【Ragflow】24.Ragflow-plus开发日志:增加分词逻辑,修复关键词检索失效问题
概述
在RagflowPlus v0.3.0 版本推出之后,反馈比较多的问题是:检索时,召回块显著变少了。
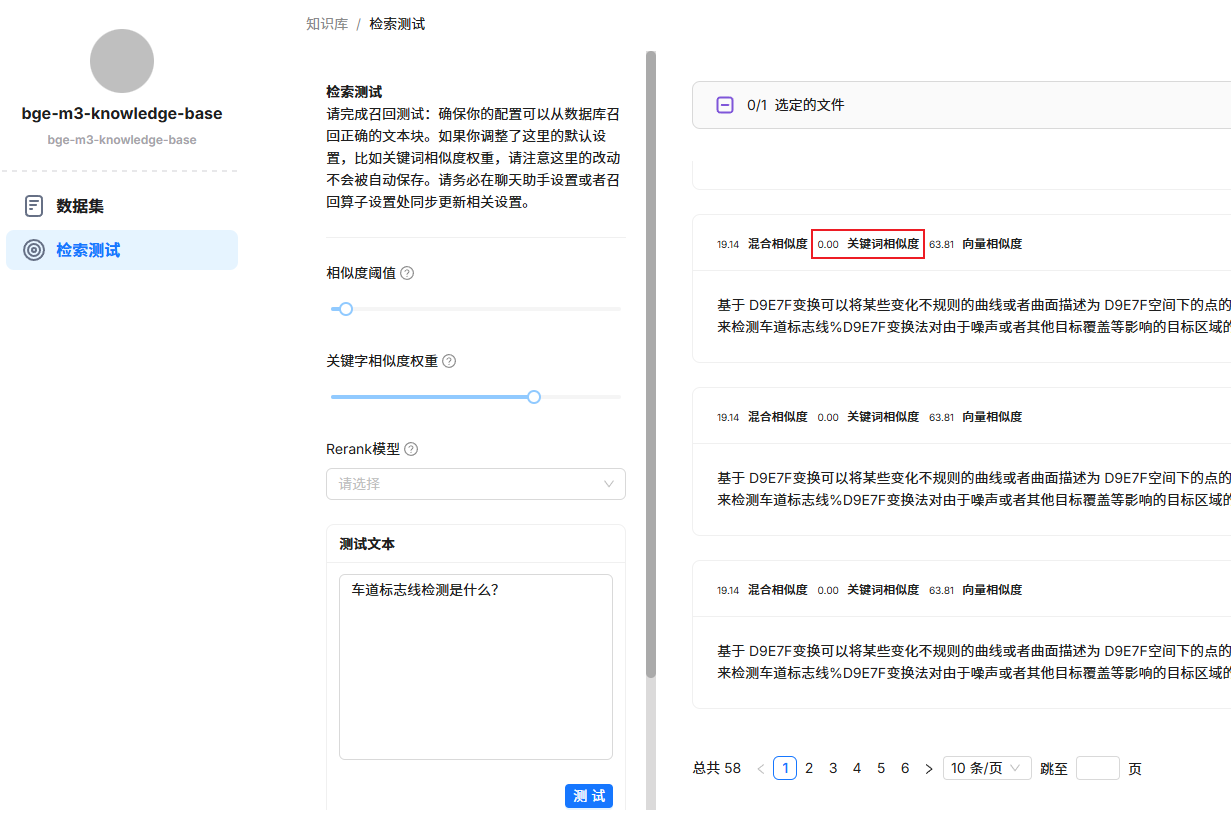
如上图所示,进行检索测试时,关键词相似度得分为0,导致混合相似度(加权相加得到)也被大幅拉低,低于设定的相似度阈值,出现无法召回的情况。
因此,问题的核心在于关键词相似度计算异常。本文通过抽丝剥茧的方式,来剖析该问题。
检索流程分析
首先,需要先了解,在前端点击测试按钮后,后端发生了什么?
查看最新版本的Ragflow(v0.19.0),相较之前的版本,检索逻辑基本没有变化。
目前看来,这部分基本处于固定成熟状态。
1. 请求接收
前端点击按钮,会通过retrieval_test接口发送Post请求。
前端请求传递以下参数:
- similarity_threshold:相似度阈值,低于此阈值将不会被检索出来。
- vector_similarity_weight:关键字相似度权重,数值越大则越突出关键字搜索结果
- question:输入的测试文本
- doc_ids:选中的文档id号,就是在一次检索之后,可通过选中特定文档信息再进行检索
- kb_id:当前知识库的id号
- page:分页显示当前页
- size:分页显示单页条目数
请求参数实例如下:
{"similarity_threshold": 0.2,"vector_similarity_weight": 0.30,"question": "测试问题","doc_ids": [],"kb_id": "1848bc54384611f0b33e4e66786d0323","page": 1,"size": 10
}
后端通过api\apps\chunk_app.py的retrieval_test函数来接收响应。
2. 检索准备
后端接收到请求后,会先验证知识库的权限,当前用户处于知识库创建人的团队,才能执行检索操作。
具体检索方式通过rag\nlp\search.py的retrieval函数进行检索。
具体检索逻辑在rag\nlp\search.py的search函数中实现。
3. 检索问题预处理
在使用es检索之前,需要先对问题进行预处理,包含以下步骤:
- 1.中文和英文混合输入时,之间添加空格(add_space_between_eng_zh)
- 2.使用正则表达式替换特殊字符为单个空格,并将文本转换为简体中文和小写(question)
- 3.移除疑问词,比如“什么”、“怎么样”、“如何”(rmWWW)
移除疑问词会让匹配更加精准,比如问题是“目标检测是什么”,它会把“是什么”这样泛问的词汇移除,留下“目标检测”这样的名词进行后续匹配。
之后,会进行关键词提取。
关键词是先通过分词器,对问题的进行切分,具体的分词器逻辑先略过,后文会提到。
提取完关键词后,还会进行同义词查找的操作。
具体的是通过同义词字典来查询,字典默认路径为rag\res\synonym.json
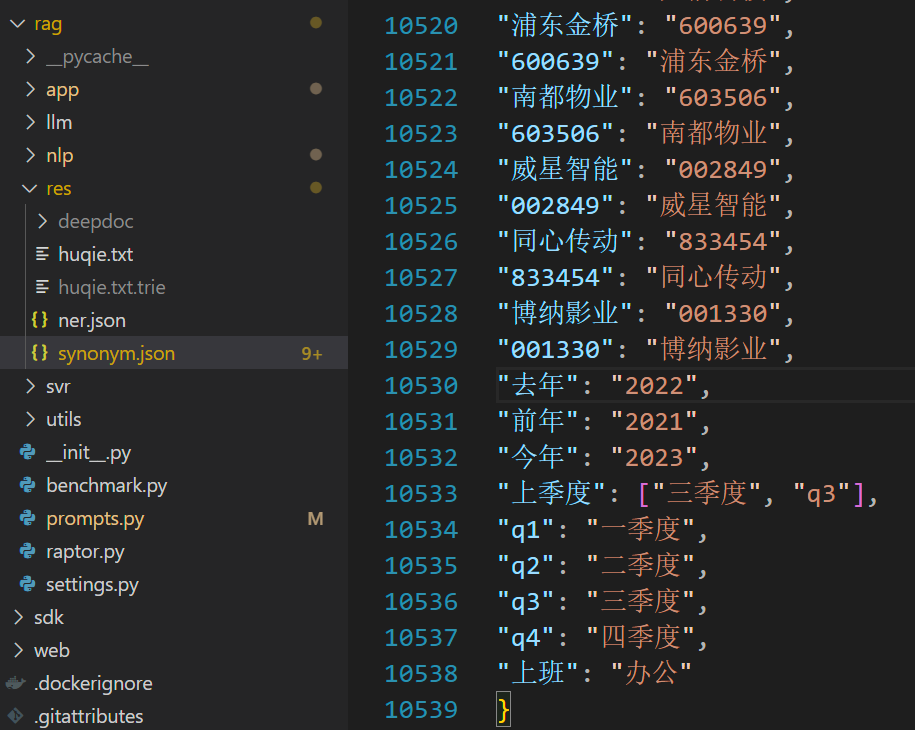
从该文件中,可以看到,里面内置了所有A股的名称和股票编号(原开发团队看来真的喜欢炒股)。
另外,今年同义词为2023,显然,前年写的文件还没更新,在某些情况下,会造成错误查询的问题。对于这个小bug,我也提交了一个pr给上游仓库。
得到同义词后,会同样对同义词进行分词操作,最后,集合所有关键词及同义词,数量上限32个。
4. 混合检索
在处理完关键词之后,原问题会通过嵌入模型变成向量形式。
最终,通过关键词和向量进行混合检索,这里设置的关键词检索权重和向量检索权重为5%/95%。
注意,该权重不是外部传递的相似度权重,而是内置的检索权重,无法通过外部方式进行修改。
# 生成查询向量
matchDense = self.get_vector(qst, emb_mdl, topk, req.get("similarity", 0.1))
q_vec = matchDense.embedding_data
# 在返回字段中加入查询向量字段
src.append(f"q_{len(q_vec)}_vec")
# 创建融合表达式:设置向量匹配为95%,关键词为5%
fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05, 0.95"})
# 构建混合查询表达式
matchExprs = [matchText, matchDense, fusionExpr]# 执行混合检索
res = self.dataStore.search(src, highlightFields, filters, matchExprs, orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)
5. 重排序
重排序是对检索块进行评分排序,即混合相似度高的块会被优先排到前面。
在重排序过程中,会进行三种相似度的计算。
无论是否设置重排序模型,都会经过重排序的步骤:
- 如果设置了重排序模型,相似度值会通过重排序模型得到。
- 如果未设置重排序模型,会通过余弦相似度进行计算。
# 执行重排序操作
if rerank_mdl and sres.total > 0:sim, tsim, vsim = self.rerank_by_model(rerank_mdl, sres, question, 1 - vector_similarity_weight, vector_similarity_weight, rank_feature=rank_feature)
else:sim, tsim, vsim = self.rerank(sres, question, 1 - vector_similarity_weight, vector_similarity_weight, rank_feature=rank_feature)
最终,混合相似度(sim)会由关键词相似度(tsim)和向量相似度(vsim)加权得到,这里的权重才会真正受到前端传递权重值的影响。
分词原理概述
理解完检索过程后,回到开篇提到的问题,就可以进一步定位:关键词相似度不足,实际原因就是解析块和问题的分词逻辑不一致。
在现版本中,解析时,文本的分词直接通过text.split()处理,即会将空格,制表符\t、换行符\n等字符,作为分隔依据,这样操作太过简单。
ragflow的分词器在rag\nlp\rag_tokenizer.py这个文件中,详细过程可参考以下注释:
1. 预处理:- 将所有非单词字符(字母、数字、下划线以外的)替换为空格。- 全角字符转半角。- 转换为小写。- 繁体中文转简体中文。
2. 按语言切分:- 将预处理后的文本按语言(中文/非中文)分割成多个片段。
3. 分段处理:- 对于非中文(通常是英文)片段:- 使用 NLTK 的 `word_tokenize` 进行分词。- 对分词结果进行词干提取 (PorterStemmer) 和词形还原 (WordNetLemmatizer)。- 对于中文片段:- 如果片段过短(长度<2)或为纯粹的英文/数字模式(如 "abc-def", "123.45"),则直接保留该片段。- 否则,采用基于词典的混合分词策略:a. 执行正向最大匹配 (FMM) 和逆向最大匹配 (BMM) 得到两组分词结果 (`tks` 和 `tks1`)。b. 比较 FMM 和 BMM 的结果:i. 找到两者从开头开始最长的相同分词序列,这部分通常是无歧义的,直接加入结果。ii. 对于 FMM 和 BMM 结果不一致的歧义部分(即从第一个不同点开始的子串):- 提取出这段有歧义的原始文本。- 调用 `self.dfs_` (深度优先搜索) 在这段文本上探索所有可能的分词组合。- `self.dfs_` 会利用Trie词典,并由 `self.sortTks_` 对所有组合进行评分和排序。- 选择得分最高的分词方案作为该歧义段落的结果。iii.继续处理 FMM 和 BMM 结果中歧义段落之后的部分,重复步骤 i 和 ii,直到两个序列都处理完毕。c. 如果在比较完所有对应部分后,FMM 或 BMM 仍有剩余(理论上如果实现正确且输入相同,剩余部分也应相同),则对这部分剩余的原始文本同样使用 `self.dfs_` 进行最优分词。
4. 后处理:- 将所有处理过的片段(英文词元、中文词元)用空格连接起来。- 调用 `self.merge_` 对连接后的结果进行进一步的合并操作,尝试合并一些可能被错误分割但实际是一个完整词的片段(基于词典检查)。
5. 返回最终分词结果字符串(词元间用空格分隔)。
不难看出,实际的分词逻辑相当复杂,并且,ragflow还专门配置了一个词典,用来记录常见词汇,词频,词性等信息。
为加速查询速度,还构建了一个Trie树的形式(huqie.txt.trie)。
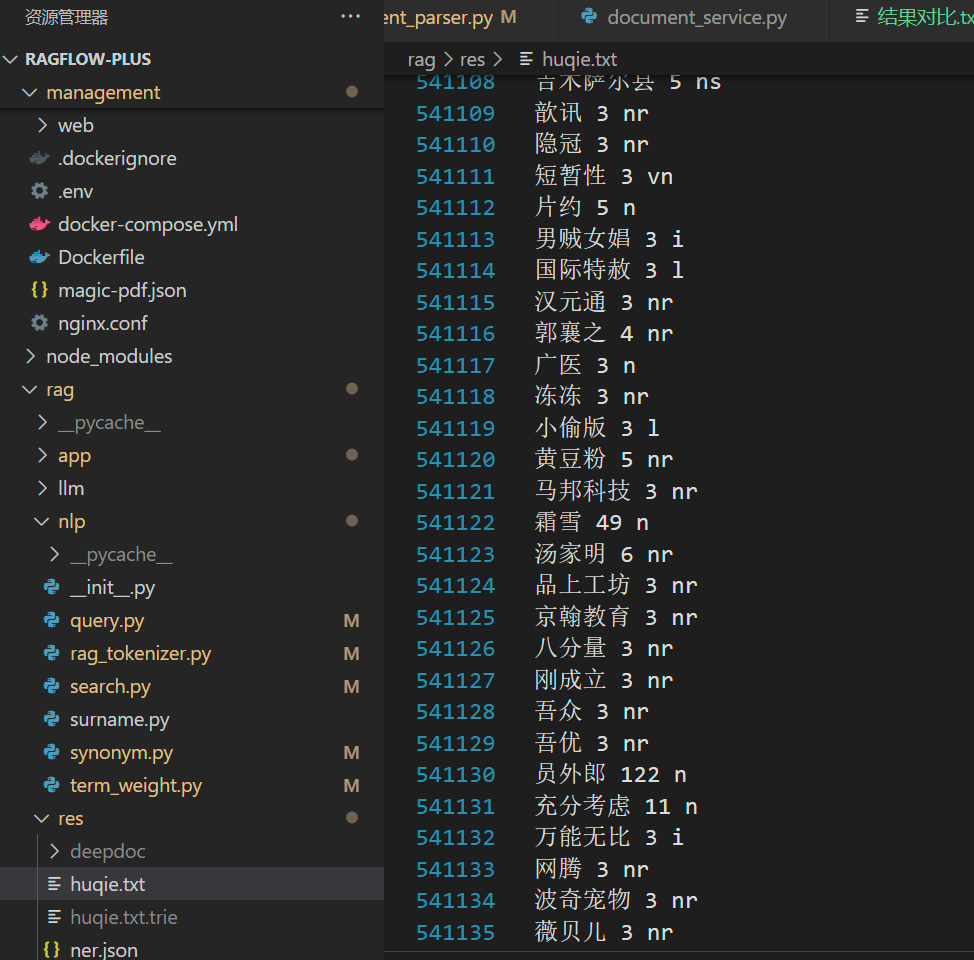
内容格式如下:
第一列:词语 (Token/Word)
第二列:词频 (Frequency/Weight)
第三列:词性标注 (Part-of-Speech Tag)
常见的词性代码有:
- n: 普通名词 (noun)
- nr: 人名 (noun, person name)
- ns:地名 (noun, place name)
- nt: 机构团体名 (noun, organization name)
- nz: 其他专有名词 (noun, other proper noun)
- v: 动词 (verb)
- a: 形容词 (adjective)
- d: 副词 (adverb)
- m: 数词 (numeral)
- q: 量词 (quantity)
- r: 代词 (pronoun)
- p: 介词 (preposition)
- c: 连词 (conjunction)
- u: 助词 (auxiliary)
- i: 成语 (idiom)
- l: 习用语 (lemma, fixed expression)
- t: 时间词 (time word)
- j: 简称略语 (abbreviation)
因此,参照原版的方式,直接将该分词器在解析过程中进行应用,即可修复此问题。
在最新的仓库提交中,在management\server\services\knowledgebases下面新增了rag_tokenizer.py文件,用来实现和原版一致的分词逻辑。
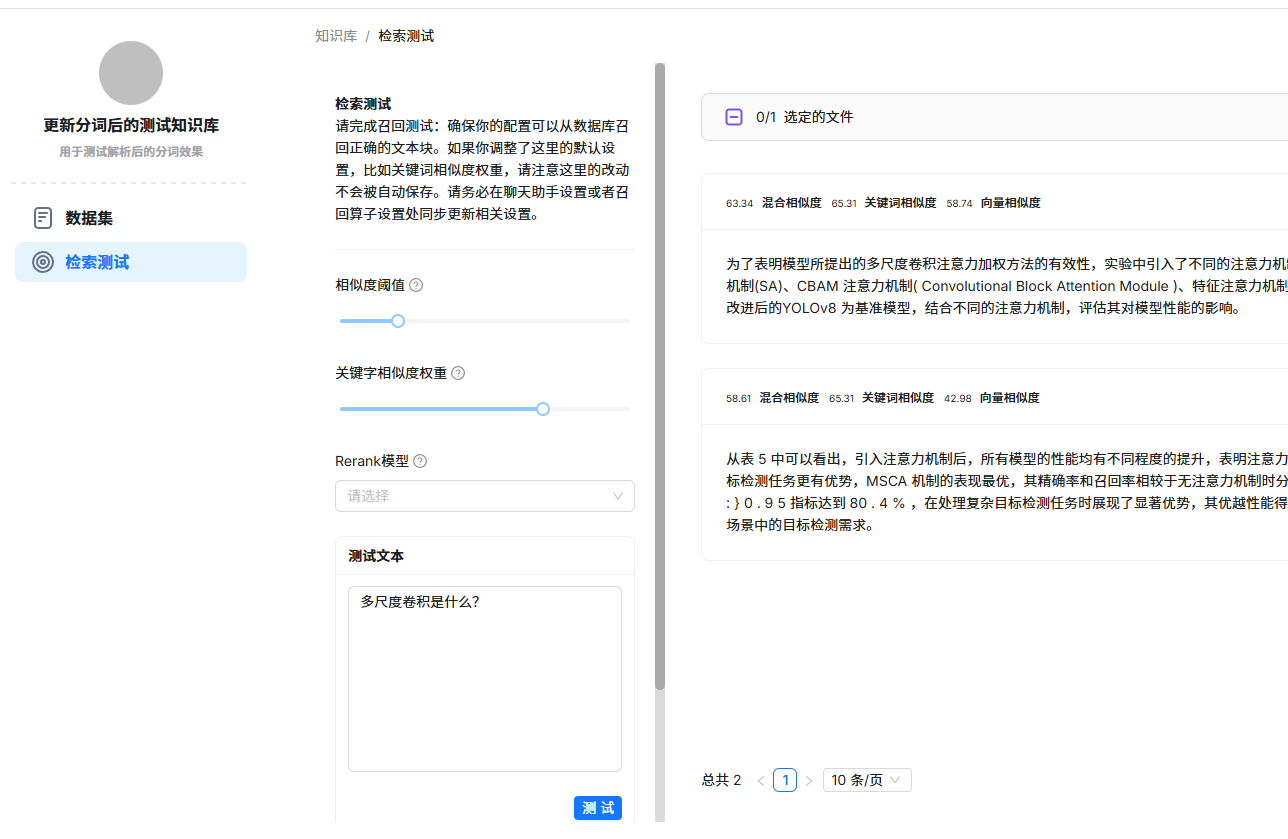
修复好后,重新解析文件,再进行检索测试,可以看到能够正常检索计算。
知识库创建人权限问题
另外,v3.0.0版本还有一个问题,即在后台创建新的知识库时,创建人选择其它用户,解析完文件无法在前台正常检索。
梳理完检索过程,可以顺带解决这一问题。
问题的原因是,ragflow进行检索时,默认是在es中寻找当前用户的序列(index_name函数)。
因此,解决该问题就需要在解析时,插入es的tenant_id从文档创建人的id改为知识库拥有者的id。
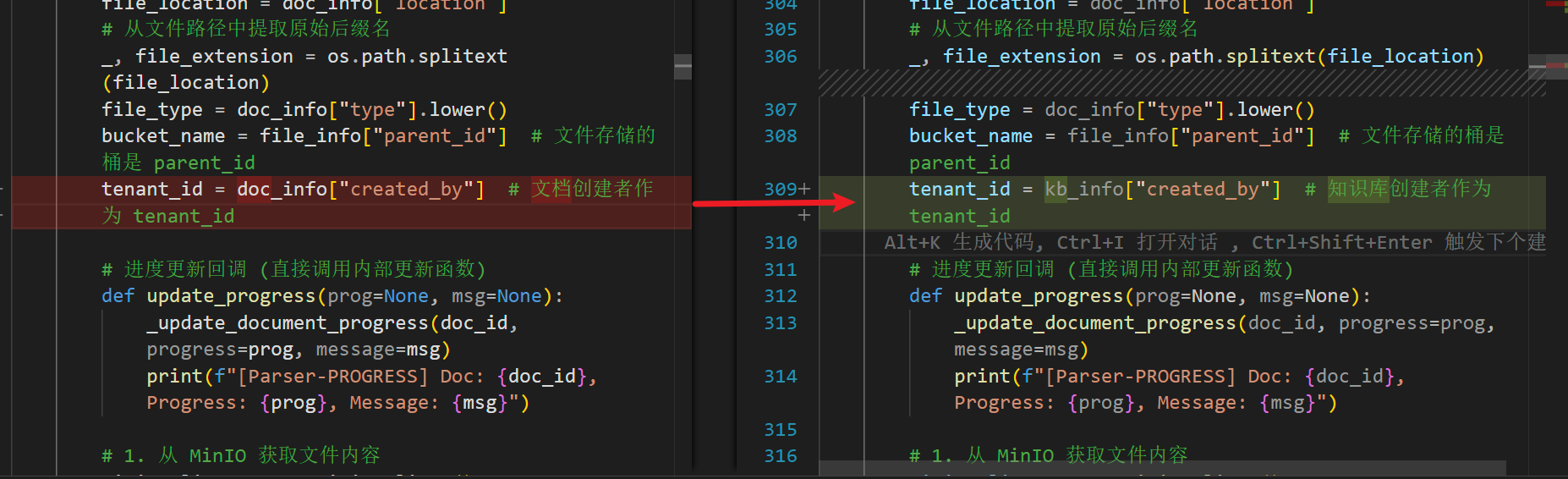
跨语言方案细节
看到此处,顺带一提ragflow v0.19.0版本中,新增了一个跨语言检索的功能。
细看代码,原来它是在rag\prompts.py中,新增了cross_languages的对应提示词。
本质上还是用语言模型来执行翻译操作。
这种方式显然有明显缺陷:
- 1.搜索需要等待模型响应完全,流程时间会显著增长
- 2.通过语言模型进行翻译,低参数模型可能存在幻觉问题。
ragflow 总是不计成本地用时间换性能,这是实地应用场景难以接受的。
后续,考虑用更轻量快速的方式,实现翻译功能。
友情提示
RagflowPlus目前仍处于早期状态,解析功能仍在高频更新中。
因此,不建议直接将其应用于生产环境,只有发展到ragflow的阶段,解析逻辑稳定,才适合去批量解析大量文件。否则,后续解析逻辑更新,仍需要重新对已有内容进行解析。
另外,有不少人问到“是否考虑加入知识图谱”的问题。
之前在仓库issue#119中进行过回复。
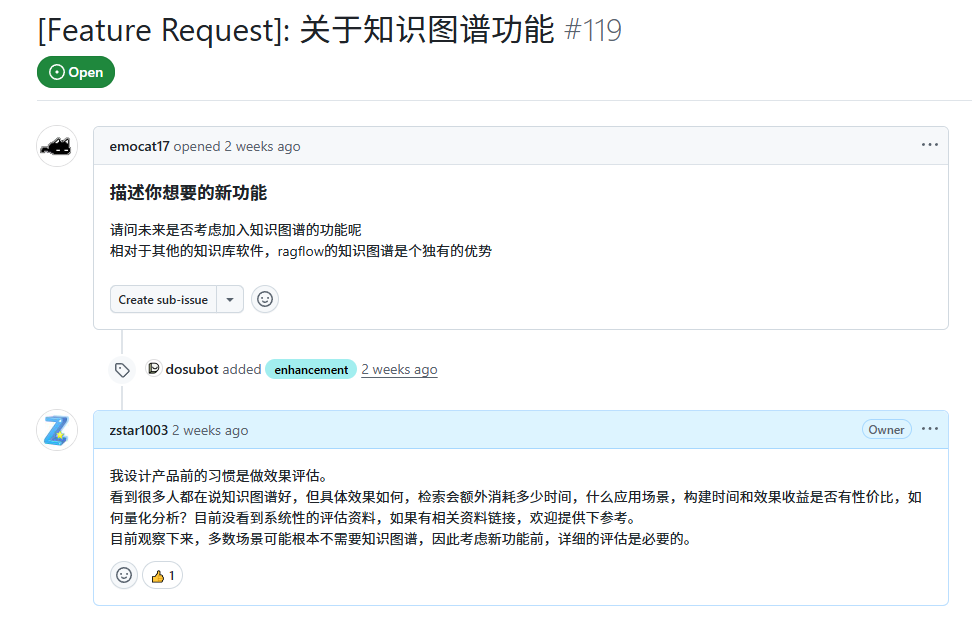
诚然,知识图谱可能在多跳问题中具备一定优势,但具体效果如何,怎样构建,都需要时间详细评估。
在这个普遍浮躁的互联网洪流中,保持慢工出细活的工作节奏,何尝不是新时代的工匠精神呢?
相关文章:
【Ragflow】24.Ragflow-plus开发日志:增加分词逻辑,修复关键词检索失效问题
概述 在RagflowPlus v0.3.0 版本推出之后,反馈比较多的问题是:检索时,召回块显著变少了。 如上图所示,进行检索测试时,关键词相似度得分为0,导致混合相似度(加权相加得到)也被大幅拉低,低于设定…...

gin 常见中间件配置
这里主要配置 请求日志中间件、跨域中间件、trace_id 中间件、安全头中间件 一般来说,这个中间件的信息 就是放在 middlewares/* 里面的*.go 进行操作 ➜ middlewares git:(main) tree . ├── cors.go ├── logging.go ├── request_id.go └── securit…...

蚂蚁森林自动收能量助手:Ant_Forest_1_5_4_3绿色行动新选择
先放软件下载链接:夸克网盘下载 便捷助力绿色生活:蚂蚁森林收能量脚本_Ant_Forest_1_5_4_3 在倡导绿色环保的当下,蚂蚁森林成为众多用户践行低碳生活的热门平台。而蚂蚁森林收能量脚本_Ant_Forest_1_5_4_3 这款软件,为用户在蚂蚁森林的体验…...

Zookeeper 集群部署与故障转移
Zookeeper 介绍 Zookeeper 是一个开源的分布式协调服务,由Apache基金会维护,专为分布式应用提供高可用、强一致性的核心基础能力。它通过简单的树形命名空间(称为ZNode树)存储数据节点(ZNode),…...

Redis最佳实践——电商应用的性能监控与告警体系设计详解
Redis 在电商应用的性能监控与告警体系设计 一、原子级监控指标深度拆解 1. 内存维度监控 核心指标: # 实时内存组成分析(单位字节) used_memory: 物理内存总量 used_memory_dataset: 数据集占用量 used_memory_overhead: 管理开销内存 us…...
区域徘徊检测算法AI智能分析网关V4助力公共场所/工厂等多场景安全升级
一、项目背景 随着数字化安全管理需求激增,重点场所急需强化人员异常行为监测。区域徘徊作为潜在安全威胁的早期征兆,例如校园围墙外的陌生逗留者,都可能引发安全隐患。传统人工监控模式效率低、易疏漏,AI智能分析网关V4的区域徘…...
修复与升级suse linux
suse linux enterprise desktop 10提示:xxx service failed when loaded shared lib . error ibgobject.so.2.0:no such file or directory. suse linux enterprise server 12.iso 通过第一启动项引导,按照如下方式直接升级解决。...
电力高空作业安全检测(2)数据集构建
数据集构建的重要性 在电力高空作业安全检测领域,利用 计算机视觉技术 进行安全监测需要大量的图像数据,这些数据需要准确标注不同的安全设备与作业人员行为。只有构建出包含真实场景的高质量数据集,才能通过深度学习等算法对高空作业中的潜…...
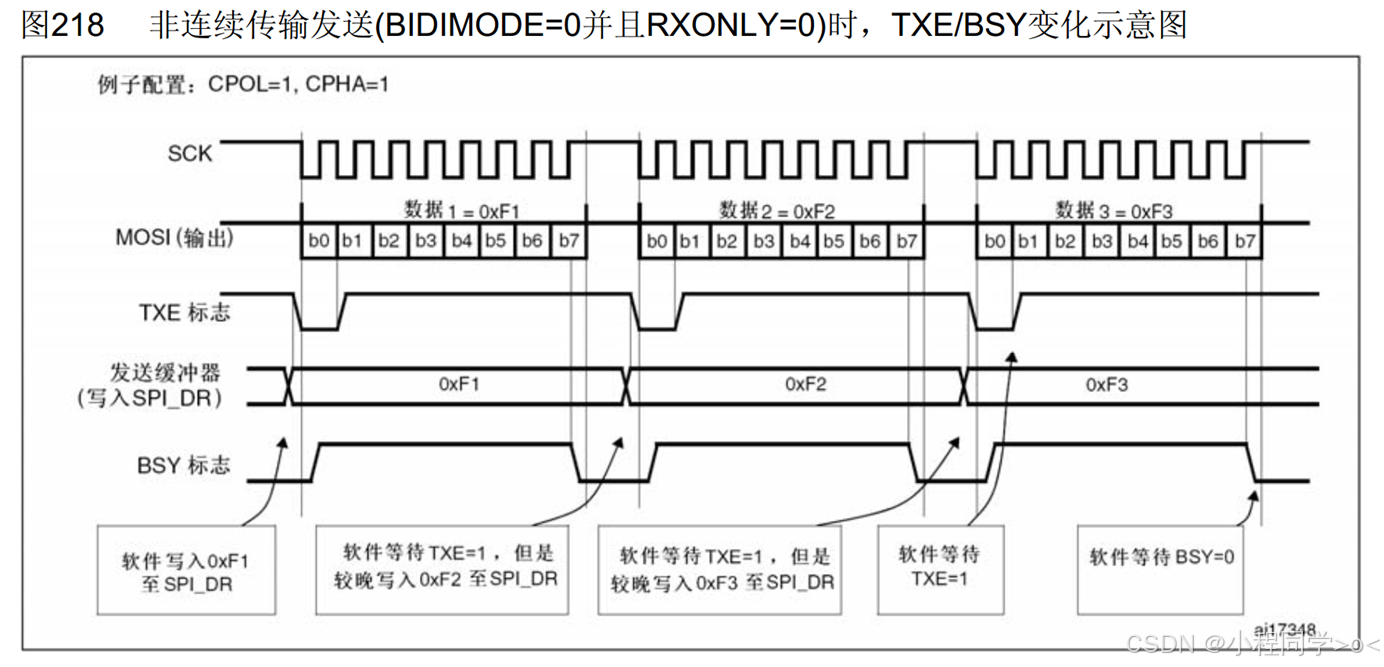
嵌入式开发之STM32学习笔记day18
STM32F103C8T6 SPI通信读写W25Q64 1 W25Q64简介 W25Qxx系列是一种低成本、小型化且易于使用的非易失性存储器(NOR Flash),它广泛应用于需要持久化存储数据的各种场景,如数据存储、字库存储以及固件程序存储等。该系列存储器采用…...

[论文阅读]PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning
PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning PPT: Backdoor Attacks on Pre-trained Models via Poisoned Prompt Tuning | IJCAI IJCAI-22 发表于2022年的论文,当时大家还都在做小模型NLP的相关工作(BERT,Ro…...
)
一键 Ubuntu、Debian、Centos 换源(阿里源、腾讯源等)
网上各种办法都不行,使用这个工具可以了。 我用的是腾讯云源 配置系统源 bash <(curl -sSL https://linuxmirrors.cn/main.sh)配置 docker 源 bash <(curl -sSL https://linuxmirrors.cn/docker.sh)...
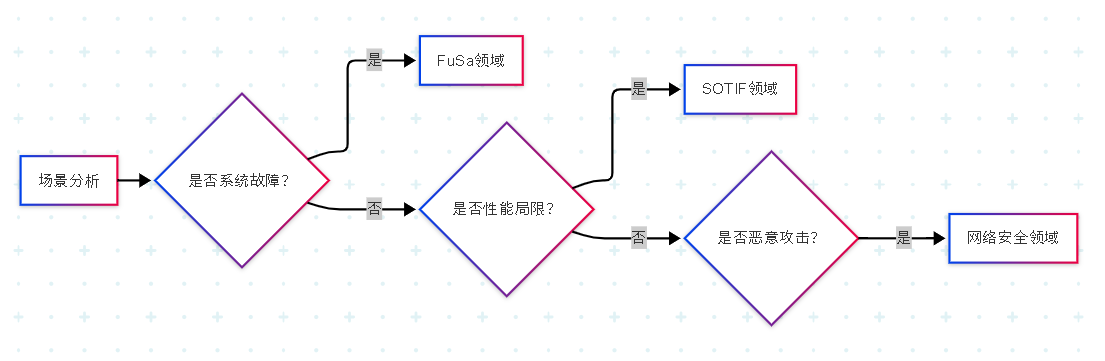
汽车安全:功能安全FuSa、预期功能安全SOTIF与网络安全Cybersecurity 解析
汽车安全的三重防线:深入解析FuSa、SOTIF与网络安全技术 现代汽车已成为装有数千个传感器的移动计算机,安全挑战比传统车辆复杂百倍。 随着汽车智能化、网联化飞速发展,汽车电子电气架构已从简单的分布式控制系统演变为复杂的移动计算平台。现…...
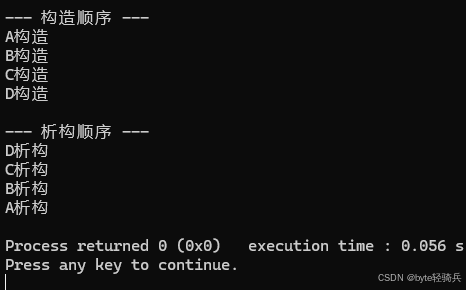
【C++高级主题】虚继承
目录 一、菱形继承:虚继承的 “导火索” 1.1 菱形继承的结构与问题 1.2 菱形继承的核心矛盾:多份基类实例 1.3 菱形继承的具体问题:二义性与数据冗余 二、虚继承的语法与核心目标 2.1 虚继承的声明方式 2.2 虚继承的核心目标 三、虚继…...
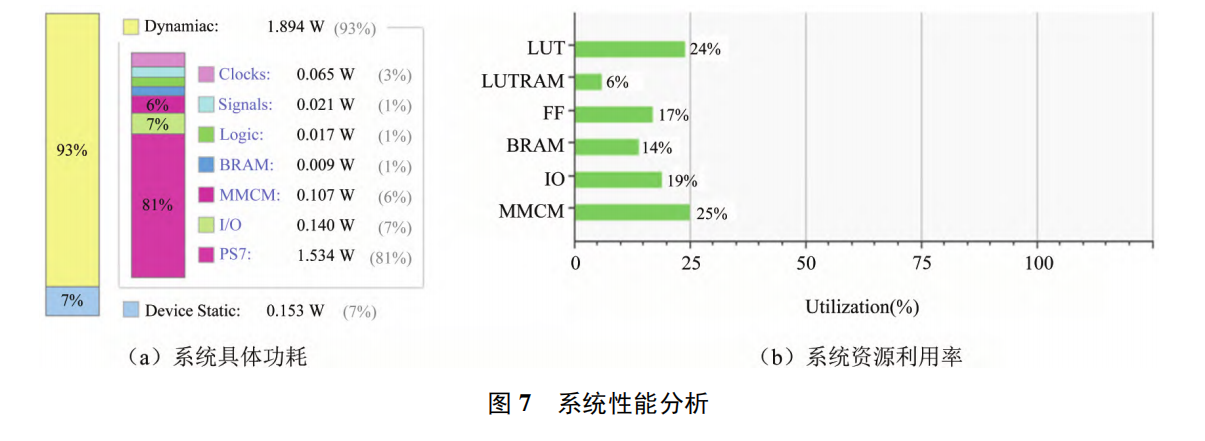
基于 ZYNQ 的实时运动目标检测系统设计
摘 要: 传统视频监控系统在实时运动目标检测时,存在目标检测不完整和目标检测错误的局限 性 。 本研究基于体积小 、 实时性高的需求,提出了一种将动态三帧差分法与 Sobel 边缘检测算法结 合的实时目标检测方法,并基于 ZYNQ 构建了视频…...
练习题)
数据结构(JAVA版)练习题
(题目难易程度与题号顺序无关哦) 目录 1、多关键字排序 2、集合类的综合应用问题 3、数组排序 4、球的相关计算问题 5、利用类对象计算日期 6、日期计算问题 7、星期日期的计算 8、计算坐标平面上两点距离 9、异常处理设计问题 10、Java源文件…...

C#编程过程中变量用中文有啥影响?
一、C#语言对中文变量名的支持规则 技术可行性 C#编译器基于Unicode标准(UTF-16编码),支持包括中文在内的非ASCII字符作为变量名。变量名规则允许字母、数字、下划线及Unicode字符(如汉字),但不能以数字开头…...
)
哈希表入门:用 C 语言实现简单哈希表(开放寻址法解决冲突)
目录 一、引言 二、代码结构与核心概念解析 1. 数据结构定义 2. 初始化函数 initList 3. 哈希函数 hash 4. 插入函数 put(核心逻辑) 开放寻址法详解: 三、主函数验证与运行结果 1. 测试逻辑 2. 运行结果分析 四、完整代码 五、优…...
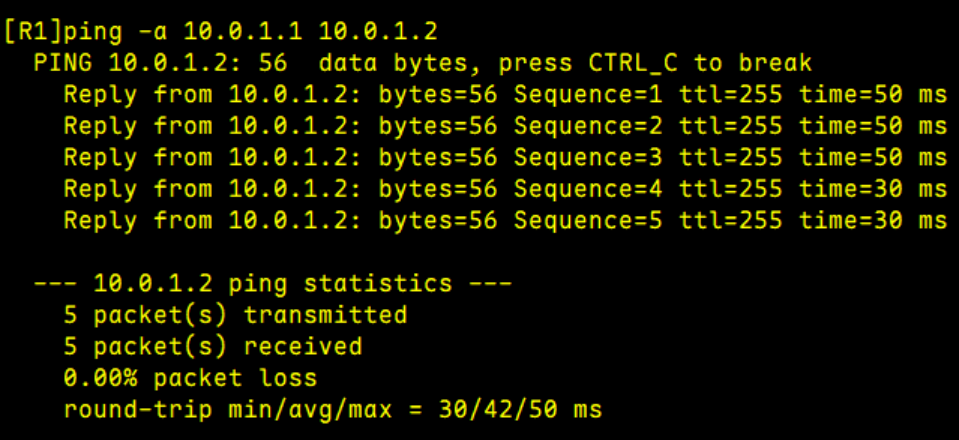
[华为eNSP] 在eNSP上实现IPv4地址以及IPv4静态路由的配置
设备名称配置 重命名设备以及关闭信息提示 此处以R1演示,R2R3以此类推 <Huawei>system-view [Huawei]sysname R1#关闭提示 undo info-center enable 配置路由接口IP地址 R1 [R1]interface GigabitEthernet 0/0/1[R1-GigabitEthernet0/0/1]ip address 10.0.…...
2024年第十五届蓝桥杯青少组c++国赛真题——快速分解质因数
2024年第十五届蓝桥杯青少组c国赛真题——快速分解质因数 题目可点下方去处,支持在线编程,在线测评~ 快速分解质因数_C_少儿编程题库学习中心-嗨信奥 题库收集了历届各白名单赛事真题和权威机构考级真题,覆盖初赛—省赛—国赛&am…...
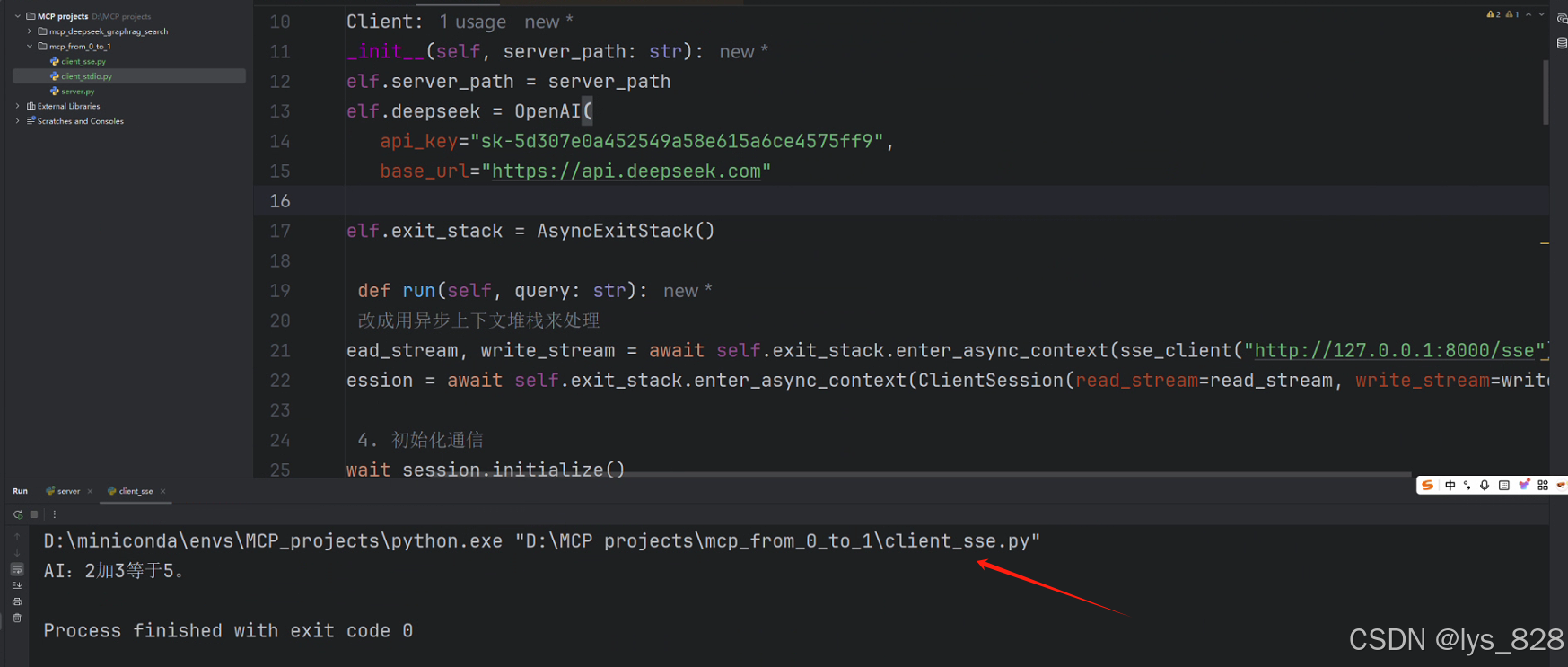
【动手学MCP从0到1】2.1 SDK介绍和第一个MCP创建的步骤详解
SDK介绍和第一个MCP 1. 安装SDK2. MCP通信协议3. 基于stdio通信3.1 服务段脚本代码3.2 客户端执行代码3.2.1 客户端的初始化设置3.2.2 创建执行进行的函数3.2.3 代码优化 4. 基于SSE协议通信 1. 安装SDK 开发mcp项目,既可以使用Anthropic官方提供的SDK,…...

基于MyBatis插件实现动态表名解决多环境单一数据库问题
业务场景 在为某新能源汽车厂商进行我司系统私有化部署时,在预演环境和生产环境中,客户仅提供了一个 MySQL 数据库实例。为了确保数据隔离并避免不同环境之间的数据冲突,常规做法是为每个环境创建独立的表(如通过添加环境前缀或后…...
测试面试题总结一
目录 列表、元组、字典的区别 nvicat连接出现问题如何排查 mysql性能调优 python连接mysql数据库方法 参数化 pytest.mark.parametrize 装饰器 list1 [1,7,4,5,5,6] for i in range(len(list1): assert list1[i] < list1[i1] 这段程序有问题嘛? pytest.i…...

Spring Boot应用多环境打包与Shell自动化部署实践
一、多环境配置管理(Profile方案) 推荐方案:通过Maven Profiles实现环境隔离 在pom.xml中定义不同环境配置,避免硬编码在application.yml中: <profiles><!-- 默认环境 --><profile><id>node…...
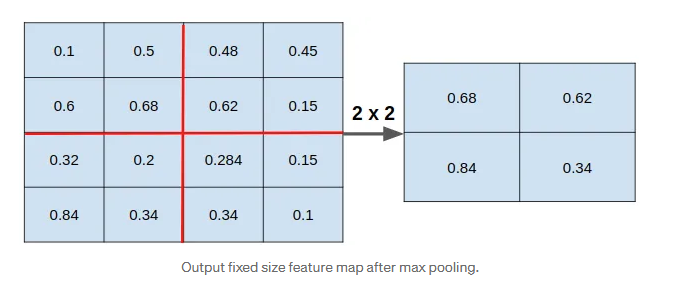
【深度学习】14. DL在CV中的应用章:目标检测: R-CNN, Fast R-CNN, Faster R-CNN, MASK R-CNN
深度学习在计算机视觉中的应用介绍 深度卷积神经网络(Deep convolutional neural network, DCNN)是将深度学习引入计算机视觉发展的关键概念。通过模仿生物神经系统,深度神经网络可以提供前所未有的能力来解释复杂的数据模式&…...

grpc的二进制序列化与http的文本协议对比
grpc的二进制序列化与http的文本协议对比 1. 二进制格式 vs 文本格式2. 编码机制:Varint 与固定长度3. 没有字段名与标点4. 较少的元信息开销4.1 HTTP/1.1 请求的元信息组成与开销4.1.1 各部分字节数示例 4.2 HTTP/2 帧结构与 HPACK 头部压缩4.2.1 HEADERS 开销对比…...

Linux 环境下 PPP 拨号的嵌入式开发实现
一、PPP 协议基础与嵌入式应用场景 PPP (Point-to-Point Protocol) 是一种在串行线路上传输多协议数据包的通信协议,广泛应用于拨号上网、VPN 和嵌入式系统的远程通信场景。在嵌入式开发中,PPP 常用于 GPRS/3G/4G 模块、工业路由器和物联网设备的网络连接…...
UE 材质基础第三天
飘动的旗帜 错乱的贴图排序,创建一个材质函数 可以用在地面材质 体积云材质制作 通过网盘分享的文件:虚幻引擎材质宝典.rar 链接: https://pan.baidu.com/s/1AYRz2V5zQFaitNPA5_JbJw 提取码: cz1q --来自百度网盘超级会员v6的分享...

【Github/Gitee Webhook触发自动部署-Jenkins】
Github/Gitee Webhook触发自动部署-Jenkins #mermaid-svg-hRyAcESlyk5R2rDn {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-hRyAcESlyk5R2rDn .error-icon{fill:#552222;}#mermaid-svg-hRyAcESlyk5R2rDn .error-tex…...

软件工程专业本科毕业论文模板
以下是软件工程专业本科毕业论文的通用模板框架,结合学术规范与工程实践要求,涵盖从需求分析到测试验证的全流程结构,并附格式说明与写作建议: 一、前置部分 1. 封面 - 包含论文标题(简明反映研究核心,如“…...
新松机械臂 2001端口服务的客户端例程
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...