Scrapy爬虫教程(新手)
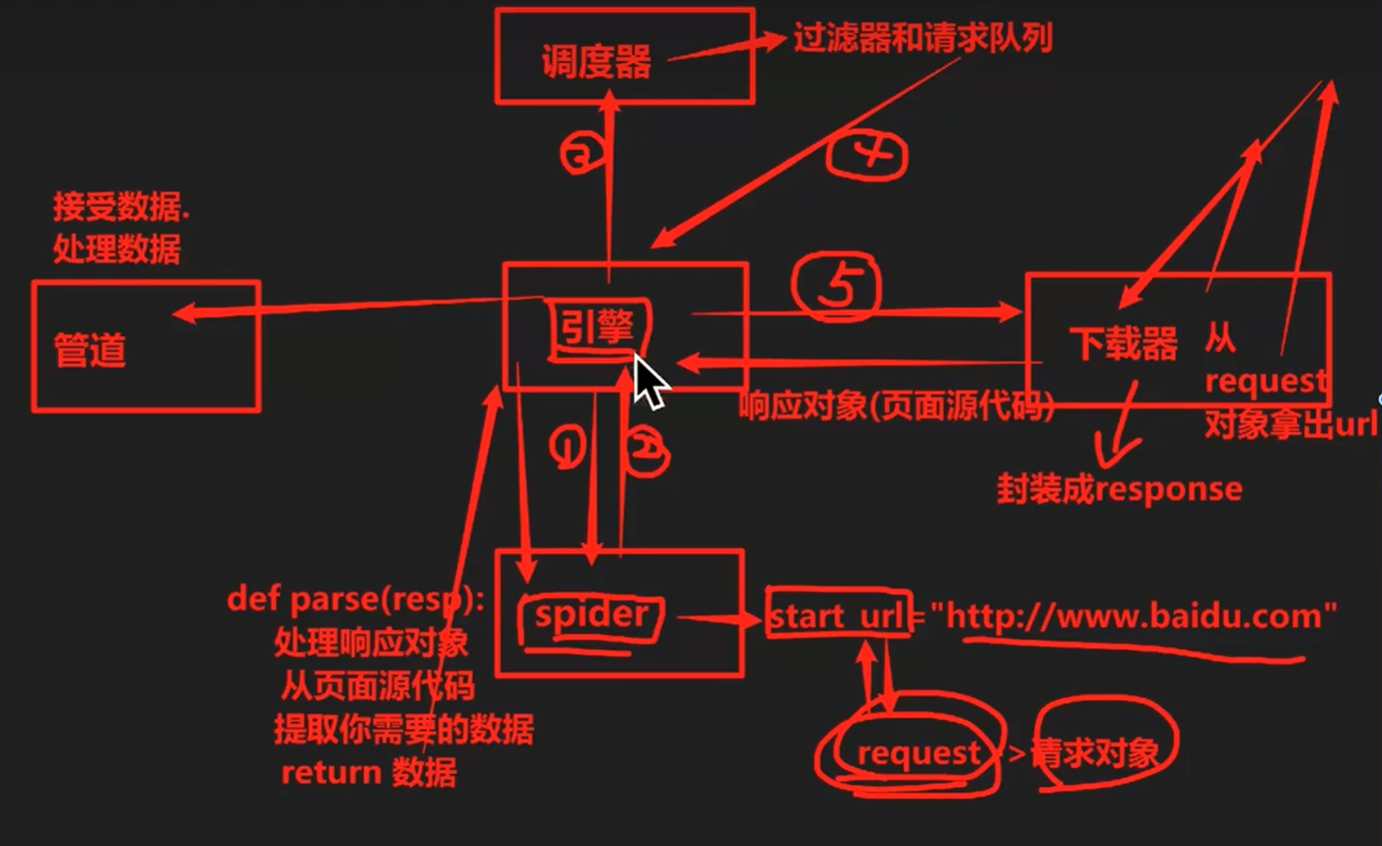
1. Scrapy的核心组成
引擎(engine):scrapy的核心,所有模块的衔接,数据流程梳理。
调度器(scheduler):本质可以看成一个集合和队列,里面存放着一堆即将要发送的请求,可以看成是一个url容器,它决定了下一步要爬取哪一个url,通常我们在这里可以对url进行去重操作。
下载器(downloader):本质是一个用来发动请求的模块,可以理解成是一个requests.get()的功能,只不过返回的是一个response对象。
爬虫(spider):负载解析下载器返回的response对象,从中提取需要的数据。
管道(pipeline):主要负责数据的存储和各种持久化操作。
2. 安装步骤
这里安装的scrapy版本为2.5.1版,在pycharm命令行内输入pip install scrapy==2.5.1即可。
pip install scrapy==2.5.1但是要注意OpenSSL的版本,其查看命令为
scrapy version --verbose
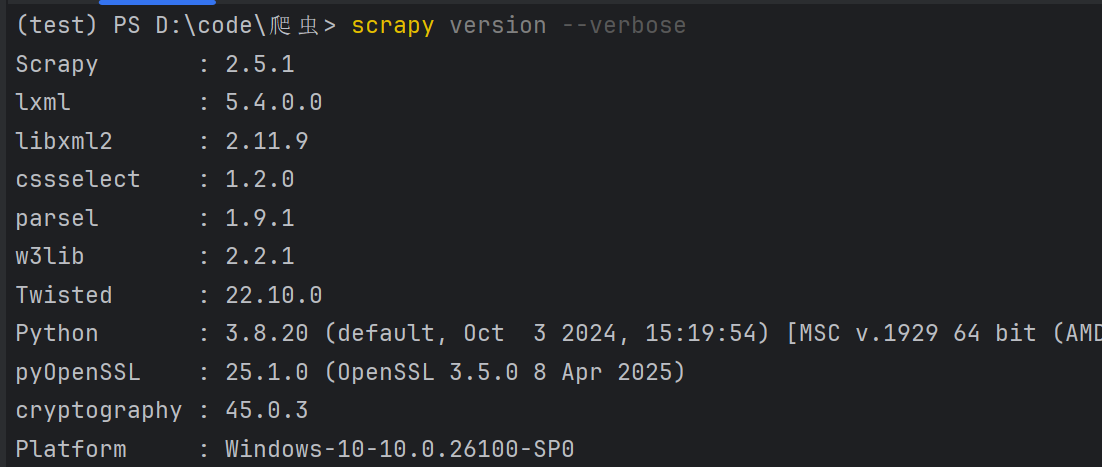
如果OpenSSL版本不为1.1版本的话,需要对其进行降级。
pip uninstall cryptography
pip install cryptography==36.0.2注:如果降级之后使用scrapy version --verbose出现错误:TypeError: deprecated() got an unexpected keyword argument 'name',可能是OpenSSL版本过低导致,这里需要根据自身情况,进行对应处理。
卸载cryptography:pip uninstall cryptography
重新安装cryptography 36.0.2:pip install cryptography==36.0.2
卸载pyOpenSSL:pip uninstall pyOpenSSL
重新安装pyOpenSSL 22.0.0:pip install pyOpenSSL==22.0.0 如果查看时出现错误:AttributeError: 'SelectReactor' object has no attribute '_handleSignals'
可能是由于Twisted版本问题,进行卸载重新安装Twisted即可。
pip uninstall Twisted
pip install Twisted==22.10.03. 基础使用
1.创建项目scrapy startproject 项目名
2.进入项目目录cd 项目名
3.生成spiderscrapy genspider 爬虫名字 网站的域名
4.调整spider给出start_urls以及如何解析数据
5.调整setting配置文件配置user_agent,robotstxt_obey,pipeline取消日志信息,留下报错,需调整日志级别 LOG_LEVEL
6.允许scrapy程序scrapy crawl 爬虫的名字
4. 案例分析
当使用 scrapy startproject csdn 之后,会出现csdn的文件夹
当输入 scrapy genspider csdn_spider blog.csdn.net 之后,会出现
我们这里以爬取自己csdn所发表的文章为例,在csdn_spider.py中编辑页面元素的定位方式
import scrapyclass CsdnSpiderSpider(scrapy.Spider):name = 'csdn_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/mozixiao__']def parse(self, response):print('===>',response)infos = response.xpath('//*[@id="navList-box"]/div[2]/div/div/div') #这里的路径需要注意的是,最后一个div不需要加确定的值,这里是一个模糊匹配,不然infos就只有一个信息for info in infos:title = info.xpath('./article/a/div/div[1]/div[1]/h4/text()').extract_first().strip()date = info.xpath('./article/a/div/div[2]/div[1]/div[2]/text()').extract_first().strip().split()[1]view = info.xpath('./article/a/div/div[2]/div[1]/div[3]/span/text()').extract_first().strip()dianzan = info.xpath('./article/a/div/div[2]/div[1]/div[4]/span/text()').extract_first().strip()pinglun = info.xpath('./article/a/div/div[2]/div[1]/div[5]/span/text()').extract_first().strip()shouchang = info.xpath('./article/a/div/div[2]/div[1]/div[6]/span/text()').extract_first().strip()yield {'title':title,'date':date,'view':view,'dianzan':dianzan,'pinglun':pinglun,'shouchang':shouchang}# print(title,date,view,dianzan,pinglun,shouchang)通过yield返回的数据会传到piplines.py文件中,在pipelines.py文件中进行数据的保存。
#管道想要使用要在setting开启
class CsdnPipeline:def process_item(self, item, spider):# print(type(item['title']),type(item['date']),type(item['view']),type(item['dianzan']),type(item['pinglun']),type(item['shouchang']))with open('data.csv',mode='a+',encoding='utf-8') as f:# line =f.write('标题:{} 更新日期:{} 浏览量:{} 点赞:{} 评论:{} 收藏:{} \n'.format(
item['title'],item['date'],item['view'],item['dianzan'],item['pinglun'],item['shouchang']))# f.write(f"标题:{item['title']} 更新日期:{item['date']} 浏览量:{item['view']} 点赞:{item['dianzan']} 评论:{item['pinglun']} 收藏:{item['shouchang']} \n")return item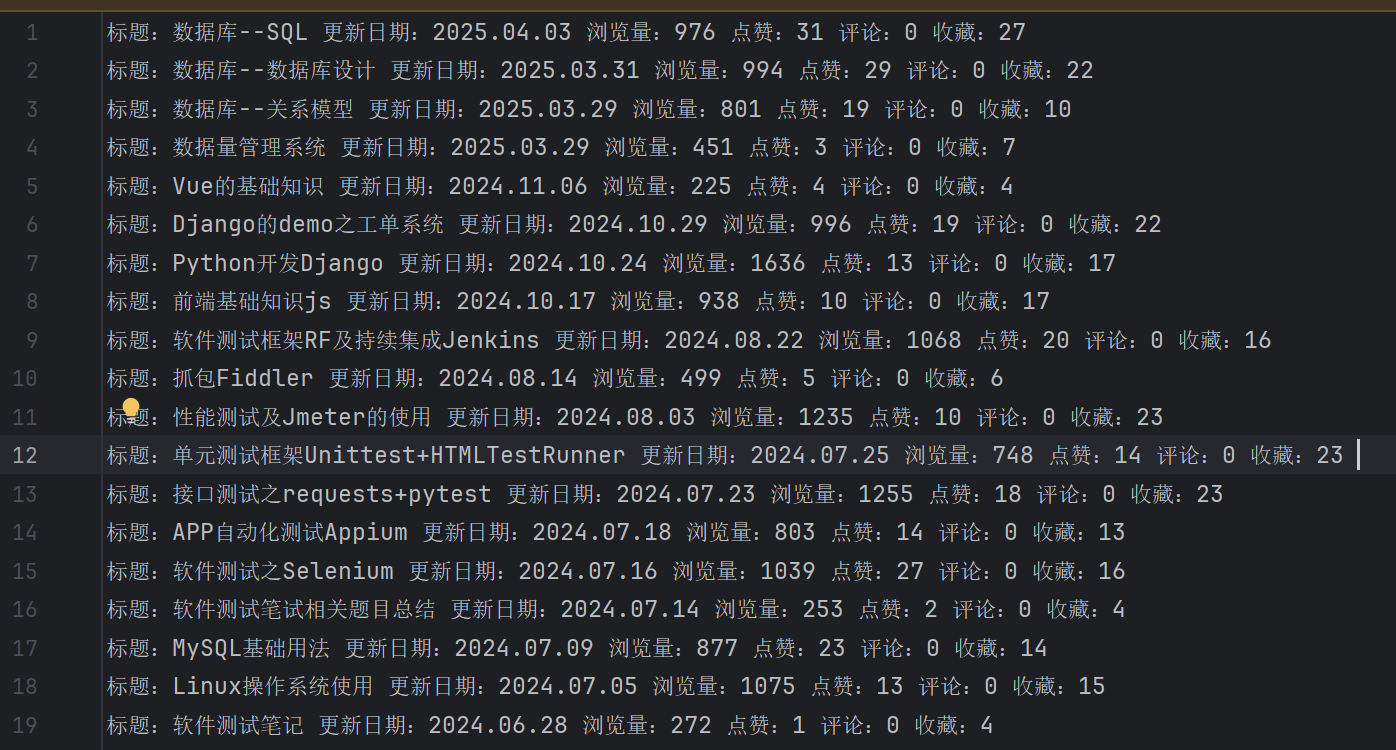
5. pipelines.py改进
上面的pipelines.py文件中对于文件的open次数与爬取的信息数量有关,为了减少文件的读取关闭操作,采用全局操作的方式。
class CsdnPipeline:def open_spider(self,spider):self.f = open('data.csv',mode='a+',encoding='utf-8')def close_spider(self,spider):self.f.close()def process_item(self, item, spider):self.f.write('标题:{} 更新日期:{} 浏览量:{} 点赞:{} 评论:{} 收藏:{} \n'.format(
item['title'],item['date'],item['view'],item['dianzan'],item['pinglun'],item['shouchang']))# f.write(f"标题:{item['title']} 更新日期:{item['date']} 浏览量:{item['view']} 点赞:{item['dianzan']} 评论:{item['pinglun']} 收藏:{item['shouchang']} \n")return item6. 爬虫时,当前页面爬取信息时,需要跳转到其他url
爬取当前页面时,爬取到的信息是一个url信息,这是需要将其与之前的url进行拼接。
以https://desk.zol.com.cn/dongman/为主url,/bizhi/123.html为跳转url为例。如果链接以 / 开头,需要拼接的是域名,最前面的 / 是根目录。结果为https://desk.zol.com.cn/bizhi/123.html。如果不是以 / 开头,需要冥界的是当前目录,同级文件夹中找到改内容。结果为https://desk.zol.com.cn/dongman/bizhi/123.html。
为了方便url的跳转,可以使用python中urllib库或者scrapy封装好的函数。
class PicSpiderSpider(scrapy.Spider):name = 'pic_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/mozixiao__']def parse(self, response):infos = response.xpath('')for info in infos:if info.endswith(''):continue#方法1from urllib.parse import urljoinchild_url = urljoin(response.url,info)#方法2child_url = response.urljoin(info)为了更好地处理跳转之后的链接(不需要用requests库写图片的提取),同时为了方式新的url继续跳转到parse,我们可以重写一个new_parse来处理跳转url。
import scrapy
from scrapy import Requestclass PicSpiderSpider(scrapy.Spider):name = 'pic_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/mozixiao__']def parse(self, response):infos = response.xpath('')for info in infos:if info.endswith(''):continue#方法1# from urllib.parse import urljoin# child_url = urljoin(response.url,info)#方法2child_url = response.urljoin(info)yield Request(child_url,callback=self.new_parse)def new_parse(self,response):img_src = response.xpath('')yield {"src":img_src}7. pipelines.py保存对象是图片或者文件等
from itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipeline
from scrapy.pipelines.files import FilesPipeline
from scrapy import Requestclass PicPipeline(ImagesPipeline):def get_media_requests(self,item,info):srcs = item['src']for src in srcs:yield Request(src,meta={'path':src})def file_path(self,request,response=None,info=None,*,item=None):path = request.meta['path']file_name = path.split('/')[-1]return '***/***/***/{}'.format(file_name)def item_completed(self, results, item,info):return item注:为了使图片可以成功的保存,需要在settings.py文件中设置一个IMAGES_STORE的路径。同时,如果在下载图片时,出现了302的问题,需要设置MEDIA_ALLOW_REDIRECTS。

8. Scrapy爬虫遇到分页跳转的时候
1.普通分页表现为:上一页 1,2,3,4,5,6 下一页类型1:观察页面源代码发现url直接在页面源代码里体现解决方案:1.访问第一页->提取下一个url,访问下一页2.直接观察最多大少爷,然后观察每一页url的变化类型2:观察页面源代码发现url不在页面源代码中体现解决方案:通过抓包找规律(可能在url上体现,也可能在参数上体现)
2.特殊分页类型1:显示为加载更多的图标,点击之后出来一推新的信息解决方案:通过抓包找规律类型2:滚动刷新,滑倒数据结束的时候会再次加载新数据这种通常的逻辑是:这一次更新时获得的参数会附加到下一次更新的请求中情况1:如果遇到分页跳转信息在url中体现,可以通过重写start_request的方式来进行
import scrapy
from scrapy import Requestclass FenyeSpiderSpider(scrapy.Spider):name = 'fenye_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/']def start_requests(self):num = int(input())for i in range(1,num):url = "https://***.com/page_{}.html".format(i)yield Request(url)def parse(self, response):pass情况2:分页跳转信息的url体现在的页面源代码中
import scrapy
from scrapy import Requestclass FenyeSpiderSpider(scrapy.Spider):name = 'fenye_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/page_1.html']def parse(self, response):infos = response.xpath('')for info in infos:if info.startswith('***'):continuechild_info = response.urljoin(info)#这里无需考虑死循环的问题,scrapy中的调度器会自动去重yield Request(child_info,callback=self.parse)9. Scrapy面对带有cookie的信息页面时的登陆操作
1.常规登录网站会在cookie中写入登录信息,在登陆成功之后,返回的响应头里面会带着set-cookie字样,后续的请求会在请求头中加入cookie内容可以用session来自动围护响应头中的set-cookie
2. ajax登陆登陆后,从浏览器中可能发现响应头没有set-cookie信息,但是在后续的请求中存在明显的cookie信息该情况90%的概率是:cookie通过JavaScript脚本语言动态设置,seesion就不能自动维护了,需要通过程序手工去完成cookie的拼接
3. 依然是ajax请求,也没有响应头,也是js和2的区别是,该方式不会把登录信息放在cookie中,而是放在storage里面。每次请求时从storage中拿出登录信息放在请求参数中。这种方式则必须要做逆向。该方式有一个统一的解决方案,去找公共拦截器。
方法1,直接在settings.py文件中设置请求头信息。但是由于scrapy(引擎和下载器之间的中间件)会自动管理cookie,因此设置时,也需要将COOKIES_ENABLED设置为False

方法2,重写start_requests函数,将cookie作为参数传入
import scrapy
from scrapy import Requestclass LoginSpiderSpider(scrapy.Spider):name = 'login_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/']def start_requests(self):cookie_info = ""cookie_dic = {}for item in cookie_info.split(';'):item = item.strip()k,v = item.split('=',1)cookie_dic[k]=v#需要注意的是,这里的cookie要以自己的参数传入,而不是字符串yield Request(self.start_urls[0],cookies=cookie_dic)def parse(self, response):pass方法3,自己走一个登录流程,登录之后,由于scrapy(引擎和下载器之间的中间件)会自己管理cookie信息,所以直接执行start_urls即可。
import scrapy
from scrapy import Requestclass LoginSpiderSpider(scrapy.Spider):name = 'login_spider'allowed_domains = ['blog.csdn.net']start_urls = ['http://blog.csdn.net/']def start_requests(self):login_url = "https://blog.csdn.net/login"data = {'login':'123456','password':'123456'}#但是这里要注意,Request中的body需要传入的是字符串信息,而不是字典#方法1login_info = []for k,v in data.items():login_info.append(k+"="+v)login_info = '&'.join(login_info)#方法2from urllib.parse import urlencodelogin_info = urlencode(data)yield Request(login_url,method='POST',body=login_info)def parse(self, response):pass10. Scrapy中间件
中间件位于middlewares.py文件中,
11. Scrapy之链接url提取器
上面提到当爬虫需要跳转url时,需要使用urljoin的函数来进行url的凭借,这个操作可以使用LinkExtractor来简化。
from urllib.request import Request
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy import Request
import reclass LinkSpiderSpider(scrapy.Spider):name = 'link_spider'allowed_domains = ['4399.com']start_urls = ['https://www.4399.com/flash_fl/5_1.htm']def parse(self, response):# print(response.text)game_le = LinkExtractor(restrict_xpaths=("//ul[@class='list affix cf']/li/a",))game_links = game_le.extract_links(response)for game_link in game_links:# print(game_link.url)yield Request(url=game_link.url,callback=self.game_name_date)if '5_1.htm' in response.url:page_le = LinkExtractor(restrict_xpaths=("//div[@class='bre m15']//div[@class='pag']/a",))else:page_le = LinkExtractor(restrict_xpaths=("//div[@class='pag']/a",))page_links = page_le.extract_links(response)for page_link in page_links:# print(page_link.url)yield Request(url=page_link.url,callback=self.parse)def game_name_date(self,response):try:name = response.xpath('//*[@id="skinbody"]/div[7]/div[1]/div[1]/div[2]/div[1]/h1/a/text()')info = response.xpath('//*[@id="skinbody"]/div[7]/div[1]/div[1]/div[2]/div[2]/text()')if not info:info = response.xpath('//*[@id="skinbody"]/div[6]/div[1]/div[1]/div[2]/div[2]/text()')# print(name,info)# print(1)name = name.extract_first()infos = info.extract()[1].strip()size = re.search(r'大小:(.*?)M',infos).group(1)date = re.search(r'日期:(\d{4}-\d{2}-\d{2})',infos).group(1)yield {'name':name,'size':size+'M','date':date}except Exception as e:print(e,info,response.url)12. 增量式爬虫
当爬取的数据中包含之前访问过的数据时,需要对url进行判断,以保证不重复爬取。增量式爬虫不能将中间数据存储在内存级别的存储,只能选择硬盘上的存储。
import scrapy
from redis import Redis
from scrapy import Request,signalsclass ZengliangSpiderSpider(scrapy.Spider):name = 'zengliang_spider'allowed_domains = ['4399.com']start_urls = ['http://4399.com/']#观察到middlewares中间间中的写法,想要减少程序连接redis数据库的次数@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()#如果遇到Crawler中找不到当前spider时,可以参考父类中的写法,将去copy过来#s._set_crawler(crawler)crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)return sdef spider_opened(self, spider):self.red = Redis(host='',port=123,db=3,password='')def spider_closed(self,spider):self.red.save()self.red.close()def parse(self, response):hrefs = response.xpath('').extract()for href in hrefs:href = response.urljoin(href)if self.red.sismember('search_path',href):continueyield Request(url=href,callback=self.new_parse,meta={'href':href} #防止url重定向)def new_parse(self,response):href = response.meta.get('href')self.red.sadd('save_path',href)pass13. 分布式爬虫
scrapy可以借助scrapy-redis插件来进行分布式爬虫,但要注意两个库的版本问题。
与普通的scrapy不同,redis版本的在spider文件中继承时采用redis的继承。
from scrapy_redis.spiders import RedisSpiderclass FbSpider(RedisSpider):name = 'fb'allowed_domains = ['4399.com']redis_key = "path"def parse(self, response):pass同时,需要在settings.py中设置redis相关的信息。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER_PERSIST = TrueITEM_PIPELINES = {'fenbu.pipelines.FenbuPipeline': 300,'scrapy_redis.pipelines.RedisPipeline':301
}
REDIS_HOST = ''
REDIS_PORT = ''
REDIS_DB = ''
REDIS_PARAMS = {'':''
}以上这些就是我关于scrapy爬虫的基本学习,有疑问可以相互交流。
相关文章:
Scrapy爬虫教程(新手)
1. Scrapy的核心组成 引擎(engine):scrapy的核心,所有模块的衔接,数据流程梳理。 调度器(scheduler):本质可以看成一个集合和队列,里面存放着一堆即将要发送的请求&#…...

数据可视化大屏案例落地实战指南:捷码平台7天交付方法论
分享大纲: 1、落地前置:数据可视化必备的规划要素 2、数据可视化双路径开发 3、验证案例:数据可视化落地成效 在当下数字化转型浪潮中,数据可视化建设已成为关键环节。数据可视化大屏的落地,成为企业数据可视化建设的难…...

第五篇:Go 并发模型全解析——Channel、Goroutine
第五篇:Go 并发模型全解析——Channel、Goroutine 一、序章:Java 的并发往事 在 Java 世界中,说到“并发”,你可能立马想到以下名词:Thread、Runnable、ExecutorService、synchronized、volatile。再复杂点,ReentrantLock、CountDownLatch、BlockingQueue 纷纷登场,仿…...

锁的艺术:深入浅出讲解乐观锁与悲观锁
在多线程和分布式系统中,数据一致性是一个核心问题。锁机制作为解决并发冲突的重要手段,被广泛应用于各种场景。乐观锁和悲观锁是两种常见的锁策略,它们在设计理念、实现方式和适用场景上各有特点。本文将深入探讨乐观锁和悲观锁的原理、实现…...
)
在网页加载时自动运行js的方法(2025最新)
在网页加载时自动运行JavaScript方法有多种实现方式,以下是常见的几种方法: 1. 使用 DOMContentLoaded 事件 当初始HTML文档完全加载和解析后触发(无需等待图片等资源加载): document.addEventListener(DOMC…...

在Windows下编译出llama_cpp_python的DLL后,在虚拟环境中使用方法
定位编译生成的文件 在VS2022编译完成后,在构建目录(如build/Release或build/Debug)中寻找以下关键文件: ggml.dll、ggml_base.dll、ggml_cpu.dll、ggml_cuda.dll、llama.dll(核心动态链接库) llama_cp…...

CSS radial-gradient函数详解
目录 基本语法 关键参数详解 1. 渐变形状(Shape) 2. 渐变大小(Size) 3. 中心点位置(Position) 4. 颜色断点(Color Stops) 常见应用场景 1. 基本圆形渐变 2. 椭圆渐变 3. 模…...
)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南) n8n 是一个强大的可视化工作流自动化工具,支持无代码或低代码地集成各种服务。本文将手把手教你如何通过 Docker 快速部署 n8n,并介绍如何使用 PostgreSQL、设置时区以…...
关于datetime获取时间的问题
import datetime print(datetime.now())如果用上述代码,会报错: 以下才是正确代码: from datetime import datetime print(datetime.now()) 结果: 如果想格式化时间,使用代码: from datetime import da…...

前端面试五之vue2基础
1.属性绑定v-bind(:) v-bind 是 Vue 2 中用于动态绑定属性的核心指令,它支持多种语法和用法,能够灵活地绑定 DOM 属性、组件 prop,甚至动态属性名。通过 v-bind,可以实现数据与视图之间的高效同…...

使用python实现奔跑的线条效果
效果,展示(视频效果展示): 奔跑的线条 from turtle import * import time t1Turtle() t2Turtle() t3Turtle() t1.hideturtle() t2.hideturtle() t3.hideturtle() t1.pencolor("red") t2.pencolor("green") t3…...

Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS
Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS 一 AUDIT_TRAIL 参数 1.1 参数功能 AUDIT_TRAIL 是 Oracle 数据库中最核心的审计控制参数,决定审计记录的存储位置和记录方式。 1.2 参数取值及含义 取值说明适用场景NONE禁用数据库审计测试环…...

Android LinearLayout、FrameLayout、RelativeLayout、ConstraintLayout大混战
一、为什么布局性能如此重要? 在Android应用中,布局渲染耗时直接决定了界面的流畅度。根据Google官方数据,超过60%的卡顿问题源于布局性能不佳。本文将彻底解析三大传统布局的性能奥秘,并提供可直接落地的优化方案。 二、三大布局…...
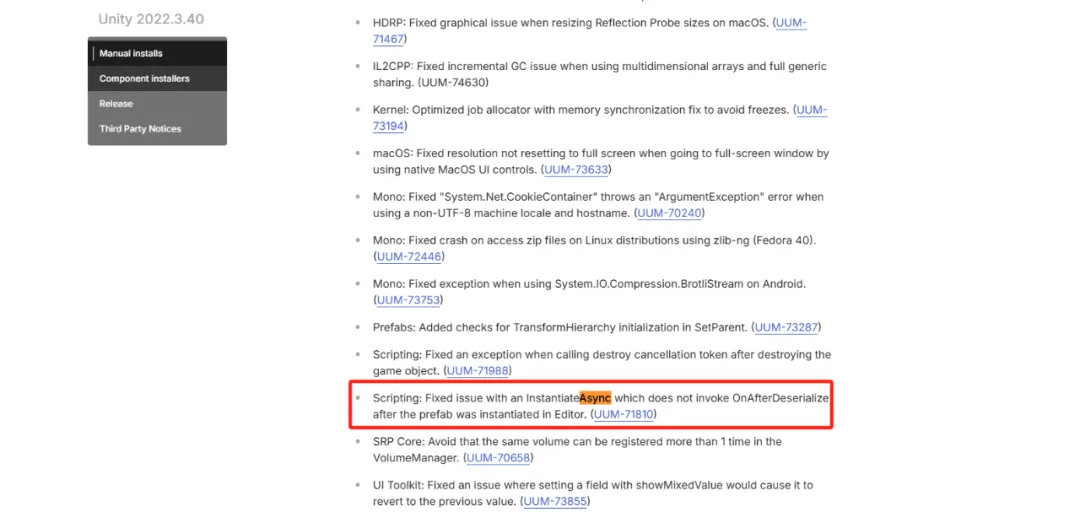
Unity版本使用情况统计(更新至2025年5月)
UWA发布|本期UWA发布的内容是Unity版本使用统计(第十六期),统计周期为2024年11月至2025年5月,数据来源于UWA网站(www.uwa4d.com)性能诊断提测的项目。希望给Unity开发者提供相关的行业趋势作为参…...

GPUCUDA 发展编年史:从 3D 渲染到 AI 大模型时代(上)
目录 文章目录 目录1960s~1999:GPU 的诞生:光栅化(Rasterization)3D 渲染算法的硬件化实现之路 学术界算法研究历程工业界产品研发历程光栅化技术原理光栅化技术的软件实现:OpenGL 3D 渲染管线设计 1. 顶点处理&…...
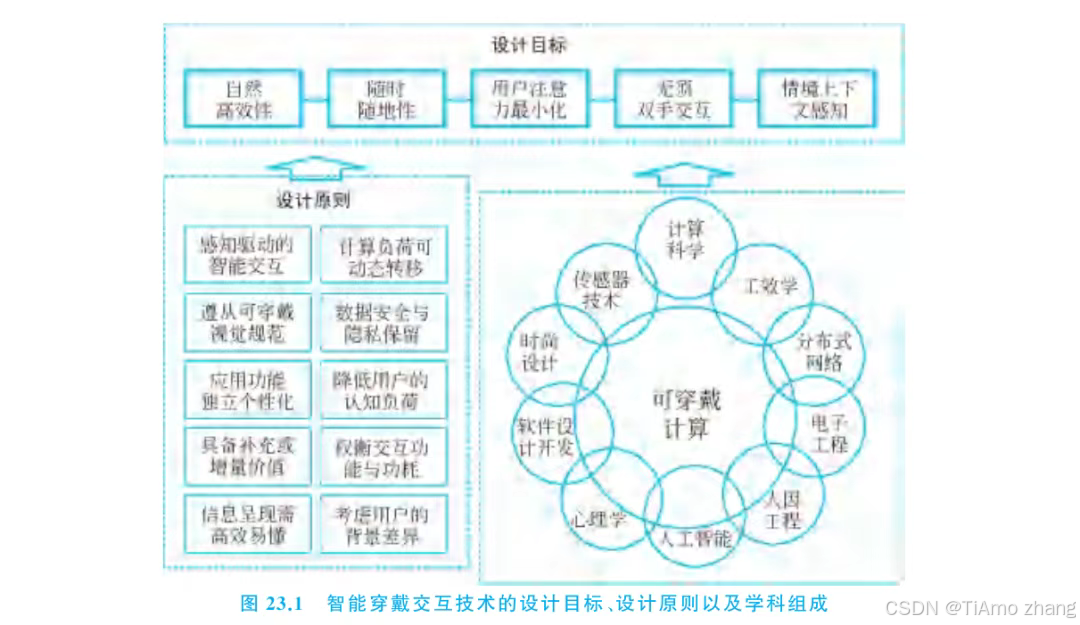
人机融合智能 | 可穿戴计算设备的多模态交互
可穿戴计算设备可以对人体以及周围环境进行连续感知和计算,为用户提供随时随地的智能交互服务。本章主要介绍人机智能交互领域中可穿戴计算设备的多模态交互,阐述以人为中心的智能穿戴交互设计目标和原则,为可穿戴技术和智能穿戴交互技术的设计提供指导,进而简述支持智能穿戴交…...
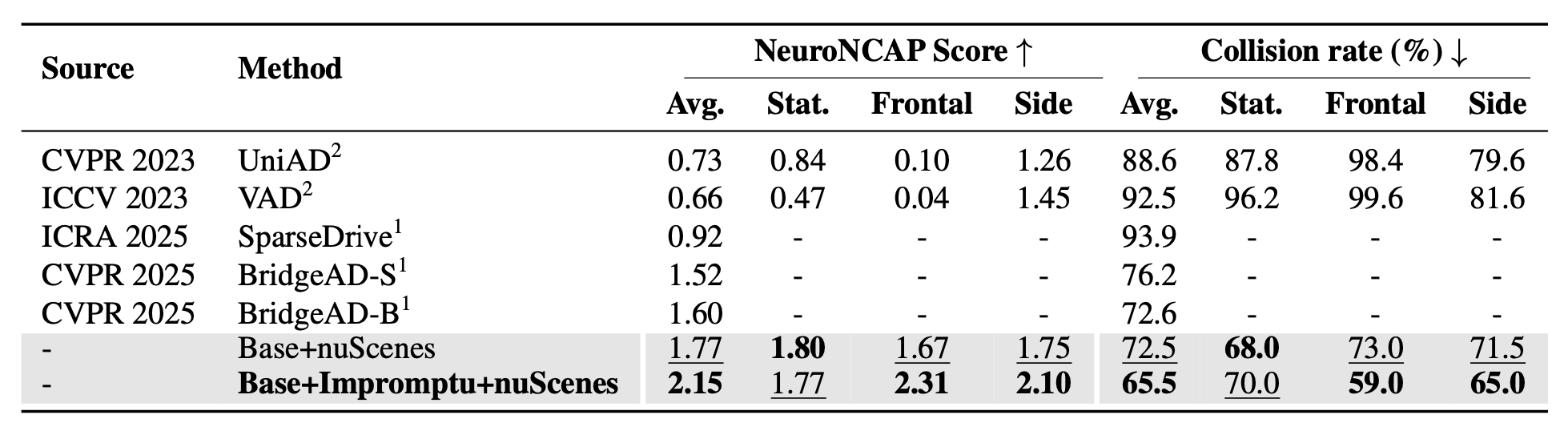
Impromptu VLA:用于驾驶视觉-语言-动作模型的开放权重和开放数据
25年5月来自清华和博世的论文“Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models”。 用于自动驾驶的“视觉-语言-动作” (VLA) 模型前景光明,但在非结构化极端场景下却表现不佳,这主要是由于缺乏有针对性的基准测…...

AI智能体,为美业后端供应链注入“智慧因子”(4/6)
摘要:本文深入剖析美业后端供应链现状,其产品具有多样性、更新换代快等特点,原料供应和生产环节也面临诸多挑战。AI 智能体的登场为美业后端供应链带来变革,包括精准需求预测、智能化库存管理、优化生产计划排程、升级供应商管理等…...
跨平台资源下载工具:res-downloader 的使用体验
一款基于 Go Wails 的跨平台资源下载工具,简洁易用,支持多种资源嗅探与下载。res-downloader 一款开源免费的下载软件(开源无毒、放心使用)!支持Win10、Win11、Mac系统.支持视频、音频、图片、m3u8等网络资源下载.支持视频号、小程序、抖音、…...

ps蒙版介绍
一、蒙版的类型 Photoshop中有多种蒙版类型,每种适用于不同的场景: 图层蒙版(Layer Mask) 作用:控制图层的可见性,黑色隐藏、白色显示、灰色半透明。特点:可随时编辑,适合精细调整。…...
数据湖是什么?数据湖和数据仓库的区别是什么?
目录 一、数据湖是什么 (一)数据湖的定义 (二)数据湖的特点 二、数据仓库是什么 (一)数据仓库的定义 (二)数据仓库的特点 三、数据湖和数据仓库的区别 (一&#…...

用Ai学习wxWidgets笔记——在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程
声明:本文整理筛选Ai工具生成的内容辅助写作,仅供参考 >> 在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程 下面是一步步指导如何在 VS Code 中配置 wxWidgets 开发环境,包括跨平台设置(Windows 和 Linux)。…...

【深度学习新浪潮】如何入门三维重建?
入门三维重建算法技术需要结合数学基础、计算机视觉理论、编程实践和项目经验,以下是系统的学习路径和建议: 一、基础知识储备 1. 数学基础 线性代数:矩阵运算、向量空间、特征分解(用于相机矩阵、变换矩阵推导)。几何基础:三维几何(点、线、面的表示)、射影几何(单…...

Android实现点击Notification通知栏,跳转指定activity页面
效果 1、点击通知栏通知,假如app正在运行,则直接跳转到指定activity显示具体内容,在指定activity中按返回键返回其上一级页面。 2、点击通知栏通知,假如app已经退出,先从SplashActivity进入,显示app启动界…...
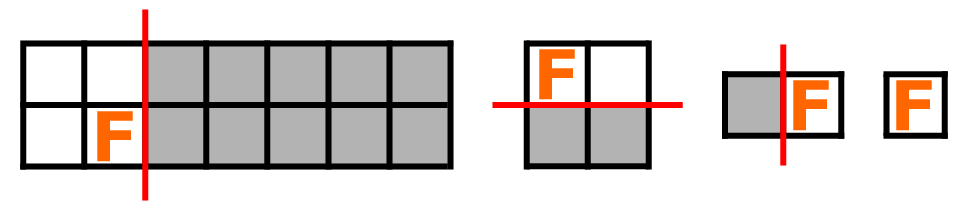
Codeforces Round 1025 (Div. 2) B. Slice to Survive
Codeforces Round 1025 (Div. 2) B. Slice to Survive 题目 Duelists Mouf and Fouad enter the arena, which is an n m n \times m nm grid! Fouad’s monster starts at cell ( a , b ) (a, b) (a,b), where rows are numbered 1 1 1 to n n n and columns 1 1 1 t…...
ubuntu中使用docker
上一篇我已经下载了一个ubuntu:20.04的镜像; 1. 查看所有镜像 sudo docker images 2. 基于本地存在的ubuntu:20.04镜像创建一个容器,容器的名为cppubuntu-1。创建的时候就会启动容器。 sudo docker run -itd --name cppubuntu-1 ubuntu:20.04 结果出…...

复制与图片文件同名的标签文件到目标路径
引言:在数据集构建中,我们经常需要挑选一些特殊类型的图片(如:零件中有特殊脏污背景的图片,写论文的时候想单独对这类情况进行热力图验证)。我们把挑选出来的图片放到一个文件夹下,这时候我想快…...

【深度学习-Day 24】过拟合与欠拟合:深入解析模型泛化能力的核心挑战
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...
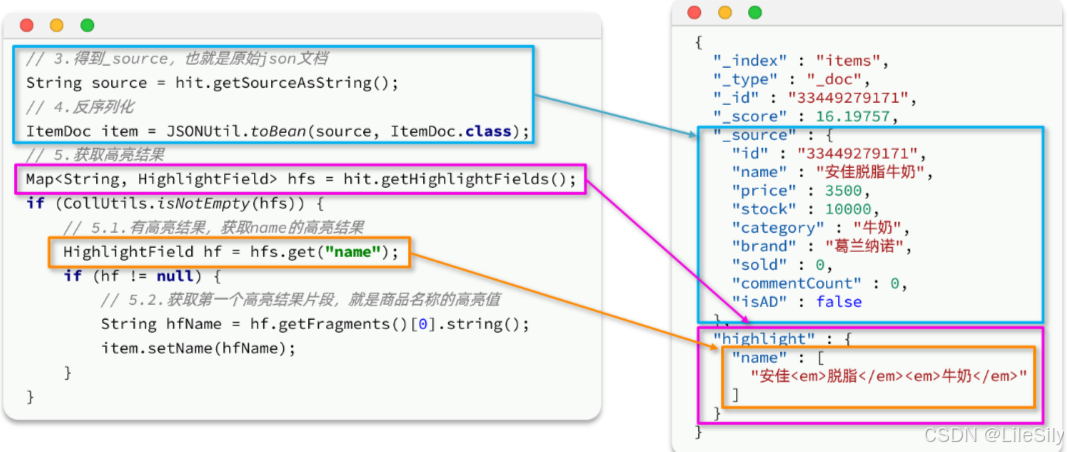
[ElasticSearch] DSL查询
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

iview中的table组件点击一行中的任意一点选中本行
<Table border ref"selection" size"small" on-row-click"onClickRow"></Table>// table组件点击一行任意位置选中onClickRow(row, index) {this.$refs.selection.toggleSelect(index)}写上toggleSelect(index)方法即可,…...