PPO和GRPO算法
verl 是现在非常火的 rl 框架,而且已经支持了多个 rl 算法(ppo、grpo 等等)。
过去对 rl 的理解很粗浅(只知道有好多个角色,有的更新权重,有的不更新),也曾硬着头皮看了一些论文和知乎,依然有很多细节不理解,现在准备跟着 verl 的代码梳理一遍两个著名的 rl 算法,毕竟代码不会隐藏任何细节!
虽然 GRPO 算法是基于 PPO 算法改进来的,但是毕竟更简单,所以我先从 GRPO 的流程开始学习,然后再看 PPO。
GRPO 论文中的展示的总体流程:
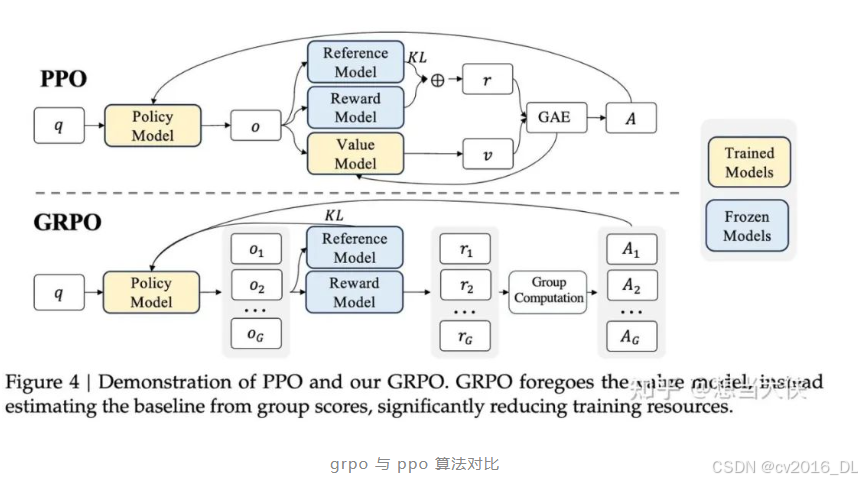
论文中这张图主要展示了 GRPO 和 PPO 的区别,隐藏了其他的细节。
图中只能注意到以下几个关键点:
-
没有 Value Model 和输出 v(value)
-
同一个 q 得出了一组的 o(从 1 到 G)
-
计算 A(Advantage) 的算法从 GAE 变成了 Group Computation
-
KL 散度计算不作用于 Reward Model,而是直接作用于 Policy Model
其他细节看不懂,结合论文也依然比较抽象,因为我完全没有 RL 的知识基础,下文中我们结合代码会再一次尝试理解。
下面是我根据 verl 代码自己 DIY 的流程图(帮助理解):
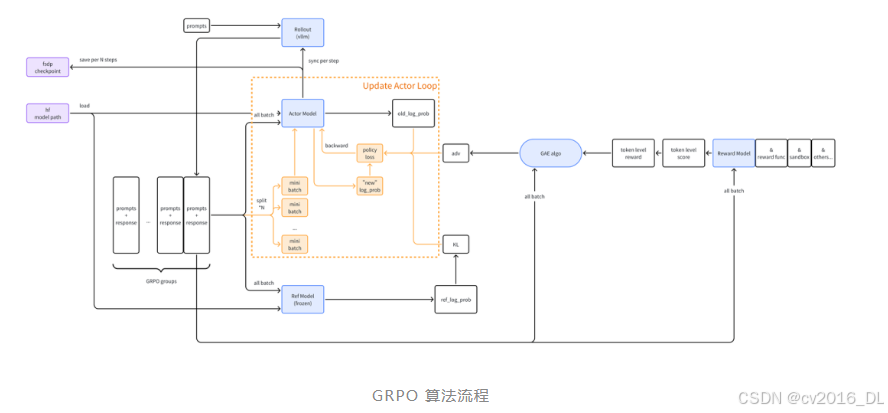
01 第一步:Rollout
第一步是 rollout,rollout 是一个强化学习专用词汇,指的是从一个特定的状态按照某个策略进行一些列动作和状态转移。
在 LLM 语境下,“某个策略”就是 actor model 的初始状态,“进行一些列动作”指的就是推理,即输入 prompt 输出 response 的过程。
verl/trainer/ppo/ray_trainer.py:
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)其背后的实现一般就是是 vllm 或 sglang 这些常见推理框架的离线推理功能,这部分功能相对独立我们先不展开。
权重同步
一个值得注意的细节是代码里面的 rollout_sharding_manager 实现,它负责每一个大 step 结束后把刚刚训练好的 actor model 参数更新到 vllm 或 sglang。
这样下一个大 step 的 rollout 采用的就是最新的模型权重(最新的策略)了。
这是每一个大 step 里面真正要做的第一件事,在真正执行 rollout 之前。
verl/workers/fsdp_workers.py:
class ActorRolloutRefWorker(Worker): # ... @register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO) def generate_sequences(self, prompts: DataProto): # ... with self.rollout_sharding_manager: # ... prompts = self.rollout_sharding_manager.preprocess_data(prompts) output = self.rollout.generate_sequences(prompts=prompts) output = self.rollout_sharding_manager.postprocess_data(output)rollout_sharding_manager 的基类是 BaseShardingManager。
verl/workers/sharding_manager/base.py:
class BaseShardingManager: def __enter__(self): pass def __exit__(self, exc_type, exc_value, traceback): pass def preprocess_data(self, data: DataProto) -> DataProto: return data def postprocess_data(self, data: DataProto) -> DataProto: return data BaseShardingManager 的派生类在各自的 __enter__ 方法中实现了把 Actor Model 的权重 Sync 到 Rollout 实例的逻辑,以保证被 with self.rollout_sharding_manager 包裹的预处理和推理逻辑都是用的最新 Actor Model 权重。
推理 N 次
此外,GRPO 算法要求对每一个 prompt 都生成多个 response,后续才能根据组间对比得出相对于平均的优势(Advantage)。
verl/trainer/config/ppo_trainer.yaml:
actor_rollout_ref: rollout: # number of responses (i.e. num sample times) n: 1 # > 1 for grpo 在 _build_rollout 的时候 actor_rollout_ref.rollout.n 被传给了 vLLMRollout 或其他的 Rollout 实现中,从而推理出 n 组 response。
verl/workers/fsdp_workers.py:
class ActorRolloutRefWorker(Worker): def _build_rollout(self, trust_remote_code=False): # ... elif rollout_name == "vllm": # ... if vllm_mode == "customized": rollout = vLLMRollout( actor_module=self.actor_module_fsdp, config=self.config.rollout, tokenizer=self.tokenizer,
model_hf_config=self.actor_model_config, )02 第二步:计算 log prob
log 是 logit,prob 是 probability,合起来就是对数概率,举一个简单的例子来说明什么是 log prob:
词表仅有 5 个词:
<pad> (ID 0)
你好 (ID 1)
世界 (ID 2)
! (ID 3)
吗 (ID 4)
prompt:你好
prompt tokens: [1]
response:世界!
response tokens: [2,3]
模型前向传播得到完整的 logits 张量:
[ [-1.0, 0.5, 2.0, -0.5, -1.5], // 表示 “你好” 后接 “世界” 概率最高,数值为 2.0 [-2.0, -1.0, 0.1, 3.0, 0.2] // 表示 “你好世界” 后接 “!” 概率最高,数值为 3.0]
对每个 logit 计算 softmax 得到:
[ [-3.65, -2.15, -0.64, -3.15, -4.08], [-4.34, -3.32, -2.20, -0.20, -2.10]]
提取实际 response 对应的数值:得到 log_probs:
[-0.64, -0.20]总结下来:
-
首先计算 prompt + response(来自 rollout)的完整 logits,即每一个 token 的概率分布
-
截取 response 部分的 logits
-
对每一个 logits 计算 log_sofmax(先 softmax,然后取对数),取出最终预测的 token 对应的 log_sofmax
-
最终输出 old_log_probs, size = [batchsize, seq_len]
此处你可能会有一个疑惑:在上一步 Rollout 的时候我们不是已经进行过完整 batch 的推理了么?
为什么现在还要重复进行一次 forward 来计算 log_prob,而不是在 generate 的过程中就把 log_prob 保存下来?
答:因为 generate_sequences 阶段为了高效推理,不会保存每一个 token 的 log_prob,相反只关注整个序列的 log_prob。因此需要重新算一遍。
答:另外,vllm 官方 Q&A 中提到了 vllm 框架并不保证 log_probs 的稳定性。因为 pytorch 的 numerical instability 与 vllm 的并发批处理策略导致每一个 token 的 logits/log_probs 结果会略有不同,假如某一个 token 位采样了不同 token id,那么这个误差在后续还会被继续累加。我们在训练过程需要保证 log_probs 的稳定性,因此需要根据已经确定的 token id(即 response)再次 forward 一遍。
old log prob
verl/workers/fsdp_workers.py:
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)指 Actor Model 对整个 batch 的数据(prompt + response)进行 forward 得到的 log_prob
此处的 “old” 是相对于后续的 actor update 阶段,因为现在 actor model 还没有更新,所以依然采用的是旧策略 (ps:当前 step 的“旧策略”也是上一个大 step 的“新策略”)
ref log prob
verl/trainer/ppo/ray_trainer.py:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)指 Ref Model 对整个 batch 的数据(prompt + response)进行 forward 得到的 log_prob。
通常 Ref Model 就是整个强化学习开始之前 Actor Model 最初的模样,换句话说第一个大 step 开始的时候 Actor Model == Ref Model,且 old_log_prob == ref_log_prob。
Ref Model 的作用是在后续计算 policy loss 之前,计算 KL 散度并作用于 policy loss,目的是让 actor model 不要和最初的 ref model 相差太远。
03第三步:advantage
advantage 是对一个策略的好坏最直接的评价,其背后就是 Reward Model,甚至也许不是一个 Model,而是一个粗暴的 function,甚至一个 sandbox 把 prompt+response 执行后得出的结果。
在 verl 中允许使用上述多种 Reward 方案中的一种或多种,并把得出的 score 做合。
verl/trainer/ppo/ray_trainer.py:
# compute reward model score
if self.use_rm: reward_tensor = self.rm_wg.compute_rm_score(batch) batch = batch.union(reward_tensor)
if self.config.reward_model.launch_reward_fn_async: future_reward = compute_reward_async.remote(batch, self.config, self.tokenizer)
else: reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)然后用这个 score 计算最终的 advantage。
verl/trainer/ppo/ray_trainer.py:
# compute advantages, executed on the driver process
norm_adv_by_std_in_grpo = self.config.algorithm.get( "norm_adv_by_std_in_grpo", True)
# GRPO adv normalization factorbatch = compute_advantage( batch,
adv_estimator=self.config.algorithm.adv_estimator, gamma=self.config.algorithm.gamma,
lam=self.config.algorithm.lam,
num_repeat=self.config.actor_rollout_ref.rollout.n, norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,)04第四步:actor update(小循环)
在 PPOTrainer 中简单地一行调用,背后可是整个 GRPO 算法中最关键的步骤:
actor_output = self.actor_rollout_wg.update_actor(batch) 在这里,会把上面提到的整个 batch 的数据再根据 actor_rollout_ref.actor.ppo_mini_batch_size 配置的值拆分成很多个 mini batch。
然后对每一个 mini batch 数据进行一轮 forward + backward + optimize step,也就是小 step。
new log prob
每一个小 step 中首先会对 mini batch 的数据计算(new)log_prob,第一个小 step 得到的值还是和 old_log_prob 一模一样的。
pg_loss
然后通过输入所有 Group 的 Advantage 以新旧策略的概率比例(old_log_prob 和 log_prob),得出 pg_loss(Policy Gradient),这是最终用于 backward 的 policy loss 的基础部分。
再次描述一下 pg_loss 的意义,即衡量当前策略(log_prob)相比于旧策略(old_log_prob),在当前优势函数(advantage)指导下的改进程度。
verl/workers/actor/dp_actor.py:
pg_loss, pg_clipfrac, ppo_kl, pg_clipfrac_lower = compute_policy_loss( old_log_prob=old_log_prob,
log_prob=log_prob,
advantages=advantages,
response_mask=response_mask,
cliprange=clip_ratio,
cliprange_low=clip_ratio_low,
cliprange_high=clip_ratio_high,
clip_ratio_c=clip_ratio_c,
loss_agg_mode=loss_agg_mode,)entropy loss
entropy 指策略分布的熵 (Entropy):策略对选择下一个动作(在这里是下一个 token)的不确定性程度。
熵越高,表示策略输出的概率分布越均匀,选择各个动作的概率越接近,策略的探索性越强;熵越低,表示策略越倾向于选择少数几个高概率的动作,确定性越强。
entropy_loss 指 entropy 的 平均值,是一个标量,表示探索性高低。
verl/workers/actor/dp_actor.py:
if entropy_coeff != 0: entropy_loss = agg_loss(loss_mat=entropy, loss_mask=response_mask, loss_agg_mode=loss_agg_mode) # compute policy loss policy_loss = pg_loss - entropy_loss * entropy_coeff
else: policy_loss = pg_loss计算 KL 散度
这里用到了前面 Ref Model 推出的 ref_log_prob,用这个来计算 KL 并作用于最后的 policy_loss,保证模型距离 Ref Model(初始的模型)偏差不会太大。
verl/workers/actor/dp_actor.py:
if self.config.use_kl_loss: ref_log_prob = data["ref_log_prob"] # compute kl loss kld = kl_penalty(logprob=log_prob, ref_logprob=ref_log_prob, kl_penalty=self.config.kl_loss_type ) kl_loss = agg_loss(loss_mat=kld, loss_mask=response_mask, loss_agg_mode=self.config.loss_agg_mode ) policy_loss = policy_loss + kl_loss * self.config.kl_loss_coef metrics["actor/kl_loss"] = kl_loss.detach().item() metrics["actor/kl_coef"] = self.config.kl_loss_coef反向计算
verl/workers/actor/dp_actor.py:
loss.backward()持续循环小 step,直到遍历完所有的 mini batch,Actor Model 就完成了本轮的训练,会在下一个大 step 前把权重 sync 到 Rollout实例当中,准备处理下一个大 batch 数据。
相关文章:
PPO和GRPO算法
verl 是现在非常火的 rl 框架,而且已经支持了多个 rl 算法(ppo、grpo 等等)。 过去对 rl 的理解很粗浅(只知道有好多个角色,有的更新权重,有的不更新),也曾硬着头皮看了一些论文和知…...

ceph 对象存储用户限额满导致无法上传文件
查看日志 kl logs -f rook-ceph-rgw-my-store-a-5cc4c4d5b5-26n6j|grep -i error|head -1Defaulted container "rgw" out of: rgw, log-collector, chown-container-data-dir (init) debug 2025-05-30T19:44:11.573+0000 7fa7b7a6d700...
rk3588 上运行smolvlm-realtime-webcam,将视频转为文字描述
smolvlm-realtime-webcam 是一个开源项目,结合了轻量级多模态模型 SmolVLM 和本地推理引擎 llama.cpp,能够在本地实时处理摄像头视频流,生成自然语言描述, 开源项目地址 https://github.com/ngxson/smolvlm-realtime-webcamhttps…...

某航参数逆向及设备指纹分析
文章目录 1. 写在前面2. 接口分析3. 加密分析4. 算法还原5. 设备指纹风控分析与绕过【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究…...

SQL思路解析:窗口滑动的应用
目录 🎯 问题目标 第一步:从数据中我们能直接得到什么? 第二步:我们想要的“7天窗口”长什么样? 第三步:SQL 怎么表达“某一天的前六天”? 🔍JOIN 比窗口函数更灵活 第四步&am…...
Rust 学习笔记:Box<T>
Rust 学习笔记:Box Rust 学习笔记:Box<T\>Box\<T> 简介使用 Box\<T\> 在堆上存储数据启用带有 box 的递归类型关于 cons 列表的介绍计算非递归类型的大小使用 Box\<T\> 获取大小已知的递归类型 Rust 学习笔记:Box<…...

C# 从 ConcurrentDictionary 中取出并移除第一个元素
C# 从 ConcurrentDictionary 中取出并移除第一个元素 要从 ConcurrentDictionary<byte, int> 中取出并移除第一个元素,需要结合 遍历 和 原子移除操作。由于 ConcurrentDictionary 是无序集合,"第一个元素" 通常是指最早添加的元素&…...
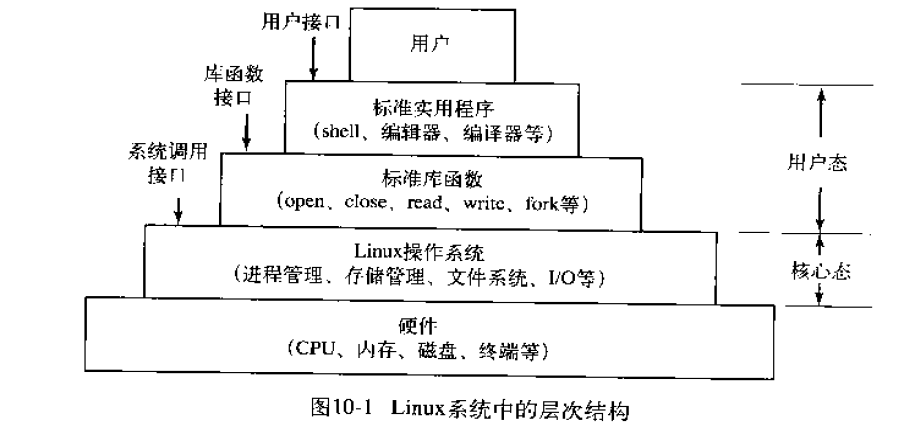
操作系统学习(十三)——Linux
一、Linux Linux 是一种类 Unix 的自由开源操作系统内核,由芬兰人 Linus Torvalds 于 1991 年首次发布。如今它广泛应用于服务器、桌面、嵌入式设备、移动设备(如 Android)等领域。 设计思想: 原则描述模块化与可移植性Linux 内…...
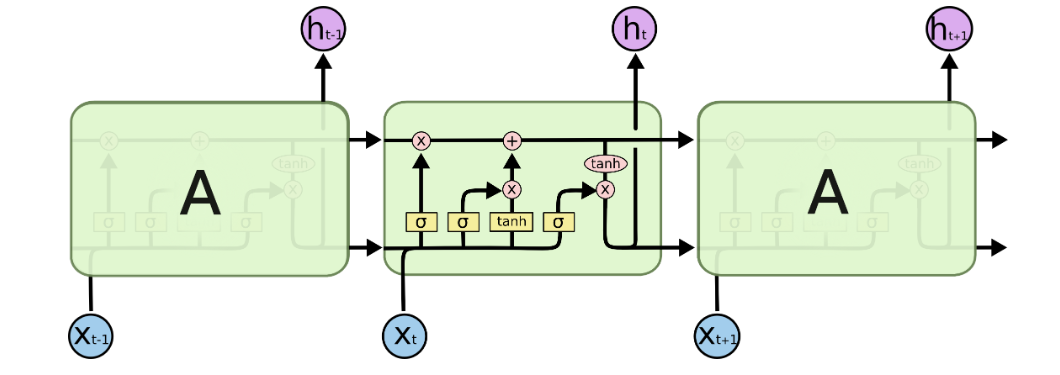
NLP学习路线图(二十二): 循环神经网络(RNN)
在自然语言处理(NLP)的广阔天地中,序列数据是绝对的核心——无论是流淌的文本、连续的语音还是跳跃的时间序列,都蕴含着前后紧密关联的信息。传统神经网络如同面对一幅打散的拼图,无法理解词语间的顺序关系,…...

每日一C(1)C语言的内存分布
目录 代码区 常量区 全局/静态区 初始化数据段(.data) 未初始化数据段(.bss) 堆区 栈区 总结 今天我们学习的是C语言的内存分布,以及这些分区所存储的内容和其特点。今天的思维导图如下。 C语言作为一款直接处…...

Photoshop使用钢笔绘制图形
1、绘制脸部路径 选择钢笔工具,再选择“路径”。 基于两个点绘制一个弯曲的曲线 使用Alt键移动单个点,该点决定了后续的曲线方向 继续绘制第3个点 最后一个点首尾是同一个点,使用钢笔保证是闭合回路。 以同样的方式绘制2个眼睛外框。 使用椭…...
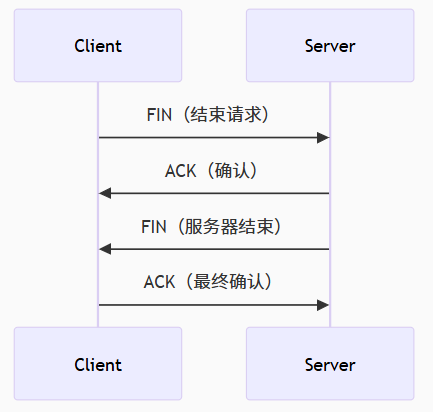
应用层协议:HTTP
目录 HTTP:超文本传输协议 1.1 HTTP报文 1.1.1 请求报文 1.1.2 响应报文 1.2 HTTP请求过程和原理 1.2.1 请求过程 1、域名(DNS)解析 2、建立TCP连接(三次握手) 3、发送HTTP请求 4、服务器处理请求 5、返回H…...

复习——C++
1、scanf和scanf_s区别 2、取地址,输出 char ba; char* p&b; cout<<*p; cout<<p; p(char*)"abc"; cout<<*p; cout<<p; cout<<(void*)p; 取地址,把b的地址给p 输出*p,是输出p的空间内的值…...

SPI通信协议(软件SPI读取W25Q64)
SPI通信协议 文章目录 SPI通信协议1.SPI通信2.SPI硬件和软件规定2.1SPI硬件电路2.2移位示意图2.3SPI基本时序单元2.3.1起始和终止条件2.3.2交换一个字节(模式1) 2.4SPI波形分析(辅助理解)2.4.1发送指令2.4.2指定地址写2.4.3指定地…...

PostgreSQL-基于PgSQL17和11版本导出所有的超表建表语句
最新版本更新 https://code.jiangjiesheng.cn/article/368?fromcsdn 推荐 《高并发 & 微服务 & 性能调优实战案例100讲 源码下载》 1. 基于pgsql 17.4 研究 查询psql版本:SELECT version(); 查看已知1条建表语句和db中数据关系 SELECT create_hypert…...
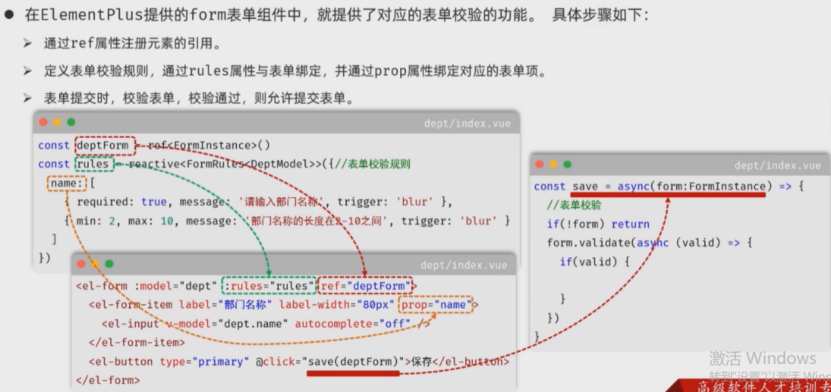
JavaWeb:前后端分离开发-部门管理
今日内容 前后端分离开发 准备工作 页面布局 整体布局-头部布局 Container 布局容器 左侧布局 资料\04. 基础文件\layout/index.vue <script setup lang"ts"></script><template><div class"common-layout"><el-containe…...

ArcGIS计算多个栅格数据的平均栅格
3种方法计算多个栅格数据的平均栅格 1->使用“ 栅格计算器”工具 原理就是把多幅影像数据相加,然后除以个数,就能得到平均栅格。 2-> 使用“像元统计数据”工具,如果是ArcGIS pro,则是“像元统计”工具。使用这个工具可以…...
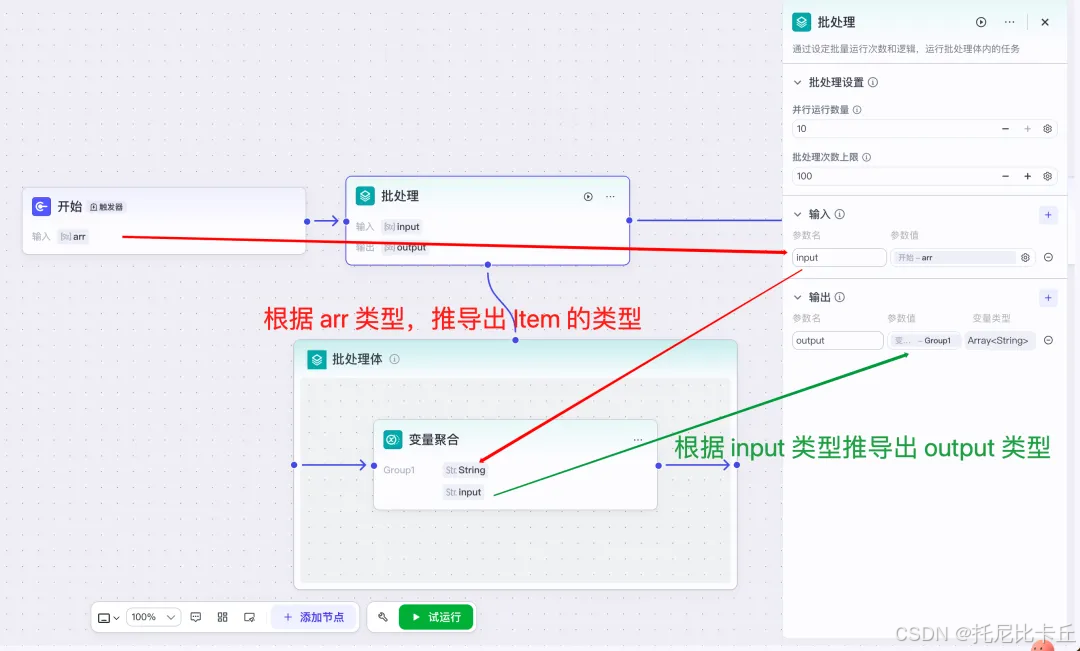
字节开源FlowGram:AI时代可视化工作流新利器
字节终于开源“扣子”同款引擎了!FlowGram:AI 时代的可视化工作流利器 字节FlowGram创新性地融合图神经网络与多模态交互技术,构建了支持动态拓扑重构的可视化流程引擎。该系统通过引入 f ( G ) ( V ′ , E ′ ) f(\mathcal{G})…...

如何选择合适的分库分表策略
选择合适的分库分表策略需要综合考虑业务特点、数据规模、访问模式、技术成本等多方面因素。以下是系统性的选择思路和关键决策点: 一、核心决策因素 业务需求分析 数据规模:当前数据量(如亿级)、增长速度(如每日新增百…...

(LeetCode 每日一题)3403. 从盒子中找出字典序最大的字符串 I (贪心+枚举)
题目:3403. 从盒子中找出字典序最大的字符串 I 题目:贪心枚举字符串,时间复杂度0(n)。 最优解的长度一定是在[1,n-numFriends]之间。 字符串在前缀都相同的情况下,长度越长越大。 C版本: class Solution { public:st…...
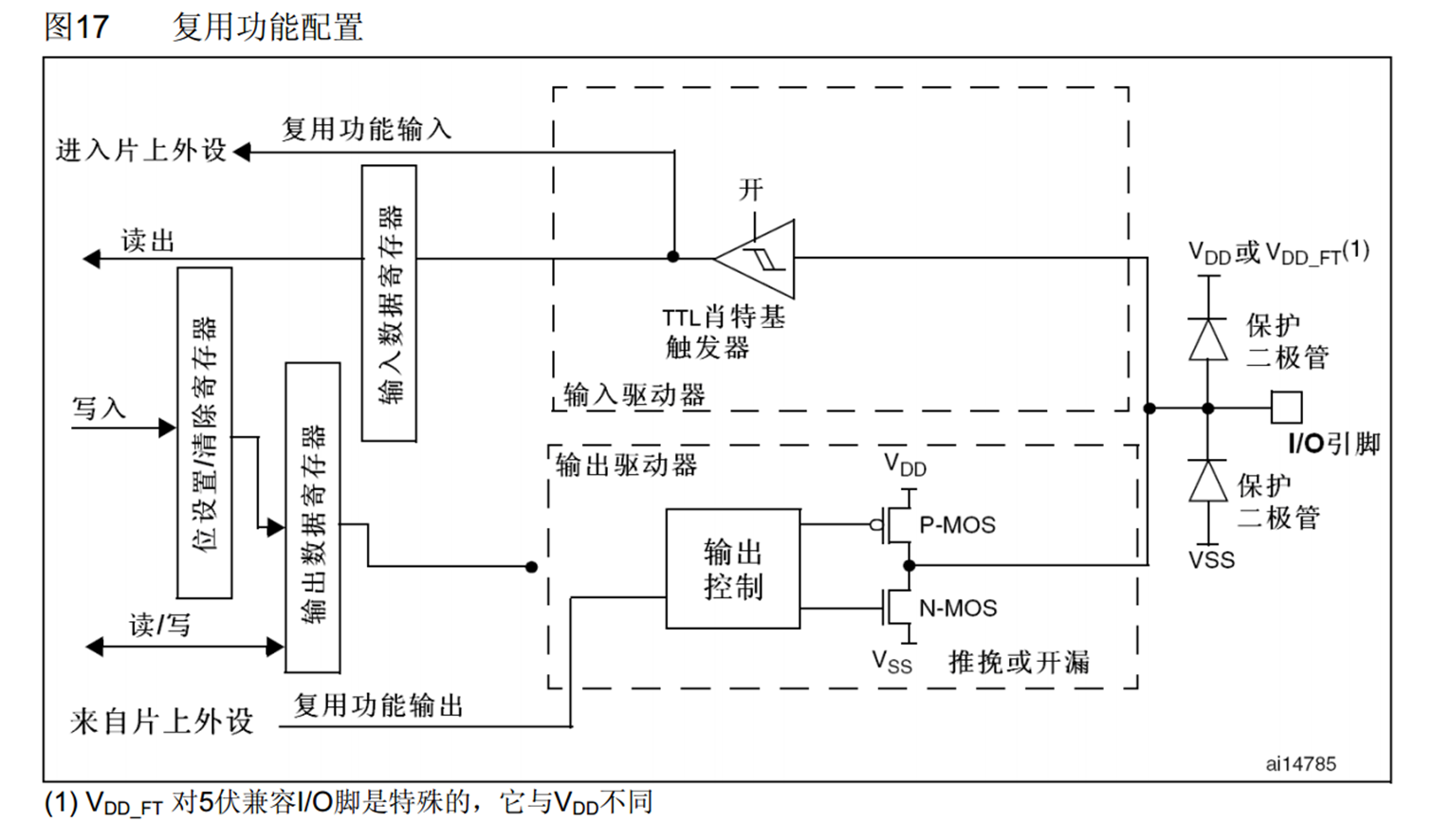
GPIO的内部结构与功能解析
一、GPIO总体结构 总体构成 1.APB2(外设总线) APB2总线是微控制器内部连接CPU与外设(如GPIO)的总线,负责CPU对GPIO寄存器的读写访问,支持低速外设通信 2.寄存器 控制GPIO的配置(输入/输出模式、上拉/下拉等&#x…...

Python训练打卡Day42
Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 在深度学习中,我们经常需要查看或修改模型中间层的输出或梯度。然而,标准的前向传播和反向传播过程通常是一个黑盒,我们很难直接访问中间层的信…...

深度学习中的负采样
深度学习中的负采样 负采样(Negative Sampling) 是一种在训练大型分类或概率模型(尤其是在输出类别很多时)中,用来加速训练、降低计算量的方法。 它常用于: 词向量训练(如 Word2Vecÿ…...

php7+mysql5.6单用户中医处方管理系统V1.0
php7mysql5.6中医处方管理系统说明文档 一、系统简介 ----------- 本系统是一款专为中医诊所设计的处方管理系统,基于PHPMySQL开发,不依赖第三方框架,采用原生HTML5CSS3AJAX技术,适配手机和电脑访问。 系统支持药品管理、处方开…...

Java 大视界 — Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制
/*Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制(简化示例)*/// 1. Event.java - 异常事件模型 package com.security.model;public class Event {private String id;private String type; // 如: "入侵", "火警"pr…...
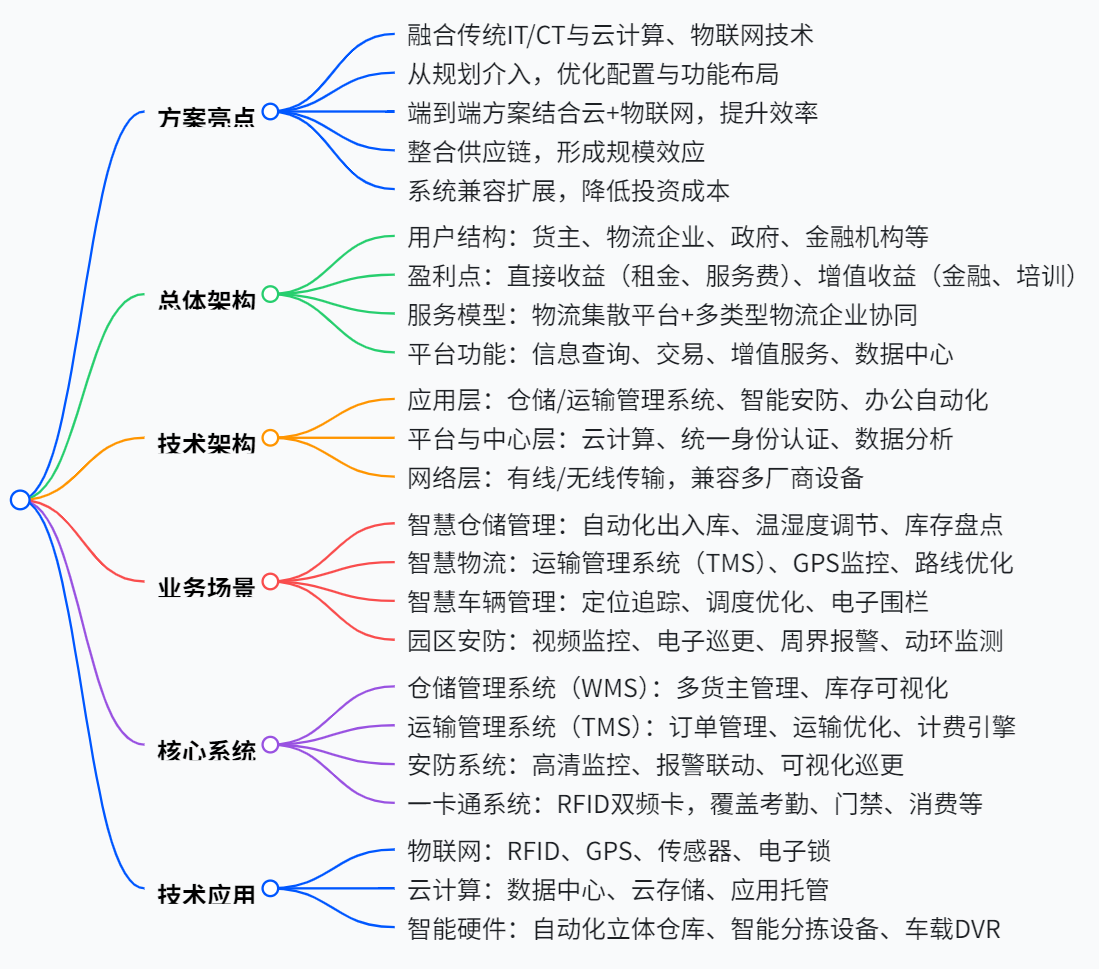
智慧物流园区整体解决方案
该智慧物流园区整体解决方案借助云计算、物联网、ICT 等技术,从咨询规划阶段介入,整合供应链上下游资源,实现物流自动化、信息化与智能化。方案涵盖智慧仓储管理(如自动化立体仓储系统、温湿度监控)、智慧物流(运输管理系统 TMS、GPS 监控)、智慧车辆管理(定位、调度、…...

审批流程管理系统开发记录:layui前端交互的实践
一、需求拆解与技术选型 本次开发围绕企业审批流程管理场景,需实现以下核心功能: 前端申请表单与流程进度可视化底部滑动审批弹窗交互多版本MySQL数据库支持流程数据的增删改查与状态管理技术栈选择: 前端采用LayUI框架,利用其时间线组件(lay-timeline)实现流程进度展示…...
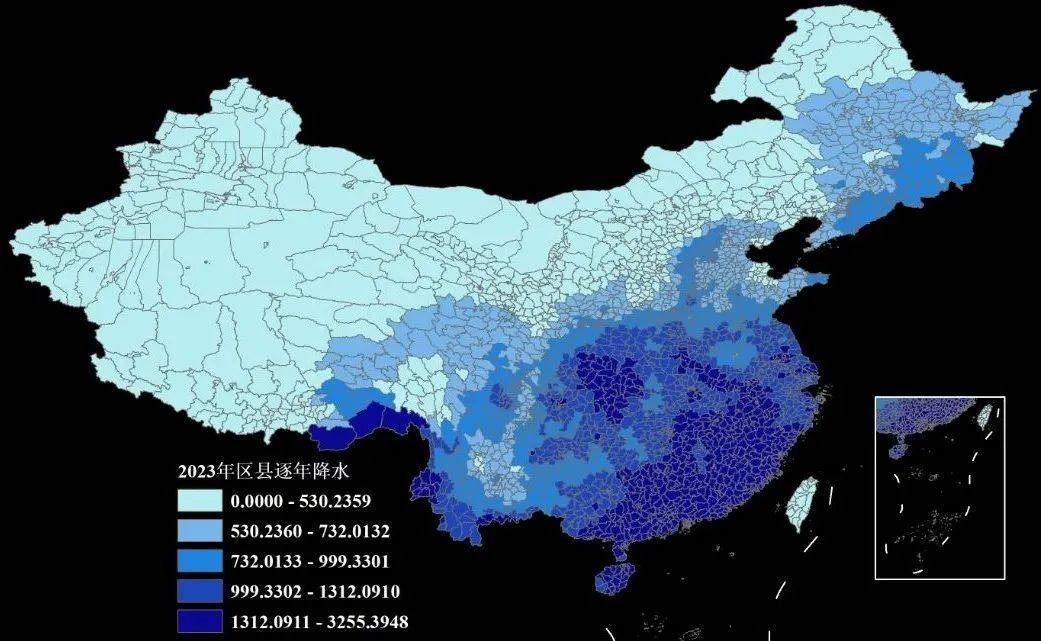
【会员专享数据】1960—2023年我国省市县三级逐年降水量数据(Shp/Excel格式)
之前我们分享过1960-2023年我国0.1分辨率的逐日、逐月、逐年降水栅格数据(可查看之前的文章获悉详情),是研究者Jinlong Hu与Chiyuan Miao分享在Zenodo平台上的数据,很多小伙伴拿到数据后反馈栅格数据不太方便使用,问我…...

2025年精通MVCC
今年找工作,无一例外又问到了MVCC这个知识点。几乎每次换工作都会被问到这个面试有用,工作毫无 * 用的知识。但是环境就是这样,既然如此,我们用一篇文章彻底搞懂MVCC 1.MVCC是什么 MVCC(Multi-Version Concurrency C…...

硬路由与软路由
目录 核心区别 ⚙️ 性能与功能定位 如何选择? 核心区别 硬路由: 本质: 专用的硬件设备。构成: 厂家将特定的路由器操作系统(通常是高度定制化、封闭或精简的)固化在专用的硬件平台上。硬件:…...