性能优化笔记
性能优化转载
https://www.cnblogs.com/tengzijian/p/17858112.html
性能优化的一般策略及方法
简言之,非必要,不优化。先保证良好的设计,编写易于理解和修改的整洁代码。如果现有的代码很糟糕,先清理重构,然后再考虑优化。
常见性能问题元凶
a. 输入/输出操作
不必要的 I/O 操作是最常见的导致性能问题的罪魁祸首。比如频繁读写磁盘上的文件、通过网络访问数据库等。
b. 缺页
c. 系统调用
系统调用需要进行上下文切换,保存程序状态、恢复内核状态等一些步骤,开销相对较大。对磁盘的读写操作、对键盘、屏幕等外设的操作、内存管理函数的调用等都属于系统调用。
Linux 系统调用可以通过 strace 查看,qnx 也有 tracelogger 等工具
d. 解释型语言
一般来说,C/C++/VB/C# 这种编译型语言的性能好于 Java 的字节码,好于 PHP/Pyhon 等解释型语言。
e. 错误
还有很大很一部分导致性能问题的原因可以归为错误:忘了把调试代码(如保存 trace 到文件)关闭,忘记释放资源/内存泄漏、数据库表设计缺陷(常用表没有索引)等。
常见操作的相对开销
| 操作 | 示例 | 相对耗时(C++) |
|---|---|---|
| 整数赋值(基准) | i = j | 1 |
| 函数调用 | ||
| 普通函数调用(无参) | foo() | 1 |
| 普通函数调用(单参) | foo(i) | 1.5 |
| 普通函数调用(双参) | foo(i,j) | 2 |
| 类的成员函数调用 | bar.foo() | 2 |
| 子类的成员函数调用 | derivedBar.foo() | 2 |
| 多态方法调用 | abstractBar.foo() | 2.5 |
| 对象解引用 | ||
| 访问对象成员(一级/二级) | i = obj1.obj2.num | 1 |
| 整数运算 | ||
| 整数赋值/加/减/乘 | i = j * k | 1 |
| 整数除法 | i = j / k | 5 |
| 浮点运算 | ||
| 浮点赋值/加/减/乘 | x = y * z | 1 |
| 浮点除法 | x = y / z | 4 |
| 超越函数 | ||
| 浮点根号 | y = sqrt(x) | 15 |
| 浮点 sin | y = sin(x) | 25 |
| 浮点对数 | y = log(x) | 25 |
| 浮点指数 | y = exp(x) | 50 |
| 数组操作 | ||
| 一维/二维整数/浮点数组下标访问 | x = a[3][j] | 1 |
注:上表仅供参考,不同处理器、不同语言、不同编译器、不同测试环境所得结果可能相差很大!
测量要准确
- 用专门的 Profiling 工具或者系统时间
- 只测量你自己的代码部分
- 必要时需要用 CPU 时钟 tick 数来替代时间戳以获得更准确的测量结果
调优一般方法
- 程序设计良好,易于理解和修改(前提)
- 如果性能不佳:
a. 保存当前状态
b. 测量,找出时间主要消耗在哪里
c. 分析问题:是否因为高层设计、数据结构、算法导致的,如果是,返回步骤 1
d. 如果设计、数据结构、算法没问题,针对上述步骤中的瓶颈进行代码调优
e. 每进行一项优化,立即进行测量
f. 如果没有效果,恢复到 a 的状态。(大多数的调优尝试几乎不会对性能产生影响,甚至产生负面影响。代码调优的前提是代码设计良好,易于理解和修改。Code tuning 通常会对设计、可读性、可维护性产生负面影响,如果 tuning 改良了设计或者可读性,那么不应该叫 tuning,而是属于步骤 1) - 重复步骤 2
并发转载
https://www.cnblogs.com/tengzijian/p/a-tour-of-cpp-modern-cpp-concurrency-1.html
多线程/并发
不要把并发当作灵丹妙药:如果顺序执行可以搞定,通常顺序会比并发更简单、更快速!
标准库还在头文件 <future> 中提供了一些机制,能够让程序员在更高的任务的概念层次上工作,而不是直接使用低层的线程、锁:
future和promise:用于从另一个线程中返回一个值packaged_task:帮助启动任务,封装了future和promise,并且建立两者之间的关联async():像调用一个函数那样启动一个任务。形式最简单,但也最强大!
future 和 promise
future 和 promise 可以在两个任务之间传值,而无需显式地使用锁,实现了高效地数据传输。其基本想法很简单:当一个任务向另一个任务传值时,把值放入 promise,通过特定的实现,使得值可以通过与之关联的 future 读出(一般谁启动了任务,谁从 future 中取结果)。
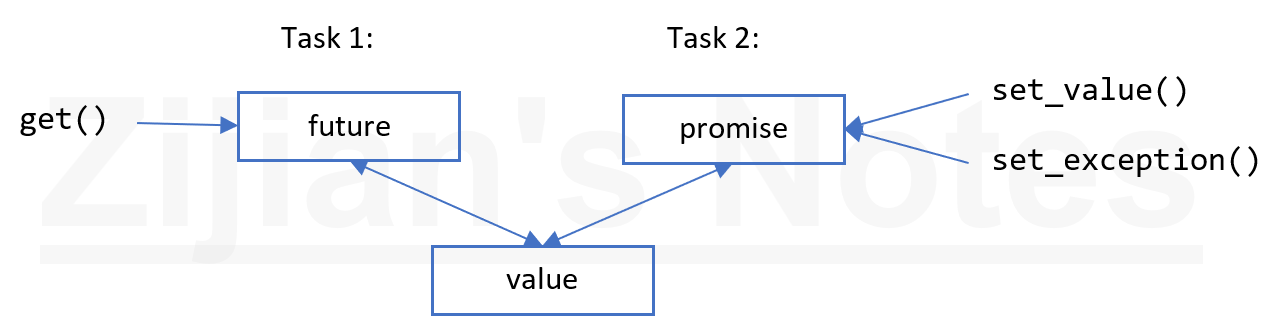
packaged_task
packaged_task 可以简化任务的设置,关联 future/promise。packaged_task 封装了把返回值或异常放入 promise 的操作,并且调用 packaged_task 的 get_future() 方法,可以得到一个与 promise 关联的 future。
async()
把任务看成是一个恰巧可能和其他任务同时运行的函数。
C++ 高性能编程实战转载
https://zhuanlan.zhihu.com/p/533708198
一、整体视角
预置知识 - Cache
Cache line size
CPU 从内存 Load 数据是一次一个 cache line;往内存里面写也是一次一个 cache line,所以一个 cache line 里面的数据最好是读写分开,否则就会相互影响。
Cache associative
全关联(full associative):内存可以映射到任意一个 Cache line;
N-way 关联:这个就是一个哈希表的结构,N 就是冲突链的长度,超过了 N,就需要替换。
Cache type
I-cache(指令)、D-cache(数据)、TLB(MMU 的 cache)
系统优化方法
1. Asynchronous
2.Polling
用于 轮询 或 轮询式检查 外设或资源的状态,通常用于 检查是否有数据可用 或 某个事件是否发生。
Polling 是网络设备里面常用的一个技术,比如 Linux 的 NAPI 或者 epoll。与之对应的是中断,或者是事件。Polling 避免了状态切换的开销,所以有更高的性能。
3. 静态内存池
静态内存有更好的性能,但是适应性较差(特别是系统里面有多个 任务的时候),而且会有浪费(提前分配,还没用到就分配了)。
4. 并发优化:lock-free 和 lock-less
lock-free 是完全无锁的设计,有两种实现方式:
• Per-CPU 数据(有时也叫 Thread-Local Storage, TLS)
• CAS based,CAS 是 compare and swap,这是一个原子操作(spinlock 的实现同样需要 compare and swap,但区别是 spinlock 只有两个状态 LOCKED 和 UNLOCKED,而 CAS 的变量可以有多个状态);其次,CAS 的实现必须由硬件来保障(原子操作),CAS 一次可以操作 32 bits,也有 MCAS,一次可以修改一块内存。基于 CAS 实现的数据结构没有一个统一、一致的实现方法,所以有时不如直接加锁的算法那么简单,直接,针对不同的数据结构,有不同的 CAS 实现方法。
lock-less 的目的是减少锁的争用(contention),而不是减少锁。这个和锁的粒度(granularity)相关,锁的粒度越小,等待的时间就越短,并发的时间就越长。
锁的争用,需要考虑不同线程在获取锁后,会执行哪些不同的动作。比如多线程队列,一般情况下,我们一把锁锁住整个队列,性能很差。如果所有的 enqueue 操作都是往队列的尾部插入新节点,而所有的 dequeue 操作都是从队列的头部删除节点,那么 enqueue 和 dequeue 大部分时候都是相互独立的,我们大部分时候根本不需要锁住整个队列,白白损失性能!那么一个很自然就能想到的算法优化方案就呼之欲出了:我们可以把那个队列锁拆成两个:一个队列头部锁(head lock)和一个队列尾部锁(tail lock)
5. 进程间通信 - 共享内存
对于本地进程间需要高频次的大量数据交互,首推共享内存这种方案。
6. I/O 优化 - 多路复用技术
网络编程中,当每个线程都要阻塞在 recv 等待对方的请求,如果访问的人多了,线程开的就多了,大量线程都在阻塞,系统运转速度也随之下降。这个时候,你需要多路复用技术,使用 select 模型,将所有等待(accept、recv)都放在主线程里,工作线程不需要再等待。
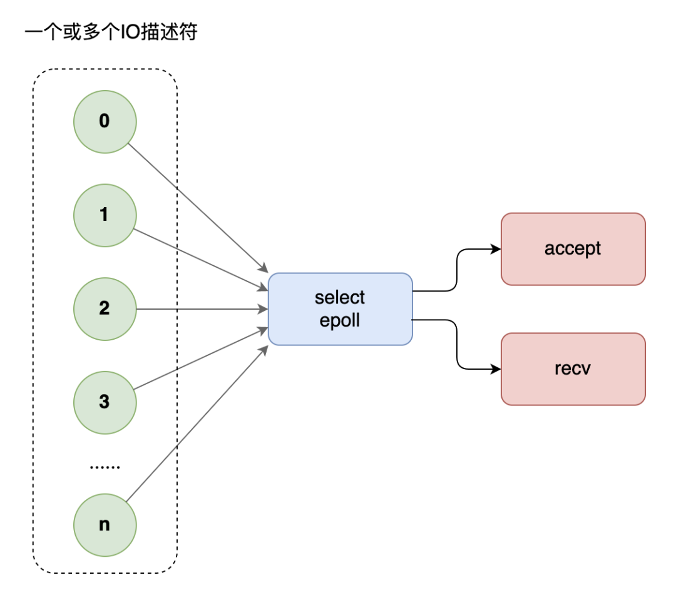
但是,select 不能应付海量的网站访问。这个时候,你需要升级多路复用模型为 epoll。select 有三弊,epoll 有三优:
- select 底层采用数组来管理套接字描述符,同时管理的数量有上限,一般不超过几千个,epoll使用树和链表来管理,同时管理数量可以很大
- select不会告诉你到底哪个套接字来了消息,你需要一个个去询问。epoll 直接告诉你谁来了消息,不用轮询
- select进行系统调用时还需要把套接字列表在用户空间和内核空间来回拷贝,循环中调用 select 时简直浪费。epoll 统一在内核管理套接字描述符,无需来回拷贝
7. 线程池技术
使用一个公共的任务队列,请求来临时向队列中投递任务,各个工作线程统一从队列中不断取出任务来处理,这就是线程池技术。
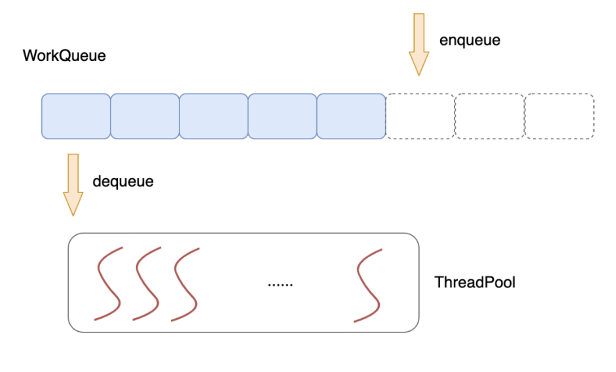
多线程技术的使用一定程度提升了服务器的并发能力,但同时,多个线程之间为了数据同步,常常需要使用互斥体、信号、条件变量等手段来同步多个线程。这些重量级的同步手段往往会导致线程在用户态/内核态多次切换,系统调用,线程切换都是不小的开销。
算法优化
代码层次优化
1. I-cache 优化
一是相关的源文件要放在一起;二是相关的函数在object文件里面,也应该是相邻的。这样,在可执行文件被加载到内存里面的时候,函数的位置也是相邻的。相邻的函数,冲突的几率比较小。而且相关的函数放在一起,也符合模块化编程的要求:那就是 高内聚,低耦合。
如果能够把一个 code path 上的函数编译到一起(需要编译器支持,把相关函数编译到一起), 很显然会提高 I-cache 的命中率,减少冲突。但是一个系统有很多个 code path,所以不可能面面俱到。不同的性能指标,在优化的时候可能是冲突的。所以尽量做对所以 case 都有效的优化,虽然做到这一点比较难。
常见的手段有函数重排(获取程序运行轨迹,重排二进制目标文件(elf 文件)里的代码段)、函数冷热分区等。
2. D-cache相关优化
- Cache line alignment (cache 对齐)
数据跨越两个 cacheline,就意味着两次 load 或者两次 store。如果数据结构是 cacheline 对齐的,就有可能减少一次读写。数据结构的首地址 cache line 对齐,意味着可能有内存浪费(特别是数组这样连续分配的数据结构),所以需要在空间和时间两方面权衡。
- 分支预测
likely/unlikely
-
Data prefetch (数据预取)
-
Register parameters (寄存器参数)
一般来说,函数调用的参数少于某个数,比如 3,参数是通过寄存器传递的(这个要看 ABI 的约定)。所以,写函数的时候,不要带那么多参数。
- Lazy computation (延迟计算)
延迟计算的意思是最近用不上的变量,就不要去初始化。通常来说,在函数开始就会初始化很多数据,但是这些数据在函数执行过程中并没有用到(比如一个分支判断,就退出了函数),那么这些动作就是浪费了。
变量初始化是一个好的编程习惯,但是在性能优化的时候,有可能就是一个多余的动作,需要综合考虑函数的各个分支,做出决定。
延迟计算也可以是系统层次的优化,比如 COW(copy-on-write) 就是在 fork 子进程的时候,并没有复制父进程所有的页表,而是只复制指令部分。当有写发生的时候,再复制数据部分,这样可以避免不必要的复制,提供进程创建的速度。
- Early computation (提前计算)
有些变量,需要计算一次,多次使用的时候。最好是提前计算一下,保存结果,以后再引用,避免每次都重新计算一次。
- Allocation on stack (局部变量)
内存尽量在栈上分配,不要用堆
- Per-cpu data structure (非共享的数据结构)
比如并发编程时,给每个线程分配独立的内存空间
- Move exception path out (把 exception 处理放到另一个函数里面)
只要引入了异常机制,无论系统是否会抛出异常,异常代码都会影响代码的大小与性能;未触发异常时对系统影响并不明显,主要影响一些编译优化手段;触发异常之后按异常实现机制的不同,其对系统性能的影响也不相同,不过一般很明显。所以,不用担心异常对正常代码逻辑性能的影响,同时不要借用异常机制处理业务逻辑。现代 C++ 编译器所使用的异常机制对正常代码性能的影响并不明显,只有出现异常的时候异常机制才会影响整个系统的性能。
另外,把 exception path 和 critical path 放到一起(代码混合在一起),就会影响 critical path 的 cache 性能。而很多时候,exception path 都是长篇大论,有点喧宾夺主的感觉。如果能把 critical path 和 exception path 完全分离开,这样对 i-cache 有很大帮助
- Read, write split (读写分离)
伪共享(false sharing):就是说两个无关的变量,一个读,一个写,而这两个变量在一个cache line里面。那么写会导致cache line失效(通常是在多核编程里面,两个变量在不同的core上引用)。读写分离是一个很难运用的技巧,特别是在code很复杂的情况下。需要不断地调试,是个力气活(如果有工具帮助会好一点,比如 cache miss时触发 cpu 的 execption 处理之类的)
瓶颈定位手段
软件性能瓶颈定位的常用手段有 perf(火焰图)以及在 Intel CPU 上使用 pmu-tools 进行 TopDown 分析**(TMAM(Top-down Micro-architecture Analysis Methodology,自顶向下的微架构分析方法))**。
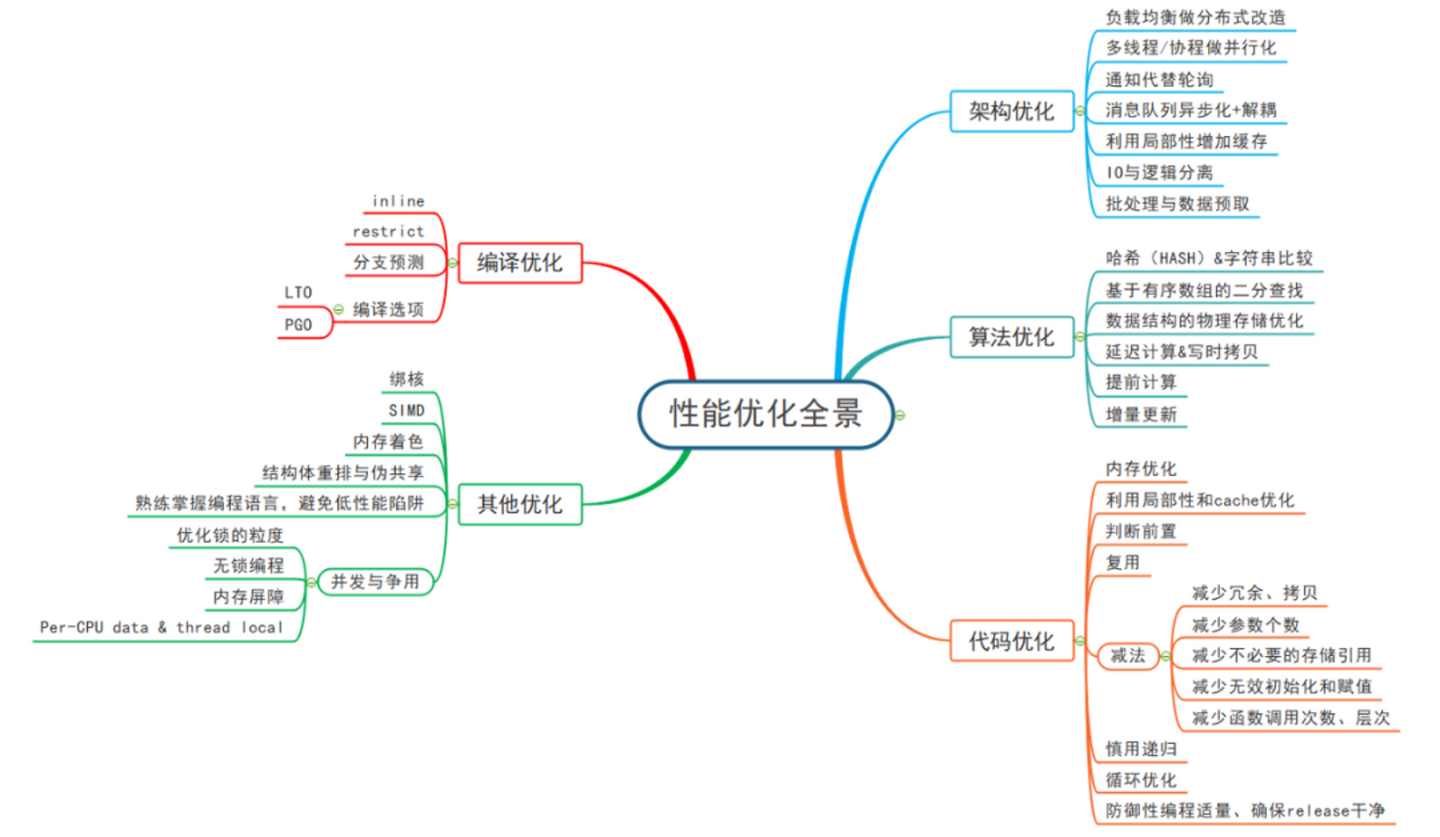
二、并发优化
单线程中的并发
1.SIMD 指令集优化
实际上单核单线程内也能利用上硬件细粒度的并发能力:SIMD(Single Instruction Multiple Data),与之相对的就是多核多线程中的 MIMD(Multiple Instruction Multiple Data)。CPU 指令集的发展经历了 MMX(Multi Media eXtension)、SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)、IMCI 等。
C/C++指令集介绍以及优化(主要针对SSE优化)
https://zhuanlan.zhihu.com/p/325632066
2.OoOE(Out of Ordered Execution)优化
经典 5 级 RISC 流水线如下图所示,分为 5 个步骤:取指 -> 译码 -> 计算 -> 访存 -> 写回。
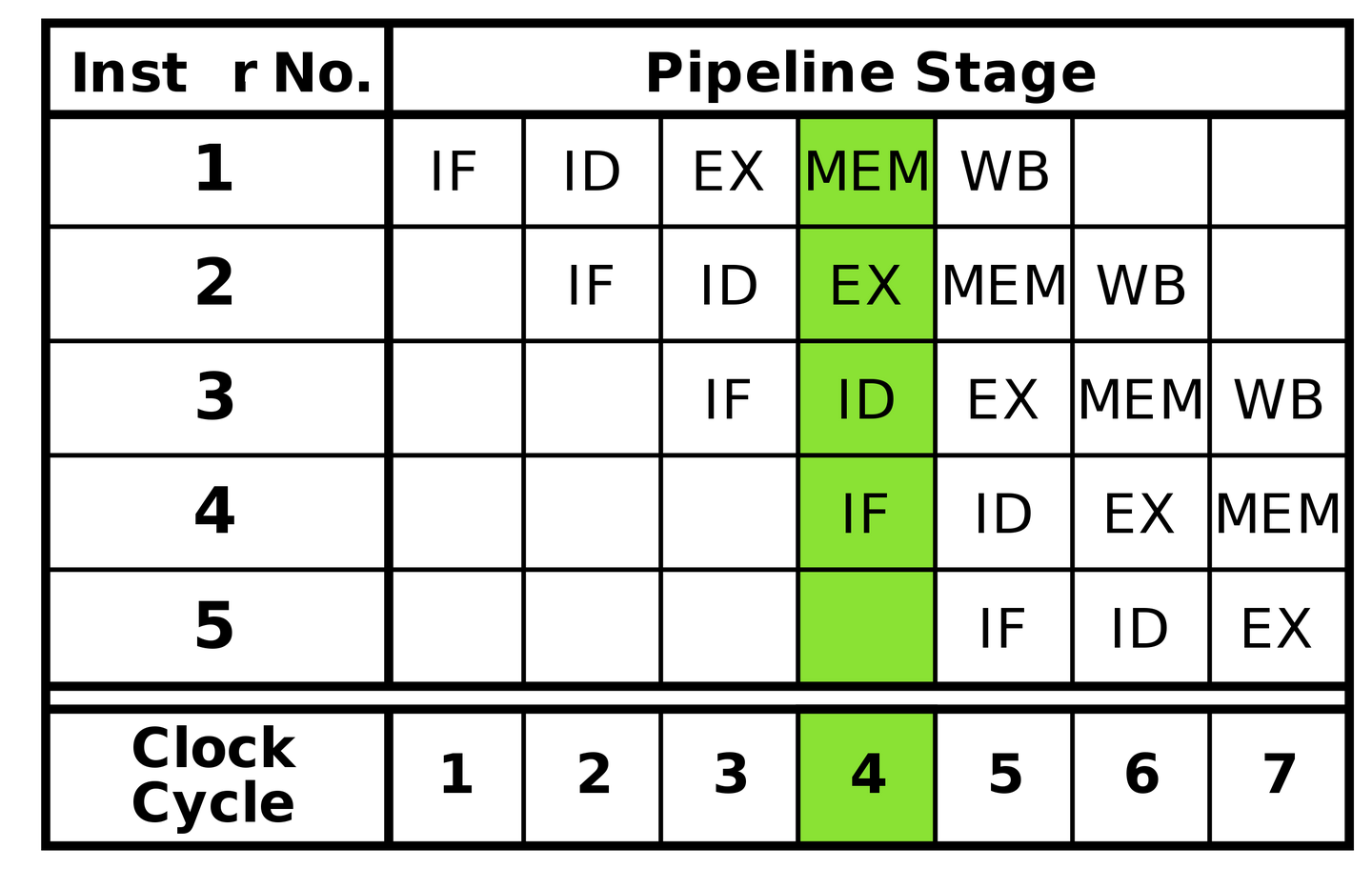
当执行环节遇到数据依赖,以及缓存未命中等场景,就会导致整体停顿的产生,其中 MEM 环节的影响尤其明显,主要是因为多级缓存及多核共享带来的单次访存所需周期数参差不齐的现象越来越严重。为了减轻停顿的影响,现代 CPU 引入了乱序执行结合超标量的技术,一方面:对于重点执行部件,比如计算、访存,增加多份来支持并行;另一方面:在执行部件前引入缓冲池/队列机制。最终从流水线模式向类似"多线程"的方式靠拢。
3.TMAM(Top-down Micro-architecture Analysis Methodology,自顶向下的微架构分析方法)
TMAM 理论基础就是将各类 CPU 微指令进行归类从大的方面先确认可能出现的瓶颈,再进一步分析找到瓶颈点,该方法也符合我们人类的思维,从宏观再到细节,过早的关注细节,往往需要花费更多的时间。这套方法论的优势在于:
- 即使没有硬件相关的知识也能够基于 CPU 的特性优化程序
- 系统性的消除我们对程序性能瓶颈的猜测:分支预测成功率低?CPU 缓存命中率低?内存瓶颈?
- 快速的识别出在多核乱序 CPU 中瓶颈点
- Intel 提供分析工具:pmu-tools
TMAM 将各种 CPU 资源大致分为 4 类:
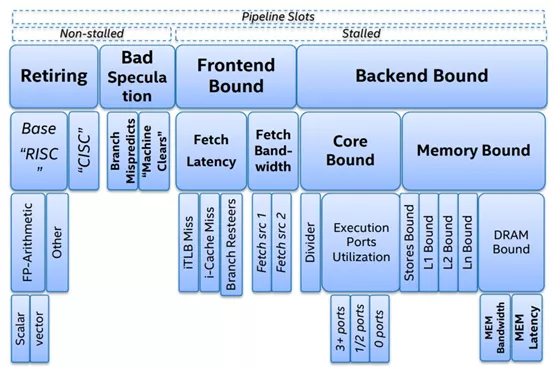
1.Retiring
Retiring 表示运行有效的 uOps 的 pipeline slot,即这些 uOps 最终会退出(注意一个微指令最终结果要么被丢弃、要么退出将结果回写到 register),它可以用于评估程序对 CPU 的相对比较真实的有效率。理想情况下,所有流水线 slot 都应该是"Retiring"。100% 的 Retiring 意味着每个周期的 uOps Retiring数将达到最大化,极致的 Retiring 可以增加每个周期的指令吞吐数(IPC)。需要注意的是,Retiring 这一分类的占比高并不意味着没有优化的空间。例如 retiring 中 Microcode assists 的类别实际上是对性能有损耗的,我们需要避免这类操作。
2.Bad Speculation
Bad Speculation 表示错误预测导致浪费 pipeline 资源,包括由于提交最终不会 retired 的 uOps 以及部分 slots 是由于从先前的错误预测中恢复而被阻塞的。由于预测错误分支而浪费的工作被归类为"错误预测"类别。例如:if、switch、while、for等都可能会产生 bad speculation。
优化建议:
(1)在使用if的地方尽可能使用gcc的内置分支预测特性
#define likely(x) __builtin_expect(!!(x), 1) //gcc内置函数, 帮助编译器分支优化
#define unlikely(x) __builtin_expect(!!(x), 0)if(likely(condition)) {// 这里的代码执行的概率比较高}if(unlikely(condition)) {// 这里的代码执行的概率比较高}// 尽量避免远调用
(2)避免间接跳转或者调用
在c++中比如switch、函数指针或者虚函数在生成汇编语言的时候都可能存在多个跳转目标,这个也是会影响分支预测的结果,虽然BTB可改善这些但是毕竟BTB的资源是很有限的。
3.Front-End-Bound
- 取指令
- 将指令进行解码成微指令
- 将指令分发给 Back-End,每个周期最多分发4条微指令
Front-End Bound 表示处理的 Front-End 的一部分 slots 没法交付足够的指令给 Back-End。Front-End 作为处理器的第一个部分其核心职责就是获取 Back-End 所需的指令。在 Front-End 中由预测器预测下一个需要获取的地址,然后从内存子系统中获取对应的缓存行,在转换成对应的指令,最后解码成uOps(微指令)。Front-End Bound 意味着,会导致部分slot 即使 Back-End 没有阻塞也会被闲置。例如因为指令 cache misses引起的阻塞是可以归类为 Front-End Bound。
优化建议:
(1)尽可能减少代码的 footprint:C/C++可以利用编译器的优化选项来帮助优化,比如 GCC -O* 都会对 footprint 进行优化或者通过指定 -fomit-frame-pointer 也可以达到效果;
**(2)充分利用 CPU 硬件特性:**宏融合(macro-fusion)特性可以将2条指令合并成一条微指令,它能提升 Front-End 的吞吐。
(3)调整代码布局(co-locating-hot-code)
- 充分利用编译器的 PGO 特性:-fprofile-generate -fprofile-use
- 可以通过__attribute__ ((hot)) __attribute__ ((code)) 来调整代码在内存中的布局,hot 的代码在解码阶段有利于 CPU 进行预取。
(4)分支预测优化
- 消除分支可以减少预测的可能性能:比如小的循环可以展开比如循环次数小于64次(可以使用GCC选项 -funroll-loops)
- 尽量用if 代替:? ,不建议使用a=b>0? x:y 因为这个是没法做分支预测的
- 尽可能减少组合条件,使用单一条件比如:if(a||b) {}else{} 这种代码CPU没法做分支预测的
- 对于多case的switch,尽可能将最可能执行的case 放在最前面
- 我们可以根据其静态预测算法投其所好,调整代码布局,满足以下条件:前置条件,使条件分支后的的第一个代码块是最有可能被执行的
4.Back-End-Bound
- 接收 Front-End 提交的微指令
- 必要时对 Front-End 提交的微指令进行重排
- 从内存中获取对应的指令操作数
- 执行微指令、提交结果到内存
Back-End Bound 表示部分 pipeline slots 因为 Back-End 缺少一些必要的资源导致没有 uOps 交付给 Back-End。
Back-End 处理器的核心部分是通过调度器乱序地将准备好的 uOps 分发给对应执行单元,一旦执行完成,uOps 将会根据程序的顺序返回对应的结果。例如:像 cache-misses 引起的阻塞(停顿)或者因为除法运算器过载引起的停顿都可以归为此类。此类别可以在进行细分为两大类:Memory-Bound 、Core Bound。
优化建议:
(1)调整算法减少数据存储,减少前后指令数据的依赖提高指令运行的并发度
(2)根据cache line调整数据结构的大小
(3)避免L2、L3 cache伪共享
归纳总结一下就是:
Front End Bound = Bound in Instruction Fetch -> Decode (Instruction Cache, ITLB)
Back End Bound = Bound in Execute -> Commit (Example = Execute, load latency)
Bad Speculation = When pipeline incorrectly predicts execution (Example branch mispredict memory ordering nuke)
Retiring = Pipeline is retiring uops
一个微指令状态可以按照下图决策树进行归类:
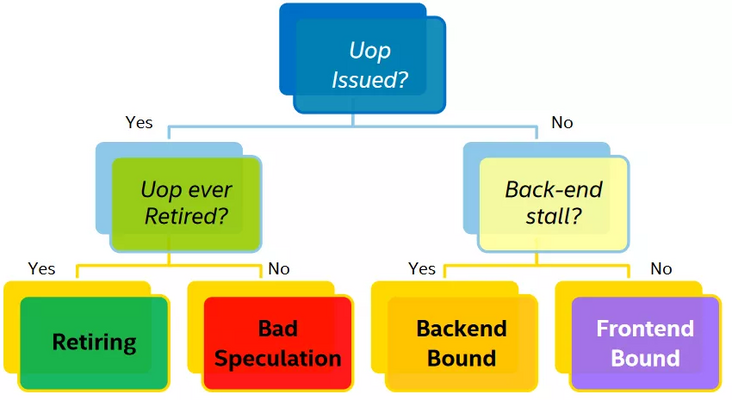
上图中的叶子节点,程序运行一定时间之后各个类别都会有一个 pipeline slot 的占比,只有 Retiring 的才是我们所期望的结果,那么每个类别占比应该是多少才是合理或者说性能相对来说是比较好,没有必要再继续优化?Intel 在实验室里根据不同的程序类型提供了一个参考的标准:
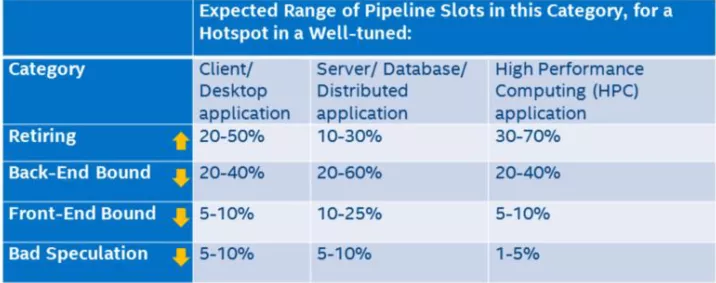
只有 Retiring 类别是越高越好,其他三类都是占比越低越好。如果某一个类别占比比较突出,那么它就是我们进行优化时重点关注的对象。
使用示例
https://segmentfault.com/a/1190000039650181
多线程中的并发
1.临界区保护技术
- Mutual Execlusion(pessimistic locking):基本的互斥技术,如果多个线程竞争同一个锁,存在某个时间周期,算法没有任何实质进展,典型的悲观锁算法
- Lock Free (optimistic locking):因为冲突组成算法的一个线程没有任何实质进展,基于 CAS 同步提交,若遇到冲突,回滚
- Wait Free:任意时间周期,算法的任意一个线程都有实质进展
**多线程累加,**上述三种技术对应以下实现方案:
-
上锁后累加:简单易懂,但会引入锁的开销和潜在的阻塞。
-
累加后 CAS 提交:无锁的实现,使用 CAS 确保线程安全,适用于高并发场景。
-
累加后 FAA:使用 Fetch and Add 原子操作,简洁且性能优越,适合频繁的累加操作。
-
优先考虑 Wait Free 的方法,如果可以的话,在性能上接近完全消除了临界区的效果
-
充分缩减临界区
-
在临界区足够小,且无 Wait Free 方案时,不必对 Lock Free 过度执着,因为 Lock Free “无效预测执行” 以及支持撤销回滚的两阶段提交算法非常复杂,反而会引起过多的消耗。锁本身的开销虽然稍重于原子操作,但其实可以接受的。真正影响性能的是临界区被迫串行执行所带来的并行能力折损。
2.并发队列
3.伪共享
三、内存优化
内存分配器tcmalloc 和 jemalloc,分别来自 google 和 facebook
针对多线程竞争的角度,tcmalloc 和 jemalloc 共同的思路是引入线程缓存机制。通过一次从后端获取大块内存,放入缓存供线程多次申请,降低对后端的实际竞争强度。主要不同点是,当线程缓存被击穿后,tcmalloc 采用了单一的 page heap(简化了中间的 transfer cache 和 central cache) 来承载;而 jemalloc 采用了多个 arena(甚至超过了服务器 core 数)来承载。一般来讲,在线程数较少,或释放强度较低的情况下,较为简洁的 tcmalloc 性能稍胜 jemalloc。在 core 数较多、申请释放频繁时,jemalloc 因为锁竞争强度远小于 tcmalloc,性能较好。
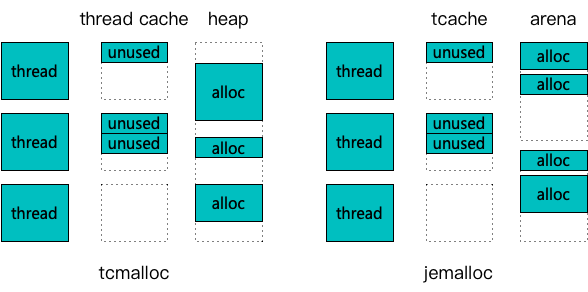
malloc 的核心要素,也就是竞争性和连续性。
线程池技术中,每个线程各司其职,完成一个一个的任务。在 malloc 看来,就是多个长生命周期的线程,随机的在各个时间节点进行内存申请和内存释放。基于这样的场景,首先,尽量分配连续地址空间。其次,多线程下需要考虑分区隔离和减少竞争。
多态内存资源(Polymorphic Memory Resource)
std::pmr::memory_resource 是 C++17 引入的多态内存资源(Polymorphic Memory Resource)的核心概念,属于 C++ 标准库中的内存管理机制。它允许开发者使用不同的内存分配策略,以提高内存管理的灵活性和性能。
PMR 将内存的分配与内存管理解耦,memory_resource 负责内存的管理,而具体的内存分配则可以通过不同的资源实现,从而提供更大的灵活性。
使用示例
https://zhuanlan.zhihu.com/p/96089089
内存分配的具体策略,可以有14种之多哦!
C++性能优化转载
https://www.cnblogs.com/qiangz/p/17085951.html
__builtin_prefetch()数据预读
为了降低内存读取的cache-miss延迟,可以通过gcc提供的这个内置函数来预读数据。当知道数据的内存地址即将要被读取(在下一个load & store指令到来之前),在数据被处理之前,就可以在代码中通过指令通知目标,去读取数据并放到缓存中。
需要注意,软件预取是有代价的:我们的系统执行了更多的指令,并将更多的数据加载到缓存中,这在某些情况下可能会导致其他方面的性能下降。
for (int i = 0; i < n; i++) {__builtin_prefetch(&array[i + 16], 0, 1); // 预取未来第16项sum += array[i]; // 实际访问当前项
}
likely和unlikely分支预测
通过先验概率提示编译器和CPU,提高分支预测准确率,降低预测错误带来的性能损失。
likely,用于修饰if/else if分支,表示该分支的条件更有可能被满足。而unlikely与之相反。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
添加分支预测后,可以增加分支预测正确性,让更大概率走到的分支对应指令顺序排放在后面,可以减少jmp指令的调用,有助于提高性能。
C++语言层面
1. 使用const引用传递而非值传递
2. for循环中使用引用遍历
3. 注意隐式转换带来的拷贝
隐式转换,创建了临时对象。
4. 定义即初始化
一次默认构造函数,一次赋值运算符函数》》》》》》》一次拷贝构造函数
5. 循环中复用临时变量
6. 尽量使用复合运算符
复合运算符实现的形式会返回自身的引用。
7. 在构造函数中使用初始化列表
构造时即初始化。
8. 使用std::move()避免拷贝
9. 定义移动构造函数、移动赋值运算符函数或右值引用函数
10. 利用好Copy Elision
在C++17以后,编译期默认启用RVO(Return Value Optimization),不会对函数返回的局部变量值进行拷贝,直接在函数调用处进行构造,只要满足以下两个条件其一:
- URVO(Unnamed Return Value Optimization):函数的各分支都返回同一个类型的匿名变量。
- NRVO(Named Return Value Optimization):函数的各分支都返回同一个非匿名变量。
11. 容器预留空间
12. 容器内原地构造
| 容器类型 | emplace_back() | emplace() | 说明 |
|---|---|---|---|
std::vector | ✅ 支持 | ✅ 支持 | 在尾部原地构造元素,效率高 |
std::deque | ✅ 支持 | ✅ 支持 | 尾部或头部插入均支持 |
std::list | ❌ | ✅ 支持 | emplace() 可插入任意位置 |
std::forward_list | ❌ | ✅ 支持 | 单向链表,只能 emplace_after() |
std::array | ❌ | ❌ | 固定大小,不支持动态插入 |
std::set / std::multiset | ❌ | ✅ 支持 | emplace() 插入有序元素 |
std::map / std::multimap | ❌ | ✅ 支持 | 用于插入 pair<key, value> |
std::unordered_set | ❌ | ✅ 支持 | 无序容器插入优化 |
std::unordered_map | ❌ | ✅ 支持 | 通常 emplace(k, v) |
std::stack / std::queue | ✅(包装容器支持) | ❌ | 取决于底层容器(如 deque) |
std::priority_queue | ✅(包装容器支持) | ❌ | 底层容器支持则支持 |
13. 容器存储指针代替对象拷贝
14. 常量集合定义添加static
15. 减少重复查找和判断
16. 利用好constexpr编译期计算
矩阵乘法
优化手段:改进运算顺序、SIMD、循环展开(减少循环控制(如跳转、比较)开销,暴露更多指令重排空间)、循环分块(A0 和 B0 加载进 cache、等 C0 运算完,再写回内存,避免 cache line 被反复换入换出)、多线程
改变运算顺序的区别:https://blog.csdn.net/LxXlc468hW35lZn5/article/details/126912933
矩阵乘法优化过程(DGEMM):https://zhuanlan.zhihu.com/p/76347262
高并发
大流量、大规模业务请求的场景,比如春运抢票、电商“双十一”抢购,秒杀促销等。
高并发的衡量指标主要有两个:一是系统吞吐率,比如 QPS(每秒查询率)、TPS(每秒事务数)、IOPS(每秒磁盘进行的 I/O 次数)。另外一个就是时延,也就是从发出 Reques 到收到 Response 的时间间隔。一般而言,用户体验良好的请求、响应系统,时延应该控制在 250 毫秒以内。
高并发的设计思路
垂直方向:提升单机能力
最大化单台服务器的性能,主要有两个手段:一是提升硬件能力,比如采用核数更多、主频更高的服务器,提升网络带宽,扩大存储空间;二是软件性能优化,尽可能榨干 CPU 的每一个 Tick。
水平方向:分布式集群
为了降低分布式软件系统的复杂性,一般会用到“架构分层和服务拆分”,通过分层做“隔离”,通过微服务实现“解耦”,这样做的一个主要目的就是为了方便扩容。然而一味地加机器扩容有时也会带来额外的问题,比如系统的复杂性增加、垂直方向的能力受限等。
高并发的关键技术
层次划分(垂直方向) + 功能划分(水平方向)
负载均衡
| 方式 | 描述 | 优缺点 |
|---|---|---|
| DNS 负载均衡 | 根据域名返回多个 IP,客户端随机或就近访问 | 简单、但受限于缓存更新速度慢 |
| 硬件负载均衡 | 使用专业设备(如 F5)分发请求 | 性能强、成本高 |
| 软件负载均衡 | NGINX、LVS 分发请求 | 成本低、灵活、易部署 |
数据库层面:分库分表 + 读写分离
| 技术 | What(做什么) | Why(为什么) | How(怎么做) |
|---|---|---|---|
| 分库分表 | 拆分成多个数据库/数据表 | 减轻单库单表压力 | 按用户 ID、时间等进行 hash 或范围划分 |
| 读写分离 | 读请求走从库,写请求走主库 | 提升读并发能力 | MySQL 主从复制 + 应用层路由 |
读多写少:缓存
| 类型 | 应用场景 | 实现方式 | 案例 |
|---|---|---|---|
| 本地缓存 | 单节点、高频访问 | Guava Cache, Caffeine | 用户最近访问记录 |
| 分布式缓存 | 多节点共享数据 | Redis, Memcached | 商品详情页、排行榜、热点文章等 |
| 缓存策略 | 控制数据生命周期 | LRU、TTL、双写一致性、Cache Aside | 读写流程设计应考虑缓存一致性问题 |
消息中间件(Why:系统间解耦 & 异步)
| 作用 | 举例 | 常用中间件 |
|---|---|---|
| 削峰填谷 | 秒杀场景中先放入 MQ 排队 | Kafka, RabbitMQ |
| 解耦微服务 | 用户注册后触发多个动作 | 用户注册 → MQ → 发送邮件、积分服务等 |
| 重试机制 | 避免失败操作立即失败 | 消息可设置重试策略 |
流控:限制流量/控制优先级,避免雪崩效应
| 策略 | 描述 |
|---|---|
| Reject 策略 | 达上限立即拒绝 |
| Queue 策略 | 达上限排队 |
| Token Bucket | 限流 + 平滑 |
| Leaky Bucket | 匀速出水 |
高并发实践
| 维度 | Why(目的) | What(做法) | How(常用手段) |
|---|---|---|---|
| 1. 单机性能优化 | 榨干单台服务器性能 | 代码优化 + 系统优化 | 内存优化、锁优化、零拷贝、epoll、线程池 |
| 2. 架构设计优化 | 让系统可以水平扩展 | 分层、拆分、解耦、异步 | 微服务、消息队列、限流、负载均衡、缓存、CDN |
| 3. 流量治理 | 控制压力、防止系统被打爆 | 限流、降级、熔断 | Sentinel、Hystrix、RateLimiter、令牌桶、漏桶算法 |
| 4. 数据层优化 | 避免 DB 成为性能瓶颈 | 分库分表、读写分离、缓存、索引 | Redis 缓存、MySQL 主从、ElasticSearch、异步写入 |
实践经验
1️⃣ 接口层:网关 + 限流 + 缓存
| 实践点 | 说明 |
|---|---|
| API网关限流 | 防止恶意访问或突发流量压垮后端,可设 QPS 阈值 |
| 静态内容走 CDN | 图片/视频/JS 等资源,不占服务带宽和 CPU |
| GET 接口缓存 | 查询接口缓存结果,避免频繁访问数据库 |
| 异步响应 | 返回结果慢的操作(如导出/视频转码)用异步任务队列 |
2️⃣ 服务层:拆分 + 异步 + 降级 + 熔断
| 实践点 | 说明 |
|---|---|
| 微服务拆分 | 把大服务拆成小服务,按功能部署,避免“大而全”模块互相拖慢 |
| MQ 解耦 + 削峰 | 秒杀、下单等请求先入队列,后端慢慢消费,防止瞬时打挂数据库 |
| 降级处理 | 非核心功能(如推荐/广告)出错时不影响主业务(如下单) |
| 熔断保护 | 某服务异常时断开调用链,防止雪崩扩散 |
3️⃣ 数据层:缓存 + 索引 + 分表分库
| 实践点 | 说明 |
|---|---|
| 热数据进缓存 | 用 Redis 缓存高频访问的数据(比如用户 Token / 商品详情) |
| 索引优化 | 查询慢的 SQL 通常缺少合适索引,尤其是多表 JOIN / 排序字段 |
| 分表分库 | 单表数据量大于千万时影响性能,可根据用户ID或时间做分片 |
| 读写分离 | 写入主库、读取从库,提高读吞吐能力 |
4️⃣ 系统层:连接池 + 多线程 + IO模型
| 实践点 | 说明 |
|---|---|
| 数据库连接池 | 用如 HikariCP、Druid 等连接池,避免频繁建立/关闭连接 |
| 线程池复用 | 用线程池处理请求,避免频繁创建线程 |
| IO 多路复用 | 使用 epoll / select 提高并发连接处理能力(如高性能 Web Server) |
5️⃣ 其他高并发常用技巧
| 技巧名称 | 作用 |
|---|---|
| 幂等性设计 | 保证请求重复不会重复处理(如重复下单) |
| 雪崩保护 | 关键缓存设置过期时间随机 + 本地缓存备份 |
| 限流算法 | 令牌桶、漏桶算法,控制每秒请求量不超过阈值 |
| 热点预热 | 大促前将热门商品、广告位数据预加载到缓存中 |
| 多线程 + IO模型 |
| 实践点 | 说明 |
|---|---|
| 数据库连接池 | 用如 HikariCP、Druid 等连接池,避免频繁建立/关闭连接 |
| 线程池复用 | 用线程池处理请求,避免频繁创建线程 |
| IO 多路复用 | 使用 epoll / select 提高并发连接处理能力(如高性能 Web Server) |
5️⃣ 其他高并发常用技巧
| 技巧名称 | 作用 |
|---|---|
| 幂等性设计 | 保证请求重复不会重复处理(如重复下单) |
| 雪崩保护 | 关键缓存设置过期时间随机 + 本地缓存备份 |
| 限流算法 | 令牌桶、漏桶算法,控制每秒请求量不超过阈值 |
| 热点预热 | 大促前将热门商品、广告位数据预加载到缓存中 |
相关文章:
性能优化笔记
性能优化转载 https://www.cnblogs.com/tengzijian/p/17858112.html 性能优化的一般策略及方法 简言之,非必要,不优化。先保证良好的设计,编写易于理解和修改的整洁代码。如果现有的代码很糟糕,先清理重构,然后再考…...

bat批量去掉本文件夹中的文件扩展名
本文本夹内 批量去掉本文件夹中的文件扩展名 假如你有一些文件,你想去掉他们的扩展名 有没有方便的办法呢 今天我们就分享一种办法。 下面,就来看看吧。 首先我们新建一个记事本,把名字改为,批量去掉本文件夹中的文件扩展名.txt 然…...

基于ROS2,撰写python脚本,根据给定的舵-桨动力学模型实现动力学更新
提问 #! /usr/bin/env python3from control_planner import usvParam as P from control_planner.courseController import courseLimitationimport tf_transformations # ROS2没有自带tf.transformations, 需装第三方库 import rclpy from rclpy.node import Node from pid_…...
Scrapy爬虫教程(新手)
1. Scrapy的核心组成 引擎(engine):scrapy的核心,所有模块的衔接,数据流程梳理。 调度器(scheduler):本质可以看成一个集合和队列,里面存放着一堆即将要发送的请求&#…...

数据可视化大屏案例落地实战指南:捷码平台7天交付方法论
分享大纲: 1、落地前置:数据可视化必备的规划要素 2、数据可视化双路径开发 3、验证案例:数据可视化落地成效 在当下数字化转型浪潮中,数据可视化建设已成为关键环节。数据可视化大屏的落地,成为企业数据可视化建设的难…...

第五篇:Go 并发模型全解析——Channel、Goroutine
第五篇:Go 并发模型全解析——Channel、Goroutine 一、序章:Java 的并发往事 在 Java 世界中,说到“并发”,你可能立马想到以下名词:Thread、Runnable、ExecutorService、synchronized、volatile。再复杂点,ReentrantLock、CountDownLatch、BlockingQueue 纷纷登场,仿…...

锁的艺术:深入浅出讲解乐观锁与悲观锁
在多线程和分布式系统中,数据一致性是一个核心问题。锁机制作为解决并发冲突的重要手段,被广泛应用于各种场景。乐观锁和悲观锁是两种常见的锁策略,它们在设计理念、实现方式和适用场景上各有特点。本文将深入探讨乐观锁和悲观锁的原理、实现…...
)
在网页加载时自动运行js的方法(2025最新)
在网页加载时自动运行JavaScript方法有多种实现方式,以下是常见的几种方法: 1. 使用 DOMContentLoaded 事件 当初始HTML文档完全加载和解析后触发(无需等待图片等资源加载): document.addEventListener(DOMC…...

在Windows下编译出llama_cpp_python的DLL后,在虚拟环境中使用方法
定位编译生成的文件 在VS2022编译完成后,在构建目录(如build/Release或build/Debug)中寻找以下关键文件: ggml.dll、ggml_base.dll、ggml_cpu.dll、ggml_cuda.dll、llama.dll(核心动态链接库) llama_cp…...

CSS radial-gradient函数详解
目录 基本语法 关键参数详解 1. 渐变形状(Shape) 2. 渐变大小(Size) 3. 中心点位置(Position) 4. 颜色断点(Color Stops) 常见应用场景 1. 基本圆形渐变 2. 椭圆渐变 3. 模…...
)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南)
n8n 自动化平台 Docker 部署教程(附 PostgreSQL 与更新指南) n8n 是一个强大的可视化工作流自动化工具,支持无代码或低代码地集成各种服务。本文将手把手教你如何通过 Docker 快速部署 n8n,并介绍如何使用 PostgreSQL、设置时区以…...
关于datetime获取时间的问题
import datetime print(datetime.now())如果用上述代码,会报错: 以下才是正确代码: from datetime import datetime print(datetime.now()) 结果: 如果想格式化时间,使用代码: from datetime import da…...

前端面试五之vue2基础
1.属性绑定v-bind(:) v-bind 是 Vue 2 中用于动态绑定属性的核心指令,它支持多种语法和用法,能够灵活地绑定 DOM 属性、组件 prop,甚至动态属性名。通过 v-bind,可以实现数据与视图之间的高效同…...

使用python实现奔跑的线条效果
效果,展示(视频效果展示): 奔跑的线条 from turtle import * import time t1Turtle() t2Turtle() t3Turtle() t1.hideturtle() t2.hideturtle() t3.hideturtle() t1.pencolor("red") t2.pencolor("green") t3…...

Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS
Oracle 审计参数:AUDIT_TRAIL 和 AUDIT_SYS_OPERATIONS 一 AUDIT_TRAIL 参数 1.1 参数功能 AUDIT_TRAIL 是 Oracle 数据库中最核心的审计控制参数,决定审计记录的存储位置和记录方式。 1.2 参数取值及含义 取值说明适用场景NONE禁用数据库审计测试环…...

Android LinearLayout、FrameLayout、RelativeLayout、ConstraintLayout大混战
一、为什么布局性能如此重要? 在Android应用中,布局渲染耗时直接决定了界面的流畅度。根据Google官方数据,超过60%的卡顿问题源于布局性能不佳。本文将彻底解析三大传统布局的性能奥秘,并提供可直接落地的优化方案。 二、三大布局…...
Unity版本使用情况统计(更新至2025年5月)
UWA发布|本期UWA发布的内容是Unity版本使用统计(第十六期),统计周期为2024年11月至2025年5月,数据来源于UWA网站(www.uwa4d.com)性能诊断提测的项目。希望给Unity开发者提供相关的行业趋势作为参…...

GPUCUDA 发展编年史:从 3D 渲染到 AI 大模型时代(上)
目录 文章目录 目录1960s~1999:GPU 的诞生:光栅化(Rasterization)3D 渲染算法的硬件化实现之路 学术界算法研究历程工业界产品研发历程光栅化技术原理光栅化技术的软件实现:OpenGL 3D 渲染管线设计 1. 顶点处理&…...
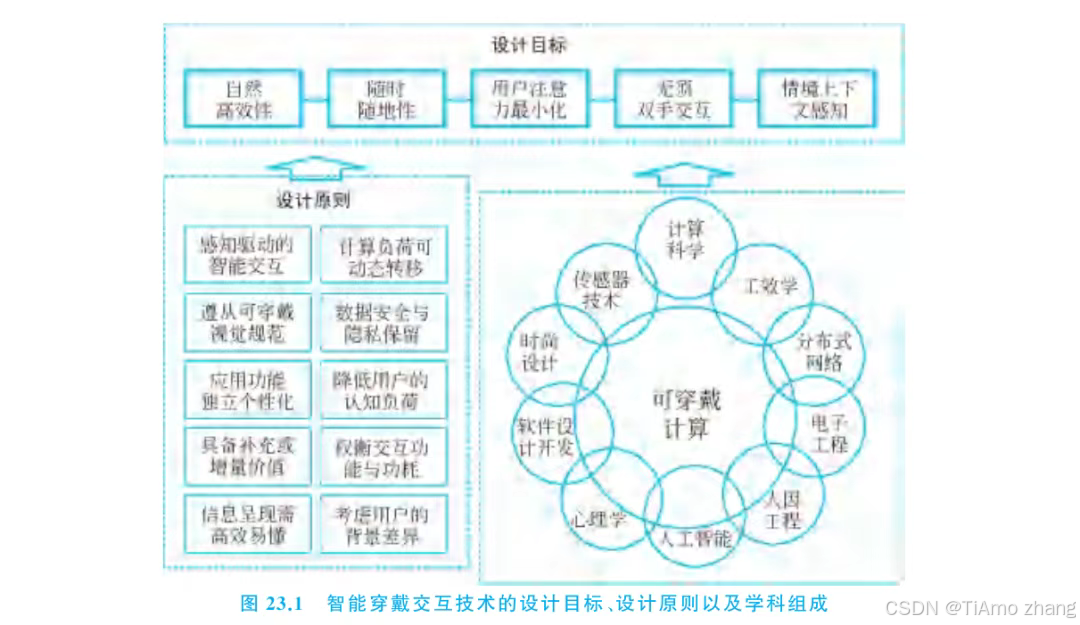
人机融合智能 | 可穿戴计算设备的多模态交互
可穿戴计算设备可以对人体以及周围环境进行连续感知和计算,为用户提供随时随地的智能交互服务。本章主要介绍人机智能交互领域中可穿戴计算设备的多模态交互,阐述以人为中心的智能穿戴交互设计目标和原则,为可穿戴技术和智能穿戴交互技术的设计提供指导,进而简述支持智能穿戴交…...
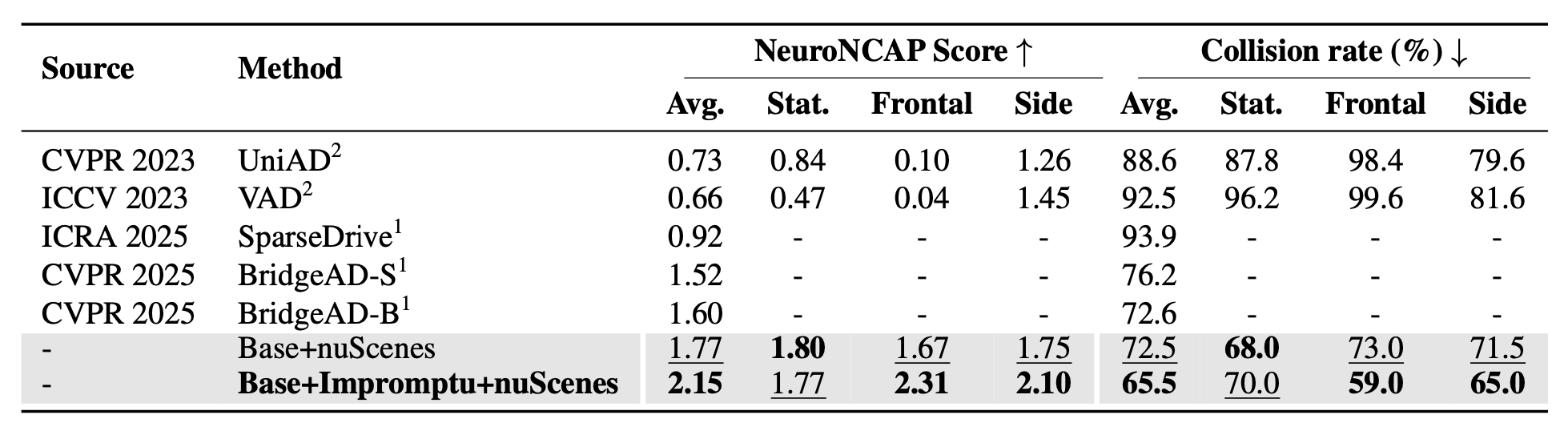
Impromptu VLA:用于驾驶视觉-语言-动作模型的开放权重和开放数据
25年5月来自清华和博世的论文“Impromptu VLA: Open Weights and Open Data for Driving Vision-Language-Action Models”。 用于自动驾驶的“视觉-语言-动作” (VLA) 模型前景光明,但在非结构化极端场景下却表现不佳,这主要是由于缺乏有针对性的基准测…...

AI智能体,为美业后端供应链注入“智慧因子”(4/6)
摘要:本文深入剖析美业后端供应链现状,其产品具有多样性、更新换代快等特点,原料供应和生产环节也面临诸多挑战。AI 智能体的登场为美业后端供应链带来变革,包括精准需求预测、智能化库存管理、优化生产计划排程、升级供应商管理等…...
跨平台资源下载工具:res-downloader 的使用体验
一款基于 Go Wails 的跨平台资源下载工具,简洁易用,支持多种资源嗅探与下载。res-downloader 一款开源免费的下载软件(开源无毒、放心使用)!支持Win10、Win11、Mac系统.支持视频、音频、图片、m3u8等网络资源下载.支持视频号、小程序、抖音、…...

ps蒙版介绍
一、蒙版的类型 Photoshop中有多种蒙版类型,每种适用于不同的场景: 图层蒙版(Layer Mask) 作用:控制图层的可见性,黑色隐藏、白色显示、灰色半透明。特点:可随时编辑,适合精细调整。…...
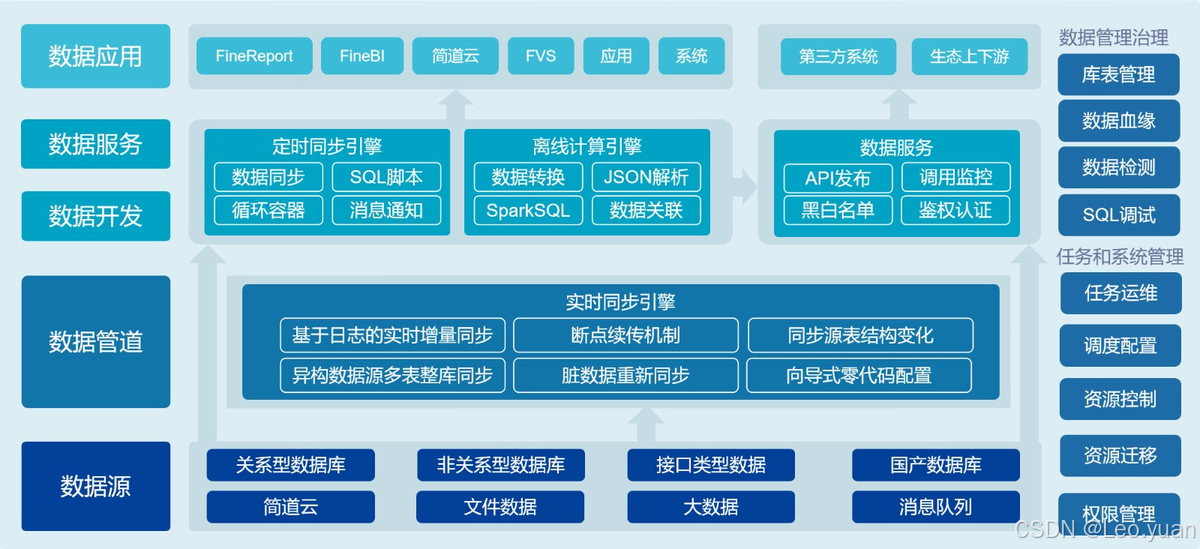
数据湖是什么?数据湖和数据仓库的区别是什么?
目录 一、数据湖是什么 (一)数据湖的定义 (二)数据湖的特点 二、数据仓库是什么 (一)数据仓库的定义 (二)数据仓库的特点 三、数据湖和数据仓库的区别 (一&#…...

用Ai学习wxWidgets笔记——在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程
声明:本文整理筛选Ai工具生成的内容辅助写作,仅供参考 >> 在 VS Code 中使用 CMake 搭建 wxWidgets 开发工程 下面是一步步指导如何在 VS Code 中配置 wxWidgets 开发环境,包括跨平台设置(Windows 和 Linux)。…...

【深度学习新浪潮】如何入门三维重建?
入门三维重建算法技术需要结合数学基础、计算机视觉理论、编程实践和项目经验,以下是系统的学习路径和建议: 一、基础知识储备 1. 数学基础 线性代数:矩阵运算、向量空间、特征分解(用于相机矩阵、变换矩阵推导)。几何基础:三维几何(点、线、面的表示)、射影几何(单…...

Android实现点击Notification通知栏,跳转指定activity页面
效果 1、点击通知栏通知,假如app正在运行,则直接跳转到指定activity显示具体内容,在指定activity中按返回键返回其上一级页面。 2、点击通知栏通知,假如app已经退出,先从SplashActivity进入,显示app启动界…...
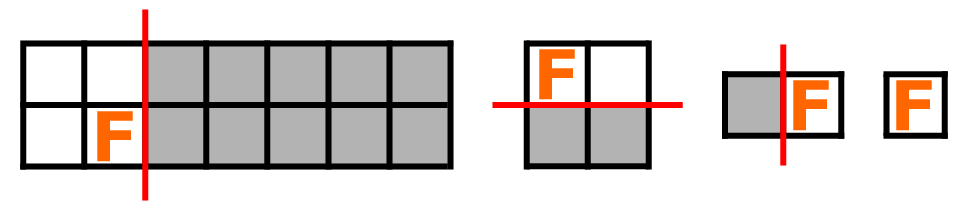
Codeforces Round 1025 (Div. 2) B. Slice to Survive
Codeforces Round 1025 (Div. 2) B. Slice to Survive 题目 Duelists Mouf and Fouad enter the arena, which is an n m n \times m nm grid! Fouad’s monster starts at cell ( a , b ) (a, b) (a,b), where rows are numbered 1 1 1 to n n n and columns 1 1 1 t…...
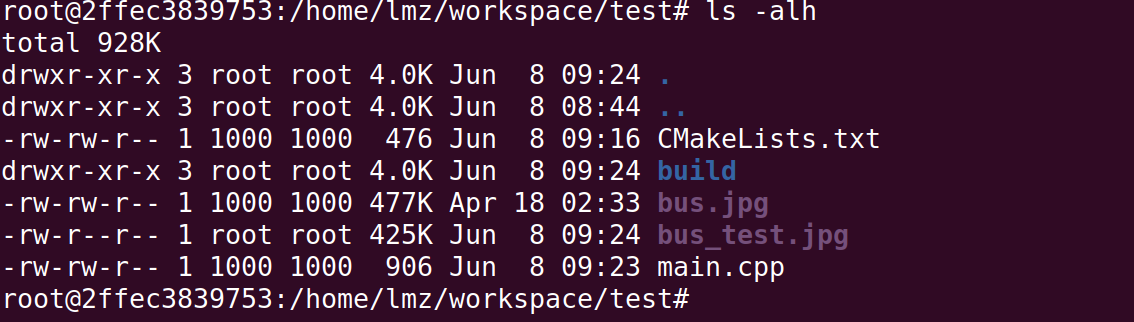
ubuntu中使用docker
上一篇我已经下载了一个ubuntu:20.04的镜像; 1. 查看所有镜像 sudo docker images 2. 基于本地存在的ubuntu:20.04镜像创建一个容器,容器的名为cppubuntu-1。创建的时候就会启动容器。 sudo docker run -itd --name cppubuntu-1 ubuntu:20.04 结果出…...

复制与图片文件同名的标签文件到目标路径
引言:在数据集构建中,我们经常需要挑选一些特殊类型的图片(如:零件中有特殊脏污背景的图片,写论文的时候想单独对这类情况进行热力图验证)。我们把挑选出来的图片放到一个文件夹下,这时候我想快…...