【深度学习-Day 24】过拟合与欠拟合:深入解析模型泛化能力的核心挑战
Langchain系列文章目录
01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南
02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖
03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南
04-玩转 LangChain:从文档加载到高效问答系统构建的全程实战
05-玩转 LangChain:深度评估问答系统的三种高效方法(示例生成、手动评估与LLM辅助评估)
06-从 0 到 1 掌握 LangChain Agents:自定义工具 + LLM 打造智能工作流!
07-【深度解析】从GPT-1到GPT-4:ChatGPT背后的核心原理全揭秘
08-【万字长文】MCP深度解析:打通AI与世界的“USB-C”,模型上下文协议原理、实践与未来
Python系列文章目录
PyTorch系列文章目录
机器学习系列文章目录
深度学习系列文章目录
Java系列文章目录
JavaScript系列文章目录
深度学习系列文章目录
01-【深度学习-Day 1】为什么深度学习是未来?一探究竟AI、ML、DL关系与应用
02-【深度学习-Day 2】图解线性代数:从标量到张量,理解深度学习的数据表示与运算
03-【深度学习-Day 3】搞懂微积分关键:导数、偏导数、链式法则与梯度详解
04-【深度学习-Day 4】掌握深度学习的“概率”视角:基础概念与应用解析
05-【深度学习-Day 5】Python 快速入门:深度学习的“瑞士军刀”实战指南
06-【深度学习-Day 6】掌握 NumPy:ndarray 创建、索引、运算与性能优化指南
07-【深度学习-Day 7】精通Pandas:从Series、DataFrame入门到数据清洗实战
08-【深度学习-Day 8】让数据说话:Python 可视化双雄 Matplotlib 与 Seaborn 教程
09-【深度学习-Day 9】机器学习核心概念入门:监督、无监督与强化学习全解析
10-【深度学习-Day 10】机器学习基石:从零入门线性回归与逻辑回归
11-【深度学习-Day 11】Scikit-learn实战:手把手教你完成鸢尾花分类项目
12-【深度学习-Day 12】从零认识神经网络:感知器原理、实现与局限性深度剖析
13-【深度学习-Day 13】激活函数选型指南:一文搞懂Sigmoid、Tanh、ReLU、Softmax的核心原理与应用场景
14-【深度学习-Day 14】从零搭建你的第一个神经网络:多层感知器(MLP)详解
15-【深度学习-Day 15】告别“盲猜”:一文读懂深度学习损失函数
16-【深度学习-Day 16】梯度下降法 - 如何让模型自动变聪明?
17-【深度学习-Day 17】神经网络的心脏:反向传播算法全解析
18-【深度学习-Day 18】从SGD到Adam:深度学习优化器进阶指南与实战选择
19-【深度学习-Day 19】入门必读:全面解析 TensorFlow 与 PyTorch 的核心差异与选择指南
20-【深度学习-Day 20】PyTorch入门:核心数据结构张量(Tensor)详解与操作
21-【深度学习-Day 21】框架入门:神经网络模型构建核心指南 (Keras & PyTorch)
22-【深度学习-Day 22】框架入门:告别数据瓶颈 - 掌握PyTorch Dataset、DataLoader与TensorFlow tf.data实战
23-【深度学习-Day 23】框架实战:模型训练与评估核心环节详解 (MNIST实战)
24-【深度学习-Day 24】过拟合与欠拟合:深入解析模型泛化能力的核心挑战
文章目录
- Langchain系列文章目录
- Python系列文章目录
- PyTorch系列文章目录
- 机器学习系列文章目录
- 深度学习系列文章目录
- Java系列文章目录
- JavaScript系列文章目录
- 深度学习系列文章目录
- 前言
- 一、理解模型的“拟合”
- 1.1 什么是拟合?
- 1.2 理想的拟合状态
- 二、欠拟合(Underfitting):学得不够
- 2.1 欠拟合的定义与表现
- 2.2 欠拟合的成因分析
- 2.3.2 学习曲线
- 三、过拟合(Overfitting):学得太过
- 3.1 过拟合的定义与表现
- 3.2 过拟合的成因分析
- 四、核心理论:偏差(Bias)与方差(Variance)的权衡
- 4.1 理解偏差与方差
- 4.1.1 偏差(Bias)
- 4.1.2 方差(Variance)
- 4.2 偏差-方差权衡(The Bias-Variance Tradeoff)
- 五、实战:如何诊断与应对
- 5.1 诊断利器:学习曲线(Learning Curves)
- 5.1.1 什么是学习曲线?
- 5.1.2 代码实战:绘制学习曲线
- 5.1.3 解读学习曲线
- 5.2 解决欠拟合的策略
- (1) 增加模型复杂度
- (2) 添加新特征
- (3) 减少正则化
- (4) 延长训练时间
- 5.3 解决过拟合的策略
- (1) 增加数据量
- (2) 使用正则化
- (3) 降低模型复杂度
- (4) 早停法(Early Stopping)
- 六、总结
前言
你好,欢迎来到我们的深度学习系列文章!在之前的章节中,我们已经成功地使用深度学习框架搭建、训练并评估了模型。我们看到模型在训练数据上表现优异,但这是否意味着它就是一个好模型呢?并非如此。一个模型真正的价值在于它对未知数据的预测能力,我们称之为泛化能力。然而,在追求高泛化能力的道路上,我们常常会遇到两个主要的“拦路虎”:欠拟合(Underfitting) 和 过拟合(Overfitting)。理解并有效处理这两个问题,是从入门迈向专业的关键一步。本文将带你深入剖析这两个概念,并探讨其背后的核心理论——偏差与方差的权衡,最后提供诊断和应对的实战策略。
一、理解模型的“拟合”
在深入探讨问题之前,让我们先建立一个直观的理解:什么是“拟合”?
1.1 什么是拟合?
想象一下,你有一堆散落在二维平面上的数据点,你的任务是找到一条曲线来尽可能好地描述这些点的分布规律。这个“寻找曲线”的过程,在机器学习中就叫做拟合(Fitting)。模型(即你找到的曲线)试图学习并捕捉数据中的潜在模式。
1.2 理想的拟合状态
一个理想的模型,应该像一位经验丰富的侦探,能够从纷繁复杂的线索(数据)中发现案件的本质规律,而不会被无关紧要的细节(噪声)所迷惑。它既能很好地解释当前的数据,也能对未来的新数据做出准确的预测。
二、欠拟合(Underfitting):学得不够
现在,我们来看看第一种不理想的状态:欠拟合。
2.1 欠拟合的定义与表现
欠拟合指的是模型过于简单,未能充分学习到数据中的规律。就像一个学生上课不认真,连最基本的概念都没掌握,导致在练习题(训练集)和期末考试(测试集)中都考得很差。
核心表现:
- 训练集误差(Training Error)高:模型在训练数据上就表现不佳。
- 验证/测试集误差(Validation/Test Error)高:模型在新数据上表现同样不佳。
2.2 欠拟合的成因分析
欠拟合通常由以下原因造成:
- 模型复杂度过低:例如,试图用一条直线去拟合呈抛物线分布的数据。
- 特征不足:提供给模型的信息太少,不足以做出准确判断。例如,预测房价只给了“房间数量”这一个特征,却忽略了地理位置、面积等关键信息。
- 训练不充分:模型训练的轮次(epochs)太少,还没有来得及学习到数据的规律。
2.3.2 学习曲线
学习曲线是展示模型性能随训练过程变化的图表。对于欠拟合,其学习曲线通常表现为:训练损失和验证损失都非常高,并且很快就收敛(不再下降)。这表明模型从一开始就“学不动了”。
图片释义:训练损失和验证损失都居高不下,且很快进入平坦期。
三、过拟合(Overfitting):学得太过
与欠拟合相对的,是另一个更常见、更隐蔽的问题:过拟合。
3.1 过拟合的定义与表现
过拟合指的是模型过于复杂,不仅学习到了数据中的普遍规律,还把训练数据中的噪声和偶然性特征也当作了“圣经”来学习。这就像一个死记硬背的学生,把练习册上的所有题目(包括错题)都背得滚瓜烂熟,但在期末考试(测试集)中遇到新题型就束手无策。
核心表现:
- 训练集误差(Training Error)极低:模型在训练数据上表现近乎完美。
- 验证/测试集误差(Validation/Test Error)高:模型在新数据上表现糟糕,泛化能力差。
3.2 过拟合的成因分析
- 模型复杂度过高:模型的能力太强(例如,网络层数过深、神经元过多),足以“记住”所有训练样本。
- 数据量不足:训练数据太少,无法代表真实的数据分布,导致模型“管中窥豹”,学习到了片面的规律。
- 过度训练:训练时间过长,模型在训练数据上迭代次数过多,最终开始拟合噪声。
四、核心理论:偏差(Bias)与方差(Variance)的权衡
欠拟合与过拟合的背后,是机器学习中一个非常深刻的理论——偏差-方差权衡。
4.1 理解偏差与方差
4.1.1 偏差(Bias)
偏差衡量的是模型的预测值与真实值之间的系统性差异。高偏差意味着模型做了过强的假设,导致它无法捕捉数据的真实规律。
- 直观理解:偏差描述了模型的**“准不准”**的问题。一个高偏差的模型,就像一把总是打偏的枪,瞄准能力本身就有问题。
- 与拟合的关系:高偏差通常与欠拟合划等号。
4.1.2 方差(Variance)
方差衡量的是模型对于训练数据中微小变化的敏感程度。高方差意味着模型会因为训练数据的不同而产生剧烈变化,即它学习到了过多的噪声。
- 直观理解:方差描述了模型的**“稳不稳”**的问题。一个高方差的模型,就像一个心理素质极差的射手,手稍微一抖,子弹就不知道飞到哪里去了。
- 与拟合的关系:高方差通常与过拟合划等号。
4.2 偏差-方差权衡(The Bias-Variance Tradeoff)
模型的总误差可以大致分解为偏差和方差的和(以及一个不可避免的噪声项)。理想的模型需要在这两者之间找到一个完美的平衡点。
Total Error ≈ Bias 2 + Variance \text{Total Error} \approx \text{Bias}^2 + \text{Variance} Total Error≈Bias2+Variance
这个权衡关系是:
- 简单的模型:偏差高,方差低(欠拟合)。
- 复杂的模型:偏差低,方差高(过拟合)。
我们的目标是找到一个模型复杂度适中的点,使得总误差最小。
图示:随着模型复杂度增加,偏差降低,方差升高。总误差呈现一个U型曲线,我们的目标是找到曲线的最低点。
五、实战:如何诊断与应对
5.1 诊断利器:学习曲线(Learning Curves)
前面我们已经看到了学习曲线的威力。它是诊断模型健康状况最直接、最有效的工具。
5.1.1 什么是学习曲线?
学习曲线是一个图表,其横轴是训练迭代次数(epochs),纵轴是模型的损失(Loss)或准确率(Accuracy)。我们通常会同时绘制训练集和验证集的曲线来进行对比。
5.1.2 代码实战:绘制学习曲线
假设你在使用 TensorFlow/Keras 训练模型,model.fit() 函数会返回一个 history 对象,其中包含了每一轮的训练和验证指标。我们可以很方便地用 matplotlib 将其可视化。
import matplotlib.pyplot as plt# 假设 model.fit() 返回了 history 对象
# history.history 是一个字典,包含了 'loss' 和 'val_loss' 等键
# history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=50)# 示例 history 数据
# 在实际使用时,请替换为你的真实训练历史数据
history_dict = {'loss': [2.1, 1.5, 1.1, 0.8, 0.6, 0.45, 0.35, 0.3, 0.25, 0.22],'val_loss': [2.2, 1.7, 1.4, 1.2, 1.1, 1.05, 1.08, 1.15, 1.24, 1.35]
}
epochs = range(1, len(history_dict['loss']) + 1)# 绘制训练损失和验证损失
plt.figure(figsize=(10, 6))
plt.plot(epochs, history_dict['loss'], 'bo-', label='Training loss') # 蓝色实线代表训练损失
plt.plot(epochs, history_dict['val_loss'], 'ro-', label='Validation loss') # 红色实线代表验证损失# 设置图表标题和坐标轴标签
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend() # 显示图例# 显示图表
plt.grid(True)
plt.show()5.1.3 解读学习曲线
- 理想状态:训练损失和验证损失都稳步下降,并最终收敛到一个较低的水平,两者差距很小。
- 欠拟合:两条曲线都早早地“躺平”在较高的损失值。
- 过拟合:训练损失曲线持续下降,而验证损失曲线在某个点后开始掉头向上,形成一个明显的“剪刀差”。
5.2 解决欠拟合的策略
如果诊断出模型欠拟合,说明模型“学得不够”,我们需要让它变得更“聪明”或学得更“久”。
(1) 增加模型复杂度
- 方法:增加网络层数、增加每层的神经元数量。
- 原理:增强模型的学习能力,使其能捕捉更复杂的模式。
(2) 添加新特征
- 方法:进行特征工程,从现有数据中提取或创建更多有用的特征。
- 原理:为模型提供更丰富的决策信息。
(3) 减少正则化
- 方法:降低或移除正则化项(如 L1/L2 惩罚、Dropout)。我们将在后续文章详述。
- 原理:减少对模型复杂度的限制,释放其学习潜力。
(4) 延长训练时间
- 方法:增加训练的 epoch 数量。
- 原理:确保模型有足够的时间来收敛。
5.3 解决过拟合的策略
如果诊断出模型过拟合,说明模型“学得太过”,我们需要对其进行限制或提供更多样化的“教材”。
(1) 增加数据量
- 方法:获取更多标记数据,或者使用**数据增强(Data Augmentation)**技术(如对图像进行翻转、旋转、缩放)来扩充数据集。
- 原理:这是解决过拟合最有效的方法。数据越多,模型越能学到普适的规律。
(2) 使用正则化
- 方法:在损失函数中加入 L1/L2 正则化(也叫权重衰减),或在网络中加入 Dropout 层。
- 原理:这些技术通过惩罚过大的权重或随机“失活”神经元来限制模型复杂度,我们将在下两篇文章中深入探讨。
(3) 降低模型复杂度
- 方法:与解决欠拟合相反,我们可以减少网络层数或神经元数量。
- 原理:直接降低模型的容量,使其难以“记住”噪声。
(4) 早停法(Early Stopping)
- 方法:在训练过程中监控验证集的性能,一旦验证损失不再下降(甚至开始上升),就立即停止训练。
- 原理:在模型开始过拟合的“拐点”处及时刹车,防止其在错误的方向上越走越远。
六、总结
今天,我们深入探讨了模型训练中至关重要的两个问题——欠拟合与过拟合。掌握它们是优化模型、提升泛化能力的基础。
- 核心概念:欠拟合是模型太简单,学得不够;过拟合是模型太复杂,学得太过,甚至记住了噪声。
- 理论基础:这两个现象的根源在于**偏差(Bias)和方差(Variance)**之间的权衡。欠拟合对应高偏差,过拟合对应高方差。
- 诊断工具:学习曲线是识别欠拟合与过拟合最直观、最强大的可视化工具,通过观察训练集和验证集损失的变化趋势可以做出准确判断。
- 解决思路:针对欠拟合,我们应增加模型复杂度或增强数据特征;针对过拟合,我们应增加数据量、使用正则化或降低模型复杂度。
- 展望未来:本文提到的正则化技术,如 L2 权重衰减和 Dropout,是抑制过拟合的强大武器。在接下来的文章中,我们将对它们进行详细的剖析和实战演练,敬请期待!
相关文章:

【深度学习-Day 24】过拟合与欠拟合:深入解析模型泛化能力的核心挑战
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...
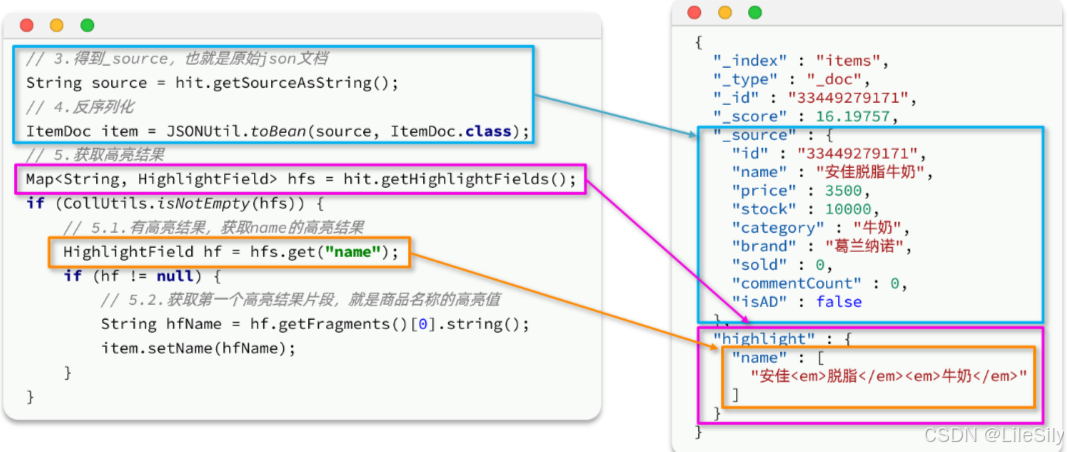
[ElasticSearch] DSL查询
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

iview中的table组件点击一行中的任意一点选中本行
<Table border ref"selection" size"small" on-row-click"onClickRow"></Table>// table组件点击一行任意位置选中onClickRow(row, index) {this.$refs.selection.toggleSelect(index)}写上toggleSelect(index)方法即可,…...

《探秘跨网段局域网IP广播:解锁网络通信的新姿势》
一、从基础出发:广播与跨网段 在计算机网络的世界中,广播域是一个至关重要的概念。简单来说,广播域是指网络中能接收任一台主机发出的广播帧的所有主机集合。当一台主机在广播域内发出一个广播帧时,同一广播域内的所有其他主机都可以收到该广播帧。在没有路由器或 VLAN 分割…...
)
Kafka 单机部署启动教程(适用于 Spark + Hadoop 环境)
🧭 Kafka 单机部署启动教程(适用于 Spark Hadoop 环境) 📦 一、Kafka 版本选择 推荐使用 Kafka 2.13-2.8.1(Scala 2.13,稳定适配 Spark 3.1.2 和 Hadoop 3.1.1) 下载地址(Apache 官…...
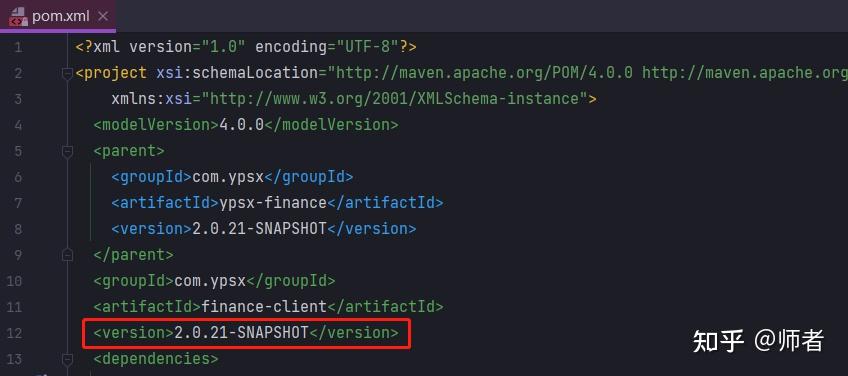
maven微服务${revision}依赖打包无法识别
1、场景描述 我现在又一个微服务项目,父pom的版本,使用<properties>定义好,如下所示: <name>ypsx-finance-center</name> <artifactId>ypsx-finance</artifactId> <packaging>pom</pack…...

2025年06月07日Github流行趋势
项目名称:netbird 项目地址url:https://github.com/netbirdio/netbird项目语言:Go历史star数:14824今日star数:320项目维护者:mlsmaycon, braginini, pascal-fischer, lixmal, pappz项目简介:使…...

WPS中将在线链接转为图片
WPS中将在线链接转为图片 文章目录 WPS中将在线链接转为图片一:解决方案1、下载图片,精确匹配(会员功能)2、将在线链接直接转为图片 一:解决方案 1、下载图片,精确匹配(会员功能) …...

实战二:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

二元函数可微 切平面逼近 线性函数逼近
二元函数 f ( x , y ) f(x, y) f(x,y) 在某点可微 的含义,可以从几何直观、严格数学定义、与一阶偏导数的关系三个层面来理解: 🔹1. 几何直观上的含义(最易理解) 二元函数 f ( x , y ) f(x, y) f(x,y) 在点 ( x 0 …...

vue生成二维码图片+文字说明
需求:点击下载图片,上方是二维码,下方显示该二维码的相关内容,并且居中显示,支持换行 解决方案步骤: 1. 使用qrcode生成二维码的DataURL。 2. 创建canvas,将二维码图片绘制到canvas的上半部分…...
机器学习监督学习实战五:六种算法对声呐回波信号进行分类
本项目基于UCI的声呐目标识别数据集(Sonar, Mines vs. Rocks),通过10种机器学习算法比较,发现集成学习方法表现最优。研究首先对60个声呐能量特征进行可视化分析(分布直方图、相关性矩阵),对比了…...

React Hooks 的闭包陷阱问题
这是主包在面试中遇到的一道题目,面试官的问题是:"这个页面初次展示出来时Count和step的值是什么,我点击按钮count和step的值有什么变化?“ 这个题目主包回答的不好,所以想做一个总结。 题目 import React, { …...
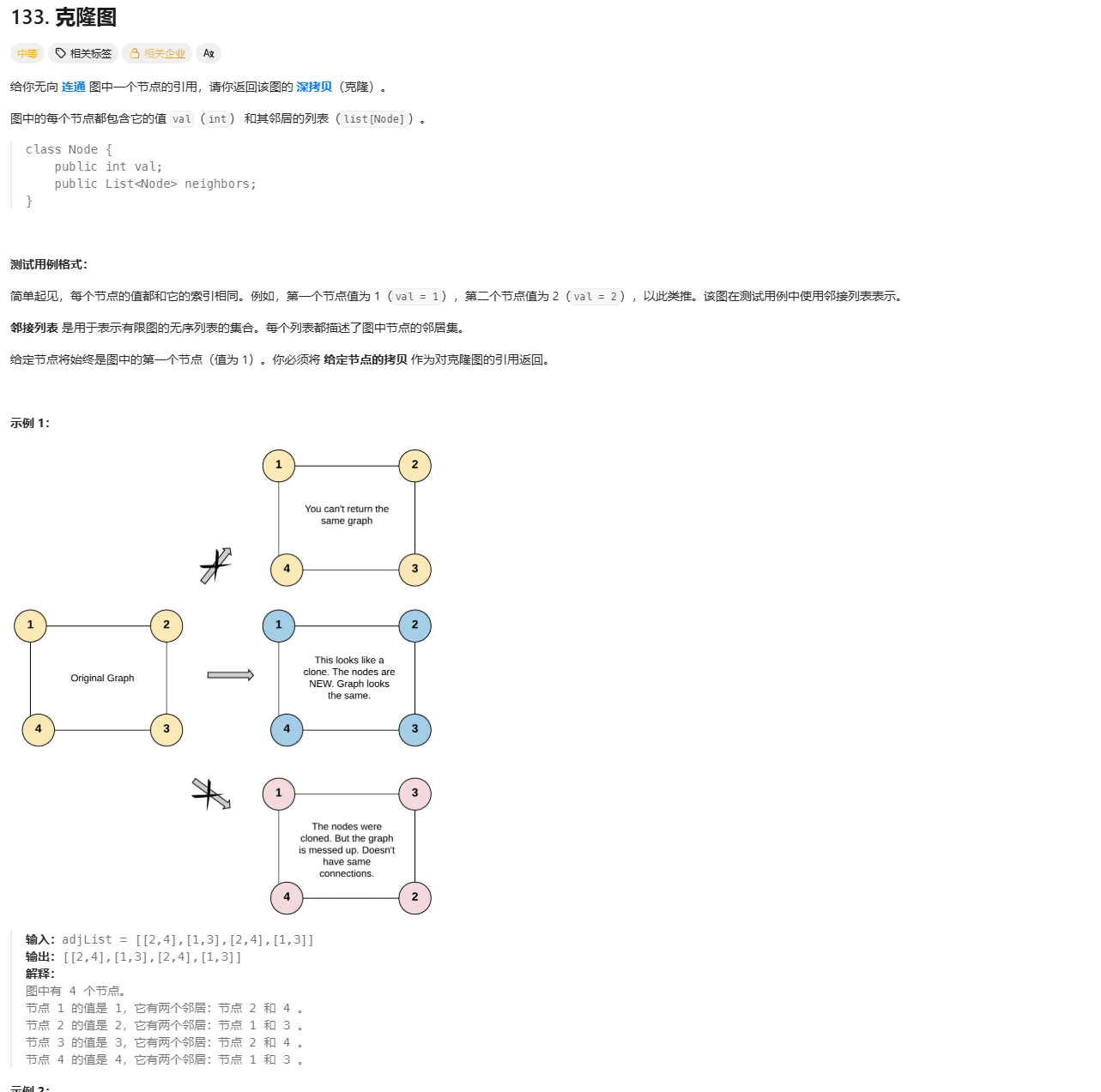
力扣面试150题--克隆图
Day 61 题目描述 思路 /* // Definition for a Node. class Node {public int val;public List<Node> neighbors;public Node() {val 0;neighbors new ArrayList<Node>();}public Node(int _val) {val _val;neighbors new ArrayList<Node>();}public N…...

【HarmonyOS 5】运动健康开发实践介绍以及详细案例
以下是 HarmonyOS 5 运动健康功能的简洁介绍,聚焦核心体验与技术亮点: 一、AI 驱动的全场景健康管理 智能运动私教:运动前推送热身指导,运动中实时纠正动作,运动后生成个性化报告与改进建议。AI 融合用户多设备数…...

STM32开发中,线程启动异常问题排查简述
1. 参数传递问题 错误类型:线程属性错误地使用。影响:线程属性(如堆栈大小、优先级)不匹配可能导致线程创建失败或行为异常。验证方法:检查 线程创建的返回值,若为 NULL 则表示线程创建失败。 2. 系统资源…...

SQL进阶之旅 Day 18:数据分区与查询性能
【SQL进阶之旅 Day 18】数据分区与查询性能 文章简述 在现代数据库系统中,随着数据量的快速增长,如何高效地管理和查询大规模数据成为开发人员和数据分析师面临的重要挑战。本文深入探讨了数据分区的概念及其对查询性能的提升作用,结合理论…...

鸿蒙PC,有什么缺点?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 价格太高,二是部分管理员权限首先,三对于开发者不太友好举个例子:VSCode的兼容性对程序员至关重要。若能支持VSCode,这台电脑将成为大多数开发者…...

前端工具:Webpack、Babel、Git与工程化流程
1. Webpack:资源打包优化工具 案例1:多入口文件打包 假设项目有多个页面(如首页index.js和登录页login.js),需要分别打包: ● 配置webpack.config.js: module.exports {entry: {index: ./sr…...

使用Python和Scikit-Learn实现机器学习模型调优
在机器学习项目中,模型的性能往往取决于多个因素,其中模型的超参数(hyperparameters)起着关键作用。超参数是模型在训练之前需要设置的参数,例如决策树的深度、KNN的邻居数等。合理地选择超参数可以显著提升模型的性能…...

灰狼优化算法MATLAB实现,包含种群初始化和29种基准函数测试
灰狼优化算法(Grey Wolf Optimizer, GWO)MATLAB实现,包含种群初始化和29种基准函数测试。代码包含详细注释和可视化模块: %% 灰狼优化算法主程序 (GWO.m) function GWO()clear; clc; close all;% 参数设置SearchAgents_no 30; …...

go语言学习 第7章:数组
第7章:数组 数组是一种基本的数据结构,用于存储相同类型的元素集合。在Go语言中,数组的大小是固定的,一旦定义,其长度不可改变。本章将详细介绍Go语言中数组的定义、初始化、访问、遍历以及一些常见的操作。 一、数组…...

PDF图片和表格等信息提取开源项目
文章目录 综合性工具专门的表格提取工具经典工具 综合性工具 PDF-Extract-Kit - opendatalab开发的综合工具包,包含布局检测、公式检测、公式识别和OCR功能 仓库:opendatalab/PDF-Extract-Kit特点:功能全面,包含表格内容提取的S…...
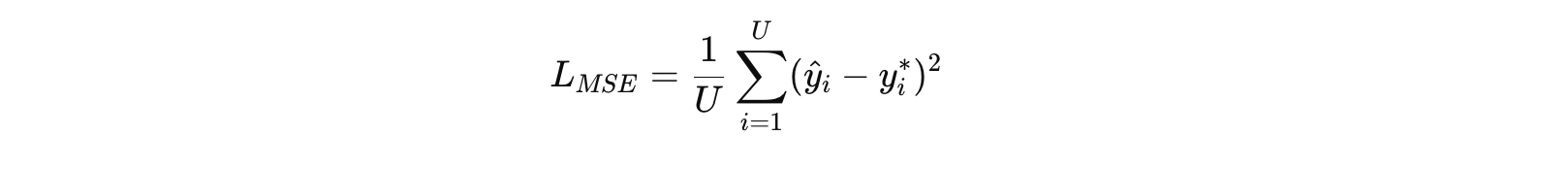
《Progressive Transformers for End-to-End Sign Language Production》复现报告
摘要 本文复现了《Progressive Transformers for End-to-End Sign Language Production》一文中的核心模型结构。该论文提出了一种端到端的手语生成方法,能够将自然语言文本映射为连续的 3D 骨架序列,并引入 Counter Decoding 实现动态序列长度控制。我…...

Haystack:AI与IoT领域的全能开源框架
一、Haystack 的定义与背景 Haystack 是一个开源框架,主要服务于两类不同领域: 物联网(IoT)与建筑自动化领域(Project Haystack): 旨在标准化物联网设备数据的语义模型,解决建筑系统(如 HVAC、能源管理)的数据互操作性问题,通过标签分类(Tagging Taxonomy)统一设…...

OpenWrt:使用ALSA实现边录边播
ALSA是Linux系统中的高级音频架构(Advanced Linux Sound Architecture)。目前已经成为了linux的主流音频体系结构,想了解更多的关于ALSA的知识,详见:http://www.alsa-project.org 在内核设备驱动层,ALSA提供…...

链表题解——回文链表【LeetCode】
算法思路 核心思想: 找到链表的中间节点。反转链表的后半部分。比较链表的前半部分和反转后的后半部分,如果值完全一致,则是回文链表。 具体步骤: 使用快慢指针找到链表的中间节点(middleNode 方法)。反转…...

CSS6404L 在物联网设备中的应用优势:低功耗高可靠的存储革新与竞品对比
物联网设备对存储芯片的需求聚焦于低功耗、小尺寸、高可靠性与传输效率,Cascadeteq 的 CSS6404L 64Mb Quad-SPI Pseudo-SRAM 凭借差异化技术特性,在同类产品中展现显著优势。以下从核心特性及竞品对比两方面解析其应用价值。 一、CSS6404L 核心产品特性…...

Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破 1.1 并行流的核心应用场景 在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环…...
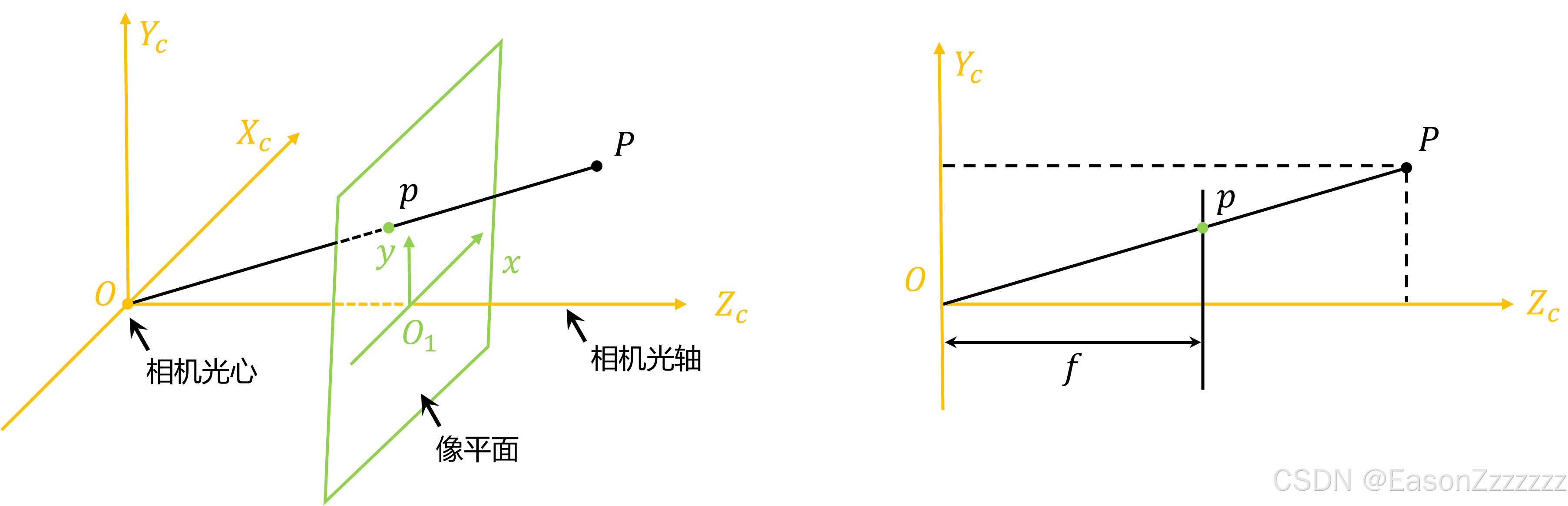
计算机视觉——相机标定
计算机视觉——相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐标系二、坐标系变换图像坐标系 → 像素坐标系相机坐标系 → 图像坐标系世界坐标系 → 相机坐标系 ⋆ \star ⋆ 世界坐标系 → 像素坐标系 三、相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐…...