R并行计算-parallel例子1
前言:
通常,如果进程运行时间超过3分钟,则会考虑使用并行处理。
这听起来可能很复杂,但是并行计算很简单。
- 当你有一个重复的任务,它占用了你太多宝贵的时间,为什么不使用并行计算来节省时间呢?
- 即使你有一个单一的任务,你也可以通过将任务分成更小的部分来从并行处理中受益。
两个广泛使用的并行处理包是parallel和foreach。
1-并行计算准备阶段:
在R中使用并行计算的主要目的 提高运行速度,由于R是单核运行的程序,现在的计算机都是多核,如果只用一个核跑程序,让计算机的其他核空闲,势必是一种资源的浪费。
library(parallel)# 设置并行计算的核心数
num_cores <- detectCores()
cl <- makeCluster(num_cores)# 执行并行计算的任务
result <- parLapply(cl, data, your_function)# 关闭并行计算的集群
stopCluster(cl)流程:设置并行计算的核数-->执行并行计算-->关闭并行计算的集群。
无论使使用哪种并行计算包,都是基于上述三个步骤,1-设置并行计算的核数;2 执行并行计算 3 关闭并行计算的集群。
2-各种方法对比
2.0生成数据:
# create test data
set.seed(1234)
df <- data.frame(matrix(data = rnorm(1e7), ncol = 1000))
dim(df)目标:对这个矩阵每行求和。
2.1使用For循环
运行事件3.83mins
# for Example 1
times1 <- Sys.time()
results <- c()for (i in 1:dim(df)[1]) {results <- c(results, sum(df[i,]))
}times2 <- Sys.time()
print(times2 - times1)
#2.77314 mins#for Example 2
times1 <- Sys.time()
results <- c()for (i in 1:dim(df)[1]) {results[i] <- sum(df[i,])
}times2 <- Sys.time()
print(times2 - times1)
#2.404386 mins2.2使用apply函数
当提到循环的时候,我们想到的是For、while循环和apply函数族,可以说apply函数族是代替循环的好方法。
#2
times1 <- Sys.time()
apply(df,1,sum)times2 <- Sys.time()
print(times2 - times1)
#0.5269971 secs2.3使用baseR中自带的函数rowSums()
#3
times1 <- Sys.time()
rowSums(df)
times2 <- Sys.time()
print(times2 - times1)
#0.146533 secs 2.4使用parallel包
这里用到了对数据进行分割,按照核数1:8进行分割,分割成8份,得到一个list列表对象。然后使用parLapply()函数进行计算。
#4
# load R Package
library(parallel)
# check cores numbers
detectCores()
# set cores numbers
num_cores <- 8
# start times
times1 <- Sys.time()
# split data
chunks <- split(df, f = rep(1:num_cores, length.out = nrow(df)))
class(chunks) #list 列表
length(chunks)
# create parallel
cl <- makeCluster(num_cores)# computed in parallel
results <- parLapply(cl, chunks, function(chunk){apply(chunk, 1, sum)
})# Turn off the cluster for parallel computing
stopCluster(cl)# combine result
final_result <- unlist(results)times2 <- Sys.time()print(times2 - times1)
#3.047416 secs2.5使用foreach包
install.packages("foreach")
install.packages("doParallel")
library(foreach)
library(doParallel)
# 创建一个集群并注册
cl <- makeCluster(8)
registerDoParallel(cl)# 启动并行计算
time1 <- Sys.time()
x2 <- foreach(i = 1:dim(df)[1], .combine = c) %dopar% {sum(df[i,])
}
time2 <- Sys.time()
print(time2-time1)# 在计算结束后别忘记关闭集群
stopImplicitCluster()
stopCluster(cl)
# 53.63808 secs参考:
Rtips 多核心并行计算
相关文章:

R并行计算-parallel例子1
前言: 通常,如果进程运行时间超过3分钟,则会考虑使用并行处理。 这听起来可能很复杂,但是并行计算很简单。 当你有一个重复的任务,它占用了你太多宝贵的时间,为什么不使用并行计算来节省时间呢ÿ…...

JavaSE复盘2
Collection接口的接口对象集合(单列集合) List接口:元素按照先后有序保存,可重复 LinkList接口实现类,链表,随机访问,没有同步,线程不安全ArrayList接口实现类,数组&…...

如何在3ds max中创建可用于真人场景的巨型机器人:第 3 部分
推荐: NSDT场景编辑器助你快速搭建可二次开发的3D应用场景 1. 创建腿部装备 步骤 1 打开 3ds Max。 打开在本教程最后一部分中保存的文件。 打开 3ds Max 步骤 2 转到创建> 系统并单击骨骼。 创建>系统 步骤 3 为的 侧视口中的腿,如下图所示…...
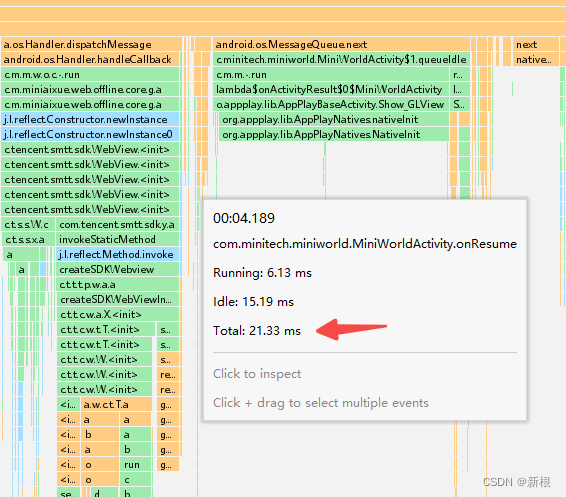
Android性能优化之游戏引擎初始化ANR
近期,着手对bugly上的anr 处理,记录下优化的方向。 借用网上的一张图: 这里的anr 问题是属于主线程的call 耗时操作。需要使用trace 来获取发生anr前一些列的耗时方法调用时间,再次梳理业务,才可能解决。 问题1 ja…...

Jmap-JVM(十六)
上篇文章说了ZGC是jdk11加入的,他是未来jvm垃圾收集器的奠定者,满足TB级别内存处理,STW时间保持在10ms以下。 Jmap 我们可以先通过jmap -histo 进程ip 来查看,但是这样看不太清晰,我们可以用这行命令生成一个文件&…...

【分布式能源的选址与定容】基于多目标粒子群算法分布式电源选址定容规划研究(Matlab代码实现)
目录 💥1 概述 1.1 功率损耗 编辑1.2 电压质量 1.3 DG总容量 📚2 运行结果 🌈3 Matlab代码实现 🎉4 参考文献 💥1 概述 参考文献: 本文采用的是换一个算法解决, 基于基于多目标粒子群算法分布…...

flink源码分析-获取JVM最大堆内存
flink版本: flink-1.11.2 代码位置: org.apache.flink.runtime.util.EnvironmentInformation#getMaxJvmHeapMemory 如果设置了-Xmx参数,就返回这个参数,如果没设置就返回机器物理内存的1/4. 这里主要看各个机器内存的获取方法。 /*** The maximum JVM…...

第17节 R语言分析:生物统计数据集 R 编码分析和绘图
生物统计数据集 R 编码分析和绘图 生物统计学,用于对给定文件 data.csv 中的医疗数据应用 R 编码,该文件是患者人口统计数据集,包含有关来自各种祖先谱系的个体的标准信息。 数据集特征解释 脚本 output= file("Output.txt") # File name of output log sink(o…...
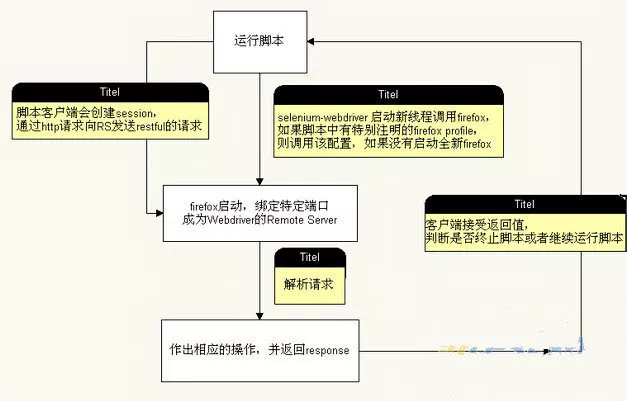
一文了解什么是Selenium自动化测试?
目录 一、Selenium是什么? 二、Selenium History 三、Selenium原理 四、Selenium工作过程总结: 五、remote server端的这些功能是如何实现的呢? 六、附: 一、Selenium是什么? 用官网的一句话来讲:Sel…...

java接口实现
文章目录 java接口实现接口中成员组成默认方法静态方法私有接口(保证自己的JDK版本大于等于9版本)类和接口的关系抽象类与接口之间的区别 java接口实现 1.接口关键字 interface2.接口不能实例化3.类与接口之间的关系是实现关系,通过 impleme…...
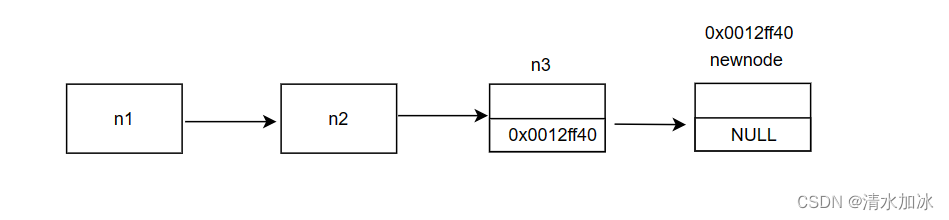
数据结构入门指南:链表(新手避坑指南)
目录 前言 1.链表 1.1链表的概念 1.2链表的分类 1.2.1单向或双向 1.2.2.带头或者不带头 1.2.33. 循环或者非循环 1.3链表的实现 定义链表 总结 前言 前边我们学习了顺序表,顺序表是数据结构中最简单的一种线性数据结构,今天我们来学习链表&#x…...

SpringBoot第24讲:SpringBoot集成MySQL - MyBatis XML方式
SpringBoot第24讲:SpringBoot集成MySQL - MyBatis XML方式 上文介绍了用JPA方式的集成MySQL数据库,JPA方式在中国以外地区开发而言基本是标配,在国内MyBatis及其延伸框架较为主流。本文是SpringBoot第24讲,主要介绍MyBatis技栈的演…...
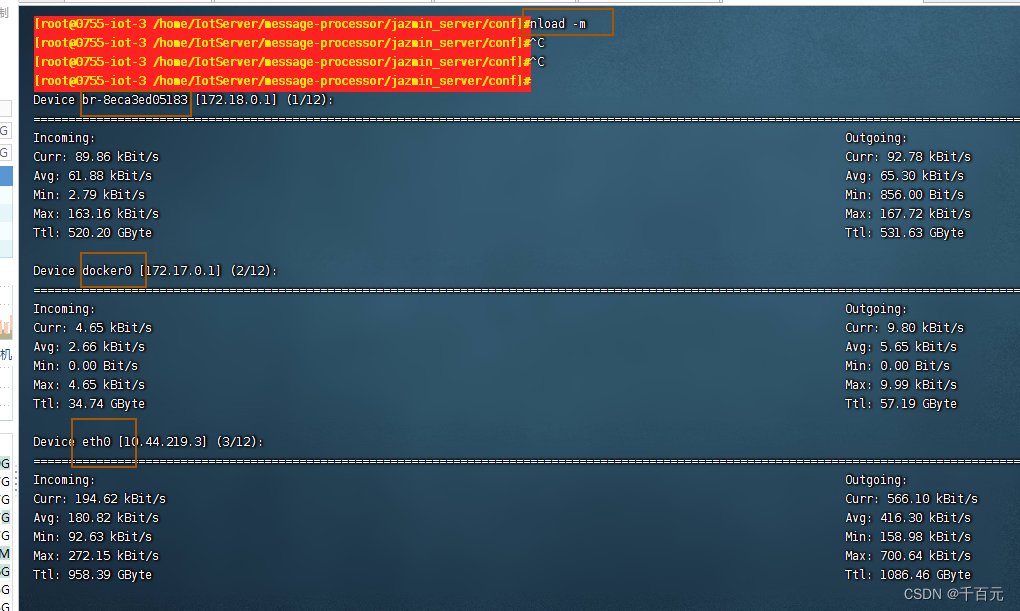
linux 查看网卡,网络情况
1,使用nload命令查看 #yum -y install nload 2, 查看eth0网卡网络情况 #nload eth0 Incoming也就是进入网卡的流量,Outgoing,也就是从这块网卡出去的流量,每一部分都有下面几个。 – Curr:当前流量 – Avg…...
在Mac上搭建Gradle环境
在Mac上搭建Gradle环境: 步骤1:下载并安装Java开发工具包(JDK) Gradle运行需要Java开发工具包(JDK)。您可以从Oracle官网下载适合您的操作系统版本的JDK。请按照以下步骤进行操作: 打开浏览器…...
Docker网络与Docker Compose服务编排
docker网络 docker是以镜像一层一层构建的,而基础镜像是linux内核,因此docker之间也需要通讯,那么就需要有自己的网络。就像windows都有自己的内网地址一样,每个docker容器也是有自己的私有地址的。 docker inspect [docker_ID]…...

opencv+ffmpeg环境(ubuntu)搭建全面详解
一.先讲讲opencv和ffmpeg之间的关系 1.1它们之间的联系 我们知道opencv主要是用来做图像处理的,但也包含视频解码的功能,而在视频解码部分的功能opencv是使用了ffmpeg。所以它们都是可以处理图像和视频的编解码,我个人感觉两个的侧重点不一…...

开发基于 LoRaWAN 的设备须知--最大兼容性
最大兼容性配置简介 LoRaWAN开放协议的建立前提是每个制造的设备都可以被唯一且安全地识别。配置是创建唯一标识和相应秘密的过程。虽然配置过程是常规的,但存在一些可能并不明显的陷阱。本章尝试描述配置基于 LoRa 的设备的一些最佳实践。 配置概念 基于 LoRa 的设备配置与银…...

一、SpringBoot基础[日志]
一、日志 解释:SpringBoot使用logback作为默认的日志框架,其中还可以导入log4j2等优秀的日志框架 1.修改日志内容 修改整个日志格式:logging.pattern.console%d{yyyy-MM-dd HH:mm:ss} %-5level [%thread] %logger{15} 你好 %msg%n %d{yyy…...

libuv库学习笔记-networking
Networking 在 libuv 中,网络编程与直接使用 BSD socket 区别不大,有些地方还更简单,概念保持不变的同时,libuv 上所有接口都是非阻塞的。它还提供了很多工具函数,抽象了恼人、啰嗦的底层任务,如使用 BSD …...
C++多线程编程(第三章 案例1,使用互斥锁+ list模拟线程通信)
主线程和子线程进行list通信,要用到互斥锁,避免同时操作 1、封装线程基类XThread控制线程启动和停止; 2、模拟消息服务器线程,接收字符串消息,并模拟处理; 3、通过Unique_lock和mutex互斥方位list 消息队列…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...

推理服务为什么一上张量并行就开始通信拖慢首 Token:从 All-Reduce 瓶颈到通信计算重叠的工程实战
一、问题的引入 部署 70B 以上大模型时,单卡显存往往捉襟见肘。张量并行(TP)把单层权重沿隐藏维度切分到多张 GPU,每张卡只存一部分。🎯 不少团队上线 TP 后遇到诡异现象:吞吐提升,首 Token 时间…...

后端开发者体验 AI 前端:用 TinyVue 做一个智能业务表单 Demo
摘要 作为 Java 后端开发者,我平时更多关注接口、SQL 和业务逻辑,但后台系统里也绕不开表单、列表和报表页面。本文结合 OpenTiny NEXT 学习体验,用 TinyVue 做一个智能业务表单 Demo,聊聊 AI 前端对后端开发者到底有没有实际帮助…...

中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限
中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 想象一下,你正在管理一个企业网络,面对几十台中兴…...

CNN 卷积神经网络面试全集|卷积、池化、感受野
前言 计算机视觉算法岗必考核心就是 CNN,从基础卷积运算、池化操作,到经典网络结构、感受野、参数量计算全是高频考题。本文整理最全 CNN 面试精简答案,条理清晰直接背诵,视觉方向面试稳稳通关。 一、CNN 整体三大核心结构 卷积层:提取局部纹理、边缘、形状等空间特征 池…...

机器学习预测细菌耐药性:从全基因组数据到公共卫生预警
1. 项目概述与核心价值抗菌药物耐药性(AMR)这事儿,现在谁提起来都头疼。它不再是实验室报告上的一个数字,而是直接关系到我们每个人生病了还有没有药可用的现实问题。弯曲杆菌,这个听起来有点拗口的名字,其…...

ESP32嵌入式GUI开发终极指南:使用lv_port_esp32构建专业级单色屏应用
ESP32嵌入式GUI开发终极指南:使用lv_port_esp32构建专业级单色屏应用 【免费下载链接】lv_port_esp32 LVGL ported to ESP32 including various display and touchpad drivers 项目地址: https://gitcode.com/gh_mirrors/lv/lv_port_esp32 在资源受限的ESP32…...

GitHub中文界面终极指南:免费脚本让英文GitHub秒变中文
GitHub中文界面终极指南:免费脚本让英文GitHub秒变中文 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitHub全英文…...

猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频
猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无…...

机器学习破解等离子体模拟维度灾难:储层计算实现Vlasov方程高效闭合
1. 项目概述与核心挑战在等离子体物理和计算流体动力学领域,有一个长期困扰研究者和工程师的“幽灵”问题:闭合问题。简单来说,我们试图用计算机里有限的、离散的网格点,去描述一个本质上连续、甚至无限维度的物理世界。比如&…...