Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
目录
- 简介
- 持久层技术概述
- Hibernate详解
- MyBatis详解
- JPA详解
- 技术选型对比
- 最佳实践与应用场景
- 性能优化策略
- 未来发展趋势
- 总结与建议
简介
在Java企业级应用开发中,持久层(Persistence Layer)作为连接业务逻辑与数据存储的桥梁,其技术选型直接影响着应用的性能、可维护性和开发效率。本文将深入比较三种主流Java持久层技术:Hibernate、MyBatis和JPA(Java Persistence API),帮助开发者根据项目需求做出最合适的技术选择。
持久层,也称为数据访问层(Data Access Layer),负责将业务对象持久化到数据库,并从数据库中重建业务对象。一个优秀的持久层框架能够简化数据库操作,提高开发效率,并确保数据的一致性和完整性。
持久层技术概述
什么是ORM
对象关系映射(Object-Relational Mapping,ORM)是一种编程技术,用于在面向对象编程语言和关系型数据库之间建立映射关系。ORM框架的核心目标是解决面向对象编程与关系型数据库之间的"阻抗不匹配"问题。
ORM的主要优势包括:
- 减少重复的SQL代码编写
- 提供面向对象的操作方式
- 自动处理数据类型转换
- 支持事务管理
- 提高代码可维护性和可读性
主流持久层技术简介
Hibernate
Hibernate是一个成熟、功能强大的ORM框架,它通过XML配置文件或注解将Java对象与数据库表进行映射。Hibernate提供了完整的ORM解决方案,包括对象关系映射、缓存机制、延迟加载等特性,大大简化了数据库操作。
// Hibernate示例代码
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
User user = new User("张三", "zhangsan@example.com");
session.save(user);
tx.commit();
session.close();
MyBatis
MyBatis(前身为iBATIS)是一个半自动化的ORM框架,它更注重SQL的灵活性和可控性。MyBatis通过XML文件或注解将SQL语句与Java方法关联起来,开发者可以直接编写和优化SQL语句,同时享受ORM框架带来的便利。
// MyBatis示例代码
SqlSession session = sqlSessionFactory.openSession();
try {UserMapper mapper = session.getMapper(UserMapper.class);User user = new User("李四", "lisi@example.com");mapper.insertUser(user);session.commit();
} finally {session.close();
}
JPA
JPA(Java Persistence API)是Java EE标准的一部分,它定义了一套标准的ORM接口规范,而不是具体的实现。Hibernate、EclipseLink和OpenJPA等都是JPA规范的实现。JPA通过注解或XML配置实现对象关系映射,提供了统一的API和查询语言(JPQL)。
// JPA示例代码
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
User user = new User("王五", "wangwu@example.com");
em.persist(user);
tx.commit();
em.close();
在接下来的章节中,我们将深入探讨这三种技术的特点、优缺点以及适用场景,帮助开发者做出明智的技术选择。
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
Hibernate详解
Hibernate是目前最流行的Java ORM框架之一,由Gavin King于2001年创建。作为一个全自动的ORM解决方案,Hibernate致力于减少开发者编写数据访问代码的工作量,让开发者能够专注于业务逻辑的实现。
核心特性
1. 完全面向对象的设计
Hibernate允许开发者以纯面向对象的方式操作数据库,无需直接编写SQL语句。它提供了丰富的对象关系映射功能,支持继承、多态、组合等面向对象的概念。
2. 透明持久化
Hibernate实现了透明持久化(Transparent Persistence),使应用程序代码几乎不需要感知到数据库的存在。开发者可以像操作普通Java对象一样操作持久化对象。
3. 强大的查询能力
Hibernate提供了多种查询方式:
- HQL(Hibernate Query Language):类似SQL但面向对象的查询语言
- Criteria API:完全面向对象的查询API
- Native SQL:支持直接使用原生SQL查询
- QueryDSL:类型安全的查询API(需要额外依赖)
4. 缓存机制
Hibernate提供了一级缓存(Session级别)和二级缓存(SessionFactory级别):
- 一级缓存是默认开启的,作用于当前Session
- 二级缓存可选配置,作用于整个应用,可以跨Session共享数据
5. 延迟加载
Hibernate支持延迟加载(Lazy Loading)策略,可以在需要时才加载关联对象,有效减少不必要的数据库查询。
基本使用
配置与初始化
Hibernate可以通过XML或Java配置进行初始化:
XML配置方式(hibernate.cfg.xml):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><!-- 数据库连接设置 --><property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property><property name="hibernate.connection.url">jdbc:mysql://localhost:3306/mydb?useSSL=false</property><property name="hibernate.connection.username">root</property><property name="hibernate.connection.password">password</property><!-- JDBC连接池设置 --><property name="hibernate.c3p0.min_size">5</property><property name="hibernate.c3p0.max_size">20</property><!-- SQL方言 --><property name="hibernate.dialect">org.hibernate.dialect.MySQL8Dialect</property><!-- Echo SQL --><property name="hibernate.show_sql">true</property><property name="hibernate.format_sql">true</property><!-- 自动创建/更新表结构 --><property name="hibernate.hbm2ddl.auto">update</property><!-- 映射文件 --><mapping class="com.example.entity.User"/><mapping class="com.example.entity.Order"/></session-factory>
</hibernate-configuration>
Java配置方式:
Configuration configuration = new Configuration().setProperty("hibernate.connection.driver_class", "com.mysql.cj.jdbc.Driver").setProperty("hibernate.connection.url", "jdbc:mysql://localhost:3306/mydb?useSSL=false").setProperty("hibernate.connection.username", "root").setProperty("hibernate.connection.password", "password").setProperty("hibernate.dialect", "org.hibernate.dialect.MySQL8Dialect").setProperty("hibernate.show_sql", "true").setProperty("hibernate.hbm2ddl.auto", "update").addAnnotatedClass(User.class).addAnnotatedClass(Order.class);StandardServiceRegistryBuilder builder = new StandardServiceRegistryBuilder().applySettings(configuration.getProperties());
SessionFactory sessionFactory = configuration.buildSessionFactory(builder.build());
实体映射
Hibernate支持通过XML或注解进行实体映射:
注解方式:
@Entity
@Table(name = "users")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name = "username", nullable = false, length = 50)private String username;@Column(name = "email", unique = true)private String email;@Temporal(TemporalType.TIMESTAMP)@Column(name = "created_at")private Date createdAt;@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)private List<Order> orders = new ArrayList<>();// 构造函数、getter和setter方法
}
XML方式(User.hbm.xml):
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC"-//Hibernate/Hibernate Mapping DTD 3.0//EN""http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping><class name="com.example.entity.User" table="users"><id name="id" column="id"><generator class="identity"/></id><property name="username" column="username" not-null="true" length="50"/><property name="email" column="email" unique="true"/><property name="createdAt" column="created_at" type="timestamp"/><bag name="orders" inverse="true" cascade="all" lazy="true"><key column="user_id"/><one-to-many class="com.example.entity.Order"/></bag></class>
</hibernate-mapping>
基本CRUD操作
创建(Create):
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();User user = new User();
user.setUsername("张三");
user.setEmail("zhangsan@example.com");
user.setCreatedAt(new Date());session.save(user); // 或 session.persist(user)
tx.commit();
session.close();
读取(Read):
Session session = sessionFactory.openSession();// 根据ID加载
User user = session.get(User.class, 1L); // 立即加载
// 或
User user = session.load(User.class, 1L); // 延迟加载// 使用HQL查询
List<User> users = session.createQuery("from User where username like :name", User.class).setParameter("name", "张%").list();// 使用Criteria API查询
CriteriaBuilder builder = session.getCriteriaBuilder();
CriteriaQuery<User> criteria = builder.createQuery(User.class);
Root<User> root = criteria.from(User.class);
criteria.select(root).where(builder.like(root.get("username"), "张%"));
List<User> users = session.createQuery(criteria).getResultList();session.close();
更新(Update):
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();User user = session.get(User.class, 1L);
user.setEmail("zhangsan_new@example.com");session.update(user); // 显式更新,通常不需要
tx.commit();
session.close();
删除(Delete):
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();User user = session.get(User.class, 1L);
session.delete(user);tx.commit();
session.close();
关联关系映射
Hibernate支持多种关联关系映射:
一对一(One-to-One)
@Entity
public class Employee {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@OneToOne(cascade = CascadeType.ALL)@JoinColumn(name = "address_id", unique = true)private Address address;// getter和setter
}@Entity
public class Address {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String street;private String city;@OneToOne(mappedBy = "address")private Employee employee;// getter和setter
}
一对多(One-to-Many)
@Entity
public class Department {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@OneToMany(mappedBy = "department", cascade = CascadeType.ALL, fetch = FetchType.LAZY)private List<Employee> employees = new ArrayList<>();// getter和setter
}@Entity
public class Employee {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToOne@JoinColumn(name = "department_id")private Department department;// getter和setter
}
多对多(Many-to-Many)
@Entity
public class Student {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})@JoinTable(name = "student_course",joinColumns = @JoinColumn(name = "student_id"),inverseJoinColumns = @JoinColumn(name = "course_id"))private Set<Course> courses = new HashSet<>();// getter和setter
}@Entity
public class Course {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(mappedBy = "courses")private Set<Student> students = new HashSet<>();// getter和setter
}
缓存使用
一级缓存(Session缓存)
一级缓存是Session范围的缓存,默认开启,无需额外配置:
Session session = sessionFactory.openSession();// 第一次查询,会发送SQL到数据库
User user1 = session.get(User.class, 1L);// 第二次查询同一对象,直接从一级缓存获取,不会发送SQL
User user2 = session.get(User.class, 1L);session.close();
二级缓存(SessionFactory缓存)
二级缓存需要额外配置:
- 添加缓存提供者依赖(如EHCache)
- 配置hibernate.cfg.xml
<!-- 启用二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 指定缓存提供者 -->
<property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
<!-- 启用查询缓存 -->
<property name="hibernate.cache.use_query_cache">true</property>
- 在实体类上添加缓存注解
@Entity
@Cacheable
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class User {// ...
}
Hibernate的优缺点
优点
- 高度抽象:几乎不需要编写SQL,大大减少了代码量
- 面向对象:完全符合面向对象编程思想
- 可移植性:支持多种数据库,切换数据库只需更改方言配置
- 缓存机制:内置一级和二级缓存,提高性能
- 自动生成表结构:可以根据实体类自动创建或更新数据库表
- 延迟加载:按需加载数据,减少不必要的查询
缺点
- 学习曲线陡峭:概念多,配置复杂,需要时间掌握
- 性能问题:在处理大量数据或复杂查询时可能存在性能瓶颈
- SQL控制力弱:自动生成的SQL可能不是最优的
- 调试困难:当出现问题时,定位和解决比直接使用SQL更困难
- 内存消耗:缓存和映射需要消耗额外的内存
适用场景
Hibernate特别适合以下场景:
- 领域驱动设计(DDD)项目:注重领域模型和业务规则
- CRUD操作为主的应用:如内部管理系统、CMS系统等
- 数据库无关的应用:需要支持多种数据库的项目
- 快速开发项目:需要快速交付的项目
- 对象关系复杂的项目:有复杂继承、组合关系的领域模型
在下一部分,我们将深入探讨MyBatis框架的特点和使用方法。
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
MyBatis详解
MyBatis(前身为iBATIS)是一个半自动化的ORM框架,由Clinton Begin于2001年创建。与Hibernate不同,MyBatis更加注重SQL的灵活性和可控性,允许开发者直接编写和优化SQL语句,同时提供了简单的ORM功能。
核心特性
1. SQL与Java代码分离
MyBatis最显著的特点是将SQL语句与Java代码分离,通过XML文件或注解来管理SQL语句,使得SQL可以独立维护和优化。
2. 灵活的SQL控制
MyBatis允许开发者完全控制SQL语句,可以编写任意复杂的SQL查询,包括存储过程、动态SQL等,非常适合复杂查询场景。
3. 动态SQL
MyBatis提供了强大的动态SQL功能,可以根据不同条件动态生成SQL语句,如<if>、<choose>、<where>、<foreach>等标签。
4. 结果映射
MyBatis提供了灵活的结果映射机制,可以将查询结果映射到Java对象,支持一对一、一对多、多对多等复杂关系映射。
5. 插件机制
MyBatis支持插件扩展,可以通过实现拦截器接口来拦截和修改MyBatis的核心行为,如分页插件、性能监控插件等。
基本使用
配置与初始化
XML配置文件(mybatis-config.xml):
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><!-- 环境配置 --><environments default="development"><environment id="development"><transactionManager type="JDBC"/><dataSource type="POOLED"><property name="driver" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/mydb?useSSL=false"/><property name="username" value="root"/><property name="password" value="password"/></dataSource></environment></environments><!-- 映射器 --><mappers><mapper resource="com/example/mapper/UserMapper.xml"/><mapper resource="com/example/mapper/OrderMapper.xml"/></mappers>
</configuration>
Java代码初始化:
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
映射文件
XML映射文件(UserMapper.xml):
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper"><!-- 结果映射 --><resultMap id="userResultMap" type="com.example.entity.User"><id property="id" column="id"/><result property="username" column="username"/><result property="email" column="email"/><result property="createdAt" column="created_at"/><collection property="orders" ofType="com.example.entity.Order"><id property="id" column="order_id"/><result property="orderNumber" column="order_number"/><result property="amount" column="amount"/></collection></resultMap><!-- 查询语句 --><select id="getUserById" parameterType="long" resultMap="userResultMap">SELECT u.*, o.id as order_id, o.order_number, o.amountFROM users uLEFT JOIN orders o ON u.id = o.user_idWHERE u.id = #{id}</select><!-- 插入语句 --><insert id="insertUser" parameterType="com.example.entity.User" useGeneratedKeys="true" keyProperty="id">INSERT INTO users (username, email, created_at)VALUES (#{username}, #{email}, #{createdAt})</insert><!-- 更新语句 --><update id="updateUser" parameterType="com.example.entity.User">UPDATE usersSET username = #{username}, email = #{email}WHERE id = #{id}</update><!-- 删除语句 --><delete id="deleteUser" parameterType="long">DELETE FROM users WHERE id = #{id}</delete><!-- 动态SQL示例 --><select id="findUsers" parameterType="map" resultMap="userResultMap">SELECT * FROM users<where><if test="username != null">username LIKE #{username}</if><if test="email != null">AND email = #{email}</if></where>ORDER BY id DESC</select>
</mapper>
Mapper接口
public interface UserMapper {User getUserById(Long id);int insertUser(User user);int updateUser(User user);int deleteUser(Long id);List<User> findUsers(Map<String, Object> params);
}
基本CRUD操作
创建(Create):
SqlSession session = sqlSessionFactory.openSession();
try {UserMapper mapper = session.getMapper(UserMapper.class);User user = new User();user.setUsername("张三");user.setEmail("zhangsan@example.com");user.setCreatedAt(new Date());mapper.insertUser(user);session.commit();
} finally {session.close();
}
读取(Read):
SqlSession session = sqlSessionFactory.openSession();
try {UserMapper mapper = session.getMapper(UserMapper.class);// 根据ID查询User user = mapper.getUserById(1L);// 条件查询Map<String, Object> params = new HashMap<>();params.put("username", "%张%");List<User> users = mapper.findUsers(params);
} finally {session.close();
}
更新(Update):
SqlSession session = sqlSessionFactory.openSession();
try {UserMapper mapper = session.getMapper(UserMapper.class);User user = mapper.getUserById(1L);user.setEmail("zhangsan_new@example.com");mapper.updateUser(user);session.commit();
} finally {session.close();
}
删除(Delete):
SqlSession session = sqlSessionFactory.openSession();
try {UserMapper mapper = session.getMapper(UserMapper.class);mapper.deleteUser(1L);session.commit();
} finally {session.close();
}
动态SQL
MyBatis的动态SQL是其最强大的特性之一,允许根据不同条件构建不同的SQL语句:
if 条件
<select id="findUsers" resultType="User">SELECT * FROM usersWHERE 1=1<if test="username != null">AND username LIKE #{username}</if><if test="email != null">AND email = #{email}</if>
</select>
where 标签
<select id="findUsers" resultType="User">SELECT * FROM users<where><if test="username != null">username LIKE #{username}</if><if test="email != null">AND email = #{email}</if></where>
</select>
choose, when, otherwise 标签
<select id="findUsers" resultType="User">SELECT * FROM users<where><choose><when test="username != null">username LIKE #{username}</when><when test="email != null">email = #{email}</when><otherwise>created_at > DATE_SUB(NOW(), INTERVAL 1 MONTH)</otherwise></choose></where>
</select>
foreach 标签
<select id="getUsersByIds" resultType="User">SELECT * FROM usersWHERE id IN<foreach collection="list" item="id" open="(" separator="," close=")">#{id}</foreach>
</select>
set 标签
<update id="updateUser" parameterType="User">UPDATE users<set><if test="username != null">username = #{username},</if><if test="email != null">email = #{email},</if><if test="createdAt != null">created_at = #{createdAt}</if></set>WHERE id = #{id}
</update>
注解方式
MyBatis也支持使用注解代替XML配置:
public interface UserMapper {@Select("SELECT * FROM users WHERE id = #{id}")User getUserById(Long id);@Insert("INSERT INTO users (username, email, created_at) VALUES (#{username}, #{email}, #{createdAt})")@Options(useGeneratedKeys = true, keyProperty = "id")int insertUser(User user);@Update("UPDATE users SET username = #{username}, email = #{email} WHERE id = #{id}")int updateUser(User user);@Delete("DELETE FROM users WHERE id = #{id}")int deleteUser(Long id);@SelectProvider(type = UserSqlProvider.class, method = "findUsers")List<User> findUsers(Map<String, Object> params);
}class UserSqlProvider {public String findUsers(Map<String, Object> params) {return new SQL() {{SELECT("*");FROM("users");if (params.get("username") != null) {WHERE("username LIKE #{username}");}if (params.get("email") != null) {WHERE("email = #{email}");}ORDER_BY("id DESC");}}.toString();}
}
关联查询
一对一关联
<resultMap id="userWithProfileMap" type="User"><id property="id" column="id"/><result property="username" column="username"/><association property="profile" javaType="Profile"><id property="id" column="profile_id"/><result property="bio" column="bio"/><result property="website" column="website"/></association>
</resultMap><select id="getUserWithProfile" resultMap="userWithProfileMap">SELECT u.*, p.id as profile_id, p.bio, p.websiteFROM users uLEFT JOIN profiles p ON u.id = p.user_idWHERE u.id = #{id}
</select>
一对多关联
<resultMap id="userWithOrdersMap" type="User"><id property="id" column="id"/><result property="username" column="username"/><collection property="orders" ofType="Order"><id property="id" column="order_id"/><result property="orderNumber" column="order_number"/><result property="amount" column="amount"/></collection>
</resultMap><select id="getUserWithOrders" resultMap="userWithOrdersMap">SELECT u.*, o.id as order_id, o.order_number, o.amountFROM users uLEFT JOIN orders o ON u.id = o.user_idWHERE u.id = #{id}
</select>
缓存机制
MyBatis提供了一级缓存和二级缓存:
一级缓存
一级缓存是Session级别的缓存,默认开启:
SqlSession session = sqlSessionFactory.openSession();// 第一次查询,会发送SQL到数据库
User user1 = session.selectOne("getUserById", 1L);// 第二次查询同一对象,直接从一级缓存获取,不会发送SQL
User user2 = session.selectOne("getUserById", 1L);// 清除缓存
session.clearCache();// 关闭会话
session.close();
二级缓存
二级缓存是命名空间级别的缓存,需要在映射文件中配置:
<mapper namespace="com.example.mapper.UserMapper"><!-- 启用二级缓存 --><cacheeviction="LRU"flushInterval="60000"size="512"readOnly="true"/><!-- 映射语句 -->
</mapper>
实体类需要实现Serializable接口:
public class User implements Serializable {private static final long serialVersionUID = 1L;// 属性和方法
}
MyBatis的优缺点
优点
- SQL控制力强:可以直接编写和优化SQL,适合复杂查询
- 学习曲线平缓:概念简单,易于上手
- 灵活性高:动态SQL功能强大,适应各种查询需求
- 与Spring集成良好:通过MyBatis-Spring可以无缝集成
- 性能较好:直接使用JDBC,减少了额外的开销
- 调试方便:SQL错误容易定位
缺点
- 工作量较大:需要手动编写SQL和映射
- 数据库依赖性强:SQL与特定数据库绑定,移植性较差
- 对象关系映射能力弱:处理复杂对象关系不如Hibernate
- 缺乏自动创建表结构功能:需要手动维护数据库结构
适用场景
MyBatis特别适合以下场景:
- 需要优化SQL的项目:如高性能要求的系统
- 复杂查询为主的应用:如报表系统、数据分析系统
- 与已有数据库集成的项目:需要适应现有数据库结构
- DBA团队参与的项目:SQL由专业DBA编写和优化
- 对SQL控制要求高的项目:需要精确控制查询执行计划
在下一部分,我们将深入探讨JPA框架的特点和使用方法。
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
JPA详解(第一部分)
JPA(Java Persistence API)是Java EE标准的一部分,它定义了一套标准的ORM接口规范,而不是具体的实现。JPA于2006年随Java EE 5发布,目前最新版本是JPA 3.1(Jakarta Persistence 3.1)。
JPA概述
1. 标准化的ORM规范
JPA是一套标准化的规范,定义了对象关系映射和数据访问的API,使开发者可以使用统一的接口进行持久化操作,而不依赖于特定的ORM实现。
2. 主要实现
JPA有多种实现,最常用的包括:
- Hibernate:最流行的JPA实现,功能丰富
- EclipseLink:Eclipse基金会的JPA实现,也是JPA参考实现
- OpenJPA:Apache基金会的JPA实现
- DataNucleus:支持多种数据存储的JPA实现
3. 核心概念
JPA的核心概念包括:
- 实体(Entity):映射到数据库表的Java类
- 实体管理器(EntityManager):管理实体的生命周期
- 持久化上下文(Persistence Context):实体实例的集合,由EntityManager管理
- 实体管理器工厂(EntityManagerFactory):创建EntityManager的工厂
- JPQL(Java Persistence Query Language):类似SQL的查询语言,但面向对象
配置与初始化
persistence.xml配置
JPA通过persistence.xml文件进行配置:
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistencehttp://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd"version="2.2"><persistence-unit name="myPersistenceUnit" transaction-type="RESOURCE_LOCAL"><provider>org.hibernate.jpa.HibernatePersistenceProvider</provider><!-- 实体类 --><class>com.example.entity.User</class><class>com.example.entity.Order</class><properties><!-- 数据库连接属性 --><property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver" /><property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/mydb?useSSL=false" /><property name="javax.persistence.jdbc.user" value="root" /><property name="javax.persistence.jdbc.password" value="password" /><!-- Hibernate特定属性 --><property name="hibernate.dialect" value="org.hibernate.dialect.MySQL8Dialect" /><property name="hibernate.show_sql" value="true" /><property name="hibernate.format_sql" value="true" /><property name="hibernate.hbm2ddl.auto" value="update" /></properties></persistence-unit>
</persistence>
初始化EntityManagerFactory和EntityManager
// 创建EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myPersistenceUnit");// 创建EntityManager
EntityManager em = emf.createEntityManager();
在Spring Boot中使用JPA
Spring Boot简化了JPA的配置,只需在application.properties或application.yml中配置:
# 数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
spring.datasource.username=root
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver# JPA配置
spring.jpa.database-platform=org.hibernate.dialect.MySQL8Dialect
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.format_sql=true
然后使用@Repository注解创建数据访问层:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {List<User> findByUsername(String username);
}
实体映射
基本实体映射
@Entity
@Table(name = "users")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name = "username", nullable = false, length = 50)private String username;@Column(name = "email", unique = true)private String email;@Temporal(TemporalType.TIMESTAMP)@Column(name = "created_at")private Date createdAt;// 构造函数、getter和setter方法
}
主键生成策略
JPA支持多种主键生成策略:
// 自增长(数据库自动生成)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;// 序列(使用数据库序列)
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "user_seq")
@SequenceGenerator(name = "user_seq", sequenceName = "USER_SEQ", allocationSize = 1)
private Long id;// 表生成(使用一个专门的表来生成ID)
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "user_gen")
@TableGenerator(name = "user_gen", table = "id_generator", pkColumnName = "gen_name", valueColumnName = "gen_value", pkColumnValue = "user_id", initialValue = 1, allocationSize = 1)
private Long id;// UUID生成
@Id
@GeneratedValue(generator = "uuid2")
@GenericGenerator(name = "uuid2", strategy = "uuid2")
@Column(columnDefinition = "VARCHAR(36)")
private String id;
字段映射
JPA提供了丰富的字段映射注解:
// 基本类型映射
@Column(name = "username", nullable = false, length = 50)
private String username;// 大文本映射
@Lob
@Column(name = "description")
private String description;// 日期时间映射
@Temporal(TemporalType.TIMESTAMP)
@Column(name = "created_at")
private Date createdAt;// 枚举映射
@Enumerated(EnumType.STRING)
@Column(name = "status")
private UserStatus status;// 嵌入对象映射
@Embedded
private Address address;// 瞬态字段(不持久化)
@Transient
private String tempField;
嵌入对象
@Embeddable
public class Address {@Column(name = "street")private String street;@Column(name = "city")private String city;@Column(name = "postal_code")private String postalCode;// 构造函数、getter和setter方法
}@Entity
@Table(name = "users")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;// 其他字段@Embeddedprivate Address address;// 自定义列名@Embedded@AttributeOverrides({@AttributeOverride(name = "street", column = @Column(name = "work_street")),@AttributeOverride(name = "city", column = @Column(name = "work_city")),@AttributeOverride(name = "postalCode", column = @Column(name = "work_postal_code"))})private Address workAddress;// 构造函数、getter和setter方法
}
关联关系映射
一对一关系
@Entity
public class Employee {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)@JoinColumn(name = "address_id", unique = true)private Address address;// getter和setter
}@Entity
public class Address {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String street;private String city;@OneToOne(mappedBy = "address")private Employee employee;// getter和setter
}
一对多关系
@Entity
public class Department {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@OneToMany(mappedBy = "department", cascade = CascadeType.ALL, fetch = FetchType.LAZY)private List<Employee> employees = new ArrayList<>();// getter和setter
}@Entity
public class Employee {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToOne@JoinColumn(name = "department_id")private Department department;// getter和setter
}
多对多关系
@Entity
public class Student {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(cascade = {CascadeType.PERSIST, CascadeType.MERGE})@JoinTable(name = "student_course",joinColumns = @JoinColumn(name = "student_id"),inverseJoinColumns = @JoinColumn(name = "course_id"))private Set<Course> courses = new HashSet<>();// getter和setter
}@Entity
public class Course {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(mappedBy = "courses")private Set<Student> students = new HashSet<>();// getter和setter
}
基本CRUD操作
创建(Create)
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();try {tx.begin();User user = new User();user.setUsername("张三");user.setEmail("zhangsan@example.com");user.setCreatedAt(new Date());em.persist(user);tx.commit();
} catch (Exception e) {if (tx != null && tx.isActive()) {tx.rollback();}throw e;
} finally {em.close();
}
读取(Read)
EntityManager em = emf.createEntityManager();try {// 根据ID查询User user = em.find(User.class, 1L);// 使用JPQL查询TypedQuery<User> query = em.createQuery("SELECT u FROM User u WHERE u.username LIKE :name", User.class);query.setParameter("name", "张%");List<User> users = query.getResultList();// 使用Criteria API查询CriteriaBuilder cb = em.getCriteriaBuilder();CriteriaQuery<User> cq = cb.createQuery(User.class);Root<User> root = cq.from(User.class);cq.select(root).where(cb.like(root.get("username"), "张%"));List<User> usersByCriteria = em.createQuery(cq).getResultList();// 使用命名查询List<User> usersByNamedQuery = em.createNamedQuery("User.findAll", User.class).getResultList();
} finally {em.close();
}
更新(Update)
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();try {tx.begin();User user = em.find(User.class, 1L);user.setEmail("zhangsan_new@example.com");// 显式更新,通常不需要,因为在事务提交时会自动更新em.merge(user);tx.commit();
} catch (Exception e) {if (tx != null && tx.isActive()) {tx.rollback();}throw e;
} finally {em.close();
}
删除(Delete)
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();try {tx.begin();User user = em.find(User.class, 1L);em.remove(user);tx.commit();
} catch (Exception e) {if (tx != null && tx.isActive()) {tx.rollback();}throw e;
} finally {em.close();
}
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
JPA详解(第二部分)
查询操作
JPA提供了多种查询方式,包括JPQL、Criteria API、命名查询和原生SQL查询。
JPQL查询
JPQL(Java Persistence Query Language)是一种类似SQL但面向对象的查询语言:
// 基本查询
TypedQuery<User> query = em.createQuery("SELECT u FROM User u", User.class);
List<User> users = query.getResultList();// 条件查询
TypedQuery<User> query = em.createQuery("SELECT u FROM User u WHERE u.username = :name", User.class);
query.setParameter("name", "张三");
User user = query.getSingleResult();// 排序
TypedQuery<User> query = em.createQuery("SELECT u FROM User u ORDER BY u.createdAt DESC", User.class);
List<User> users = query.getResultList();// 分页
TypedQuery<User> query = em.createQuery("SELECT u FROM User u", User.class);
query.setFirstResult(0); // 起始位置
query.setMaxResults(10); // 最大结果数
List<User> users = query.getResultList();// 聚合函数
TypedQuery<Long> query = em.createQuery("SELECT COUNT(u) FROM User u", Long.class);
Long count = query.getSingleResult();// 连接查询
TypedQuery<User> query = em.createQuery("SELECT u FROM User u JOIN u.orders o WHERE o.amount > :amount", User.class);
query.setParameter("amount", 100.0);
List<User> users = query.getResultList();// 分组查询
TypedQuery<Object[]> query = em.createQuery("SELECT u.status, COUNT(u) FROM User u GROUP BY u.status", Object[].class);
List<Object[]> results = query.getResultList();
Criteria API查询
Criteria API提供了类型安全的查询方式:
// 基本查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> root = cq.from(User.class);
cq.select(root);
List<User> users = em.createQuery(cq).getResultList();// 条件查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> root = cq.from(User.class);
cq.select(root).where(cb.equal(root.get("username"), "张三"));
User user = em.createQuery(cq).getSingleResult();// 多条件查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> root = cq.from(User.class);
Predicate usernamePredicate = cb.like(root.get("username"), "张%");
Predicate emailPredicate = cb.equal(root.get("email"), "zhangsan@example.com");
cq.select(root).where(cb.and(usernamePredicate, emailPredicate));
List<User> users = em.createQuery(cq).getResultList();// 排序
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> root = cq.from(User.class);
cq.select(root).orderBy(cb.desc(root.get("createdAt")));
List<User> users = em.createQuery(cq).getResultList();// 连接查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> root = cq.from(User.class);
Join<User, Order> orderJoin = root.join("orders");
cq.select(root).where(cb.gt(orderJoin.get("amount"), 100.0));
List<User> users = em.createQuery(cq).getResultList();// 分组查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Object[]> cq = cb.createQuery(Object[].class);
Root<User> root = cq.from(User.class);
cq.multiselect(root.get("status"), cb.count(root));
cq.groupBy(root.get("status"));
List<Object[]> results = em.createQuery(cq).getResultList();
命名查询
命名查询可以在实体类上定义:
@Entity
@Table(name = "users")
@NamedQueries({@NamedQuery(name = "User.findAll", query = "SELECT u FROM User u"),@NamedQuery(name = "User.findByUsername", query = "SELECT u FROM User u WHERE u.username = :username"),@NamedQuery(name = "User.countByStatus", query = "SELECT COUNT(u) FROM User u WHERE u.status = :status")
})
public class User {// 属性和方法
}
使用命名查询:
// 查询所有用户
List<User> users = em.createNamedQuery("User.findAll", User.class).getResultList();// 根据用户名查询
TypedQuery<User> query = em.createNamedQuery("User.findByUsername", User.class);
query.setParameter("username", "张三");
User user = query.getSingleResult();// 统计特定状态的用户数
TypedQuery<Long> query = em.createNamedQuery("User.countByStatus", Long.class);
query.setParameter("status", UserStatus.ACTIVE);
Long count = query.getSingleResult();
原生SQL查询
JPA也支持原生SQL查询:
// 基本SQL查询
Query query = em.createNativeQuery("SELECT * FROM users", User.class);
List<User> users = query.getResultList();// 带参数的SQL查询
Query query = em.createNativeQuery("SELECT * FROM users WHERE username = ?", User.class);
query.setParameter(1, "张三");
User user = (User) query.getSingleResult();// 复杂SQL查询
String sql = "SELECT u.*, COUNT(o.id) as order_count " +"FROM users u LEFT JOIN orders o ON u.id = o.user_id " +"GROUP BY u.id";
Query query = em.createNativeQuery(sql);
List<Object[]> results = query.getResultList();
Spring Data JPA
Spring Data JPA是Spring框架的一部分,它在JPA的基础上提供了更高级的抽象,简化了数据访问层的开发。
基本用法
首先,定义一个继承自JpaRepository的接口:
public interface UserRepository extends JpaRepository<User, Long> {// 自定义查询方法
}
这样就可以使用UserRepository进行基本的CRUD操作:
@Service
public class UserService {private final UserRepository userRepository;@Autowiredpublic UserService(UserRepository userRepository) {this.userRepository = userRepository;}public User createUser(User user) {return userRepository.save(user);}public Optional<User> getUserById(Long id) {return userRepository.findById(id);}public List<User> getAllUsers() {return userRepository.findAll();}public void deleteUser(Long id) {userRepository.deleteById(id);}
}
方法命名查询
Spring Data JPA支持通过方法名自动生成查询:
public interface UserRepository extends JpaRepository<User, Long> {// 根据用户名查询User findByUsername(String username);// 根据邮箱查询Optional<User> findByEmail(String email);// 根据用户名模糊查询List<User> findByUsernameLike(String username);// 根据创建时间范围查询List<User> findByCreatedAtBetween(Date start, Date end);// 根据状态查询并按创建时间排序List<User> findByStatusOrderByCreatedAtDesc(UserStatus status);// 统计特定状态的用户数long countByStatus(UserStatus status);// 检查用户名是否存在boolean existsByUsername(String username);// 删除指定邮箱的用户void deleteByEmail(String email);
}
自定义查询
可以使用@Query注解自定义查询:
public interface UserRepository extends JpaRepository<User, Long> {// 使用JPQL@Query("SELECT u FROM User u WHERE u.username LIKE %:keyword% OR u.email LIKE %:keyword%")List<User> searchUsers(@Param("keyword") String keyword);// 使用原生SQL@Query(value = "SELECT * FROM users WHERE YEAR(created_at) = :year", nativeQuery = true)List<User> findByYear(@Param("year") int year);// 更新查询@Modifying@Transactional@Query("UPDATE User u SET u.status = :status WHERE u.lastLoginDate < :date")int updateInactiveUsers(@Param("status") UserStatus status, @Param("date") Date date);// 命名原生查询@Query(name = "User.findByStatus")List<User> findByStatus(@Param("status") UserStatus status);
}
分页和排序
Spring Data JPA提供了分页和排序功能:
@Service
public class UserService {private final UserRepository userRepository;@Autowiredpublic UserService(UserRepository userRepository) {this.userRepository = userRepository;}// 分页查询public Page<User> getUsersByPage(int page, int size) {return userRepository.findAll(PageRequest.of(page, size));}// 排序查询public List<User> getUsersSortedByUsername() {return userRepository.findAll(Sort.by("username"));}// 分页和排序组合public Page<User> getUsersByPageSorted(int page, int size) {return userRepository.findAll(PageRequest.of(page, size, Sort.by("createdAt").descending()));}// 条件分页查询public Page<User> getUsersByStatus(UserStatus status, int page, int size) {return userRepository.findByStatus(status, PageRequest.of(page, size));}
}
JPA的优缺点
优点
- 标准化:作为Java EE标准,JPA提供了统一的API,减少了对特定ORM实现的依赖
- 可移植性:可以在不同的JPA实现之间切换,如Hibernate、EclipseLink等
- 面向对象:完全符合面向对象编程思想,无需直接处理SQL
- 生产力:特别是与Spring Data JPA结合,可以大大提高开发效率
- 类型安全:通过Criteria API提供类型安全的查询
- 丰富的映射能力:支持复杂的对象关系映射
缺点
- 性能开销:在某些场景下,自动生成的SQL可能不是最优的
- 学习曲线:完全掌握JPA需要一定的学习成本
- 复杂查询支持有限:对于非常复杂的查询,可能需要使用原生SQL
- 调试困难:当出现问题时,定位和解决比直接使用SQL更困难
适用场景
JPA特别适合以下场景:
- 标准化项目:需要遵循Java EE标准的项目
- 领域驱动设计(DDD)项目:注重领域模型和业务规则
- 需要ORM框架但又希望避免厂商锁定的项目:通过JPA可以在不同ORM实现之间切换
- 与Spring Boot结合的项目:可以利用Spring Data JPA简化开发
- 快速开发项目:需要快速交付的项目
Spring Data JPA与JPA的区别
Spring Data JPA是在JPA基础上的进一步抽象和简化:
- JPA:是Java持久化的标准规范,定义了基本的ORM接口和功能
- Spring Data JPA:是Spring框架的一部分,在JPA的基础上提供了更高级的抽象和功能
主要区别:
- 接口层次:Spring Data JPA提供了Repository接口体系,简化了DAO层的开发
- 方法命名查询:Spring Data JPA支持通过方法名自动生成查询
- 分页和排序:Spring Data JPA提供了内置的分页和排序功能
- 查询方法:Spring Data JPA提供了更多便捷的查询方法
- 集成度:Spring Data JPA与Spring生态系统深度集成
在下一部分,我们将对Hibernate、MyBatis和JPA进行全面的技术选型对比,帮助开发者根据项目需求做出最合适的选择。
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
技术选型对比
在选择合适的持久层技术时,需要考虑多个因素,如项目需求、团队技能、性能要求等。下面我们将从多个维度对Hibernate、MyBatis和JPA进行对比,帮助开发者做出明智的技术选择。
功能特性对比
| 特性 | Hibernate | MyBatis | JPA |
|---|---|---|---|
| ORM完整性 | 完全的ORM框架 | 半自动ORM框架 | ORM规范,具体实现依赖于提供商 |
| SQL控制 | 自动生成,控制力弱 | 完全手动,控制力强 | 自动生成,但可以使用原生SQL |
| 学习曲线 | 陡峭 | 平缓 | 中等 |
| 配置复杂度 | 较高 | 中等 | 中等(取决于实现) |
| 对象关系映射 | 强大 | 基本 | 强大 |
| 缓存机制 | 一级、二级缓存 | 一级、二级缓存 | 依赖于实现 |
| 延迟加载 | 支持 | 支持 | 支持 |
| 批量操作 | 支持 | 支持 | 支持 |
| 数据库无关性 | 高 | 低 | 高 |
| 与Spring集成 | 良好 | 良好 | 优秀(Spring Data JPA) |
性能对比
性能是选择持久层技术时的重要考量因素,但性能往往与具体的使用场景和优化方式有关:
Hibernate性能特点
-
优势:
- 缓存机制可以减少数据库访问
- 批量操作优化
- 延迟加载减少不必要的查询
-
劣势:
- 自动生成的SQL可能不是最优的
- 复杂映射可能导致性能开销
- 初始化加载时间较长
MyBatis性能特点
-
优势:
- 直接控制SQL,可以编写高效查询
- 轻量级,启动快
- 可以针对特定数据库优化SQL
-
劣势:
- 缺乏自动化的性能优化
- 手动编写SQL可能存在效率问题
- 缓存机制相对简单
JPA性能特点
-
优势:
- 取决于具体实现(如使用Hibernate实现)
- Spring Data JPA提供了性能优化选项
- 支持批处理和缓存
-
劣势:
- 自动生成的SQL可能不是最优的
- 抽象层可能带来额外开销
- 性能调优选项可能受限
适用场景对比
Hibernate适用场景
- 领域驱动设计(DDD)项目
- CRUD操作为主的应用
- 数据库无关的应用
- 快速开发项目
- 对象关系复杂的项目
MyBatis适用场景
- 需要优化SQL的项目
- 复杂查询为主的应用
- 与已有数据库集成的项目
- DBA团队参与的项目
- 对SQL控制要求高的项目
JPA适用场景
- 标准化项目
- 领域驱动设计(DDD)项目
- 需要ORM框架但又希望避免厂商锁定的项目
- 与Spring Boot结合的项目
- 快速开发项目
开发效率对比
Hibernate开发效率
-
优势:
- 自动生成SQL,减少代码量
- 自动创建和更新表结构
- 丰富的映射功能减少手动编码
-
劣势:
- 配置复杂
- 学习曲线陡峭
- 调试困难
MyBatis开发效率
-
优势:
- 概念简单,易于上手
- SQL直观,便于调试
- 与已有数据库结构兼容性好
-
劣势:
- 需要手动编写SQL和映射
- 对象关系映射需要手动处理
- 表结构变更需要手动更新SQL
JPA开发效率
-
优势:
- 标准化API,易于学习
- 自动生成SQL,减少代码量
- Spring Data JPA进一步简化开发
-
劣势:
- 配置可能复杂
- 复杂查询可能需要额外学习JPQL
- 性能调优可能受限
维护性对比
Hibernate维护性
-
优势:
- 对象模型变更自动反映到数据库
- 减少SQL维护工作
- 统一的API简化代码维护
-
劣势:
- 自动生成的SQL难以审计
- 性能问题难以定位
- 版本升级可能带来兼容性问题
MyBatis维护性
-
优势:
- SQL独立管理,便于优化
- 直观的SQL便于审计
- 简单的架构易于理解和维护
-
劣势:
- SQL与Java代码分离,可能导致不一致
- 对象模型变更需要手动更新SQL
- 大量SQL可能导致维护困难
JPA维护性
-
优势:
- 标准化API,减少厂商锁定
- 对象模型变更自动反映到数据库
- Spring Data JPA简化代码维护
-
劣势:
- 不同JPA实现可能有差异
- 自动生成的SQL难以审计
- 性能问题难以定位
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
最佳实践与应用场景
技术选型决策流程
选择合适的持久层技术是项目成功的关键因素之一。以下是一个建议的决策流程:
-
评估项目需求:
- 是否需要复杂的对象关系映射?
- 是否有大量复杂查询?
- 是否需要数据库无关性?
- 是否需要快速开发?
-
评估团队技能:
- 团队是否熟悉特定技术?
- 学习新技术的成本是否可接受?
- 是否有DBA参与项目?
-
评估性能要求:
- 系统的性能要求是什么?
- 是否需要精确控制SQL?
- 数据量和并发量如何?
-
评估长期维护:
- 谁将负责长期维护?
- 代码可读性和可维护性的重要程度?
- 是否需要考虑未来的扩展性?
-
做出决策:
- 根据以上因素权衡利弊
- 可能的话,进行小规模原型验证
- 记录决策理由,便于未来参考
典型应用场景分析
场景一:企业内部管理系统
特点:
- CRUD操作为主
- 业务逻辑复杂
- 数据量适中
- 性能要求不苛刻
推荐技术:Hibernate 或 Spring Data JPA
理由:
- 自动化程度高,减少代码量
- 面向对象的方式符合业务建模需求
- 快速开发和迭代
- 维护成本较低
最佳实践:
- 使用领域驱动设计(DDD)方法
- 合理设计实体关系
- 适当使用缓存提高性能
- 对复杂查询使用原生SQL
场景二:高性能交易系统
特点:
- 高并发
- 性能要求苛刻
- 复杂查询多
- 可能需要特定数据库优化
推荐技术:MyBatis
理由:
- 完全控制SQL,便于优化
- 轻量级,性能开销小
- 可以针对特定数据库优化
- 直观的SQL便于调试和优化
最佳实践:
- 精心设计和优化SQL
- 使用批处理提高性能
- 合理配置连接池
- 实施分库分表策略
- 利用数据库特定功能
场景三:微服务架构
特点:
- 服务独立部署
- 不同服务可能使用不同数据库
- 需要快速开发和迭代
- 团队自治
推荐技术:Spring Data JPA + 特定场景使用MyBatis
理由:
- Spring Data JPA提供统一的数据访问层
- 标准化API便于团队协作
- 可以在性能关键的服务中使用MyBatis
- 与Spring Boot生态系统无缝集成
最佳实践:
- 每个微服务使用独立的数据库
- 合理设计领域模型
- 对性能关键路径使用优化的查询
- 实施CQRS模式(命令查询责任分离)
场景四:遗留系统集成
特点:
- 需要与现有数据库结构集成
- 数据库结构复杂且不规范
- 可能需要调用存储过程
- 不希望改变现有数据库
推荐技术:MyBatis
理由:
- 灵活适应现有数据库结构
- 可以直接调用存储过程
- 不强制要求对象关系映射
- SQL直接编写,便于与DBA协作
最佳实践:
- 使用XML配置管理复杂SQL
- 创建合理的DTO对象
- 实施仓库模式隔离数据访问细节
- 考虑使用适配器模式封装遗留系统
混合使用策略
在某些项目中,混合使用多种持久层技术可能是最佳选择:
混合使用Hibernate和MyBatis
适用场景:
- 大部分是简单CRUD操作,但有少量复杂查询
- 需要自动化ORM,但也需要优化特定查询
实施策略:
- 使用Hibernate处理实体映射和基本CRUD
- 使用MyBatis处理复杂查询和批量操作
- 通过Spring事务管理器统一事务
示例代码:
@Service
@Transactional
public class UserService {private final SessionFactory sessionFactory;private final SqlSession sqlSession;@Autowiredpublic UserService(SessionFactory sessionFactory, SqlSession sqlSession) {this.sessionFactory = sessionFactory;this.sqlSession = sqlSession;}// 使用Hibernate进行简单CRUDpublic User createUser(User user) {Session session = sessionFactory.getCurrentSession();session.save(user);return user;}// 使用MyBatis进行复杂查询public List<UserStatistics> getUserStatistics() {UserMapper mapper = sqlSession.getMapper(UserMapper.class);return mapper.getUserStatistics();}
}
混合使用JPA和原生SQL
适用场景:
- 希望使用JPA的标准化API
- 有些查询需要特定优化
实施策略:
- 使用JPA处理大部分数据访问
- 对性能关键的查询使用
@Query注解和原生SQL - 利用Spring Data JPA的扩展点
示例代码:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {// 使用JPA方法命名查询List<User> findByStatus(UserStatus status);// 使用JPQL@Query("SELECT u FROM User u WHERE u.lastLoginDate > :date")List<User> findRecentlyActiveUsers(@Param("date") Date date);// 使用原生SQL@Query(value = "SELECT u.*, COUNT(o.id) as order_count " +"FROM users u LEFT JOIN orders o ON u.id = o.user_id " +"GROUP BY u.id HAVING COUNT(o.id) > :minOrders", nativeQuery = true)List<Object[]> findUserOrderStatistics(@Param("minOrders") int minOrders);
}
性能优化策略
无论选择哪种持久层技术,性能优化都是必不可少的。以下是一些通用的性能优化策略:
Hibernate性能优化
-
合理使用缓存:
- 配置二级缓存和查询缓存
- 为频繁访问但很少修改的数据启用缓存
-
优化加载策略:
- 使用延迟加载避免不必要的查询
- 对需要立即加载的关联使用连接抓取(join fetch)
-
批量操作优化:
- 使用批量插入、更新和删除
- 配置适当的批处理大小
-
使用投影查询:
- 只查询需要的字段,避免加载整个实体
- 使用构造器表达式创建DTO
-
优化HQL/JPQL:
- 使用命名参数而非位置参数
- 避免使用
SELECT * - 使用分页查询处理大结果集
MyBatis性能优化
-
SQL优化:
- 只查询需要的列
- 使用适当的索引
- 避免复杂连接查询
-
使用缓存:
- 配置二级缓存
- 为只读查询启用缓存
-
批量操作:
- 使用批量插入和更新
- 使用
<foreach>标签优化IN查询
-
结果映射优化:
- 使用延迟加载
- 只映射需要的字段
-
动态SQL优化:
- 避免不必要的条件判断
- 使用
<where>和<trim>标签简化SQL
JPA/Spring Data JPA性能优化
-
查询优化:
- 使用投影接口减少数据传输
- 使用分页和排序减少数据量
- 对复杂查询使用原生SQL
-
N+1问题处理:
- 使用连接抓取(join fetch)
- 使用EntityGraph指定加载路径
-
批量操作:
- 使用
saveAll()和deleteAllInBatch() - 配置批处理大小
- 使用
-
缓存使用:
- 配置二级缓存
- 使用Spring缓存抽象
-
事务优化:
- 使用只读事务优化查询
- 适当设置事务隔离级别
未来发展趋势
持久层技术不断发展,以下是一些值得关注的趋势:
-
响应式持久层:
- Spring Data R2DBC
- Hibernate Reactive
- 支持非阻塞数据库访问
-
云原生数据访问:
- 适应容器化和微服务架构
- 支持分布式事务
- 与云服务集成
-
多模型数据库支持:
- 支持关系型和NoSQL数据库
- 统一的数据访问API
- Spring Data已经在这方面取得进展
-
更智能的ORM:
- 自动性能优化
- 智能缓存策略
- 更好的开发者体验
-
与现代Java特性集成:
- 记录类(Record)支持
- 模式匹配
- 密封类(Sealed Classes)
Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
总结与结论
在本系列文章中,我们深入探讨了Java持久层技术的三大主流框架:Hibernate、MyBatis和JPA。通过详细分析它们的特性、优缺点和适用场景,我们可以得出以下结论。
核心差异总结
-
设计理念:
- Hibernate:完全面向对象,自动化程度高,专注于领域模型
- MyBatis:注重SQL控制,半自动化,专注于数据库操作
- JPA:标准化的ORM规范,提供统一接口,实现可替换
-
开发模式:
- Hibernate:领域驱动设计,对象优先
- MyBatis:数据库驱动设计,SQL优先
- JPA:标准化设计,可适应不同风格
-
技术特点:
- Hibernate:功能丰富,抽象层次高,学习曲线陡
- MyBatis:简单直观,灵活性高,学习曲线平缓
- JPA:标准化API,可移植性好,学习曲线适中
选型建议
何时选择Hibernate
- 项目需要完全面向对象的设计
- 团队熟悉领域驱动设计
- 需要快速开发和迭代
- 数据库无关性要求高
- 对象关系复杂
何时选择MyBatis
- 需要精确控制SQL
- 项目包含大量复杂查询
- 性能要求高
- 与已有数据库集成
- 团队包含DBA或SQL专家
何时选择JPA
- 需要标准化的持久层API
- 希望避免厂商锁定
- 使用Spring Boot生态系统
- 需要平衡开发效率和灵活性
- 团队熟悉JPA规范
何时混合使用
- 项目同时具有简单CRUD和复杂查询需求
- 不同模块有不同的性能和开发效率要求
- 团队技能多样化
- 需要在特定场景中优化性能
实际应用中的考量因素
在实际项目中,技术选型不仅仅是技术因素,还需要考虑以下方面:
-
团队因素:
- 团队的技术背景和经验
- 学习新技术的意愿和能力
- 团队规模和组织结构
-
项目因素:
- 项目时间线和交付压力
- 长期维护需求
- 与现有系统的集成需求
-
业务因素:
- 业务复杂度和变化频率
- 性能和可扩展性要求
- 数据一致性和事务要求
-
组织因素:
- 技术标准和规范
- 组织文化和决策流程
- 长期技术战略
持久层技术的未来展望
随着Java生态系统和数据库技术的不断发展,持久层技术也在不断演进:
-
响应式编程模型:
- 非阻塞数据访问将成为主流
- 响应式持久层框架将获得更广泛应用
-
云原生适应性:
- 持久层技术将更好地支持云环境
- 分布式数据访问将成为标准功能
-
多模型数据支持:
- 单一框架支持关系型和NoSQL数据库
- 统一的数据访问API跨不同数据存储
-
低代码/无代码趋势:
- 更多自动化和代码生成功能
- 图形化配置和管理工具
-
AI辅助开发:
- 智能查询优化
- 自动化性能调优
- 代码建议和生成
最终思考
选择合适的持久层技术没有放之四海而皆准的答案,关键是根据具体项目需求、团队能力和长期目标做出明智决策。在某些情况下,混合使用多种技术可能是最佳选择。
无论选择哪种技术,都应该遵循以下原则:
- 关注点分离:将业务逻辑与数据访问逻辑分离
- 适当抽象:创建合适的抽象层,隐藏持久化细节
- 持续优化:根据实际性能数据进行优化
- 保持简单:避免过度工程化,选择最简单的解决方案
最后,技术选型是一个权衡的过程,没有完美的解决方案,只有最适合当前需求和约束的选择。
参考资料
- Hibernate官方文档:https://hibernate.org/orm/documentation/
- MyBatis官方文档:https://mybatis.org/mybatis-3/
- JPA规范:https://jakarta.ee/specifications/persistence/
- Spring Data JPA文档:https://spring.io/projects/spring-data-jpa
- Java Persistence with Hibernate (Christian Bauer, Gavin King)
- MyBatis in Action (Clinton Begin)
- Pro JPA 2 in Java EE 8 (Mike Keith, Merrick Schincariol)
- Spring Boot实战(Craig Walls)
- 《Java持久化技术》(孙卫琴)
- 《深入理解Java虚拟机》(周志明)
相关文章:

Java持久层技术对比:Hibernate、MyBatis与JPA的选择与应用
目录 简介持久层技术概述Hibernate详解MyBatis详解JPA详解技术选型对比最佳实践与应用场景性能优化策略未来发展趋势总结与建议 简介 在Java企业级应用开发中,持久层(Persistence Layer)作为连接业务逻辑与数据存储的桥梁,其技…...

Spring Boot实现接口时间戳鉴权
Spring Boot实现接口时间戳鉴权,签名(sign)和时间戳(ts)放入请求头(Header)。 一、请求头参数设计 参数名类型说明tsLong13位时间戳(Unix毫秒值),必填&…...

视觉SLAM基础补盲
3D Gaussian Splatting for Real-Time Radiance Field Rendering SOTA方法3DGS contribution传统重建基于点的渲染NeRF 基础知识补盲光栅化SFM三角化极线几何标准的双目立体视觉立体匹配理论与方法立体匹配的基本流程李群和李代数 李群和李代数的映射李代数的求导李代数解决求导…...

STM32外设问题总结
SPI: ①.软件SPI和硬件SPI有什么不一样? 答:软件SPI需要在代码中进行配置相关代码,如配置引脚等,而硬件SPI的话是它已经在硬件上已经配置好SPI了,已经可以直接实现,所以可以直接使…...

Vue-3-前端框架Vue基础入门之VSCode开发环境配置和Tomcat部署Vue项目
文章目录 1 安装配置VSCode1.1 安装中文语言插件1.2 主题颜色1.3 禁用自动更新1.4 开启代码提示设置1.5 安装open in browser插件2 安装配置nodejs2.1 配置环境变量2.2 npm与maven的区别2.3 使用npm避坑3 创建Vue项目3.1 两种创建方式3.2 package.json3.3 安装新的依赖3.4 运行…...

动态IP与静态IP:数字世界的“变脸术”与“身份证”
目录 动态IP:互联网的“游牧民族” 静态IP:数字世界的“常驻公民” 动态VS静态:场景驱动的选择逻辑 未来演进:IP地址的“液态化”趋势 选型指南:没有最好,只有最合适 在互联网的海洋里,每个…...
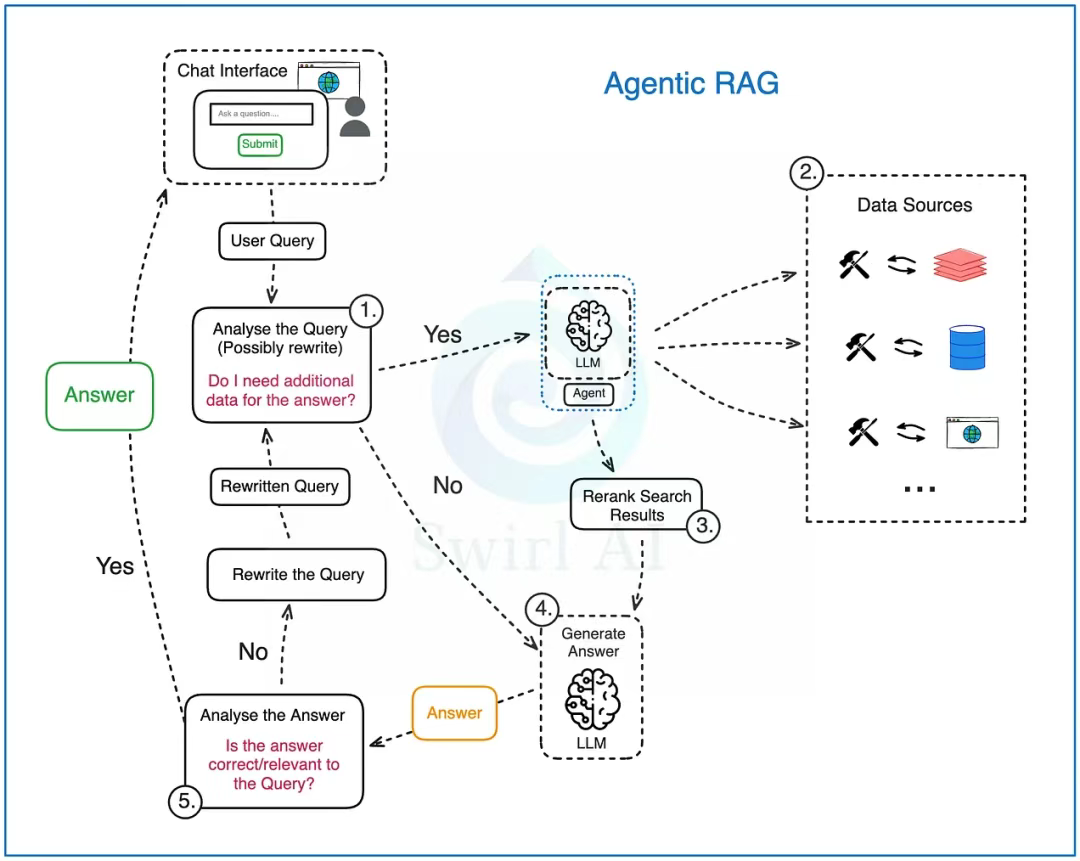
“一代更比一代强”:现代 RAG 架构的演进之路
编者按: 我们今天为大家带来的文章,作者的观点是:RAG 技术的演进是一个从简单到复杂、从 Naive 到 Agentic 的系统性优化过程,每一次优化都是在试图解决无数企业落地大语言模型应用时出现的痛点问题。 文章首先剖析 Naive RAG 的基…...
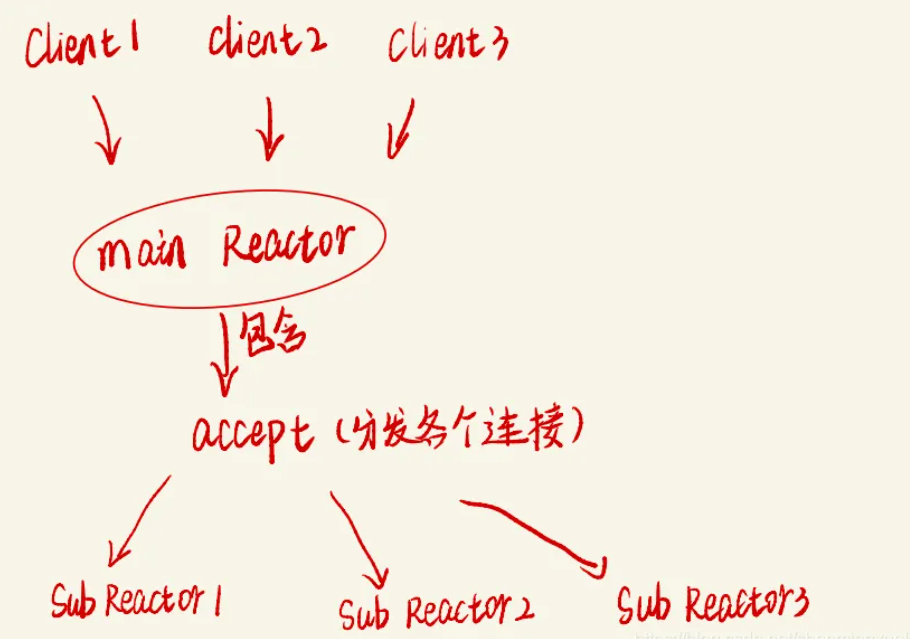
My图床项目
引言: 在海量文件存储中尤其是小文件我们通常会用上fastdfs对数据进行高效存储,在现实生产中fastdfs通常用于图片,文档,音频等中小文件。 一.项目中用到的基础组件(Base) 1.网络库(muduo) 我们就以muduo网络库为例子讲解IO多路复用和reactor网络模型 1.1 IO多路复用 我们可以…...

SpringBoot3项目架构设计与模块解析
一、项目概述 这是一个基于SpringBoot3构建的企业级后台管理系统,从项目结构来看,系统采用了经典的分层架构设计,包含完整的控制器层、服务层、数据访问层和实体层。项目整合了Web开发、数据库访问、权限控制等核心功能模块。 二、项目整体…...

C#文件压缩与解压缩全攻略:使用ZipFile与ZipArchive实现高效操作
C#文件压缩与解压缩全攻略:使用ZipFile与ZipArchive实现高效操作 在.NET 开发中,文件压缩与解压缩是常见的需求。无论是减少存储空间、加速网络传输,还是实现数据备份,System.IO.Compression命名空间都提供了强大的工具。本文将结…...
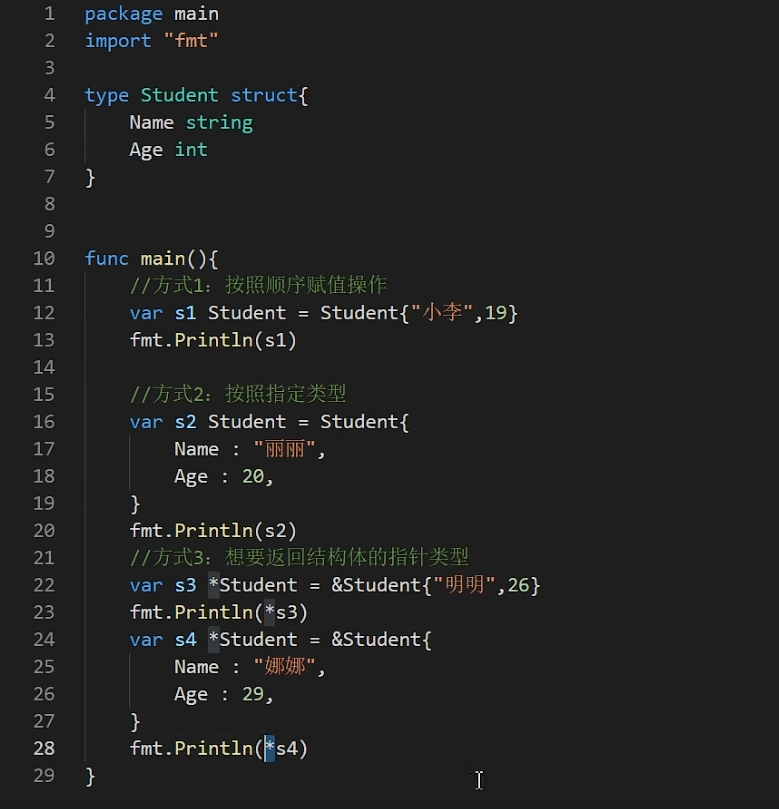
1、Go语言基础中的基础
摘要:马士兵教育的Go语言基础的视频笔记。 第一章:走进Golang 1.1、Go的SDK介绍 1.2、Go的项目基本目录结构 1.3、HelloWorld 1.4、编译 1.5、执行 1.6、一步到位 1.7、执行流程分析 1.8、语法注意事项 (1)源文件以"go&qu…...
)
Go语言基础知识总结(超详细整理)
1. Go语言简介 Go语言(又称Golang)是Google于2009年发布的开源编程语言,具备简洁、高效、并发等特点,适合服务器开发、云计算、大数据等场景。 2. 环境安装与配置 下载地址:https://golang.org/dl/安装后配置环境变量…...

buuctf——web刷题第二页
[网鼎杯 2018]Fakebook和[SWPU2019]Web1没有,共30题 目录 [BSidesCF 2020]Had a bad day [网鼎杯 2020 朱雀组]phpweb [BJDCTF2020]The mystery of ip [BUUCTF 2018]Online Tool [GXYCTF2019]禁止套娃 [GWCTF 2019]我有一个数据库 [CISCN2019 华北赛区 Day2…...

MVC与MVP设计模式对比详解
MVC(Model-View-Controller)和MVP(Model-View-Presenter)是两种广泛使用的分层架构模式,核心目标是解耦业务逻辑、数据和界面,提升代码可维护性和可测试性。以下是它们的对比详解: MVC 模式&…...

内嵌式mqtt server
添加moquette依赖 <dependency><groupId>io.moquette</groupId><artifactId>moquette-broker</artifactId><version>0.17</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>…...
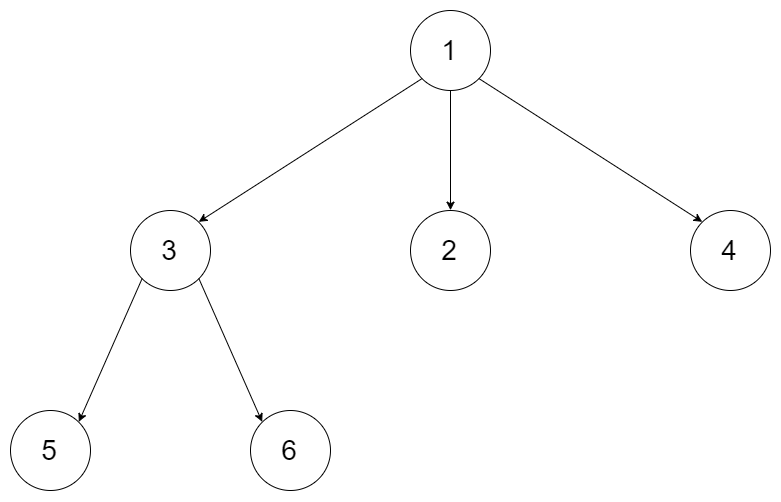
二叉树的遍历总结
144.二叉树的前序遍历(opens new window)145.二叉树的后序遍历(opens new window)94.二叉树的中序遍历 二叉数的先中后序统一遍历法 public static void preOrder(BiTree root){BiTree p root;LinkedList<BiTree> stack new LinkedList<>();while(p ! null ||…...

win32相关(远程线程和远程线程注入)
远程线程和远程线程注入 CreateRemoteThread函数 作用:创建在另一个进程的虚拟地址空间中运行的线程 HANDLE CreateRemoteThread([in] HANDLE hProcess, // 需要在哪个进程中创建线程[in] LPSECURITY_ATTRIBUTES lpThreadAttributes, // 安全…...

【Go语言基础【5】】Go module概述:项目与依赖管理
文章目录 一、Go Module 概述二、Go Module 核心特性1. 项目结构2. 依赖查找机制 三、如何启用 Go Module四、创建 Go Module 项目五、Go Module 关键命令 一、Go Module 概述 Go Module 是 Go 1.11 版本(2018 年 8 月)引入的依赖管理系统,用…...
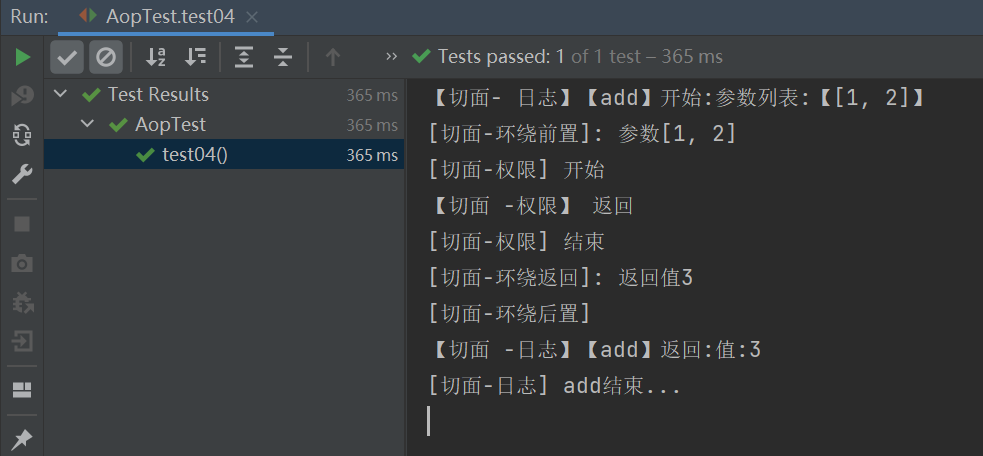
[Spring]-AOP
AOP场景 AOP: Aspect Oriented Programming (面向切面编程) OOP: Object Oriented Programming (面向对象编程) 场景设计 设计: 编写一个计算器接口和实现类,提供加减乘除四则运算 需求: 在加减乘除运算的时候需要记录操作日志(运算前参数、运算后结果)实现方案:…...
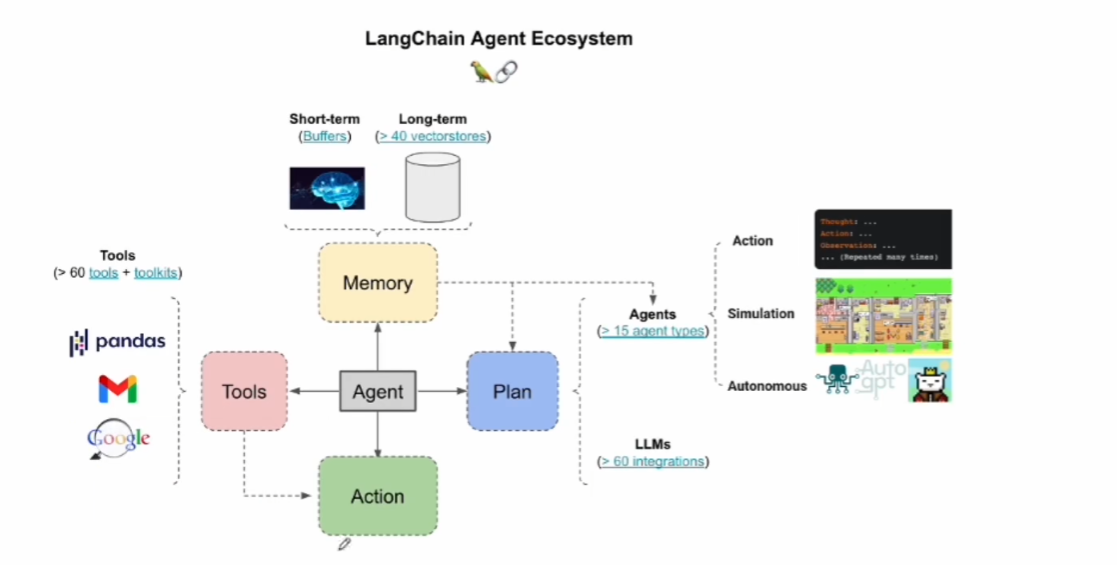
agent 开发
什么是 agent? Agent智能体(又称AI Agent)是一种具备自主感知、决策与行动能力的智能系统,其核心在于模仿人类的认知过程来处理复杂任务。以下是其关键特性和发展现状的综合分析: 一、核心定义与特征 ### 自主决策…...

多系统一键打包docker compose下所有镜像并且使用
本方法适合在已经pull好docker镜像正常使用的机器 将环境迁移到无网络 或者网络不好的机器使用 linux 用法 cd 到 docker-compose.yml 所在目录 ./save_compose_images.sh #!/bin/bash # 拉取镜像并保存为 .tar 文件 docker save $(docker-compose images | awk {print…...

Golang——5、函数详解、time包及日期函数
函数详解、time包及日期函数 1、函数1.1、函数定义1.2、函数参数1.3、函数返回值1.4、函数类型与变量1.5、函数作参数和返回值1.6、匿名函数、函数递归和闭包1.7、defer语句1.8、panic和recover 2、time包以及日期函数2.1、time.Now()获取当前时间2.2、Format方法格式化输出日期…...

【HarmonyOS 5】出行导航开发实践介绍以及详细案例
以下是 HarmonyOS 5 出行导航的核心能力详解(无代码版),聚焦智能交互、多端协同与场景化创新: 一、交互革新:从被动响应到主动服务 意图驱动导航 自然语义理解:用户通过语音指令(如…...
深度学习环境配置指南:基于Anaconda与PyCharm的全流程操作
一、环境搭建前的准备 1. 查看基础环境位置 conda env list 操作说明:通过该命令确认Anaconda默认环境(base)所在磁盘路径(如D盘),后续操作需跳转至该磁盘根目录。 二、创建与激活独立虚拟环境 1. 创…...
--吴恩达)
03 Deep learning神经网络的编程基础 代价函数(Cost function)--吴恩达
深度学习中的损失函数(Cost Function)用于量化模型预测与真实数据的差距,是优化神经网络的核心指标。以下是常见类型及数学表达: 核心原理 逻辑回归通过sigmoid函数将线性预测结果转换为概率: y ^ ( i ) \hat{y}^{(i)}...
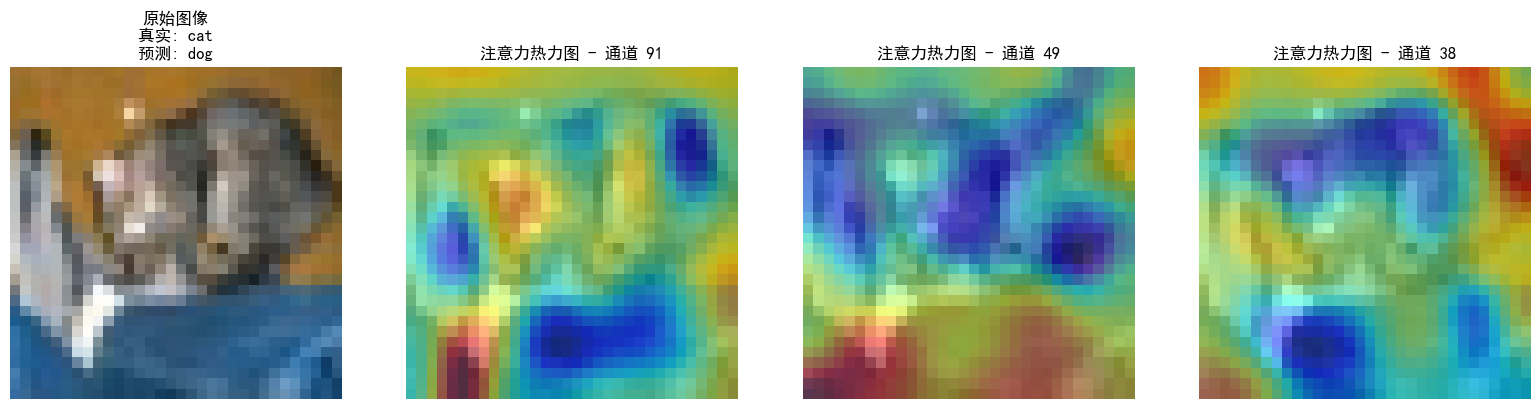
打卡day46
知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后的特征图和热力图 内…...

在SpringBoot中使用AWS SDK实现邮箱验证码服务
1.依赖导入(maven) <dependency><groupId>software.amazon.awssdk</groupId><artifactId>ses</artifactId><version>2.31.46</version></dependency> 2.申请两个key 发件人邮箱需要验证: …...

AndroidR车机TextToSpeech音频焦点异常问题分析
一、引言 文章《Android车机之TextToSpeech》介绍了TextToSpeech的使用,当前较多座舱系统语音服务都接入了原生TextToSpeech接口调用。 我司自研语音TTS服务,也接入了此TTS接口调用,对外提供TextToSpeech能力,播报时由客户端Client自行管理音频焦点,播报前申请音频焦点,…...

ArcGIS Maps SDK for JavaScript:使用图层过滤器只显示FeatureLayer的部分要素
文章目录 引言1 需求场景分析2精确过滤实现方案2.1 基础过滤语法2.2 动态过滤实现 3 模糊查询进阶技巧3.1 LIKE操作符使用3.2 特殊字段处理 4. 性能优化与注意事项4.1 服务端vs客户端过滤4.2 最佳实践建议 5 常见问题解答 引言 在地图应用开发中,图层过滤是常见的需…...

深入理解二叉搜索树:原理到实践
1.二叉搜索树的概念 ⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,或者是具有以下性质的⼆叉树 若它的左树不为空,则左子树上所有节点的值都小于或等于根节点的值。若它的右树不为空,则右子树上所有节点的值都大于或等于根节点的…...