Flink进阶之路:解锁大数据处理新境界
目录
一、Flink 基础回顾
二、Flink 进阶知识深入
2.1 数据类型与序列化
2.2 双流 Join 操作
2.3 复杂事件处理(CEP)
2.4 状态管理与优化
三、Flink 在实际场景中的应用
3.1 实时智能推荐
3.2 实时欺诈检测
3.3 实时数仓与 ETL
四、Flink 性能优化策略
4.1 网络传输优化
4.2 状态管理优化
4.3 检查点优化
五、总结与展望
一、Flink 基础回顾
在深入探索 Flink 进阶知识之前,我们先来简单回顾一下 Flink 的基础知识。Flink 是一个开源的分布式流处理框架,其核心是由 Java 和 Scala 编写的分布式数据流引擎,用于对无界和有界数据流进行有状态计算。它最初由柏林工业大学的学生开发,后捐赠给 Apache 软件基金会,如今已成为大数据领域中备受瞩目的明星项目。
Flink 的基础架构主要由 JobManager、TaskManager 和 ResourceManager 组成。
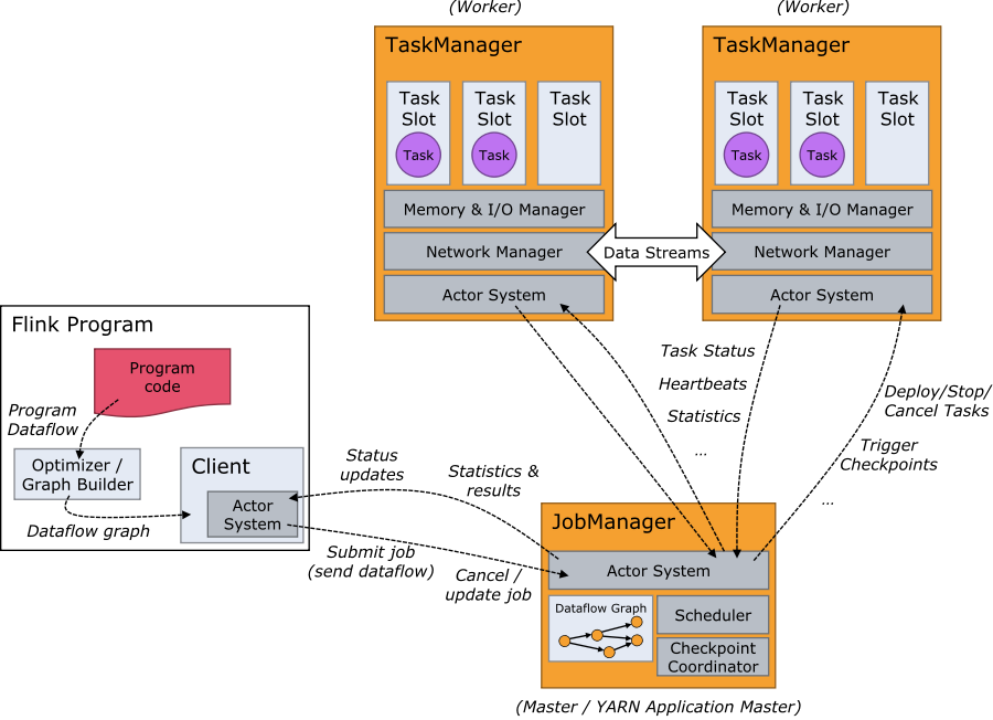
JobManager 是 Flink 集群的主进程,负责管理和调度作业执行,它接收客户端提交的作业,将作业图转换为执行图,并协调检查点和故障恢复等操作。TaskManager 则是实际执行任务的工作节点,它从 JobManager 接收任务,在自己的插槽(slot)中执行任务,并负责数据的处理和传输。ResourceManager 负责管理 TaskManager 的插槽资源,为作业分配所需的计算资源,同时,它还与外部资源管理系统(如 YARN、Mesos、K8s 等)进行交互,以获取更多的资源。
Flink 的核心组件包括 Flink API、Flink Cluster、Flink Job 和 Flink State。Flink API 提供了多种编程接口,如 DataStream API、Table API 和 SQL API,方便开发者根据不同的需求编写流处理程序。DataStream API 是 Flink 的主要 API,适用于对实时性要求较高、需要进行复杂流处理逻辑的场景,它提供了丰富的操作符,如 map、filter、reduce、join 等,可以对数据流进行灵活的转换和处理;Table API 则以表为中心,提供了声明式的 DSL,更适合于对结构化数据进行查询和分析;SQL API 则允许熟悉 SQL 的开发者使用 SQL 语句来处理流数据,进一步降低了学习门槛。Flink Cluster 是 Flink 的运行时环境,由多个 TaskManager 和工作节点组成,实现了并行处理和负载均衡,确保作业能够高效地运行。Flink Job 是一个完整的流处理任务,包含数据源、数据接收器和数据处理程序,定义了数据的处理逻辑和流程。Flink State 用于存储和恢复流处理任务的状态,使得 Flink 能够处理有状态的计算,例如窗口聚合、会话管理等。
Flink 的基本编程模型基于流(streams)和转换(transformations)。流是数据记录的序列,可以是有界的(如文件中的数据)或无界的(如实时产生的日志数据)。转换则是对流进行的操作,它接受一个或多个输入流,经过处理后生成一个或多个输出流。例如,map 转换可以对每个输入元素进行一对一的转换,filter 转换可以根据条件筛选出符合要求的元素,reduce 转换可以对元素进行聚合操作等。在 Flink 中,程序的执行是通过将转换操作连接成一个有向无环图(DAG)来实现的,这个 DAG 描述了数据流的处理流程,从数据源开始,经过一系列的转换操作,最终将结果输出到数据接收器。
二、Flink 进阶知识深入
2.1 数据类型与序列化
在 Flink 中,了解和正确使用数据类型及其序列化方式对于编写高效的流处理程序至关重要。Flink 支持丰富的数据类型,包括原生类型、数组、复合类型和辅助类型等。
原生类型涵盖了 Java 和 Scala 中的基本数据类型,如 Int、Double、Long、String 等,这些类型是 Flink 处理数据的基础,Flink 对它们进行了高度优化,以确保高效的处理和序列化。例如,在一个简单的单词计数程序中,输入的单词通常是 String 类型,而单词的计数则可以用Int类型表示。
数组类型包括基本类型数组和对象数组。基本类型数组,如 int[]、double[] 等,在 Flink 中可以直接使用,它们在存储和传输时具有较高的效率。对象数组则用于存储对象的集合,每个元素都是一个对象实例。例如,String[] 数组可以用于存储一组单词,User[] 数组可以用于存储一组用户对象,其中 User 是自定义的类。
复合类型是由多个基本类型或其他复合类型组成的复杂数据结构,Flink 支持的复合类型有 Java 元组类型、Scala 样例类及 Scala 元组、行类型(ROW)和 POJO。Java 元组类型是 Flink 内置的元组类型,是 Java API 的一部分,最多支持 25 个字段,从 Tuple0 到 Tuple25,它不支持空字段,常用于存储多个相关数据,比如 Tuple2<String, Integer> 可以用来存储一个单词及其出现的次数。Scala 样例类及 Scala 元组与 Java 元组类似,但在 Scala 语言中使用更为便捷,它们也不支持空字段。行类型(ROW)可以看作是具有任意个字段的元组,并且支持空字段,这使得它在处理结构化数据时非常灵活。POJO(Plain Old Java Objects)是遵循 Java Bean 规范的类,Flink 对 POJO 类型进行了专门的处理,要求类是公共的、有公共的无参构造方法,并且所有字段是公共的或有公共的 getter 和 setter 方法,POJO 类型常用于表示业务对象,如 User 类,它包含用户的各种属性,如 id、name、age 等。
辅助类型包括 Option、Either、List、Map 等泛型类型。Option 类型用于表示可能存在或不存在的值,它可以避免空指针异常,例如 Option[String] 表示一个可能为空的字符串。Either 类型用于表示两种可能类型中的一种,比如 Either[String, Integer] 表示一个值要么是字符串,要么是整数。List 和 Map 类型则用于存储列表和键值对集合,例如 List<String> 可以存储一组字符串,Map<String, Integer> 可以存储单词到其出现次数的映射。
Flink 拥有自己的序列化框架,这一框架具有诸多优势。它对类型信息有深入的了解,能够在早期完成类型检查,从而更好地选取序列化方式。例如,对于基本类型,Flink 可以直接使用高效的二进制序列化方式,而对于复杂的 POJO 类型,Flink 会根据其结构进行优化,以节省数据的存储空间。Flink 还可以直接操作二进制数据,减少数据转换的开销,提高处理效率。
在选择不同数据类型的序列化方式时,需要考虑多种因素。对于基本类型和一些简单的复合类型,Flink 默认的序列化方式通常已经足够高效。例如,Int类型的数据在网络传输或存储到状态后端时,会被直接序列化为紧凑的二进制格式。对于复杂的 POJO 类型,Flink 会使用 Avro 等序列化框架,通过分析 POJO 的结构,生成高效的序列化代码。如果需要进一步优化性能,还可以自定义序列化器。例如,对于一些包含大量重复数据的对象,可以实现自定义的序列化器,通过压缩或其他优化策略,减少数据的存储空间和传输带宽。
2.2 双流 Join 操作
在流处理中,双流 Join 操作是一种常见的操作,用于将两个数据流中的相关数据进行关联。Flink 提供了强大的双流 Join 功能,其中 Window Join 和 Interval Join 是两种常用的双流 Join 操作。
Window Join 基于时间窗口机制,它将两个流中共享一个公共键(key)且处于相同时间窗口内的数据进行配对处理。在电商场景中,我们可能有一个订单流和一个用户信息流,希望将订单流中的每个订单与用户信息流中对应的用户信息进行关联。假设订单流中的订单数据包含订单 ID、用户 ID、订单金额等字段,用户信息流中的用户数据包含用户 ID、用户姓名、用户地址等字段。我们可以使用 Window Join,以用户 ID 作为公共键,在相同的时间窗口内将订单数据和用户数据进行匹配。
在代码实现上,首先需要调用 DataStream 的 .join() 方法来合并两条流,得到一个 JoinedStreams;接着通过. where() 和 .equalTo() 方法指定两条流中联结的 key;然后通过 .window() 开窗口,并调用 .apply() 传入联结窗口函数进行处理计算,如下所示:
stream1.join(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>);在处理流程上,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的 .join() 方法进行计算处理,得到的结果直接输出。所以窗口中每有一对数据成功联结匹配,JoinFunction 的 .join() 方法就会被调用一次,并输出一个结果。
Interval Join 则利用 Flink 的 Watermark 机制,将一条流中的元素与另一条流中在指定时间间隔内的元素进行关联。在电商网站中,用户行为往往会有短时间内的强关联。假设有两条流,一条是下订单的流,一条是浏览数据的流,可针对同一个用户做一个联结,使用户的下订单事件和用户的最近十分钟的浏览数据进行一个联结查询(Interval Join)。对于黄色流(A)中的任意一个数据元素 a,划分一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],绿色流(B)中的数据元素 b,key 相同且时间戳在这个区间范围内,a 和 b 成功配对。
在代码实现上,Interval Join 的调用方式如下:
orangeStream.keyBy(<KeySelector>).intervalJoin(greenStream.keyBy(<KeySelector>)).between(Time.milliseconds(-2), Time.milliseconds(1)).process(new ProcessJoinFunction<Integer, Integer, String>() {@Overridepublic void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {out.collect(left + "," + right);}});其中,.between() 方法用于指定时间间隔,lowerBound 和 upperBound 可以是负数或正数,只要 lowerBound 始终小于或等于 upperBound 即可。当前 Interval Join 仅支持内连接,当一对元素传递给 ProcessJoinFunction 时,它们将被分配两个元素中较大的时间戳(可以通过 ProcessJoinFunction.Context 访问)。
2.3 复杂事件处理(CEP)
复杂事件处理(Complex Event Processing,CEP)是 Flink 提供的一项强大功能,用于在数据流中识别复杂的事件模式。CEP 的核心概念是将多个简单事件组合成一个复杂事件,通过定义和匹配这些复杂事件模式,我们可以从海量的数据流中提取出有价值的信息。
在金融领域,我们可以使用 CEP 来检测欺诈行为。例如,当一个用户在短时间内进行多次大额转账,并且这些转账的目标账户是一些可疑账户时,我们可以将这些事件组合成一个复杂事件,标记为可能的欺诈行为。在电商领域,我们可以使用 CEP 来分析用户的购买行为,当一个用户在浏览了某类商品后,短时间内又购买了相关的商品,我们可以将这些事件组合成一个复杂事件,用于精准营销。
Flink CEP 库提供了丰富的 API,用于在数据流中定义和识别复杂模式。定义一个模式序列,使用 Pattern 类的静态方法 begin() 开始定义一个模式,然后通过调用一系列的方法,如 where()、next()、followedBy() 等,来定义模式的条件和顺序。where() 方法用于指定单个事件的条件,next() 方法表示下一个事件必须紧跟当前事件,followedBy() 方法表示下一个事件可以在当前事件之后的任意时间出现。
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getId() == 42;}}).next("middle").subtype(SubEvent.class).where(new SimpleCondition<SubEvent>() {@Overridepublic boolean filter(SubEvent subEvent) {return subEvent.getVolume() >= 10.0;}}).followedBy("end").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getName().equals("end");}});将模式序列作用到流上,使用 CEP.pattern() 方法,将定义好的模式应用到输入的数据流上,得到一个 PatternStream。
PatternStream<Event> patternStream = CEP.pattern(input, pattern);提取匹配上的数据和输出,使用 PatternStream 的 process() 方法,传入一个 PatternProcessFunction,重写 processMatch() 方法,在方法中处理匹配到的事件模式,并输出结果。
DataStream<Alert> result = patternStream.process(new PatternProcessFunction<Event, Alert>() {@Overridepublic void processMatch(Map<String, List<Event>> pattern, Context ctx, Collector<Alert> out) throws Exception {out.collect(createAlertFrom(pattern));}
});2.4 状态管理与优化
状态管理是 Flink 流处理中的关键部分,它允许 Flink 在处理数据流时保存和维护中间结果,以便进行有状态的计算。Flink 的状态管理机制包括算子状态(Operator State)和键控状态(Keyed State)。
算子状态是与特定算子实例相关联的状态,它在算子的并行实例之间是独立的。在从 Kafka 读取数据时,每个 Kafka 消费者实例都需要维护自己的偏移量(offset),这个偏移量就是一种算子状态。算子状态的存储、访问和更新是由 Flink 框架自动管理的,开发者只需要在需要的时候获取和更新状态即可。例如,在实现一个自定义的 Source 算子时,可以通过 RichParallelSourceFunction 类的 getRuntimeContext().getOperatorStateStore() 方法获取算子状态存储,然后使用 ListState、UnionListState 等接口来存储和访问状态。
键控状态是基于键(key)的状态,它与输入流中的键值对相关联。在一个按用户 ID 进行分组的数据流中,每个用户的相关状态(如用户的登录次数、购物车商品列表等)就可以存储为键控状态。键控状态的存储、访问和更新是通过 KeyedStateDescriptor 来定义和管理的,开发者可以使用 ValueState、ListState、MapState 等接口来操作键控状态。例如,要使用 ValueState 来存储用户的登录次数,可以这样定义和使用:
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("loginCount", // 状态名称Integer.class, // 状态数据类型0 // 默认值
);ValueState<Integer> loginCountState = getRuntimeContext().getState(stateDescriptor);
Integer count = loginCountState.value();
loginCountState.update(count + 1);状态后端(State Backend)是 Flink 中用于存储和管理状态的组件,它负责将应用程序的状态保存到持久化存储中,并在需要时从存储中加载状态。Flink 提供了多种状态后端实现,如内存状态后端(MemoryStateBackend)、文件系统状态后端(FsStateBackend)、RocksDB 状态后端(RocksDBStateBackend)等。内存状态后端将状态存储在内存中,适用于数据量较小、对性能要求极高的场景;文件系统状态后端将状态存储在文件系统中,具有较高的可靠性和可扩展性;RocksDB 状态后端则将状态存储在 RocksDB 数据库中,适用于处理大规模数据和需要进行增量检查点的场景。在选择状态后端时,需要根据应用程序的性能、可靠性和数据量等需求进行权衡。例如,对于一个实时性要求极高、数据量较小的流处理任务,可以选择内存状态后端;对于一个数据量较大、需要长期保存状态的任务,可以选择 RocksDB 状态后端。
增量检查点(Incremental Checkpointing)是 Flink 提供的一种优化机制,用于减少检查点的时间和资源消耗。传统的全量检查点会将所有的状态数据都保存到持久化存储中,而增量检查点只保存自上次检查点以来状态的变化部分。这大大减少了检查点的大小和保存时间,提高了系统的性能和可用性。在使用 RocksDB 状态后端时,可以通过配置 enableIncrementalCheckpointing 参数来启用增量检查点功能。例如:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
RocksDBStateBackend backend = new RocksDBStateBackend("hdfs://namenode:8020/flink/checkpoints", true);
env.setStateBackend(backend);三、Flink 在实际场景中的应用
3.1 实时智能推荐
在电商领域,实时智能推荐系统对于提升用户体验和促进销售起着至关重要的作用。Flink 凭借其强大的流处理能力,能够根据用户的历史行为进行实时分析,从而为用户提供精准的个性化商品推荐。
Flink 实时智能推荐系统的工作原理是基于对用户行为数据的实时采集和处理。当用户在电商平台上进行浏览、搜索、购买等操作时,这些行为数据会被实时收集并发送到 Flink 系统中。Flink 首先会对这些原始数据进行清洗和预处理,去除噪声和无效数据,确保数据的准确性和完整性。接着,Flink 会利用机器学习算法和模型,对清洗后的数据进行分析和挖掘,提取用户的兴趣特征和行为模式。例如,通过分析用户的浏览历史,可以了解用户对不同商品类别的偏好;通过分析用户的购买记录,可以发现用户的购买习惯和消费趋势。
以京东为例,京东拥有庞大的用户群体和海量的商品数据。Flink 实时智能推荐系统在京东的应用中,能够实时处理用户在平台上的各种行为数据。当用户浏览某类商品时,系统会立即捕捉到这一行为,并根据该用户的历史浏览和购买数据,以及其他具有相似行为模式用户的购买情况,快速生成个性化的商品推荐列表。这些推荐商品会实时展示在用户的页面上,引导用户进行进一步的购买行为。据京东的数据统计,使用 Flink 实时智能推荐系统后,用户的购买转化率有了显著提升,平均提升幅度达到了 [X]%。同时,用户在平台上的停留时间也有所延长,平均延长了 [X] 分钟,这充分证明了 Flink 在实时智能推荐方面的有效性和价值。
3.2 实时欺诈检测
在金融行业,实时欺诈检测是保障金融安全的关键环节。随着金融交易的日益频繁和数字化,欺诈行为也呈现出多样化和复杂化的趋势,给金融机构和用户带来了巨大的风险。Flink 以其卓越的实时处理能力和强大的状态管理功能,成为了实时欺诈检测的有力工具。
Flink 实时欺诈检测系统通过实时监控金融交易数据,能够快速识别出潜在的欺诈行为。系统会实时采集来自银行、支付机构等金融数据源的交易数据,包括交易金额、交易时间、交易地点、交易双方信息等。Flink 首先对这些数据进行实时清洗和转换,将数据格式统一并进行必要的预处理。然后,利用复杂事件处理(CEP)技术和机器学习算法,对交易数据进行实时分析和模式匹配。例如,通过设定一些规则和模型,当检测到某一账户在短时间内出现大量异常交易,如频繁的小额试探性交易后紧接着大额交易,或者交易地点在短时间内发生大幅度变化等情况时,系统会立即发出警报,将这些交易标记为可能的欺诈行为。
以支付宝为例,支付宝作为全球领先的支付平台,每天处理着海量的交易数据。Flink 实时欺诈检测系统在支付宝中发挥着重要作用,它能够实时监控每一笔交易,对交易数据进行毫秒级的分析处理。通过不断学习和更新欺诈行为模式,系统能够准确地识别出各种新型欺诈手段。据支付宝公布的数据,自使用 Flink 实时欺诈检测系统以来,欺诈交易的拦截率大幅提高,达到了 [X]% 以上,有效保护了用户的资金安全,为支付宝的稳定运营提供了坚实的保障。
3.3 实时数仓与 ETL
在大数据时代,数据的价值越来越受到企业的重视。实时数仓作为一种能够实时处理和分析数据的数据仓库,为企业提供了及时、准确的决策支持。而 ETL(Extract, Transform, Load)作为数据处理的关键环节,负责将数据从数据源提取出来,经过清洗、转换后加载到目标数据仓库中。Flink 在实时数仓构建和 ETL 过程中扮演着重要角色,为企业实现高效的数据处理和分析提供了强大的支持。
在实时数仓构建方面,Flink 能够实时处理来自各种数据源的海量数据,包括结构化数据(如数据库中的数据)、半结构化数据(如 JSON、XML 格式的数据)和非结构化数据(如日志文件、文本文件等)。Flink 通过其丰富的数据源连接器,能够方便地与 Kafka、HDFS、MySQL 等数据源进行集成,实时读取数据并将其转换为 Flink 的数据流。在数据处理过程中,Flink 利用其强大的流处理能力和丰富的算子,对数据流进行实时清洗、转换和聚合。例如,通过过滤算子去除无效数据,通过映射算子对数据进行格式转换,通过窗口算子对数据进行时间窗口聚合等。经过处理后的数据会被实时加载到目标数据仓库中,如 Hive、HBase、Elasticsearch 等,为企业的实时分析和决策提供数据支持。
在 ETL 过程中,Flink 同样展现出了卓越的性能和灵活性。以从 MySQL 数据库中抽取数据并加载到 Hive 数据仓库为例,Flink 首先通过 JDBC 连接器从 MySQL 数据库中读取数据,将其转换为 Flink 的数据流。然后,对数据流进行清洗和转换操作,如去除重复数据、纠正数据格式错误等。接着,根据业务需求对数据进行聚合和转换,生成符合 Hive 表结构的数据。最后,通过 Flink 的 Hive 连接器将处理后的数据加载到 Hive 数据仓库中。在这个过程中,Flink 能够实现数据的实时抽取、转换和加载,大大提高了 ETL 的效率和实时性。同时,Flink 还支持对 ETL 过程的监控和管理,通过其内置的监控指标和可视化界面,用户可以实时了解 ETL 任务的执行情况,及时发现和解决问题。
四、Flink 性能优化策略
4.1 网络传输优化
在 Flink 的运行过程中,网络传输是一个关键环节,它直接影响着系统的性能和效率。Flink 通过 NetworkBuffer 实现攒批,以此来提高网络传输的效率。当上游 Task 产生数据后,这些数据并不会立即被发送到下游 Task,而是先被缓存到 NetworkBuffer 中,当 Buffer 满足一定条件时,才会被发送出去。
在 Flink 中,有三种情况会触发 Buffer 的发送。当 Buffer 被写满时,默认 Buffer 大小是 32KB,一旦 32KB 的 Buffer 被写满,就会认为当前 Buffer 写完了,可以将其发送到下游 Task;当 Buffer 超时,Flink 引入了一个时间策略,默认超时时间是 100ms,如果 100ms 内 Buffer 还没写满,为了保障数据的实时性,也会认为 Buffer 写完并发送;当遇到特殊的 Event,比如 Checkpoint barrier 时,为了加快 Checkpoint 效率,会直接认为 Buffer 写完并发送。
Flink 1.10 及以后的版本,可以直接通过配置参数 execution.buffer-timeout: 100ms 来设置超时时间,在 Flink 1.10 之前,则需要通过代码 env.setBufferTimeout(100) 来设置。这个参数的设置非常关键,它涉及到系统的吞吐和延迟的权衡。当设置为 0 时,表示没有 timeout 策略,即每条数据来了都认为 buffer 满了,将这一条数据单独发送给下游,这样可以保障实时性,但由于频繁的小数据传输,会导致网络开销增大,吞吐可能会下降,如果要维持吞吐不下降,就需要消耗更多的资源。而 100ms 是 Flink 经过权衡后的 timeout 默认值,它既能保证一定的吞吐,又能将延迟控制在 100ms 以内。在实际应用中,对于一些对实时性要求极高的场景,如金融交易的实时监控,可能需要将 execution.buffer-timeout 设置得较小,以确保数据能够及时传输;而对于一些对吞吐量要求较高,对延迟不太敏感的场景,如大规模日志数据的处理,可以适当增大该参数的值,以提高系统的整体吞吐量。
4.2 状态管理优化
在处理包含无限多键的数据时,状态管理变得尤为重要,不合理的状态管理可能导致内存占用过高、性能下降等问题。使用 TTL(Time-To-Live)定时器来清理未使用的状态数据是一种有效的优化策略。
在 Flink 中,如果使用 Keyed State Descriptor 来管理状态,可以很方便地添加 TTL 配置。通过 StateTtlConfig 来配置 TTL 相关参数,如下所示:
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).cleanupFullSnapshot().build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("myState", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
ValueState<String> state = getRuntimeContext().getState(stateDescriptor);在上述代码中,StateTtlConfig.newBuilder(Time.seconds(10)) 表示设置状态的过期时间为 10 秒,setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) 表示只在创建和写的时候更新状态的过期时间,setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) 表示永远不返回过期的状态,cleanupFullSnapshot() 表示在全量快照时清理过期状态。
如果使用 mapWithState 方法来管理状态,由于状态对开发者是隐藏的,无法直接设置 TTL,在处理包含无限多键的数据时,可能会引发问题。在这种情况下,可以考虑声明诸如 RichMapFunction 之类的函数,来更好地控制状态的生命周期。通过 RichMapFunction 的 open 方法获取状态描述符,并为其配置 TTL,从而实现对状态的有效管理。
4.3 检查点优化
检查点是 Flink 实现容错的重要机制,但在处理大状态时,传统的全量检查点会带来较大的开销,包括较长的检查点时间和大量的网络传输。增量检查点的使用可以有效解决这些问题。
增量检查点仅包含上次检查点和本次检查点之间状态的差异,而不是所有状态。这大大减少了检查点的数据量,从而加快了检查点的保存速度,降低了对系统性能的影响。目前,只有 RocksDB 状态后端支持增量检查点。在代码中启用增量检查点非常简单,只需在创建 RocksDBStateBackend 时,将第二个参数设置为 true 即可,如下所示:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
RocksDBStateBackend backend = new RocksDBStateBackend("hdfs://namenode:8020/flink/checkpoints", true);
env.setStateBackend(backend);除了启用增量检查点,还可以通过配置相关参数来进一步提高检查点的性能。通过 env.getCheckpointConfig().setCheckpointInterval(5000) 设置检查点的时间间隔为 5 秒,这样可以根据业务需求合理控制检查点的触发频率;通过 env.getCheckpointConfig().setMaxConcurrentCheckpoints(2) 设置最大并行执行的检查点数量为 2,当有多个检查点需要执行时,可以同时触发多个,从而提升检查点的整体效率。还可以设置 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000),指定两个检查点之间的最小时间间隔为 1 秒,防止因状态数据过大导致检查点执行时间过长,进而避免检查点积压过多,影响整个应用的性能。
五、总结与展望
通过对 Flink 进阶知识的深入探讨,我们领略到了 Flink 在流处理领域的强大功能和广阔应用前景。从数据类型与序列化的底层优化,到双流 Join 操作、复杂事件处理以及状态管理与优化等关键技术,Flink 为开发者提供了丰富而灵活的工具,以应对各种复杂的实时数据处理场景。
在实际应用中,Flink 在实时智能推荐、实时欺诈检测、实时数仓与 ETL 等场景中展现出了卓越的性能和价值,为企业的数字化转型和智能化发展提供了有力支持。通过性能优化策略,如网络传输优化、状态管理优化和检查点优化,Flink 能够进一步提升系统的效率和可靠性,满足企业对大数据处理的高性能需求。
展望未来,随着大数据和人工智能技术的不断发展,Flink 有望在更多领域发挥重要作用。它将继续与其他大数据技术和人工智能算法深度融合,为企业提供更加智能、高效的数据处理和分析解决方案。我们鼓励读者深入学习 Flink,不断探索其更多的创新应用,在大数据的浪潮中把握机遇,创造更大的价值。
相关文章:
Flink进阶之路:解锁大数据处理新境界
目录 一、Flink 基础回顾 二、Flink 进阶知识深入 2.1 数据类型与序列化 2.2 双流 Join 操作 2.3 复杂事件处理(CEP) 2.4 状态管理与优化 三、Flink 在实际场景中的应用 3.1 实时智能推荐 3.2 实时欺诈检测 3.3 实时数仓与 ETL 四、Flink 性能…...
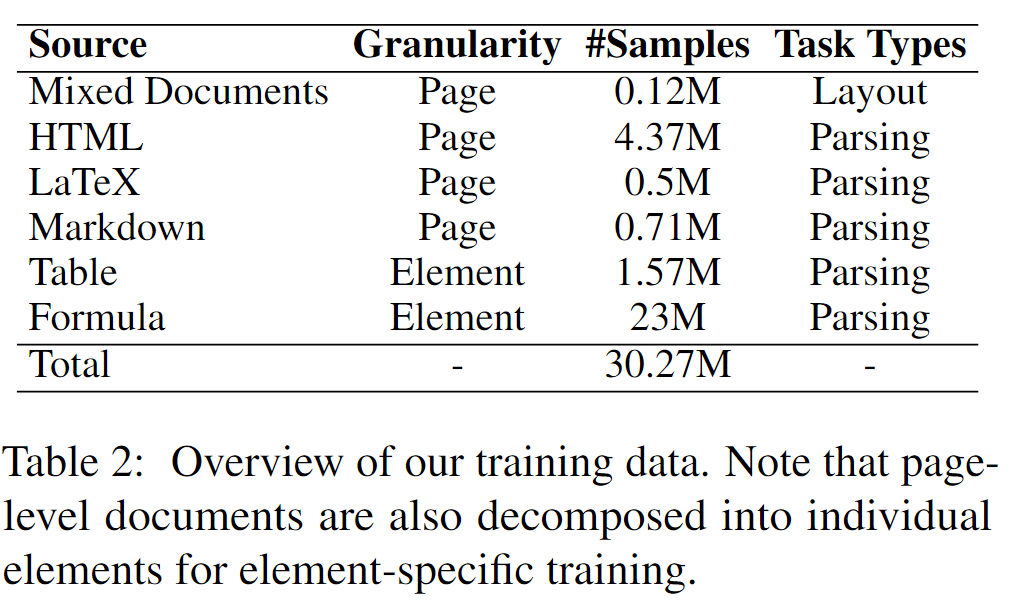
【论文阅读】Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
Paper:https://arxiv.org/abs/2505.14059 Source code: https://github.com/bytedance/Dolphin 作者机构:字节跳动 背景 业务场景 企业数据大多数都以文本、图片、扫描件、电子表格、在线文档、邮件等文档的形式存在,例如:PDF文…...
谷歌地图免费下载手机版
软件标签: 谷歌地图 谷歌卫星高清地图 下载链接:夸克网盘分享 手机地图 谷歌地图免费下载(google maps)是谷歌公司打造的手机高清电子地图。2024谷歌地图官方中文版能够直观的表达出世界各地的地点,在地图中能够清晰的了解到自身的定位,让…...
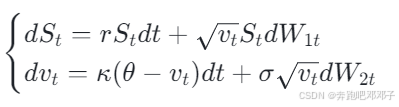
DeepSeek 赋能金融衍生品:定价与风险管理的智能革命
目录 一、引言1.1 金融衍生品市场发展现状1.2 DeepSeek 的技术特点和优势1.3 研究目的和意义 二、金融衍生品定价与风险管理基础2.1 金融衍生品定价常用方法2.2 金融风险管理主要策略 三、DeepSeek 在金融衍生品定价中的应用3.1 DeepSeek 助力定价模型构建3.2 案例分析…...

SpringBoot-15-多表查询之多对多查询可选中间表
文章目录 1 mysql数据库1.1 role角色表1.2 user用户表1.3 user_role中间表2 实体类2.1 Role.java2.2 User.java3 mapper3.1 RoleMapper.java3.2 UserMapper.java4 xml4.1 RoleMapper.xml4.2 UserMapper.xml5 UserController.java6 测试7 参考附录多对多查询,一个用户可以有多个…...
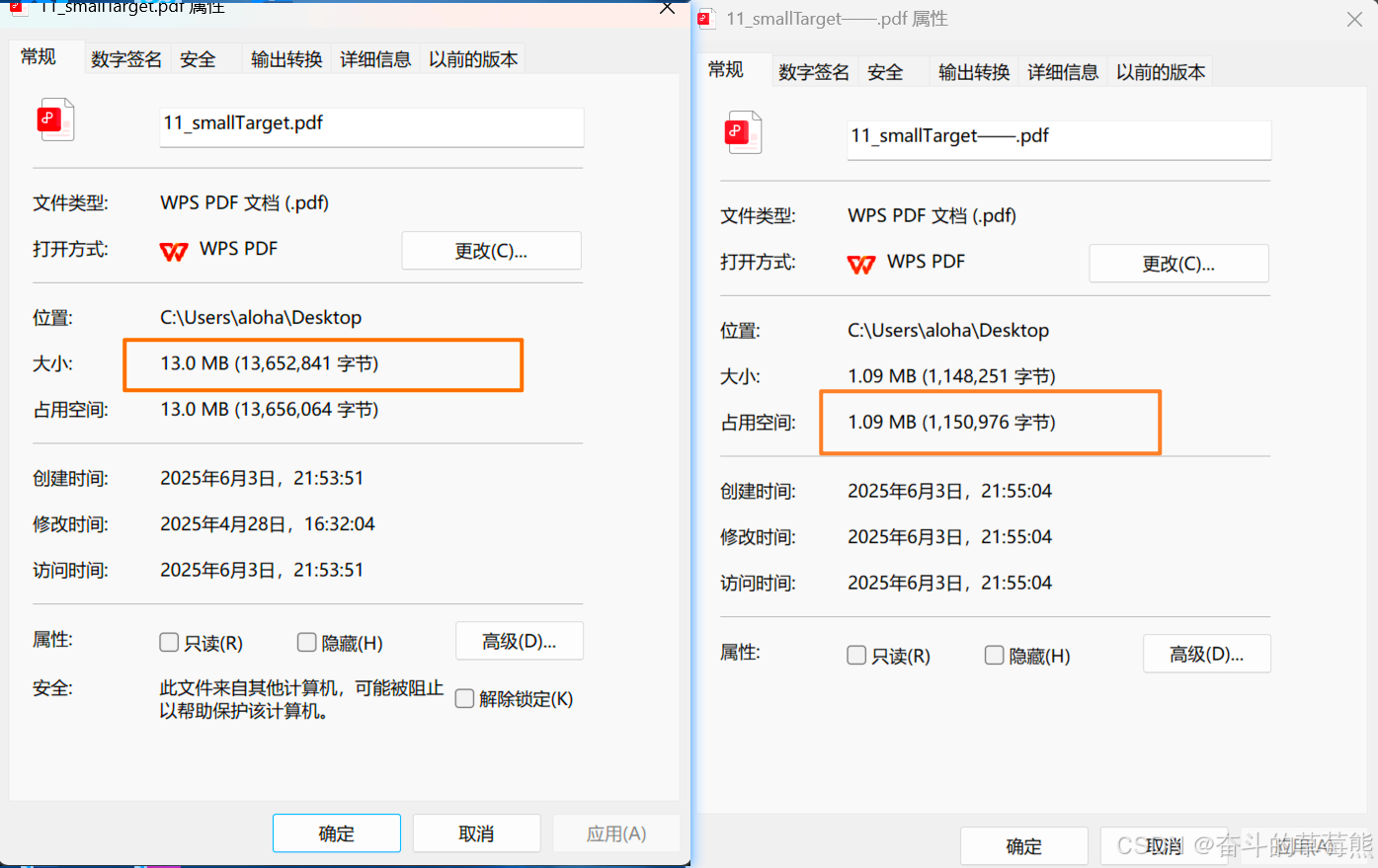
论文中pdf图片文件太大怎么办
文章目录 1.使用pdf文件的打印功能将文件导出2.操作3.前后文件大小对比 1.使用pdf文件的打印功能将文件导出 该方法在保证清晰度的同时,内存空间也能实现减少(如果使用线上的压缩pdf工具,清晰度会直线下降) 2.操作 点击文件—&…...

简单爬虫框架实现
1. 框架功能概述 (1) HttpSession 类:请求管理 功能:封装 requests 库,实现带重试机制的 HTTP 请求(GET/POST)。关键特性: 自动处理 429(请求过多)、5xx(服务器错误&am…...
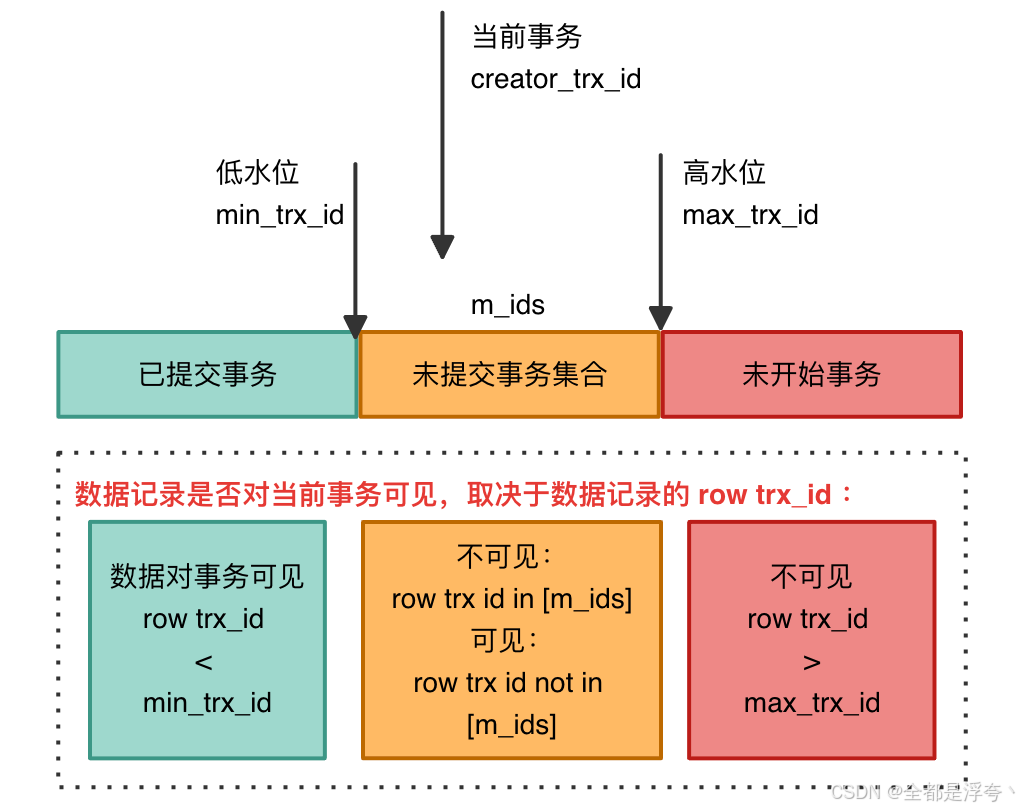
MVCC理解
MySQL的MVCC(Multi-Version Concurrency Control,多版本并发控制)是一种高效的并发控制机制,通过维护数据的多个版本实现读写操作的并行执行,显著提升数据库的并发性能和数据一致性。 MVCC 的实现依赖于:隐…...

705SJBH超市库存管理系统文献综述
前言 信息化的发展已经对我们的日常生活产生了积极的影响,无论是企业、商店、机关、甚至个人,每天都面对着大量的信息,而如果能有效地识别有用信息,并在对它们加工的基础上充分的利用信息,无疑会给我们的生活带来很巨…...
shell:基础
本文主要探讨shell相关知识。 变量 $? 上一次执行命令返回状态 $$ 当前进程进程号 $! 后台运行的最后一个进程的进程号 $# 位置参数的数量 $* 参数内容 $ 参数内容 $和$*解析"hello word"为"hello" "word" "$"解析"hello word&…...
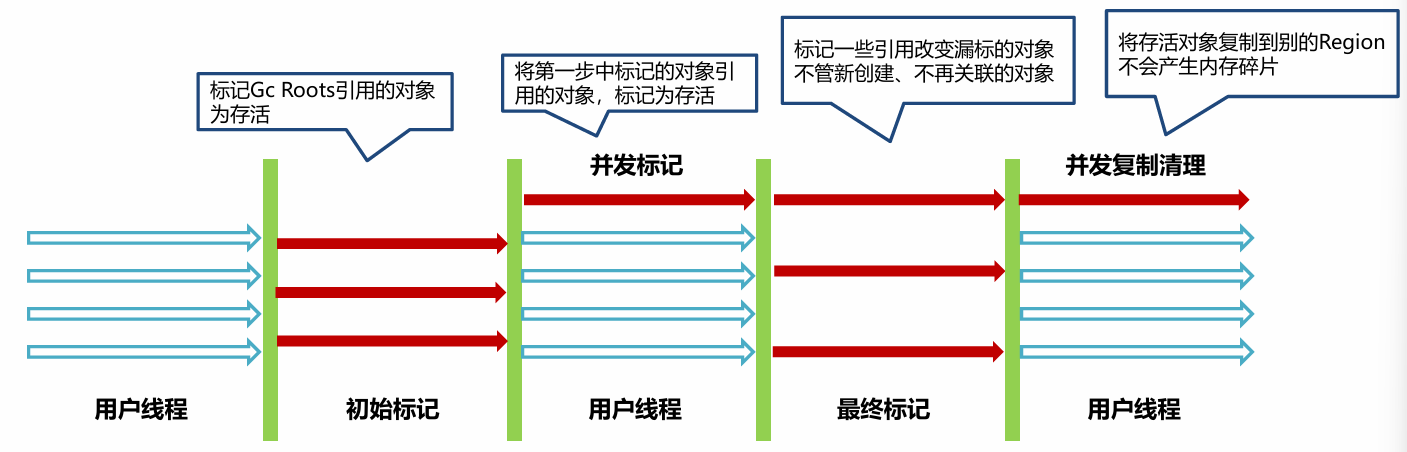
【JVM】万字总结GC垃圾回收
【JVM】GC垃圾回收 概念 在程序运行过程中,会不断创建对象来使用内存,当这些对象不再被引用时,其所占用的内存若不及时释放,会导致内存占用不断增加,最终可能引发内存溢出。GC 机制能自动检测并回收这些不再使用的对…...
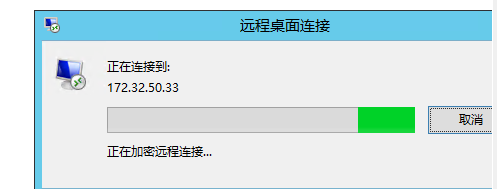
内网横向之RDP缓存利用
RDP(远程桌面协议)在连接过程中会缓存凭据,尤其是在启用了 "保存密码" 或 "凭据管理器" 功能时。这个缓存的凭据通常是用于自动填充和简化后续连接的过程。凭据一般包含了用户的用户名和密码信息,或者是经过加…...
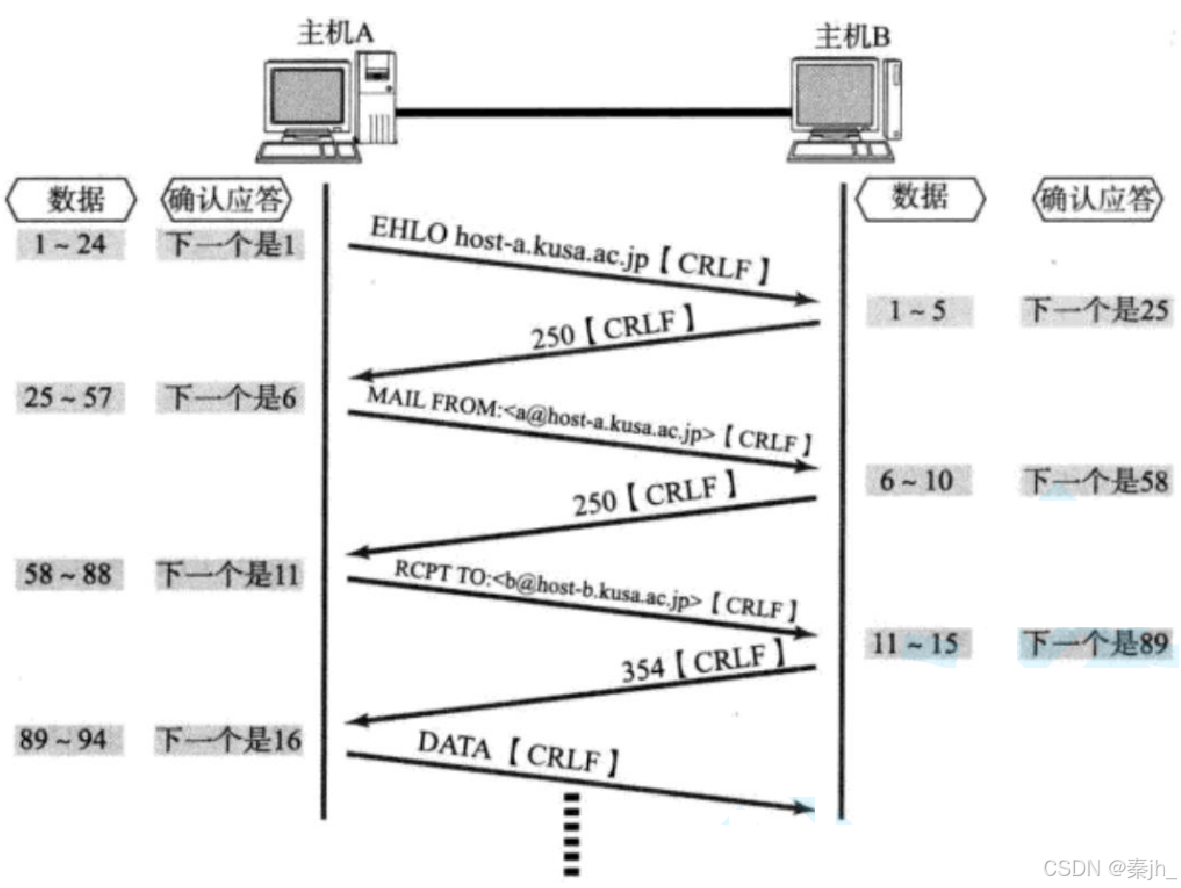
【Linux网络】传输层TCP协议
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 TCP 协议 TCP 协议段格式 确认应答(ACK)机制 超时重传机制 连接管理机制 …...
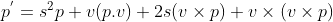
不同视角理解三维旋转
在二维空间中,绕任意点旋转可以分解为: 1)平移旋转点到原点,2)绕原点旋转,3)逆平移旋转点; 可用矩阵表示为 , 其中, 表示绕原点旋转 , 为平移矩…...
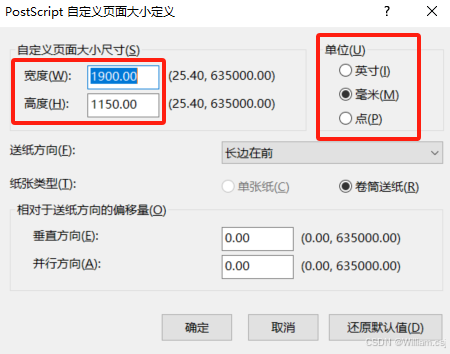
Adobe Acrobat——设置PDF打印页面的大小
1. 打开 PDF 文件; 2. 点击菜单栏的 “文件” → “打印”; 3. 在打印对话框中,点击 “属性”; 4. 点击 “布局”→ “高级”; 5. 点击 “纸张规格”,选择 “PostScript 自定义页面大小”,然后…...
Android apk装机编译类型: verify、speed-profile, speed与启动耗时
Android apk装机编译类型: verify、speed-profile, speed与启动耗时 Dex2oat (dalvik excutable file to optimized art file) ,对 dex 文件进行编译优化,Android 虚拟机可识别的是dex文件,应用运行过程如果每次都将dex文件加载内存ÿ…...

纹理压缩格式优化
🎯 Unity 项目纹理压缩格式优化终极指南 ——不同平台、不同手机型号,如何正确选择 🧩 什么是纹理压缩(Texture Compression)? Texture压缩 = 减小显存占用,提升加载速度,减轻GPU负担纹理是游戏中最大资源,占用50%+内存正确压缩:减少GPU Bandwidth,提高渲染性能错…...
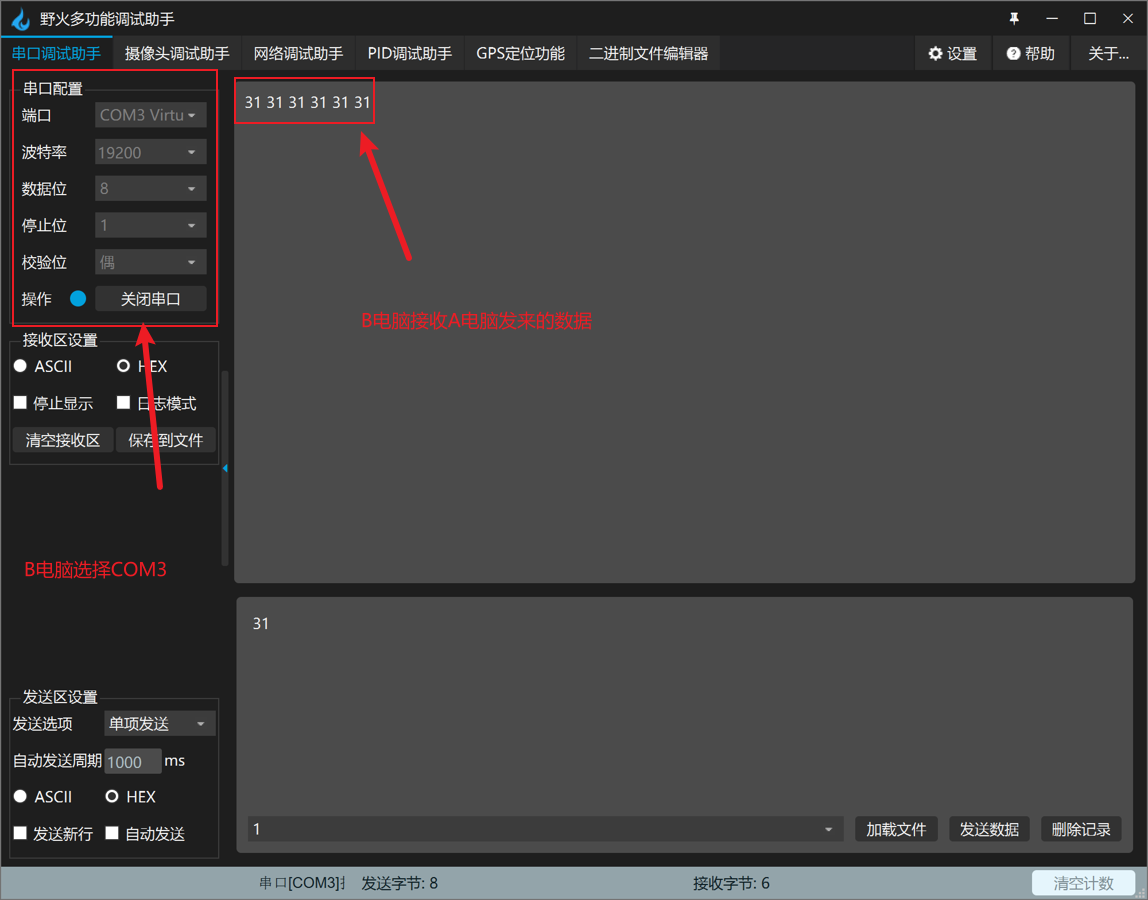
使用Virtual Serial Port Driver+com2tcp(tcp2com)进行两台电脑的串口通讯
使用Virtual Serial Port Drivercom2tcp或tcp2com进行两台电脑的串口通讯 问题说明解决方案方案三具体操作流程网上教程软件安装拓扑图准备工作com2tcp和tcp2com操作使用串口助手进行验证 方案三存在的问题数据错误通讯延时 问题说明 最近想进行串口通讯的一个测试,…...

【从0-1的HTML】第3篇:html引入css的3种方式
文章目录 HTML中引入CSS的方式行内样式内部样式外部样式yinru.css文件 完整html文件 引入CSS方式的优先级 HTML中引入CSS的方式 HTML:是使用标签来描述网页元素 CSS:是Cascading Style Sheets,层叠样式表,用来控制样式来显示网页…...

数智破局·生态共生:重构全球制造新引擎 2025 WOD制造业数字化博览会即将在沪盛大启幕
共探数智化未来,共创新质生产力。2025年6月17日—19日,上海浦东新国际博览中心将迎来全球制造业数字化转型的盛会——WOD制造业数字化博览会。作为全球首个聚焦制造业数字化全场景的专业展会,本届展会以“数智破局生态共生:重构全…...

machine_env_loader must have been assigned before creating ssh child instance
在主机上执行roslaunch命令时,报错:machine_env_loader must have been assigned before creating ssh child instance。 解决办法: 打开hostos文件,检查local host 前的内部ip是否正常。操作示例: 先输入下方指令打…...
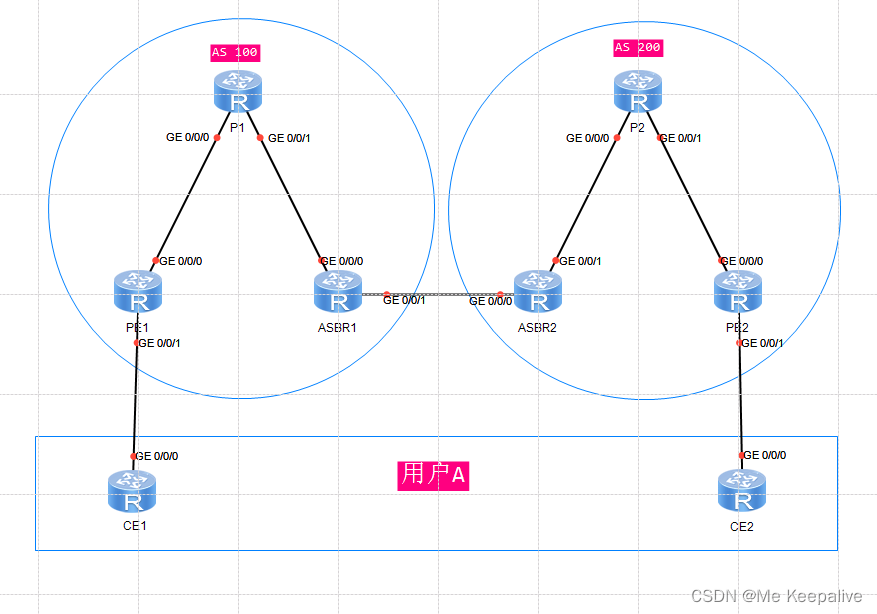
BGP/MPLS IP VPN跨域解决方案
目录 MPLS VPN跨域方案出现背景: MPLS VPN回顾 VRF(Virtual Route Forward)虚拟路由转发 MPLS(Multiple Protcol Label Swtich)多协议标签交换 MP-BGP多协议BGP MPLS VPN跨域OptionA 控制平面: 转发平面: 总结: 挑战: MPLS VPN跨域OptionB 非RR场景: 控制平面: 转发…...

C语言-10.字符串
10.1字符串 10.1-1字符串 字符数组 char word[] = {‘H’,‘e’,‘l’,‘l’,‘o’,‘!’}; word[0]Hword[1]eword[2]lword[3]lword[4]oword[5]!这不是C语言的字符串,因为不能用字符串的方式做计算 字符串 char word[] = {‘H’,‘e’,‘l’,‘l’,‘o’,‘!’}; word[0]Hwo…...
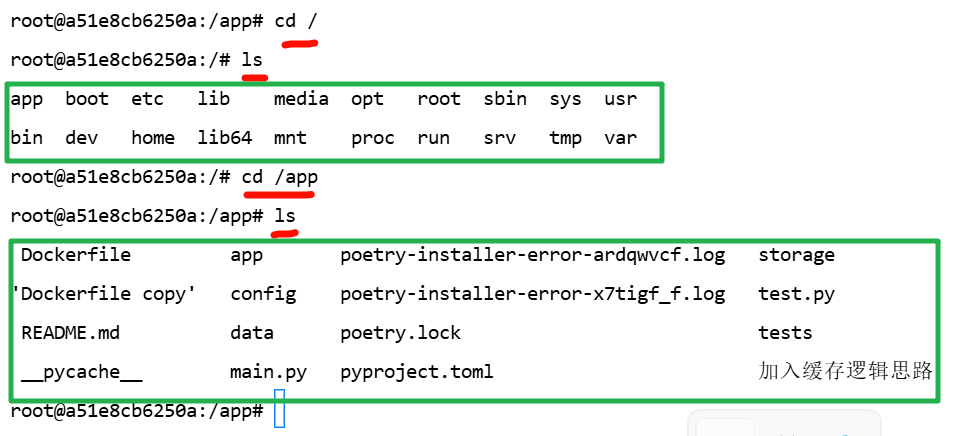
backend 服务尝试连接 qdrant 容器,但失败了,返回 502 Bad Gateway 问题排查
遇到的问题是: backend 报错:502 Bad Gateway 来自 Qdrant → 导致接口 /api/chat 返回 500 Internal Server Error并且日志中提示: QDRANT_URL http://qdrant:6333✅ 问题分析 这个错误的根本原因是: 你的 backend 服务尝试连…...

硬件学习笔记--66 MCU的DMA简介
DMA(Direct Memory Access,直接存储器访问)是MCU中一种重要的数据传输机制,它允许外设与存储器之间或存储器与存储器之间直接传输数据,而无需CPU的持续干预。 1、DMA的基本原理 1.1 核心概念: 1…...

18. Qt系统相关:多线程
一、概述 在Qt中,使用QThread类对系统线程进行了封装。QThread代表一个在应用程序中可独立控制的线程,也可以和进程中的其他线程共享数据。 二、QThread常用API 三、QThread使用 自定义一个类,继承自QThread,并且只有一个线程处…...

6个月Python学习计划 Day 14 - 异常处理基础( 补充学习)
第二周 Day 8 - Python 函数基础 Day 9 - 函数进阶用法 Day 10 - 模块与标准库入门 Day 11 - 列表推导式、内置函数进阶、模块封装实战 Day 12 - 字符串处理 & 文件路径操作 Day 13 - 文件操作基础 🎯 今日目标 理解异常的概念和常见异常类型掌握 try-except …...
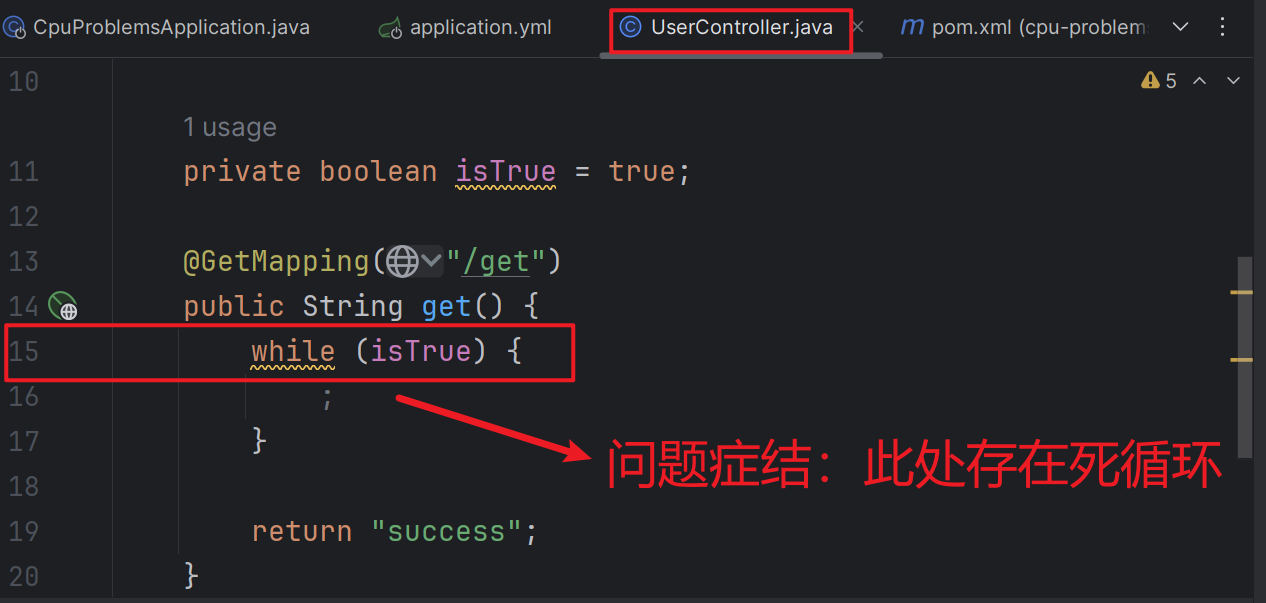
使用jstack排查CPU飙升的问题记录
最近,看到短视频传播了一个使用jstack来协助排查CPU飙升的案例。我也是比较感兴趣,参考了视频博主的流程,自己做了下对应案例的实战演练,在此,想做一下,针对相关问题模拟与排查演练的实战过程记录。 案例中…...
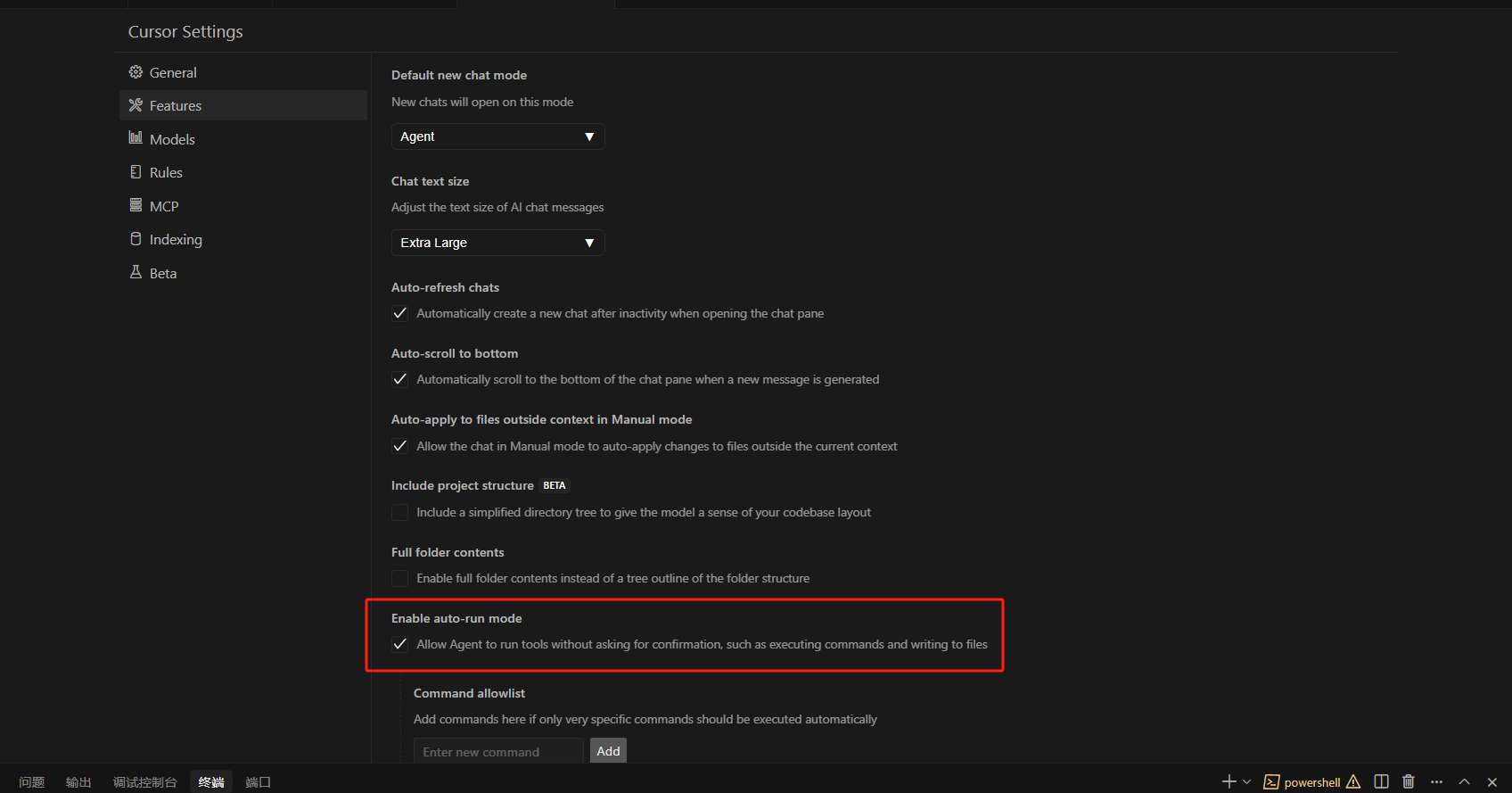
cursor如何开启自动运行模式
在Cursor中,开启自动运行模式即启用“Yolo Mode”,具体操作如下: 按下Ctrl Shift J(Windows/Linux)或Cmd Shift J(Mac)打开Cursor设置。导航到“Features”(功能)选…...
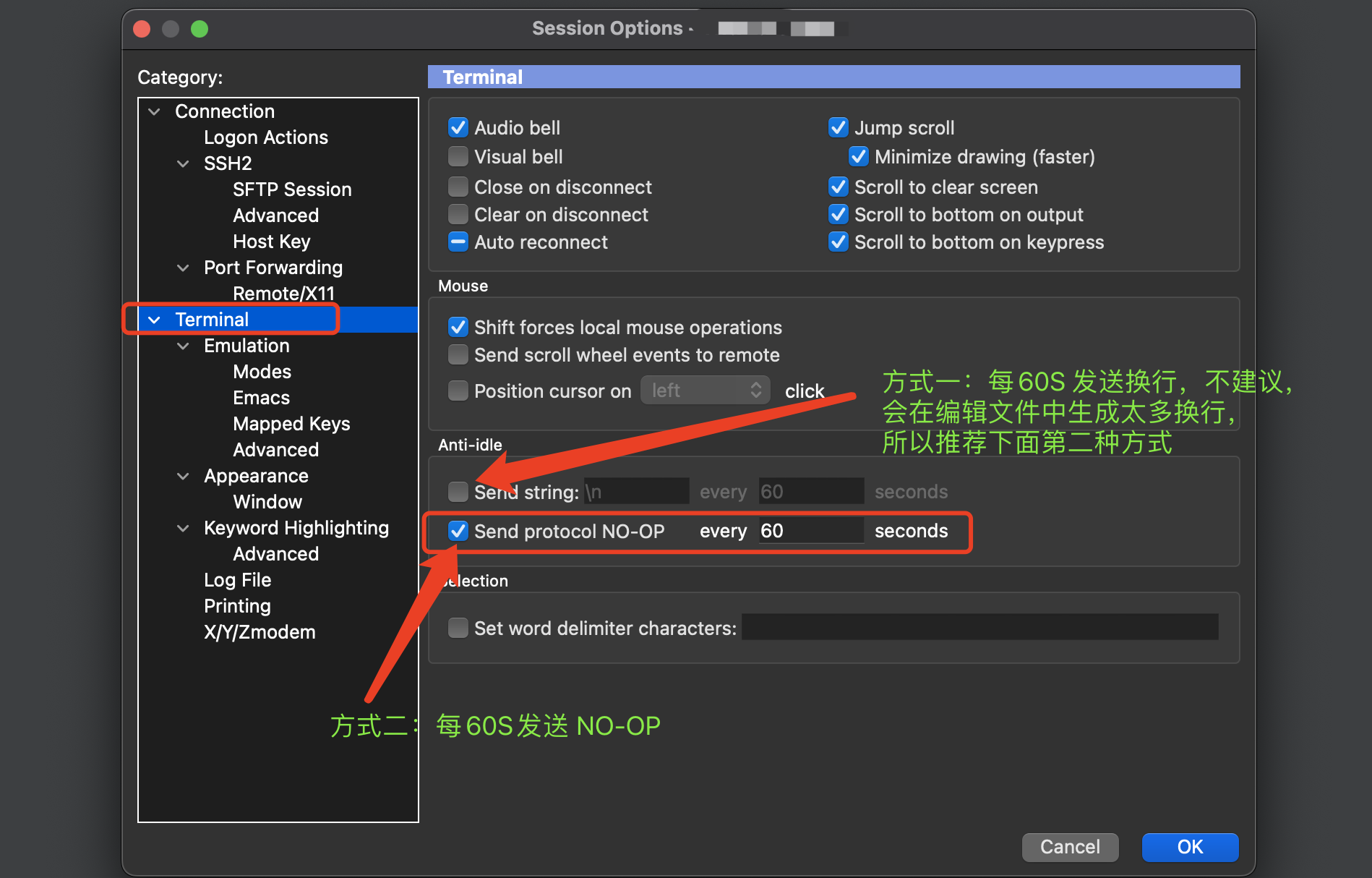
SecureCRT 设置超时自动断开连接时长
我们在使用SecureCRT 连接服务器时,经常性出现2分钟未操作已连接的服务器,就会自动断开连接,此时需要重新连接,非常影响服务器操作,本文可以很好带领大家解决这种问题。...