抑郁症患者数据分析
导入数据
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as optsdf=pd.read_csv('YiYuZheng.csv')
df.head(1)
| Patient_name | Label | Date | Title | Communications | Doctor | Hospital | Faculty | |
|---|---|---|---|---|---|---|---|---|
| 0 | 患者:女 43岁 | 压抑 | 05.28 | 压抑 个人情况:去年1月份开始夫妻两地分居,孩子13岁男孩住校,平... 这种情况是否需要去... | 115 | 杨胜文 | 襄阳市安定医院 | 心理科 |
# 查看数据
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8400 entries, 0 to 8399
Data columns (total 8 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Patient_name 8400 non-null object1 Label 8400 non-null object2 Date 8288 non-null object3 Title 8400 non-null object4 Communications 8400 non-null int64 5 Doctor 8400 non-null object6 Hospital 8400 non-null object7 Faculty 8400 non-null object
dtypes: int64(1), object(7)
memory usage: 525.1+ KB
从数据反馈结果来看:Date列存在空缺值,并且不是日期类型。
Patient_name列存在信息混合一起情况,需要拆分年龄和性别。
数据预处理
拆分年龄和性别
#获取性别,作为新列
#患者:女 43岁,首先按照空格拆分,结果为[患者:女]\[ ]\[43岁],选取第一个,第二次按照中文冒号拆分,[患者][: ][女]
df['Sex']=df['Patient_name'].map(lambda x:x.split(" ")[0]).map(lambda x:x.split(":")[-1])#获取年龄,作为新列
#患者:女 43岁,首先按照空格拆分,结果为[患者:女]\[ ]\[43岁],选取第三个,并且去掉“岁”
df['Age']=df['Patient_name'].map(lambda x:x.split(" ")[2][:-1])df.head()
| Patient_name | Label | Date | Title | Communications | Doctor | Hospital | Faculty | Sex | Age | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 患者:女 43岁 | 压抑 | 05.28 | 压抑 个人情况:去年1月份开始夫妻两地分居,孩子13岁男孩住校,平... 这种情况是否需要去... | 115 | 杨胜文 | 襄阳市安定医院 | 心理科 | 女 | 43 |
| 1 | 患者:女 32岁 | 生气。心梗。抑郁 | 05.28 | 生气。心梗。抑郁 郁郁寡欢。被他人语言刺激。卧床不起。没动力。心疼。受伤 是什么病。怎么办 | 12 | 郭汉法 | 泰安八十八医院 | 临床心理科 | 女 | 32 |
| 2 | 患者:女 15岁 | 情绪低落,烦躁抑郁 | 05.28 | 情绪低落,烦躁抑郁 情绪低落,压抑烦躁,思考能力降低。长时间学习,睡眠时间少。睡... 还有... | 2 | 郭苏皖 | 南京脑科医院 | 医学心理科 | 女 | 15 |
| 3 | 患者:女 16岁 | 抑郁 | 05.28 | 抑郁 前面已简述,2024年夏季中考,本来学习非常好,非常自律,自... 已经服用9个月的艾... | 2 | 刘丽 | 联勤保障部队第九〇四医院(常州院区) | 精神3科(物质依赖科) | 女 | 16 |
| 4 | 患者:女 67岁 | 焦虑症 严重躯干反应、抑郁症 | 05.28 | 焦虑症 严重躯干反应 抑郁症 草酸加量以后,还是有比较严重的躯干反应,主要表现为背痛 脖... | 2 | 刘晓华 | 上海市精神卫生中心 | 精神科 | 女 | 67 |
处理空缺值
df.isnull().sum()
Patient_name 0
Label 0
Date 112
Title 0
Communications 0
Doctor 0
Hospital 0
Faculty 0
Sex 0
Age 0
dtype: int64
#因为空缺数据较少,并且不适合使用填充法,故而删除
df.dropna(inplace=True)#在原来的数据上删除
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 8288 entries, 0 to 8399
Data columns (total 10 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Patient_name 8288 non-null object1 Label 8288 non-null object2 Date 8288 non-null object3 Title 8288 non-null object4 Communications 8288 non-null int64 5 Doctor 8288 non-null object6 Hospital 8288 non-null object7 Faculty 8288 non-null object8 Sex 8288 non-null object9 Age 8288 non-null object
dtypes: int64(1), object(9)
memory usage: 712.2+ KB
修改Date列
#df['Date']
#转换成字符串类型
df['Date']=df['Date'].astype(str)#定义函数,实现date列格式统一:年-月-日
def trans_date(tag):if tag.startswith("20"):#查看是否以20开头,即查看是否存在年tag=tag.replace(".","-")else:tag="2025-"+tag.replace(".","-")#否则加上年份return tagdf['Date']= df['Date'].map(lambda x:trans_date(x))#调用函数转换格式#转换成日期类型
df['Date']=pd.to_datetime(df['Date'])#df.info()
数据可视化分析
from pyecharts.globals import ThemeType #导入主题库
查看患者性别分布情况
#准备数据:按照性别统计个数
data=df['Sex'].value_counts()
#data
x=data.index.tolist()
y=data.tolist()#绘制饼图
pie=(Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))#设置主题.add("",[list(z) for z in zip(x,y)],#数据需要打包成[(key,value),(key,value),...]label_opts=opts.LabelOpts(formatter="{b}:{d}%")#以百分比形式显示标签).set_global_opts(title_opts=opts.TitleOpts(title="患者性别分布情况"))
)
pie.render_notebook()
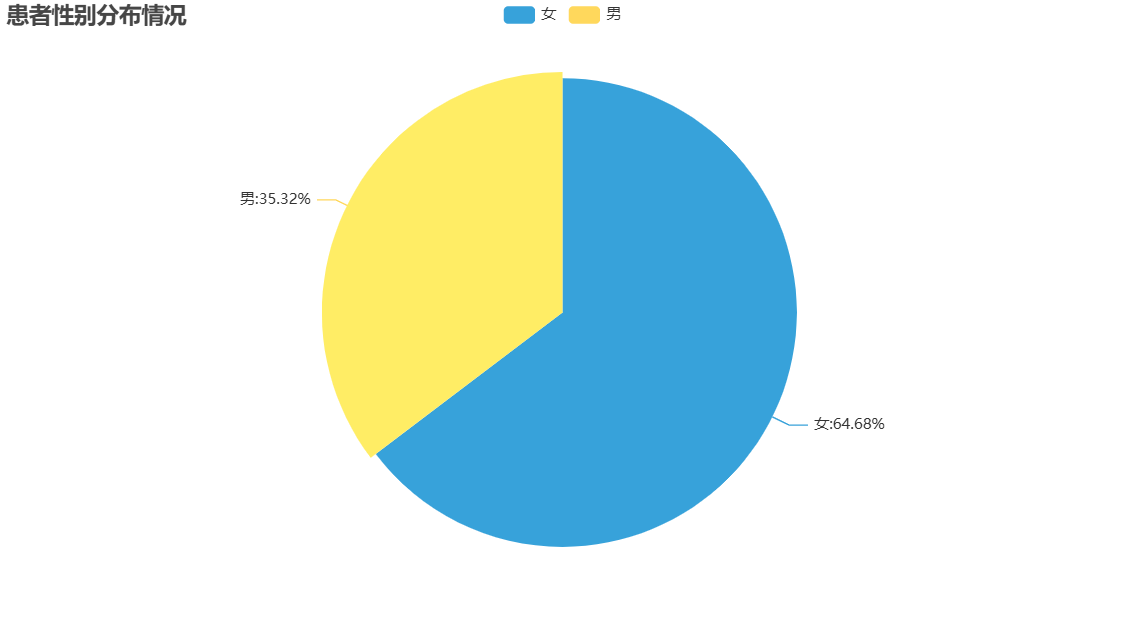
可见:女性抑郁症更为常见。
患者年龄分布情况
#数据准备
#1.转换年龄为数值类型
#df['Age']=df['Age'].astype(int)
#因为年龄数据不规范,存在:X岁Y月 形式的数据,再次进行数据处理
df['Age']=df['Age'].map(lambda x:"1" if ("天" in x or "个" in x or "月" in x) else x).astype(int)
#df.info()
#2.年龄分箱
labels=["0~18","19~40","41~60","61~80","80+"]#区间标签
df['age_label']=pd.cut(df['Age'],bins=[0,18,40,60,80,100],labels=labels)#分箱#3.统计各个年龄区间人数
data=df['age_label'].value_counts().sort_index()#按照索引值排序
#datax=data.index.tolist()
y=data.tolist()#画柱状图
bar=(Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))#主题配置.add_xaxis(x).add_yaxis("人数",y).set_global_opts(title_opts=opts.TitleOpts(title="患者年龄分布情况")).reversal_axis()
)
bar.render_notebook()
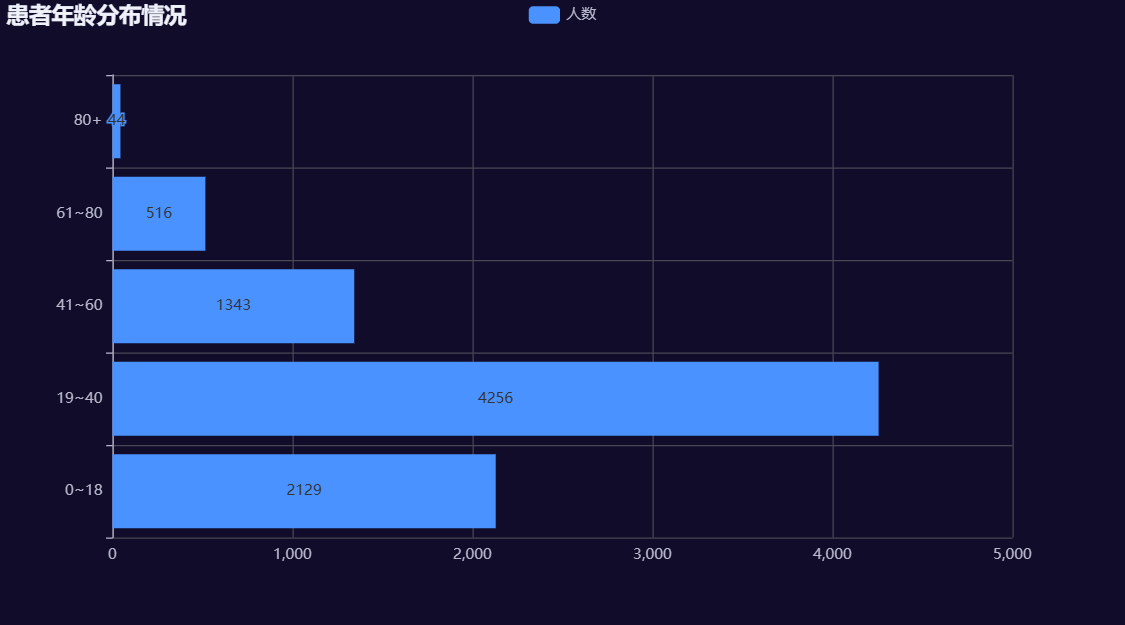
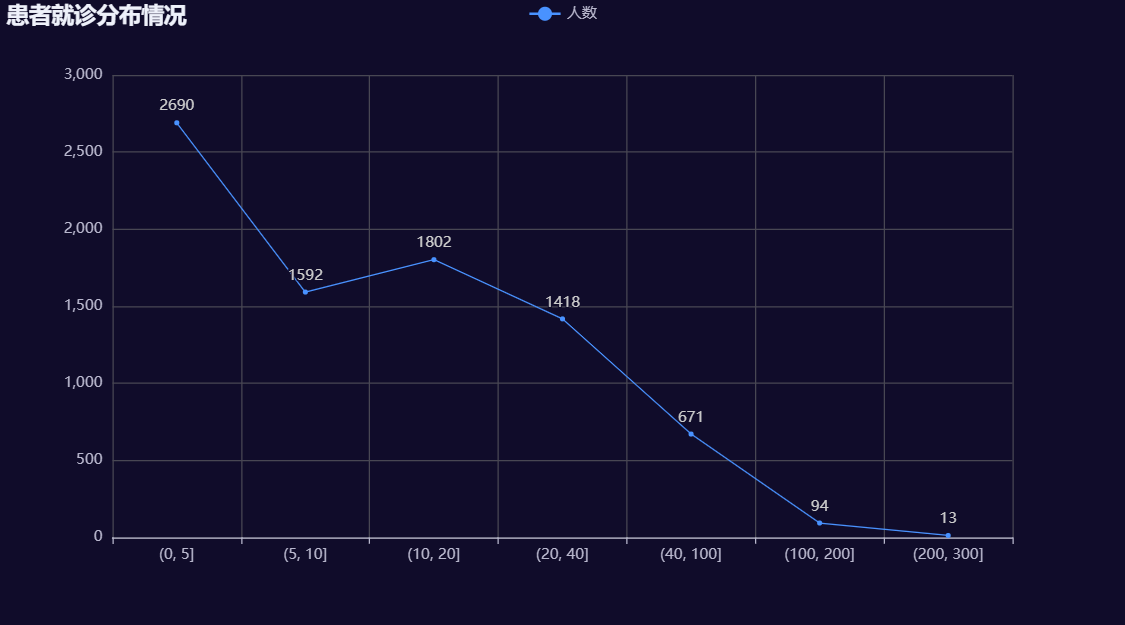
查看患者就诊次数分布
#对就诊次数分箱
bins=[0,5,10,20,40,100,200,300]
df['Communications_count']=pd.cut(df['Communications'],bins=bins)
#按照就诊分箱数据统计数据
data=df['Communications_count'].value_counts().sort_index()#按照索引排序
#data
x=data.index.astype(str).tolist()
y=data.tolist()#画柱状图
line=(Line(init_opts=opts.InitOpts(theme=ThemeType.DARK))#主题配置.add_xaxis(x).add_yaxis("人数",y).set_global_opts(title_opts=opts.TitleOpts(title="患者就诊分布情况"),xaxis_opts=opts.AxisOpts(type_='category'),#x轴数据为类别类型yaxis_opts=opts.AxisOpts(type_='value'),)#y轴数据为数值类型)
line.render_notebook()
<div id="22f20d64280d408c96ed5b60aa15391a" style="width:900px; height:500px;"></div>
患者标签分布
#pip install jieba
^C
Note: you may need to restart the kernel to use updated packages.
import jieba
from collections import Counter
#定义函数分词
def chinese_word_cut(text):seg_list=jieba.cut(text,cut_all=False)return [word for word in seg_list if len(word)>1]#对表格数据进行分词
all_word=[]
for text in df['Title']:all_word.extend(chinese_word_cut(text))#统计词频
word_count=Counter(all_word)
top_words=word_count.most_common(100)#取前100个高频词data=[(word,count) for word,count in top_words]w=(WordCloud().add("",data)
)
w.render_notebook()

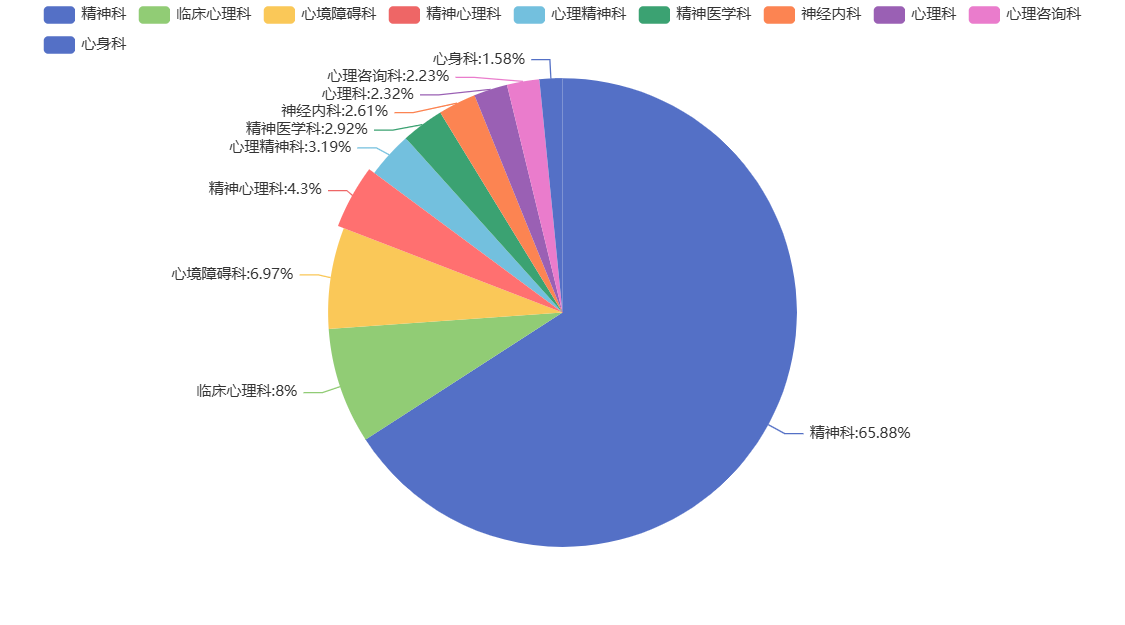
患者就诊的科室分布
data=df['Faculty'].value_counts()[:10] #选取前十科室pie=(Pie().add('',[list(z) for z in zip(data.index.tolist(),data.tolist())],#饼图数据格式[[key1,value1],[key2,value2],...]label_opts=opts.LabelOpts(formatter="{b}:{d}%")#标签格式)
)
pie.render_notebook()
相关文章:
抑郁症患者数据分析
导入数据 import pandas as pd from pyecharts.charts import * from pyecharts import options as optsdfpd.read_csv(YiYuZheng.csv) df.head(1)Patient_nameLabelDateTitleCommunicationsDoctorHospitalFaculty0患者:女 43岁压抑05.28压抑 个人情况:…...

ros2--图像/image
原始图像 接口类型: 压缩图像 接口类型: sensor_msgs/msg/CompressedImage ros2 interface show sensor_msgs/msg/CompressedImage # This message contains a compressed image.std_msgs/Header header # Header timestamp should be acquisition ti…...

Rust 学习笔记:关于智能指针的练习题
Rust 学习笔记:关于智能指针的练习题 Rust 学习笔记:关于智能指针的练习题问题一问题二问题三问题四问题五问题六问题七问题八问题九问题十 Rust 学习笔记:关于智能指针的练习题 参考视频: https://www.bilibili.com/video/BV1S…...
6.RV1126-OPENCV 形态学基础膨胀及腐蚀
一.膨胀 1.膨胀原理 膨胀的本质就是通过微积分的转换,将图像A和图形B进行卷积操作合并成一个AB图像。核就是指任意的形状或者大小的图形B。例如下图,将核(也就是图形B)通过微积分卷积,和图像A合并成一个图像AB。 2.特点 图像就会更加明亮 …...

筑牢企业网管域安全防线,守护数字核心——联软网管域安全建设解决方案
在当今数字化浪潮中,企业网管域作为数据中心的核心,其安全防护至关重要。一旦网管域遭受攻击,整个网络系统可能陷入瘫痪,给企业带来巨大损失。联软科技凭借其创新的网管域安全建设解决方案,为企业提供了全方位的安全保…...
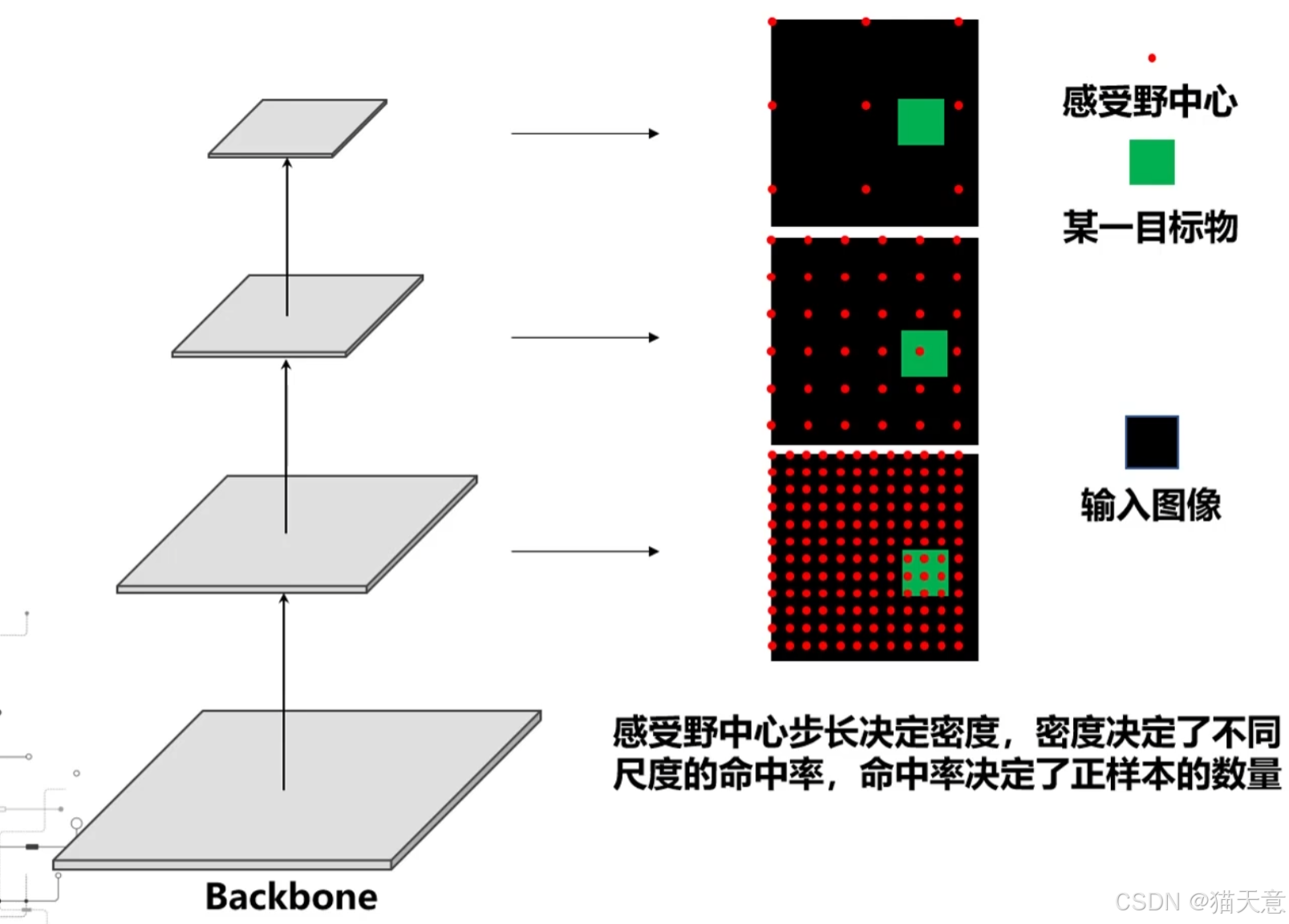
【目标检测】backbone究竟有何关键作用?
backbone的核心在于能为检测提供若干种感受野大小和中心步长的组合,以满足对不同尺度和类别的目标检测。...

一个小小的 flask app, 几个小工具,拼凑一下
1. 起因, 目的: 自己的工具,为自己服务。给大家做参考。项目地址: https://github.com/buxuele/flask_utils 2. 先看效果 3. 过程: 一个有趣的 Flask 工具集:从无到有的开发历程 缘起:为什么要做这个项目ÿ…...

对抗性提示:大型语言模型的安全性测试
随着大语言模型(LLM)在虚拟助手、企业平台等现实场景中的深度应用,其智能化与响应速度不断提升。然而能力增长的同时,风险也在加剧。对抗性提示已成为AI安全领域的核心挑战,它揭示了即使最先进的模型也可能被操纵生成有…...

好得睐:以品质守味、以科技筑基,传递便捷与品质
据相关数据显示,超市半成品菜是冻品区增长最快品类,再加上商超渠道作为消费者日常高频接触场景,是促进半成品菜成为冻品生鲜消费领域的关键一环。好得睐作为半成品菜领军品牌,其商超渠道布局是连接消费者与品质生活的重要桥梁。商…...
docker-部署Nginx以及Tomcat
一、docker 部署Nginx 1、搜索镜像(nginx) [rootlocalhost /]# docker search nginx Error response from daemon: Get "https://index.docker.io/v1/search?qnginx&n25": dial tcp 192.133.77.133:443: connect: connection refused 简…...

Servlet 体系结构
文章目录 Servlet 类图SpringBoot 测试案例HttpServlet 原理伪代码理解原理理解差异为什么 HttpServlet 实现 service() Servlet 类图 --- title: Servlet 类图 ---classDiagramdirection LRclass Servlet {<<interface>>init(conf)service(req,res)destroy()}cla…...
蒙特卡罗模拟: 高级应用的思路和实例
蒙特卡罗模拟不仅仅是一种理论练习,它还是一种强大的工具,在金融、医疗保健、物流等领域都有实际应用。本篇文章将探讨高级和复杂的现实生活场景,深入探讨它们的细微差别,并通过详细的解释在 Python 中实现它们。 什么是蒙特卡罗…...

Java集合中Stream流的使用
前言 Java 8 引入了 Stream API,它是一种用于处理集合(Collection)数据的强大工具。Stream 不是数据结构,而是对数据源进行操作的一种方式,支持声明式、函数式的操作,如过滤、映射、排序等。 Stream 操作…...

Python批量转换Word、Excel、PPT、TXT、HTML及图片格式到PDF,包含错误处理和日志记录功能
完整的Python脚本,支持批量转换Word、Excel、PPT、TXT、HTML及图片格式到PDF,并包含错误处理和日志记录功能: import os import sys import logging from win32com import client from PIL import Image from fpdf import FPDF import pdfkit import traceback# 配置日志 l…...

数据分析Agent构建
数据分析agent构建 代码资料来源于 Streamline-Analyst,旨在通过该仓库上的代码了解如何使用大语言模型构建数据分析工具; 个人仓库:Data-Analysis-Agent-Tutorial 不同的在于 Data-Analysis-Agent-Tutorial 是在 Streamline-Analyst 基础…...
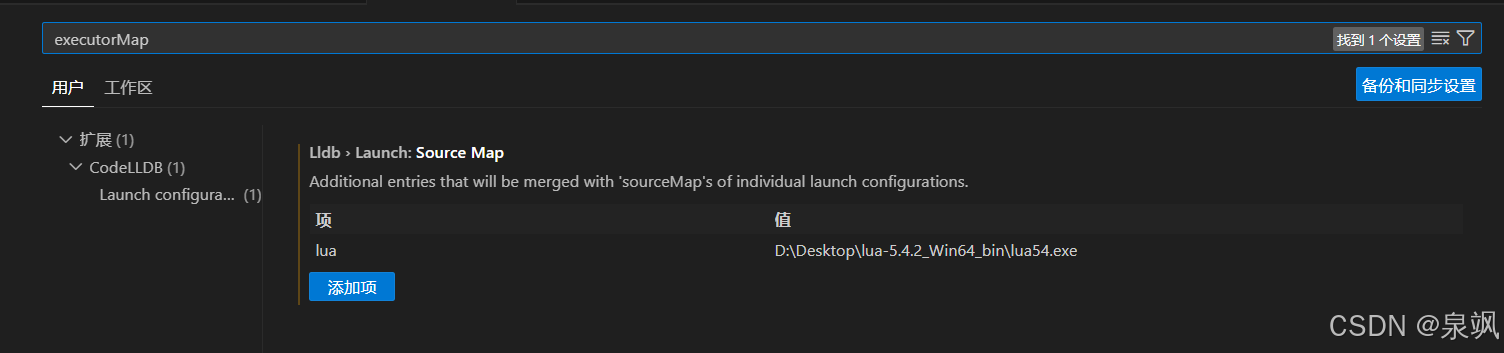
vscode配置lua
官网下载lua得到如下 打开vscode的扩展下载如下三个 打开vscode的此处设置 搜索 executorMap,并添加如下内容...

【笔记】MSYS2 的 MINGW64 环境 全面工具链
#工作记录 MSYS2 的 MINGW64 环境(mingw64.exe),下面是为该环境准备的最全工具链安装命令(包括 C/C、Python、pip/wheel、GTK3/GTK4、PyGObject、Cairo、SDL2 等)。 这一环境适用于构建原生 64 位 Windows 应用程序。…...

国内头部的UWB企业介绍之品铂科技
一、核心优势与技术实力 厘米级定位精度 自主研发的ABELL无线实时定位系统,在复杂工业环境中实现静态与动态场景下10-30厘米高精度定位,尤其擅长金属设备密集的化工、电力等场景,抗干扰能力行业领先。多技术融合能力 支持卫星…...
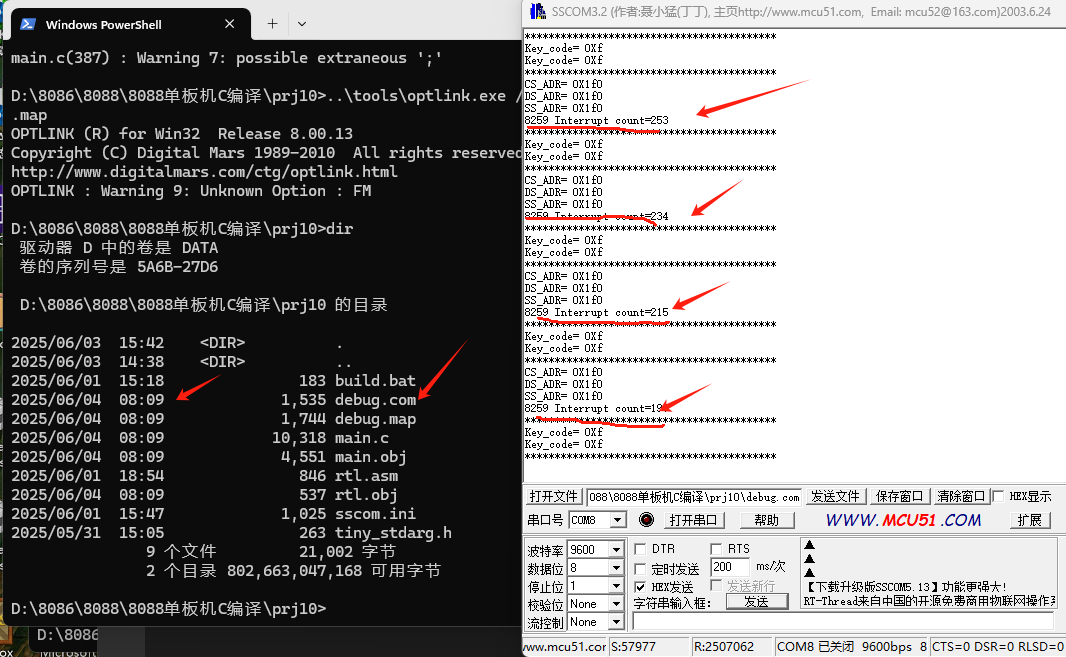
Prj10--8088单板机C语言8259中断测试(2)
1.测试结果 2.全部代码 #include "tiny_stdarg.h" // 使用自定义可变参数实现#define ADR_273 0x0200 #define ADR_244 0x0400 #define LED_PORT 0x800 #define PC16550_THR 0x1f0 #define PC16550_LSR 0x1f5 / //基本的IO操作函数 / char str[]"Hel…...

《前端面试题:CSS对浏览器兼容性》
CSS浏览器兼容性完全指南:从原理到实战 跨浏览器兼容性是前端开发的核心挑战,也是面试中的高频考点。查看所有css属性对各个浏览器兼容网站:https://caniuse.com 一、浏览器兼容性为何如此重要? 在当今多浏览器生态中,…...

使用 Docker Compose 安装 Redis 7.2.4
前面是指南,后面是主要步骤实际执行日志 使用 Docker Compose 安装 Redis 7.2.4 以下是使用 Docker Compose 安装 Redis 7.2.4 的完整指南: 1. 创建项目目录和文件 bash 复制 下载 # 创建项目目录 mkdir redis-docker && cd redis-docker#…...

35.x64汇编写法(二)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:34.x64汇编写法(一) 上一个内容写了,汇编调…...

安全大模型的思考
马上要准备2025年的护网了,最近就一直很忙,被事情裹挟着前进,忙的晕头转向,近乎感冒,昨天部门搞了一场AI大模型培训,演讲者有着很深的技术底蕴,我听到了一句关于Sass数据验证这块大为感悟&#…...

SQL Server 2025 预览版新功能
T-SQL 语言增强 正则表达式 (Regex) 支持 功能概述: SQL Server 2025 在 T-SQL 中原生引入了 POSIX 兼容的正则表达式支持,通过内置函数(如 REGEXP_LIKE、REGEXP_REPLACE 等)可直接在查询中对文本进行复杂模式匹配、查找和替换。…...
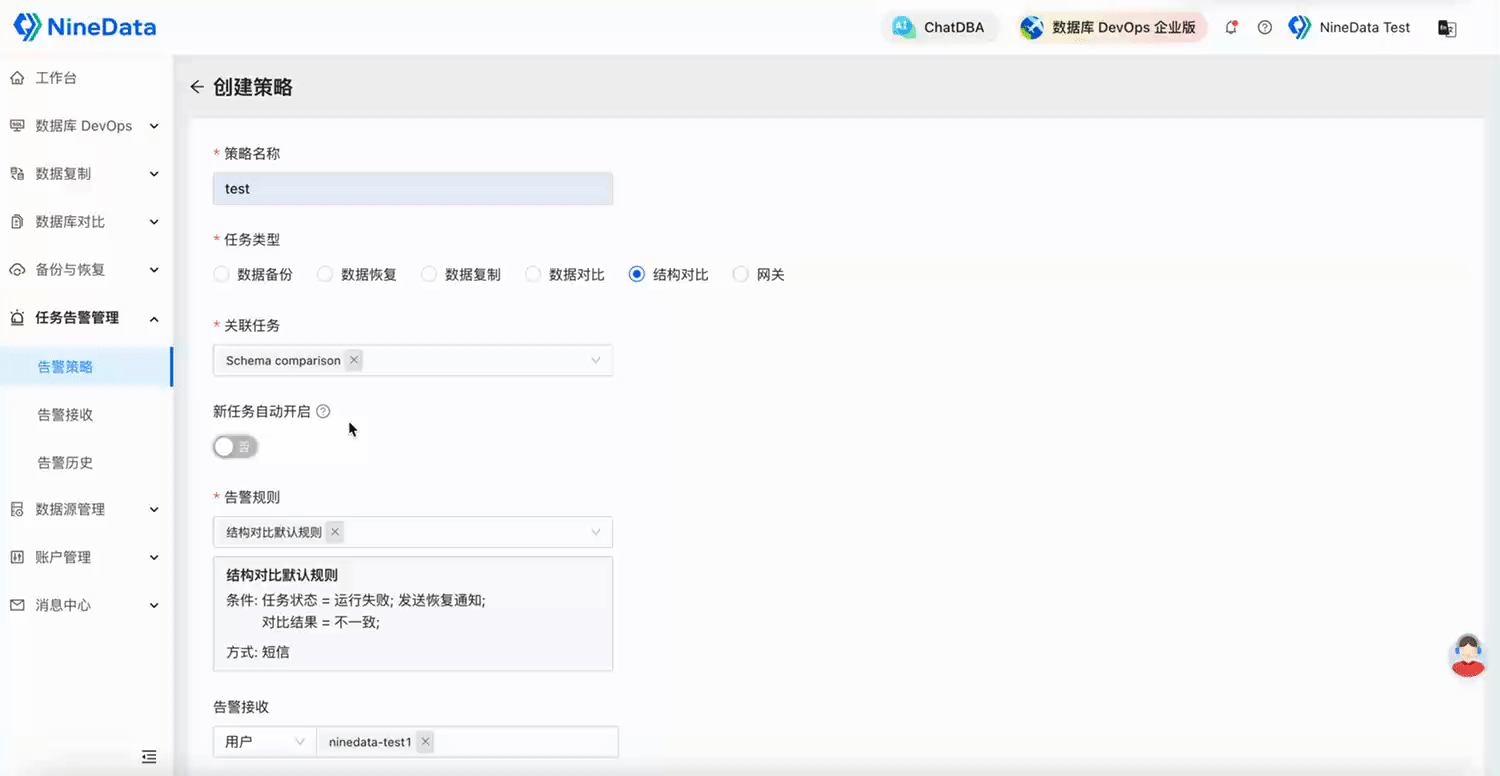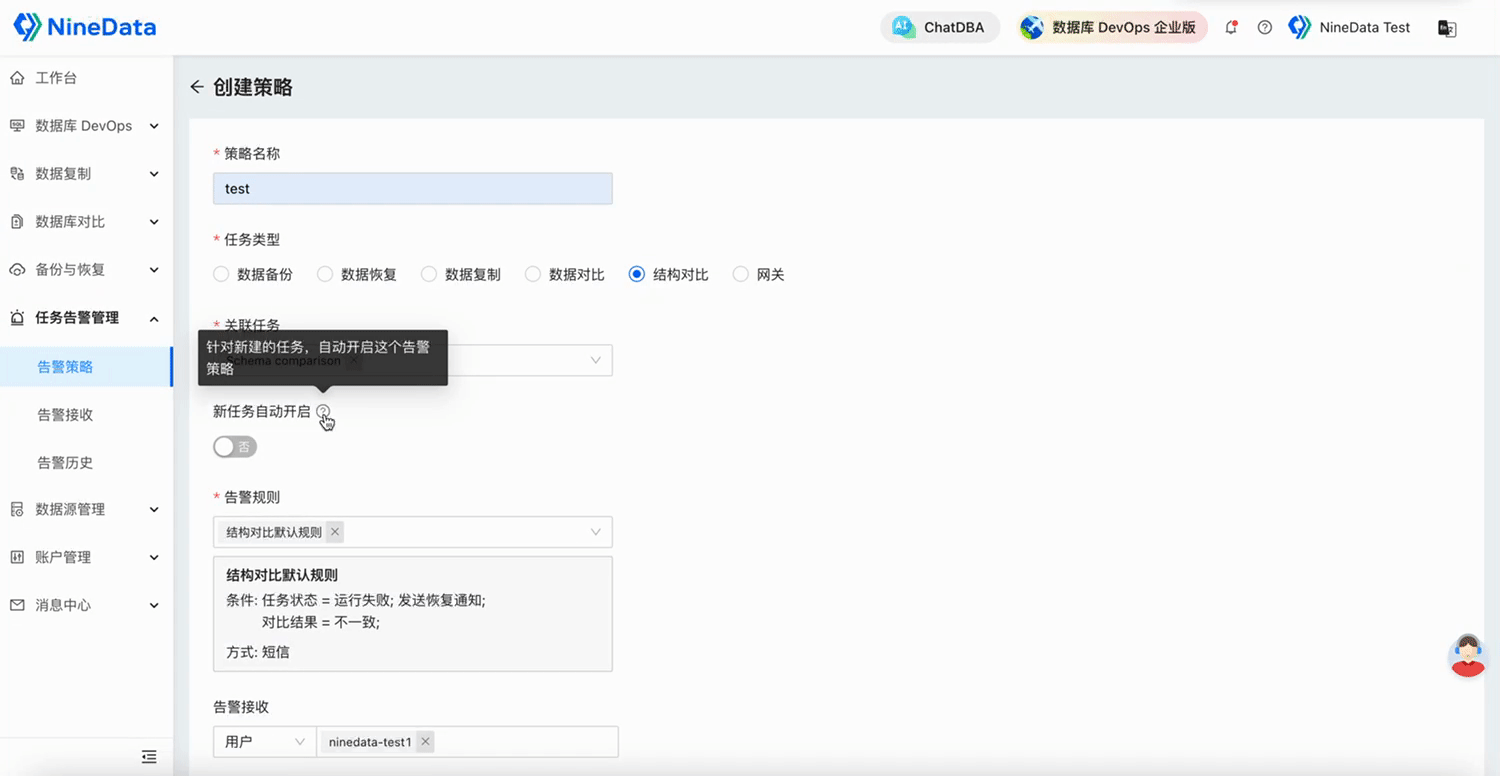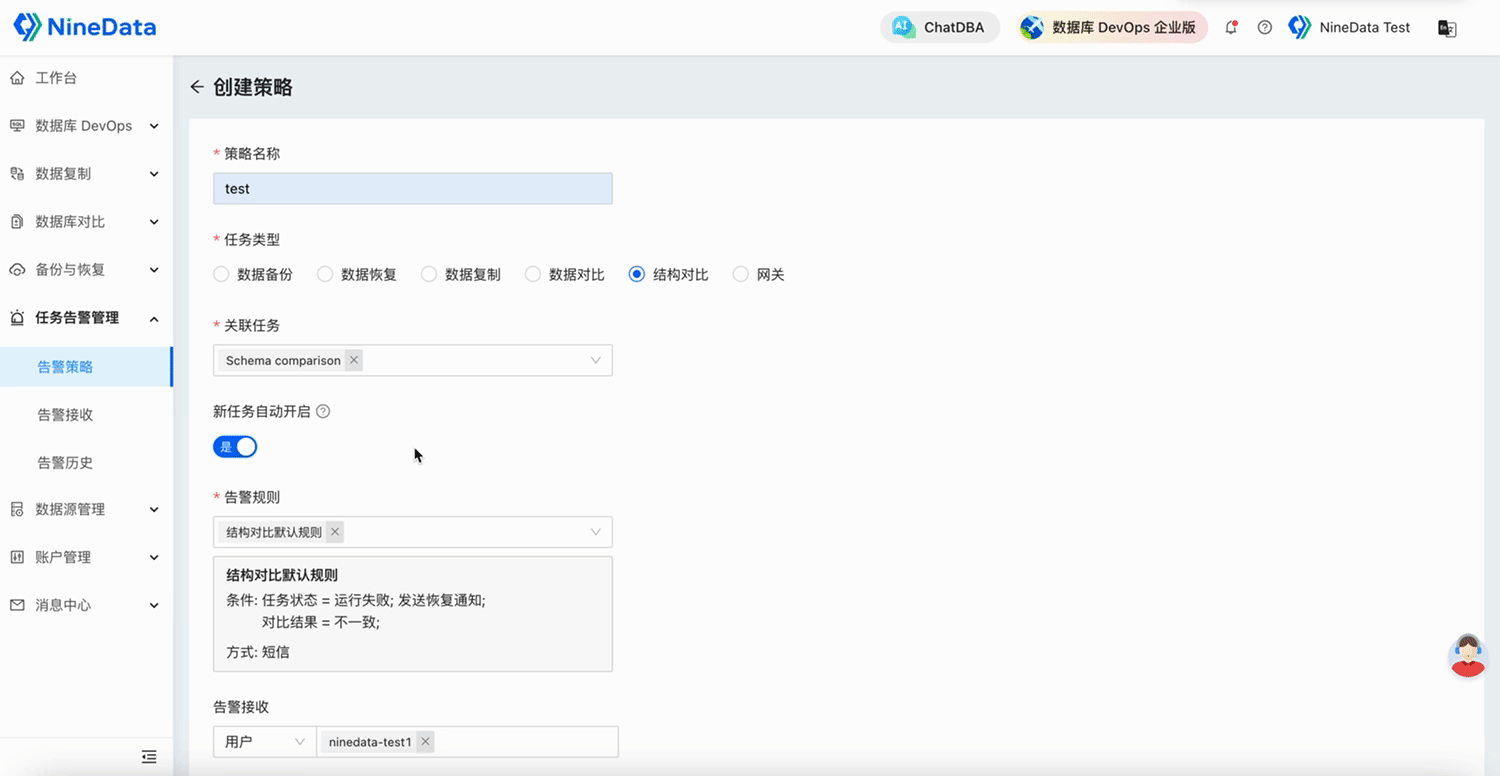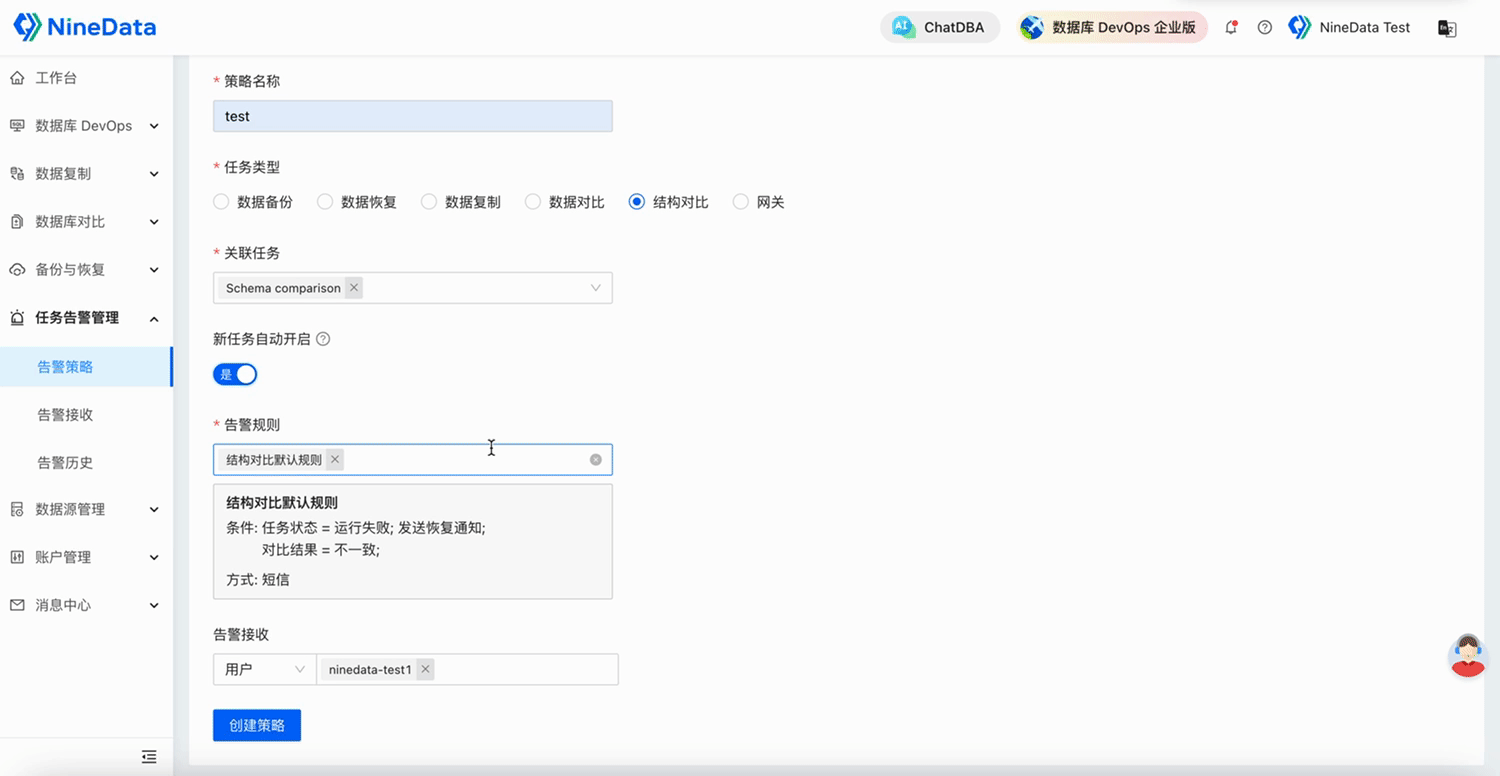
NineData云原生智能数据管理平台新功能发布|2025年5月版
本月发布 6 项更新,其中重点发布 3 项、功能优化 3 项。 重点发布 数据库 DevOps - 多源敏感数据保护 敏感数据扫描能力大幅扩展,新增支持 TiDB、Doris、SelectDB、OceanBase MySQL、GreatSQL、StarRocks、ClickHouse、SingleStore、Lindorm 9 种大数据…...

数学复习笔记 25
今天能把第五章学完。加油。今年是最好上岸的一年。 5.23:全是单根,笑死,居然难受了。我现在每个题,都要总结。总结。总结实际上也总结不出啥东西。但是我一定要总结。主动让自己思考一下。老师的思路很清奇。他认为考的稀松平常…...
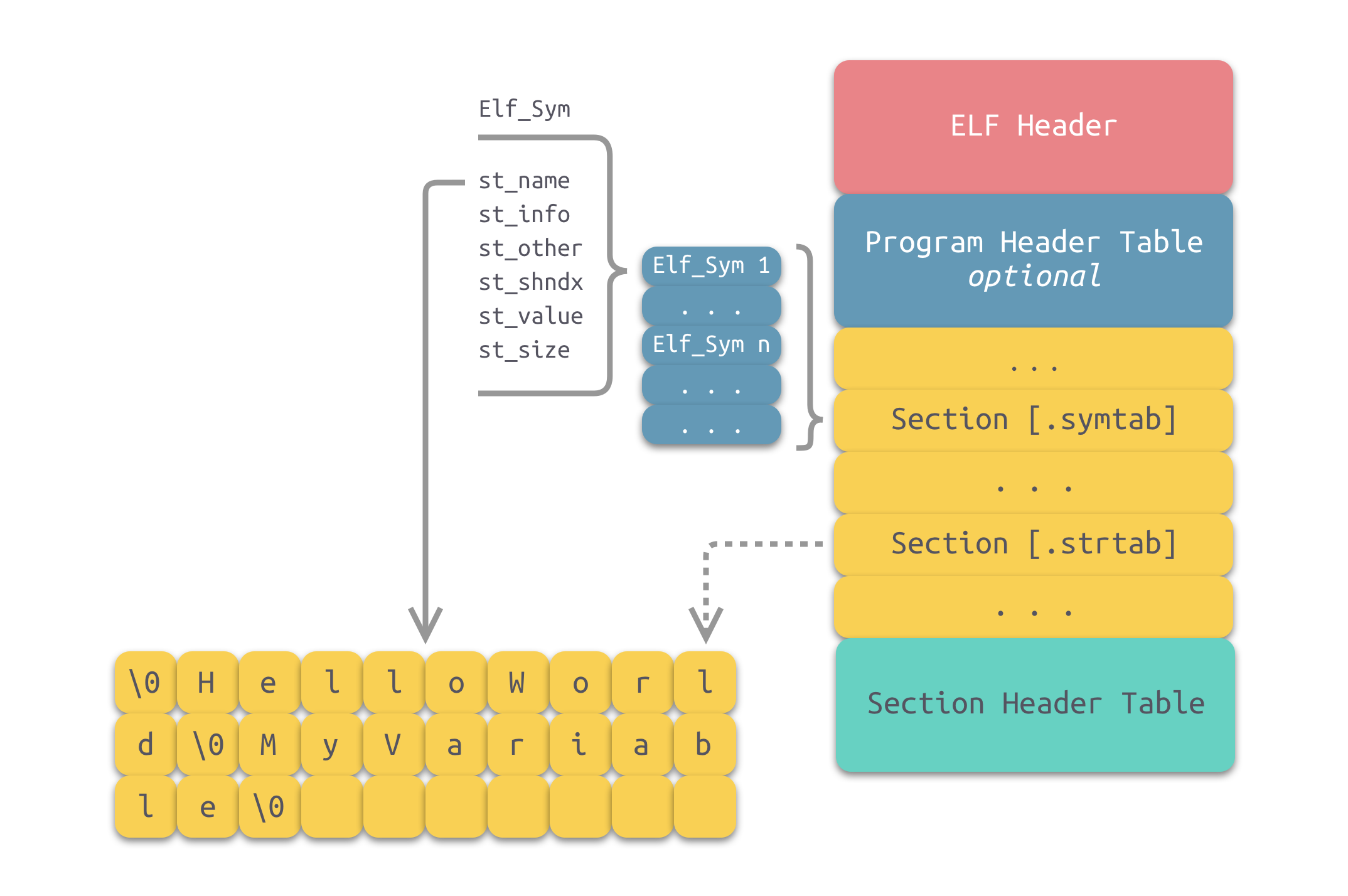
Linux可执行文件ELF文件结构
目标文件格式 编译器编译源代码后生成的文件叫做目标文件,而目标文件经过编译器链接之后得到的就是可执行文件。那么目标文件到底是什么?它和可执行文件又有什么区别?链接到底又做了什么呢?接下来,我们将探索一下目标…...

RAG:大模型微调的革命性增强——检索增强生成技术深度解析
RAG:大模型微调的革命性增强——检索增强生成技术深度解析 当大模型遇到知识瓶颈,RAG(检索增强生成)为模型装上"外部记忆库",让静态知识库与动态生成能力完美融合。本文将深入拆解RAG的技术原理、微调策略及…...

DisplayPort 2.0协议介绍(1)
最近开始学习DisplayPort 2.0协议,相比于DP1.4a,最主要的是速率提升到了10Gbps/lane,还有就是128b/132b编码方式的修改。至于速率13.5Gbps和20Gbps还只是可选项,在DP2.1协议才成为必须支持选项。 那在实现技术细节上有哪些变化呢…...
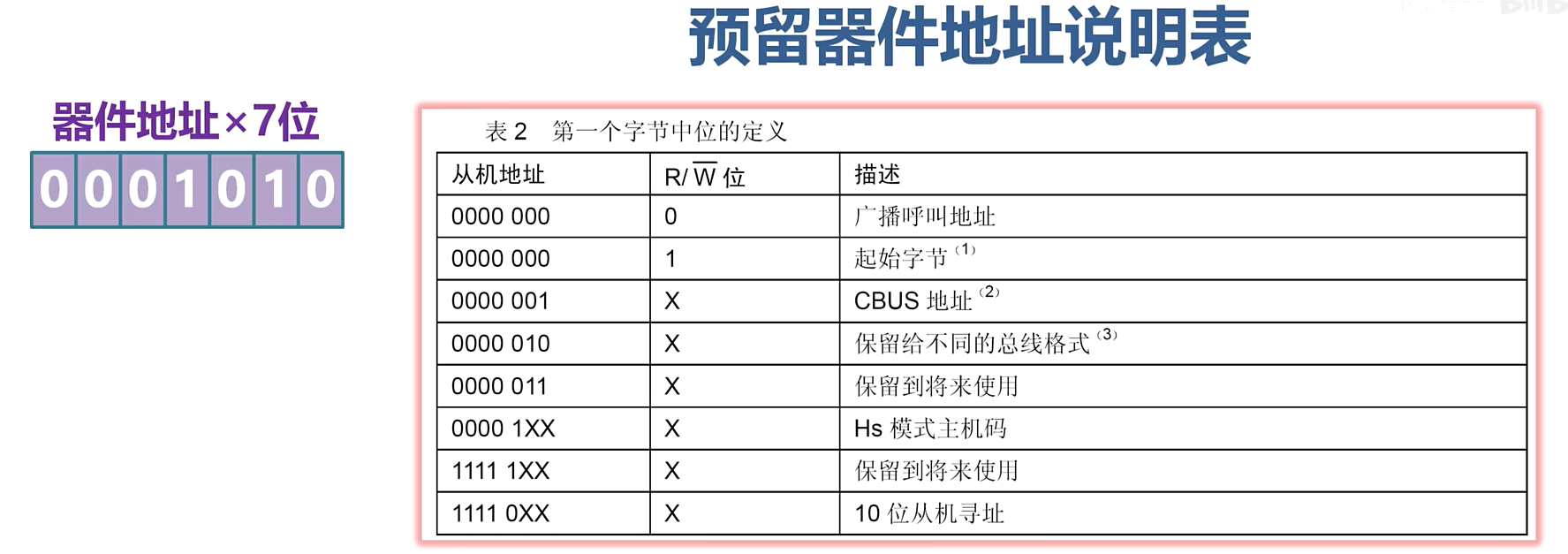
I2C通信讲解
I2C总线发展史 怎么在一条串口线上连接多个设备呢? 由于速度同步线是由主机实时发出的,所以主机可以按需求修改通信速度,这样在一条线上可以挂接不同速度的器件,单片机和性能差的器件通信,就输出较慢的脉冲信号&#x…...