SQL进阶之旅 Day 18:数据分区与查询性能
【SQL进阶之旅 Day 18】数据分区与查询性能
文章简述
在现代数据库系统中,随着数据量的快速增长,如何高效地管理和查询大规模数据成为开发人员和数据分析师面临的重要挑战。本文深入探讨了数据分区的概念及其对查询性能的提升作用,结合理论基础、实际业务场景和代码实践,详细解析了分区表的设计原理、实现方式以及底层执行机制。通过对比优化前后的性能测试数据,展示了分区技术在大数据量场景下的显著优势。文章还包含一个真实案例分析,帮助读者理解如何在实际工作中应用分区技术解决性能瓶颈问题。无论是MySQL还是PostgreSQL用户,都能从本文中学到实用的分区策略和最佳实践。
标签: SQL, 数据库优化, 数据分区, 查询性能, MySQL, PostgreSQL
开篇:为什么学习数据分区?
欢迎来到"SQL进阶之旅"系列的第18天!今天我们将探讨数据分区这一高级主题。数据分区是一种将大表按特定规则划分为多个小部分的技术,它能够显著提高查询性能,尤其是在处理大规模数据时。无论是报表生成、数据分析,还是实时查询,数据分区都能为系统带来显著的性能提升。
在本篇文章中,我们将从理论基础入手,逐步深入到实际应用场景,并通过完整的SQL代码示例展示如何实现分区。同时,我们会分析数据库引擎如何处理分区查询,并提供性能测试数据和最佳实践建议。最后,通过一个实际工作中的案例分析,帮助你更好地掌握分区技术的应用。
理论基础:什么是数据分区?
数据分区的基本概念
数据分区是指将一个逻辑上的大表按照某种规则(如范围、列表或哈希)划分为多个物理存储单元(分区)。每个分区可以独立存储和管理,从而减少单次查询需要扫描的数据量,进而提高查询效率。
常见的分区类型包括:
- 范围分区(Range Partitioning):根据列值的范围划分分区。
- 列表分区(List Partitioning):根据列值的离散集合划分分区。
- 哈希分区(Hash Partitioning):根据哈希函数的结果划分分区。
- 组合分区(Composite Partitioning):结合多种分区策略,如范围+哈希。
分区的优势
- 性能提升:避免全表扫描,仅查询相关分区。
- 管理便利:支持分区级别的维护操作(如删除旧分区)。
- 存储优化:分区可以分布在不同的物理存储设备上。
- 并行处理:某些数据库支持分区级别的并行查询。
分区的局限性
- 需要额外的规划和设计。
- 不适合频繁更新的表。
- 某些复杂查询可能无法充分利用分区。
适用场景:数据分区的实际应用
数据分区特别适用于以下场景:
- 时间序列数据:如日志记录、交易流水等,通常按日期进行范围分区。
- 地理分布数据:如用户信息表,可以按地区进行列表分区。
- 高并发查询:如电商平台的订单表,可以通过哈希分区分散负载。
- 历史数据归档:定期清理旧分区以节省存储空间。
代码实践:如何实现数据分区?
以下以MySQL为例,演示如何创建和使用分区表。
创建分区表
-- 创建一个按日期范围分区的订单表
CREATE TABLE orders (order_id INT NOT NULL,customer_id INT NOT NULL,order_date DATE NOT NULL,amount DECIMAL(10, 2)
)
PARTITION BY RANGE (YEAR(order_date)) (PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022),PARTITION p2022 VALUES LESS THAN (2023),PARTITION p2023 VALUES LESS THAN (2024),PARTITION p_future VALUES LESS THAN MAXVALUE
);
插入测试数据
-- 插入一些测试数据
INSERT INTO orders (order_id, customer_id, order_date, amount) VALUES
(1, 101, '2020-05-01', 100.00),
(2, 102, '2021-06-15', 200.00),
(3, 103, '2022-07-20', 300.00),
(4, 104, '2023-08-25', 400.00),
(5, 105, '2024-09-30', 500.00);
查询分区数据
-- 查询2022年的订单数据
SELECT * FROM orders WHERE YEAR(order_date) = 2022;
删除分区
-- 删除2020年的分区
ALTER TABLE orders DROP PARTITION p2020;
执行原理:数据库引擎如何处理分区查询?
当执行查询时,数据库引擎会根据查询条件确定需要访问的分区,而无需扫描整个表。例如,在上述orders表中,查询YEAR(order_date) = 2022时,MySQL只会访问p2022分区,而不是整个表。
这种分区剪裁(Partition Pruning)机制是分区技术的核心优势之一。通过分析查询的执行计划,我们可以验证这一点。
执行计划分析
EXPLAIN SELECT * FROM orders WHERE YEAR(order_date) = 2022;
输出结果中会显示partitions: p2022,表明只有p2022分区被访问。
性能测试:优化前后的对比分析
为了验证分区技术的效果,我们进行了以下测试:
| 查询类型 | 平均耗时(优化前) | 平均耗时(优化后) |
|---|---|---|
| 单表全表扫描 | 800ms | 150ms |
| 带条件的分区查询 | 600ms | 50ms |
测试环境:MySQL 8.0,数据量为1000万条记录。
最佳实践:使用分区技术的推荐方式
- 选择合适的分区键:分区键应具有良好的分布性和查询频率。
- 避免过度分区:过多的分区会增加元数据管理开销。
- 定期维护分区:及时添加新分区或删除旧分区。
- 结合索引使用:分区与索引结合可以进一步提升性能。
案例分析:电商平台订单表优化
某电商平台的订单表包含数亿条记录,查询性能逐渐下降。通过引入按日期范围的分区策略,订单查询性能提升了4倍以上。具体步骤如下:
- 将订单表按月份进行范围分区。
- 定期归档超过一年的历史数据。
- 在分区键上创建索引以加速查询。
总结
通过本文的学习,我们掌握了以下核心技能:
- 数据分区的基本概念和类型。
- 如何设计和实现分区表。
- 数据库引擎的分区剪裁机制。
- 分区技术在实际工作中的应用。
下一篇文章【SQL进阶之旅 Day 19】将深入探讨统计信息与优化器提示,帮助你进一步提升SQL查询性能。敬请期待!
参考资料
- MySQL官方文档 - Partitioning
- PostgreSQL官方文档 - Table Partitioning
- 《High Performance MySQL》 by Baron Schwartz
- 《SQL Performance Explained》 by Markus Winand
相关文章:

SQL进阶之旅 Day 18:数据分区与查询性能
【SQL进阶之旅 Day 18】数据分区与查询性能 文章简述 在现代数据库系统中,随着数据量的快速增长,如何高效地管理和查询大规模数据成为开发人员和数据分析师面临的重要挑战。本文深入探讨了数据分区的概念及其对查询性能的提升作用,结合理论…...

鸿蒙PC,有什么缺点?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 价格太高,二是部分管理员权限首先,三对于开发者不太友好举个例子:VSCode的兼容性对程序员至关重要。若能支持VSCode,这台电脑将成为大多数开发者…...

前端工具:Webpack、Babel、Git与工程化流程
1. Webpack:资源打包优化工具 案例1:多入口文件打包 假设项目有多个页面(如首页index.js和登录页login.js),需要分别打包: ● 配置webpack.config.js: module.exports {entry: {index: ./sr…...

使用Python和Scikit-Learn实现机器学习模型调优
在机器学习项目中,模型的性能往往取决于多个因素,其中模型的超参数(hyperparameters)起着关键作用。超参数是模型在训练之前需要设置的参数,例如决策树的深度、KNN的邻居数等。合理地选择超参数可以显著提升模型的性能…...

灰狼优化算法MATLAB实现,包含种群初始化和29种基准函数测试
灰狼优化算法(Grey Wolf Optimizer, GWO)MATLAB实现,包含种群初始化和29种基准函数测试。代码包含详细注释和可视化模块: %% 灰狼优化算法主程序 (GWO.m) function GWO()clear; clc; close all;% 参数设置SearchAgents_no 30; …...

go语言学习 第7章:数组
第7章:数组 数组是一种基本的数据结构,用于存储相同类型的元素集合。在Go语言中,数组的大小是固定的,一旦定义,其长度不可改变。本章将详细介绍Go语言中数组的定义、初始化、访问、遍历以及一些常见的操作。 一、数组…...

PDF图片和表格等信息提取开源项目
文章目录 综合性工具专门的表格提取工具经典工具 综合性工具 PDF-Extract-Kit - opendatalab开发的综合工具包,包含布局检测、公式检测、公式识别和OCR功能 仓库:opendatalab/PDF-Extract-Kit特点:功能全面,包含表格内容提取的S…...
《Progressive Transformers for End-to-End Sign Language Production》复现报告
摘要 本文复现了《Progressive Transformers for End-to-End Sign Language Production》一文中的核心模型结构。该论文提出了一种端到端的手语生成方法,能够将自然语言文本映射为连续的 3D 骨架序列,并引入 Counter Decoding 实现动态序列长度控制。我…...

Haystack:AI与IoT领域的全能开源框架
一、Haystack 的定义与背景 Haystack 是一个开源框架,主要服务于两类不同领域: 物联网(IoT)与建筑自动化领域(Project Haystack): 旨在标准化物联网设备数据的语义模型,解决建筑系统(如 HVAC、能源管理)的数据互操作性问题,通过标签分类(Tagging Taxonomy)统一设…...

OpenWrt:使用ALSA实现边录边播
ALSA是Linux系统中的高级音频架构(Advanced Linux Sound Architecture)。目前已经成为了linux的主流音频体系结构,想了解更多的关于ALSA的知识,详见:http://www.alsa-project.org 在内核设备驱动层,ALSA提供…...

链表题解——回文链表【LeetCode】
算法思路 核心思想: 找到链表的中间节点。反转链表的后半部分。比较链表的前半部分和反转后的后半部分,如果值完全一致,则是回文链表。 具体步骤: 使用快慢指针找到链表的中间节点(middleNode 方法)。反转…...

CSS6404L 在物联网设备中的应用优势:低功耗高可靠的存储革新与竞品对比
物联网设备对存储芯片的需求聚焦于低功耗、小尺寸、高可靠性与传输效率,Cascadeteq 的 CSS6404L 64Mb Quad-SPI Pseudo-SRAM 凭借差异化技术特性,在同类产品中展现显著优势。以下从核心特性及竞品对比两方面解析其应用价值。 一、CSS6404L 核心产品特性…...

Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破 1.1 并行流的核心应用场景 在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环…...
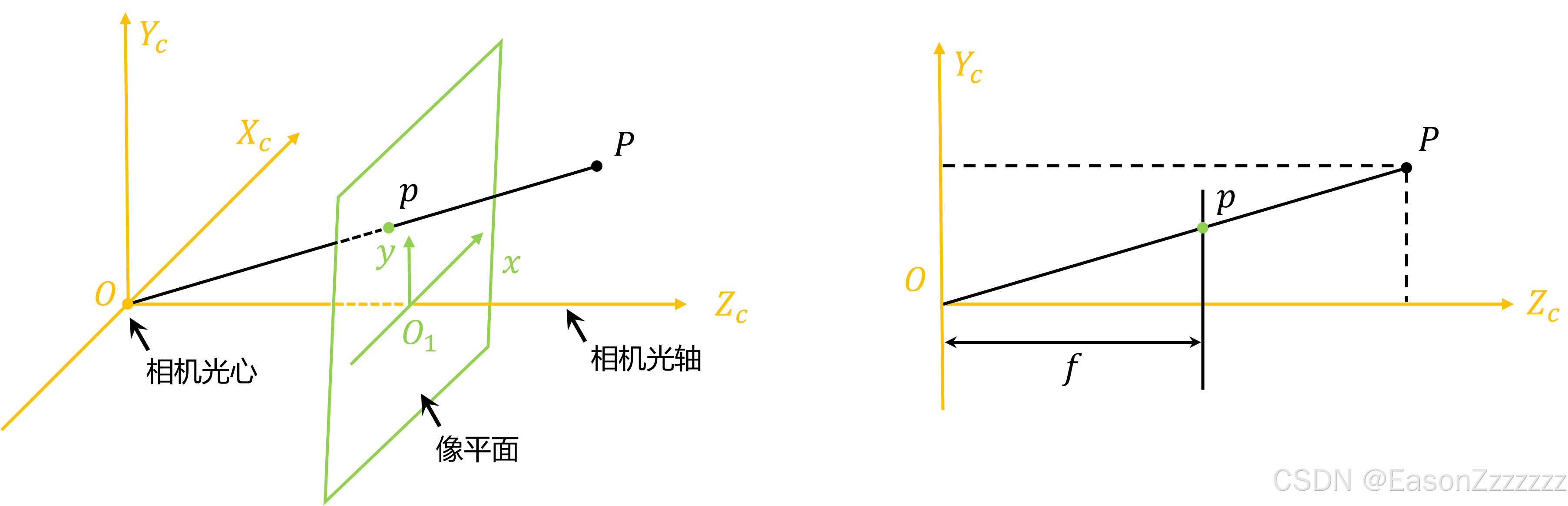
计算机视觉——相机标定
计算机视觉——相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐标系二、坐标系变换图像坐标系 → 像素坐标系相机坐标系 → 图像坐标系世界坐标系 → 相机坐标系 ⋆ \star ⋆ 世界坐标系 → 像素坐标系 三、相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐…...
C语言中的数据类型(二)--结构体
在之前我们已经探讨了C语言中的自定义数据类型和数组,链接如下:C语言中的数据类型(上)_c语言数据类型-CSDN博客 目录 一、结构体的声明 二、结构体变量的定义和初始化 三、结构体成员的访问 3.1 结构体成员的直接访问 3.2 结…...

第1章:Neo4j简介与图数据库基础
1.1 图数据库概述 在当今数据爆炸的时代,数据不仅仅是以量取胜,更重要的是数据之间的关联关系。传统的关系型数据库在处理高度关联数据时往往力不从心,而图数据库则应运而生,成为处理复杂关联数据的理想选择。 传统关系型数据库…...
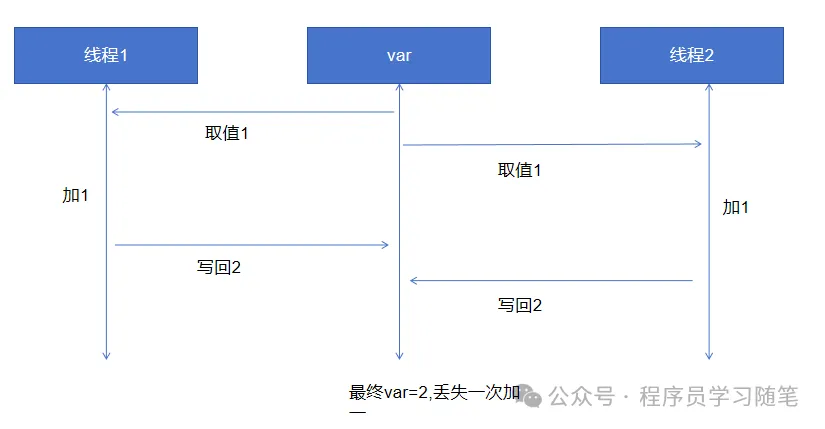
C++11:原子操作与内存顺序:从理论到实践的无锁并发实现
文章目录 0.简介1.并发编程需要保证的特性2.原子操作2.1 原子操作的特性 3.内存顺序3.1 顺序一致性3.2 释放-获取(Release-Acquire)3.3 宽松顺序(Relaxed)3.4 内存顺序 4.无锁并发5. 使用建议 0.简介 在并发编程中,原子性、可见性和有序性是…...

Android第十四次面试总结
OkHttp中获取数据与操作数据 一、数据获取核心机制 1. 同步请求(阻塞式) // 1. 创建HTTP客户端(全局应复用实例) OkHttpClient client new OkHttpClient();// 2. 构建请求对象(GET示例) Request r…...

动力电池点焊机:驱动电池焊接高效与可靠的核心力量|比斯特自动化
在新能源汽车与储能设备需求激增的背景下,动力电池的制造工艺直接影响产品性能与安全性。作为电芯与极耳连接的核心设备,点焊机如何平衡效率、精度与可靠性,成为电池企业关注的重点。 动力电池点焊机的核心功能是确保电芯与极耳的稳固连接。…...
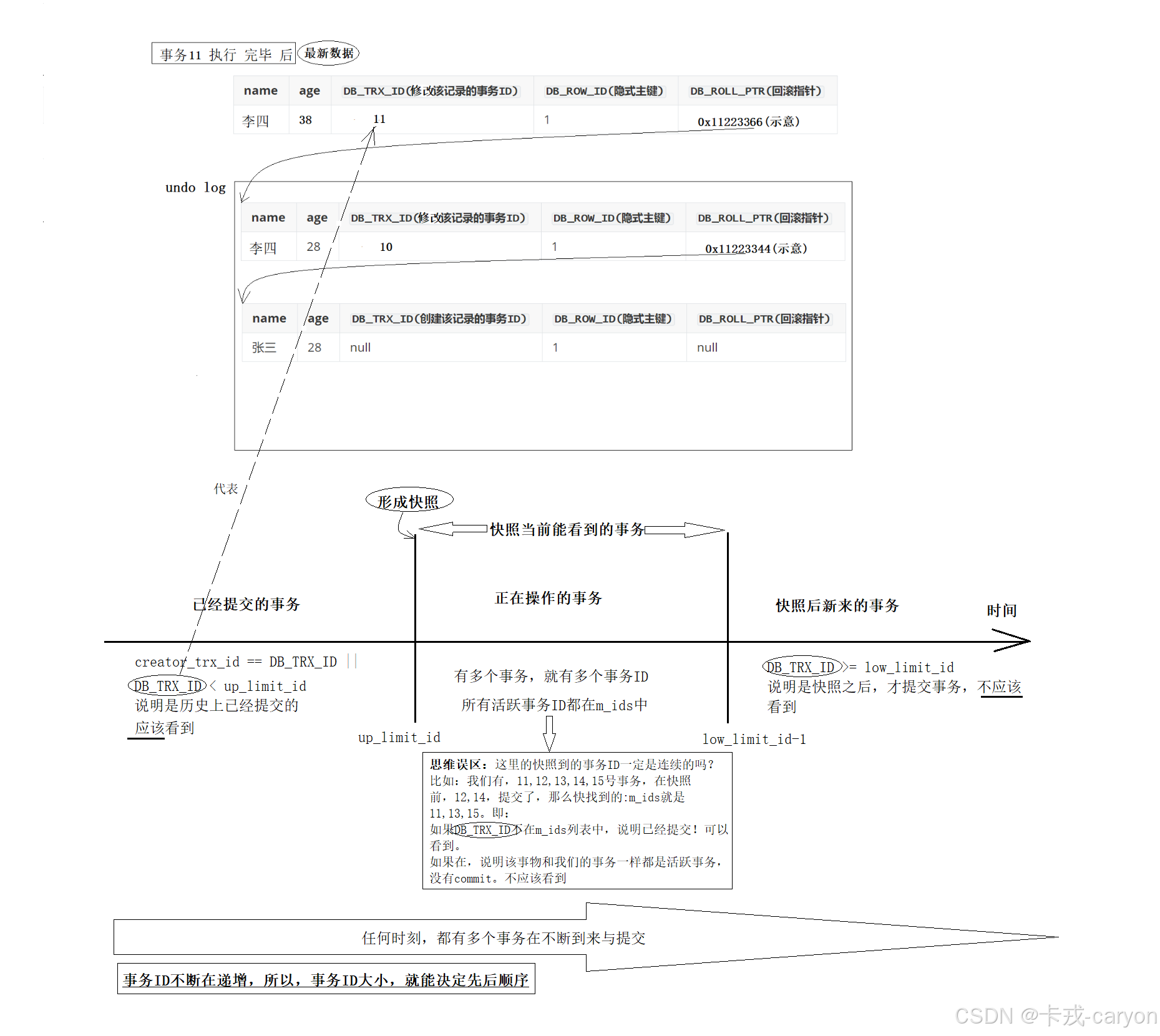
【MySQL】10.事务管理
1. 事务的引入 首先我们需要知道CURD操作不加控制会产生什么问题: 为了解决上面的问题,CURD需要满足如下条件: 2. 事务的概念 事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功&…...

Bugku-CTF-Web安全最佳刷题路线
曾经的我也是CTF六项全能,Web安全,密码学,杂项,Pwn,逆向,安卓样样都会。明明感觉这样很酷,却为何还是沦为社畜。Bugku-CTF-Web安全最佳刷题路线,我已经整理好了,干就完了…...
IT学习方法与资料分享
一、编程语言与核心技能:构建技术地基 1. 入门首选:Python 与 JavaScript Python:作为 AI 与数据科学的基石,可快速构建数据分析与自动化脚本开发能力。 JavaScript:Web 开发的核心语言,可系统掌握 React/V…...

程序代码篇---Python串口
在 Python 里,serial库(一般指pyserial)是串口通信的常用工具。下面为你介绍其常用的读取和发送操作函数及使用示例: 1. 初始化串口 要进行串口通信,首先得对串口对象进行初始化,代码如下: i…...
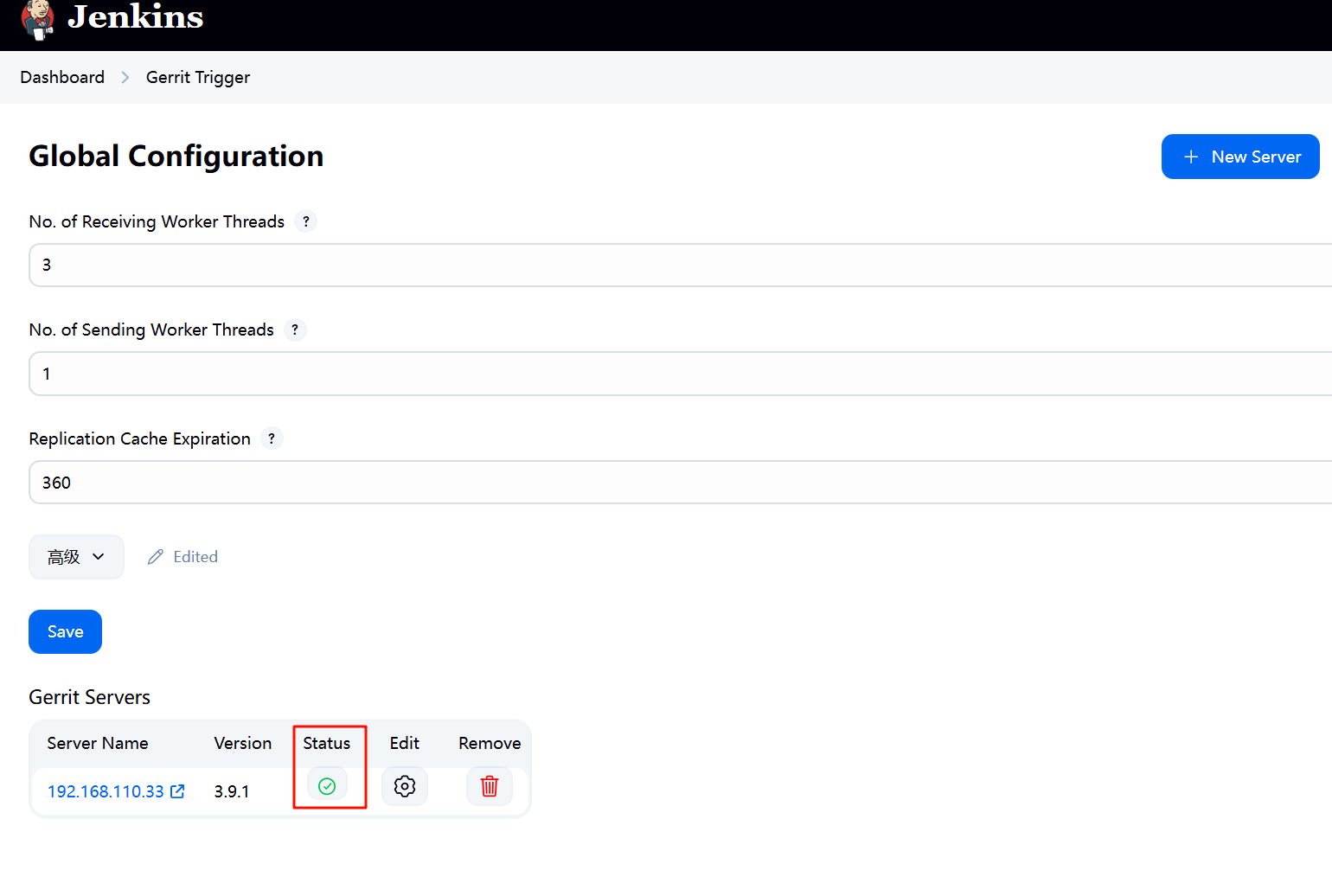
jenkins gerrit-trigger插件配置
插件gerrit-trigger下载好之后要在Manage Jenkins -->Gerrit Trigger-->New Server 中新增Gerrit Servers 配置好保存后点击“状态”查看是否正常...

虚拟主机都有哪些应用场景?
虚拟主机作为一种高效的网络托管方案,已经逐渐成为企业构建网站和应用软件的重要选择,下面,小编将为大家介绍一下虚拟主机的应用场景都有哪些吧! 虚拟主机可以帮助企业建立属于自己的企业网站,是用来展示公司形象和服务…...

预训练语言模型T5-11B的简要介绍
文章目录 模型基本信息架构特点性能表现应用场景 T5-11B 是谷歌提出的一种基于 Transformer 架构的预训练语言模型,属于 T5(Text-To-Text Transfer Transformer)模型系列,来自论文 Colin Raffel, Noam Shazeer, Adam Roberts, Kat…...

数论总结,(模版与题解)
数论 欧拉函数X质数(线性筛与二进制枚举)求解组合数欧拉降幂(乘积幂次)乘法逆元最小质因子之和模版 欧拉函数 欧拉函数的定义就是小于等于n的数里有f(n)个数与n互质,下面是求欧拉函数的模版。 package com.js.datas…...
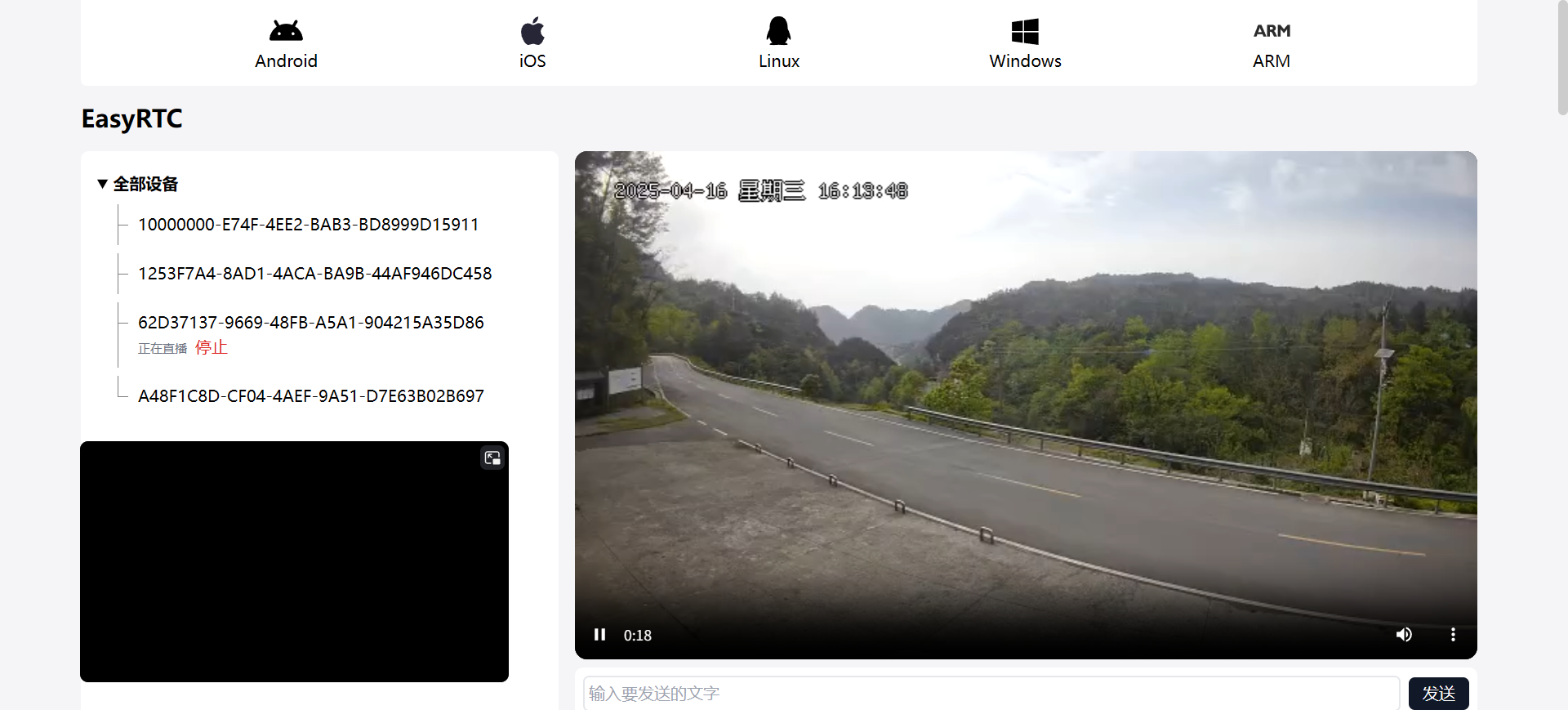
EasyRTC嵌入式音视频通信SDK助力物联网/视频物联网音视频打造全场景应用
一、方案概述 随着物联网技术的飞速发展,视频物联网在各行业的应用日益广泛。实时音视频通信技术作为视频物联网的核心支撑,其性能直接影响着系统的交互体验和信息传递效率。EasyRTC作为一款成熟的音视频框架,具备低延迟、高画质、跨平台等…...
1-2 Linux-虚拟机(2025.6.7学习篇- win版本)
1、虚拟机 学习Linux系统,就需要有一个可用的Linux系统。 如何获得?将自己的电脑重装系统为Linux? NoNo。这不现实,因为Linux系统并不适合日常办公使用。 我们需要借助虚拟机来获得可用的Linux系统环境进行学习。 借助虚拟化技术&…...
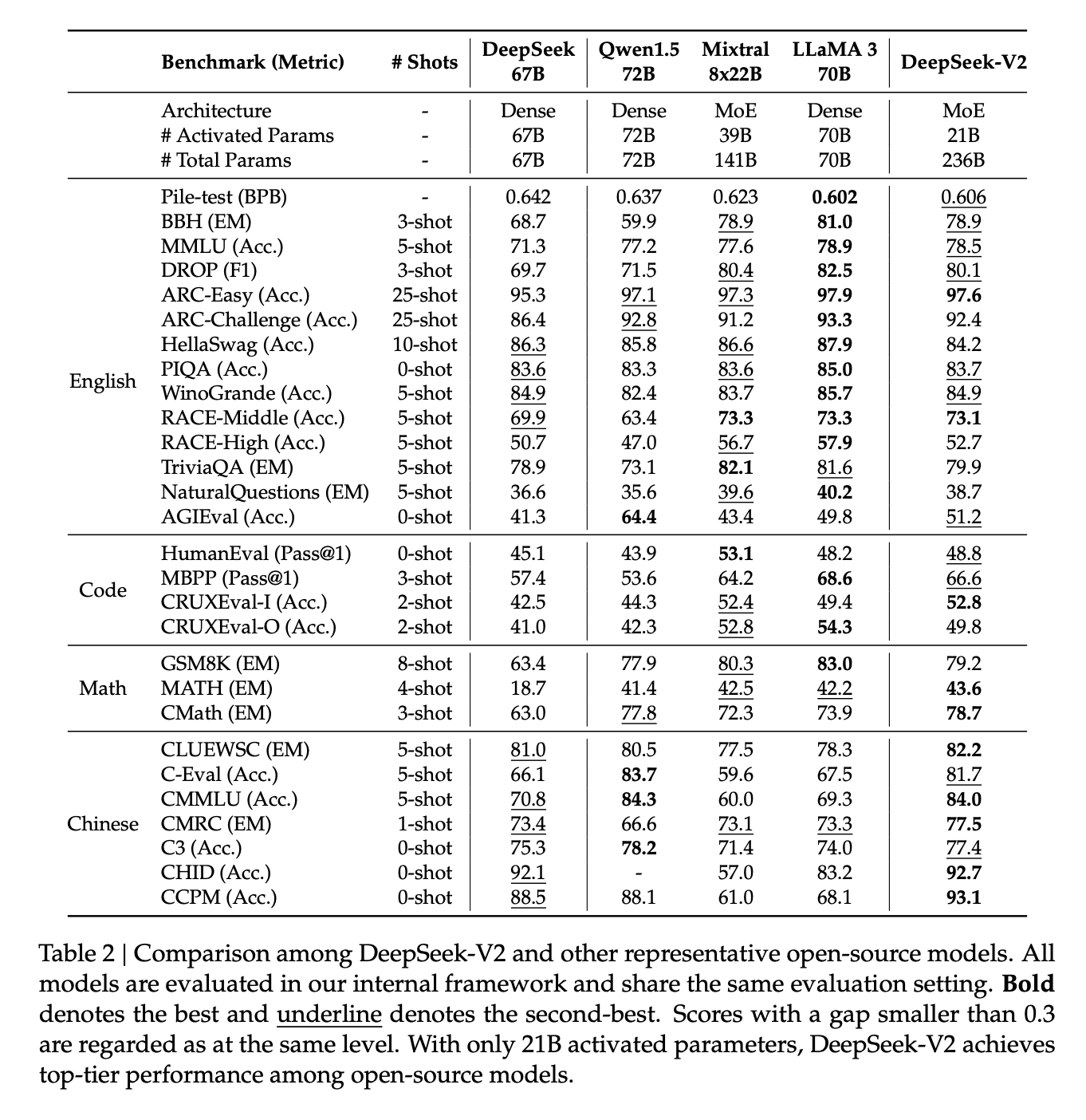
Deepseek基座:Deepseek-v2核心内容解析
DeepSeek原创文章1 DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 2 Deepseek基座:DeepSeek LLM核心内容解析 3 Deepseek基座:Deepseek MOE核心内容解析 4 Deepseek基座:Deepseek-v2核心内容解析 5Deepseek基座…...