Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录
0. 相关文章链接
1. 概述
2. socket source
3. file source
3.1. 读取普通文件夹内的文件
3.2. 读取自动分区的文件夹内的文件
4. kafka source
4.1. 导入依赖
4.2. 以 Streaming 模式创建 Kafka 工作流
4.3. 通过 Batch 模式创建 Kafka 工作流
5. Rate Source
0. 相关文章链接
Spark文章汇总
1. 概述
使用 Structured Streaming 最重要的就是对 Streaming DataFrame 和 Streaming DataSet 进行各种操作。从 Spark2。0 开始, DataFrame 和 DataSet 可以表示静态有界的表, 也可以表示流式无界表。与静态 Datasets/DataFrames 类似,我们可以使用公共入口点 SparkSession 从流数据源创建流式 Datasets/DataFrames,并对它们应用与静态 Datasets/DataFrames 相同的操作。通过spark.readStream()得到一个DataStreamReader对象, 然后通过这个对象加载流式数据源, 就得到一个流式的 DataFrame。
// 1. 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()
import spark.implicits._// 2. 从数据源(socket)中加载数据.
val lines: DataFrame = spark.readStream.format("socket") // 设置数据源.option("host", "localhost").option("port", 9999).loadspark 内置了几个流式数据源, 基本可以满足我们的所有需求:
- File source 读取文件夹中的文件作为流式数据。 支持的文件格式: text, csv, josn, orc, parquet。 注意, 文件必须放置的给定的目录中, 在大多数文件系统中, 可以通过移动操作来完成。
- kafka source 从 kafka 读取数据。 目前兼容 kafka 0。10。0+ 版本
- socket source 用于测试。 可以从 socket 连接中读取 UTF8 的文本数据。 侦听的 socket 位于驱动中。 注意, 这个数据源仅仅用于测试。
- rate source 用于测试。 以每秒指定的行数生成数据,每个输出行包含一个 timestamp 和 value。其中 timestamp 是一个 Timestamp类型(信息产生的时间),并且 value 是 Long 包含消息的数量。 用于测试和基准测试。
| Source | Options | Fault-tolerant | Notes |
| File source | path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to true, the following files would be considered as the same file, because their filenames, “dataset.txt”, are the same: “file:///dataset.txt” “s3://a/dataset.txt” “s3n://a/b/dataset.txt” “s3a://a/b/c/dataset.txt” For file-format-specific options, see the related methods in DataStreamReader(Scala/Java/Python/R). E.g. for “parquet” format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for “parquet”, see Parquet configuration section. | Yes | Supports glob paths, but does not support multiple comma-separated paths/globs. |
| Socket Source | host: host to connect to, must be specified port: port to connect to, must be specified | No | |
| Rate Source | rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark’s default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. | Yes | |
| Kafka Source | See the Kafka Integration Guide. | Yes |
2. socket source
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.streaming.StreamingQueryobject StreamTest {def main(args: Array[String]): Unit = {// 1. 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 2. 从数据源(socket)中加载数据.val lines: DataFrame = spark.readStream.format("socket") // 设置数据源.option("host", "localhost").option("port", 9999).load// 3. 把每行数据切割成单词val words: Dataset[String] = lines.as[String].flatMap((_: String).split("\\W"))// 4. 计算 word countval wordCounts: DataFrame = words.groupBy("value").count()// 5. 启动查询, 把结果打印到控制台val query: StreamingQuery = wordCounts.writeStream.outputMode("complete").format("console").startquery.awaitTermination()spark.stop()}
}
3. file source
3.1. 读取普通文件夹内的文件
代码示例:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.types.{LongType, StringType, StructType}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 定义 Schema, 用于指定列名以及列中的数据类型val userSchema: StructType = new StructType().add("name", StringType).add("job", StringType).add("age", LongType)// 使用SparkSession通过readStream方法读取文件(必须是目录, 不能是文件名)val user: DataFrame = spark.readStream.format("csv").schema(userSchema).load("/Project/Data/csv")// DataStreamReader中还有csv、json、text等方法,可以直接读取对应的文件val userCopy: DataFrame = spark.readStream.schema(userSchema).csv("/Project/Data/csv")// 将对应的数据输出(trigger表示触发器:数字表示毫秒值. 0 表示立即处理)val query: StreamingQuery = user.writeStream.outputMode("append").trigger(Trigger.ProcessingTime(0)).format("console").start()// 启动执行器query.awaitTermination()spark.stop()}
}
模板数据:
lisi,male,18
zhiling,female,28
结果输出:

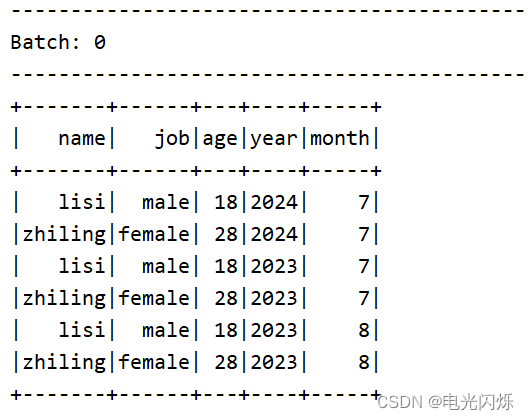
3.2. 读取自动分区的文件夹内的文件
当文件夹被命名为 “key=value” 形式时, Structured Streaming 会自动递归遍历当前文件夹下的所有子文件夹, 并根据文件名实现自动分区。如果文件夹的命名规则不是“key=value”形式, 则不会触发自动分区。 另外, 同级目录下的文件夹的命名规则必须一致。
步骤一:创建如下目录结构
year=2023month=07month=08
year=2024month=07
步骤二:写入文件数据
lisi,male,18
zhiling,female,28步骤三:编写代码(如上 读取普通文件夹内的文件 代码完全一致)
步骤四:启动运行打印日志
4. kafka source
4.1. 导入依赖
在其余Spark依赖的情况下,还需要导入如下SparkSQL的kafka依赖,参考文档: Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) - Spark 3.4.1 Documentation
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql-kafka-0-10_2.12</artifactId><version>2.4.3</version>
</dependency>
4.2. 以 Streaming 模式创建 Kafka 工作流
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用spark通过readStream方法可以以流的方式读取kafka里面的数据// 通过format设置 kafka 数据源// 通过 kafka.bootstrap.servers 设置kafka的参数// 通过 subscribe 设置订阅的主题,也可以订阅多个主题: "topic1,topic2"// load后会返回一个DataFrame类型, 其schema是固定的: key,value,topic,partition,offset,timestamp,timestampTypeval df: DataFrame = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092").option("subscribe", "topic1").load// 通过 selectExpr 只获取其中的value字段// 通过as转换成 Datasetval lines: Dataset[String] = df.selectExpr("CAST(value AS string)").as[String]// 可以对 Dataset 进行各种操作val query: DataFrame = lines.flatMap((_: String).split("\\W+")).groupBy("value").count()// 进行输出,并且可以通过checkpointLocation来设置checkpoint// 下次启动的时候, 可以从上次的位置开始读取query.writeStream.outputMode("complete").format("console").option("checkpointLocation", "./ck1") .start.awaitTermination()// 关闭执行环境spark.stop()}
}4.3. 通过 Batch 模式创建 Kafka 工作流
这种模式一般需要设置消费的其实偏移量和结束偏移量, 如果不设置 checkpoint 的情况下, 默认起始偏移量 earliest, 结束偏移量为 latest。该模式为一次性作业(批处理), 而非持续性的处理数据。
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._// 使用 read 方法,而不是 readStream 方法val lines: Dataset[String] = spark.read.format("kafka").option("kafka.bootstrap.servers", "bigdata1:9092,bigdata2:9092,bigdata3:9092").option("subscribe", "topic1").option("startingOffsets", "earliest").option("endingOffsets", "latest").load.selectExpr("CAST(value AS STRING)").as[String]// 同样对 Dataset[String] 进行各种操作val query: DataFrame = lines.flatMap(_.split("\\W+")).groupBy("value").count()// 使用 write 而不是 writeStreamquery.write.format("console").save()// 关闭执行环境spark.stop()}
}5. Rate Source
以固定的速率生成固定格式的数据, 用来测试 Structured Streaming 的性能
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, SparkSession}object StreamTest {def main(args: Array[String]): Unit = {// 创建 SparkSession. 因为 ss 是基于 spark sql 引擎, 所以需要先创建 SparkSessionval spark: SparkSession = SparkSession.builder().master("local[*]").appName("StreamTest").getOrCreate()import spark.implicits._val rows: DataFrame = spark.readStream.format("rate") // 设置数据源为 rate.option("rowsPerSecond", 10) // 设置每秒产生的数据的条数, 默认是 1.option("rampUpTime", 1) // 设置多少秒到达指定速率 默认为 0.option("numPartitions", 2) /// 设置分区数 默认是 spark 的默认并行度.loadrows.writeStream.outputMode("append").trigger(Trigger.Continuous(1000)).format("console").start().awaitTermination()// 关闭执行环境spark.stop()}
}注:其他Spark相关系列文章链接由此进 -> Spark文章汇总
相关文章:
Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录 0. 相关文章链接 1. 概述 2. socket source 3. file source 3.1. 读取普通文件夹内的文件 3.2. 读取自动分区的文件夹内的文件 4. kafka source 4.1. 导入依赖 4.2. 以 Streaming 模式创建 Kafka 工作流 4.3. 通过 Batch 模式创建 Kafka 工作流 5. Rate Source…...

SpringBoot集成Thymeleaf
Spring Boot 集成 Thymeleaf 模板引擎 1、Thymeleaf 介绍 Thymeleaf 是适用于 Web 和独立环境的现代服务器端 Java 模板引擎。 Thymeleaf 的主要目标是为开发工作流程带来优雅的自然模板,既可以在浏览器中正确显示的 HTML,也可以用作静态原型…...
:牛客在线编程03 二叉树)
算法练习(2):牛客在线编程03 二叉树
package jz.bm;import jz.TreeNode;import java.util.*;public class bm3 {/*** BM23 二叉树的前序遍历*/public int[] preorderTraversal (TreeNode root) {ArrayList<Integer> list new ArrayList<>();preOrder(root, list);int[] res new int[list.size()];fo…...

回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测
回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积…...
Linux 系列 常见 快捷键总结
强制停止 Ctrl C 退出程序、退出登录 Ctrl D 等价 exit 查看历史命令 history !命令前缀,自动匹配上一个命令 (历史命令中:从最新——》最老 搜索) ctrl r 输入内去历史命令中检索 # 回车键可以直接执行 ctrl a 跳到命令开头 …...
OA系统构建排座
目录 一.排座的介绍,作用 1.排座介绍 A.前端实现 B.数据库实现 C.后端实现 2.排座作用 A.座位预订 B.座位安排 C. 实时座位状态显示 二.利用Layui实现排座 1.基础版(通过htmlcssjs实现) A.基础版源码(html): 2.进阶版 …...

微信小程序 居中、居右、居底和横向、纵向布局,文字在图片中间,网格布局
微信小程序居中、居右、横纵布局 1、水平垂直居中(相对父类控件)方式一:水平垂直居中 父类控件: display: flex;align-items: center;//子控件垂直居中justify-content: center;//子控件水平居中width: 100%;height: 400px //注意…...

【C++】总结2
文章目录 1.final和override关键字2.extern "C"的用法3.野指针和垂悬指针(悬空指针)4.指针指向的内存被释放是什么意思5.C和C的类型安全6.C中的重载、重写(覆盖)和隐藏的区别 1.final和override关键字 final和override是C11引入的关键字&…...

vue2项目中使用svg图标
在开发项目的时候经常会用到svg矢量图,而且我们使用SVG以后,页面上加载的不再是图片资源, 这对页面性能来说是个很大的提升,而且我们SVG文件比img要小的很多,放在项目中几乎不占用资源。 1、安装SVG依赖插件并配置加载器和路径 npm instal…...
阿里云盘自动每日签到无需部署无需服务器(仅限学习交流使用)
一、前言 阿里云盘自动每日签到,无需部署,无需服务器 执行思路:使用金山文档的每日定时任务,执行阿里云盘签到接口。 二、效果展示: 三、步骤: 1、进入金山文档网页版 金山文档官网:https:…...
Blazor前后端框架Known-V1.2.7
V1.2.7 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazor…...
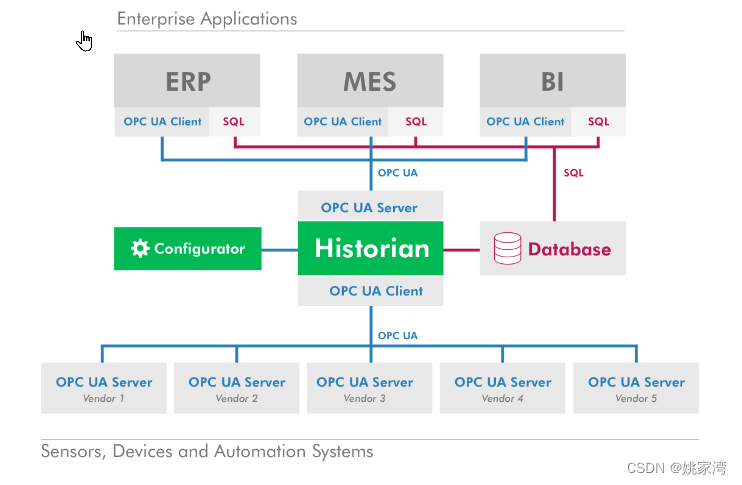
工业边缘计算为什么?
在工厂环境中使用边缘计算并不新鲜。可编程逻辑控制器(PLC)、微控制器、服务器和PC进行本地数据处理,甚至是微型数据中心都是边缘技术,已经在工厂系统中存在了几十年。在车间里看到的看板系统,打卡系统,历史…...
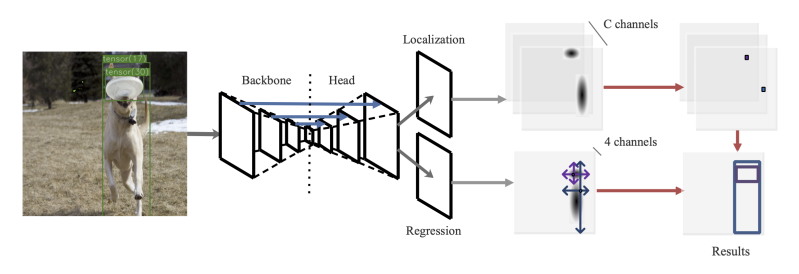
Training-Time-Friendly Network for Real-Time Object Detection 论文学习
1. 解决了什么问题? 目前的目标检测器很少能做到快速训练、快速推理,并同时保持准确率。直觉上,推理越快的检测器应该训练也很快,但大多数的实时检测器反而需要更长的训练时间。准确率高的检测器大致可分为两类:推理时…...

HTTP改HTTPS
tomcat中http协议改https 第一步,配置server.xml <?xml version"1.0" encoding"UTF-8"?> <Server port"8005" shutdown"SHUTDOWN"><Listener className"org.apache.catalina.startup.VersionLogger…...
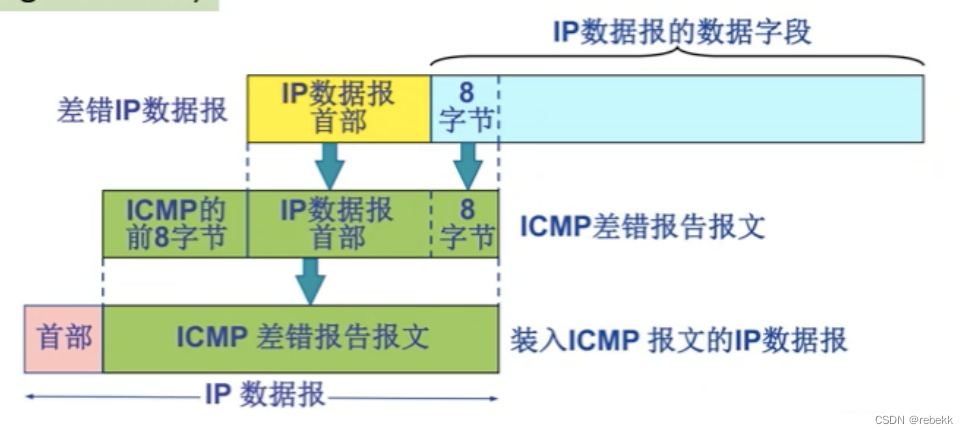
网络层中一些零碎且易忘的知识点
异构网络:指传输介质、数据编码方式、链路控制协议以及数据单元格式和转发机制不同,异构即物理层和数据链路层均不同RIP、OSPF、BGP分别是哪一层的协议: -RIPOSPFBGP所属层次应用层网络层应用层封装在什么协议中UDPIPTCP 一个主机可以有多个I…...
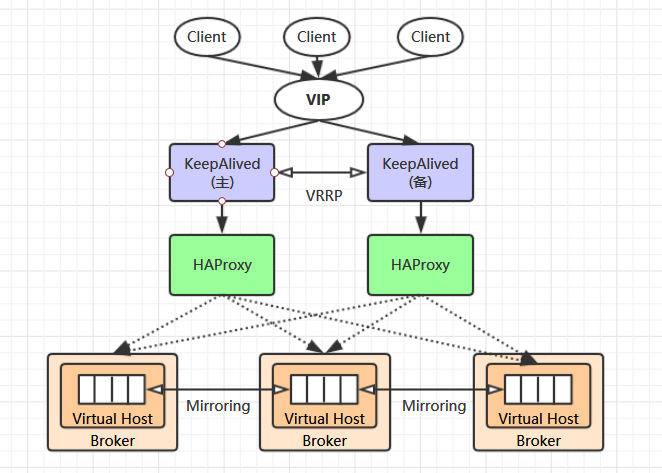
【RabbitMQ】之高可用集群搭建
目录 一、RabbitMQ 集群原理 1、默认集群原理2、镜像集群原理3、负载均衡方案 二、RabbitMQ 高可用集群搭建 1、RabbitMQ 集群搭建2、配置镜像队列3、HAProxy 环境搭建4、Keepalived 环境搭建 一、RabbitMQ 集群简介 1、默认集群原理 3-1、RabbitMQ 集群简介 单台 RabbitM…...
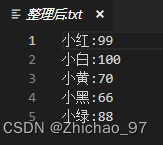
【node.js】01-fs读写文件内容
目录 一、fs.readFile() 读取文件内容 二、fs.writeFile() 向指定的文件中写入内容 案例:整理txt 需求: 代码: 一、fs.readFile() 读取文件内容 代码: //导入fs模块,从来操作文件 const fs require(fs)// 2.调…...

GitHub仓库如何使用
核心:GitHub仓库如何使用 目录 1.创建仓库: 2.克隆仓库到本地: 3.添加、提交和推送更改: 4.分支管理: 5.拉取请求(Pull Requests): 6.合并代码: 7.其他功能&…...

雪花算法,在分布式环境下实现高效的ID生成
其实雪花算法比较简单,可能称不上什么算法就是一种构造UID的方法。 点1:UID是一个long类型的41位时间戳,10位存储机器码,12位存储序列号。 点2:时间戳的单位是毫秒,可以同时链接1024台机器,每台…...

使用css 动画实现,水波纹的效果
每日鸡汤:每个你想要学习的瞬间都是未来的你向自己求救 需求,实现水波纹动画效果,要求中心一个圆点,然后有3个圈,一圈一圈的向里面缩小。 说实话我第一个想到了给3个圈设置不同的宽高,然后设置动画0-100%&a…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

ImageGlass:一个支持90+图像格式的轻量级Windows图片查看器
ImageGlass:一个支持90图像格式的轻量级Windows图片查看器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows自带的图片查看器功能单一而烦恼吗&…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...

第5章 薪资重构——AI时代的程序员价值重估
第5章 薪资重构——AI时代的程序员价值重估 核心问题:AI时代,程序员的薪资会发生怎样的变化?哪些人在涨薪?哪些人在降薪? 5.1 问题定义:薪资分化的真相是什么? 5.1.1 一个令人震惊的数据 2026年第一季度,一个对比让整个技术圈哗然: 同一家公司内部: - 一个AI方向…...