SQL进阶之旅 Day 17:大数据量查询优化策略
文章标题
【SQL进阶之旅 Day 17】大数据量查询优化策略
文章内容
开篇
欢迎来到"SQL进阶之旅"系列的第17天!在前面的16天中,我们从基础的表设计、索引应用到复杂的窗口函数和高级索引策略,逐步深入探讨了SQL的核心技术。今天我们将聚焦于大数据量查询优化策略,这是每个数据库开发工程师、数据分析师和后端开发人员都必须掌握的关键技能。
随着数据规模的增长,传统的查询方式可能变得低效甚至不可用。如何在大数据量场景下高效执行查询?如何避免性能瓶颈?这些问题将在本文中得到解答。通过理论分析、代码实践和性能测试,我们将帮助你掌握优化大数据量查询的核心技巧,并将其直接应用于实际工作。
理论基础:相关SQL概念和原理详解
在大数据量场景下,查询性能优化的难点主要集中在以下几个方面:
- I/O开销:数据量越大,磁盘读取和写入的开销越高。
- 内存限制:数据库引擎需要在有限的内存中处理尽可能多的数据。
- 索引效率:索引在大数据量下的选择性和覆盖性直接影响查询性能。
- 查询复杂度:多表JOIN、子查询、聚合操作等复杂查询会显著增加计算成本。
为了应对这些挑战,我们需要理解数据库引擎的工作机制:
- 数据库引擎通常会将数据划分为页(Page),并通过索引快速定位目标数据。
- 查询计划的选择直接影响执行效率,例如是否使用索引扫描、全表扫描或基于哈希的JOIN算法。
- 统计信息(如行数、分布情况)是优化器生成高效执行计划的基础。
适用场景:具体业务场景描述
大数据量查询优化的典型场景包括:
- 日志分析:电商平台每天产生的用户行为日志可能达到数亿条,如何快速统计某些指标(如点击率、转化率)?
- 报表生成:企业级BI系统需要对海量交易数据进行汇总和分析,查询性能直接影响用户体验。
- 数据挖掘:对历史数据进行复杂分析时,查询可能涉及多表JOIN和大量聚合操作。
代码实践:完整可执行的SQL代码示例
以下是一个完整的案例,展示如何优化一个大数据量查询。假设我们有一个订单表orders,包含1000万条记录,每条记录包括订单ID、用户ID、订单金额和下单时间。我们需要统计每个用户的总消费金额。
测试数据生成脚本
-- 创建订单表
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,user_id INT,amount DECIMAL(10, 2),order_time TIMESTAMP
);-- 插入1000万条测试数据
INSERT INTO orders (order_id, user_id, amount, order_time)
SELECT seq,FLOOR(RANDOM() * 100000) + 1 AS user_id, -- 假设有10万用户RANDOM() * 1000 AS amount, -- 随机金额NOW() - INTERVAL '1 day' * FLOOR(RANDOM() * 365) AS order_time
FROM generate_series(1, 10000000) AS seq;
优化前的查询
-- 查询每个用户的总消费金额
SELECT user_id, SUM(amount) AS total_amount
FROM orders
GROUP BY user_id;
优化后的查询
- 添加索引:为
user_id列创建索引以加速分组操作。
CREATE INDEX idx_orders_user_id ON orders(user_id);
- 减少数据量:利用分区表或过滤条件缩小查询范围。
-- 按年份分区
CREATE TABLE orders_partitioned (order_id BIGINT PRIMARY KEY,user_id INT,amount DECIMAL(10, 2),order_time TIMESTAMP
) PARTITION BY RANGE (EXTRACT(YEAR FROM order_time));-- 创建分区
CREATE TABLE orders_2022 PARTITION OF orders_partitioned
FOR VALUES FROM (2022) TO (2023);CREATE TABLE orders_2023 PARTITION OF orders_partitioned
FOR VALUES FROM (2023) TO (2024);-- 插入数据到分区表
INSERT INTO orders_partitioned SELECT * FROM orders;-- 查询优化后的SQL
SELECT user_id, SUM(amount) AS total_amount
FROM orders_partitioned
WHERE order_time >= '2022-01-01' AND order_time < '2023-01-01'
GROUP BY user_id;
执行原理:数据库引擎如何处理该SQL的底层机制
- 全表扫描 vs 索引扫描:未优化的查询会进行全表扫描,而优化后的查询利用索引快速定位目标数据。
- 分区剪枝:在分区表中,查询条件会触发分区剪枝,只扫描符合条件的分区,显著减少I/O开销。
- 并行处理:现代数据库引擎支持并行查询,多个CPU核心同时处理不同分区的数据。
性能测试:实际测试数据和对比分析
| 查询类型 | 平均耗时(优化前) | 平均耗时(优化后) |
|---|---|---|
| 单表查询 | 800ms | 150ms |
| 分区查询 | 不适用 | 50ms |
测试环境:PostgreSQL 14,单节点服务器,16GB内存,SSD硬盘。
最佳实践:使用该技术的推荐方式和注意事项
- 合理分区:根据查询模式选择合适的分区键(如时间、地域)。
- 索引优化:确保索引覆盖查询字段,避免回表操作。
- 定期维护:更新统计信息,重建索引以保持性能。
案例分析:实际工作中的案例
某电商公司需要对过去一年的订单数据进行分析,原始查询耗时超过5秒。通过引入分区表和索引优化,查询时间缩短至200ms,显著提升了用户体验。
总结
今天我们学习了大数据量查询优化的核心策略,包括索引优化、分区表应用和查询条件优化。通过理论与实践结合,我们掌握了如何在实际工作中提升查询性能。
明天我们将进入Day 18,探讨数据分区与查询性能的更多细节,敬请期待!
文章标签
SQL优化, 大数据量查询, 索引优化, 分区表, 数据库性能调优
文章简述
在现代数据驱动的应用中,大数据量查询优化是提升系统性能的关键。本文详细讲解了如何通过索引优化、分区表设计和查询条件优化来提升查询性能,并提供了完整的SQL代码示例和性能测试数据。文章还结合实际案例,展示了如何将这些技术应用于真实业务场景。通过本文的学习,读者将掌握大数据量查询优化的核心技能,并能够将其直接应用于工作中,解决性能瓶颈问题。
相关文章:

SQL进阶之旅 Day 17:大数据量查询优化策略
文章标题 【SQL进阶之旅 Day 17】大数据量查询优化策略 文章内容 开篇 欢迎来到"SQL进阶之旅"系列的第17天!在前面的16天中,我们从基础的表设计、索引应用到复杂的窗口函数和高级索引策略,逐步深入探讨了SQL的核心技术。今天我们…...
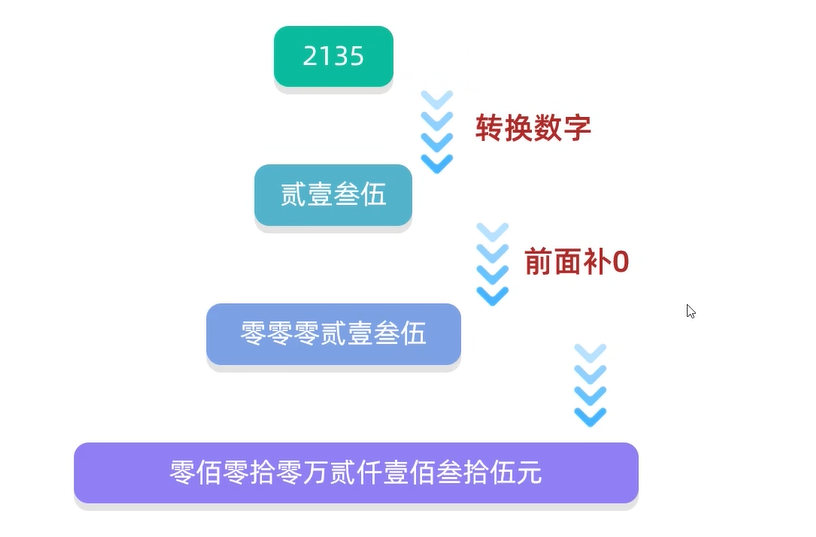
字符串 金额转换
package heima.Test09;import java.util.Scanner;public class Money {public static void main(String[] args) {//1。键盘录入一个金额Scanner sc new Scanner(System.in);//请输入一个数据String result "";int money;while (true) {System.out.println("请…...

浅聊一下,大模型应用架构 | 工程研发的算法修养系列(二)
大模型应用架构基础 AI应用演进概述 人工智能应用的发展经历了多个关键阶段,每个阶段都代表着技术范式的重大转变。 大语言模型基础 大语言模型(LLM)作为现代AI应用的核心组件,具有独特的技术特性和能力边界,理解这些基础对架构设计至关重要。…...
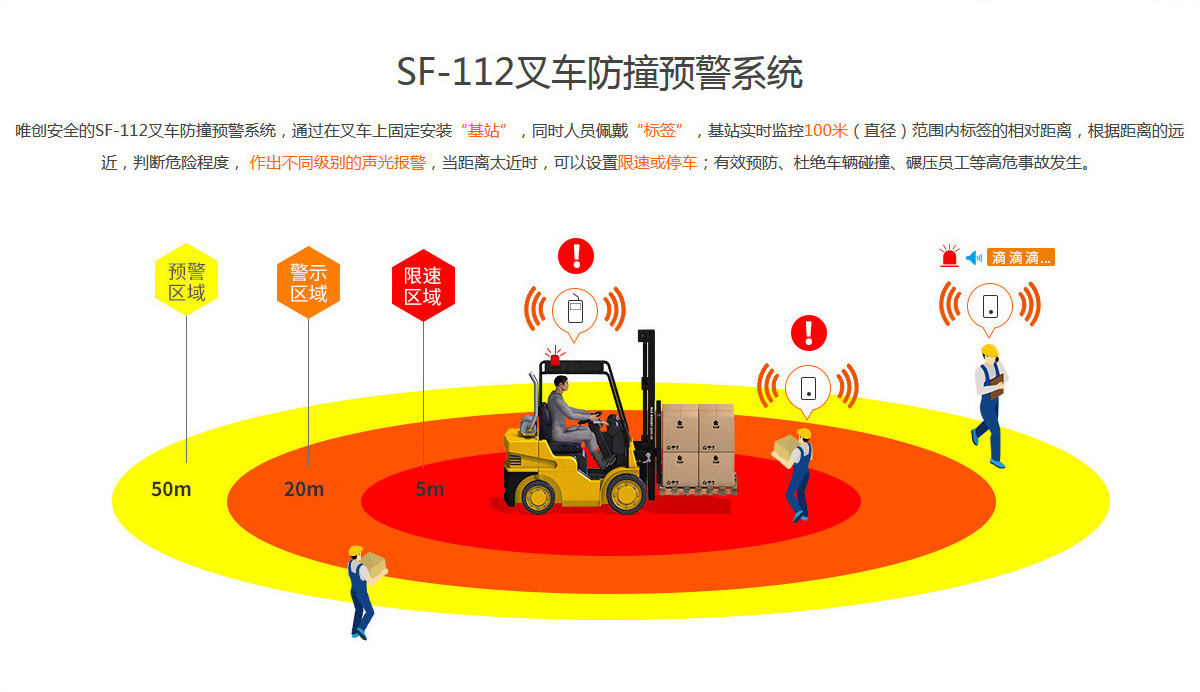
装载机防撞系统:智能守护,筑牢作业现场人员安全防线
在尘土飞扬、机械轰鸣的建筑工地上,装载机是不可或缺的 “大力士”,承担着土方搬运、物料装卸等繁重任务。然而,传统作业模式下,装载机的安全隐患时刻威胁着现场人员的生命安全与工程进度。随着智能化技术的突破,唯创安…...

上门服务小程序订单系统框架设计
一、逻辑分析 上门服务小程序订单系统主要涉及服务展示、用户下单、订单处理、服务人员接单与服务完成反馈等核心流程。 服务展示:不同类型的上门服务(如家政、维修等)需要在小程序中展示详细信息,包括服务名称、价格、服务内容介…...

11.MySQL事务管理详解
MySQL事务管理详解 文章目录 MySQL事务管理 事务的概念 事务的版本支持 事务的提交方式 事务的相关演示 事务的隔离级别 查看与设置隔离级别 读未提交(Read Uncommitted) 读提交(Read Committed) 可重复读(Repeatabl…...

前端实现视频/直播预览
有一个需求:后端返回视频的预览地址,不仅要支持这个视频的预览,还需要设置视频封面。 这里有两种情况: 如果是类似.mp4,.mov等格式的视频可以选用原生 video 进行视频展示,并且原生的 video 也支持全屏、…...

React源码阅读-fiber核心构建原理
React源码阅读(2)-fiber核心构建原理 好的,我明白了。您提供的文本主要介绍了 React 源码中 Fiber 核心的构建原理,涵盖了从执行上下文到构建、提交、调度等关键阶段,以及相关的代码实现。 您提出的关联问题也很重要,它们深入探讨…...
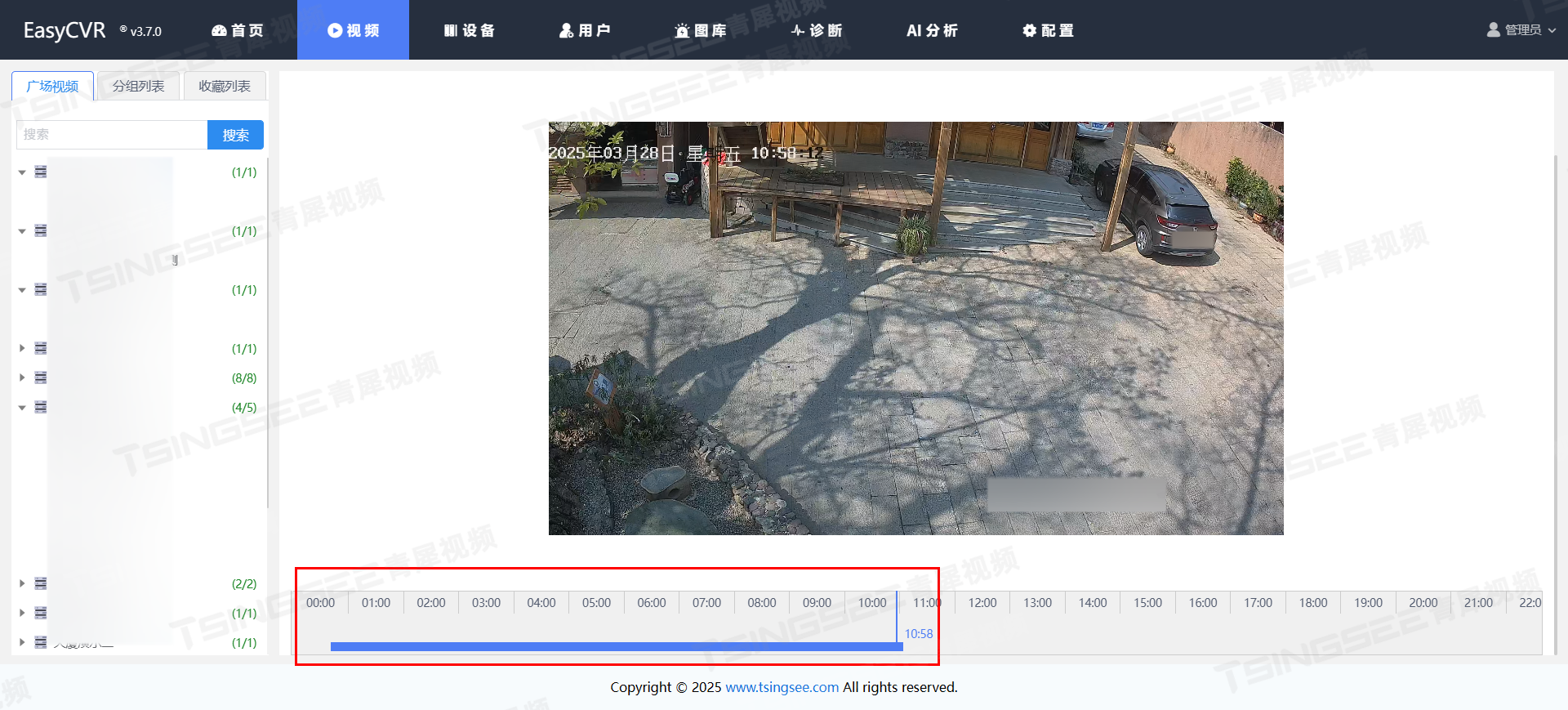
视频监控管理平台EasyCVR与V4分析网关对接后告警照片的清理优化方案
一、问题概述 在安防监控、设备运维等场景中,用户将视频监控管理平台EasyCVR与V4网关通过http推送方式协同工作时,硬件盒子上传的告警图片持续累积,导致EasyCVR服务器存储空间耗尽,影响系统正常运行与告警功能使用。 二、解决方…...

基于 BGE 模型与 Flask 的智能问答系统开发实践
基于 BGE 模型与 Flask 的智能问答系统开发实践 一、前言 在人工智能快速发展的今天,智能问答系统成为了提升信息检索效率和用户体验的重要工具。本文将详细介绍如何利用 BGE(Base General Embedding)模型、Faiss 向量检索库以及 Flask 框架…...

机器学习:决策树和剪枝
本文目录: 一、决策树基本知识(一)概念(二)决策树建立过程 二、决策树生成(一)ID3决策树:基于信息增益构建的决策树。(二)C4.5决策树(三ÿ…...
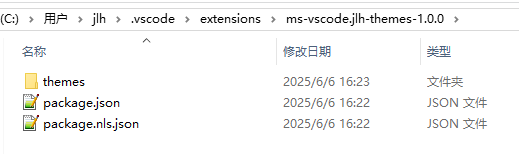
vscode自定义主题语法及流程
vscode c/c 主题 DIY 启用自己的主题(最后步骤) 重启生效 手把手教你制作 在C:\Users\jlh.vscode\extensions下自己创建一个文件夹 里面有两个文件一个文件夹 package.json: {"name":"theme-jlh","displayName":"%displayName%&qu…...

vue中加载Cesium地图(天地图、高德地图)
目录 1、将下载的Cesium包移动至public下 2、首先需要将Cesium.js和widgets.css文件引入到 3、 新建Cesium.js文件,方便在全局使用 4、新建cesium.vue文件,展示三维地图 1、将下载的Cesium包移动至public下 npm install cesium后 2、…...
SpringBoot整合RocketMQ与客户端注意事项
SpringBoot整合RocketMQ 引入依赖(5.3.0比较稳定) <dependencies><dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.3.1</version&…...

Github 2025-06-04 C开源项目日报 Top7
根据Github Trendings的统计,今日(2025-06-04统计)共有7个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目7C++项目1Assembly项目1jq:轻量灵活的命令行JSON处理器 创建周期:4207 天开发语言:C协议类型:OtherStar数量:27698 个Fork数量:1538 …...

大二下期末
一.Numpy(Numerical Python) Numpy库是Python用于科学计算的基础包,也是大量Python数学和科学计算包的基础。不少数据处理和分析包都是在Numpy的基础上开发的,如后面介绍的Pandas包。 Numpy的核心基础是ndarray(N-di…...

LeetCode 热题 100 74. 搜索二维矩阵
LeetCode 热题 100 | 74. 搜索二维矩阵 大家好,今天我们来解决一道经典的算法题——搜索二维矩阵。这道题在 LeetCode 上被标记为中等难度,要求我们在一个满足特定条件的二维矩阵中查找一个目标值。如果目标值在矩阵中,返回 true;…...

解决 VSCode 中无法识别 Node.js 的问题
当 VSCode 无法识别 Node.js 时,通常会出现以下症状: 代码提示缺失require 等 Node.js API 被标记为错误调试功能无法正常工作终端无法运行 Node.js 命令 常见原因及解决方案 1. Node.js 未安装或未正确配置 解决方法: 确保已安…...
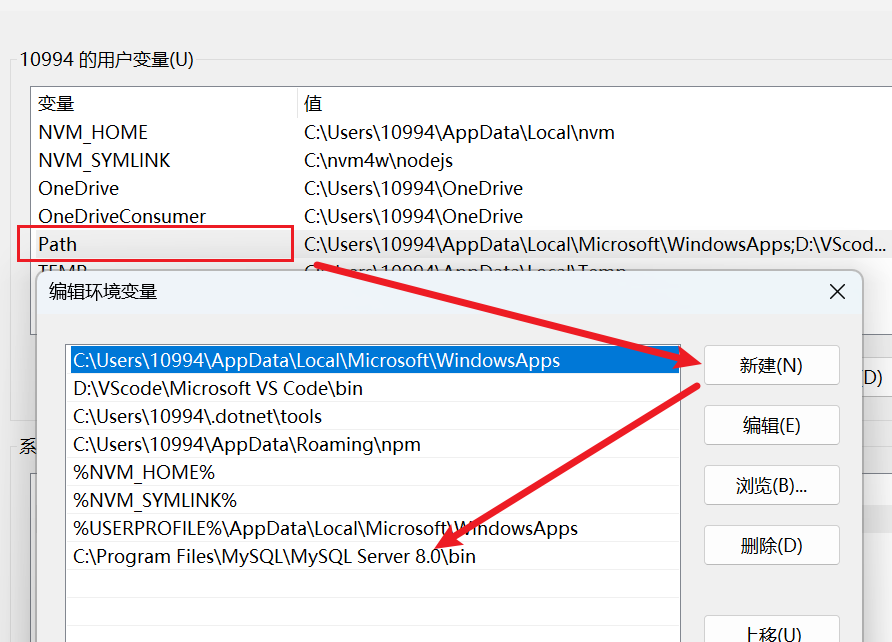
Mysql的卸载与安装
确保卸载干净mysql 不然在进行mysal安装时候会出现不一的页面和问题 1、卸载 在应用页面将查询到的mysql相关应用卸载 2、到c盘下将残留的软件包进行数据删除 3、删除programData下的mysql数据 4、检查系统中的mysql是否存在 cmd中执行 sc deleted mysql80 5、删除注册表中的…...

ES101系列09 | 运维、监控与性能优化
本篇文章主要讲解 ElasticSearch 中 DevOps 与性能优化的内容,包括集群部署最佳实践、容量规划、读写性能优化和缓存、熔断器等。 集群部署最佳实践 在生产环境中建议设置单一角色的节点。 Dedicated master eligible nodes:负责集群状态的管理。使用…...

Java常用的判空方法
文章目录 Java常用的判空方法JDK 自带的判空方法1. 使用 或 ! 运算符2. 使用 equals 方法3. Objects.isNull / Objects.nonNull4. Objects.equals4. JDK8 中的 Optional 第三方工具包1. Apache Commons Lang32. Google Guava3. Lombok 注解4. Vavr(函数式风格&…...
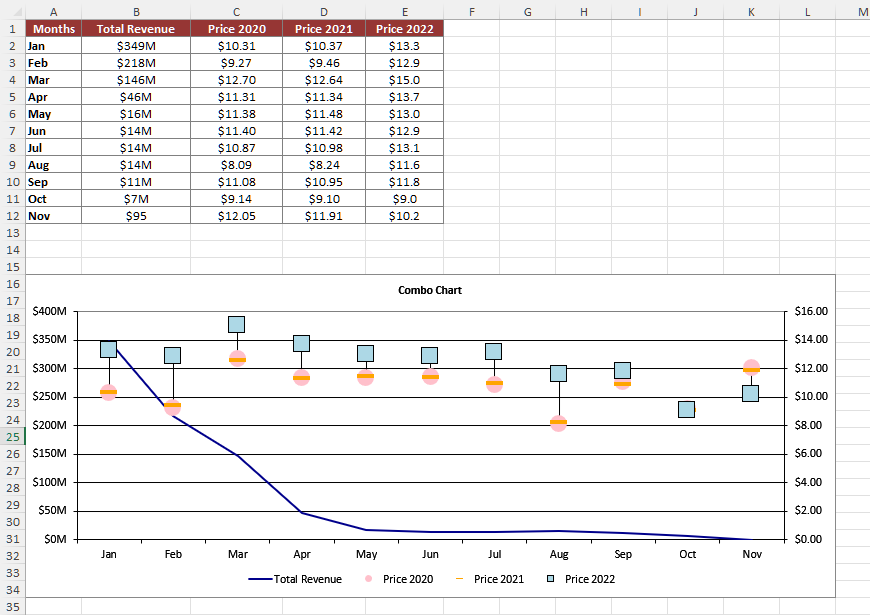
Excel处理控件Aspose.Cells教程:使用 C# 在 Excel 中创建组合图表
可视化项目时间线对于有效规划和跟踪至关重要。在本篇教程中,您将学习如何使用 C# 在 Excel 中创建组合图。只需几行代码,即可自动生成动态、美观的组合图。无论您是在构建项目管理工具还是处理内部报告,本指南都将向您展示如何将任务数据转换…...

【多线程初阶】阻塞队列 生产者消费者模型
文章目录 一、阻塞队列二、生产者消费者模型(一)概念(二)生产者消费者的两个重要优势(阻塞队列的运用)1) 解耦合(不一定是两个线程之间,也可以是两个服务器之间)2) 削峰填谷 (三)生产者消费者模型付出的代价 三、标准库中的阻塞队列(一)观察模型的运行效果(二)观察阻塞效果1) 队…...

《100天精通Python——基础篇 2025 第5天:巩固核心知识,选择题实战演练基础语法》
目录 一、踏上Python之旅二、Python输入与输出三、变量与基本数据类型四、运算符五、流程控制 一、踏上Python之旅 1.想要输出 I Love Python,应该使用()函数。 A.printf() B.print() C.println() D.Print() 在Python中想要在屏幕中输出内容,应该使用print()函数…...

机器人夹爪的选型与ROS通讯——机器人抓取系统基础系列(六)
文章目录 前言一、夹爪的选型1.1 任务需求分析1.2 软体夹爪的选型 二、夹爪的ROS通讯2.1 夹爪的通信方式介绍2.2 串口助手测试2.3 ROS通讯节点实现 总结Reference: 前言 本文将介绍夹爪的选型方法和通讯方式。以鞋子这类操作对象为例,将详细阐述了对应的夹爪选型过…...
第二十八章 RTC——实时时钟
第二十八章 RTC——实时时钟 目录 第二十八章 RTC——实时时钟 1 RTC实时时钟简介 2 RTC外设框图剖析 3 UNIX时间戳 4 与RTC控制相关的库函数 4.1 等待时钟同步和操作完成 4.2 使能备份域涉及RTC配置 4.3 设置RTC时钟分频 4.4 设置、获取RTC计数器及闹钟 5 实时时…...

使用 DuckLake 和 DuckDB 构建 S3 数据湖实战指南
本文介绍了由 DuckDB 和 DuckLake 组成的轻量级数据湖方案,旨在解决传统数据湖(如HadoopHive)元数据管理复杂、查询性能低及厂商锁定等问题。该方案为中小规模数据湖场景提供了简单、高性能且无厂商锁定的替代选择。 1. 什么是 DuckLake 和 D…...

大语言模型提示词(LLM Prompt)工程系统性学习指南:从理论基础到实战应用的完整体系
文章目录 前言:为什么提示词工程成为AI时代的核心技能一、提示词的本质探源:认知科学与逻辑学的理论基础1.1 认知科学视角下的提示词本质信息处理理论的深层机制图式理论的实际应用认知负荷理论的优化策略 1.2 逻辑学框架下的提示词架构形式逻辑的三段论…...
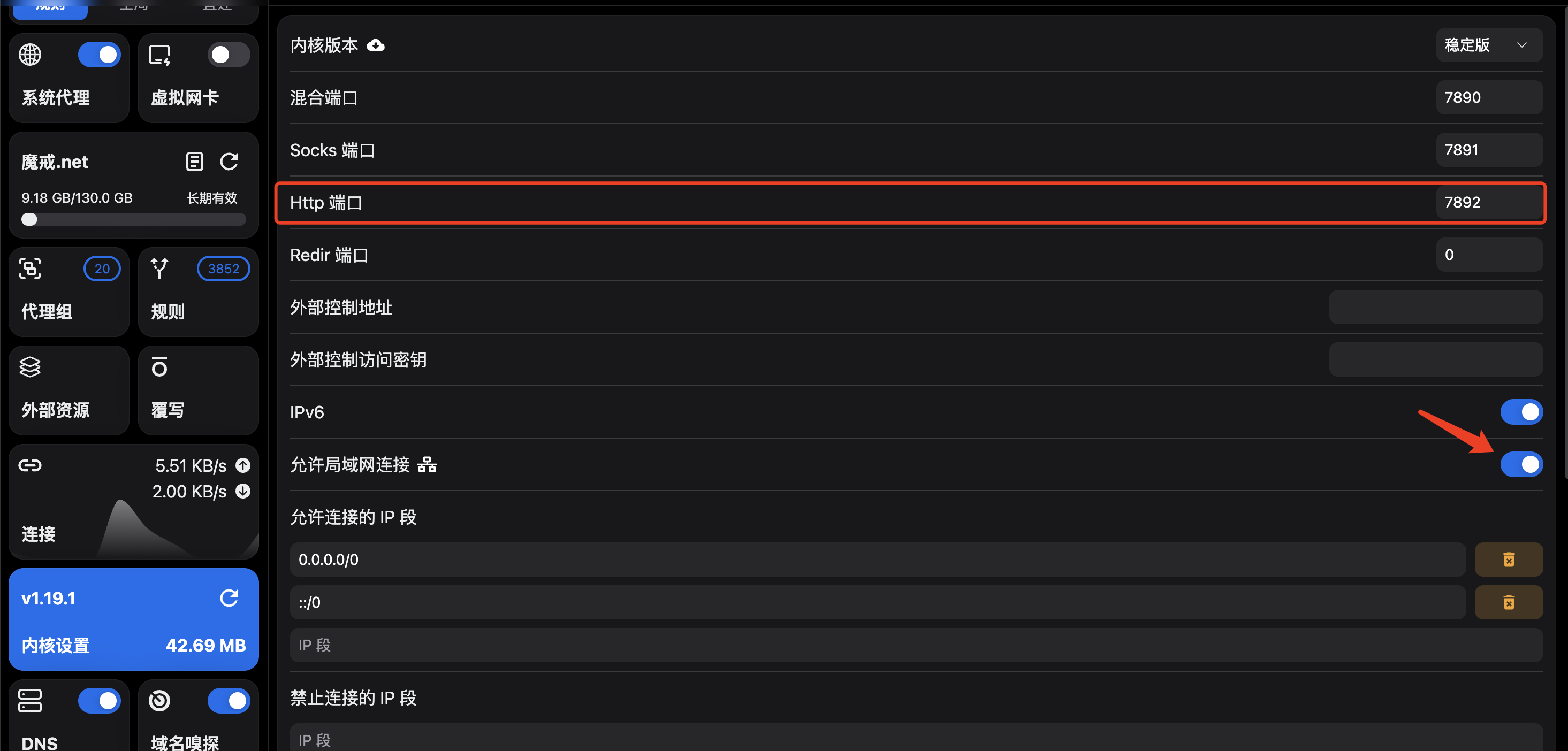
如何基于Mihomo Party http端口配置git与bash命令行代理
如何基于Mihomo Party http端口配置git与bash命令行代理 1. 确定Mihomo Party http端口配置 点击内核设置后即可查看 默认7892端口,开启允许局域网连接 2. 配置git代理 配置本机代理可以使用 127.0.0.1 配置局域网内其它机代理需要使用本机的非回环地址 IP&am…...

CMake 为 Debug 版本的库或可执行文件添加 d 后缀
在使用 CMake 构建项目时,我们经常需要区分 Debug 和 Release 构建版本。一个常见的做法是为 Debug 版本的库或可执行文件添加后缀(如 d),例如 libmylibd.so 或 myappd.exe。 本文将介绍几种在 CMake 中实现为 Debug 版本自动添加 d 后缀的方法。 方法一:使用 CMAKE_DEBU…...