Cell-o1:强化学习训练LLM解决单细胞推理问题
细胞类型注释是分析scRNA-seq数据异质性的关键任务。尽管最近的基础模型实现了这一过程的自动化,但它们通常独立注释细胞,未考虑批次水平的细胞背景或提供解释性推理。相比之下,人类专家常基于领域知识为不同细胞簇注释不同的细胞类型。为模拟这一工作流程,作者引入了CellPuzzles任务,其目标是为一批细胞分配唯一的细胞类型。该基准涵盖多种组织、疾病和供体条件,要求跨批次水平的细胞背景进行推理以确保标签唯一性。现成的 LLMs 在CellPuzzles任务上表现不佳,最佳基线模型(OpenAI的o1)仅实现19.0%的批次水平准确率。为填补这一空白,提出Cell-o1,这是一个70亿参数的LLM,通过对蒸馏的推理轨迹进行监督微调,再结合批次水平奖励的强化学习进行训练。Cell-o1实现了最先进的性能,比o1高出73%以上,并且在不同背景下具有良好的泛化能力。对训练动态和推理行为的进一步分析为批次水平注释性能和新兴的专家级推理提供了见解。
Cell-o1: Training LLMs to Solve Single-Cell Reasoning Puzzles with Reinforcement Learning
https://github.com/ncbi-nlp/cell-o1
目录
- 背景概述
- CellPuzzles:用于细胞类型注释的批次级推理
- Cell-o1:用于批次注释的推理LLM
- 用于结构化推理的提示模板
- 推理蒸馏和冷启动
- 推理蒸馏和拒绝采样
- SFT
- GRPO强化学习
- 数据集和metrics
背景概述
为scRNA-seq图谱分配准确的细胞类型,是理解不同组织、疾病和个体间生物学异质性的基础。传统注释流程高度依赖专家知识,通常包括通过聚类将相似细胞分组,然后基于生物领域知识手动检查标记基因表达以分配细胞类型标签。尽管这种方法准确性高,但耗时费力,在大规模或新数据集上的可扩展性有限。
深度学习领域的最新进展通过开发单细胞基础模型,显著提升了自动化细胞类型注释的水平。这些模型利用大规模无监督预训练来捕捉复杂的基因表达模式,从而实现更优的表征学习,并在各种下游任务中提升性能。与此同时,大语言模型(LLMs)也被适配于单细胞应用场景,具体方式包括将基因表达谱转化为文本表示(C2S),或整合多模态基因嵌入(LangCell)。然而:
- 基础模型和大语言模型通常独立注释每个细胞,未考虑共享的生物学背景或批次水平的基因表达信息,这与专家注释实践存在根本差异。
- 大多数自动化方法直接预测细胞类型,却不阐明潜在的推理过程,导致其决策难以解释和验证。
为了弥补这一差距,作者首先引入了CellPuzzles,这是一个将细胞类型注释构建为批次级推理任务的新型基准,紧密模拟专家注释工作流程。如图1所示,与传统方法独立标记每个细胞不同,CellPuzzles要求利用批次中所有细胞的基因表达谱和共享上下文元数据,为每个细胞联合分配唯一标签。大量评估表明,最先进的大型语言模型(LLMs)在该任务中表现不佳,性能最佳的模型(OpenAI的o1)仅实现了19.0%的批次级准确率,反映了该任务的复杂性。
Cell-o1是一种经过两阶段训练的推理增强型大语言模型(如图1所示):首先对从前沿大语言模型中蒸馏出的专家级推理轨迹进行监督微调(SFT),以引导结构化和可解释的决策;随后通过带有批次级奖励的强化学习(RL)来促进一致的、上下文感知的标签分配。在CellPuzzles任务中,Cell-o1在细胞级和批次级准确率上均优于所有基线模型。对训练动态、推理行为和预测误差的进一步分析,揭示了模型的泛化能力、可解释性和推理能力。值得注意的是,Cell-o1表现出了诸如自我反思和课程推理等新兴行为——前者指模型重新审视并修正早期预测,后者指模型在处理难题前优先解决简单案例,这两种行为均与人类专家采用的策略相似。

- 图1:Cell-o1整体概述。
CellPuzzles:用于细胞类型注释的批次级推理
在实际的单细胞分析中,细胞类型注释很少孤立地对单个细胞进行。相反,它通常在批次水平上进行,即对来自同一供体或样本的细胞群体进行联合分析。专家通常会根据基因表达谱对细胞进行聚类,为每个聚类确定代表性的标记基因,并通过整合表达模式和组织来源、疾病状态等背景元数据来分配标签。
为了模拟这一专家驱动的过程,引入了CellPuzzles——如图2所示的全新基准,该基准将细胞类型注释定义为批次级推理任务。从形式上讲,每个任务实例包含一批 N N N个细胞 C = c 1 , c 2 , . . . , c N C={c_{1}, c_{2}, ..., c_{N}} C=c1,c2,...,cN,每个细胞均取自同一供体和实验批次中的不同细胞类型。每个细胞 c i c_{i} ci作为聚类质心的代表,由其前 M M M个高表达基因的排序列表 g i = [ g i 1 , g i 2 , . . . , g i M ] g_{i}=[g_{i 1}, g_{i 2}, ..., g_{i M}] gi=[gi1,gi2,...,giM]表示,这些基因近似于专家用于定义和注释单细胞聚类的差异表达基因。
整个细胞批次关联有一个上下文描述 m m m,该描述源自供体水平的元数据,例如组织类型、疾病状态、性别、发育阶段以及其他可用的生物学相关属性。此外,还提供一个候选标签集 Y = y 1 , y 2 , … , y N Y = {y_1, y_2, …, y_N} Y=y1,y2,…,yN,其中包含该批次中N个细胞的真实细胞类型,并经过随机打乱以消除位置偏差。这种设置模拟了专家注释场景——细胞类型从生物学合理的候选池中选择,而非自由生成。目标是学习一个映射 f : C → Y f: C → Y f:C→Y,通过联合考虑基因表达谱和上下文元数据,将每个细胞分配到 Y Y Y中的唯一标签,同时生成可解释的推理轨迹以证明标签分配的合理性。

- 图2:CellPuzzles 从专家实际注释细胞的方式中获得启发,将细胞类型注释构建为整合基因表达和背景元数据的批次级推理任务。
如图3所示,CellPuzzles基于Cell×Gene网站中的人类单细胞数据集构建,涵盖多种组织、疾病状态和供体特征。

- 图3:CellPuzzles的数据分布。A) 按性别划分的年龄组分布。B) 不同疾病条件下的样本分布。C) 不同组织中观察到的细胞类型数量。为清晰起见,B)和C)中仅显示前20项。
Cell-o1:用于批次注释的推理LLM
基于CellPuzzles,引入Cell-o1,其模拟专家在批次级单细胞分析中的注释策略。该模型对高表达基因和共享生物学背景进行推理,以从给定的候选集中分配唯一的细胞类型标签。
图1展示了训练策略。首先引入统一的提示模板,以标准化模型输出并在各个训练阶段保持格式一致。接下来,通过拒绝采样进行推理蒸馏,构建高质量的生物学解释数据集,随后进行监督微调(SFT)以实现冷启动初始化。最后,在批次级奖励信号的引导下,应用基于组相对策略优化(GRPO)的强化学习(RL)对模型进行进一步优化。
用于结构化推理的提示模板
为确保各训练阶段的输出格式统一,作者设计了一个标准化提示模板,该模板适用于蒸馏、监督微调(SFT)和强化学习(RL)的整个过程。如表1所示,此模板通过指示模型整合背景信息并从候选集中为所有细胞联合分配细胞类型,推动对整个细胞批次的全局推理。

- 你是专门从事细胞类型注释的专家助理。将为你提供来自同一供体的N个细胞的批次,其中每个细胞代表一种独特的细胞类型。对于每个细胞,将按表达降序提供其高表达基因。请利用基因表达数据和供体信息,确定每个细胞的正确细胞类型。你还将收到一个包含N个候选细胞类型的列表,每个候选类型必须恰好分配给一个细胞。请确保综合考虑所有细胞和候选类型,而非单独注释每个细胞。请在
<thinking>和</thinking>标签内包含你的详细推理,并在<answer>和</answer>标签内提供最终答案。最终答案应为按顺序列出分配的细胞类型的单个字符串,以“ | ”分隔。
推理蒸馏和冷启动
基准测试中引入的批次级推理任务对模型训练提出了重大挑战。与传统分类任务不同,模型必须同时分析一组细胞,比较基因表达模式,纳入共享元数据,并生成一致的标签分配。输入和输出之间的高度相关性使得生成有效且正确的预测变得困难,尤其是在训练早期阶段。首先使用OpenAI的o1(一种具有强大多步推理能力的前沿大型语言模型)进行推理蒸馏,以构建高质量推理轨迹和预测的合成数据集。然后,该蒸馏数据集用于监督微调(SFT),作为后续强化学习(RL)的冷启动初始化。
推理蒸馏和拒绝采样
作者使用o1模型为CellPuzzles中的10,155个实例生成推理轨迹和预测结果。每个输入均搭配表1所示的标准化提示模板。对于每个实例,生成8条候选response。随后应用拒绝采样过滤低质量输出,仅当response满足以下条件时才被接受:(1)符合预期格式;(2)生成的细胞类型分配与真实标签完全一致。这一过程最终形成包含3,912个可接受示例的蒸馏数据集,对应38.52%的接受率。
收集的推理轨迹展现出引导模型学习专家注释行为的若干理想特性,并为监督微调(SFT)奠定了坚实基础:首先,它们通过引用已知基因marker和生物学关联,体现了领域特定知识;其次,它们展示了全局推理行为,即联合考虑多个细胞和候选标签以确保标签分配的一致性;第三,推理过程结构化且可解释,与最终预测分离,并以标准化的提示-响应格式呈现。
SFT
在进行强化学习(RL)之前,作者对蒸馏数据集应用监督微调(SFT)以初始化模型。尽管最终的训练目标涉及优化奖励信号,但作者发现,仅从纯预训练的大型语言模型开始无法实现有意义的学习进展。如果模型事先未接触过任务特定的推理格式和预测结构,它将难以生成有效的输出。在实践中,这会导致早期训练阶段持续出现格式错误和标签分配错误,进而导致奖励为零或负值,并使策略陷入停滞。
监督微调(SFT)作为一种冷启动机制,通过向模型提供结构化推理和正确预测的高质量示范来缓解这一问题。通过从蒸馏数据集中学习,模型获得了遵循指令、遵守所需响应格式以及对批次内多个实体进行推理的基本能力。这提高了响应的有效性,减少了奖励的稀疏性,并为强化学习(RL)阶段更稳定、高效的策略优化奠定了基础。
GRPO强化学习
为了减少RL的训练开销,使用GRPO。给定训练输入 x x x,GRPO从旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样 G G G个候选响应 { y i } i = 1 G \left\{y_{i}\right\}_{i=1}^{G} {yi}i=1G。更新后的策略 π θ \pi_{\theta} πθ通过最大化进行优化:

其中, r i r_{i} ri为第 i i i个response的奖励值。
为了激励结构化推理并确保答案有效性,作者设计了一个基于规则的奖励函数,用于评估模型输出的格式和正确性。如表1所示,模型需要按照严格格式生成响应,其中必须包含一个由<thinking>...</thinking>标签包裹的推理段和一个由<answer>...</answer>标签包裹的答案段。标签错误或包含额外文本的响应将被视为无效,并受到惩罚。
为了验证response,作者提取预测的 answer y ^ = [ y ^ 1 , . . . , y ^ N ] \widehat{\textbf{y}}=[\widehat{y}_{1},...,\widehat{y}_{N}] y =[y 1,...,y N],与真实标签比较 y = [ y 1 , . . . , y N ] \textbf{y}=[y_{1},...,y_{N}] y=[y1,...,yN]:

1(·)是一个指示函数。此设置确保仅当批次中的所有细胞类型均被正确预测时才给予1的奖励;任何错误预测均导致奖励为0。
数据集和metrics
作者在提出的CellPuzzles基准上进行实验。每个任务实例包含 8 ≤N ≤15 个细胞,每个细胞由其排序的高表达基因列表和共享的供体水平上下文描述表示。在训练阶段,使用强推理模型进行推理蒸馏,生成3,912条高质量推理轨迹,用于监督微调(SFT)。此外,额外采样3,000个实例构建强化学习(RL)数据集,使GRPO阶段的总训练实例达到6,912个。最终评估使用包含1,095个细胞批次的预留测试集。
作者使用以下指标报告结果:(1)细胞级准确率:每个批次中正确预测标签的平均比例。(2)批次级准确率:所有预测标签与真实标签完全匹配的批次比例。(3)格式有效性:符合所需响应格式的输出比例。(4)答案唯一性:每个批次中唯一细胞类型预测的平均比例。
相关文章:
Cell-o1:强化学习训练LLM解决单细胞推理问题
细胞类型注释是分析scRNA-seq数据异质性的关键任务。尽管最近的基础模型实现了这一过程的自动化,但它们通常独立注释细胞,未考虑批次水平的细胞背景或提供解释性推理。相比之下,人类专家常基于领域知识为不同细胞簇注释不同的细胞类型。为模拟…...

求解插值多项式及其余项表达式
例 求满足 P ( x j ) f ( x j ) P(x_j) f(x_j) P(xj)f(xj) ( j 0 , 1 , 2 j0,1,2 j0,1,2) 及 P ′ ( x 1 ) f ′ ( x 1 ) P(x_1) f(x_1) P′(x1)f′(x1) 的插值多项式及其余项表达式。 解: 由给定条件,可确定次数不超过3的插值多项式。…...
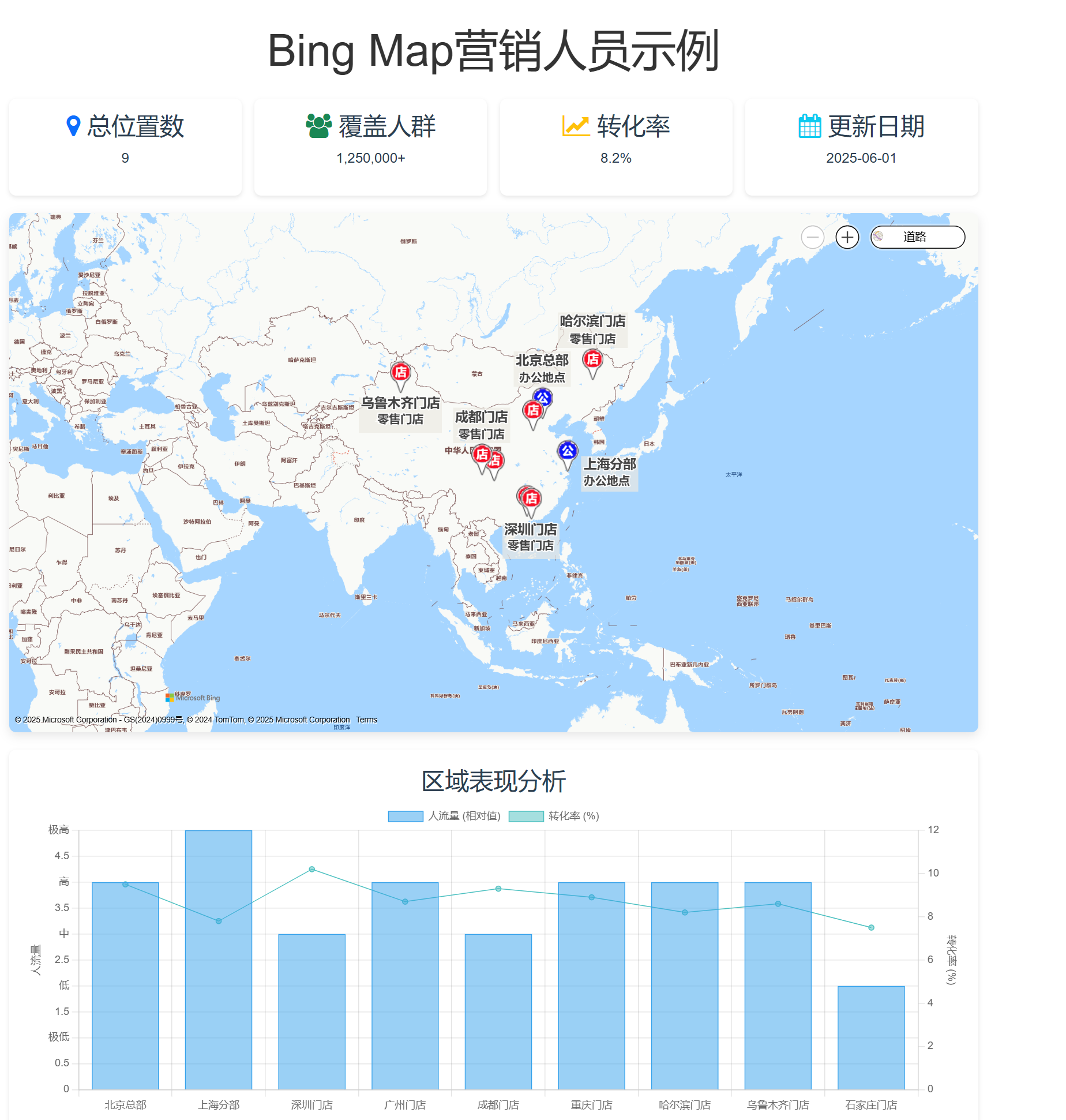
vue3: bingmap using typescript
项目结构: <template><div class"bing-map-market"><!-- 加载遮罩层 --><div class"loading-overlay" v-show"isLoading || errorMessage"><div class"spinner-container"><div class&qu…...

vue3前端实现导出Excel功能
前端实现导出功能可以使用一些插件 我使用的是xlsx库 1.首先我们需要在vue3的项目中安装xlsx库。可以使用npm 或者 pnpm来进行安装 npm install xlsx或者 pnpm install xlsx2.在vue组件中引入xlsx库 import * as XLSX from xlsx;3.定义导出实例方法 const exportExcel () …...

超大规模芯片验证:基于AMD VP1902的S8-100原型验证系统实测性能翻倍
引言: 随着AI、HPC及超大规模芯片设计需求呈指数级增长原型验证平台已成为芯片设计流程中验证复杂架构、缩短迭代周期的核心工具。然而,传统原型验证系统受限于单芯片容量(通常<5000万门)、多芯片分割效率及系统级联能力&#…...
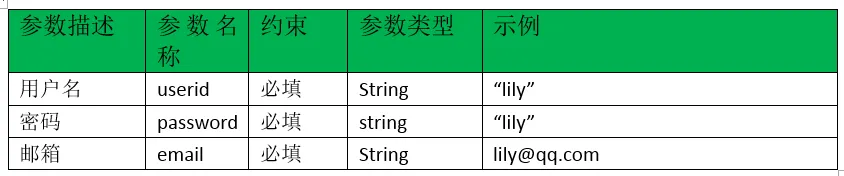
【工作记录】接口功能测试总结
如何对1个接口进行接口测试 一、单接口功能测试 1、接口文档信息 理解接口文档的内容: 请求URL: https://[ip]:[port]/xxxserviceValidation 请求方法: POST 请求参数: serviceCode(必填), servicePsw(必填) 响应参数: status, token 2、编写测试用例 2.1 正…...

Dubbo Logback 远程调用携带traceid
背景 A项目有调用B项目的服务,A项目使用 logback 且有 MDC 方式做 traceid,调用B项目的时候,traceid 没传递过期,导致有时候不好排查问题和链路追踪 准备工作 因为使用的是 alibaba 的 dubbo 所以需要加入单独的包 <depend…...

【element-ui】el-autocomplete实现 无数据匹配
文章目录 方法一:使用 default 插槽方法二:使用 empty-text 属性(适用于列表类型)总结 在使用 Element UI 的 el-autocomplete 组件时,如果你希望在没有任何数据匹配的情况下显示特定的内容,你可以通过自定…...
NLP学习路线图(二十):FastText
在自然语言处理(NLP)领域,词向量(Word Embedding)是基石般的存在。它将离散的符号——词语——转化为连续的、富含语义信息的向量表示,使得计算机能够“理解”语言。而在众多词向量模型中,FastText 凭借其独特的设计理念和卓越性能,尤其是在处理形态丰富的语言和罕见词…...

力扣面试150题--除法求值
Day 62 题目描述 做法 此题本质是一个图论问题,对于两个字母相除是否存在值,其实就是判断,从一个字母能否通过其他字母到达,做法如下: 遍历所有等式,为每个变量分配唯一的整数索引。初始化一个二维数组 …...

SQL进阶之旅 Day 20:锁与并发控制技巧
【JDK21深度解密 Day 20】锁与并发控制技巧 文章简述 在高并发的数据库环境中,锁与并发控制是保障数据一致性和系统稳定性的核心机制。本文作为“SQL进阶之旅”系列的第20天,深入探讨SQL中的锁机制、事务隔离级别以及并发控制策略。文章从理论基础入手…...

美业破局:AI智能体如何用数据重塑战略决策(5/6)
摘要:文章深入剖析美业现状与挑战,指出其市场规模庞大但竞争激烈,面临获客难、成本高、服务标准化缺失等问题。随后阐述 AI 智能体与数据驱动决策的概念,强调其在美业管理中的重要性。接着详细说明 AI 智能体在美业数据收集、整理…...
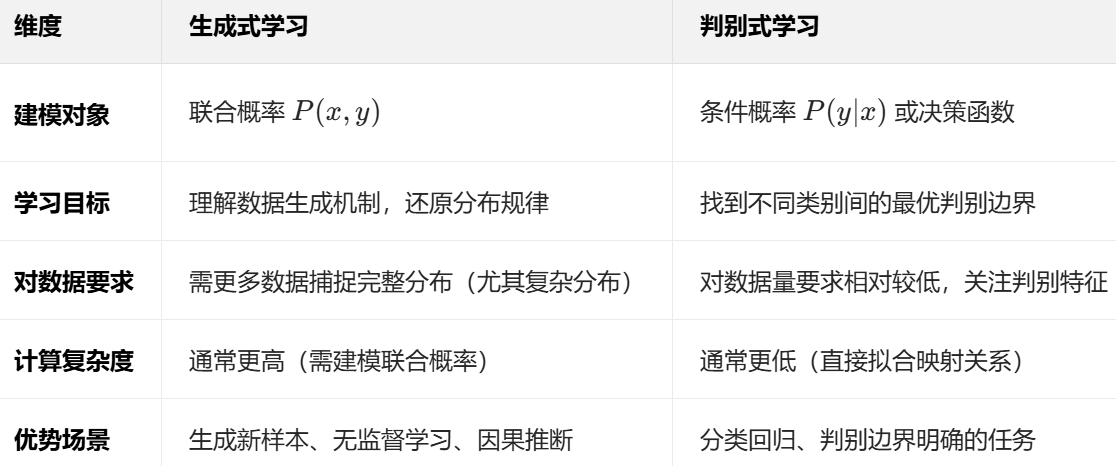
生成模型+两种机器学习范式
生成模型:从数据分布到样本创造 生成模型(Generative Model) 是机器学习中一类能够学习数据整体概率分布,并生成新样本的模型。其核心目标是建模输入数据 x 和标签 y 的联合概率分布 P(x,y),即回答 “数据是如何产生的…...

【学习笔记】Python金融基础
Python金融入门 1. 加载数据与可视化1.1. 加载数据1.2. 折线图1.3. 重采样1.4. K线图 / 蜡烛图1.5. 挑战1 2. 计算2.1. 收益 / 回报2.2. 绘制收益图2.3. 累积收益2.4. 波动率2.5. 挑战2 3. 滚动窗口3.1. 创建移动平均线3.2. 绘制移动平均线3.3 Challenge 4. 技术分析4.1. OBV4.…...

在Linux查看电脑的GPU型号
VGA 是指 Video Graphics Array,这是 IBM 于 1987 年推出的一种视频显示标准。 lspci | grep vga 📌 lspci | grep -i vga 的含义 lspci:列出所有连接到 PCI 总线的设备。 grep -i vga:过滤输出,仅显示包含“VGA”字…...

A Execllent Software Project Review and Solutions
The Phoenix Projec: how do we produce software? how many steps? how many people? how much money? you will get it. i am a pretty judge of people…a prank...
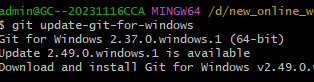
windows命令行面板升级Git版本
Date: 2025-06-05 11:41:56 author: lijianzhan Git 是一个 分布式版本控制系统 (DVCS),由 Linux 之父 Linus Torvalds 于 2005 年开发,用于管理 Linux 内核开发。它彻底改变了代码协作和版本管理的方式,现已成为软件开发的事实标准工具&…...

Langgraph实战--自定义embeding
概述 在Langgraph中我想使用第三方的embeding接口来实现文本的embeding。但目前langchain只提供了两个类,一个是AzureOpenAIEmbeddings,一个是:OpenAIEmbeddings。通过ChatOpenAI无法使用第三方的接口,例如:硅基流平台…...

大故障,阿里云核心域名疑似被劫持
2025年6月5日凌晨,阿里云多个服务突发异常,罪魁祸首居然是它自家的“核心域名”——aliyuncs.com。包括对象存储 OSS、内容分发 CDN、镜像仓库 ACR、云解析 DNS 等服务在内,全部受到波及,用户业务连夜“塌房”。 更让人惊讶的是&…...
)
什么是「镜像」?(Docker Image)
🧊 什么是「镜像」?(Docker Image) 💡 人话解释: Docker 镜像就像是一个装好程序的“快照包”,里面包含了程序本体、依赖库、运行环境,甚至是系统文件。 你可以把镜像理解为&…...
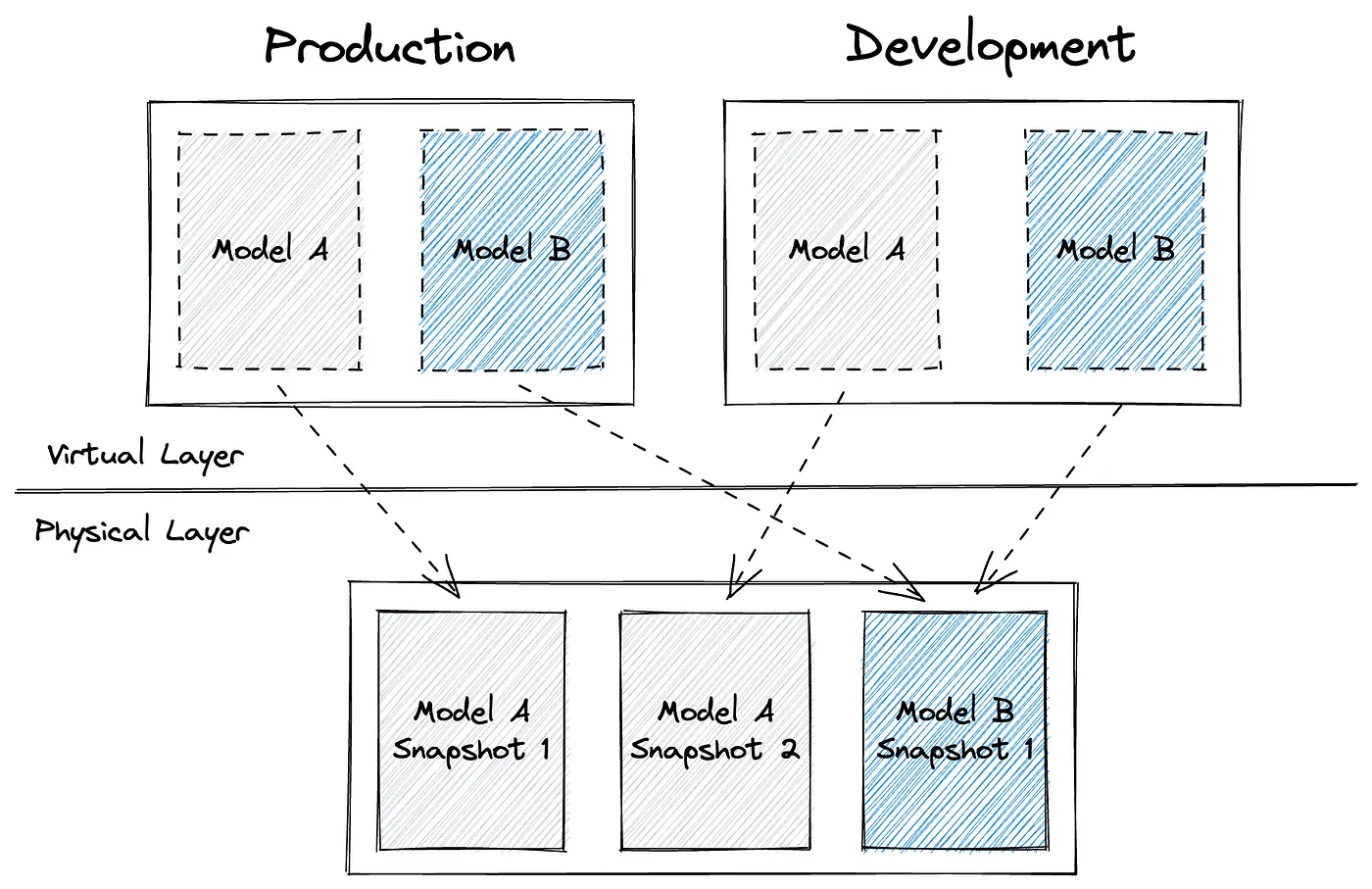
SQLMesh实战:用虚拟数据环境和自动化测试重新定义数据工程
在数据工程领域,软件工程实践(如版本控制、测试、CI/CD)的引入已成为趋势。尽管像 dbt 这样的工具已经推动了数据建模的标准化,但在测试自动化、工作流管理等方面仍存在不足。 SQLMesh 应运而生,旨在填补这些空白&…...

服务器健康摩尔斯电码:深度解读S0-S5状态指示灯
当服务器机柜中闪烁起神秘的琥珀色灯光,运维人员的神经瞬间绷紧——这些看似简单的Sx指示灯,实则是服务器用硬件语言发出的求救信号。掌握这套"摩尔斯电码",等于拥有了预判故障的透视眼。 一、状态指示灯:服务器的生命体…...
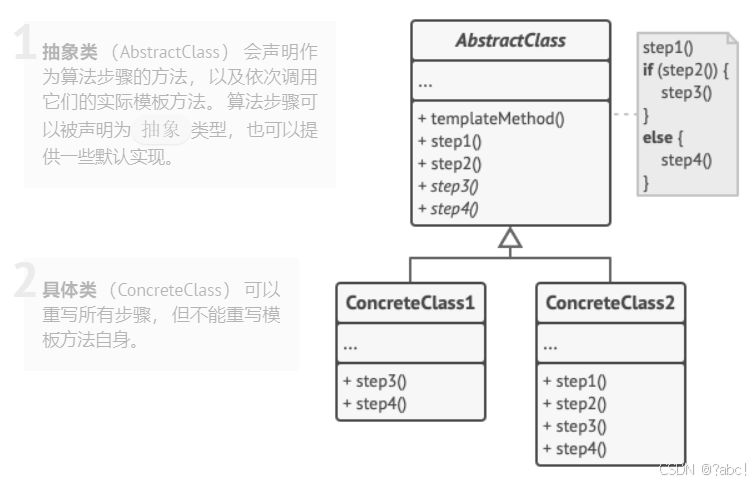
设计模式基础概念(行为模式):模板方法模式 (Template Method)
概述 模板方法模式是一种行为设计模式, 它在超类中定义了一个算法的框架, 允许子类在不修改结构的情况下重写算法的特定步骤。 是基于继承的代码复用的基本技术,模板方法模式的类结构图中,只有继承关系。 需要开发抽象类和具体子…...
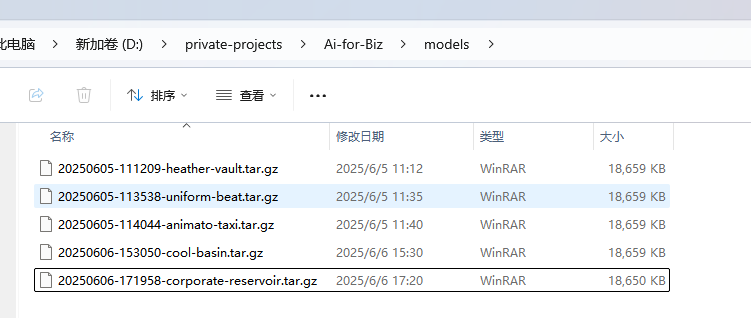
传统业务对接AI-AI编程框架-Rasa的业务应用实战(番外篇2)-- Rasa 训练数据文件的清理
经过我的【传统业务对接AI-AI编程框架-Rasa的业务应用实战】系列 1-6 的表述 已经实现了最初的目标:将传统平台业务(如发票开具、审核、计税、回款等)与智能交互结合,通过用户输入提示词或语音,识别用户意图和实体信…...

LVDS的几个关键电压概念
LVDS的几个关键电压概念 1.LVDS的直流偏置 直流偏置指的是信号的电压围绕的基准电压,信号的中心电压。在LVDS中,信号是差分的, 两根线之间的电压差表示数据,很多时候两根线的电压不是在0v开始变化的,而是在某个 固定的…...
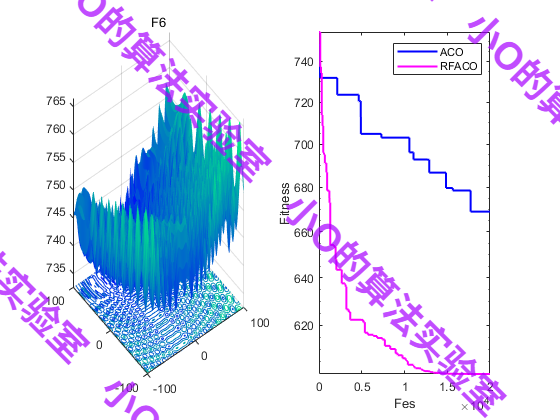
2023年ASOC SCI2区TOP,随机跟随蚁群优化算法RFACO,深度解析+性能实测
目录 1.摘要2.连续蚁群优化算法ACOR3.随机跟随策略4.结果展示5.参考文献6.代码获取7.算法辅导应用定制读者交流 1.摘要 连续蚁群优化是一种基于群体的启发式搜索算法(ACOR),其灵感来源于蚁群的路径寻找行为,具有结构简单、控制参…...
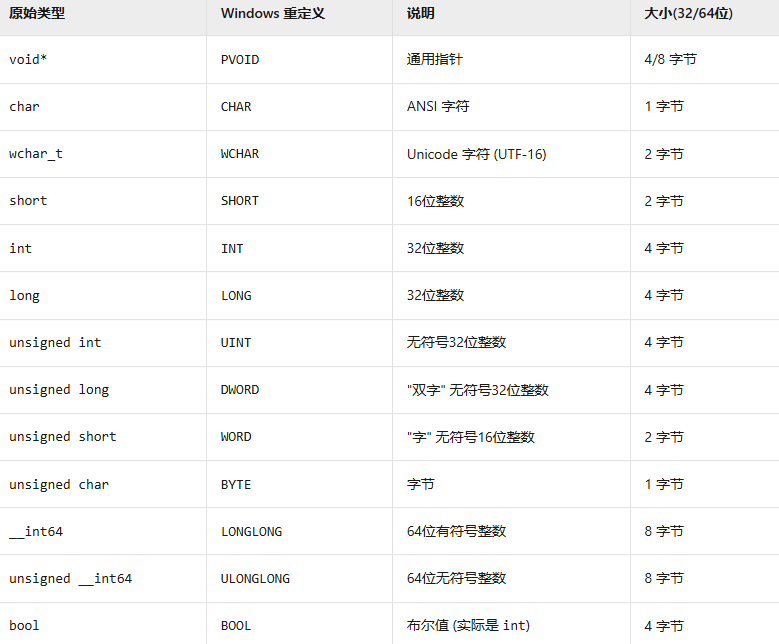
DLL动态库实现文件遍历功能(Windows编程)
源文件: 文件遍历功能的动态库,并支持用户注册回调函数处理遍历到的文件 a8f80ba 周不才/cpp_linux study - Gitee.com 知识准备 1.Windows中的数据类型 2.DLL导出/导入宏 使用__declspec(dllexport)修饰函数,将函数标记为导出函数存放到…...

Java Map完全指南:从基础到高级应用
文章目录 1. Map接口概述Map的基本特性 2. Map接口的核心方法基本操作方法批量操作方法 3. 主要实现类详解3.1 HashMap3.2 LinkedHashMap3.3 TreeMap3.4 ConcurrentHashMap 4. 高级特性和方法4.1 JDK 1.8新增方法4.2 Stream API结合使用 5. 性能比较和选择建议性能对比表选择建…...
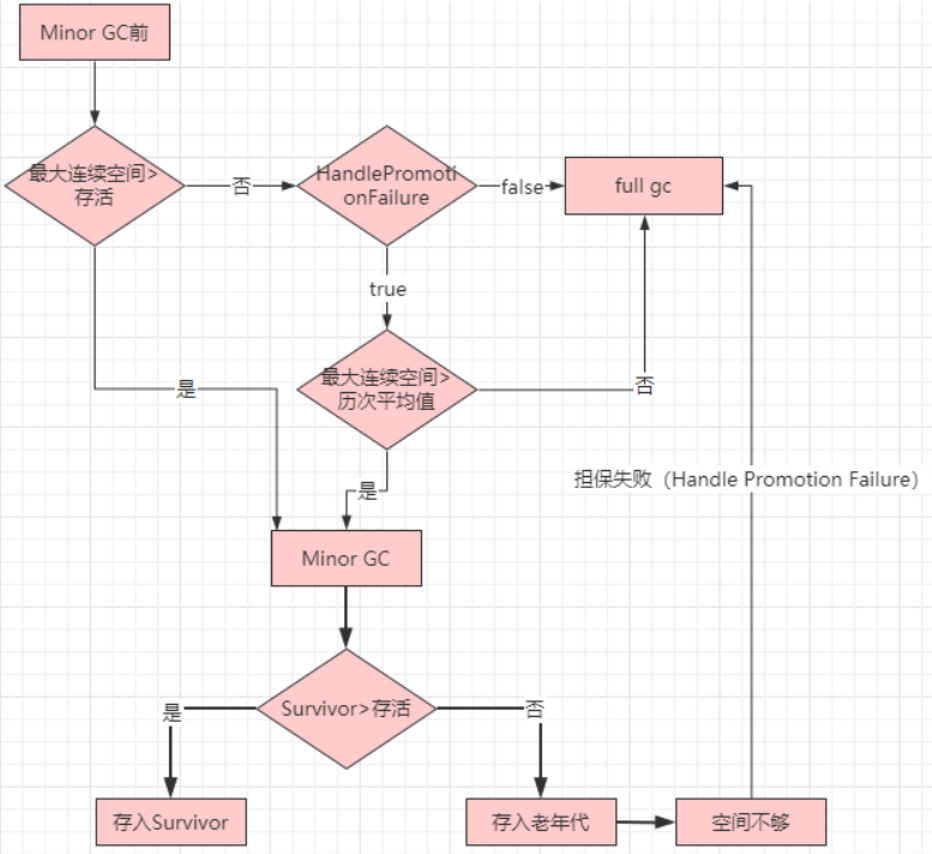
jvm 垃圾收集算法 详解
垃圾收集算法 分代收集理论 垃圾收集器的理论基础,它建立在两个分代假说之上: 弱分代假说:绝大多数对象都是朝生夕灭的。强分代假说:熬过越多次垃圾收集过程的对象就越难以消亡。 这两个分代假说共同奠定了多款常用的垃圾收集…...
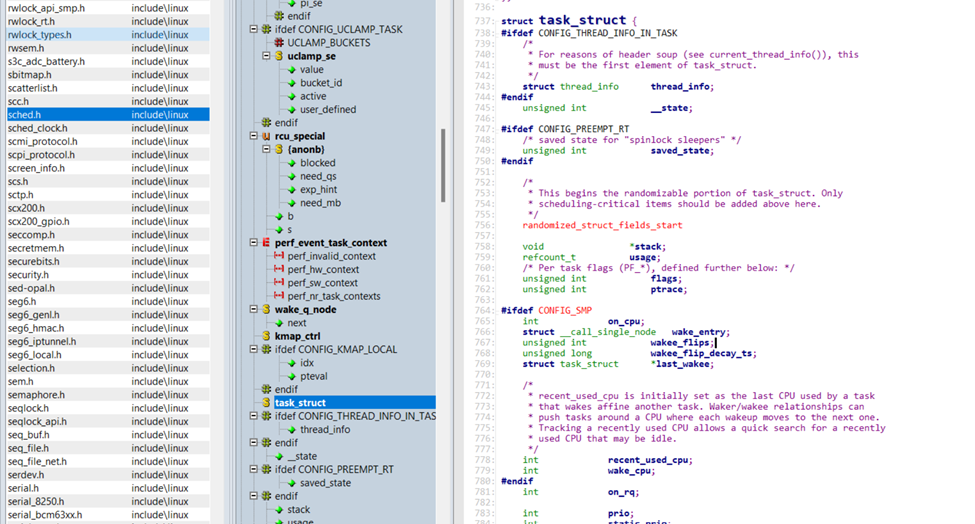
[特殊字符] 深入理解 Linux 内核进程管理:架构、核心函数与调度机制
Linux 内核作为一个多任务操作系统,其进程管理子系统是核心组成部分之一。无论是用户应用的运行、驱动行为的触发,还是系统调度决策,几乎所有操作都离不开进程的创建、调度与销毁。本文将从进程的概念出发,深入探讨 Linux 内核中进…...