Mnist分类与气温预测任务
目录
- 传统机器学习与深度学习的特征工程
- 特征向量
- pytorch实现minist代码解析
- 归一化
- 损失函数
- 计算图
- Mnist分类
- 获取Mnist数据集,预处理,输出一张图像
- 面向工具包编程
- 使用TensorDataset和DataLoader来简化数据预处理
- 计算验证集准确率
- 气温预测
- 回归
- 构建神经网络
- 调包
- 预测训练结果
- 画图对比
传统机器学习与深度学习的特征工程

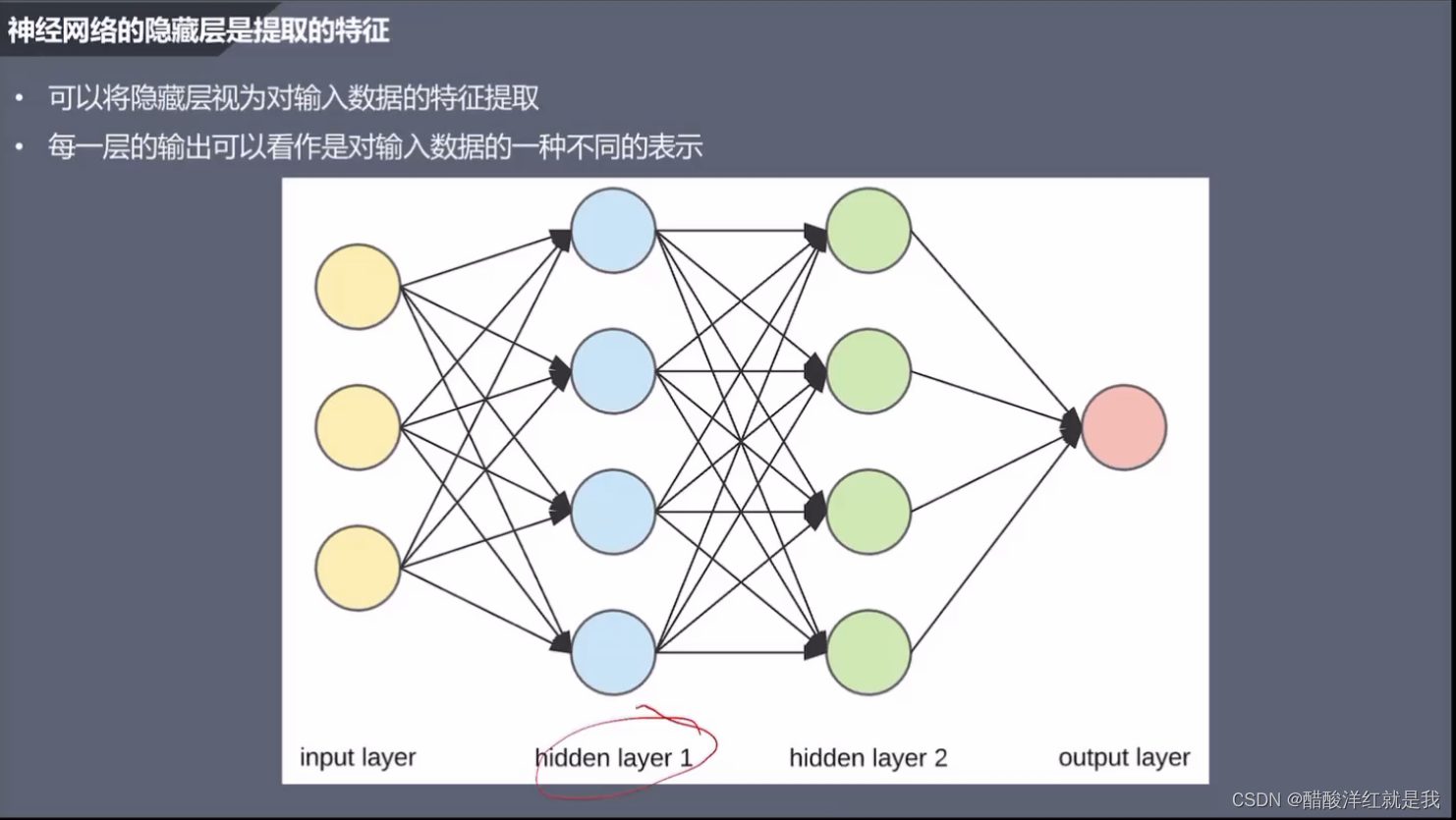
卷积层:原始输入中间提取有用的一个局部特征
激活函数:用于增加模型的一些非线性,可以让模型学习更加复杂模式
池化层:用于减少数据的维度
特征向量

pytorch实现minist代码解析

首先继承nn.Module类的一个子类ConvNet,super方法就是在调用nn.Module的一个__init__方法,确保__init__方法中定义的属性和方法都可以在ConvNet中使用
归一化
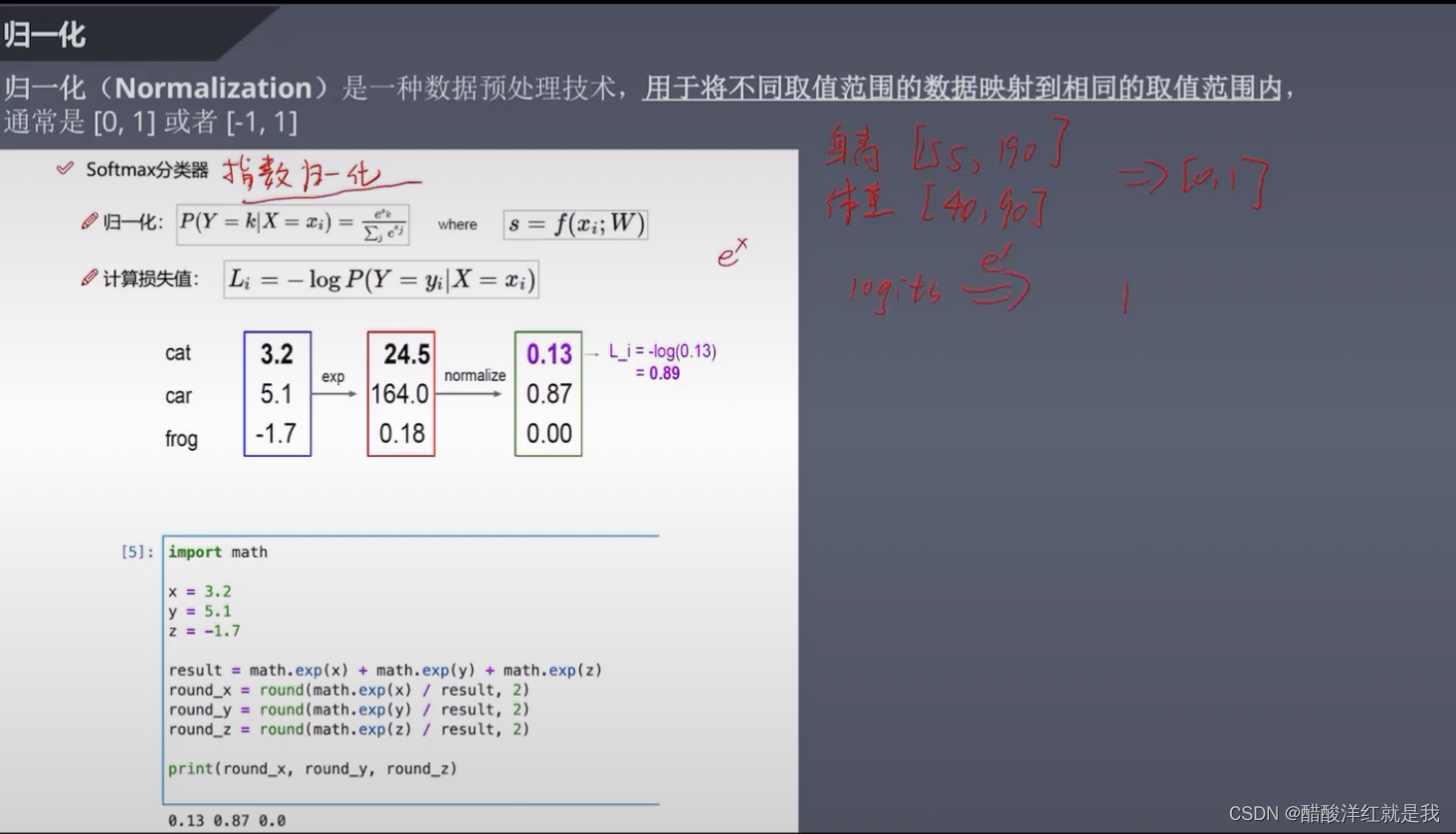
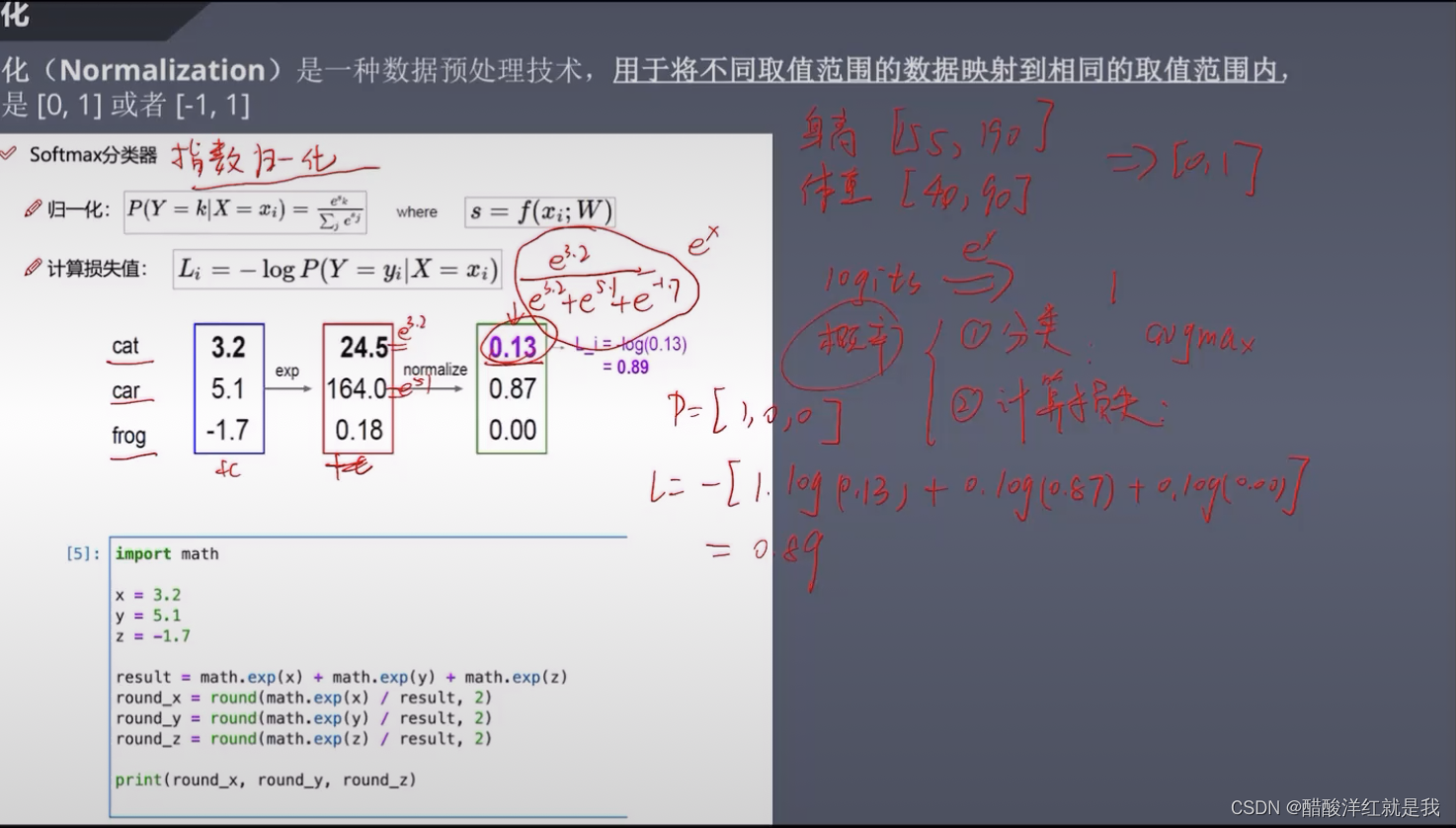
损失函数

计算图

Mnist分类
获取Mnist数据集,预处理,输出一张图像
import torch
print(torch.__version__)
#win用户
DEVICE=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#mac用户
DEVICE=torch.device('mps' if torch.backends.mps.is_available() else 'cpu')
print('当前设备',DEVICE)

#将图像嵌入输出的单元格
%matplotlib inline
from pathlib import Path # 处理文件路径
import requestsDATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"if not (PATH / FILENAME).exists():content = requests.get(URL + FILENAME).content(PATH / FILENAME).open("wb").write(content)
import pickle
import gzipwith gzip.open((PATH / FILENAME).as_posix(), "rb") as f:((x_train, y_train), (x_valid, y_valid), (x_test, y_test)) = pickle.load(f, encoding="latin-1")
print("x_train: ", type(x_train), x_train.dtype, x_train.size, x_train.shape, "; y_train: ", y_train.shape)
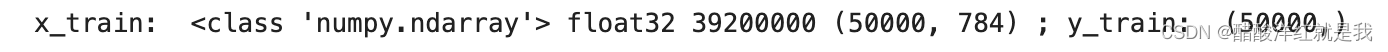
print("x_valid: ", type(x_valid), x_valid.dtype, x_valid.size, x_valid.shape, "; y_valid: ", y_valid.shape)

from matplotlib import pyplotpyplot.imshow(x_train[2].reshape((28, 28)), cmap="gray")
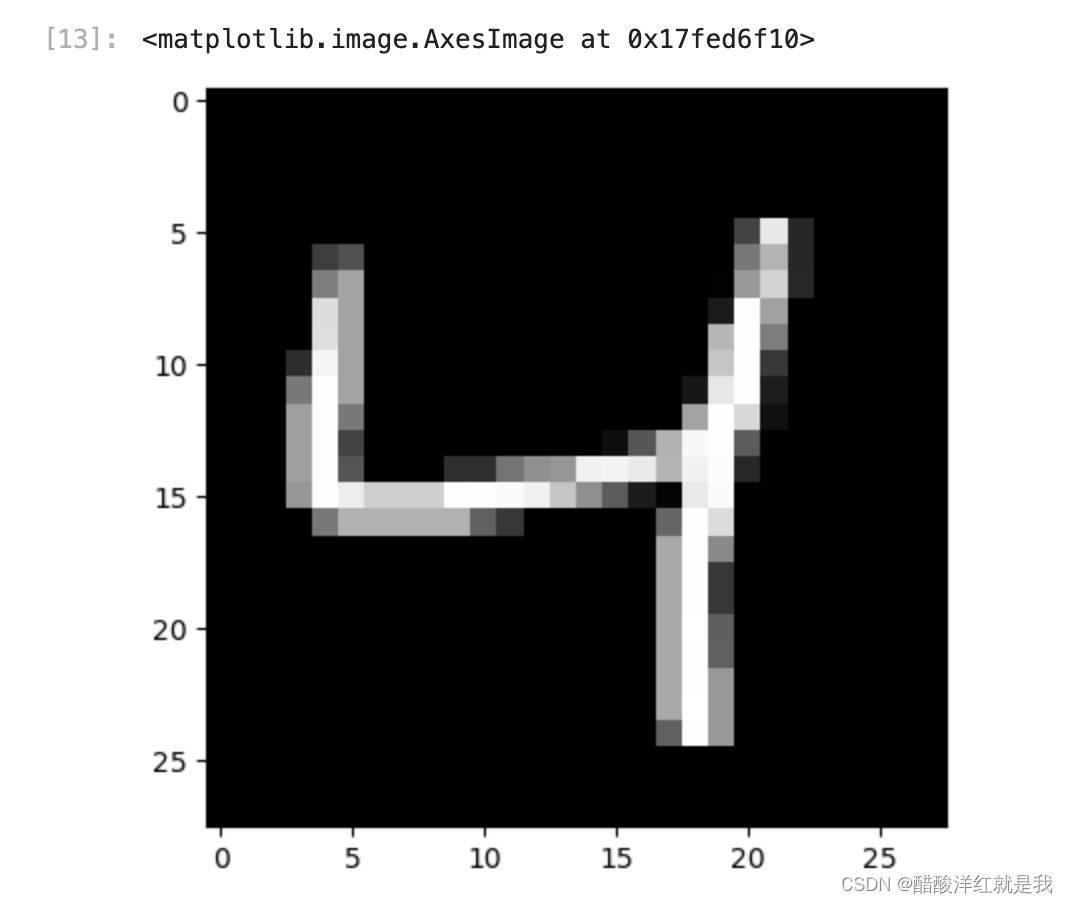
y_train[:10]

x_train, y_train, x_valid, y_valid = map(lambda x: torch.tensor(x, device=DEVICE),(x_train, y_train, x_valid, y_valid)
)
print("x_train: ", x_train, "; y_train: ", y_train)
x_train[0]
import torch.nn.functional as Floss_func = F.cross_entropy # 损失函数,传入预测、真实值的标签def model(xb):xb = xb.to(DEVICE)return xb.mm(weights) + bias # x*w+b
bs = 64xb = x_train[0:bs] # 64, 784yb = y_train[0:bs] # 真实标签weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)bias = torch.zeros(10, requires_grad = True)weights = weights.to(DEVICE)
bias = bias.to(DEVICE)print(loss_func(model(xb), yb))

补充:关于map函数的例子
def square(x):return x**2
numbers=[1,2,3,4,5]
squares=map(square,numbers)
print(list(squares))

也就是map函数第一个参数是函数,第二个参数是数值,将函数作用于数值
面向工具包编程
from torch import nn # 提供神经网网络的类和函数 ,nn.Moduleclass Mnist_NN(nn.Module):def __init__(self): # 设计房屋图纸super(Mnist_NN, self).__init__()self.hidden1 = nn.Linear(784, 256) # 784-输入层,256-隐藏层1self.hidden2 = nn.Linear(256, 128)self.out = nn.Linear(128, 10)def forward(self, x): # 实际造房子x2 = F.relu(self.hidden1(x)) # x: [bs, 784], w1: [784, 256], b1: [256] -> x2:[bs,256]x3 = F.relu(self.hidden2(x2)) # x2: [bs, 256], w2:[256, 128], b2[128] -> x3[bs, 128]x_out = self.out(x3) # x3: [bs, 128], w3: [128, 10], b3[10] -> x_out: [bs, 10]return x_out
net = Mnist_NN().to(DEVICE)
print(net)

print(net.hidden1.weight)

for name, parameter in net.named_parameters():print(name, parameter)
使用TensorDataset和DataLoader来简化数据预处理
from torch.utils.data import TensorDatasetfrom torch.utils.data import DataLoadertrain_ds = TensorDataset(x_train, y_train) #torch.utils.data.Dataset
train_dl = DataLoader(train_ds, batch_size=64, shuffle=True)valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs)
data_iter = iter(train_dl)batch_x, batch_y = next(data_iter)
print(batch_x.shape, batch_y.shape)
print(batch_y)

batch_x, batch_y = next(data_iter)
print(batch_x.shape, batch_y.shape)
print(batch_y)

def get_data(train_bs, valid_bs, bs): # 创建数据加载器return (DataLoader(train_ds, batch_size=bs, shuffle=True),DataLoader(valid_ds, batch_size=bs))
from torch import optim
def get_model():model = Mnist_NN().to(DEVICE)optimizer = optim.SGD(model.parameters(), lr=0.01) # model.parameters()包含了所有的权重和偏执参数return model, optimizer
注:adam相比于SGD是引入了一个惯性,相当于一个平行四边形的一个合成法则
def loss_batch(model, loss_func, xb, yb, opt=None):loss = loss_func(model(xb), yb)if opt is not None: # 此时是训练集opt.zero_grad()loss.backward()opt.step()return loss.item(), len(xb)
opt为True是训练集测试损失,opt为None是验证集测试损失
def loss_batch(model, loss_func, xb, yb, opt=None):loss = loss_func(model(xb), yb)if opt is not None: # 此时是训练集opt.zero_grad()loss.backward()opt.step()return loss.item(), len(xb)
import numpy as npdef fit(epoch, model, loss_func, opt, train_dl, valid_dl):for step in range(epoch):model.train()for xb, yb in train_dl:loss_batch(model, loss_func, xb, yb, opt)model.eval() # 考试with torch.no_grad():losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl] # "*"——解包/解开)# print(f"losses: {losses}")# print(f"nums: {nums}")val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) # 加权平均损失print('当前step: '+str(step), '验证集损失: '+str(val_loss))
train_dl, valid_dl = get_data(train_ds, valid_ds, bs=64)
model, optimizer = get_model()
fit(30, model, loss_func, optimizer, train_dl, valid_dl)

计算验证集准确率
torch.set_printoptions(precision=4, sci_mode=False)
for xb, yb in valid_dl:output = model(xb)print(output)print(output.shape)break
for xb, yb in valid_dl:output = model(xb)probs = torch.softmax(output, dim=1)print(probs)print(probs.shape)break
for xb, yb in valid_dl:output = model(xb)probs = torch.softmax(output, dim=1)preds = torch.argmax(probs, dim=1)print(preds)print(preds.shape)break
correct_predict = 0 # 计数正确预测图片的数目
total_quantity = 0 # 计数验证集总数for xb, yb in valid_dl:output = model(xb)probs = torch.softmax(output, dim=1)preds = torch.argmax(probs, dim=1)total_quantity += yb.size(0)# print(yb.size(0))# print((preds == yb).sum())# print((preds == yb).sum().item())correct_predict += (preds == yb).sum().item()print(f"验证集的准确率是: {100 * correct_predict / total_quantity} % ")

气温预测
回归
import numpy as np # 矩阵运算
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optimimport warnings
warnings.filterwarnings("ignore")%matplotlib inline
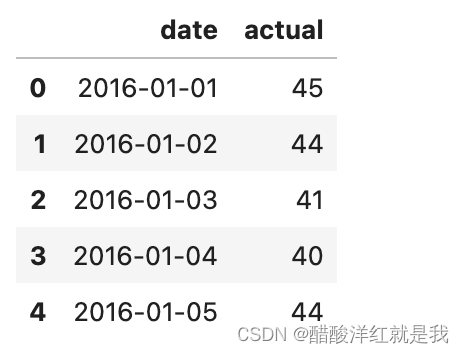
features = pd.read_csv('temps.csv')features.head()
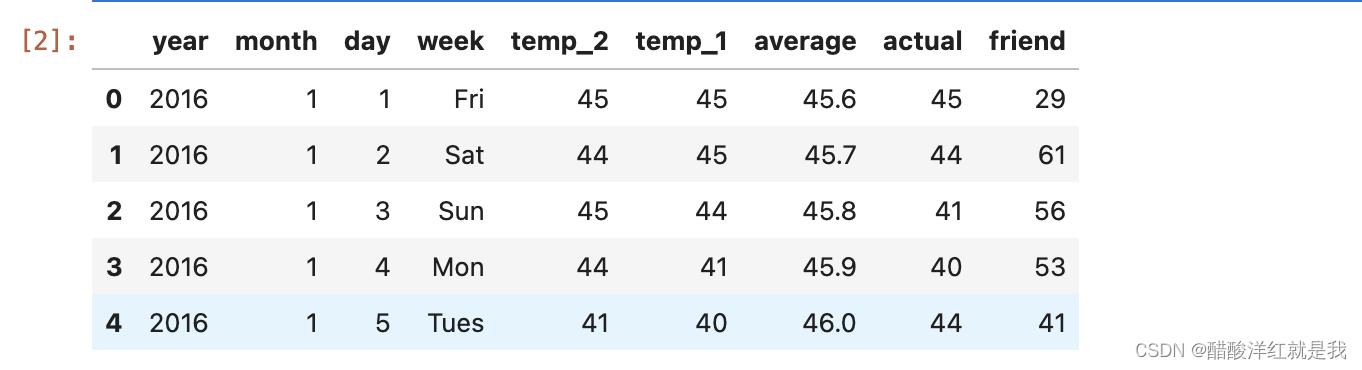
print("数据维度: ", features.shape)

# 处理时间数据
import datetimeyears = features['year']
months = features['month']
days = features['day']dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates[:5]
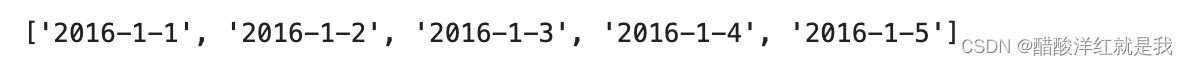
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
dates[:5]

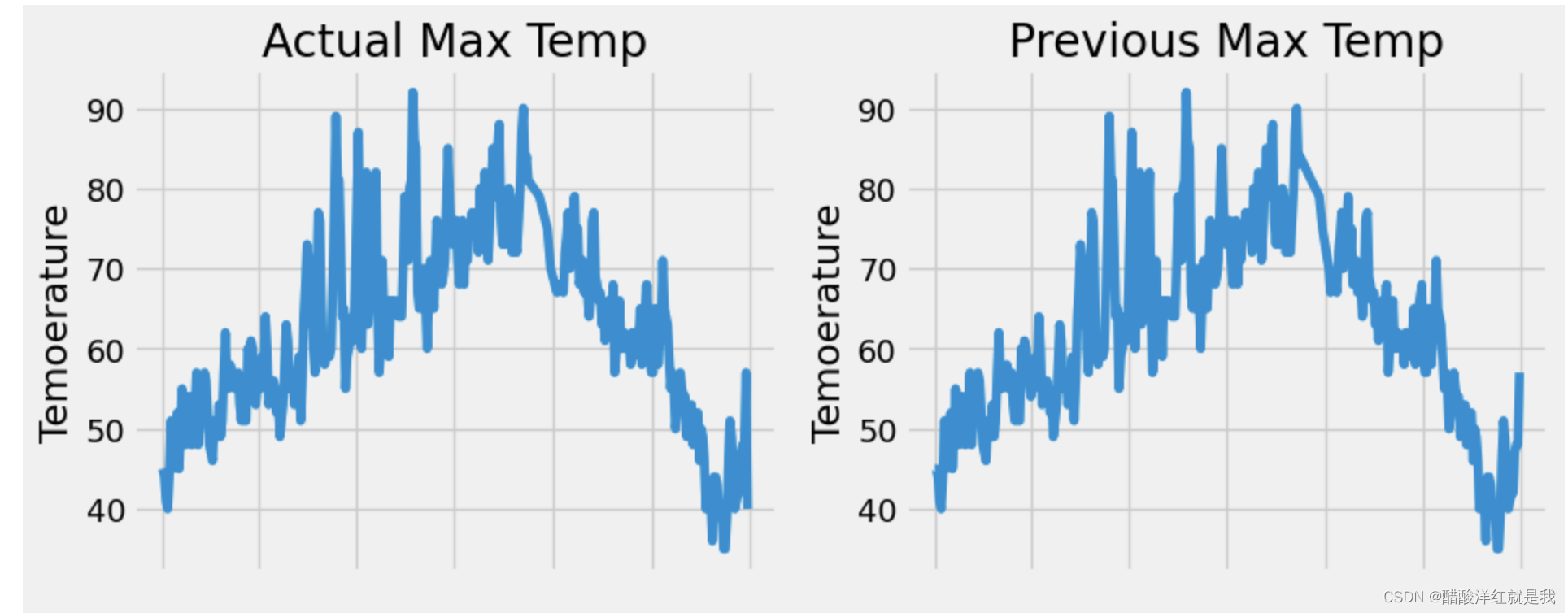
plt.style.use('fivethirtyeight')fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10, 10))
fig.autofmt_xdate(rotation=45) #x轴翻转45度# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temoerature'); ax1.set_title('Actual Max Temp')# 昨天温度
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temoerature'); ax2.set_title('Previous Max Temp')# 前天温度
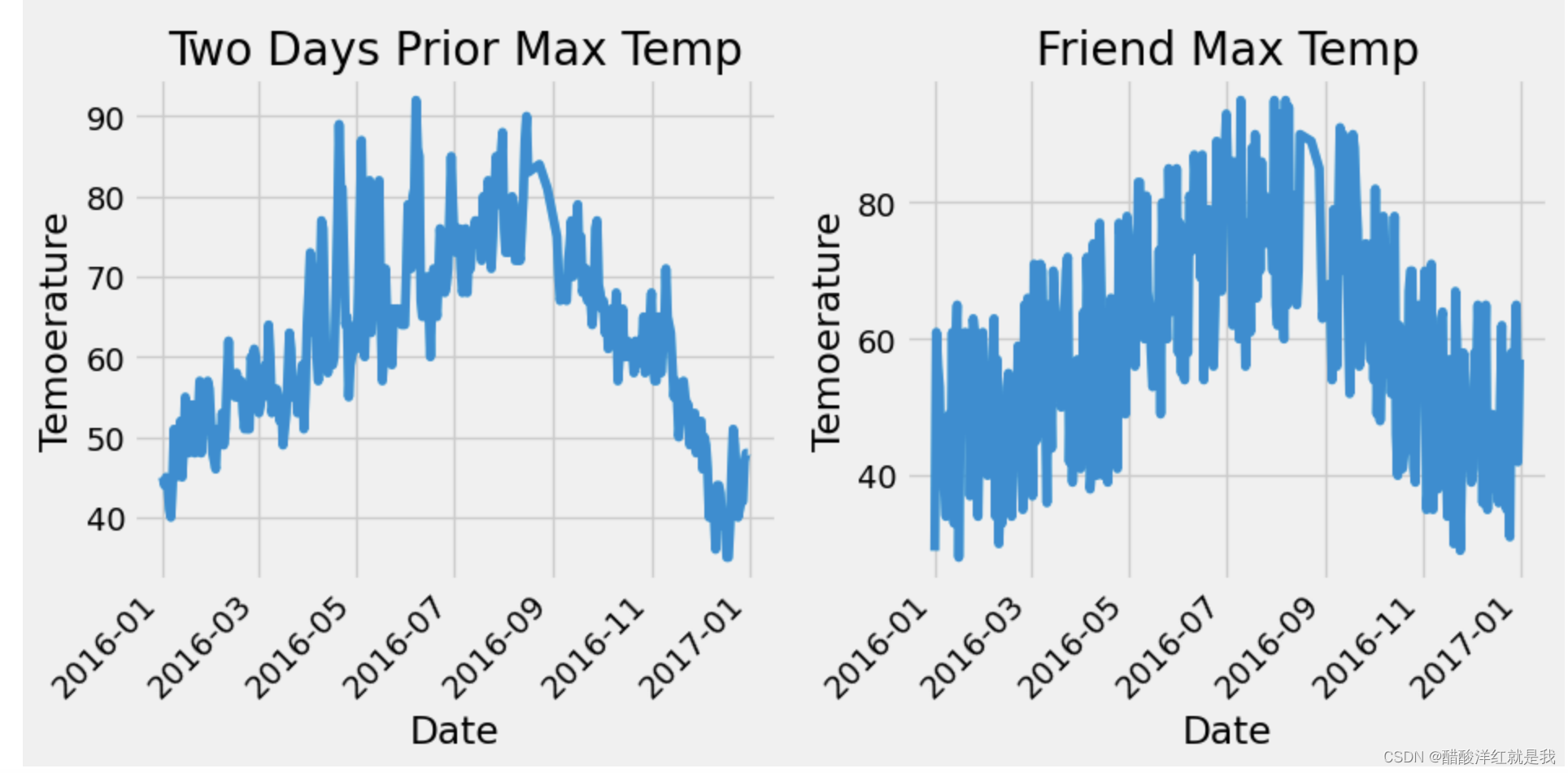
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temoerature'); ax3.set_title('Two Days Prior Max Temp')# 朋友预测温度
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temoerature'); ax4.set_title('Friend Max Temp')
features = pd.get_dummies(features)
features.head()

labels = np.array(features['actual'])# 在特征中去掉标签
features = features.drop('actual', axis=1)feature_list = list(features.columns)features = np.array(features)
features.shape

from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[:5]
构建神经网络
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype=float)
print(x.shape, y.shape)
# 权重初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True) learning_rate = 0.001
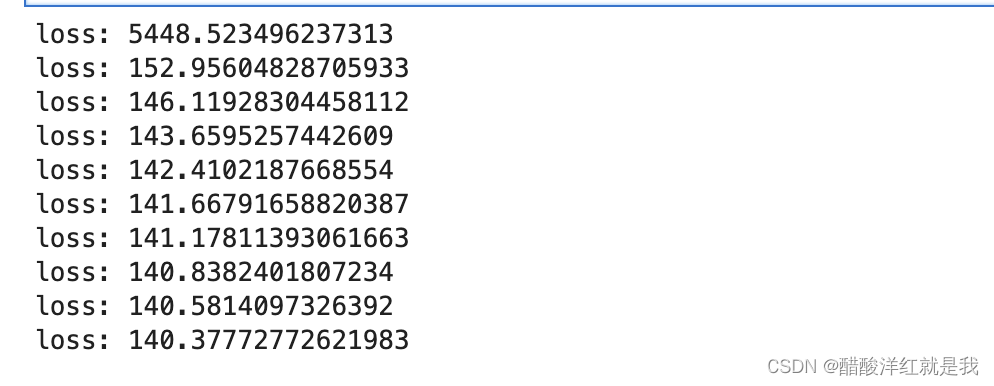
losses = []for i in range(1000):hidden = x.mm(weights) + biaseshidden = torch.relu(hidden)predictions = hidden.mm(weights2) + biases2loss = torch.mean((predictions - y)**2)losses.append(loss.item())if i % 100 == 0:print(f"loss: {loss}")# 反向传播loss.backward()# 更新,相当于optim.step()weights.data.add_(- learning_rate * weights.grad.data) biases.data.add_(- learning_rate * biases.grad.data)weights2.data.add_(- learning_rate * weights2.grad.data)biases2.data.add_(- learning_rate * biases2.grad.data)# 清空梯度,optim.zero_grad()weights.grad.data.zero_()biases.grad.data.zero_()weights2.grad.data.zero_()biases2.grad.data.zero_()
调包
import torch.optim as optim# 数据准备
# 将数据都转化为tensor张量
x = torch.tensor(input_features, dtype = torch.float)
y = torch.tensor(labels, dtype=torch.float).view(-1, 1) # 改成(n, 1)
print(x.shape, y.shape)
model = torch.nn.Sequential(torch.nn.Linear(14, 128),torch.nn.ReLU(),torch.nn.Linear(128, 1)
)# 均方误差MSE
criterion = torch.nn.MSELoss(reduction='mean')optimizer = optim.Adam(model.parameters(), lr=0.001)losses = [] # 存储每一次迭代的损失for i in range(3000):predictions = model(x) # [348, 1]loss = criterion(predictions, y)losses.append(loss.item())if i % 200 == 0:print(f"loss: {loss.item()}")optimizer.zero_grad()loss.backward()optimizer.step()

预测训练结果
x = torch.tensor(input_features, dtype = torch.float)
predict = model(x).data.numpy()
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]# 创建一个表格来存日期和对应的真实标签
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})# 创建一个表格来存日期和对应的预测值
predictions_data = pd.DataFrame(data = {'date': dates, 'prediction': predict.reshape(-1)})predict.shape, predict.reshape(-1).shape

true_data[:5]
predictions_data[:5]

画图对比
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = "actual")# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = "prediction")plt.xticks(rotation = 60)plt.legend()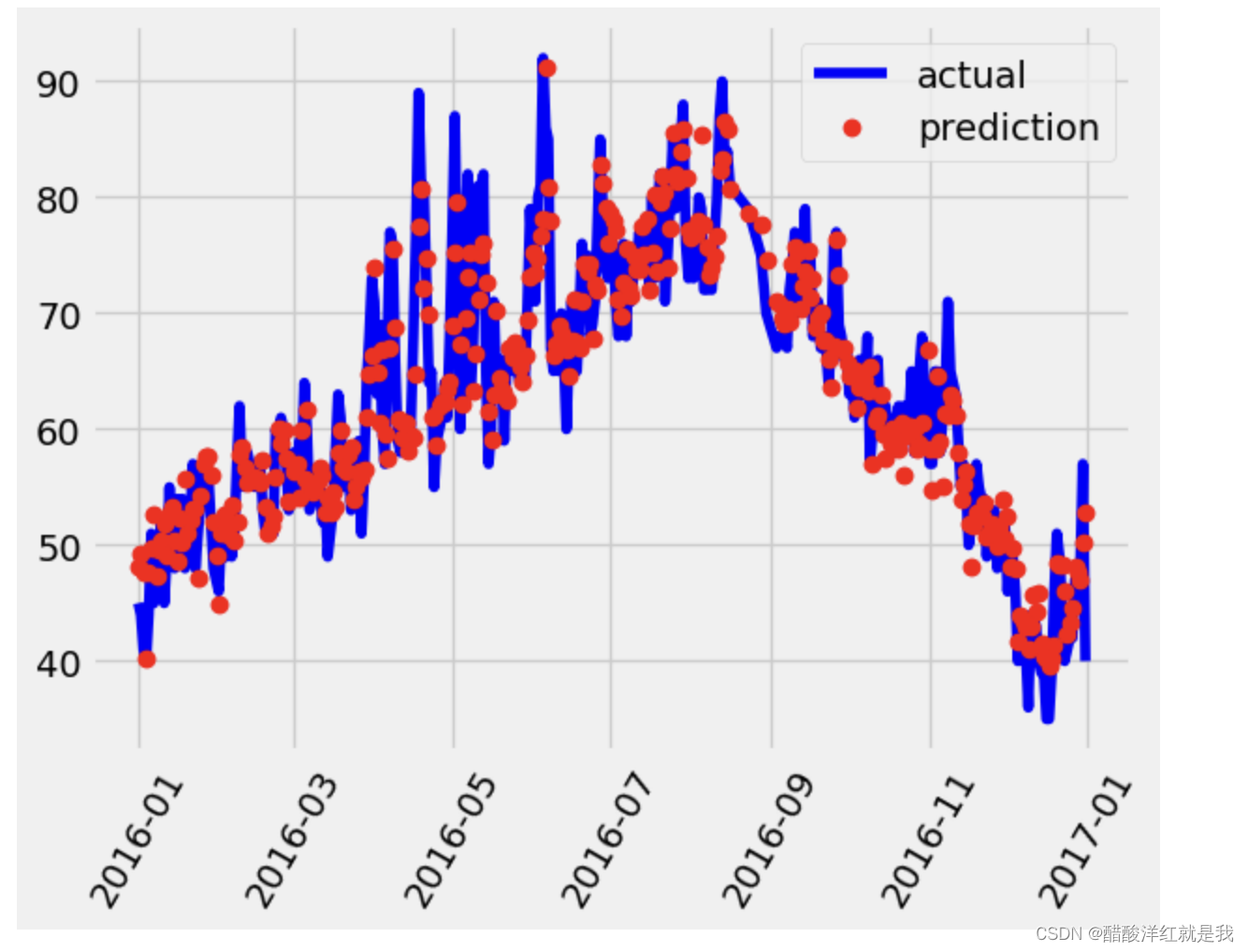
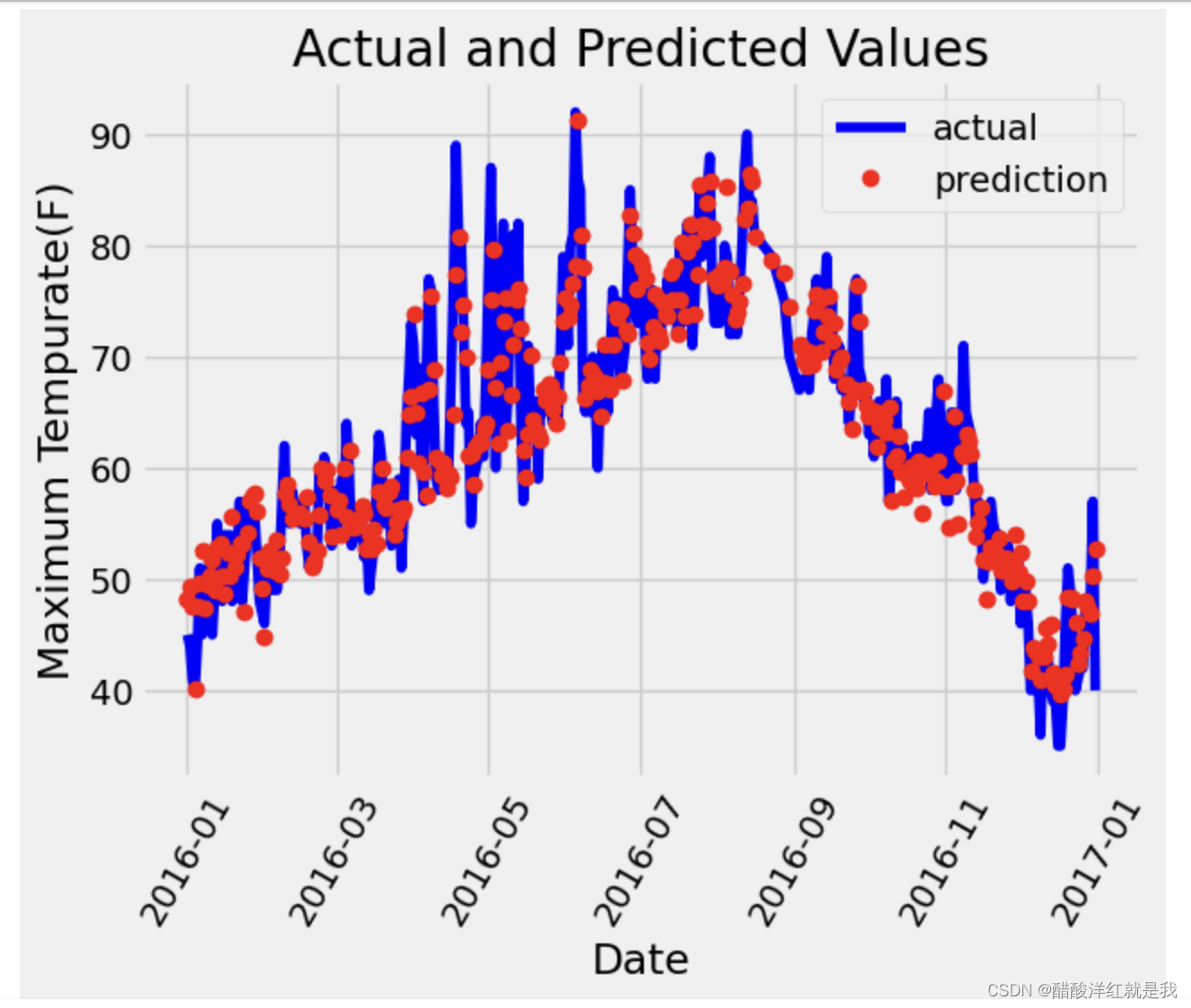
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = "actual")# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = "prediction")plt.xticks(rotation = 60)plt.legend()plt.xlabel('Date'); plt.ylabel('Maximum Tempurate(F)'); plt.title('Actual and Predicted Values')
相关文章:
Mnist分类与气温预测任务
目录 传统机器学习与深度学习的特征工程特征向量pytorch实现minist代码解析归一化损失函数计算图Mnist分类获取Mnist数据集,预处理,输出一张图像面向工具包编程使用TensorDataset和DataLoader来简化数据预处理计算验证集准确率 气温预测回归构建神经网络…...

Pytorch深度学习-----神经网络的卷积操作
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...

微信小程序转抖音小程序的坑:The component <xxx> used in pages/xxx/xxx is undefined
微信小程序组件定义在根目录的 app.json 中了,在抖音小程序中出现找不到的情况。 在需要用到组件的 pages 目录中页面文件夹的 json "usingComponents": {} 大括号中添加页面使用的组件,即可使用......

Vue+element Ui的el-select同时获取value和label的方法总结
1.通过ref的形式(推荐) <template><div class"root"><el-selectref"optionRef"change"handleChange"v-model"value"placeholder"请选择"style"width: 250px"><el-optionv-for&q…...
乐划锁屏充分发挥强创新能力,打造内容业新生态
乐划锁屏作为新型内容媒体,在这一市场有着众多独特的优势,不仅能够通过多场景的联动给内容创作者带来了更多可能性,还促进了更多优质作品的诞生,为用户带来更加丰富多彩的锁屏使用体验。 作为OPPO系统原生的OS应用,乐划锁屏一直致力于打造为用户提供至美内容的内容平台,吸引了全…...

防御第三天
1.总结当堂NAT与双机热备原理,形成思维导图 2.完成课堂NAT与双机热备实验 fw1: <USG6000V1>sy [USG6000V1]int g0/0/0 [USG6000V1-GigabitEthernet0/0/0]ip add 192.168.18.2 24 [USG6000V1-GigabitEthernet0/0/0]service-manage all permit (地址无所谓&…...

用JavaScript和HTML实现一个精美的计算器
文章目录 一、前言二、技术栈三、功能实现3.1 引入样式3.2 编写显示页面3.2 美化计算器页面3.3 实现计算器逻辑 四、总结 一、前言 计算器是我们日常生活中经常使用的工具之一,可以帮助我们进行简单的数学运算。在本博文中,我将使用JavaScript编写一个漂…...
地址省市区解析函数)
基于postgresl的gaussDB(DWS)地址省市区解析函数
地址格式为: 省(自治区,直辖市)、市、区。 直辖市的地址格式为, 北京市北京市海淀区xxxxx。 若是北京市海淀区xxx,自己改改就可以了 采用的是笨办法,穷举。 涉及的两个主要内置函数。 1. instr( <start_positio…...

【Golang】Golang进阶系列教程--Go 语言 new 和 make 关键字的区别
文章目录 前言new源码使用 make源码使用 总结 前言 本篇文章来介绍一道非常常见的面试题,到底有多常见呢?可能很多面试的开场白就是由此开始的。那就是 new 和 make 这两个内置函数的区别。 在 Go 语言中,有两个比较雷同的内置函数…...

Day 9 C++ 内存分区模型
目录 内存四区 代码区 全局区 栈区 堆区 内存四区意义: 程序运行前后内存变化 程序运行前 代码区 全局区 程序运行后 栈区 堆区 new操作符 基本语法 创建 释放(delete) 内存四区 代码区 代码区(Code Segment&…...
STM32 CubeMX 定时器(普通模式和PWM模式)
STM32 CubeMX STM32 CubeMX 定时器(普通模式和PWM模式) STM32 CubeMXSTM32 CubeMX 普通模式一、STM32 CubeMX 设置二、代码部分STM32 CubeMX PWM模式一、STM32 CubeMX 设置二、代码部分总结 STM32 CubeMX 普通模式 一、STM32 CubeMX 设置 二、代码部分 …...

mysql清除主从复制关系
mysql清除主从复制关系 mysql主从复制中,需要将主从复制关系清除,需要取消其从库角色。这可通过执行RESET SLAVE ALL清除从库的同步复制信息、包括连接信息和二进制文件名、位置。从库上执行这个命令后,使用show slave status将不会有输出。reset slave是各版本Mysql都有的功…...
Spring Cloud Eureka 服务注册和服务发现超详细(附加--源码实现案例--及实现逻辑图)
文章目录 EurekaEureka组件可以实现哪些功能什么是CAP原则?服务注册代码实战搭建注册中心服务A搭建服务B搭建启动服务启动注册中心启动服务A启动服务B 结束语 Eureka 这篇文章先讲述一下Eureka的应用场景、代码实现案例,多个服务模块注册到Euraka中&…...

【docker】docker部署nginx
目录 一、步骤二、示例 一、步骤 1.搜索nginx镜像 2.拉取nginx镜像 3.创建容器 4.测试nginx 二、示例 1.搜索nginx镜像 docker search nginx2.拉取nginx镜像 docker pull nginx3.创建容器,设置端口映射、目录映射 # 在root目录下创建nginx目录用于存储nginx数据…...

苍穹外卖-day08
苍穹外卖-day08 本项目学自黑马程序员的《苍穹外卖》项目,是瑞吉外卖的Plus版本 功能更多,更加丰富。 结合资料,和自己对学习过程中的一些看法和问题解决情况上传课件笔记 视频:https://www.bilibili.com/video/BV1TP411v7v6/?sp…...
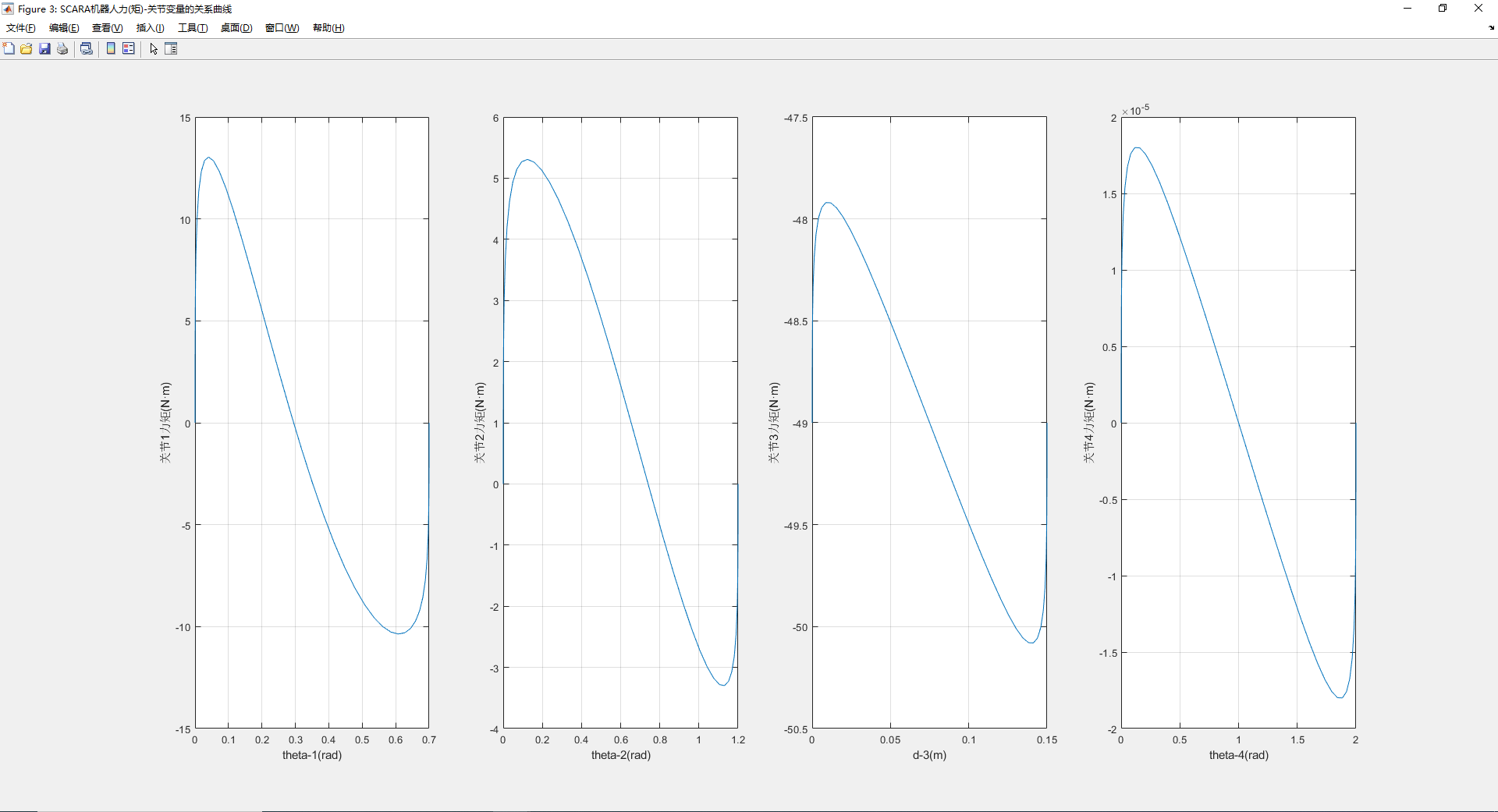
【matlab】机器人工具箱快速上手-动力学仿真(代码直接复制可用)
动力学代码,按需修改参数 各关节力矩-关节变量的关系曲线: %%%%%%%%SCARA机器人仿真模型 l[0.457 0.325]; L(1) Link(d,0,a,l(1),alpha,0,standard,qlim,[-130 130]*pi/180);%连杆1 L(2)Link(d,0,a,l(2),alpha,pi,standard,qlim,[-145 145]*pi/180);%连…...

MySQL高级篇第2章(MySQL的数据目录)
文章目录 1、MySQL8的主要目录结构1.1 数据库文件的存放路径1.2 相关命令目录1.3 配置文件目录 2、数据库和文件系统的关系2.1 查看默认数据库2.2 数据库在文件系统中的表示2.3 表在文件系统中的表示2.3.1 InnoDB存储引擎模式2.3.2 MyISAM存储引擎模式 2.4 小结 1、MySQL8的主要…...

【通过改变压缩视频的分辨率实现高效的视频语义分割】CVPR2022论文精度
Efficient Semantic Segmentation by Altering Resolutions for Compressed Videos Efficient Semantic Segmentation by Altering Resolutions for Compressed VideosBasic Information:论文简要 :背景信息:a. 理论背景:b. 技术路线: 结果:a. 详细的实验设置:b. 详细的实验结果…...

golang 时间工具类
用不习惯也嫌麻烦每次都去操作时间,然后就自己写了个时间工具类 package timeutilimport ("time" )func New() *TimeUtil {return &TimeUtil{} }// TimeUtil 是时间操作工具类 type TimeUtil struct{}// GetFormattedDate 获取格式化的日期字符串 fun…...

剑指 Offer 44.!! 数字序列中某一位的数字
参考资料 剑指 Offer 44. 数字序列中某一位的数字 中等 351 相关企业 数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等。…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

DeepSeek重复代码识别失效了?5个被90%团队忽略的AST解析盲区及修复清单
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测失效的真相与影响 DeepSeek-R1 模型在代码理解任务中表现出色,但其内置的代码重复检测机制在特定场景下存在系统性失效。根本原因在于模型对语义等价但语法结构差异显著的代…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...