简单爬虫框架实现
1. 框架功能概述
(1) HttpSession 类:请求管理
- 功能:封装
requests库,实现带重试机制的 HTTP 请求(GET/POST)。 - 关键特性:
- 自动处理 429(请求过多)、5xx(服务器错误)等错误,最多重试 3 次。
- 自动设置请求头(
User-Agent、Accept等),降低被网站封禁的风险。 - 自动检测响应编码(
response.encoding = response.apparent_encoding)。
(2) DataParser 类:数据解析
- 功能:统一解析接口,支持三种解析方式:
- XPath:使用
lxml库,适合复杂层级结构解析。 - CSS 选择器:使用
BeautifulSoup,适合快速定位元素。 - 正则表达式:处理非结构化数据(如 JavaScript 生成的内容)。
- XPath:使用
- 使用示例:
parser = DataParser(response) titles = parser.css(".title") # CSS选择器 links = parser.xpath('//a/@href') # XPath numbers = parser.regex(r'\d+') # 正则表达式
(3) Spider 基类:爬虫流程模板
- 功能:定义爬虫的通用流程,强制子类实现核心逻辑。
- 关键方法:
start_requests():生成初始请求 URL 列表(子类必须实现)。parse(response):解析页面数据(子类必须实现)。run():主流程控制,包括请求发送、解析、数据保存和防封禁延迟。
- 模板方法模式:子类只需聚焦业务逻辑(如 URL 生成和数据提取),框架自动处理请求重试、解析器初始化等通用逻辑。
2. 如何使用该框架?
步骤 1:创建类爬虫
新建一个 Python 文件(如 spider_framework.py)
'''
@Author : 小宇
@File : spider_framework.py
'''import re
import time
import requests
from bs4 import BeautifulSoup
from lxml import etree
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry# ---------------------------
# 全局配置(请求头)
# ---------------------------
DEFAULT_HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 Safari/537.36","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}# ---------------------------
# 请求类(带重试机制)
# ---------------------------
class HttpSession:"""负责发送HTTP请求,支持失败重试"""def __init__(self, retries=3, timeout=10):self.session = requests.Session()self.timeout = timeout # 请求超时时间(秒)# 配置重试策略(遇到429/5xx错误时重试)retry_strategy = Retry(total=retries, # 最大重试次数backoff_factor=1, # 重试间隔(秒)status_forcelist=[429, 500, 502, 503, 504])self.session.mount("http://", HTTPAdapter(max_retries=retry_strategy))self.session.mount("https://", HTTPAdapter(max_retries=retry_strategy))def get(self, url, headers=None):"""发送GET请求"""headers = headers or DEFAULT_HEADERS # 使用默认请求头try:response = self.session.get(url, headers=headers, timeout=self.timeout)response.raise_for_status() # 失败时抛出异常response.encoding = response.apparent_encoding # 自动识别编码return responseexcept Exception as e:print(f"GET请求失败: {url}, 错误: {str(e)}")return Nonedef post(self, url, headers=None, data=None):"""发送POST请求(简化版,实际项目可扩展)"""headers = headers or DEFAULT_HEADERStry:response = self.session.post(url, headers=headers, data=data, timeout=self.timeout)response.raise_for_status()response.encoding = response.apparent_encodingreturn responseexcept Exception as e:print(f"POST请求失败: {url}, 错误: {str(e)}")return None# ---------------------------
# 解析类(支持3种解析方式)
# ---------------------------
class DataParser:"""统一解析接口,接收响应后生成解析对象"""def __init__(self, response):self.text = response.text # 页面文本self.soup = BeautifulSoup(self.text, "lxml") # 使用BeautifulSoup解析self.html = etree.HTML(self.text) # 使用lxml解析XPathdef xpath(self, pattern):"""用XPath提取数据,返回列表"""return self.html.xpath(pattern)def css(self, selector):"""用CSS选择器提取数据,返回列表"""return self.soup.select(selector)def regex(self, pattern, flags=re.S):"""用正则表达式提取数据,返回匹配列表"""return re.findall(pattern, self.text, flags=flags)# ---------------------------
# 爬虫基类(模板方法)
# ---------------------------
class Spider:"""爬虫基类,定义通用流程,子类需实现关键方法"""def __init__(self, name):self.name = name # 爬虫名称self.http = HttpSession() # 初始化请求对象self.parser = None # 解析器对象def start_requests(self):"""生成初始请求URL列表(需子类实现)"""raise NotImplementedError("请在子类中定义起始URL")def parse(self, response):"""解析页面数据(需子类实现)"""raise NotImplementedError("请在子类中定义解析逻辑")def run(self):"""爬虫主流程"""print(f"启动爬虫: {self.name}")for url in self.start_requests(): # 遍历所有请求URLresponse = self.http.get(url) # 发送请求if not response: # 请求失败时跳过continueself.parser = DataParser(response) # 创建解析器print(f"成功获取页面: {url}")data = self.parse(response) # 解析数据if data:self.save_data(data) # 保存数据time.sleep(1) # 暂停1秒防封禁def save_data(self, data):"""保存数据(默认打印到控制台,可自定义)"""print(f"解析到数据: {data}")
步骤 2:创建子类爬虫
1:BeautifulSoup
新建一个 Python 文件(如 douban_BeautifulSoup.py),继承 Spider 基类并实现抽象方法:
'''
@Time : 2025/6/3 13:49
@Author : 小宇
@File : douban_BeautifulSoup .py'''
from spider_framework import Spiderclass DoubanSpider(Spider):def __init__(self):super().__init__(name="豆瓣电影TOP250爬虫")self.base_url = "https://movie.douban.com/top250"def start_requests(self):"""生成多页 URL(每页 25 条数据)"""return [f"{self.base_url}?start={i*25}" for i in range(10)]def parse(self, response):"""解析电影列表页,提取电影信息"""movies = []for item in self.parser.css(".item"): # 使用 CSS 选择器定位每个电影项title = item.select_one(".title").get_text(strip=True) # 标题rating = item.select_one(".rating_num").text # 评分quote = item.select_one(".inq")?.text.strip() or "无引言" # 引言(处理可能不存在的情况)cover_url = item.select_one(".pic a img")["src"] # 封面链接movies.append({"标题": title,"评分": rating,"引言": quote,"封面": cover_url})return moviesif __name__ == "__main__":spider = DoubanSpider()spider.run() # 启动爬虫
2:XPath
'''
@Time : 2025/6/3 14:01
@Author : 小宇
@File : douban_XPath.py
'''from spider_framework import Spiderclass DoubanSpider(Spider):def __init__(self):super().__init__(name="豆瓣电影TOP250爬虫")self.base_url = "https://movie.douban.com/top250"def start_requests(self):"""生成多页URL(每页25条)"""return [f"{self.base_url}?start={i * 25}" for i in range(10)]def parse(self, response):movies = []# 使用 XPath 选择所有电影项for item in self.parser.xpath('//div[@class="item"]'): # lxml 元素title = item.xpath('.//span[@class="title"]/text()')[0]rating = item.xpath('.//span[@class="rating_num"]/text()')[0]quote = item.xpath('.//span[@class="inq"]/text()')quote = quote[0] if quote else "无引言"# 使用 XPath 获取封面链接cover_url = item.xpath('.//div[@class="pic"]/a/img/@src')[0]movies.append({"标题": title,"评分": rating,"引言": quote,"封面": cover_url})return moviesif __name__ == "__main__":spider = DoubanSpider()spider.run()步骤 2:运行爬虫
执行脚本,输出类似以下内容:

3. 框架扩展建议
(1) 数据存储扩展
- 需求:默认
save_data方法仅打印数据,实际应用中需保存到文件或数据库。 - 示例:保存到 CSV
import csvclass DoubanSpider(Spider):def __init__(self):super().__init__(name="豆瓣电影TOP250爬虫")self.filename = "douban_movies.csv"self.csv_header = ["标题", "评分", "引言", "封面"]with open(self.filename, "w", newline="", encoding="utf-8") as f:self.writer = csv.DictWriter(f, fieldnames=self.csv_header)self.writer.writeheader()def save_data(self, data):"""重写保存方法,写入 CSV 文件"""with open(self.filename, "a", newline="", encoding="utf-8") as f:self.writer.writerows(data)print(f"已保存 {len(data)} 条数据到 {self.filename}")
(2) 代理池集成
- 需求:避免 IP 被封禁,添加代理轮换功能。
- 修改
HttpSession类:class HttpSession:def __init__(self, retries=3, timeout=10, proxies=None):self.proxies = proxies # 代理列表# ... 其他初始化代码 ...def get(self, url, headers=None):headers = headers or DEFAULT_HEADERStry:# 随机选择代理(示例:proxies = ["http://proxy1.com", "http://proxy2.com"])proxy = random.choice(self.proxies) if self.proxies else Noneresponse = self.session.get(url,headers=headers,timeout=self.timeout,proxies={"http": proxy, "https": proxy} # 设置代理)# ... 其他请求逻辑 ...except Exception as e:# ... 错误处理 ...
(3) 异步请求优化
- 需求:提升爬取效率,使用异步框架(如
aiohttp+asyncio)。 - 说明:需重写
HttpSession为异步版本,并修改Spider.run()为异步流程,适合大规模数据爬取。
4. 常见问题与解决方案
(1) 解析器混用导致的错误
- 问题:误用
BeautifulSoup对象调用xpath方法,或反之。item = parser.css(".item")[0] # BeautifulSoup 对象 cover_url = item.xpath('.//img/@src') # 错误:BeautifulSoup 无 xpath 方法 - 解决方案:
- 统一解析方式:要么全用 CSS 选择器(
soup.select()),要么全用 XPath(html.xpath())。 - 使用
DataParser的对应方法:# 使用 CSS 选择器 cover_url = item.select_one("img")["src"] # 或使用 XPath(需通过 parser.html 获取 lxml 根节点) cover_url = self.parser.xpath('//div[@class="item"][1]/img/@src')[0]
- 统一解析方式:要么全用 CSS 选择器(
(2) 反爬机制应对
- 现象:网站返回 403(禁止访问)或空白页面。
- 解决方案:
- 增加请求头(如
Referer、Cookie)。 - 调整
time.sleep(1)间隔(如改为随机延迟time.sleep(random.uniform(2, 5)))。 - 使用代理池或轮换 User-Agent。
- 增加请求头(如
(3) 动态内容爬取
- 现象:数据通过 JavaScript 生成,静态请求无法获取。
- 解决方案:
- 使用
Selenium或Playwright等浏览器自动化工具。 - 分析接口,直接请求后端 API(如通过浏览器开发者工具抓包)。
- 使用
5. 框架优势总结
- 模块化设计:请求、解析、流程控制分离,易于维护和扩展。
- 防封禁机制:自动重试、请求头设置、延迟等待,提升爬取稳定性。
- 多解析支持:灵活选择 CSS/XPath/正则,适应不同页面结构。
- 代码复用性:基类定义通用逻辑,子类只需实现业务相关方法,减少重复代码。
通过该框架,可快速开发各类静态网页爬虫,后续可根据具体需求逐步添加反爬策略、数据存储、异步请求等高级功能。
相关文章:
简单爬虫框架实现
1. 框架功能概述 (1) HttpSession 类:请求管理 功能:封装 requests 库,实现带重试机制的 HTTP 请求(GET/POST)。关键特性: 自动处理 429(请求过多)、5xx(服务器错误&am…...
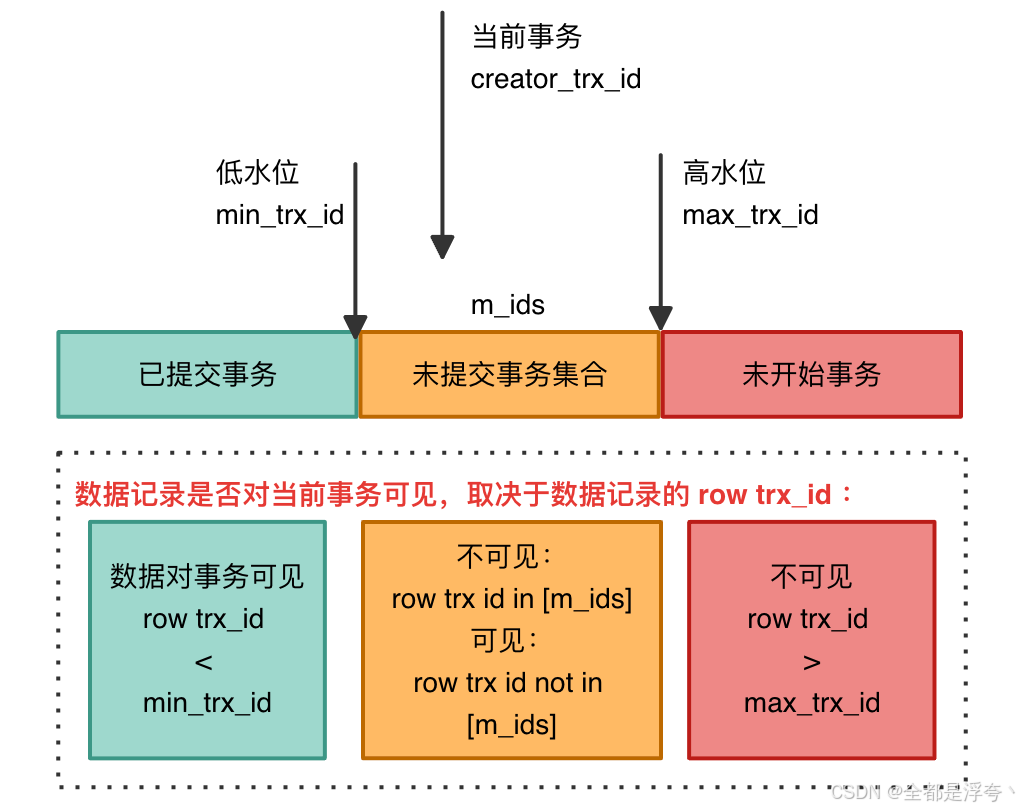
MVCC理解
MySQL的MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种高效的并发控制机制,通过维护数据的多个版本实现读写操作的并行执行,显著提升数据库的并发性能和数据一致性。 MVCC 的实现依赖于:隐…...

705SJBH超市库存管理系统文献综述
前言 信息化的发展已经对我们的日常生活产生了积极的影响,无论是企业、商店、机关、甚至个人,每天都面对着大量的信息,而如果能有效地识别有用信息,并在对它们加工的基础上充分的利用信息,无疑会给我们的生活带来很巨…...
shell:基础
本文主要探讨shell相关知识。 变量 $? 上一次执行命令返回状态 $$ 当前进程进程号 $! 后台运行的最后一个进程的进程号 $# 位置参数的数量 $* 参数内容 $ 参数内容 $和$*解析"hello word"为"hello" "word" "$"解析"hello word&…...
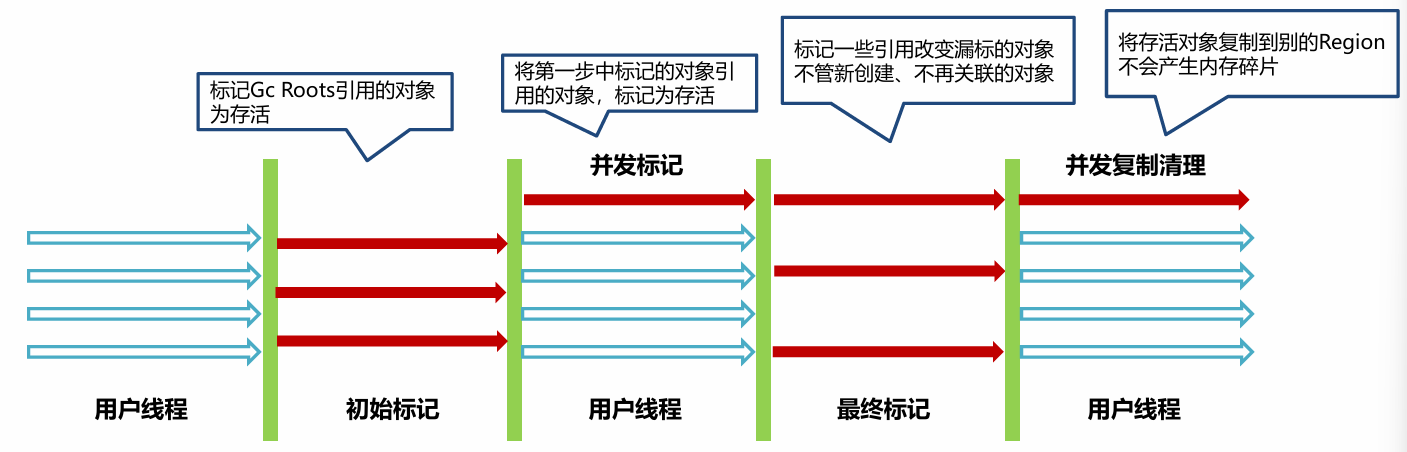
【JVM】万字总结GC垃圾回收
【JVM】GC垃圾回收 概念 在程序运行过程中,会不断创建对象来使用内存,当这些对象不再被引用时,其所占用的内存若不及时释放,会导致内存占用不断增加,最终可能引发内存溢出。GC 机制能自动检测并回收这些不再使用的对…...
内网横向之RDP缓存利用
RDP(远程桌面协议)在连接过程中会缓存凭据,尤其是在启用了 "保存密码" 或 "凭据管理器" 功能时。这个缓存的凭据通常是用于自动填充和简化后续连接的过程。凭据一般包含了用户的用户名和密码信息,或者是经过加…...
【Linux网络】传输层TCP协议
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 TCP 协议 TCP 协议段格式 确认应答(ACK)机制 超时重传机制 连接管理机制 …...
不同视角理解三维旋转
在二维空间中,绕任意点旋转可以分解为: 1)平移旋转点到原点,2)绕原点旋转,3)逆平移旋转点; 可用矩阵表示为 , 其中, 表示绕原点旋转 , 为平移矩…...
Adobe Acrobat——设置PDF打印页面的大小
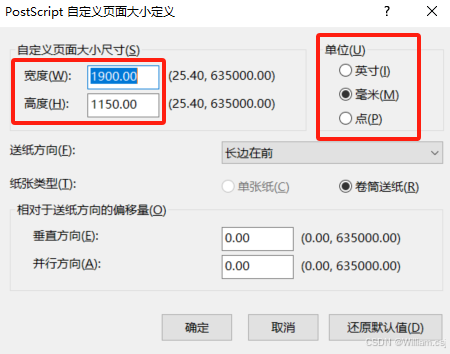
1. 打开 PDF 文件; 2. 点击菜单栏的 “文件” → “打印”; 3. 在打印对话框中,点击 “属性”; 4. 点击 “布局”→ “高级”; 5. 点击 “纸张规格”,选择 “PostScript 自定义页面大小”,然后…...
Android apk装机编译类型: verify、speed-profile, speed与启动耗时
Android apk装机编译类型: verify、speed-profile, speed与启动耗时 Dex2oat (dalvik excutable file to optimized art file) ,对 dex 文件进行编译优化,Android 虚拟机可识别的是dex文件,应用运行过程如果每次都将dex文件加载内存ÿ…...

纹理压缩格式优化
🎯 Unity 项目纹理压缩格式优化终极指南 ——不同平台、不同手机型号,如何正确选择 🧩 什么是纹理压缩(Texture Compression)? Texture压缩 = 减小显存占用,提升加载速度,减轻GPU负担纹理是游戏中最大资源,占用50%+内存正确压缩:减少GPU Bandwidth,提高渲染性能错…...
使用Virtual Serial Port Driver+com2tcp(tcp2com)进行两台电脑的串口通讯
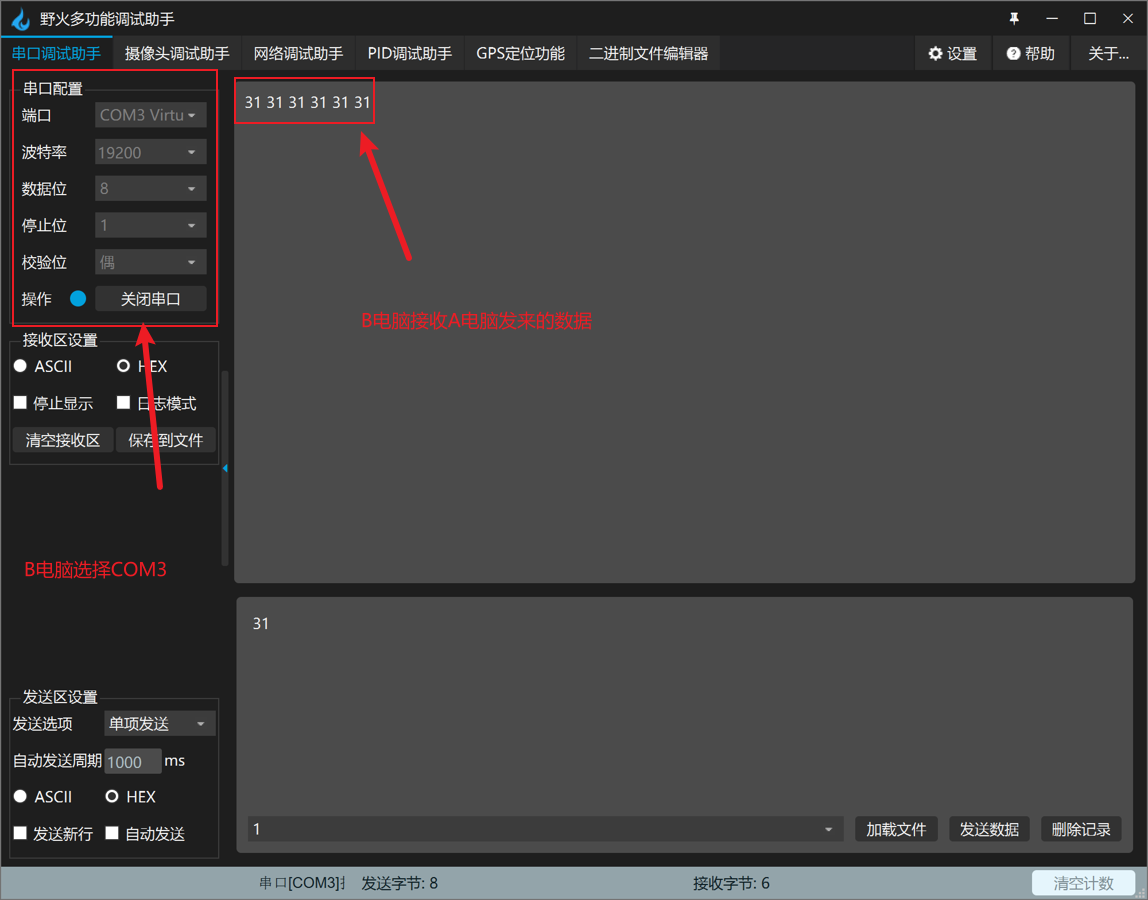
使用Virtual Serial Port Drivercom2tcp或tcp2com进行两台电脑的串口通讯 问题说明解决方案方案三具体操作流程网上教程软件安装拓扑图准备工作com2tcp和tcp2com操作使用串口助手进行验证 方案三存在的问题数据错误通讯延时 问题说明 最近想进行串口通讯的一个测试,…...

【从0-1的HTML】第3篇:html引入css的3种方式
文章目录 HTML中引入CSS的方式行内样式内部样式外部样式yinru.css文件 完整html文件 引入CSS方式的优先级 HTML中引入CSS的方式 HTML:是使用标签来描述网页元素 CSS:是Cascading Style Sheets,层叠样式表,用来控制样式来显示网页…...

数智破局·生态共生:重构全球制造新引擎 2025 WOD制造业数字化博览会即将在沪盛大启幕
共探数智化未来,共创新质生产力。2025年6月17日—19日,上海浦东新国际博览中心将迎来全球制造业数字化转型的盛会——WOD制造业数字化博览会。作为全球首个聚焦制造业数字化全场景的专业展会,本届展会以“数智破局生态共生:重构全…...

machine_env_loader must have been assigned before creating ssh child instance
在主机上执行roslaunch命令时,报错:machine_env_loader must have been assigned before creating ssh child instance。 解决办法: 打开hostos文件,检查local host 前的内部ip是否正常。操作示例: 先输入下方指令打…...
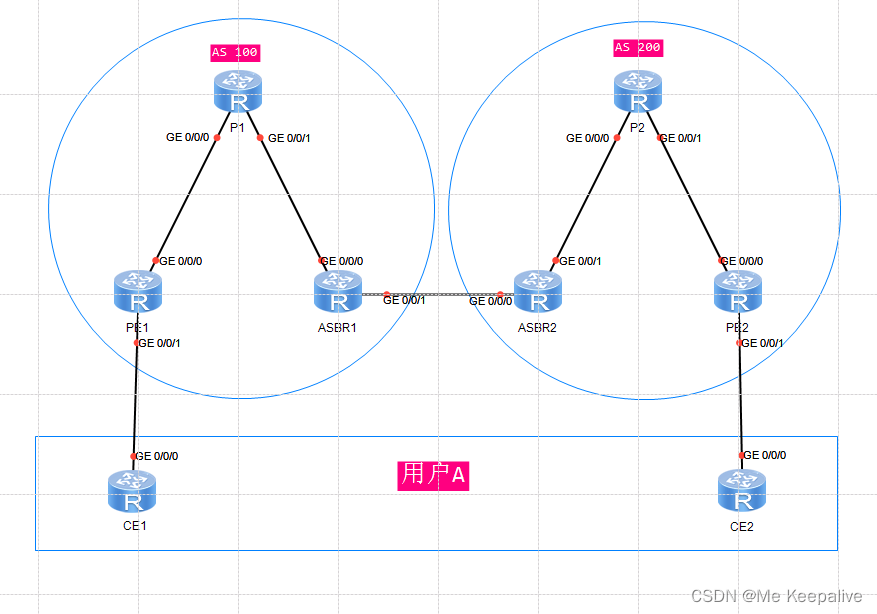
BGP/MPLS IP VPN跨域解决方案
目录 MPLS VPN跨域方案出现背景: MPLS VPN回顾 VRF(Virtual Route Forward)虚拟路由转发 MPLS(Multiple Protcol Label Swtich)多协议标签交换 MP-BGP多协议BGP MPLS VPN跨域OptionA 控制平面: 转发平面: 总结: 挑战: MPLS VPN跨域OptionB 非RR场景: 控制平面: 转发…...

C语言-10.字符串
10.1字符串 10.1-1字符串 字符数组 char word[] = {‘H’,‘e’,‘l’,‘l’,‘o’,‘!’}; word[0]Hword[1]eword[2]lword[3]lword[4]oword[5]!这不是C语言的字符串,因为不能用字符串的方式做计算 字符串 char word[] = {‘H’,‘e’,‘l’,‘l’,‘o’,‘!’}; word[0]Hwo…...
backend 服务尝试连接 qdrant 容器,但失败了,返回 502 Bad Gateway 问题排查
遇到的问题是: backend 报错:502 Bad Gateway 来自 Qdrant → 导致接口 /api/chat 返回 500 Internal Server Error并且日志中提示: QDRANT_URL http://qdrant:6333✅ 问题分析 这个错误的根本原因是: 你的 backend 服务尝试连…...

硬件学习笔记--66 MCU的DMA简介
DMA(Direct Memory Access,直接存储器访问)是MCU中一种重要的数据传输机制,它允许外设与存储器之间或存储器与存储器之间直接传输数据,而无需CPU的持续干预。 1、DMA的基本原理 1.1 核心概念: 1…...

18. Qt系统相关:多线程
一、概述 在Qt中,使用QThread类对系统线程进行了封装。QThread代表一个在应用程序中可独立控制的线程,也可以和进程中的其他线程共享数据。 二、QThread常用API 三、QThread使用 自定义一个类,继承自QThread,并且只有一个线程处…...

6个月Python学习计划 Day 14 - 异常处理基础( 补充学习)
第二周 Day 8 - Python 函数基础 Day 9 - 函数进阶用法 Day 10 - 模块与标准库入门 Day 11 - 列表推导式、内置函数进阶、模块封装实战 Day 12 - 字符串处理 & 文件路径操作 Day 13 - 文件操作基础 🎯 今日目标 理解异常的概念和常见异常类型掌握 try-except …...
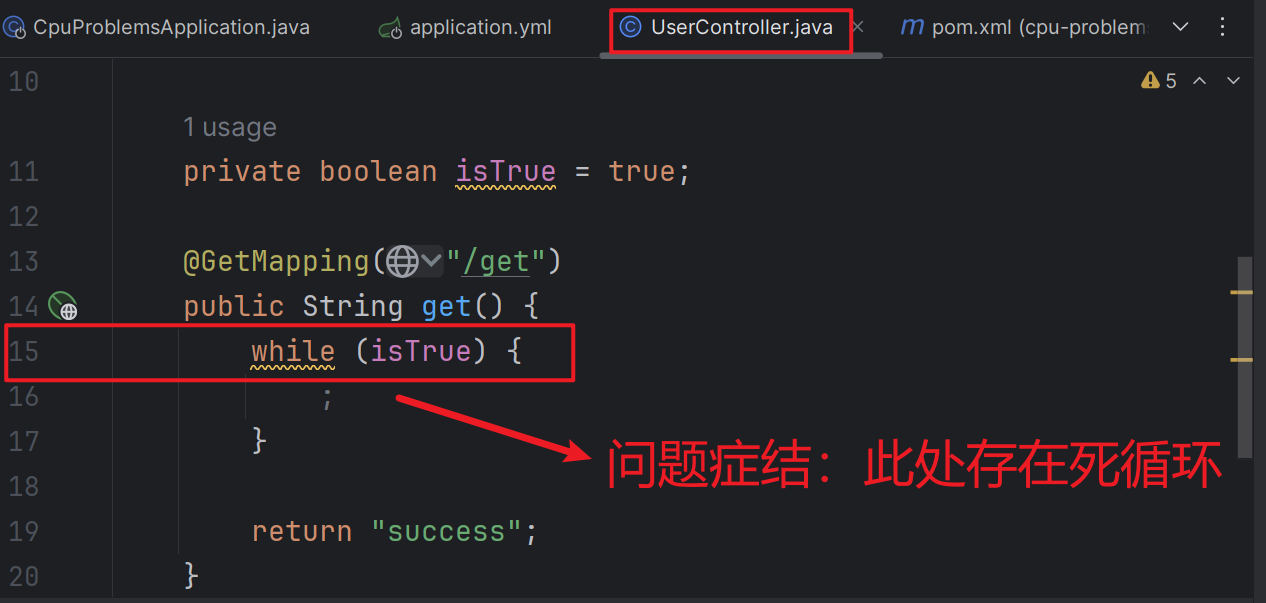
使用jstack排查CPU飙升的问题记录
最近,看到短视频传播了一个使用jstack来协助排查CPU飙升的案例。我也是比较感兴趣,参考了视频博主的流程,自己做了下对应案例的实战演练,在此,想做一下,针对相关问题模拟与排查演练的实战过程记录。 案例中…...
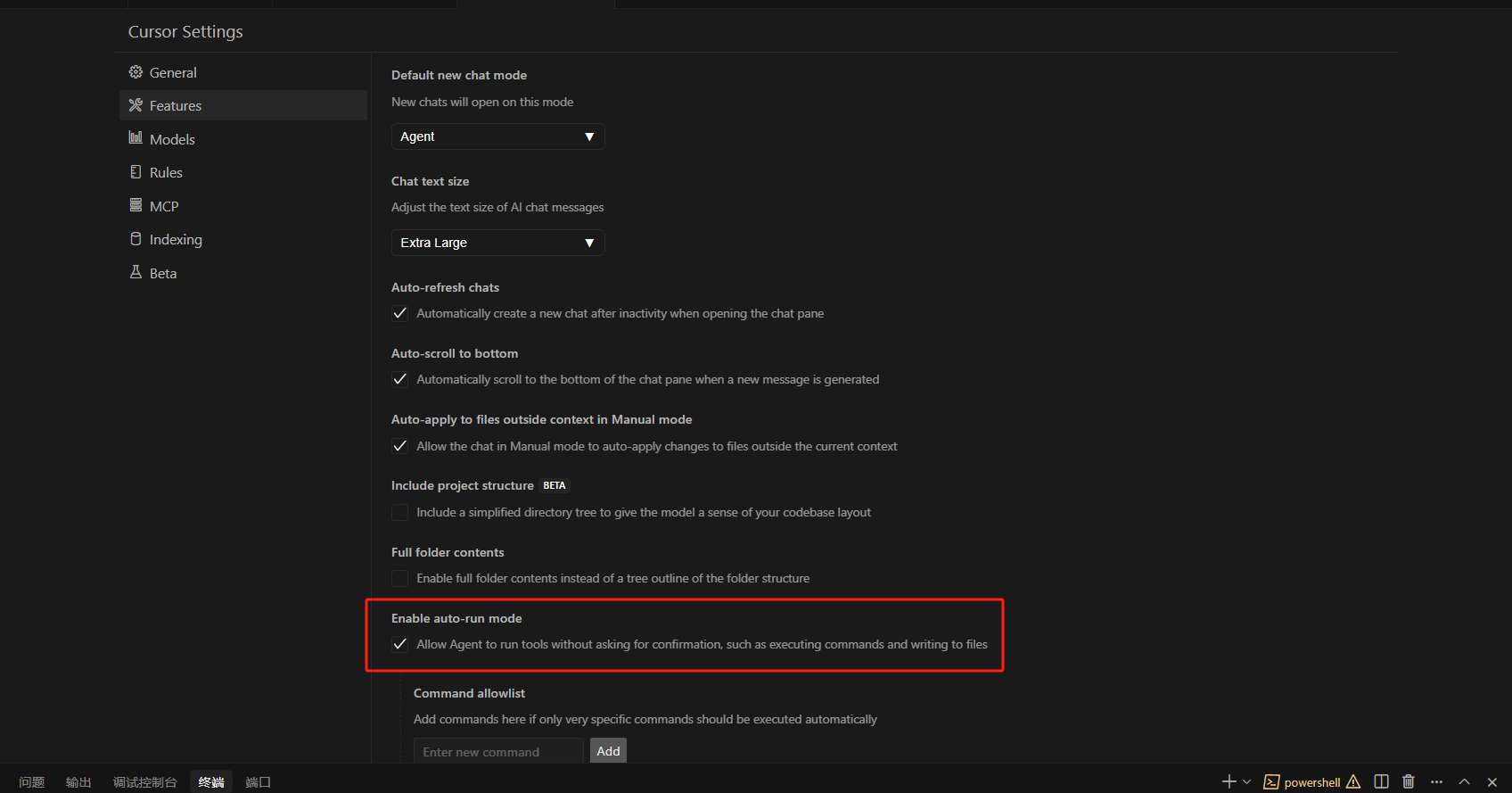
cursor如何开启自动运行模式
在Cursor中,开启自动运行模式即启用“Yolo Mode”,具体操作如下: 按下Ctrl Shift J(Windows/Linux)或Cmd Shift J(Mac)打开Cursor设置。导航到“Features”(功能)选…...
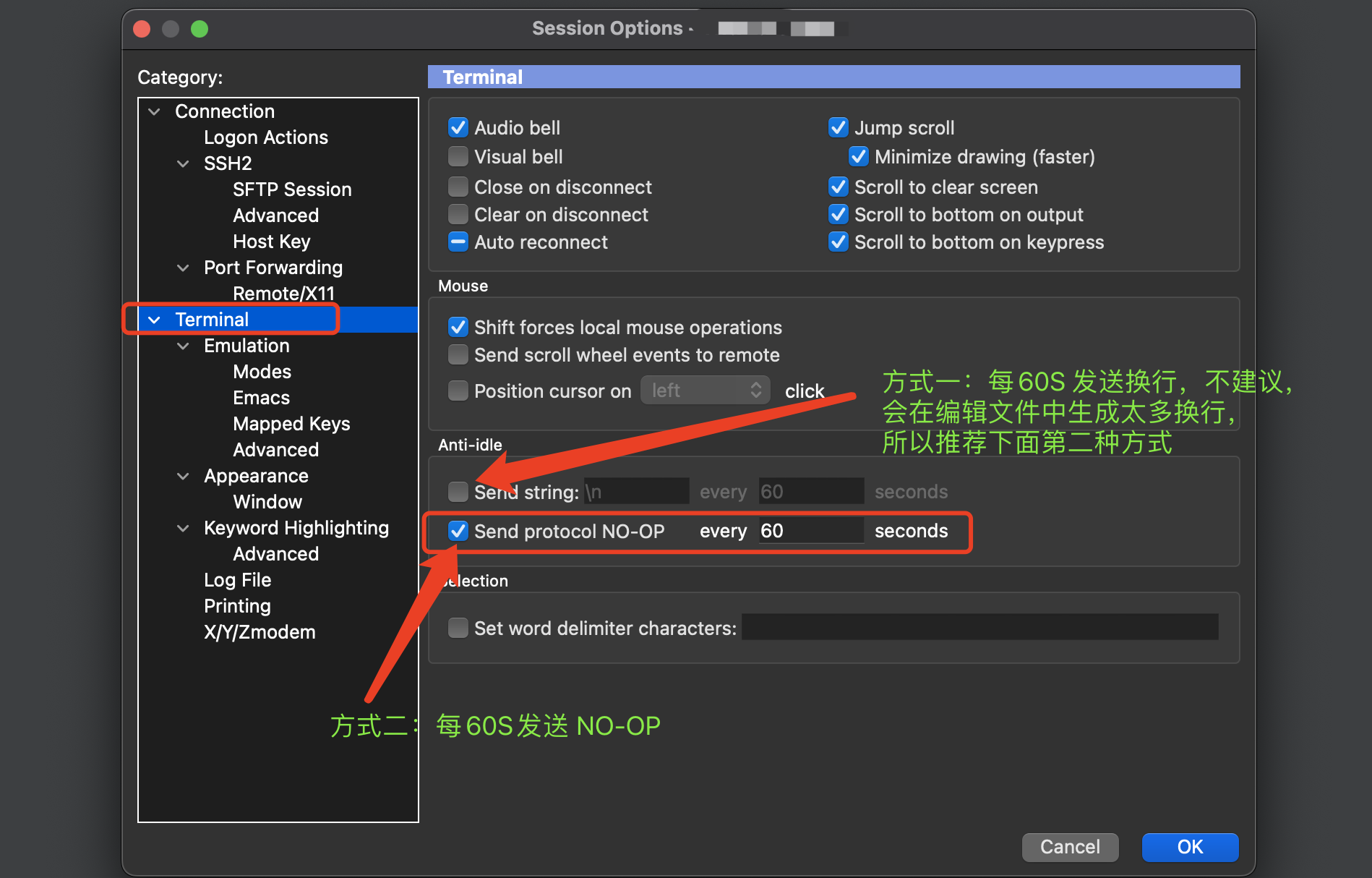
SecureCRT 设置超时自动断开连接时长
我们在使用SecureCRT 连接服务器时,经常性出现2分钟未操作已连接的服务器,就会自动断开连接,此时需要重新连接,非常影响服务器操作,本文可以很好带领大家解决这种问题。...

《复制粘贴的奇迹:原型模式》
📖 背景故事 创业初期,小明每天加班写配送路线、配送策略、营销套餐。可当业务做大后,他发现大家常常下单“上次那个套餐”—— “老板,再来一个上次的奶茶水果!” “老样子,照搬昨天晚上的宵夜套餐&#…...
IEC 61347-1:2015 灯控制装置安全标准详解
IEC 61347-1:2015灯控制装置安全标准详解 IEC 61347-1:2015 是国际电工委员会(IEC)发布的灯控制装置第1部分:通用要求和安全要求的核心标准,为各类照明用电子控制设备设定了全球通用的安全基准。该标准适用于独立式或内置于灯具/…...
Ansys Zemax | 手机镜头设计 - 第 4 部分:用 LS-DYNA 进行冲击性能分析
附件下载 联系工作人员获取附件 该系列文章将讨论智能手机镜头模组设计的挑战,从概念和设计到制造和结构变形分析。本文是四部分系列中的第四部分,它涵盖了相机镜头的显式动态模拟,以及对光学性能的影响。使用 Ansys Mechanical 和 LS - DY…...

[蓝桥杯]实现选择排序
实现选择排序 题目描述 实现选择排序算法。介绍如下: 选择排序的工作原理是每一次从需要排序的数据元素中选出最小的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排列完毕。 请编写代码,完成选择排序,…...
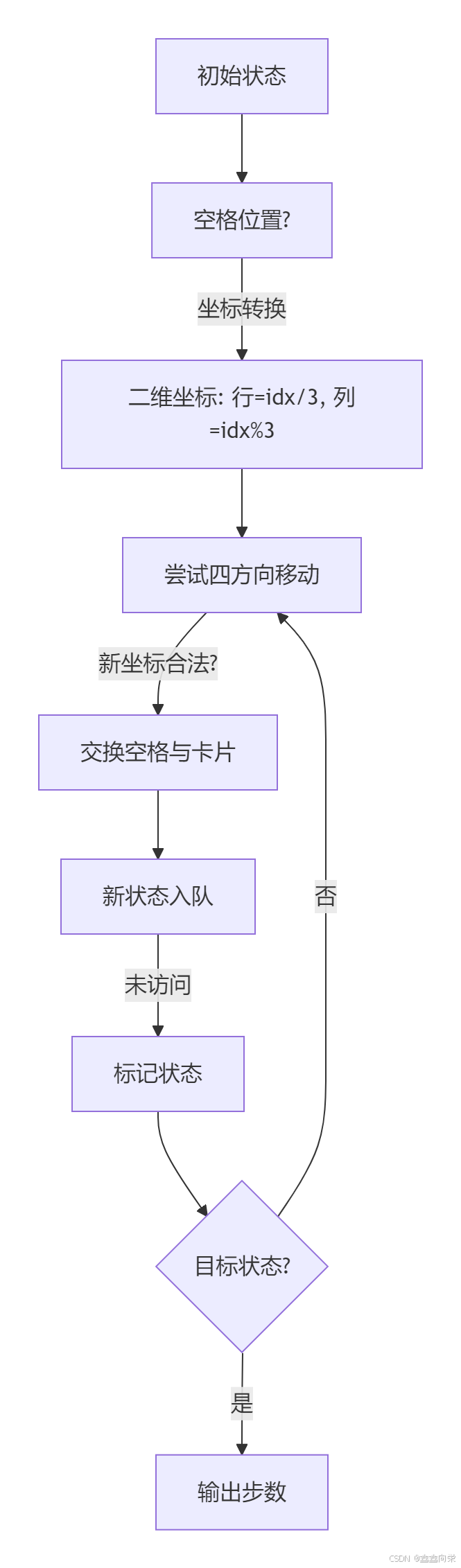
[蓝桥杯]卡片换位
卡片换位 题目描述 你玩过华容道的游戏吗? 这是个类似的,但更简单的游戏。 看下面 3 x 2 的格子 --------- | A | * | * | --------- | B | | * | --------- 在其中放 5 张牌,其中 A 代表关羽,B 代表张飞,* …...
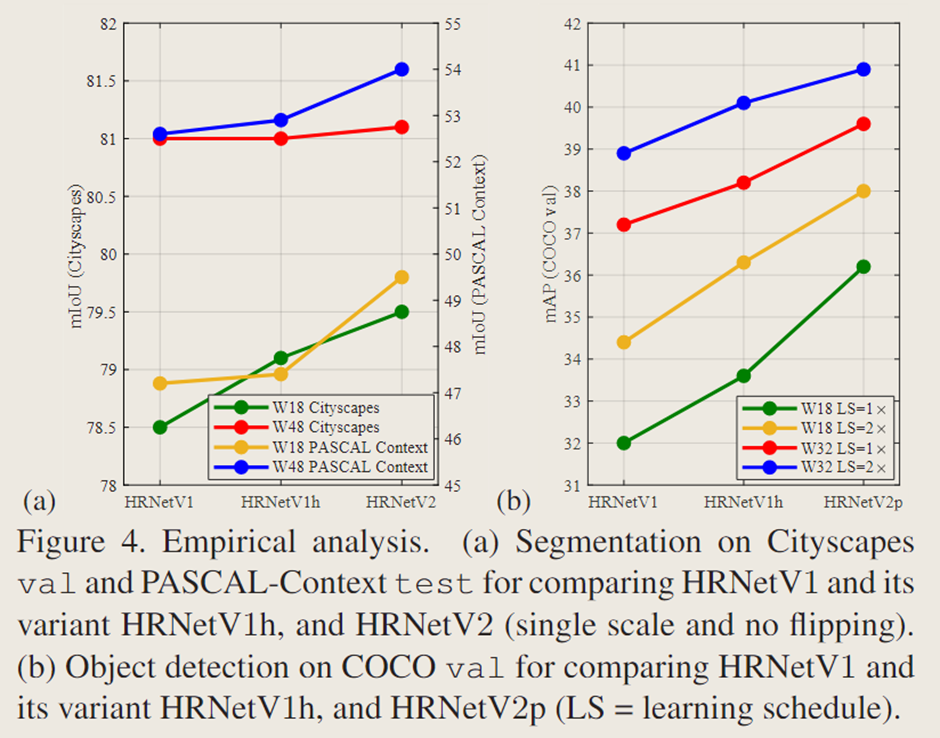
【论文笔记】High-Resolution Representations for Labeling Pixels and Regions
【题目】:High-Resolution Representations for Labeling Pixels and Regions 【引用格式】:Sun K, Zhao Y, Jiang B, et al. High-resolution representations for labeling pixels and regions[J]. arXiv preprint arXiv:1904.04514, 2019. 【网址】…...