打造高效多模态RAG系统:原理与评测方法详解
引言
随着信息检索与生成式AI的深度融合,检索增强生成(RAG, Retrieval-Augmented Generation) 已成为AI领域的重要技术方向。传统RAG系统主要依赖文本数据,但真实世界中的信息往往包含图像、表格等多模态内容。多模态RAG(Multimodal RAG)通过结合文本与视觉信息,显著提升了系统的理解能力与应用场景。然而,如何科学、全面地评测多模态RAG系统的性能,是测试工程师必须掌握的核心技能。
本文将结合 EvalScope 多模态RAG评测实践,系统介绍多模态RAG的原理、评测流程、关键指标及代码实现,帮助测试工程师快速上手并深入理解评测要点。
一、RAG与多模态RAG简介
1.1 传统RAG的局限性
传统RAG系统通过以下流程工作:
- 检索:从大规模文本数据库中查找与用户问题相关的片段。
- 生成:将检索到的文本输入大语言模型(LLM),生成最终答案。
然而,传统RAG的局限性在于:
- 忽略非文本信息:无法处理图像、表格等非结构化数据。
- 上下文理解受限:仅依赖文本可能导致信息缺失或歧义。
1.2 多模态RAG的优势
多模态RAG通过以下改进,解决了传统RAG的不足:
- 多模态检索:支持文本、图片、表格的联合检索。
- 多模态生成:利用多模态LLM(如Qwen-VL、GPT-4o)结合文本与视觉信息生成答案。
- 更贴近真实场景:适用于医疗影像诊断、工业质检、农业识别等需结合图像的场景。
二、多模态RAG的评测流程
多模态RAG的评测分为四个核心步骤,每个步骤均需严格验证:
2.1 文档解析
目标:将PDF、扫描文档等非结构化数据转换为可检索的多模态元素(文本、图片、表格)。
关键技术:
- 工具:
unstructured、MinerU等库用于解析PDF。 - 实现细节:
- 图像提取:从PDF中提取高清图片,存储为独立文件。
- 文本与表格提取:分割文本段落和表格,保留结构信息。
- 示例代码:
from unstructured.partition.pdf import partition_pdf def extract_pdf_elements(file_path, output_image_path):elements = partition_pdf(filename=file_path,strategy="hi_res", # 高分辨率解析extract_images_in_pdf=True,extract_image_block_output_dir=output_image_path # 图片保存路径)return elements
2.2 多模态向量存储
目标:将文本与图像统一编码为向量,存入向量数据库,便于后续检索。
关键技术:
- 嵌入模型:使用多模态模型(如CLIP、Chinese-CLIP)计算文本与图像的联合向量。
- 向量数据库:Chroma、FAISS 等支持高效相似性搜索。
- 实现细节:
- 统一编码:通过CLIP模型将文本和图像映射到同一向量空间。
- 向量存储:将向量与元数据(如图片URI)存入数据库。
- 示例代码:
from langchain_chroma import Chroma from evalscope.backend.rag_eval import VisionModel# 加载CLIP模型 vectorstore = Chroma(collection_name="mm_rag_clip",embedding_function=VisionModel.load(model_name="AI-ModelScope/chinese-clip-vit-large-patch14-336px") )# 添加图片到向量库 image_uris = [os.path.join(image_path, img) for img in os.listdir(image_path) if img.endswith(".jpg")] vectorstore.add_images(uris=image_uris)
2.3 检索增强生成
目标:根据用户问题检索相关多模态内容,并生成答案。
关键技术:
- 相似性搜索:通过向量数据库找到最相关的文本和图像。
- 多模态生成:将检索到的内容输入多模态LLM生成答案。
- 实现细节:
- 检索策略:使用
similarity_search查找Top-K相关结果。 - 生成策略:将检索到的文本和图像作为上下文输入LLM。
- 示例代码:
class RAGPipeline:def __init__(self, retriever, model):self.retriever = retrieverself.model = modeldef invoke(self, question):# 检索相关上下文context = self.retriever.invoke(question)# 生成答案response = self.model.generate(context=context, question=question)return response
- 检索策略:使用
2.4 评测模型生成结果
目标:利用评测框架(如EvalScope)评估生成结果的准确性、相关性与一致性。
关键技术:
- 评测指标:多模态忠实度、相关性、正确性等。
- 评测工具:EvalScope、RAGAS 等框架。
- 实现细节:
- 数据准备:生成包含用户输入、检索上下文、模型输出的评测集。
- 评测执行:调用评测框架自动计算指标。
- 示例代码:
from evalscope.run import run_taskmulti_modal_task_cfg = {"eval_backend": "RAGEval","eval_config": {"tool": "RAGAS","eval": {"testset_file": "./pdf/output.json","critic_llm": {"model_name": "qwen-vl-max","api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1","api_key": os.getenv("DASHSCOPE_API_KEY"),},"metrics": ["MultiModalFaithfulness","MultiModalRelevance","AnswerCorrectness"],"language": "chinese"},}, }run_task(task_cfg=multi_modal_task_cfg)
三、关键评测指标详解
多模态RAG的评测分为独立评测(仅评估检索模块)和端到端评测(评估检索+生成全流程)。以下是核心指标的详细说明:
3.1 忠实度(Faithfulness)
定义:答案是否严格基于检索到的上下文(文本或图像)。
评分规则:
- 若答案中的所有陈述均可从上下文中推断,则得分为1。
- 否则,得分按不一致部分比例递减。
示例:
- 高忠实度:
用户问题:“特斯拉Model X怎么样?”
检索上下文:一张特斯拉Model X的图片
答案:“特斯拉Model X是一款由特斯拉制造的电动SUV。”
得分:1 - 低忠实度:
用户问题:“特斯拉Model X怎么样?”
检索上下文:一张特斯拉Model X的图片
答案:“猫很可爱。”
得分:0
3.2 相关性(Relevance)
定义:答案是否与用户问题及检索到的上下文直接相关。
评分规则:
- 若答案直接回答问题且引用上下文信息,则得分为1。
- 若答案描述上下文但未回答问题,或与问题无关,则得分递减。
示例:
- 高相关性:
用户问题:“这幅画是谁画的?”
检索上下文:一幅毕加索的画
答案:“这幅画是毕加索画的。”
得分:1 - 低相关性:
用户问题:“这幅画是谁画的?”
检索上下文:一幅毕加索的画
答案:“这是一幅美丽的画。”
得分:0
3.3 正确性(Answer Correctness)
定义:答案是否与标准答案匹配(通常用于有参考答案的场景)。
评分规则:
- F1 Score:结合TP(正确覆盖)、FP(错误添加)、FN(遗漏)计算。
F 1 S c o r e = ∣ T P ∣ ∣ T P ∣ + 0.5 × ( ∣ F P ∣ + ∣ F N ∣ ) F1Score = \frac{|TP|}{|TP| + 0.5 \times (|FP| + |FN|)} F1Score=∣TP∣+0.5×(∣FP∣+∣FN∣)∣TP∣
示例:
- 高正确性:
用户问题:“爱因斯坦什么时候出生?”
标准答案:“爱因斯坦于1879年在德国出生。”
生成答案:“爱因斯坦于1879年在德国出生。”
F1 Score:1 - 低正确性:
用户问题:“爱因斯坦什么时候出生?”
标准答案:“爱因斯坦于1879年在德国出生。”
生成答案:“爱因斯坦于1879年在西班牙出生。”
F1 Score:0.5
四、实践流程与代码详解
4.1 环境准备
依赖安装:
# 安装评测框架
pip install evalscope[rag]# 安装文档解析工具
pip install "unstructured[all-docs]"# 安装OCR与PDF处理工具
apt install poppler-utils tesseract-ocr -y
4.2 文档解析(提取图片/文本)
代码详解:
from unstructured.partition.pdf import partition_pdfdef extract_pdf_elements(file_path, output_image_path):"""解析PDF文件,提取文本、图片和表格。:param file_path: PDF文件路径:param output_image_path: 图片保存路径"""# 创建图片存储目录os.makedirs(output_image_path, exist_ok=True)# 使用Unstructured解析PDFelements = partition_pdf(filename=file_path,strategy="hi_res", # 高分辨率解析策略extract_images_in_pdf=True, # 提取图片infer_table_structure=False, # 不推断表格结构chunking_strategy="by_title", # 按标题分块max_characters=1000, # 每块最大字符数new_after_n_chars=1000, # 新块的字符间隔combine_text_under_n_chars=1000, # 合并短文本hi_res_model_name="yolox", # 使用YOLOX模型检测布局extract_image_block_output_dir=output_image_path # 图片保存路径)return elements
4.3 构建多模态检索器
代码详解:
from langchain_chroma import Chroma
from evalscope.backend.rag_eval import VisionModel# 加载CLIP模型
vectorstore = Chroma(collection_name="mm_rag_clip", # 向量库名称embedding_function=VisionModel.load( # 加载CLIP嵌入模型model_name="AI-ModelScope/chinese-clip-vit-large-patch14-336px")
)# 获取图片路径
image_uris = sorted([os.path.join(image_path, img) for img in os.listdir(image_path) if img.endswith(".jpg")
])# 将图片添加到向量库
vectorstore.add_images(uris=image_uris)# 创建检索器
retriever = vectorstore.as_retriever(search_type="similarity", # 使用相似性搜索search_kwargs={'k': 2} # 返回Top-2结果
)
4.4 RAG流程构建
代码详解:
class RAGPipeline:def __init__(self, retriever, model):self.retriever = retrieverself.model = modeldef split_image_text_types(self, docs):"""将检索到的文档分为图片和文本两类"""images = []text = []for doc in docs:if isinstance(doc, Image): # 假设doc为PIL.Image对象images.append(doc)else:text.append(doc)return images, textdef invoke(self, question):# 检索相关上下文context = self.retriever.invoke(question)# 分离图片和文本images, text = self.split_image_text_types(context)# 生成答案response = self.model.generate(images=images, text=text, question=question)return response
4.5 生成评测数据
代码详解:
from evalscope.backend.rag_eval import LLM# 加载多模态LLM
model = LLM.load(model_name="qwen-vl-plus",api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key=os.getenv("DASHSCOPE_API_KEY"),
)# 构建RAG流程
pipeline = RAGPipeline(retriever=retriever, model=model)# 生成评测数据
test_cases = ["玉米", "西兰花", "洋芋", "水稻", "汽车"]
results = []
for prompt in test_cases:response = pipeline.invoke(f"{prompt}是什么?")results.append({"user_input": f"{prompt}是什么?","retrieved_contexts": [base64_image1, base64_image2], # 检索到的图片"response": response # 生成的答案})# 保存评测数据
with open("./pdf/output.json", "w") as f:json.dump(results, f, ensure_ascii=False, indent=2)
4.6 执行评测
代码详解:
multi_modal_task_cfg = {"eval_backend": "RAGEval","eval_config": {"tool": "RAGAS","eval": {"testset_file": "./pdf/output.json", # 评测数据路径"critic_llm": { # 评测使用的LLM"model_name": "qwen-vl-max","api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1","api_key": os.getenv("DASHSCOPE_API_KEY"),},"embeddings": { # 嵌入模型"model_name_or_path": "AI-ModelScope/bge-large-zh",},"metrics": [ # 评测指标"MultiModalFaithfulness","MultiModalRelevance","AnswerCorrectness"],"language": "chinese" # 评测语言},},
}# 执行评测
from evalscope.run import run_task
run_task(task_cfg=multi_modal_task_cfg)
五、评测结果解读与优化建议
5.1 评测结果示例
假设评测后得到如下结果:
| 问题 | 忠实度 | 相关性 | 正确性 |
|---|---|---|---|
| 玉米是什么? | 1 | 1 | 0.69 |
| 汽车是什么? | 0 | 0 | 0.59 |
5.2 结果分析与优化
-
高分案例(玉米):
- 成功原因:检索到的图片与问题高度相关,模型能结合图片描述玉米特征。
- 优化方向:无需调整,保持当前策略。
-
低分案例(汽车):
- 失败原因:检索库中无汽车相关图片,模型依赖文本生成答案,但文本未提供足够信息。
- 优化方向:
- 扩展检索库:添加更多类别(如交通工具)的图片。
- 增强提示词:在生成时提示模型优先使用文本信息。
- 调整检索策略:若无图像匹配,优先返回文本上下文。
六、总结
多模态RAG系统的评测是确保其有效性和可靠性的重要环节。通过EvalScope等框架,测试工程师可以全面评估系统的忠实度、相关性和正确性,并针对性优化。本文提供了从文档解析、向量存储到生成评测的完整实践流程,结合代码示例与评测结果分析,帮助工程师快速构建高效的多模态RAG系统。
参考链接
- EvalScope官方文档与多模态RAG评测实践
- ModelScope 多模态模型与数据集
- CLIP: Connecting Text and Images
- RAGAS: RAG Evaluation Framework
通过本文的实践指南,测试工程师不仅能掌握多模态RAG的评测方法,还能深入理解其技术细节,为实际项目落地提供坚实基础。整理了部分资料,已上传云盘。云盘链接:https://pan.quark.cn/s/c196744b0181
后续也会持续收集上传。

相关文章:
打造高效多模态RAG系统:原理与评测方法详解
引言 随着信息检索与生成式AI的深度融合,检索增强生成(RAG, Retrieval-Augmented Generation) 已成为AI领域的重要技术方向。传统RAG系统主要依赖文本数据,但真实世界中的信息往往包含图像、表格等多模态内容。多模态RAG…...
)
SSM 框架核心知识详解(Spring + SpringMVC + MyBatis)
🌱 第一部分:Spring 核心原理与使用 1. 什么是 Spring Spring 是一个开源的 Java 企业级开发框架,旨在简化 Java 企业应用程序开发。它核心思想是控制反转(IoC)和面向切面编程(AOP)࿰…...

1.2 fetch详解
浏览器 Fetch API 详解 Fetch API 是现代浏览器提供的用于发起网络请求的接口,它基于 Promise 实现,替代了传统的 XMLHttpRequest,提供了更强大、更灵活的功能。 1. 基本用法 使用 fetch() 函数发起请求,返回一个 Promise&…...
【C#】Quartz.NET怎么动态调用方法,并且根据指定时间周期执行,动态配置类何方法以及Cron表达式,有请DeepSeek
🌹欢迎来到《小5讲堂》🌹 🌹这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!&#…...
02 Deep learning神经网络的编程基础 逻辑回归--吴恩达
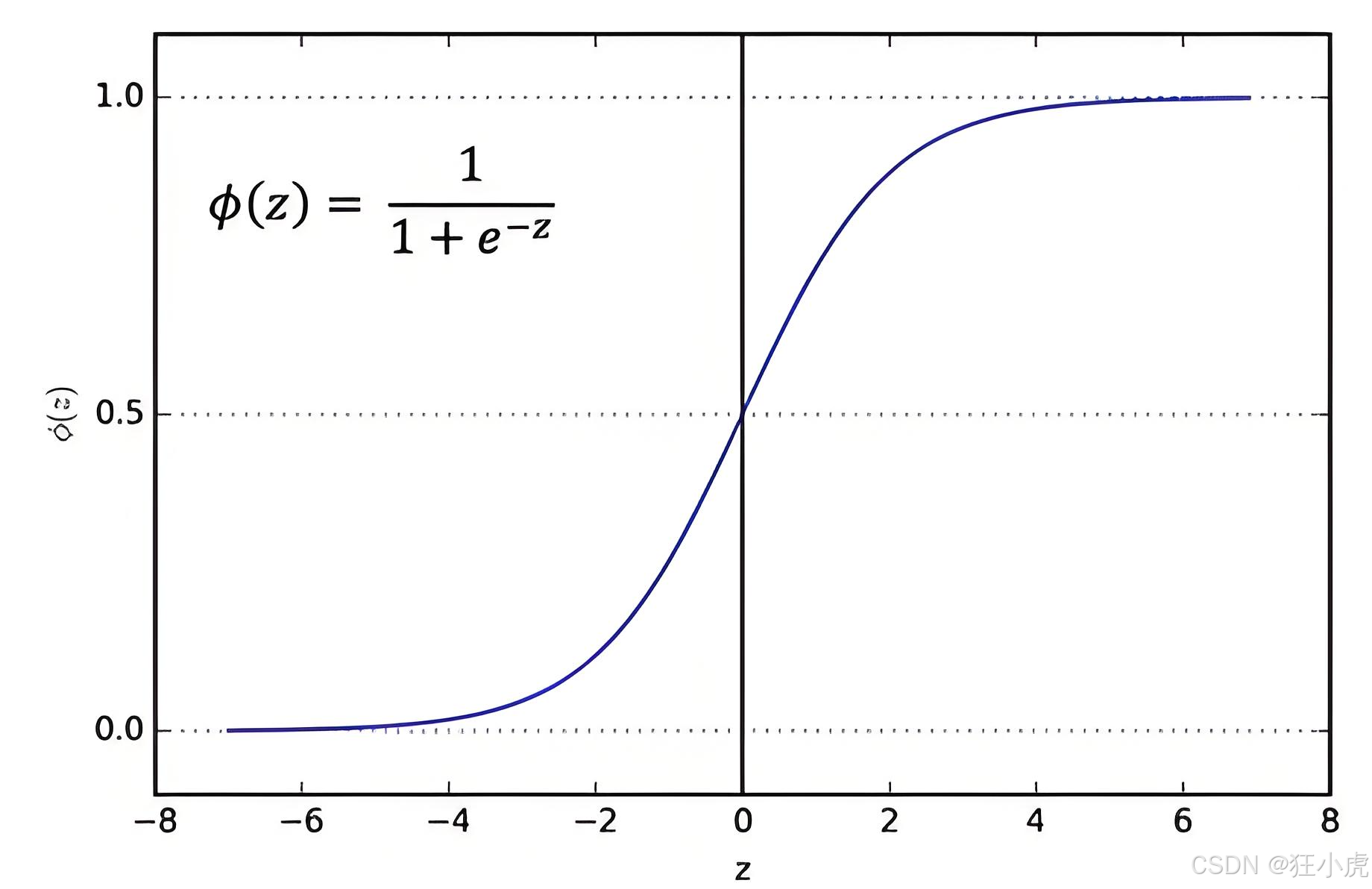
逻辑回归 逻辑回归是一种用于解决二分类任务(如预测是否是猫咪等)的统计学习方法。尽管名称中包含“回归”,但其本质是通过线性回归的变体输出概率值,并使用Sigmoid函数将线性结果映射到[0,1]区间。 以猫咪预测为例 假设单个样…...

Android Native 内存泄漏检测全解析:从原理到工具的深度实践
引言 Android应用的内存泄漏不仅发生在Java/Kotlin层,Native(C/C)层的泄漏同样普遍且隐蔽。由于Native内存不受Java虚拟机(JVM)管理,泄漏的内存无法通过GC自动回收,长期积累会导致应用内存占用…...

React---扩展补充
一些额外的扩展 4.3 高阶组件 高阶组件是参数为组件,返回值为新组件的函数; 高阶组件 本身不是一个组件,而是一个函数;其次,这个函数的参数是一个组件,返回值也是一个组件; import React fr…...

HTML 中 class 属性介绍、用法
1、🔖 什么是 class class 是 HTML 元素的一个核心属性,用来为元素指定一个或多个类名。它在网页开发中承担三大作用: 🎨 连接样式(CSS):让元素应用预定义的视觉效果⚙️ 绑定行为(…...
MySQL的并发事务问题及事务隔离级别
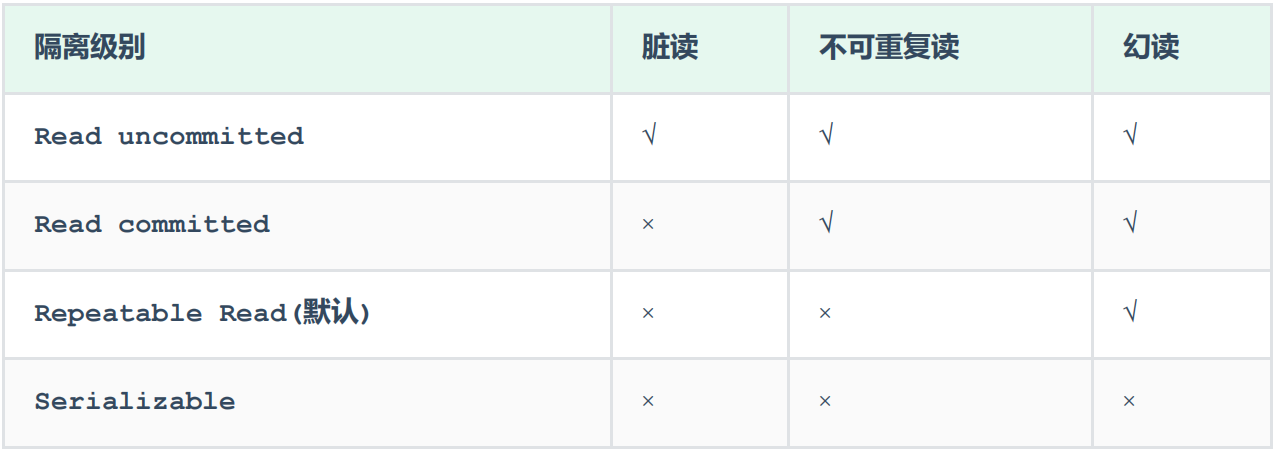
一、并发事务问题 1). 赃读:一个事务读到另外一个事务还没有提交的数据。 比如 B 读取到了 A 未提交的数据。 2). 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。 事务 A 两次读取同一条记录&…...

ProfiNet 分布式 IO 在某污水处理厂的应用
随着城市化进程的加速,污水处理厂的规模和复杂性不断增加,对自动化控制系统的要求也越来越高。PROfinet 分布式 IO 作为一种先进的工业通信技术,以其高速、可靠、灵活的特性,为污水处理厂的自动化升级提供了有力支持。本文将结合某…...

vue2使用笔记、vue2和vue3的区别
文章目录 vue2和vue3的区别1. 实现数据响应式的原理不同2. 生命周期不同3. vue 2.0 采用了 option 选项式 API,vue 3.0 采用了 composition 组合式 API4. 新特性编译宏5. 父子组件间双向数据绑定 v-model 不同6. v-for 和 v-if 优先级不同7. 使用的 diff 算法不同8.…...

Vue2数组数字字段求和技巧 数字求和方法
<template><div><p>总和: {{ totalSum }}</p></div> </template><script> export default {data() {return {items: [{ id: 1, value: 10 },{ id: 2, value: 20 },{ id: 3, value: 30 }]};},computed: {totalSum() {return this.ite…...
vue2 , el-select 多选树结构,可重名
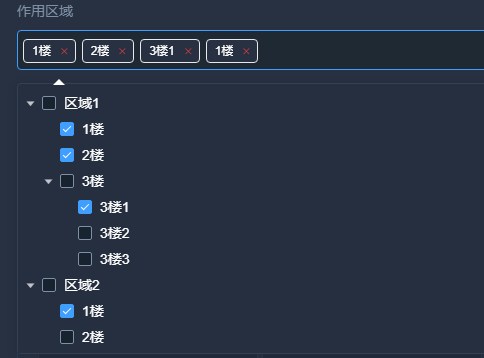
人家antd都支持,elementplus 也支持,vue2的没有,很烦。 网上其实可以搜到各种的,不过大部分不支持重名,在删除的时候可能会删错,比如树结构1F的1楼啊,2F的1楼啊这种同时勾选的情况。。 可以全…...
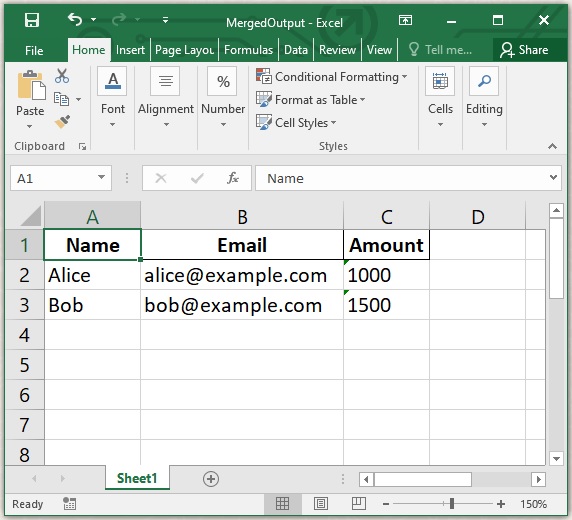
Excel处理控件Aspose.Cells教程:使用 C# 从 Excel 进行邮件合并
邮件合并功能让您能够轻松批量创建个性化文档,例如信函、电子邮件、发票或证书。您可以从模板入手,并使用电子表格中的数据进行填充。Excel 文件中的每一行都会生成一个新文档,并在正确的位置包含正确的详细信息。这是一种自动化重复性任务&a…...

Jenkins | Jenkins构建成功服务进程关闭问题
Jenkins构建成功服务进程关闭问题 1. 原因2. 解决 1. 原因 Jenkins 默认会在构建结束时终止所有由构建任务启动的子进程,即使使用了nohup或后台运行符号&。 2. 解决 在启动脚本中加上 BULID_IDdontkillme #--------------解决jenkins 自动关闭进程问题-----…...

模块化架构下的前端调试体系建设:WebDebugX 与多工具协同的工程实践
随着前端工程化的发展,越来越多的项目采用模块化架构:单页面应用(SPA)、微前端、组件化框架等。这类架构带来了良好的可维护性和复用性,但也带来了新的调试挑战。 本文结合我们在多个模块化项目中的真实经验ÿ…...
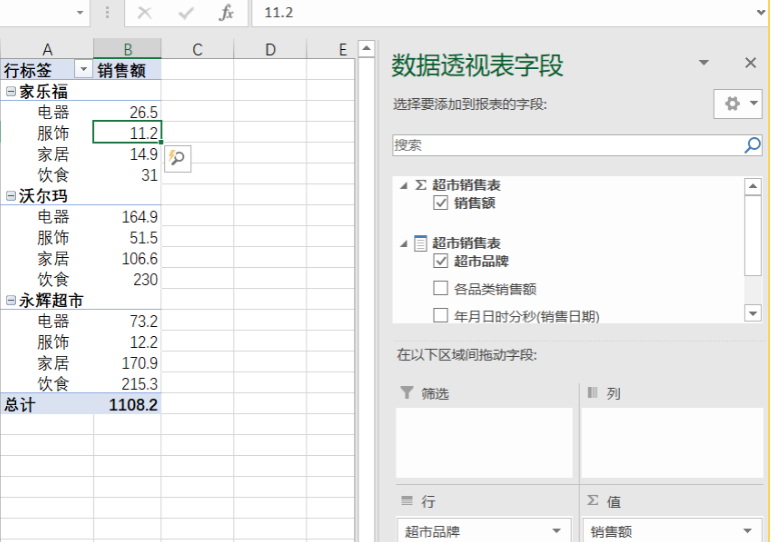
EXCEL通过DAX Studio获取端口号连接PowerBI
EXCEL通过DAX Studio获取端口号连接PowerBI 昨天我分享了EXCEL链接模板是通过获取端口号和数据库来连接PowerBI模型的,链接:浅析EXCEL自动连接PowerBI的模板,而DAX Studio可以获取处于打开状态的PowerBI的端口号。 以一个案例分享如何EXCEL…...

PostgreSQL 技术峰会,为您打造深度交流优质平台
峰会背景 PostgreSQL 作为全球领先的开源关系型数据库管理系统,凭借其强大的功能、高度的扩展性和稳定性,在云计算、大数据、人工智能等领域得到了广泛应用。随着数字化转型的加速,企业对数据库技术的需求日益复杂和多样化,Postg…...
 进行人脸边缘提取)
使用 OpenCV (C++) 进行人脸边缘提取
使用 OpenCV (C) 进行人脸边缘提取 本文将介绍如何使用 C 和 OpenCV 库来检测图像中的人脸,并提取这些区域的边缘。我们将首先使用 Haar级联分类器进行人脸检测,然后在检测到的人脸区域(ROI - Region of Interest)内应用 Canny 边…...

C# 委托UI控件更新例子,何时需要使用委托
1. 例子1 private void UdpRxCallBackFunc(UdpDataStruct info) {// 1. 前置检查防止无效调用if (textBoxOutput2.IsDisposed || !textBoxOutput2.IsHandleCreated)return;// 2. 使用正确的委托类型Invoke(new Action(() >{// 3. 双重检查确保安全if (textBoxOutput2.IsDis…...
大模型数据流处理实战:Vue+NDJSON的Markdown安全渲染架构
在Vue中使用HTTP流接收大模型NDJSON数据并安全渲染 在构建现代Web应用时,处理大模型返回的流式数据并安全地渲染到页面是一个常见需求。本文将介绍如何在Vue应用中通过普通HTTP流接收NDJSON格式的大模型响应,使用marked、highlight.js和DOMPurify等库进…...
python项目如何创建docker环境
这里写自定义目录标题 python项目创建docker环境docker配置国内镜像源构建一个Docker 镜像验证镜像合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPant…...

Eureka 高可用集群搭建实战:服务注册与发现的底层原理与避坑指南
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...
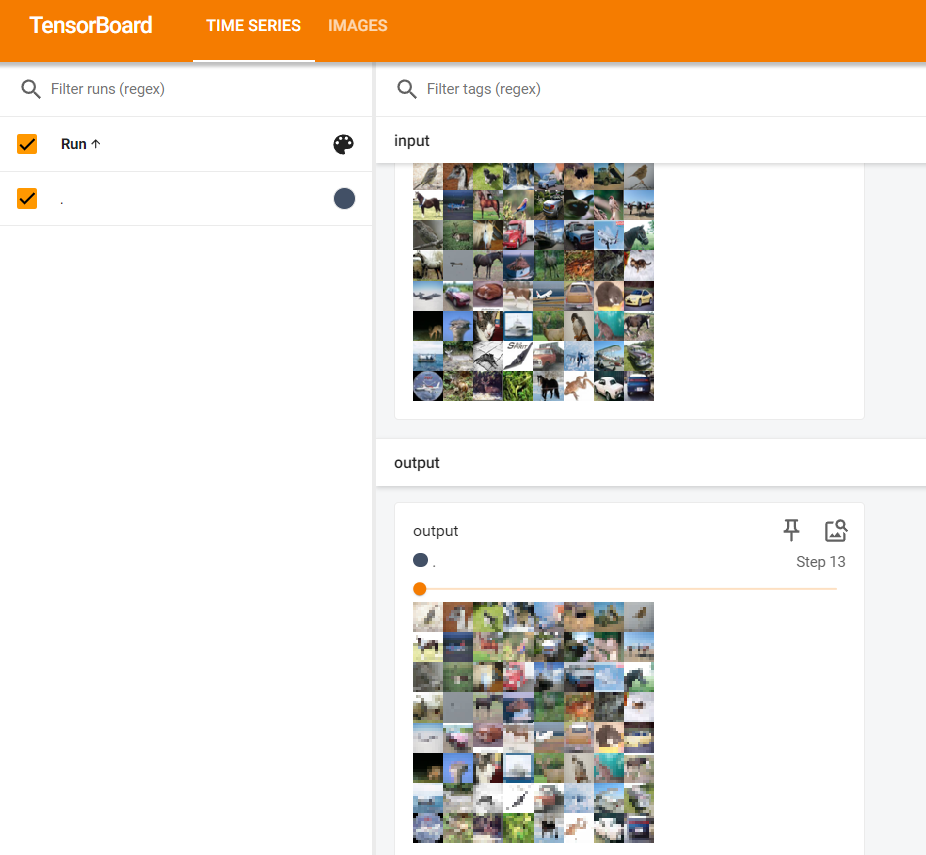
PyTorch--池化层(4)
池化层(Pooling Layer) 用于降低特征图的空间维度,减少计算量和参数数量,同时保留最重要的特征信息。 池化作用:比如1080p视频——720p 池化层的步长默认是卷积核的大小 ceil 允许有出界部分;floor 不允许…...

GPU加速与非加速的深度学习张量计算对比Demo,使用PyTorch展示关键差异
import torch import time # 创建大型随机张量 (10000x10000) tensor_size 10000 x_cpu torch.randn(tensor_size, tensor_size) x_gpu x_cpu.cuda() # 转移到GPU # CPU矩阵乘法 start time.time() result_cpu torch.mm(x_cpu, x_cpu.t()) cpu_time time.time() - sta…...

Vue中的自定义事件
一、前言 在 Vue 的组件化开发中,组件之间的数据通信是构建复杂应用的关键。而其中最常见、最推荐的方式之一就是通过 自定义事件(Custom Events) 来实现父子组件之间的交互。 本文将带你深入了解: Vue 中事件的基本概念如何在…...

2025年大模型平台落地实践研究报告|附75页PDF文件下载
本报告旨在为各行业企业在建设落地大模型平台的过程中,提供有效的参考和指引,助力大模型更高效更有价值地规模化落地。本报告系统性梳理了大模型平台的发展背景、历程和现状,结合大模型平台的特点提出了具体的落地策略与路径,同时…...
PPTAGENT:让PPT生成更智能
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。 1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。 CSDN教学平台录播地址…...

Kotlin 中 companion object 扩展函数和普通函数区别
在 Kotlin 中,companion object 的扩展函数与普通函数(包括普通成员函数和普通扩展函数)有显著区别。以下是它们的核心差异和适用场景: 1. 定义位置与归属 特性companion object 扩展函数普通函数定义位置在类外部为伴生对象添加…...
《汇编语言》第13章 int指令
中断信息可以来自 CPU 的内部和外部,当 CPU 的内部有需要处理的事情发生的时候,将产生需要马上处理的中断信息,引发中断过程。在第12章中,我们讲解了中断过程和两种内中断的处理。 这一章中,我们讲解另一种重要的内中断…...