Kafka入门-消费者
消费者
Kafka消费方式:采用pull(拉)的方式,消费者从broker中主动拉去数据。使用pull的好处就是消费者可以根据自身需求,进行拉取数据,但是坏处就是如果Kafka没有数据,那么消费者可能会陷入循环中,一直返回空数据。
消费者与消费者之间是独立的,一个消费者可以消费多个分区数据。但是消费组不同,每个分区的数据只能由消费者组中的一个消费者消费,避免重复消费导致数据重复。
消费者组:
- 消费者组由多个consumer组成,形成一个消费者组的条件,是所有消费者的groupid相同。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
消费者组初始化流程:
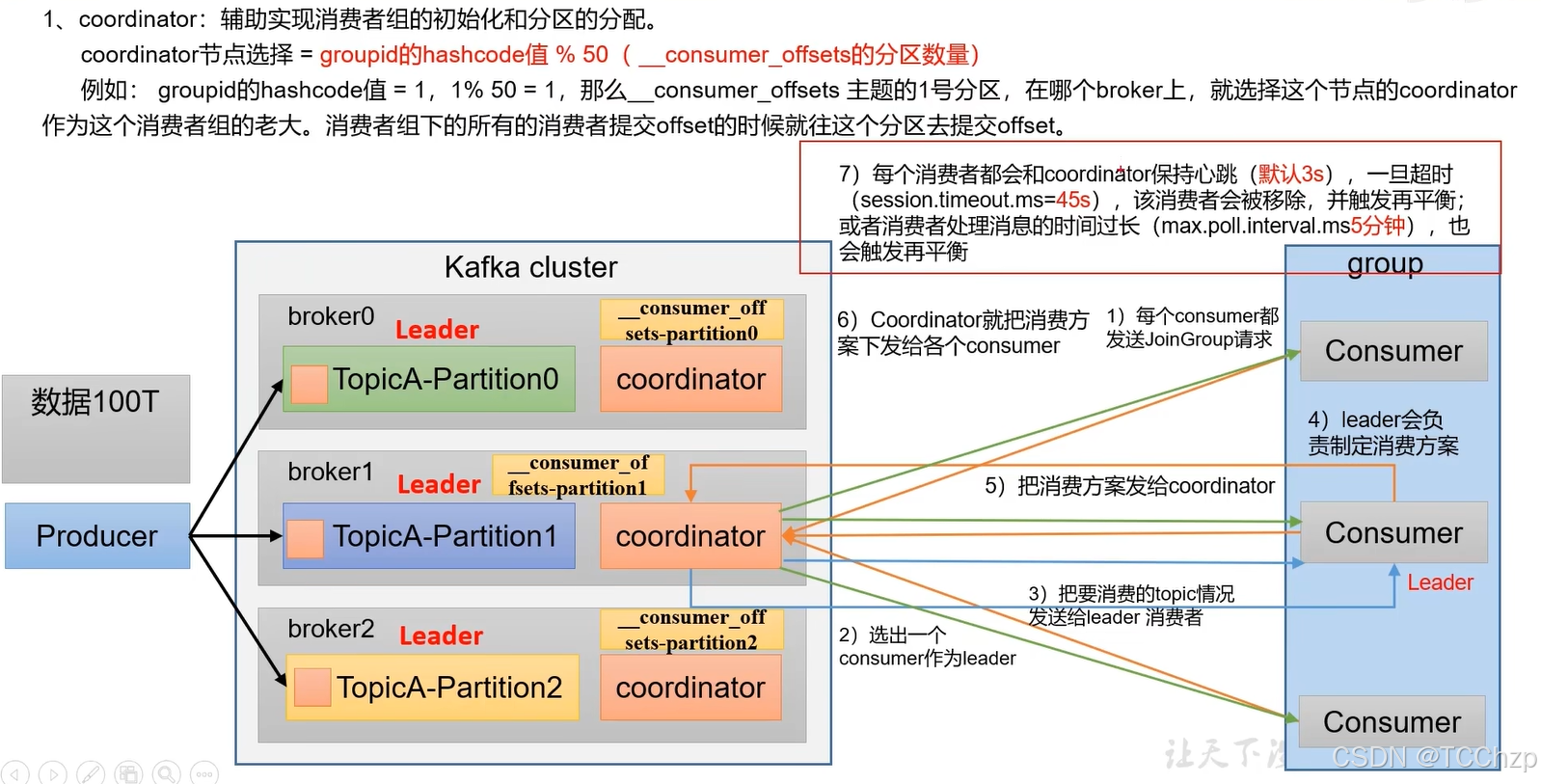
消费者组详细消费流程
Java创建消费者
注意:在消费者API代码中必须配置消费者组id。命令行启动消费者不需要填写是因为id被自动填写为随机的消费者组id。
通过API消费一个主题的数据
//配置Properties properties = new Properties();//连接集群properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.27.101:9092,192.168.27.102:9092");//反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());//消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");//1.创建一个消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//2.定义主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);//3.消费数据while (true){//拉取的间隔时间ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {System.out.println(record);}}
消费者消费指定分区
需要指定分区只需要在定义主题时,使用定义主题以及分区方法
//2.定义主题以及分区ArrayList<TopicPartition> topicPartitions = new ArrayList<>();topicPartitions.add(new TopicPartition("first",0));kafkaConsumer.assign(topicPartitions);
消费者组案例
创建三个消费者,进行消费不同分区
直接复制上面消费主题的代码,因为设置的groupid都是test,因此会自动成为一个消费者组。运行消费者组test内的三个消费者,然后运行生产者对每个分区进行发送消息,可以看到每个消费者都只消费了一个分区的消息。
注意:消费者组内的消费者在底层进行了编号,跟java类取名无关。
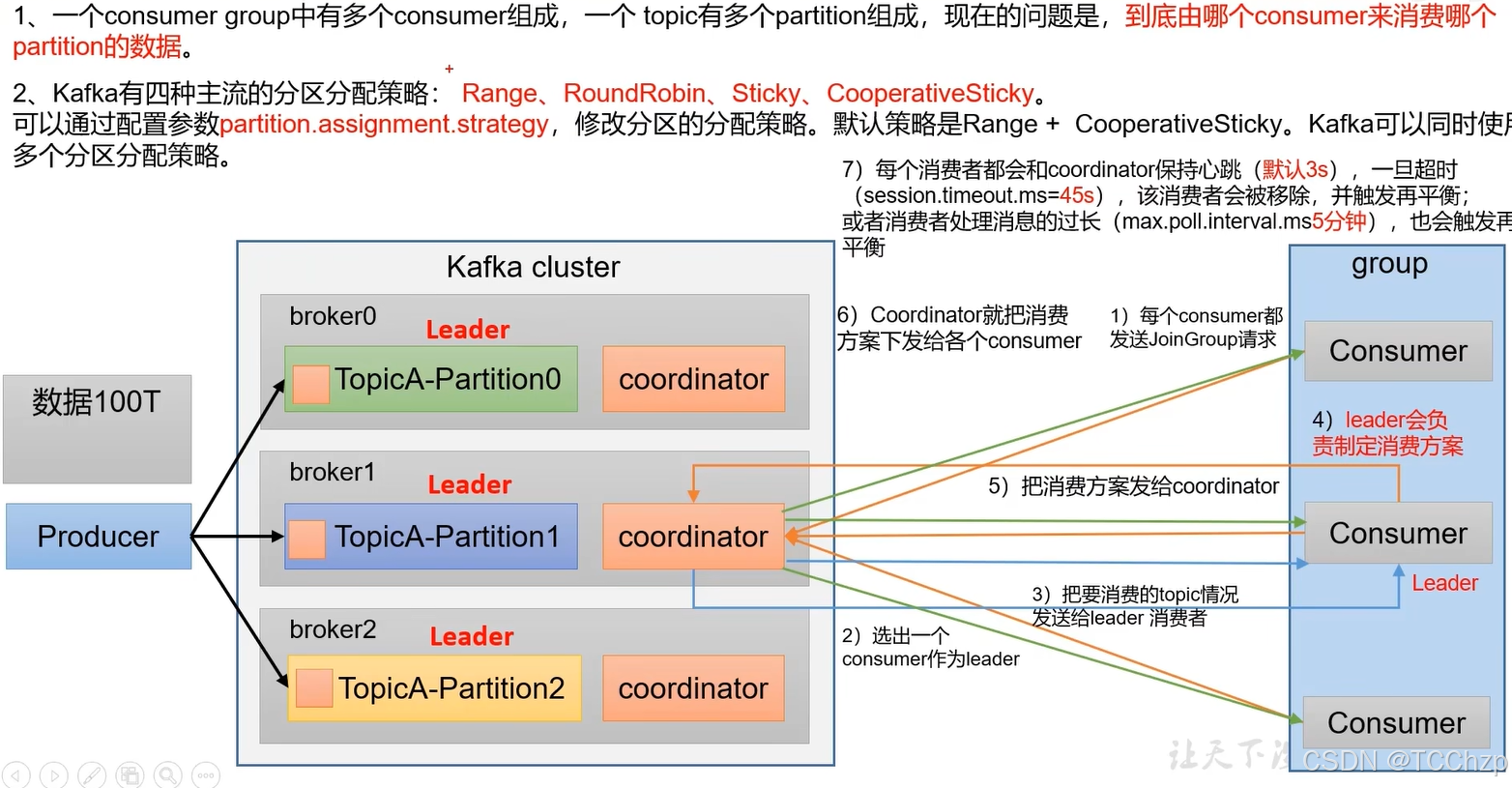
分区的分配以及再平衡
消费者组有多个消费者,而一个topic又有多个分区,那么应该由哪个消费者消费哪个分区呢?
Kafka有三种主流的分区分配策略,可以通过配置参数partiton.assignment.strategy修改分配策略,默认的策略是Range+CooperativeSticky。Kafka可以同时使用多个分区分配策略。
//设置分区分配策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
再平衡:相当于原有分区的消费者突然发送意外,不能再进行消费,重新分配该分区给其他消费者;或者消费者组中新增了消费组,需要重新分配分区。
-
Range
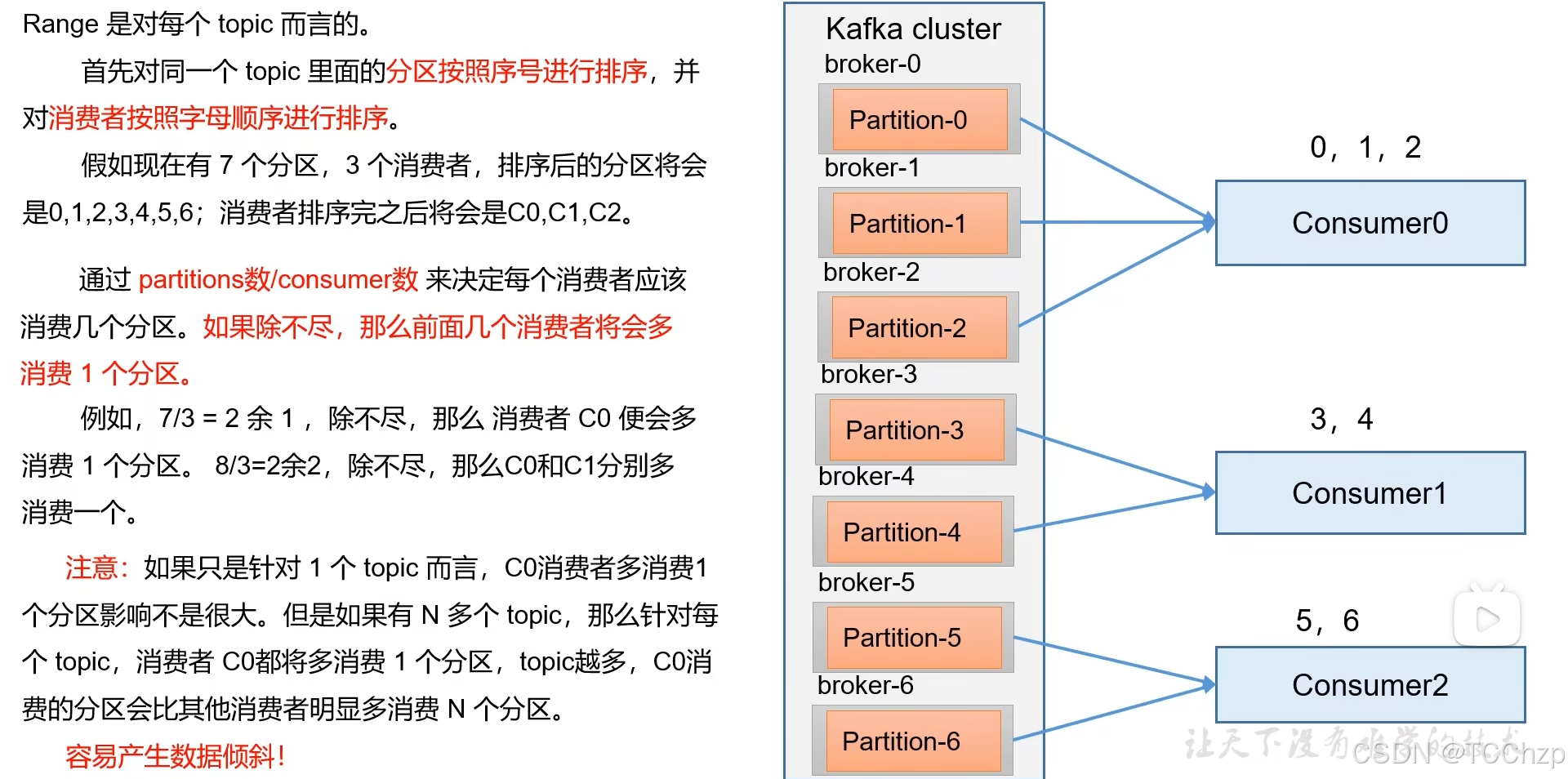
Range的再平衡,会将原消费者负责的分区一次性全部交给剩下的某一个消费者
-
RoundRobin
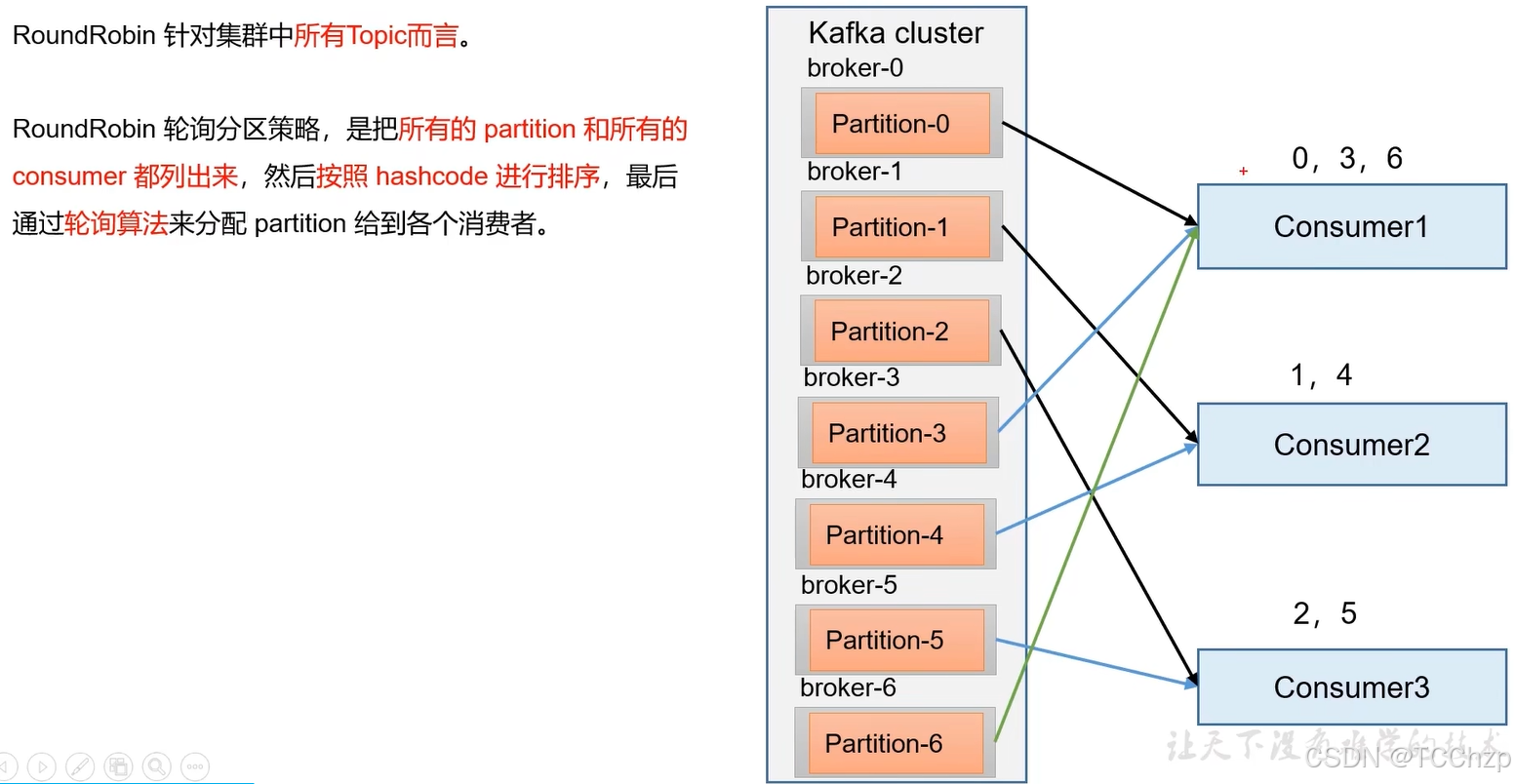
当触发再分配时,会将原消费者负责的分区按照RoundRobin一样进行重新分发
-
Sticky
Sticky也是针对所有topic的策略,黏性分区是一种均匀随机的分配策略,会在执行一次新的分配之前,考虑上一次的分配结果,尽量少的调整分配的变动,可以节省开销。首先会尽量均衡的分配分区给消费者,在同一组内的消费者出现问题,也会尽量保持原有分配的分区不发送变化。但是在发生再平衡时,所有的消费者需要先放弃当前持有的分区资源,等待重新分配。
-
CooperativeSticky
CooperativeSticky是2.4版本新增的策略,在原有Sticky策略上,将原本大规模的再平衡操作,拆分成了多次小规模的再平衡,直到平衡完成。
Offset位移
offset的默认维护位置
Offset,消息位移,它表示分区中每条消息的位置信息,是一个单调递增且不变的值。换句话说,offset可以用来唯一的标识分区中每一条记录。消费者消费完一条消息记录之后,需要提交offset来告诉Kafka Broker自己消费到哪里了。
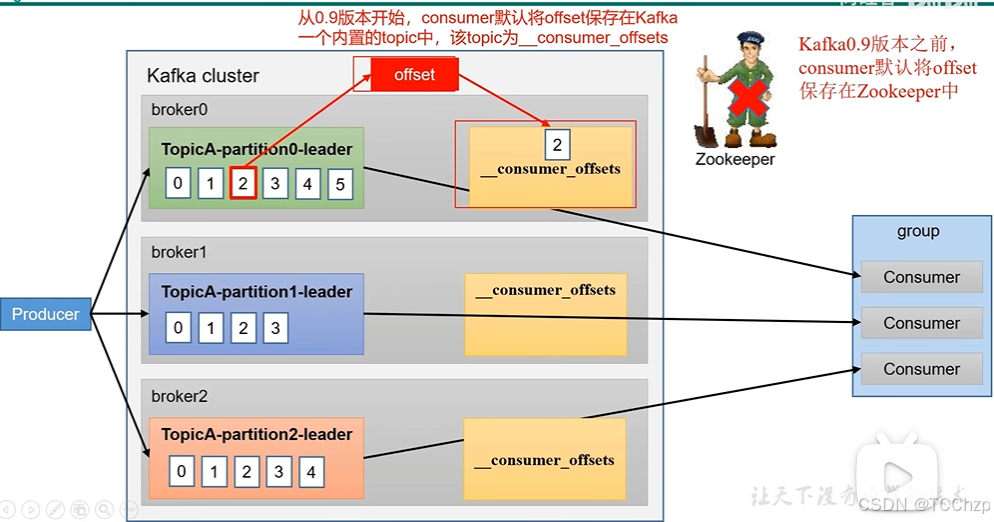
_consumer_offsets主题采用key和value的方式存储数据,key是group.id+topic+分区号,value就是当前offset的值,每隔一段时间,kafka内部会对这个topic进行compact,也就是每个key都保留最新数据。
默认情况下,是不允许查看消费系统主题数据的,如果需要查看该系统主题数据,要设置config/consumer.properties中添加配置exclude.internal.topics=false。默认是true,表示不能看系统相关信息。
自动提交offset
为了让用户更专注于自己的业务逻辑,Kafka提供了自动提交offset的功能,一段时间后自动提交offset。相关参数:
enable.auto.commit 是否开启自动提交offset功能,默认为true
auto.commmit.intervalms 自动提交offset分时间间隔,默认是5s。
//自动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);//提交时间间隔properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
手动提交offset
自动提交是基于时间提交,开发人员很难把握提交的时机,因此Kafka还提供了手动提交offset的API。
//设置手动提交(关闭自动)properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
手动提交分为同步提交和异步提交。两者的共同点是都会将本次提交的一批数据最高的偏移量提交,不同的是同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试,而异步提交则没有失败重试机制,所有有可能提交失败。
同步提交:必须等待offset提交完毕,再去消费下一批数据。
//手动提交(同步)kafkaConsumer.commitSync();
异步提交:发送完offset请求后,就开始消费下一批数据了。
//手动提交(异步)kafkaConsumer.commitAsync();
指定Offset消费
//指定位置进行消费,先获取分区信息Set<TopicPartition> assignment = kafkaConsumer.assignment();//保证分区分配方案已经指定完毕,刚订阅主题时不能立即获取到分区信息while (assignment.size()==0){kafkaConsumer.poll(Duration.ofSeconds(1));assignment = kafkaConsumer.assignment();}for (TopicPartition topicPartition : assignment) {// 分区 指定offsetkafkaConsumer.seek(topicPartition,100);}
指定时间消费
//指定位置进行消费,先获取分区信息Set<TopicPartition> assignment = kafkaConsumer.assignment();//保证分区分配方案已经指定完毕,刚订阅主题时不能立即获取到分区信息while (assignment.size()==0){kafkaConsumer.poll(Duration.ofSeconds(1));assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> topicPartitionLongHashMap = new HashMap<>();for (TopicPartition topicPartition : assignment) {//如果希望是一天前的当前时刻,那么就用当前时间减去一天间隔,单位为mstopicPartitionLongHashMap.put(topicPartition,System.currentTimeMillis()- 1 * 24 * 3600 * 1000);}//将时间转换为对应的offsetMap<TopicPartition, OffsetAndTimestamp> topicPartitionOffsetAndTimestampMap = kafkaConsumer.offsetsForTimes(topicPartitionLongHashMap);for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp = topicPartitionOffsetAndTimestampMap.get(topicPartition);kafkaConsumer.seek(topicPartition,offsetAndTimestamp.offset());}
消费者事务
在消费者消费的过程中会遇到重复消费和漏消费的情况发生。
漏消费:先提交offset后进行消费,有可能造成数据的漏消费
重复消费:已经消费数据,但是offset没有提交
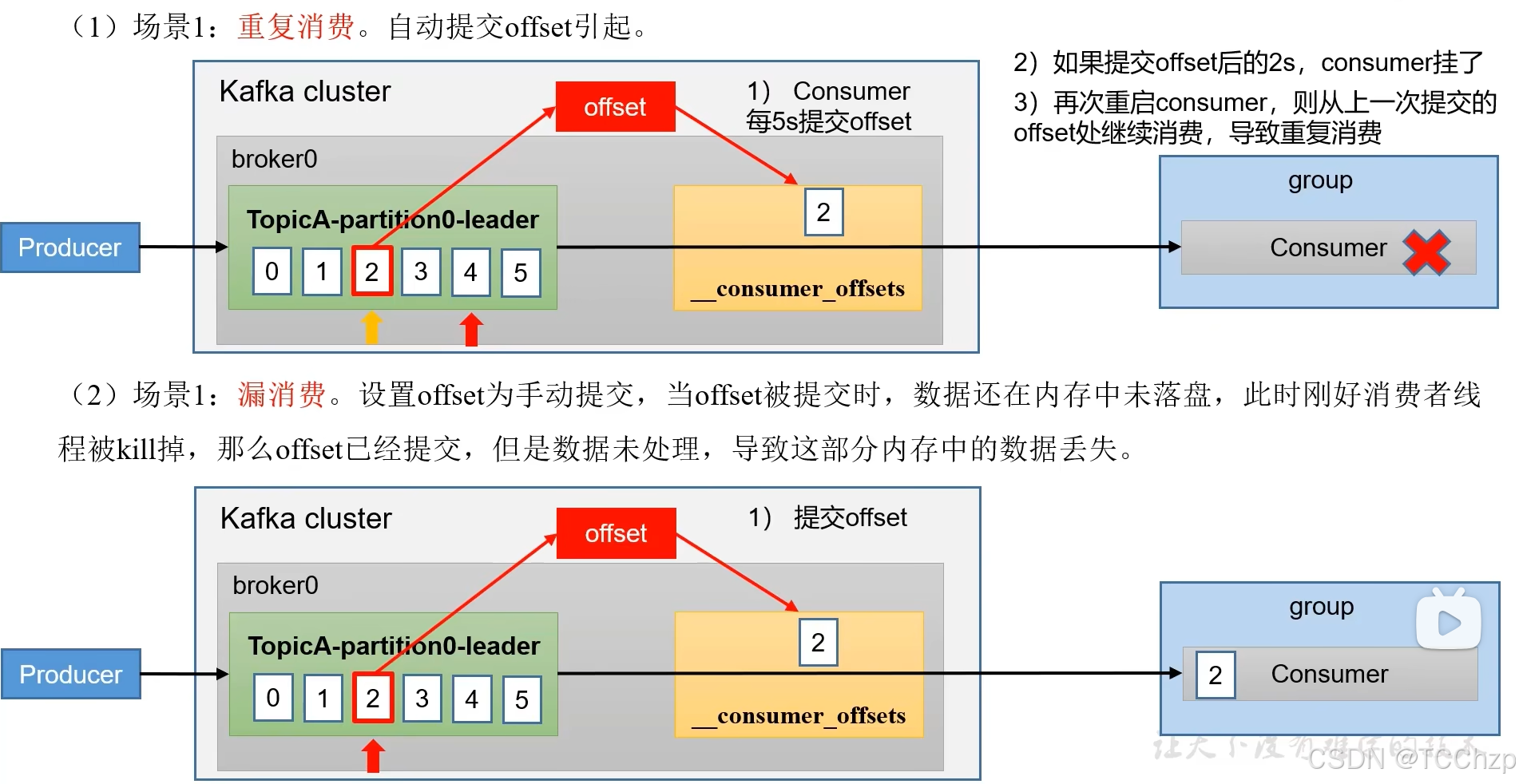
如果想精准的进行一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。可以将Kafka的offset保存到支持事务的工具中。(比如MySQL)
数据积压
默认日志存储时间为7天,如果当消费速度低于消息的发送速度,那么就很可能造成数据积压。
如果Kafka消费能力不足,那么可以增加Topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数。
如果下游数据处理不及时,那么提高每批次拉取的数据量。批次拉取数据过少,使得处理的数据小于生产的数据,也会造成数据积压。
相关文章:
Kafka入门-消费者
消费者 Kafka消费方式:采用pull(拉)的方式,消费者从broker中主动拉去数据。使用pull的好处就是消费者可以根据自身需求,进行拉取数据,但是坏处就是如果Kafka没有数据,那么消费者可能会陷入循环…...

[论文阅读] 人工智能 | 搜索增强LLMs的用户偏好与性能分析
【论文解读】Search Arena:搜索增强LLMs的用户偏好与性能分析 论文信息 作者: Mihran Miroyan, Tsung-Han Wu, Logan King等 标题: Search Arena: Analyzing Search-Augmented LLMs 来源: arXiv preprint arXiv:2506.05334v1, 2025 一、研究背景:…...

中电金信:从智能应用到全栈AI,大模型如何重构金融业务价值链?
导语 当前,AI大模型技术正加速重构金融行业的智能化图景。为助力金融机构精准把握这一变革机遇,中电金信与IDC联合发布《中国金融大模型发展白皮书》。《白皮书》在梳理了AI大模型整体发展现状的基础上,结合金融行业用户的需求调研深入分析了…...

巴西医疗巨头尤迈Kafka数据泄露事件的全过程分析与AI安防策略分析
一、事件背景与主体信息 涉事主体:Unimed,全球最大医疗合作社,巴西医疗行业龙头企业,拥有约1500万客户。技术背景:泄露源于其未保护的Kafka实例(开源实时数据传输平台),用于客户与聊天机器人“Sara”及医生的实时通信。二、时间线梳理 时间节点关键事件描述2025年3月24…...
快速上手 Metabase:从安装到高级功能实战
文章目录 1. 引言:Metabase——轻量级的数据分析工具🎯 学完本教程你能掌握: 2. 安装 Metabase:本地部署实操2.1 环境准备2.2 使用 Docker 安装 Metabase2.3 初始化设置2.4 连接外部数据库 3. 第一个数据探索:5分钟创建…...

多区域协同的异地多活AI推理服务架构
🌐多区域协同的异地多活AI推理服务架构 #mermaid-svg-TTnpRKKC7k3twxhE {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-TTnpRKKC7k3twxhE .error-icon{fill:#552222;}#mermaid-svg-TTnpRKKC7k3twxhE .er…...

Linux基础命令which 和 find 简明指南
🎯 Linux which 和 find 命令简明指南:从入门到实用 📅 更新时间:2025年6月7日 🏷️ 标签:Linux | which | find | 命令行 | 文件查找 文章目录 前言🌟 一、Linux 命令的本质与 which、find 的作…...

【学习记录】在 Ubuntu 中将新硬盘挂载到 /home 目录的完整指南
文章目录 📋 一、准备工作1. 备份重要数据2. 确认新硬盘设备信息 🛠️ 二、格式化新硬盘(如未格式化)1. 格式化为 ext4 文件系统(推荐) 🔁 三、临时挂载并迁移数据1. 创建临时挂载点2. 挂载新硬…...

思尔芯携手Andes晶心科技,加速先进RISC-V 芯片开发
在RISC-V生态快速发展和应用场景不断拓展的背景下,芯片设计正面临前所未有的复杂度挑战。近日,RISC-V处理器核领先厂商Andes晶心科技与思尔芯(S2C)达成重要合作,其双核单集群AX45MPV处理器已在思尔芯最新一代原型验证系…...

kafka消息积压排查
kafka监控搭建:https://insights.blog.csdn.net/article/details/139129552?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2%7Edefault%7Ebaidujs_baidulandingword%7EPaidSort-1-139129552-blog-132216491.235%5Ev43%5Econtrol…...
drawio 开源免费的流程图绘制
开源地址 docker-compose 一键启动 #This compose file adds draw.io to your stack version: 3.5 services:drawio:image: jgraph/drawiocontainer_name: drawiorestart: unless-stoppedports:- 8081:8080- 8443:8443environment:PUBLIC_DNS: domainORGANISATION_UNIT: unitOR…...

YOLOv8 升级之路:主干网络嵌入 SCINet,优化黑暗环境目标检测
文章目录 引言1. 低照度图像检测的挑战1.1 低照度环境对目标检测的影响1.2 传统解决方案的局限性 2. SCINet网络原理2.1 SCINet核心思想2.2 网络架构 3. YOLOv8与SCINet的集成方案3.1 总体架构设计3.2 关键集成代码3.3 训练策略 4. 实验结果与分析4.1 实验设置4.2 性能对比4.3 …...

传输层:udp与tcp协议
目录 再谈端口号 端口号范围划分 认识知名端口号(Well-Know Port Number) 两个问题 netstat pidof 如何学习下三层协议 UDP协议 UDP协议端格式 UDP的特点 面向数据报 UDP的缓冲区 UDP使用注意事项 基于UDP的应用层协议 TCP协议 TCP协议段格式 1.源端口号…...

centos7.9源码安装zabbix7.12,求赞
centos7.9源码安装zabbix7.12-全网独有 3.CentOS7_Zabbix7.0LTS3.1.安装环境3.2.换成阿里源3.3.安装相关依赖包3.3.1.直接安装依赖3.3.2.编译安装-遇到问题01-net-snmp3.3.3.编译安装-遇到问题02-libevent3.3.4.编译安装-遇到问题03-安装openssl 3.4.创建用户和组3.5.下载上传源…...

亚远景科技助力东风日产通过ASPICE CL2评估
热烈祝贺东风日产通过ASPICE CL2评估 近日,东风日产PK1B VCM热管理项目成功通过ASPICE CL2级能力评估,标志着东风日产在汽车电子软件研发管理体系及技术创新能力上已达到国际领先水平,为其全球化布局注入强劲动能。 ASPICE:国际竞…...

Go语言进阶④:Go的数据结构和Java的有啥不一样
Go语言进阶④:数据结构大冒险! ——写惯了 Java 的你,看 Go 的容器世界会头皮发麻吗? 一、写在前面:Java 程序员的容器情怀 在 Java 世界,你可能习惯了满手的 ArrayList、HashMap、Set、Queue 等容器类,配合着各种范型、接口和 Lambda 表达式,写得风生水起。 可一到…...
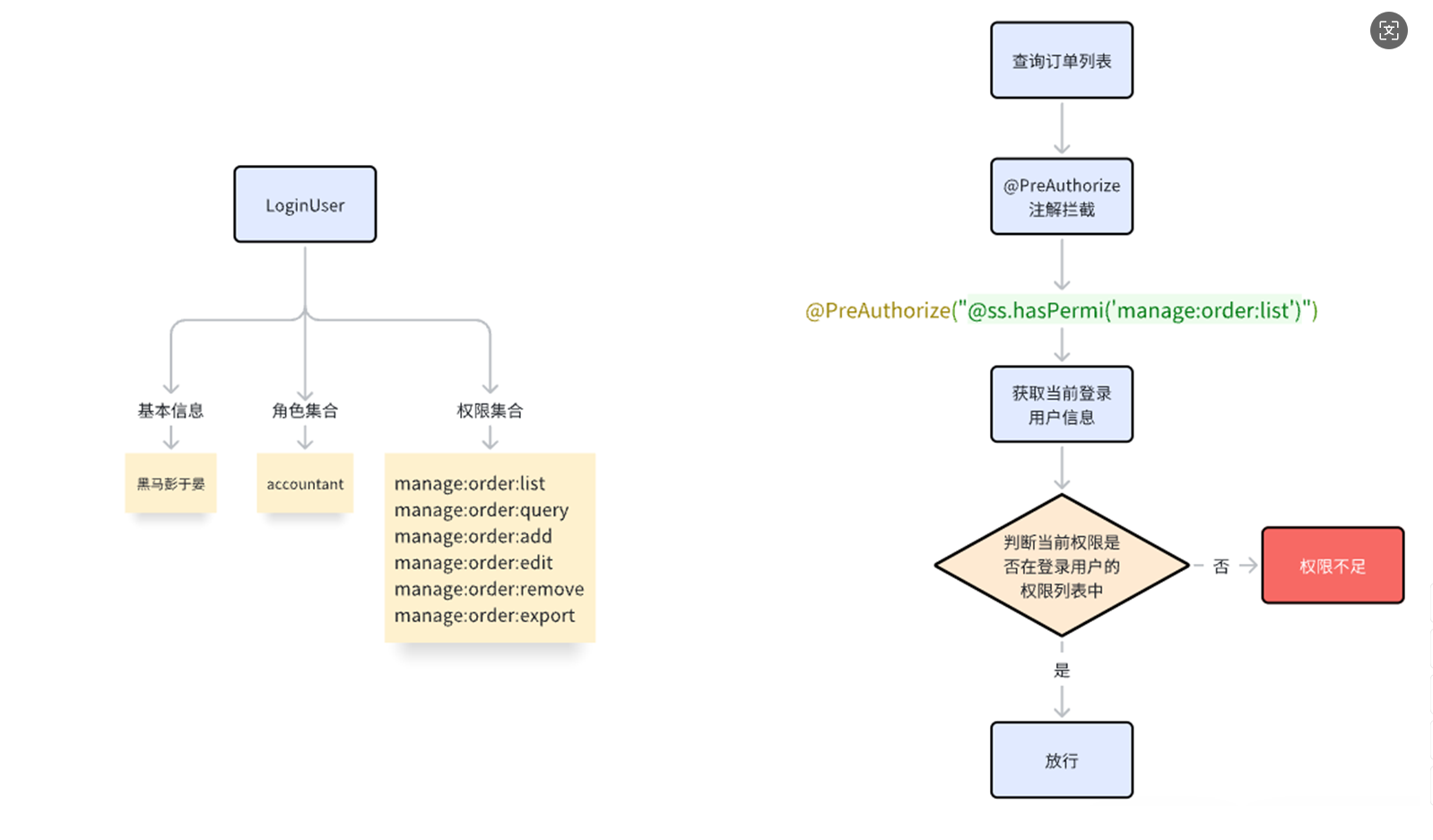
基于JWT+SpringSecurity整合一个单点认证授权机制
基于 JWT Spring Security 的授权认证机制,在整体架构设计上体现了高度的安全性与灵活性。其在整合框架中的应用,充分展示了模块化、可扩展性和高效鉴权的设计理念,为开发者提供了一种值得借鉴的安全架构模式。 1.SpringSecurity概念理解 …...
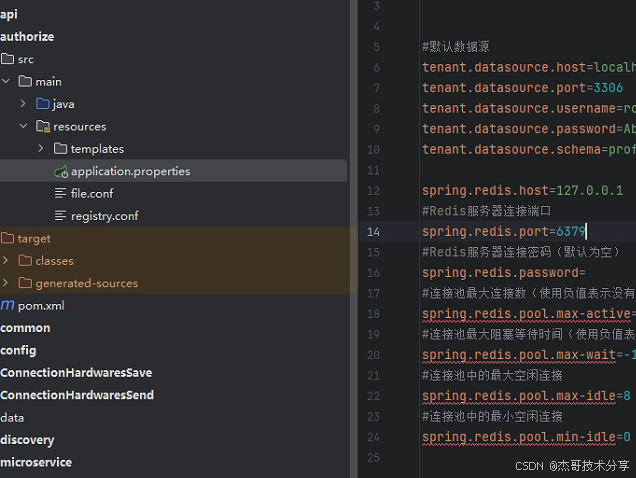
IDEA 打开文件乱码
问题:文件乱码 底部编码无法切换 解决方案: 第一步 使用Nodepad 查询文件编码 本项目设置为 转为 UTF-8 无 BOM 第二步:在 IntelliJ IDEA 中:右键点击文件 → File Encoding → 选择目标编码(如 UTF-8) 最…...
第2章:Neo4j安装与配置
在了解了Neo4j的基本概念和优势之后,下一步就是将其安装并配置好,以便开始实际操作。本章将详细介绍Neo4j的各种部署方式,涵盖不同操作系统的安装步骤,深入探讨关键配置项,并介绍常用的管理工具,为读者顺利…...
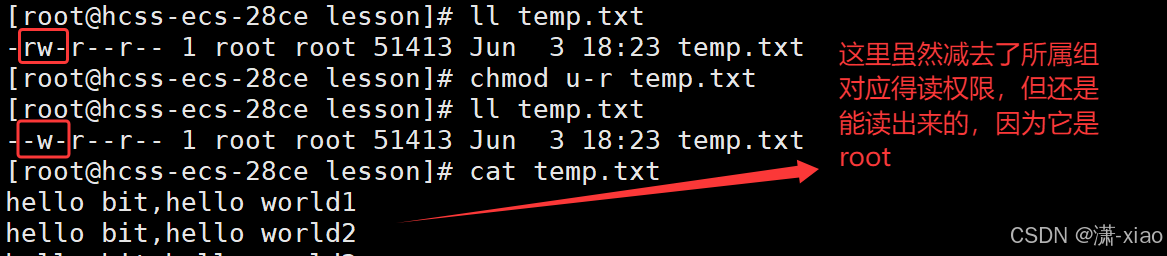
Shell 命令及运行原理 + 权限的概念(7)
文章目录 Shell 命令以及运行原理(4-1.22.08)Linux权限的概念1. 什么是权限2. 认识人(普通用户,root用户)以及两种用户的切换认识普通用户和root用户两种用户之间的切换指令提权 3. 文件的属性解析 权限属性指令ll显示…...
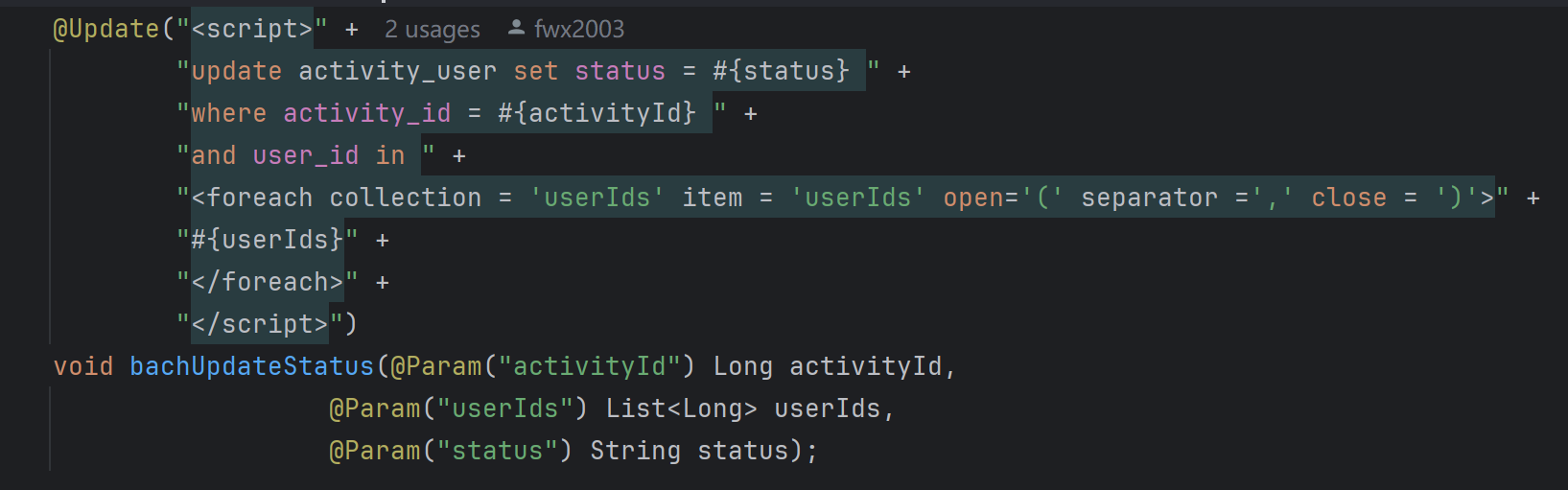
抽奖系统核心——抽奖管理
目录 前端逻辑: 核心全局变量: reloadConf函数: nextStep函数: 后端实现: 抽奖接口: Controller层: Service层: MqReceiver: drawPrizeService: statusConvert()方法: activityStatu…...

Android 蓝牙通信
Android 平台提供了完整的蓝牙 API,支持 传统蓝牙(Bluetooth Classic)和低功耗蓝牙(BBluetooth Low Energy, BLE)两种通信方式。 以下是开发蓝牙应用的关键知识点。 1. 基本概念 传统蓝牙(Bluetooth Classic) 适合大流量数据传输(如音频、文件传输) 典型协议: R…...

任务调度器-关于中心化调度 vs 去中心化调度的核心区别
1. 定义与架构模型 维度中心化调度去中心化调度核心角色存在一个中央调度器(如XXL-JOB的调度中心),统一管理任务分配、状态监控和故障处理。无中心节点,调度逻辑分散在多个节点,通过共识算法(如选举机制&a…...

二、【ESP32开发全栈指南:ESP32 GPIO深度使用】
GPIO(通用输入输出) 是ESP32最基础却最核心的功能。本文将带你深入ESP32的GPIO操作,通过按键读取和LED控制实现物理按键→ESP32→LED的完整信号链路。 一、ESP32 GPIO核心特性速览 34个可编程GPIO(部分引脚受限)输入模…...
)
力扣刷题(第四十九天)
灵感来源 - 保持更新,努力学习 - python脚本学习 反转链表 解题思路 迭代法:通过遍历链表,逐个改变节点的指针方向。具体步骤如下: 使用三个指针:prev(初始为None)、curr(初始为…...
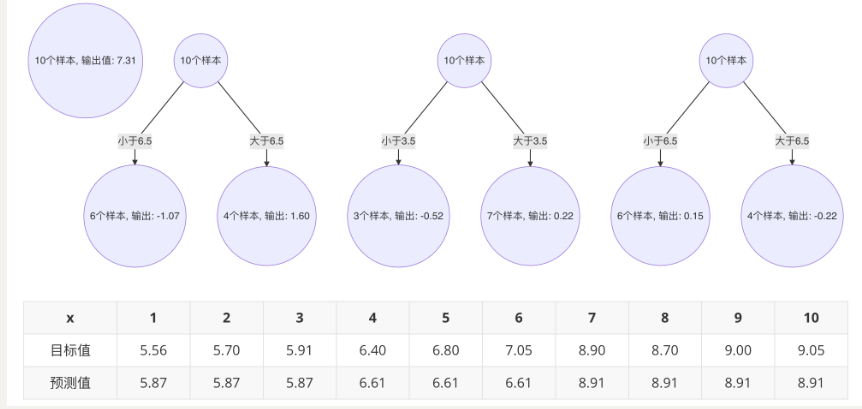
机器学习:集成学习概念和分类、随机森林、Adaboost、GBDT
本文目录: 一、集成学习概念**核心思想:** 二、集成学习分类(一)Bagging集成(二)Boosting集成(三)两种集成方法对比 三、随机森林(一)构造过程(二…...
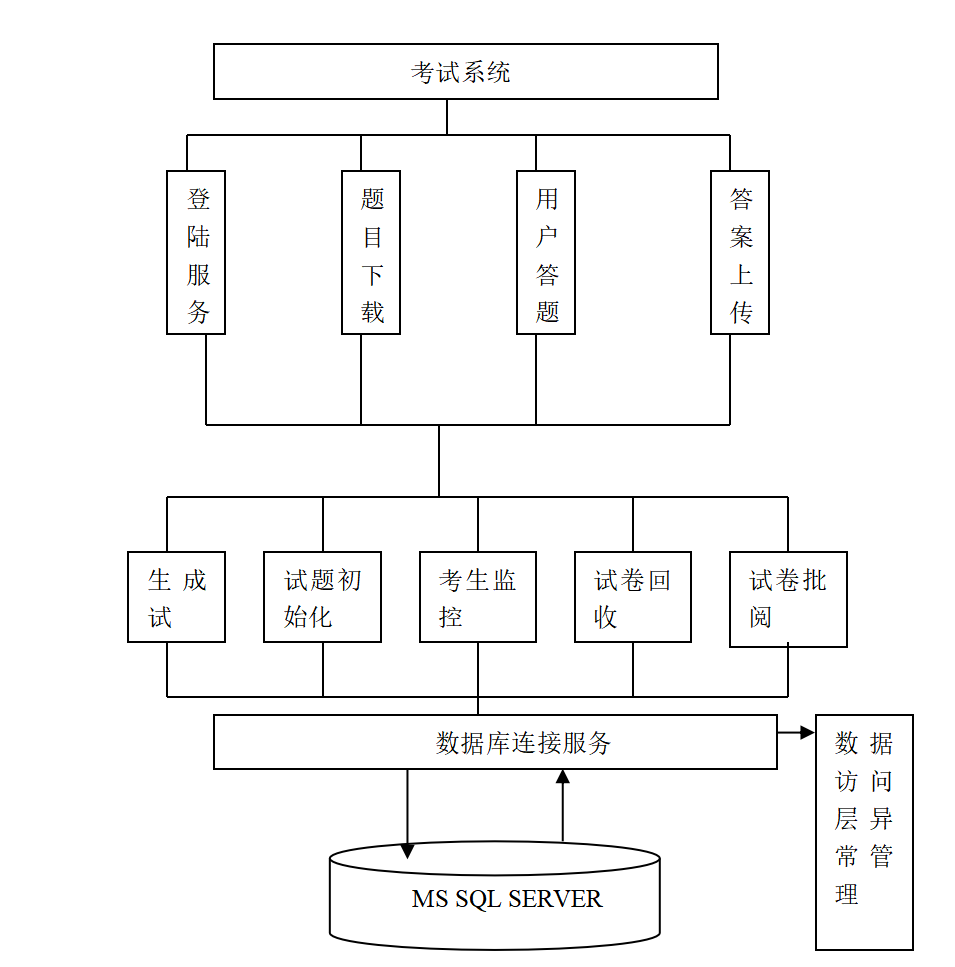
基于J2EE架构的在线考试系统设计与实现【源码+文档】
目录 摘要: Abstract: 1 引言 2 在线考试系统构架 2.1 在线考试系统一般需求分析 2.2 当前在线考试系统现状分析 2.3 基于J2EE的在线考试系统架构介绍及拥有的优势 2.3.1 结构总体介绍 2.3.2 客户层组件 2.3.2.1 Applets 2.3.2.2 应用程序客户端 2.3.3 …...

tpc udp http
TCP(传输控制协议)、UDP(用户数据报协议)和 HTTP(超文本传输协议)是网络通信中常用的三种协议,它们在不同的层次和场景中发挥作用。以下是对这三种协议的详细解释以及它们之间的区别:…...
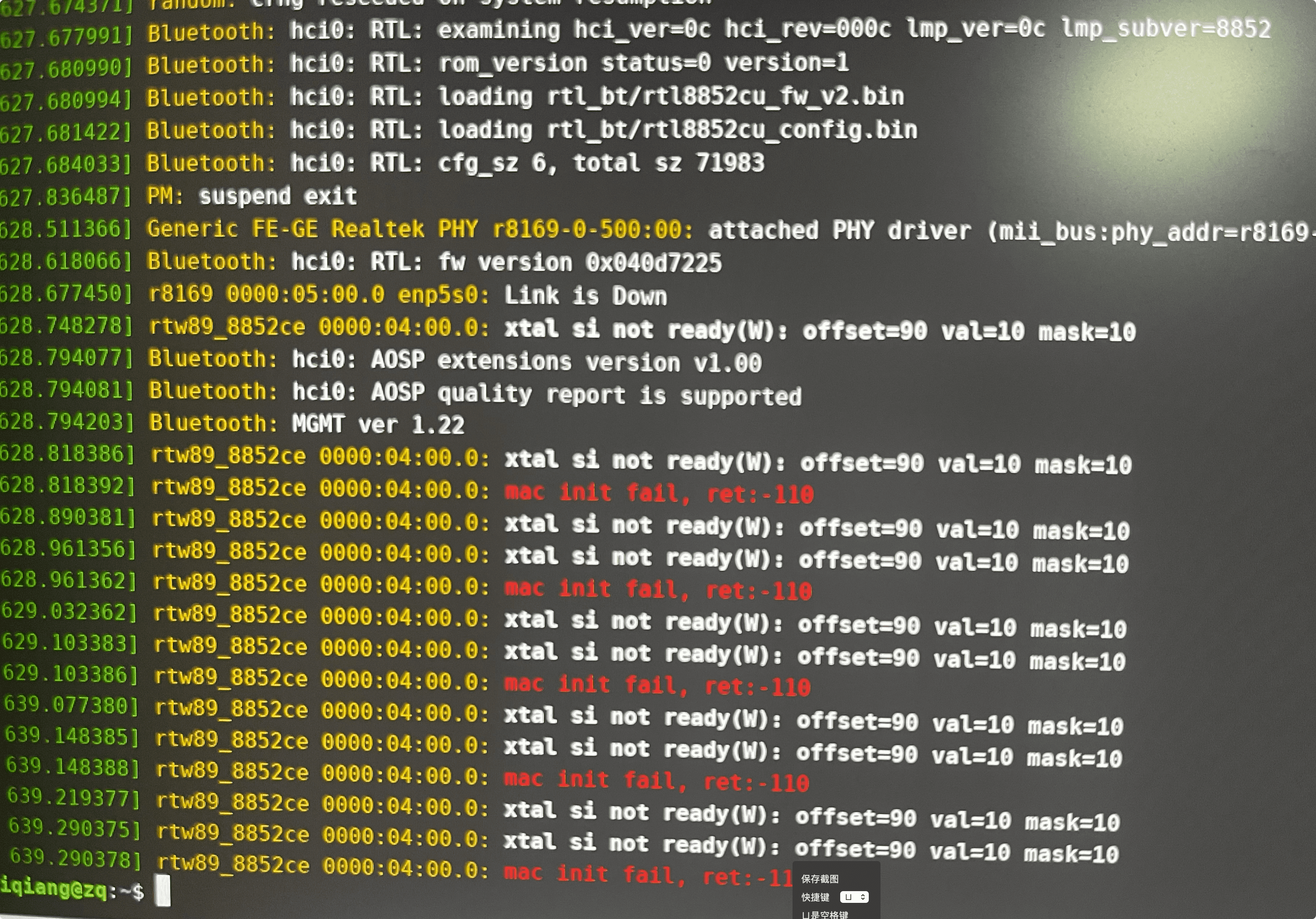
联想拯救者R9000P 网卡 Realtek 8852CE Ubuntu/Mint linux 系统睡眠后,无线网卡失效
联想拯救者R9000P 网卡型号 Realtek PCle GbE Family Controller Realtek 8852CE WiFi 6E PCI-E NIC 系统版本 Ubuntu 24.04 / mint 22.1 问题现象 rtw89_8852ce,Link is Down,xtal si not ready,mac init fail,xtal si not …...
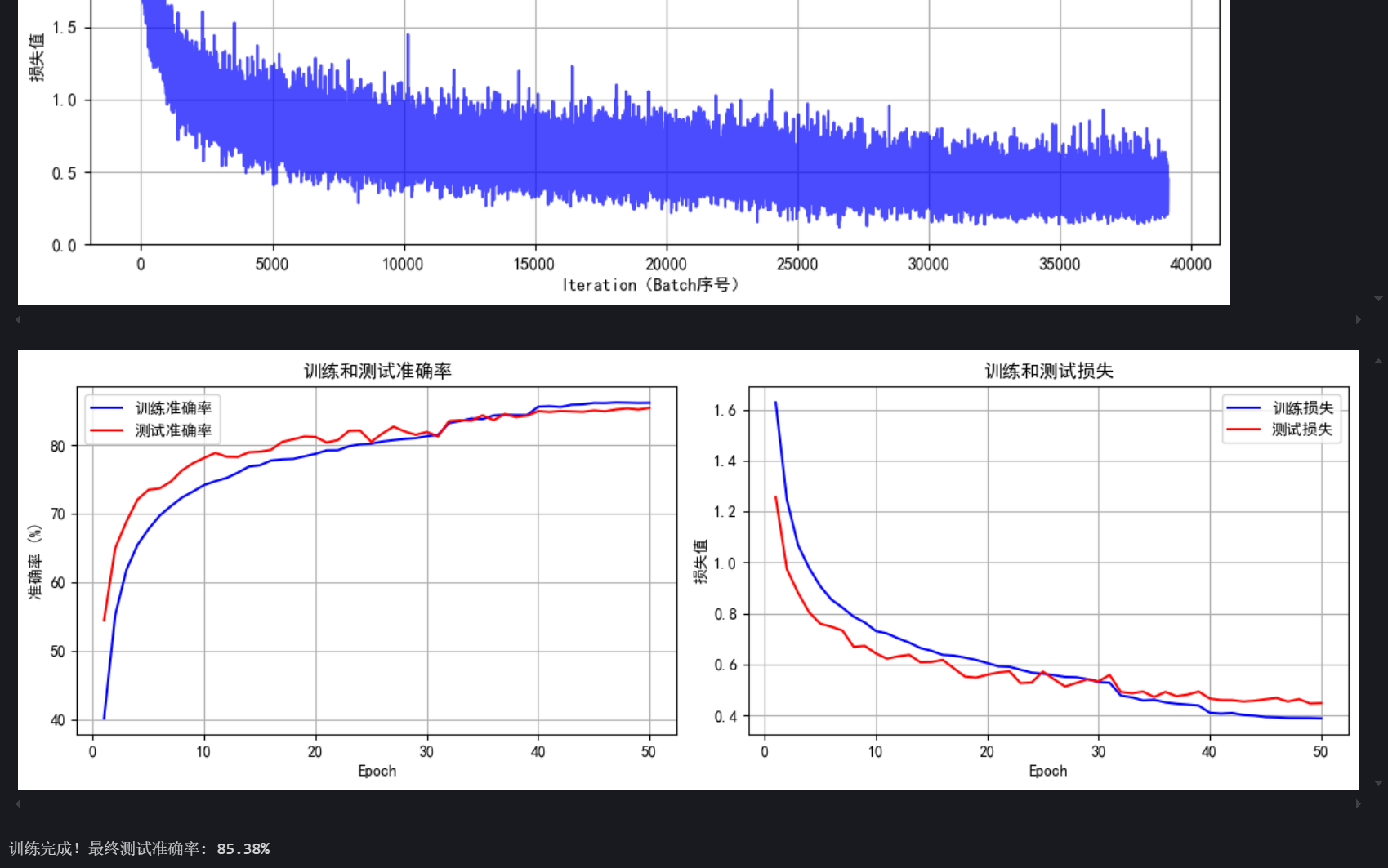
Python训练营打卡 Day46
道注意力(SE注意力) 知识点回顾: 不同CNN层的特征图:不同通道的特征图什么是注意力:注意力家族,类似于动物园,都是不同的模块,好不好试了才知道。通道注意力:模型的定义和插入的位置通道注意力后…...