数据结构基础之排序算法
在数据结构中,常见的排序算法有以下几种:
- 冒泡排序(Bubble Sort):通过比较相邻元素并交换它们的位置,每轮将最大(或最小)的元素冒泡到末尾,重复执行直到排序完成。
function bubbleSort(arr) {const n = arr.length;for (let i = 0; i < n - 1; i++) {for (let j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];}}}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(bubbleSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:简单易懂,但对于大型数据集效率较低。
时间复杂度:
最优情况:O(n)(当数组已经排序好时)。
平均情况:O(n^2)。
最坏情况:O(n^2)。
- 插入排序(Insertion Sort):将数组分为已排序和未排序两部分,每次从未排序部分选择一个元素插入到已排序部分的正确位置,重复执行直到排序完成。
function insertionSort(arr) {const n = arr.length;for (let i = 1; i < n; i++) {let key = arr[i];let j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(insertionSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:适用于小型数据集和部分有序数组。
时间复杂度:
最优情况:O(n)(当数组已经排序好时)。
平均情况:O(n^2)。
最坏情况:O(n^2)。
- 选择排序(Selection Sort):每轮从未排序部分选择最小(或最大)的元素,将其与未排序部分的首元素交换,重复执行直到排序完成。
function selectionSort(arr) {const n = arr.length;for (let i = 0; i < n - 1; i++) {let minIdx = i;for (let j = i + 1; j < n; j++) {if (arr[j] < arr[minIdx]) {minIdx = j;}}[arr[i], arr[minIdx]] = [arr[minIdx], arr[i]];}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(selectionSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:简单易懂,但对于大型数据集效率较低。
时间复杂度:
最优情况:O(n^2)。
平均情况:O(n^2)。
最坏情况:O(n^2)。
- 快速排序(Quick Sort):通过选取一个基准元素,将数组分成比基准元素小和大的两部分,然后递归地对两部分进行排序。
function quickSort(arr) {if (arr.length <= 1) return arr;const pivot = arr[0];const left = [];const right = [];for (let i = 1; i < arr.length; i++) {if (arr[i] < pivot) {left.push(arr[i]);} else {right.push(arr[i]);}}return [...quickSort(left), pivot, ...quickSort(right)];
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(quickSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:高效且被广泛使用的排序算法。
时间复杂度:
最优情况:O(n log n)。
平均情况:O(n log n)。
最坏情况:O(n^2)。
- 归并排序(Merge Sort):将数组不断分割成较小的子数组,然后再将子数组按顺序合并,重复执行直到排序完成。
function mergeSort(arr) {if (arr.length <= 1) return arr;const mid = Math.floor(arr.length / 2);const left = mergeSort(arr.slice(0, mid));const right = mergeSort(arr.slice(mid));return merge(left, right);
}function merge(left, right) {const mergedArr = [];let leftIdx = 0;let rightIdx = 0;while (leftIdx < left.length && rightIdx < right.length) {if (left[leftIdx] < right[rightIdx]) {mergedArr.push(left[leftIdx]);leftIdx++;} else {mergedArr.push(right[rightIdx]);rightIdx++;}}return [...mergedArr, ...left.slice(leftIdx), ...right.slice(rightIdx)];
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(mergeSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:稳定的排序算法,适用于大型数据集。
时间复杂度:
最优情况:O(n log n)。
平均情况:O(n log n)。
最坏情况:O(n log n)。
- 堆排序(Heap Sort):利用二叉堆(最大堆或最小堆)的特性进行排序,将堆顶元素与最后一个元素交换,然后重建堆,重复执行直到排序完成。
function heapSort(arr) {const n = arr.length;for (let i = Math.floor(n / 2) - 1; i >= 0; i--) {heapify(arr, n, i);}for (let i = n - 1; i >= 0; i--) {[arr[0], arr[i]] = [arr[i], arr[0]];heapify(arr, i, 0);}return arr;
}function heapify(arr, n, i) {let largest = i;const left = 2 * i + 1;const right = 2 * i + 2;if (left < n && arr[left] > arr[largest]) {largest = left;}if (right < n && arr[right] > arr[largest]) {largest = right;}if (largest !== i) {[arr[i], arr[largest]] = [arr[largest], arr[i]];heapify(arr, n, largest);}
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(heapSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:高效的原地排序算法。
时间复杂度:
最优情况:O(n log n)。
平均情况:O(n log n)。
最坏情况:O(n log n)。
- 希尔排序(Shell Sort):是插入排序的一种改进算法,通过分组进行插入排序,逐渐缩小分组间隔,直到分组间隔为1。
function shellSort(arr) {const n = arr.length;for (let gap = Math.floor(n / 2); gap > 0; gap = Math.floor(gap / 2)) {for (let i = gap; i < n; i++) {let temp = arr[i];let j;for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap];}arr[j] = temp;}}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(shellSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:插入排序的改进版本,适用于中等大小的数据集。
时间复杂度:
最优情况:O(n log^2 n)(取决于步长序列)。
平均情况:取决于步长序列。
最坏情况:取决于步长序列。
- 计数排序(Counting Sort):适用于一定范围内的整数排序,通过统计每个元素出现的次数,然后计算每个元素的位置,重复执行直到排序完成。
function countingSort(arr) {const n = arr.length;let max = Math.max(...arr);let min = Math.min(...arr);const range = max - min + 1;const count = Array(range).fill(0);const output = Array(n);for (let i = 0; i < n; i++) {count[arr[i] - min]++;}for (let i = 1; i < range; i++) {count[i] += count[i - 1];}for (let i = n - 1; i >= 0; i--) {output[count[arr[i] - min] - 1] = arr[i];count[arr[i] - min]--;}for (let i = 0; i < n; i++) {arr[i] = output[i];}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(countingSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:适用于小范围整数排序。
时间复杂度:O(n + k),其中 n 是输入数组元素个数,k 是输入范围大小。
- 桶排序(Bucket Sort):将元素根据一定规则放入不同的桶中,每个桶内部进行排序,然后按顺序合并桶内的元素,重复执行直到排序完成。
function bucketSort(arr, bucketSize = 5) {if (arr.length === 0) return arr;const max = Math.max(...arr);const min = Math.min(...arr);const bucketCount = Math.floor((max - min) / bucketSize) + 1;const buckets = Array(bucketCount).fill().map(() => []);for (let i = 0; i < arr.length; i++) {const bucketIndex = Math.floor((arr[i] - min) / bucketSize);buckets[bucketIndex].push(arr[i]);}arr.length = 0;for (let i = 0; i < buckets.length; i++) {insertionSort(buckets[i]);arr.push(...buckets[i]);}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(bucketSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:适用于均匀分布的数据。
时间复杂度:O(n + k),其中 n 是输入数组元素个数,k 是桶的个数。
- 基数排序(Radix Sort):按照位数将元素分配到不同的桶中,然后按顺序合并桶内的元素,重复执行直到所有位数排序完成。
function radixSort(arr) {const max = Math.max(...arr);const maxLength = String(max).length;let bucket = Array.from({ length: 10 }, () => []);for (let i = 0; i < maxLength; i++) {for (let j = 0; j < arr.length; j++) {const digit = Math.floor(arr[j] / 10 ** i) % 10;bucket[digit].push(arr[j]);}arr.length = 0;for (let k = 0; k < bucket.length; k++) {arr.push(...bucket[k]);bucket[k].length = 0;}}return arr;
}const arr = [64, 34, 25, 12, 22, 11, 90];
console.log(radixSort(arr)); // Output: [11, 12, 22, 25, 34, 64, 90]特点:适用于数字位数相同的整数排序。
时间复杂度:O(d * (n + k)),其中 d 是最大数字的位数,n 是输入数组元素个数,k 是输入范围大小。
每种排序算法都有不同的时间复杂度和适用场景。在实际应用中,根据数据规模和性能要求选择合适的排序算法是很重要的。
相关文章:

数据结构基础之排序算法
在数据结构中,常见的排序算法有以下几种: 冒泡排序(Bubble Sort):通过比较相邻元素并交换它们的位置,每轮将最大(或最小)的元素冒泡到末尾,重复执行直到排序完成。 fun…...
Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录 0. 相关文章链接 1. 概述 2. socket source 3. file source 3.1. 读取普通文件夹内的文件 3.2. 读取自动分区的文件夹内的文件 4. kafka source 4.1. 导入依赖 4.2. 以 Streaming 模式创建 Kafka 工作流 4.3. 通过 Batch 模式创建 Kafka 工作流 5. Rate Source…...

SpringBoot集成Thymeleaf
Spring Boot 集成 Thymeleaf 模板引擎 1、Thymeleaf 介绍 Thymeleaf 是适用于 Web 和独立环境的现代服务器端 Java 模板引擎。 Thymeleaf 的主要目标是为开发工作流程带来优雅的自然模板,既可以在浏览器中正确显示的 HTML,也可以用作静态原型…...
:牛客在线编程03 二叉树)
算法练习(2):牛客在线编程03 二叉树
package jz.bm;import jz.TreeNode;import java.util.*;public class bm3 {/*** BM23 二叉树的前序遍历*/public int[] preorderTraversal (TreeNode root) {ArrayList<Integer> list new ArrayList<>();preOrder(root, list);int[] res new int[list.size()];fo…...

回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测
回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积…...
Linux 系列 常见 快捷键总结
强制停止 Ctrl C 退出程序、退出登录 Ctrl D 等价 exit 查看历史命令 history !命令前缀,自动匹配上一个命令 (历史命令中:从最新——》最老 搜索) ctrl r 输入内去历史命令中检索 # 回车键可以直接执行 ctrl a 跳到命令开头 …...
OA系统构建排座
目录 一.排座的介绍,作用 1.排座介绍 A.前端实现 B.数据库实现 C.后端实现 2.排座作用 A.座位预订 B.座位安排 C. 实时座位状态显示 二.利用Layui实现排座 1.基础版(通过htmlcssjs实现) A.基础版源码(html): 2.进阶版 …...

微信小程序 居中、居右、居底和横向、纵向布局,文字在图片中间,网格布局
微信小程序居中、居右、横纵布局 1、水平垂直居中(相对父类控件)方式一:水平垂直居中 父类控件: display: flex;align-items: center;//子控件垂直居中justify-content: center;//子控件水平居中width: 100%;height: 400px //注意…...

【C++】总结2
文章目录 1.final和override关键字2.extern "C"的用法3.野指针和垂悬指针(悬空指针)4.指针指向的内存被释放是什么意思5.C和C的类型安全6.C中的重载、重写(覆盖)和隐藏的区别 1.final和override关键字 final和override是C11引入的关键字&…...

vue2项目中使用svg图标
在开发项目的时候经常会用到svg矢量图,而且我们使用SVG以后,页面上加载的不再是图片资源, 这对页面性能来说是个很大的提升,而且我们SVG文件比img要小的很多,放在项目中几乎不占用资源。 1、安装SVG依赖插件并配置加载器和路径 npm instal…...
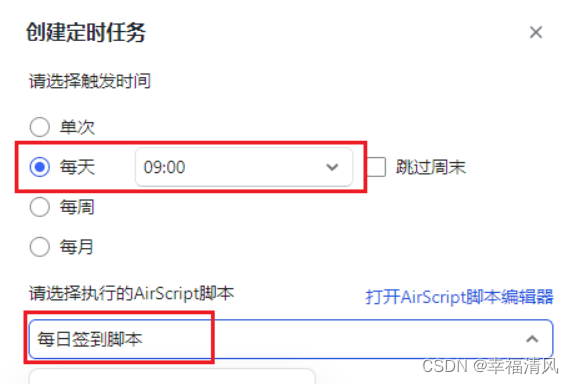
阿里云盘自动每日签到无需部署无需服务器(仅限学习交流使用)
一、前言 阿里云盘自动每日签到,无需部署,无需服务器 执行思路:使用金山文档的每日定时任务,执行阿里云盘签到接口。 二、效果展示: 三、步骤: 1、进入金山文档网页版 金山文档官网:https:…...
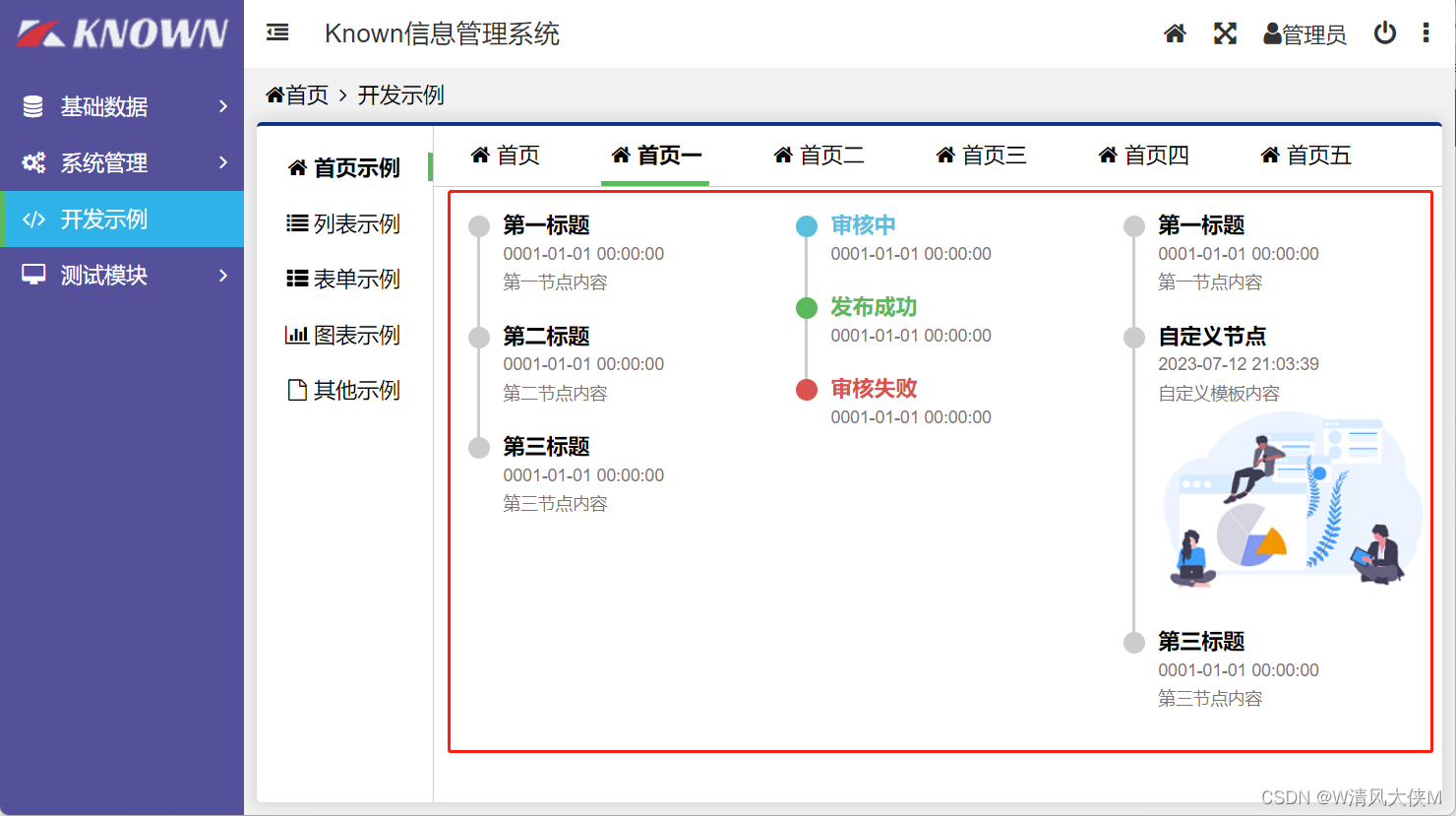
Blazor前后端框架Known-V1.2.7
V1.2.7 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行。 Gitee: https://gitee.com/known/KnownGithub:https://github.com/known/Known 概述 基于C#和Blazor…...
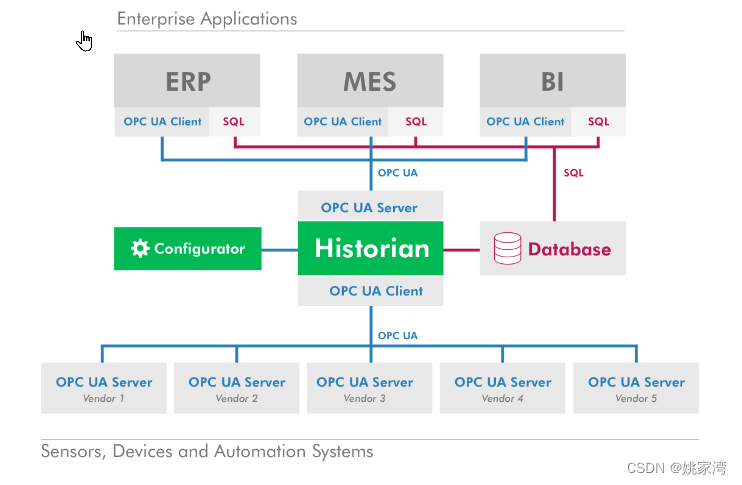
工业边缘计算为什么?
在工厂环境中使用边缘计算并不新鲜。可编程逻辑控制器(PLC)、微控制器、服务器和PC进行本地数据处理,甚至是微型数据中心都是边缘技术,已经在工厂系统中存在了几十年。在车间里看到的看板系统,打卡系统,历史…...
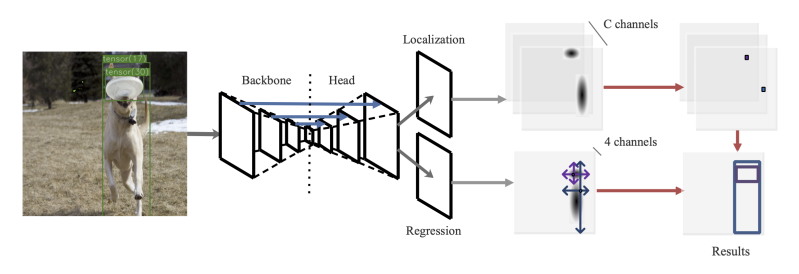
Training-Time-Friendly Network for Real-Time Object Detection 论文学习
1. 解决了什么问题? 目前的目标检测器很少能做到快速训练、快速推理,并同时保持准确率。直觉上,推理越快的检测器应该训练也很快,但大多数的实时检测器反而需要更长的训练时间。准确率高的检测器大致可分为两类:推理时…...

HTTP改HTTPS
tomcat中http协议改https 第一步,配置server.xml <?xml version"1.0" encoding"UTF-8"?> <Server port"8005" shutdown"SHUTDOWN"><Listener className"org.apache.catalina.startup.VersionLogger…...
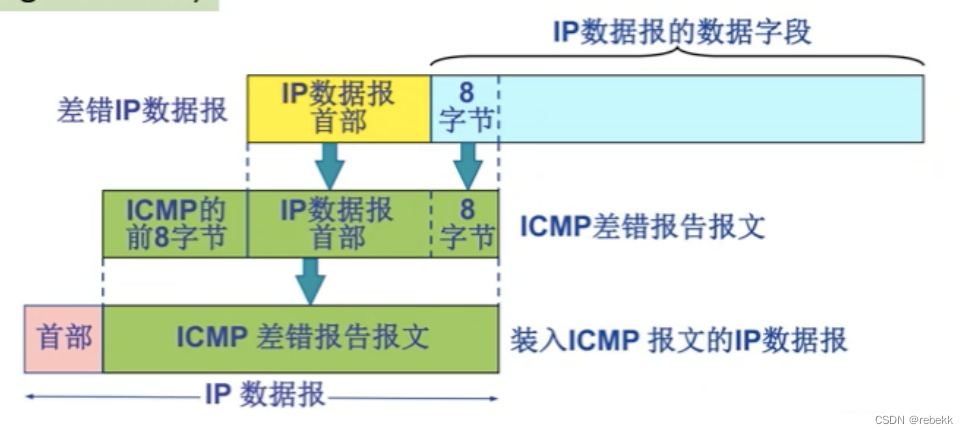
网络层中一些零碎且易忘的知识点
异构网络:指传输介质、数据编码方式、链路控制协议以及数据单元格式和转发机制不同,异构即物理层和数据链路层均不同RIP、OSPF、BGP分别是哪一层的协议: -RIPOSPFBGP所属层次应用层网络层应用层封装在什么协议中UDPIPTCP 一个主机可以有多个I…...
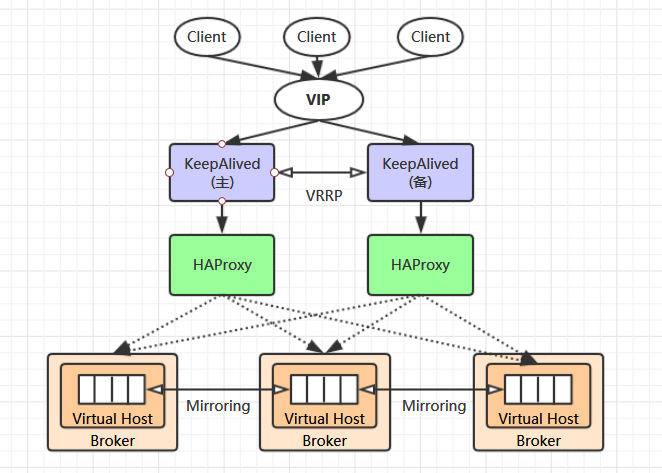
【RabbitMQ】之高可用集群搭建
目录 一、RabbitMQ 集群原理 1、默认集群原理2、镜像集群原理3、负载均衡方案 二、RabbitMQ 高可用集群搭建 1、RabbitMQ 集群搭建2、配置镜像队列3、HAProxy 环境搭建4、Keepalived 环境搭建 一、RabbitMQ 集群简介 1、默认集群原理 3-1、RabbitMQ 集群简介 单台 RabbitM…...
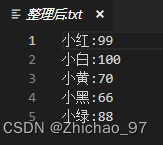
【node.js】01-fs读写文件内容
目录 一、fs.readFile() 读取文件内容 二、fs.writeFile() 向指定的文件中写入内容 案例:整理txt 需求: 代码: 一、fs.readFile() 读取文件内容 代码: //导入fs模块,从来操作文件 const fs require(fs)// 2.调…...

GitHub仓库如何使用
核心:GitHub仓库如何使用 目录 1.创建仓库: 2.克隆仓库到本地: 3.添加、提交和推送更改: 4.分支管理: 5.拉取请求(Pull Requests): 6.合并代码: 7.其他功能&…...

雪花算法,在分布式环境下实现高效的ID生成
其实雪花算法比较简单,可能称不上什么算法就是一种构造UID的方法。 点1:UID是一个long类型的41位时间戳,10位存储机器码,12位存储序列号。 点2:时间戳的单位是毫秒,可以同时链接1024台机器,每台…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...