【Pandas】pandas DataFrame reset_index
Pandas2.2 DataFrame
Reindexing selection label manipulation
| 方法 | 描述 |
|---|---|
| DataFrame.add_prefix(prefix[, axis]) | 用于在 DataFrame 的行标签或列标签前添加指定前缀的方法 |
| DataFrame.add_suffix(suffix[, axis]) | 用于在 DataFrame 的行标签或列标签后添加指定后缀的方法 |
| DataFrame.align(other[, join, axis, level, …]) | 用于对齐两个 DataFrame 或 Series 的方法 |
| DataFrame.at_time(time[, asof, axis]) | 用于筛选 特定时间点 的行的方法 |
| DataFrame.between_time(start_time, end_time) | 用于筛选 指定时间范围内的数据行 的方法 |
| DataFrame.drop([labels, axis, index, …]) | 用于从 DataFrame 中删除指定行或列的方法 |
| DataFrame.drop_duplicates([subset, keep, …]) | 用于删除重复行的方法 |
| DataFrame.duplicated([subset, keep]) | 用于检测 重复行 的方法 |
| DataFrame.equals(other) | 用于比较两个 DataFrame 是否完全相等的方法 |
| DataFrame.filter([items, like, regex, axis]) | 用于筛选列或行标签的方法 |
| DataFrame.first(offset) | 用于选取 时间序列型 DataFrame 中从起始时间开始的一段连续时间窗口 的方法 |
| DataFrame.head([n]) | 用于快速查看 DataFrame 前几行数据 的方法 |
| DataFrame.idxmax([axis, skipna, numeric_only]) | 用于查找 每列或每行中最大值的索引标签 的方法 |
| DataFrame.idxmin([axis, skipna, numeric_only]) | 用于查找 每列或每行中最小值的索引标签 的方法 |
| DataFrame.last(offset) | 用于选取 时间序列型 DataFrame 中从最后时间点开始向前截取一段指定长度的时间窗口 的方法 |
| DataFrame.reindex([labels, index, columns, …]) | 用于重新索引 DataFrame 的核心方法 |
| DataFrame.reindex_like(other[, method, …]) | 用于将当前 DataFrame 的索引和列重新设置为与另一个对象(如另一个 DataFrame 或 Series)相同 |
| DataFrame.rename([mapper, index, columns, …]) | 用于重命名 DataFrame 的行索引标签或列名的方法 |
| DataFrame.rename_axis([mapper, index, …]) | 用于**重命名 DataFrame 的索引轴名称(index axis name)或列轴名称(column axis name)**的方法 |
| DataFrame.reset_index([level, drop, …]) | 用于将 DataFrame 的索引(index)重置为默认整数索引,并将原索引作为列添加回 DataFrame 中的方法 |
pandas.DataFrame.reset_index()
pandas.DataFrame.reset_index() 是一个用于将 DataFrame 的索引(index)重置为默认整数索引,并将原索引作为列添加回 DataFrame 中的方法。它常用于处理具有自定义索引的 DataFrame,使其恢复为标准的从 0 开始的整数索引。
📌 方法签名
DataFrame.reset_index(level=None, *, drop=False, inplace=False, col_level=0, col_fill='', allow_duplicates=<no_default>, names=None)
🔧 参数说明
| 参数 | 类型 | 说明 |
|---|---|---|
level | int、str 或 list,默认 None | 指定要重置的索引层级(适用于 MultiIndex) |
drop | bool,默认 False | 是否丢弃原索引而不将其作为列加入结果中 |
inplace | bool,默认 False | 是否在原对象上修改 |
col_level | int 或 str,默认 0 | 在多级列的情况下,指定新索引列插入到哪一级 |
col_fill | str,默认 ‘’ | 在多级列时,用于填充未使用的层级名称 |
names | str 或 list,默认 None | 设置新列的名称(如果原索引有名称则自动使用) |
allow_duplicates | bool,默认 False | 是否允许列名重复(仅在设置 names 时有效) |
✅ 返回值
- 返回一个新的
DataFrame,其索引被重置为从 0 开始的整数索引; - 若
drop=True,则原始索引不会作为列保留; - 若
inplace=True,则直接修改原对象并返回None。
🧪 示例代码及结果
示例 1:基本用法 - 重置普通索引
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
}, index=['x', 'y', 'z'])print("Original DataFrame:")
print(df)# 重置索引
df_reset = df.reset_index()print("\nAfter reset_index():")
print(df_reset)
输出结果:
Original DataFrame:A B
x 1 4
y 2 5
z 3 6After reset_index():index A B
0 x 1 4
1 y 2 5
2 z 3 6
原索引
'x','y','z'被转换为一列名为'index'的列。
示例 2:不保留原索引(drop=True)
df_reset_drop = df.reset_index(drop=True)
print("\nAfter reset_index(drop=True):")
print(df_reset_drop)
输出结果:
After reset_index(drop=True):A B
0 1 4
1 2 5
2 3 6
原索引被完全丢弃,不再作为列出现。
示例 3:自定义新列名(names 参数)
df_reset_named = df.reset_index(names='old_index')
print("\nAfter reset_index(names='old_index'):")
print(df_reset_named)
输出结果:
After reset_index(names='old_index'):old_index A B
0 x 1 4
1 y 2 5
2 z 3 6
使用
names自定义了原索引列的列名。
示例 4:多级索引重置(MultiIndex)
# 创建多级索引 DataFrame
index = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('b', 1)], names=['group', 'id'])
df_multi = pd.DataFrame({'value': [10, 20, 30]}, index=index)print("Original MultiIndex DataFrame:")
print(df_multi)# 重置所有索引
df_reset_multi = df_multi.reset_index()
print("\nAfter reset_index() on MultiIndex:")
print(df_reset_multi)
输出结果:
Original MultiIndex DataFrame:value
group id
a 1 102 20
b 1 30After reset_index() on MultiIndex:group id value
0 a 1 10
1 a 2 20
2 b 1 30
多级索引被展开为多个列。
示例 5:只重置某一层索引(level 参数)
# 只重置第一层索引(group)
df_reset_level = df_multi.reset_index(level='group')
print("\nAfter reset_index(level='group'):")
print(df_reset_level)
输出结果:
After reset_index(level='group'):group value
id
1 a 10
2 a 20
1 b 30
只重置了
'group'层,保留'id'作为索引。
示例 6:重置索引并重命名列名(names + level)
# 重置所有索引并命名新列
df_reset_names = df_multi.reset_index(names=['category', 'identifier'])
print("\nAfter reset_index(names=['category', 'identifier']):")
print(df_reset_names)
输出结果:
After reset_index(names=['category', 'identifier']):category identifier value
0 a 1 10
1 a 2 20
2 b 1 30
使用
names给多级索引列分别命名。
示例 7:与 drop=True 结合使用
# 重置索引但不保留原索引列
df_reset_drop = df.reset_index(drop=True)
print("\nAfter reset_index(drop=True):")
print(df_reset_drop)
输出结果:
After reset_index(drop=True):A B
0 1 4
1 2 5
2 3 6
🧠 应用场景
- 数据清洗:将非连续或非数字索引转换为标准整数索引;
- 模型输入准备:确保索引是标准整数,便于后续处理;
- 导出数据前处理:避免索引丢失或无法写入文件;
- 合并多个 DataFrame:统一索引结构;
- 可视化和展示:标准化输出格式,方便查看和分析。
⚠️ 注意事项
- 默认会将原索引作为列加入新的
DataFrame; - 如果是
MultiIndex,可以控制只重置某一层; - 使用
drop=True可避免新增索引列; - 支持通过
names自定义列名; - 不会修改原始数据内容,除非设置
inplace=True; - 对于大型数据集非常安全且高效,适合链式调用。
相关文章:

【Pandas】pandas DataFrame reset_index
Pandas2.2 DataFrame Reindexing selection label manipulation 方法描述DataFrame.add_prefix(prefix[, axis])用于在 DataFrame 的行标签或列标签前添加指定前缀的方法DataFrame.add_suffix(suffix[, axis])用于在 DataFrame 的行标签或列标签后添加指定后缀的方法DataFram…...
综合案例:斗地主
综合案例:斗地主 1.程序概述 这是一个模拟斗地主游戏发牌过程的C语言程序,实现了扑克牌的初始化、洗牌和发牌功能。 2.功能需求 2.1 扑克牌定义 使用结构体 Card 表示一张牌,包含: 花色属性suit(0-3表示普通花色♥…...
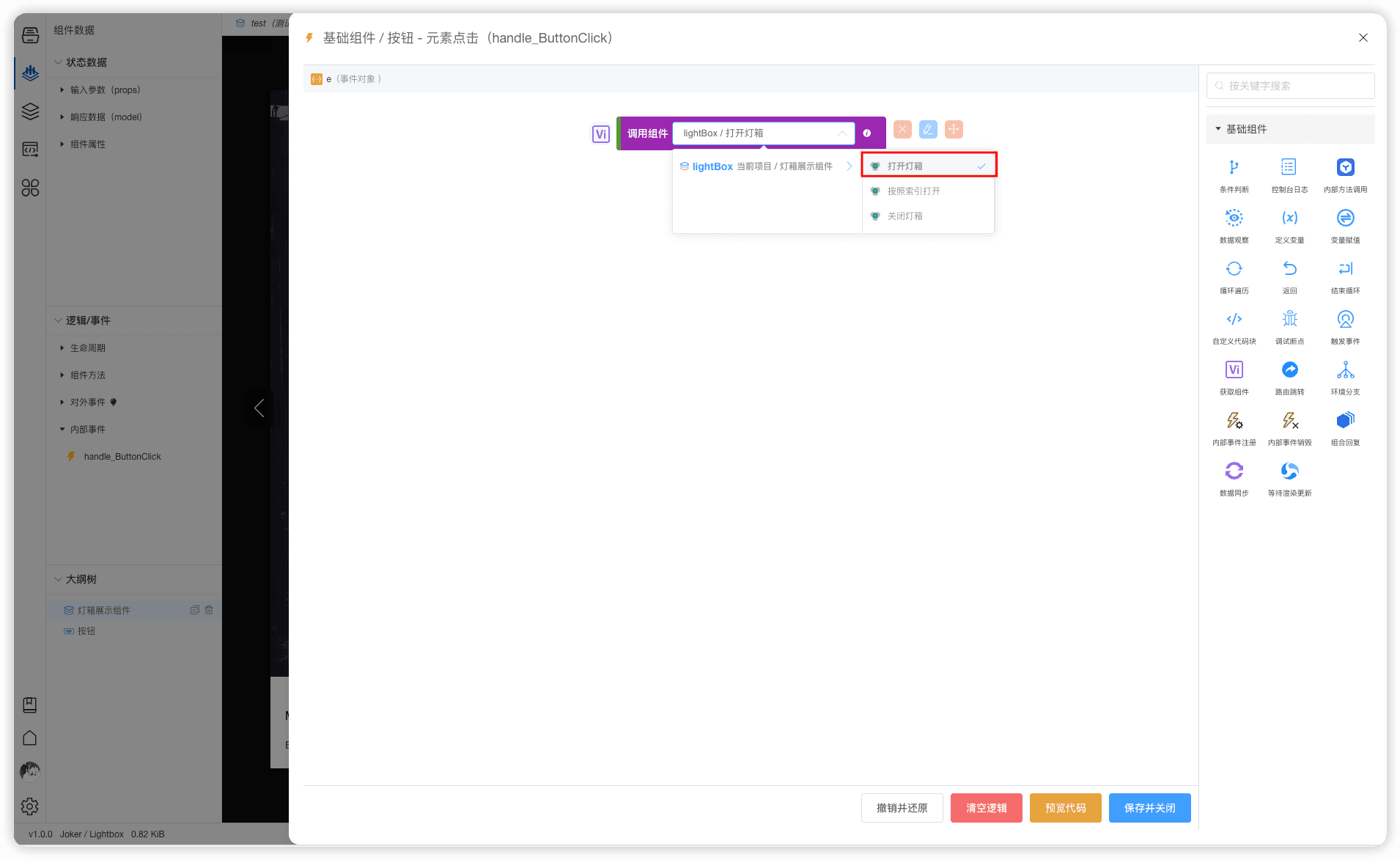
前端组件推荐 Swiper 轮播与 Lightbox 灯箱组件深度解析
在互联网产品不断迭代升级的今天,用户对于页面交互和视觉效果的要求越来越高。想要快速打造出吸睛又实用的项目,合适的组件必不可少。今天就为大家推荐两款超好用的组件 ——Swiper 轮播组件和 Lightbox 灯箱组件,轻松解决你的展示难题&#…...
加密视频)
解密并下载受DRM保护的MPD(DASH流媒体)加密视频
要解密并下载受DRM保护的MPD(DASH流媒体)加密视频,需结合技术工具与合法授权。以下是关键方法与步骤: 一、工具与技术要求 Widevine-DL 这是一个开源Python工具,支持下载和解密Widevine DRM保护的MPD内容。它依赖ffmpe…...

数据可视化有哪些步骤?2025高效落地指南
分享大纲 1、科学框架:从数据到洞察落地 2、可视化实战:捷码快速搭建专业大屏 3、关键避坑指南 根据IBM研究,规范的数据可视化流程,可以使得数据可视化搭建效率提升41%。那有标准的数据可视化搭建方法是哪些呢?本文将借…...

Deepfashion2 数据集使用笔记
目录 数据类别: 筛选类别数据: 验证精度筛选前2个类别: 提取类别数据 可视化类别数据: Deepfashion2 的解压码 旋转数据增强 数据类别: 类别含义: Class idx类别名称英文名称0短上衣short sleeve top1长上衣long sleeve top2短外套short sleeve outwear3长外套lo…...
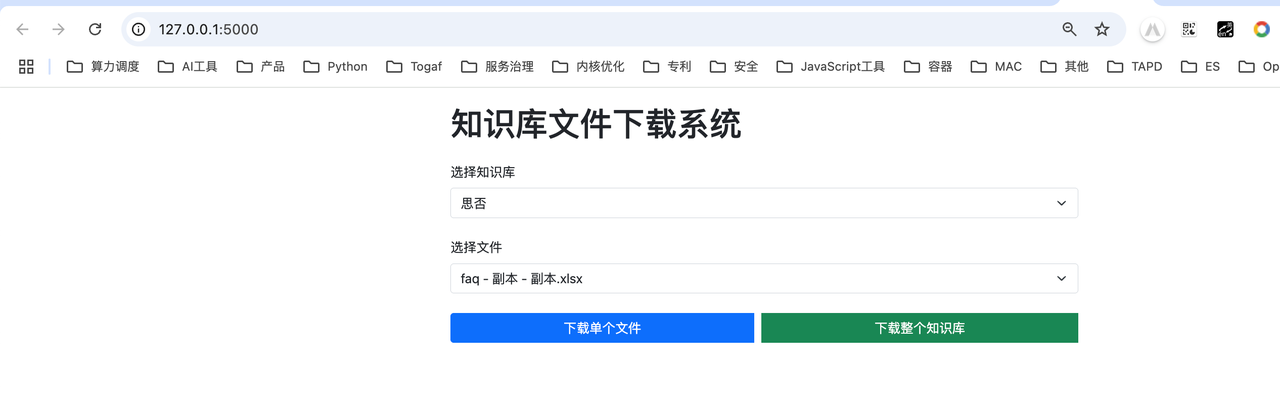
Dify知识库下载小程序
一、Dify配置 1.查看或创建知识库的API 二、下载程序配置 1. 安装依赖resquirements.txt ######requirements.txt##### flask2.3.3 psycopg2-binary2.9.9 requests2.31.0 python-dotenv1.0.0#####安装依赖 pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.…...

匀速旋转动画的终极对决:requestAnimationFrame vs CSS Animation
引言:旋转动画的隐藏陷阱 在现代Web开发中,实现一个流畅的无限旋转动画似乎是个简单任务。但当我深入探究时,发现这个看似基础的需求背后隐藏着性能陷阱、数学精度问题和浏览器渲染机制的深层奥秘。本文将带你从一段常见的requestAnimationF…...

数据库中求最小函数依赖集-最后附解题过程
今天来攻克数据库设计里一个超重要的知识点 —— 最小函数依赖集。对于刚接触数据库的小白来说,这概念可能有点绕,但别担心,咱们一步步拆解,轻松搞定💪! (最后fuyou) 什么是最小函数…...
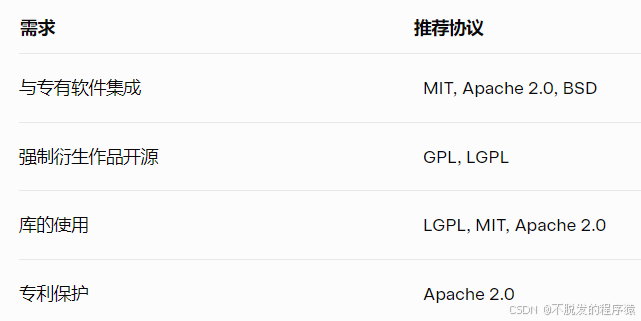
嵌入式系统中常用的开源协议
目录 1、GNU通用公共许可证(GPL) 2、GNU宽松通用公共许可证(LGPL) 3、MIT许可证 4、Apache许可证2.0 5、BSD许可证 6、如何选择合适的协议 在嵌入式系统开发中,开源软件的使用已成为主流趋势。从物联网设备到汽车…...

MySQL 索引底层原理剖析:B+ 树结构、索引创建维护与性能优化策略全解读
引言 在 MySQL 数据库的世界里,索引是提升查询性能的关键利器。然而,很多开发者虽然知道索引的重要性,但对于索引背后的底层原理却知之甚少。本文将深入 MySQL 索引的底层实现,剖析 B 树的结构特点,以及如何利用这些知…...

系统架构设计论文
disstertation 软考高级-系统架构设计师-论文:论文范围(十大知识领域)、历年论题、预测论题及论述过程、论文要点、论文模板等。 —— 2025 年 4 月 4 日 甲辰年三月初七 清明 目录 disstertation1、论文范围(十大核心领域&#x…...

第二篇:Liunx环境下搭建PaddleOCR识别
第二篇:Liunx环境下搭建Paddleocr识别 一:前言二:安装PaddleOCR三:验证PaddleOCR是否安装成功 一:前言 PaddleOCR作为业界领先的多语言开源OCR工具库,其核心优势在于深度整合了百度自主研发的飞桨PaddlePa…...

图片上传问题解决方案与实践
一、问题描述 在校园二手交易平台中,上传商品图片后出现以下异常情况: 图片访问返回404错误,无法正常加载服务器错误识别文件类型为text/plain图片 URL 路径存在不完整问题 二、原因分析 (一)静态资源访问配置问题…...

复杂业务场景下 JSON 规范设计:Map<String,Object>快速开发 与 ResponseEntity精细化控制HTTP 的本质区别与应用场景解析
Moudle 1 Json使用示例 在企业开发中,构造 JSON 格式数据的方式需兼顾 可读性、兼容性、安全性和开发效率,以下是几种常用方式及适用场景: 一、直接使用 Map / 对象转换(简单场景) 通过 键值对集合(如 M…...
二叉数-965.单值二叉数-力扣(LeetCode)
一、题目解析 顾名思义,就是二叉树中所存储的值是相同,如果有不同则返回false 二、算法原理 对于二叉树的遍历,递归无疑是最便捷、最简单的方法,本题需要用到递归的思想。 采取前序遍历的方法,即根、左、右。 我们…...

redis集群和哨兵的区别
Redis Sentinel系统监控并确保主从数据库的正常运行,当主数据库故障时自动进行故障迁移。哨兵模式提供高可用性,客户端通过Sentinel获取主服务器地址,简化管理。Redis集群实现数据分布式存储,通过槽分区提高并发量,解决…...

[蓝桥杯]对局匹配
对局匹配 题目描述 小明喜欢在一个围棋网站上找别人在线对弈。这个网站上所有注册用户都有一个积分,代表他的围棋水平。 小明发现网站的自动对局系统在匹配对手时,只会将积分差恰好是 K 的两名用户匹配在一起。如果两人分差小于或大于 KK,…...

BBU 电源市场报告:深入剖析与未来展望
在当今数字化时代,数据中心的稳定运行至关重要。BBU 电源作为保障数据中心设备在停电或电压下降期间临时电力供应的关键系统,其市场发展备受关注。本文将从市场规模、竞争格局、产品类型、应用领域等多个维度对 BBU 电源市场进行深入分析,并为…...

Redis 持久化机制详解:RDB 与 AOF 的原理、优缺点与最佳实践
目录 前言1. Redis 持久化机制概述2. RDB 持久化机制详解2.1 RDB 的工作原理2.2 RDB 的优点2.3 RDB 的缺点 3. AOF 持久化机制详解3.1 AOF 的工作原理3.2 AOF 的优点3.3 AOF 的缺点 4. RDB 与 AOF 的对比分析5. 持久化机制的组合使用与最佳实践6. 结语 前言 Redis 作为一款高性…...

Hadoop企业级高可用与自愈机制源码深度剖析
Hadoop企业级高可用与自愈机制源码深度剖析 前言 在大数据平台生产环境中,高可用(HA)与自动化自愈能力直接决定了数据安全与服务稳定性。本文结合源码与实战,深入剖析Hadoop生态中YARN高可用、HDFS自动扩容、故障自愈三大核心机…...
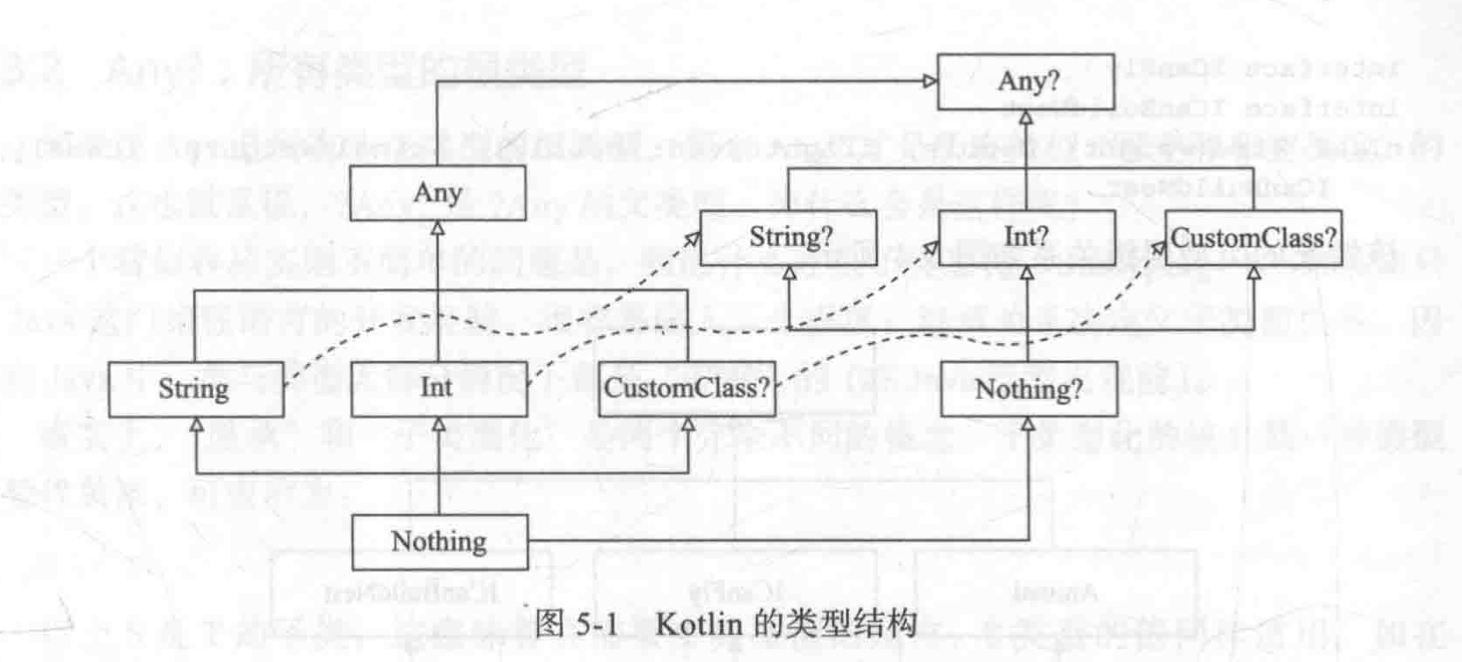
【Kotlin】简介变量类接口
【Kotlin】简介&变量&类&接口 【Kotlin】数字&字符串&数组&集合 【Kotlin】高阶函数&Lambda&内联函数 【Kotlin】表达式&关键字 文章目录 Kotlin_简介&变量&类&接口Kotlin的特性Kotlin优势创建Kotlin项目变量变量保存了指向对…...
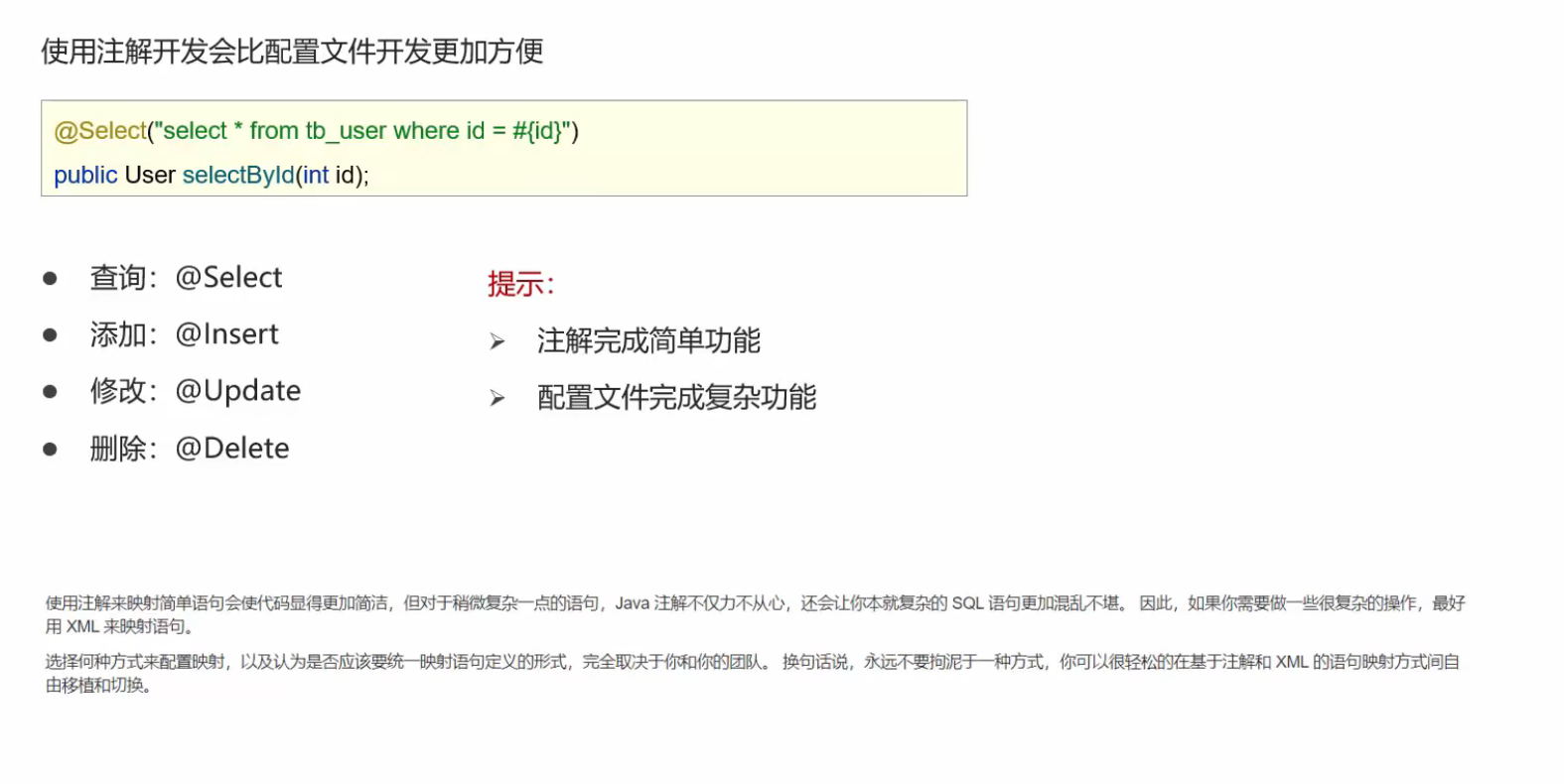
Mybatis入门到精通
一:什么是Mybatis 二:Mybatis就是简化jdbc代码的 三:Mybatis的操作步骤 1:在数据库中创建一个表,并添加数据 我们这里就省略了 2:Mybatis通过maven来导入坐标(jar包) 3:…...
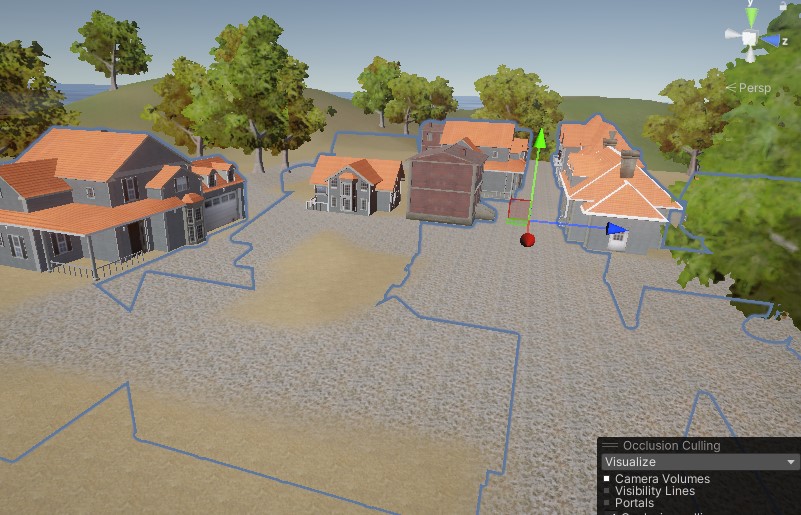
Unity性能优化笔记
降低Draw Call 降低draw call(unity里叫batches)的方法有: 模型减少材质; 多模型共用材质; 烘焙灯光; 关闭阴影和雾; 遮挡剔除; 使用LOD; 模型减少材质 > 见…...

BERT vs Rasa 如何选择 Hugging Face 与 Rasa 的区别 模型和智能体的区别
我在之前的一篇文章中提到我的短期目标的问题,即想通过Hugging Face的BERT或Rasa搭建一个简单的意图识别模型,针对发票业务场景来展示其效果 [如:开发票、查询发票]。 开篇,有必要记录几个英文缩写或术语 (如果喜欢&a…...
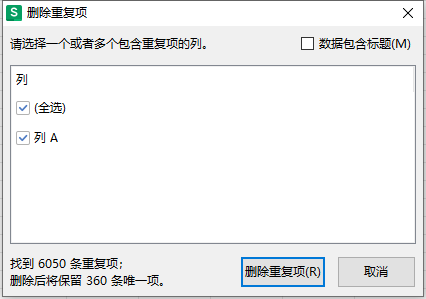
Excel 重复项标记,删除重复项时出现未响应的情况
目录 一、重复值标记: 二、删除重复值: 三、未响应问题 一、重复值标记: 方法1:开始 》条件格式 》突出显示单元格规则 》重复值 》设置颜色 》确定 PS:样式可自定义(边框、字体、背景填充...࿰…...

CppCon 2015 学习:Beyond Sanitizers
Sanitizers,一类基于编译时插桩(instrumentation)的动态测试工具,用来检测程序运行时的各种错误。 Sanitizers 简介 基于编译时插桩:编译器在编译代码时自动插入检测代码。动态运行时检测:程序运行时实时…...

Mysql选择合适的字段创建索引
1. 考虑字段的选择性 选择性:字段的选择性是指字段中不重复值的比例。选择性越高(即不重复值越多),索引的效率越高。 示例: 如果一个字段有100万行数据,但只有2个不重复值(如性别字段ÿ…...

Python:操作 Excel 格式化
🔧Python 操作 Excel 格式化完整指南(openpyxl 与 xlsxwriter 双方案) 在数据处理和报表自动化中,Python 是一把利器,尤其是配合 Excel 文件的读写与格式化处理。本篇将详细介绍两大主流库: openpyxl:适合读取与修改现有 Excel 文件xlsxwriter:适合创建新文件并进行复…...

ant-design-vue select 下拉框不好用解决
将optionFilterProp设置为label和a-select-option的:label"item.name"自定义属性 <a-selectshowSearchallowClearoptionFilterProp"label"placeholder"请选择选项"style"width: 120px; margin-right: 16px"><a-select-optio…...