
import torch.nn.functional as F
import jieba#示例中文文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '再见。']#使用结巴分词进行分词
tokenized_texts = [list(jieba.cut(text)) for text in texts]#构建词汇表
word_index = {}
index_word = {}
for i,word in enumerate(set([word for text in tokenized_texts for word in text])):word_index[word] = iindex_word[i] = word#将文本转化为整数序列
sequences =[[word_index[word] for word in text] for text in tokenized_texts]#获取词汇表大小
vocab_size =len(word_index)#将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts),vocab_size)
for i,seq in enumerate(sequences):one_hot_results[i,seq]=1#打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n分词结果")
print(tokenized_texts)
print("\n文本序列:")
print(sequences)
print("\none-Hot编码:")
print(one_hot_results)词汇表:
{'你好': 0, '得': 1, '再见': 2, '?': 3, '怎么样': 4, ',': 5, '最近': 6, '很': 7, '!': 8, '谢谢': 9, '。': 10, '我过': 11, '好': 12}
文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '再见。']
分词结果
[['你好', ',', '最近', '怎么样', '?'], ['我过', '得', '很', '好', ',', '谢谢', '!'], ['再见', '。']]
文本序列:
[[0, 5, 6, 4, 3], [11, 1, 7, 12, 5, 9, 8], [2, 10]]
one-Hot编码:
tensor([[1., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 1., 0., 1., 1., 1., 0., 1., 1.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]])
四、任务案例
import torch
import torch.nn.functional as F
import jieba# 定义文件路径
file_name = 'F:/jupyter lab/DL-100-days/datasets/one_hot/任务文件.txt'# 打开文件并读取内容
with open(file_name, "r", encoding="utf-8") as file:context = file.read()# 将内容分割成句子sentences = context.split()# 使用jieba对每个句子进行分词
tokenized_texts = [list(jieba.lcut(sentence)) for sentence in sentences]# 构建词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set([word for text in tokenized_texts for word in text])):word_index[word] = iindex_word[i] = word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in tokenized_texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(sentences), vocab_size)
for i, seq in enumerate(sequences):one_hot_results[i, seq] = 1# 打印结果
print("====词汇表:====\n", word_index)
print("====文本:====\n", sentences)
print("====分词结果:====\n", tokenized_texts)
print("====文本序列:====\n", sequences)
print("====One-Hot编码:====\n", one_hot_results)====词汇表:====
{'训练营': 0, '实际意义': 1, '深度': 2, '顺序': 3, '模型': 4, '不同': 5, '值': 6, '的': 7, '错误': 8, '字典': 9, '距离': 10, 'one': 11, '或': 12, '是': 13, '实际上': 14, '例如': 15, '存在': 16, '2': 17, '认为': 18, '使用': 19, '这是': 20, '内容': 21, '啊': 22, '有': 23, '-': 24, '独立': 25, '就是': 26, '向量': 27, '“': 28, '情况': 29, '和': 30, '具有': 31, '问题': 32, '365': 33, '分别': 34, '为了': 35, '地': 36, '将': 37, '同学': 38, ',': 39, 'K': 40, '其余': 41, '1': 42, '之间': 43, '这种': 44, '称': 45, 'hot': 46, '如下': 47, '直观': 48, '。': 49, '用': 50, '其中': 51, '或者': 52, ')': 53, '比较': 54, '上面': 55, '为': 56, '3': 57, '可能': 58, '这些': 59, '引入': 60, '每个': 61, '相互': 62, ':': 63, '序列': 64, '编码方式': 65, '关系': 66, '、': 67, '表示': 68, '避免': 69, '不': 70, '但是': 71, '类别': 72, '也': 73, '思想': 74, '0': 75, '学习': 76, '了': 77, '这样': 78, '一个': 79, '编码': 80, '基本': 81, '元素': 82, '”': 83, '采用': 84, '三个': 85, '到': 86, '天': 87, '这': 88, '提到': 89, '而': 90, '映射': 91, '对于': 92, '教案': 93, '(': 94, '可以': 95, '只有': 96, '一些': 97, '会': 98, '独热': 99}
====文本:====
['比较直观的编码方式是采用上面提到的字典序列。', '例如,对于一个有三个类别的问题,可以用1、2和3分别表示这三个类别。', '但是,这种编码方式存在一个问题,就是模型可能会错误地认为不同类别之间存在一些顺序或距离关系', '而实际上这些关系可能是不存在的或者不具有实际意义的,为了避免这种问题,引入了one-hot编码(也称独热编码)。', 'one-hot编码的基本思想是将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。', '这样,每个类别之间就是相互独立的,不存在顺序或距离关系。', '例如,对于三个类别的情况,可以使用如下的one-hot编码:', '这是K同学啊的“365天深度学习训练营”教案内容']
====分词结果:====
[['比较', '直观', '的', '编码方式', '是', '采用', '上面', '提到', '的', '字典', '序列', '。'], ['例如', ',', '对于', '一个', '有', '三个', '类别', '的', '问题', ',', '可以', '用', '1', '、', '2', '和', '3', '分别', '表示', '这', '三个', '类别', '。'], ['但是', ',', '这种', '编码方式', '存在', '一个', '问题', ',', '就是', '模型', '可能', '会', '错误', '地', '认为', '不同', '类别', '之间', '存在', '一些', '顺序', '或', '距离', '关系'], ['而', '实际上', '这些', '关系', '可能', '是', '不', '存在', '的', '或者', '不', '具有', '实际意义', '的', ',', '为了', '避免', '这种', '问题', ',', '引入', '了', 'one', '-', 'hot', '编码', '(', '也', '称', '独热', '编码', ')', '。'], ['one', '-', 'hot', '编码', '的', '基本', '思想', '是', '将', '每个', '类别', '映射', '到', '一个', '向量', ',', '其中', '只有', '一个', '元素', '的', '值', '为', '1', ',', '其余', '元素', '的', '值', '为', '0', '。'], ['这样', ',', '每个', '类别', '之间', '就是', '相互', '独立', '的', ',', '不', '存在', '顺序', '或', '距离', '关系', '。'], ['例如', ',', '对于', '三个', '类别', '的', '情况', ',', '可以', '使用', '如下', '的', 'one', '-', 'hot', '编码', ':'], ['这是', 'K', '同学', '啊', '的', '“', '365', '天', '深度', '学习', '训练营', '”', '教案', '内容']]
====文本序列:====
[[54, 48, 7, 65, 13, 84, 55, 89, 7, 9, 64, 49], [15, 39, 92, 79, 23, 85, 72, 7, 32, 39, 95, 50, 42, 67, 17, 30, 57, 34, 68, 88, 85, 72, 49], [71, 39, 44, 65, 16, 79, 32, 39, 26, 4, 58, 98, 8, 36, 18, 5, 72, 43, 16, 97, 3, 12, 10, 66], [90, 14, 59, 66, 58, 13, 70, 16, 7, 52, 70, 31, 1, 7, 39, 35, 69, 44, 32, 39, 60, 77, 11, 24, 46, 80, 94, 73, 45, 99, 80, 53, 49], [11, 24, 46, 80, 7, 81, 74, 13, 37, 61, 72, 91, 86, 79, 27, 39, 51, 96, 79, 82, 7, 6, 56, 42, 39, 41, 82, 7, 6, 56, 75, 49], [78, 39, 61, 72, 43, 26, 62, 25, 7, 39, 70, 16, 3, 12, 10, 66, 49], [15, 39, 92, 85, 72, 7, 29, 39, 95, 19, 47, 7, 11, 24, 46, 80, 63], [20, 40, 38, 22, 7, 28, 33, 87, 2, 76, 0, 83, 93, 21]]
====One-Hot编码:====
tensor([[0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0.,
1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1.,
0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 0.,
0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0.,
1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0., 1., 0.,
0., 0., 1., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 1., 1., 1., 0., 0., 1., 0., 1., 0., 1., 0., 0., 0., 1., 0.,
1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
1., 0., 0., 1., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1.,
1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 1., 0.],
[0., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 1., 1., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 1.,
0., 0., 0., 1., 0., 0., 0., 0., 1., 1., 1., 0., 0., 1., 0., 0., 1., 1.,
0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 1., 0., 0., 1., 1., 0.,
0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 1., 0., 1., 1., 0., 0., 0., 1., 0., 0., 1., 0., 1., 0., 0.,
0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 1., 1., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 1., 0., 0., 0.,
0., 1., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0.,
1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0.,
0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 1., 0., 0., 1., 0., 0., 0., 0.],
[1., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
五、学习心得
1.学习了one-hot编码并将其应用于英文案例和中文案例中。在英文案例中,能够识别独立的单词并自动进行分词。而在中文案例中,不能自动识别,而是一个字。借助结巴分词工具可以很好地分割一句话中的词语。
2.掌握了构建词汇表及其在文本向量化中的作用。在进行One-Hot编码之前,需要先构建一个完整的词汇表,将每个唯一的词分配一个唯一的索引。
3.虽然One-Hot编码实现简单,但随着词汇量增大,其向量维度会急剧增加,且不同词之间的语义关系无法体现。
相关文章:
第N1周:one-hot编码案例
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 一、one-hot编码概念 自然语言处理(NLP)中的文本数字化:文字对于计算机来说就仅仅只是一个个符号,计算…...
Windows安装docker desktop
Windows 版本: Windows 10/11(64位)专业版、企业版或教育版(家庭版需手动配置)。 版本号需 ≥ 1909(建议更新到最新系统) 打开程序 启动服务后点点点 重启生效(没有的话 安装WSL…...
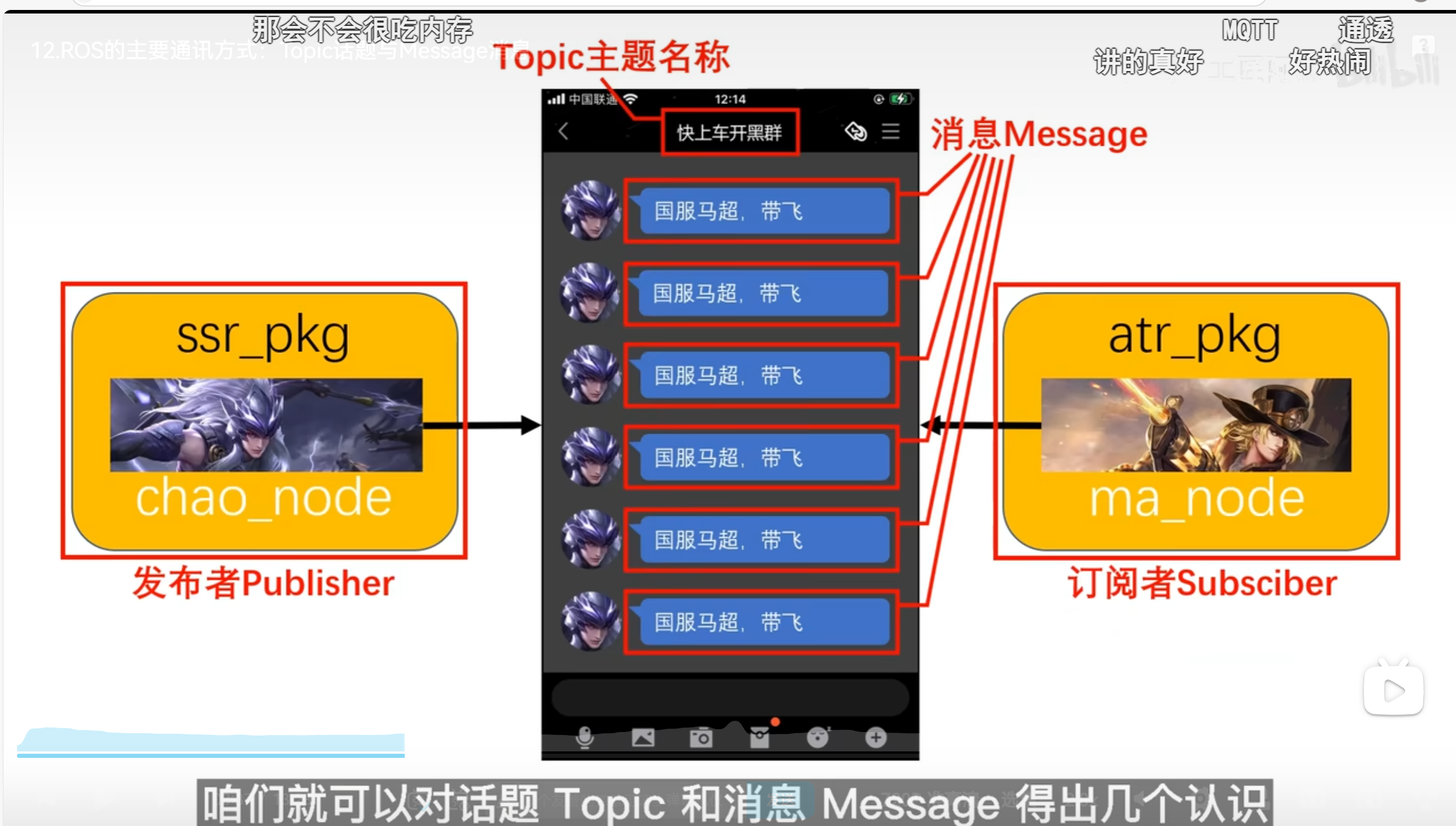
Ros(俩不同包的节点 交流 topic message)
不同的俩节点 如chao_node 和ma_node .在俩不同的包下。 他们若想互相产生联系, 就需要靠这个关系了。 想象一下是开黑的场景 其实群名就是topic 而发送的消息就是Message。 其中主动刷屏的message的一方 就是 Publisher 而接受的那一方 就是subsciber...
李沐《动手学深度学习》 | 数值稳定性
文章目录 数值稳定性梯度消失Sigmoid作为激活函数 梯度爆炸 让训练更加稳定合理的权重初始化Xavier初始化(常用)He初始化/Kaiming方法 Batch Normalization Q&A 数值稳定性 当神经网络的深度比较深时,非常容易数值不稳定。 不稳定梯度是…...

OpenCV CUDA模块图像处理------图像连通域标记接口函数connectedComponents()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数在 GPU 上执行二值图像的连通域标记操作,即将图像中所有相连的前景像素区域赋予相同的标签(label)&…...
Android Studio 打包时遇到了签名报错问题:Invalid keystore format
错误指出密钥库的格式无效,可能是由于密钥库本身的问题导致的,还有一种可能是由于jdk版本导致。我试过重新签名,也是不行,后来发现是JDK版本问题,我的Studio之前是jbr11,好像后来合并代码重新下载编译了项目…...

内存管理【Linux操作系统】
文章目录 简单谈一下物理内存管理页框为什么要把物理内存划分成一个一个固定大小的页框使用?对页框进行描述对页框进行组织管理虚拟地址→物理地址(真实的页表)真实的页表那我们如何把虚拟地址→物理地址呢?页表懒加载时ÿ…...
Go语言学习-->从零开始搭建环境
Go语言学习–>从零开始搭建环境 1 开发环境 Go官网下载地址:https://golang.org/dl/ Go官方镜像站(推荐):https://golang.google.cn/dl/ windos 平台下载: 我这里下载1.22稳定版 双击下载好的.msi文件 修改安装…...

【力扣】3403. 从盒子中找出字典序最大的字符串 I
解法一: class Solution {public String answerString(String word, int numFriends) {//对字符的划分,word长度为n,共有n1个位置可以插入,但是要求被分为非空字符串,所以插入的位置最多为n-1。int n word.length();…...

苹果企业签名撤销
苹果企业签名证书被撤销的原因通常涉及违反苹果的**《Apple Developer Program企业协议》**或相关安全政策,以下是常见原因: ### 一、核心违规原因 1. **证书滥用分发公开应用** * 企业证书仅限**内部员工使用**,若用于以下场景会被撤销&…...

12306高并发计算架构揭秘:Apache Geode 客户端接入与实践
目录 Apache Geode 客户端入门指南 一、安装 Apache Geode 二、启动 Geode 集群 三、Java 客户端接入 Geode Maven 示例依赖 Gradle 示例依赖 Java 示例代码 四、Spring Boot 客户端接入 Geode Maven 配置 Gradle 配置 运行应用 五、Apache Geode 原生客户端 .NET…...

JSON to Excel 3.0.0 版本发布 - 从Excel插件到Web应用的转变
1. 简介 JSON to Excel 3.0.0 是一个重大更新版本,将原有的Excel插件扩展为完整的Web应用。现在您可以直接在浏览器中使用它,无需安装任何插件。所有的转换在浏览器中完成,预览后,可点击下载按钮,导出成xlsx格式文件。…...
【前端】Vue3+elementui+ts,给标签设置样式属性style时,提示type check failed for prop,再次请出DeepSeek来解答
🌹欢迎来到《小5讲堂》🌹 🌹这是《前端》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!&…...

Neo4j 监控全解析:原理、技术、技巧与最佳实践
高效的监控是保障 Neo4j 图数据库性能、稳定性和可观察性的基石。本文将深入探讨 Neo4j 监控的核心原理、关键技术、实用技巧及行业最佳实践,助您构建强大的数据库运维体系。 掌握这些监控技术,将使您的 Neo4j 数据库在稳定性、性能和可维护性上达到企业…...
PyTorch——优化器(9)
优化器根据梯度调整参数,以达到降低误差 import torch.optim import torchvision from torch import nn from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear from torch.utils.data import DataLoader# 加载CIFAR10测试数据集,设置tr…...
07 APP 自动化- appium+pytest+allure框架封装
文章目录 一、PO二、代码简单实现项目框架预览:base_page.pydir_config.pyget_data.pylogger.pystart_session.pyconfig.yamlkey_code.yamllaunch_page_loc.pylogin_page_loc.pylaunch_page.pylogin_page.pytest_login.pypytest.inirun.py 一、PO PO 分为四层 &…...

Postgresql常规SQL语句操作
目录 一、数据库与对象管理 二、数据操作 (CRUD) 三、查询优化与执行计划分析 四、事务控制 五、数据类型与高级特性应用 六、系统查询与维护 研发中的重要注意事项 在 PostgreSQL 研发中,以下这些 SQL 应用是极其常见且核心的操作,涵盖了数据库设…...

智能合约安全漏洞解析:从 Reentrancy 到 Integer Overflow
目录 🌀 Reentrancy(重入攻击) 原理解析 典型案例:The DAO 攻击事件 漏洞示例 防范措施 🔢 Integer Overflow(整数溢出) 原理解析 漏洞示例 防范措施 🛡️ 总结与建议 随着…...

英国2025年战略防御评估报告:网络与电磁域成现代战争核心
英国 2025 年战略防御评估 (SDR) 详细制定了一项计划,通过加强使用网络、人工智能和数字战争来整合其军事防御和进攻能力。 与美国一样,英国也被认为(尽管未被公开证实)会开展进攻性网络行动,甚至针对盟友。斯诺登泄露…...

基于QPSK调制解调+Polar编译码(SCL译码)的matlab性能仿真,并对比BPSK
目录 1.引言 2.算法仿真效果演示 3.数据集格式或算法参数简介 4.MATLAB核心程序 5.算法涉及理论知识概要 6.参考文献 7.完整算法代码文件获得 1.引言 Polar码由土耳其教授Erdal Arikan于2008年提出,是第一种被严格证明可以达到香农极限的构造性编码方法。其核…...

go语言学习 第5章:函数
第5章:函数 函数是编程中不可或缺的一部分,它封装了一段可重复使用的代码,用于执行特定的任务。在Go语言中,函数同样扮演着重要的角色。本章将详细介绍Go语言中函数的定义、调用、参数传递、返回值处理以及一些高级特性ÿ…...

Qt Quick快速入门笔记
Qt Quick快速入门笔记 基本的程序结构int main(int argc, char *argv[]) { #if QT_VERSION < QT_VERSION_CHECK(6, 0, 0)QCoreApplication::setAttribute(Qt::AA_EnableHighDpiScaling); #endifQGuiApplication app(argc, argv);QQmlApplicationEngine engine;const QUrl ur…...

《波段操盘实战技法》速读笔记
文章目录 书籍信息概览实战八法波段见顶信号中长线大顶形态投资理念 书籍信息 书名:《波段操盘实战技法》 作者:何瑞东 概览 实战八法 投资理念和投资理论概述:波段操作的核心是通过捕捉股价波动中的趋势性机会,结合技术分析与…...

Glide NoResultEncoderAvailableException异常解决
首先将解决方法提出来:缓存策略DiskCacheStrategy.DATA。 使用Glide加载图片,版本是4.15.0,有天发现无法显示gif图片,原始代码如下: Glide.with(context).load(本地资源路径).diskCacheStrategy(DiskCacheStrategy.A…...

工厂模式与多态结合
工厂模式与多态的结合是平台化项目中实现灵活架构的核心技术之一。这种组合能够创建可扩展、易维护的系统架构。 多态(Polymorphism)指同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。 例子1: public abstract class Pay…...

无人机巡检智能边缘计算终端技术方案——基于EFISH-SCB-RK3588工控机/SAIL-RK3588核心板的国产化替代方案
一、方案核心价值 实时AI处理:6TOPS NPU实现无人机影像的实时缺陷检测(延迟<50ms)全国产化:芯片、操作系统、算法工具链100%自主可控极端环境适配:-40℃~85℃稳定运行,IP65防护等…...
相机--相机成像原理和基础概念
教程 成像原理 基础概念 焦距(物理焦距) 镜头的光学中心到感光元件之间的距离,用f表示,单位:mm;。 像素焦距 相机内参矩阵中的 fx 和 fy 是将物理焦距转换到像素坐标系的产物,可能不同。…...
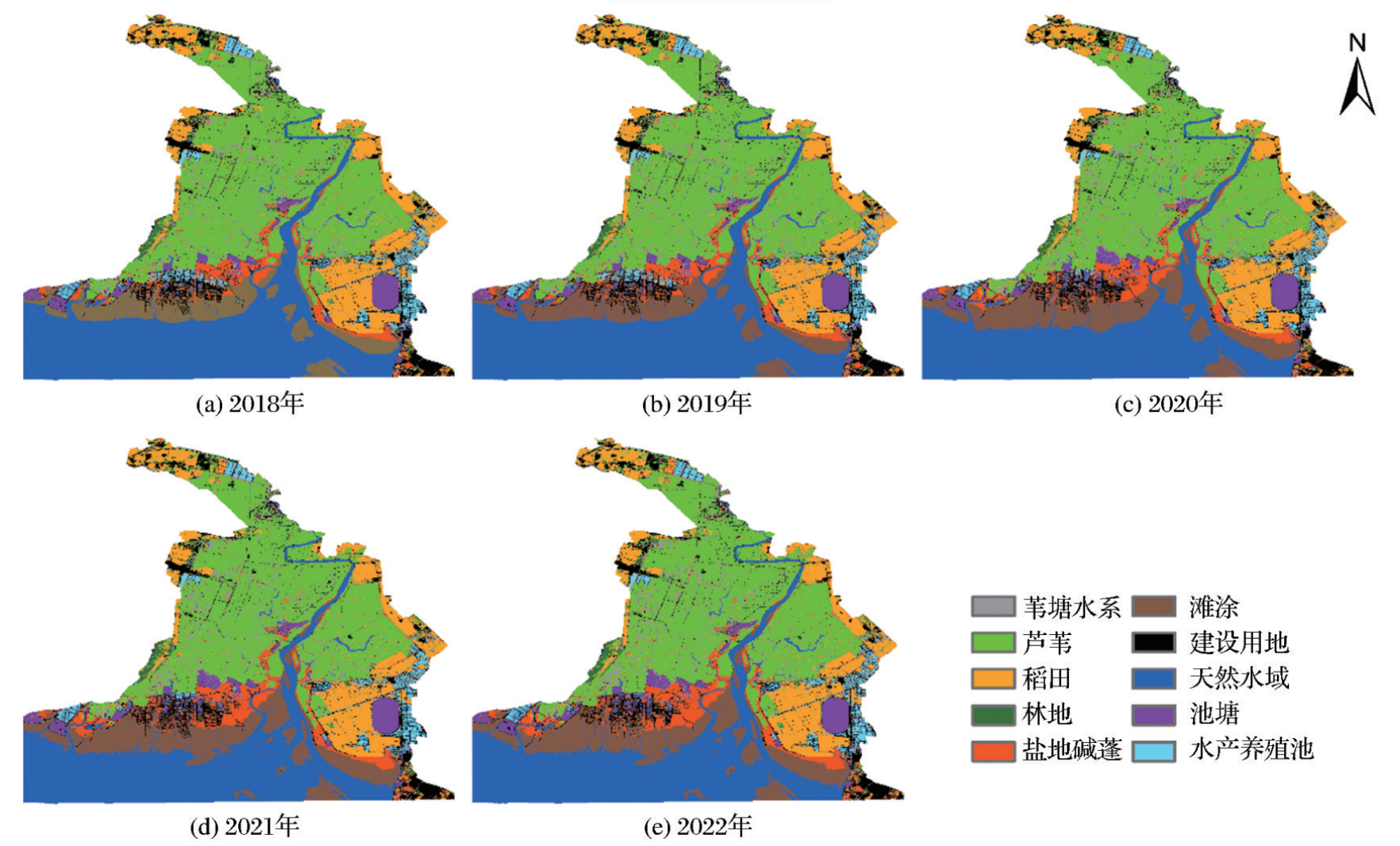
2025-0604学习记录17——文献阅读与分享(2)
最近不是失踪了!也不是弃坑了...这不是马上要毕业了嘛!所以最近在忙毕业论文答辩、毕业去向填报、户档去向填报等等,事情太多了,没顾得上博客。现在这些事基本上都解决完了,也有时间静下心来写写文字了~ 想要写的内容…...
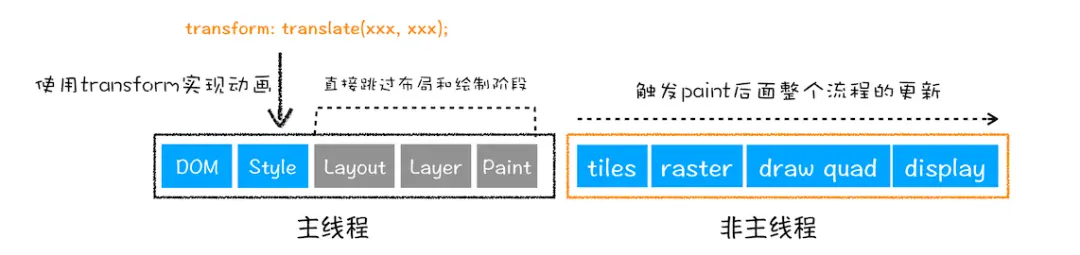
图解浏览器多进程渲染:从DNS到GPU合成的完整旅程
目录 浅谈浏览器进程 浏览器进程架构的演化 进程和线程关系图示 进程(Process) 线程(Thread) 协程(Coroutine) 进程&线程&协程核心对比 单进程和多进程浏览器 单进程浏览器编辑 单进程…...
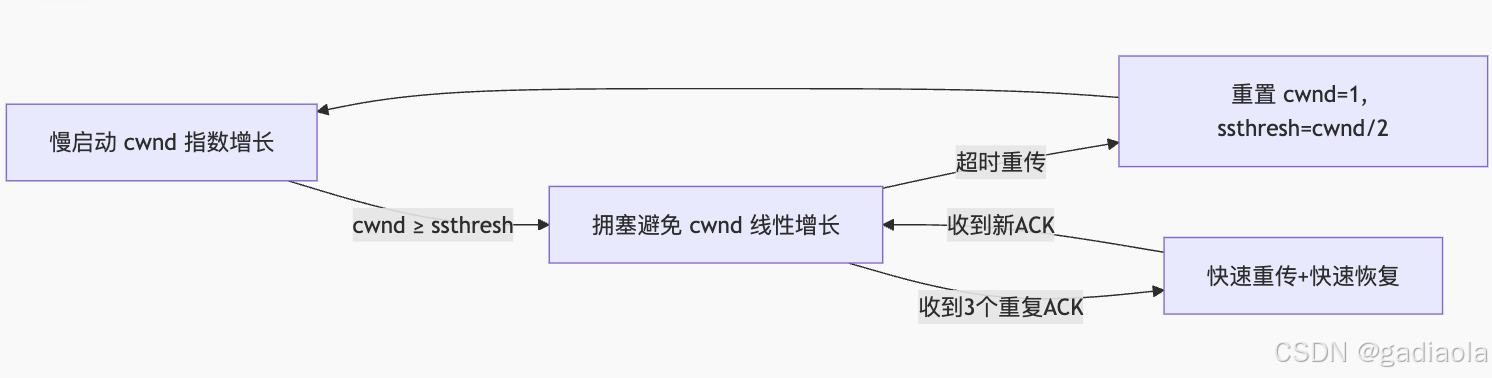
【计算机网络】第3章:传输层—TCP 拥塞控制
目录 一、PPT 二、总结 TCP 拥塞控制详解 ⭐ 核心机制与算法 1. 慢启动(Slow Start) 2. 拥塞避免(Congestion Avoidance) 3. 快速重传(Fast Retransmit) 4. 快速恢复(Fast Recovery&…...