图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index

LLM 如火如荼地发展了大半年,各类大模型和相关框架也逐步成型,可被大家应用到业务实际中。在这个过程中,我们可能会遇到一类问题是:现有的哪些数据,如何更好地与 LLM 对接上。像是大家都在用的知识图谱,现在的图谱该如何借助大模型,发挥更大的价值呢?
在本文,我便会和大家分享下如何利用知识图谱构建更好的 In-context Learning 大语言模型应用。
此文最初以英文撰写的,而后我麻烦 ChatGPT 帮我翻译成了英文。下面是翻译的 prompt:
“In this thread, you are a Chinese Tech blogger to help translate my blog in markdown from English into Chinese, the blog style is clear, fun yet professional. I will paste chapters in markdown to you and you will send back the translated and polished version.”
LLM 应用的范式
作为认知智能的一大突破,LLM 已经改变了许多行业,以一种我们没有预料到的方式进行自动化、加速和启用。我们每天都会看到新的 LLN 应用被创建出来,我们仍然在探索如何利用这种魔力的新方法和用例。
将 LLM 引入流程的最典型模式之一,是要求 LLM 根据专有的/特定领域的知识理解事物。目前,我们可以向 LLM 添加两种范式以获取这些知识:微调——fine-tune 和 上下文学习—— in-context learning。
微调是指对 LLM 模型进行附加训练,以增加额外的知识;而上下文学习是在查询提示中添加一些额外的知识。
据观察,目前由于上下文学习比微调更简单,所以上下文学习比微调更受欢迎,在这篇论文中讲述了这一现象:https://arxiv.org/abs/2305.16938。
下面,我来分享 NebulaGraph 在上下文学习方法方面所做的工作。
Llama Index:数据与 LLM 之间的接口
上下文学习
上下文学习的基本思想是使用现有的 LLM(未更新)来处理特定知识数据集的特殊任务。
例如,要构建一个可以回答关于某个人的任何问题,甚至扮演一个人的数字化化身的应用程序,我们可以将上下文学习应用于一本自传书籍和 LLM。在实践中,应用程序将使用用户的问题和从书中"搜索"到的一些信息构建提示,然后查询 LLM 来获取答案。
┌───────┐ ┌─────────────────┐ ┌─────────┐
│ │ │ Docs/Knowledge │ │ │
│ │ └─────────────────┘ │ │
│ User │─────────────────────────────────────▶ LLM │
│ │ │ │
│ │ │ │
└───────┘ └─────────┘
在这种搜索方法中,实现从文档/知识(上述示例中的那本书)中获取与特定任务相关信息的最有效方式之一是利用嵌入(Embedding)。
嵌入(Embedding)
嵌入通常指的是将现实世界的事物映射到多维空间中的向量的方法。例如,我们可以将图像映射到一个(64 x 64)维度的空间中,如果映射足够好,两个图像之间的距离可以反映它们的相似性。
嵌入的另一个例子是 word2vec 算法,它将每个单词都映射到一个向量中。例如,如果嵌入足够好,我们可以对它们进行加法和减法操作,可能会得到以下结果:
vec(apple) + vec(pie) ≈ vec("apple apie"),或者向量测量值 vec(apple) + vec(pie) - vec("apple apie") 趋近于 0:
|vec(apple) + vec(pie) - vec("apple apie")| ≈ 0
类似地,“pear” 应该比 “dinosaur” 更接近 “apple”:|vec(apple) - vec(pear)| < |vec(apple) - vec(dinosaur)|
有了这个基础,理论上我们可以搜索与给定问题更相关的书籍片段。基本过程如下:
- 将书籍分割为小片段,为每个片段创建嵌入并存储它们
- 当有一个问题时,计算问题的嵌入
- 通过计算距离找到与书籍片段最相似的前 K 个嵌入
- 使用问题和书籍片段构建提示
- 使用提示查询 LLM
┌────┬────┬────┬────┐ │ 1 │ 2 │ 3 │ 4 │ ├────┴────┴────┴────┤ │ Docs/Knowledge │
┌───────┐ │ ... │ ┌─────────┐
│ │ ├────┬────┬────┬────┤ │ │
│ │ │ 95 │ 96 │ │ │ │ │
│ │ └────┴────┴────┴────┘ │ │
│ User │─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─▶ LLM │
│ │ │ │
│ │ │ │
└───────┘ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ └─────────┘│ ┌──────────────────────────┐ ▲ └────────┼▶│ Tell me ....., please │├───────┘ └──────────────────────────┘ │ ┌────┐ ┌────┐ │ │ 3 │ │ 96 │ │ └────┘ └────┘ │ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
Llama Index
Llama Index 是一个开源工具包,它能帮助我们以最佳实践去做 in-context learning:
- 它提供了各种数据加载器,以统一格式序列化文档/知识,例如 PDF、维基百科、Notion、Twitter 等等,这样我们可以无需自行处理预处理、将数据分割为片段等操作。
- 它还可以帮助我们创建嵌入(以及其他形式的索引),并以一行代码的方式在内存中或向量数据库中存储嵌入。
- 它内置了提示和其他工程实现,因此我们无需从头开始创建和研究,例如,《用 4 行代码在现有数据上创建一个聊天机器人》。
文档分割和嵌入的问题
嵌入和向量搜索在许多情况下效果良好,但在某些情况下仍存在挑战,比如:丢失全局上下文/跨节点上下文。
想象一下,当查询"请告诉我关于作者和 foo 的事情",在这本书中,假设编号为 1、3、6、19-25、30-44 和 96-99 的分段都涉及到 foo 这个主题。那么,在这种情况下,简单地搜索与书籍片段相关的前 k 个嵌入可能效果不尽人意,因为这时候只考虑与之最相关的几个片段(比如 k = 3),会丢失了许多上下文信息。
┌────┬────┬────┬────┐
│ 1 │ 2 │ 3 │ 4 │
├────┴────┴────┴────┤
│ Docs/Knowledge │
│ ... │
├────┬────┬────┬────┤
│ 95 │ 96 │ │ │
└────┴────┴────┴────┘
而解决、缓解这个问题的方法,在 Llama Index 工具的语境下,可以创建组合索引和综合索引。
其中,向量存储(VectorStore)只是其中的一部分。除此之外,我们可以定义一个摘要索引、树形索引等,以将不同类型的问题路由到不同的索引,从而避免在需要全局上下文时错失它。
然而,借助知识图谱,我们可以采取更有意思的方法:
知识图谱
知识图谱这个术语最初由谷歌在 2012 年 5 月提出,作为其增强搜索结果,向用户提供更多上下文信息的一部分实践。知识图谱旨在理解实体之间的关系,并直接提供查询的答案,而不仅仅返回相关网页的列表。
知识图谱是一种以图结构形式组织和连接信息的方式,其中节点表示实体,边表示实体之间的关系。图结构允许用户高效地存储、检索和分析数据。
它的结构如下图所示:
现在问题就来了,上面说过知识图谱能帮忙搞定文档分割和嵌入的问题。那么,知识图谱到底能怎么帮到我们呢?
嵌入和知识图谱的结合
这里的基本实现思想是,作为信息的精炼格式,知识图谱可切割的数据颗粒度比我们人工的分割的更细、更小。将知识图谱的小颗粒数据与原先人工处理的大块数据相结合,我们可以更好地搜索需要全局/跨节点上下文的查询。
下面来做个题:请看下面的图示,假设提问同 x 有关,所有数据片段中有 20 个与 x 高度相关。现在,除了获取主要上下文的前 3 个文档片段(比如编号为 1、2 和 96 的文档片段),我们还从知识图谱中对 x 进行两次跳转查询,那么完整的上下文将包括:
- 问题:“Tell me things about the author and x”
- 来自文档片段编号 1、2 和 96 的原始文档。在 Llama Index 中,它们被称为节点 1、节点 2 和节点 96。
- 包含 “x” 的知识图谱中的 10 个三元组,通过对
x进行两层深度的图遍历得到:- x -> y(来自节点 1)
- x -> a(来自节点 2)
- x -> m(来自节点 4)
- x <- b-> c(来自节点 95)
- x -> d(来自节点 96)
- n -> x(来自节点 98)
- x <- z <- i(来自节点 1 和节点 3)
- x <- z <- b(来自节点 1 和节点 95)
┌──────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ .─. .─. │ .─. .─. │ .─. │ .─. .─. │
│( x )─────▶ y ) │ ( x )─────▶ a ) │ ( j ) │ ( m )◀────( x ) │
│ `▲' `─' │ `─' `─' │ `─' │ `─' `─' │
│ │ 1 │ 2 │ 3 │ │ 4 │
│ .─. │ │ .▼. │ │
│( z )◀────────────┼──────────────────┼───────────( i )─┐│ │
│ `◀────┐ │ │ `─' ││ │
├───────┼──────────┴──────────────────┴─────────────────┼┴──────────────────┤
│ │ Docs/Knowledge │ │
│ │ ... │ │
│ │ │ │
├───────┼──────────┬──────────────────┬─────────────────┼┬──────────────────┤
│ .─. └──────. │ .─. │ ││ .─. │
│ ( x ◀─────( b ) │ ( x ) │ └┼▶( n ) │
│ `─' `─' │ `─' │ │ `─' │
│ 95 │ │ │ 96 │ │ │ 98 │
│ .▼. │ .▼. │ │ ▼ │
│ ( c ) │ ( d ) │ │ .─. │
│ `─' │ `─' │ │ ( x ) │
└──────────────────┴──────────────────┴──────────────────┴──`─'─────────────┘
显然,那些(可能很宝贵的)涉及到主题 x 的精炼信息来自于其他节点以及跨节点的信息,都因为我们引入知识图谱,而能够被包含在 prompt 中,用于进行上下文学习,从而克服了前面提到的问题。
Llama Index 中的知识图谱进展
最初,William F.H.将知识图谱的抽象概念引入了 Llama Index,其中知识图谱中的三元组与关键词相关联,并存储在内存中的文档中,随后Logan Markewich还增加了每个三元组的嵌入。
最近的几周中,我一直在与 Llama Index 社区合作,致力于将 “GraphStore” 存储上下文引入 Llama Index,从而引入了知识图谱的外部存储。首个知识图谱的外部存储是对接开源分布式图数据库 NebulaGraph,目前在我的努力下已经实现了。
在实现过程中,还引入了遍历图的多个跳数选项以及在前 k 个节点中收集更多关键实体的选项,用于在知识图谱中搜索以获得更多全局上下文。上面提到的这些变更还在陆续完善中。
在大模型中引入 GraphStore 后,还可以从现有的知识图谱中进行上下文学习,并与其他索引结合使用,这也非常有前景。因为知识图谱被认为具有比其他结构化数据更高的信息密度。
本文作为开篇,讲述了一些知识图谱和 LLM 的关系。在后续的文章中,将会偏向实操同大家分享具体的知识图谱和 LLM 的应用实践。
–
谢谢你读完本文 (///▽///)
欢迎前往 GitHub 来阅读 NebulaGraph 源码,或是尝试用它解决你的业务问题 yo~ GitHub 地址:https://github.com/vesoft-inc/nebula 想要交流图技术和其他想法,请前往论坛:https://discuss.nebula-graph.com.cn/
相关文章:
图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index
LLM 如火如荼地发展了大半年,各类大模型和相关框架也逐步成型,可被大家应用到业务实际中。在这个过程中,我们可能会遇到一类问题是:现有的哪些数据,如何更好地与 LLM 对接上。像是大家都在用的知识图谱,现在…...
)
SpringBoot自动配置、启动器原理爆肝解析(干货满满)
文章目录 前言一、SpringBoot优势概要二、SpringBoot自动配置1. ☠注意☠2.自动配置详解 三、Starter(场景启动器)原理总结 前言 本文详细解析面试重点—SpringBoot自动配置原理、场景启动器原理,深入源码,直接上干货、绝不拖泥带…...

chrome扩展控制popup页面动态切换
文章目录 1、通过控制元素的显示隐藏达到popup页面切换的效果2、通过监听页面重新加载完成不同popup的切换3、直接修改popup页面location.href,无需刷新页面 1、通过控制元素的显示隐藏达到popup页面切换的效果 下面在mv2版本的API下完成 实际上通过控制页面元素实…...
:PyTorch常用函数)
【AI】《动手学-深度学习-PyTorch版》笔记(三):PyTorch常用函数
AI学习目录汇总 1、torch.arange 返回一维张量(一维数组),官网说明,常见的三种用法如下 输入:torch.arange(5) 输出:tensor([0, 1, 2, 3, 4]) 输入:torch.arange(5, 16) 输出:tensor([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]) 输入:torch.arange(1, 25, 2) …...

某文化馆三维建模模型-glb格式-三维漫游-室内导航测试
资源描述 某文化馆某个楼层的三维建模模型,glb格式,适用于three.js开发,可用来做一些三维室内漫游测试和室内导航测试 资源下载地址...
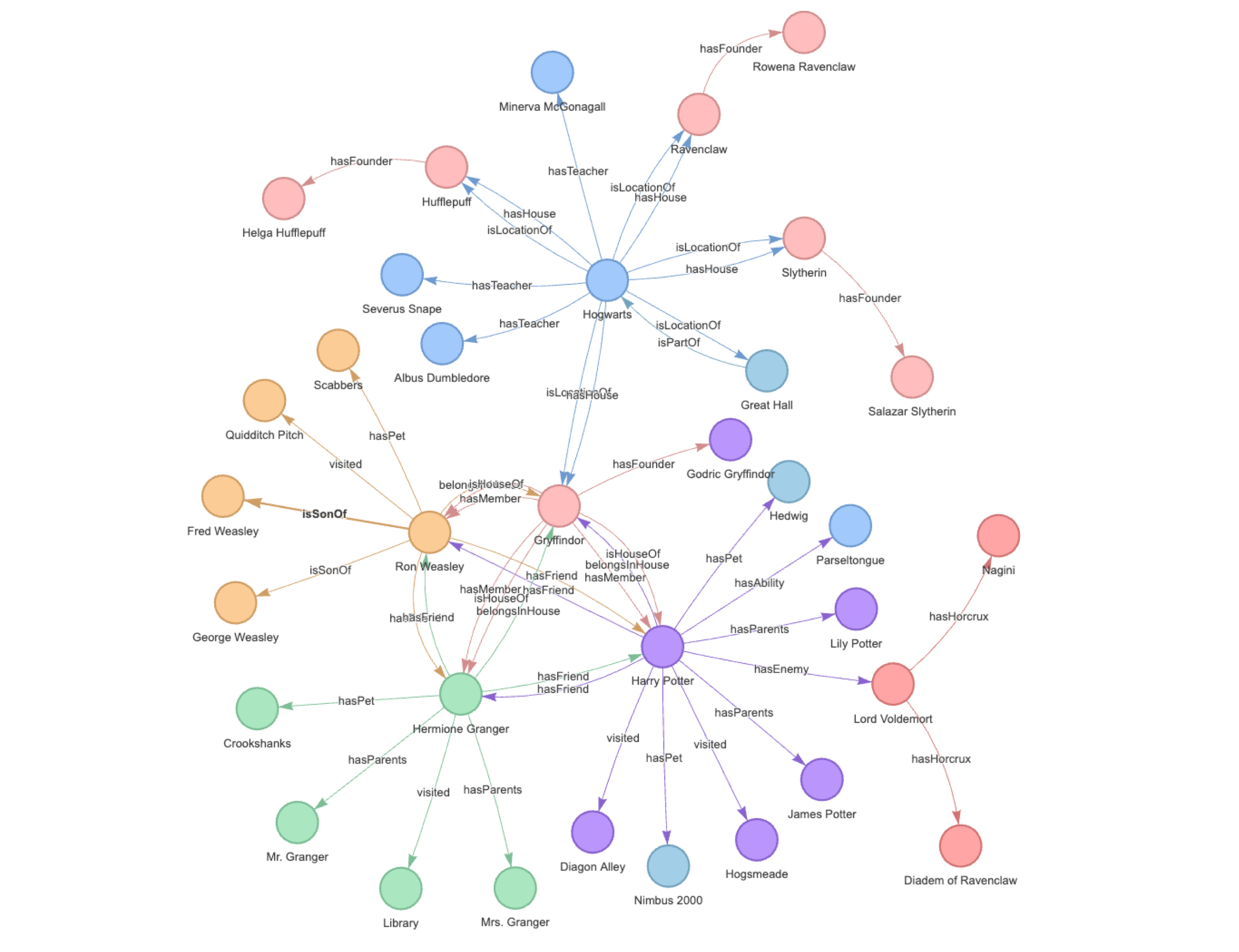
网络安全 Day19-计算机网络基础知识04(网络协议)
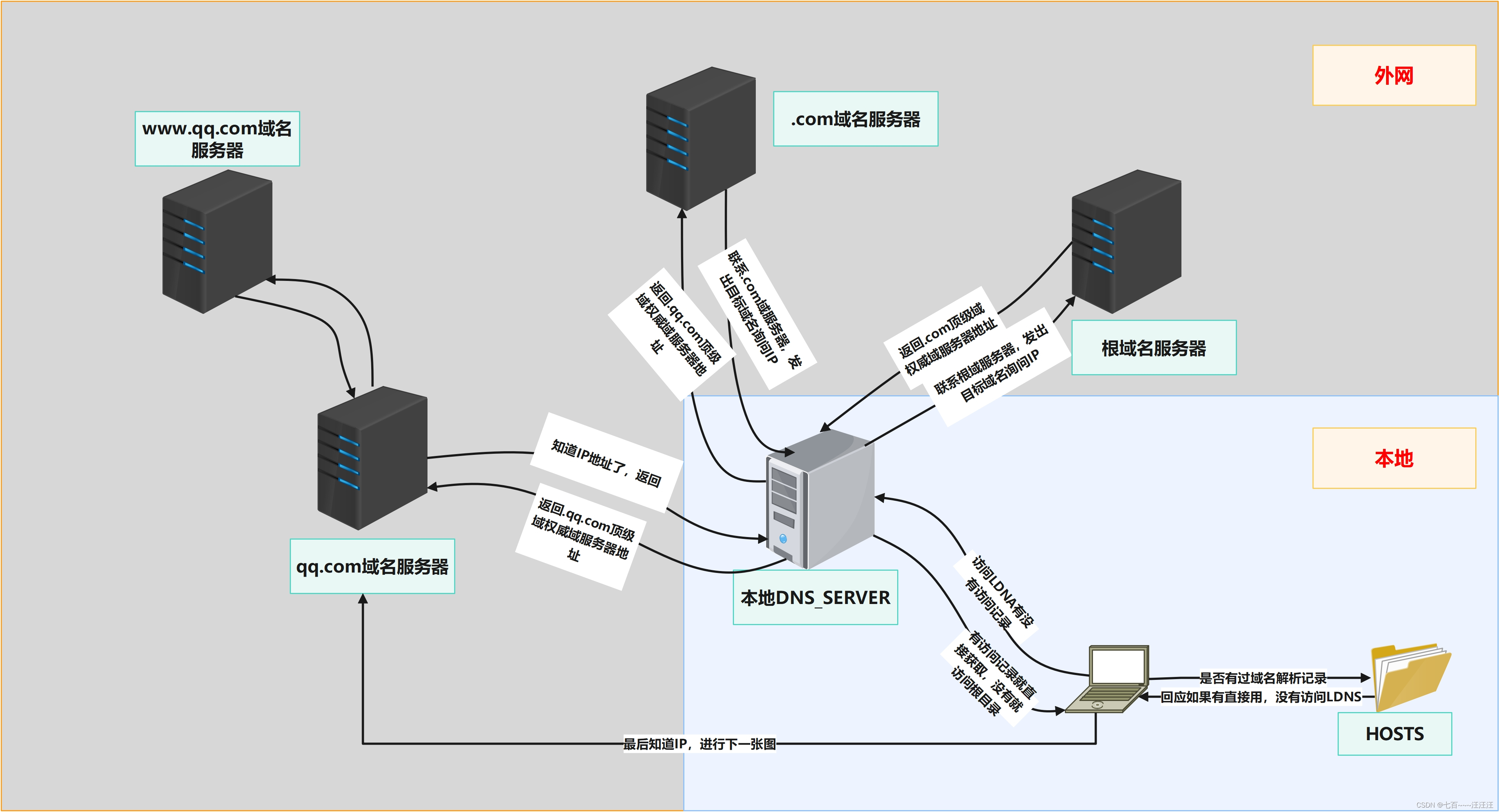
计算机网络基础知识04(网络协议) 1. ARP1.1 ARP通讯原理1.2 arp欺骗1.3 ARP欺骗与预防1.4 排查ARP病毒 2. DHCP工作原理(自动分配内网IP)3. TCP协议三次握手、四次挥手原理4. DNS协议工作原理 1. ARP Linux查看arp:ar…...

Verilog语法学习——LV5_位拆分与运算
LV5_位拆分与运算 题目来源于牛客网 [牛客网在线编程_Verilog篇_Verilog快速入门 (nowcoder.com)](https://www.nowcoder.com/exam/oj?page1&tabVerilog篇&topicId301) 题目 题目描述: 现在输入了一个压缩的16位数据,其实际上包含了四个数据…...

❤️创意网页:创意动态画布~缤纷移动涂鸦~图片彩色打码
✨博主:命运之光 🌸专栏:Python星辰秘典 🐳专栏:web开发(简单好用又好看) ❤️专栏:Java经典程序设计 ☀️博主的其他文章:点击进入博主的主页 前言:欢迎踏入…...

数值分析第六章节 用Python实现解线性方程组的迭代法
参考书籍:数值分析 第五版 李庆杨 王能超 易大义编 第5章 解线性方程组的迭代法 文章声明:如有发现错误,欢迎批评指正 文章目录 迭代法的基本概念雅可比迭代法与高斯-塞格尔迭代法雅可比迭代法高斯-塞格尔迭代法 迭代法的基本概念 6.1.1引言…...

【低代码专题方案】使用iPaaS平台下发数据,快捷集成MDM类型系统
01 场景背景 伴随着企业信息化建设日趋完善化、体系化,使用的应用系统越来越多,业务发展中沉淀了大量数据。主数据作为数据治理中枢,保存大量标准数据库,如何把庞大的数据下发到各个业务系统成了很棘手的问题。 传统的数据下发方…...
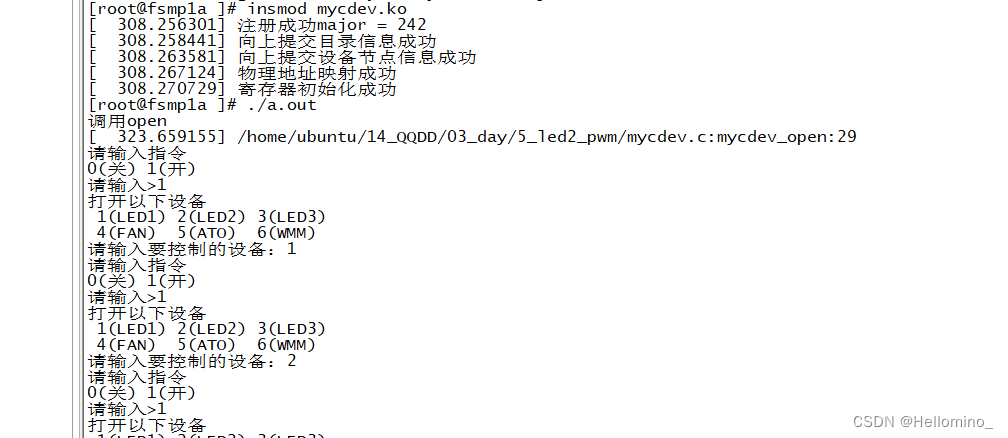
驱动开发 day3 (模块化驱动启动led,蜂鸣器,风扇,震动马达)
模块化驱动启动led,蜂鸣器,风扇,震动马达并加上Makefile 封装模块化驱动,可自由安装卸载驱动,便于驱动更新(附图) 1.安装模块驱动同时初始化各个设备并使能 2.该驱动会自动创建驱动节点. 3.通过c函数程序输入控制各个设备 4.卸载模块驱动 //编译驱动…...
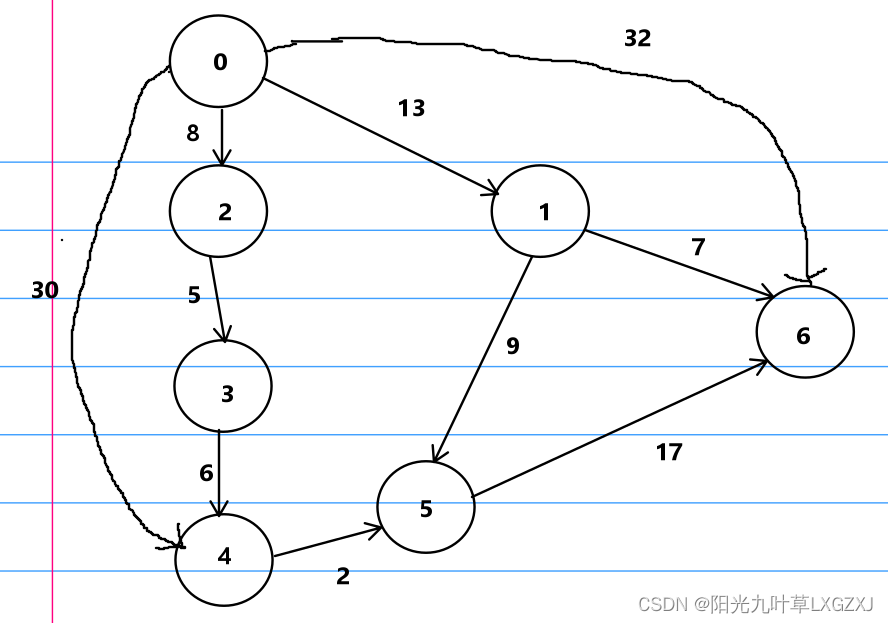
数据结构与算法基础-学习-27-图之最短路径之Dijkstra(迪杰斯特拉)算法
一、最短路径应用案例 例如从北京到上海旅游,有多条路可以到目的地,哪条路线最短,哪条路线最省钱,就是典型的最短路径问题。 二、最短路径问题分类 最短路径问题可以分为两类,第一类为:两点间最短路径。第…...
Windows Server 2012 能使用的playwright版本
由于在harkua_bot里面使用到了playwright,我的服务器又是Windows Server 2012 R2,最新版playwright不支持Windows Server 2012 R2,支持Windows Server 2016以上,所以有了这个需求 https://cdn.npmmirror.com/binaries/playwright…...

css实现溢出变为省略号
单行文本溢出省略 text-overflow:规定当文本溢出时,显示省略符号来代表被修剪的文本 white-space:设置文字在一行显示,不能换行 overflow:文字长度超出限定宽度,则隐藏超出的内容overflow设为hidden&#…...

nginx如何配置两个服务器的连接
nginx 中通过server_name listen的方式配置多个服务器 nginx配置两个站点的windows操作方法,双域名双站点...

Linux环境Arduino IDE中配置ATOM S3
linux选择ubuntu发行版。 硬件设备有多小呢: 功能超级强大。 之前的ROS1和ROS2案例已经全部移植完成并测试结束(三轮纯人力校验😎)。 官网文档信息非常非常好: https://docs.m5stack.com/zh_CN/quick_start/atoms3…...
【C#】.Net Framework框架下的Authorize权限类
2023年,第31周,第3篇文章。给自己一个目标,然后坚持总会有收货,不信你试试! 在C#的.NET Framework中,你可以使用Authorize类来处理权限认证。Authorize类位于System.Web.Mvc命名空间中,它提供了…...

C++ list底层实现原理
文章目录 一、list底层实现二、类构成三、构造函数四、迭代器五、获取第一个元素六、获取最后一个元素七、插入元素 一句话:list底层实现一个双向循环链表 一、list底层实现 一个双向循环链表 二、类构成 class list : protected_List_base_list_base.lsit_impl…...

C#实现数字验证码
开发环境:VS2019,.NET Core 3.1,ASP.NET Core API 1、建立一个验证码控制器 新建两个方法Create和Check,Create用于创建验证码,Check用于验证它是否有效。 声明一个静态类变量存放列表,列表中存放包含令…...

Git的常用命令以及使用场景
文章目录 1.前言2.工作区,暂存区,版本库简介3.Git的常用命令4.版本回退5.撤销修改6.删除文件7.总结 1.前言 在学习Git命令之前,需要先了解工作区,暂存区和版本库这三个概念 2.工作区,暂存区,版本库简介 在使用Git进行版本控制时,有三个重要的概念:工作…...

3步构建企业级实时日志分析系统:从数据采集到智能告警
3步构建企业级实时日志分析系统:从数据采集到智能告警 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher 在现代企业IT架构中…...

亚马逊/Shopee关键词排名高就一定好?你可能陷入了“数据幻觉”
关键词排名高只说明“看得见”,不代表“卖得动”,更不等于“值得投”。理论锚点信息经济学信号噪音理论:排名只是表层信号,可能混杂品牌词截流等无关信息。SEO 搜索意图分类:信息型搜索不等于交易型搜索。一、误区揭露…...

golang如何实现零知识证明基础_golang零知识证明基础实现教程
Go 不内置零知识证明能力,需依赖第三方库;主流ZKP工具链绑定Rust/C/TS,Go生态缺乏生产级原生实现;crypto包仅提供基础原语,无法支撑ZKP所需多项式承诺、配对运算等高级密码操作。Go 本身不内置零知识证明(Z…...
通义千问Qwen2-VL模型部署避坑指南:如何用transformers库绕过Flash-Attention2安装
通义千问Qwen2-VL模型轻量化部署实战:避开Flash-Attention2的安装陷阱 最近在测试通义千问的多模态模型Qwen2-VL时,发现官方推荐的Flash-Attention2依赖项安装过程异常繁琐,不仅编译耗时数小时,还经常因环境配置问题报错。经过多次…...

模糊逻辑温度控制器:技术革新与市场前景深度解析
在工业自动化与智能制造浪潮中,温度控制作为核心工艺环节,其精度与稳定性直接影响产品质量与生产效率。模糊逻辑温度控制器凭借其独特的算法优势,正从传统PID控制器的“替代者”升级为高端制造场景的“刚需品”。本文将从技术原理、市场格局、…...
)
告别PX4,试试APM!用ArduPilot+Gazebo搭建你的第一个无人机仿真环境(附QGC地面站连接)
从PX4到APM:ArduPilot无人机仿真环境全攻略 如果你已经熟悉PX4生态,却对ArduPilot(APM)固件在仿真领域的表现充满好奇,这篇文章将为你打开一扇新的大门。不同于市面上大量聚焦PX4的教程,我们将深入探讨APM在…...

AI绘图小说配图批量生成 小说插图制作神器 小说配图 动漫图片生成 低配显卡可用 解决图片一致性的问题 生成的图片一致性 可控
简介说明 AI绘图小说配图批量生成 小说插图制作神器 小说配图 动漫图片生成 低配显卡可用 把常见的出图流程整理成更容易操作、更适合生产使用的工作台,且支持低配显卡稳定运行,无需升级硬件即可流畅出图。 它可以帮助用户把“启动服务、填写提示词、切…...
:Chat Memory对话记忆实战,基于Redis实现持久化多轮对话)
Spring AI实战系列(七):Chat Memory对话记忆实战,基于Redis实现持久化多轮对话
一、系列回顾与本篇定位1.1 系列回顾第一篇:完成Spring AI与阿里云百炼的基础集成,基于ChatModel 实现同步对话与API Key安全注入。第二篇:解锁ChatClient,实现全局统一配置与链式调用,告别重复样板代码。第三篇&#…...

RT thread—iic—at24c04读写操作
at24c04介绍:存储容量:4 Kbits(即 512 字节)。内部结构为 32 页,每页 16 字节。地址0x000-0x1FF通信接口:标准 I2C(时钟线 SCL 和数据线 SDA),支持最高 400 kHz 的快速模…...

别等宕机才后悔!UPS蓄电池定期巡检,这4点才是核心!
|机房里设备林立,大多数人把目光聚焦在服务器、精密空调上。但其实,潜伏在机房角落的“隐形杀手”,往往是看起来默默无闻的UPS蓄电池。今天我们不谈复杂的技术参数,只用大白话讲清楚:为什么蓄电池必须定期巡…...