Stream流性能分析及优雅使用
文章目录
- 摘要
- 一、Stream原理解析
- 1.1、Stream总概
- 1.2、Stream运行机制
- 1.2.1、创建结点
- 1.2.1、搭建流水线
- 1.2.3、启动流水线
- 1.3、ParallelStream
- 二、性能对比
- 三、优雅使用
- 3.1 Collectors.toMap()
- 3.2 findFirst(),findAny()
- 3.3 增删元素
- 3.4 ParallelStream
- 四、总结
- 参考文献
摘要
Java 8引入的Stream API作为集合数据处理的革新性工具,采用函数式编程范式,显著提升了数据操作的效率与表达力。其核心特征体现在非存储性数据处理模式上,与传统的集合不同,Stream并不存储数据元素,而是构建于数据源(如集合或数组)之上,通过流水线式的操作链实现数据处理。其高效的执行机制和优雅的编程模式使其成为现代Java开发不可或缺的核心组件。
关键字:Stream API, 流式处理;
一、Stream原理解析
1.1、Stream总概
在日常开发工作中,存在诸多对象类型转换、集合元素去重和过滤等典型数据处理场景,而传统基于for循环和if-else条件语句的实现方式存在明显的局限性,如代码结构冗长复杂,显著增加维护成本,手动迭代操作容易引入边界条件错误和逻辑缺陷等。而Java8引入的Stream API具有如下特性:
-
非存储性特征
Stream本质上并非数据结构,而是对底层数据源(包括数组、Java容器或I/O通道等)的抽象视图。这种设计使其摆脱了数据存储的负担,专注于数据处理流程的构建。 -
函数式编程范式支持
遵循函数式编程原则,Stream的所有操作均保持数据源的不可变性。例如,过滤操作并非直接修改源数据,而是生成包含筛选结果的新Stream实例,确保了原始数据的完整性。 -
延迟执行机制
Stream采用惰性求值策略,其操作指令不会立即执行,仅在终端操作触发时才进行实际计算。这种机制有效优化了资源利用率。 -
单次消费特性
与迭代器类似,Stream具有一次性消费特征。遍历完成后即进入失效状态,如需再次操作必须重新生成Stream实例。
Stream操作可分为三类核心操作:源操作(创建数据流)、中间操作(数据转换与传递)以及终止操作(结果归约)。源操作建立数据管道入口;中间操作实现元素级转换并维持流式传递;终止操作触发计算并生成最终输出,完成整个流处理生命周期。而中间操作又可细分为:
- 无状态:如map(),仅依赖输入元素执行纯函数转换,不维护操作间状态。
- 有状态:如limit()需维护内部状态以跟踪处理进度,其执行行为依赖于累积的上下文信息(如已处理元素数与预设阈值)。
终止操作可细分为:
- 短路:如findFirst()采用提前终止策略,当满足预设条件时立即中断流处理并返回结果,无需遍历全部元素.
- 非短路:如max()需执行完全遍历,通过全局比较确定最终结果。此类操作必须处理流中所有元素才能保证计算结果的完备性和正确性。
1.2、Stream运行机制
Stream操作的执行流程可分为三个关键阶段:首先构建包含各处理阶段的流水线结构;随后通过反向遍历生成操作实例链(Sink链);最终数据流经流水线逐级处理并输出结果。该机制实现了高效的数据管道处理模式。接下来基于
ist<String> resList = Stream.of("a", "b", "c", "d").map(String::toUpperCase).limit(2).collect(Collectors.toList());
语句进行流程分析。
1.2.1、创建结点
在对原理进行介绍前,先对Stream整体类图进行介绍,如下图所示。

很清晰的将类划分成了API层和实现层,对于用户来说,在日常开发中经常接触的就是Stream和Collector,而对于内部的实现无感知。其中Stream是一个接口,它定义了对Stream的各种操作。

在实现层,Java利用Pipline来刻画流上的每个结点。AbstractPipline是一个抽象类,定义了流水线节点的常用属性,sourceStage指向流水线首节点,previousStage指向本节点上层节点,nextStage指向本节点下层节点,depth代表本节点处于流水线第几层(从0开始计数),sourceSpliterator指向数据源。ReferencePipline则实现Stream接口,继承AbstractPipline类,它主要对Stream中的各个操作进行实现,此外,它还定义了三个内部类Head、StatelessOp和StatefulOp,分别代表不同类型的结点。Head为流水线首节点,在集合转为流后,生成Head节点,StatelessOp为无状态结点,StatefulOp为有状态结点。
以1.1节所给代码为例,stream()作为流水线的入口,对应一个Head结点;map作为Stream中的无状态中间操作,对应一个StatelessOp结点;limit作为Stream中的有状态中间操作,对应一个StatefulOp结点;collect作为终止操作,结束结点的创建。最终由双向链表联结而成的Stream流水线如下图所示:

1.2.1、搭建流水线
各结点创建好后,需要一个能够串接各个结点的角色,实现类似“流水线”的效果,这个角色就是Sink,其作为核心组件实现了Consumer接口,承担着数据消费者的关键角色,该接口主要负责接收并处理上游传输的数据流。上节所述各结点在实例化时都需要定义各自的Sink创建逻辑,即明确数据消费方式及向下游Sink传输数据的机制。当触发终止操作时,如下图代码所示:系统会采用逆向初始化策略,从末端节点开始逐级向前初始化各节点的Sink实例。在此过程中,后续节点的Sink会被作为前置节点Sink的下游接收器(downStream),流水线触发后即可依次执行。

最终经反向操作形成层层Sink嵌套如下图所示:

1.2.3、启动流水线

通过“套娃”式的串接各结点的Sink后,遍历数据源各元素,依次送入“流水线”,调用每个Sink的accept()方法执行预定义的lambda处理逻辑并得到结果,如下图所示:

综合以上各节,Stream流水线通过双向链表结构实现各处理结点的串联,其执行机制具有显著的惰性特征:仅当遇到终结操作时才会触发实际计算并生成结果数据,否则不执行任何数据处理。此外,每个中间操作节点都会生成新的Stream对象,这一设计严格遵循函数式编程的不可变原则:所有流操作均通过创建新流实现数据处理,而原始数据容器始终保持不变。
1.3、ParallelStream
ParallelStream是Java8提供的并行流处理机制,通过Fork/Join框架自动将数据分割为多个子任务并行处理,充分利用多核CPU优势。其底层默认使用公共ForkJoinPool,基于Spliterator实现数据分割,采用工作窃取算法实现任务调度,适用于大规模数据集处理和CPU密集型计算任务等场景。并行Stream流可通过parallel()方法启用,通过isParallel()检查并行状态,用sequential()切换串行模式。

ParallelStream与串行Stream的不同体现在对有状态结点的处理上。如果是并行处理且包含有状态结点(上图1处),则从头开始遍历流水线上各结点,一旦当前结点是有状态结点(上图2处),就调用对应有状态结点的处理方法(上图3处),这个方法会通过SliceTask(继承自ForkJoinTask)将当前结点之前的操作并行执行并返回新的Spliterator,这个新的Spliterator是树状结构,通过ReduceTask(同样继承自ForkJoinTask)聚合得到结果。即:在并行流处理模型中,系统通过SliceTask等并行计算单元直接对源Spliterator执行无状态操作链式转换,生成经过处理的新Spliterator实例,从而避免了串行处理中的多层包装开销。
二、性能对比
本节针对Java集合处理中常用的外部迭代(for循环)与内部迭代(Stream API)两种方式,结合实际开发场景(数据源选取list集合,数据类型为实体对象)展开性能对比实验。实验通过随机数据构建不同规模的测试数据集,为保障结果可靠性,每组实验设置10次重复测量并取平均值作为最终性能指标。本次测试重点关注两种迭代方式在不同数据量级下的时间复杂度反映出的性能差异。测试环境为:
| 参数 | 信息 |
|---|---|
| JDK版本 | 1.8.0_131 |
| CPU | Intel core i7-10700(8C16T) |
如下列图所示,依次为map()、filter()、sorted()及上述操作组合在for循环、Stream和parallelStream下的数据量和执行时间的统计图。为清晰展示数据,将测试结果分为(a)(b)两张子图展示,其中(a)图表示小数据量(测试数据量选择10,100,1000,10000)测试结果,(b)图表示大数据量(测试数据量选择10万,50万和100万)测试结果。分析测试结果可以得出如下结论:
- 在小数据量(dataNums<1000)时,Stream的处理效率略低于for循环,但毫秒级别的效率差值在实际业务场景中可忽略不计。而Stream使代码简洁性提升显著,且可维护性优势明显,因此在小数据量业务场景下建议使用Stream,parallelStream就没有使用的必要了。
- 在大数据量(dataNums>10000)时,Stream的处理效率低于for循环,但是parallelStream的效率明显高于Stream和for循环,甚至可以成倍提高。因此在做大批量数据处理,建议使用parallelStream,前提是CPU配置足够(使用Intel core i7-7500U测试,parallelStream低于另外两者)。




三、优雅使用
本节主要针对日常开发中常见Stream踩坑点及解决思路进行总结。
3.1 Collectors.toMap()
Collectors.toMap()是Java Stream的终端收集器,通过指定的键值映射函数将流元素转换为Map集合,常用于开发中的拼接操作。有两个需要注意的点:
- key不能有重复,否则会报:
java.lang.IllegalStateException: Duplicate key。 - value不能为null,否则报空指针:
java.lang.NullPointerException。
针对上述问题,开发中可根据实际业务场景做以下处理:存在重复key时指定merge方法(保留最后一个、保留第一个或其他复杂逻辑)或直接将key为null的数据过滤掉。 存在value为null时可过滤掉或转为其他值或保留。
- 直接将key或value为null的数据过滤掉,指定merge方法并保留最后一个
/* 将贷款列表转为:贷款编号为key,贷款余额为value的map */
Map<String, BigDecimal> loanNumBalMap = loanList.stream().filter(loan -> Objects.nonNull(loan.getLoanNum()) && Objects.nonNull(loan.getLoanBal())).collect(Collectors.toMap(Loan::getLoanNum, Loan::getLoanBal, (newLoan, oldLoan) -> oldLoan));
- 保留value为null的数据,key相同时利用putAll进行覆盖
HashMap<Object, Object> loanNumBalMap = loanList.stream().collect(HashMap::new, (map, loan) -> map.put(loan.getLoanNum(), loan.getLoanBal()), HashMap::putAll);
3.2 findFirst(),findAny()
Stream.findFirst()用于返回流中首个匹配元素,Stream.findAny()用于返回任意匹配元素。可通过Optional.get()获取具体元素,但这个方法并不是找得到就返回,找不到就不做处理,而是会抛出异常java.util.NoSuchElementException: No value present,可采用Optional.orElse()设置找不到时的默认值:
Loan resLoan = loanList.stream().filter(loan -> null != loan.getLoanBal() && new BigDecimal("10000").compareTo(loan.getLoanBal()) < 0).findFirst().orElse(loan1);
System.out.println(resLoan);
3.3 增删元素
建议在执行Stream流操作前,确定好需要处理的所有数据元素,不要在执行过程中进行增删元素操作,会报:java.lang.UnsupportedOperationException,如:
loanList.forEach(loan -> {if ("rcrd001".equals(loan.getRcrdId())){loanList.add(loan3);}
});
当然结合Stream的惰性执行特性,只要在终结操作触发之前调整数据元素即可,这种操作虽然可行,但不推荐。
3.4 ParallelStream
- 在并行处理场景下,应优先选用
groupingByConcurrent()或toConcurrentMap()替代其非并发的collectors.groupingBy()和collectors.toMa()。原因在于并行执行时,对多个子任务产生的局部Map进行基于key的合并操作会产生显著的性能开销。当处理大规模数据集时,这种合并操作可能成为性能瓶颈。 - ParallelStream处理性能受底层数据结构可分解性影响显著,如:ArrayList支持O(1)时间复杂度的随机访问拆分,而LinkedList必须进行O(n)的线性遍历才能实现任务划分,导致并行效率差异显著。
- 尽管可通过parallel() 和sequential()实现Stream并行流和串行流的切换,也允许同时出现在一个Stream中,但最终流的执行机制由最后一次调用决定,即:流的并行性或串行性由最后一次调用的 parallel() 或 sequential() 决定,其作用不是叠加而是覆盖。如:
stream.parallel().filter(...).sequential().map(...);,最终 sequential() 生效,整个流串行执行。
四、总结
Java Stream API 通过声明式函数式编程范式,显著提升了数据处理的抽象层次,其核心优势体现在:代码简洁性(据官方性能报告,stream较传统循环减少40%代码量);内置并行化支持(利用多核CPU自动优化计算密集型任务);惰性求值机制(优化资源使用效率);高可组合性(操作符自由组合支持复杂业务逻辑),这些特性使其成为现代Java工程中大数据处理的标准范式
Stream的并行处理机制可利用多核CPU优势显著提升大数据量的处理效率,但是要满足:操作必须是线程安全的,且处理结果不应依赖元素顺序的前提。当处理大规模数据集时,该机制能充分利用多核CPU优势,显著提升计算效率。需要注意的是,并行化会带来任务拆分、线程调度等额外开销,在数据量较小时可能适得其反。
本文着重围绕Java8中新增的Stream特性原理开始,深入解析底层“流水线”的结点搭建、串接过程和启动机制,并就时间复杂度与传统for外部迭代进行性能对比。最后结合实际开发中Stream常见踩坑点给出提示和解决思路,能够更好的帮助开发人员了解Stream的运行逻辑并在日常开发中尽可能做到“优雅使用”。
参考文献
[1] https://mp.weixin.qq.com/s/UGWoRO5-pFB0p01mc73wLA
[2] https://docs.oracle.com/javase/tutorial/collections/streams/parallelism.html#concurrent_reduction
[3]《Java核心技术卷2》
相关文章:
Stream流性能分析及优雅使用
文章目录 摘要一、Stream原理解析1.1、Stream总概1.2、Stream运行机制1.2.1、创建结点1.2.1、搭建流水线1.2.3、启动流水线 1.3、ParallelStream 二、性能对比三、优雅使用3.1 Collectors.toMap()3.2 findFirst(),findAny()3.3 增删元素3.4 ParallelStream 四、总结…...

iOS 电子书听书功能的实现
在 iOS 应用中实现电子书听书(文本转语音)功能,可以通过系统提供的 AVFoundation 框架实现。以下是详细实现步骤和代码示例: 核心步骤: 导入框架创建语音合成器配置语音参数实现播放控制处理后台播放添加进度跟踪 完整…...

【和春笋一起学C++】(十七)C++函数新特性——内联函数和引用变量
C提供了新的函数特性,使之有别于C语言。主要包括: 内联函数;按引用传递变量;默认参数值;函数重载(多态);模版函数; 因篇幅限制,本文首先介绍内联函数和引用…...
)
GitHub 趋势日报 (2025年06月02日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1339 prompt-eng-interactive-tutorial 1080 courses 624 onlook 596 system-desi…...

卫星的“太空陀螺”:反作用轮如何精准控制姿态?
卫星的“太空陀螺”:反作用轮如何精准控制姿态? 在距地面500公里的轨道上,一颗遥感卫星正以7.8km/s的速度飞越目标区域。此时星载计算机发出指令:“滚转15并对准目标点”。短短数秒后,数吨重的卫星如同被无形之手推动般…...
proteus新建工程
1 点击新建工程 2 输入项目名,选择工程文件夹 3 下一步 4 不创建pcb 5 直接下一步 6 点击完成 7 创建完毕...

缓存击穿 缓存穿透 缓存雪崩
缓存击穿 缓存穿透 缓存雪崩 在日常开发中,我们经常会在后端引入 Redis 缓存来减轻数据库压力、提高访问性能。本文将逐点介绍 Redis 缓存常见问题及解决策略。 缓存穿透 问题描述: 缓存穿透指的是客户端请求的数据,在缓存中和数据库中都不…...
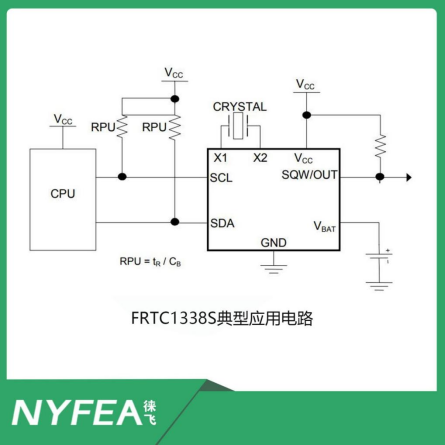
RTC实时时钟DS1338Z-33/PT7C433833WEX国产替代FRTC1338S
FRTC1338S是NYFEA徕飞公司推出的一种高性能的实时时钟芯片,它采用了SOP8封装技术,这种技术因其紧凑的尺寸和出色的性能而被广泛应用于各类电子设备中。 FRTC1338S串行实时时钟(RTC)是一种低功耗的全二进制编码十进制(BCD)时钟/日历外加56字节的非易失性…...
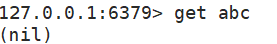
Redis命令使用
Redis是以键值对进行数据存储的,添加数据和查找数据最常用的2个指令就是set和get。 set:set指令用来添加数据。把key和value存储进去。get:get指令用来查找相应的键所对应的值。根据key来取value。 首先,我们先进入到redis客户端…...
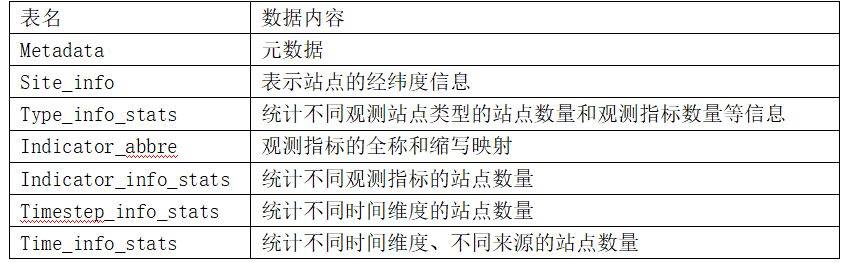
【免费数据】1980-2022年中国2384个站点的水质数据
水,是生命之源,关乎着地球上每一个生物的生存与发展。健康的水生生态系统维持着整个水生态的平衡与活力;更是确保人类能持续获得清洁水源的重要保障。水质数据在水质研究、海洋生物量测算以及生物多样性评估等诸多关键领域都扮演着举足轻重的…...

Java基础 Day28 完结篇
一、方法引用 对 Lambda 表达式的进一步简化 方法引用使用一对冒号 :: Tips:静态方法用类名加双冒号,非静态方法用对象名加双冒号 通过方法的名字来指向一个方法 参数可推导即可省略 可以使语言的构造更紧凑简洁,减少冗余代码 二、单元…...

小红薯商品搜索详情分析与实现
前言 小红书作为国内知名的社交电商平台,拥有丰富的商品数据和用户评价信息。对于数据分析师、产品经理或电商从业者来说,能够获取小红书的商品数据具有重要的商业价值。本文将详细介绍如何通过逆向工程实现小红书商品搜索API的调用。 免责声明:本文仅用于技术学习和研究目…...

Git 极简使用指南
Git 是一个强大的分布式版本控制系统,但入门只需要掌握几个核心概念和命令。本指南旨在帮助你快速上手,处理日常开发中最常见的 80% 的场景。 核心概念 仓库 (Repository / Repo): 你的项目文件夹,包含了项目的所有文件和完整的历史记录。…...

力扣刷题Day 69:搜索二维矩阵(74)
1.题目描述 2.思路 首先判断target是否有可能在矩阵的某一行里,没可能直接返回False,有可能就在这一行里二分查找。 3.代码(Python3) class Solution:def searchMatrix(self, matrix: List[List[int]], target: int) -> boo…...

c#压缩与解压缩-SharpCompress
SharpCompress SharpCompress 是一个开源项目库,能够处理文件。c#库对于压缩已经有很多,可以随意选择,看了SharpCompress感觉比较简洁,还是介绍给大家。 项目地址: sharpcompress 项目使用 引入nuget包࿱…...

Neo4j 安全深度解析:原理、技术与最佳实践
在当今数据驱动的世界中,图数据库承载着关键的关系信息,其安全性至关重要。Neo4j 提供了一套多层次、纵深防御的安全体系。 Neo4j 的安全体系提供了从认证授权到数据加密、审计追溯的完整解决方案。安全不是单一功能而是一种持续状态,其有效…...

MySQL指令个人笔记
MySQL学习,SQL语言笔记 一、MySQL 1.1 启动、停止 启动 net start mysql83停止 net stop mysql831.2 连接、断开 连接 mysql -h localhost -P 3306 -u root -p断开 exit或者ctrlc 二、DDL 2.1 库管理 2.1.1 直接创建库 使用默认字符集和排序方式…...
2022年 国内税务年鉴PDF电子版Excel
2022年 国内税务年鉴PDF电子版Excelhttps://download.csdn.net/download/2401_84585615/89784658 https://download.csdn.net/download/2401_84585615/89784658 2022年国内税务年鉴是对中国税收政策、税制改革和税务管理实践的全面总结。这份年鉴详细记录了中国税收系统的整体状…...
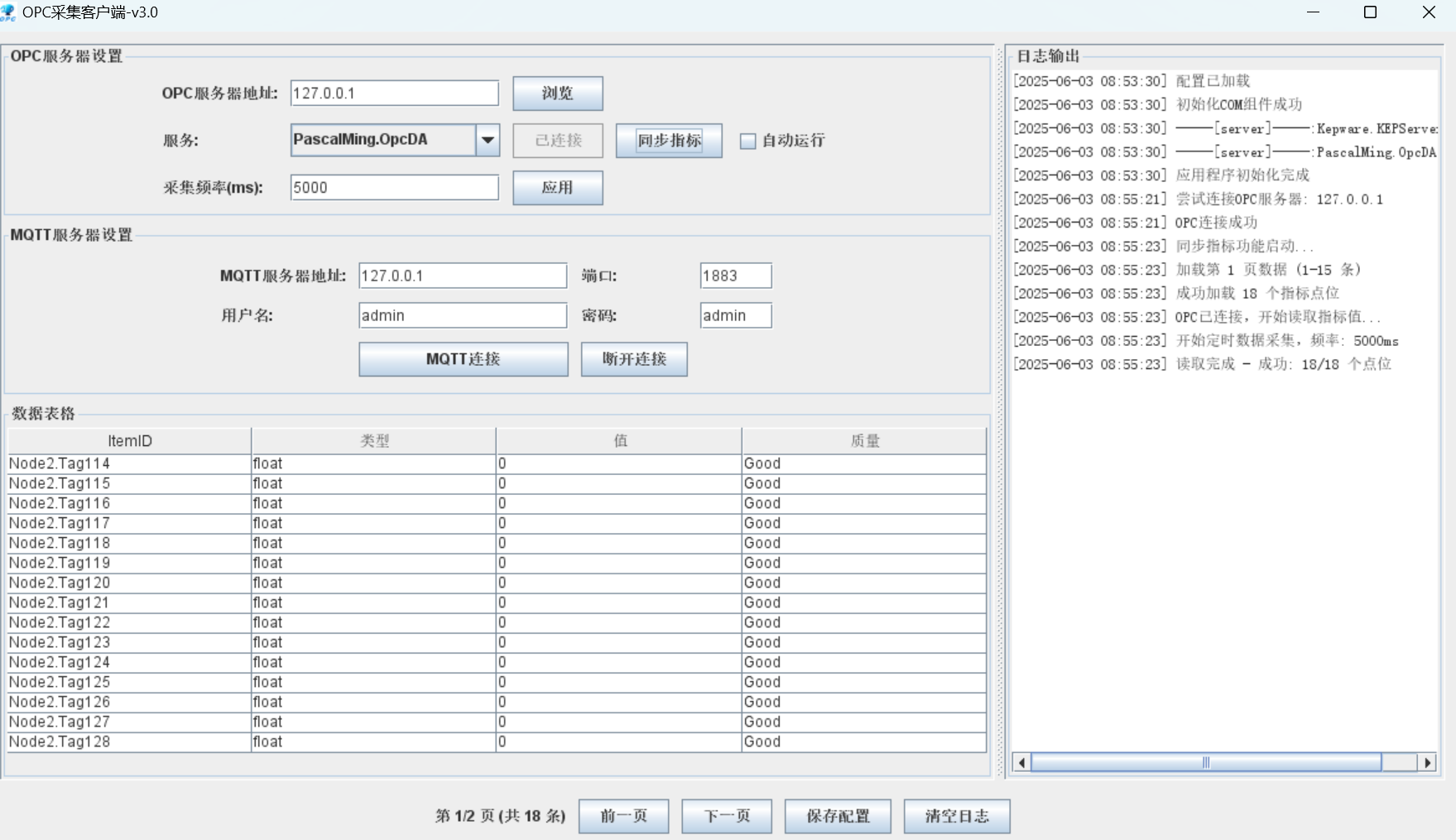
基于Java的OPCDA采集中间件
1.软件功能及技术特点简介: 软件功能及技术特点简介: OPCDA是基于Java语言开发的OPC client(OPC客户端)跨平台中间件软件,他支持OPC SERVER的OPC DA1.0/2.0/3.0。OPCDA实时采集数据(包括实时数据、报警数…...

基于PyQt5的相机手动标定工具:原理、实现与应用
基于PyQt5的相机手动标定工具:原理、实现与应用 一、背景介绍二、功能详解与实现原理2.1 图像加载与预处理2.2 交互式透视调整2.3 透视变换数学原理2.4 图像拼接核心技术2.5 用户界面优化细节三、完整使用流程四、应用场景实例五、技术优势分析六、代码七、总结一、背景介绍 …...

vue2 项目中 npm run dev 运行98% after emitting CopyPlugin 卡死
今天在运行项目时,发现如下问题: 开始以为是node_modules依赖的问题,于是重新 npm install,重启项目后还是未解决。 在网上找了一圈发现有人说是 require引入图片地址没有写。在我的项目中排查没有这个问题,最后发现某…...
JavaScript 性能优化实战:从原理到框架的全栈优化指南
在 Web 应用复杂度指数级增长的今天,JavaScript 性能优化已成为衡量前端工程质量的核心指标。本文将结合现代浏览器引擎特性与一线大厂实践经验,构建从基础原理到框架定制的完整优化体系,助你打造高性能 Web 应用。 一、性能优化基础&#x…...
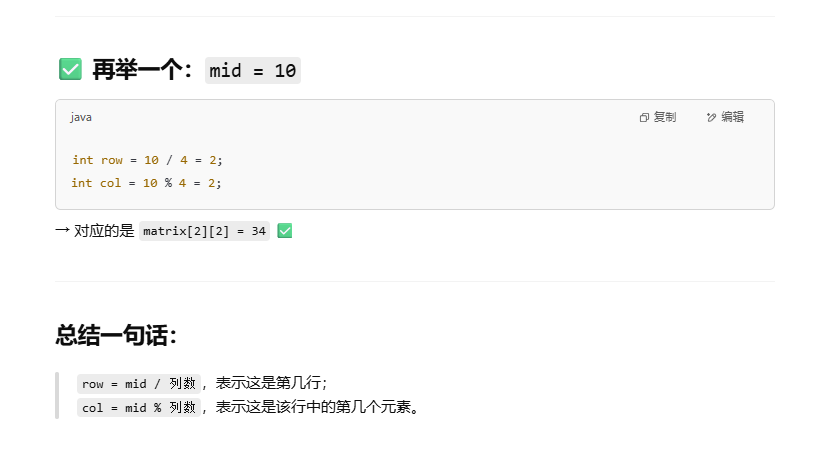
2025年- H61-Lc169--74.搜索二维矩阵(二分查找)--Java版
1.题目描述 2.思路 方法一: 定义其实坐标,右上角的元素(0,n-1)。进入while循环(注意边界条件,行数小于m,列数要>0)从右上角开始开始向左遍历(比当…...

微服务商城-用户微服务
数据表 用户表 CREATE DATABASE user; USE user;CREATE TABLE user (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 用户ID,username varchar(50) NOT NULL DEFAULT COMMENT 用户名,password varchar(50) NOT NULL DEFAULT COMMENT 用户密码,MD5加密…...

数学复习笔记 26
5.25:这题还是有点难度的。主要是出现了新的知识点,我现在还没有那么熟悉这个新的知识点。这块就是,假设一个矩阵可以写成一个列向量乘以一个行向量的形式,这两个向量都是非零向量,那么这个矩阵的秩等于一。这个的原理…...

创建型-设计模式
文章目录 单例模式工厂模式建造者模式原型模式 单例模式 单例模式有饿汉式 和 懒汉式。这个我觉得无需多言,每个学过Java的都知道。 1.单例的使用:我一般就是用饿汉式,因为App开发的开发一般数据处理并不复杂,所以直接使用饿汉式…...

移动AI神器GPT Mobile:多模型自由切换
GPT Mobile是什么 GPT Mobile是一款开源的本地移动部署AI工具,主要用于安卓设备。以下是其相关介绍: 功能特点 多模型交互:支持与多个大型语言模型(LLM)同时进行对话,用户导入相应的API密钥,就可连接OpenAI、Anthropic、Google、Ollama等平台,还能根据需求自由切换不同…...
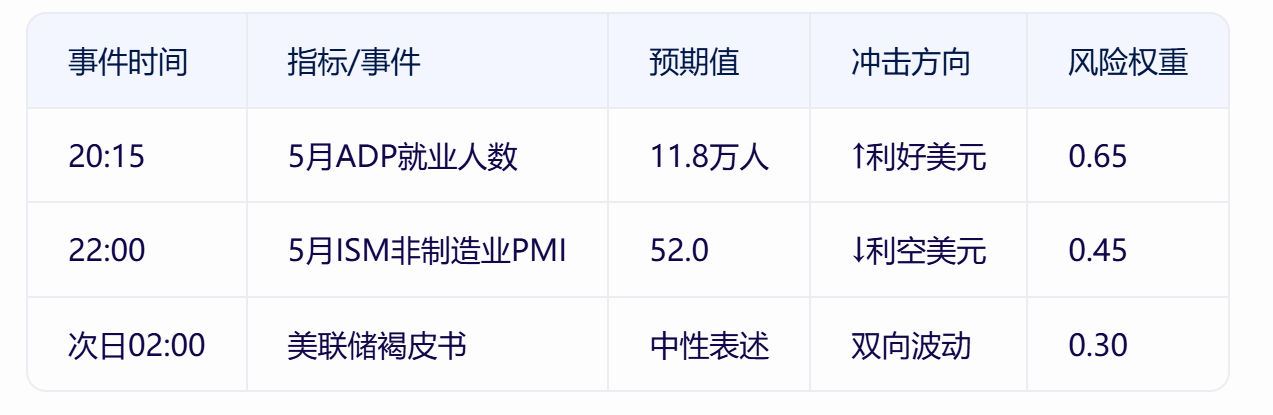
【黄金评论】美元走强压制金价:基于NLP政策因子与ARIMA-GARCH的联动效应解析
一、基本面:多因子模型解析黄金承压逻辑 1. 政策冲击因子驱动美元强势 通过NLP模型对关税政策文本进行情感分析,构建政策不确定性指数(PUI)达89.3,触发美元避险需求溢价。DSGE模型模拟显示,钢铁关税上调至…...

ubutu修改网关
修改Netplan配置以指定静态网关 1. 编辑Netplan配置文件 打开Netplan配置文件(通常位于 /etc/netplan/01-netcfg.yaml 或类似路径): sudo nano /etc/netplan/01-netcfg.yaml 2. 修改配置文件 在DHCP配置基础上,添加静态网关和…...
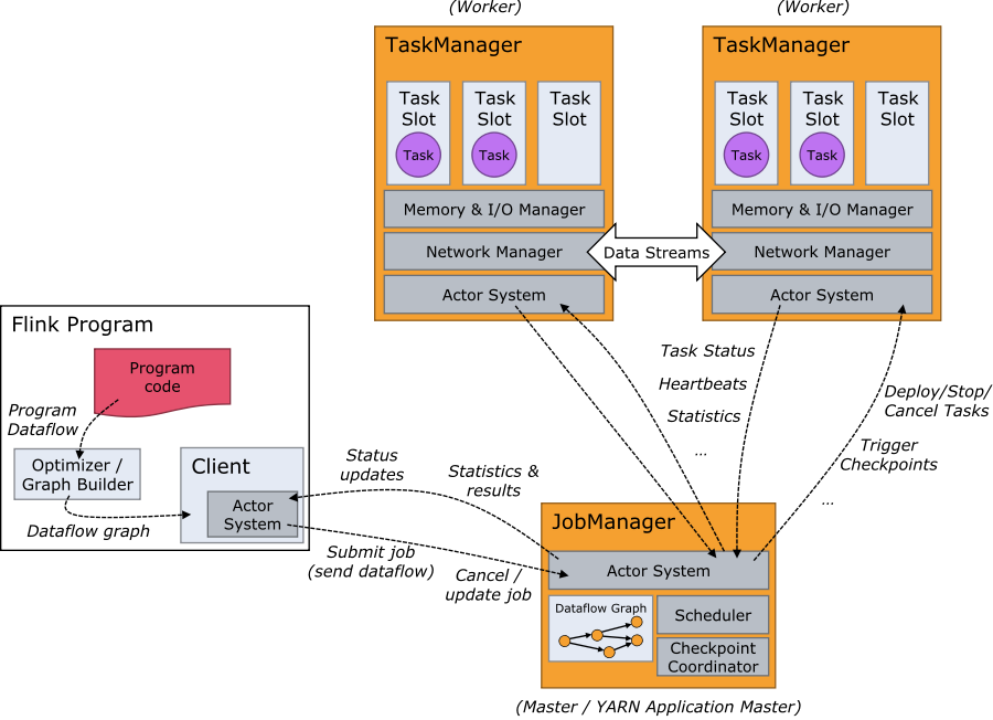
Flink进阶之路:解锁大数据处理新境界
目录 一、Flink 基础回顾 二、Flink 进阶知识深入 2.1 数据类型与序列化 2.2 双流 Join 操作 2.3 复杂事件处理(CEP) 2.4 状态管理与优化 三、Flink 在实际场景中的应用 3.1 实时智能推荐 3.2 实时欺诈检测 3.3 实时数仓与 ETL 四、Flink 性能…...