CentOS7 + JDK8 虚拟机安装与 Hadoop + Spark 集群搭建实践
前言
在大数据时代,Hadoop 和 Spark 是两种非常重要的分布式计算框架。本文将详细介绍如何在 CentOS7 + JDK8 的虚拟机环境中搭建 Hadoop + Spark 分布式集群,包括 Spark Standalone 和 Hadoop + Spark on YARN 两种模式,并提供具体的代码示例。
一、CentOS7 + JDK8 虚拟机安装与基础配置
1. 虚拟机准备
使用已安装好的 CentOS7 操作系统虚拟机文件,克隆出三台虚拟机,分别命名为 CentOS7_x64-vm01、CentOS7_x64-vm02、CentOS7_x64-vm03,并使用 root 账户登录。
2. 配置 IP 地址
通过 VMware 的“虚拟网络编辑器”查看网络配置信息,确保虚拟机的 IP 地址固定且不冲突。在每台虚拟机中,修改 /etc/sysconfig/network-scripts/ifcfg-eth0 文件,配置静态 IP 地址,例如:
BOOTPROTO=static
IPADDR=192.168.163.201
NETMASK=255.255.255.0
GATEWAY=192.168.163.2
DNS1=8.8.8.83. 修改主机名和 hosts 文件
在每台虚拟机中,使用以下命令修改主机名:
hostnamectl set-hostname CentOS7_x64-vm01编辑 /etc/hosts 文件,添加所有虚拟机的主机名与 IP 地址的映射关系:
192.168.163.201 CentOS7_x64-vm01
192.168.163.202 CentOS7_x64-vm02
192.168.163.203 CentOS7_x64-vm034. 测试网络连通性
在每台虚拟机上执行以下命令,测试与其他虚拟机的网络连通性:
ping -c 4 CentOS7_x64-vm02
ping -c 4 CentOS7_x64-vm035. 配置免密登录
在每台虚拟机上生成 SSH 密钥对,并将公钥添加到其他虚拟机的 ~/.ssh/authorized_keys 文件中,实现免密登录:
ssh-keygen -t rsa
ssh-copy-id root@CentOS7_x64-vm02
ssh-copy-id root@CentOS7_x64-vm036. 安装 JDK
下载并安装 JDK 8,配置环境变量:
wget https://example.com/jdk-8uXXX-linux-x64.rpm
rpm -ivh jdk-8uXXX-linux-x64.rpm编辑 /etc/profile 文件,添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_XXX
export PATH=$JAVA_HOME/bin:$PATH执行以下命令使配置生效:
source /etc/profile
java -version二、Hadoop + Spark Standalone 分布式集群环境搭建
1. 软件包准备
将 Hadoop 和 Spark 的安装包(如 hadoop-2.6.5.tar.gz 和 spark-2.4.8-bin-withouthadoop.tgz)上传到 vm01 虚拟机的 /root 目录下。
2. 解压软件包
在 vm01 虚拟机上,将 Hadoop 和 Spark 的安装包解压到 /usr/local 目录下:
tar -zxvf hadoop-2.6.5.tar.gz -C /usr/local/
tar -zxvf spark-2.4.8-bin-withouthadoop.tgz -C /usr/local/3. 配置环境变量
编辑 /etc/profile 文件,添加以下内容:
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export SPARK_HOME=/usr/local/spark-2.4.8
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATH执行以下命令使配置生效:
source /etc/profile4. 配置 HDFS
修改 Hadoop 的 core-site.xml 和 hdfs-site.xml 文件,配置 HDFS 的存储路径、副本数量等参数:
<!-- core-site.xml -->
<configuration><property><name>fs.defaultFS</name><value>hdfs://vm01:9000</value></property>
</configuration><!-- hdfs-site.xml -->
<configuration><property><name>dfs.replication</name><value>3</value></property>
</configuration>5. 配置 Spark
修改 Spark 的 spark-defaults.conf 文件,配置 Spark Standalone 模式下的主节点地址、内存分配等参数:
spark.master spark://vm01:7077
spark.executor.memory 2g
spark.executor.cores 26. 分发配置文件
将配置好的 Hadoop 和 Spark 文件夹从 vm01 虚拟机分发到 vm02 和 vm03 虚拟机上:
scp -r /usr/local/hadoop-2.6.5 root@vm02:/usr/local/
scp -r /usr/local/hadoop-2.6.5 root@vm03:/usr/local/
scp -r /usr/local/spark-2.4.8 root@vm02:/usr/local/
scp -r /usr/local/spark-2.4.8 root@vm03:/usr/local/7. 启动集群
在 vm01 虚拟机上,启动 HDFS 和 Spark 集群服务:
start-dfs.sh
start-master.sh
start-slaves.sh8. 测试集群
在 vm01 虚拟机上,通过提交 SparkPi 计算任务和启动 PySparkShell 来测试集群的配置是否正常:
spark-submit --class org.apache.spark.examples.SparkPi \/usr/local/spark-2.4.8/examples/jars/spark-examples_2.11-2.4.8.jar 10
pyspark三、Hadoop + Spark on YARN 分布式集群环境搭建
1. 软件包准备与解压
与 Hadoop + Spark Standalone 模式类似,将 Hadoop 和 Spark 的安装包上传到 vm01 虚拟机并解压到 /usr/local 目录下。
2. 配置环境变量
编辑 /etc/profile 文件,添加 Hadoop 和 Spark 的环境变量。
3. 配置 HDFS、MapReduce 和 YARN
修改 Hadoop 的 core-site.xml、hdfs-site.xml、mapred-site.xml 和 yarn-site.xml 文件,配置 HDFS、MapReduce 和 YARN 的相关参数:
<!-- core-site.xml -->
<configuration><property><name>fs.defaultFS</name><value>hdfs://vm01:9000</value></property>
</configuration><!-- hdfs-site.xml -->
<configuration><property><name>dfs.replication</name><value>3</value></property>
</configuration><!-- mapred-site.xml -->
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration><!-- yarn-site.xml -->
<configuration><property><name>yarn.resourcemanager.hostname</name><value>vm01</value></property>
</configuration>4. 分发配置文件
将配置好的 Hadoop 和 Spark 文件夹从 vm01 虚拟机分发到 vm02 和 vm03 虚拟机上。
5. 启动集群
在 vm01 虚拟机上,启动 HDFS 和 YARN 集群服务:
start-dfs.sh
start-yarn.sh6. 配置 Spark on YARN
修改 Spark 的 spark-defaults.conf 文件,配置 Spark 在 YARN 集群
相关文章:

CentOS7 + JDK8 虚拟机安装与 Hadoop + Spark 集群搭建实践
前言 在大数据时代,Hadoop 和 Spark 是两种非常重要的分布式计算框架。本文将详细介绍如何在 CentOS7 JDK8 的虚拟机环境中搭建 Hadoop Spark 分布式集群,包括 Spark Standalone 和 Hadoop Spark on YARN 两种模式,并提供具体的代码示例。…...
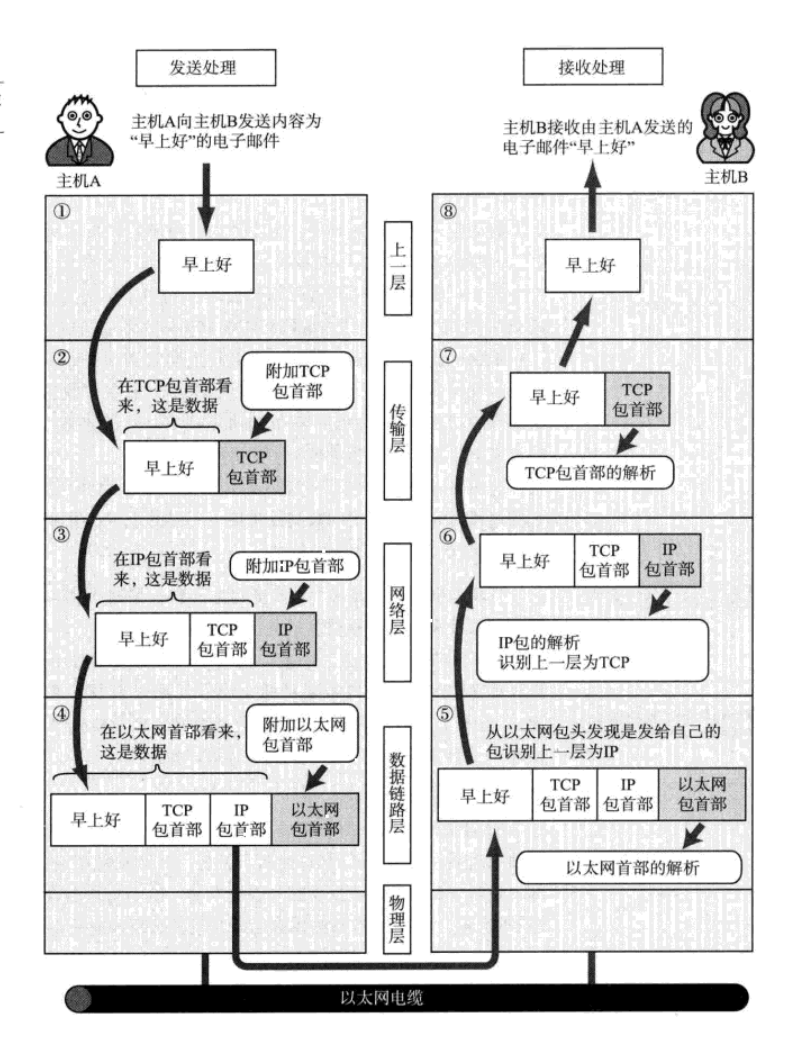
从OSI到TCP/IP:网络协议的演变与作用
个人主页:chian-ocean 文章专栏-NET 从OSI到TCP/IP:网络协议的演变与作用 个人主页:chian-ocean文章专栏-NET 前言网络发展LANWAN 协议举个例子: 协议的产生背景 协议的标准化OSI模型参考OSI各个分层的作用各层次的功能简介 TCP/…...

Stream流性能分析及优雅使用
文章目录 摘要一、Stream原理解析1.1、Stream总概1.2、Stream运行机制1.2.1、创建结点1.2.1、搭建流水线1.2.3、启动流水线 1.3、ParallelStream 二、性能对比三、优雅使用3.1 Collectors.toMap()3.2 findFirst(),findAny()3.3 增删元素3.4 ParallelStream 四、总结…...

iOS 电子书听书功能的实现
在 iOS 应用中实现电子书听书(文本转语音)功能,可以通过系统提供的 AVFoundation 框架实现。以下是详细实现步骤和代码示例: 核心步骤: 导入框架创建语音合成器配置语音参数实现播放控制处理后台播放添加进度跟踪 完整…...

【和春笋一起学C++】(十七)C++函数新特性——内联函数和引用变量
C提供了新的函数特性,使之有别于C语言。主要包括: 内联函数;按引用传递变量;默认参数值;函数重载(多态);模版函数; 因篇幅限制,本文首先介绍内联函数和引用…...
)
GitHub 趋势日报 (2025年06月02日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 1339 prompt-eng-interactive-tutorial 1080 courses 624 onlook 596 system-desi…...

卫星的“太空陀螺”:反作用轮如何精准控制姿态?
卫星的“太空陀螺”:反作用轮如何精准控制姿态? 在距地面500公里的轨道上,一颗遥感卫星正以7.8km/s的速度飞越目标区域。此时星载计算机发出指令:“滚转15并对准目标点”。短短数秒后,数吨重的卫星如同被无形之手推动般…...
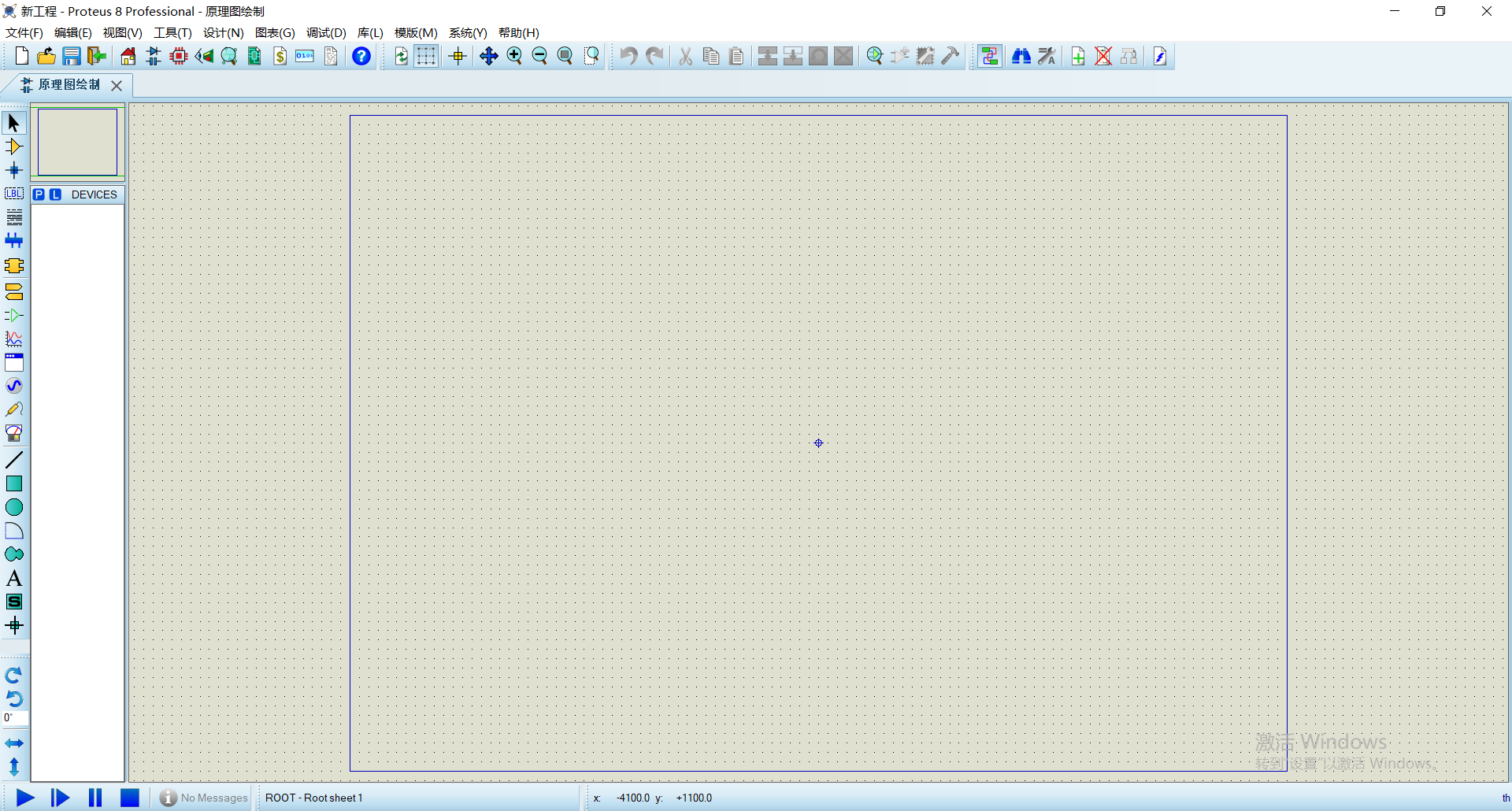
proteus新建工程
1 点击新建工程 2 输入项目名,选择工程文件夹 3 下一步 4 不创建pcb 5 直接下一步 6 点击完成 7 创建完毕...

缓存击穿 缓存穿透 缓存雪崩
缓存击穿 缓存穿透 缓存雪崩 在日常开发中,我们经常会在后端引入 Redis 缓存来减轻数据库压力、提高访问性能。本文将逐点介绍 Redis 缓存常见问题及解决策略。 缓存穿透 问题描述: 缓存穿透指的是客户端请求的数据,在缓存中和数据库中都不…...
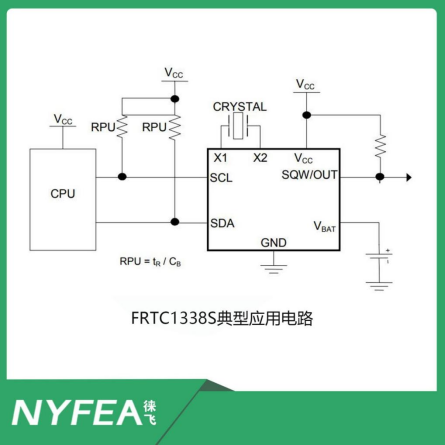
RTC实时时钟DS1338Z-33/PT7C433833WEX国产替代FRTC1338S
FRTC1338S是NYFEA徕飞公司推出的一种高性能的实时时钟芯片,它采用了SOP8封装技术,这种技术因其紧凑的尺寸和出色的性能而被广泛应用于各类电子设备中。 FRTC1338S串行实时时钟(RTC)是一种低功耗的全二进制编码十进制(BCD)时钟/日历外加56字节的非易失性…...
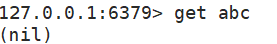
Redis命令使用
Redis是以键值对进行数据存储的,添加数据和查找数据最常用的2个指令就是set和get。 set:set指令用来添加数据。把key和value存储进去。get:get指令用来查找相应的键所对应的值。根据key来取value。 首先,我们先进入到redis客户端…...
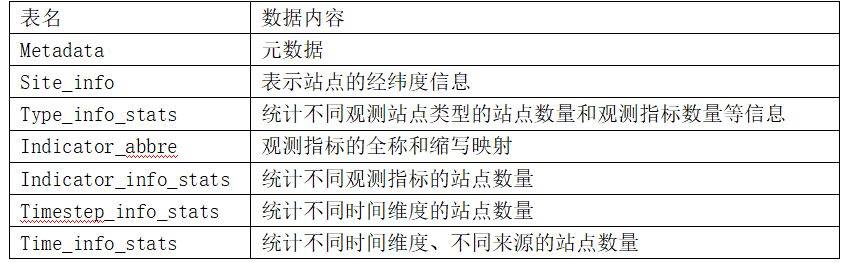
【免费数据】1980-2022年中国2384个站点的水质数据
水,是生命之源,关乎着地球上每一个生物的生存与发展。健康的水生生态系统维持着整个水生态的平衡与活力;更是确保人类能持续获得清洁水源的重要保障。水质数据在水质研究、海洋生物量测算以及生物多样性评估等诸多关键领域都扮演着举足轻重的…...

Java基础 Day28 完结篇
一、方法引用 对 Lambda 表达式的进一步简化 方法引用使用一对冒号 :: Tips:静态方法用类名加双冒号,非静态方法用对象名加双冒号 通过方法的名字来指向一个方法 参数可推导即可省略 可以使语言的构造更紧凑简洁,减少冗余代码 二、单元…...

小红薯商品搜索详情分析与实现
前言 小红书作为国内知名的社交电商平台,拥有丰富的商品数据和用户评价信息。对于数据分析师、产品经理或电商从业者来说,能够获取小红书的商品数据具有重要的商业价值。本文将详细介绍如何通过逆向工程实现小红书商品搜索API的调用。 免责声明:本文仅用于技术学习和研究目…...

Git 极简使用指南
Git 是一个强大的分布式版本控制系统,但入门只需要掌握几个核心概念和命令。本指南旨在帮助你快速上手,处理日常开发中最常见的 80% 的场景。 核心概念 仓库 (Repository / Repo): 你的项目文件夹,包含了项目的所有文件和完整的历史记录。…...

力扣刷题Day 69:搜索二维矩阵(74)
1.题目描述 2.思路 首先判断target是否有可能在矩阵的某一行里,没可能直接返回False,有可能就在这一行里二分查找。 3.代码(Python3) class Solution:def searchMatrix(self, matrix: List[List[int]], target: int) -> boo…...

c#压缩与解压缩-SharpCompress
SharpCompress SharpCompress 是一个开源项目库,能够处理文件。c#库对于压缩已经有很多,可以随意选择,看了SharpCompress感觉比较简洁,还是介绍给大家。 项目地址: sharpcompress 项目使用 引入nuget包࿱…...

Neo4j 安全深度解析:原理、技术与最佳实践
在当今数据驱动的世界中,图数据库承载着关键的关系信息,其安全性至关重要。Neo4j 提供了一套多层次、纵深防御的安全体系。 Neo4j 的安全体系提供了从认证授权到数据加密、审计追溯的完整解决方案。安全不是单一功能而是一种持续状态,其有效…...

MySQL指令个人笔记
MySQL学习,SQL语言笔记 一、MySQL 1.1 启动、停止 启动 net start mysql83停止 net stop mysql831.2 连接、断开 连接 mysql -h localhost -P 3306 -u root -p断开 exit或者ctrlc 二、DDL 2.1 库管理 2.1.1 直接创建库 使用默认字符集和排序方式…...
2022年 国内税务年鉴PDF电子版Excel
2022年 国内税务年鉴PDF电子版Excelhttps://download.csdn.net/download/2401_84585615/89784658 https://download.csdn.net/download/2401_84585615/89784658 2022年国内税务年鉴是对中国税收政策、税制改革和税务管理实践的全面总结。这份年鉴详细记录了中国税收系统的整体状…...
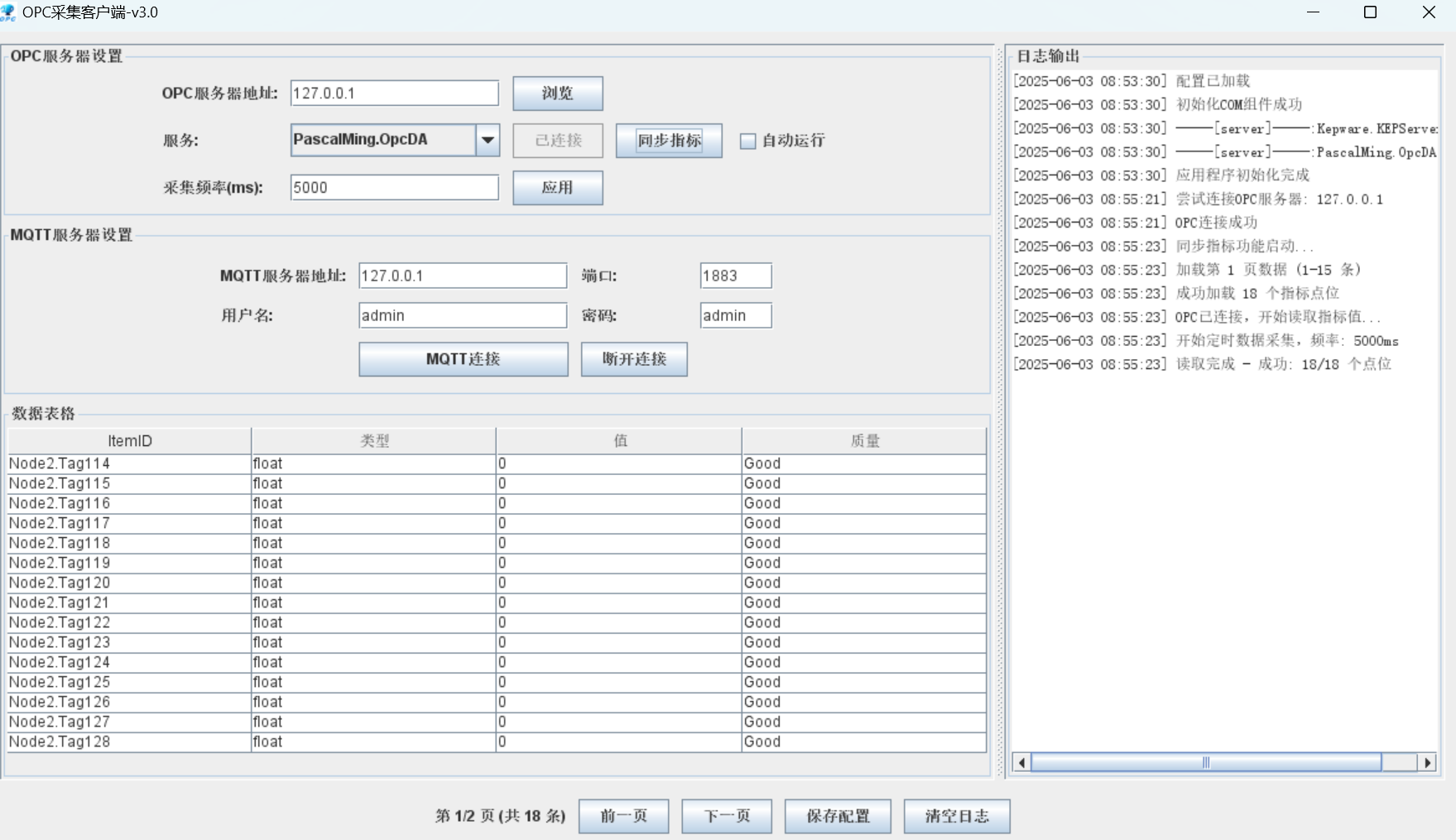
基于Java的OPCDA采集中间件
1.软件功能及技术特点简介: 软件功能及技术特点简介: OPCDA是基于Java语言开发的OPC client(OPC客户端)跨平台中间件软件,他支持OPC SERVER的OPC DA1.0/2.0/3.0。OPCDA实时采集数据(包括实时数据、报警数…...

基于PyQt5的相机手动标定工具:原理、实现与应用
基于PyQt5的相机手动标定工具:原理、实现与应用 一、背景介绍二、功能详解与实现原理2.1 图像加载与预处理2.2 交互式透视调整2.3 透视变换数学原理2.4 图像拼接核心技术2.5 用户界面优化细节三、完整使用流程四、应用场景实例五、技术优势分析六、代码七、总结一、背景介绍 …...

vue2 项目中 npm run dev 运行98% after emitting CopyPlugin 卡死
今天在运行项目时,发现如下问题: 开始以为是node_modules依赖的问题,于是重新 npm install,重启项目后还是未解决。 在网上找了一圈发现有人说是 require引入图片地址没有写。在我的项目中排查没有这个问题,最后发现某…...
JavaScript 性能优化实战:从原理到框架的全栈优化指南
在 Web 应用复杂度指数级增长的今天,JavaScript 性能优化已成为衡量前端工程质量的核心指标。本文将结合现代浏览器引擎特性与一线大厂实践经验,构建从基础原理到框架定制的完整优化体系,助你打造高性能 Web 应用。 一、性能优化基础&#x…...
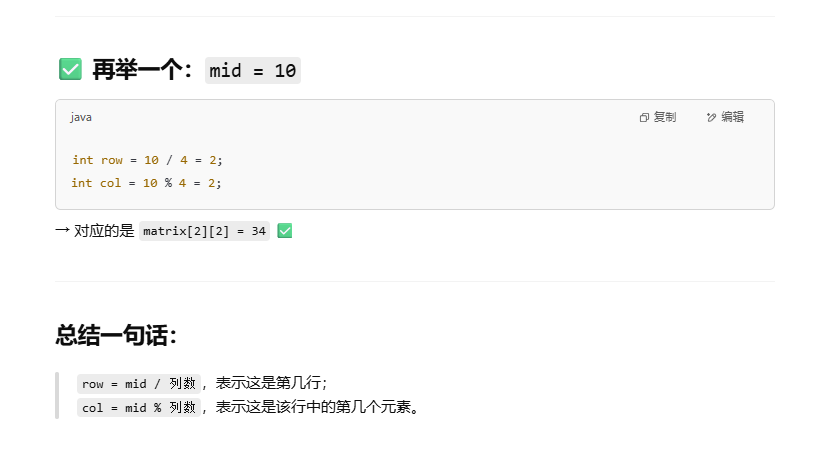
2025年- H61-Lc169--74.搜索二维矩阵(二分查找)--Java版
1.题目描述 2.思路 方法一: 定义其实坐标,右上角的元素(0,n-1)。进入while循环(注意边界条件,行数小于m,列数要>0)从右上角开始开始向左遍历(比当…...

微服务商城-用户微服务
数据表 用户表 CREATE DATABASE user; USE user;CREATE TABLE user (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 用户ID,username varchar(50) NOT NULL DEFAULT COMMENT 用户名,password varchar(50) NOT NULL DEFAULT COMMENT 用户密码,MD5加密…...

数学复习笔记 26
5.25:这题还是有点难度的。主要是出现了新的知识点,我现在还没有那么熟悉这个新的知识点。这块就是,假设一个矩阵可以写成一个列向量乘以一个行向量的形式,这两个向量都是非零向量,那么这个矩阵的秩等于一。这个的原理…...

创建型-设计模式
文章目录 单例模式工厂模式建造者模式原型模式 单例模式 单例模式有饿汉式 和 懒汉式。这个我觉得无需多言,每个学过Java的都知道。 1.单例的使用:我一般就是用饿汉式,因为App开发的开发一般数据处理并不复杂,所以直接使用饿汉式…...

移动AI神器GPT Mobile:多模型自由切换
GPT Mobile是什么 GPT Mobile是一款开源的本地移动部署AI工具,主要用于安卓设备。以下是其相关介绍: 功能特点 多模型交互:支持与多个大型语言模型(LLM)同时进行对话,用户导入相应的API密钥,就可连接OpenAI、Anthropic、Google、Ollama等平台,还能根据需求自由切换不同…...
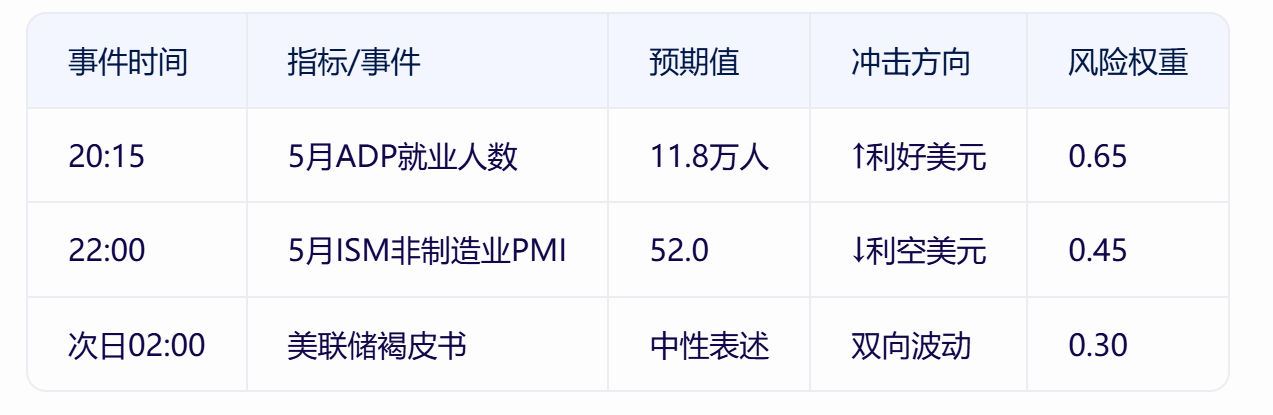
【黄金评论】美元走强压制金价:基于NLP政策因子与ARIMA-GARCH的联动效应解析
一、基本面:多因子模型解析黄金承压逻辑 1. 政策冲击因子驱动美元强势 通过NLP模型对关税政策文本进行情感分析,构建政策不确定性指数(PUI)达89.3,触发美元避险需求溢价。DSGE模型模拟显示,钢铁关税上调至…...