NoSQl之Redis部署
一、Redis 核心概念与技术定位
1. 数据库分类与 Redis 的诞生背景
-
关系型数据库的局限性
- 数据模型:基于二维表结构,通过 SQL 操作,强一致性(ACID 特性),适合结构化事务场景(如银行转账、订单管理)。
- 性能瓶颈:
- 高并发写:磁盘 I/O 成为瓶颈,无法支撑上万次 / 秒的写请求(如社交平台动态更新)。
- 海量数12据查询:单表超 2.5 亿条记录时,SQL 查询效率显著下降(如 Friendfeed 用户动态场景)。
- 横向扩34展困难:数据库无法像 Web 服务一样简单添加节点,升级需停机迁移数据(如 24 小时在线业务)。
-
NoSQL 的56崛起
- 核心价值:解决关系型数据库在 ** 高并发(High Performance)、海量存储(Huge Storage)、高扩展性(High Scalability)** 场景下的缺陷。
- Redis7的独特性:
- 基于内存的键值存储,兼具高性能(读写速度达 10 万次 / 秒级)与持久化能力(RDB/AOF)。
- 支持丰富数据结构(String/List/Hash 等),超越传统 Key-Value 数据库(如 Memcached 仅支持 String)。
2. Redis 架构特性
-
单进程模型
- Redis 服务器以单进程运行,通过事件驱动机制处理多客户端请求,避免多线程上下文切换开销。
- 并发扩展策略:
- 单服务器可启动多个 Redis 进程(每个进程独立端口),提升并发处理能力,但需注意 CPU 资源占用。
- 生产环境建8议:高并发场景下按 CPU 核心数开多个进程,CPU 紧张时优先单进程。
-
数据模型与应用场景
- 基础数据类型:
类型 典型操作 场景示例 String SET/GET/INCR 缓存用户信息、计数器 List LPUSH/RPOP/BRPOP 消息队列、最新 N 条数据列表 Hash HSET/HGET/HMGET 存储对象属性(如用户详情) Set SADD/SMEMBERS/SINTER 标签管理、去重集合 Sorted Set ZADD/ZRANGE/ZREVRANGE 排行榜、地理位置排序 - 复合场景应用:
- 缓存穿透优化:用 Set 存储已存在的 Key,拦截无效请求。
- 实时统计:HyperLogLog 类型统计独立用户数(内存占用极低)。
- 基础数据类型:
二、Redis 安装与配置全流程
1. 环境准备与源码编译
-
依赖工具安装
# CentOS系统示例 yum install -y tar gcc make # 安装编译工具链- 作用:
gcc编译 C 语言源码,make管理编译流程,tar解压安装包。
- 作用:
-
源码下载与解压
wget https://download.redis.io/releases/redis-6.2.7.tar.gz # 下载稳定版 tar xvzf redis-6.2.7.tar.gz -C /usr/local/src/ # 解压至指定目录 cd /usr/local/src/redis-6.2.7 -
免配置编译安装
make && make install PREFIX=/usr/local/redis # 编译并指定安装路径- 关键点:Redis 源码自带
Makefile,无需./configure步骤,直接编译二进制文件。
- 关键点:Redis 源码自带
2. 服务化配置与启动
-
初始化脚本部署
cd utils/ ./install_server.sh # 运行安装脚本- 交互式配置项:
- 端口号(默认 6379)、配置文件路径(
/etc/redis/6379.conf)、数据目录(/var/lib/redis/6379)、日志文件(/var/log/redis_6379.log)。
- 端口号(默认 6379)、配置文件路径(
- 交互式配置项:
-
服务控制命令9
systemctl start redis_6379.service # 启动服务 systemctl stop redis_6379.service # 停止服务 systemctl restart redis_6379.service # 重启服务 systemctl status redis_6379.service # 查看状态- 验证端口监听:
netstat -anpt | grep 6379,确保服务正常运行。
- 验证端口监听:
3.10 核心配置文件解析(redis.conf)
-
网络与安全配置
bind 0.0.0.0 # 允许所有IP访问(生产环境需限制为服务器IP) port 6379 # 服务端口 requirepass your_password # 设置访问密码- 安全建议:生产环境禁止
bind 0.0.0.0,通过防火墙(如 iptables)限制访问 IP,避免公网暴露。
- 安全建议:生产环境禁止
-
持久化配置
# RDB配置 save 900 1 # 900秒内至少1个Key变更则生成RDB快照 save 300 10 # 300秒内至少10个Key变更 dbfilename dump.rdb # RDB文件名 dir /var/lib/redis/ # RDB存储目录# AOF配置 appendonly yes # 开启AOF appendfsync everysec # 每秒同步日志(默认策略) -
内存与淘汰策略
maxmemory 10737418240 # 最大内存限制(10GB) maxmemory-policy allkeys-lru # 使用LRU算法淘汰所有Key- 策略选择:若大部分 Key 有过期时间,可改为
volatile-lru仅淘汰过期 Key。
- 策略选择:若大部分 Key 有过期时间,可改为
-
其他关键配置
maxclients 50000 # 最大客户端连接数(默认1万,根据服务器性能调整) timeout 300 # 客户端闲置300秒后断开连接 loglevel notice # 日志级别(debug/verbose/notice/warning)
三、Redis 命令体系与实战操作
1. 基础数据操作命令
-
String 类型(最常用)
- 存储与读取:
127.0.0.1:6379> SET user:1001 name "Alice" # 设置键值对 OK 127.0.0.1:6379> GET user:1001 # 获取值 "Alice" - 原子计数器:
127.0.0.1:6379> INCR page_view:1001 # 自增1,用于统计页面访问量 (integer) 1 127.0.0.1:6379> INCRBY page_view:1001 10 # 自增指定值 (integer) 11
- 存储与读取:
-
List 类型(列表操作)
- 左 / 右插入:
127.0.0.1:6379> LPUSH messages "msg3" # 左插入,列表变为["msg3"] (integer) 1 127.0.0.1:6379> RPUSH messages "msg1" "msg2" # 右插入,列表变为["msg3", "msg1", "msg2"] (integer) 3 - 范围查询与弹出:
127.0.0.1:6379> LRANGE messages 0 -1 # 获取所有元素 1) "msg3" 2) "msg1" 3) "msg2" 127.0.0.1:6379> RPOP messages # 弹出右元素,返回"msg2",列表剩余["msg3", "msg1"]
- 左 / 右插入:
-
Hash 类型(对象存储)
127.0.0.1:6379> HSET user:1001 id 1001 name "Bob" age 30 # 设置多个字段 (integer) 3 127.0.0.1:6379> HGETALL user:1001 # 获取所有字段值 1) "id" 2) "1001" 3) "name" 4) "Bob" 5) "age" 6) "30"
2. 管理与运维命令
-
Key 生命周期管理
127.0.0.1:6379> EXPIRE user:1001 3600 # 设置Key过期时间(3600秒后自动删除) (integer) 1 127.0.0.1:6379> TTL user:1001 # 查看剩余存活时间(-2表示已过期,-1表示永久有效) (integer) 3589 -
多数据库操作
127.0.0.1:6379> SELECT 1 # 切换至数据库1 OK 127.0.0.1:6379[1]> MOVE user:1001 0 # 将Key移动至数据库0 (integer) 1 -
性能测试命令
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 # 50并发,1万次请求测试 # 输出示例: # 50.00% <= 1 milliseconds # 99.00% <= 2 milliseconds # requests per second: 9876.54
3. 高级命令与最佳实践
-
Pipeline 批量操作
redis-cli -p 6379 << EOF MULTI SET key1 value1 SET key2 value2 EXEC EOF- 作用:将多个命令打包发送,减少网络往返次数,提升批量操作效率。
-
脚本执行(Lua)
127.0.0.1:6379> EVAL "return {KEYS[1],ARGV[1]}" 1 key "value" 1) "key" 2) "value"- 优势:原子性执行复杂逻辑,减少客户端与服务器交互次数。
四、Redis 持久化深度解析
1. RDB 快照机制
-
生成流程
- 主进程接收到
SAVE/BGSAVE命令或满足save配置条件。 - 主进程 fork 出子进程,子进程负责将内存数据写入临时 RDB 文件。
- 子进程写入完成后,主进程用临时文件替换旧 RDB 文件,完成快照。
- 主进程接收到
-
优缺点对比11
优点 缺点 文件体积小,恢复速度快 可能丢失最后一次快照后所有数据 适合全量备份(如每天一次) 生成大文件时可能阻塞主进程(SAVE 命令) 二进制格式,压缩效率高 无法实时持久化 -
生产环境配置建议
save 86400 1 # 每天至少1次变更则生成快照(夜间低峰期) save 3600 100 # 每小时至少100次变更 rdbcompression yes # 启用LZF压缩(牺牲CPU换取存储空间)
2. AOF 日志机制
-
写入流程
- 客户端发送写命令(如 SET/DEL)到主进程。
- 主进程将命令追加到 AOF 缓冲区。
- 根据
appendfsync策略将缓冲区数据写入磁盘(如每秒一次)。
-
三种同步策略12对比
策略 写入性能 数据安全性 适用场景 always最低 最高(不丢数据) 金融交易等极致安全场景 everysec中等 高(最多丢 1 秒数据) 大多数生产环境(默认) no最高 低(依赖 OS 刷新) 非关键数据场景 -
AOF 重写原理
- 触发条件:
- 手动执行
BGREWRITEAOF命令。 - 自动触发:当 AOF 文件体积超过
auto-aof-rewrite-min-size(如 64MB)且比上次重写后增长auto-aof-rewrite-percentage(如 100%)。
- 手动执行
- *核心优化13*:合并重复命令(如
SET key 1+SET key 2合并为最终的SET key 2),删除过期 Key 的操作日志。
- 触发条件:
3. 混合持久化(RDB+AOF)
- 配置方法:
aof-use-rdb-preamble yes # 在AOF文件开头写入RDB快照,后续追加操作日志- 优势:结合 RDB 的快速恢复与 AOF 的实时持久化,重启时先加载 RDB 快照,再执行 AOF 增量日志,提升恢复效率。
五、Redis 性能优化与问题排查
1. 内存管理核心指标
-
关键参数解析(
info memory输出)# Memory used_memory: 1073741824 # Redis分配的内存总量(1GB) used_memory_rss: 1258291200 # 操作系统分配的物理内存(约1.17GB) mem_fragmentation_ratio: 1.17 # 内存碎片率(=used_memory_rss/used_memory) maxmemory: 2147483648 # 最大内存限制(2GB)- 碎片率优化:
1.0 < ratio < 1.5:正常范围,无需干预。ratio > 1.5:执行SHUTDOWN SAVE重启 Redis,释放内存碎片。rati{insert\_element\_10\_}o < 1:内存不足,需增加物理内存或调整maxmemory。
- 碎片率优化:
-
内存淘汰策略实战
127.0.0.1:6379> CONFIG SET maxmemory-policy allkeys-lru # 动态切换为LRU策略 OK 127.0.0.1:6379> INFO stats | grep evicted_keys # 监控淘汰次数 evicted_keys: 12345- 若
evicted_keys持续增长,说明内存不足,需扩容或优化数据结构。
- 若
2. 性能瓶颈排查流程
-
确认是否发生内存交换(swap)
free -h # 查看内存使用情况,若swap空间非零,说明发生交换- 影响:内存交换会导致 Redis 响应延迟激增,需立即处理(如增加物理内存或减少
maxmemory)。
- 影响:内存交换会导致 Redis 响应延迟激增,需立即处理(如增加物理内存或减少
-
定位慢查询命令
127.0.0.1:6379> SLOWLOG GET 10 # 查看最近10条慢查询(默认阈值10
五、Redis 性能优化与问题排查(续)
3. 数据结构优化实践
-
避免大 Key(Big Key)
- 定义:单个 Key 对应的值占用内存过大(如 String 类型超过 1MB,Hash 字段数超过 1000)。
- 风险:
- 内存碎片化加剧,导致
mem_fragmentation_ratio升高。 - 网络传输延迟增加(如
GET大 Value 时阻塞客户端)。 - RDB/AOF 持久化时耗时更长,可能引发主进程阻塞。
- 内存碎片化加剧,导致
- 检测方法:
# 使用SCAN命令遍历Key并统计大小 redis-cli --bigkeys - 优化策略:
- 拆分大 Hash 为多个小 Hash(如按用户 ID 尾号分片)。
- 用 List 分页存储大数据集(如
LPUSH分批次插入,LRANGE按页获取)。
-
减少 Key 数量
- 场景:用 Hash 结构替代多个独立 String 键。
- 示例对比:
- 反模式:
SET user:1001:name "Alice"+SET user:1001:age 28(2 个 Key)。 - 优化模式:
HSET user:1001 name "Alice" age 28(1 个 Key,字段数 = 2)。
- 反模式:
- 优势:减少 Key 空间占用,提升查询效率(单次
HGETALL获取所有属性)。
4. 网络与连接优化
-
TCP 参数调优
- 背景:Redis 基于 TCP 协议通信,默认参数可能不适应高并发场景。
- 优化配置(
redis.conf):tcp-backlog 511 # 调整TCP半连接队列长度,提升SYN请求处理能力 tcp-keepalive 300 # 启用TCP保活机制,清理空闲连接(单位:秒)
-
连接池管理
- 客户端层面:使用连接池(如 Jedis Pool、Lettuce)复用连接,避免频繁创建 / 销毁连接的开销。
- 服务端限制:通过
maxclients控制最大连接数,防止文件描述符耗尽:maxclients 50000 # 根据服务器性能调整,建议不超过系统最大文件描述符限制 - 查看连接数:
redis-cli info clients | grep connected_clients
5. 主从复制与读写分离
-
配置主从复制
# 从服务器配置(slave节点) slaveof <master_ip> <master_port> # 指向主服务器IP和端口 masterauth <master_password> # 主服务器密码(若有设置)- 流程:从服务器启动后自动连接主服务器,通过全量同步(RDB 快照)和增量同步(AOF 日志)保持数据一致。
-
读写分离应用
- 读请求分发到从服务器,减轻主服务器压力。
- 注意事项:
- 从服务器可能存在数据延迟,需根据业务容忍度选择(如缓存场景可接受弱一致性)。
- 主服务器需开启持久化,避免单节点故障导致从服务器无法恢复。
六、持久化高级配置与故障恢复
1. RDB 快照最佳实践
-
备份策略
- 每日凌晨执行全量 RDB 备份,存储到远程服务器或云存储(如 OSS、S3)。
- 脚本示例(
crontab -e):bash
0 2 * * * redis-cli -h 127.0.0.1 -p 6379 bgsave && \ cp /var/lib/redis/dump.rdb /backup/redis/$(date +%Y%m%d).rdb && \ find /backup/redis/ -mtime +7 -type f -delete # 保留最近7天备份
-
故障恢复步骤
- 停止故障节点 Redis 服务:
systemctl stop redis_6379.service。 - 替换 RDB 文件:将备份的
.rdb文件复制到/var/lib/redis/目录。 - 重启服务:
systemctl start redis_6379.service,Redis 自动加载 RDB 恢复数据。
- 停止故障节点 Redis 服务:
2. AOF 日志修复与压缩
-
日志损坏修复
redis-check-aof --fix /etc/redis/6379.aof # 修复损坏的AOF文件- 场景:若 AOF 文件写入中途宕机,可能导致日志不完整,需通过工具修复。
-
手动触发重写
redis-cli bgrewriteaof # 非阻塞式重写AOF文件- 建议:在低峰期执行,避免影响主进程性能。
3. 混合持久化配置
- 开启混合模式
aof-use-rdb-preamble yes # 在AOF文件开头写入RDB快照- 效果:
- 重启时先加载 RDB 快照(速度快),再执行 AOF 增量日志(数据全)。
- AOF 文件前部分为二进制 RDB 内容,后部分为文本日志,总体积小于纯 AOF。
- 效果:
七、实战场景与性能调优案例
案例 1:缓存穿透优化
- 问题描述:大量请求访问不存在的 Key,导致 Redis 穿透到后端数据库,引发性能问题。
- 解决方案:
- 用 Set 存储所有存在的 Key:
127.0.0.1:6379> SADD existing_keys user:1001 user:1002 # 预存有效Key - 客户端请求前先检查 Key 是否存在:
if (redis.exists("key")) {// 访问Redis } else {// 拒绝请求或返回默认值 }
- 用 Set 存储所有存在的 Key:
案例 2:计数器场景优化
- 需求:统计用户每日登录次数,要求高并发写入与快速查询。
- 方案设计:
- 数据结构:用 Hash 存储每日计数,Key 为
user:1001:logins,字段为日期(如2023-10-01),值为次数。 - 命令组合:
HINCRBY user:1001:logins 2023-10-01 1 # 原子递增 HGET user:1001:logins 2023-10-01 # 查询单日次数 - 优势:Hash 结构减少 Key 数量,
HINCRBY保证原子性,避免多线程竞争。
- 数据结构:用 Hash 存储每日计数,Key 为
案例 3:排行榜实时更新
- 需求:实时展示游戏玩家分数排行榜,支持分页查询与分数更新。
- 方案设计:
- 数据结构:Sorted Set,Key 为
rank:scores,成员为用户 ID,分值为分数。 - 核心操作:
ZADD rank:scores 950 user:1001 # 更新分数 ZREVRANGE rank:scores 0 9 WITHSCORES # 获取前10名(降序) - 优化点:
- 定期对冷数据(如历史排行榜)进行归档,避免 Sorted Set 体积过大。
- 从服务器读取排行榜数据,减轻主服务器压力。
- 数据结构:Sorted Set,Key 为
八、常见问题与排查清单
| 问题现象 | 可能原因 | 排查步骤 | |
|---|---|---|---|
| Redis 服务无法启动 | 端口被占用 / 配置文件错误 | `netstat -anpt | grep 6379检查端口状态,验证redis.conf` 语法 |
| 写入性能突然下降 | 内存碎片率过高 / 持久化阻塞主进程 | info memory查看mem_fragmentation_ratio,观察latest_fork_usec是否异常 | |
| 数据丢失(未开启持久化) | 未配置 RDB/AOF 或持久化文件损坏 | 检查redis.conf中appendonly和save配置,修复 AOF/RDB 文件 | |
| 客户端连接超时 | maxclients限制 / 网络延迟 | info clients查看连接数,测试客户端与服务器网络连通性 | |
| 淘汰策略未生效 | maxmemory设置过大 / 未匹配 Key 类型 | 确认maxmemory小于物理内存,检查maxmemory-policy是否针对目标 Key 类型 |
相关文章:

NoSQl之Redis部署
一、Redis 核心概念与技术定位 1. 数据库分类与 Redis 的诞生背景 关系型数据库的局限性 数据模型:基于二维表结构,通过 SQL 操作,强一致性(ACID 特性),适合结构化事务场景(如银行转账、订单管…...
学习设计模式《十二》——命令模式
一、基础概念 命令模式的本质是【封装请求】命令模式的关键是把请求封装成为命令对象,然后就可以对这个命令对象进行一系列的处理(如:参数化配置、可撤销操作、宏命令、队列请求、日志请求等)。 命令模式的定义:将一个…...
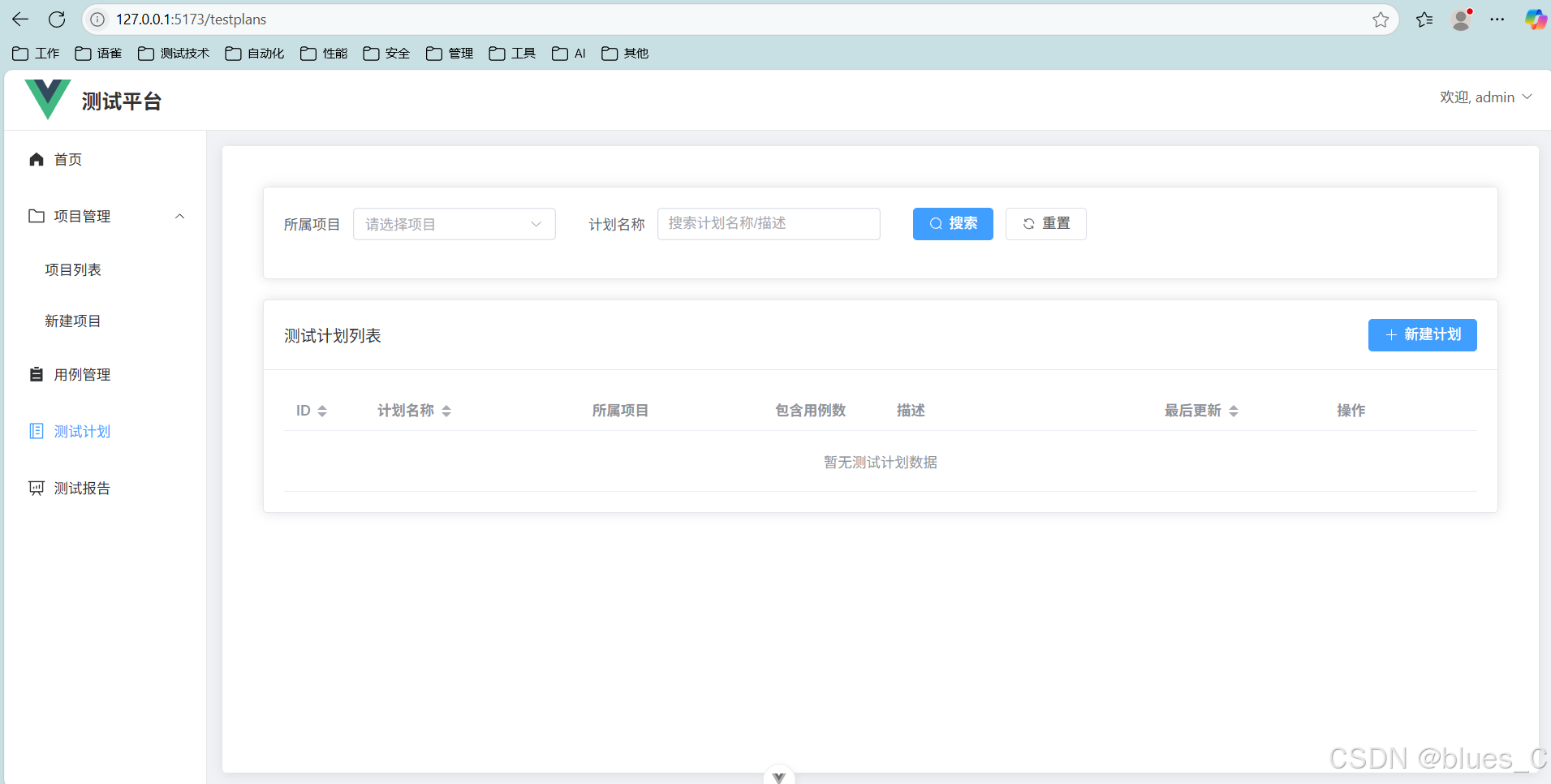
十三、【核心功能篇】测试计划管理:组织和编排测试用例
【核心功能篇】测试计划管理:组织和编排测试用例 前言准备工作第一部分:后端实现 (Django)1. 定义 TestPlan 模型2. 生成并应用数据库迁移3. 创建 TestPlanSerializer4. 创建 TestPlanViewSet5. 注册路由6. 注册到 Django Admin 第二部分:前端…...
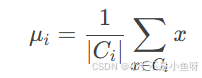
手撕 K-Means
1. K-means 的原理 K-means 是一种经典的无监督学习算法,用于将数据集划分为 kk 个簇(cluster)。其核心思想是通过迭代优化,将数据点分配到最近的簇中心,并更新簇中心,直到簇中心不再变化或达到最大迭代次…...

SmolVLA: 让机器人更懂 “看听说做” 的轻量化解决方案
🧭 TL;DR 今天,我们希望向大家介绍一个新的模型: SmolVLA,这是一个轻量级 (450M 参数) 的开源视觉 - 语言 - 动作 (VLA) 模型,专为机器人领域设计,并且可以在消费级硬件上运行。 SmolVLAhttps://hf.co/lerobot/smolvla…...
day45python打卡
知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensorbo…...
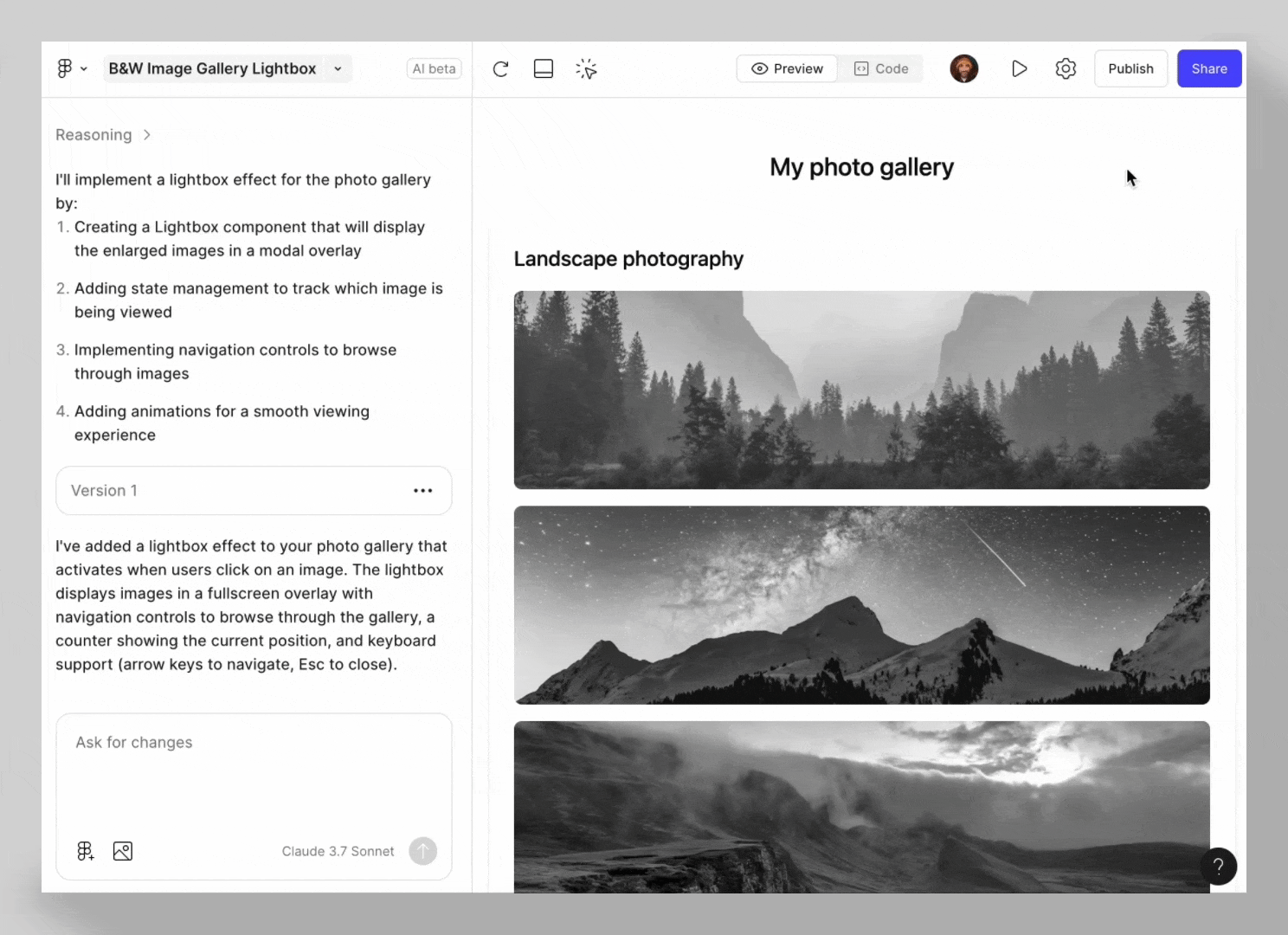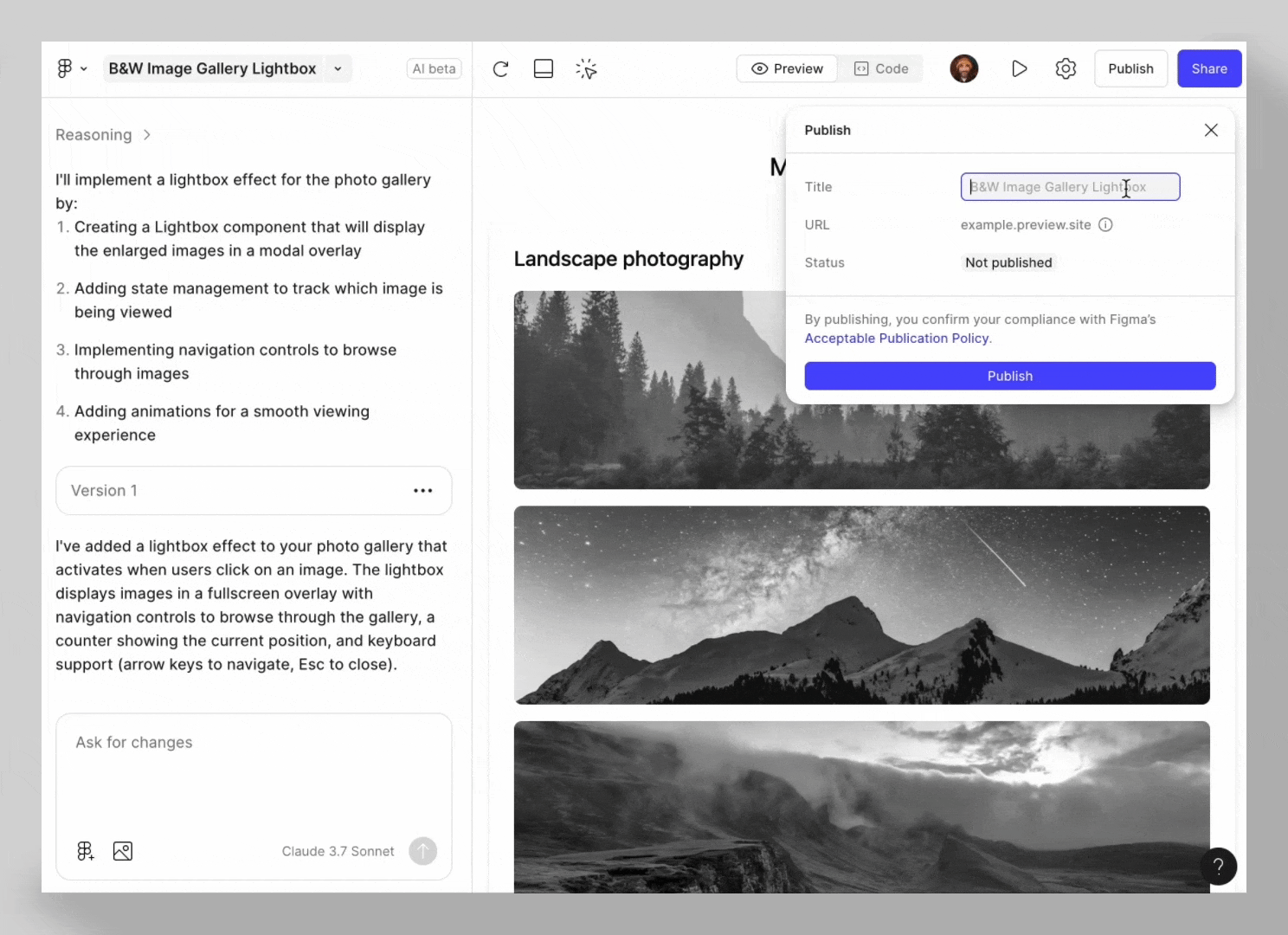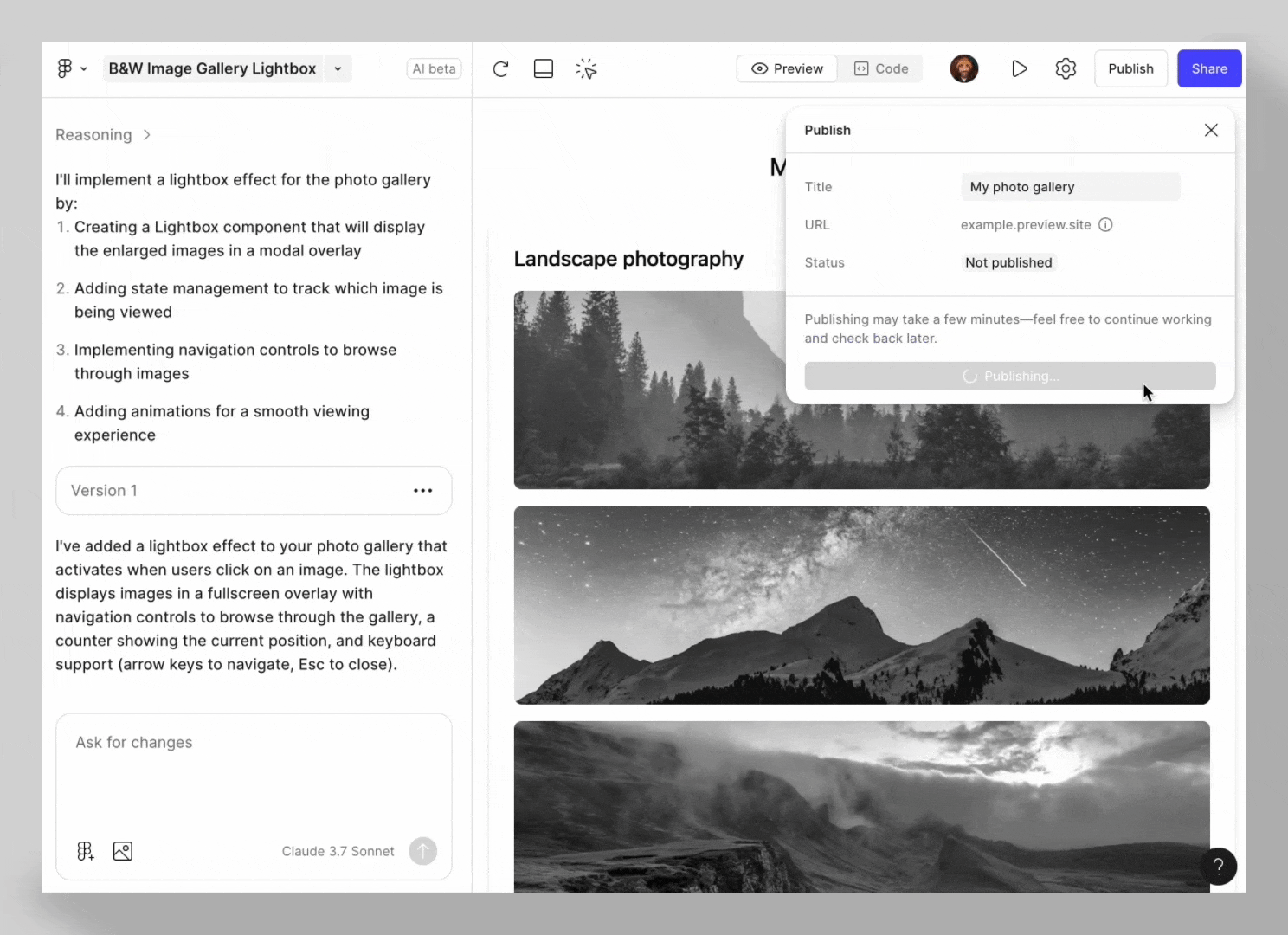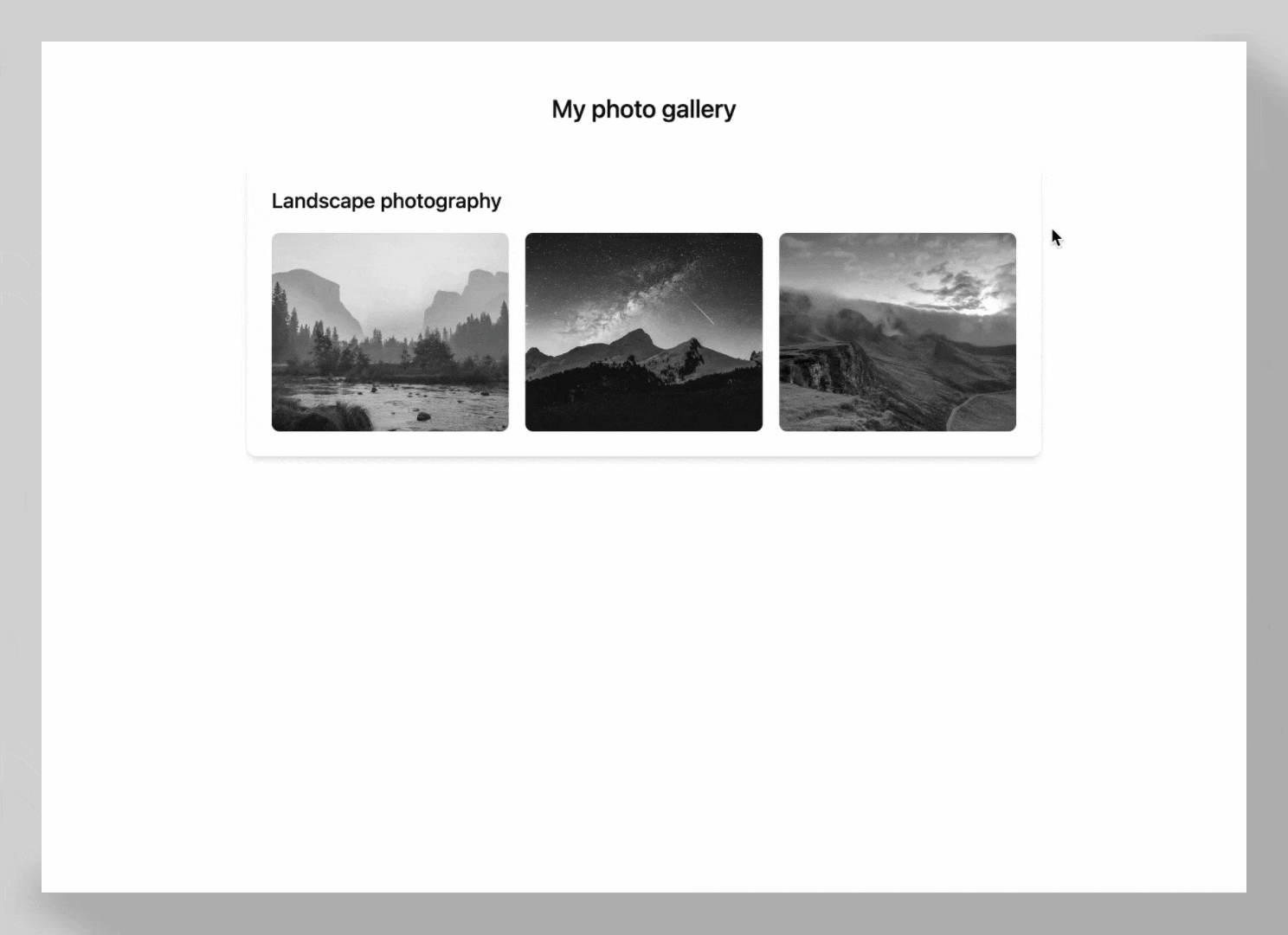
AIGC赋能前端开发
一、引言:AIGC对前端开发的影响 1. AIGC与前端开发的关系 从“写代码”到“生成代码”传统开发痛点:重复性编码工作、UI 设计稿还原、问题定位与调试...核心场景的AI化:需求转代码(P2C)、设计稿转代码(D2…...

Web 3D协作平台开发案例:构建制造业远程设计与可视化协作
HOOPS Communicator为开发者提供了丰富的定制化能力,助力他们在实现强大 Web 3D 可视化功能的同时,灵活构建符合特定业务需求的工程应用。对于希望构建在线协同设计工具的企业而言,如何在保障性能与用户体验的前提下实现高效开发,…...

AI Agent开发第78课-大模型结合Flink构建政务类长公文、长文件、OA应用Agent
开篇 AI Agent2025确定是进入了爆发期,到处都在冒出各种各样的实用AI Agent。很多人、组织都投身于开发AI Agent。 但是从3月份开始业界开始出现了一种这样的声音: AI开发入门并不难,一旦开发完后没法用! 经历过至少一个AI Agent从开发到上线的小伙伴们其实都听到过这种…...

极空间z4pro配置gitea mysql,内网穿透
极空间z4pro配置gitea mysql等记录,内网穿透 1、mysql、gitea镜像下载,极空间不成功,先用自己电脑科学后下载镜像,拉取代码: docker pull --platform linux/amd64 gitea/gitea:1.23 docker pull --platform linux/amd64 mysql:5.…...

第三方测试机构进行科技成果鉴定测试有什么价值
在当今科技创新的浪潮中,科技成果的鉴定测试至关重要,而第三方测试机构凭借其独特优势,在这一领域发挥着不可替代的作用。那么,第三方测试机构进行科技成果鉴定测试究竟有什么价值呢? 一、第三方测试机构能提供独立、公…...
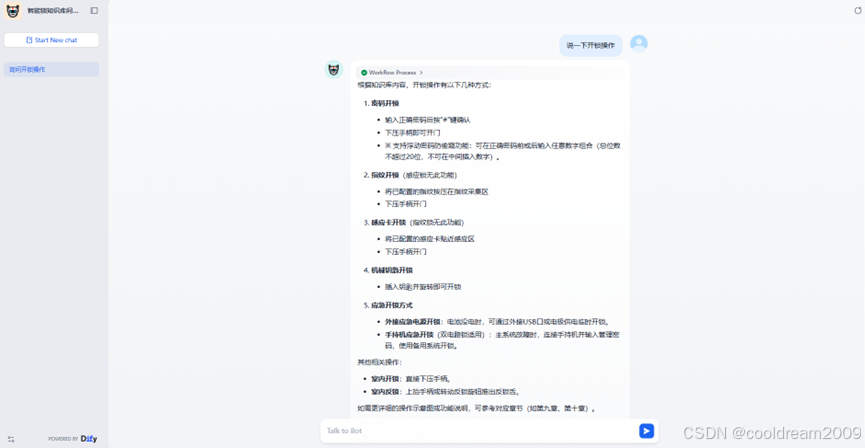
华为云Flexus+DeepSeek征文|基于华为云Flexus X和DeepSeek-R1打造个人知识库问答系统
目录 前言 1 快速部署:一键搭建Dify平台 1.1 部署流程详解 1.2 初始配置与登录 2 构建专属知识库 2.1 进入知识库模块并创建新库 2.2 选择数据源导入内容 2.3 上传并识别多种文档格式 2.4 文本处理与索引构建 2.5 保存并完成知识库创建 3接入ModelArts S…...

【数据结构】_排序
【本节目标】 排序的概念及其运用常见排序算法的实现排序算法复杂度及稳定性分析 1.排序的概念及其运用 1.1排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 1.2特性…...

《前端面试题:JS数据类型》
JavaScript 数据类型指南:从基础到高级全解析 一、JavaScript 数据类型概述 JavaScript 作为一门动态类型语言,其数据类型系统是理解这门语言的核心基础。在 ECMAScript 标准中,数据类型分为两大类: 1. 原始类型(Pr…...
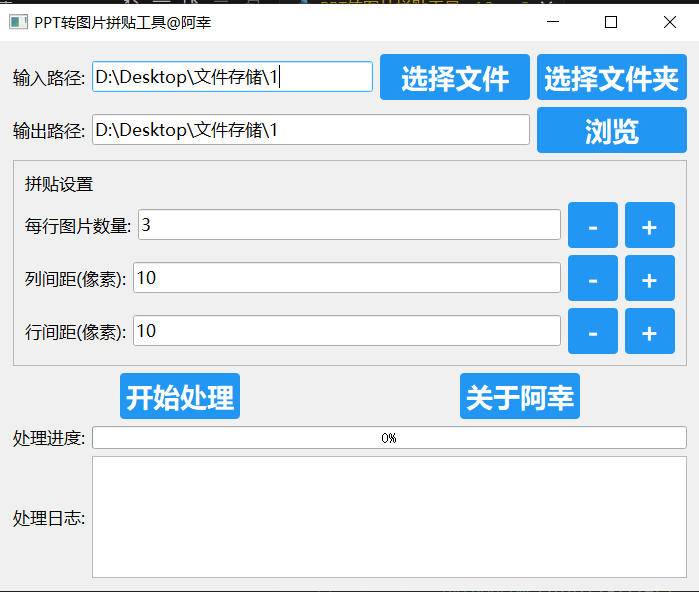
PPT转图片拼贴工具 v4.3
软件介绍 这个软件就是将PPT文件转换为图片并且拼接起来。 效果展示 支持导入文件和支持导入文件夹,也支持手动输入文件/文件夹路径 软件界面 这一次提供了源码和开箱即用版本,exe就是直接用就可以了。 软件源码 import os import re import sys …...
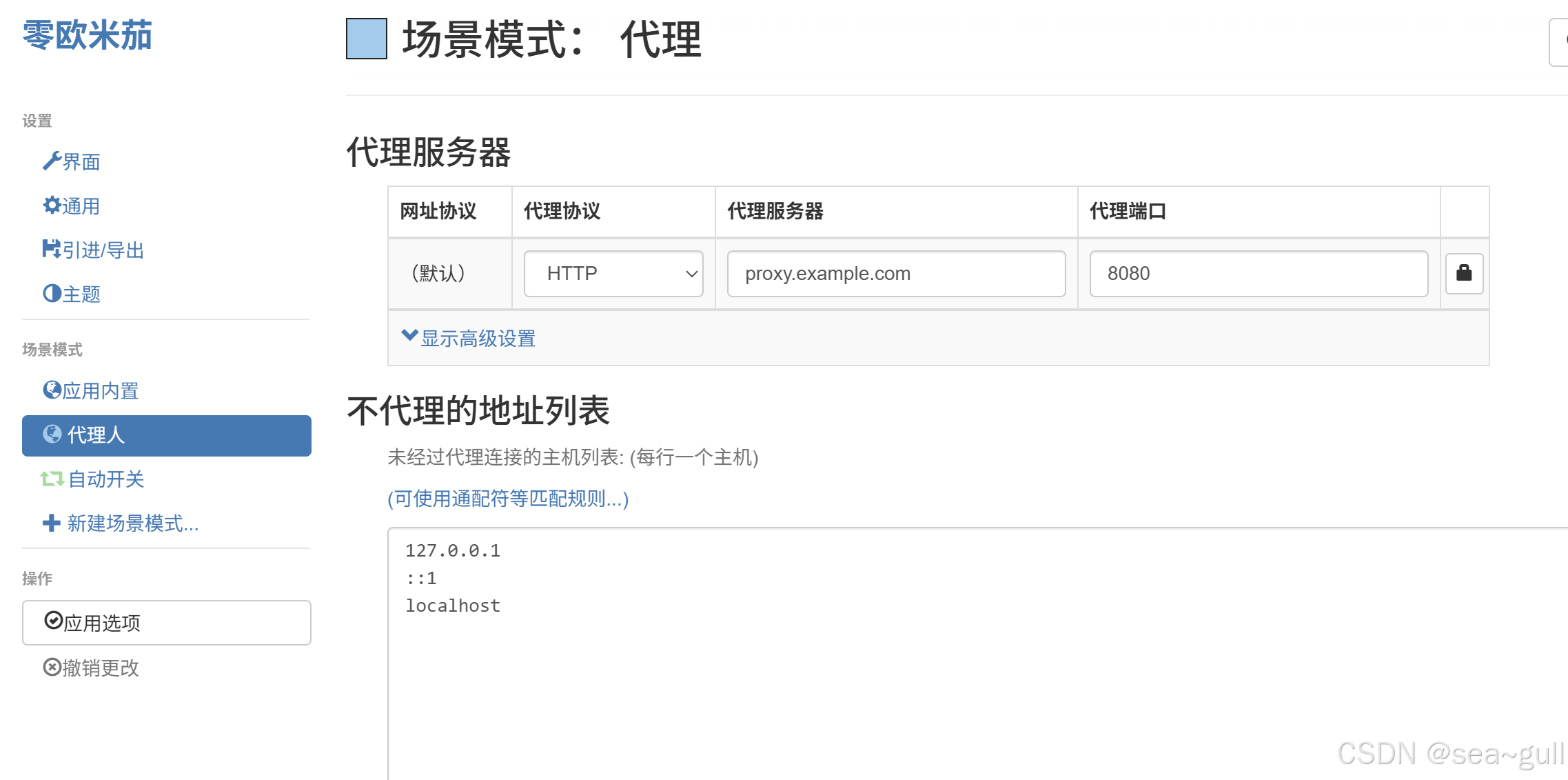
Chrome安装代理插件ZeroOmega(保姆级别)
目录 本文直接讲解一下怎么本地安装ZeroOmega一、下载文件在GitHub直接下ZeroOmega 的文件(下最新版即可) 二、安装插件打开 Chrome 浏览器,访问 chrome://extensions/ 页面(扩展程序管理页面),并打开开发者…...
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)
Transformer-BiGRU多变量时序预测(Matlab完整源码和数据) 目录 Transformer-BiGRU多变量时序预测(Matlab完整源码和数据)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现Transformer-BiGRU多变量时间序列预测&…...

新华三H3CNE网络工程师认证—Easy IP
Easy IP 就是“用路由器自己的公网IP,给全家所有设备当共享门牌号”的技术!(省掉额外公网IP,省钱又省配置!) 生活场景对比,想象你住在一个小区:普通动态NAT:物业申请了 …...

《视觉SLAM十四讲》自用笔记 第二讲:SLAM系统概述
在rm队伍里作为算法组梯队队员度过了一个赛季,为了促进和负责其他工作的算法组成员的交流,我决定在接下来的半个学期里(可能更快)读完这本书,并将其中的部分理论应用于我自制的雷达导航小车上。 以下为第二讲的部分笔记…...

vscode 插件 eslint, 检查 js 语法
1. 起因, 目的: 我的需求 vscode 写js代码, 有什么插件能进行语法检查。 比如某个函数没有定义,getName(), 但是却调用了。 那么这个插件会给出警告,在 getName() 给出红色波浪线。类似这种效果的插件, 有吗…...
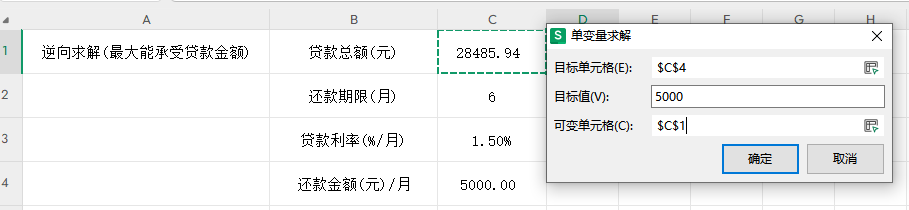
Excel 模拟分析之单变量求解简单应用
正向求解 利用公式根据贷款总额、还款期限、贷款利率,求每月还款金额 反向求解 根据每月还款能力,求最大能承受贷款金额 参数: 目标单元格:求的值所在的单元格 目标值:想要达到的预期值 可变单元格:变…...

装备制造项目管理具备什么特征?如何选择适配的项目管理软件系统进行项目管控?
国内某大型半导体装备制造企业与奥博思软件达成战略合作,全面引入奥博思 PowerProject 打造企业专属项目管理平台,进一步提升智能制造领域的项目管理效率与协同能力。 该项目管理平台聚焦半导体装备研发与制造的业务特性,实现了从项目立项、…...
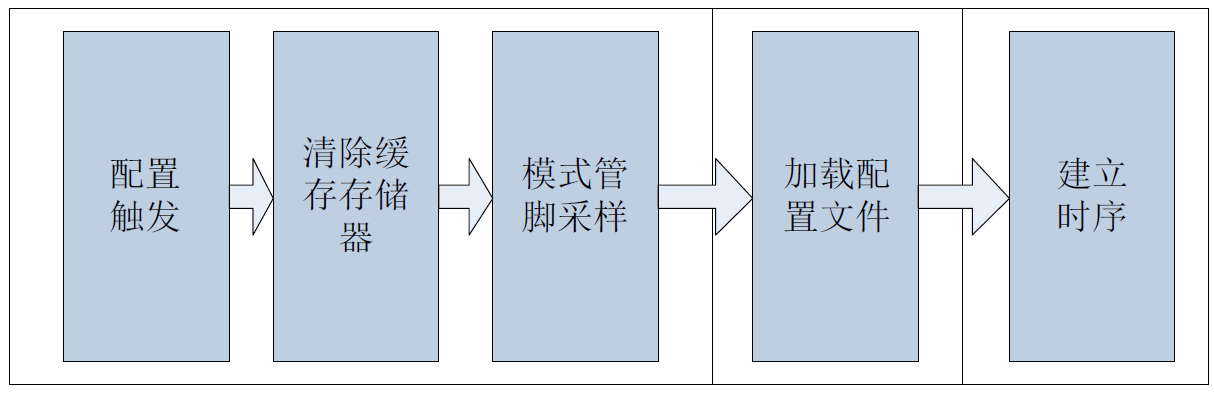
FPGA 动态重构配置流程
触发FPGA 进行配置的方式有两种,一种是断电后上电,另一种是在FPGA运行过程中,将PROGRAM 管脚拉低。将PROGRAM 管脚拉低500ns 以上就可以触发FPGA 进行重构。 FPGA 的配置过程大致可以分为:配置的触发和建立阶段、加载配置文件和建…...
介绍)
Elasticsearch的审计日志(Audit Logging)介绍
Elasticsearch 的审计日志(Audit Logging)是一种记录与安全相关事件的功能,用于监控和追踪对集群的访问行为。通过审计日志,管理员可以了解谁在何时对哪些资源执行了什么操作,从而满足合规性要求、进行安全分析和排查异常行为。 一、审计日志的核心功能 记录安全事件捕获…...

软件测试:质量保障的基石与未来趋势
软件测试作为软件开发生命周期中的关键环节,不仅是发现和修复缺陷的手段,更是确保产品质量、提升用户体验和降低开发成本的重要保障。在当今快速迭代的互联网时代,测试已从单纯的验证活动演变为贯穿整个开发过程的质量管理体系。本文将系统阐…...

网络安全逆向分析之rust逆向技巧
rust逆向技巧 rust逆向三板斧: 快速定位关键函数 (真正的main函数):观察输出、输入,字符串搜索,断点等方法。定位关键 加密区 :根据输入的flag,打硬件断点,快速捕获程序中对flag访问的位置&am…...

Docker容器化技术概述与实践
哈喽,大家好,我是左手python! Docker 容器化的基本概念 Docker 容器化是一种轻量级的虚拟化技术,通过将应用程序及其依赖项打包到一个可移植的容器中,使其在任何兼容 Docker 的环境中都能运行。与传统的虚拟机技术不同…...

win中将pdf转为图片
0 资料 博客 1 正文 直接使用这个软件即可https://sourceforge.net/projects/pkpdfconverter/...
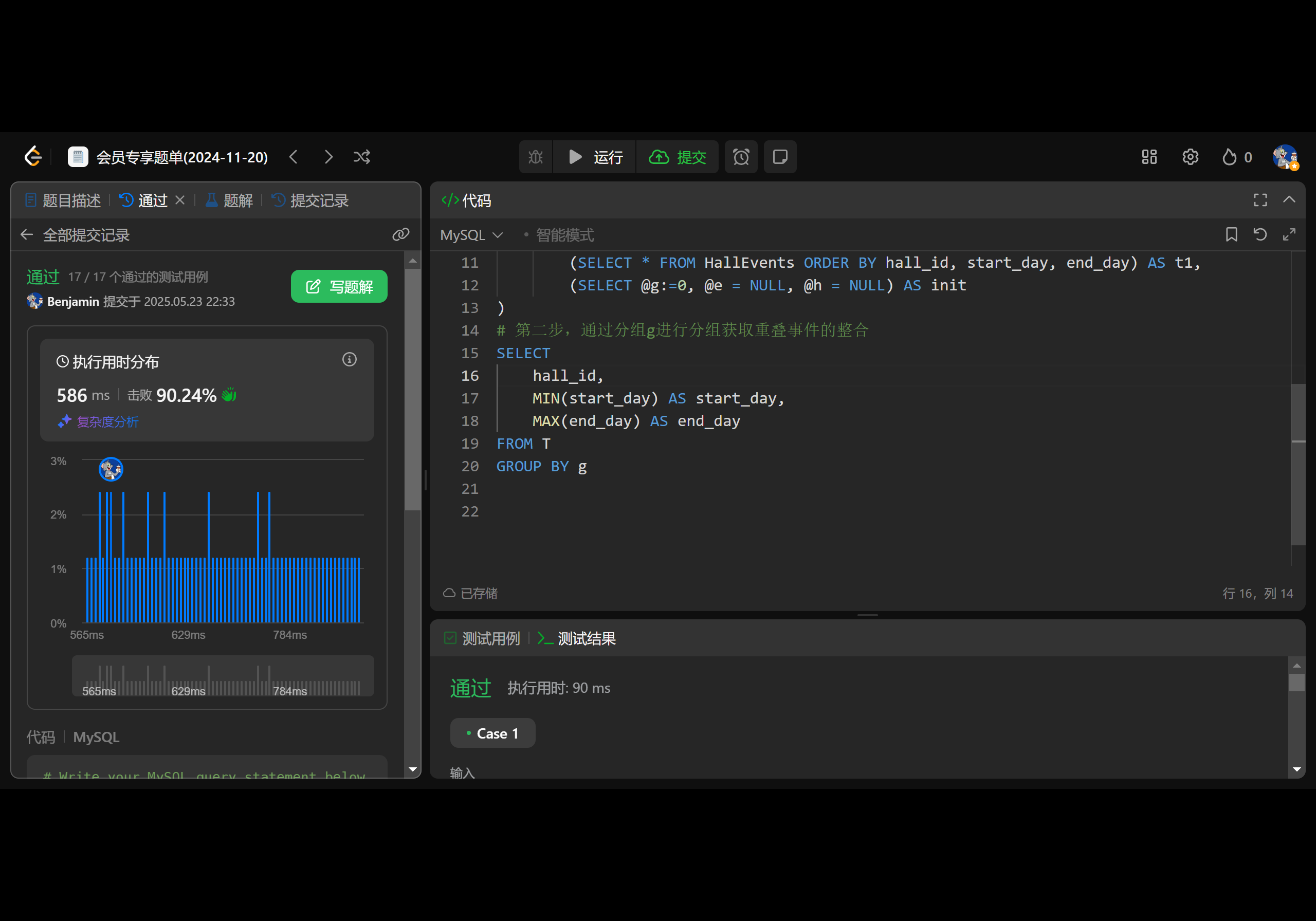
Leetcode 2494. 合并在同一个大厅重叠的活动
1.题目基本信息 1.1.题目描述 表: HallEvents ----------------- | Column Name | Type | ----------------- | hall_id | int | | start_day | date | | end_day | date | ----------------- 该表可能包含重复字段。 该表的每一行表示活动的开始日期和结束日期&…...
vue+elementui 网站首页顶部菜单上下布局
菜单集合后台接口动态获取,保存到store vuex状态管理器 <template><div id"app"><el-menu:default-active"activeIndex2"class"el-menu-demo"mode"horizontal"select"handleSelect"background-…...