[ElasticSearch] DSL查询
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(97平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(96平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
💻 项目总结(97平均质量分) https://blog.csdn.net/2301_80050796/category_12936070.html?spm=1001.2014.3001.5482
🎈JVM(97平均质量分) https://blog.csdn.net/2301_80050796/category_12976744.html?spm=1001.2014.3001.5482
🔍ElasticSearch(96平均质量分) https://blog.csdn.net/2301_80050796/category_12978995.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 1. DSL查询
- 1.1 快速入门
- 1.2 叶子查询
- 1.2.1 全文检索查询
- 1.2.2 精确查询
- 1.3 复合查询
- 1.3.1 算分函数查询
- 1.3.2 bool查询
- 1.4 排序
- 1.5 分页
- 1.5.1 基础分页
- 1.5.2 深度分页
- 1.6 高亮
- 1.6.1 高亮显示原理
- 1.6.2 实现高亮
- 1.7 总结
- 2. RestClient查询
- 2.1 快速入门
- 2.2.1 发送请求
- 2.1.2 解析响应结果
- 2.1.3 总结
- 2.2 叶子查询
- 2.3 复合查询
- 2.4 排序和分页
- 2.5 高亮
今天我们来研究以下ElasticSearch的数据搜索功能,ElasticSearch提供了基于json的DSL语句来定义查询条件,其javaAPI就是在组织DSL条件.
因此我们先学习DSL的查询语法,在基于DSL来对照学习javaAPI,就会事半功倍.
1. DSL查询
ElasticSearch的查询可以分为两大类:
- 叶子查询: 一般是在特定的字段里查询特定的值,属于简单查询,很少单独使用.
- 复合查询: 以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式.
1.1 快速入门
我们依然在Kibana的DevTools中学习查询的DSL语法,首先来看查询的语法结构:
GET /{索引库名}/_search
{"query": {"查询类型": {// .. 查询条件}}
}
说明: GET /{索引库名}/_search: 其中的_search是固定路径,不能更改.
例如,我们以最简单的无条件查询,无条件查询的类型是: match_all,因此查询语句如下:
GET /items/_search
{"query": {"match_all": {}}
}
由于match_all无条件,所以条件位置不写即可.
执行结果如下:
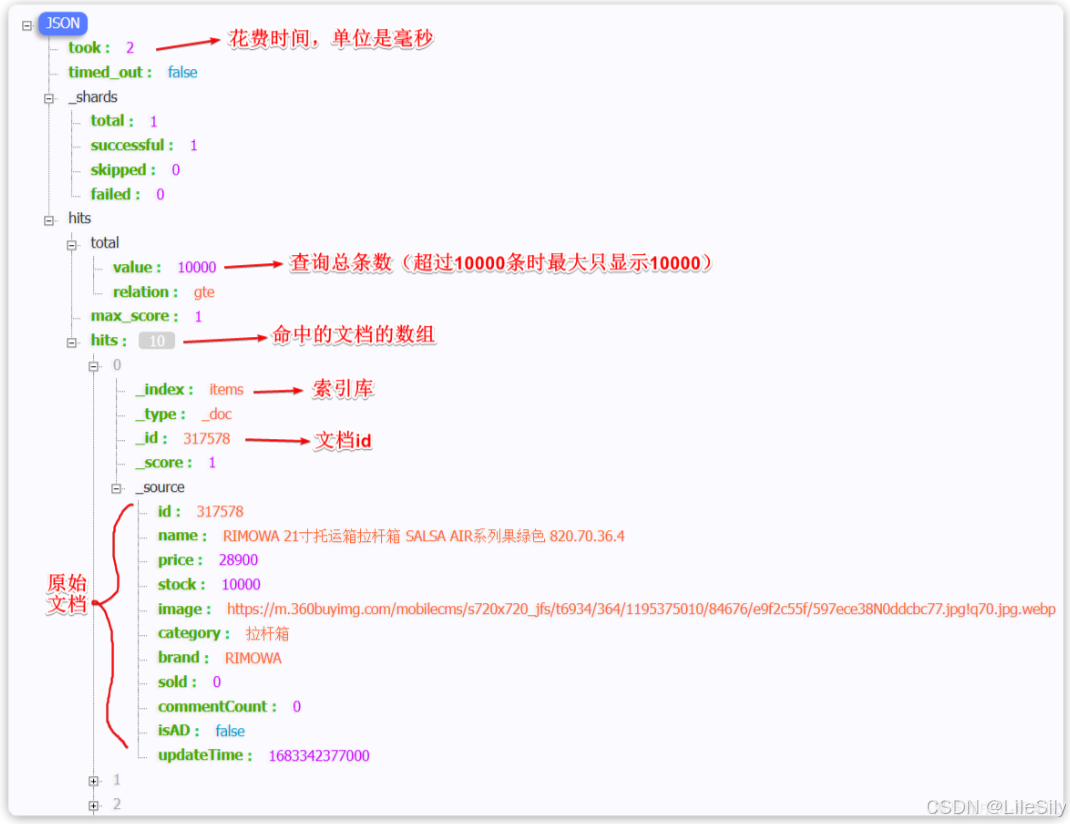
你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅仅有10条,这是因为出于安全考虑,elasticSearch设置了默认的查询页数.
1.2 叶子查询
叶子查询的类型也可以做进一步细分,详情大家可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/query-dsl.html
如图:
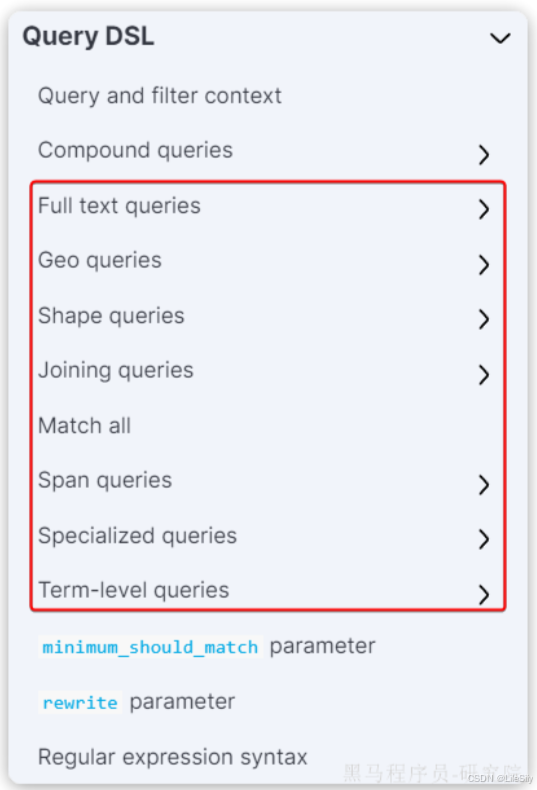
这里列举一些常见的,例如:
- 全文检索查询(Full Text Queries): 利用分词器对用户输入搜索条件先分词,得到词条,然后在利用倒排索引搜索词条,例如:
- match
- multi_match
- 精确查询(Term-level queries): 不对用户输入搜索条件分词,根据字段内容精确值匹配,但是只能查找keyword,数值,日期,boolean类型的字段,比如:
- ids
- term
- range
- 地理坐标查询: 用于搜索地理位置,搜索方式很多,例如:
geo_bounding_box: 按照矩形搜索geo_distance: 按点和半径搜索
1.2.1 全文检索查询
全文检索的种类也很多,详情可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/full-text-queries.html
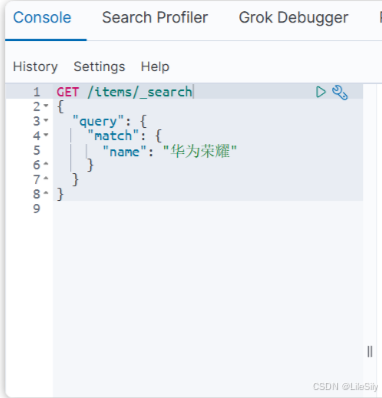
以全文检索中的match为例,语法如下:
GET /{索引库名}/_search
{"query": {"match": {"字段名": "搜索条件"}}
}
示例:
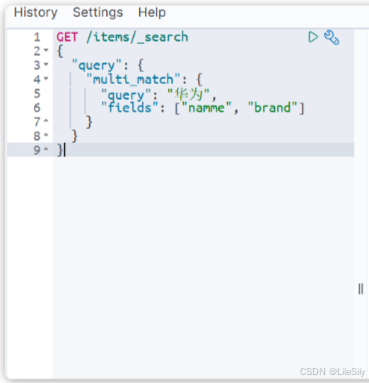
与match类似的语法还有multi_match,区别在于可以同时对多个字段字段进行搜索,而且多个字段都要满足,语法示例:
GET /{索引库名}/_search
{"query": {"multi_match": {"query": "搜索条件","fields": ["字段1", "字段2"]}}
}
示例:
1.2.2 精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询,也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配,因此推荐查找keyword,数值,日期,boolean类型的字段,例如:
- id
- price
- 城市
- 地名
- 人名
等等,作为一个整体才有含义的字段.
详情可以查看官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/term-level-queries.html
以term为例,其语法如下:
GET /{索引库名}/_search
{"query": {"term": {"字段名": {"value": "搜索条件"}}}
}
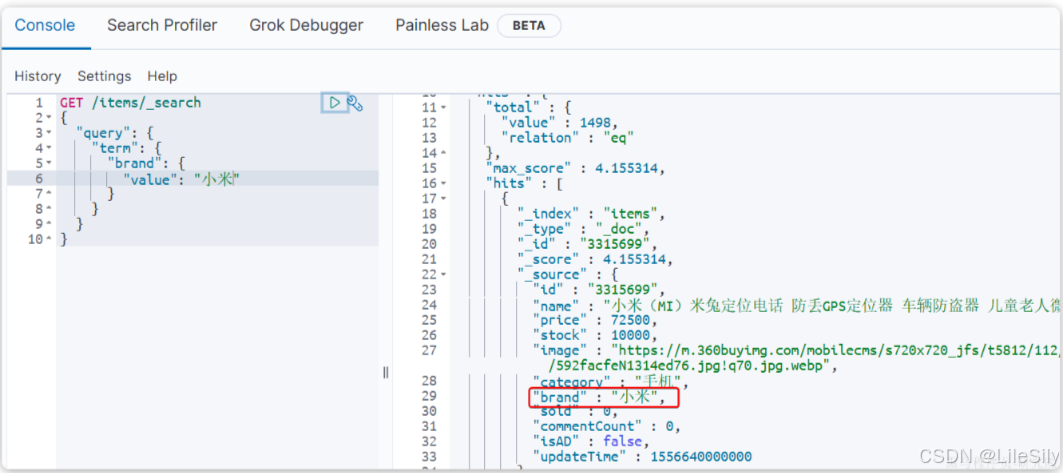
当输入的搜索条件不是词条,而是短语是,由于不做分词,反而搜索不到:
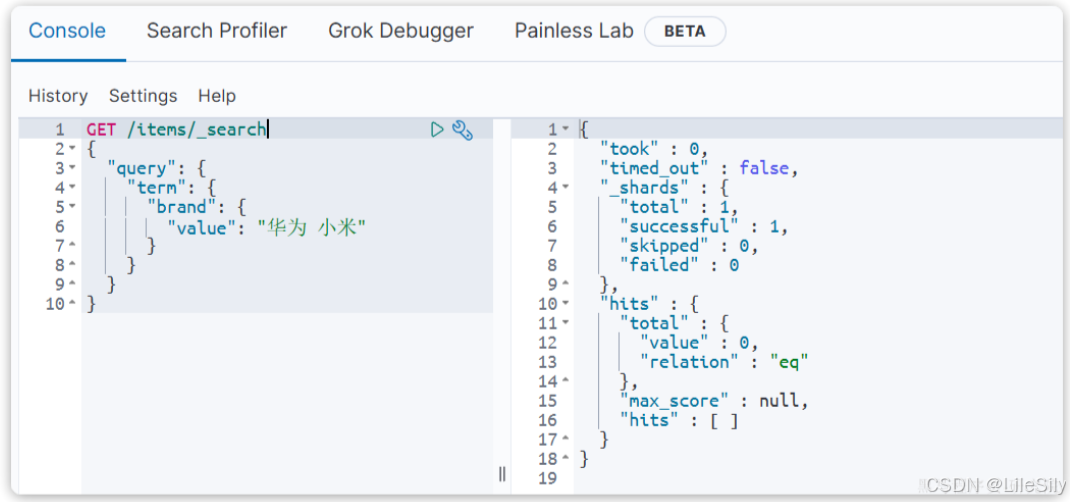
再看接下来range查询,语法如下:
GET /{索引库名}/_search
{"query": {"range": {"字段名": {"gte": {最小值},"lte": {最大值}}}}
}
range是范围查询,对于范围筛选的关键字有:
- gte: 大于等于
- gt: 大于
- lte: 小于等于
- lt: 小于
示例:
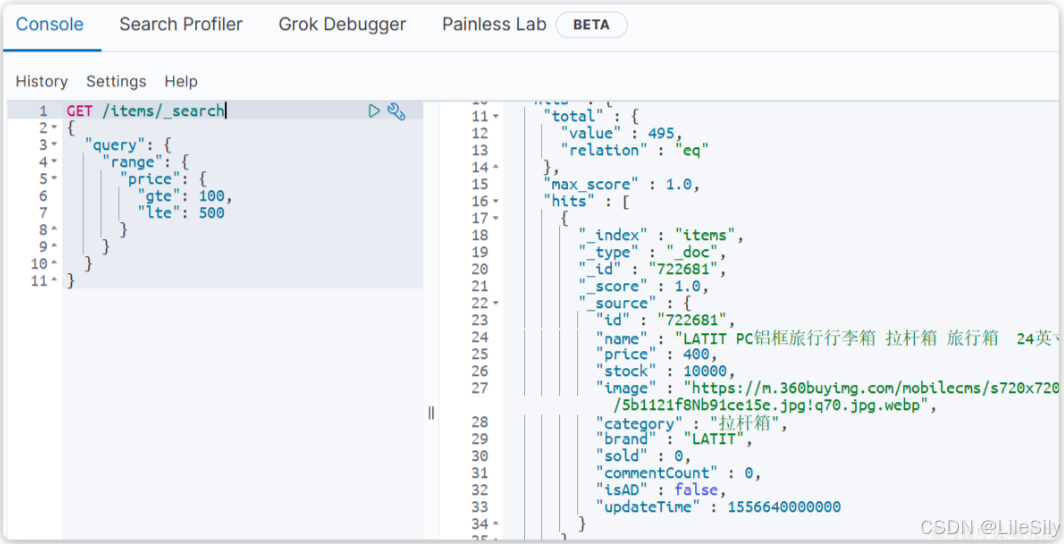
1.3 复合查询
复合查询大致可以分为两类:
- 第一类: 基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
- 第二类: 基于某种算法修改查询时的文档相关性算分,从而改变文档排名,例如:
- function_score
- dis_max
其他复合查询以及相关语法可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/compound-queries.html
1.3.1 算分函数查询
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列.
例如我们搜索"手机",结果如下:
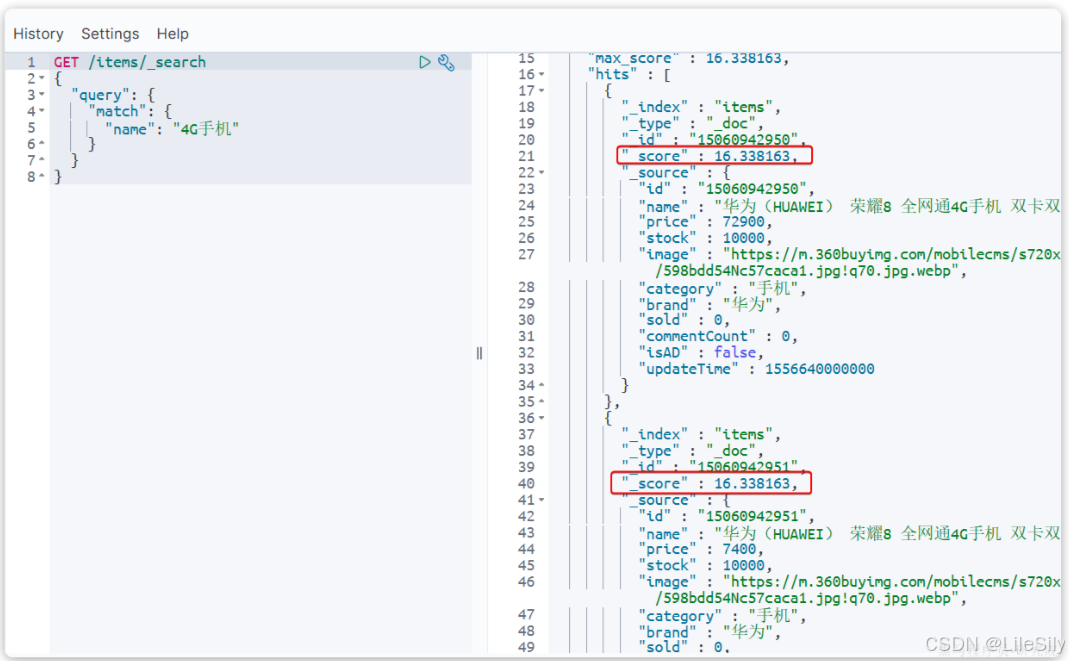
从es5.1开始,采用的相关性打分算法是BM25算法,公式如下:

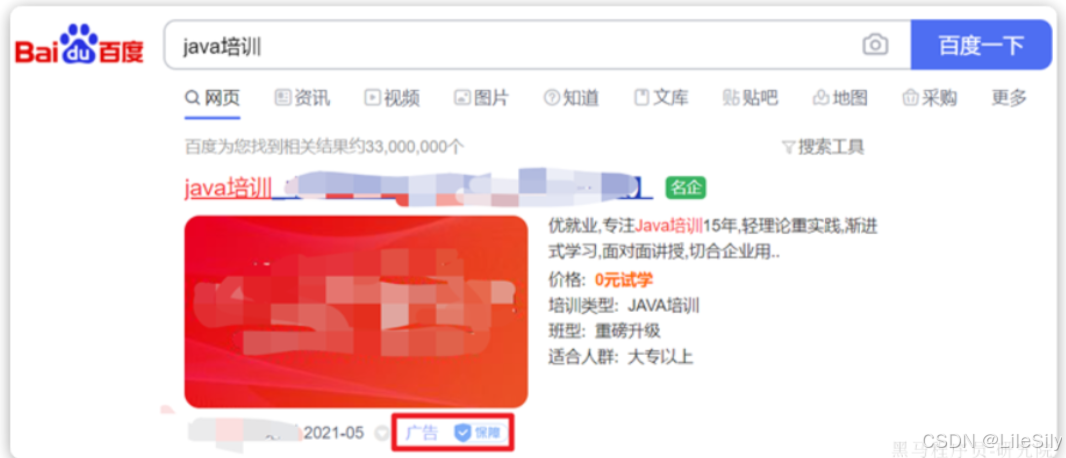
基于这套公式,救护可以判断出某个文档与用户搜索的关键字之间的关联度,还是比较准确的,但是,在实际业务需求中,常常会有竞价排名的功能,不是相关度越高排名越靠前,而是基于掏的钱多的排名更加靠前.
例如在百度中搜索java培训,排名靠前的就是广告推广:
要想人为控制相关性算分,就需要利用elasticsearch中的function sorce查询了.
基本语法:
function socre查询中包含了四部分内容:
- 原始查询条件: query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分.
- 过滤条件: filter部分,复合该条件的文档才会重新算分.
- 算分函数: 复合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight: 函数结果是常量
- field_value_factor: 以文档中的某个字段值作为函数结果
- random_socre: 以随机数作为函数结果
- script_score: 自定义算分函数算法
- 运算模式: 算分函数的结果,原始查询的相关性算分,两者之间的运算方式,包括:
- multiply: 相乘
- replace: 用function socre替换query socre
- 其他,例如: sum,avg,max,min
function socre的运行流程如下:
- 根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分.
- 根据过滤条件,过滤文档
- 复合过滤条件的文档,基于算分函数运算,得到函数算分.
- 将原始算分和函数算分基于运算模式做运算,得到最终结果,作为相关性算分.
因此,其中的关键点是:
- 过滤条件: 决定哪些文档的算分被修改
- 算分函数: 决定函数算分的算法
- 运算模式: 决定最终算分结果
示例: 给iPhone这个品牌的手机算分提高十倍,分析如下:
- 过滤条件: 品牌必须为iPhone
- 算分函数: 常量weight,值为10
- 算分模式: 相乘multiply
对应代码如下:
GET /hotel/_search
{"query": {"function_score": {"query": { .... }, // 原始查询,可以是任意条件"functions": [ // 算分函数{"filter": { // 满足的条件,品牌必须是Iphone"term": {"brand": "Iphone"}},"weight": 10 // 算分权重为2}],"boost_mode": "multipy" // 加权模式,求乘积}}
}
1.3.2 bool查询
bool查询,即布尔查询,就是利用逻辑运算来组合一个或者多个子查询子句的组合.
bool查询支持的逻辑运算有:
- must: 必须匹配每个子查询,类似于"与"
- should; 选择性匹配子查询,类似"或"
- must_not: 必须不匹配,不参与算分,类似于"非"
- filter: 必须匹配,不参与算分(和must的区别).
bool查询语法如下:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"should": [{"term": {"brand": { "value": "vivo" }}},{"term": {"brand": { "value": "小米" }}}],"must_not": [{"range": {"price": {"gte": 2500}}}],"filter": [{"range": {"price": {"lte": 1000}}}]}}
}
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分.
例如黑马商城的搜索页面:
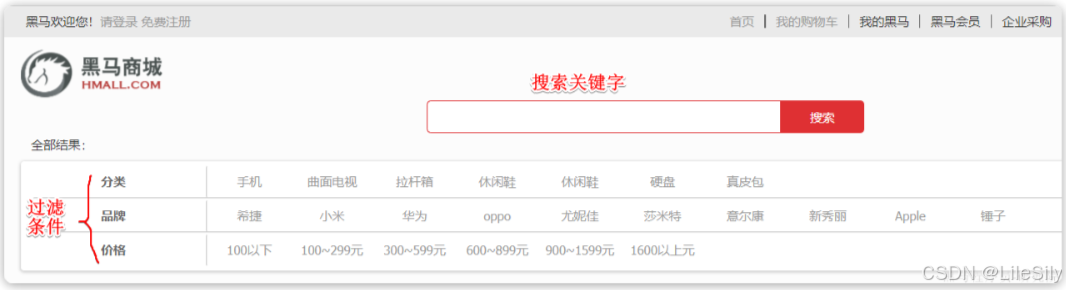
其中输入框的搜索条件肯定要参与相关性算分,可以采用match,但是价格范围过滤,品牌过滤,分类过滤尽量采用filter,不要参与相关性算分.
比如,我们要搜索"手机",但是品牌必须是"华为",价格必须是900~1599,那么可以这样写:
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"filter": [{"term": {"brand": { "value": "华为" }}},{"range": {"price": {"gte": 90000, "lt": 159900}}}]}}
}
1.4 排序
elasticSearch默认是根据相关度算分(_socre)来排序,但是也支持自定方式对搜索结果排序.不过分词字段无法排序,能参与排序字段类型有: keyword类型,数值类型,地理坐标类型,日期类型.
详细说明可以参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/sort-search-results.html
语法说明:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"排序字段": {"order": "排序方式asc和desc"}}]
}
示例,我们按照商品价格排序:
GET /items/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}]
}
1.5 分页
elasticsearch默认情况下只返回top10的数据.而如果要查询的更多数据就需要修改分页参数了.
1.5.1 基础分页
elasticSearch中通过修改form,size参数来控制要返回的分页结果:
- from: 从第几个文档开始
- size: 总共查询几个文档
类似于MySQL中的limit ?,?,官方文档如下:
官方文档如下:
https://www.elastic.co/guide/en/elasticsearch/reference/7.12/paginate-search-results.html
语法如下:
GET /items/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页文档数量,默认10"sort": [{"price": {"order": "desc"}}]
}
1.5.2 深度分页
elasticSearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同的节点上,这种存储方式比较有利于数据扩展,但是给分页带来了一些麻烦.
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据.现在每页查询10条,查询99页,那么分页查询的条件如下:
GET /items/_search
{"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}]
}
从语句来分析,要查询第990-1000名的数据.从数显思路来分析,坑定是将所有数据排序,找出前1000名,截取其中的990-1000的部分,但是问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第一片上的第990-1000,在另一个节点上并不一定依然是990-1000名,所以我们只能在每一个分片上都要找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取的990-1000的数据即可.
就像我们高中的时候有普通班,有尖子班,比如有5个班,其中有一个尖子班,我们找全年级前50的时候,肯定不能只挑每个班的前10名,全年级前50肯定是尖子班多一些,所以我们在选人的时候需要对全年级进行排名.
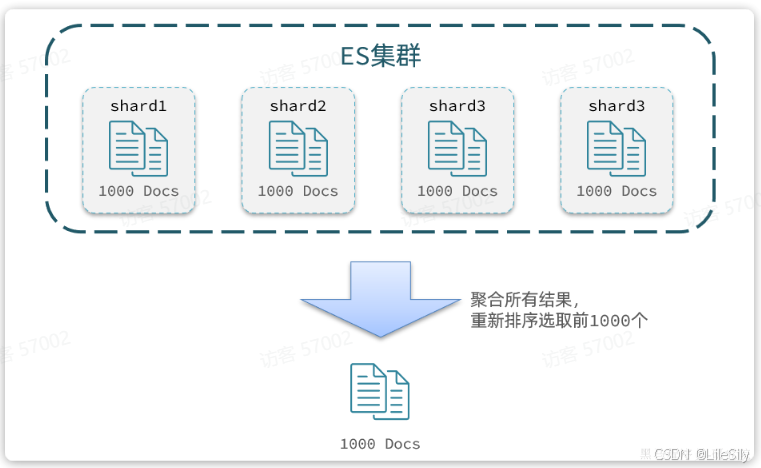
试想一下,加入我们现在要查询的是第999页数据呢,是不是要找地9990-10000的数据,那岂不是要把每个分片中的前10000名的数据都查询出来,汇总到一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总的数据过多,对内存和CPU会产生非常大的压力.
因此elasticSearch会禁止from+ size超过10000的请求.
针对深度分页,elasticSearch提供了两种解决方案:
- Search after: 分页时需要排序,原理是从上一次的排序开始,查询下一页数据,官方推荐使用的方式.
- scroll: 原理将排序后的文档id形成快照,保存下来,基于快照做分页,官方已经不推荐使用.
总结:
大多数情况下,我们采用普通分页就是可以了,一般我们采用限制分页深度的方式即可,无需实现深度分页.
1.6 高亮
1.6.1 高亮显示原理
什么是高亮显示呢?
我们在百度,京东搜索的时候,关键字就会变成红色,比较醒目,这就叫高亮显示:
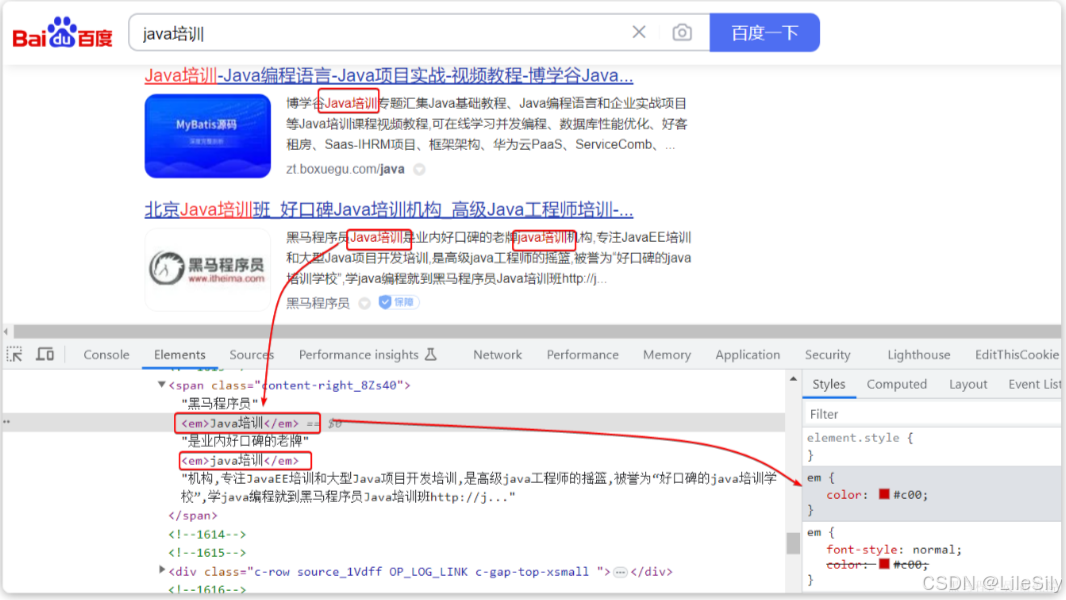
观察页面源码,你会发现两件事情:
- 高亮词条都被加上的了
<em>标签. <em>标签都添加了红色样式.
css样式肯定是前端实现页面的时候写好的,但是前端编写页面的时候是不知道页面要展示什么数据的,不可能给数据加标签,而服务端实现搜索功能,要是有elasticSearch做分词搜索,要是知道哪些词条需要高亮的.
因此词条的高亮标签肯定是有服务端提供数据的时候已经加上的.
因此实现高亮的思路就是:
- 用户搜索关键字搜索数据
- 服务端根据搜索关键字找到elasticSearch搜索,并给搜索结果中的关键字词条添加一个html标签
- 前端提前给约定好的
html标签添加css样式.
1.6.2 实现高亮
事实上elasticSearch已经提供了给搜索关键字加标签的语法,无需我们自己编码.基本语法如下:
GET /{索引库名}/_search
{"query": {"match": {"搜索字段": "搜索关键字"}},"highlight": {"fields": {"高亮字段名称": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如match
- 参与高亮的字段必须是text类型的字段.
- 默认情况下参与高亮的字段要与搜索字段一致,除非添加
required_field_match=false.
示例:
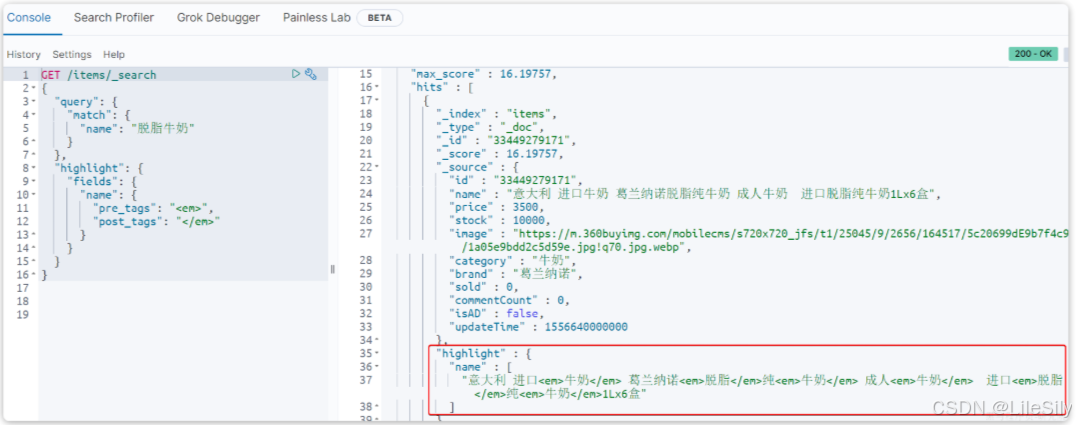
1.7 总结
查询的DSL是一个大的json对象,包含下列属性:
- query: 查询条件
- from和size: 分页条件
- sort: 排序条件
- hightlight: 高亮条件
示例:
2. RestClient查询
文档的查询依然使用上一节学习的RestHighLevelClient对象,查询的基本步骤如下:
- 创建request对象,这次是搜索,所以是
searchRequest - 准备请求参数,也就是查询DSL对应的json参数
- 发起请求
- 解析响应,响应对应的结果相对复杂,需要逐层解析
2.1 快速入门
之前说过,由于elasticSearch对外暴露的接口都是restful风格的接口,因此JavaAPI调用就是在发送http请求,而我们核心要做的就是利用Java代码组织请求参数,解析响应结果.
这个参数的格式完全参考DSL查询语句的json结构,因此我们在学习的过程中,会不断的把JavaAPI与DSL语句做对比.
2.2.1 发送请求
首先以match_all查询为例,其DSL和JavaAPI的对比如图:
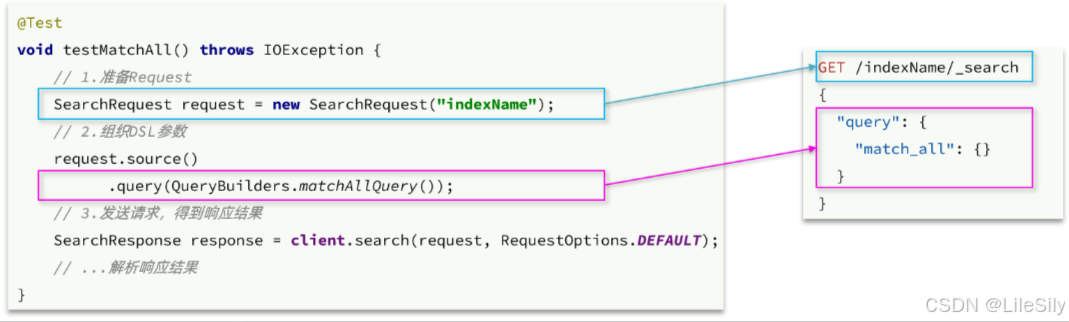
代码解读:
- 第一步,创建
SearchRequest对象,指定索引库名 - 第二部,利用
request.source()创建DSL,DSL中可以包含查询,分页,排序,高亮等query(): 代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL.
- 第三步,利用
client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整的json参数,其中包含了query、sort、from、size、highlight等所有功能:
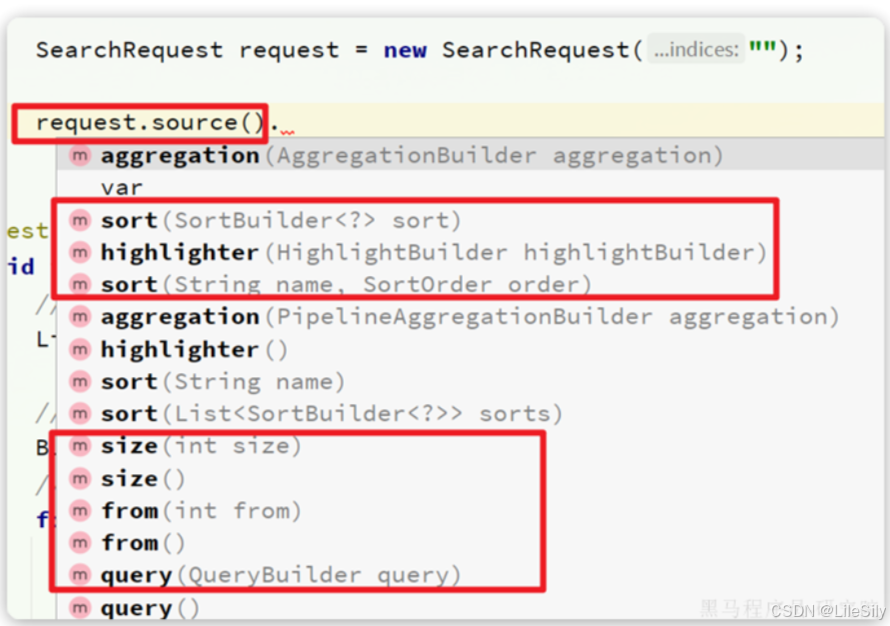
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询,复合查询等:

2.1.2 解析响应结果
在发送请求以后,得到了相应的结果SearchResponse,这个类的结构与我们在kibana中看到的相应结果json接口完全一致:
{"took" : 0,"timed_out" : false,"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "heima","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"info" : "Java讲师","name" : "赵云"}}]}
}
因此,我们解析SearchResponse的代码就是在解析这个json结果,对比如下:
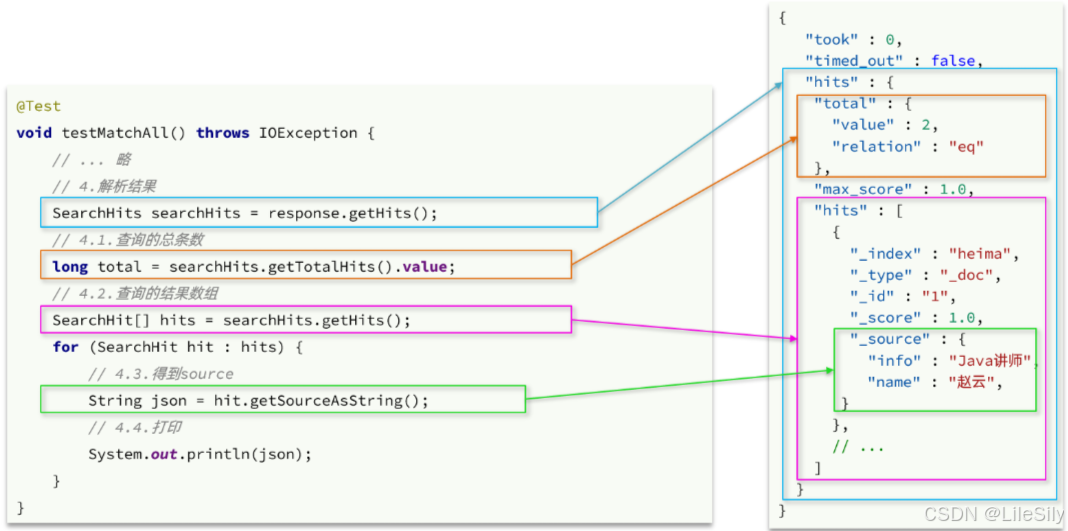
代码解读:
elasticsearch返回的结果是一个json字符串,结构包含:
- hit: 命中的结果
- total: 总条数,其中value是具体的总条数值
- max_score: 所有的结果中得分最高的文档的相关性算分
- hit: 搜索结果的文档数组,其中的每个文档都是json对象
- _source: 文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析json字符串,流程如下:
- SearchHits: 通过
response.getHits()获取,就是json中最外层的hits,代表命中的结果SearchHits#getTotalHits().value: 获取总条数信息SearchHits#getHits(): 获取SearchHit数组,也就是文档数组SearchHit#getSourceAsString(): 获取文档结果中的_source,也就是原始的json文档数据
2.1.3 总结
文档搜索的基本步骤是:
- 创建
SearchRequest对象 - 准备
request.source(),也就是DSL.QueryBuilders来构建查询条件- 传入
request.source()的query()方法
- 发送请求,得到结果
- 解析结果(参考json结果,从外到内,逐层解析)
完整代码如下:
@Test
void testMatchAll() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化并打印ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);System.out.println(item);}
}
2.2 叶子查询
所有条件都是由QueryBuilders来构建的,叶子查询页不例外,因此整套代码中变化的部分仅仅是query条件构造的方式,其他的不动:
@Test
void testMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
再比如multi_match查询:
@Test
void testMultiMatch() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有range查询:
@Test
void testRange() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.rangeQuery("price").gte(10000).lte(30000));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
还有term查询:
@Test
void testTerm() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数request.source().query(QueryBuilders.termQuery("brand", "华为"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
2.3 复合查询
复合查询也是由QueryBuilders构建,我们以bool查询为例,DSL和javaAPI的对比如图:
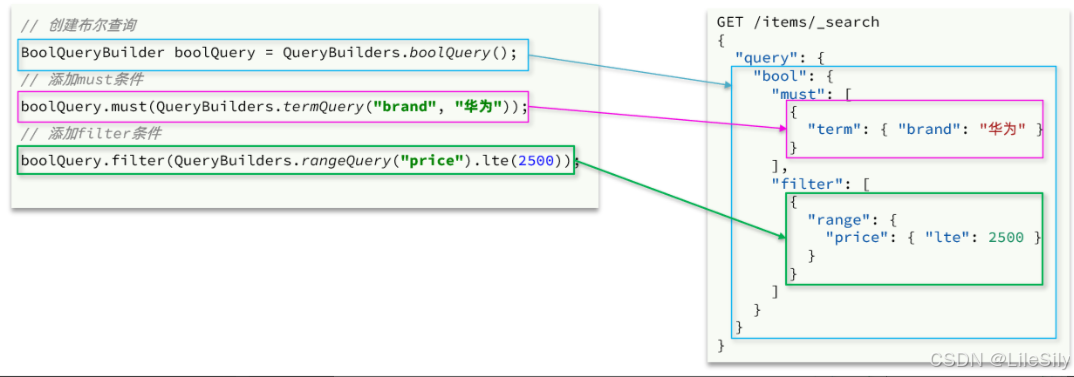
完整代码如下:
@Test
void testBool() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.准备bool查询BoolQueryBuilder bool = QueryBuilders.boolQuery();// 2.2.关键字搜索bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.3.品牌过滤bool.filter(QueryBuilders.termQuery("brand", "德亚"));// 2.4.价格过滤bool.filter(QueryBuilders.rangeQuery("price").lte(30000));request.source().query(bool);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
2.4 排序和分页
之前说过,requeset.source()就是整个请求json参数,所以排序,分页都是基于这个来设置,其DSL和JavaAPI的对比如下:
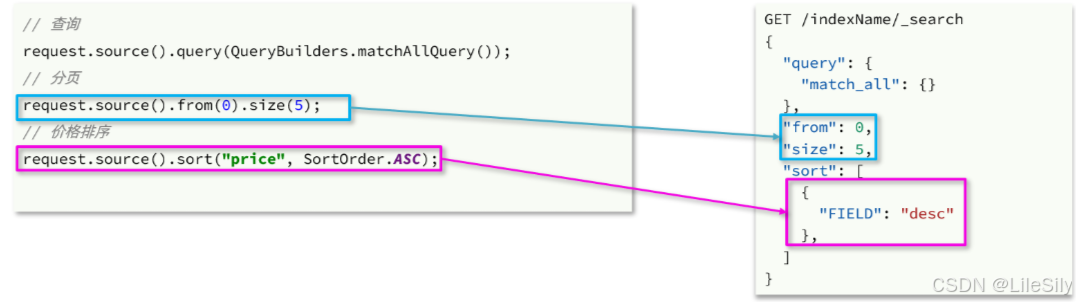
完整的示例代码:
@Test
void testPageAndSort() throws IOException {int pageNo = 1, pageSize = 5;// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.搜索条件参数request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.排序参数request.source().sort("price", SortOrder.ASC);// 2.3.分页参数request.source().from((pageNo - 1) * pageSize).size(pageSize);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
2.5 高亮
高亮查询与前面的查询有两点不同:
- 条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造 - 高亮相应结果与搜索的文档结果不在一起,需要单独解析
首先来看高亮条件构造,其DSL和JavaAPI的对比如图:
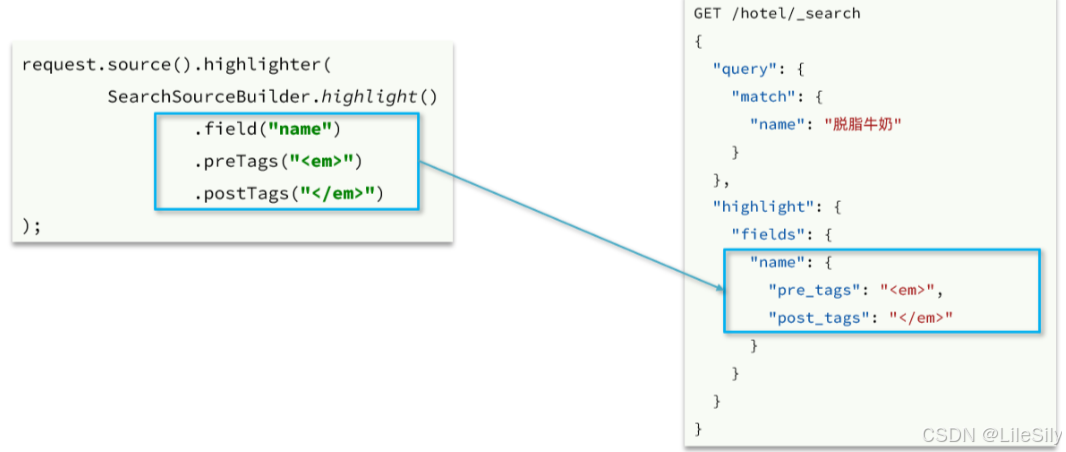
示例代码如下:
@Test
void testHighlight() throws IOException {// 1.创建RequestSearchRequest request = new SearchRequest("items");// 2.组织请求参数// 2.1.query条件request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));// 2.2.高亮条件request.source().highlighter(SearchSourceBuilder.highlight().field("name").preTags("<em>").postTags("</em>"));// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}
再来看结果解析,文档解析的部分不变,主要是高亮内容需要单独解析出来,其DSL和JavaAPI的对比如图:
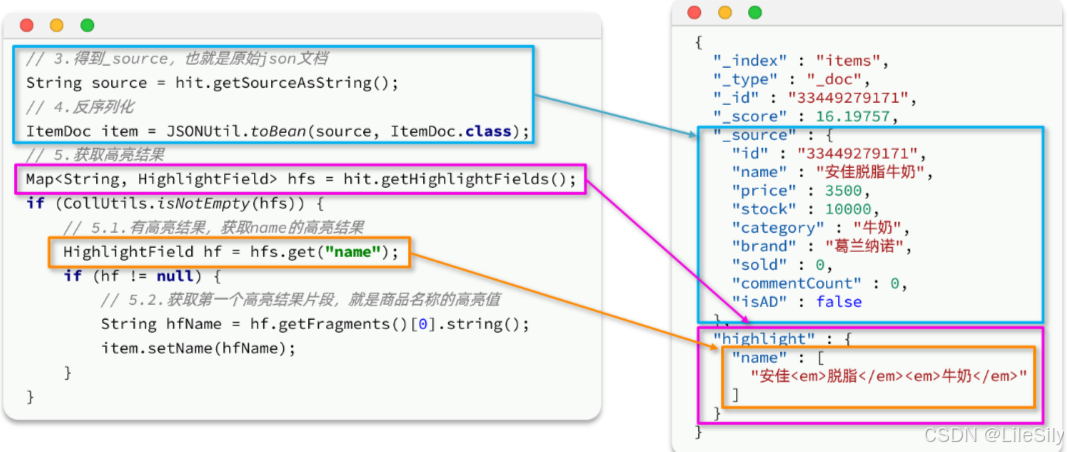
代码解读:
- 第3、4步:从结果中获取_source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为ItemDoc对象
- 第5步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值
- 第5.1步:从Map中根据高亮字段名称,获取高亮字段值对象HighlightField
- 第5.2步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了
- 最后:用高亮的结果替换ItemDoc中的非高亮结果
完整代码如下:
private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 2.遍历结果数组SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// 3.得到_source,也就是原始json文档String source = hit.getSourceAsString();// 4.反序列化ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);// 5.获取高亮结果Map<String, HighlightField> hfs = hit.getHighlightFields();if (CollUtils.isNotEmpty(hfs)) {// 5.1.有高亮结果,获取name的高亮结果HighlightField hf = hfs.get("name");if (hf != null) {// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值String hfName = hf.getFragments()[0].string();item.setName(hfName);}}System.out.println(item);}
}
相关文章:
[ElasticSearch] DSL查询
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

iview中的table组件点击一行中的任意一点选中本行
<Table border ref"selection" size"small" on-row-click"onClickRow"></Table>// table组件点击一行任意位置选中onClickRow(row, index) {this.$refs.selection.toggleSelect(index)}写上toggleSelect(index)方法即可,…...

《探秘跨网段局域网IP广播:解锁网络通信的新姿势》
一、从基础出发:广播与跨网段 在计算机网络的世界中,广播域是一个至关重要的概念。简单来说,广播域是指网络中能接收任一台主机发出的广播帧的所有主机集合。当一台主机在广播域内发出一个广播帧时,同一广播域内的所有其他主机都可以收到该广播帧。在没有路由器或 VLAN 分割…...
)
Kafka 单机部署启动教程(适用于 Spark + Hadoop 环境)
🧭 Kafka 单机部署启动教程(适用于 Spark Hadoop 环境) 📦 一、Kafka 版本选择 推荐使用 Kafka 2.13-2.8.1(Scala 2.13,稳定适配 Spark 3.1.2 和 Hadoop 3.1.1) 下载地址(Apache 官…...
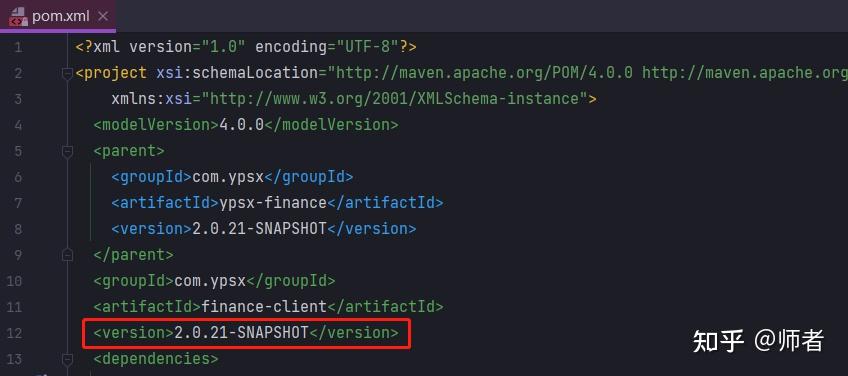
maven微服务${revision}依赖打包无法识别
1、场景描述 我现在又一个微服务项目,父pom的版本,使用<properties>定义好,如下所示: <name>ypsx-finance-center</name> <artifactId>ypsx-finance</artifactId> <packaging>pom</pack…...

2025年06月07日Github流行趋势
项目名称:netbird 项目地址url:https://github.com/netbirdio/netbird项目语言:Go历史star数:14824今日star数:320项目维护者:mlsmaycon, braginini, pascal-fischer, lixmal, pappz项目简介:使…...

WPS中将在线链接转为图片
WPS中将在线链接转为图片 文章目录 WPS中将在线链接转为图片一:解决方案1、下载图片,精确匹配(会员功能)2、将在线链接直接转为图片 一:解决方案 1、下载图片,精确匹配(会员功能) …...

实战二:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

二元函数可微 切平面逼近 线性函数逼近
二元函数 f ( x , y ) f(x, y) f(x,y) 在某点可微 的含义,可以从几何直观、严格数学定义、与一阶偏导数的关系三个层面来理解: 🔹1. 几何直观上的含义(最易理解) 二元函数 f ( x , y ) f(x, y) f(x,y) 在点 ( x 0 …...

vue生成二维码图片+文字说明
需求:点击下载图片,上方是二维码,下方显示该二维码的相关内容,并且居中显示,支持换行 解决方案步骤: 1. 使用qrcode生成二维码的DataURL。 2. 创建canvas,将二维码图片绘制到canvas的上半部分…...
机器学习监督学习实战五:六种算法对声呐回波信号进行分类
本项目基于UCI的声呐目标识别数据集(Sonar, Mines vs. Rocks),通过10种机器学习算法比较,发现集成学习方法表现最优。研究首先对60个声呐能量特征进行可视化分析(分布直方图、相关性矩阵),对比了…...

React Hooks 的闭包陷阱问题
这是主包在面试中遇到的一道题目,面试官的问题是:"这个页面初次展示出来时Count和step的值是什么,我点击按钮count和step的值有什么变化?“ 这个题目主包回答的不好,所以想做一个总结。 题目 import React, { …...
力扣面试150题--克隆图
Day 61 题目描述 思路 /* // Definition for a Node. class Node {public int val;public List<Node> neighbors;public Node() {val 0;neighbors new ArrayList<Node>();}public Node(int _val) {val _val;neighbors new ArrayList<Node>();}public N…...

【HarmonyOS 5】运动健康开发实践介绍以及详细案例
以下是 HarmonyOS 5 运动健康功能的简洁介绍,聚焦核心体验与技术亮点: 一、AI 驱动的全场景健康管理 智能运动私教:运动前推送热身指导,运动中实时纠正动作,运动后生成个性化报告与改进建议。AI 融合用户多设备数…...

STM32开发中,线程启动异常问题排查简述
1. 参数传递问题 错误类型:线程属性错误地使用。影响:线程属性(如堆栈大小、优先级)不匹配可能导致线程创建失败或行为异常。验证方法:检查 线程创建的返回值,若为 NULL 则表示线程创建失败。 2. 系统资源…...

SQL进阶之旅 Day 18:数据分区与查询性能
【SQL进阶之旅 Day 18】数据分区与查询性能 文章简述 在现代数据库系统中,随着数据量的快速增长,如何高效地管理和查询大规模数据成为开发人员和数据分析师面临的重要挑战。本文深入探讨了数据分区的概念及其对查询性能的提升作用,结合理论…...

鸿蒙PC,有什么缺点?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 价格太高,二是部分管理员权限首先,三对于开发者不太友好举个例子:VSCode的兼容性对程序员至关重要。若能支持VSCode,这台电脑将成为大多数开发者…...

前端工具:Webpack、Babel、Git与工程化流程
1. Webpack:资源打包优化工具 案例1:多入口文件打包 假设项目有多个页面(如首页index.js和登录页login.js),需要分别打包: ● 配置webpack.config.js: module.exports {entry: {index: ./sr…...

使用Python和Scikit-Learn实现机器学习模型调优
在机器学习项目中,模型的性能往往取决于多个因素,其中模型的超参数(hyperparameters)起着关键作用。超参数是模型在训练之前需要设置的参数,例如决策树的深度、KNN的邻居数等。合理地选择超参数可以显著提升模型的性能…...

灰狼优化算法MATLAB实现,包含种群初始化和29种基准函数测试
灰狼优化算法(Grey Wolf Optimizer, GWO)MATLAB实现,包含种群初始化和29种基准函数测试。代码包含详细注释和可视化模块: %% 灰狼优化算法主程序 (GWO.m) function GWO()clear; clc; close all;% 参数设置SearchAgents_no 30; …...

go语言学习 第7章:数组
第7章:数组 数组是一种基本的数据结构,用于存储相同类型的元素集合。在Go语言中,数组的大小是固定的,一旦定义,其长度不可改变。本章将详细介绍Go语言中数组的定义、初始化、访问、遍历以及一些常见的操作。 一、数组…...

PDF图片和表格等信息提取开源项目
文章目录 综合性工具专门的表格提取工具经典工具 综合性工具 PDF-Extract-Kit - opendatalab开发的综合工具包,包含布局检测、公式检测、公式识别和OCR功能 仓库:opendatalab/PDF-Extract-Kit特点:功能全面,包含表格内容提取的S…...
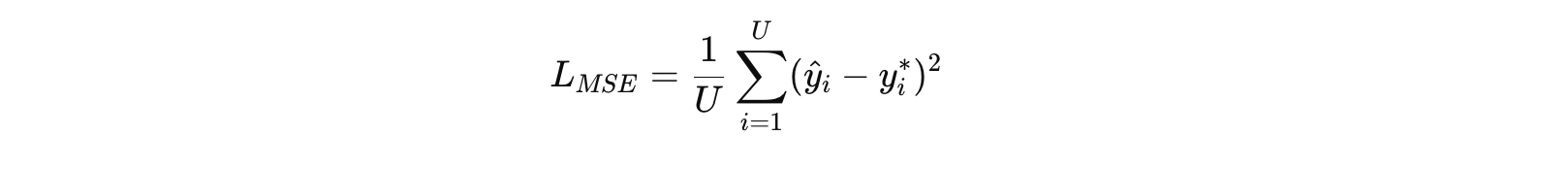
《Progressive Transformers for End-to-End Sign Language Production》复现报告
摘要 本文复现了《Progressive Transformers for End-to-End Sign Language Production》一文中的核心模型结构。该论文提出了一种端到端的手语生成方法,能够将自然语言文本映射为连续的 3D 骨架序列,并引入 Counter Decoding 实现动态序列长度控制。我…...

Haystack:AI与IoT领域的全能开源框架
一、Haystack 的定义与背景 Haystack 是一个开源框架,主要服务于两类不同领域: 物联网(IoT)与建筑自动化领域(Project Haystack): 旨在标准化物联网设备数据的语义模型,解决建筑系统(如 HVAC、能源管理)的数据互操作性问题,通过标签分类(Tagging Taxonomy)统一设…...

OpenWrt:使用ALSA实现边录边播
ALSA是Linux系统中的高级音频架构(Advanced Linux Sound Architecture)。目前已经成为了linux的主流音频体系结构,想了解更多的关于ALSA的知识,详见:http://www.alsa-project.org 在内核设备驱动层,ALSA提供…...

链表题解——回文链表【LeetCode】
算法思路 核心思想: 找到链表的中间节点。反转链表的后半部分。比较链表的前半部分和反转后的后半部分,如果值完全一致,则是回文链表。 具体步骤: 使用快慢指针找到链表的中间节点(middleNode 方法)。反转…...

CSS6404L 在物联网设备中的应用优势:低功耗高可靠的存储革新与竞品对比
物联网设备对存储芯片的需求聚焦于低功耗、小尺寸、高可靠性与传输效率,Cascadeteq 的 CSS6404L 64Mb Quad-SPI Pseudo-SRAM 凭借差异化技术特性,在同类产品中展现显著优势。以下从核心特性及竞品对比两方面解析其应用价值。 一、CSS6404L 核心产品特性…...

Java Stream 高级实战:并行流、自定义收集器与性能优化
一、并行流深度实战:大规模数据处理的性能突破 1.1 并行流的核心应用场景 在电商用户行为分析场景中,需要对百万级用户日志数据进行实时统计。例如,计算某时段内活跃用户数(访问次数≥3次的用户),传统循环…...
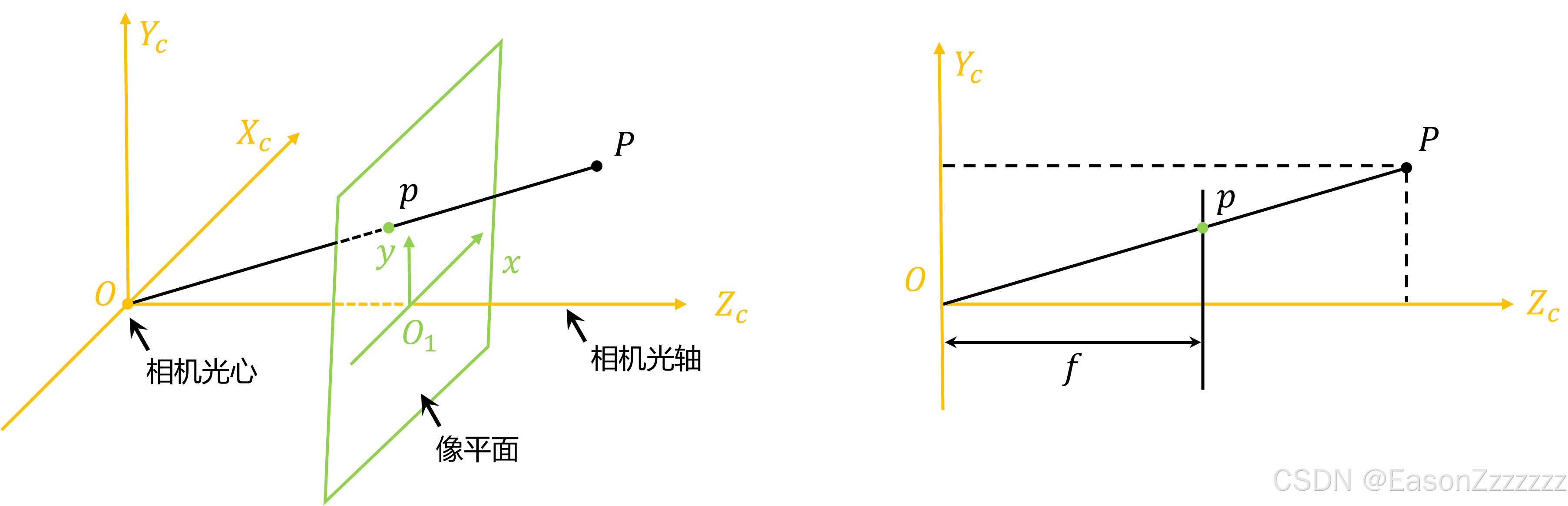
计算机视觉——相机标定
计算机视觉——相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐标系二、坐标系变换图像坐标系 → 像素坐标系相机坐标系 → 图像坐标系世界坐标系 → 相机坐标系 ⋆ \star ⋆ 世界坐标系 → 像素坐标系 三、相机标定 一、像素坐标系、图像坐标系、相机坐标系、世界坐…...
C语言中的数据类型(二)--结构体
在之前我们已经探讨了C语言中的自定义数据类型和数组,链接如下:C语言中的数据类型(上)_c语言数据类型-CSDN博客 目录 一、结构体的声明 二、结构体变量的定义和初始化 三、结构体成员的访问 3.1 结构体成员的直接访问 3.2 结…...