Kaggle-Predicting Optimal Fertilizers-(多分类+xgboost+同一特征值多样性)
Predicting Optimal Fertilizers
题意:
给出土壤的特性,预测出3种最佳的肥料
数据处理:
1.有数字型和类别型,类别不能随意换成数字,独热编码。cat可以直接处理category类型。
2.构造一些相关土壤特性特征
3.由于label是category类型,但是xgb不可以处理category类型,因此需要先编码,最后求出结果之后再解码。
建立模型:
1.catboost交叉验证、xgboost交叉验证
代码:
import os
import sys
import warnings
import numpy as np
import pandas as pd
import seaborn
from catboost import CatBoostRegressor, CatBoostClassifier
from lightgbm import LGBMRegressor
from matplotlib import pyplot as plt
import lightgbm
from mlxtend.regressor import StackingCVRegressor
from sklearn import clone
from sklearn.ensemble import VotingRegressor, StackingClassifier, StackingRegressor
from sklearn.linear_model import Lasso, LogisticRegression, RidgeCV
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, make_scorer, mean_squared_log_error
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler, LabelEncoder, PolynomialFeatures
from xgboost import XGBRegressor, XGBClassifier
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold
from sklearn.linear_model import Ridge
from catboost import Pool, CatBoostClassifierdef init():os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 仅输出错误日志warnings.simplefilter('ignore') # 忽略警告日志pd.set_option('display.width', 1000)pd.set_option('display.max_colwidth', 1000)pd.set_option("display.max_rows", 1000)pd.set_option("display.max_columns", 1000)def show_dataframe(df):print("查看特征值和特征值类型\n" + str(df.dtypes) + "\n" + "-" * 100)print("查看前10行信息\n" + str(df.head()) + "\n" + "-" * 100)print("查看每个特征值的各种数据统计信息\n" + str(df.describe()) + "\n" + "-" * 100)print("输出重复行的个数\n" + str(df.duplicated().sum()) + "\n" + "-" * 100)print("查看每列的缺失值个数\n" + str(df.isnull().sum()) + "\n" + "-" * 100)print("查看缺失值的具体信息\n" + str(df.info()) + "\n" + "-" * 100)# print("输出X所有值出现的是什么,还有对应出现的次数\n" + str(df['X'].value_counts()) + "\n" + "-" * 100)def show_relation(data, colx, coly):if data[colx].dtype == 'object' or data[colx].dtype == 'category' or len(data[colx].unique()) < 20:seaborn.boxplot(x=colx, y=coly, data=data)else:plt.scatter(data[colx], data[coly])plt.xlabel(colx)plt.ylabel(coly)plt.show()def mapk(actual, predicted, k=3):def apk(a, p, k):score = 0.0for i in range(min(k, len(p))):if p[i] == a:score += 1.0 / (i + 1)breakreturn scorereturn np.mean([apk(a, p, k) for a, p in zip(actual, predicted)])if __name__ == '__main__':init()df_train = pd.read_csv('/kaggle/input/playground-series-s5e6/train.csv')df_test = pd.read_csv('/kaggle/input/playground-series-s5e6/test.csv')df_train_additional = pd.read_csv('/kaggle/input/fertilizer-prediction/Fertilizer Prediction.csv')pd.concat([df_train, df_train_additional], ignore_index=True)print("Start Feature enggering" + "-" * 70 + "\n")df_all = pd.concat([df_train.drop(['id', 'Fertilizer Name'], axis=1), df_test.drop(['id'], axis=1)], axis=0)df_all['Temp_Humidity_Interaction'] = df_all['Temparature'] * df_all['Humidity']df_all['N_P_Ratio'] = df_all['Nitrogen'] / (df_all['Phosphorous'].replace(0, 1e-6))df_all['K_P_Ratio'] = df_all['Potassium'] / (df_all['Phosphorous'].replace(0, 1e-6))df_all['Soil_Crop_Combination'] = df_all['Soil Type'].astype(str) + '_' + df_all['Crop Type'].astype(str)df_all['P_to_K'] = df_all['Phosphorous'] / (df_all['Potassium'] + 1e-5)df_all['Total_NPK'] = df_all['Nitrogen'] + df_all['Phosphorous'] + df_all['Potassium']df_all['Climate_Index'] = (df_all['Temparature'] + df_all['Humidity']) / 2df_all['Water_Stress'] = df_all['Humidity'] - df_all['Moisture']original_numerical_cols = ['Temparature', 'Humidity', 'Moisture', 'Nitrogen', 'Potassium', 'Phosphorous']for col in original_numerical_cols:df_all[f'{col}_Binned'] = df_all[col].astype(str)numerical_features = ['Temparature', 'Humidity', 'Moisture', 'Nitrogen', 'Potassium', 'Phosphorous','Temp_Humidity_Interaction', 'N_P_Ratio', 'K_P_Ratio']categorical_features = ['Soil Type', 'Crop Type', 'Soil_Crop_Combination']categorical_features.extend([f'{col}_Binned' for col in original_numerical_cols])poly_features_to_transform = original_numerical_colspoly = PolynomialFeatures(degree=2, include_bias=False)df_all_transformers = poly.fit_transform(df_all[poly_features_to_transform])poly_feature_names = poly.get_feature_names_out(poly_features_to_transform)df_all = df_all.drop(columns=poly_features_to_transform)df_all = pd.concat([df_all, pd.DataFrame(df_all_transformers, columns=poly_feature_names,index=df_all.index)], axis=1)numerical_features = df_all.select_dtypes(include=['int64', 'float64']).columns.tolist()categorical_features = df_all.select_dtypes(exclude=['int64', 'float64']).columns.tolist()all_features_ordered = numerical_features + categorical_featuresdf_all = df_all[all_features_ordered]all_categories_union = {}for col in categorical_features:if col in df_all.columns:all_categories_union[col] = pd.concat([df_all[col],], axis=0).astype(str).unique()else:print(f"Warning: Categorical column '{col}' not found after feature engineering. Skipping conversion.")for col in categorical_features:if col in df_all.columns:df_all[col] = pd.Categorical(df_all[col], categories=all_categories_union[col])le = LabelEncoder()X_train = df_all[:df_train.shape[0]]Y_train = df_train['Fertilizer Name']Y_train = le.fit_transform(Y_train)X_test = df_all[df_train.shape[0]:]print("Training model" + "-" * 70 + "\n")model_xgb = XGBClassifier(max_depth=8, # 降低树深度colsample_bytree=0.5, # 控制特征采样比例subsample=0.7, # 控制数据采样比例n_estimators=3000, # 减少迭代轮数learning_rate=0.03, # 降低学习率gamma=0.5, # 增加分裂难度max_delta_step=2, # 限制权重更新步长reg_alpha=5, # 增强L1正则化reg_lambda=3, # 增强L2正则化early_stopping_rounds=100, # 更早停止训练objective='multi:softprob',random_state=13,enable_categorical=True,tree_method='hist',device='cuda')kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)pred_xgb = np.zeros((X_test.shape[0], len(le.classes_)))for fold, (train_idx, val_idx) in enumerate(kfold.split(X_train, Y_train)):print(f"\nFold {fold + 1}/{kfold.n_splits}")x_fold_train, x_fold_val = X_train.iloc[train_idx], X_train.iloc[val_idx]y_fold_train, y_fold_val = Y_train[train_idx], Y_train[val_idx]model_xgb.fit(x_fold_train, y_fold_train,eval_set = [(x_fold_val, y_fold_val)],verbose = 100,)pred_xgb += model_xgb.predict_proba(X_test) / kfold.n_splitspred_top3_xgb = np.argsort(pred_xgb, axis=1)[:, -3:][:, ::-1]top3_label = []for row in pred_top3_xgb:converted = [le.classes_[i] for i in row]top3_label.append(converted)submission = pd.DataFrame({'id': df_test['id'],'Fertilizer Name': [' '.join(preds) for preds in top3_label],})submission.to_csv('/kaggle/working/submission.csv', index=False)
#xgb0.35642
相关文章:
)
Kaggle-Predicting Optimal Fertilizers-(多分类+xgboost+同一特征值多样性)
Predicting Optimal Fertilizers 题意: 给出土壤的特性,预测出3种最佳的肥料 数据处理: 1.有数字型和类别型,类别不能随意换成数字,独热编码。cat可以直接处理category类型。 2.构造一些相关土壤特性特征 3.由于la…...
uniapp+<script setup lang=“ts“>解决有数据与暂无数据切换显示,有数据加载时暂无数据闪现(先加载空数据)问题
声明showEmpty 为false,在接口返回处判断有数据时设置showEmpty 为false,接口返回数据为空则判断showEmpty 为true (这样就解决有数据的时候会闪现暂无数据的问题啦) <!--* Date: 2024-02-26 03:38:52* LastEditTime: 2025-06…...

详解鸿蒙Next仓颉开发语言中的动画
大家上午好,今天来聊一聊仓颉开发语言中的动画开发。 仓颉中的动画通常有两种方式,分别是属性动画和显示动画,我们今天以下面的加载动画为例,使用显示动画和属性动画分别实现一下,看看他们有什么区别。 显示动画 显示…...
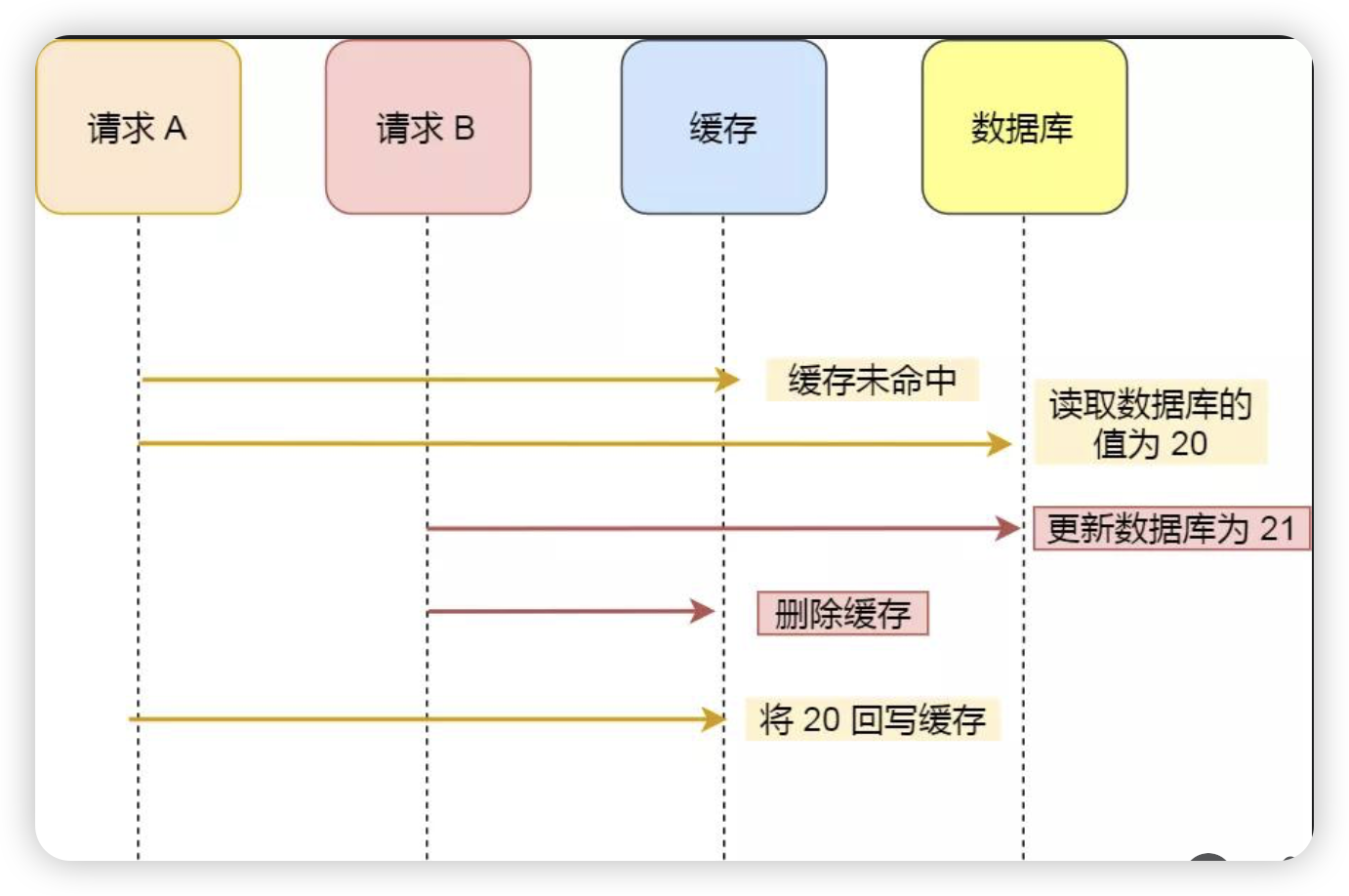
Redis常见使用场景解析
1. 数据库缓存 Redis 作为典型的 Key-Value 型内存数据库,数据缓存是其最广为人知的应用场景。使用 Redis 缓存数据操作简便,通常将序列化后的对象以 string 类型存储。但在实际应用中,需注意以下关键要点: Key 设计:必须确保不同对象的 Key 具有唯一性,且尽量缩短长度,…...

C语言指针与数组sizeof运算深度解析:从笔试题到内存原理
前两天跟着数组指针的教程: // #self 视频里的笔试题 !!!vipint b12[3][4] {0};printf("%ld \n", sizeof(b12[0]));printf("%ld \n", sizeof(*b12));printf("%ld \n", sizeof(*(b12 1)));printf("%ld \n", sizeof(*(&am…...

起重机指挥人员在工作中需要注意哪些安全事项?
起重机指挥人员在作业中承担着协调设备运行、保障作业安全的关键职责,其安全操作直接关系到整个起重作业的安全性。以下从作业前、作业中、作业后的全流程,详细说明指挥人员需注意的安全事项: 一、作业前的安全准备 资质与状态检查ÿ…...

JVM内存区域与溢出异常详解
当然可以。以下是结合了程序计数器和Java内存区域以及内存溢出异常的详细解释: JVM内存区域与内存溢出异常 Java虚拟机(JVM)管理着不同类型的内存区域,每个区域都有其特定的功能和可能导致的内存溢出异常。 程序计数器ÿ…...

ES海量数据更新及导入导出备份
一、根据查询条件更新字段 from elasticsearch import Elasticsearch import redis import json# 替换下面的用户名、密码和Elasticsearch服务器地址 username elastic password password es_host https://127.0.0.2:30674# 使用Elasticsearch实例化时传递用户名和密码 es…...

Java线程池核心原理与最佳实践
Java 线程池详解 线程池是Java并发编程的核心组件,它能高效管理线程生命周期,避免频繁创建销毁线程的开销,提升系统性能和资源利用率。 一、线程池核心优势 降低资源消耗:复用已创建的线程,减少线程创建销毁开销提高…...
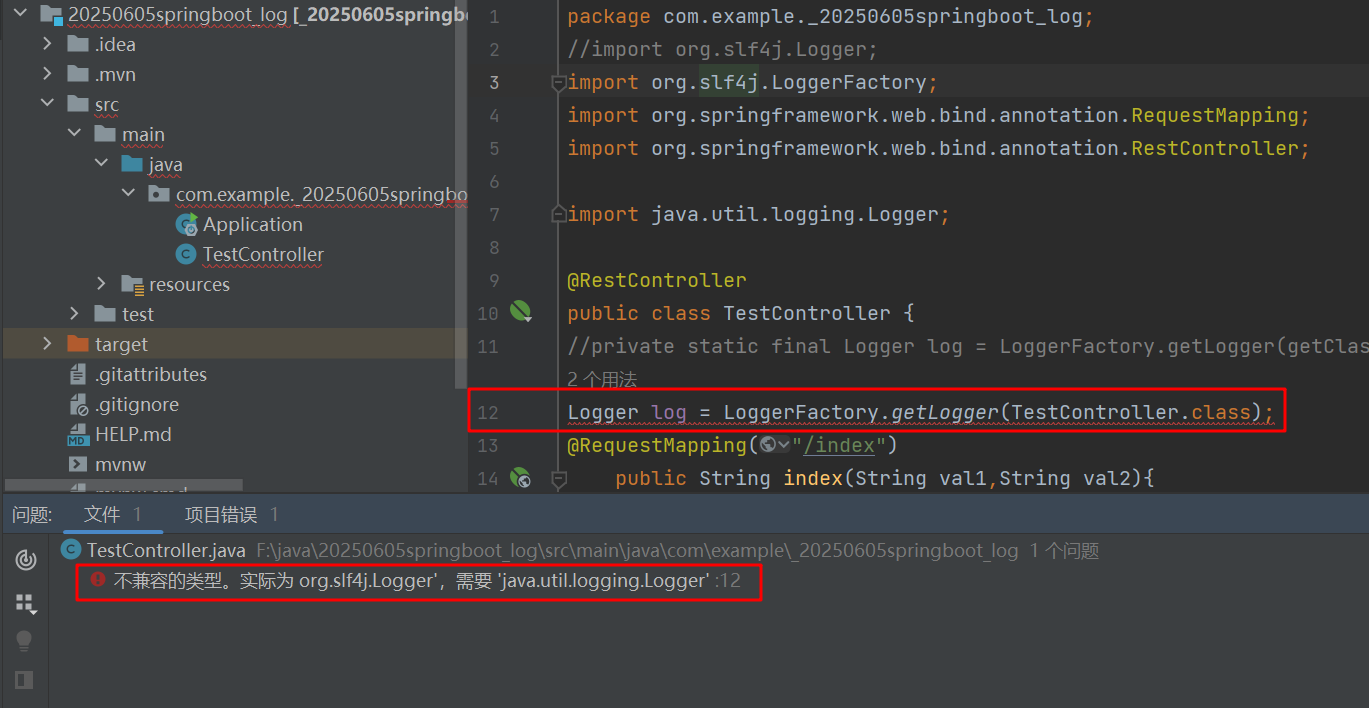
JAVA-springboot log日志
SpringBoot从入门到精通-第8章 日志的操作 一、Spring Boot默认的日志框架 SpringBoot支持很多种日志框架,通常情况下,这些日志框架都是由一个日志抽象层和一个日志实现层搭建而成的,日志抽象层是为记录日志提供的一套标准且规范的框架&…...
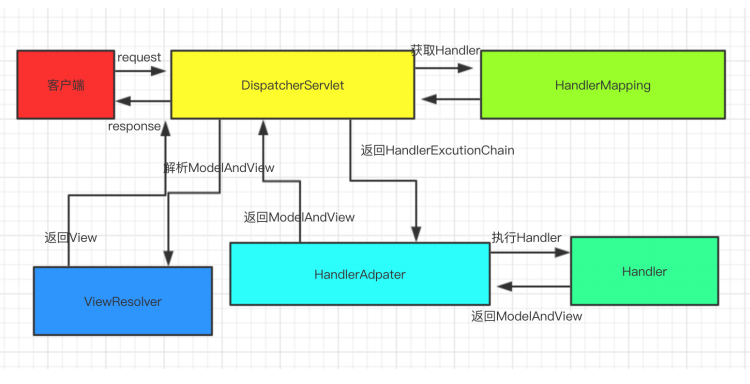
1.springmvc基础入门(一)
1.Spring MVC概念 Spring MVC 是 Spring Framework 提供的 Web 组件,全称是 Spring Web MVC,是⽬前主流的实现 MVC 设计模式的框架,提供前端路由映射、视图解析等功能。 Java Web 开发者必须要掌握的技术框架。 2.Spring MVC 功能 MVC&am…...

AI 时代下语音与视频伪造的网络安全危机
引言 在人工智能技术的推动下,语音合成、视频生成等技术取得了突破性进展,Deepfake、AI 语音克隆等工具让语音和视频伪造变得愈发简单且逼真。这些技术在娱乐、影视等领域带来便利的同时,也被不法分子利用,引发了一系列网络安全问…...
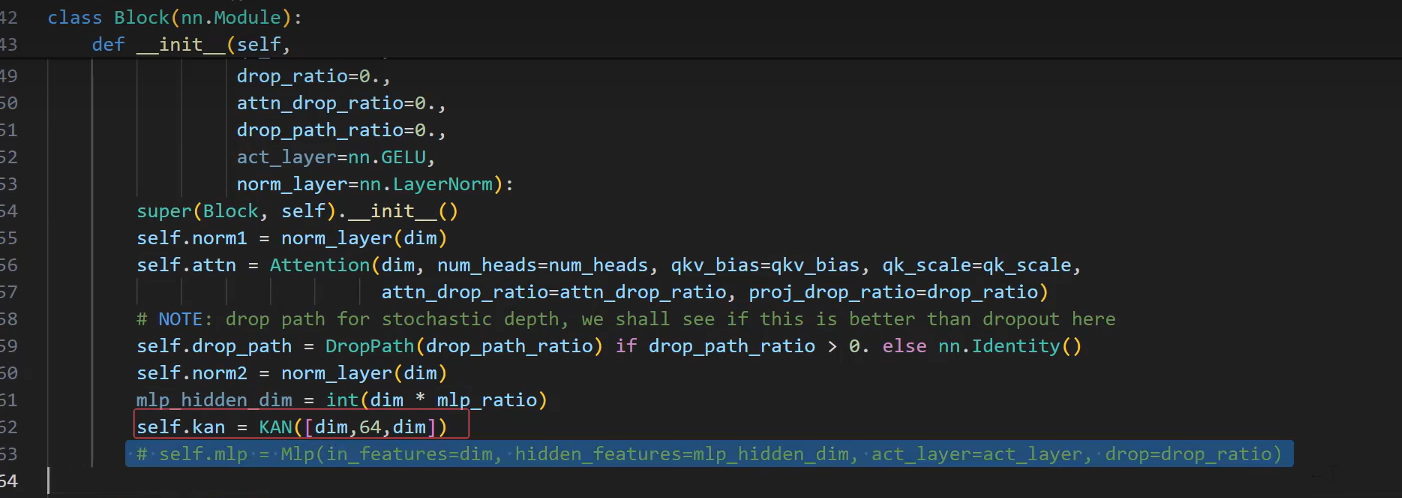
模块缝合-把A模块换成B模块(没写完)
把MLP Head替换为KAN 1.在model文件下新建一个python文件 2.把 模块文件里的整个KAN代码复制到新的python文件中 3.在开头导入 from model.KAN(新建文件名) import KAN(新建文件中的类名) 4.sys.path.append(r"D: Icode(Kansformer"…...
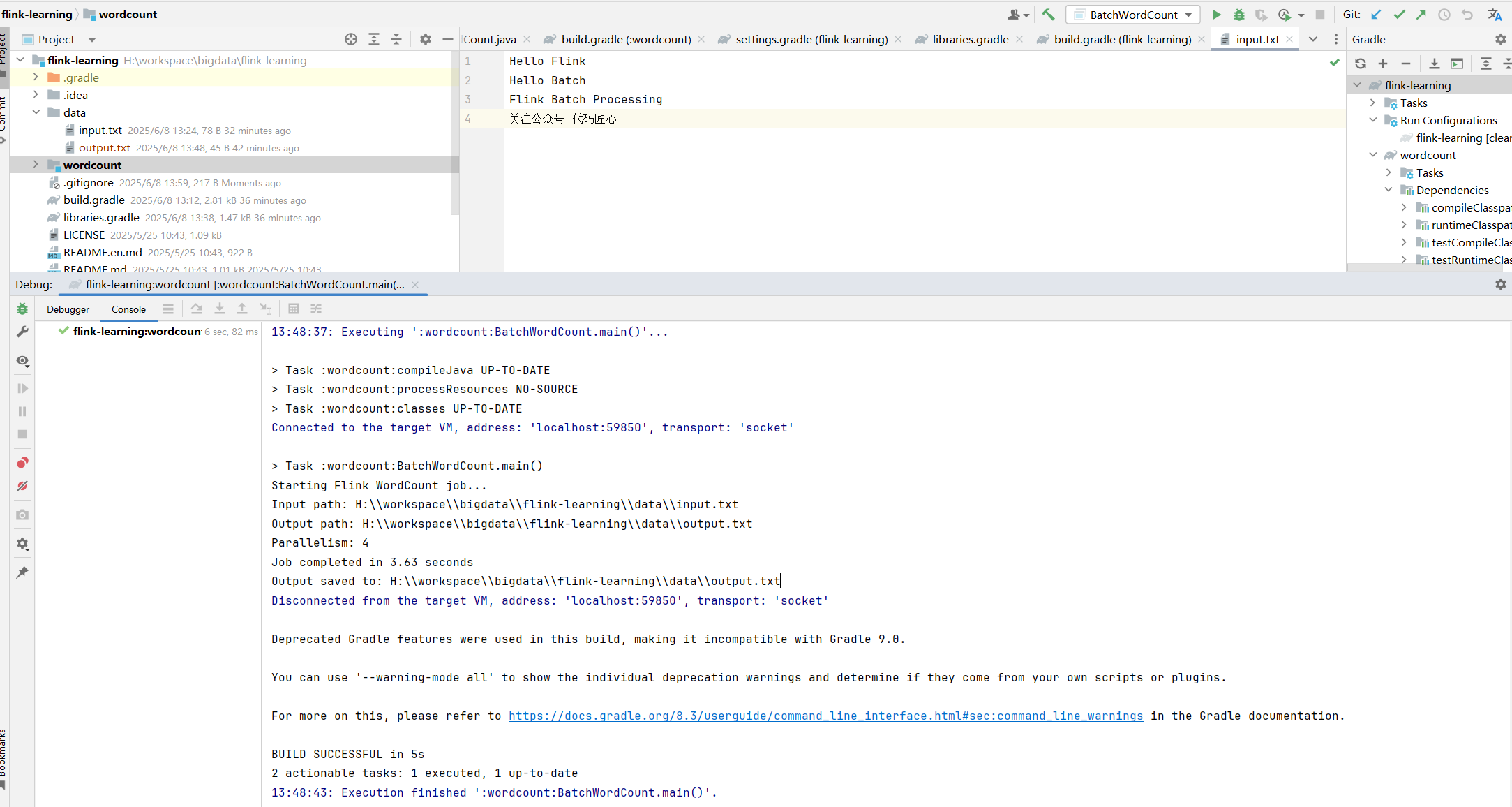
从零开始学Flink:揭开实时计算的神秘面纱
一、为什么需要Flink? 当你在电商平台秒杀商品时,1毫秒的延迟可能导致交易失败;当自动驾驶汽车遇到障碍物时,10毫秒的计算延迟可能酿成事故。这些场景揭示了一个残酷事实:数据的价值随时间呈指数级衰减。 传统批处理…...

一、ES6-let声明变量【解刨分析最详细】
一、块级作用域 { let Tim"Tim是靓仔!" } console.log("Tim:",Tim) 打印结果:Tim未进行任何定义! 原因:因为Tim定义再块级{}里面,它的声音Tim只服务于该块级里面。而打印结果是再块级外面&#…...
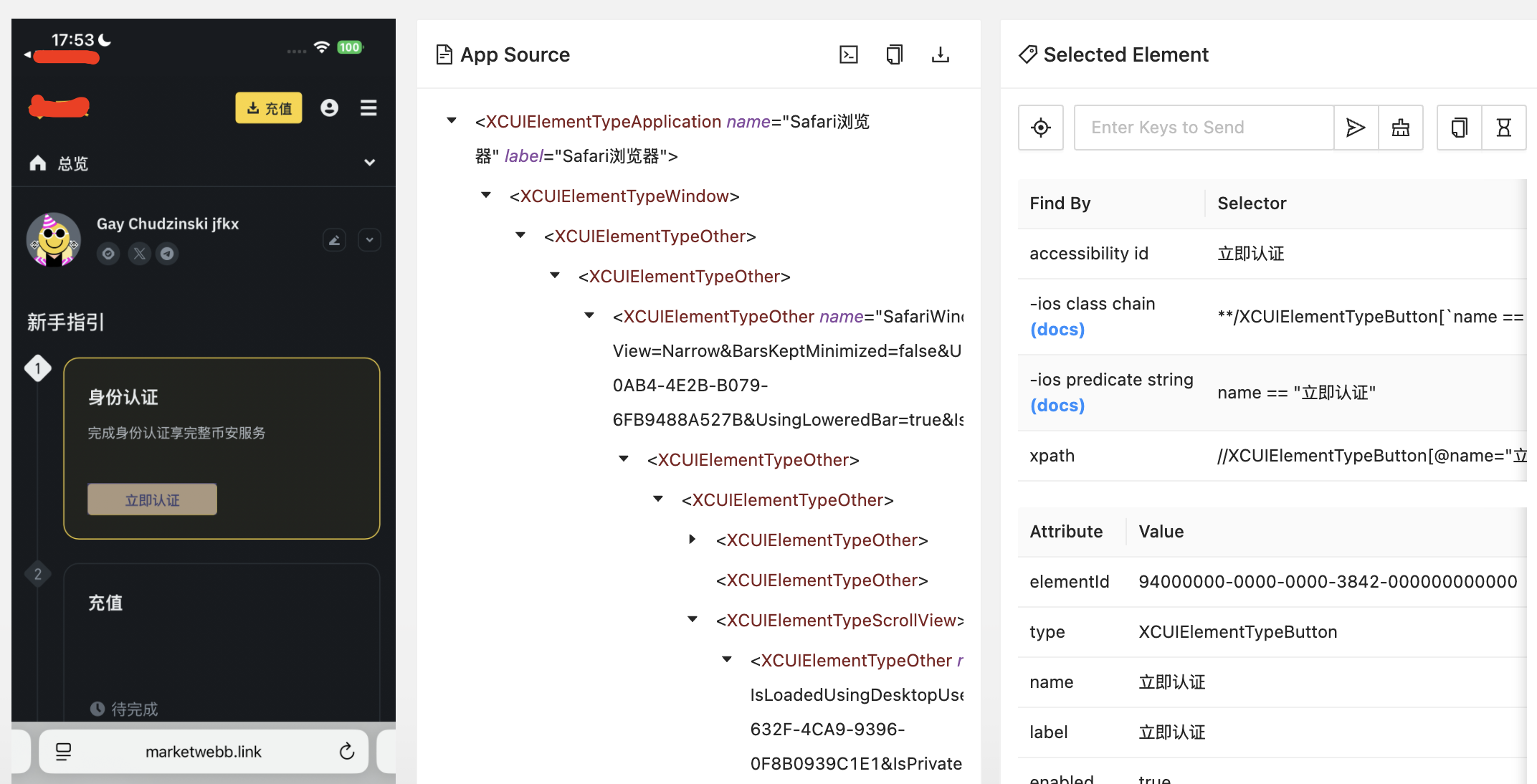
Appium如何支持ios真机测试
ios模拟器上UI自动化测试 以appiumwebdriverio为例,详细介绍如何在模拟器上安装和测试app。在使用ios模拟器前,需要安装xcode,创建和启动一个simulator。simulator创建好后,就可以使用xcrun simctl命令安装被测应用并开始测试了。…...
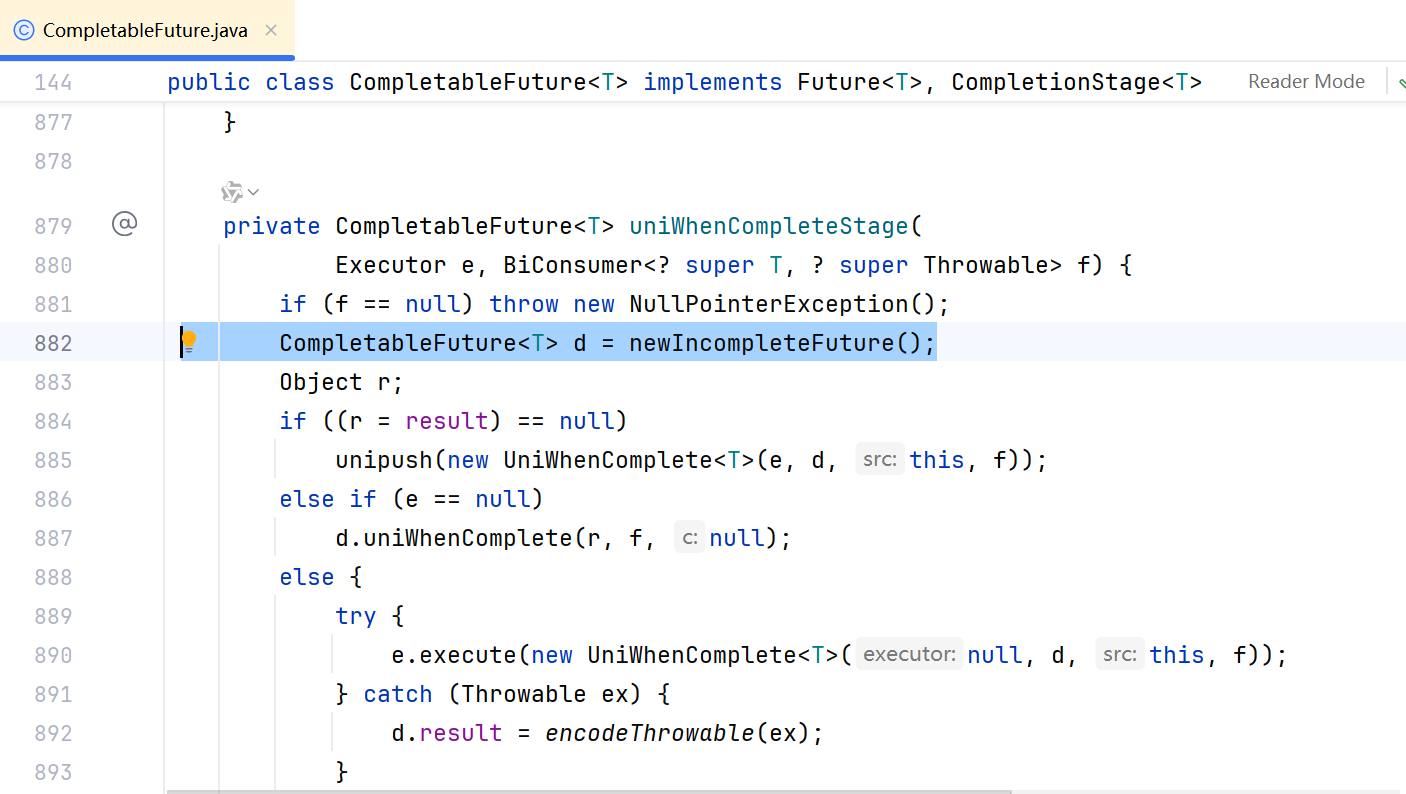
JDK17 Http Request 异步处理 源码刨析
为什么可以异步? #调用起始源码 // 3. 发送异步请求并处理响应 CompletableFuture future client.sendAsync( request, HttpResponse.BodyHandlers.ofString() // 响应体转为字符串 ).thenApply(response -> { // 状态码检查(非200系列抛出异常&…...
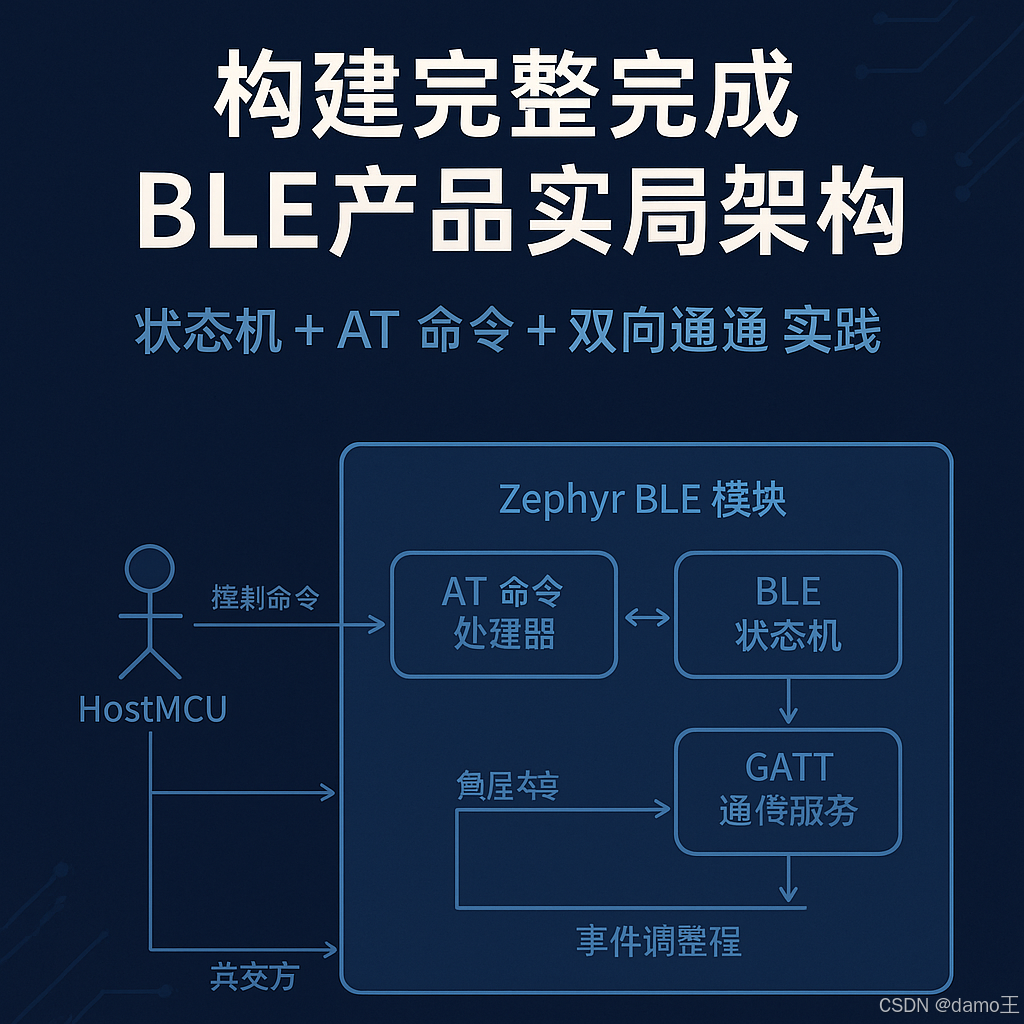
【Zephyr 系列 8】构建完整 BLE 产品架构:状态机 + AT 命令 + 双通道通信实战
🧠关键词:Zephyr、BLE、状态机、双向透传、AT 命令、Buffer、主从共存、系统架构 📌适合人群:希望开发 BLE 产品(模块/标签/终端)具备可控、可测、可维护架构的开发者 🧭 引言:从“点功能”到“系统架构” 前面几篇我们已经逐步构建了 BLE 广播、连接、数据透传系统…...
【Mac 从 0 到 1 保姆级配置教程 16】- Docker 快速安装配置、常用命令以及实际项目演示
文章目录 前言1. Docker 是什么?2. 为什么要使用 Docker? 安装 Docker1. 安装 Docker Desktop2. 安装 OrbStack3. Docker Desktop VS OrbStack5. 验证安装 使用 Docker 运行项目1. 克隆项目到本地2. 进入项目目录3. 启动容器: 查看运行效果1. OrbStack 中…...
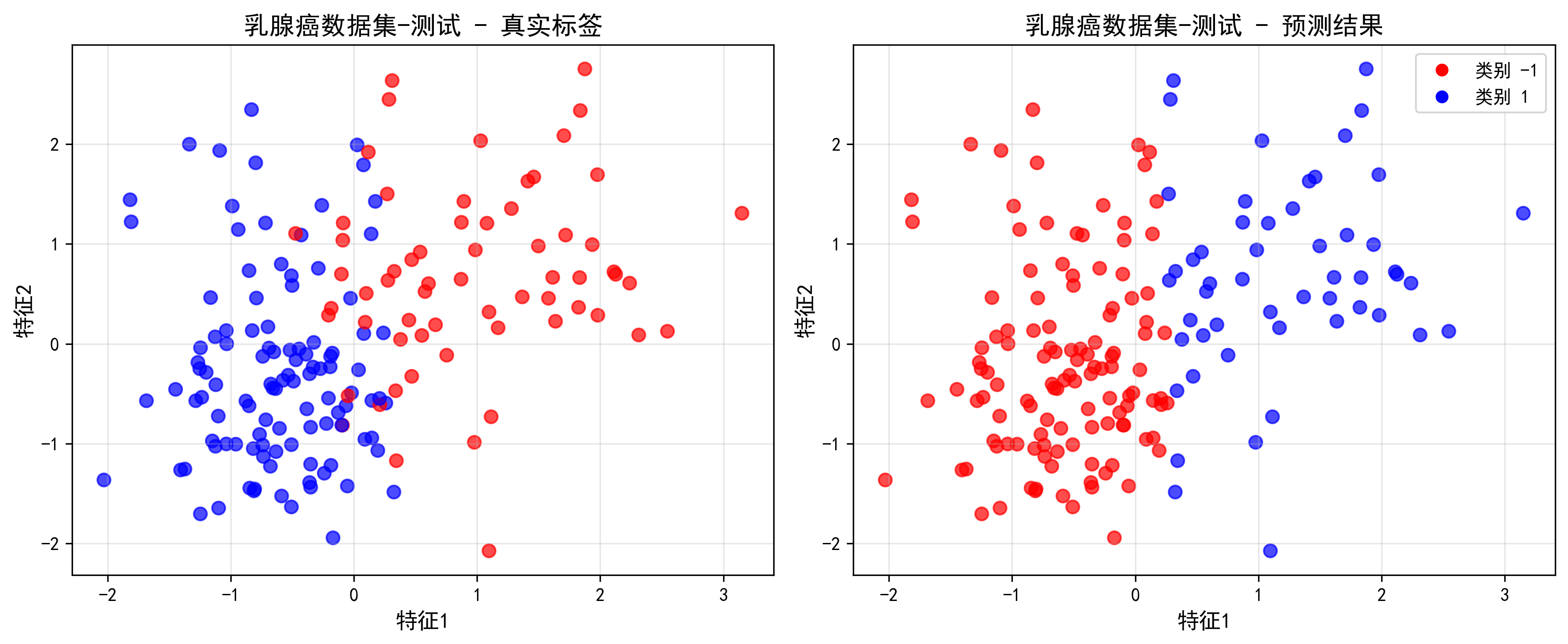
2025-05-01-决策树算法及应用
决策树算法及应用 参考资料 GitHub - zhaoyichanghong/machine_learing_algo_python: implement the machine learning algorithms by p(机器学习相关的 github 仓库)决策树实现与应用决策树 概述 机器学习算法分类 决策树算法 决策树是一种以树状结构对数据进行划分的分类…...

Redis知识体系
1. 概述 本文总结了Redis基本的核心知识体系,在学习Redis的过程中,可以将其作为学习框架,以此更好的从整体的角度去理解和学习Redis的内容和设计思想。同时知识框架带来的好处是可以帮助我们更好的进行记忆,在大脑中形成相应的知识…...
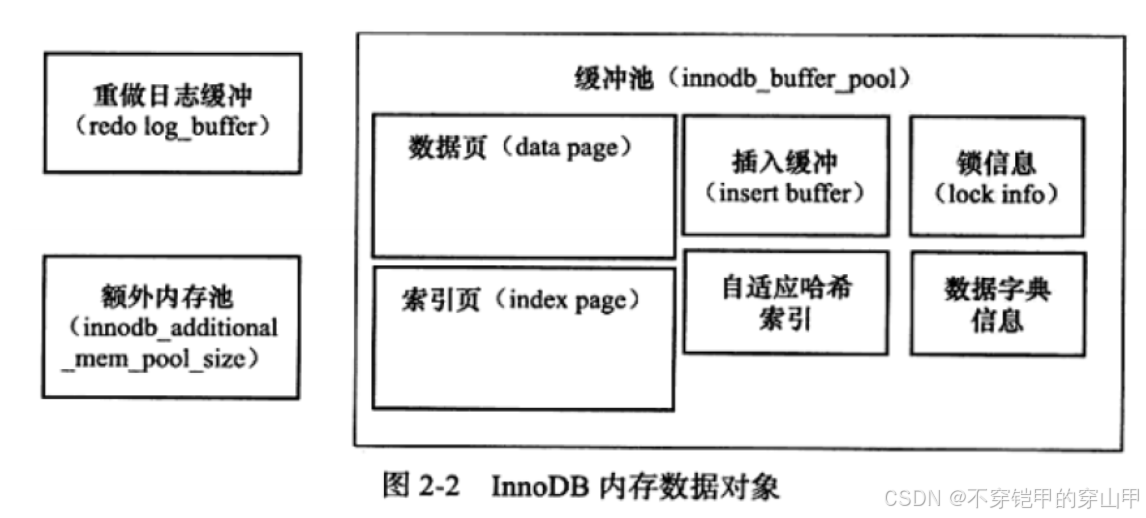
mysql-MySQL体系结构和存储引擎
1. MySQL体系结构和存储引擎 MySQL被设计成一个单进程多线程架构的数据库,MySQL数据库实例在系统上的表现就是一个进 程当启动实例时,读取配置文件,根据配置文件的参数来启动数据库实例;若没有,按编译时的默认 参数设…...

Pycharm 函数注释
1 Docstring format File -> Settings -> Tools -> Python Integrated Tools -> Docstrings -> Docstring format,选择google File -> Settings -> Editor -> General -> Smart Keys -> Insert type placeholders in the documenta…...

如何使用 Redis 快速实现布隆过滤器?
以下是使用 Redis 实现布隆过滤器的两种方案,结合原理说明和操作步骤: 方案一:手动实现(基于 Redis Bitmap) 原理 利用 Redis 的 SETBIT 和 GETBIT 操作位数组,结合多个哈希函数计算位置。 步骤 确定参数…...
黑马Javaweb Request和Response
一.介绍 在 Web 开发中,HttpServletRequest 和 HttpServletResponse 是两个非常重要的类,它们分别用于处理客户端的请求和服务器的响应。以下是它们的详细说明和使用方法: 1. HttpServletRequest HttpServletRequest 是一个接口࿰…...

山东大学深度学习2025年期末考试
一、名词解释(24) 1.反向传播 2.激活函数 3.梯度裁剪 4.数据增强 5.迁移学习 6.过拟合 7.word2Vec 8.注意力机制 二、简答题(48) 1.池化的概念(作用)以及常见的两种池化操作 2.LSTM为什么能解决…...

添加按钮跳转页面并且根据网站的用户状态判断是否显示按钮
现在我们需要的是为页面添加一个按钮,这个按钮是动态的,需要根据网站用户登录过后是否是vip来判断是否显示,然后按钮的效果是跳转到某个页面。 首先我们需要在页面中找到我们需要添加按钮的位置,找到对应的文件,然后比…...

Gerrit+repo管理git仓库,如果本地有新分支不能执行repo sync来同步远程所有修改,会报错
问题:创建一个本地分支TEST 来关联远程已有分支origin/TEST,直接执行repo sync可能会出现问题:比如,本地分支TES会错乱关联到origin/master,或者拉不下最新代码等问题。 // git checkout -b 新分支名 远程分支名字 git…...
豆瓣图书评论数据分析与可视化
【题目描述】豆瓣图书评论数据爬取。以《平凡的世界》、《都挺好》等为分析对象,编写程序爬取豆瓣读书上针对该图书的短评信息,要求: (1)对前3页短评信息进行跨页连续爬取; (2)爬取…...

Vue ④-组件通信 || 进阶语法
组件三大部分 template:只有能一个根元素 style:全局样式(默认):影响所有组件。局部样式:scoped 下样式,只作用于当前组件 script:el 根实例独有,data 是一个函数,其他配置项一致…...