机器学习监督学习实战五:六种算法对声呐回波信号进行分类
本项目基于UCI的声呐目标识别数据集(Sonar, Mines vs. Rocks),通过10种机器学习算法比较,发现集成学习方法表现最优。研究首先对60个声呐能量特征进行可视化分析(分布直方图、相关性矩阵),对比了基础算法(如KNN、SVM)和集成算法(如随机森林、梯度提升)的10折交叉验证准确率。结果显示标准化后模型性能提升,其中额外树(ExtraTrees)表现最佳(准确率88.6%),并通过网格搜索优化超参数。最后利用SHAP值解释模型,揭示关键特征(如Feature 10)对预测的贡献度,为声呐目标分类提供了可解释的解决方案。完整代码已开源在个人GitHubhttps://github.com/KLWU07/Machine-learning-Project-practice。
一、数据集
onar.all-data 是 UCI 机器学习仓库中的经典二分类数据集,用于声呐信号处理与目标识别任务,区分声呐回波来自岩石(Rock)还是金属圆柱体(如地雷,Mine)。 原始数据通过主动声呐发射宽带声波,接收目标反射信号并进行数字化处理后得到。共 208 个样本,其中:岩石(R)97 个样本金属圆柱体(M)111 个样本;两类样本数量接近平衡,适合二分类算法测试。
数据集的 60 个特征均为连续型数值范围在 0.0 到 1.0 之间。每个数字代表特定频段内在一定时间内积分的能量。,本质上是声呐信号在不同处理阶段的能量响应值,反映目标对声波的反射特性。每个特征可能对应声呐信号在某个特定频率点的振幅值(通过傅里叶变换得到的频谱分量),部分特征可能对应信号在不同时间窗口的能量分布(短时傅里叶变换的结果),更多数据集信息来自于https://archive.ics.uci.edu/dataset/151,可在里面下载。
二、可视化
1.60个特征的分布情况(直方图和密度图)

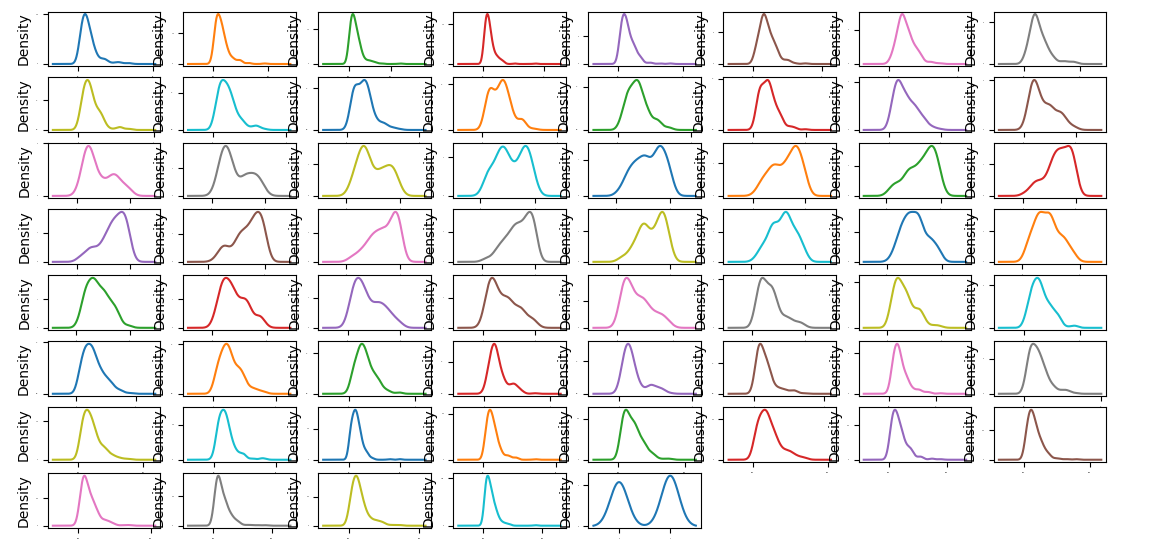
2.特征之间的相关性(矩阵图)
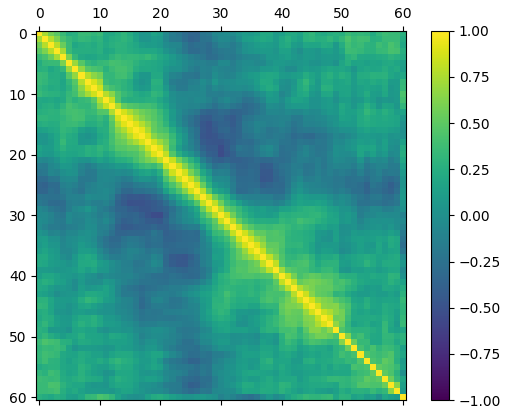
三、算法和评估
逻辑回归、线性判别分析、K近邻、决策树、朴素贝叶斯、支持向量机
1.10折交叉验证准确率(箱线图)
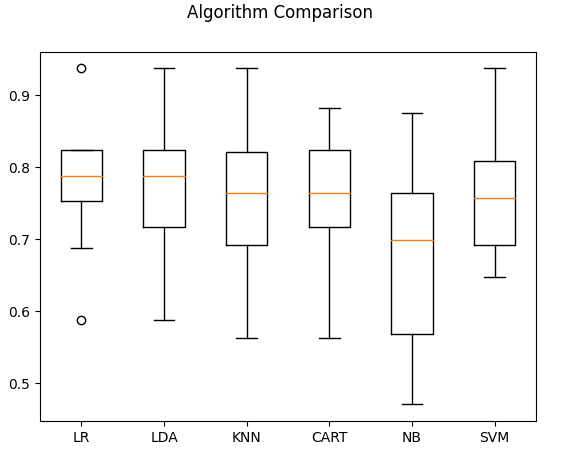
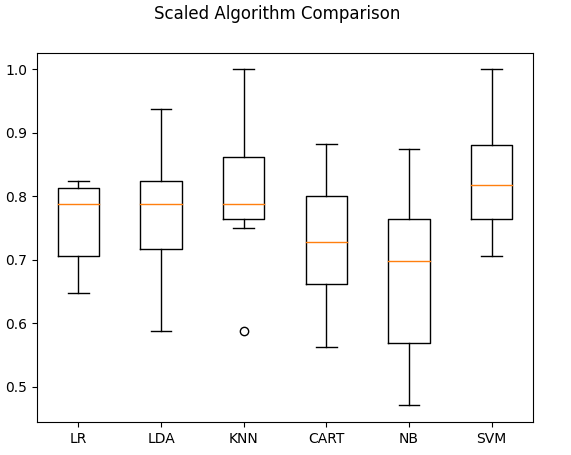
2.数据标准化和10折交叉验证准确率(箱线图)
数据标准化后准确率有提升。
四,改进算法和集合算法
- ** 网格搜索GridSearchCV寻找超参数,从上面挑出最好的:K近邻KNN和支持向量机SVR**
- 集成学习方法:AdaBoost、梯度提升、随机森林、额外树
1.数据标准化、10折交叉验证和网格搜索准确率(结果)
KNN最优:0.8360294117647058 使用{'n_neighbors': 1} SVR最优:0.85 使用{'C': 1.7, 'kernel': 'rbf'}
2.集成算法标准化和10折交叉验证(箱线图)

3.梯度提升、数据标准化、10折交叉验证和网格搜索
额外树ETR-ExtraTreesClassifier()
最优:0.8860294117647058 使用{'n_estimators': 400}
4.最终模型(分类报告)
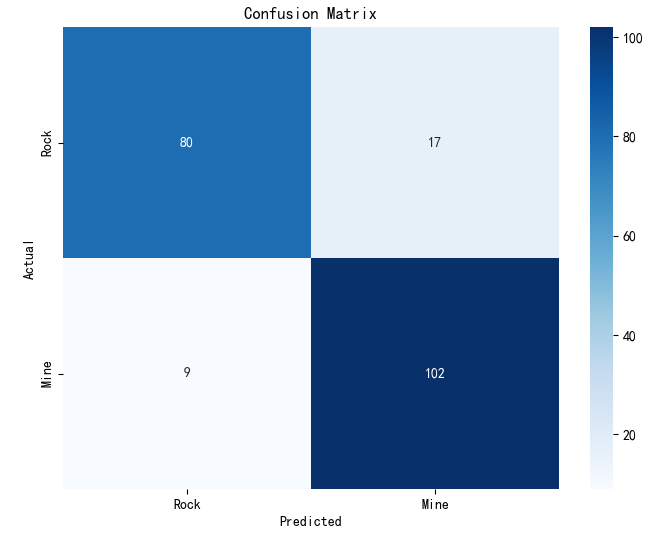
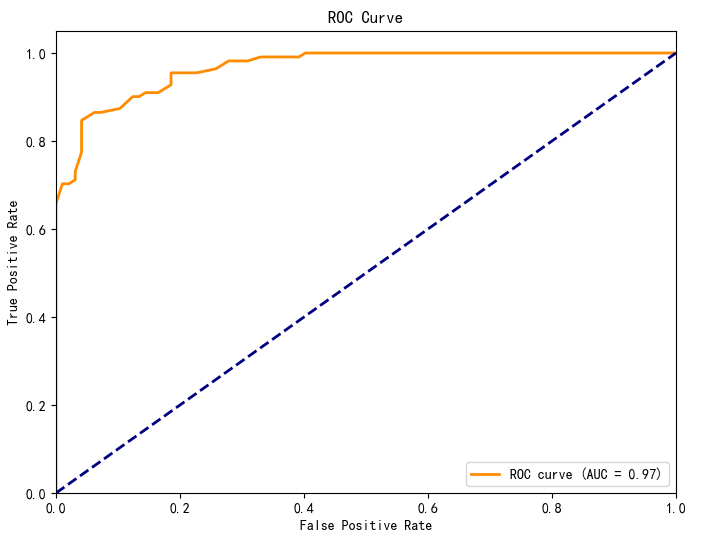
额外树ETR-ExtraTreesClassifier(),使用10折交叉验证。混淆矩阵、ROC曲线
=== 交叉验证评估 ===
Accuracy: 0.874 (±0.080)
Precision: 0.846 (±0.140)
Recall: 0.910 (±0.101)
F1-score: 0.873 (±0.110)
ROC-AUC: 0.971 (±0.031)
=== 分类报告 ===precision recall f1-score supportRock 0.90 0.82 0.86 97Mine 0.86 0.92 0.89 111accuracy 0.88 208macro avg 0.88 0.87 0.87 208
weighted avg 0.88 0.88 0.87 208
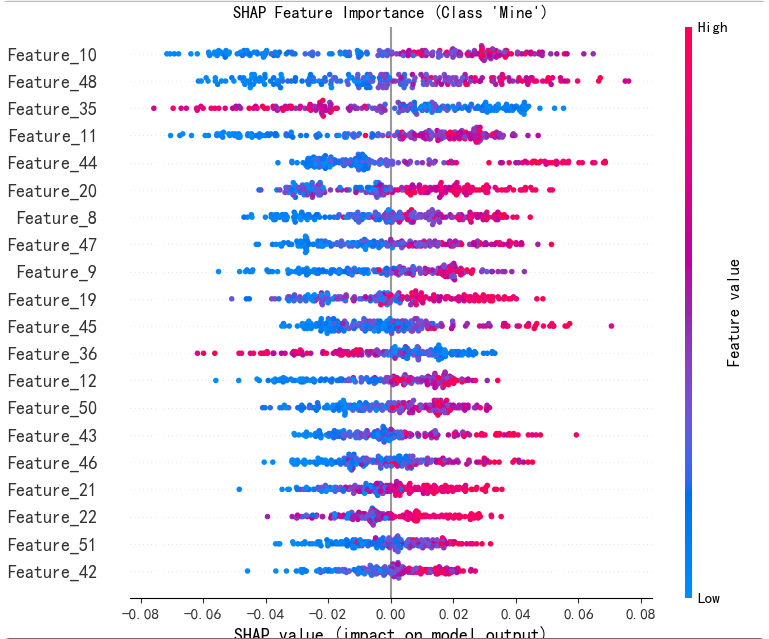
5. 解释模型计算特征重要性(SHAP 值的摘要图)
展示Mine类特征贡献度可视化(‘M’: 1)。
- 解释展现关系
- 单个特征对模型预测的影响方向(正相关/负相关)和影响程度(SHAP值绝对值大小)。
- 特征取值与SHAP值的分布关系(。
- 横轴为SHAP值,纵轴为特征名称,点的颜色表示特征取值(如颜色越深代表特征值越大)。
- 比如:特征x10的SHAP值多为正值,且随特征值增大而增大,表明x10与预测结果呈正相关;特征x2的SHAP值多为负值,表明其与预测结果呈负相关。很多都有正负相关。
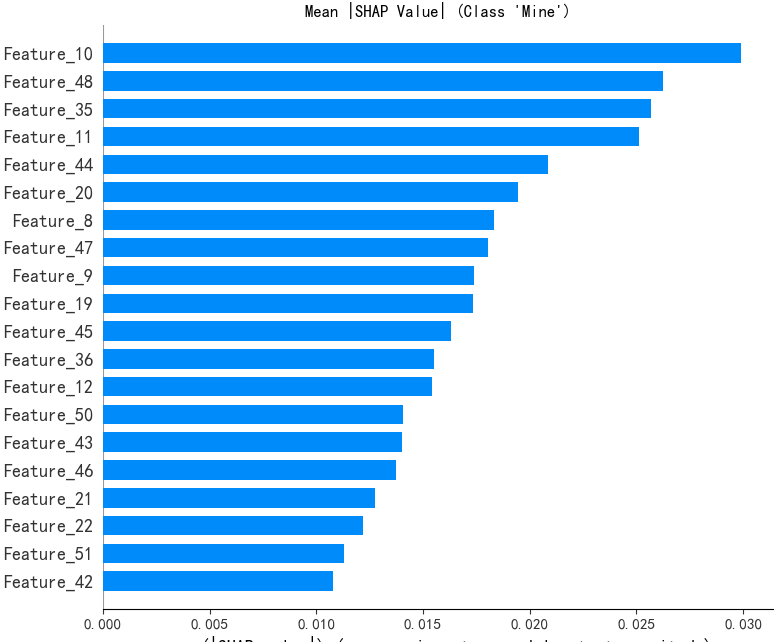
6.特征重要性排序
各特征的平均SHAP值绝对值排名,直观展示特征重要性排序。横轴为平均SHAP值绝对值,纵轴为特征名称,特征按重要性降序排列。特征Feature 10的平均SHAP值最大,对模型预测的贡献度最高。
7.单个样本的SHAP决策图(第一个样本)
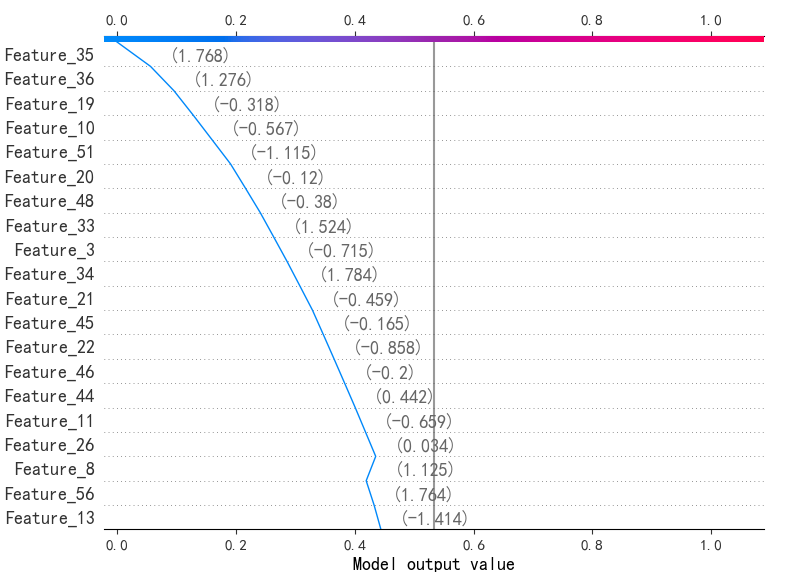
五、完整代码
# 导入类库
import numpy as np
import pandas as pd
from matplotlib import pyplot
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
import shap# 导入数据
filename = 'sonar.all-data.csv'
dataset = pd.read_csv(filename, header=None)# 将目标变量转换为数值类型
dataset[60] = dataset[60].map({'R': 0, 'M': 1})# 数据维度
print(dataset.shape)# 查看数据类型
print(dataset.dtypes)# 查看最初的20条记录
pd.set_option('display.width', 100)
print(dataset.head(20))# 描述性统计信息
pd.set_option('display.precision', 3)
print(dataset.describe())# 数据的分类分布
print(dataset.groupby(60).size())# 直方图
dataset.hist(sharex=False, sharey=False, xlabelsize=1, ylabelsize=1)
pyplot.show()# 密度图
dataset.plot(kind='density', subplots=True, layout=(8, 8), sharex=False, legend=False, fontsize=1)
pyplot.show()# 关系矩阵图
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(dataset.corr(), vmin=-1, vmax=1, interpolation='none')
fig.colorbar(cax)
pyplot.show()# 分离评估数据集
array = dataset.values
X = array[:, 0:60].astype(float)
Y = array[:, 60]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y, test_size=validation_size, random_state=seed)# 评估算法的基准
num_folds = 10
seed = 7
scoring = 'accuracy'# 评估算法 - 原始数据
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
results = []
for key in models:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_results = cross_val_score(models[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))# 评估算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()# 评估算法 - 正态化数据
pipelines = {}
pipelines['ScalerLR'] = Pipeline([('Scaler', StandardScaler()), ('LR', LogisticRegression())])
pipelines['ScalerLDA'] = Pipeline([('Scaler', StandardScaler()), ('LDA', LinearDiscriminantAnalysis())])
pipelines['ScalerKNN'] = Pipeline([('Scaler', StandardScaler()), ('KNN', KNeighborsClassifier())])
pipelines['ScalerCART'] = Pipeline([('Scaler', StandardScaler()), ('CART', DecisionTreeClassifier())])
pipelines['ScalerNB'] = Pipeline([('Scaler', StandardScaler()), ('NB', GaussianNB())])
pipelines['ScalerSVM'] = Pipeline([('Scaler', StandardScaler()), ('SVM', SVC())])
results = []
for key in pipelines:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_results = cross_val_score(pipelines[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))# 评估算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Scaled Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()# 调参改进算法 - KNN
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_neighbors': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21]}
model = KNeighborsClassifier()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))
cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['std_test_score'],grid_result.cv_results_['params'])
for mean, std, param in cv_results:print('%f (%f) with %r' % (mean, std, param))# 调参改进算法 - SVM
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train).astype(float)
param_grid = {}
param_grid['C'] = [0.1, 0.3, 0.5, 0.7, 0.9, 1.0, 1.3, 1.5, 1.7, 2.0]
param_grid['kernel'] = ['linear', 'poly', 'rbf', 'sigmoid']
model = SVC()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))
cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['std_test_score'],grid_result.cv_results_['params'])
for mean, std, param in cv_results:print('%f (%f) with %r' % (mean, std, param))# 集成算法
ensembles = {}
ensembles['ScaledAB'] = Pipeline([('Scaler', StandardScaler()), ('AB', AdaBoostClassifier())])
ensembles['ScaledGBM'] = Pipeline([('Scaler', StandardScaler()), ('GBM', GradientBoostingClassifier())])
ensembles['ScaledRF'] = Pipeline([('Scaler', StandardScaler()), ('RFR', RandomForestClassifier())])
ensembles['ScaledET'] = Pipeline([('Scaler', StandardScaler()), ('ETR', ExtraTreesClassifier())])results = []
for key in ensembles:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_result = cross_val_score(ensembles[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_result)print('%s: %f (%f)' % (key, cv_result.mean(), cv_result.std()))# 集成算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(ensembles.keys())
pyplot.show()# 集成算法ETR - 调参
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_estimators': [10, 50, 100, 200, 300, 400, 500, 600, 700, 800, 900]}
model = ExtraTreesClassifier()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)
print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))# 模型最终化
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
model = ExtraTreesClassifier()
model.fit(X=rescaledX, y=Y_train)
# 评估模型
rescaled_validationX = scaler.transform(X_validation)
predictions = model.predict(rescaled_validationX)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))相关文章:
机器学习监督学习实战五:六种算法对声呐回波信号进行分类
本项目基于UCI的声呐目标识别数据集(Sonar, Mines vs. Rocks),通过10种机器学习算法比较,发现集成学习方法表现最优。研究首先对60个声呐能量特征进行可视化分析(分布直方图、相关性矩阵),对比了…...

React Hooks 的闭包陷阱问题
这是主包在面试中遇到的一道题目,面试官的问题是:"这个页面初次展示出来时Count和step的值是什么,我点击按钮count和step的值有什么变化?“ 这个题目主包回答的不好,所以想做一个总结。 题目 import React, { …...
力扣面试150题--克隆图
Day 61 题目描述 思路 /* // Definition for a Node. class Node {public int val;public List<Node> neighbors;public Node() {val 0;neighbors new ArrayList<Node>();}public Node(int _val) {val _val;neighbors new ArrayList<Node>();}public N…...

【HarmonyOS 5】运动健康开发实践介绍以及详细案例
以下是 HarmonyOS 5 运动健康功能的简洁介绍,聚焦核心体验与技术亮点: 一、AI 驱动的全场景健康管理 智能运动私教:运动前推送热身指导,运动中实时纠正动作,运动后生成个性化报告与改进建议。AI 融合用户多设备数…...

STM32开发中,线程启动异常问题排查简述
1. 参数传递问题 错误类型:线程属性错误地使用。影响:线程属性(如堆栈大小、优先级)不匹配可能导致线程创建失败或行为异常。验证方法:检查 线程创建的返回值,若为 NULL 则表示线程创建失败。 2. 系统资源…...

SQL进阶之旅 Day 18:数据分区与查询性能
【SQL进阶之旅 Day 18】数据分区与查询性能 文章简述 在现代数据库系统中,随着数据量的快速增长,如何高效地管理和查询大规模数据成为开发人员和数据分析师面临的重要挑战。本文深入探讨了数据分区的概念及其对查询性能的提升作用,结合理论…...

鸿蒙PC,有什么缺点?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 价格太高,二是部分管理员权限首先,三对于开发者不太友好举个例子:VSCode的兼容性对程序员至关重要。若能支持VSCode,这台电脑将成为大多数开发者…...

前端工具:Webpack、Babel、Git与工程化流程
1. Webpack:资源打包优化工具 案例1:多入口文件打包 假设项目有多个页面(如首页index.js和登录页login.js),需要分别打包: ● 配置webpack.config.js: module.exports {entry: {index: ./sr…...

使用Python和Scikit-Learn实现机器学习模型调优
在机器学习项目中,模型的性能往往取决于多个因素,其中模型的超参数(hyperparameters)起着关键作用。超参数是模型在训练之前需要设置的参数,例如决策树的深度、KNN的邻居数等。合理地选择超参数可以显著提升模型的性能…...

灰狼优化算法MATLAB实现,包含种群初始化和29种基准函数测试
灰狼优化算法(Grey Wolf Optimizer, GWO)MATLAB实现,包含种群初始化和29种基准函数测试。代码包含详细注释和可视化模块: %% 灰狼优化算法主程序 (GWO.m) function GWO()clear; clc; close all;% 参数设置SearchAgents_no 30; …...

go语言学习 第7章:数组
第7章:数组 数组是一种基本的数据结构,用于存储相同类型的元素集合。在Go语言中,数组的大小是固定的,一旦定义,其长度不可改变。本章将详细介绍Go语言中数组的定义、初始化、访问、遍历以及一些常见的操作。 一、数组…...

PDF图片和表格等信息提取开源项目
文章目录 综合性工具专门的表格提取工具经典工具 综合性工具 PDF-Extract-Kit - opendatalab开发的综合工具包,包含布局检测、公式检测、公式识别和OCR功能 仓库:opendatalab/PDF-Extract-Kit特点:功能全面,包含表格内容提取的S…...
《Progressive Transformers for End-to-End Sign Language Production》复现报告
摘要 本文复现了《Progressive Transformers for End-to-End Sign Language Production》一文中的核心模型结构。该论文提出了一种端到端的手语生成方法,能够将自然语言文本映射为连续的 3D 骨架序列,并引入 Counter Decoding 实现动态序列长度控制。我…...

Haystack:AI与IoT领域的全能开源框架
一、Haystack 的定义与背景 Haystack 是一个开源框架,主要服务于两类不同领域: 物联网(IoT)与建筑自动化领域(Project Haystack): 旨在标准化物联网设备数据的语义模型,解决建筑系统(如 HVAC、能源管理)的数据互操作性问题,通过标签分类(Tagging Taxonomy)统一设…...

OpenWrt:使用ALSA实现边录边播
ALSA是Linux系统中的高级音频架构(Advanced Linux Sound Architecture)。目前已经成为了linux的主流音频体系结构,想了解更多的关于ALSA的知识,详见:http://www.alsa-project.org 在内核设备驱动层,ALSA提供…...

链表题解——回文链表【LeetCode】
算法思路 核心思想: 找到链表的中间节点。反转链表的后半部分。比较链表的前半部分和反转后的后半部分,如果值完全一致,则是回文链表。 具体步骤: 使用快慢指针找到链表的中间节点(middleNode 方法)。反转…...

CSS6404L 在物联网设备中的应用优势:低功耗高可靠的存储革新与竞品对比
物联网设备对存储芯片的需求聚焦于低功耗、小尺寸、高可靠性与传输效率,Cascadeteq 的 CSS6404L 64Mb Quad-SPI Pseudo-SRAM 凭借差异化技术特性,在同类产品中展现显著优势。以下从核心特性及竞品对比两方面解析其应用价值。 一、CSS6404L 核心产品特性…...

Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破 1.1 并行流的核心应用场景 在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环…...
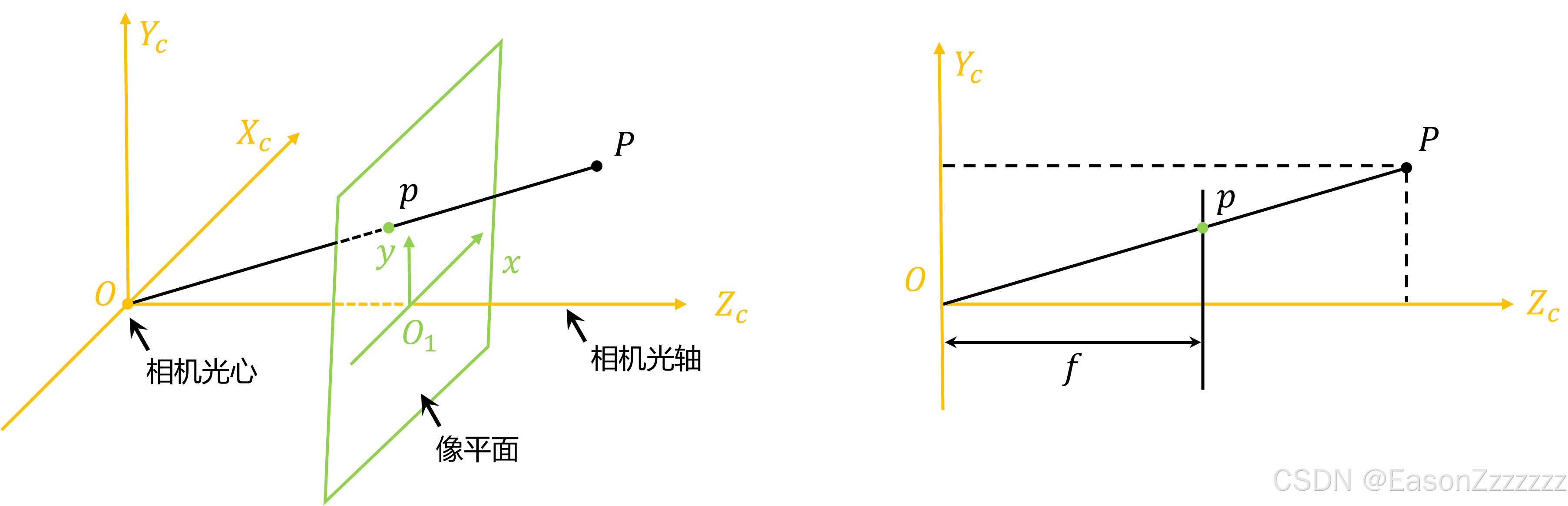
计算机视觉——相机标定
计算机视觉——相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐标系二、坐标系变换图像坐标系 → 像素坐标系相机坐标系 → 图像坐标系世界坐标系 → 相机坐标系 ⋆ \star ⋆ 世界坐标系 → 像素坐标系 三、相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐…...
C语言中的数据类型(二)--结构体
在之前我们已经探讨了C语言中的自定义数据类型和数组,链接如下:C语言中的数据类型(上)_c语言数据类型-CSDN博客 目录 一、结构体的声明 二、结构体变量的定义和初始化 三、结构体成员的访问 3.1 结构体成员的直接访问 3.2 结…...

第1章:Neo4j简介与图数据库基础
1.1 图数据库概述 在当今数据爆炸的时代,数据不仅仅是以量取胜,更重要的是数据之间的关联关系。传统的关系型数据库在处理高度关联数据时往往力不从心,而图数据库则应运而生,成为处理复杂关联数据的理想选择。 传统关系型数据库…...
C++11:原子操作与内存顺序:从理论到实践的无锁并发实现
文章目录 0.简介1.并发编程需要保证的特性2.原子操作2.1 原子操作的特性 3.内存顺序3.1 顺序一致性3.2 释放-获取(Release-Acquire)3.3 宽松顺序(Relaxed)3.4 内存顺序 4.无锁并发5. 使用建议 0.简介 在并发编程中,原子性、可见性和有序性是…...

Android第十四次面试总结
OkHttp中获取数据与操作数据 一、数据获取核心机制 1. 同步请求(阻塞式) // 1. 创建HTTP客户端(全局应复用实例) OkHttpClient client new OkHttpClient();// 2. 构建请求对象(GET示例) Request r…...

动力电池点焊机:驱动电池焊接高效与可靠的核心力量|比斯特自动化
在新能源汽车与储能设备需求激增的背景下,动力电池的制造工艺直接影响产品性能与安全性。作为电芯与极耳连接的核心设备,点焊机如何平衡效率、精度与可靠性,成为电池企业关注的重点。 动力电池点焊机的核心功能是确保电芯与极耳的稳固连接。…...
【MySQL】10.事务管理
1. 事务的引入 首先我们需要知道CURD操作不加控制会产生什么问题: 为了解决上面的问题,CURD需要满足如下条件: 2. 事务的概念 事务就是一组DML语句组成,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功&…...

Bugku-CTF-Web安全最佳刷题路线
曾经的我也是CTF六项全能,Web安全,密码学,杂项,Pwn,逆向,安卓样样都会。明明感觉这样很酷,却为何还是沦为社畜。Bugku-CTF-Web安全最佳刷题路线,我已经整理好了,干就完了…...
IT学习方法与资料分享
一、编程语言与核心技能:构建技术地基 1. 入门首选:Python 与 JavaScript Python:作为 AI 与数据科学的基石,可快速构建数据分析与自动化脚本开发能力。 JavaScript:Web 开发的核心语言,可系统掌握 React/V…...

程序代码篇---Python串口
在 Python 里,serial库(一般指pyserial)是串口通信的常用工具。下面为你介绍其常用的读取和发送操作函数及使用示例: 1. 初始化串口 要进行串口通信,首先得对串口对象进行初始化,代码如下: i…...
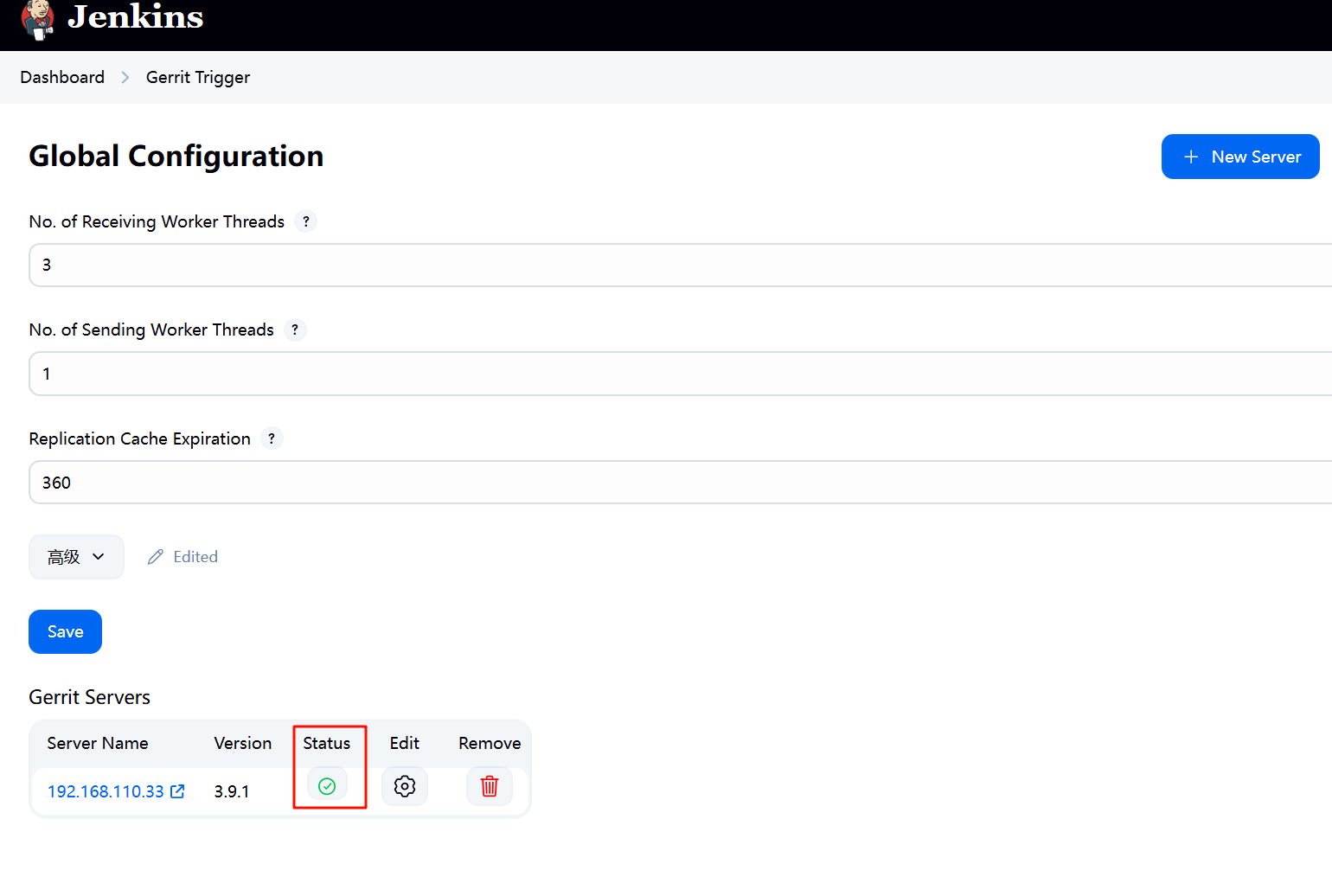
jenkins gerrit-trigger插件配置
插件gerrit-trigger下载好之后要在Manage Jenkins -->Gerrit Trigger-->New Server 中新增Gerrit Servers 配置好保存后点击“状态”查看是否正常...

虚拟主机都有哪些应用场景?
虚拟主机作为一种高效的网络托管方案,已经逐渐成为企业构建网站和应用软件的重要选择,下面,小编将为大家介绍一下虚拟主机的应用场景都有哪些吧! 虚拟主机可以帮助企业建立属于自己的企业网站,是用来展示公司形象和服务…...