Gemini开源项目DeepResearch:基于LangGraph的智能研究代理技术原理与实现
引言
在人工智能快速发展的今天,如何构建一个能够进行深度研究、自主学习和迭代优化的AI系统成为了技术前沿的重要课题。Gemini开源的DeepResearch一周收获7.9k Star,Google的开源项目Gemini DeepResearch技术通过结合LangGraph框架和Gemini大语言模型,实现了一个具备自主研究能力的智能代理系统。本文将深入分析这一技术的核心原理和具体实现方式。
开源项目 Gemini Fullstack LangGraph Quickstart
技术架构概览
Gemini DeepResearch采用了基于状态图(StateGraph)的多节点协作架构,通过LangGraph框架实现了一个完整的研究工作流。整个系统包含以下核心组件:
1. 状态管理系统
系统定义了多种状态类型来管理不同阶段的数据流:
class OverallState(TypedDict):messages: Annotated[list, add_messages]search_query: Annotated[list, operator.add]web_research_result: Annotated[list, operator.add]sources_gathered: Annotated[list, operator.add]initial_search_query_count: intmax_research_loops: intresearch_loop_count: intreasoning_model: str
这种设计允许系统在不同节点间传递和累积信息,确保研究过程的连续性和完整性。
2. 核心工作流程
整个研究流程分为五个关键阶段:
阶段一:查询生成(Query Generation)
系统首先分析用户输入,使用Gemini 2.0 Flash模型生成多个优化的搜索查询:
def generate_query(state: OverallState, config: RunnableConfig) -> QueryGenerationState:llm = ChatGoogleGenerativeAI(model=configurable.query_generator_model,temperature=1.0,max_retries=2,api_key=os.getenv("GEMINI_API_KEY"),)structured_llm = llm.with_structured_output(SearchQueryList)formatted_prompt = query_writer_instructions.format(current_date=current_date,research_topic=get_research_topic(state["messages"]),number_queries=state["initial_search_query_count"],)result = structured_llm.invoke(formatted_prompt)return {"query_list": result.query}
关键特点:
- 多样化查询生成:系统会生成多个不同角度的搜索查询,确保信息收集的全面性
- 结构化输出:使用Pydantic模型确保输出格式的一致性
- 时效性考虑:查询中包含当前日期信息,确保获取最新数据
阶段二:并行网络研究(Parallel Web Research)
系统使用LangGraph的Send机制实现并行搜索:
def continue_to_web_research(state: QueryGenerationState):return [Send("web_research", {"search_query": search_query, "id": int(idx)})for idx, search_query in enumerate(state["query_list"])]
每个搜索查询都会启动一个独立的web_research节点,实现真正的并行处理。
阶段三:智能网络搜索(Web Research)
这是系统的核心功能之一,集成了Google Search API和Gemini模型:
def web_research(state: WebSearchState, config: RunnableConfig) -> OverallState:response = genai_client.models.generate_content(model=configurable.query_generator_model,contents=formatted_prompt,config={"tools": [{"google_search": {}}],"temperature": 0,},)# 处理搜索结果和引用resolved_urls = resolve_urls(response.candidates[0].grounding_metadata.grounding_chunks, state["id"])citations = get_citations(response, resolved_urls)modified_text = insert_citation_markers(response.text, citations)return {"sources_gathered": sources_gathered,"search_query": [state["search_query"]],"web_research_result": [modified_text],}
技术亮点:
- 原生Google Search集成:直接使用Google的搜索API获取实时信息
- 自动引用处理:系统自动提取和格式化引用信息
- URL优化:将长URL转换为短链接以节省token消耗
阶段四:反思与知识缺口分析(Reflection)
这是DeepResearch的核心创新之一,系统会自动评估已收集信息的充分性:
def reflection(state: OverallState, config: RunnableConfig) -> ReflectionState:formatted_prompt = reflection_instructions.format(current_date=current_date,research_topic=get_research_topic(state["messages"]),summaries="\n\n---\n\n".join(state["web_research_result"]),)llm = ChatGoogleGenerativeAI(model=reasoning_model,temperature=1.0,max_retries=2,api_key=os.getenv("GEMINI_API_KEY"),)result = llm.with_structured_output(Reflection).invoke(formatted_prompt)return {"is_sufficient": result.is_sufficient,"knowledge_gap": result.knowledge_gap,"follow_up_queries": result.follow_up_queries,"research_loop_count": state["research_loop_count"],"number_of_ran_queries": len(state["search_query"]),}
反思机制的核心功能:
- 知识缺口识别:自动分析当前信息是否足够回答用户问题
- 后续查询生成:针对发现的知识缺口生成新的搜索查询
- 迭代控制:决定是否需要进行下一轮研究
阶段五:答案综合(Answer Finalization)
最终阶段将所有收集的信息综合成完整的答案:
def finalize_answer(state: OverallState, config: RunnableConfig):formatted_prompt = answer_instructions.format(current_date=current_date,research_topic=get_research_topic(state["messages"]),summaries="\n---\n\n".join(state["web_research_result"]),)llm = ChatGoogleGenerativeAI(model=reasoning_model,temperature=0,max_retries=2,api_key=os.getenv("GEMINI_API_KEY"),)result = llm.invoke(formatted_prompt)# 处理引用链接unique_sources = []for source in state["sources_gathered"]:if source["short_url"] in result.content:result.content = result.content.replace(source["short_url"], source["value"])unique_sources.append(source)return {"messages": [AIMessage(content=result.content)],"sources_gathered": unique_sources,}
技术创新点
1. 自适应研究循环
系统通过evaluate_research函数实现智能的研究循环控制:
def evaluate_research(state: ReflectionState, config: RunnableConfig) -> OverallState:configurable = Configuration.from_runnable_config(config)max_research_loops = (state.get("max_research_loops")if state.get("max_research_loops") is not Noneelse configurable.max_research_loops)if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:return "finalize_answer"else:return [Send("web_research",{"search_query": follow_up_query,"id": state["number_of_ran_queries"] + int(idx),},)for idx, follow_up_query in enumerate(state["follow_up_queries"])]
这种设计确保了系统既能深入研究复杂问题,又能避免无限循环。
2. 智能引用管理
系统实现了完整的引用管理机制:
- URL解析:将复杂的搜索结果URL转换为简洁的引用格式
- 引用插入:自动在文本中插入引用标记
- 去重处理:确保最终答案中只包含实际使用的引用源
3. 多模型协作
系统巧妙地使用不同的Gemini模型处理不同任务:
- Gemini 2.0 Flash:用于查询生成和网络搜索,速度快
- Gemini 2.5 Flash:用于反思分析,平衡速度和质量
- Gemini 2.5 Pro:用于最终答案生成,确保高质量输出
系统架构图
用户输入 → 查询生成 → 并行网络搜索 → 反思分析 → 评估决策↓ ↓ ↓ ↓多个搜索查询 收集网络信息 知识缺口分析 继续研究/结束↓ ↓生成后续查询 答案综合↓ ↓返回搜索 最终答案
相关文章:
Gemini开源项目DeepResearch:基于LangGraph的智能研究代理技术原理与实现
引言 在人工智能快速发展的今天,如何构建一个能够进行深度研究、自主学习和迭代优化的AI系统成为了技术前沿的重要课题。Gemini开源的DeepResearch一周收获7.9k Star,Google的开源项目Gemini DeepResearch技术通过结合LangGraph框架和Gemini大语言模型&…...

React状态管理Context API + useReducer
在 React 中,Context API useReducer 是一种轻量级的状态管理方案,适合中小型应用或需要跨组件共享复杂状态的场景。它避免了 Redux 的繁琐配置,同时提供了清晰的状态更新逻辑。 1. 基本使用步骤 (1) 定义 Reducer 类似于 Redux 的 reduce…...

【无标题】路径着色问题的革命性重构:拓扑色动力学模型下的超越与升华
路径着色问题的革命性重构:拓扑色动力学模型下的超越与升华 一、以色列路径着色模型的根本局限 mermaid graph TB A[以色列路径着色模型] --> B[强连通约束] A --> C[仅实边三角剖分] A --> D[静态色彩分配] B --> E[无法描述非相邻关系] C --> F[忽…...
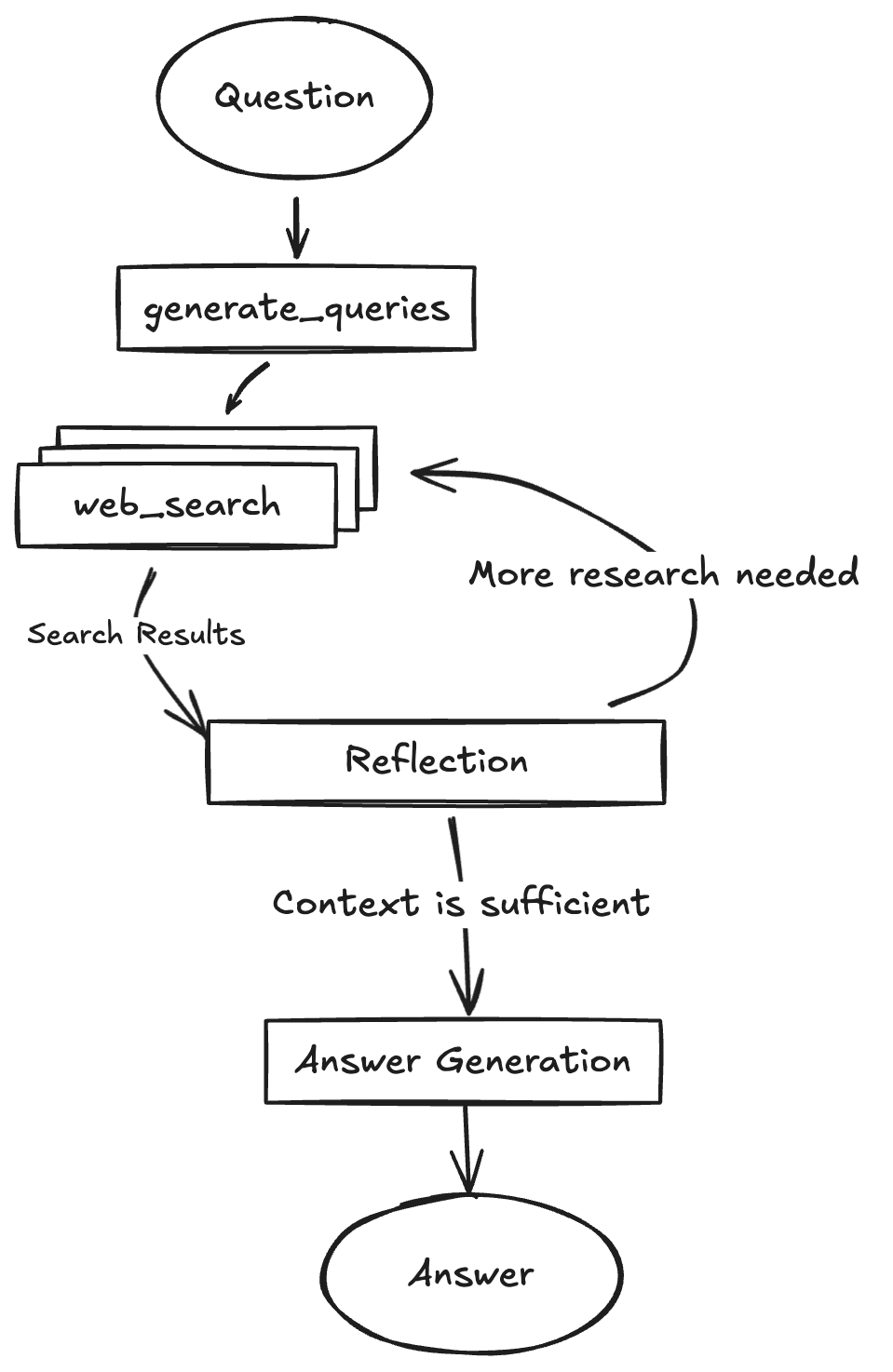
Doris Catalog 联邦分析查询性能优化:从排查到优化的完整指南
在大数据分析中,Doris 的 Catalog 联邦分析功能为整合多源数据提供了有力支持。然而,在实际应用中,可能会遇到各种问题影响其正常运行。本文将详细剖析这些问题并提供解决方案。 一、联邦分析查询慢:内外表通用排查逻辑 当遇到 …...

01 Deep learning神经网络的编程基础 二分类--吴恩达
二分类 1. 核心定义 二分类任务是监督学习中最基础的问题类型,其目标是将样本划分为两个互斥类别。设样本特征空间为 X ⊆ R n \mathcal{X} \subseteq \mathbb{R}^n X⊆Rn,输出空间为 Y { 0 , 1 } \mathcal{Y} \{0,1\} Y{0,1},学习目标为…...
视频自动化分割方案:支持按时间与段数拆分
在日常视频处理任务中,如何快速将一个较长的视频文件按照指定规则拆分为多个片段,是许多用户都会遇到的问题。尤其对于需要批量处理视频的开发者、自媒体运营者或内容创作者来说,手动剪辑不仅效率低下,还容易出错。这是一款绿色免…...

Open SSL 3.0相关知识以及源码流程分析
Open SSL 3.0相关知识以及源码流程分析 编译 windows环境编译1、工具安装 安装安装perl脚本解释器、安装nasm汇编器(添加到环境变量)、Visual Studio编译工具 安装dmake ppm install dmake # 需要过墙2、开始编译 # 1、找到Visual Studio命令行编译工具目录 或者菜单栏直接…...

股指期货合约价值怎么算?
股指期货合约价值就是你买一手股指期货合约,理论上值多少钱。这个价值是根据期货的价格和合约乘数来计算的。就好比你买了一斤苹果,价格是5块钱一斤,那你买一斤就得付5块钱。股指期货也是一样,只不过它的计算稍微复杂一点点。 一…...
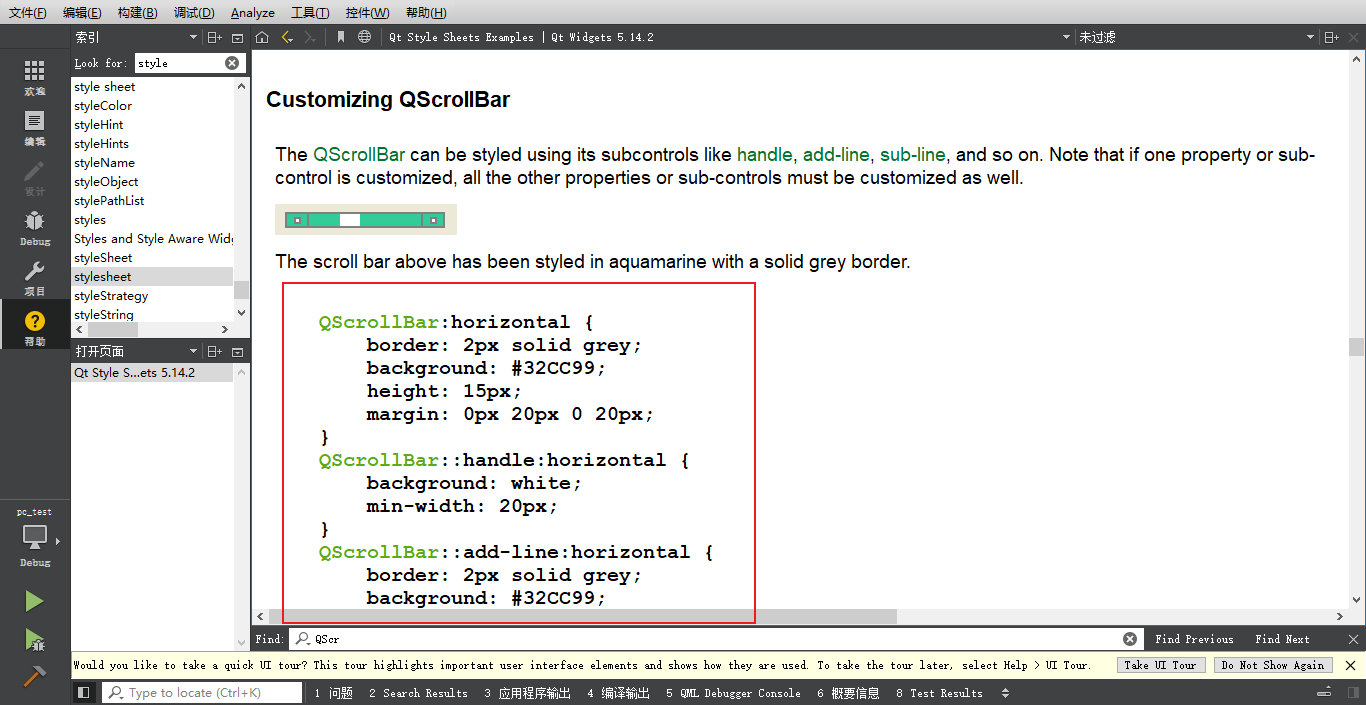
【QT】使用QT帮助手册找控件样式
选择帮助—》输入stylesheet(小写)—》选择stylesheet—》右侧选择Qt Style Sheets Reference 2.使用CtrlF—》输入要搜索的控件—》点击Customizing QScrollBar 3.显示参考样式表–》即可放入QT-designer的样式表中...

计算机网络(5)——数据链路层
1.概述 数据链路层负责一套链路上从一个节点向另一个物理链路直接相连的相邻节点传输数据报。换言之,主要解决相邻节点间的可靠数据传输 节点(nodes):路由器和主机 链路(links):连接相邻节点的通信信道 2.数据链路层服务 2.1 组帧 组帧(fra…...
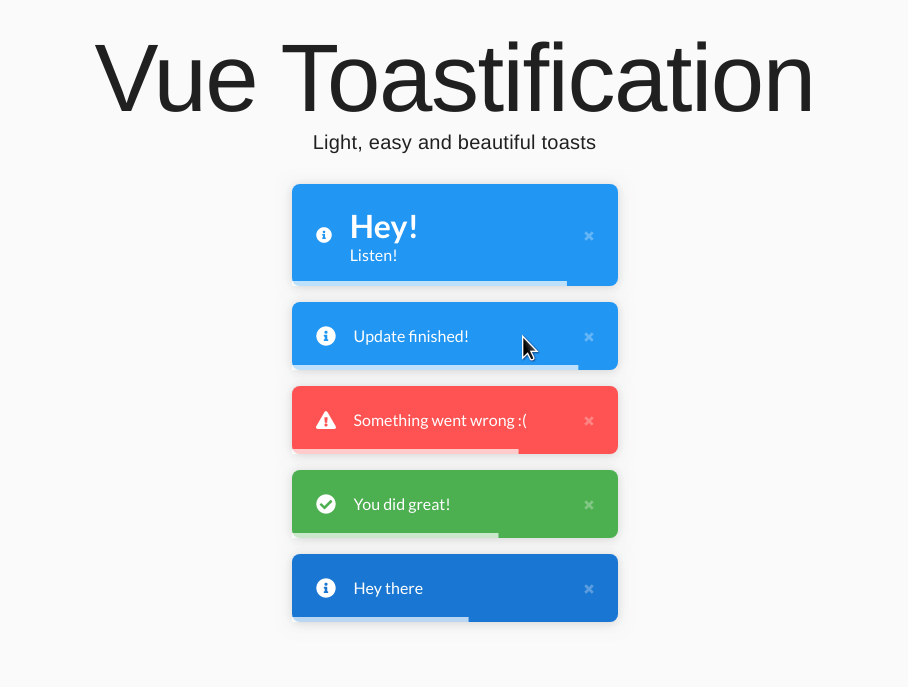
VuePress完美整合Toast消息提示
VuePress 整合 Vue-Toastification 插件笔记 记录如何在 VuePress 项目中整合使用 vue-toastification 插件,实现优雅的消息提示。 一、安装依赖 npm install vue-toastification或者使用 yarn: yarn add vue-toastification二、配置 VuePress 客户端增…...

JVM 调优参数详解与实践
JVM 是 Java 程序性能的关键,合理的调优可以显著提升系统稳定性和吞吐量。本文将从基础参数出发,结合线上生产实践,对常用调优参数进行深入剖析与实战分享。 一、JVM内存结构概览 在进行JVM参数调优前,了解JVM内存结构非常关键 堆内存(Heap):用于存储对象,是GC主要处理…...
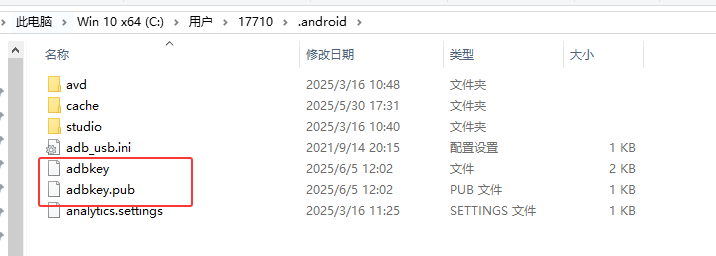
adb 连不上真机设备问题汇总
问题一、无法弹出 adb 调试授权弹窗 详细描述: 开发者选项中已打开 usb 调试,仅充电模式下 usb 调试也已打开,电脑通过 usb 连上手机后,一直弹出 adb 调试授权弹窗,尝试取消授权再次连接,还是无法弹出问题…...
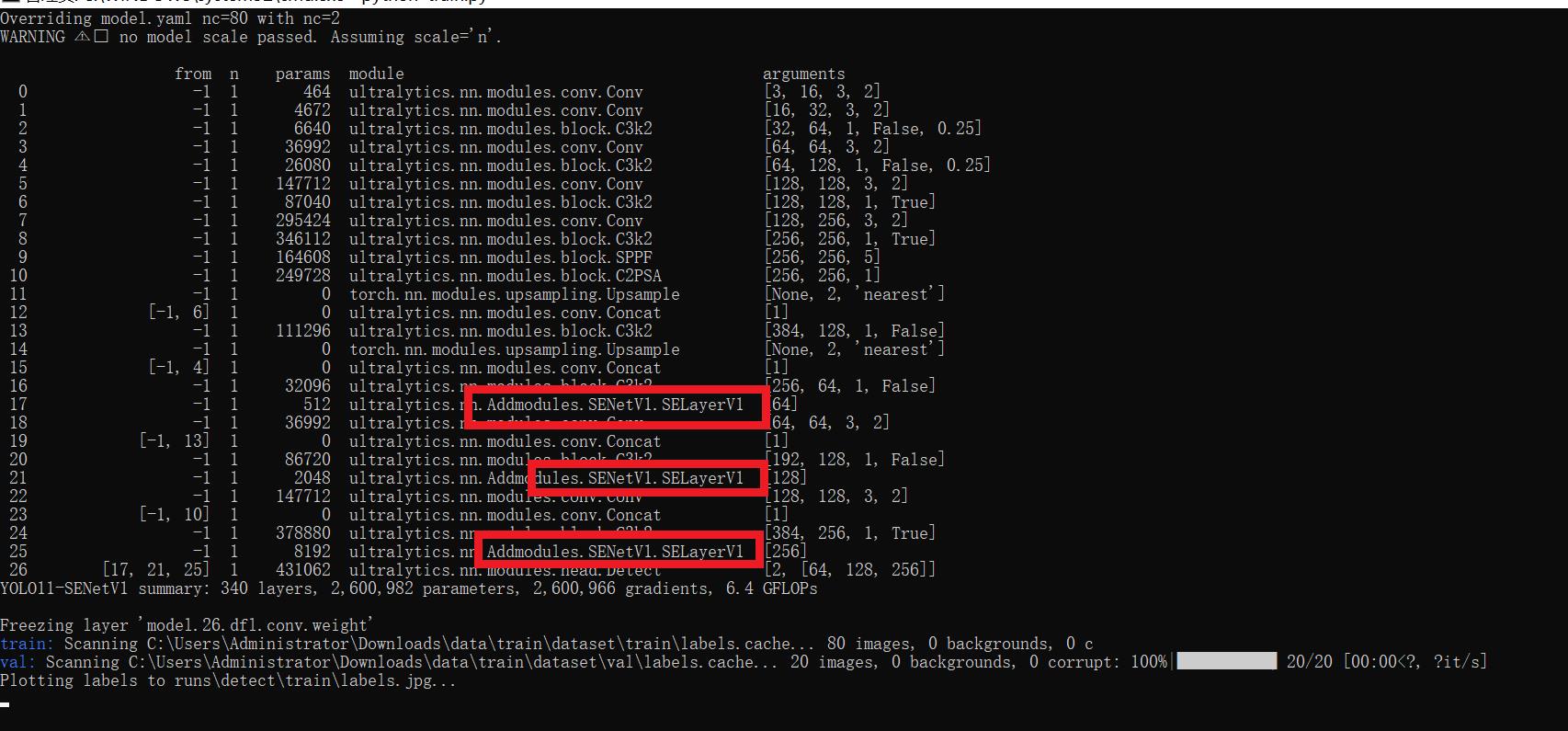
[yolov11改进系列]基于yolov11引入注意力机制SENetV1或者SENetV2的python源码+训练源码
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型Q,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一种…...

鸿蒙仓颉语言开发实战教程:商城搜索页
大家好,今天要分享的是仓颉语言商城应用的搜索页。 搜索页的内容比较多,都有点密集恐惧症了,不过我们可以从上至下将它拆分开来,逐一击破。 导航栏 搜索页的的最顶部是导航栏,由返回按钮和搜索框两部分组成,比较简单…...

上门服务小程序会员系统框架设计
逻辑分析 会员注册与登录:用户需要能够通过小程序进行会员注册,提供必要信息如手机号码、密码等,注册成功后可登录系统。会员信息管理:包括会员基本信息(姓名、联系方式等)的修改、查看,同时可能…...

图像去雾数据集总汇
自然去雾数据集 部分的数据清洗可以看这里:图像去雾数据集的下载和预处理操作 RESIDE-IN 将ITS作为训练集,SOTSindoor作为测试集。训练集13990对,验证集500对。 目前室内sota常用,最高已经卷到PSNR-42.72 最初应该是dehazefo…...

小程序引入deepseek
首先需要申请key: 地址 deepseek文档地址 使用wx.request获取数据 const task wx.request({url: https://api.deepseek.com/chat/completions,method: POST,responseType: text,headers: {Content-Type: application/json,Authorization: Bearer YOUR_API_KEY},dataType: te…...

网络攻防技术十四:入侵检测与网络欺骗
文章目录 一、入侵检测概述二、入侵系统的分类三、入侵检测的分析方法1、特征检测(滥用检测、误用检测)2、异常检测 四、Snort入侵检测系统五、网络欺诈技术1、蜜罐2、蜜网3、网络欺骗防御 六、简答题1. 入侵检测系统对防火墙的安全弥补作用主要体现在哪…...
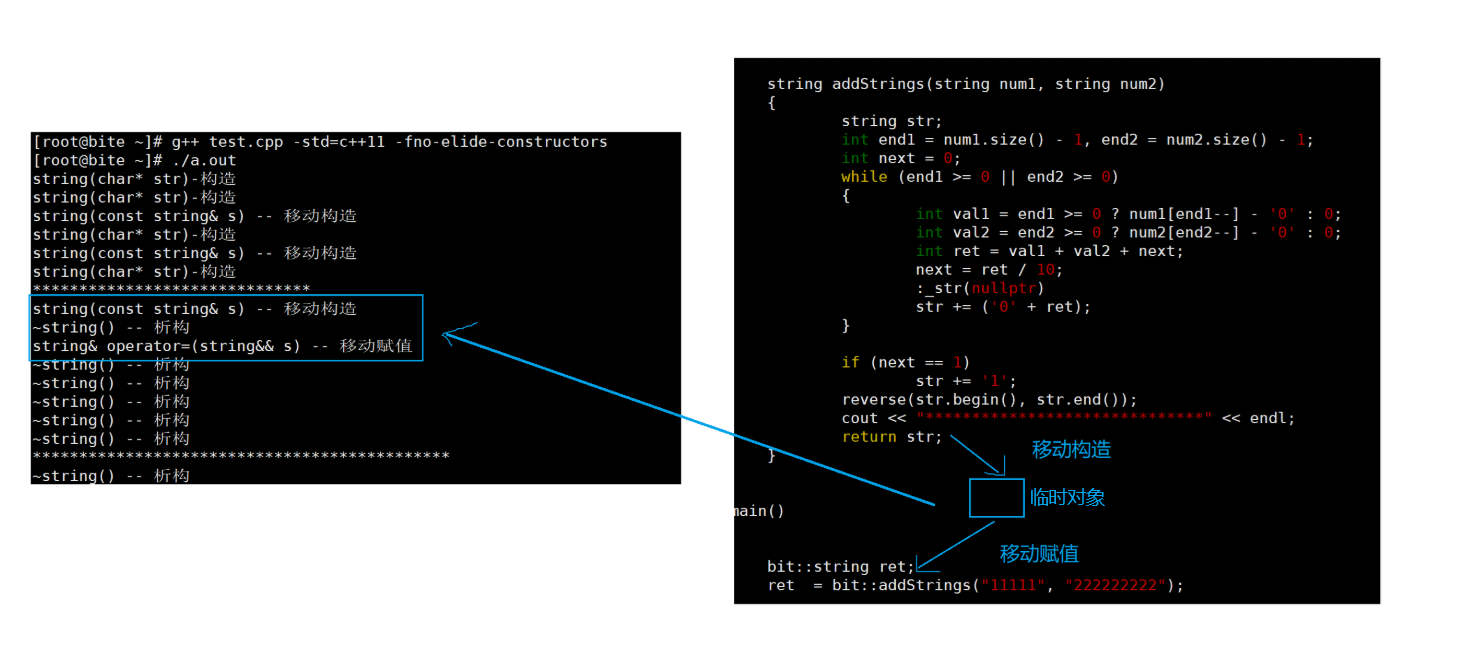
C++笔记-C++11(一)
1.C11的发展历史 C11 是 C 的第⼆个主要版本,并且是从 C98 起的最重要更新。它引⼊了⼤量更改,标准化了既有实践,并改进了对 C 程序员可⽤的抽象。在它最终由 ISO 在 2011 年 8 ⽉ 12 ⽇采纳前,⼈们曾使⽤名称“C0x”,…...
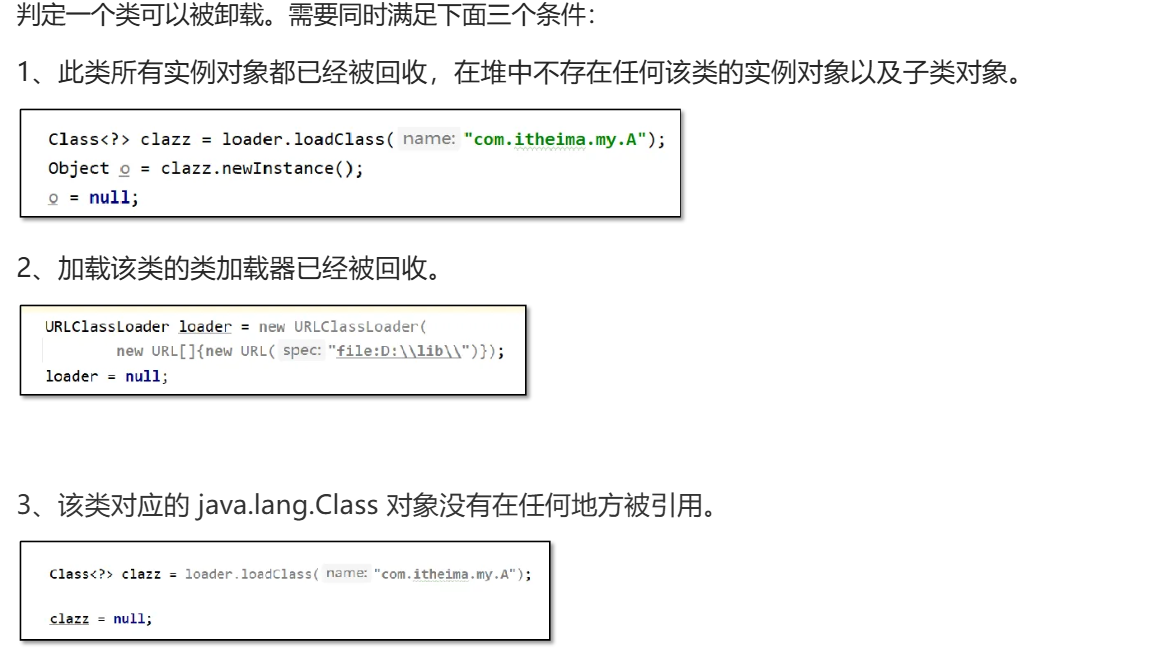
JVM 类初始化和类加载 详解
类初始化和类加载 类加载的时机 加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始(懒解析)&am…...
B站缓存视频数据m4s转mp4
B站缓存视频数据m4s转mp4 结构分析 结构分析 在没有改变数据存储目录的情况下,b站默认数据保存目录为: Android->data->tv.danmaku.bili->download每个文件夹代表一个集合的视频,比如,我下载的”java从入门到精通“&…...

DeepSeek 助力 Vue3 开发:打造丝滑的日历(Calendar),日历_天气预报日历示例(CalendarView01_18)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

【机器学习】主成分分析 (PCA)
目录 一、基本概念 二、数学推导 2.1 问题设定:寻炸最大方差的投影方向 2.2 数据中心化 2.3 目标函数:最大化投影后的方差 2.4 约束条件 2.5 拉格朗日乘子法 编辑 2.6 主成分提取 2.7 降维公式 三、SVD 四、实际案例分析 一、基本概念 主…...
二叉树-104.二叉树的最大深度-力扣(LeetCode)
一、题目解析 这里需要注意根节点的深度是1,也就是说计算深度的是从1开始计算的 二、算法原理 解法1:广度搜索,使用队列 解法2:深度搜索,使用递归 当计算出左子树的深度l,与右子树的深度r时,…...

物料转运人形机器人适合应用于那些行业?解锁千行百业的智慧物流革命
当传统物流设备困于固定轨道,当人力搬运遭遇效率与安全的天花板,物料转运人形机器人正以颠覆性姿态重塑产业边界。富唯智能凭借GRID大模型驱动的"感知-决策-执行"闭环系统,让物料流转从机械输送升级为智慧调度——这不仅是工具的革…...

k8s开发webhook使用certmanager生成证书
1.创建 Issuer apiVersion: cert-manager.io/v1 kind: Issuer metadata:name: selfsigned-issuernamespace: default spec:selfSigned: {}2.Certificate(自动生成 TLS 证书) apiVersion: cert-manager.io/v1 kind: Certificate metadata:name: webhook…...
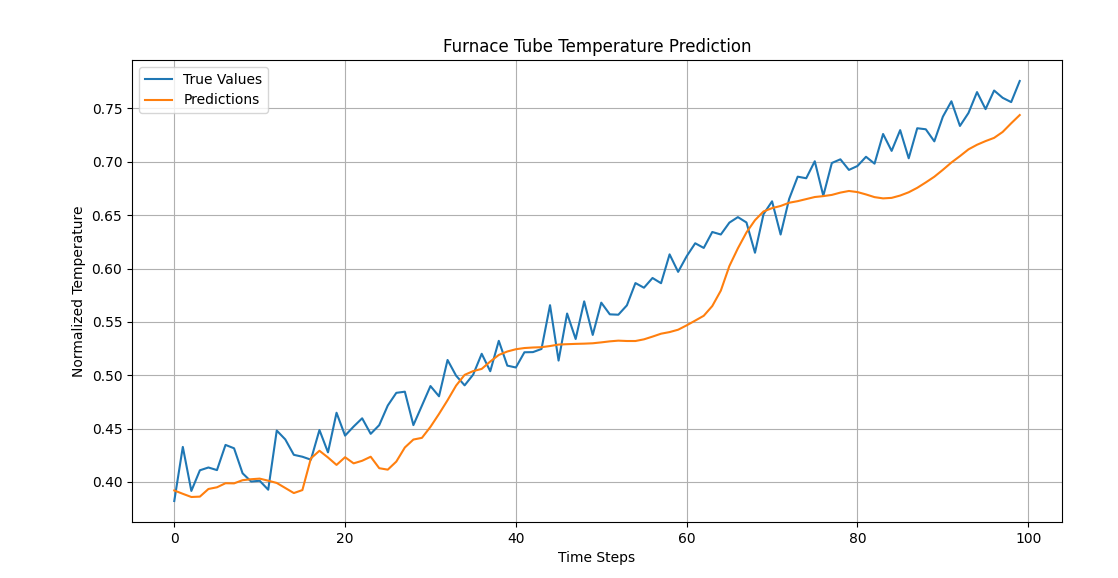
时序预测模型测试总结
0.背景描述 公司最近需要在仿真平台上增加一些AI功能,针对于时序数据,想到的肯定是时序数据处理模型,典型的就两大类:LSTM 和 tranformer 。查阅文献,找到一篇中石化安全工程研究院有限公司的文章,题目为《…...
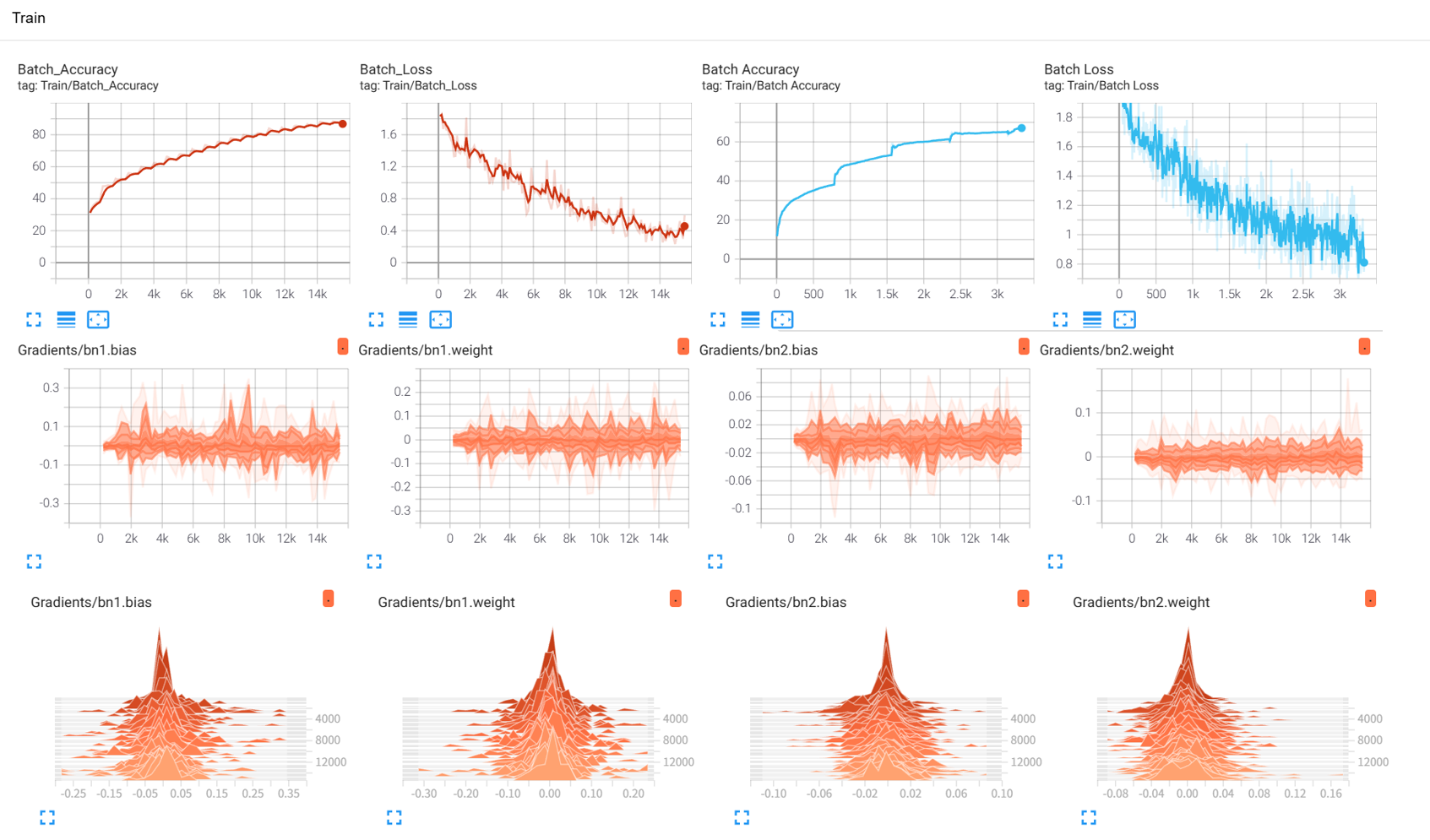
第四十五天打卡
知识点回顾: tensorboard的发展历史和原理 tensorboard的常见操作 tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensor…...
springboot mysql/mariadb迁移成oceanbase
前言:项目架构为 springbootmybatis-plusmysql 1.部署oceanbase服务 2.springboot项目引入oceanbase依赖(即ob驱动) ps:删除原有的mysql/mariadb依赖 <dependency> <groupId>com.oceanbase</groupId> …...