python学习打卡day45
知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
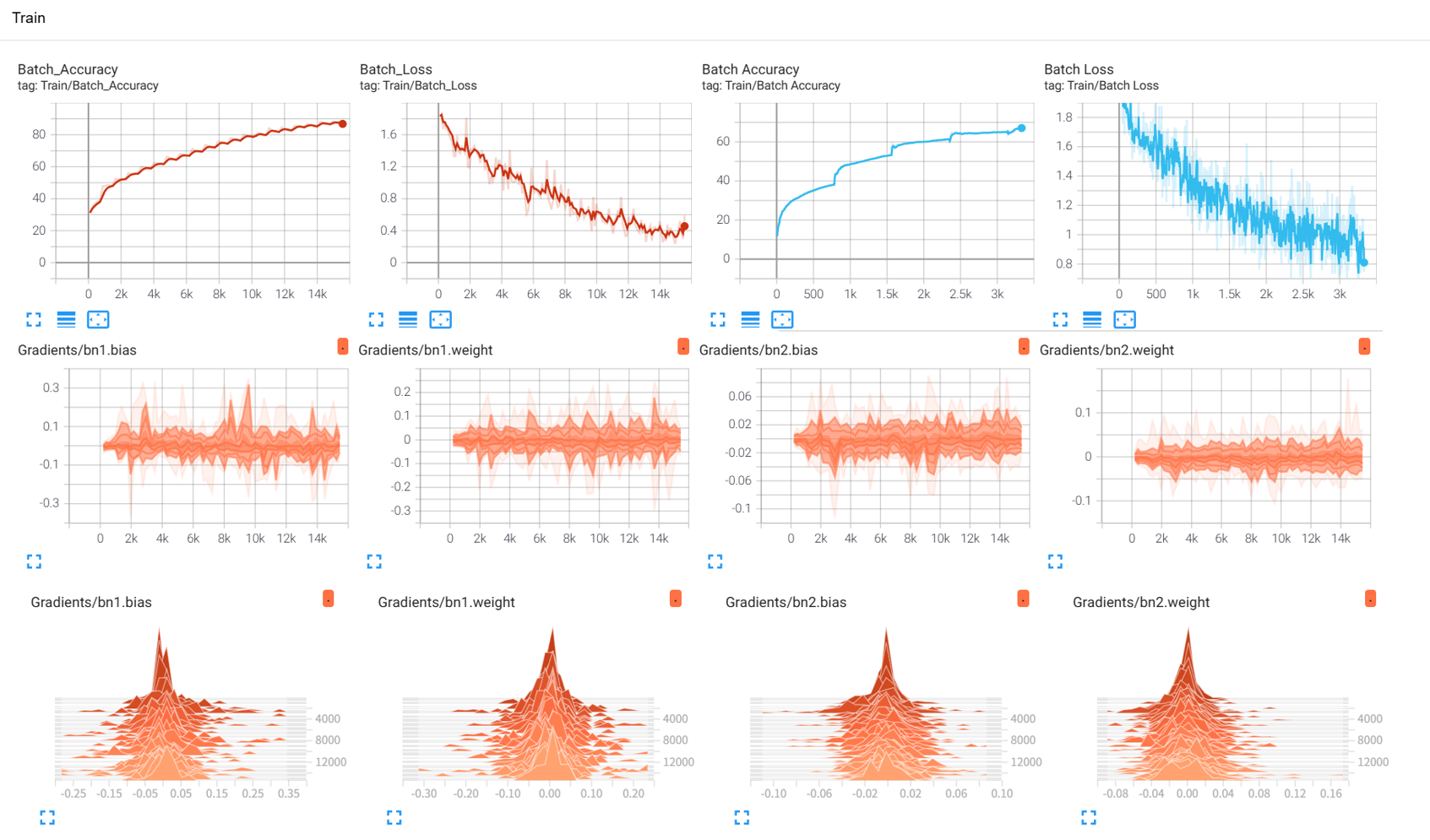
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。
- tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都是类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容
- 实际上对目前的ai而言,你只需要先完成最简单的demo,然后让他给你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms, models from torch.utils.data import DataLoader import matplotlib.pyplot as plt from torch.utils.tensorboard import SummaryWriter import os import torchvision # 设置中文字体支持 plt.rcParams["font.family"] = ["SimHei"] plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化) train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) ])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) ])# 2. 加载CIFAR-10数据集 train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform )test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform )# 3. 创建数据加载器 batch_size = 64 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)log_dir = "runs/cifar10_resnet18_exp" if os.path.exists(log_dir):version = 1while os.path.exists(f"{log_dir}_v{version}"):version += 1log_dir = f"{log_dir}_v{version}" writer = SummaryWriter(log_dir)# 4. 定义ResNet18模型 def create_resnet18(pretrained=True, num_classes=10):model = models.resnet18(pretrained=pretrained)# 修改最后一层全连接层in_features = model.fc.in_featuresmodel.fc = nn.Linear(in_features, num_classes)return model.to(device)# 5. 冻结/解冻模型层的函数 def freeze_model(model, freeze=True):"""冻结或解冻模型的卷积层参数"""# 冻结/解冻除fc层外的所有参数for name, param in model.named_parameters():if 'fc' not in name:param.requires_grad = not freeze# 打印冻结状态frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)total_params = sum(p.numel() for p in model.parameters())if freeze:print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")else:print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")return model# 6. 训练函数(支持阶段式训练) def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []global_step=0# 初始冻结卷积层if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解冻控制:在指定轮次后解冻所有层if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解冻后调整优化器(可选)optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合model.train() # 设置为训练模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# ======================== TensorBoard 标量记录 ========================# 记录每个 batch 的损失、准确率batch_acc = 100. * correct_train / total_trainwriter.add_scalar('Train/Batch Loss', iter_loss, global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)# 记录学习率(可选)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)global_step += 1# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# ======================== TensorBoard epoch 标量记录 ========================writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0wrong_images = [] # 存储错误预测样本(用于可视化)wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本(用于可视化)wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# ======================== TensorBoard 测试集记录 ========================writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 测试准确率: {epoch_test_acc:.2f}%')writer.close()return epoch_test_acc # (可选)CIFAR-10 类别名 classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 主函数:训练模型 def main():# 参数设置epochs = 30 # 总训练轮次freeze_epochs = 5 # 冻结卷积层的轮次learning_rate = 1e-3 # 初始学习率weight_decay = 1e-4 # 权重衰减# 创建ResNet18模型(加载预训练权重)model = create_resnet18(pretrained=True, num_classes=10)# 定义优化器和损失函数optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)criterion = nn.CrossEntropyLoss()# 定义学习率调度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2)# 开始训练(前5轮冻结卷积层,之后解冻)final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")print("训练后执行: tensorboard --logdir=runs 查看可视化")# # 保存模型# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')# print("模型已保存至: resnet18_cifar10_finetuned.pth")if __name__ == "__main__":main()
部分结果图像展示
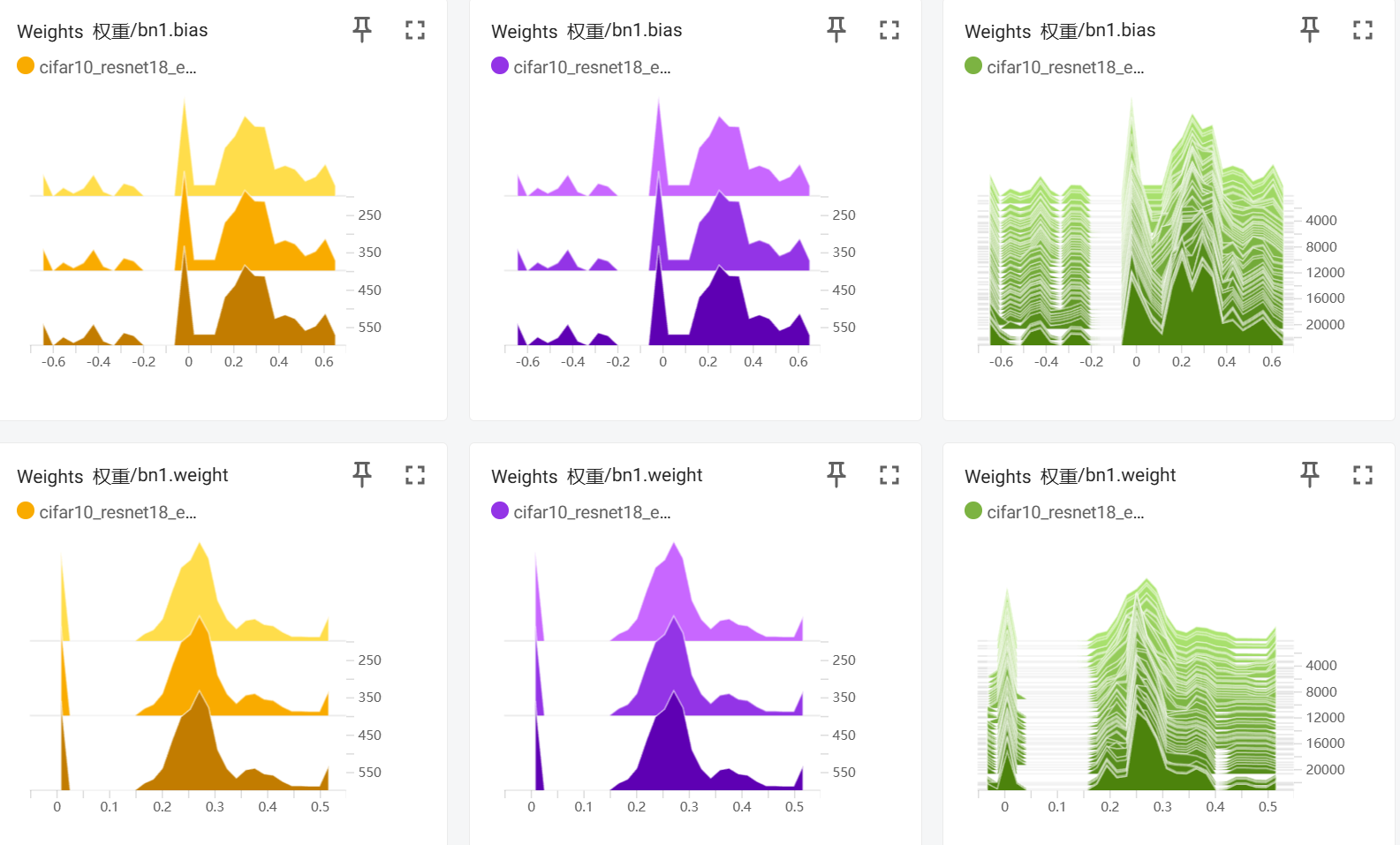
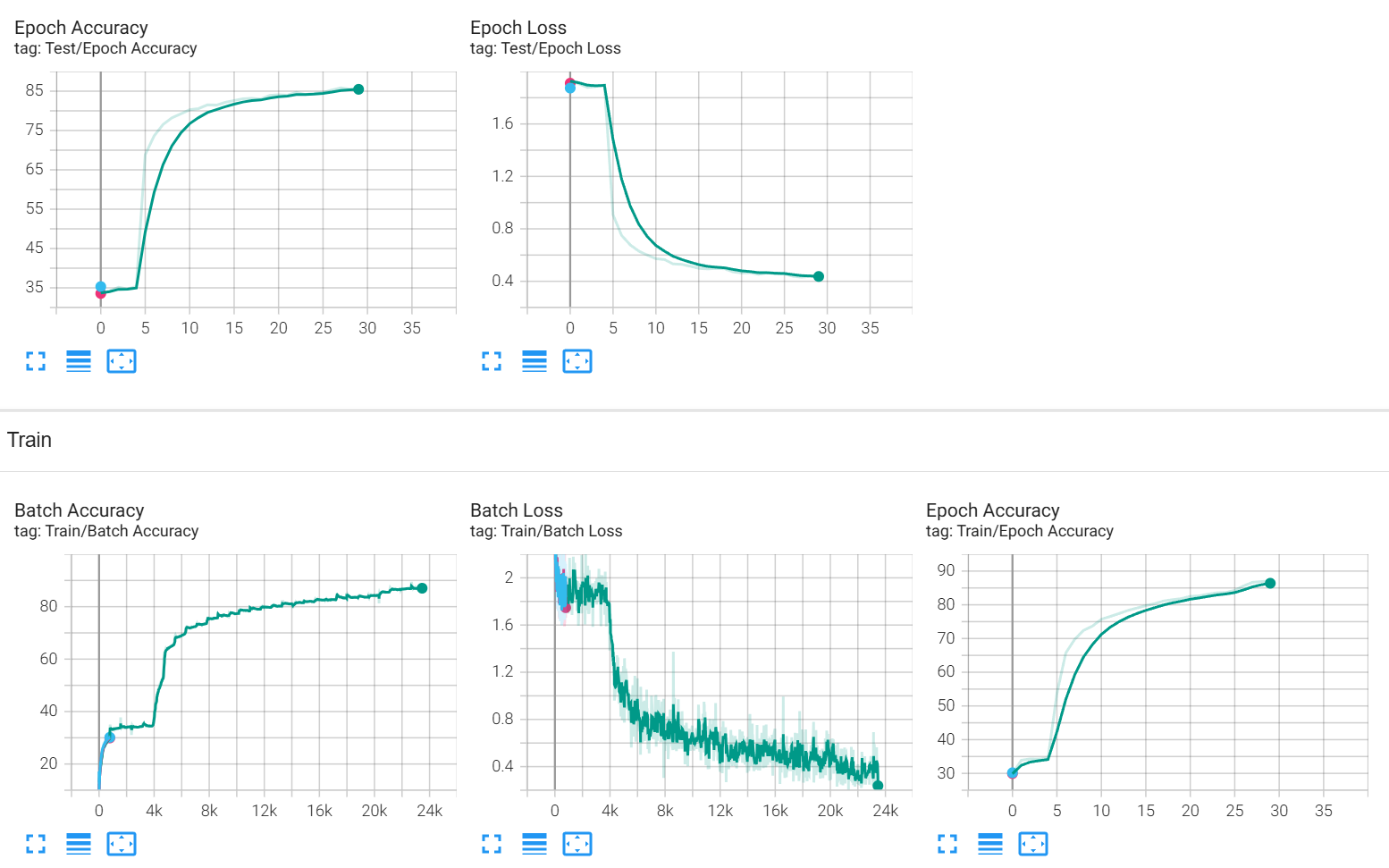
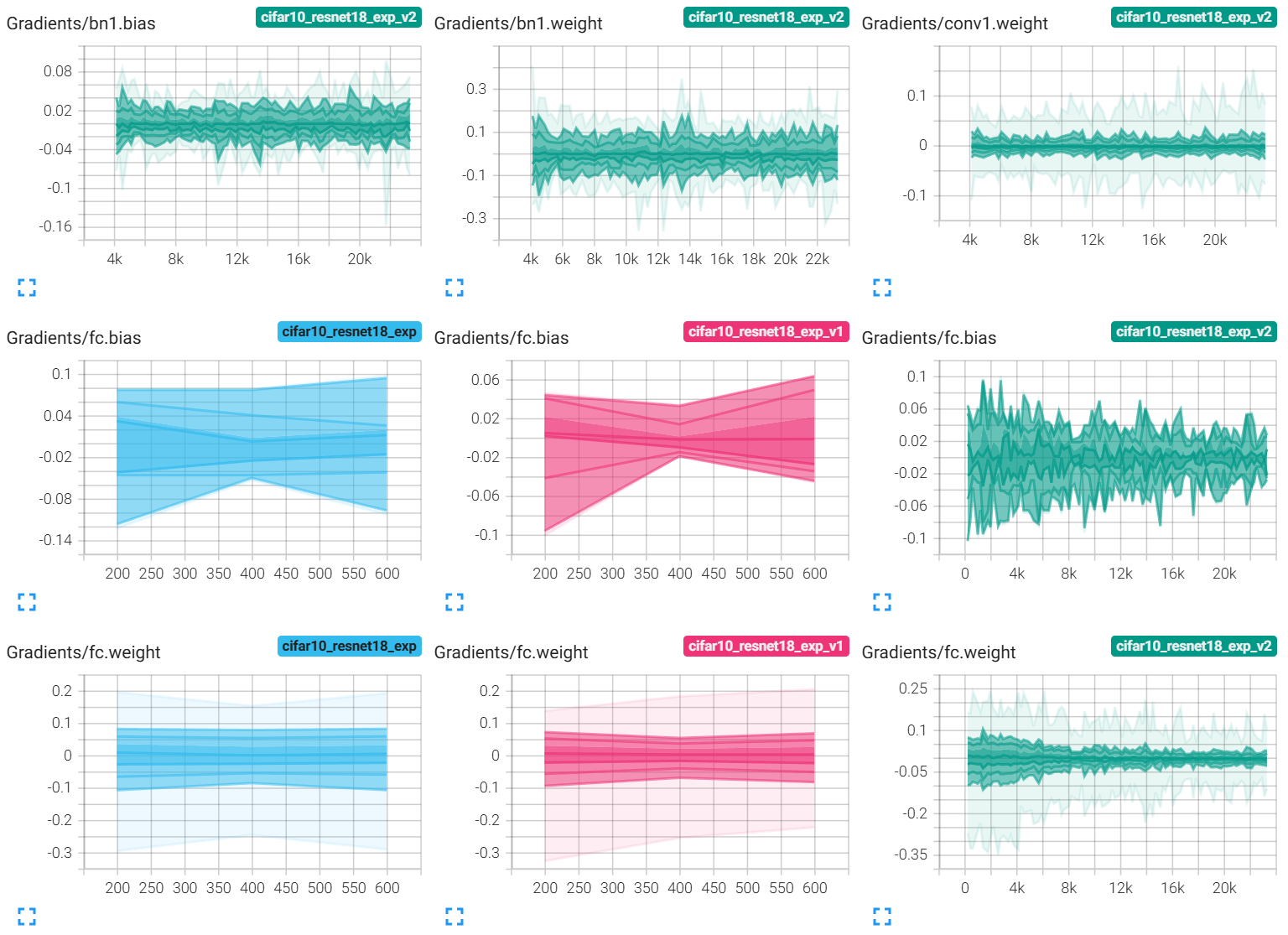
@浙大疏锦行
相关文章:
python学习打卡day45
DAY 45 Tensorboard使用介绍 知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策…...

JAVA元编程
一、引言:元编程的本质与 Java 实现 元编程(Metaprogramming)是一种 “操纵程序的程序” 的编程范式,其核心思想是通过代码动态操作代码本身。在 Java 中,元编程主要通过 ** 反射(Reflection)、…...

Verilog编程技巧01——如何编写三段式状态机
前言 Verilog编程技巧系列文章将聚焦于介绍Verilog的各种编程范式或者说技巧,编程技巧和编程规范有部分重合,但并非完全一样。规范更注重编码的格式,像变量命名、缩进、注释风格等,而编程技巧则更偏重更直观易读、更便于维护、综合…...
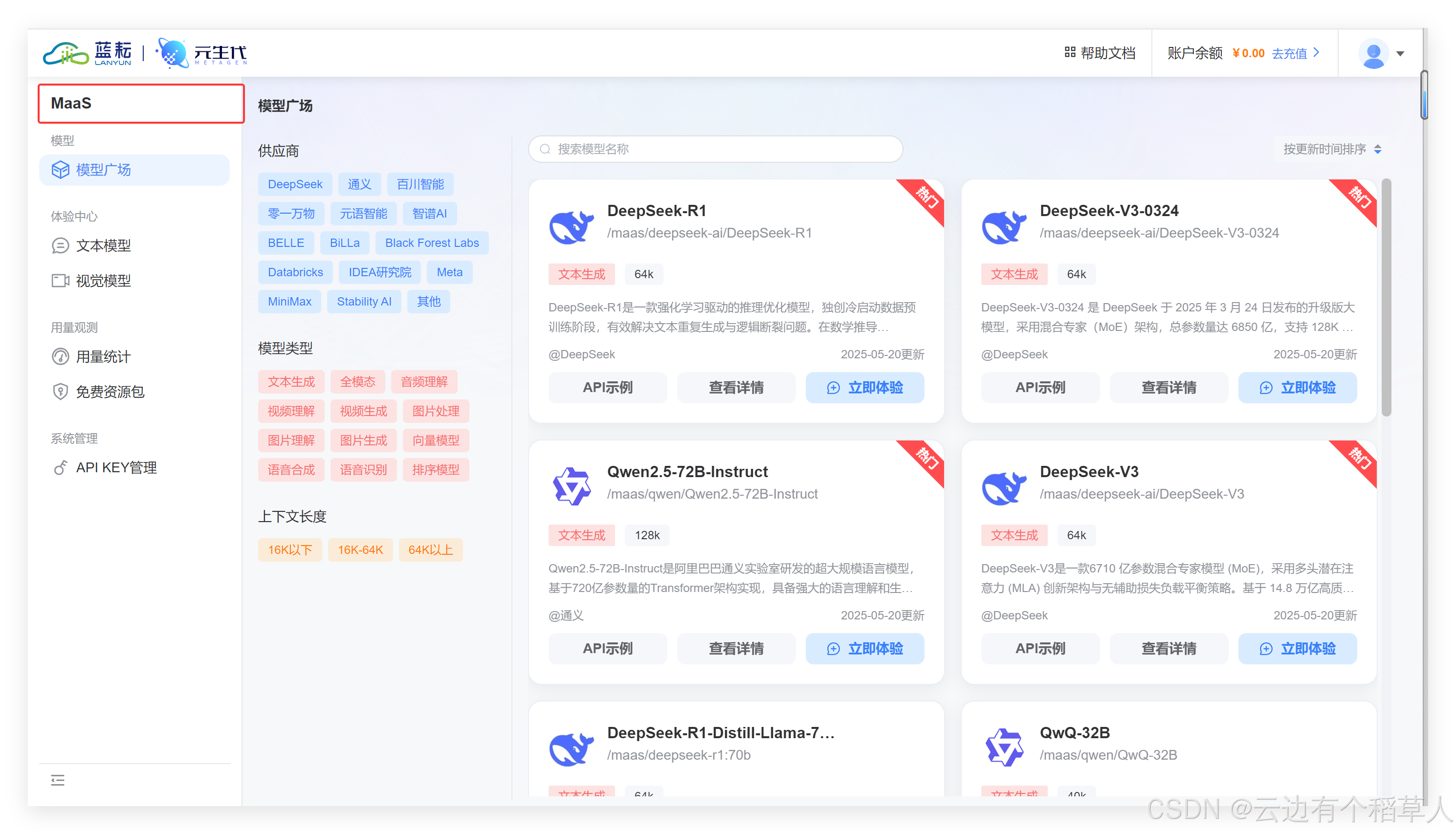
智启未来:当知识库遇见莫奈的调色盘——API工作流重构企业服务美学
目录 引言 一、初识蓝耘元生代MaaS平台 1.1 平台架构 1.2 平台的优势 1.3 应用场景 二、手把手教你如何在蓝耘进行注册 (1)输入手机号,将验证码正确填入即可快速完成注册 (2)进入下面的页面表示已经成功注册&…...
-泛型)
java教程笔记(十一)-泛型
Java 泛型(Generics)是 Java 5 引入的重要特性之一,它允许在定义类、接口和方法时使用类型参数。泛型的核心思想是将类型由具体的数据类型推迟到使用时再确定,从而提升代码的复用性和类型安全性。 1.泛型的基本概念 1. 什么是泛…...

JUnit 和 Mockito 的详细说明及示例,涵盖核心概念、常用注解、测试场景和实战案例。
一、JUnit 详解 1. JUnit 核心概念 测试类:以 Test 结尾的类(或通过 Test 注解标记的方法)。断言(Assertions):验证预期结果与实际结果是否一致(如 assertEquals()࿰…...

【Go语言基础【7】】条件语句
文章目录 零、概述一、if 条件语句1. 单条件模型2. 多条件模型(else if)3. 条件嵌套与优化 二、switch 条件判断1. 基本用法2. fallthrough 穿透执行3. break 终止执行 零、概述 语句类型适用场景核心特点if-else单条件或简单多条件判断逻辑清晰&#x…...

【Python 算法零基础 4.排序 ⑪ 十大排序算法总结】
目录 一、选择排序回顾 二、冒泡排序回顾 三、插入排序回顾 四、计数排序回顾 五、归并排序回顾 六、快速排序回顾 七、桶排序回顾 八、基数排序 九、堆排序 十、希尔排序 十一、十大排序算法对比 十二、各算法详解与应用场景 1. 选择排序(Selection Sortÿ…...

解决神经网络输出尺寸过小的实战方案
训练CIFAR10分类模型时出现报错:RuntimeError: Given input size: (256x1x1). Calculated output size: (256x0x0). Output size is too small。该问题由网络结构设计缺陷导致图像尺寸过度缩小引发。 核心原因分析 网络结构缺陷 原始模型采用六层卷积层,…...

Python备忘
1. 自定义多线程程序: import concurrent.futures import threadingclass CustomThreadPool:def __init__(self, max_workers):self.max_workers max_workersself.pool concurrent.futures.ThreadPoolExecutor(max_workers)self.running_num 0self.semaphore t…...
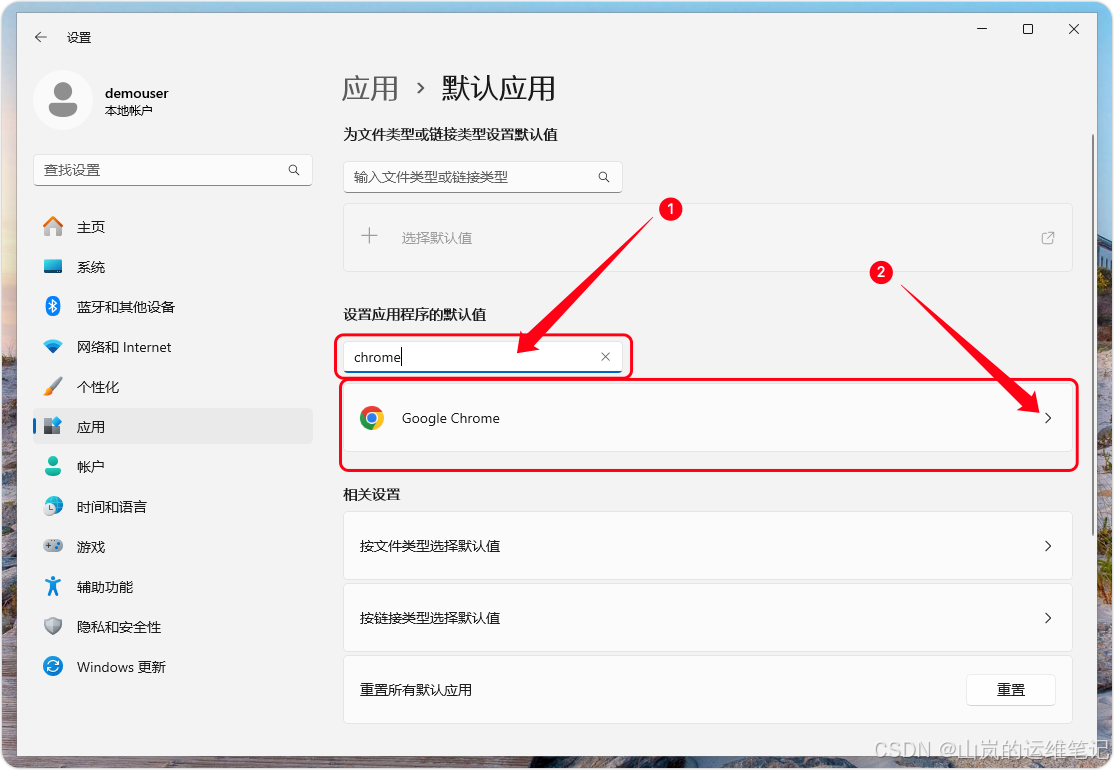
如何在 Windows 11 中永久更改默认浏览器:阻止 Edge 占据主导地位
在 Windows 11 中更改默认浏览器对于新手或技术不太熟练的用户来说可能会令人沮丧。 为什么要在 Windows 11 中更改默认浏览器? 这是一个重要的问题:你为什么要从 Microsoft Edge 切换过来? 生态系统集成:如果你已经在广泛使用 Google 服务,Chrome 可以提供无缝集成。同…...

量子比特实现方式
经典计算机是通过电子电路运转起来的。使用硅制半导体制成的名为晶体管的小元件发挥了开关的作用,将其与金属布线组合起来即可实现逻辑门,再将逻辑门集成起来就能制造出经典计算机。量子计算机的制造过程则要复杂许多,因为量子计算机既需要量…...

智慧水务发展迅猛:从物联网架构到AIoT系统的跨越式升级
AI大模型引领智慧水务迈入新纪元 2025年5月25日,水利部自主研发的“水利标准AI大模型”正式发布,它标志着水务行业智能化进程的重大突破。该模型集成1800余项水利标准、500余项法规及海量科研数据,支持立项、编制、审查等全流程智能管理&…...

1、cpp实现Python的print函数
实现一 #include <iostream> #include <list> #include <string>using namespace std;// 定义一个空的print函数,作为递归终止条件 void print(){// };// 可变参数模板函数,用于递归输出传入的参数 template <typename T, typenam…...

【Linux基础知识系列】第十四篇-系统监控与性能优化
一、简介 随着信息技术的飞速发展,Linux系统在服务器领域占据着重要地位。无论是web服务器、数据库服务器还是文件服务器,都需要高效的运行以满足业务需求。系统监控与性能优化是确保Linux系统稳定、高效运行的关键任务。通过实时监测系统资源的使用情况…...

云原生思维重塑数字化基座:从理念到实践的深度剖析
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:云原生为何成为数字化的“基础设施语言”? 随着5G、人工智能、物联网等技术逐步进入规模化落地阶段&am…...

Animate On Scroll 用于在用户滚动页面时实现元素的动画效果
AOS (Animate On Scroll) 详细介绍 什么是AOS? AOS(Animate On Scroll)是一个轻量级的JavaScript库,用于在用户滚动页面时实现元素的动画效果。它允许网页元素在进入或离开视口(viewport)时触发各种CSS动…...

Java高级 | 【实验五】Spring boot+mybatis操作数据库
隶书文章:Java高级 | (二十二)Java常用类库-CSDN博客 系列文章:Java高级 | 【实验一】Springboot安装及测试 |最新-CSDN博客 Java高级 | 【实验二】Springboot 控制器类相关注解知识-CSDN博客 Java高级 | 【实验三】Springboot 静…...

[蓝桥杯]搭积木
搭积木 题目描述 小明对搭积木非常感兴趣。他的积木都是同样大小的正立方体。 在搭积木时,小明选取 mm 块积木作为地基,将他们在桌子上一字排开,中间不留空隙,并称其为第 0 层。 随后,小明可以在上面摆放第 1 层&a…...

在MATLAB中使用自定义的ROS2消息
简明结论: 无论ROS2节点和MATLAB运行在哪,MATLAB本机都必须拥有自定义消息源码并本地用ros2genmsg生成,才能在Simulink里订阅这些消息。只要你想让MATLAB或Simulink能识别自定义消息,必须把消息包源码(.msg等)拷到本机指定目录&a…...

使用C/C++和OpenCV实现图像拼接
使用 C 和 OpenCV 实现图像拼接 本文将详细介绍如何利用 OpenCV 库,在 C 环境中实现图像拼接。图像拼接技术可以将多张具有重叠区域的图像合成为一张高分辨率的全景图。OpenCV 提供了一个功能强大的 Stitcher 类,它封装了从特征点检测、匹配到图像融合的…...

神经网络-Day46
目录 一、 什么是注意力二、 特征图的提取2.1 简单CNN的训练2.2 特征图可视化 三、通道注意力3.1 通道注意力的定义3.2 模型的重新定义(通道注意力的插入) 一、 什么是注意力 注意力机制,本质从onehot-elmo-selfattention-encoder-bert这就是…...

Ubuntu中常用的网络命令指南
Ubuntu中常用的网络命令指南 在Ubuntu系统中,网络管理是日常运维和故障排查的核心技能。 🛠️ 基础网络诊断 ping - 测试网络连通性 ping google.com # 持续测试 ping -c 4 google.com # 发送4个包后停止traceroute / tracepath - 追踪数据包路径 …...

JVM——如何打造一个类加载器?
引入 在Java应用程序的生命周期中,类加载器扮演着至关重要的角色。它是Java运行时环境的核心组件之一,负责在需要时动态加载类文件到JVM中。理解类加载器的工作原理以及如何自定义类加载器,不仅可以帮助我们更好地管理应用程序的类加载过程&…...

【MATLAB去噪算法】基于ICEEMDAN联合小波阈值去噪算法
ICEEMDAN联合小波阈值去噪算法相关文献 (注:目前相关论文较少,应用该套代码可发直接一些水刊) 一、CEEMDAN的局限性 模式残留噪声问题:原始CEEMDAN在计算每个IMF时直接对噪声扰动的信号进行模态分解并平均。 后果&a…...

c++ Base58编码解码
Base58 字符集 Base58 使用 58 个字符进行编码,字符集为:123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz。注意:0(零)、O(大写字母O)、I(大写字母I)和 l&a…...

证券交易柜台系统解析与LinkCounter解决方案开发实践
第一章 证券交易柜台系统基础解析 1.1 定义与行业定位 证券交易柜台系统(Trading Counter System)是券商经纪业务的核心支撑平台,承担投资者指令传输、风险控制、清算结算等职能。根据中国证监会《证券期货业网络信息安全管理办法》要求&am…...

XXTEA,XTEA与TEA
TEA、XTEA和XXTEA都是分组加密算法,它们在设计、安全性、性能等方面存在显著区别。以下是它们的主要区别: 密钥长度 TEA:使用128位密钥。 XTEA:通常使用128位或256位密钥。 XXTEA:密钥长度更灵活,可以使用任…...

机器人玩转之---嵌入式开发板基础知识到实战选型指南(包含ORIN、RDK X5、Raspberry pi、RK系列等)
1. 基础知识讲解 1.1 什么是嵌入式开发板? 嵌入式开发板是一种专门设计用于嵌入式系统开发的硬件平台,它集成了微处理器、内存、存储、输入输出接口等核心组件于单块印刷电路板上。与传统的PC不同,嵌入式开发板具有体积小、功耗低、成本适中…...

腾讯云国际版和国内版账户通用吗?一样吗?为什么?
在当今全球化的数字化时代,云计算服务成为众多企业和个人拓展业务、存储数据的重要选择。腾讯云作为国内领先的云服务提供商,其国际版和国内版备受关注。那么,腾讯云国际版和国内版账户是否通用?它们究竟一样吗?背后又…...