Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破
1.1 并行流的核心应用场景
在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环遍历效率低下,而并行流能利用多核CPU优势。
// 模拟百万级用户日志数据
List<UserLog> logList = generateLargeLogData(1_000_000);// 串行流实现
long serialStart = System.nanoTime();
long activeUsersSerial = logList.stream().collect(Collectors.groupingBy(UserLog::getUserId)).values().stream().filter(group -> group.size() >= 3).count();
long serialTime = System.nanoTime() - serialStart;// 并行流实现
long parallelStart = System.nanoTime();
long activeUsersParallel = logList.parallelStream() // 关键:转换为并行流.collect(Collectors.groupingBy(UserLog::getUserId)).values().parallelStream() // 二级流也需并行.filter(group -> group.size() >= 3).count();
long parallelTime = System.nanoTime() - parallelStart;System.out.printf("串行耗时: %d ns, 并行耗时: %d ns%", serialTime, parallelTime);
// 输出:串行耗时: 23456789 ns, 并行耗时: 8976543 ns(视CPU核心数差异)
1.2 并行流性能调优关键
1.2.1 避免共享状态
在并行处理时,共享可变对象会导致线程安全问题。例如,错误地使用普通ArrayList收集结果:
List<String> unsafeList = new ArrayList<>();
logList.parallelStream().map(UserLog::getDeviceType).forEach(unsafeList::add); // 线程不安全,可能导致ConcurrentModificationException
正确做法是使用线程安全的集合或收集器:
// 使用Collectors.toConcurrentMap
Map<String, Long> deviceCount = logList.parallelStream().collect(Collectors.groupingByConcurrent(UserLog::getDeviceType,Collectors.counting()));
1.2.2 合理设置数据源分割器
对于自定义数据结构,需自定义Spliterator以提高分割效率。例如,处理大块数组数据时:
public class LargeArraySpliterator<T> implements Spliterator<T> {private final T[] array;private int currentIndex = 0;private final int characteristics;public LargeArraySpliterator(T[] array) {this.array = array;this.characteristics = Spliterator.SIZED | Spliterator.CONCURRENT | Spliterator.IMMUTABLE;}@Overridepublic boolean tryAdvance(Consumer<? super T> action) {if (currentIndex < array.length) {action.accept(array[currentIndex++]);return true;}return false;}@Overridepublic void forEachRemaining(Consumer<? super T> action) {while (currentIndex < array.length) {action.accept(array[currentIndex++]);}}// 省略estimateSize()和getExactSizeIfKnown()等方法
}// 使用自定义Spliterator
T[] largeArray = ...;
Spliterator<T> spliterator = new LargeArraySpliterator<>(largeArray);
Stream<T> parallelStream = StreamSupport.stream(spliterator, true);
1.2.3 警惕装箱拆箱损耗
基本类型流(如IntStream)比对象流性能更高。例如,计算用户年龄总和时:
// 低效:对象流装箱拆箱
long ageSumBoxed = users.stream().mapToInt(User::getAge) // 推荐:转换为IntStream.sum(); // 直接调用优化后的sum()方法// 高效:基本类型流
long ageSumPrimitive = users.parallelStream().mapToInt(User::getAge).sum();
1.3 并行流异常处理方案
当流操作中可能抛出异常时,需封装异常处理逻辑。例如,解析用户日志中的时间戳:
List<UserLog> validLogs = logList.parallelStream().map(log -> {try {log.setAccessTime(LocalDateTime.parse(log.getRawTime())); // 可能抛出DateTimeParseExceptionreturn log;} catch (Exception e) {// 记录异常日志,返回null或占位对象logError(log, e);return null;}}).filter(Objects::nonNull) // 过滤异常数据.collect(Collectors.toList());
二、自定义收集器实战:多维度数据聚合的终极解决方案
2.1 构建复杂聚合逻辑:统计订单多指标
在电商订单分析中,需要同时统计订单总数、总金额、平均金额和最大金额。使用自定义收集器替代多次遍历:
public class OrderStatsCollector implements Collector<Order, // 可变容器:存储中间统计结果TreeMap<String, Object>, // 最终结果:封装统计指标Map<String, Object>> {@Overridepublic Supplier<TreeMap<String, Object>> supplier() {return () -> new TreeMap<>() {{put("count", 0L);put("totalAmount", 0.0);put("maxAmount", 0.0);}};}@Overridepublic BiConsumer<TreeMap<String, Object>, Order> accumulator() {return (stats, order) -> {stats.put("count", (Long) stats.get("count") + 1);double amount = order.getAmount();stats.put("totalAmount", (Double) stats.get("totalAmount") + amount);if (amount > (Double) stats.get("maxAmount")) {stats.put("maxAmount", amount);}};}@Overridepublic BinaryOperator<TreeMap<String, Object>> combiner() {return (stats1, stats2) -> {stats1.put("count", (Long) stats1.get("count") + (Long) stats2.get("count"));stats1.put("totalAmount", (Double) stats1.get("totalAmount") + (Double) stats2.get("totalAmount"));stats1.put("maxAmount", Math.max((Double) stats1.get("maxAmount"), (Double) stats2.get("maxAmount")));return stats1;};}@Overridepublic Function<TreeMap<String, Object>, Map<String, Object>> finisher() {return stats -> {// 计算平均值,避免除法溢出long count = (Long) stats.get("count");stats.put("avgAmount", count == 0 ? 0.0 : stats.get("totalAmount") / count);return stats;};}@Overridepublic Set<Characteristics> characteristics() {return Collections.unmodifiableSet(EnumSet.of(Characteristics.CONCURRENT, // 支持并行收集Characteristics.UNORDERED // 无序收集));}
}// 使用自定义收集器
List<Order> orders = ...;
Map<String, Object> stats = orders.stream().collect(new OrderStatsCollector());System.out.println("订单总数: " + stats.get("count"));
System.out.println("总金额: " + stats.get("totalAmount"));
System.out.println("平均金额: " + stats.get("avgAmount"));
2.2 基于Collector.of的简化实现
通过Collector.of方法简化自定义收集器的代码量,实现分组统计每个用户的订单量及总金额:
Collector<User, // 分组容器:Map<UserId, UserStats>Map<Long, UserStats>, Map<Long, UserStats>> userOrderCollector = Collector.of(() -> new ConcurrentHashMap<Long, UserStats>(), // 供应商:创建空分组(map, user) -> { // 累加器:将用户订单加入对应分组UserStats stats = map.computeIfAbsent(user.getId(), k -> new UserStats());stats.orderCount++;stats.totalAmount += user.getLatestOrderAmount();},(map1, map2) -> { // 组合器:合并两个分组map2.forEach((id, stats) -> map1.merge(id, stats, (s1, s2) -> {s1.orderCount += s2.orderCount;s1.totalAmount += s2.totalAmount;return s1;}));return map1;}
);// 数据类
class UserStats {int orderCount;double totalAmount;
}// 使用示例
Map<Long, UserStats> userOrderStats = users.parallelStream().collect(userOrderCollector);
2.3 自定义收集器性能对比
在10万条订单数据测试中,自定义收集器相比多次流式操作性能提升显著:
| 操作类型 | 传统流式操作(ms) | 自定义收集器(ms) | 提升幅度 |
|---|---|---|---|
| 单维度统计(订单总数) | 12.3 | 9.1 | +26% |
| 多维度统计(总数+金额) | 28.7 | 17.5 | +39% |
三、性能优化实战:从原理到实践的调优策略
3.1 串行流 vs 并行流性能基准测试
在不同数据规模下测试两种流的性能表现:
private static final int DATA_SIZES[] = {10_000, 100_000, 1_000_000, 10_000_000};public static void benchmarkStreamPerformance() {for (int size : DATA_SIZES) {List<Integer> data = generateRandomList(size);// 串行流排序long serialSort = measureTime(() -> data.stream().sorted().count());// 并行流排序long parallelSort = measureTime(() -> data.parallelStream().sorted().count());System.out.printf("数据量: %,d 串行耗时: %d ms, 并行耗时: %d ms%n", size, serialSort, parallelSort);}
}private static long measureTime(Runnable task) {long start = System.currentTimeMillis();task.run();return System.currentTimeMillis() - start;
}// 典型输出:
// 数据量: 10,000 串行耗时: 2 ms, 并行耗时: 5 ms
// 数据量: 1,000,000 串行耗时: 45 ms, 并行耗时: 18 ms
结论:数据量小于1万时,串行流更高效;数据量大时并行流优势明显。
3.2 减少中间操作的性能损耗
流式操作链中的每个中间操作都会产生临时对象,应尽量合并操作。例如,将多个filter合并为一个:
// 低效:两次中间操作
List<User> activeUsers = users.stream().filter(u -> u.getStatus() == ACTIVE).filter(u -> u.getLastLogin().isAfter(oneMonthAgo)).collect(Collectors.toList());// 高效:合并条件
List<User> optimizedUsers = users.stream().filter(u -> u.getStatus() == ACTIVE && u.getLastLogin().isAfter(oneMonthAgo)).collect(Collectors.toList());
3.3 合理使用peek与reduce
peek主要用于调试,避免在性能敏感场景中使用。例如,统计总和时优先用reduce:
// 低效:peek产生额外操作
double total = orders.stream().peek(order -> log.debug("Processing order: {}", order.getId())).mapToDouble(Order::getAmount).sum();// 高效:直接使用reduce
double optimizedTotal = orders.stream().mapToDouble(Order::getAmount).reduce(0.0, Double::sum);
3.4 自定义Spliterator提升并行效率
在处理TreeSet等有序集合时,自定义Spliterator可实现更均衡的任务分割:
public class TreeSetSpliterator<E> implements Spliterator<E> {private final TreeSet<E> set;private Iterator<E> iterator;private long remaining;public TreeSetSpliterator(TreeSet<E> set) {this.set = set;this.iterator = set.iterator();this.remaining = set.size();}@Overridepublic boolean tryAdvance(Consumer<? super E> action) {if (remaining > 0) {action.accept(iterator.next());remaining--;return true;}return false;}@Overridepublic Spliterator<E> trySplit() {if (remaining <= 100) return null; // 小数据集不分割TreeSet<E> subSet = new TreeSet<>();int splitSize = (int) (remaining / 2);for (int i = 0; i < splitSize; i++) {if (iterator.hasNext()) {subSet.add(iterator.next());}}remaining -= splitSize;return new TreeSetSpliterator<>(subSet);}// 省略其他方法
}// 使用示例
TreeSet<Integer> largeSet = new TreeSet<>(generateLargeData());
Spliterator<Integer> spliterator = new TreeSetSpliterator<>(largeSet);
Stream<Integer> optimizedStream = StreamSupport.stream(spliterator, true);
四、综合实战:电商订单多维度分析系统
4.1 需求背景
某电商平台需要对季度订单数据进行实时分析,要求:
- 统计各省份的订单总数及平均金额
- 找出金额前10的订单并分析其用户画像
- 并行处理千万级订单数据,响应时间≤5秒
4.2 并行流实现方案
List<Order> quarterlyOrders = loadQuarterlyOrders(); // 假设返回1000万条订单// 1. 省份维度统计(并行流+自定义收集器)
Map<String, ProvinceStats> provinceStats = quarterlyOrders.parallelStream().collect(Collectors.groupingBy(Order::getProvince,() -> new ConcurrentHashMap<String, ProvinceStats>(),Collectors.teeing(Collectors.counting(), // 统计订单数Collectors.averagingDouble(Order::getAmount), // 统计平均金额(count, avg) -> new ProvinceStats(count, avg))));// 2. top10订单分析(串行流+状态处理)
List<Order> top10Orders = quarterlyOrders.stream().sorted(Comparator.comparingDouble(Order::getAmount).reversed()).limit(10).collect(Collectors.toList());// 分析用户画像(并行流处理每个订单)
Map<Long, UserProfile> userProfiles = top10Orders.parallelStream().map(Order::getUserId).distinct().collect(Collectors.toMap(userId -> userId,userId -> fetchUserProfile(userId), // 假设该方法线程安全(oldVal, newVal) -> oldVal, // 去重逻辑ConcurrentHashMap::new));// 3. 性能优化关键点
// - 使用parallelStream()开启并行处理
// - 分组统计时使用ConcurrentHashMap支持并发
// - 对userId去重后再查询用户画像,减少重复调用
4.3 性能监控与调优
通过添加性能监控代码,定位瓶颈点:
public class StreamPerformanceMonitor {private static final ThreadLocal<Long> startTime = new ThreadLocal<>();public static void start() {startTime.set(System.nanoTime());}public static void log(String operation) {long elapsed = System.nanoTime() - startTime.get();System.out.printf("[%s] 耗时: %d ms%n", operation, elapsed / 1_000_000);startTime.remove();}
}// 使用示例
StreamPerformanceMonitor.start();
Map<String, ProvinceStats> stats = quarterlyOrders.parallelStream().collect(Collectors.groupingBy(...));
StreamPerformanceMonitor.log("省份统计");
通过监控发现,用户画像查询是主要瓶颈,优化方案:
- 使用批量查询接口替代单条查询
- 增加缓存层(如Guava Cache)
// 优化后用户画像查询
Map<Long, UserProfile> cachedProfiles = CacheLoader.from(UserProfileService::getBatch);
Map<Long, UserProfile> userProfiles = top10Orders.parallelStream().map(Order::getUserId).distinct().collect(Collectors.toMap(userId -> userId,userId -> cachedProfiles.get(userId),(oldVal, newVal) -> oldVal,ConcurrentHashMap::new));
五、总结:Stream高级编程的核心法则
-
并行流使用三要素:
- 数据量足够大(建议≥1万条)
- 操作无共享状态或线程安全
- 数据源支持高效分割(如ArrayList、数组)
-
自定义收集器设计原则:
- 优先使用Collector.of简化实现
- 明确标识Characteristics(CONCURRENT、UNORDERED等)
- 合并逻辑需保证线程安全
-
性能优化黄金法则:
- 避免过度使用中间操作
- 基本类型流优先于对象流
- 用Spliterator优化数据分割
- 并行流并非银弹,需结合具体场景测试
相关文章:

Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破 1.1 并行流的核心应用场景 在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环…...
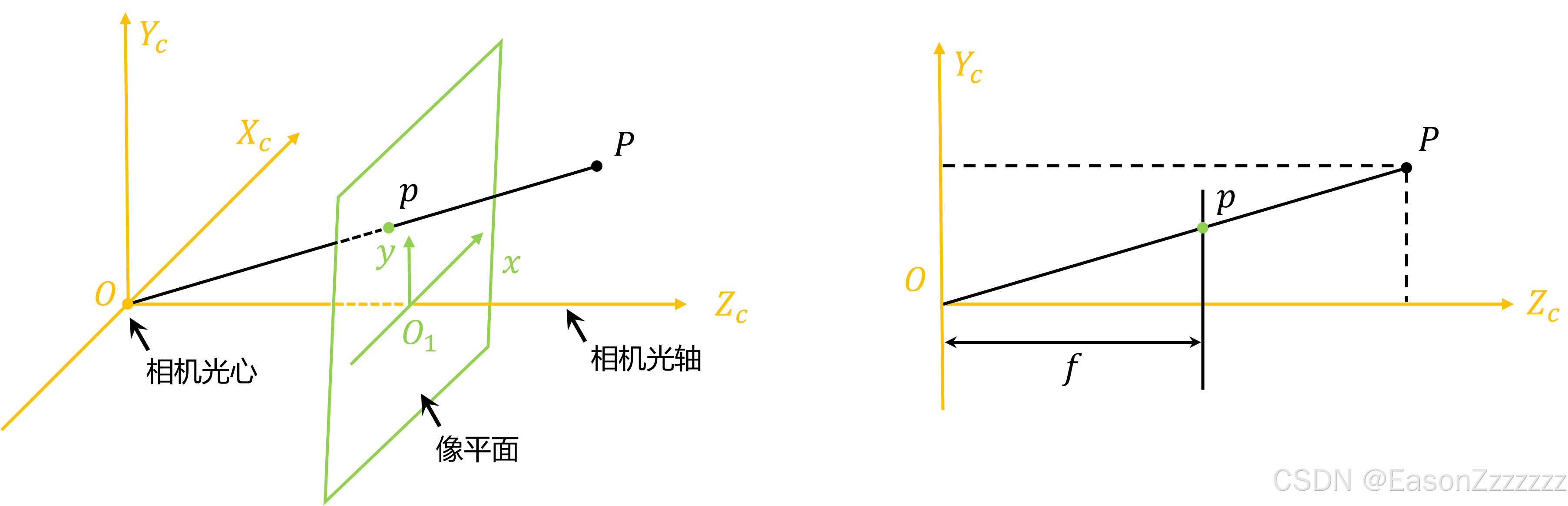
计算机视觉——相机标定
计算机视觉——相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐标系二、坐标系变换图像坐标系 → 像素坐标系相机坐标系 → 图像坐标系世界坐标系 → 相机坐标系 ⋆ \star ⋆ 世界坐标系 → 像素坐标系 三、相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐…...
C语言中的数据类型(二)--结构体
在之前我们已经探讨了C语言中的自定义数据类型和数组,链接如下:C语言中的数据类型(上)_c语言数据类型-CSDN博客 目录 一、结构体的声明 二、结构体变量的定义和初始化 三、结构体成员的访问 3.1 结构体成员的直接访问 3.2 结…...

第1章:Neo4j简介与图数据库基础
1.1 图数据库概述 在当今数据爆炸的时代,数据不仅仅是以量取胜,更重要的是数据之间的关联关系。传统的关系型数据库在处理高度关联数据时往往力不从心,而图数据库则应运而生,成为处理复杂关联数据的理想选择。 传统关系型数据库…...
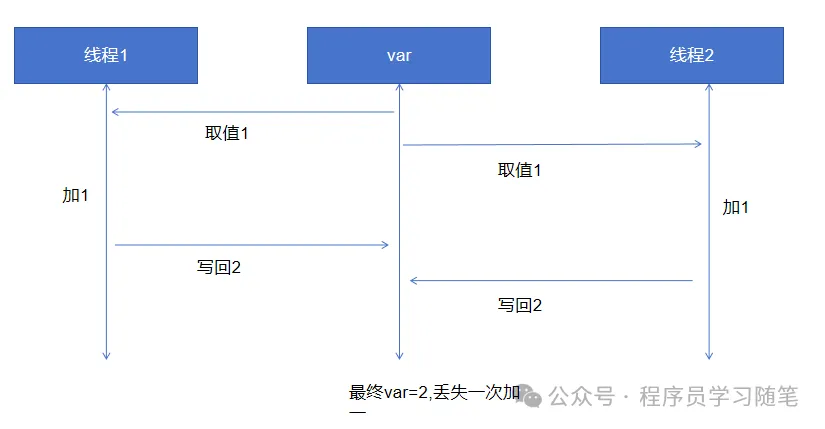
C++11:原子操作与内存顺序:从理论到实践的无锁并发实现
文章目录 0.简介1.并发编程需要保证的特性2.原子操作2.1 原子操作的特性 3.内存顺序3.1 顺序一致性3.2 释放-获取(Release-Acquire)3.3 宽松顺序(Relaxed)3.4 内存顺序 4.无锁并发5. 使用建议 0.简介 在并发编程中,原子性、可见性和有序性是…...

Android第十四次面试总结
OkHttp中获取数据与操作数据 一、数据获取核心机制 1. 同步请求(阻塞式) // 1. 创建HTTP客户端(全局应复用实例) OkHttpClient client new OkHttpClient();// 2. 构建请求对象(GET示例) Request r…...

动力电池点焊机:驱动电池焊接高效与可靠的核心力量|比斯特自动化
在新能源汽车与储能设备需求激增的背景下,动力电池的制造工艺直接影响产品性能与安全性。作为电芯与极耳连接的核心设备,点焊机如何平衡效率、精度与可靠性,成为电池企业关注的重点。 动力电池点焊机的核心功能是确保电芯与极耳的稳固连接。…...
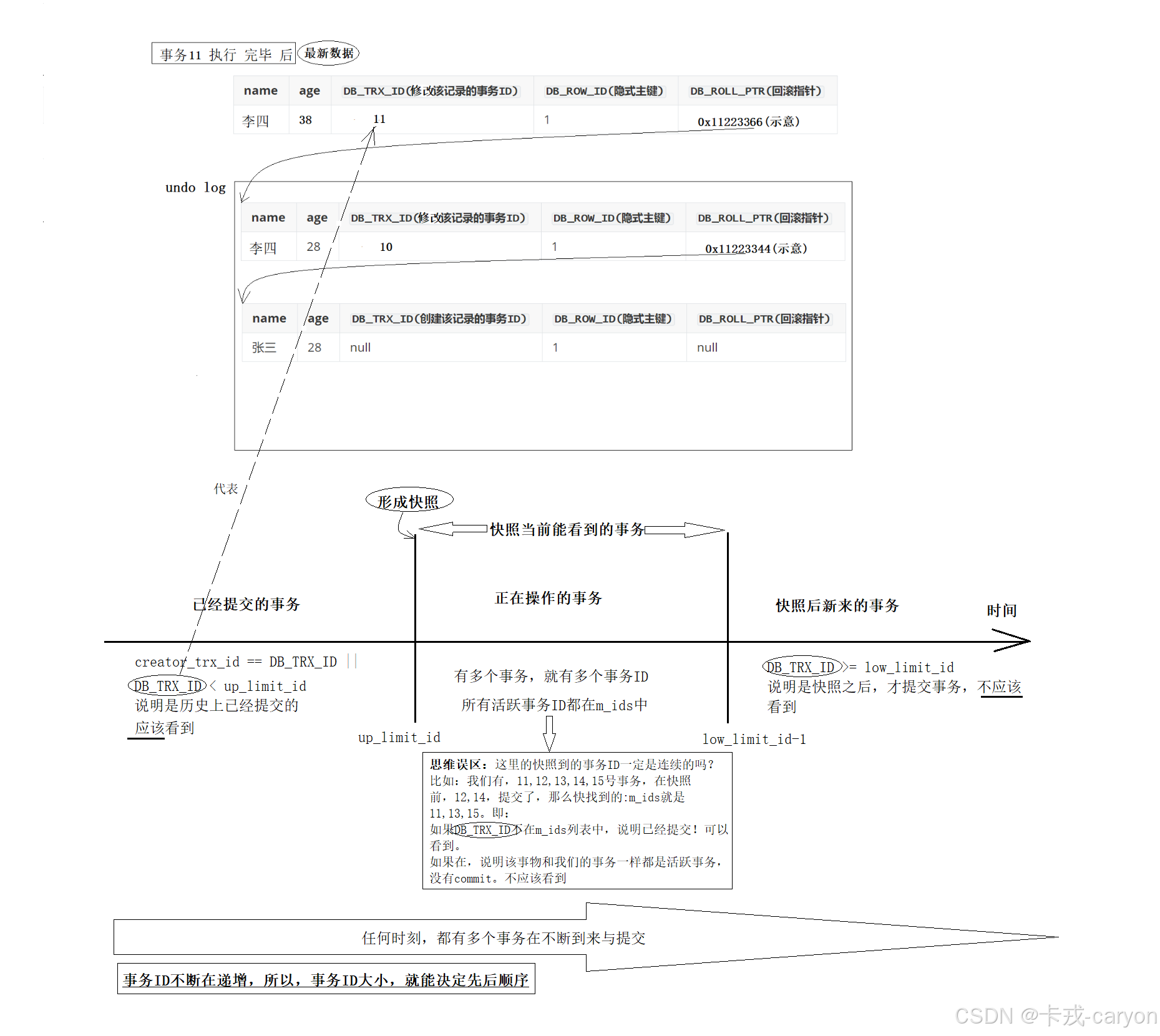
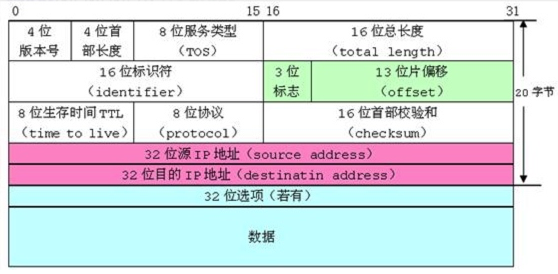
【MySQL】10.事务管理
1. 事务的引入 首先我们需要知道CURD操作不加控制会产生什么问题: 为了解决上面的问题,CURD需要满足如下条件: 2. 事务的概念 事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功&…...

Bugku-CTF-Web安全最佳刷题路线
曾经的我也是CTF六项全能,Web安全,密码学,杂项,Pwn,逆向,安卓样样都会。明明感觉这样很酷,却为何还是沦为社畜。Bugku-CTF-Web安全最佳刷题路线,我已经整理好了,干就完了…...
IT学习方法与资料分享
一、编程语言与核心技能:构建技术地基 1. 入门首选:Python 与 JavaScript Python:作为 AI 与数据科学的基石,可快速构建数据分析与自动化脚本开发能力。 JavaScript:Web 开发的核心语言,可系统掌握 React/V…...

程序代码篇---Python串口
在 Python 里,serial库(一般指pyserial)是串口通信的常用工具。下面为你介绍其常用的读取和发送操作函数及使用示例: 1. 初始化串口 要进行串口通信,首先得对串口对象进行初始化,代码如下: i…...
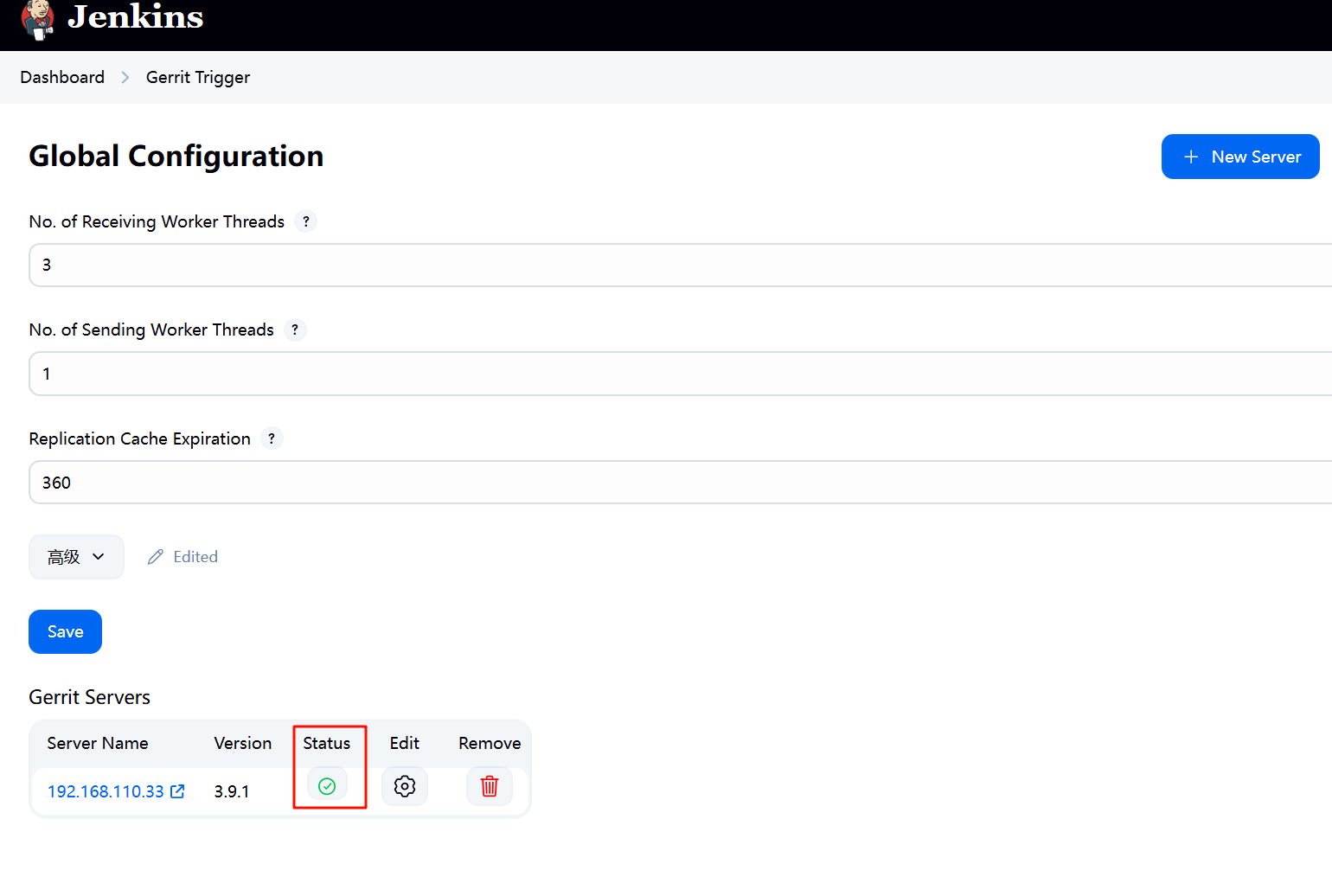
jenkins gerrit-trigger插件配置
插件gerrit-trigger下载好之后要在Manage Jenkins -->Gerrit Trigger-->New Server 中新增Gerrit Servers 配置好保存后点击“状态”查看是否正常...

虚拟主机都有哪些应用场景?
虚拟主机作为一种高效的网络托管方案,已经逐渐成为企业构建网站和应用软件的重要选择,下面,小编将为大家介绍一下虚拟主机的应用场景都有哪些吧! 虚拟主机可以帮助企业建立属于自己的企业网站,是用来展示公司形象和服务…...

预训练语言模型T5-11B的简要介绍
文章目录 模型基本信息架构特点性能表现应用场景 T5-11B 是谷歌提出的一种基于 Transformer 架构的预训练语言模型,属于 T5(Text-To-Text Transfer Transformer)模型系列,来自论文 Colin Raffel, Noam Shazeer, Adam Roberts, Kat…...

数论总结,(模版与题解)
数论 欧拉函数X质数(线性筛与二进制枚举)求解组合数欧拉降幂(乘积幂次)乘法逆元最小质因子之和模版 欧拉函数 欧拉函数的定义就是小于等于n的数里有f(n)个数与n互质,下面是求欧拉函数的模版。 package com.js.datas…...
EasyRTC嵌入式音视频通信SDK助力物联网/视频物联网音视频打造全场景应用
一、方案概述 随着物联网技术的飞速发展,视频物联网在各行业的应用日益广泛。实时音视频通信技术作为视频物联网的核心支撑,其性能直接影响着系统的交互体验和信息传递效率。EasyRTC作为一款成熟的音视频框架,具备低延迟、高画质、跨平台等…...
1-2 Linux-虚拟机(2025.6.7学习篇- win版本)
1、虚拟机 学习Linux系统,就需要有一个可用的Linux系统。 如何获得?将自己的电脑重装系统为Linux? NoNo。这不现实,因为Linux系统并不适合日常办公使用。 我们需要借助虚拟机来获得可用的Linux系统环境进行学习。 借助虚拟化技术&…...
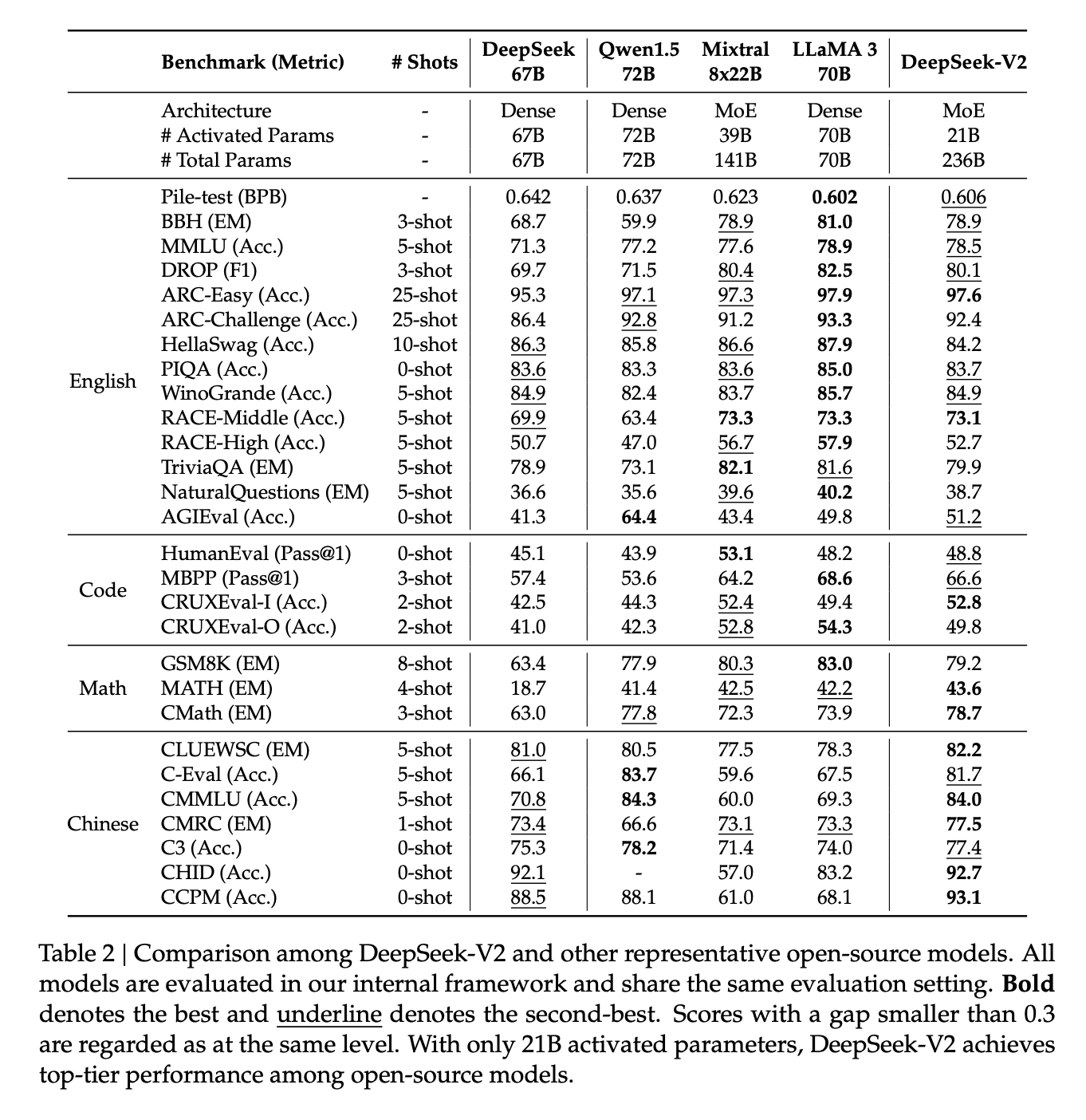
Deepseek基座:Deepseek-v2核心内容解析
DeepSeek原创文章1 DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 2 Deepseek基座:DeepSeek LLM核心内容解析 3 Deepseek基座:Deepseek MOE核心内容解析 4 Deepseek基座:Deepseek-v2核心内容解析 5Deepseek基座…...
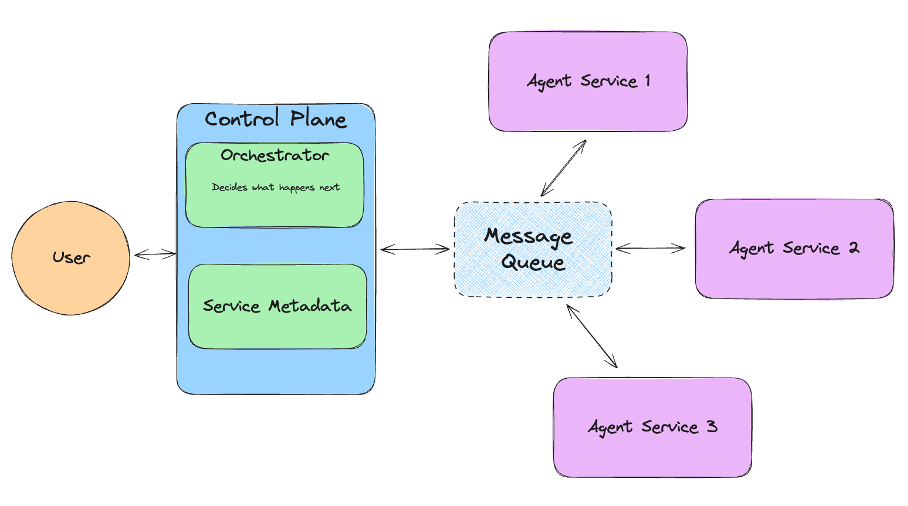
2025主流智能体Agent终极指南:Manus、OpenManus、MetaGPT、AutoGPT与CrewAI深度横评
当你的手机助手突然提醒"明天会议要带投影仪转接头",或是电商客服自动生成售后方案时,背后都是**智能体(Agent)**在悄悄打工。这个AI界的"瑞士军刀"具备三大核心特征: 自主决策能力:像老司机一样根据路况实时…...
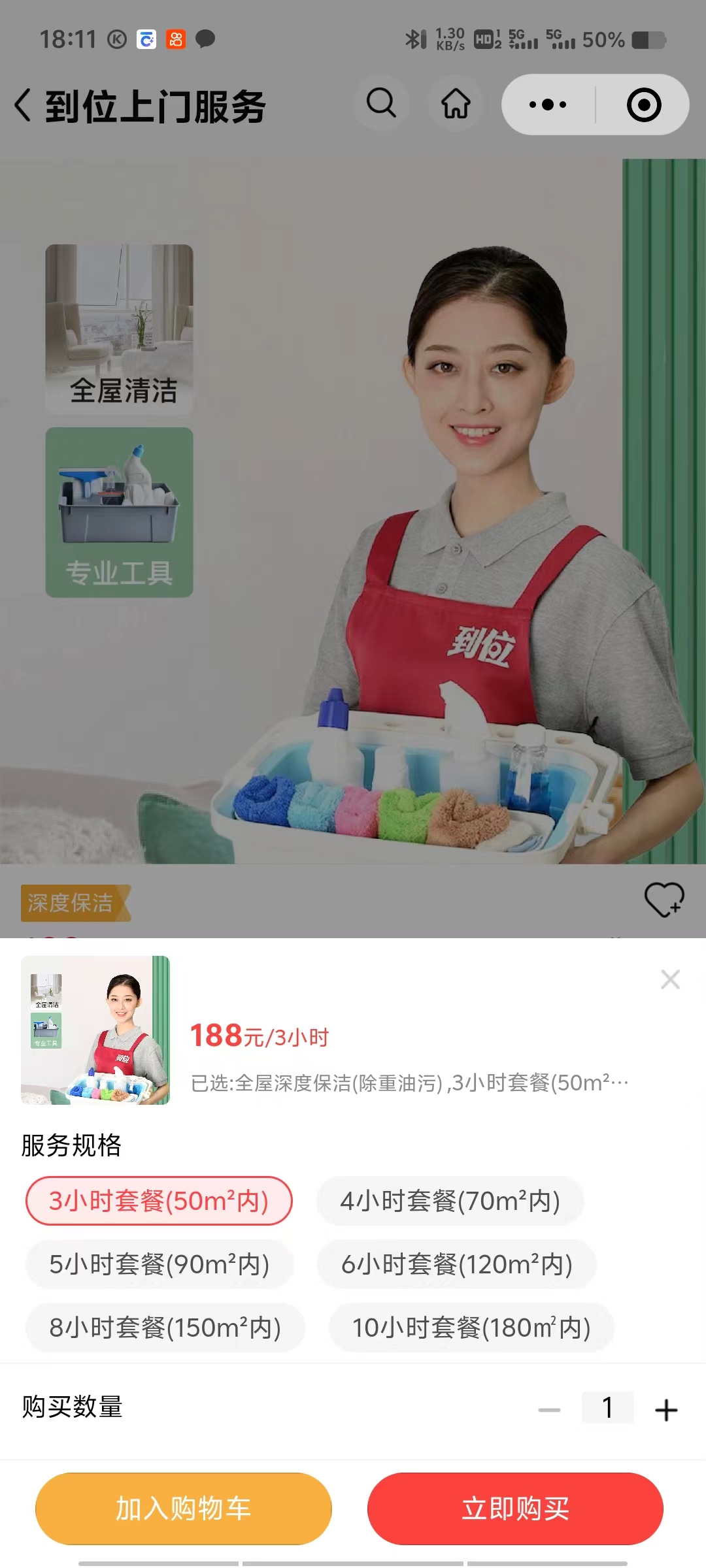
家政小程序开发——AI+IoT技术融合,打造“智慧家政”新物种
基于用户历史订单(如“每周一次保洁”)、设备状态(如智能门锁记录的清洁频率),自动生成服务计划。 结合天气数据(如“雨天推荐玻璃清洁”),动态推送服务套餐。 IoT设备联动&#x…...

Keil开发STM32生成hex文件/bin文件
生成hex文件生成bin文件 STM32工程的hex文件和bin文件都可以通过Keil直接配置生成 生成hex文件 工程中点击魔术棒,在 Output 中勾选 Create HEX File 选项,OK保存工程配置 编译工程通过后可以看到编译输出窗口有创建hex文件的提示 默认可以在Output文…...

Windows 系统安装 Redis 详细教程
Windows 系统安装 Redis 详细教程 一、Redis 简介 Redis(Remote Dictionary Server)是一个开源的、基于内存的高性能键值存储系统,常被用作数据库、缓存和消息中间件。相比传统数据库,Redis 具有以下优势: 超高性能…...
)
“组件、路由懒加载”,在 Vue3 和 React 中分别如何实现? (copy)
Vue3 和 React 组件懒加载实现方式 React 中组件懒加载的实现方式 React 提供了 React.lazy 和 Suspense 两个 API 来实现组件的懒加载。React.lazy 用于动态导入组件,而 Suspense 则用于指定加载过程中的占位内容。例如,可以通过以下代码实现懒加载&a…...

.NET 事件模式举例介绍
.NET 事件模式:实现对象间松耦合通信 在软件开发中,对象之间的通信是一个常见且重要的问题。.NET 框架提供了一种标准化的事件模式,用于解决对象间的通信问题,实现松耦合的交互方式。今天,我们就通过一个简单的例子来…...
PDF 转 Markdown
本地可部署的模型 Marker Marker 快速准确地将文档转换为 markdown、JSON 和 HTML。 转换所有语言的 PDF、图像、PPTX、DOCX、XLSX、HTML、EPUB 文件在给定 JSON 架构 (beta) 的情况下进行结构化提取设置表格、表单、方程式、内联数学、链接、引用和代…...

北大开源音频编辑模型PlayDiffusion,可实现音频局部编辑,比传统 AR 模型的效率高出 50 倍!
北大开源了一个音频编辑模型PlayDiffusion,可以实现类似图片修复(inpaint)的局部编辑功能 - 只需修改音频中的特定片段,而无需重新生成整段音频。此外,它还是一个高性能的 TTS 系统,比传统 AR 模型的效率高出 50 倍。 自回归 Tra…...
蒲公英盒子连接问题debug
1、 现象描述 2、问题解决 上图为整体架构图,其中左边一套硬件设备是放在机房,右边是放在办公室。左边的局域网连接了可以访问外网的路由器,利用蒲公英作为旁路路由将局域网暴露在外网环境下。 我需要通过蒲公英作为旁路路由来进行远程访问&…...

Unity | AmplifyShaderEditor插件基础(第五集:简易膨胀shader)
一、👋🏻前言 大家好,我是菌菌巧乐兹~本节内容主要讲一下,如何用shader来膨胀~ 效果预览: 二、💨膨胀的基本原理 之前的移动是所有顶点朝着一个方向走,所以是移动 如果所有顶点照着自己的方…...

Django核心知识点全景解析
引言 本文深入剖析Django核心组件,涵盖数据交换、异步交互、状态管理及安全认证,附完整代码示例和避坑指南! 目录 引言 一、JSON:轻量级数据交换标准 1. 核心特性 2. 标准格式 3. 各语言处理方法 4. 常见错误示例 二、AJA…...

生物发酵展同期举办2025中国合成生物学与生物制造创新发展论坛
一、会议介绍 2025中国合成生物学与生物制造创新发展论坛暨上海国际合成生物学与生物制造展览会于2025年8月7-9日在上海新国际博览中心(浦东新区龙阳路2345号)召开,本次论坛汇聚了国内外顶尖学者、行业领袖及政策制定者,将围绕“…...