Spark实战能力测评模拟题精析【模拟考】
1.println(Array(1,2,3,4,5).filter(_%2==0).toList()
输出结果是(B)
A.
2
4
B.
List(2,4)
C.
List(1,3,5)
D.
1
3
5
2.println(Array("tom","team","pom")
.filter(_.matches("")).toList)
输出结果为(List(tom,team)请填空
A.t[a-z]+m
B.t[a-z]m
C.la-z]+
D.t[a-z]{2}
答案:A
3.println(List("c","java","c","python").map(myf))
def myf(s:String):Map[String,Int]={
Map(s->s.length)
输出结果是(C)
A.Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6)
B.List(Map(c ->1),Map(java->1),Map(c ->1),Map(python ->1))
C.List(Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6))
D.Tuple4(Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6))
4.println(Array("tom","jerry").filter().toList)
输出结果为List("jerry")
下列错误的是
A._.length>3
B._.startsWith("j")
C._≥7”
D._.endsWith("y")
5.println(List"信计-201,信计-202",大数据-201",大数据-202)
.groupBy(_.split("-")(0)))
输出结果是
A
Map(大数据->List(大数据-201,大数据-202),信计->List(信计-201,信计-202)
B
Map(大数据-20->List(大数据-201,大数据-202),信计-20->List(信计-201,信计-202)
C
Map(大数据-->List(大数据-201,大数据-202),信计-->List(信计-201,信计-202)
D
Map(大数据->List(201,202),信计->List(201,202)
6. (阅读理解, 25.0 分)资料--data--ajk_utf8.csv(utf-8编码)数据处理分析。
第一列是小区,第二列是地址,第三列是租金。
var rdd1=sc.textFile("d:/ajk/ajk_utf8.csv") //spark-core读取数据
(1) (单选题)统计共有多少个小区?
A.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x->(x(2),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
B.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x<-(x(0),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
C.var rdd2=rdd1.map(_.split(" "))
var rdd3=rdd2.map(x=>(x(0),x(1)))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
D.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
正确答案是:D
解释:
- 选项D正确地使用了第一列(小区名)作为key:
x(0) - 使用
groupByKey()来分组统计 - 最后使用
count()计算总数
其他选项的问题:
- A选项使用了第三列(租金)作为key:
x(2) - B选项使用了错误的语法:
x<-应该是x=> - C选项使用了空格分隔符:
split(" ")而不是逗号split(",")
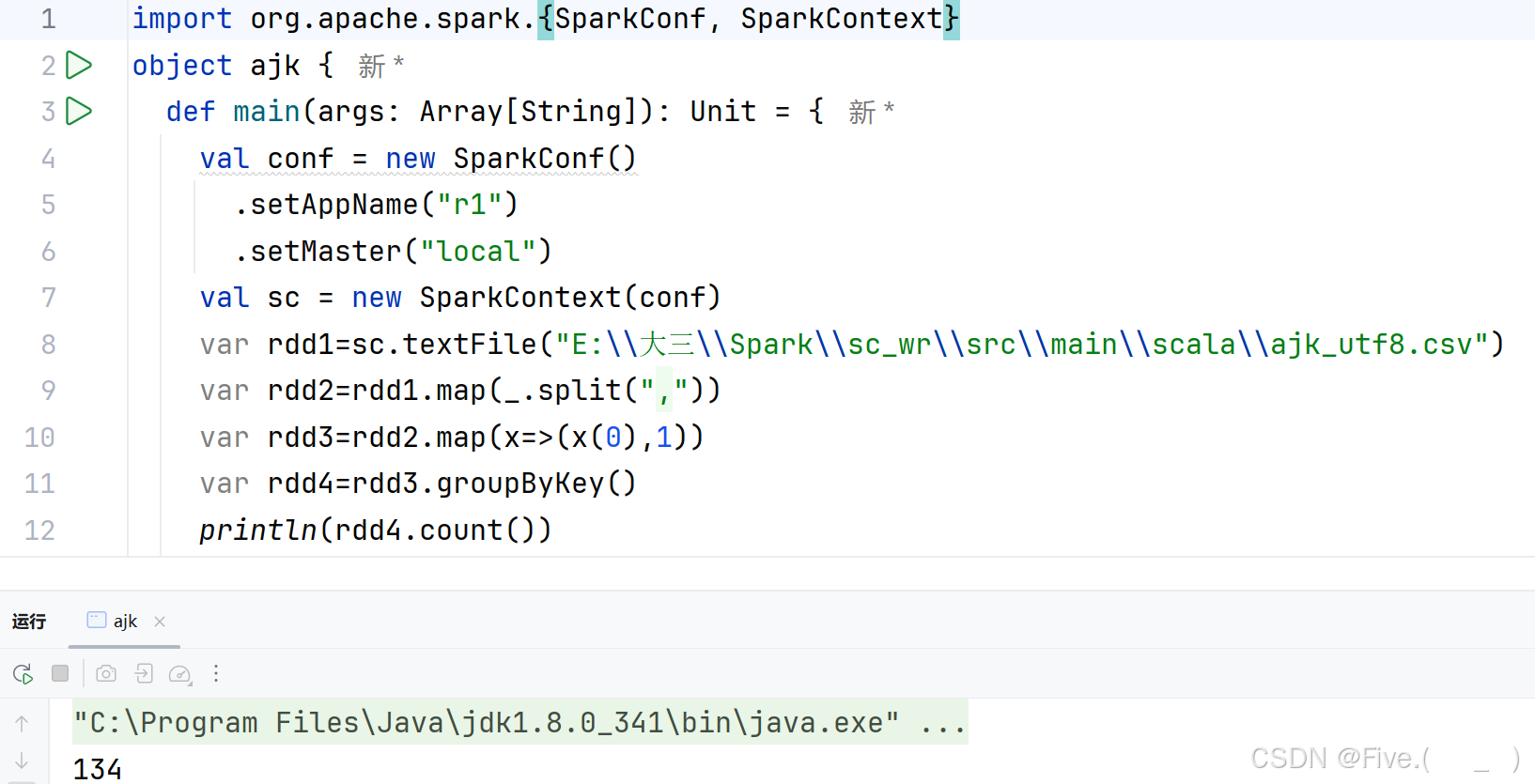
(2) (单选题)统计每个小区有多少房子出租?请选择
A var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(2),1))
var rdd4=rdd3.reduce(_+_)
rdd4.foreach(println)
B var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.reduce(_+_)
rdd4.foreach(println)
C var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
正确答案是:D
解释:
- 使用第一列(小区名)作为key:
x(0) - 使用
reduceByKey(_+_)来统计每个小区的房源数量 - 使用
foreach(println)打印结果
其他选项的问题:
- A选项使用了第三列(租金)作为key:
x(2) - B选项使用了
reduce而不是reduceByKey,这会导致所有数据被合并成一个值 - C选项使用了第二列(地址)作为key:
x(1)
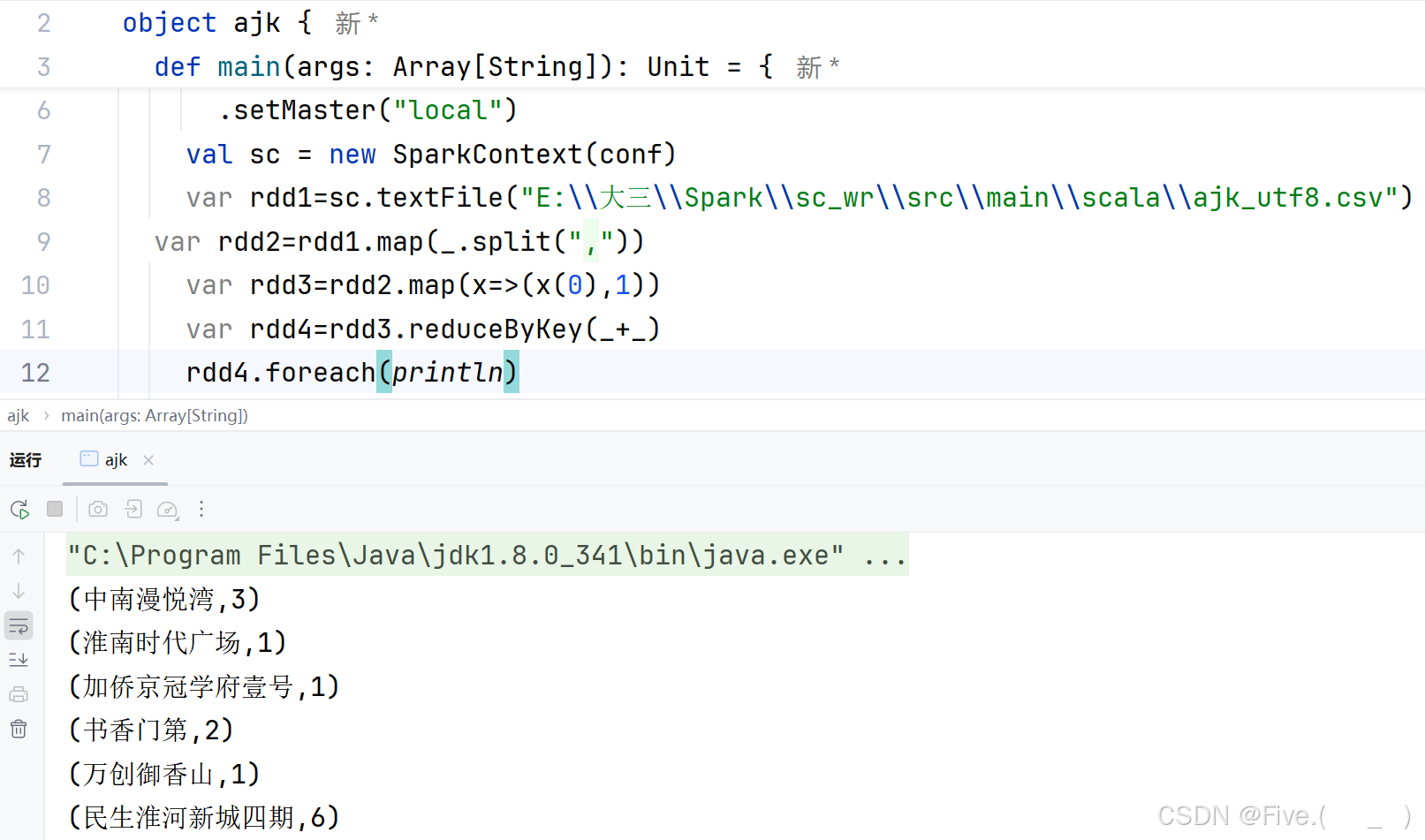
(3) (单选题)统计不同区、县房源数量,请选择
A.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1).split("-")(0),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
B.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(2).split("-")(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
C.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0).split("-")(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1).split("-")(0),1))
var rdd4=rdd3.groupByKey()
rdd4.foreach(println)
正确答案是:A
解释:
- 从地址列(第二列)中提取区县信息:
x(1).split("-")(0) - 使用
reduceByKey(_+_)来统计每个区县的房源数量 - 使用
foreach(println)打印结果
其他选项的问题:
- B选项使用了第三列(租金)来提取区县信息:
x(2) - C选项使用了第一列(小区名)来提取区县信息:
x(0) - D选项虽然提取地址正确,但使用了
groupByKey()而不是reduceByKey(_+),这会导致结果是分组后的集合而不是计数
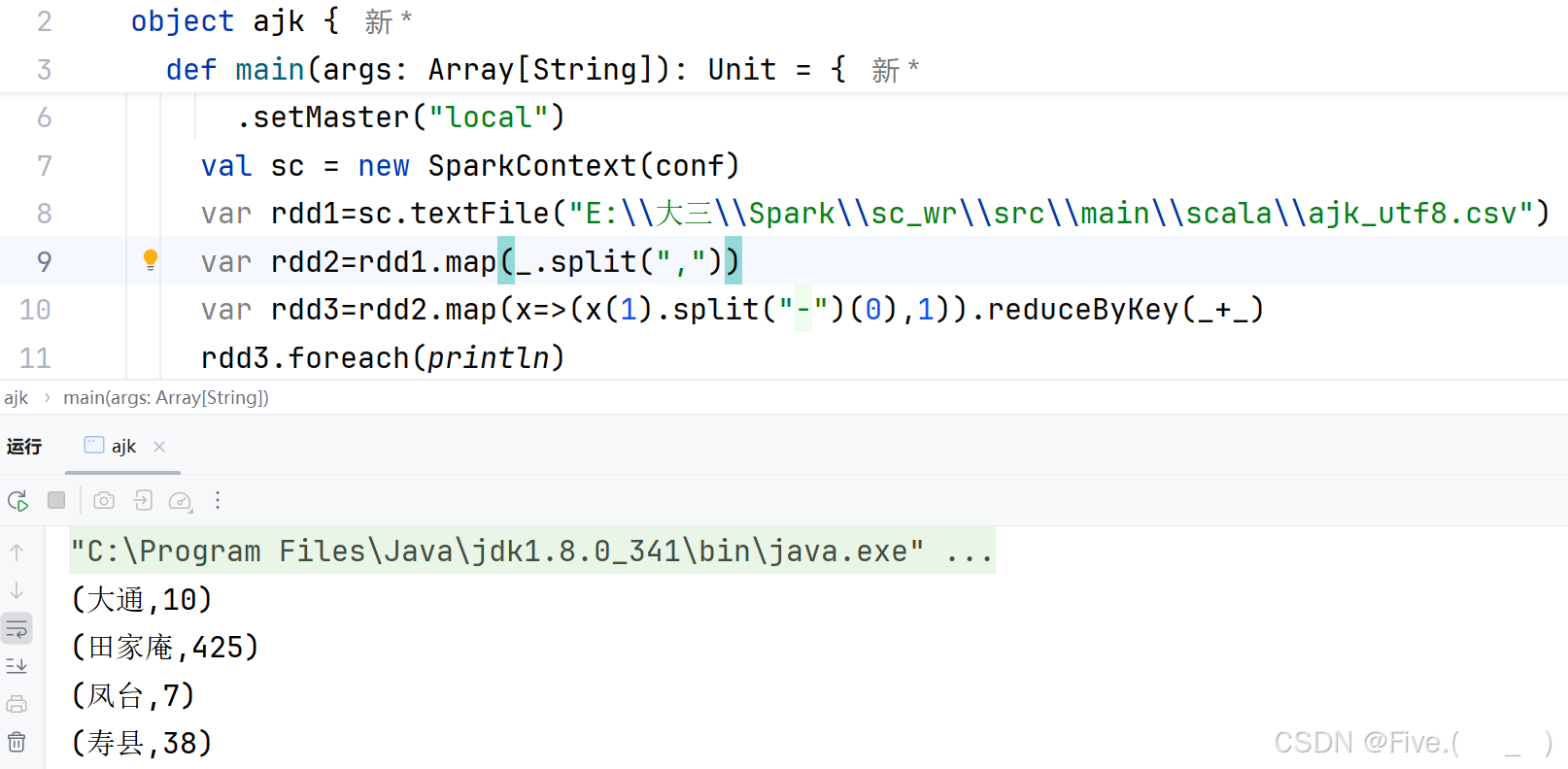
(4) (单选题)统计每个区、县的出租均价,请选择
A.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).toInt))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.sum/x._2.size)).foreach(println)
B.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(0).toInt))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.sum/x._2.size)).foreach(println)
C.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(0).toInt))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(1)))
//var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.avgvalue)).foreach(println)
正确答案是:B
解释:
- 从地址列(x(1))中提取区县信息:
x(1).split("-")(0) - 从租金列(x(2))中提取数字部分:
x(2).split(" ")(0).toInt - 使用
groupByKey()将相同区县的租金分组 - 计算平均值:
x._2.sum/x._2.size - 使用
foreach(println)打印结果
其他选项的问题:
- A选项直接将租金转为整数:
x(2).toInt,没有处理可能存在的单位(如"元") - C选项虽然处理了租金格式,但使用了
reduceByKey(_+)只计算总和,没有计算平均值 - D选项使用了错误的索引
split(" ")(1),并且avgvalue是不存在的方法
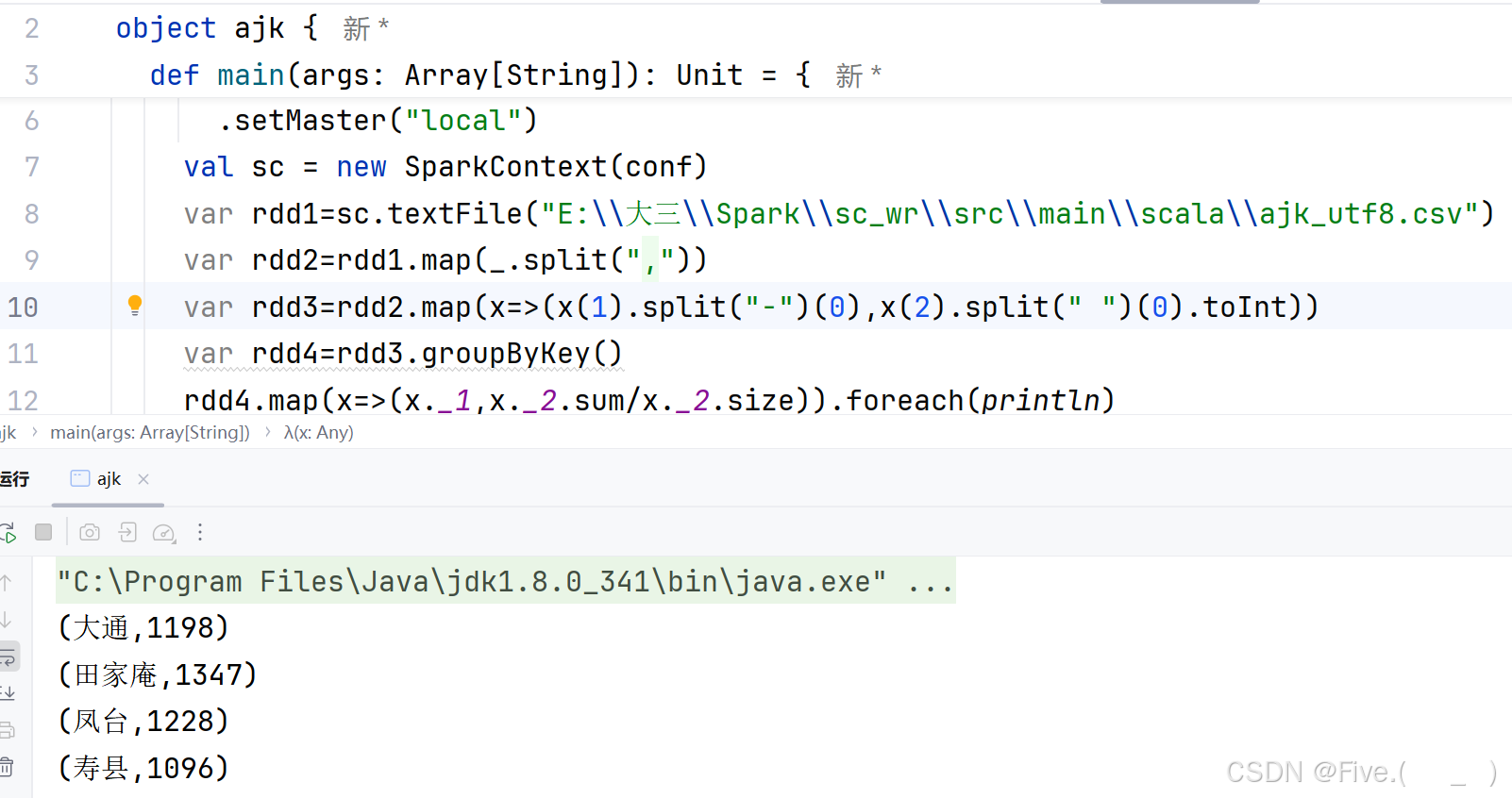
(5) (单选题)上一小题计算出各区县的出租均价是()
A.(大通,1198)
(田家庵,1347)
(凤台,1228)
(寿县,1096)
B.(大通,1098)
(田家庵,1347)
(凤台,1228)
(寿县,1016)
C.(大通,1198)
(田家庵,1447)
(凤台,1228)
(寿县,1196)
D.(大通,1298)
(田家庵,1447)
(凤台,1228)
(寿县,1026)
答案为A,运行结果看上方
7. (阅读理解, 30.0 分)统计学习通--资料--data--sale2.csv.进行数据处理和分析。
var rdd1=spark.read
.option("header",true)
.csv("d:/sale2.csv")
var df1=rdd1.toDF()
df1.createOrReplaceTempView("sale")
var sql1=______________
var rs=spark.sql(sql1)
rs.show()
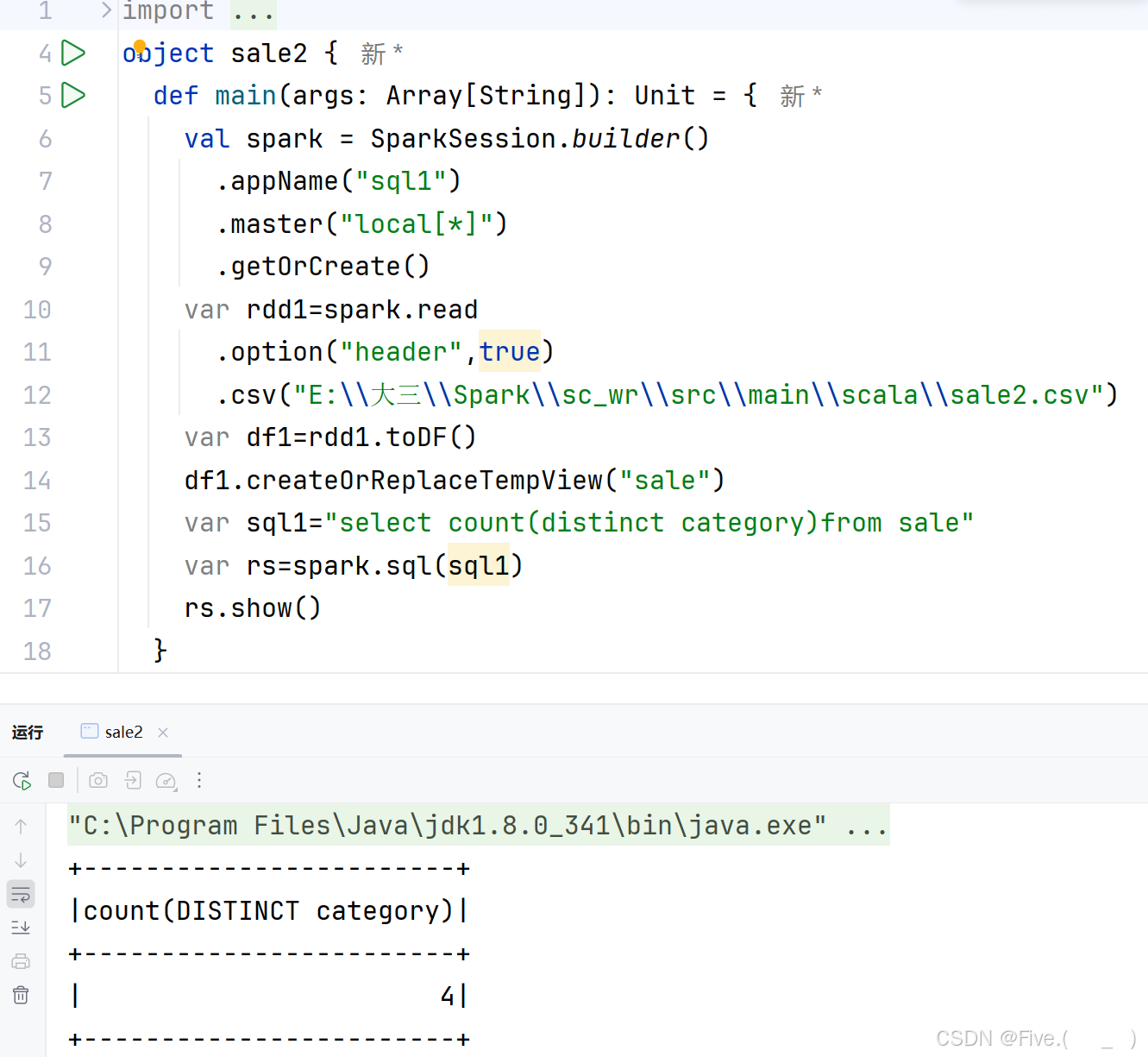
(1) (单选题)统计商品(product)有几个大类(category)。
A.select count(category) from sale
B.select count(distinct category) from sale
C.select sum(distinct category) from sale
D.select count(distinct product) from category
正确答案是:B
解释:
原因:
- 使用
distinct去重,统计唯一的大类 - 使用
count统计数量
其他选项的问题:
- A选项没有
distinct,会统计所有记录 - C选项使用
sum,对分类进行求和是错误的 - D选项语法错误,
category不是表名
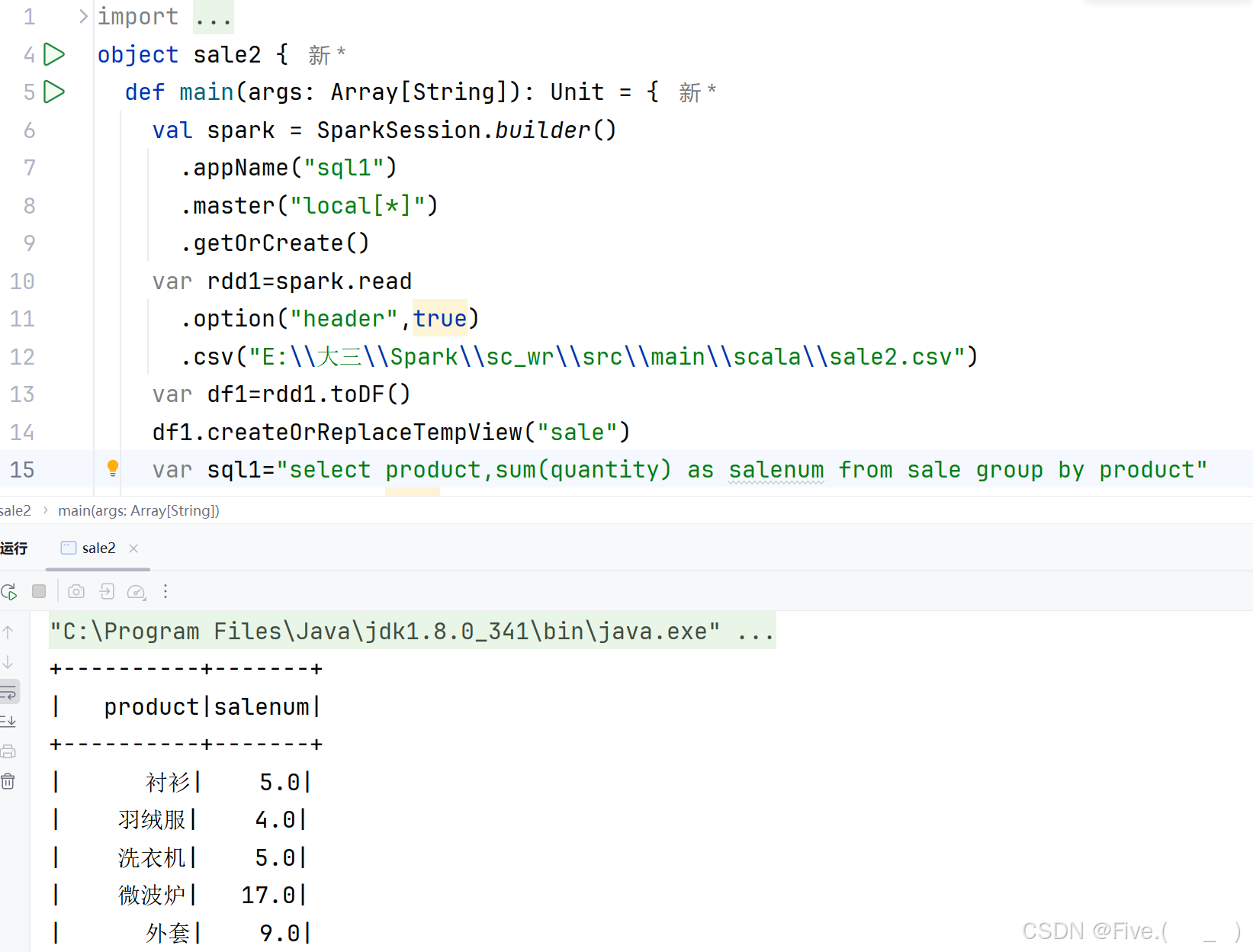
(2) (单选题)统计在售商品销量。
A.select product,quantity from sale
B.select product,count(quantity) as salenum from sale group by product
C.select product,sum(product) as salenum from sale group by quantity
D.select product,sum(quantity) as salenum from sale group by product
正确答案是:D
解释:
原因:
- 使用
sum(quantity)计算每个商品的总销量 - 使用
group by product按商品分组 - 使用
as salenum给结果列命名
其他选项的问题:
- A选项只选择了商品和数量,没有聚合
- B选项使用
count,统计的是数量的记录数而不是总销量 - C选项
group by quantity是错误的分组方式,应该按商品分组
(3) (单选题)商品大类(category)销售数量排行,请选择
A.select category,count(quantity) as num_cate from sale group by category order by num_cate desc
B.select category,count(*) as num_cate from sale group by category order by num_cate
C.select category,sum(quantity) as num_cate from sale group by category order by num_cate desc
D.select category,sum(quantity) as num_cate from sale order by category group by num_cate desc
正确答案是:C
解释:
原因:
- 使用
sum(quantity)计算每个大类的总销量 - 使用
group by category按大类分组 - 使用
order by num_cate desc按销量降序排列 - 使用
as num_cate给结果列命名
其他选项的问题:
- A选项使用
count,统计的是数量的记录数而不是总销量 - B选项使用
count(*),统计的是记录数而不是销量 - D选项语法错误,
order by和group by的顺序错误
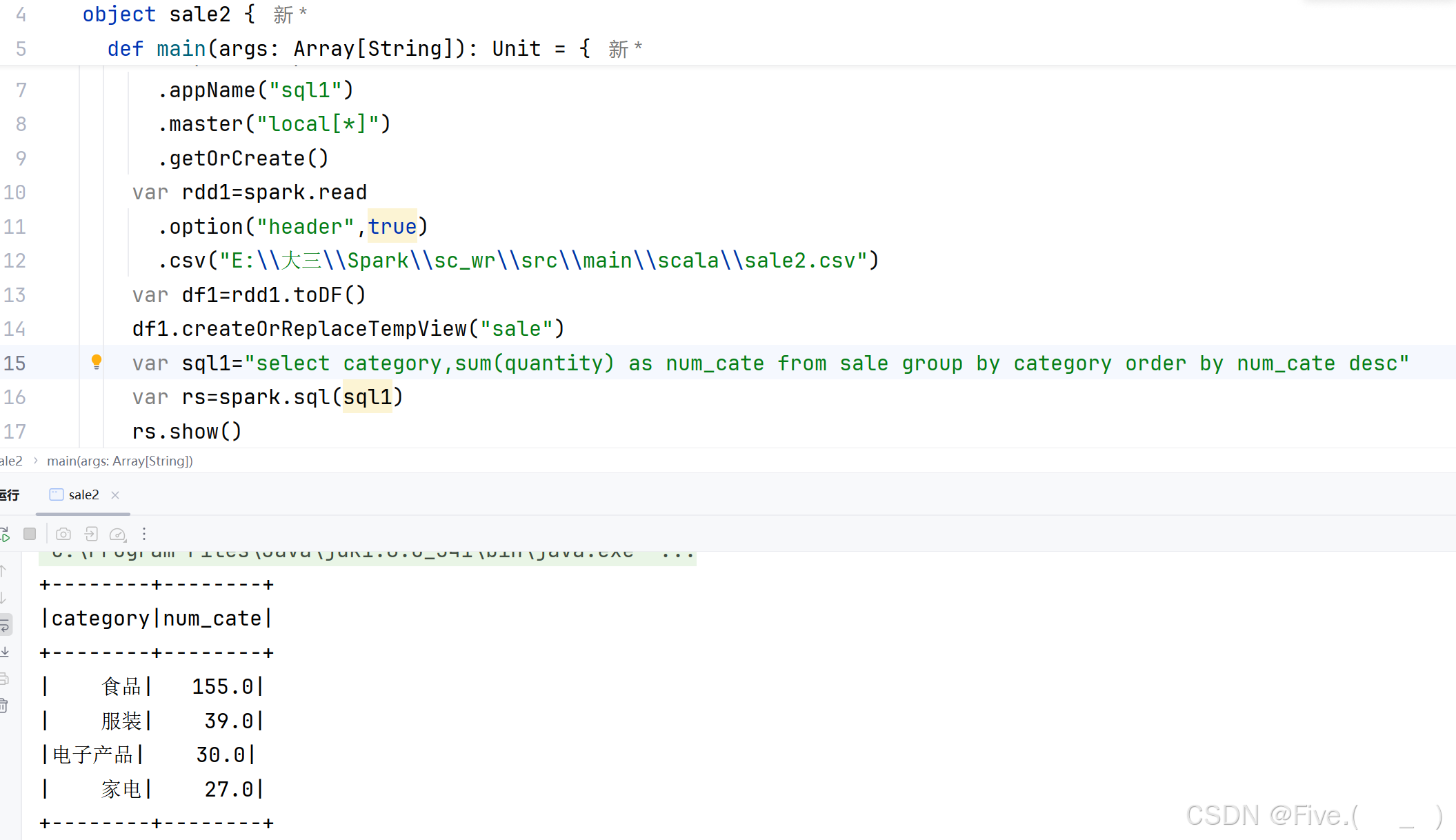
(4) (单选题)商品大类(category)营业金额,排行榜
A.select category,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
B.select quantity,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
C.select price,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
D.select category,sum(price) as sum_cate from sale group by category order by sum_cate desc
正确答案是:A
解释:
原因:
- 使用
price*quantity计算每个商品的销售额 - 使用
sum计算每个大类的总销售额 - 使用
group by category按大类分组 - 使用
order by sum_cate desc按销售额降序排列 - 使用
as sum_cate给结果列命名
其他选项的问题:
- B选项使用
quantity分组,这是错误的,应该按category分组 - C选项使用
price分组,这是错误的,应该按category分组 - D选项只计算了价格总和,没有考虑数量,无法得到正确的销售额
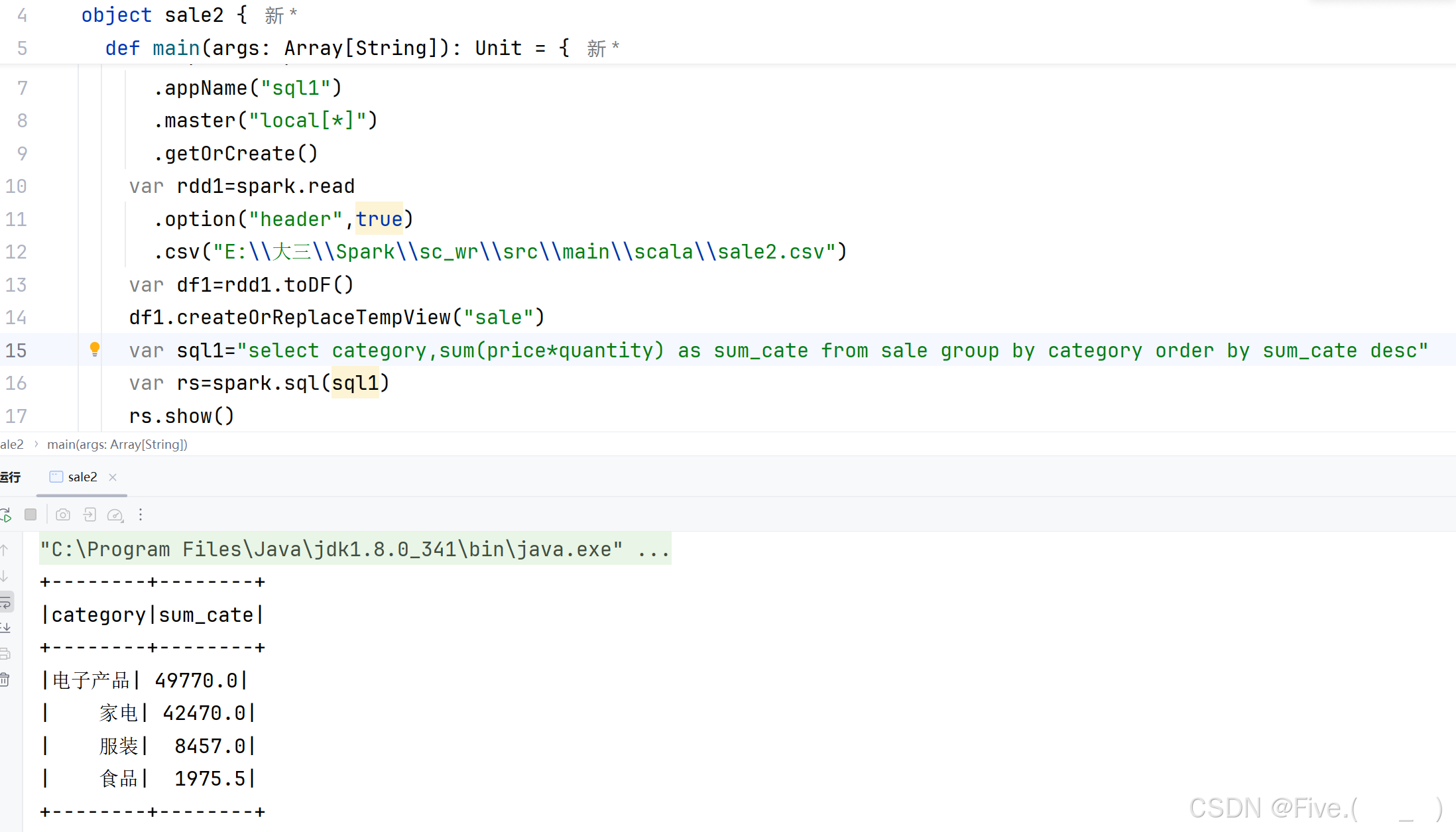
(5) (单选题)按季度顺序统计销售金额。
A var sql1="select quarter(to_date(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by quarters"
B var sql1="select quarter(to_date(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by sum_sale"
C var sql1="select quarter(to_timestamp(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by sum_sale desc"
D var sql1="select quarter(to_timestamp(date,'yyyy/MM/dd HH:mm:ss'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by quarters"
正确答案是:A
解释:
原因:
- 使用
to_date将日期字符串转换为日期格式 - 使用
quarter函数提取季度 - 使用
sum(price*quantity)计算销售额 - 使用
group by quarters按季度分组 - 使用
order by quarters按季度顺序排序
其他选项的问题:
- B选项按销售额排序,不符合按季度顺序的要求
- C选项虽然按销售额降序排序,但不符合按季度顺序的要求
- D选项使用了错误的日期格式字符串
yyyy/MM/dd HH:mm:ss,而原始数据应该是yyyy-MM-dd格式
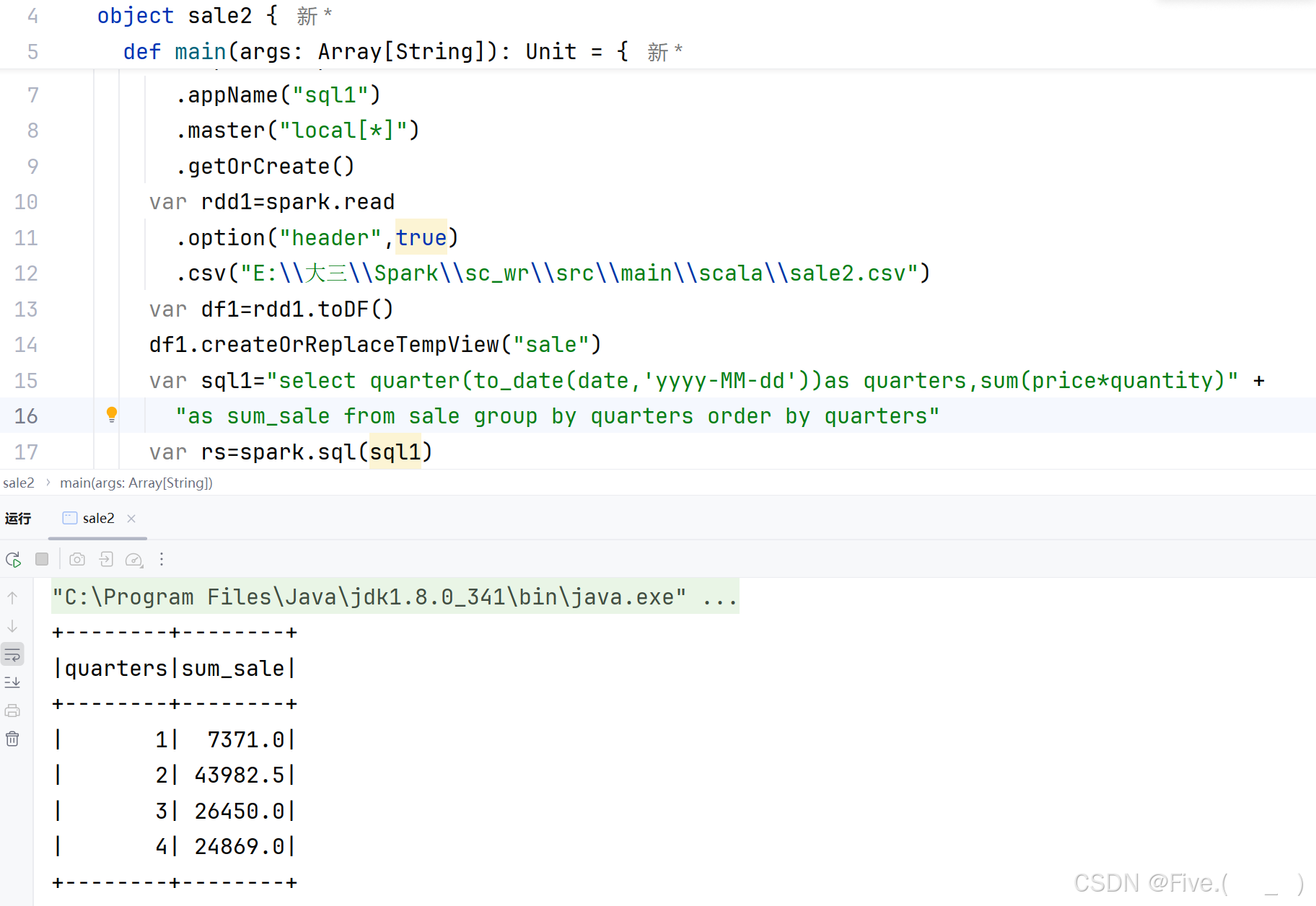
(6) (单选题)按年统计销售商品数量
A.var sql1="select year(to_date(date,'yyyy-MM-dd'))as years,sum(quantity) as nums from sale group by years"
B.var sql1="select month(to_date(date,'yyyy-MM-dd'))as years,sum(quantity) as nums from sale group by years"
C.var sql1="select year(to_date(date,'yyyy-MM'))as years,sum(quantity) as nums from sale group by nums"
D.var sql1="select year(to_date(date,'yyyy/MM'))as years,sum(quantity) as nums from sale group
正确答案是:A
解释:
原因:
- 使用
to_date将日期字符串转换为日期格式 - 使用
year函数提取年份 - 使用
sum(quantity)计算每年的销售数量 - 使用
group by years按年份分组
其他选项的问题:
- B选项使用
month提取月份,不符合按年统计的要求 - C选项按
nums分组,这是错误的,应该按years分组 - D选项缺少
by关键字,语法错误
8. (阅读理解, 20.0 分)读取学习通--资料--data--weather.csv
并进行数据处理与分析
var rdd1=sc.textFile("d:/weather.csv")
var header=rdd1.first()
var data=rdd1.filter(_!=header)
var rdd2=data.map((_.split(",")))
(1) (单选题)统计出这一年中有多少雾霾天?
A.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.equals("雾霾"))
println(rdd3.count())
输出 结果:12
B.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.contains("雾霾"))
println(rdd3.count())
输出 结果:12
C.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.contains("雾霾"))
println(rdd3.count())
输出 结果:11
D.var rdd3=rdd2.map(x=>(x(4),1)).filter(_._1.substring("雾霾"))
println(rdd3.count())
输出结果:11
正确答案:C
解释:
- 使用第四列(天气情况):
x(3) - 使用
contains("雾霾")来匹配包含"雾霾"的天气 - 最终统计结果是11天
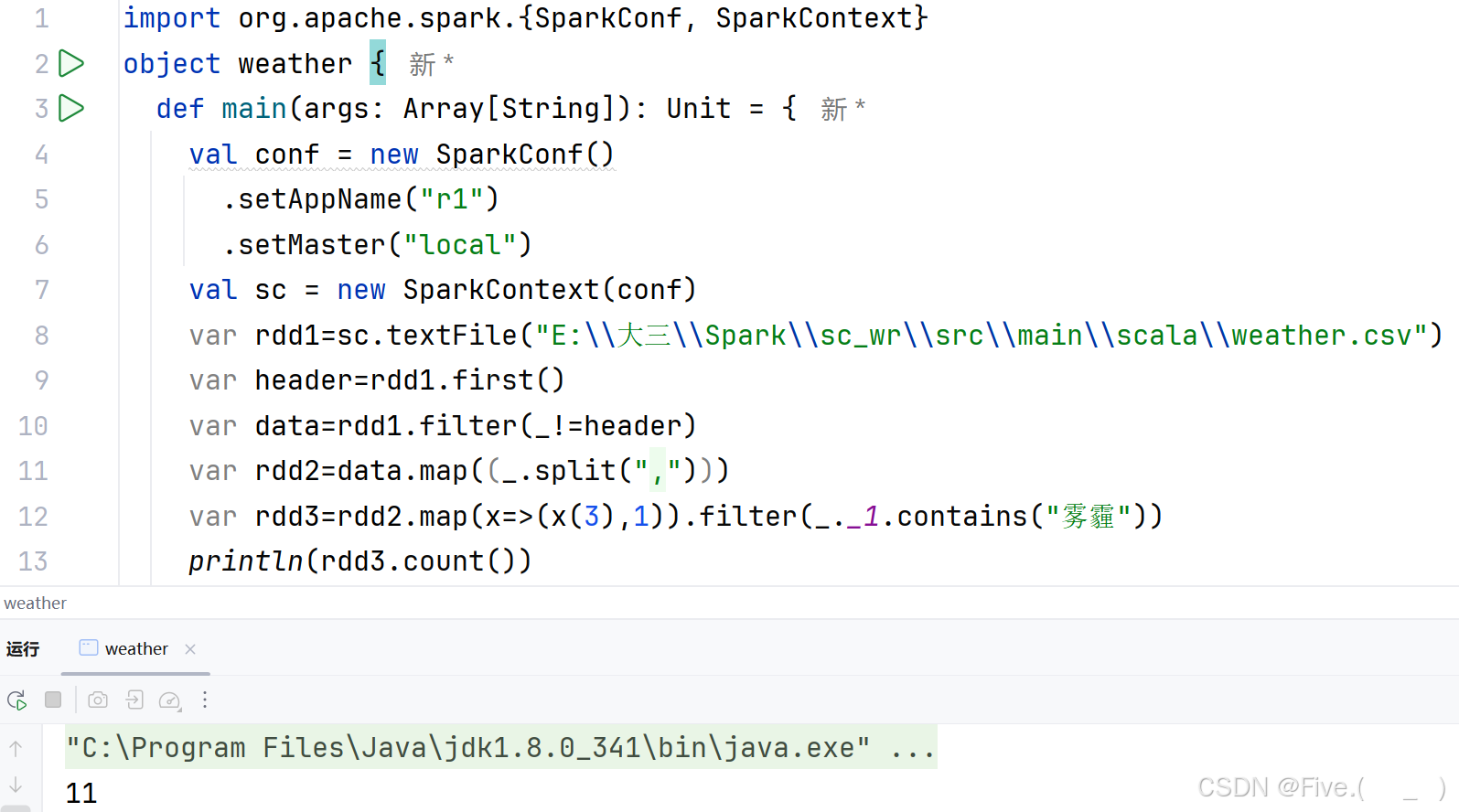
(2) (单选题)求出气温最低的10天。
A.var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortBy(_._2)
rdd3.take(10).foreach(println)
B.var rdd3=rdd2.map(x=>(x(0),x(2))).sortBy(_._2)
rdd3.take(10).foreach(println)
C.var rdd3=rdd2.map(x=>(x(0),x(1).toInt)).sortBy(_._2)
rdd3.take(10).foreach(println)
D.var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortByKey()
rdd3.take(10).foreach(println)
正确答案是:A
解释:
var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortBy(_._2) rdd3.take(10).foreach(println) 原因:
- 使用
x(0)作为日期 - 使用
x(2)作为最低温度列 - 使用
toInt将温度转换为整数 - 使用
sortBy(_._2)按温度排序 - 使用
take(10)获取最低的10天
其他选项的问题:
- B选项没有转换温度为整数,字符串排序可能不正确
- C选项使用了
x(1),这是最高温度列而不是最低温度 - D选项使用了
sortByKey(),这会按日期排序而不是温度
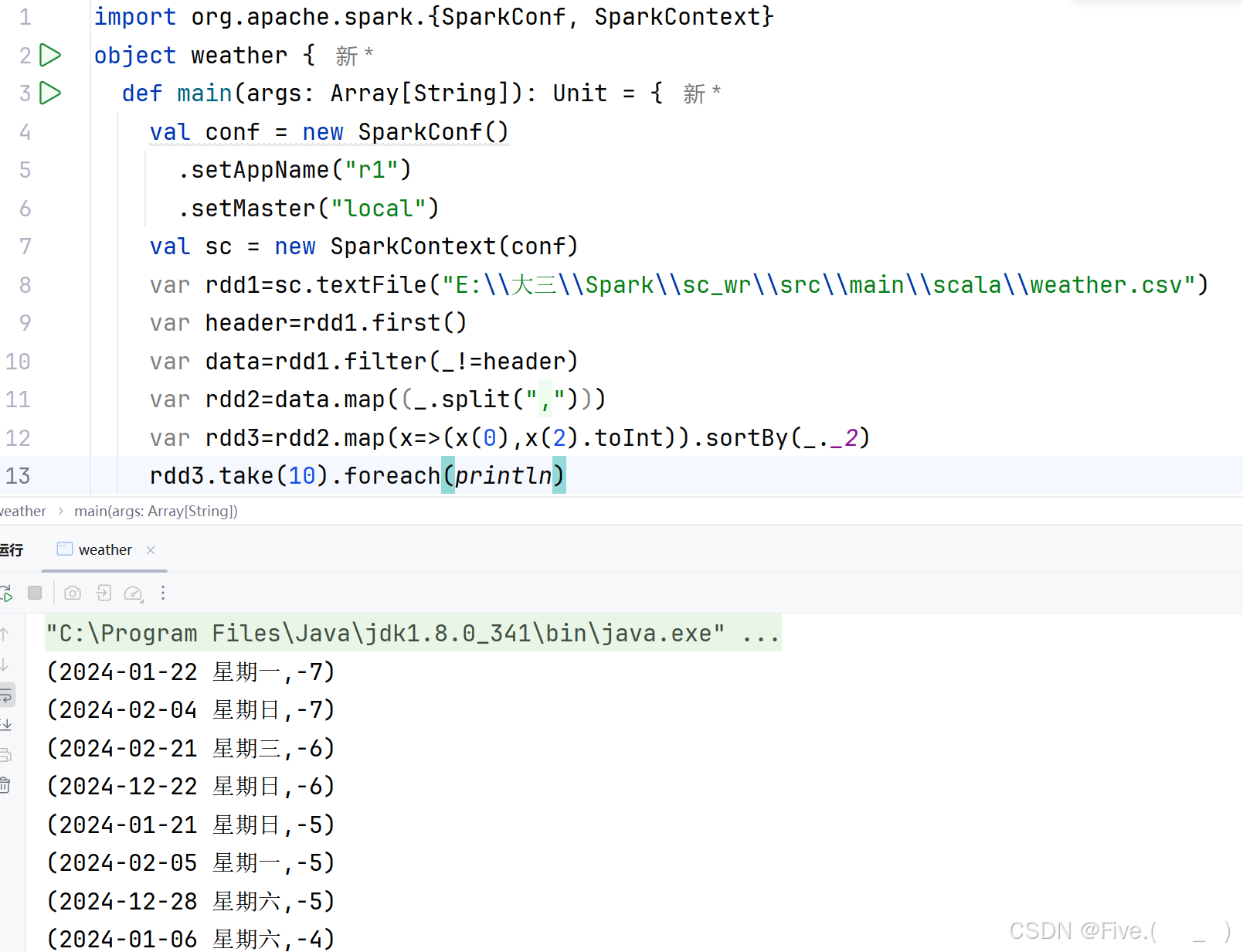
(3) (单选题)统计各种风向各多少天(例如:东风,20)
A.var rdd3=rdd2.map(x=>(x(4).split(" ")(0),1))
rdd3.groupByKey(_+_).foreach(println)
B.var rdd3=rdd2.map(x=>(x(4).split(" ")(0),1))
rdd3.reduceByKey(_+_).foreach(println)
C.var rdd3=rdd2.map(x=>(x(0),x(4).split(" ")(0)))
rdd3.reduceByKey(_+_).foreach(println)
D.var rdd3=rdd2.map(x=>(x(4),1))
rdd3.orderByKey(_+_).foreach(println)
正确答案是:B
解释:
- 使用
x(4)作为风向列 - 使用
split(" ")(0)提取风向(假设风向和风力是用空格分隔的) - 使用
reduceByKey(_+_)来统计每个风向出现的天数 - 使用
foreach(println)打印结果
其他选项的问题:
- A选项使用了
groupByKey(_+),语法错误,groupByKey后面不能直接加操作符 - C选项将日期作为key,映射关系错误
- D选项没有分割风向和风力,直接使用
x(4),并且使用了orderByKey,这是排序操作而不是统计
(4) (单选题)最高温度大于30的有多少天?
A.var rdd3=rdd2.map(x=>(x(1),1)).filter(_._1>30)
println(rdd3.count())
输出结果:105
B.var rdd3=rdd2.map(x=>x(1).toInt).filter(_>30)
println(rdd3.count())
输出结果:104
C.var rdd3=rdd2.map(x=>(x(1).toInt,1)).filter(_>30)
println(rdd3.count())
输出结果:105
D.var rdd3=rdd2.map(x=>(x(1).toInt,1)).reduce(_._1>30)
println(rdd3.count())
输出结果:104
正确答案是:B
解释:
原因:
- 直接映射温度列:
x(1) - 使用
toInt转换为整数 - 使用
filter(_>30)过滤大于30的温度 - 使用
count()统计结果
其他选项的问题:
- A选项没有转换温度为整数,直接比较字符串
- C选项虽然转换了温度,但过滤条件写错了,应该用
filter(_._1>30) - D选项使用了
reduce,语法错误,reduce用于聚合操作而不是过滤
相关文章:
Spark实战能力测评模拟题精析【模拟考】
1.println(Array(1,2,3,4,5).filter(_%20).toList() 输出结果是(B) A. 2 4 B. List(2,4) C. List(1,3,5) D. 1 3 5 2.println(Array("tom","team","pom") .filter(_.matches("")).toList) 输出结果为(List(tom,…...

【OSG学习笔记】Day 15: 路径动画与相机漫游
本章来学习下漫游相机。 路径动画与相机漫游 本届内容比较简单,其实就是实现物体的运动和相机的运动 当然这两个要一起执行。 贝塞尔曲线 贝塞尔曲线(Bzier curve)是一种在计算机图形学、动画制作、工业设计等领域广泛应用的参数曲线&am…...
PostgreSQL(PostGIS)触发器+坐标转换案例
需求,只录入一份坐标参考为4326的数据,但是发布的数据要求坐标必须是3857 对这种需求可以利用数据库触发器实现数据的同步 步骤: 1. 使用ArcGIS Pro创建一个名字为testfc_4326的图层,坐标参考为4326 2. 使用Pro再创建一个名字…...

Constraints and Triggers
目录 Kinds of Constraints Single-Attribute Keys Multiattribute Key Foreign Keys Expressing Foreign Keys Enforcing Foreign-Key Constraints Actions Taken Attribute-Based Checks Timing of Checks Tuple-Based Checks Assertions Timing of Assertion Ch…...

基于windows系统的netcore架构与SqlServer数据库,实现双机热备。
以下是基于 SQL Server Always On 可用性组 和 故障转移群集 的详细配置步骤,用于实现双机热备。 步骤 1:准备环境 1.1 硬件和软件准备 两台服务器:分别作为主服务器和备用服务器。SQL Server版本:确保两台服务器上安装的SQL S…...

【转bin】EXCEL数据转bin
如果DEC2BIN函数的默认设置无法满足需求(它最多只能处理10位的二进制转换),可以通过VBA宏方法来处理较大数的二进制转换并提取特定位置的数字: 十进制转二进制(不限位宽) 1、打开VBA编辑器(Al…...

BERT:让AI真正“读懂”语言的革命
BERT:让AI真正“读懂”语言的革命 ——图解谷歌神作《BERT: Pre-training of Deep Bidirectional Transformers》 2018年,谷歌AI团队扔出一篇核弹级论文,引爆了整个NLP领域。这个叫BERT的模型在11项任务中屠榜,甚至超越人类表现…...

【计算机组成原理】SPOOLing技术
SPOOLing技术 关键点内容核心思想通过输入/输出井虚拟化独占设备,实现共享,即让多个作业共享一台独占设备依赖条件1. 外存(井文件)2. 多道程序设计虚拟实现多道程序技术磁盘缓冲数据流方向输入设备 → 输入井 → CPU → 输出井 →…...
冷雨泉教授团队:新型视觉驱动智能假肢手,拟人化抓握技术突破,助力截肢者重获生活自信
研究背景:日常生活中,健康人依靠手完成对物体的操作。对于手部截肢患者,手部的缺失导致他们难以有效地操作物体,进而影响正常的日常生活。拥有一个能够实现拟人地自然抓取多种日常物体的五指动力假手是手部截肢患者的夙愿…...

CanvasGroup篇
🎯 Unity UI 性能优化终极指南 — CanvasGroup篇 🧩 什么是 CanvasGroup? CanvasGroup 是UGUI的透明控制器,用于整体控制一组UI元素的: 可见性 (alpha)交互性 (interactable)射线检测 (blocksRaycasts) 🎯…...

[Java 基础]银行账户程序
编写一个 Java 控制台应用程序,模拟一个简单的银行账户。该程序应允许用户执行以下操作: 查询账户余额。 账户初始余额设置为 1000.0 元。向账户存入资金。 用户可以输入存款金额,程序应更新账户余额。存款金额必须为正数。从账户提取资金。…...

2025.6.4总结
工作:今天效率比较高,早上回归4个问题,下午找了3个bug,晚上二刷了科目一(贪吃蛇系统),写了四个点,唯一没达标的就是两自动化没完成。美中不足的是电脑上下载不了PC版的番茄工作软件。…...

将音频数据累积到缓冲区,达到阈值时触发处理
实现了音频处理中的 AEC(声学回声消除)和 AES(音频增强)功能,其核心功能是: 数据缓冲管理:将输入的麦克风和扬声器音频数据块累积到缓冲区中块处理机制:当缓冲区填满预设大小&#…...
pikachu靶场通关笔记14 XSS关卡10-XSS之js输出(五种方法渗透)
目录 一、源码分析 1、进入靶场 2、代码审计 二、渗透实战 1、根据提示输入tmac 2、XSS探测 3、注入Payload1 4、注入Payload2 5、注入Payload3 6、注入Payload4 7、注入Payload5 本系列为通过《pikachu靶场通关笔记》的XSS关卡(共10关)渗透集合&#x…...
)
5.Promise,async,await概念(1)
Promise 是 JavaScript 原生提供的异步处理机制,而 async 和 await 是基于 Promise 的语法糖,由 JavaScript 语言和其运行时环境(如浏览器、Node.js)支持,用于更清晰地编写异步代码,从而避免回调地狱。 Pr…...
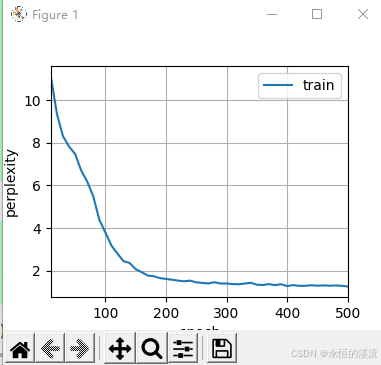
李沐-动手学深度学习:RNN
1.RNN从零开始实现 import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l#8.3.4节 #batch_size:每个小批量中子序列样本的数目,num_steps:每个子序列中预定义的时间步数 #loa…...

Windows系统下npm报错node-gyp configure got “gyp ERR“解决方法
感谢原博主,此文参考网址:https://zhuanlan.zhihu.com/p/398279220 确保已经安装node.js (官方网址:https://nodejs.org/zh-cn/download) 首先在命令窗口执行命令安装windows-build-tools: npm install -…...
介绍)
Elasticsearch中的文档(Document)介绍
在Elasticsearch(ES)中,文档(Document)是最基本的数据单元,类似于关系型数据库中的“行”。它以JSON格式存储,包含多个字段(Field),每个字段可以是不同类型(如文本、数值、日期等)。文档是索引(Index)的组成部分,通过唯一ID标识,并支持动态映射(Dynamic Mappi…...

15个基于场景的 DevOps 面试问题及答案
第一部分:持续集成和部署 (CI/CD) 场景 1:构建中断 “您的 CI 流水线突然出现‘找不到依赖项’的错误。您会如何处理这个问题?” 回答:首先,我会检查是否有新的依赖项被添加到需求文件中,但这些依赖项并未包含在需求文件中。我还会验证构建服务器是否可以访问互联网来下…...
)
今日主题二分查找(寻找峰值 力扣162)
峰值元素是指其值严格大于左右相邻值的元素。 给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。 你可以假设 nums[-1] nums[n] -∞ 。 你必须实现时间复杂度为 O(…...
【教学类-36-10】20250531蝴蝶图案描边,最适合大小(一页1图1图、2图图案不同、2图图案相同对称)
背景说明: 之前做了动物头像扇子(描边20),并制作成一页一套图案对称两张 【教学类-36-09】20250526动物头像扇子的描边(通义万相)对称图40张,根据图片长宽,自动旋转图片,最大化图片-CSDN博客文章浏览阅读1k次,点赞37次,收藏6次。【教学类-36-09】20250526动物头像…...

高效DBA的日常运维主题沙龙
2024年11月10日,在宁波组织了高效DBA的日常运维沙龙活动,大概有20人左右现场参加。会议的主题为: 目标: 1、识别高频低效操作并制定自动化方案 2、建立关键运维指标健康度体系 3、输出可立即落地的优化清单 会议议程 一、效能瓶…...
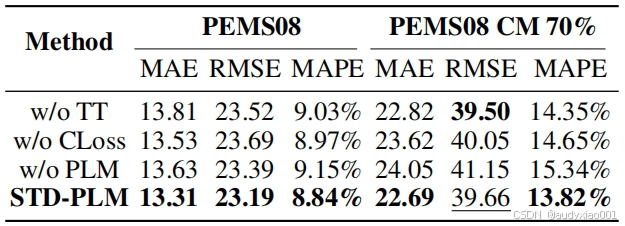
AAAI 2025论文分享│STD-PLM:基于预训练语言模型的时空数据预测与补全方法
本文详细介绍了一篇发表于人工智能顶级会议AAAI 2025的论文《STD-PLM: Understanding Both Spatial and Temporal Properties of Spatial-Temporal Data with PLM》。该论文提出了一种基于预训练语言模型(Pre-trained Language Model,PLM)的…...

Ethernet/IP转DeviceNet网关:驱动大型矿山自动化升级的核心纽带
在大型矿山自动化系统中,如何高效整合新老设备、打通数据孤岛、实现统一控制,是提升效率与安全的关键挑战。JH-EIP-DVN疆鸿智能EtherNet/IP转DeviceNet网关,正是解决这一难题的核心桥梁,为矿山各环节注入强劲连接力: …...

Android 11以上App主动连接WIFI的完整方案
早期Android版本App内连接指定的WIFI还是比较简单的,但是随着Android版本的提升,限制也越来越多。以下是一套完整的Android 11以上的WIFI应用内主动连接方案。 第一步:添加到建议连接: val wifiManager getSystemService(WIFI_…...
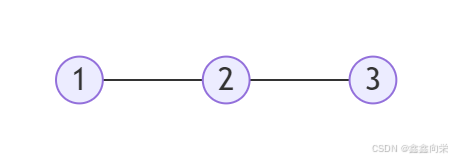
[蓝桥杯]模型染色
模型染色 题目描述 在电影《超能陆战队》中,小宏可以使用他的微型机器人组合成各种各样的形状。 现在他用他的微型机器人拼成了一个大玩具给小朋友们玩。为了更加美观,他决定给玩具染色。 小宏的玩具由 nn 个球型的端点和 mm 段连接这些端点之间的边…...

力扣上C语言编程题
一. 简介 本文简单记录一下力扣上 C语言编程题。作为自己做题笔记。 二. 力扣上 C 语言编程题 1. 从数组中找到两个元素之和,等于一个 target目标值 具体题目说明:给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为…...

卡西欧模拟器:Windows端功能强大的计算器
引言 大家还记得初中高中时期用的计算器吗?今天给大家分享的就是一款windows端的卡西欧计算器。 软件介绍 大家好,我是逍遥小欢。 CASIO fx-9860G是一款功能强大的图形计算器,适用于数学、科学和工程计算。以下是其主要功能和特点的详细介…...

鸿蒙OSUniApp结合机器学习打造智能图像分类应用:HarmonyOS实践指南#三方框架 #Uniapp
UniApp结合机器学习打造智能图像分类应用:HarmonyOS实践指南 引言 在移动应用开发领域,图像分类是一个既经典又充满挑战的任务。随着机器学习技术的发展,我们现在可以在移动端实现高效的图像分类功能。本文将详细介绍如何使用UniApp结合Ten…...

机器学习基础(三) 逻辑回归
目录 逻辑回归的概念核心思想 Sigmoid 函数 逻辑回归的原理和底层优化手段伯努利分布最大似然估计 Maximum Likelihood Estimation (MLE)伯努利分布的似然函数交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失&…...