LLMs 系列科普文(11)
目前我们已经介绍了大语言模型训练的两个主要阶段。第一阶段被称为预训练阶段,主要是基于互联网文档进行训练。当你用互联网文档训练一个语言模型时,得到的就是所谓的 base 模型,它本质上就是一个互联网文档模拟器,我们发现这是个有趣的产物,需要数千台计算机耗费数月时间训练。它有点像互联网的有损压缩版本。虽然极其有趣,但它并不直接实用,因为我们并不需要生成互联网文档样本。
我们想要向 AI 提问并让它回答我们的问题。为此,我们需要一个助手。我们发现,实际上可以在后训练的过程中,特别是在我们称之为监督微调的过程中构建这样一个助手。因此在这个阶段,我们发现它在算法上与预训练完全相同,不会有任何改变。唯一变化的是数据集。因此,我们不再局限于互联网文档,而是希望构建并精心打造一个优质的对话数据集。我们的目标是收集数百万条涵盖各类话题的人机对话记录。从根本上说,这些对话内容都将由人类创造生成。
人类负责编写提示词,人类也负责撰写理想回复。他们依据标注文档来完成这些工作。在现代技术栈中,这些工作实际上并非完全由人工手动完成,如今他们其实得到了这些工具的大量协助。因此,我们可以利用语言模型来协助创建这些数据集。并且我们会对其进行全面测试。但归根结底,这一切最终仍源自人类的精心筛选。所以我们创建了这些对话,这现在成为了我们的数据集。我们对其进行微调或继续训练,最终得到一个助手。
然后我们转变了话题,开始讨论这个助手可能带来的一些认知影响。我们发现,如果不采取一些缓解措施,助手会出现幻觉现象。因此,我们认识到幻觉可能会很常见。然后我们研究了一些缓解这些幻觉的方法。接着我们发现这些模型相当出色,能在脑海中处理大量信息。但我们也发现它们可以借助工具来提升表现。我们可以借助网络搜索来减少幻觉的产生,或许还能获取一些更新的信息或类似的内容。或者我们可以利用代码解释器等工具,这样大语言模型就能编写代码并实际运行它、查看结果。这些就是我们目前探讨过的部分主题。
现在我想做的是介绍这个流程的最后也是最重要的阶段,那就是强化学习。目前强化学习仍被认为属于后训练微调的范畴。但这是最后一个主要阶段。这是一种不同的语言模型训练方式,通常作为第三步进行。
十一、强化学习阶段
上面提到的这些阶段基本都是由独立的团队负责,有的团队专门负责预训练的数据工作,另一个团队负责预训练的训练工作。此外,还有一个团队专门负责对话生成,而另一个不同的团队则负责监督微调。还会有一个团队负责强化学习部分。这有点像这些模型的生产流水线过程:你先获得基础模型,然后微调成助手,接着进入强化学习阶段。这就是大致的主要流程。
现在让我们专注于强化学习,这是训练的最后主要阶段。首先,让我解释一下为什么要进行强化学习,以及从高层次来看它是什么样的。那么现在我想试着解释一下强化学习阶段及其对应的含义,基本上,这就相当于上学的过程。
就像你上学是为了精通某项技能一样,我们也要让大语言模型接受学校教育。实际上,我们正在通过几种范式来赋予它们知识或传授技能。具体来说,当我们使用学校教材时,你会发现这些教材包含三大类信息——三类主要的知识模块。

(蓝色箭头)首先你会注意到的是书本中存在大量解释性内容,就像是背景知识之类的,当你阅读这些说明性文字时,可以大致将其视为对这些数据的训练,这就是为什么当你阅读这些背景知识和上下文信息时,它有点像预训练的过程,我们在这里构建了一个关于这些数据的知识库,并对主题有了初步了解。
(红色箭头)接下来你会看到的主要信息是这些练习题的问题及其解决方案。简单来说,这本书的作者作为人类专家,不仅给我们提出了问题,还提供了解决方案。这个解决方案基本上等同于一个理想助手的完美回答。也就是说,专家实际上是在向我们示范如何解决这个问题。当我们阅读解决方案时,实际上是在用专家数据进行训练。之后,我们就可以尝试模仿专家的做法。这大致相当于拥有了 SFT 模型。所以基本上,我们已经完成了预训练,并且已经涵盖了专家模仿以及他们如何解决这些问题。
(绿色箭头)学习的第三阶段基本上是练习题。有时你会看到这里只有一个练习题,任何教科书的每章末尾通常都会有许多练习题。当然,我们知道练习题对学习至关重要,因为它们能让你做什么呢?它们能让你自己动手实践,并探索解决问题的方法。在练习题中,你会看到一个问题的描述,但不会直接给出解法,不过通常会提供最终答案(一般在教科书的最后答案部分)。所以你知道自己要达到的目标答案,也有问题的陈述,但没有具体的解题步骤。你正在尝试实践解决方案。你尝试了很多不同的方法,看看哪种方法能最好地帮你找到最终解决方案。因此,你正在自己探索如何解决这些问题。
在这个过程中,你首先依赖于来自预训练的背景信息,其次可能还会稍微模仿人类专家的做法。你或许可以尝试类似的解决方案等等。我们已经完成了这些步骤,现在在这一部分,我们将尝试进行实践。因此,我们将获得提示内容以及最终的答案,但我们不会得到专家级的解决方案。我们必须不断自己实践和尝试。这正是强化学习的核心 所在。
强化学习
在前文中,我们曾演示过,小明买苹果和橙子的计算题示例,我们把这个问题扔给 chatgpt,它可以每次都输出一些不同的中间过程,并且最终计算的结果也是正确的,例如我们重复了 4 次,这里有四个可能的候选解决方案作为例子,它们都得出答案 3。现在,我想让你意识到的是,如果你是负责创建对话的人类数据标注员,要将对话输入训练集,你应该做什么样的选择呢?实际上你可能并不确定该将其中哪个对话添加到数据集中。
其中一些对话会建立方程组,有些则只是用文字的形式讨论问题,还有些则直接跳到解决方案。但我们必须明白并区分的是,解决方案的首要目的当然是得出正确答案。我们想要得到最终答案 3,这是这里的重要目的。但还有一个次要目的,就是我们也在努力让它对人类友好,因为我们假设这个人想看到解决方案,他们想看到中间步骤,我们想很好地呈现它,等等。
所以这里有两件不同的事情。第一件是向人类展示,第二件,我们实际上是在试图得到正确的答案。所以让我们暂时专注于得出最终答案。如果我们只关心最终答案,那么在这些选项中,哪个是最优的或者说最佳解决方案,能让大语言模型得出正确答案?我们并不知道。
也许让 token 更分散地展开会更有效,也许把它列成方程式会更好,也许通过讨论来解决会更合适。从根本上说,我们并不清楚。我们不清楚的原因是,对你我或人类标注员而言容易或困难的任务,与对大语言模型来说的难易程度并不相同,它的认知方式与我们不同,对我来说轻而易举的 token 序列,对 LLMs 来说可能是个巨大的跨越。
而且,由于一些书写格式的问题,我们创建的许多 token 对 LLMs 来说可能毫无意义。我们只是在浪费 token,既然这些都无关紧要,为何要浪费这些 token 呢,如果我们唯一关心的是得到最终答案,而将呈现给人的问题分开考虑,那么我们实际上并不知道该如何标注这个例子。
我们不知道应该给大语言模型提供什么解决方案,因为我们不是大语言模型。这在数学案例中表现得非常明显,但实际上这是一个普遍存在的问题。我们的知识并不等同于大语言模型的知识。这个大型语言模型实际上掌握了大量数学、物理、化学等领域的博士级知识。在很多方面,它确实比我们知道得更多。而我可能在解决问题时并没有充分利用这些知识。
但反过来,我可能在解决方案中注入了一堆大语言模型参数中并不掌握的知识。这些突如其来的知识跃迁会让模型感到非常困惑。因此,我们的认知方式存在差异。如果我们只关心最终解决方案并以经济高效的方式实现目标,那我真的不知道该在这里写些什么。简而言之,我们目前并不擅长为 LLM 创建这些 token 序列。但我们真正希望的是让大语言模型自己去发现适合它的 token 序列。它需要自行找出在给定提示下能可靠得出答案的 token 序列,它需要通过强化学习和试错的过程来发现这一点。
强化学习的基本运作方式其实相当简单。我们需要尝试多种不同的解决方案,然后观察哪些方案效果好,哪些效果不佳。所以我们要做的就是输出提示,运行模型。模型会生成解决方案。然后我们会检查这个解决方案。我们知道这道题的正确答案是 3 元。然后我们多重复运行几次,每次模型都会给出不一样的内容,每次得到的答案也可能正确,也可能不正确。
因此在实际操作中,你可能会针对同一个提示采样数千个独立解,甚至可能达到百万量级。其中一些会是正确的,另一些则不太正确。基本上,我们希望做的是鼓励那些能得出正确答案的解决方案。

这个示意图,展示了大致的样貌。我们有一个提示,然后我们并行尝试了许多不同的解决方案。其中一些方案可能表现良好,因此它们得到了正确的答案,用绿色表示。有些解决方案可能效果不佳,甚至无法得出正确答案——也就是红色。不过,眼前这个问题其实算不上最佳范例,因为它实在过于简单。
但让我们发挥一下想象力。假设绿色的代表好的,红色的代表坏的。好的,我们生成了 15 个解决方案,其中只有 4(3 绿 1 黄)个得到了正确答案。那么现在我们要做的就是,基本上,我们希望鼓励那些能得出正确答案的解决方案类型。所以,在这些红色解决方案中出现的任何 token 序列,显然在某个环节出了问题,它们并不是解决这个问题的好方法。那些绿色解决方案中的任何 token 序列,在这种情况下都表现得相当不错。因此,我们希望在这类提示中更多地采用类似的做法。
而我们鼓励未来这种行为的方式,本质上就是对这些序列进行训练。但现在这些训练序列并非来自专家的人工标注,也没有人判定这就是正确的解决方案,这个解决方案源自模型本身。因此,模型在这里进行实践,它尝试了几种解决方案,其中 4 种似乎奏效了,现在模型将对这些方案进行某种训练。而这相当于一种认可,就像在说:“好吧,这个确实效果很好。所以我应该用这种方式来解决这类问题。”
为了传达核心概念,或许可以简单地理解为从这 4 个方案中选出最优的一个,比如标为黄色的这个。这个方案不仅得出了正确答案,可能还具有其他优点。也许它是最简洁的,或者在某种程度上看起来最漂亮,或者你还能想到其他评判标准作为例子。但我们会认定这是最佳解决方案,并据此进行训练。经过参数更新后,模型在未来遇到类似情境时,就会更倾向于选择这条路径。但必须记住,我们会在大量数学、物理等各种问题上运行多种多样的提示。
因此,成千上万的提示词背后,可能对应着每个提示词都有数千种解决方案。这一切几乎是在同时发生的。随着我们不断迭代这一过程,模型会自行发现哪些 token 序列能引导它得出正确答案。这不是来自人类标注者的数据。模型就像在这个游乐场里玩耍。它知道自己想要达到什么目标,并且正在发现对它有效的序列。这些序列不需要任何思维跳跃。它们看起来可靠且符合统计规律,并充分利用了模型已有的知识。这就是强化学习的过程。这基本上就是一个不断试错的过程。我们会尝试各种不同的解决方案,验证它们的效果,并在未来更多地采用那些行之有效的方法。这就是强化学习的核心思想。
因此,结合之前的讨论,我们现在可以看到,监督微调模型仍然是有帮助的,因为它有点像将模型初步引导到正确解决方案的附近。可以说,它是对模型的一种初始化,让模型能够生成解决方案,比如写出解题步骤,或许还能理解如何建立方程组,或者以某种方式与解决方案进行"对话"。这样,它就能让你接近正确的解决方案。
但强化学习才是真正让一切趋于完美的关键。我们会不断探索适合模型的解决方案,找到正确答案并加以鼓励,这样模型就会随着时间的推移逐渐变得更好。
以上就是我们训练大语言模型的高层次流程。简而言之,我们训练 AI 的方式与教育儿童非常相似。唯一的区别在于,儿童是通过书籍的章节学习,在每本书的不同章节中完成各类训练练习。而我们训练 AI 时,更像是根据每个阶段的特点分步骤进行。
首先,我们进行预训练,这相当于阅读所有的说明性材料。我们会同时浏览所有教材,阅读所有解释内容,并尝试构建一个知识库。接下来,我们进入监督微调阶段,这一阶段主要是研究人类专家提供的各种固定解法,涵盖所有教材中的各类习题解答。而我们得到的只是一个 SFT 模型,它能够模仿专家的行为,但某种程度上是盲目模仿。它更像是尽最大努力去猜测,试图从统计角度模仿专家的行为。因此,当你查看所有解决方案时,这就是你所得到的结果。
最后,在最后一个阶段,我们会在强化学习阶段完成所有的练习题。我们只做所有教材中的练习题。这就是我们得到强化学习模型的方法。
事实上前两个阶段——预训练和监督微调——已经存在多年,它们非常标准化,所有不同的大语言模型提供商都在采用。而最后一个阶段,即强化学习训练,目前仍处于发展初期,在该领域尚未形成统一标准。原因在于,我实际上跳过了这个过程中的大量细节,但此处我们暂不展开更多内容。
但高层次的理念的确非常简单,就是一种不断试错学习的过程,但其中涉及大量细节和微妙的数学技巧——比如如何挑选最优解、训练量如何把控、提示词分布如何设计,以及如何设置训练流程才能使其真正奏效。核心思想虽然极其简单,却需要调节无数细枝末节的参数。因此,要把这些细节做到位绝非易事。
相关文章:
LLMs 系列科普文(11)
目前我们已经介绍了大语言模型训练的两个主要阶段。第一阶段被称为预训练阶段,主要是基于互联网文档进行训练。当你用互联网文档训练一个语言模型时,得到的就是所谓的 base 模型,它本质上就是一个互联网文档模拟器,我们发现这是个…...
)
DQN算法(详细注释版)
DQN算法 DQN算法使用的常见问题 Q1: 为什么用目标网络而非Q网络直接计算? 答案:避免“移动目标”问题(训练中Q网络频繁变化导致目标不稳定),提高收敛性。 Q2: 为什么用 max 而不是像SARSA那样采样动作?…...

sizeof 与strlen的区别
sizeof 和 strlen 是C和C 中用于处理数据大小和字符串长度的两个不同的操作符/函数,它们的区别如下: 概念和用途 - sizeof 是一个操作符,用于计算数据类型或变量在内存中所占的字节数,它是在编译时确定的,与数据的…...

论文阅读:HySCDG生成式数据处理流程
论文地址: The Change You Want To Detect: Semantic Change Detection In Earth Observation With Hybrid Data Generation Abstract 摘要内容介绍 📌 问题背景 “Bi-temporal change detection at scale based on Very High Resolution (VHR) images is crucia…...
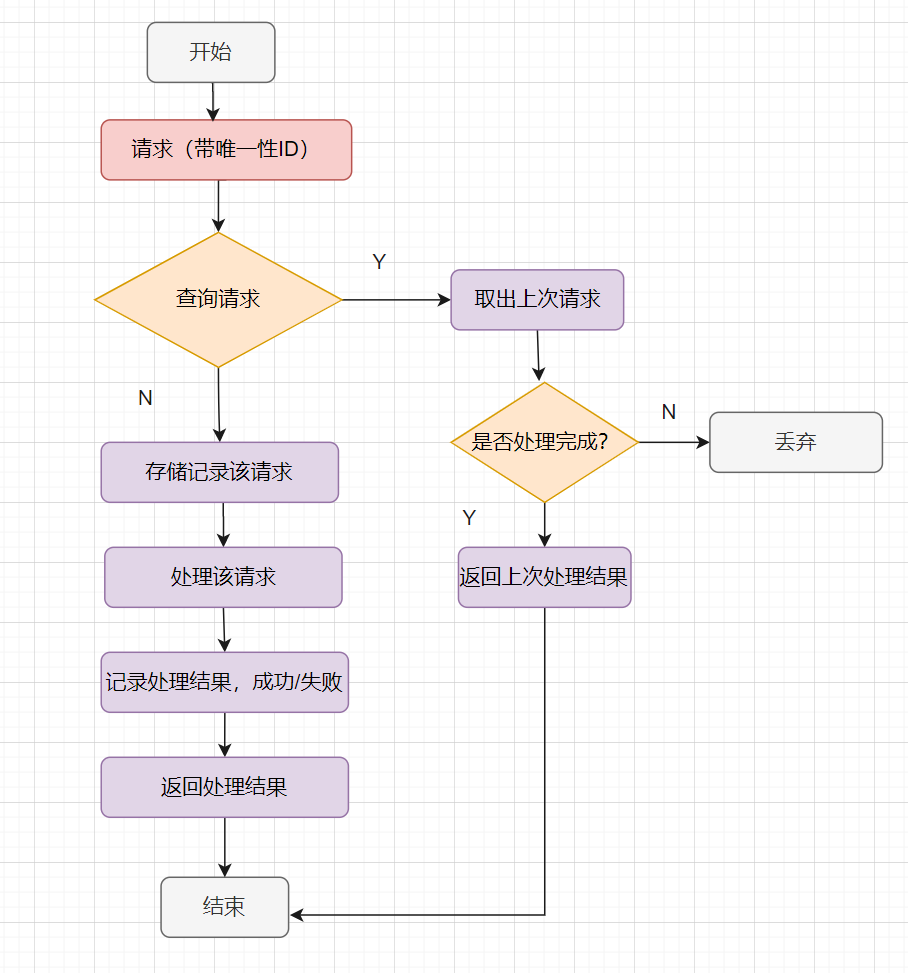
10万QPS高并发请求,如何防止重复下单
1. 前端拦截 首先因为是10万QPS的高并发请求,我们要保护好系统,那就是尽可能减少用户无效请求。 1.1 按钮置灰 很多用户抢票、抢购、抢红包等时候,为了提高抢中的概率,都是疯狂点击按钮。会触发多次请求,导致重复下…...

Xilinx IP 解析之 Block Memory Generator v8.4 ——02-如何配置 IP(仅 Native 接口)
相关文章: Xilinx IP 解析之 Block Memory Generator v8.4 ——01-手册重点解读(仅Native RAM) – 徐晓康的博客 Xilinx IP 解析之 Block Memory Generator v8.4 ——02-如何配置 IP(仅 Native RAM) – 徐晓康的博客 V…...

什么是高考?高考的意义是啥?
能见到这个文章的群体,应该都经历过高考,突然想起“什么是高考?意义何在?” 一、高考的定义与核心功能 **高考(普通高等学校招生全国统一考试)**是中国教育体系的核心选拔性考试,旨在为高校选拔…...

RISC-V 开发板 + Ubuntu 23.04 部署 open_vins 过程
RISC-V 开发板 Ubuntu 23.04 部署 open_vins 过程 1. 背景介绍2. 问题描述3. 解决过程3.1 卸载旧版本3.2 安装 Suitesparse v5.8.03.3 安装 Ceres Solver v2.0.03.4 解决编译爆内存问题 同步发布在个人笔记RISC-V 开发板 Ubuntu 23.04 部署 open_vins 过程 1. 背景介绍 最近…...

量子计算突破:新型超导芯片重构计算范式
2024年IBM 1281量子比特超导芯片实现0.001%量子错误率,计算速度达经典超算2.5亿倍。本文解析: 物理突破:钽基超导材料使量子相干时间突破800μs(提升15倍)架构革命:十字形…...

Spring Cloud 多机部署与负载均衡实战详解
🧱 一、引言 为什么需要多机部署? 解决单节点性能瓶颈,提升系统可用性和吞吐量 在传统单机部署模式下,系统的所有服务或应用都运行在单一服务器上。这种模式在小型项目或低并发场景中可能足够,但随着业务规模扩大、用…...

基于定制开发开源AI智能名片S2B2C商城小程序的首屏组件优化策略研究
摘要:在数字化转型背景下,用户对首屏交互效率的诉求日益提升。本文以"定制开发开源AI智能名片S2B2C商城小程序"为技术载体,结合用户行为数据与认知心理学原理,提出首屏组件动态布局模型。通过分析搜索栏、扫码入口、个人…...
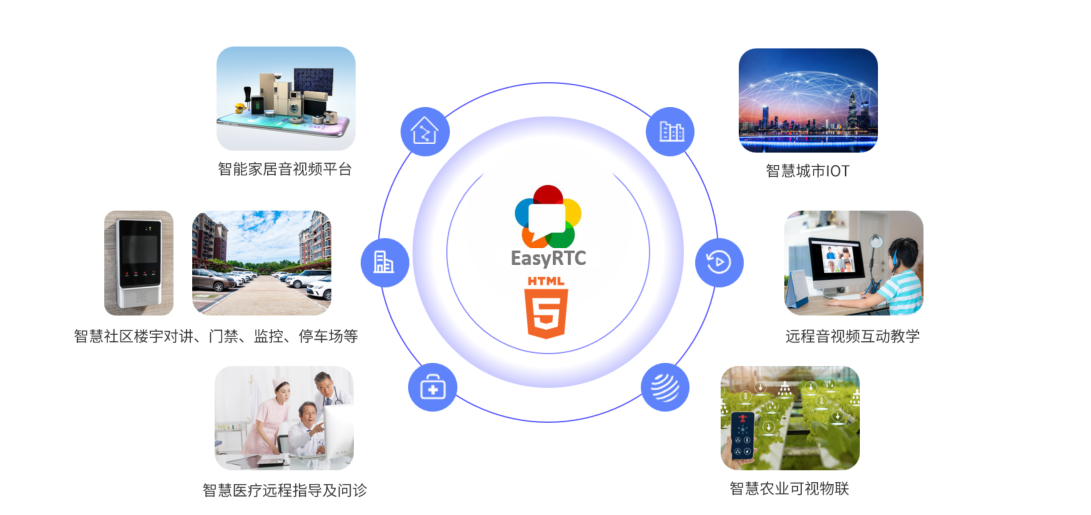
EasyRTC嵌入式音视频通信SDK音视频功能驱动视频业务多场景应用
一、方案背景 随着互联网技术快速发展,视频应用成为主流内容消费方式。用户需求已从高清流畅升级为实时互动,EasyRTC作为高性能实时音视频框架,凭借低延迟、跨平台等特性,有效满足市场对多元化视频服务的需求。 二、EasyRTC技术…...

Flink 失败重试策略 :restart-strategy.type
在 Apache Flink 中,restart-strategy.type 用于指定作业的重启策略(Restart Strategy),它决定了作业在失败后如何恢复。 Flink 提供了 4 种内置重启策略,可以通过 flink-conf.yaml 或代码动态配置。 1. 可配置的 rest…...
linux下gpio控制
linux下gpio控制 文章目录 linux下gpio控制1.中断命令控制/sys/class/gpio/export终端命令控制led 2.应用程序控制 3.驱动代码控制 1.中断命令控制 通用GPIO主要用于产生输出信号和捕捉输入信号。每组GPIO均可以配置为输出输入以及特定的复用功能。 当作为输入时,内…...
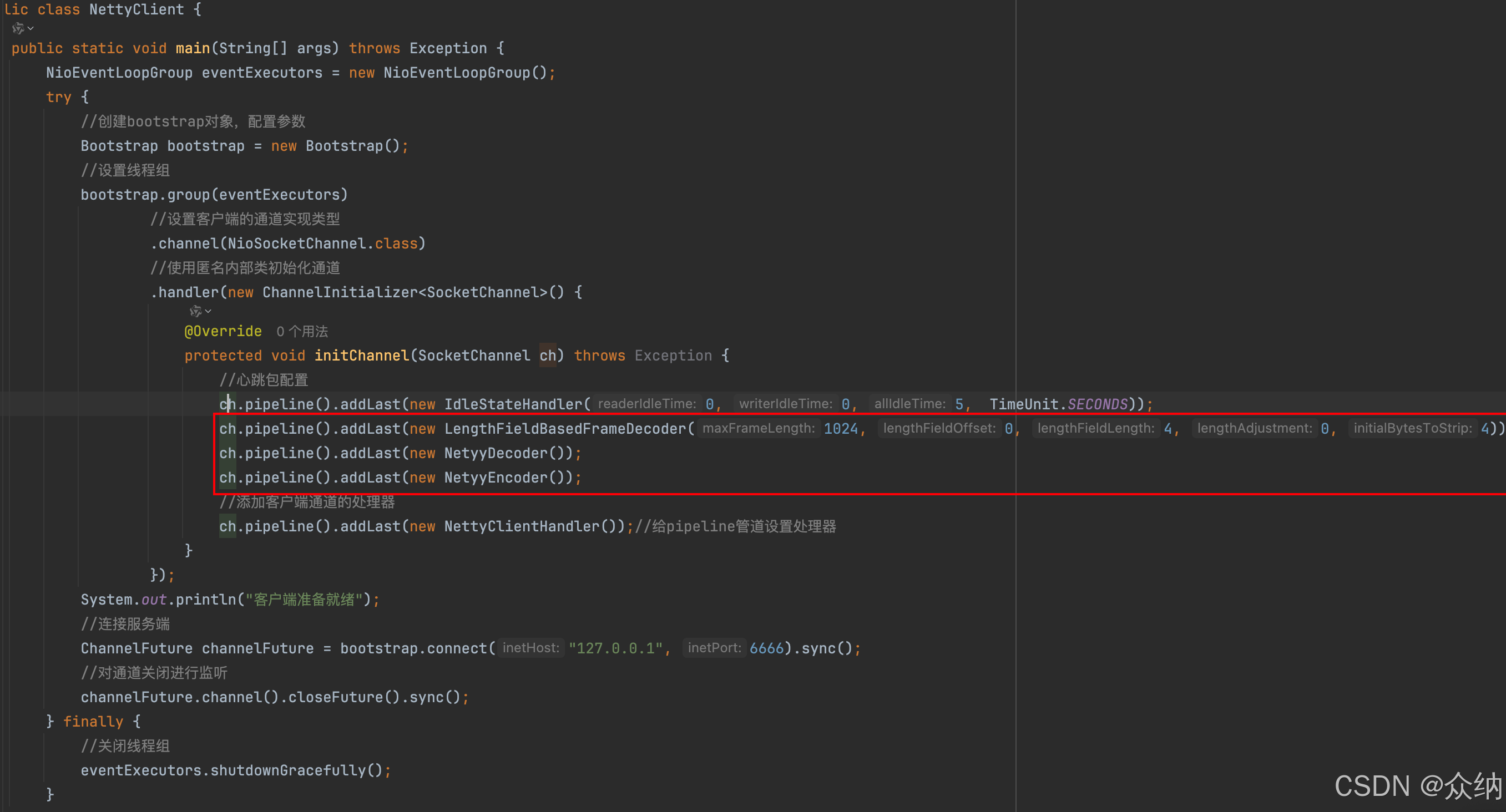
Spring Boot 从Socket 到Netty网络编程(下):Netty基本开发与改进【心跳、粘包与拆包、闲置连接】
上一篇:《Spring Boot 从Socket 到Netty网络编程(上):SOCKET 基本开发(BIO)与改进(NIO)》 前言 前文中我们简单介绍了基于Socket的BIO(阻塞式)与NIO(非阻塞式࿰…...
Orthanc:轻量级PACS服务器与DICOMweb支持的技术详解
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...
量子计算导论课程设计 之 PennyLane环境搭建
文章目录 具体配置conda 虚拟环境配置Pennylane 正所谓,磨刀不误砍柴工,想要进行量子计算导论的课程设计,首先就是搭建好平台,推荐大家就是本地搭建,那么下面有三种选择 QiskitTensorFlow QuantumPennylane 具体配置…...

GAN优化与改进:从条件生成到训练稳定性
摘要 本文聚焦生成对抗网络(GAN)的核心优化技术与改进模型。系统解析 条件生成对抗网络(CGAN) 的可控生成机制、深度卷积GAN(DCGAN) 的架构创新,揭示GAN训练崩溃的本质原因,并介绍W…...

【Dv3Admin】系统视图下载中心API文件解析
大文件导出与批量数据下载常常成为后台系统性能瓶颈,合理管理下载任务是保障系统稳定运行的关键。任务化下载机制通过异步处理,避免前端等待阻塞,提升整体交互体验。 围绕 download_center.py 模块,剖析其在下载任务创建、查询、…...

linux库(AI回答)
STL POSIX关系 DeepSeek-R1 回答完成 搜索全网22篇资料 STL(标准模板库)和 POSIX(可移植操作系统接口)是两种不同领域的技术标准,它们在 C/C 开发中各有侧重,但可以协同使用。以下是它们的关系和区别&…...
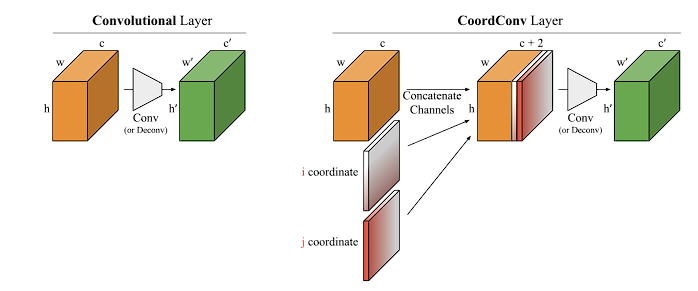
CoordConv: CNN坐标感知特征适应
传统卷积 vs CoordConv 详细对比 传统卷积对空间位置不敏感,CoordConv通过显式添加坐标信息解决这个问题在特征图中嵌入(x, y)坐标和可选的径向距离r使模型能够感知空间位置关系 1. 传统卷积的"空间位置不敏感"问题 传统卷积的特点: 输入: …...
)
Kafka 快速上手:安装部署与 HelloWorld 实践(二)
四、Kafka 的 HelloWorld 实践 完成 Kafka 的安装部署后,我们就可以进行一些简单的操作来体验 Kafka 的功能了。下面通过一个 HelloWorld 示例,展示如何在 Kafka 中创建主题、发送消息和消费消息。 (一)创建主题(Top…...

opencv学习笔记2:卷积、均值滤波、中值滤波
目录 一、卷积概念 1.定义 2.数学原理 3.实例计算 (1) 输入与卷积核 (2)计算输出 g(2,2) 4.作用 二、针对图像噪声的滤波技术——均值滤波 1.均值滤波概念 (1)均值滤波作用 (2&#…...
在 Android Studio 中使用 GitLab 添加图片到 README.md
1. 将图片文件添加到项目中 在项目根目录下创建一个 images 或 assets 文件夹 将你的图片文件(如 screenshot.png)复制到这个文件夹中 2. 跟提交项目一样,提交图片到 GitLab 在 Android Studio 的 Git 工具窗口中: 右键点击图片…...
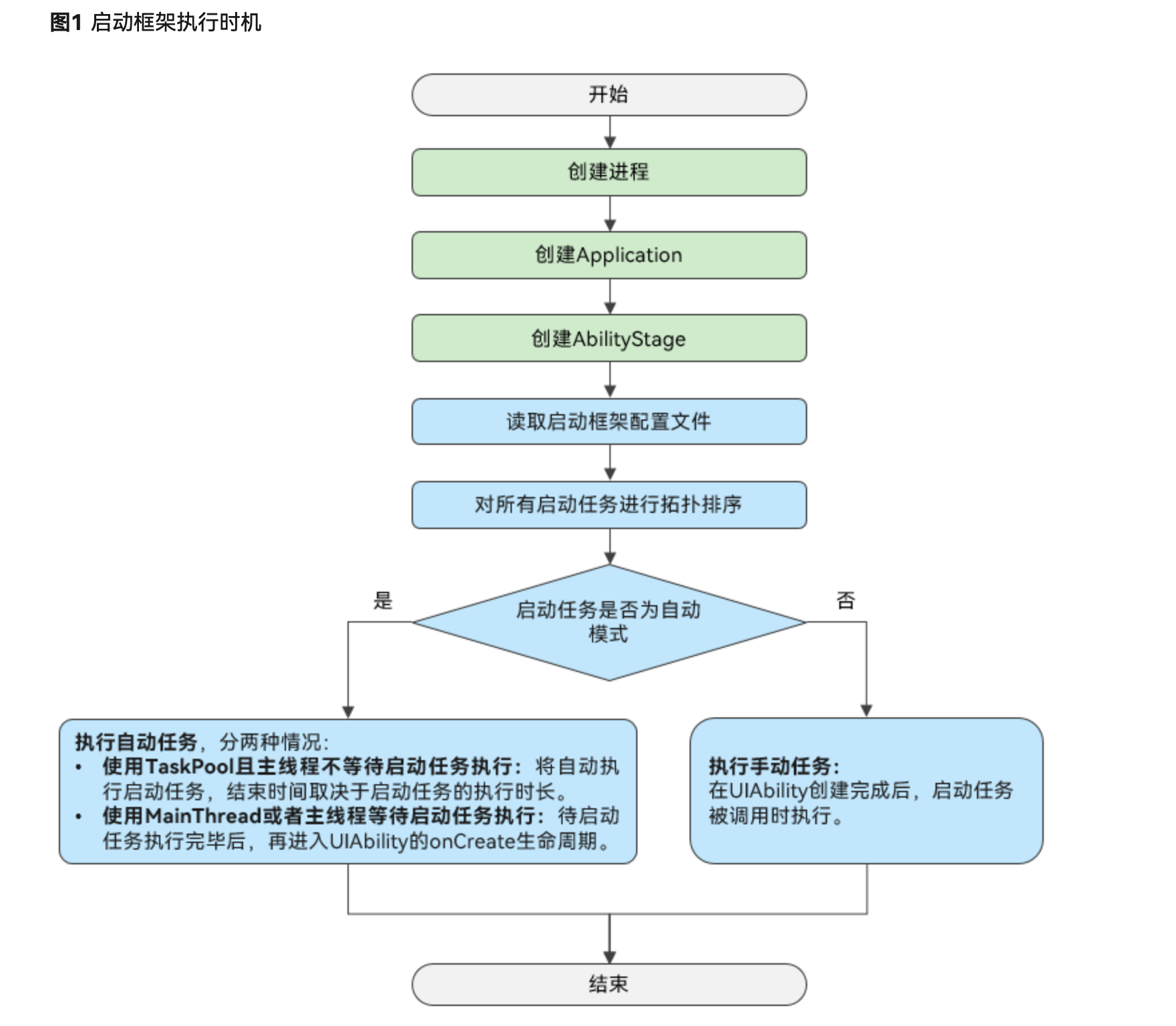
HarmonyOS:如何在启动框架中初始化HMRouter
应用启动时通常需要执行一系列初始化启动任务,如果将启动任务都放在应用主模块(即entry类型的Module)的UIAbility组件的onCreate生命周期中,那么只能在主线程中依次执行,不但影响应用的启动速度,而且当启动…...

Ubuntu下有关UDP网络通信的指令
1、查看防火墙状态: sudo ufw status # Ubuntu 2、 检查系统全局广播设置 # 查看是否忽略广播包(0表示接收,1表示忽略) sysctl net.ipv4.icmp_echo_ignore_broadcasts# 查看是否允许广播转发(1表示允许)…...
)
JavaWeb预习(jdbc)
基础 1.驱动程序接口Driver 每种数据库都提供了数据库驱动程序,并且都提供了一个实现java.sql.Driver接口的类,称为Driver 对于MySql,其Driver类为com.mysql.jdbc.Driver,加载该类的语句为: Class.forName("c…...
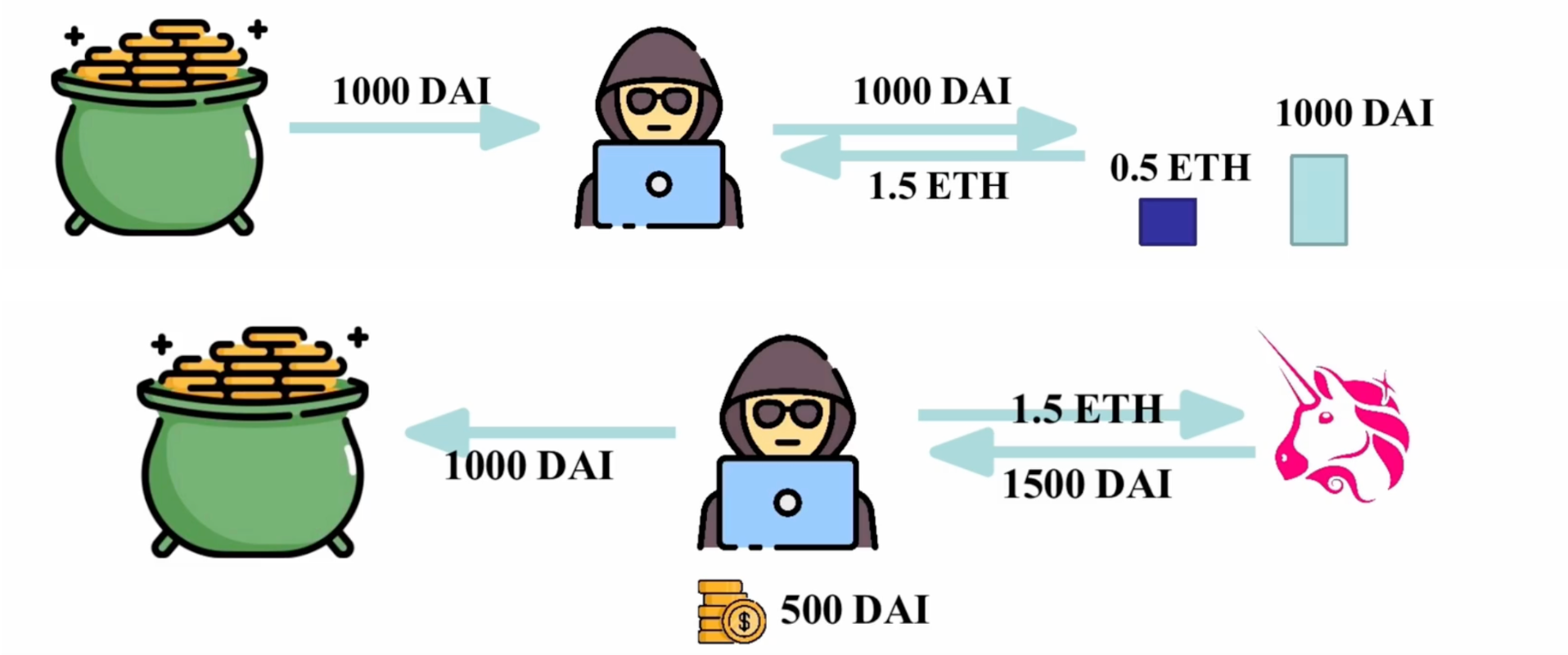
Web3 借贷与清算机制全解析:链上金融的运行逻辑
Web3 借贷与清算机制全解析:链上金融的运行逻辑 超额抵押借款 例如,借款人用ETH为抵押借入DAI;借款人的ETH的价值一定是要超过DAI的价值;借款人可以任意自由的使用自己借出的DAI 稳定币 第一步:借款人需要去提供一定…...

【Vue3】(三)vue3中的pinia状态管理、组件通信
目录 一、vue3的pinia 二、【props】传参 三、【自定义事件】传参 四、【mitt】传参 五、【v-model】传参(平常基本不写) 六、【$attrs】传参 七、【$refs和$parent】传参 八、provide和inject 一、vue3的pinia 1、什么是pinia? pinia …...

ingress-nginx 开启 Prometheus 监控 + Grafana 查看指标
环境已经部署了 ingress-nginx(DaemonSet 方式),并且 Prometheus Grafana 也已经运行。但之前 /metrics 端点没有暴露 Nginx 核心指标(如 nginx_ingress_controller_requests_total),经过调整后现在可以正…...