机器学习:集成学习概念和分类、随机森林、Adaboost、GBDT
本文目录:
- 一、集成学习概念
- **核心思想:**
- 二、集成学习分类
- (一)Bagging集成
- (二)Boosting集成
- (三)两种集成方法对比
- 三、随机森林
- (一)构造过程
- (二)代码实现—泰坦尼克号例子
- 四、Adaboost
- (一)核心公式
- (二)主要过程演示
- (三)Adaboost构建过程(例)
- 1. 构建第一个弱学习器
- 2.构建第二个弱学习器
- 3.照着如上步骤,构建好的第三个弱学习器
- 最后,由三个弱学习器组成的强学习器
- (四)代码实现—葡萄酒例子
- 五、GBDT(梯度提升树)
- (一)GBDT算法流程
- (二)GBDT构建流程(例)
- 1.初始化弱学习器(CART树)
- 2.构建第一个cart树
- 3.构建第二个cart树
- 4.构建第三个cart树
- 5.最终的强学习器:
- (三)代码实现—泰坦尼克号例子
一、集成学习概念
集成学习是一种通过结合多个基学习器(弱学习器)的预测结果来提升模型整体性能的机器学习方法。其核心思想是“集思广益”,通过多样性(Diversity)和集体决策降低方差(Variance)或偏差(Bias),从而提高泛化能力。
核心思想:
弱学习器:指性能略优于随机猜测的简单模型(如决策树桩、线性模型);
强学习器:通过组合多个弱学习器构建的高性能模型;
核心目标:减少过拟合(降低方差)或欠拟合(降低偏差)。
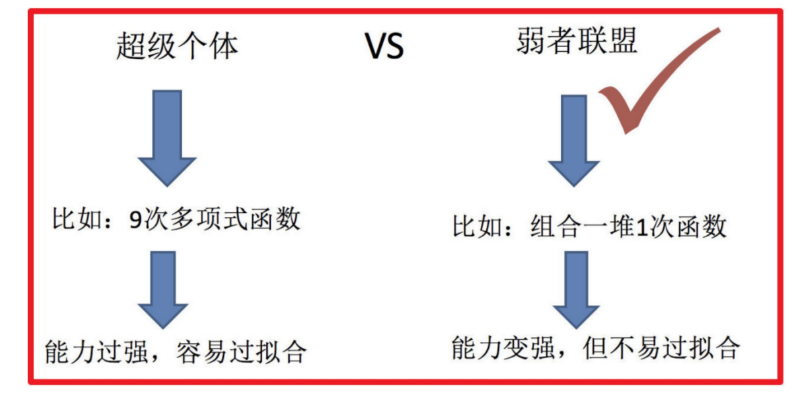
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。
二、集成学习分类
集成学习算法一般分为:bagging和boosting
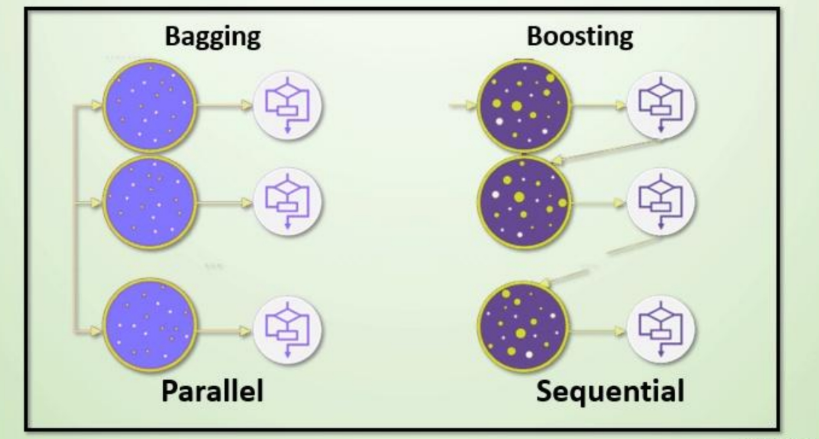
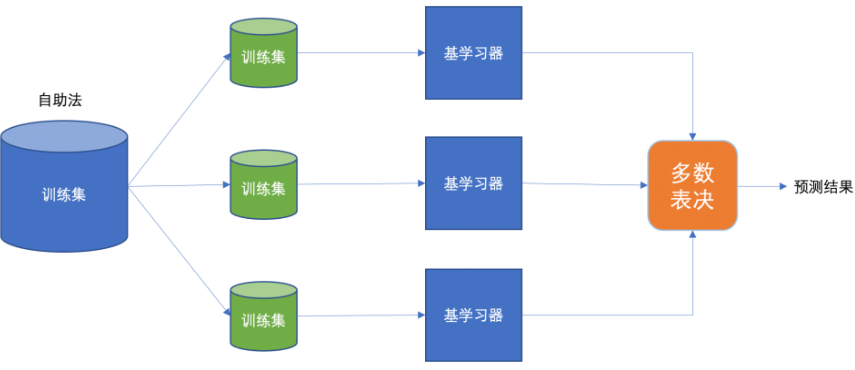
(一)Bagging集成
Bagging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
(二)Boosting集成
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
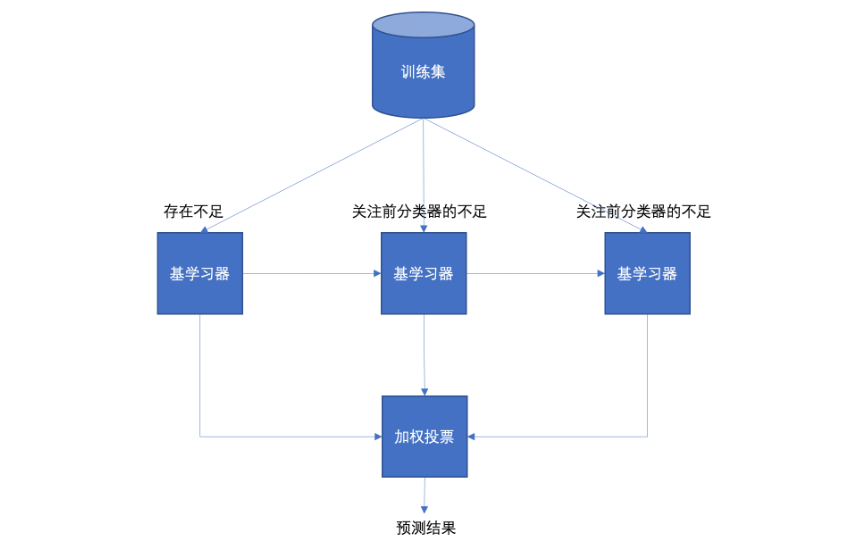
Boosting是一组可将弱学习器升为强学习器算法,这类算法的工作机制类似:
1.先从初始训练集训练出一个基学习器;
2.在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本(增加权重)在后续得到最大的关注;
3.然后基于调整后的样本分布来训练下一个基学习器;
4.如此重复进行,直至基学习器数目达到实现指定的值T为止。
5.再将这T个基学习器进行加权结合得到集成学习器。
简而言之:每新加入一个弱学习器,整体能力就会得到提升

(三)两种集成方法对比

三、随机森林
随机森林是基于 Bagging 思想实现的一种集成学习算法,通过构建多棵决策树并结合它们的预测结果来提高模型的准确性和鲁棒性。它由Leo Breiman在2001年提出,广泛应用于分类和回归任务。
(一)构造过程
- 训练:
(1)有放回的产生训练样本;
(2)随机挑选 n 个特征(n 小于总特征数量)。 - 预测:
(1)分类任务:投票(多数表决);
(2)回归任务:平均预测值。
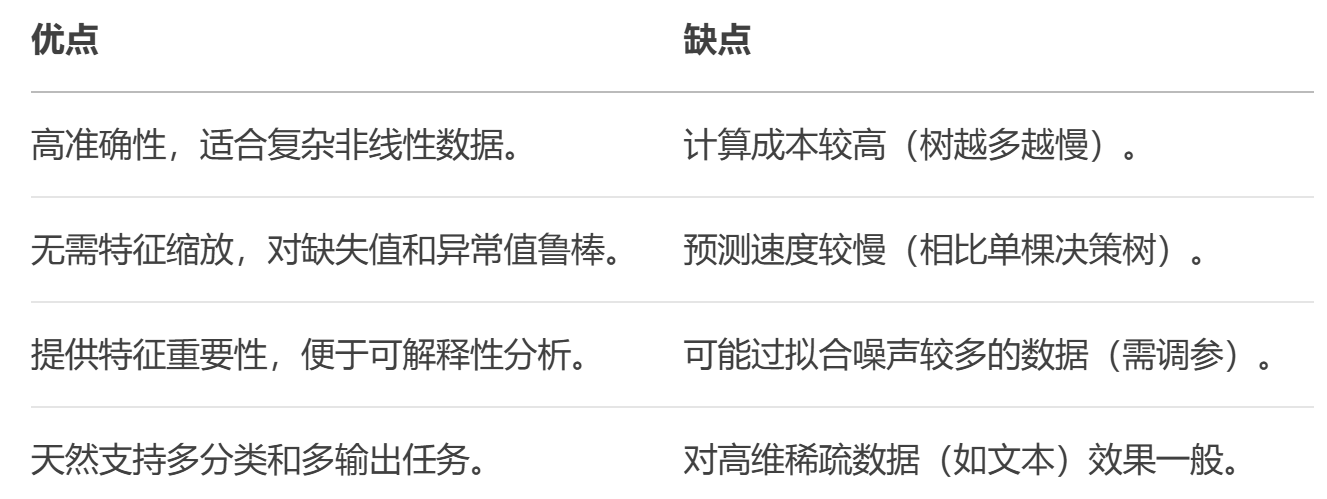
优点与缺点:
(二)代码实现—泰坦尼克号例子
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块从互联网中收集泰坦尼克号数据集
titanic=pd.read_csv("data/泰坦尼克号.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
X = pd.get_dummies(X)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
dtc.score(X_test,y_test)#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(max_depth=6,random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
rfc.score(X_test,y_test)#6.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))# 随机森林做预测
# 1 实例化随机森林
rf = RandomForestClassifier()
# 2 定义超参数的选择列表
param={"n_estimators":[80,100,200], "max_depth": [2,4,6,8,10,12],"random_state":[9]}
# 超参数调优
# 3 使用GridSearchCV进行网格搜索
from sklearn.model_selection import GridSearchCV
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))
四、Adaboost
Adaptive Boosting(自适应提升)是基于 Boosting思想实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。
弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本会加大权重,算法更加关注错误样本。
(一)核心公式
AdaBoost模型公式:
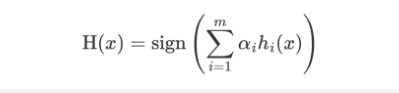
- α 为模型的权重
- m 为弱学习器数量
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost权重更新公式:
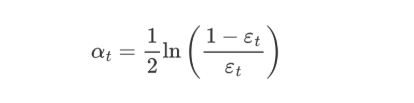
εt 表示第 t 个弱学习器的错误率
AdaBoost 样本权重更新公式:
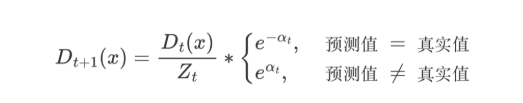
- Zt 为归一化值(所有样本权重的总和)
- Dt(x) 为样本权重
- αt 为模型权重。
(二)主要过程演示
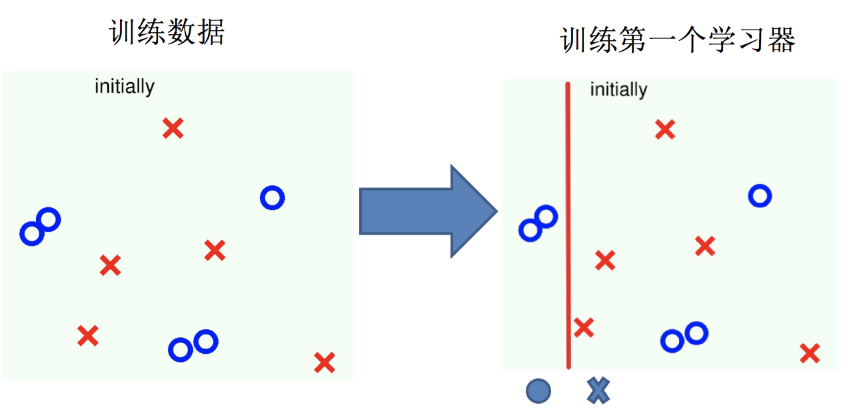
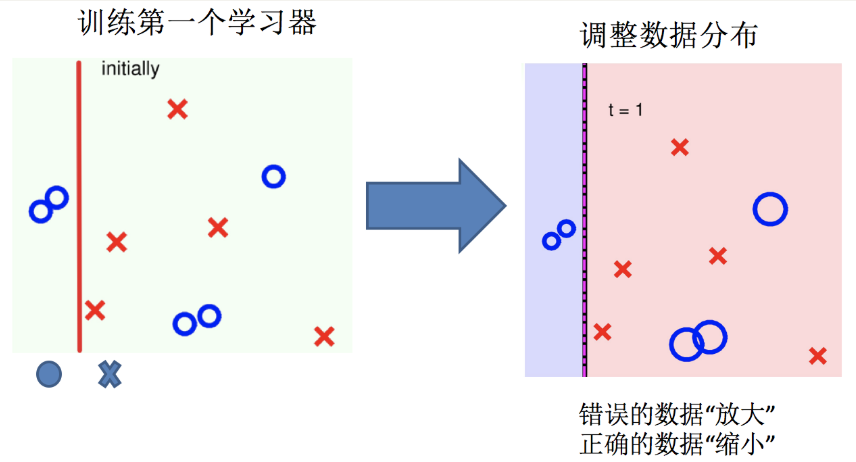
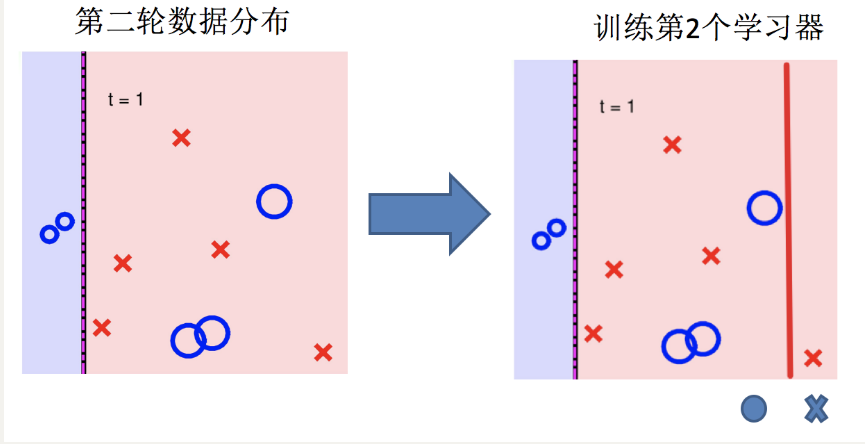
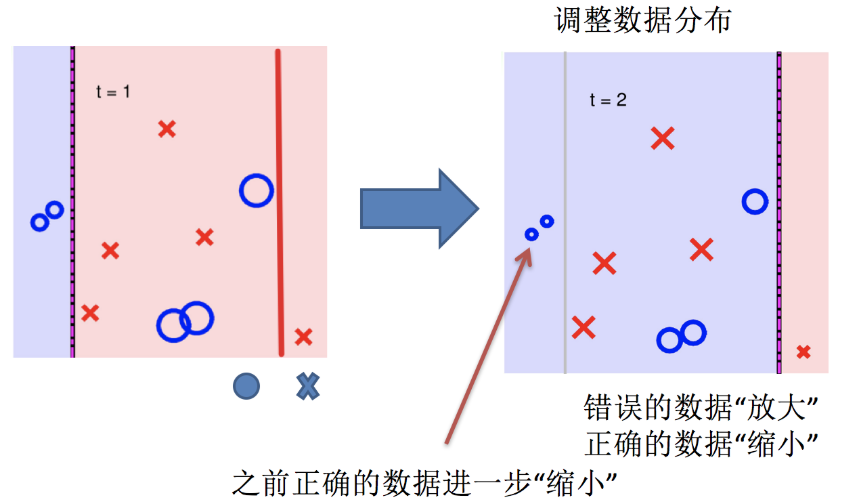
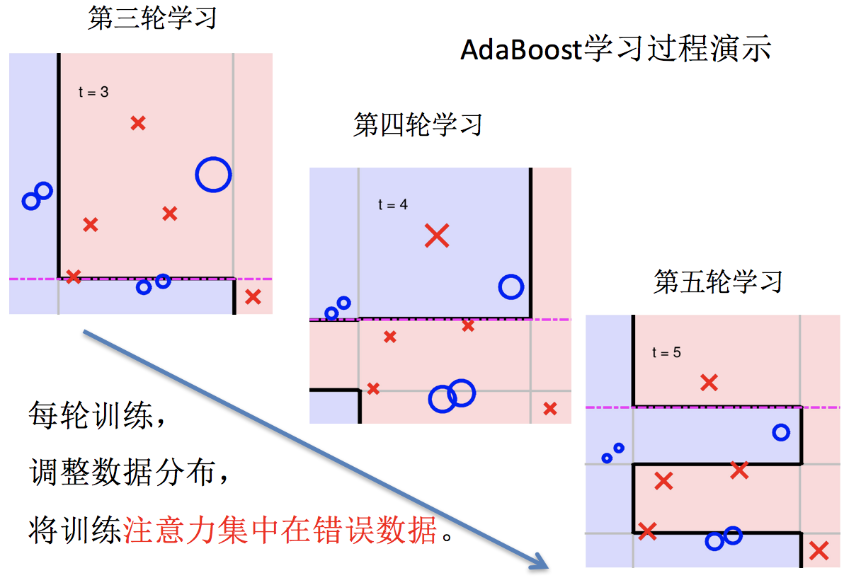
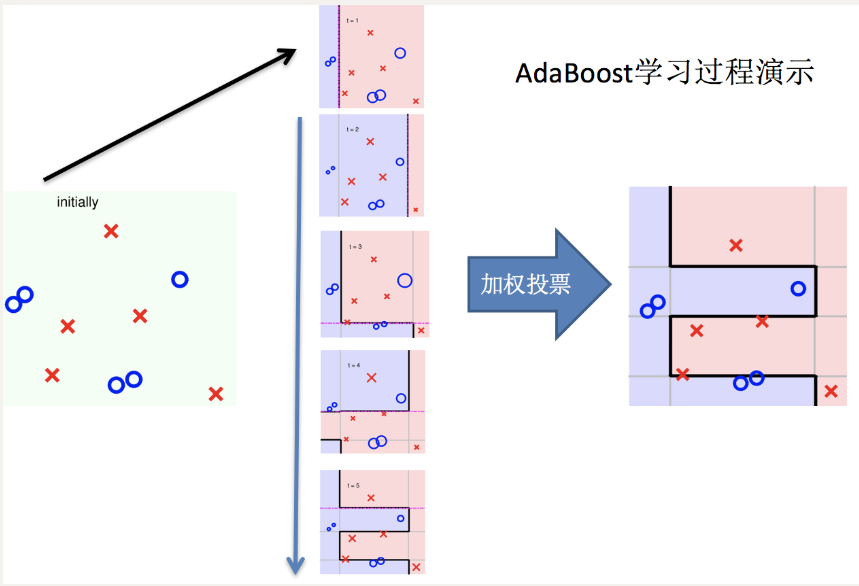
AdaBoost算法的两个核心步骤:
权值调整: AdaBoost算法提高那些被前一轮基分类器错误分类样本的权值,而降低那些被正确分类样本的权值。从而使得那些没有得到正确分类的样本,由于权值的加大而受到后一轮基分类器的更大关注。
基分类器组合: AdaBoost采用加权多数表决的方法。
-
分类误差率较小的弱分类器的权值大,在表决中起较大作用。
-
分类误差率较大的弱分类器的权值小,在表决中起较小作用。
(三)Adaboost构建过程(例)
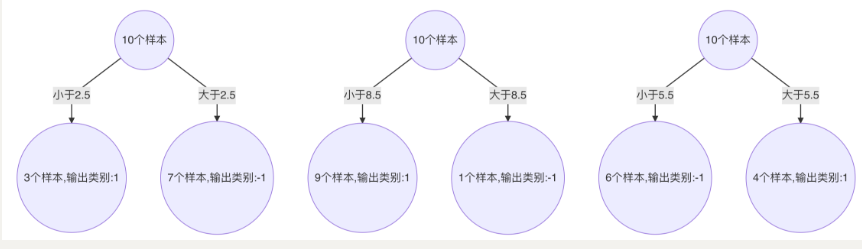
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。

1. 构建第一个弱学习器
-
初始化工作:初始化 10 个样本的权重,每个样本的权重为:0.1
-
构建第一个基(弱)学习器:
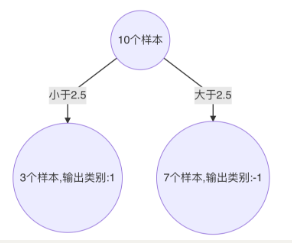
(1)寻找最优分裂点
a. 对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
b. 当以 0.5 为分裂点时,有 5 个样本分类错误
c. 当以 1.5 为分裂点时,有 4 个样本分类错误
d. 当以 2.5 为分裂点时,有 3 个样本分类错误
e. 当以 3.5 为分裂点时,有 4 个样本分类错误
f. 当以 4.5 为分裂点时,有 5 个样本分类错误
g. 当以 5.5 为分裂点时,有 4 个样本分类错误
h. 当以 6.5 为分裂点时,有 5 个样本分类错误
i. 当以 7.5 为分裂点时,有 4 个样本分类错误
j. 当以 8.5 为分裂点时,有 3 个样本分类错误
k. 最终,选择以 2.5 作为分裂点,计算得出基学习器错误率为:3/10=0.3(2) 计算模型权重:
1/2 * np.log((1-0.3)/0.3)=0.4236(3)更新样本权重:
a. 分类正确样本为:1、2、3、4、5、6、10 共 7 个,其计算公式为:e-αt,则正确样本权重变化系数为:e-0.4236 = 0.6547
b. 分类错误样本为:7、8、9 共 3 个,其计算公式为:eαt,则错误样本权重变化系数为:e0.4236 = 1.5275
c. 样本 1、2、3、4、5、6、10 权重值为:0.06547
d. 样本 7、8、9 的样本权重值为:0.15275
e. 归一化 Zt 值为:0.06547 * 7 + 0.15275 * 3 = 0.9165
f. 样本 1、2、3、4、5、6、10 最终权重值为:0.07143
g. 样本 7、8、9 的样本权重值为:0.1667
h. 此时得到:

2.构建第二个弱学习器
-
寻找最优分裂点:
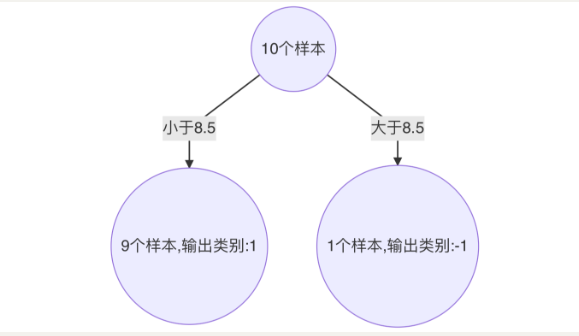
(1)对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
(2) 当以 0.5 为分裂点时,有 5 个样本分类错误,错误率为:0.07143 * 5 = 0.35715
(3)当以 1.5 为分裂点时,有 4 个样本分类错误,错误率为:0.07143 * 1 + 0.16667 * 3 = 0.57144
(4)当以 2.5 为分裂点时,有 3 个样本分类错误,错误率为:0.16667 * 3 = 0.57144
。。。 。。。
(5) 当以 8.5 为分裂点时,有 3 个样本分类错误,错误率为:0.07143 * 3 = 0.21429
(6) 最终,选择以 8.5 作为分裂点,计算得出基学习器错误率为:0.21429
-
计算模型权重:
1/2 * np.log((1-0.21429)/0.21429)=0.64963 -
分类正确的样本:1、2、3、7、8、9、10,其权重调整系数为:0.5222
-
分类错误的样本:4、5、6,其权重调整系数为:1.9148
-
分类正确样本权重值:
(1)样本 0、1、2、、9 为:0.0373
(2)样本 6、7、8 为:0.087 -
分类错误样本权重值:0.1368
-
归一化 Zt 值为:
0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206 -
最终权重:
(1)样本 0、1、2、9 为 :0.0455
(2) 样本 6、7、8 为:0.1060
(3)样本 3、4、5 为:0.1667 -
最后得到:
3.照着如上步骤,构建好的第三个弱学习器
如下:
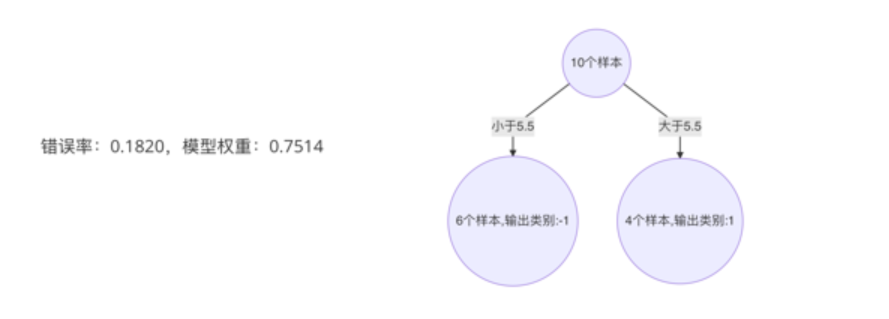
最后,由三个弱学习器组成的强学习器
如下:
(四)代码实现—葡萄酒例子
葡萄酒分为白葡萄酒和红葡萄酒两类。
该分析涉及白葡萄酒,并基于数据集中显示的13个变量/特征:
固定酸度,挥发性酸度,柠檬酸,残留糖,氯化物,游离二氧化硫,总二氧化硫,密度,pH值,硫酸盐,酒精,质量等。为了评估葡萄酒的质量,我们提出的方法就是根据酒的物理化学性质与质量的关系,找出高品质的葡萄酒具体与什么性质密切相关,这些性质又是如何影响葡萄酒的质量。
# 获取数据
import pandas as pd
df_wine = pd.read_csv('data/wine.data')
# 修改列名
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
# 去掉一类(1,2,3)
df_wine = df_wine[df_wine['Class label'] != 1]
# 获取特征值和目标值
X = df_wine[['Alcohol', 'Hue']].values
y = df_wine['Class label'].valuesfrom sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 类别转化 (2,3)=>(0,1),将类别2,3分别转化为0,1
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
# 机器学习(决策树和AdaBoost)
tree = DecisionTreeClassifier(criterion='entropy',max_depth=1,random_state=0)
ada= AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=0)
from sklearn.metrics import accuracy_score
# 决策树和AdaBoost分类器性能评估
# 决策树性能评估
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# Decision tree train/test accuracies 0.845/0.854# AdaBoost性能评估
ada = ada.fit(X_train,y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# Adaboost train/test accuracies 1/0.875
总结:AdaBosst预测准确了所有的训练集指标,与单层决策树相比,它在测试集上表现稍微好一些。单决策树对于训练数据过拟合的程度更加严重一些。总之,我们可以发现Adaboost分类器能够些许提高分类器性能,并且与bagging分类器的准确率接近。
五、GBDT(梯度提升树)
梯度提升树(Gradient Boosting Decision Tre)是提升树(Boosting Decision Tree)的一种改进算法,是一种基于梯度下降和决策树的集成学习算法,通过逐步优化损失函数来提升模型性能。
它在Kaggle等数据科学竞赛中表现优异,是XGBoost、LightGBM等现代算法的基础。
假设:
- 我们前一轮迭代得到的强学习器是:fi-1(x)
- 损失函数是:L(y,fi−1(x))
- 本轮迭代的目标是找到一个弱学习器:hi(x)
- 让本轮的损失最小化: L(y, fi(x))=L(y, fi−1(x)) + hi(x))
当采用平方损失函数时:
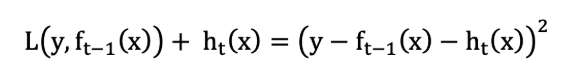
则:
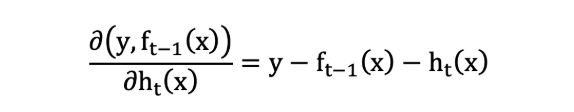
损失函数为平方损失, 则每个样本要拟合的负梯度为:
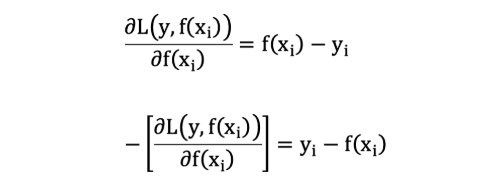
此时, 我们发现 GBDT 拟合的负梯度就是残差,或者说对于回归问题,拟合的目标值就是残差。
如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss(对数损失),此时拟合的目标值就是该损失函数的负梯度值(对数损失的负梯度 y−p 始终在 [−1,1] 之间)。
(一)GBDT算法流程
1 初始化弱学习器(目标值的均值作为预测值);
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度;
3 直到达到指定的学习器个数;
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出。
(二)GBDT构建流程(例)

1.初始化弱学习器(CART树)
我们通过计算当模型预测值为何值时,会使得第一个基学习器的平方误差最小,即:求损失函数对 f(xi) 的导数,并令导数为0。(下文平方误差之所以乘以1/2,是为了方便计算导数【1/2*2可抵消】。)

2.构建第一个cart树
由于我们拟合的是样本的负梯度,即:
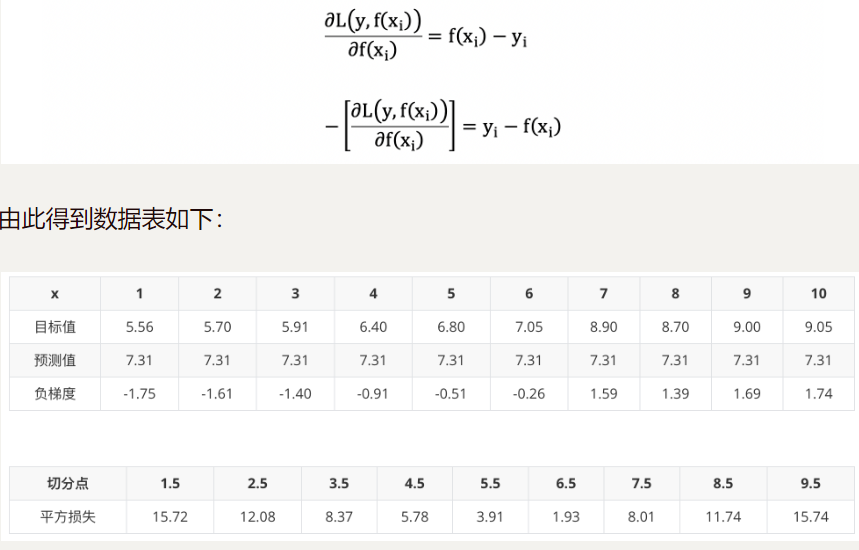
上表中平方损失计算过程说明(以切分点1.5为例):
切分点1.5 将数据集分成两份 [5.56],[5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9. 9.05]
第一份的平均值为5.56 第二份数据的平均值为(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9 = 7.5011
由于是回归树,每份数据的平均值即为预测值,则可以计算误差,第一份数据的误差为0,第二份数据的平方误差为 :
( 5.70 − 7.5011 ) 2 + ( 5.91 − 7.5011 ) 2 + . . . + ( 9.05 − 7.5011 ) 2 = 15.72308 (5.70-7.5011)^2+(5.91-7.5011)^2+...+(9.05-7.5011)^2 = 15.72308 (5.70−7.5011)2+(5.91−7.5011)2+...+(9.05−7.5011)2=15.72308
以 6.5 作为切分点损失最小,构建决策树如下:
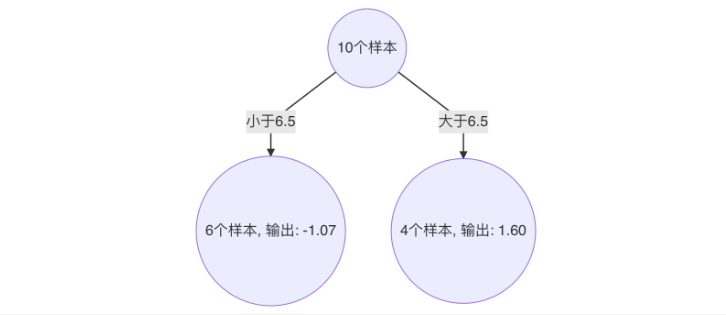
3.构建第二个cart树
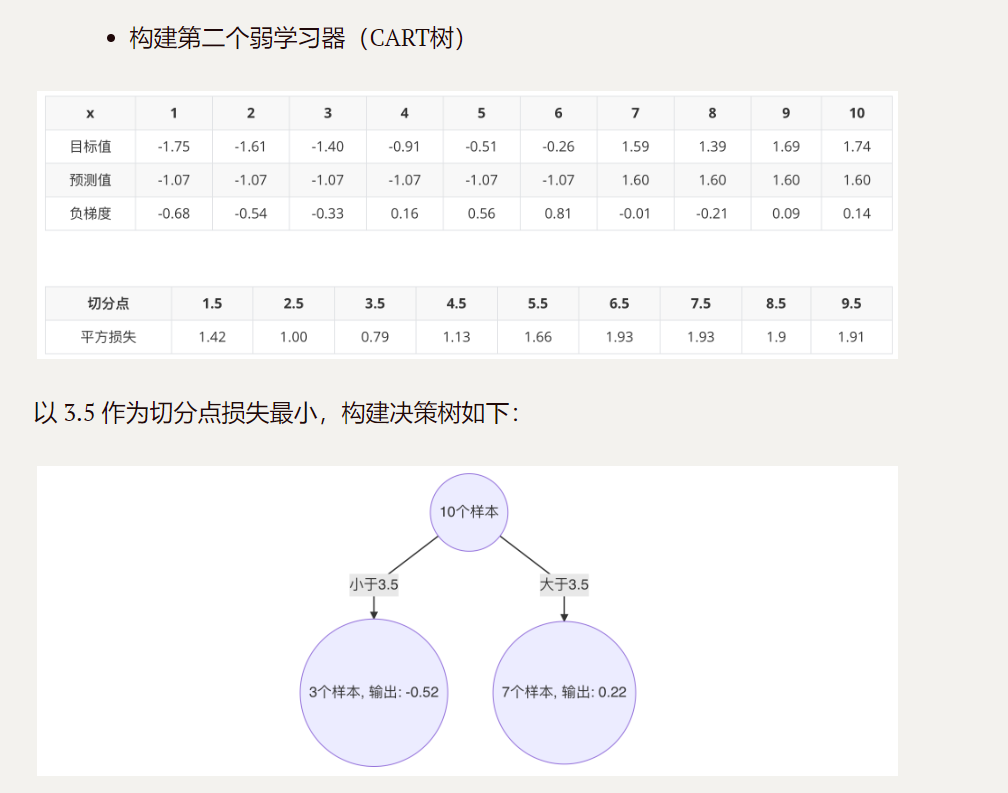
4.构建第三个cart树
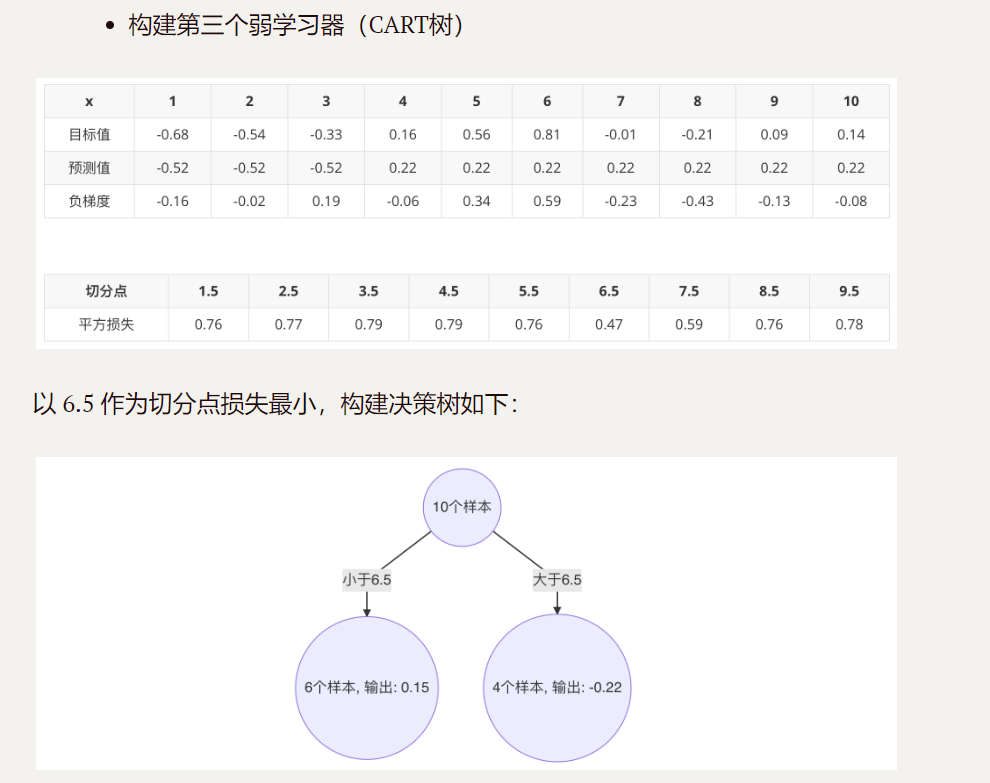
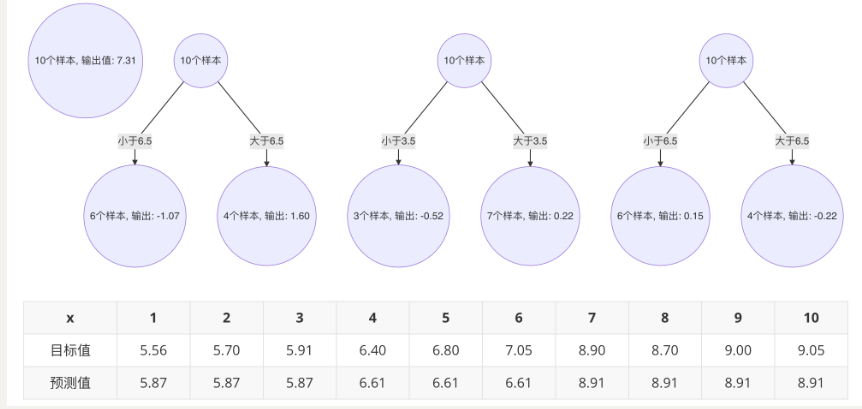
5.最终的强学习器:
(三)代码实现—泰坦尼克号例子
#1.数据导入
#1.1导入数据
import pandas as pd
#1.2.利用pandas的read.csv模块泰坦尼克号数据集
titanic=pd.read_csv("../data/泰坦尼克号数据集.csv")
titanic.info() #查看信息
#2人工选择特征pclass,age,sex
X=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#3.特征工程
#数据的填补
X['Age'].fillna(X['Age'].mean(),inplace=True)
#数据的切分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=0.25,random_state=22)
#将数据转化为特征向量
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='records'))
X_test=vec.transform(X_test.to_dict(orient='records'))
#4.使用单一的决策树进行模型的训练及预测分析
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_pred=dtc.predict(X_test)
print("score",dtc.score(X_test,y_test))
#5.随机森林进行模型的训练和预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(random_state=9)
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
print("score:forest",rfc.score(X_test,y_test))
#6.GBDT进行模型的训练和预测分析
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_pred=gbc.predict(X_test)
print("score:GradientBoosting",gbc.score(X_test,y_test))
#7.性能评估
from sklearn.metrics import classification_report
print("dtc_report:",classification_report(dtc_y_pred,y_test))
print("rfc_report:",classification_report(rfc_y_pred,y_test))
print("gbc_report:",classification_report(gbc_y_pred,y_test))
今天的分享到此结束。
相关文章:
机器学习:集成学习概念和分类、随机森林、Adaboost、GBDT
本文目录: 一、集成学习概念**核心思想:** 二、集成学习分类(一)Bagging集成(二)Boosting集成(三)两种集成方法对比 三、随机森林(一)构造过程(二…...
基于J2EE架构的在线考试系统设计与实现【源码+文档】
目录 摘要: Abstract: 1 引言 2 在线考试系统构架 2.1 在线考试系统一般需求分析 2.2 当前在线考试系统现状分析 2.3 基于J2EE的在线考试系统架构介绍及拥有的优势 2.3.1 结构总体介绍 2.3.2 客户层组件 2.3.2.1 Applets 2.3.2.2 应用程序客户端 2.3.3 …...

tpc udp http
TCP(传输控制协议)、UDP(用户数据报协议)和 HTTP(超文本传输协议)是网络通信中常用的三种协议,它们在不同的层次和场景中发挥作用。以下是对这三种协议的详细解释以及它们之间的区别:…...
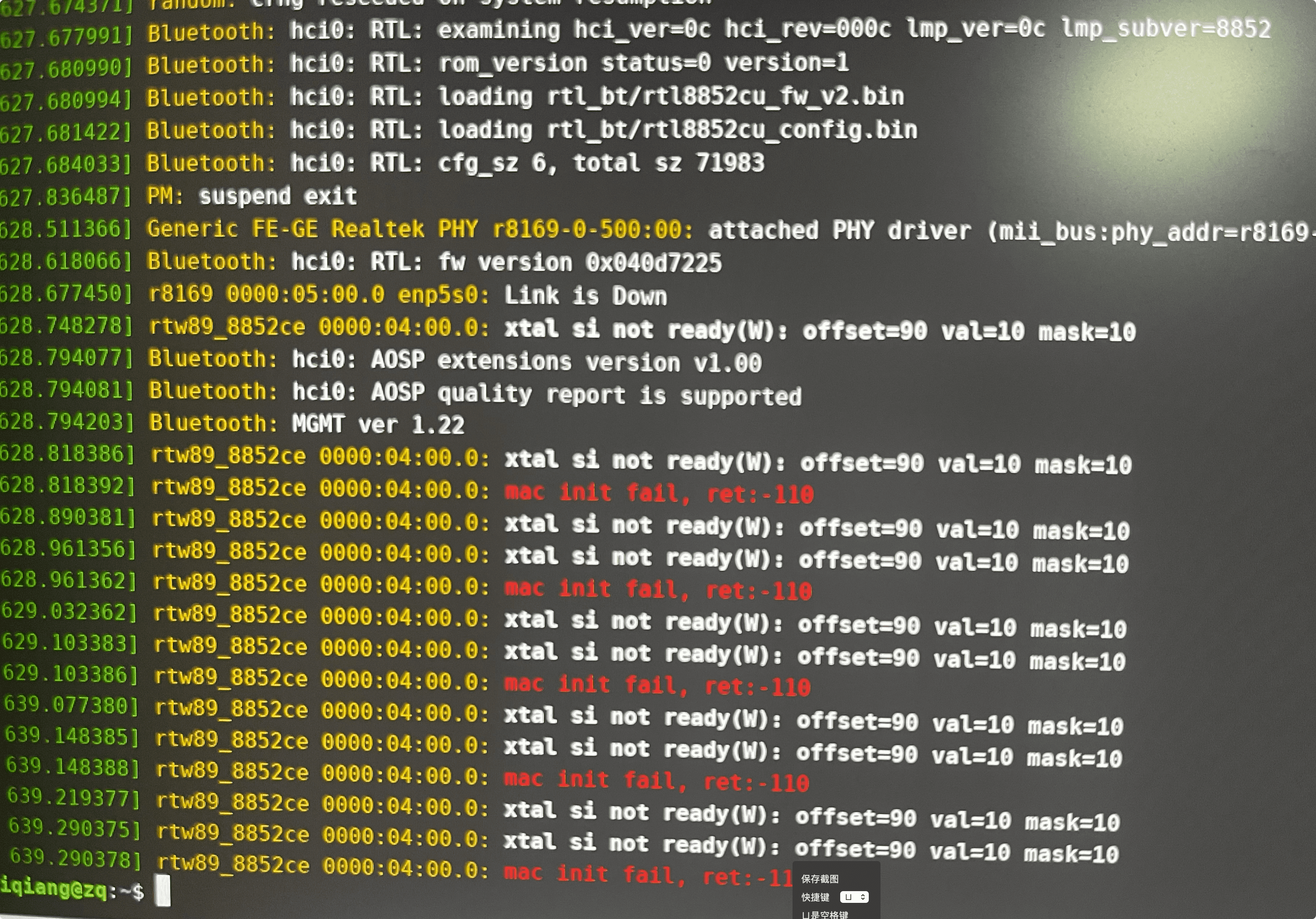
联想拯救者R9000P 网卡 Realtek 8852CE Ubuntu/Mint linux 系统睡眠后,无线网卡失效
联想拯救者R9000P 网卡型号 Realtek PCle GbE Family Controller Realtek 8852CE WiFi 6E PCI-E NIC 系统版本 Ubuntu 24.04 / mint 22.1 问题现象 rtw89_8852ce,Link is Down,xtal si not ready,mac init fail,xtal si not …...
Python训练营打卡 Day46
道注意力(SE注意力) 知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后…...
解决微软应用商店 (Microsoft store) 打不开,无网络连接的问题!
很多小伙伴都会遇见微软应用商店 (Microsoft store)打开后出现无网络的问题,一般出现这种问题基本都是因为你的电脑安装了某些银行的网银工具,因为网银工具为了安全会关闭Internet 选项中的最新版本的TLS协议,而微软商店又需要最新的TLS协议才…...

《影像引导下骨盆创伤手术的术前骨折复位规划:基于学习的综合流程》|文献速递-深度学习医疗AI最新文献
Title 题目 Preoperative fracture reduction planning for image-guided pelvic trauma surgery: A comprehensive pipeline with learning 《影像引导下骨盆创伤手术的术前骨折复位规划:基于学习的综合流程》 01 文献速递介绍 《影像引导下骨盆创伤手术的术前…...
如何使用Webhook触发器,在 ONLYOFFICE 协作空间构建智能工作流
在数字化办公中,ONLYOFFICE 协作空间作为一款功能强大的文档协作平台,提供了丰富的自动化功能。对于开发者而言,Webhook 触发器是实现业务流程自动化与系统集成的关键工具。本文将深入探讨如何在 ONLYOFFICE 协作空间中高效利用 Webhook&…...

跟我学c++中级篇——理解类型推导和C++不同版本的支持
一、类型推导 在前面反复分析过类型推导(包括前面提到的类模板参数推导CTAD),类型推导其实就是满足C语言这种强类型语言的要求即编译期必须确定对象的数据类型。换一句话说,理论上如果编译器中能够自动推导所有的相关数据类型&am…...

什么是DevOps智能平台的核心功能?
在数字化转型的浪潮中,DevOps智能平台已成为企业提升研发效能、加速产品迭代的核心工具。然而,许多人对“DevOps智能平台”的理解仍停留在“自动化工具链”的表层概念。今天,我们从一个真实场景切入:假设你是某互联网公司的技术负…...
Windows账户管理,修改密码,创建帐户...(无需密码)
前言 我们使用wWindows操作系统时,账户是非常重要的概念 它不仅能够帮助我们区分文档主题权限等等 嗯还有最重要的解锁电脑的作用! 但想要管理他,不仅需要原本的密码,而且设置中的管理项也非常的不全。 Windows有一款netplwi…...

软件功能模块归属论证方法
文章目录 **一、核心设计原则****二、论证方法****三、常见决策模式****四、验证方法****五、反模式警示****总结** 在讨论软件功能点应该归属哪些模块时,并没有放之四海而皆准的固定方法,但可以通过系统化的论证和设计原则来做出合理决策。以下是常见的…...

【Java后端基础 005】ThreadLocal-线程数据共享和安全
📚博客主页:代码探秘者 ✨专栏:文章正在持续更新ing… ✅C语言/C:C(详细版) 数据结构) 十大排序算法 ✅Java基础:JavaSE基础 面向对象大合集 JavaSE进阶 Java版数据结构JDK新特性…...
【C语言】C语言经典小游戏:贪吃蛇(下)
文章目录 一、游戏前准备二、游戏开始1、游戏开始函数(GameStart)1)打印欢迎界⾯(WelcomeToGame)2)创建地图(CreateMap)3)初始化蛇⾝(InitSnake)4…...

NTT印地赛车:数字孪生技术重构赛事体验范式,驱动观众参与度革命
引言:数字孪生技术赋能体育赛事,开启沉浸式观赛新纪元 在传统体育赛事观赛模式遭遇体验天花板之际,NTT与印地赛车系列赛(NTT INDYCAR SERIES)的深度合作,通过数字孪生(Digital Twin)…...
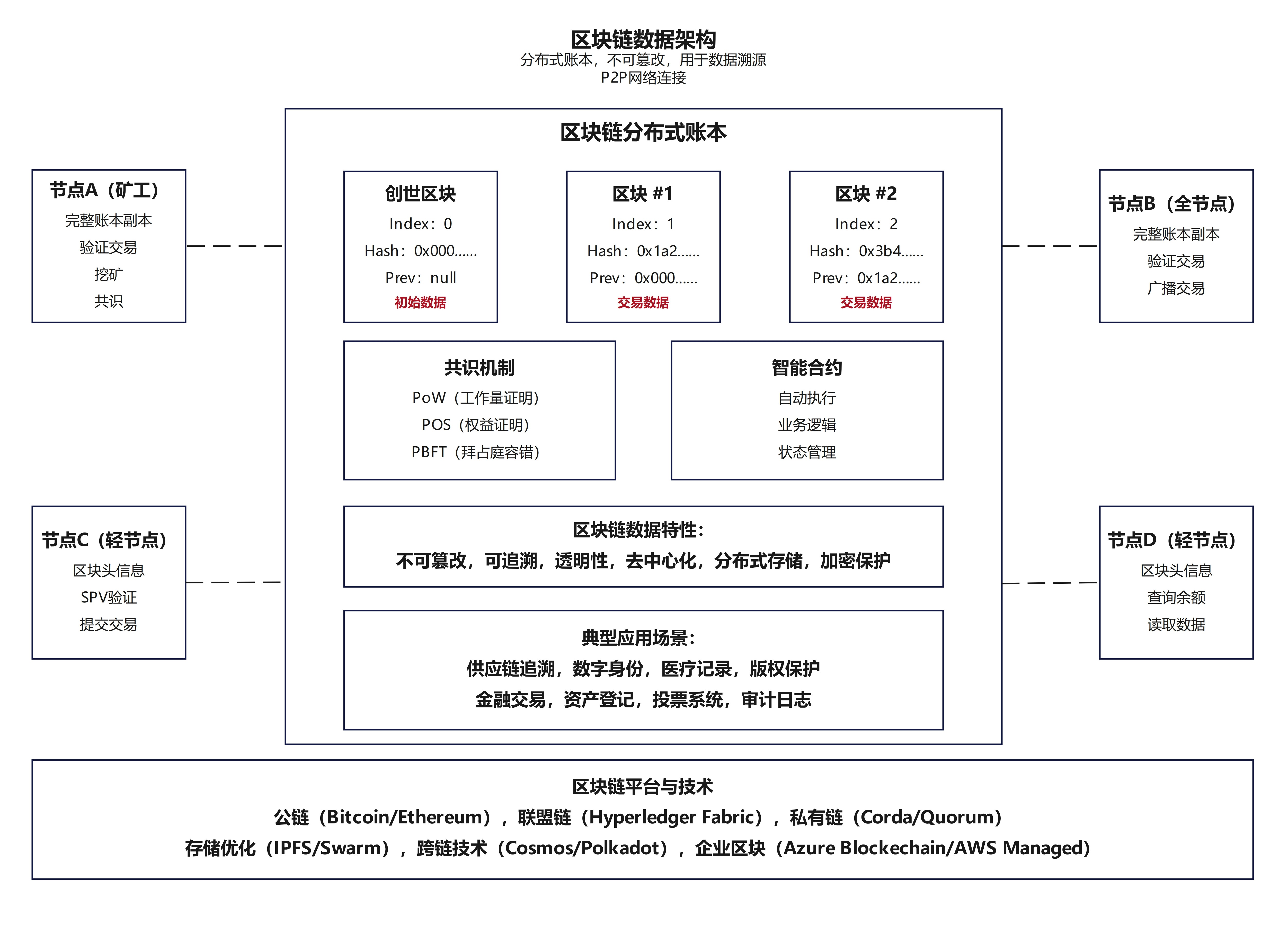
30.【新型数据架构】-区块链数据架构
30.【新型数据架构】-区块链数据架构:分布式账本,不可篡改性,用于数据溯源 一、区块链数据架构的本质:分布式账本的革新 区块链的核心是分布式账本技术(Distributed Ledger Technology, DLT),它颠覆了传统中心化数据库的架构模式: 去中心化存储: 账本数据不再集中存储…...
版本)
使用docker 安装Redis 带配置文件(x86和arm)版本
一、安装redis 1.1 拉去ARM镜像(7.4.2) docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/linux_arm64_redis:latest1.2 拉去x86镜像(8.0.1)版本 docker pull registry.cn-hangzhou.aliyuncs.com/qiluo-images/redis:latest新建文件夹 mkd…...
在CSDN发布AWS Proton解决方案:实现云原生应用的标准化部署
引言:云原生时代的部署挑战 在云原生应用开发中,基础设施管理的复杂性已成为团队面临的核心挑战。随着微服务架构的普及,每个服务可能包含数十个AWS资源(如Lambda、API Gateway、ECS集群等),传统的手动配置…...

小白的进阶之路系列之十----人工智能从初步到精通pytorch综合运用的讲解第三部分
本文将介绍Autograd基础。 PyTorch的Autograd特性是PyTorch灵活和快速构建机器学习项目的一部分。它允许在一个复杂的计算中快速而简单地计算多个偏导数(也称为梯度)。这个操作是基于反向传播的神经网络学习的核心。 autograd的强大之处在于它在运行时动态地跟踪你的计算,…...

[蓝桥杯]整理玩具
整理玩具 题目描述 小明有一套玩具,一共包含 NMNM 个部件。这些部件摆放在一个包含 NMNM 个小格子的玩具盒中,每个小格子中恰好摆放一个部件。 每一个部件上标记有一个 0 ~ 9 的整数,有可能有多个部件标记相同的整数。 小明对玩具的摆放有…...

C++11 Move Constructors and Move Assignment Operators 从入门到精通
文章目录 一、引言二、基本概念2.1 右值引用(Rvalue References)2.2 移动语义(Move Semantics) 三、移动构造函数(Move Constructors)3.1 定义和语法3.2 示例代码3.3 使用场景 四、移动赋值运算符ÿ…...

JavaScript 中的单例内置对象:Global 与 Math 的深度解析
JavaScript 中的单例内置对象:Global 与 Math 的深度解析 在 JavaScript 的世界中,单例内置对象是开发者必须了解的核心概念之一。它们是语言规范中预定义的对象,无需显式创建即可直接使用。本文将深入解析 JavaScript 中最重要的两个单例内…...

11 - ArcGIS For JavaScript -- 高程分析
这里写自定义目录标题 描述代码实现结果 描述 高程分析是地理信息系统(GIS)中的核心功能之一,主要涉及对地表高度数据(数字高程模型, DEM)的处理和分析。 ArcGIS For JavaScript4.32版本的发布,提供了Web端的针对高程分析的功能。 代码实现 <!doct…...
通道注意力
一、 什么是注意力 其中注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景,聚焦于图片中的主体(如猫、汽车)。 transformer中的叫做自注意力机制,他是一种自己学习自己的机制…...

2048游戏的技术实现分析-完全Java和Processing版
目录 简介Processing库基础项目构建指南项目结构核心数据结构游戏核心机制图形界面实现性能优化代码详解设计模式分析测试策略总结与展望简介 2048是一款由Gabriele Cirulli开发的经典益智游戏。本文将深入分析其Java实现版本的技术细节。该实现使用了Processing库来创建图形界…...
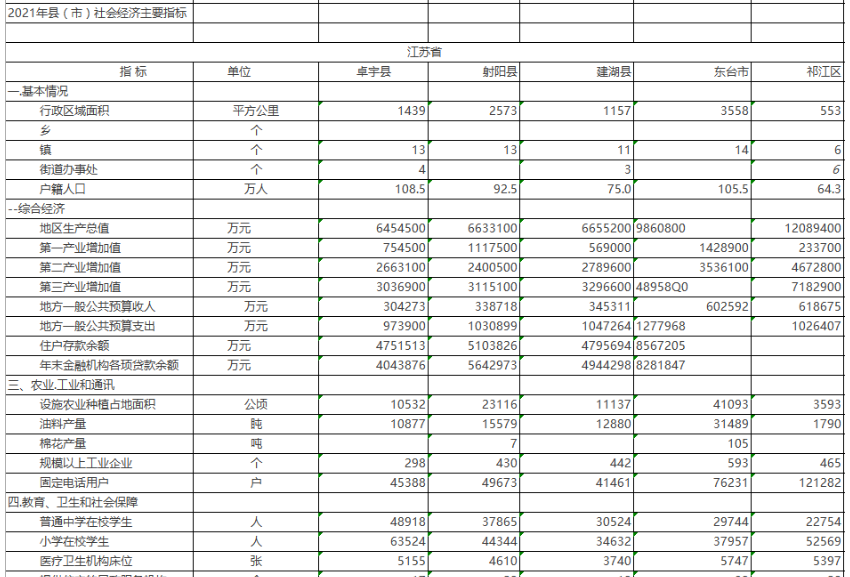
全国县域统计年鉴PDF-Excel电子版-2022年
全国县域统计年鉴PDF-Excel电子版-2022年.ziphttps://download.csdn.net/download/2401_84585615/89784662 https://download.csdn.net/download/2401_84585615/89784662 《中国县域统计年鉴》是一部全面反映中国县域社会经济发展状况的资料性年鉴。自2014年起,该年…...
)
平滑技术(数据处理,持续更新...)
一.介绍 “平滑”是一种用于减少数据中的短期波动、噪声或者异常值的技术,从而更清晰地揭示数据的长期趋势或周期性特征。 平滑的主要作用: 1.减少噪声。数据中常常包含各种随机噪声或误差,这些误差可能会掩盖数据的真实趋势。平滑可以降低…...
)
App 上线后还能加固吗?iOS 应用的动态安全补强方案实战分享(含 Ipa Guard 等工具组合)
很多开发者以为 App 一旦上线,安全策略也就定型了。但现实是,App 上线只是攻击者的起点——从黑产扫描符号表、静态分析资源文件、注入调试逻辑,到篡改功能模块,这些行为都可能在你“以为很安全”的上线版本里悄然发生。 本篇文章…...
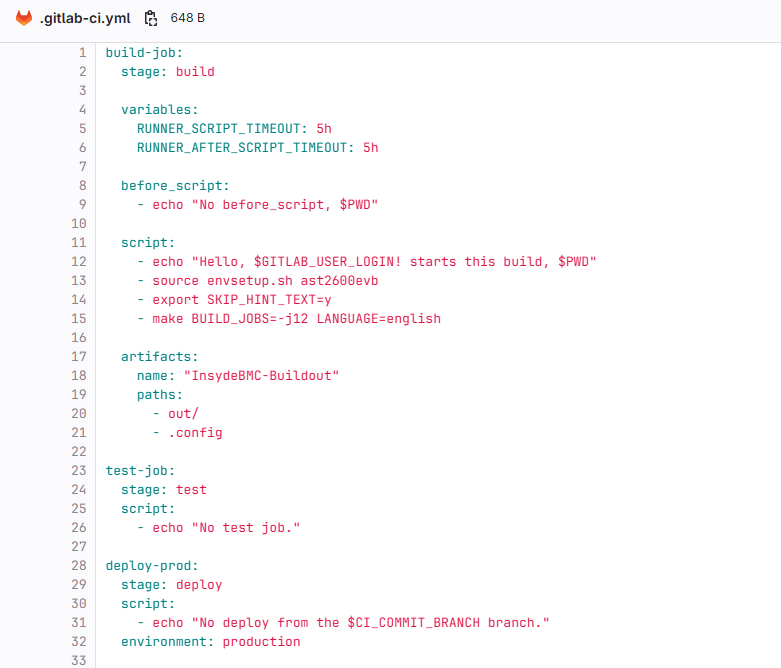
gitlab CI/CD本地部署配置
背景: 代码管理平台切换为公司本地服务器的gitlab server。为了保证commit的代码至少编译ok,也为了以后能拓展test cases,现在先搭建本地gitlab server的CI/CD基本的编译job pipeline。 配置步骤: 先安装gitlab-runner: curl -L "ht…...
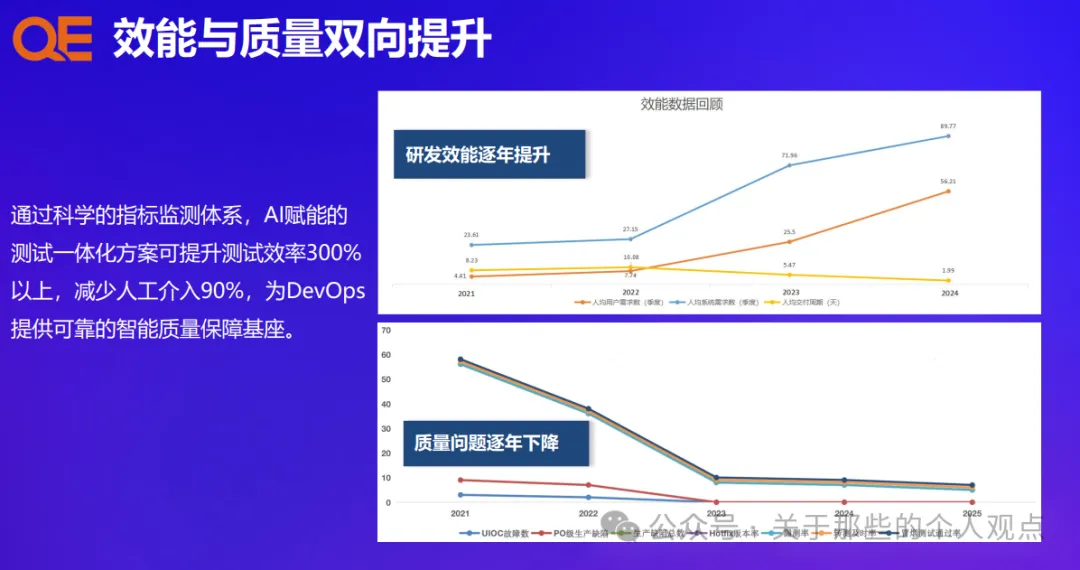
AI大模型在测试领域应用案例拆解:AI赋能的软件测试效能跃迁的四大核心引擎(顺丰科技)
导语 5月份QECon深圳大会已经结束,继续更新一下案例拆解,本期是来自顺丰科技。 文末附完整版材料获取方式。 首先来看一下这个案例的核心内容,涵盖了测四用例设计、CI/CD辅助、测试执行、监控预警四大方面,也是算大家比较熟悉的…...