Python 训练营打卡 Day 45
TensorBoard
简单来说,TensorBoard 是 TensorFlow 自带的一个「可视化工具」,就像给机器学习模型训练过程装了一个「监控屏幕」。你可以用它直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等,不用盯着一堆枯燥的数字看,对新手非常友好,目前这个工具还在不断发展,比如一些额外功能在tensorboardX上存在,但是我们目前只需要要用到最经典的几个功能即可
- 保存模型结构图
- 保存训练集和验证集的loss变化曲线,不需要手动打印了
- 保存每一个层结构权重分布
- 保存预测图片的预测信息
原理:TensorBoard的核心原理就是在训练过程中,把训练过程中的数据(比如损失、准确率、图片等)先记录到日志文件里,再通过工具把这些日志文件可视化成图表,这样就不用自己手动打印数据或者用其他工具画图,所以核心就是2个步骤:
1. 数据怎么存?—— 先写日志文件
训练模型时,TensorBoard 会让程序把训练数据(比如损失值、准确率)和模型结构等信息,写入一个特殊的日志文件(.tfevents 文件)
2. 数据怎么看?—— 用网页展示日志
写完日志后,TensorBoard会启动一个本地网页服务,自动读取日志文件里的数据,用图表、图像、文本等形式展示出来。如果只用 print(损失值) 或者自己用 matplotlib 画图,不仅麻烦,还得手动保存数据、写代码,尤其训练几天几夜时,根本没法实时盯着看。而 TensorBoard 能自动把这些数据 “存下来 + 画出来”,还能生成网页版的可视化界面,随时刷新查看!
常用到的核心代码解析:
# 1.日志目录自动管理:自动创建新目录,避免重复覆盖
log_dir = 'runs/cifar10_mlp_experiment' #设置存储目录
if os.path.exists(log_dir):
# 检查目录是否存在i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir) #关键入口,用于写入数据到日志目录# 2.记录标量数据:跟踪训练过程中的损失、准确率等
# 记录每个 Batch 的损失和准确率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录每个 Epoch 的训练指标
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 3.可视化结构模型:记录模型的计算图
dataiter = iter(train_loader) # 从训练数据集中获取一个批次的图像和标签
images, labels = next(dataiter) # 获取第一个批次的数据
images = images.to(device)
writer.add_graph(model, images) # 通过真实输入样本生成模型计算图# 4.可视化图像:记录训练过程中的原始图像和预测结果
# 可视化原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 将多张图像拼接成网格状(方便可视化),将前8张图像拼接成一个网格
writer.add_image('原始训练图像', img_grid) # 记录原始图像# 可视化错误预测样本(训练结束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('错误预测样本', wrong_img_grid) # 记录错误预测的图像# 5.记录权重和梯度直方图
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 权重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布CIFAR-10实例(MLP模型训练)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器,用于批量处理数据
batch_size = 64 # 每个批次的样本数
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 训练集打乱
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 测试集不打乱# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPUcriterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,学习率为0.001# 创建TensorBoard的SummaryWriter,指定日志保存目录
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目录已存在,添加后缀避免覆盖
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 训练模型(使用TensorBoard记录各种信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 设置为训练模式# 记录训练开始时间,用于计算训练速度global_step = 0# 可视化模型结构dataiter = iter(train_loader) # 获取一个批次的样本images, labels = next(dataiter) # 获取图像和标签images = images.to(device) writer.add_graph(model, images) # 添加模型图# 可视化原始图像样本img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张图像writer.add_image('原始训练图像', img_grid) for epoch in range(epochs):running_loss = 0.0 #累计损失correct = 0 #正确预测数total = 0 #总样本数for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次记录一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 记录标量数据(损失、准确率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 记录学习率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500个批次记录一次直方图(权重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练损失和准确率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0# 用于存储预测错误的样本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集预测错误的样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试损失和准确率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 计算并记录训练速度(每秒处理的样本数)# 这里简化处理,假设每个epoch的时间相同samples_per_epoch = len(train_loader.dataset)# 实际应用中应该使用time.time()来计算真实时间print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 可视化预测错误的样本(只在最后一个epoch进行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多显示8个错误样本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 创建错误预测的标签文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid)writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 关闭TensorBoard写入器writer.close()return epoch_test_acc # 返回最终测试准确率# 6. 执行训练和测试
epochs = 20 # 训练轮次
print("开始训练模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")相关文章:

Python 训练营打卡 Day 45
TensorBoard 简单来说,TensorBoard 是 TensorFlow 自带的一个「可视化工具」,就像给机器学习模型训练过程装了一个「监控屏幕」。你可以用它直观看到训练过程中的数据变化(比如损失值、准确率)、模型结构、数据分布等,…...

自托管图书搜索引擎Bookologia
简介 什么是 Bookologia ? Bookologia 是一个专门的书籍搜索引擎,可以在几秒钟内找到任何书籍。它是开源的,可以轻松自托管在 Docker 上,为用户提供一个简单而高效的书籍查找体验。 主要特点 简洁的用户界面:界面设计…...

前端flex、grid布局
flex布局 弹性布局是指通过调整其内元素的宽高,从而在任何的显示设备上实现对可用显示空间最佳填充的能力。弹性容器扩展其内元素来填充可用空间,或将其收缩来避免溢出 简单来说,弹性盒子模型,是为了你的网页可以在不同分辨率设…...
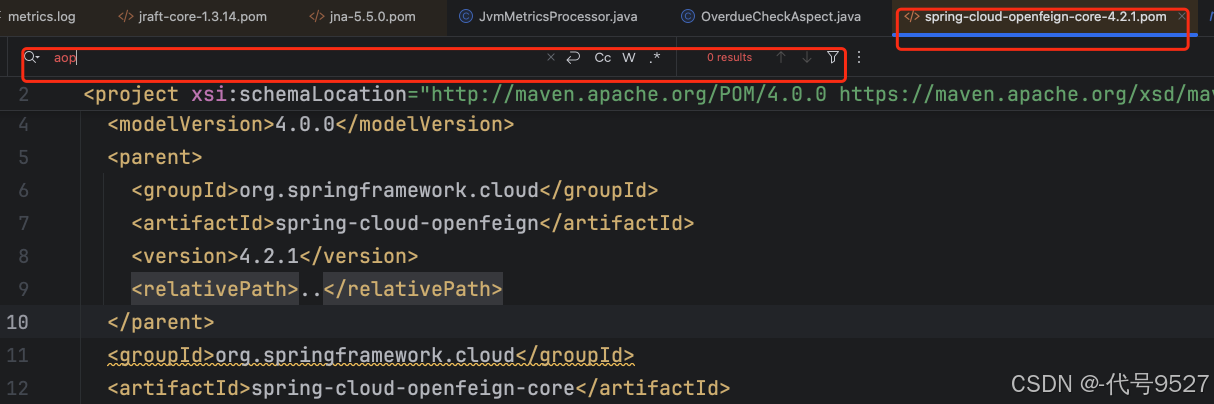
Maven相关问题:jna版本与ES冲突 + aop失效
文章目录 1、背景2、解决3、一点思考4、环境升级导致AOP失效5、okhttp Bean找不到6、总结 记录一些Maven依赖相关的思考 1、背景 做一个监控指标收集,用一下jna依赖: <dependency><groupId>net.java.dev.jna</groupId><artifact…...
Tomcat全方位监控实施方案指南
#作者:程宏斌 文章目录 一.二进制部署1、安装包信息2、新建配置文件2.1 配置config.yaml文件2.2 上传jar包 3、修改配置3.1 备份3.2 修改bin目录下的startup.sh文件 4、重启tomcat5、访问测试 二.docker部署1、临时方案1.1、重新启动容器1.2…...

开源PHP在线客服系统源码搭建教程
在当今数字化时代,在线客服系统已成为企业与客户沟通的重要桥梁。开源PHP客服系统因其灵活性、低成本和高可定制性而受到众多企业的青睐。本文将介绍几款优秀的开源PHP客服系统,并提供详细的搭建教程。 演示网站:gofly.v1kf.com 1.1 主流开源…...

centos7升级glibic-2.28
centos7升级glibic-2.28 最近使用trae连接服务器的时候,提示远程系统不兼容: Trae CN需要glibc 2.28或更高版本。检测到的版本: 2.17。下面是升级步骤。centos7默认的glibc不支持node v18及以上。 1、进入/home/download目录(没有download,则新建一个)…...

在Docker里面运行Docker
Docker 凭借其轻量级和可移植的容器,无疑改变了软件开发和部署的世界。但如果我告诉你 Docker 本身可以在另一个 Docker 容器中运行,你会怎么想?没错!这个概念通常被称为“Docker Inside Docker”或“DinD”,它为开发人员和系统管理员开辟了一个全新的可能性领域。在这篇博…...

设计模式复习小结
1.容易忘得设计原则 接口隔离:指接口中的功能太杂则可以拆分一下。防止实现类实现了接口后自动依赖了一些不需要的功能。不同功能拆分成不同的接口。 里氏代换:强调父类能出现的地方,子类一定能正常跑。 迪米特法则:又称最少知…...
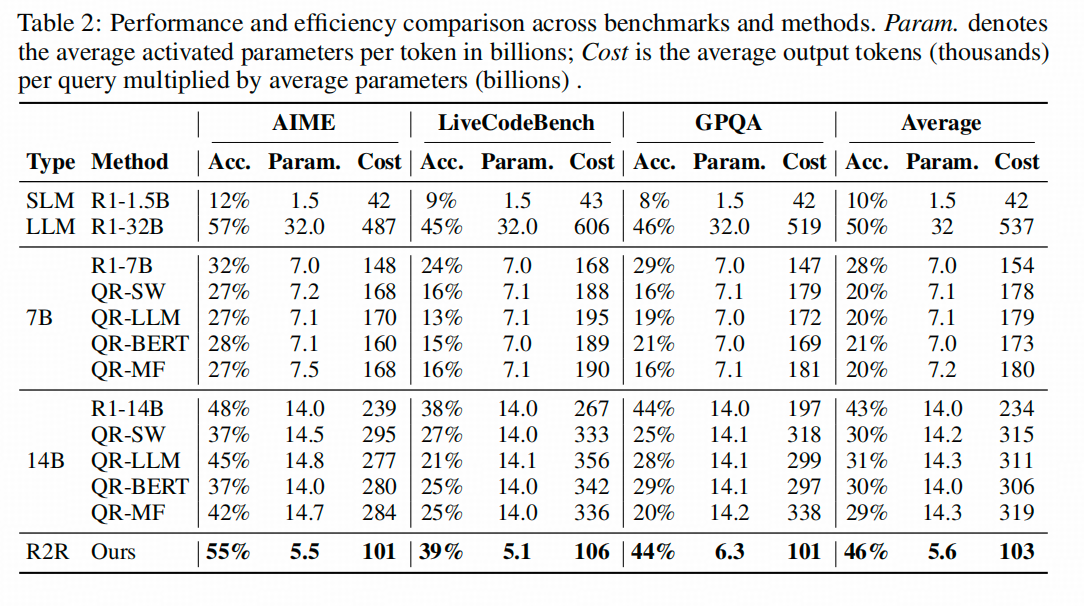
To be or Not to be, That‘s a Token——论文阅读笔记——Beyond the 80/20 Rule和R2R
本周又在同一方向上刷到两篇文章,可以说,……同学们确实卷啊,要不卷卷开放场域的推理呢? 这两篇都在讲:如何巧妙的利用带有分支能力的token来提高推理性能或效率的。 第一篇叫 Beyond the 80/20 Rule: High-Entropy Mi…...

【基础】每天掌握一个Linux命令 - awk
目录 【基础】每天掌握一个Linux命令 - awk一、工具概述二、安装方式Ubuntu/Debian系统:CentOS/RHEL系统:macOS系统: 三、核心功能四、基础用法基本语法常用选项内置变量基本操作示例1. 打印文件所有内容2. 打印每行的第一个字段3. 指定分隔符…...

《UE5_C++多人TPS完整教程》学习笔记37 ——《P38 变量复制(Variable Replication)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P38 变量复制(Variable Replication)》 的学习笔记,该系列教学视频为计算机工程师、程序员、游戏开发者、作家(Engineer, Programmer, Game Developer, Author)…...
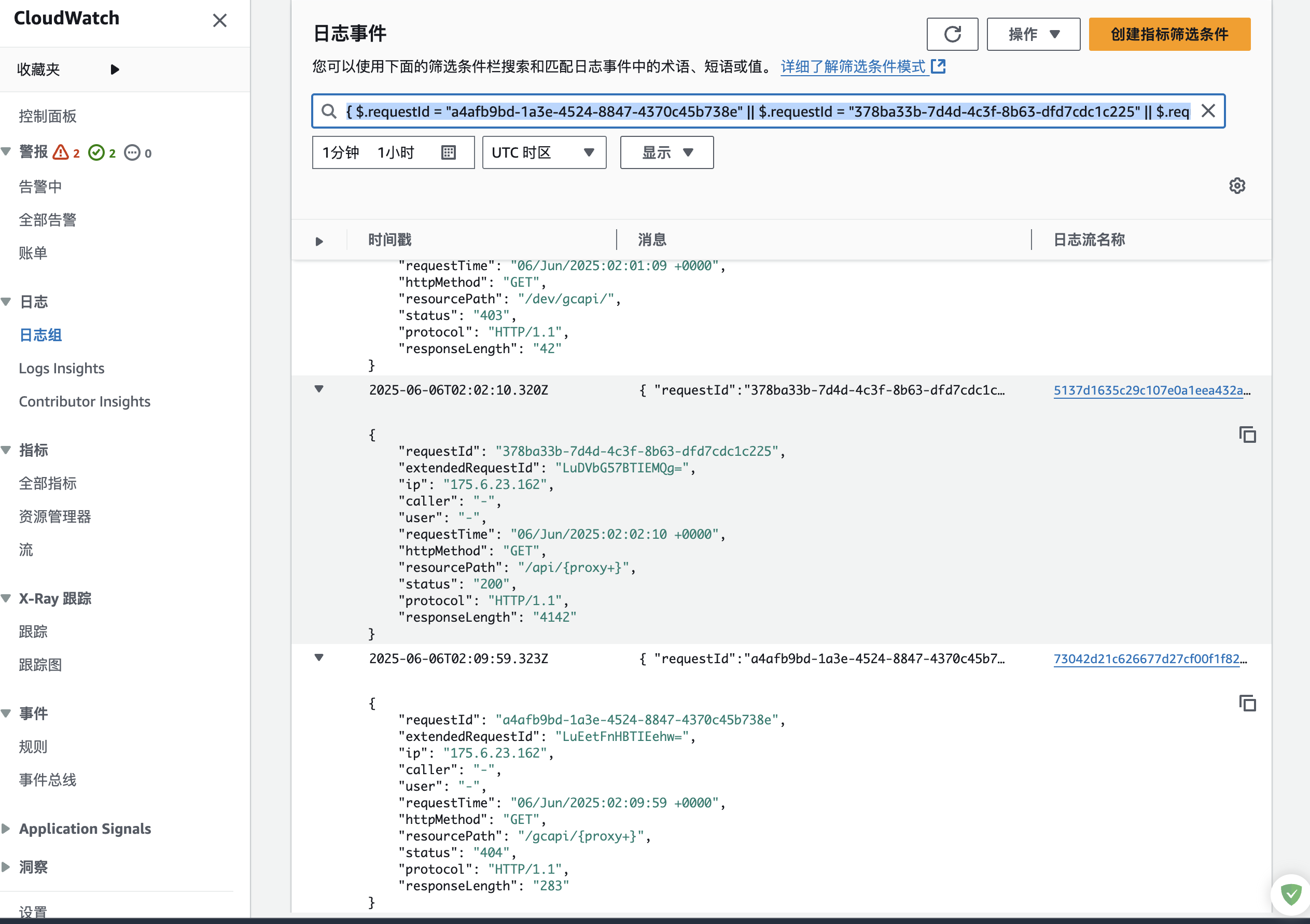
AWS API Gateway配置日志
问题 访问API Gateway接口出现了403问题,具体报错如下: {"message":"Missing Authentication Token"}需要配置AWS API Gateway日志,看请求过程是什么样子的。 API Gateway 先找到API Gateway的的日志角色,…...

Towards Open World Object Detection概述(论文)
论文:https://arxiv.org/abs/2103.02603 代码:https://github.com/JosephKJ/OWOD Towards Open World Object Detection 迈向开放世界目标检测 Abstract 摘要 Humans have a natural instinct to identify unknown object instances in their environ…...

轻松备份和恢复 Android 系统 | 4 种解决方案
我们通常会在 Android 手机上存储大量重要的个人数据,包括照片、视频、联系人、信息等等。如果您不想丢失宝贵的数据,可以备份 Android 数据。当您需要访问和使用这些数据时,可以将其恢复到 Android 设备。如果您想了解 Android 备份和恢复&a…...

具备强大的数据处理和分析能力的智慧地产开源了
智慧地产视觉监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。 AI是新形势下数…...

RK3588和FPGA桥片之间IO电平信号概率性不能通信原因
1.GPIO管脚配置问题 RK3588对IO进行配置的时候,如果配置为多功能复用,没有明确IO功能,可能引起信号接收不稳定, 需要在驱动中设备树中配置管脚为GPIO功能,确保没有功能复用的干扰。 2.上下拉电阻阻值设置不当 GPIO引脚…...
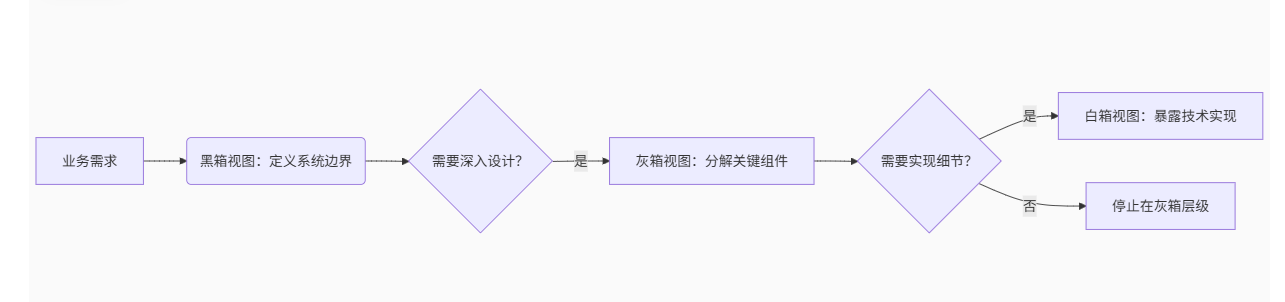
【iSAQB软件架构】软件架构中构建块的视图:黑箱、灰箱和白箱及其交互机制
在软件架构描述中,黑箱视图(Black-box)、灰箱视图(Gray-box)和白箱视图(White-box) 是不同抽象层级的构建模块表示方式,用于满足不同受众和设计阶段的需求。以下是基于ISAQB标准的清…...

.net jwt实现
.NET 中实现 JWT 认证:详细指南 在现代的 Web 应用开发中,安全认证是至关重要的一环。JSON Web Token(JWT)作为一种广泛使用的认证机制,为 API 提供了安全、便捷的身份验证方式。本文将详细介绍如何在 ASP.NET Core 项…...

LangChain【7】之工具创建和错误处理策略
文章目录 一 LangChain 自定义工具概述二创建自定义工具的三种方法2.1 方法一:tool 装饰器2.1.1 同步方法案例2.1.2 工具描述方式1:传参2.1.3 工具描述方式2:文档字符串 2.2 方法二:StructuredTool类2.2.1 StructuredTool创建自定…...
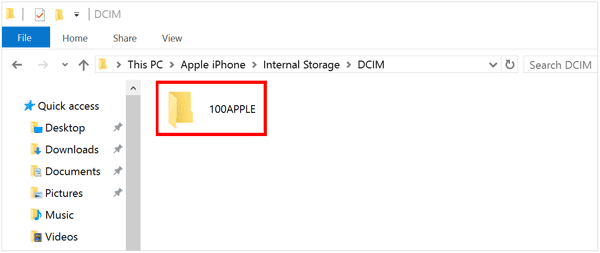
如何在电脑上轻松访问 iPhone 文件
我需要将 iPhone 下载文件夹中的文件传输到 Windows 11 电脑上。我该怎么做?我可以在 Windows 11 上访问 iPhone 下载吗? 由于 iOS 和 Windows 系统之间的差异,在 PC 上访问 iPhone 文件似乎颇具挑战性。然而,只要使用正确的工具…...

Eureka REST 相关接口
可供非 Java 应用程序使用的 Eureka REST 操作。 appID 是应用程序的名称,instanceID 是与实例关联的唯一标识符。在 AWS 云中,instanceID 是实例的实例 ID;在其他数据中心,它是实例的主机名。 对于 XML/JSON,HTTP 的…...

C语言字符数组输入输出方法大全(附带实例)
在 C语言中,字符数组是一种特殊的数组,用于存储和处理字符串。理解字符数组的输入和输出操作对于初学者来说至关重要,因为这是处理文本数据的基础。 字符数组的定义与初始化 在讨论输入输出之前,我们先来回顾一下字符数组的定义…...
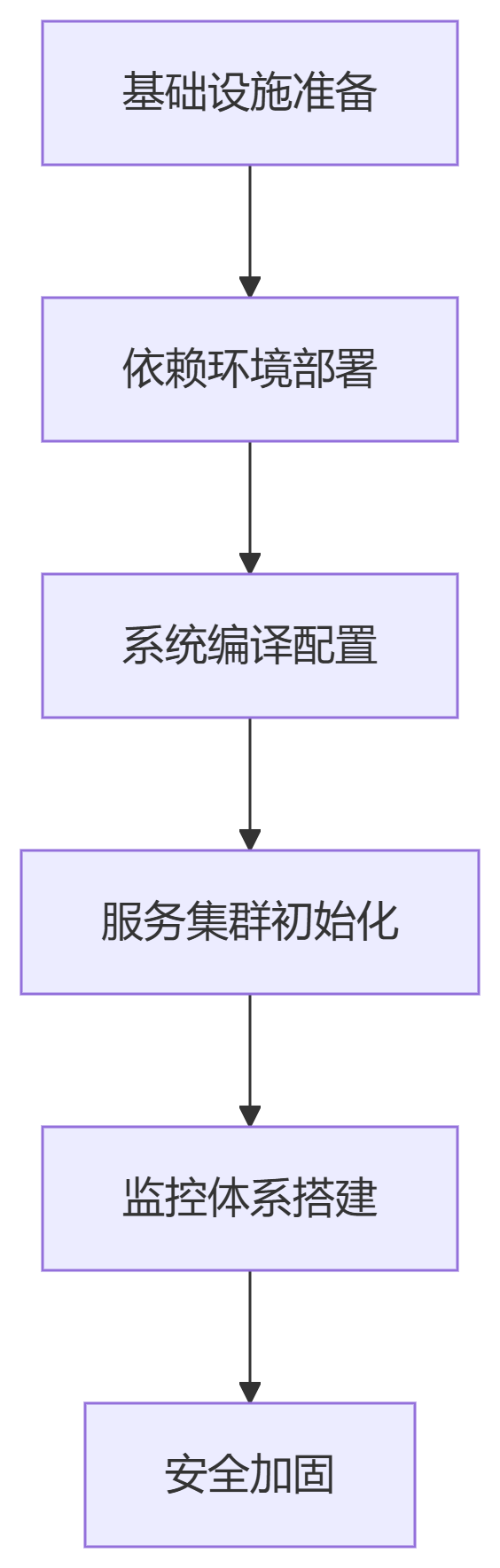
短视频矩阵SaaS系统:开源部署与核心功能架构指南
一、系统架构概述 短视频矩阵系统是基于SaaS(软件即服务)模式的多平台内容管理解决方案,通过开源技术实现账号聚合、智能创作、跨平台分发及数据闭环。系统采用微服务架构,支持高并发场景下的弹性扩展。 二、核心功能模块开发逻辑…...

每日算法 -【Swift 算法】电话号码字母组合
🚀 LeetCode 字符串数字映射(Swift)——电话号码字母组合 在日常刷题或面试中,我们经常会遇到字符串 回溯组合的问题。这道经典题——电话号码的字母组合 就是典型代表。本文将带你用 Swift 实现这道题,思路清晰&…...

深入解析YUM与DNF:RPM包管理器的架构演进与功能对比
在Linux系统管理中,软件包管理器是连接用户与底层RPM(Red Hat Package Manager)包的核心工具。作为RPM生态的两大代表性工具,YUM(Yellowdog Updater Modified)与DNF(Dandified YUM)的…...

解决cocos 2dx/creator2.4在ios18下openURL无法调用的问题
由于ios18废弃了旧的openURL接口,我们需要修改CCApplication-ios.mm文件的Application::openURL方法: //修复openURL在ios18下无法调用的问题 bool Application::openURL(const std::string &url) {// NSString* msg [NSString stringWithCString:…...
:30/10/10用户参与法则与定价策略的科学制定)
精益数据分析(94/126):30/10/10用户参与法则与定价策略的科学制定
精益数据分析(九十四):30/10/10用户参与法则与定价策略的科学制定 在创业过程中,如何衡量用户参与度是否健康?又该如何制定科学的定价策略实现营收最大化?今天,我们将深入解析Union Square Ven…...
oss:上传图片到阿里云403 Forbidden
访问图片出现403Forbidden问题,我们可以直接登录oss账号,查看对应权限是否开通,是否存在跨域问题...
)
Windows系统中如何使用符号链接将.vscode等配置文件夹迁移到D盘(附 CMD PowerShell 双版本命令)
在日常开发和使用中,很多应用程序都会在 Windows 用户目录(如 C:\Users\你的用户名\)下创建一些以点开头的隐藏配置文件夹,例如: .vscode — Visual Studio Code 的设置和插件数据.cursor — Cursor 编辑器的缓存和设…...