分词算法BBPE详解和Qwen的应用
一、TL;DR
- BPE有什么问题:依旧会遇到OOV问题,并且中文、日文这些大词汇表模型容易出现训练中未出现过的字符
- Byte-level BPE怎么解决:与BPE一样是高频字节进行合并,但BBPE是以UTF-8编码UTF-8编码字节序列而非字符序列
- Byte-level BPE利用utf-8编码,利用动态规划解码,最大程度的还原字符的语义和上下文信息(这是我理解为什么LLM能够通过NTP进行理解的最主要原因)
- Qwen是使用BBPE算法,增加了中文的能力,词汇表包括151,643 tokens
二、实际业务的使用
字节级别字节对编码(BBPE)是一种高效的分词算法,它将输入文本分割为可变长度的字节 n-gram(子词),并将其映射为词汇表中的 token ID。以下是 BBPE 分词算法将输入文本转换为 token ID 的详细过程,以及如何结合词表进行文件操作:
2.1 输入文本的字节表示
-
UTF-8 编码:首先,输入文本(如一行字符串)会被转换为 UTF-8 字节序列。UTF-8 编码将每个 Unicode 字符映射为 1 到 4 个字节。
-
示例:假设输入文本是
"Hello, 世界",其 UTF-8 字节序列为:[72, 101, 108, 108, 111, 44, 32, 228, 189, 160, 229, 165, 189]其中,
"Hello,"是 ASCII 字符,每个字符占用 1 个字节;而"世界"是 UTF-8 编码的中文字符,每个字符占用 3 个字节。
2.2 BBPE 分词
-
学习词汇表:BBPE 通过迭代合并最频繁出现的字节对来构建词汇表。词汇表中包含基本字节(0-255)和通过 BPE 合并生成的字节 n-gram。
-
分词过程:输入的字节序列会被分割成词汇表中存在的子词(字节 n-gram)。这些子词是通过 BPE 合并规则生成的。
-
示例:假设词汇表中有以下条目:
72, 101, 108, 108, 111, 44, 32, 228, 189, 160, 229, 165, 189
72 101, 108 108, 111 44, 32 228, 189 160, 229 165 1892.3 映射为 Token ID
-
词汇表文件:BBPE 的词汇表通常存储在一个文件中,文件格式类似于:
-
72 101 108 108 108 111 44 32 228 189 160 229 165 189 -
映射过程:分词器将分割后的子词与词汇表文件进行匹配,找到对应的 token ID。
-
示例:假设分词后的子词为
[72 101, 108 108, 111 44, 32 228, 189 160, 229 165 189],其对应的 token ID 可能是:[10, 15, 20, 25, 30, 35]其中,
72 101在词汇表中的行号是 10,108 108的行号是 15,依此类推。
2.4 文件操作
-
加载词汇表:分词器在初始化时会加载词汇表文件,将其内容存储到内存中,以便快速查找。
# 假设词汇表文件名为 vocab.txt
with open('vocab.txt', 'r', encoding='utf-8') as f:vocab = [line.strip() for line in f.readlines()]# 将子词映射为 token ID
def tokenize(input_text):# 将输入文本转换为 UTF-8 字节序列byte_sequence = input_text.encode('utf-8')# 分词(这里简化为直接匹配,实际分词器会更复杂)tokens = []for subword in byte_sequence.split():subword_str = ' '.join(map(str, subword))token_id = vocab.index(subword_str)tokens.append(token_id)return tokensinput_text = "Hello, 世界"
token_ids = tokenize(input_text)
print(token_ids)2.5 总结
-
输入文本 → UTF-8 字节序列 → BBPE 分词 → 映射为 Token ID
-
词汇表文件是 BBPE 分词的核心,它存储了所有可能的子词及其对应的 token ID。
三、Byte-level BPE算法原理
paper链接: https://arxiv.org/pdf/1909.03341
papr:Neural Machine Translation with Byte-Level Subwords
3.1 为什么要开发Byte-level BPE
- 解决不了中文/日语这种语言:几乎所有的分词算法都是基于字符级词汇表构建的(字符、子词或单词),但对于日语和中文的字符丰富且存在噪声文本的语言,罕见字符可能会不必要地占据词汇表的槽位,从而限制其紧凑性
- 字节表示会引入计算成本:使用字节级别表示文本,并将 256 个字节集作为词汇表可以解决这个问题,但是会引入高昂的计算成本
3.2 实际合并方法和举例
与BPE算法的差异:

来自日语 - 英语的不同词汇表分词示例。
空格被下划线替换,而空格用于分隔词元。,随着分词粒度从细到粗,词元的形态是如何变化的:字节(256)→ 字节级别字节对编码(BBPE,1K、2K、4K、8K)→ 字符(8K)→ 字节级别字节对编码(BBPE,16K、32K)→ 字节对编码(BPE,16K、32K)。

BBPE算法在基于字节(Byte)进行合并过程和BPE一致、也是选取出现频数最高的字符对进行合并,合并过程如下图所示: 关注到红色箭头,输入是日文当词表大小是1K时,A8 BC 两个字节并没有合并成一个 Token,在词表大小是2K时,A8BC被BBPE合并成一个Token。
3.3 原理上具体怎么做?
别看了,直接用就好,最重要的还是理解对input text进行分词后查表再转成encoder的过程
字节级别表示的编码:
- 使用 UTF-8 编码文本,它将每个 Unicode 字符编码为 1 到 4 个字节。这使得我们可以将句子建模为字节序列,而不是字符序列。
- 13.8 万个 Unicode 字符覆盖了 150 多种语言,但我们使用 UTF-8 字节(256 个可能字节中的 248 个)来表示任何语言的句子。
如何解决计算成本高昂的问题?
字节级别的n-gram方法来减少计算成本:
编码过程:
- 将Unicode字符映射为1-4个字节
- 将字节序列分割为可变长度的 n 元组(字节级别的“子词”)
- 使用深度卷积层或双向循环层与门控循环单元(GRU)来对 BBPE embedding进行上下文化
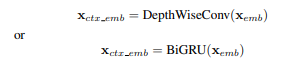
解码过程:
- 采用动态规划算法从字节序列恢复Unicode字符
- 对于给定的字节序列 {B}kN,我们用 f(k) 表示我们可以从中恢复的最大字符数。然后 f(k) 具有最优子结构
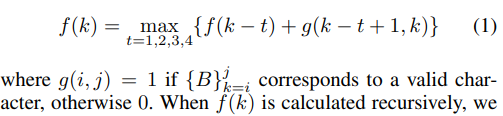
如果 {B}kj 对应一个有效的字符,则 g(i,j)=1,否则为 0。当 f(k) 递归计算时,我们还在每个位置 k 记录选择,以便通过回溯恢复解决方案。
解码过程中-说人话:
- 使用动态规划去恢复最有效(g代表有效性指示函数)和可恢复的最大字符数(动态词汇表便于最大化的数据还原)
四、Qwen的应用
4.1 Qwen3的技术报告原文:

4.2 Qwen实际代码实现:
参考:https://github.com/QwenLM/Qwen/blob/main/tokenization_note.md
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True)
特殊字符的处理:
特殊标记对模型具有特殊功能,例如表示文档结束。理论上,这些标记在输入文本中不存在,仅在输入文本经过处理后才会出现。
可以在微调或其他需要它们的框架中这样指定特殊标记:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True, pad_token='<|endoftext|>')相关文章:
分词算法BBPE详解和Qwen的应用
一、TL;DR BPE有什么问题:依旧会遇到OOV问题,并且中文、日文这些大词汇表模型容易出现训练中未出现过的字符Byte-level BPE怎么解决:与BPE一样是高频字节进行合并,但BBPE是以UTF-8编码UTF-8编码字节序列而非字符序列B…...

关于ETL的BackgroundScheduler同步方案和misfire_grace_time
如果做ETL避免脏数据,那么不可以允许同一个job有并行允许的情况,也就是说max_instance参数始终设置成1。 这时候执行ETL任务,会有以下情况。 1 任务不超时。正常执行 2 任务超时。如果下一个时间点上一次任务还没有执行完,那么…...

多线程下使用缓存+锁Lock, 出现“锁失效” + “缓存未命中竞争”的缓存击穿情况,双重检查缓存解决问题
多线程情况下,想通过缓存同步锁的机制去避免多次重复处理逻辑,尤其是I/0操作,但是在实际的操作过程中发现多次访问的日志 2025-06-05 17:30:27.683 [ForkJoinPool.commonPool-worker-3] INFO Rule - [vagueNameMilvusReacll,285] - embeddin…...

Playwright 测试框架 - .NET
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】...

命令行以TLS/SSL显式加密方式访问FTP服务器
昨天留了一个小尾巴~~就是在命令行或者代码调用命令,以TLS/SSL显式加密方式,访问FTP服务器,上传和下载文件。 有小伙伴可能说ftp命令不可以吗?不可以哦~~ ftp 命令本身不支持显式加密。要实现 FTP 的显式加密,可以使…...

Mac 双系统
准备——Windows10 ISO文件下载 下载地址:https://msdn.itellyou.cn 操作系统 Win10-1903镜像 复制链接迅雷下载 第一步——查看系统磁盘剩余空间 打开“启动台”找到“其他”文件夹,打开“磁盘工具”(剩余空间要大于40GB) 第二…...
Linux配置yum 时间同步服务 关闭防火墙 关闭ESlinux
1、配置yum 1.1、Could not resolve host: mirrorlist.centos.org; 未知的错误 https://blog.csdn.net/fansfi/article/details/146369946?fromshareblogdetail&sharetypeblogdetail&sharerId146369946&sharereferPC&sharesourceRockandrollman&sharefr…...

SpringBoot 系列之集成 RabbitMQ 实现高效流量控制
系列博客专栏: JVM系列博客专栏SpringBoot系列博客 Spring Boot 2.2.1 集成 RabbitMQ 实现高效流量控制 在分布式系统中,消息队列是实现异步通信、解耦服务的重要组件。RabbitMQ 作为一款成熟的开源消息队列,广泛应用于各类项目中。本文将…...
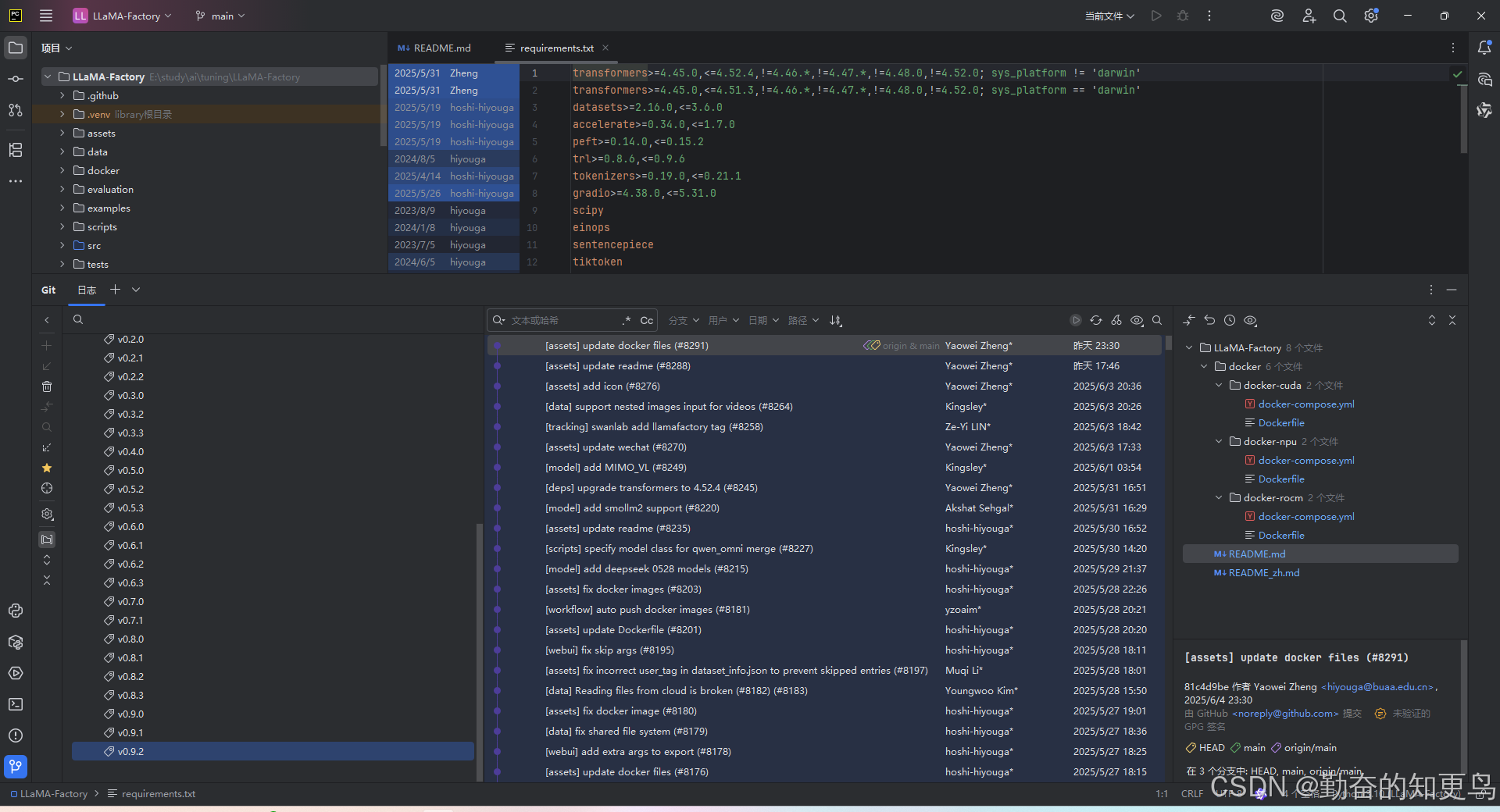
LLaMA-Factory和python版本的兼容性问题解决
引言 笔者今天在电脑上安装下LLaMA-Factory做下本地的模型调优。 从github上拉取代码git clone https://github.com/hiyouga/LLaMA-Factory.git. pycharm建立工程,按照官网指导如下: LLaMA-Factory 安装 在安装 LLaMA-Factory 之前,请确保您安装了下列依赖: 运行以…...

掌握子网划分:优化IP分配与管理
子网划分是通过调整子网掩码,将单一IP网络划分为多个逻辑子网的过程,其核心原理是借用主机位作为子网位以优化地址分配和管理。具体方法与原理如下: 一、子网划分基本原理 核心目的: 减少IP浪费:避免大块地址闲置&…...

Linux中shell编程表达式和数组讲解
一、表达式 1.1 测试表达式 样式1: test 条件表达式 样式2: [ 条件表达式 ] 注意:以上两种方法的作用完全一样,后者为常用。但后者需要注意方括号[、]与条件表达式之间至少有一个空格。test跟 [] 的意思一样条件成立,状态返回值是0条件不成…...

每日算法-250605
每日算法 - 20240605 525. 连续数组 题目描述 给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。 思路 前缀和 哈希表 解题过程 核心思想是将问题巧妙地转换为寻找和为特定值的子数组问题。 转换问题:我…...
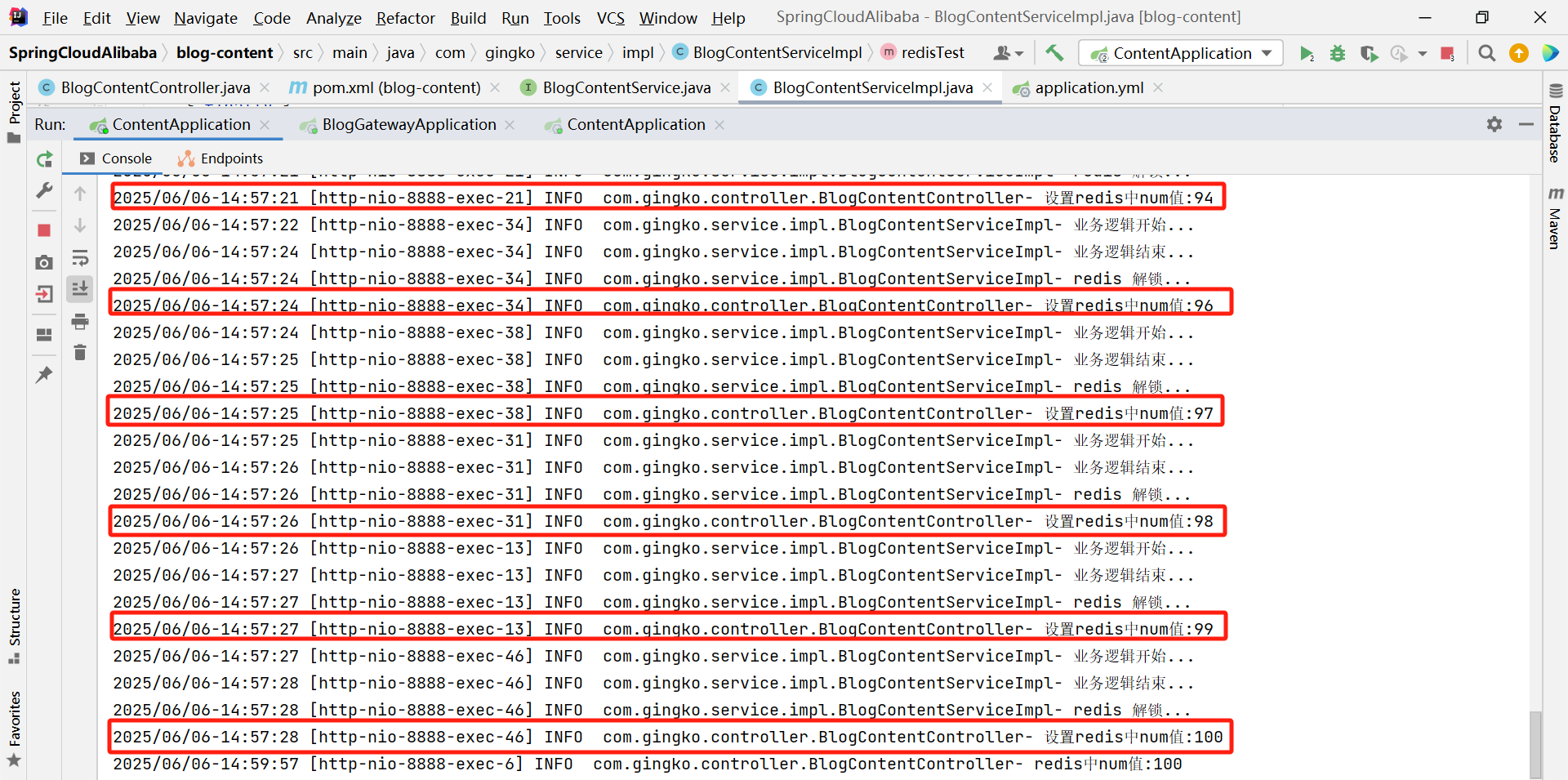
分布式锁-Redisson实现
目录 本地锁的局限性 Redisson解决分布式锁问题 在分布式环境下,分布式锁可以保证在多个节点上的并发操作时数据的一致性和互斥性。分布式锁有多种实现方案,最常用的两种方案是:zookeeper和redis,本文介绍redis实现分布式锁方案…...

HTTP 请求协议简单介绍
目录 常见的 HTTP 响应头字段 Java 示例代码:发送 HTTP 请求并处理响应 代码解释: 运行结果: 文件名: 总结: HTTP(HyperText Transfer Protocol)是用于客户端与服务器之间通信的协议。它定…...
C++学习-入门到精通【14】标准库算法
C学习-入门到精通【14】标准库算法 目录 C学习-入门到精通【14】标准库算法一、对迭代器的最低要求迭代器无效 二、算法1.fill、fill_n、generate和generate_n2.equal、mismatch和lexicographical_compare3.remove、remove_if、remove_copy和remove_copy_if4.replace、replace_…...

银行用户评分规则 深度学习
思考模型的实际应用场景。用户的核心疑问在于:在银行真实的评级系统中,基于规则的评级和基于模型的预测评级哪个更有价值?ta担心自己写的代码只是学术练习而没有实际意义。 从用户提到的银行评级规则来看(AAAA到E的划分ÿ…...

HarmonyOS运动语音开发:如何让运动开始时的语音播报更温暖
##鸿蒙核心技术##运动开发##Core Speech Kit(基础语音服务)# 前言 在运动类应用中,语音播报功能不仅可以提升用户体验,还能让运动过程更加生动有趣。想象一下,当你准备开始运动时,一个温暖的声音提醒你“…...

# 从底层架构到应用实践:为何部分大模型在越狱攻击下失守?
从底层架构到应用实践:为何部分大模型在越狱攻击下失守? 引言 近期,我们对多个主流大语言模型(LLM)进行了安全性测试,使用了极具诱导性的越狱提示词,试图绕过其内容安全机制。测试结果显示&am…...

vscode使用系列之快速生成html模板
一.欢迎来到我的酒馆 vscode,yyds! 目录 一.欢迎来到我的酒馆二.vscode下载安装1.关于vscode你需要知道2.开始下载安装 三.vscode快速创建html模板 二.vscode下载安装 1.关于vscode你需要知道 Q:为什么使用vscode? A:使用vscode写…...

Thinkphp6软删除
方法一 从控制器层直接操作 删除 此操作不会直接删除数据 而是在delete_time字段更新删除时间 ->useSoftDelete(delete_time,get_datetime())->delete() 查询 这里的数据库字段需要设置为默认NULL 查询的时候仅查询未更新删除时间的数据 ->whereNull("dele…...
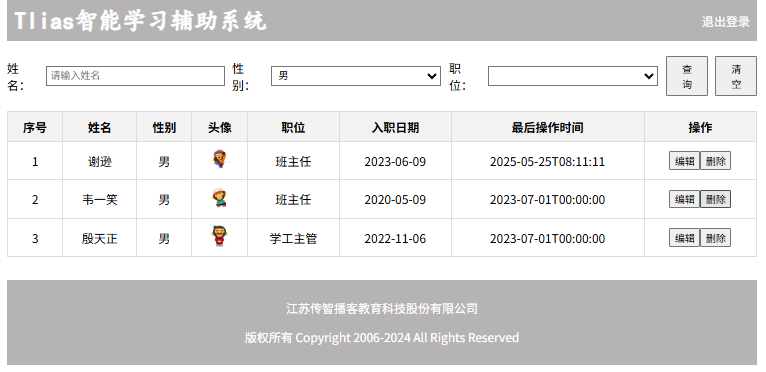
网页前端开发(基础进阶4--axios)
Ajax Ajax(异步的JavaScript和XML) 。 XML是可扩展标记语言,本质上是一种数据格式,可以用来存储复杂的数据结构。 可以通过Ajax给服务器发送请求,并获取服务器响应的数据。 Ajax采用异步交互:可以在不重新加载整个页面的情况下&am…...

软件安全:漏洞利用与渗透测试剖析、流程、方法、案例
在数字时代,软件已深度融入生活与工作的方方面面,从手机应用到企业核心系统,软件安全至关重要。而漏洞利用与渗透测试,作为软件安全领域中相互关联的两个关键环节,一个是黑客攻击的手段,一个是安全防护的方…...
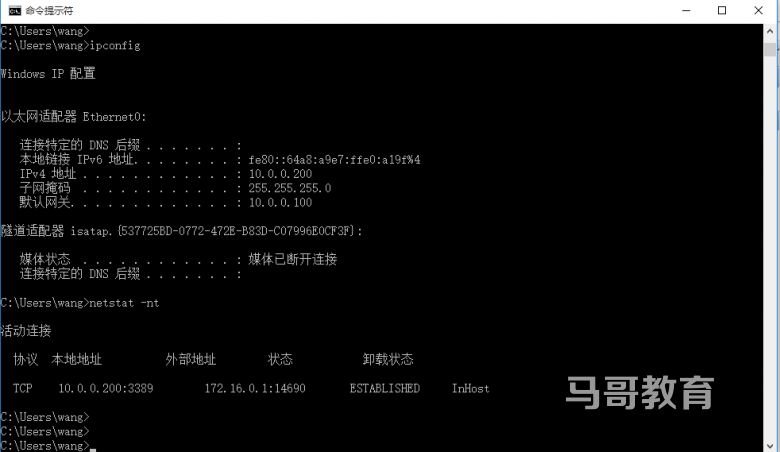
Haproxy的基础配置
1、参考文档 官方文档:HAProxy version 2.2.22 - Configuration Manual 运维派配置手册:Haproxy-基础配置详解 - 运维派 Haproxy 的配置文件haproxy.cfg由两大部分组成,分别是global和proxies部分。 2、haproxy global 配置 global&…...
考研系列—操作系统:冲刺笔记(1-3章)
目录 第一章 计算机系统概述 1.基本概念 2.内核态和用户态 3.中断(外中断)、异常(内中断-与当前执行的) 4.系统调用 5.操作系统引导程序 2021年真题: 6.操作系统结构 大纲新增 (1)分层结构 (2)模块化 (3)外核 7.虚拟机 第二章 进程管理 1.画作业运行的顺序和甘…...
持续集成环境)
使用 Docker Compose 部署 Jenkins(LTS 版)持续集成环境
一、前言 Jenkins 是目前最流行的开源持续集成工具之一。本教程将手把手带你使用 Docker Compose 快速部署 Jenkins LTS(长期支持版本),同时保留数据持久化、Docker 命令转发等功能,适合用于生产或本地开发测试环境。 二、环境准…...
Java调用大模型API实战指南
文章目录 前言调用大模型的流程概述和基本原理获取 DeepSeek 的 API keyJava 实现调用大模型 API 的Demo进阶扩展建议 前言 随着大语言模型(如 OpenAI、DeepSeek、通义千问等)的发展,我们可以很方便地用 API 接口调用这些强大的智能助手。在…...
)
C#中的路由事件(Routed Events)
路由事件的基本概念 路由事件是WPF中特有的事件系统,它允许事件在可视化树中"路由"传递,具有以下特点: 事件路由方向: 冒泡(Tunneling):从事件源向根元素传递 隧道(Bubbling):从根元素向事件源…...

[蓝桥杯]通电
通电 题目描述 2015 年,全中国实现了户户通电。作为一名电力建设者,小明正在帮助一带一路上的国家通电。 这一次,小明要帮助 nn 个村庄通电,其中 1 号村庄正好可以建立一个发电站,所发的电足够所有村庄使用。 现在…...
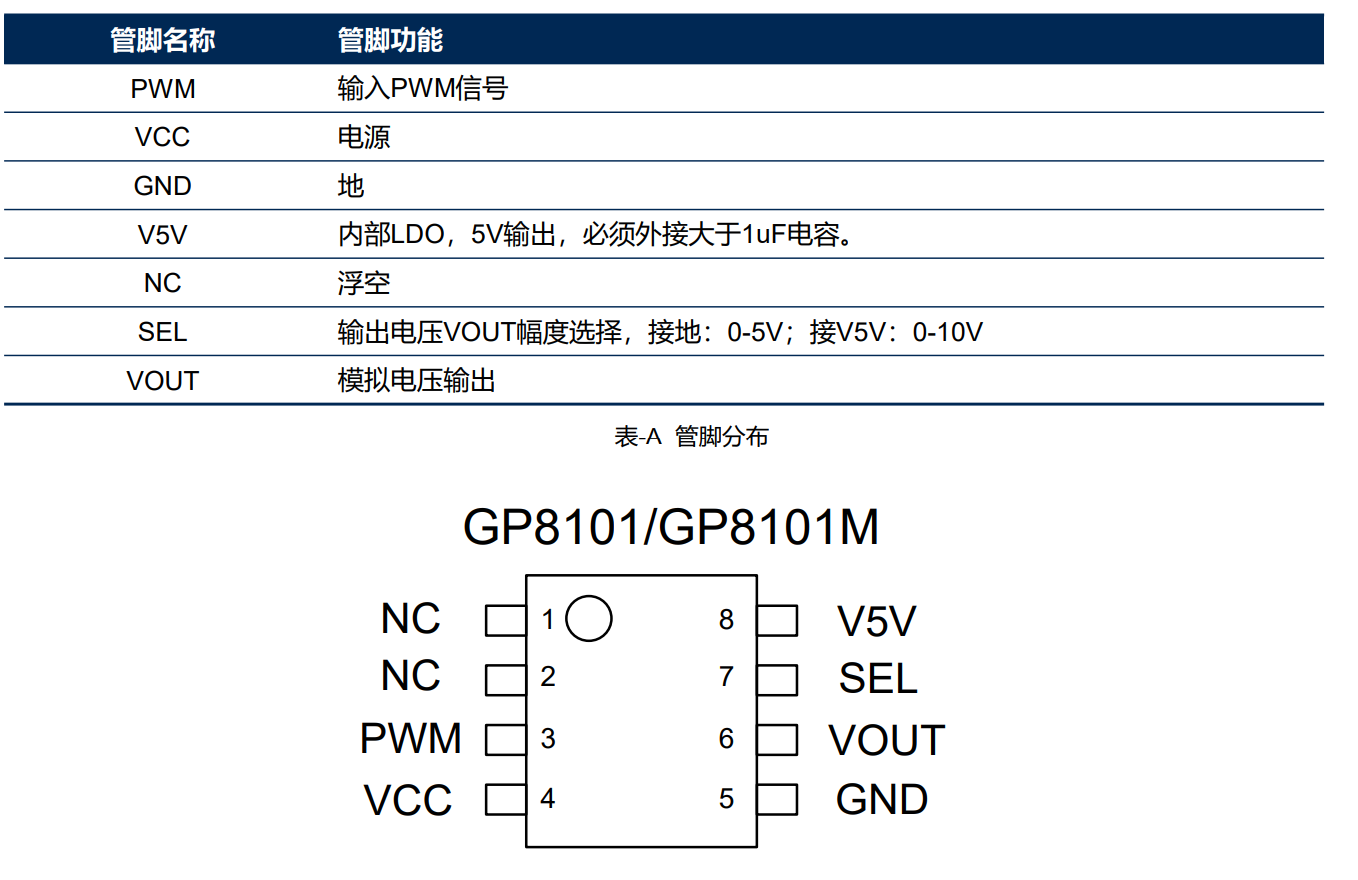
单片机0-10V电压输出电路分享
一、原理图 二、芯片介绍 GP8101是一个PWM信号转模拟信号转换器,相当于一个PWM信号输入,模拟信号输出的DAC。此 芯片可以将占空比为0%到100%的PWM信号线性转换成0-5V或者0-10V的模拟电压,并且输出电压 精度小于1%。GP8101M可以处理高频调制的…...

从零开始,搭建一个基于 Django 的 Web 项目
🎯 主要步骤概述 1️⃣ 安装 Python 和 pip 2️⃣ 创建虚拟环境 3️⃣ 安装 Django 4️⃣ 创建 Django 项目 5️⃣ 运行开发服务器 6️⃣ 创建一个简单的应用(app) 7️⃣ 配置数据库并迁移 8️⃣ 创建超级用户(admin)…...